habilitation a diriger des rechercheshydrologie.org/the/arnaud_p_hdr.pdf · stochastique de...
TRANSCRIPT

Ecole Doctorale 251 – Sciences de l’Environnement
HABILITATION A DIRIGER DES
RECHERCHES
« L’aléa hydrométéorologique : estimation régionale
par simulation stochastique des processus »
CV Détaillé - Liste de publications - Manuscrit détaillé
HDR présentée par Patrick Arnaud à Aix-Marseille Université devant le jury :
Olivier BELLIER Professeur – HDR, Cerege – OSU Pytheas, AMU Président
Eric GAUME ICPEF - HDR, IFSTTAR, Nantes Rapporteur
Catherine FAVRE Professeur – HDR, Ense3, Grenoble Rapporteur
Roger MOUSSA Directeur de Recherche – HDR, INRA, Montpellier Rapporteur
Michel LANG IDEA – HDR, Irstea, Lyon Examinateur
Pierre RIBSTEIN Professeur – HDR, UMR Sisyphe, Paris VI Examinateur
Irstea – Centre d’Aix-en-Provence

RESUME
Issu d’une formation d’ingénieur en Sciences de l’Eau, je me suis orienté vers la recherche en
effectuant une thèse en hydrologie au Cemagref d’Aix-en-Provence portant sur une méthode
originale de prédétermination des crues, basée sur la simulation stochastique de pluies horaires.
Après quatre années en tant qu’enseignent-chercheur (ATER à l’Université Montpellier II puis
Maitre de Conférences à l’Ecole Nationale du Génie de l’Eau et de l’Environnement de Strasbourg),
j’ai réintégré le Cemagref, devenu aujourd’hui l’Irstea, pour poursuivre mes recherches sur l’étude
des risques hydrologiques associés aux événements extrêmes (de crues) à travers deux thématiques
principales que sont la prévention (ou prédétermination) et la prévision.
Depuis 2011, j’ai pris en charge l’animation et la programmation scientifique de l’équipe
Hydrologie, ainsi que de sa programmation et son suivi budgétaire. L’équipe est composée de 5
permanents (dont 4 chercheurs) et complétée par un effectif moyen annuel de 4 CDD de longue
durée (plus d’un an), de 3 thésards et de stagiaires.
Au cours de ces années, l’objectif de mes recherches a été de développer des approches
permettant d’appréhender au mieux l’aléa hydrométéorologique de l’ensemble d’un territoire. Ces
approches sont basées sur la modélisation des processus, en particulier de la relation pluie-débit.
Initialement complexes, ces approches ont cependant une finalité opérationnelle forte. Pour cela, un
compromis entre efficacité, robustesse et transposabilité des modélisations a été recherché, afin
d’aboutir à des méthodologies plus facilement régionalisables et applicables en sites non
instrumentés. Cette philosophie est un principe commun aux recherches développées par l’équipe et
auxquelles je participe en tant qu’animateur de l’équipe. Ces recherches concernent la
prédétermination et la prévision des crues et des étiages. Cependant, pour plus de concision, je
n’aborderai ici que la thématique de la prédétermination des crues extrêmes qui représente mon
champ d’investigation principal.
La problématique de la prédétermination des crues réside dans le besoin d’extrapoler en
fréquence et d’extrapoler dans l’espace un phénomène aléatoire très variable et relativement peu
observé par rapport à sa variabilité. Cette problématique est abordée ici par la modélisation et la
simulation des phénomènes, réalisées à partir de deux outils de modélisation : un générateur
stochastique de chroniques de pluies horaires et une modélisation hydrologique conceptuelle
permettant de transformer la pluie en événements de crues. Du couplage de ces modèles résulte une
méthode originale de prédétermination des crues extrêmes, la méthode SHYPRE (Simulation
d’Hydrogrammes pour la PREdétermination des crues) appartenant à la famille des méthodes dites
par simulation. Le développement de cette méthode est passé par les différentes étapes suivantes,
énumérées rapidement dans ce résumé et développées dans le manuscrit détaillé consacré à cet
aspect de mes recherches : un discours sur une méthode...

Recherches liées au développement de la méthode :
Développement d’un générateur stochastique de pluies horaires (§ B.1) : « pierre
angulaire » de la méthode, le générateur de pluies horaires a été initialement développé dans la
thèse de Cernesson [1993; 1996] sur des données méditerranéennes. La généralisation de son
champ d’application sur des données provenant de régimes climatiques différents a nécessité
des développements supplémentaires remettant en cause certaines hypothèses initiales [Arnaud,
1997; Patrick Arnaud and Jacques Lavabre, 1999a; b; Arnaud et al., 1999; Arnaud et al.,
2007]. L’utilisation de nouveaux outils mathématiques, tels que les copules, ont permis
d’affiner la prise en compte de dépendances entre des variables du modèle [Cantet, 2009;
Cantet and Arnaud, 2014] impactant le comportement du modèle vers les valeurs extrêmes.
Mise en œuvre régionale du générateur de pluie (§ B.2) : cette phase est primordiale pour
obtenir une information régionale sur l’aléa pluviométrique à pas de temps fins. Une descente
d’échelle temporelle statistique est réalisée en paramétrant le générateur de pluie horaire par
une information journalière. La plus grande disponibilité de l’information de pluies journalières
permet alors de faire reposer la régionalisation de l’approche sur une densité de points
d’observation plus dense, rendant cette régionalisation plus performante [Arnaud et al., 2006;
Arnaud et al., 2008a]. L’application et la régionalisation de la méthode ont été réalisées sur le
territoire national métropolitain et outre-mer (plus de 3000 postes étudiés) pour aboutir à une
base de données unique sur l’aléa pluviographique en France, à pas de temps fins [Arnaud and
Lavabre, 2010].
Le couplage avec une modélisation hydrologique parcimonieuse (§ C.1) : une modélisation
hydrologique a été choisie pour répondre à différents critères : modélisation des crues au pas de
temps horaire et fonctionnement événementiel (en période de crue), faible paramétrisation et
bonnes performances [Arnaud and Lavabre, 2002]. Le comportement asymptotique du modèle
(saturation progressive pour des pluies extrêmes) et les problèmes d’équifinalité ont aussi été
abordés au cours de la thèse de Yoann Aubert [2012]. Les hypothèses retenues conduisent à
une modélisation hydrologique à trois paramètres permettant de construire des scénarios de
crues statistiquement équivalents aux observations, et fournissant une information temporelle
complète disponible pour l’estimation de l’aléa (pointe, volume,…) mais aussi pour un
couplage avec d’autres modélisations (hydraulique par exemple).
Régionalisation de l’approche hydrologique (§ C.2) : la nature ponctuelle des pluies simulées
par le générateur et les difficultés liées à la régionalisation du modèle hydrologique ont conduit
à une simplification de l’approche appliquée dans le cadre régionale. Cette approche régionale
a été étudiée au cours de la thèse de Catherine Fouchier [2010] et approfondie au cours de celle
de Yoann Aubert [2012]. Ces travaux ont aboutit à la mise en œuvre de la méthode régionalisée
(SHYREG) sur l’ensemble du territoire français [Yoann Aubert et al., 2014; Organde et al.,
2013], produisant in fine une base de données nationale sur l’aléa hydrologique.

Recherches liées à la mise en œuvre de la méthode :
Analyse des performances/Benchmarking (§ B.5) : l’analyse des performances de la méthode
est nécessaire à la fois pour entrevoir les marges d’améliorations, mais aussi pour justifier son
développement par rapport aux autres méthodes disponibles en recherche et en opérationnel.
Ces comparaisons ont été initiées dès le développement de la méthode [Neppel et al., 2007b;
Tchiguirinskaia et al., 2008], et largement étendues dans le cadre d’un projet de recherche
ANR visant une inter-comparaison nationale des méthodes de prédétermination des crues
(projet ANR Extraflo - https://extraflo.cemagref.fr/ 2009-2013) ([Patrick Arnaud et al., 2014b;
Carreau et al., 2013; Kochanek et al., 2013; B. Renard et al., 2013; Veysseire et al., 2011]).
Les conclusions de ce projet ont mis en évidence de l’intérêt de l’approche pour ces qualités de
justesse et de robustesse dans ces estimations des valeurs extrêmes.
Détermination des incertitudes (§ B.3) : la complexité de la méthode peut laisser penser
qu’elle ait du mal à se caler, et par là, conduire à de fortes incertitudes. Dans un premier temps
ce sont les incertitudes sur les estimations fournies par le générateur de pluie qui ont été étudiée
dans la thèse de Aurélie Muller [Muller, 2006; Muller et al., 2009], dans un cadre bayésien par
des approches de type MCMC. Ces travaux ont montré que les intervalles de confiance de la
méthode développée étaient plus restreints que ceux des méthodes statistiques classiques, de
par une paramétrisation basée sur des valeurs moyennes. Des travaux sur la propagation des
incertitudes à travers les différentes étapes de modélisation ont été réalisé sur l’approche calée
localement [P. Arnaud et al., 2014], afin d’estimer les incertitudes sur les quantiles de débits
proposés. Un travail de thèse en cours, approfondit cette question sur l’approche régionalisée.
Changement climatique (§ B.4) : l’impact du changement climatique sur l’estimation des
valeurs extrêmes a été étudié à travers le « prisme » du générateur de pluie, dans le cadre du
travail de thèse de Philippe Cantet [Cantet, 2009; Cantet et al., 2011]. L’originalité de ce
travail a été d’étudier la stationnarité des pluies extrêmes à travers celle des paramètres du
générateur, définis par des valeurs moyennes moins fortement soumises aux problèmes
d’échantillonnage. Ce même générateur a aussi été calé sur des chroniques de pluies
journalières issues de projections climatiques, aux horizons 2050 et 2100. L’utilisation du
générateur de pluies permet de prendre en compte la non-linéarité entre les précipitations
moyennes et les précipitations extrêmes, non-linéarité difficilement appréhendée par les
modèles climatiques.
Couplage à une modélisation hydraulique (§ C.3.3) : l’intérêt de la méthode de
prédétermination basée sur la simulation est de proposer de multiples scénarios de crues à partir
desquels les distributions de fréquences de diverses caractéristiques liées aux crues peuvent être
extraites. L’utilisation de ces scénarios permet d’étudier de façon relativement exhaustive le
comportement des ouvrages hydrauliques soumis à l’aléa hydrologiques [Carvajal et al.,
2009a; Lavabre et al., 2009] et d’en déduire facilement la distribution de fréquence de leur
défaillance [Arnaud and Aubert, 2014].

L’approche complète, développée par ces différents travaux de recherche, a été mise en œuvre
sur le territoire nationale Français (Métropole et DOM) pour répondre à une demande
opérationnelle croissante de connaissance des aléas liés aux phénomènes hydrométéorologiques
extrêmes. Ce travail a conduit à l’élaboration d’une base de données, mise à disposition des services
de l’état dans le cadre de la mise en œuvre de la Directive Inondation, montrant ainsi l’intérêt de ce
travail de recherche, répondant à la demande de connaissances généralisées sur l’aléa hydrologique.
Des limites liées à la méthode ont aussi étaient déterminées. Des améliorations sont donc
attendues et nécessitent des investigations plus poussées sur les différentes étapes de sa conception.
Parmi ces développements futurs, devant faire l’objet de recherches supplémentaires, il y a :
- La modélisation de bassins au comportement spécifique : les hypothèses de simplification
nécessaires à une mise en œuvre régionale, conduisent à négliger certains processus et à les
modéliser de façon unique, que ce soit dans la modélisation des pluies ou dans la modélisation
de la relation pluie-débit. Des recherches sont donc à réaliser pour mieux prendre en compte
des particularités tels que la typologie des pluies, les échanges nappes-rivières, la fonte nivale
pouvant influer les débits de crues, les fonctionnements karstiques, la prise en compte de
l’abattement hydraulique des champs d’expansion des crues,…
- La descente d’échelle temporelle : le passage à des pas de temps infra-horaires, par des
méthodes de désagrégation de la pluie horaire par exemple, permettra d’adapter l’approche
aux problématiques de l’hydrologie urbaine ou à l’hydrologie des petits bassins montagneux
(crues et laves torrentielles, problème d’érosion,…). La modélisation hydrologique sera aussi
revue pour mieux mettre en avant la sensibilité des bassins à l’intensité des pluies sur des pas
de temps plus petits. Cette descente d’échelle temporelle étant liée à l’étude de bassins
versants de plus en plus petits, des questions relatives à la détermination régionale de la
relation pluie-débit se poseront, avec la recherche de descripteurs pertinents pour la
régionalisation.
- La prise en compte de la non-stationnarité : dans le contexte du changement climatique, les
scénarios fournis par les climatologues peuvent être intégrés dans le générateur de pluie et
être traduits en termes d’évolution du risque hydrologique. La complexité des processus et
leur interaction doivent être étudiées pour réduire les incertitudes liées à des hypothèses
simplificatrices trop fortes. Cela concerne la genèse des pluies, mais surtout la relation pluie-
débit qui va être directement influencée par la pluie mais aussi par les autres variables
climatiques impactant l’état hydrique des sols avant la crue.
- L’étude des incertitudes : les travaux menés sur les incertitudes associées au générateur de
pluie sont à poursuivre pour évaluer les incertitudes associées à la modélisation hydrologique
et aux hypothèses simplificatrices associées, en particulier pour l’approche régionalisée.
L’intérêt, et les performances, que présente l’approche par simulation des processus pour
l’étude de l’aléa hydrologique, nous poussent à poursuivre nos recherches en ce sens. De plus, des
interactions fortes avec les autres recherches effectuées par l’équipe nous font avancer dans le
domaine de la connaissance des risques hydrologiques en milieux non jaugés (prédétermination des
étiages et la prévision des crues rapides). Les résultats de ces recherches présentent un intérêt aussi
pour d’autres discipline nécessitant la connaissance de l’aléa hydro-climatique comme variable de
forçage (hydraulique, hydrobiologie, transfert de polluants,…)

1
Ecole Doctorale 251 – Sciences de l’Environnement
HABILITATION A DIRIGER DES RECHERCHES
Présentée à Aix-Marseille Université
CV DETAILLE
Parcours professionnel ......................................................................................................................................... 2
Responsabilités administratives ........................................................................................................................... 4
Enseignements ...................................................................................................................................................... 5
Encadrements d’étudiants .................................................................................................................................... 7
Irstea – Centre d’Aix-en-Provence

2
PARCOURS PROFESSIONNEL
Patrick ARNAUD
Né le 23 Octobre 1970
Ingénieur de Recherche – 1ère
classe – 4ème
échelon
Responsable de l’équipe Hydrologie de l’Unité de Recherche OHAX (Ouvrages hydrauliques et Hydrologie)
A Irstea (ex Cemagref) – centre d’Aix-en-Provence
Thème de Recherche ARCEAU (Aléas et Risques liés au Cycle de l'EAU)
Diplômes
Qualifications aux fonctions de maître de conférences : section 60 (mécanique) et section 37
(météorologie), année 1999.
Doctorat de l'Université Montpellier II, spécialité "Mécanique, génie mécanique, génie civil",
formation doctorale "Sciences de l'eau dans l'environnement continental", école doctorale
"Géosciences", année 1997.
Diplôme d'ingénieur de l'Institut des Sciences de l'Ingénieur de Montpellier (actuel Polytech
Montpellier), spécialité "Sciences et Technologies de l'Eau" (STE), année 1993.
D.E.A. national d'hydrologie, à l'Université Montpellier II, formation doctorale "Sciences de l'eau dans
l'environnement continental", école doctorale "Géosciences", année 1993.
Expériences professionnelles
Directeur adjoint de l’UR OHAX, Irstea - Centre d'Aix en Provence, depuis janvier 2011.
Animation scientifique de l’équipe Hydrologie de l’UR OHAX.
Programmation et budget de l’équipe Hydrologie.
Ingénieur de Recherche, Irstea - Centre d'Aix en Provence, depuis janvier 2004, UR OHAX.
Recherches et développements autour de méthodes de prédétermination des crues (méthodes par
simulation stochastique : SHYPRE/SHYREG)
Recherches et développements autour de modèles hydrologiques distribués adaptés à la prévision
des crues (modèle GR distribué et méthode AIGA).
Suivi de projets : Projets Interreg FRAMEA (2005-2008) et CRISTAL (2008-2011), ANR
Prediflood (2008-2011), ANR Extraflo (2009-2012), conventions pluri-annuelles Irstea-
MEDDE/DGPR…
Expertises scientifiques et techniques (appuis techniques) – volet hydrologique
Encadrements de thèses et de stages de Master.
Enseignements en hydrologie en formation initiale et continue.

3
Maître de conférences en hydrologie, à l'Ecole Nationale du Génie de l'Eau et de
l'Environnement de Strasbourg (ENGEES), section CNECA n°2, de mars 2001 à déc. 2003.
Recherches dans l’UMR CEVH (Centre d'Écologie Végétale et d'Hydrologie) sur la prévision des
crues par modélisation pluie-débit sur les bassins versants Vosgiens.
Enseignements (en Ecole d’Ingénieur, DEA, Master, Licence) : hydrologie, statistiques,
géostatistiques, informatique, programmation, système de gestion de bases de données,
bureautique.
Attaché Temporaire de l'Enseignement et de la Recherche (ATER) à temps plein à l'Institut des
Sciences de l'Ingénieur de Montpellier (ISIM) (filière : Sciences et Technologies de l'Eau) – Université
Montpellier II, d’octobre 1999 à février 2001.
Recherches sur la variabilité spatiale des champs de pluies et sur la modélisation hydrologique
spatialisée, dans l'équipe "Risques hydrologiques liés aux aléas extrêmes", de l'U.M.R
Hydrosciences.
Enseignements (en Ecole d’Ingénieur) : statistiques, analyse numérique, mathématiques,
informatique, programmation.
Contractuel au Cemagref en tant qu'ingénieur de recherche, dans l'équipe de recherche en Hydrologie
du groupement d'Aix-en-Provence, de décembre 1997 à septembre 1999.
Etude comparative de deux approches de prédétermination des crues
Etude de la prévision des crues par la modélisation conceptuelle.
Procédure de recalage des paramètres en temps réel.
Participation aux activités liées au fonctionnement de l'équipe de recherche.
Doctorant au Cemagref, d’octobre 1994 à novembre 1997.
modélisation stochastique de la pluie horaire ponctuelle.
modélisation conceptuelle globale de la transformation pluie-débit (modèles GR).
couplage de ces modélisations aux pas de temps horaire et journalier.
paramétrisation régionale du modèle de génération de pluie horaire.
Compétences acquises
compétences disciplinaires : Sciences de l’Univers : Hydrologie
autres compétences : modélisation, statistiques, gestion d’équipe (adjoint au chef d’UR) et de
projets (Conventions, ANR, Interreg)
compétences par champ d’application : aléas naturels (inondations, crues), prévision et prévention
des risques naturels.

4
RESPONSABILITES ADMINISTRATIVES
Directeur adjoint de l’Unité de Recherche « Ouvrages hydrauliques et Hydrologie » depuis 2011
Responsable de l’animation scientifique de l’équipe « Hydrologie » composée de six permanents
(quatre ingénieurs-chercheurs, un assistant ingénieur, une assistance de gestion), quatre ingénieurs
contractuels de longue durée (plus d’un an), trois thésards (en moyenne). La taille relativement petite de
l’équipe favorise un travail de proximité et de mise en commun des compétences (méthodes, données et
codes de calcul). Notre équipe gère aussi l’équipement d’un bassin versant de recherche sur le Réal
Collobrier (83) depuis 1966 (17 pluviographes et 11 limnigraphes sur 70 km²).
Responsable de la gestion budgétaire (budget moyen de 700 k€/an sur les 4 dernières années) et de la
programmation des moyens de l’équipe (CDD, sous-traitance, …).
Participation à des projets nationaux et internationaux (projets récents)
Projet CRISTAL - Interreg France-Italie (2008-2011) « Gestion des CRues par Intégration des
Systèmes Transfrontalier de prévision et de prévention des bassins versants ALpins ». Partenariat Irstea-
ARPA Piemonte Financement FEDER-CG06. Responsable de la coordination pour la partie française,
animation et organisation de séminaires. Ce projet a permis de mettre en place d’un radar en bande X
sur le Mont Vial (50km au Nord de Nice), en service depuis 2008. Des outils opérationnels ont été
développés pour fournir une information en temps réel sur le risque de crues, à partir de l’unique
information des Radars Météorologiques. http://www.risknet-alcotra.org/fr/index.cfm/base-donnees-
projets/cristal.html
Projet RHYTMME - CPER FEDER Région PACA (2008-2015) « Risques HYdrométéorologiques
en Territoires de Montagnes et MEditerranéens ». Le projet vise l’élaboration d’une plateforme de
services d’avertissement des risques hydrométéorologiques, exploitant un réseau de Radars de nouvelles
technologies en bande X. Dans le cadre de ce projet 3 nouveaux Radars en bande X ont été installés
dans les Alpes du Sud et une plateforme temps réel fournit des alertes sur le risque de crues. Co-pilotage
Météo-France/Irstea. http://rhytmme.irstea.fr/
Projet ANR PREDIFLOOD (2009-2012) « Prévision distribuée des crues pour la gestion des routes
en région Cévennes-Vivarais ». Ce projet a contribué aux développements et à la comparaison de
modélisations hydrologiques distribuées de prévision des crues adaptées à la prévision des coupures de
routes par submersion. Coordination LCPC, partenariat LCPC, Météo-France, LTHE, UMR PACTE,
Irstea. http://heberge.ifsttar.fr/prediflood/index.php
Projet ANR EXTRAFLO (2009-2013) « Prédétermination des valeurs extrêmes de pluies et de
crues ». Ce projet a permis la comparaison d’approche de prédétermination des pluies et des débits
extrêmes pour tester leurs performances et déterminer leur domaine d’application. Coordination Irstea,
partenariat EDF, HydroSciences Montpellier, Géosciences Montpellier, Météo-France.
https://extraflo.cemagref.fr/
Convention pluriannuelle avec le MEDDE : responsable de la partie « Prévention des Inondations »
pour l’équipe. Subventions de la DGPR (Direction Générale de la Prévention des Risques) pour nos
recherches sur la détermination de l’aléa hydro-météorologique à travers le développement de la
méthode SHYREG.

5
Recherche et maintien de partenariat forts
Collaboration étroite avec Météo-France, en particulier la Direction Sud-Est (brevet commun sur la
méthode AIGA, développement et exploitation de la base SHYREG et co-pilotage du projet CPER
RHYTMME).
MEDDE : conventions annuelles avec la DPPR/BRM (Bureau de Risque Météorologiques) et le
SCHAPI (Service Central d’hydrométéorologie et d’appui à la prévision des inondations)
Unité de Recherche externes dans le cadre de projets ANR (Extraflo et Prediflood) (voir
Partenariats liés aux projets)
Autres partenaires privilégiés : Institut de Mathématiques et Modélisation de Montpellier (UMR
5149) pour la direction de deux thèses, la Maison des Sciences de l’Eau (UMR Hydrosciences)
pour la direction de thèses et la comparaison d’approches, Université Avignon, ENGREF,
IFSTTAR…
Contrat de transfert de méthode vers le privé avec le Bureau d’Etude HYDRIS-Hydrologie.
Activités d’expertise
Organisation de journées thématiques/séminaires : séminaire de clôture du projet CRISTAL (Turin-
Italie), journées techniques dans le cadre du projet CRISTAL (Nice), séminaire « Régionalisation »
dans le cadre de l’animation du TR Arceau,…
Présentations techniques devant des instances : CTPBOH (Comité Technique Permanent des
Barrages et Ouvrages Hydrauliques), tables rondes d’élus (CR PACA), journée technique dans le cadre
de la Directive Inondation (DREALs), IPGR (Institut de Prévention et de Gestion des Risques
Urbains,…
Relecture d’articles scientifiques : 3 articles pour Hydrological Sciences Journal – 3 articles pour
Revue des Sciences de l’Eau.
Conférence invité : « Prise en compte de l’aléa hydrologique dans le dimensionnement et la gestion
des ouvrages hydrauliques » 8ème Journées Fiabilité des Matériaux et des Structures – Aix-en-
Provence, 9-10 avril 2014.
Autres : depuis 2011 - Représentant du personnel (suppléant) dans la commission administrative
paritaire du corps des ingénieurs de recherche – grade 1.
ENSEIGNEMENTS
2001-2003 – Maitre de Conférences à l’ENGEES (Ecole Nationale du Génie de l'Eau et de
l'Environnement de Strasbourg)
Cours en formation initiale 2ème cycle :
Hydrologie (les données, traitements statistiques, modélisation) : T.D. ENGEES et animation de
mini-projets.
Statistiques descriptive, probabilités, inférence statistique : Cours et T.D. ENGEES.
Mathématiques (algèbre linéaire, calcul vectoriel et intégral, équation différentielles) : T.D.
ENGEES.
Informatique, programmation (sous Visual Basic) : T.D. ENGEES

6
Système de Gestion de Base de Données (Access) : T.D. ENGEES.
Cours en formation initiale 3ème cycle :
Méthodes d'interpolation spatiale : Module optionnel du D.E.A. "Systèmes Spatiaux et
Environnement".
Hydrologie : Cours et T.D. en Mastère "Eau Potable et Assainissement".
Approfondissement Excel (solveur, fonctions avancées, macros) : T.D. en Mastère "Déchets".
Activités : Création de cours polycopiés (en statistiques), contrôle des connaissances, jury de soutenance,
jury de rattrapage, jury de recrutement.
1999-2001 –Attaché Temporaire de l’Enseignement et de la Recherche (ATER) à l'I.S.I.M. - STE
Cours en formation initiale 2ème cycle :
Statistiques (probabilité mathématique et distributions théoriques – inférence statistique) : cours et
T.D. en première année
Analyse numérique (méthodes d'interpolation et d'intégration, recherche de racines, résolution de
systèmes d'équations linéaires : approches directes et itératives) : cours et T.D. en première année,
T.P. en deuxième année
Mathématiques (opérateurs différentiels, transformations de Fourier et de Laplace, Filtrage) : T.D. en
première année, encadrement de projets de mathématiques (résolution d'équations aux dérivées
partielles).
Informatique, programmation (programmation sous Visual Basic) : T.P. de première année
Encadrement de deux projets industriels de fin d'étude et de deux stages de troisième année
Intervenant extérieur en formation initiale
Université d’Avignon – Master Hydrogéologie : « Modélisation des crues rapides » 18h/an (2008 à
2014)
Aix-Marseille-Université – Master SET – Filière GEMA et GERINAT – 4 heures de cours en 2014
et prévision de participation au futur CMI (Cursus de Master en Ingénierie).
Intervenant extérieur en formation continue
ENGREF - Montpellier et Mastère Gestion de l'Eau : « Prévision des crues » 12h/an (2008 à
2010)
IFORE AgroParisTech : « Sécurité des barrages » 2h/an (2008 à 2014)
IFORE – Toulouse : Formation des agents des Services de Prévision des Crues 6h/an (2008-2014)
C.N.E.A.R.C. (Centre National d'Études Agronomiques des Régions Chaudes) : cours de
Statistiques en 2001
ENTE (Ecole Nationale des Techniciens de l'Equipement) : Hydrologie 6h/an (1995 à1998)

7
ENCADREMENTS D’ETUDIANTS
Encadrements de thèses
Les encadrements de thèses cités ci-dessous correspondent à un encadrement quotidien de proximité que j’ai
assuré pour des doctorants accueillis dans l’équipe Hydrologie d’Irstea-Aix-en-Provence et dont la direction
était assurée par des directeurs de thèse hors Irstea.
Ces thèses m’ont amené à participer à chaque fois au jury de thèse.
1. Jean ODRY (2014-2016) : Etudiant de l’Ecole Centrale de Nantes « SHYREG amélioration et
incertitudes ». Débutera en novembre 2014, sous la direction de Corine Curt (reprise de la direction de
thèse prévue après mon HDR).
2. Yoann AUBERT (2009-2012) : Encadrement de la thèse « Estimation des valeurs extrêmes de débit par
la méthode SHYREG » sous la direction par Pierre Ribstein, Université Pierre et Marie Curie - UMR
7619 Sisyphe. Thèse soutenue le 12 mars 2012. Actuellement employé en CDI par BRLi.
3. Catherine FOUCHIER (2006-2010) : Encadrement de la thèse « Développement d’une méthodologie
d’alerte du risque d’inondation » sous la direction de Christophe Bouvier – Université Montpellier II –
UMR Hydrosciences. Thèse soutenue le 18 novembre 2010. Actuellement Ingénieure-Chercheuse (IPEF)
dans l’équipe Hydrologie – Irstea Aix-en-Provence
4. Philippe CANTET (2006-2009) : Encadrement de la thèse « Instationnarité climatique : impact sur les
crues. Approche par modélisation de la pluie en débit et aspect régional. » sous la direction de Jean-Noël
Bacro, Université Montpellier II – I3M. Thèse soutenue le 9 décembre 2009. Actuellement en CDD dans
l’équipe Hydrologie – Irstea Aix-en-Provence
5. Stéphanie DISS (2006-2009) : Co-encadrement avec Jacques Lavabre (Irstea-Aix) de la thèse « Apport
de l’imagerie radar pour la connaissance spatio-temporelle des champs de pluie. Utilisation pour une
modélisation prédictive des crues » sous la direction par Pierre Ribstein, Université Pierre et Marie Curie
- UMR 7619 Sisyphe. Thèse soutenue le 22 avril 2009. Actuellement employée en CDI au bureau d’étude
ARTELIA-Grenoble.
6. Aurélie MULLER (2003-2006) : Co-encadrement, avec Michel Lang (Irstea-Lyon), de la thèse
« Analyse du comportement asymptotique de la distribution des pluies extrêmes en France » sous la
direction de Jean-Noël Bacro, Université Montpellier II – I3M. Thèse soutenue le 24 novembre 2006.
Actuellement Maître de Conférences – Agrégée de Mathématiques à l’Université de Lorraine – Institut
Elie Cartan UMR 7502.

8
Comités de pilotage de thèses
1. Carine PONCELET : Calage régional des modèles hydrologiques, utilisé en site non jaugés. AgroParis
Tech. Accueil UR HBAN (Irstea – Antony)
2. David PENOT : « Cartographie de pluies extrêmes et application de la méthode SCHADEX en site non
jaugé ». Thèse soutenue le 17 octobre 2014 à EDF/DTG, Université Grenoble.
3. Annie ANDRIANASOLO : « Généralisation de l'approche d'ensemble pour la prévision hydrologique
dans les bassins versants non jaugés ». AgroParis Tech. Thèse soutenue le 19 décembre 2012.
4. Lionel BERTHET : « Prévision des crues au pas de temps horaire : pour une meilleure assimilation de
l’information de débit dans un modèle hydrologique». Ecole doctorale Géosciences et Ressources
naturelles – AgroParis Tech. Thèse soutenue le 14 février 2010.
5. Nicolas PUJOL : «Développement d’approches régionales et multivariées pour la détection de non
stationnarités d’extrêmes climatiques. Applications aux précipitations du pourtour méditerranéen
français». UMR Hydrosciences, Université Montpellier II. Thèse soutenue en 2008.
Encadrements de stages de niveau Bac +4/5
1. Alix GUILLOT, 2013 : « Détermination des bassins versants français influencés par la présence de zones
karstiques ». Master 2 Pro Eaux Souterraine, Université Joseph Fourier, Grenoble.
2. Anthony CARUSO, 2011 : « Application de la méthode SHYREG dans le cadre de l'Evaluation
Préliminaire des Risques d'Inondation». Master 2 Pro : Université François Rabelais –Tours.
3. Camille MOULARD, 2010 : « Apport des connaissances en hydrogéologie pour la régionalisation d'un
modèle hydrologique». Master 2 Recherche, Université d’Avignon.
4. Yoann AUBERT, 2008 : « Génération d'hydrogrammes de crue pour le dimensionnement d'ouvrages :
recherche d'un paramètre de transfert "équivalent" ». Stage de 3ème
année ingénieur ENPC.
5. Jérémy MICHEL, 2006 : « Prévision de crues sur le bassin du Gardon à Anduze. Etude de différentes
approches : globales et spatialisées. » stage de 3ème
année ingénieur TPE.
6. Malek KARED, 2005 : « Influence de la variabilité spatiale de la pluie sur la paramétrisation des
modèles hydrologiques globaux. », stage de Master2 professionnel.
7. Jean-Luc PAYAN, 2003 : « Prévision des crues sur les petits bassins versants : rôle de la variabilité
spatiale des pluies». Stage de D.E.A.
8. Colette MORVAN, 1999 : « Effets chroniques des Rejets Urbains par Temps de Pluie : recherche d'une
année pluvieuse représentative. ». Stage de 3ème
année ingénieur ISIM
9. Mathieu MONCHY-OLIVET, 1999 : « Recherche d'une procédure d'optimisation en temps réel d'un
modèle hydrologique adapté à la prévision des crues. ». Stage de Maitrise.

1
Ecole Doctorale 251 – Sciences de l’Environnement
HABILITATION A DIRIGER DES RECHERCHES
Présentée à Aix-Marseille Université
LISTE DE PUBLICATIONS
SYNTHESE .......................................................................................................................................................... 2
LISTE DETAILLEE ............................................................................................................................................ 2
Publications d’articles de revues scientifiques à comité de lecture ........................................................................... 2
Publications d’ouvrage ou chapitre d’ouvrage scientifique....................................................................................... 5
Communications scientifiques en congrès ................................................................................................................ 5
Posters ....................................................................................................................................................................... 9
Irstea – Centre d’Aix-en-Provence
2
SYNTHESE
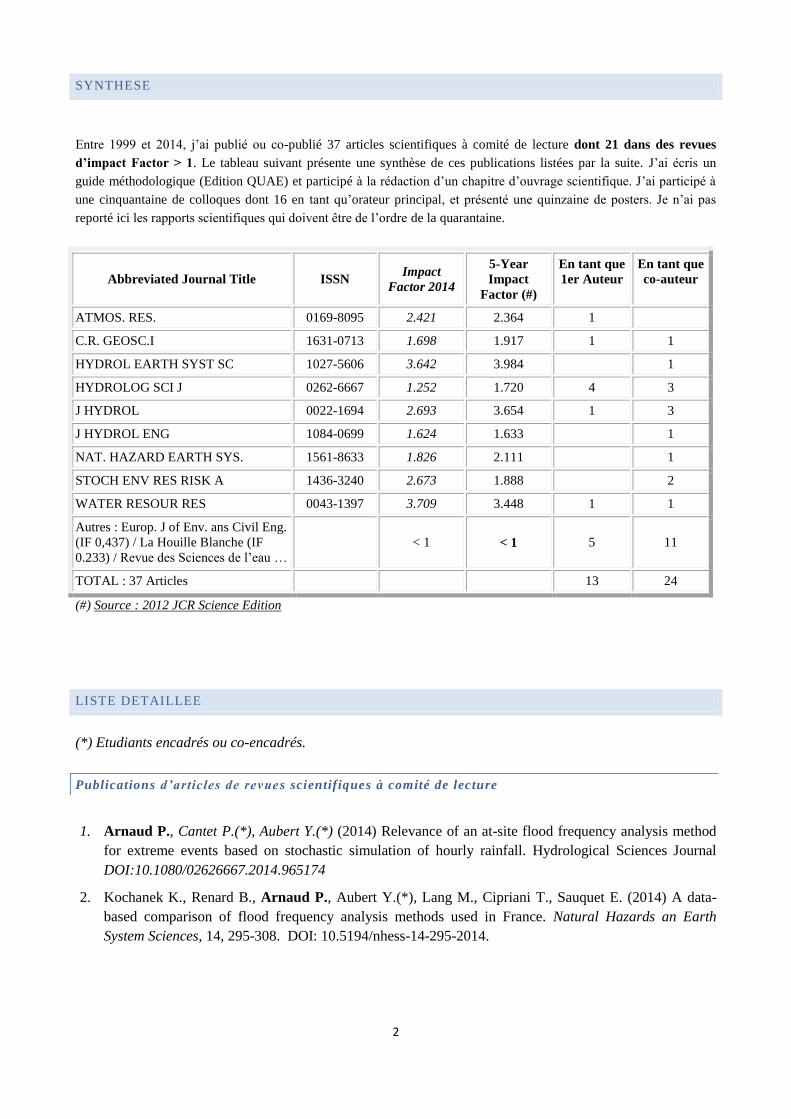
Entre 1999 et 2014, j’ai publié ou co-publié 37 articles scientifiques à comité de lecture dont 21 dans des revues
d’impact Factor > 1. Le tableau suivant présente une synthèse de ces publications listées par la suite. J’ai écris un
guide méthodologique (Edition QUAE) et participé à la rédaction d’un chapitre d’ouvrage scientifique. J’ai participé à
une cinquantaine de colloques dont 16 en tant qu’orateur principal, et présenté une quinzaine de posters. Je n’ai pas
reporté ici les rapports scientifiques qui doivent être de l’ordre de la quarantaine.
Abbreviated Journal Title ISSN Impact
Factor 2014
5-Year
Impact
Factor (#)
En tant que
1er Auteur
En tant que
co-auteur
ATMOS. RES. 0169-8095 2.421 2.364 1
C.R. GEOSC.I 1631-0713 1.698 1.917 1 1
HYDROL EARTH SYST SC 1027-5606 3.642 3.984 1
HYDROLOG SCI J 0262-6667 1.252 1.720 4 3
J HYDROL 0022-1694 2.693 3.654 1 3
J HYDROL ENG 1084-0699 1.624 1.633 1
NAT. HAZARD EARTH SYS. 1561-8633 1.826 2.111 1
STOCH ENV RES RISK A 1436-3240 2.673 1.888 2
WATER RESOUR RES 0043-1397 3.709 3.448 1 1
Autres : Europ. J of Env. ans Civil Eng.
(IF 0,437) / La Houille Blanche (IF
0.233) / Revue des Sciences de l’eau …
< 1 < 1
5
11
TOTAL : 37 Articles
13 24
(#) Source : 2012 JCR Science Edition
LISTE DETAILLEE
(*) Etudiants encadrés ou co-encadrés.
Publications d’articles de revues scientifiques à comité de lecture
1. Arnaud P., Cantet P.(*), Aubert Y.(*) (2014) Relevance of an at-site flood frequency analysis method
for extreme events based on stochastic simulation of hourly rainfall. Hydrological Sciences Journal
DOI:10.1080/02626667.2014.965174
2. Kochanek K., Renard B., Arnaud P., Aubert Y.(*), Lang M., Cipriani T., Sauquet E. (2014) A data-
based comparison of flood frequency analysis methods used in France. Natural Hazards an Earth
System Sciences, 14, 295-308. DOI: 10.5194/nhess-14-295-2014.

3
3. Arnaud P., Aubert Y.(*), Organde D., Cantet P.(*), Fouchier C.(*), Folton N. (2014) Estimation de
l’aléa hydrométéorologique par une méthode par simulation : la méthode SHYREG – Présentation –
Performances – Base de données. La Houille Blanche - Revue Internationale de l’Eau. 2 (2014) 20-26.
4. Cantet P.(*), Arnaud P. (2014) Extreme rainfall analysis by a stochastic model : impact of the copula
choice on the sub-daily rainfall generation. Stochastic Environmental Research and Risk Assessment.
28 (6) 1479-1492. DOI 10.1007/s00477-014-0852-0
5. Defrance D., Javelle, P., Organde, D., Ecrepont, S., Andréassian, V., and Arnaud, P.: Using damage
reports to assess different versions of a hydrological early warning system, Hydrol. Earth Syst. Sci.
Discuss., 11, 4365-4401, DOI : 10.5194/hessd-11-4365-2014, 2014.
6. Lang M., Arnaud P., Carreau J., Deaux N., Dezileau L., Garavaglia F., Latapie A., Neppel L., Paquet
E., Renard B., Soubeyroux J.-M., Terrier B., Veysseire J.-M., Aubert Y.(*), Auffray A., Borchi F.,
Bernardara P., Carre J.-C., Chambon D., Cipriani T., Delgado J.-L., Doumenc H., Fantin R., Jourdain
S., Kochanek K., Paquier A., Sauquet E. and Tramblay Y. (2014) Résultats du projet ExtraFlo (ANR
2009-2013) sur l'estimation des pluies et crues extrêmes. La Houille Blanche - Revue Internationale de
l’Eau. 2 (2014) 5-13.
7. Aubert Y(*), Arnaud P., Ribstein P., Fine J.-A. (2014) La méthode SHYREG débit - application sur
1605 bassins versants en France Métropolitaine. Hydrological Sciences Journal, 59 (5) 2014, 993-1005.
DOI: 10.1080/02626667.2014.902061.
8. Neppel L., Arnaud P., Borchi F., Carreau J., Garavaglia F., Lang M ., Paquet E., Renard B.,
Soubeyroux J.M. and Veysseire J.M. (2014) Résultats du projet Extraflo sur la comparaison des
méthodes d'estimation des pluies extrêmes en France. La Houille Blanche - Revue Internationale de
l’Eau. 2 (2014) 14-19.
9. Paquet E., Aubert Y.(*), Arnaud P., Royet P. et Fine J.A., (2014) Prédétermination des crues et cotes de
projet par les méthodes SHYPRE et SCHADEX – Application à un aménagement fictif sur le Tech. La
Houille Blanche. 5 (2014) 65-72. DOI 10.1051/lhb/2014052
10. Javelle, P., Demargne, J., Defrance, D., Pansu, J., Arnaud, P. (2013) Evaluating flash flood warnings at
ungauged locations: a case study with the AIGA warning system, Hydrological Sciences Journal -
Special issue: Weather Radar and Hydrology. 59(7) 1390-1402. DOI : 10.1080/02626667.2014.923970
11. Carreau, J., Neppel L., Arnaud P. and Cantet P.(*) (2013) Extreme rainfall analysis at ungauged sites
in the South of France : comparison of three approaches." Journal de la Société Française de Statistique
154 (2) 119-138.
12. Tolsa M., Aubert Y.(*), Le Coz J., Renard B., Arnaud P. (2013) Fine J.A., Organde D. Méthode de
consolidation des courbes de tarage pour les crues d’occurrence rare sur le bassin versant expérimental
du Real Collobrier. La Houille Blanche - Revue Internationale de l’Eau n°6, 2013, 16-23. DOI
10.1051/lhb/2013045.
13. Renard B., Kochanek K., Lang M., Garavaglia F., Paquet E., Neppel L., Najib K., Carreau J., Arnaud
P., Aubert Y.(*), Borchi F., Soubeyroux J.-M., Jourdain S., Veysseire J.-M., Sauquet E., Cipriani T. and
Auffray A.. (2013) Data-based comparison of frequency analysis methods: a general framework. Water
Resources Research, vol. 49, p. 1-19, DOI: 10.1002/wrcr.20087
14. Organde D., Arnaud P., Fine J.-A., Fouchier C.(*), Folton N., Lavabre J. (2013) Régionalisation d'une
méthode de prédétermination de crue sur l'ensemble du territoire français : la méthode SHYREG. Revue
des sciences de l'eau / Journal of Water Science 26 (1) 65-78. DOI: 10.7202/1014920ar.

4
15. Javelle P., Pansu J., Arnaud P., Bidet Y., and Janet B. (2012), The AIGA method: an operational
method using radar rainfall for flood warning in the south of France, in Weather Radar and Hydrology,
edited by R. J. Moore, S. J. Cole and A. J. Illingworth, pp. 550-555, Int Assoc Hydrological Sciences,
Wallingford.
16. Organde, D., P. Arnaud, E. Moreau, S. Diss (*), P. Javelle, J. A. Fine, and J. Testud (2012), A rainfall-
runoff model and a French-Italian X-band radar network for flood forecasting in the southern Alps, in
Weather Radar and Hydrology, edited by R. J. Moore, S. J. Cole and A. J. Illingworth, pp. 460-465, Int
Assoc Hydrological Sciences, Wallingford.
17. Hoang C.T., Tchiguirinskaia I, Schertzer D., Arnaud P., Lavabre J. and Lovejoy S. (2012) Assessing
the high frequency quality of long rainfall series. Journal of Hydrology 438-439 (2012) 39-51.
18. Arnaud P., J. Lavabre, Fouchier C.(*), Diss S.(*), Javelle P. (2011). "Sensitivity of hydrological
models to uncertainties in rainfall input." Hydrological Sciences Journal 56 (3) 397-410.
19. Cantet P.(*), J.-N. Bacro, Arnaud P. (2011). "Using a rainfall stochastic generator to detect trends in
extreme rainfall." Stochastic Environmental Research and Risk Assessment 2011 (25) 429-441.
20. Javelle, P., Fouchier C.(*), Arnaud P. Lavabre J. (2010). "Flash flood warning at ungauged locations
using radar rainfall and antecedent soil moisture estimations." Journal of Hydrology, 394 (1-2) 267-274.
DOI 10.1016/j.jhydrol.2010.03.032
21. Lavabre J., Arnaud P., Royet P., Finé J.A., Delichère S., Fang Z.X., Foussard F. (2010). Design flood
or design water level ? The departement du Gard's flood attenuation dams example. Houille Blanche-
Revue Internationale de l’eau, n° 2-2010, p. 58 – 64.
22. Carvajal C., Peyras L., Arnaud P., and Royet P. (2009) Probabilistic Modelling of Flood Water Level
for Dam Reservoirs. Journal of Hydrologic Engineering, 14 (3) 223-232.
23. Carvajal C., Peyras L., Arnaud P., Boissier D., Royet P. (2009) Assessment of hydraulic load acting on
dams including filling variability and stochastic simulations. European Journal of Environmental and
Civil Engineering 01/2009. 13 (4) 399-411.
24. Arnaud P., Lavabre J., Sol B. et Desouches Ch. (2008) Regionalization of an hourly rainfall generating
model over metropolitan France for flood hazard estimation. Hydrological Sciences Journal, 53 (1) 34-
47.
25. Muller A.(*), Arnaud P., Lang M., Lavabre J. (2008) Uncertainties of extreme rainfall quantiles
estimated by a stochastic rainfall model and by a generalized Pareto distribution. Hydrological Sciences
Journal, 54 (3) 417-429.
26. Arnaud P., Fine J.A. and Lavabre J., 2007. An hourly rainfall generation model adapted to all types of
climate. Atmospheric Research, 85 (2) 230-242.
27. Neppel L., Arnaud P., Lavabre J. (2007) Extreme rainfall mapping : comparison between two
approaches in the Mediterranean area. Comptes Rendus de l'Académie des Sciences, séries II-a – Earth
and Planetary Science 339 (2007) 820–830
28. Arnaud P., Lavabre J., Sol B. et Desouches C. (2006). Rainfall risk of France. La Houille Blanche –
Revue Internationale de l’Eau (5) 102-111.
29. Kreis N., Leviandier T. and Arnaud P. (2005) Hydrological and hydraulics modelling to assess
mitigation effectiveness of floodplain reconnection in the context of a mountain river. International
Journal of River Basin Management Vol. 3, n°2, 117–123.

5
30. Arnaud P., Lavabre J. (2002) Coupled rainfall model and discharge model for flood frequency
estimation. Water Resources Research, 38 (6) 11-1-11-11, DOI : DOI: 10.1029/2001WR000474.
31. Arnaud P., Bouvier C., Cisneros L. and Dominguez R. (2002) Influence of rainfall localization on the
flood study. Journal of Hydrology, 260 (1-4) 216-230.
32. Leviandier T., Lavabre J., Arnaud P. (2000) Rainfall contrast enhancing clustering processes and flood
analysis.Journal of Hydrology, 240 (1-2) 62-79.
33. Arnaud P., Lavabre J. (2000) La modélisation stochastique des pluies horaires et leur transformation en
débits pour la prédétermination des crues. Revue des Sciences de l'Eau, 13 (4) 441-462.
34. Arnaud P., Lavabre J. (1999) Using a stochastic model for generating hourly hyetographs to study
extreme rainfalls. Hydrological Sciences Journal, 44 (3) 433-446.
35. Arnaud P., Lavabre J. (1999) A new approach for extreme rainfall estimation. Comptes Rendus de
l'Acadamie des Sciences, séries II-a – Earth and Planetary Science, Paris, 328 (9) 615-620.
36. Lavabre J., Arnaud P., Masson J.M., Folton N. (1999) Apport de la modélisation de la pluie en débit
pour la connaissance de la ressource en eau et la prédétermination des crues. La Houille Blanche –
Revue Internationale de l’Eau, 54, n°3-4, 67-72.
37. Arnaud P., Lavabre J., Masson J.-M. (1999) Amélioration des performances d’un modèle stochastique
de génération de hyétogrammes horaires. Revue des Sciences de l'Eau, 12 (2) 251-271.
Publications d’ouvrage ou chapitre d’ouvrage scientifique
Arnaud P., Lavabre J. (2010). Guide méthodologique sur l’approche SHYPRE. Partie 1 : analyse du
risque pluvial. Edition QUAE, 125 pages.
Fourmigué P., Arnaud, P. (2009). Modèle à réservoirs en hydrologie. De la goutte de pluie jusqu'à la mer
- Traité d'hydraulique environnementale. Volume 4. Modèles mathématiques en hydraulique maritime et
modèles de transport. Lavoisier; Hermès Science Publications, Paris, p. 227 – 238
Communications scientifiques en congrès
1. Arnaud P., Paquet E., Aubert Y.(*), Royet P., Fine J.A., Lang M. (2015) Estimation de la distribution
de cotes de retenue par simulation stochastique pluie-débit. Cas d'un barrage fictif. Vingt cinquième
congrès des grands barrages, 2015 Norvège, juin 2015.
2. Organde D., Javelle P., Demargne J., Arnaud P., Caseri A., Fine J.-A., de Saint Aubin C. (2015)
Implementing the national AIGA flash flood warning system in France. Geophysical Research Abstracts
Vol. 17, EGU2015-12820 - EGU General Assembly 2015.
3. Arnaud P. et Aubert Y(*). (2014) Prise en compte de l’aléa hydrologique dans le dimensionnement et la
gestion des ouvrages hydrauliques – 8ème
Journées Fiabilité des Matériaux et des Structures – Aix-en-
Provence, 9-10 avril 2014.

6
4. Cantet P.(*), Arnaud P. (2014) Using a stochastic hydrological model to study the sensitivity of flood
frequency to climate change. Geophysical Research Abstracts, vol 16, EGU2014-7220. EGU General
Assembly 2014.
5. Arnaud P, Aubert Y.(*), Organde D., Cantet P. (*), Fouchier C. (*), Folton N. (2013) Estimation de
l’aléa hydrométéorologique par une méthode par simulation : la méthode SHYREG : Présentation –
performances – bases de données. Congrès SHF : « Evénements extrêmes d’inondation 2013 », Lyon,
13-14 novembre 2013.
6. Paquet E., Aubert Y.(*), Arnaud P., Royet P, Fine J.A. (2013) Prédétermination des crues et côtes de
projet par les méthodes SHYPRE et SCHADEX – Application à un aménagement fictif sur le Tech.
Congrès SHF : « Evénements extrêmes d’inondation 2013 », Lyon, 13-14 novembre 2013.
7. Folton, N., Arnaud, P. (2012) Régionalisation d'une modélisation hydrologique distribuée pour la
cartographie des débits d’étiage. Application au territoire français. 9ème congrès international
GRUTTTEE 2012, Aix-en-Provence, 29-31 octobre 2012 29/10/2012-31/10/2012, Aix-en-Provence,
FRA. 5 p.
8. Folton N., Tolsa M., Arnaud P. (2012). Le Bassin de recherche du Réal Collobrier - Étude des
processus hydrologiques en milieu méditerranéen a échelle fine. 50 ans de l'Orgeval 20/11/2012-
23/11/2012, Paris, FRA. Actes du Colloque 50 ans de l'Orgeval et 37èmes journées du GFHN. 7 p.
9. Pons F., Bader B., Caruso A., Arnaud P. and Leblois E. (2012) Cartino Project: A French automatized
hazard floodmap. Simhydro 2012 conference, Nice 12-14/10/2012.
10. Kochanek, K., Renard, B., Lang, M., Arnaud, P. (2012) Comparison of several at-site flood frequency
models on a large set of French discharge series. 2nd European Conference of Flood risk management
20/11/2012-22/11/2012, Rotterdam, NLD. Comprehensive Flood Risk Management. p. 183-190.
11. Organde D, Arnaud P, Moreau E, Diss S. (*), Javelle P, Fine J-A, (2012) A rainfall–runoff model and a
French-Italian X-band radar network for flood forecasting in the southern Alps, Weather Radar and
Hydrology, Proceedings of a symposium held in Exeter, UK, April 2011, IAHS Publ. 351, 2012, 460-
465
12. Pons F., Bader B., Chassé P., Caruso A., Arnaud P., Leblois E.. Cartino Project : An French
automatized hazard floodmap. In proceeding of Simhydro 2012, at Sophia-Antipolis, Nice.
13. Javelle P., Pansu J., Arnaud P., Bidet Y., Janet B., The AIGA method: an operational method using
radar rainfall for flood warning in the south of France, Weather Radar and Hydrology, Proceedings of a
symposium held in Exeter, UK, April 2011, IAHS Publ. 351, 2012, 550-555
14. Lavabre, J., Arnaud, P.,Royet, P.,Fine, J.A.,Delichère, S., Fang, Z.X., Foussard, F. Crues de projet ou
cotes de projet ? Exemple des barrages écrêteurs de crue du département du Gard. Paris, Colloques SHF
« Dimensionnement et Fonctionnement des Evacuateurs de crues » des 20-21 janvier 2009.
15. Peyras, L., Arnaud, P., Royet, P., Carvajal, C., Boissier, D. - 2009. Modélisation probabiliste de la cote
de remplissage d'un barrage. Colloque CFBR-SHF : «Dimensionnement et fonctionnement des
évacuateurs de crues» 20/01/2009-21/01/2009, Paris, FRA. 8 p.
16. Javelle, P., Berthet, L., Arnaud, P., Lavabre, J., Perrin, C. - 2008. Comparaison de deux versions du
modèle GR pour la prévision des crues sur un grand échantillon de bassins versants français. Colloque
SHF-191e CST «Prévisions hydrométéorologiques», Lyon, 18-19 novembre 2008. Colloque SHF-191e
CST «Prévisions hydrométéorologiques», 18/11/2008 - 19/11/2008, Lyon, FRA. 5 p.
17. Lavabre, J., P. Arnaud and J.-P. Mizzi (2008). La méthode AIGA : un dispositif d'alerte des crues.
Description et aspects opérationnels. . Colloque SHF - 191e CST-«Prévisions hydrométéorologiques», ,
Lyon, 18-19 novembre 2008. .
18. Lavabre J., Arnaud P., Folton N. Impact d’un incendie de forêt sur l’hydrologie d’un petit bassin
versant méditerranéen. In Publication S.H.F. L’eau, l’homme et la nature. 24èmes journées de
l’hydraulique. Congrès de la Société Hydrotechnique de France. Paris, 18-20 septembre 1996, pages
151-162.

7
19. Moreau, E., Testud J., Organde D., Arnaud, P., Javelle P., Fiquet, M. (2012). RAINPOL a web
platform for hydro meteorological monitoring from an X-band dual polarization radar. Seminary ERAD
Toulouse.
20. Cremonini R., Lavabre J., Arnaud P., Fiquet M., Ponzone M., Testud J. et Organde D. (2010)
CRISTAL : a project to manage hydrological risk in alpine areas by x-band polarimetric radar. ERAD
2010 - the sixth european conference on radar in meteorology and hydrology
21. Garavaglia F., Paquet E., Lang M., Renard B., Arnaud P., Aubert Y., Carre J.M., and Bernardara P.,
Flood risk assessment in France: comparison of extreme flood estimation methods (EXTRAFLO
project, action 7). Geophysical Research Abstracts, Vol. 14, EGU2012-6111, 2012, EGU General
Assembly 2012.
22. Renard, B., Kochanek, K., Lang, M., Arnaud, P., Aubert, Y., Cipriani, T., Sauquet, E. - 2012. A data-
based comparison of flood frequency analysis approaches used in France. AGU Fall Meeting
02/12/2012-07/12/2012, San Francisco, USA. 15 p.
23. Maire A, Fouchier C., Arnaud P., Aubert Y. (2011). Assessment of the daily areal reduction factor of
precipitations with distributed rainfall data: a means of improvement of a prediction method of extremes
events in France. EGU General Assembly, May 2012, Vienna.
24. Naulin P., Payrastre O., Gaume E., Delrieu G., Arnaud P., Lutoff C. and Vincendon B., Prediflood: A
French research project aiming at developing a road submersion warning system for flash flood prone
areas. Vol 12, Plinius 12 47, 12 th Plinius Conference on Mediterranean Storms, Corfus Island Greece,
Sept 2010.
25. Tchiguirinskaia I., Arnaud P., Schertzer D. and Lavabre J. The Return Periods of Hydro-
Meteorological Extremes: Comparison of two Stochastic Models of Heavy Rains. EGU General
Assembly 2009, vol 11, EGU2009 10256.
26. Tchiguirinskaia I., Arnaud P., Schertzer D. and Lavabre J. Extrêmes multifractals, incertitudes et
estimation des quantiles hydrologiques, enjeux pour la région parisienne. Colloque CNFSH-2009, 11-12
Juin 2009, Paris.
27. Tchiguirinskaia I., Arnaud P., Lavabre J. and Schertzer D., 2008. Intercomparison of two stochastic
methods to simulate heavy rains and floods. Abstract 2nd International HyMeX Workshop, 2-4 juin
2008. Ecole Polytechnique, Palaiseau, France
28. Lang M., Muller A., Arnaud P., Lavabre. Comparison of uncertainties in extreme rainfall distribution
using a QPD distribution and the SHYPRE regional stochastic rainfall model. Unesco workshop:
Modelling Floods and Droughts, Uncertainty estimates for Water Resources Management. Prague, 14-
15 march 2008.
29. Diss, S., Arnaud, P., Lavabre J. et Testud J., Contribution of the rain rate by radar in operational flood
forecasting. International Symposium “Weather Radar and Hydrology 2008”, Grenoble, 10-12 mars
2008.
30. Cantet, P., Arnaud, P. - 2008. Impact of climate change on hydrological risks. World Water Congress,
Montpellier 01/09/2008-04/09/2008, Montpellier.
31. Fouchier C., Arnaud P., Lavabre J., Mizzi J.P. AIGA: an operational tool for flood warning in southern
France. Principle and performances on Mediterranean flash floods. Abstract EGU Vienne, AUT, 15-20
avril 2007.
32. Lavabre J., Fourmigue P., Arnaud P., Fromental A.M., Fine J.A. Utilisation de modèles de
transformation de la pluie en débit pour la prévision des crues. Analyse des performances de différentes
modélisations, Q87, R29, Vol IV – 22éme congrès des grands barrages, Barcelone, juin 2006, 407-428.
33. Arnaud P., Lavabre J., Sol B., Desouches. Cartographie de l'aléa pluviographique de la France.
Colloque SHF sur les Valeurs rares et extrêmes de débit pour une meilleure maîtrise des risques, Lyon,
15-16 Mars 2006. 14 p.

8
34. Fine J.A., Arnaud P., Fouchier C., Lavabre J., 2005. Intérêt d'un modèle spatialisé pour la prévision des
crues sur un bassin versant non homogène. Actes du Colloque SIRNAT, Montpellier 2005.
35. Arnaud P., Lavabre J., Sol B., Desouches Ch., 2005. Cartographie de l'alea pluviographique de la
France, Actes du colloque « Système d’information et risques naturels (SIRNAT) », Montpellier – 10-
11 mars 2005.
36. Lavabre J., Folton N., Arnaud P., Pasquier C., 2001. Prédétermination régionale des débits de crue ;
exemple d'application à la Corse. International seminar – Hydrology of the Mediterranean Regions,
Montpellier, 11-13 october 2000, 357-365.
37. Leviandier T., Kreis N., Arnaud P., Drogue G., Bariz R., and Herrmann A., 2001. Sensitivity analysis
of hydraulic and rainfall-runoff models as premiminary investigations of climatic change influence on
flood risk. In Management of Hydroclimatologic risks in the Rhin Meuse basin. Luxembourg Centre de
recherches public Gabriel Lippmann. Novembre 2001.
38. Arnaud P., Modèle de prédétermination des crues basé sur la simulation : méthode SHYPRE :
application à la région méditerranéenne. International seminar – Hydrology of the Mediterranean
Regions, Montpellier, 11-13 october 2000.
39. Lavabre J., Arnaud P. Prédétermination des pluies extrêmes. Colloque SHF - Catastrophes naturelles –
Aléas extrêmes et niveaux de protection de référence. 10 octobre 2000 – Paris.
40. Arnaud P., Lang M. et Lavabre J., 1999. Estimation des probabilités de crues extrêmes – Comparaison
des méthodes SHYPRE et AGREGEE. Séminaire de l'Action scientifique structurante 1998 – Risques
naturels – 19 mars 1999, Paris.
41. Lavabre J., Folton N., Arnaud P. et Martin C. Impact d’un incendie de forêt sur l’hydrologie d’un petit
bassin versant méditerranéen ; incertitudes liées à la méthodologie d’analyse et à la métrologie.
Séminaire Les bassins versants expérimentaux de Draix, Draix Le Brusquet Digne, 22-24 octobre 1997,
p. 41-52.
42. Arnaud, P., Lavabre, J. - 1999. Modèle de prédétermination des crues basé sur la simulation : méthode
SHYPRE. Colloque de la SHF crues de la normale à l'extrême, Lyon, 10-11 mars 1999. 6 p.
43. Arnaud, P., Lavabre, J. - 1999. Flood predetermination model based on hourly rainfalls stochastic
generation. Poster EGS XXIII General Assembly session NH2-03: flood hazards an flood risk regional
analysis of extremes, Nice, 20-24 avril 1998. 1 p.
44. Arnaud P., Lavabre J., Folton N., Michel C. Hydrological response of a little mediterranean basin
flows after fire. Conférence internationale : XXIII General assembly, E.G.S. (European Geophysical
Society), Nice, 20-24 april 1998.
45. Arnaud P., Picard S., Lavabre J. et Douguedroit A.. Hourly rainfall stochastic generation : application
on French mediterranean seaboard. XXIII General assembly, E.G.S. (European Geophysical Society),
Nice, 20-24 april 1998.
46. Lavabre J., Arnaud P., Masson J.M., Folton N. Apport de la modélisation de la pluie en débit pour la
connaissance de la ressource en eau et la prédétermination des crues. In Publication S.H.F. L’école
française de l'eau au service du développement mondial. 25èmes journées de l’hydraulique. Congrès de
la Société Hydrotechnique de France. Chambéry, 15-18 septembre 1998, pages 349-358.
47. Arnaud P., Picard S., Lavabre J., Douguedroit A. Modélisation stochastique des pluies horaires.
Application à la région méditerranéenne française. Association Internationale de Climatologie, 10ème
colloque international de climatologie, Québec, 9-12 septembre 1997, 8 pages.
48. Arnaud P., Lavabre J. Simulation du fonctionnement hydrologique d’une retenue d’eau. Comité
National Suisse des Grands Barrages, Research in the Field Dams, CIGB-ICOLD, Crans-Montana,
Suisse, 7-9 septembre 1995, pages 641-652.
49. Arnaud P., Lavabre J. Contribution of hyetograph simulation to the knowledge of extreme rainfalls.
Rainfall modelling, 1995 annual general meeting à l'Institute of Environmental and Biological Sciences,
Lancaster University, 17 may 1995.

9
50. Arnaud P., Lavabre J., Couplage de modèles de simulation de hyétogrammes aux pas de temps horaire
et journalier. Séminaire Inter-chercheurs – Les modèles au Cemagref. Gif-sur-Yvette - 13 et 13 octobre
1995, p.23-31.
51. Lavabre J., Arnaud P. Apport de la modélisation des hyétogrammes horaires pour la connaissance des
pluies extrêmes. Méthodes statistiques et Bayesiennes en hydrologie, Conférence internationale en
l’honneur de Jacques BERNIER, UNESCO, Paris, 11-13 septembre 1995, chapitre II, 10 pages.
52. Arnaud P., Lavabre J., 1997. Simulation du fonctionnement hydrologique d’un bassin versant :
application à la conception et à la gestion d’un barrage. In Ingénieries-E.A.T., n°10, pages 43-54.
53. Lavabre J., Arnaud P., Folton N., Michel C., 1996. Les écoulements d’un petit bassin versant
méditerranéen après incendie de forêt. In Ingénieries-E.A.T., n°7, pages 21-30.
Posters
1. Aubert Y., Arnaud P., Fine J.-A., Cantet P., 2014. Rainfall frequency analysis using a hourly rainfall
model calibrated on weather patterns : application on Reunion Island. Geophysical Research Abstracts,
vol 16, EGU2014-7220.EGU General Assembly 2014.
2. Folton N., Cantet P., Arnaud P., Fouchier C. - 2012. Prise en compte de scénarios de changement
climatique dans des méthodes de cartographie de l'aléa hydrologique : application aux pluies intenses et
aux débits d'étiage.. CNFCG Les changements Globaux : enjeux et défis, Toulouse, 9-11 juillet 2012
09/07/2012-11/07/2012, Toulouse, FRA. 1 p.
3. Defrance, D., Javelle, P., Arnaud, P., Andreassian, V., Moreau, E., Meriaux, P. - 2011. Flash flood
warning methods: how to evaluate them? An application in the French Southern Alps using the AIGA
warning method and different rainfall input data.. EGU General Assembly 2011 03/04/2011-
08/04/2011, Vienna, AUT.
4. Lang, M., Renard, B., Kochaneck, K., Sauquet, E., Garavaglia, F., Paquet, E., Soubeyroux, J.M.,
Jourdain, S., Veysseire, J.M., Borchi, F., Neppel,, L., Najib, K., Arnaud, P., Aubert, Y., Auffray, A. -
2011. Data-based comparison of frequency analysis approaches: methodological framework and
application to rainfall-runoff data in France. EGU General Assembly 2011 03/05/2011-08/05/2011,
Vienna, AUT. 1 p.
5. Fouchier C., Javelle P., Arnaud P., DeFrance D. (2010). Looking at catchments in colors: why not? But
what if we can't even look at them? EGU Leonardo Topical Conference on the hydrological cycle
“Looking at Catchments in Colors”, 10-12 November 2010, Luxembourg.
6. Fouchier C., Javelle P., Diss S., Arnaud P., Lavabre J., and Organde D., A simple distributed model for
flood forecasting. Poster EGU General Assembly 2010.
7. Lang, M., Renard, B., Kochanek, K., Sauquet, E., Garavaglia, F., Paquet, E., Soubeyroux, J.M.,
Jourdain, S., Veysseire, J., Borchi, F., Neppel, L., Najib, K., Arnaud P., Aubert, Y., Auffray, A. -.
Data-Based Comparison of Frequency Analysis Approaches: Methodological Framework and
Application to Rainfall / Runoff Data in France. AGU Fall Meeting, 13/12/2010 - 17/12/2010, San
Francisco, USA. 1 p.
8. Javelle, P., Defrance, D., Aubert, Y., Diss, S., Cantet, P., Tolsa, M., Fouchier, C., Arnaud, P., Lavabre,
J., Breil, D. - 2010. Application of the AIGA flash flood warning method to the 15th of June 2010 event
on the Nartuby and Argens rivers (South of France). EGU Leonardo Topical Conference on the
hydrological cycle Looking at Catchments in Colors 10/11/2010-12/11/2010, Luxembourg, LUX. 1 p.
9. Javelle, P., Fouchier, C., Arnaud, P., Lavabre, J. - 2010. Flash flood warning at ungauged locations
using radar rainfall and antecedent soil moisture estimations.. European Geosciences Union General
assembly 2010, Vienna, AUT, 2-7 May 2010 02/05/2010-07/05/2010, Vienna, AUT. 1 p.

10
10. Aubert, Y. Arnaud P. (2009). Comportement vers les valeurs extrêmes des distributions de fréquence
des pluies et des débits : réflexions sur l’équifinalité des modèles de transformation de la pluie en débit.
Poster Journée Doctoriale ENTPE.
11. Javelle P., Berthet L., Arnaud P., Lavabre J., 2008. Monsters in flood forecasting: can we reduce the
number of 'outlier' catchments by using two different model initialization strategies?, Court of Miracles
Workshop, Paris, June 18th-20th 2008.
12. Cantet, P., Arnaud, P. - 2008. Impact of Climate Change on Extreme Rainfall in France Through Trend
Detections in Average Climatic Characteristics. AGU fall, San Francisco, USA, December 2008 San
Francisco, USA.
13. Arnaud P., Modèle de prédétermination des crues basé sur la simulation : méthode SHYPRE :
application à la région méditerranéenne. International seminar – Hydrology of the Mediterranean
Regions, Montpellier, 11-13 october 2000.
14. Arnaud P., Lavabre J. Modèle de prédétermination des crues basé sur la simulation : méthode
SHYPRE. Crues de la normale à l'extrême – Colloque SHF - 160ème session du CST – Lyon, 10-
11/03/1999.
15. Arnaud P., Lavabre J. Flood predetermination model based on hourly rainfalls stochastic generation.
XXIII General assembly, E.G.S. (European Geophysical Society), Nice, 20-24 april 1998, Annales
geophysicae, part II: hydrology, oceans and atmosphere, supplement II to volume 16, 1999.
16. Arnaud P., Lavabre J. Apport de la modélisation des hyétogrammes horaires pour la connaissance des
pluies extrêmes. Méthodes statistiques et Bayesiennes en hydrologie, la Conférence internationale en
l’honneur de Jacques BERNIER, UNESCO, Paris, 11-13 septembre 1995.

1
Ecole Doctorale 251 – Sciences de l’Environnement
HABILITATION A DIRIGER DES RECHERCHES
Présentée à Aix-Marseille Université
Manuscrit détaillé
Partie « Synthèse des activités de recherches et projet scientifique »
L’aléa hydrométéorologique : estimation régionale
par simulation stochastique des processus.
Irstea – Centre d’Aix-en-Provence

2
SOMMAIRE GENERAL
Sommaire général ...................................................................................................................... 2
Environnement scientifique ...................................................................................................... 3
A – Contexte et état de l’art sur la prédétermination des crues ................................ 4
A.1 L’aléa hydrométéorologique .................................................................................... 5
A.2 Les « approches probabilistes directes » .................................................................. 8
A.3 Les « approches par simulation » ........................................................................... 14
A.4 La démarche scientifique choisie ........................................................................... 20
B – Simulation de pluies horaires pour l’estimation de l’aléa pluviographique ........ 21
B.1 Développement d’un générateur stochastique de pluies horaires. ......................... 23
B.2 Estimation de l’aléa pluvial en site non instrumenté ............................................. 37
B.3 Etude des incertitudes du générateur de pluie ........................................................ 44
B.4 Etude de la non-stationnarité des pluies extrêmes ................................................. 52
B.5 Conclusion et perspectives ..................................................................................... 60
C - Estimation de l’aléa hydrologique par la simulation des crues ......................... 62
C.1 Modélisation hydrologique parcimonieuse ............................................................ 65
C.2 Mise en œuvre régionale de l’approche par simulation ......................................... 71
C.3 Evaluation des performances de la méthode et applications .................................. 79
C.4 Etude des incertitudes de la méthode par simulation ............................................. 87
D – Conclusions et Persepctives scientifiques ............................................................ 97
D.1 Modélisation des processus .................................................................................... 98
D.2 Impact du changement global sur les extrêmes hydrologiques ............................ 102
D.3 Ouverture vers d’autres thématiques. ................................................................... 103
E - Références bibliographiques citées ........................................................................ 107

3
ENVIRONNEMENT SCIENTIFIQUE
Mes travaux de recherche, menés au sein de l’EPST Irstea (ex-Cemagref), dépendent du
thème de recherche ARCEAU (Aléas et Risques liés au Cycle de l’EAU). Ce thème de recherche
regroupe des équipes de plusieurs centres (Antony – Aix-en-Provence – Lyon – Montpellier) qui
travaillent sur des activités couvrant «l’étude du cycle de l’eau, la connaissance et la gestion des
ressources, des aléas et des risques associés (inondation, sècheresse, pollution) et l’évaluation du
changement global » (http://www.irstea.fr/la-recherche/themes-de-recherche/arceau). L’équipe du
centre d’Aix-en-Provence est spécialisée en Hydrologie et fait partie de l’Unité de Recherche
OHAX (Ouvrages hydrauliques et Hydrologie d’AiX). La proximité avec des chercheurs travaillant
sur les ouvrages hydrauliques a aussi conduit l’équipe à s’intéresser aux problèmes liés à la
protection des ouvrages hydrauliques (barrages, digues,…) face au risque de crues.
L’équipe de recherche, dont j’ai la charge en tant qu’animateur scientifique depuis 2011,
travaille sur les risques hydrologiques à partir du développement d’approches basées sur la
modélisation des processus. « L'objectif est de fournir des connaissances sur le risque hydrologique
(excès et pénurie) en tout point d'un territoire et donc en milieux non jaugés. Ces méthodes
régionales s'appuient sur l'exploitation de l'ensemble des données disponibles sur ce territoire. Le
domaine d'étude actuel est le territoire Français, DOM compris.» http://www.irstea.fr/la-
recherche/unites-de-recherche/ohax/hydrologie. Cet objectif se décline en des approches
probabilistes (prédétermination des crues et des étiages) et en des approches prévisionnistes
(prévision/alerte en crue). L’usage d’informations hydro-climatiques (longues séries chronologiques
de pluies et de débits, et information spatiale fournie par les radars météorologiques) et de
modélisations du processus de transformation de la pluie en débit, nous permet aussi d’appréhender
l’impact du changement global sur l’évolution de l’aléa hydrologique.
Pour ma part, mon activité de recherche principale s’est orientée vers l’étude de l’aléa lié aux
crues. Cette recherche sur la prédétermination des crues est abordée par une approche originale
basée sur la simulation de scénarios de crues à pas de temps fins, appliquée à des jeux de données
exhaustifs, puis régionalisée. L’objectif est d’appréhender cet aléa dans toute sa composante
temporelle et fréquentielle, en fournissant l’ensemble des caractéristiques nécessaires à la
connaissance de l’aléa hydrométéorologique à partir d’une même modélisation. Ces travaux ont été
menés dans le cadre de ma thèse [Arnaud, 1997], après ceux initiés par Cernesson [1993], puis dans
le cadre de projets de recherches (subventions de la Direction Générale de la Prévention des
Risques du MEDDE, projet ANR Extraflo) et lors de thèses accueillies par l’équipe et que j’ai
encadrées ou co-encadrées [Aubert, 2012; Cantet, 2009; Diss, 2009; Fouchier, 2010; Muller, 2006].
Ils m’ont permis d’approfondir mes connaissances dans des domaines tels que la statistique, la
modélisation stochastique, la modélisation hydrologique, l’étude des incertitudes, la régionalisation,
etc. Ce sont ces points qui sont présentés à travers cette synthèse, portant d’une part sur l’estimation
de l’aléa pluvial et d’autre part sur l’estimation de l’aléa hydrologique, en faisant référence au
mieux aux travaux de recherches auxquels j’ai participé directement ou à travers l’encadrement
d’étudiants.

4
A – CONTEXTE ET ETAT DE L’ART SUR LA
PREDETERMINATION DES CRUES
De façon un peu béotienne, la prédétermination des crues pose les
questions suivantes :
- Quelle est la hauteur d’eau qui peut être atteinte dans cette rivière ?
- Cette hauteur d’eau est-elle fréquente ou rare ?
- Comment cette hauteur d’eau évolue-t-elle le long de la rivière ?
- La rivière voisine présente-t-elle les mêmes caractéristiques ?
- Ces caractéristiques sont-elles immuables dans le temps ?
- Quels sont les facteurs pouvant expliqués leur variation ?
- Dans quelle mesure peut-on se protéger face à la montée des eaux ?
- …
Autant de questions que se posent toutes personnes, habitant ou devant gérer des activités à
proximité d’un cours, et soumises au risque de voir ce cours d’eau « sortir de son lit » et provoquer
des inondations...
La prédétermination des crues est donc un champ de recherche de l’hydrologie qui vise à
répondre à ces questions, en s’appuyant sur l’observation du phénomène, afin de se prémunir du
risque d’inondation. La difficulté de cette thématique réside dans la nécessité de fournir une
information sur un phénomène très variable et insuffisamment observé. La recherche de méthodes
d’extrapolation est donc nécessaire : extrapolation en fréquence pour estimer des phénomènes
extrêmes par nature peu observés et extrapolation dans l’espace pour estimer le phénomène le long
d’un réseau hydrographique instrumenté très ponctuellement…
Le pont Saint Nicolas lors de la crue du Gard pendant la crue des 8-9 septembre 2002.
Pendant la crue Après la crue
Repères de crues du
Vidourle à Sommières

5
A.1 L’aléa hydrométéorologique
L’aléa hydrométéorologique peut être défini comme « un processus ou phénomène de nature
atmosphérique, hydrologique ou océanographique susceptible de provoquer des pertes en vies
humaines, des blessures ou autres impacts sur la santé, des dégâts matériels, la perte des moyens
de subsistance et des services, des perturbations sociales et économiques ou une dégradation
environnementale » [UNISDR, 2009]. Il inclut donc un très grand nombre de phénomènes naturels
liés aux grandeurs climatiques telles que le vent (tornades, tempêtes, submersions marines..), les
précipitations (cyclones, orages, neige, grêle,..), les températures (vagues de chaleurs,…), les
ruissellements associés aux précipitations (crues soudaines, inondation,…). Dans le cadre de mes
recherches, et donc pour la suite de mes propos, l’aléa hydrométéorologique étudié se restreindra
aux pluies intenses et aux crues qui en résultent.
Situées au premier rang des catastrophes naturelles dans le monde, les inondations causent en
moyenne 20 000 victimes par an. Sur le territoire français parcouru par 160 000 km de cours d'eau,
c’est une surface de 22 000 km² qui est reconnue particulièrement inondable, répartie sur 7 600
communes et touchant 2 millions de riverains [DGPR, 2004]. Les crues occasionnent ainsi près de
80% des dommages associés aux aléas naturels. La lutte contre ce phénomène passe bien sûr par la
mise en place de systèmes d’alerte ou de prévision du phénomène, permettant d’en réduire l’impact
lors de son apparition. En amont de la gestion de crise, une gestion préventive est nécessaire pour à
la fois mettre en place des ouvrages de protections au niveau ou en amont des zones à risque
(digues, barrages écrêteurs de crues, bassins de rétention, …) et à la fois déterminer les zones
susceptibles d’être soumises aux inondations afin de limiter leur occupation. La mise en place de
dispositifs de protection face aux risques de crues nécessite alors une bonne connaissance de cet
aléa naturel. L’étude de l’aléa hydrologique représente alors un des axes de recherche que compte
l’hydrologie : la prédétermination des débits de crues et des pluies qui les génèrent.
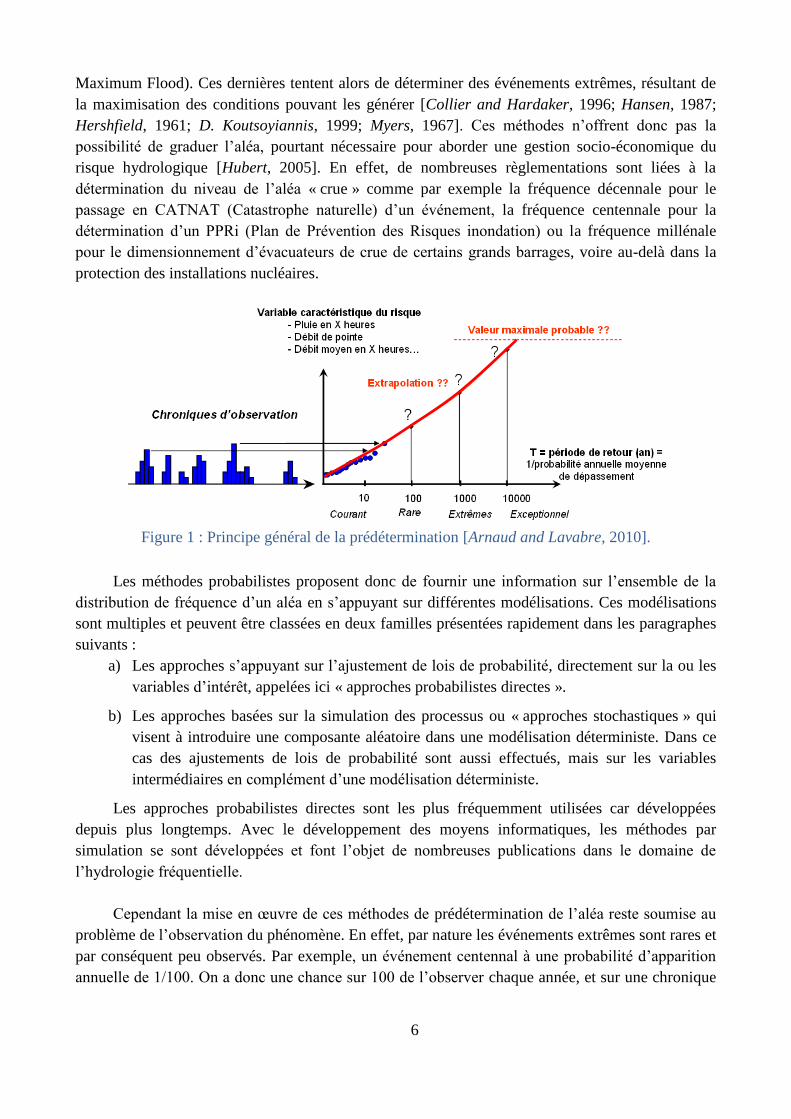
En général, la prédétermination d’un aléa se résume à associer une valeur caractéristique de
cet aléa à sa probabilité de dépassement, généralement ramenée à une probabilité de dépassement
annuelle (facilement traduite en période de retour). L’observation du phénomène1 sur de longues
périodes permet alors d’extraire, pour une caractéristique, des valeurs indépendantes à partir
desquelles une distribution de fréquence empirique peut être établie. Cette distribution guidera alors
le choix d’un modèle théorique qui permettra d’extrapoler vers des fréquences plus rares et
d’estimer ainsi différents niveaux de l’aléa (du courant à l’exceptionnel) en fonction des enjeux
associés (Figure 1). Cette approche est dite « probabiliste » par opposition aux approches
« maximalistes » telles que la PMP (Probable Maximum Precipitation) ou la PMF (Probable
1 Dans le cas des crues, l’aléa étudié est généralement la pluviométrie et/ou les débits des cours d’eau. Les
variables caractérisant ces aléas sont des pluies maximales ou des débits maximums déterminés sur une durée courte,
liée à la période intense du phénomène. L’estimation de ces aléas hydrométéorologiques est nécessaire en aménagement
du territoire rural ou urbain, pour le dimensionnement d'ouvrages hydrauliques, de ponts, de voies de communication à
proximité de cours d'eau, etc.
6
Maximum Flood). Ces dernières tentent alors de déterminer des événements extrêmes, résultant de
la maximisation des conditions pouvant les générer [Collier and Hardaker, 1996; Hansen, 1987;
Hershfield, 1961; D. Koutsoyiannis, 1999; Myers, 1967]. Ces méthodes n’offrent donc pas la
possibilité de graduer l’aléa, pourtant nécessaire pour aborder une gestion socio-économique du
risque hydrologique [Hubert, 2005]. En effet, de nombreuses règlementations sont liées à la
détermination du niveau de l’aléa « crue » comme par exemple la fréquence décennale pour le
passage en CATNAT (Catastrophe naturelle) d’un événement, la fréquence centennale pour la
détermination d’un PPRi (Plan de Prévention des Risques inondation) ou la fréquence millénale
pour le dimensionnement d’évacuateurs de crue de certains grands barrages, voire au-delà dans la
protection des installations nucléaires.
Figure 1 : Principe général de la prédétermination [Arnaud and Lavabre, 2010].
Les méthodes probabilistes proposent donc de fournir une information sur l’ensemble de la
distribution de fréquence d’un aléa en s’appuyant sur différentes modélisations. Ces modélisations
sont multiples et peuvent être classées en deux familles présentées rapidement dans les paragraphes
suivants :
a) Les approches s’appuyant sur l’ajustement de lois de probabilité, directement sur la ou les
variables d’intérêt, appelées ici « approches probabilistes directes ».
b) Les approches basées sur la simulation des processus ou « approches stochastiques » qui
visent à introduire une composante aléatoire dans une modélisation déterministe. Dans ce
cas des ajustements de lois de probabilité sont aussi effectués, mais sur les variables
intermédiaires en complément d’une modélisation déterministe.
Les approches probabilistes directes sont les plus fréquemment utilisées car développées
depuis plus longtemps. Avec le développement des moyens informatiques, les méthodes par
simulation se sont développées et font l’objet de nombreuses publications dans le domaine de
l’hydrologie fréquentielle.
Cependant la mise en œuvre de ces méthodes de prédétermination de l’aléa reste soumise au
problème de l’observation du phénomène. En effet, par nature les événements extrêmes sont rares et
par conséquent peu observés. Par exemple, un événement centennal à une probabilité d’apparition
annuelle de 1/100. On a donc une chance sur 100 de l’observer chaque année, et sur une chronique
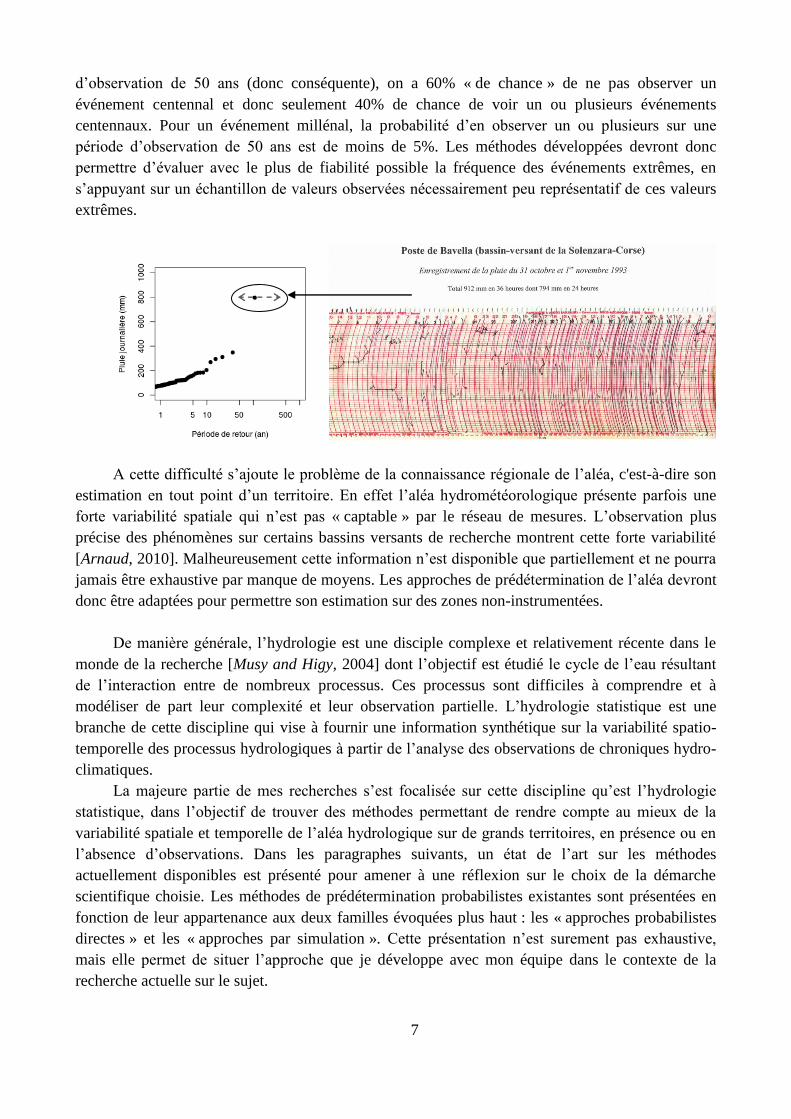
7
d’observation de 50 ans (donc conséquente), on a 60% « de chance » de ne pas observer un
événement centennal et donc seulement 40% de chance de voir un ou plusieurs événements
centennaux. Pour un événement millénal, la probabilité d’en observer un ou plusieurs sur une
période d’observation de 50 ans est de moins de 5%. Les méthodes développées devront donc
permettre d’évaluer avec le plus de fiabilité possible la fréquence des événements extrêmes, en
s’appuyant sur un échantillon de valeurs observées nécessairement peu représentatif de ces valeurs
extrêmes.
A cette difficulté s’ajoute le problème de la connaissance régionale de l’aléa, c'est-à-dire son
estimation en tout point d’un territoire. En effet l’aléa hydrométéorologique présente parfois une
forte variabilité spatiale qui n’est pas « captable » par le réseau de mesures. L’observation plus
précise des phénomènes sur certains bassins versants de recherche montrent cette forte variabilité
[Arnaud, 2010]. Malheureusement cette information n’est disponible que partiellement et ne pourra
jamais être exhaustive par manque de moyens. Les approches de prédétermination de l’aléa devront
donc être adaptées pour permettre son estimation sur des zones non-instrumentées.
De manière générale, l’hydrologie est une disciple complexe et relativement récente dans le
monde de la recherche [Musy and Higy, 2004] dont l’objectif est étudié le cycle de l’eau résultant
de l’interaction entre de nombreux processus. Ces processus sont difficiles à comprendre et à
modéliser de part leur complexité et leur observation partielle. L’hydrologie statistique est une
branche de cette discipline qui vise à fournir une information synthétique sur la variabilité spatio-
temporelle des processus hydrologiques à partir de l’analyse des observations de chroniques hydro-
climatiques.
La majeure partie de mes recherches s’est focalisée sur cette discipline qu’est l’hydrologie
statistique, dans l’objectif de trouver des méthodes permettant de rendre compte au mieux de la
variabilité spatiale et temporelle de l’aléa hydrologique sur de grands territoires, en présence ou en
l’absence d’observations. Dans les paragraphes suivants, un état de l’art sur les méthodes
actuellement disponibles est présenté pour amener à une réflexion sur le choix de la démarche
scientifique choisie. Les méthodes de prédétermination probabilistes existantes sont présentées en
fonction de leur appartenance aux deux familles évoquées plus haut : les « approches probabilistes
directes » et les « approches par simulation ». Cette présentation n’est surement pas exhaustive,
mais elle permet de situer l’approche que je développe avec mon équipe dans le contexte de la
recherche actuelle sur le sujet.
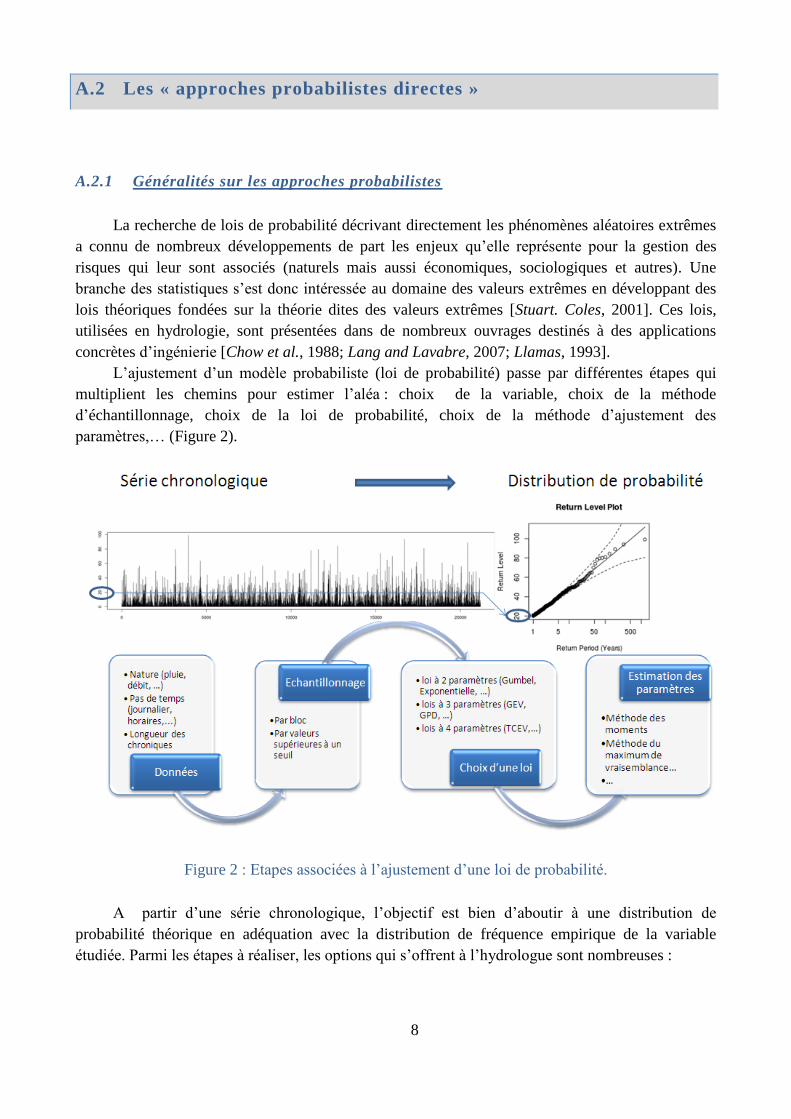
8
A.2 Les « approches probabilistes directes »
A.2.1 Généralités sur les approches probabilistes
La recherche de lois de probabilité décrivant directement les phénomènes aléatoires extrêmes
a connu de nombreux développements de part les enjeux qu’elle représente pour la gestion des
risques qui leur sont associés (naturels mais aussi économiques, sociologiques et autres). Une
branche des statistiques s’est donc intéressée au domaine des valeurs extrêmes en développant des
lois théoriques fondées sur la théorie dites des valeurs extrêmes [Stuart. Coles, 2001]. Ces lois,
utilisées en hydrologie, sont présentées dans de nombreux ouvrages destinés à des applications
concrètes d’ingénierie [Chow et al., 1988; Lang and Lavabre, 2007; Llamas, 1993].
L’ajustement d’un modèle probabiliste (loi de probabilité) passe par différentes étapes qui
multiplient les chemins pour estimer l’aléa : choix de la variable, choix de la méthode
d’échantillonnage, choix de la loi de probabilité, choix de la méthode d’ajustement des
paramètres,… (Figure 2).
Figure 2 : Etapes associées à l’ajustement d’une loi de probabilité.
A partir d’une série chronologique, l’objectif est bien d’aboutir à une distribution de
probabilité théorique en adéquation avec la distribution de fréquence empirique de la variable
étudiée. Parmi les étapes à réaliser, les options qui s’offrent à l’hydrologue sont nombreuses :

9
a) L’échantillonnage de la variable d’intérêt : l’étude d’un phénomène hydrométéorologique se
fait généralement à partir de chroniques d’observations du phénomène, à un pas de temps
donné (parfois variable). Pour l’étude des caractéristiques extrêmes du phénomène, des valeurs
maximales sont échantillonnées à partir de ces observations. Ces valeurs maximales peuvent
être échantillonnées de deux façons : un échantillonnage de valeurs maximales par bloc (la
chronique est découpée en périodes d’observations définies sur lesquelles la valeur observée
maximale est extraite) ou un échantillonnage par valeurs supérieures à un seuil élevé (toutes les
valeurs supérieures à un seuil suffisamment élevé, pour ne retenir que les valeurs « record »
indépendantes entre elles). Les valeurs maximales ainsi échantillonnées seront alors
considérées comme les réalisations d’une variable aléatoire dont on cherchera à identifier la
distribution de probabilité par l’ajustement d’une loi de probabilité théorique. Au-delà de la
méthode d'échantillonnage, il est bien clair que l'échantillon est tributaire des caractéristiques
de la période d'observation, c’est à dire de sa durée (plus la durée d’observation sera grande,
plus l’échantillon sera représentatif) et de sa position par rapport à des successions d'années
sèches et humides (bien que les hypothèses de stationnarité du phénomène et de l’indépendance
des années successives soient généralement faites). L’objectif de l’échantillonnage reste de
déterminer un ensemble de valeurs indépendantes, appartenant à une même population.
Les deux types d’échantillonnage présentés sont généralement réalisés sur l’ensemble des
valeurs observées d’une série chronologique, en faisant l’hypothèse que ces valeurs
représentent un même phénomène. Cette hypothèse peut être remise en cause, en mettant en
avant des processus différents au cours de l’année (par exemple, certains bassins présentent des
crues issues d’un régime « nival » et « pluvial » n’ayant pas les mêmes caractéristiques). La
chronique des observations peut alors être découpée en « sous chroniques » dans lesquelles le
phénomène observé sera alors plus facilement considéré comme appartenant à une même
population. C’est le cas des analyses réalisées par saison, ou par type de temps [Garavaglia et
al., 2011]. Dans ce cas, chaque « sous-chronique » est analysée séparément par des lois
« saisonnières » qui seront combinées pour fournir une loi de probabilité composite, annuelle.
b) Le choix d’une loi de probabilité : ce choix va dépendre de la méthode d’échantillonnage
utilisé. L’étude des valeurs maximales par bloc (comme par exemple les valeurs maximales
annuelles) ont conduit Fisher et Tippett [1928] à montrer que la distribution de ces variables ne
peut suivre que trois lois de probabilité : la loi de Fréchet [1927], de Gumbel [1935] et de
Weibull [1951]. Ces lois seront reformulées en une loi plus générale appelée loi GEV (loi
généralisée des extrêmes ou Generalized Extreme Value distribution) [Jenkinson, 1955]. Des
développements similaires ont été réalisés pour un échantillonnage de valeurs supérieures à un
seuil élevé et ont conduit à définir la loi GP (loi Pareto généralisée ou Generalized Pareto
distribution) [Pickands, 1975] dont la loi exponentielle est un cas particulier. L’étude des
valeurs supérieures à un seuil permet de s’affranchir du coté réducteur d’un échantillonnage par
bloc qui impose un seul maximum par bloc (par an par exemple). La difficulté réside cependant
dans la détermination du seuil de sélection qui ne doit, ni être trop élevé ni trop bas. Les
ouvrages de Coles [2001] ou Beirlant et al. [2004] réalisent une synthèse des multiples travaux
sur la théorie des valeurs extrêmes en présentant les différentes lois qui en résultent en fonction
de l’échantillonnage choisi, les différentes méthodes d’estimation des paramètres
(vraisemblance, L-moments, moments pondérés,…), l’estimation des intervalles de confiances

10
associés,… D’autres lois de probabilité théoriques peuvent être utilisées comme la loi log-
Pearson Type III retenue par le gouvernement fédéral américain [(WRC), 1967].
c) L’estimation des paramètres : La plupart des lois de probabilités utilisées en hydrologie pour
étudier les valeurs extrêmes, présentent 2 ou 3 paramètres. Ces paramètres permettent
généralement de caractériser la tendance centrale de la variable (paramètre de position), la
dispersion des valeurs autour de ces valeurs « centrales » (paramètre d’échelle) et la
dissymétrie de la distribution (paramètre de forme). Il existe de nombreuses méthodes
d’estimation des paramètres, étudiées par de nombreux auteurs en fonction de la loi de
probabilité utilisée. Parmi ces méthodes il y a : la méthode des moments (elle consiste à mettre
en lien les moments de la variable avec les paramètres de la loi de probabilité théorique), la
méthode du maximum de vraisemblance (introduite par Fisher en 1922 [Aldrich, 1997], elle
vise à déterminer le paramétrage qui maximise les probabilités des réalisations observées), la
méthode des L-moment (basée sur des combinaisons linéaires des moments de probabilité
pondérés),…
L’application de ces méthodes statistiques sur des données locales reste particulièrement
sensible aux problèmes de l'échantillonnage. L'ajustement statistique reste très fortement influencé
par la présence, ou l'absence, des valeurs "exceptionnelles" dans l'échantillon des observations, en
particulier lors de la détermination d’un paramètre de forme. Le poids de ces valeurs, souvent
entachées d'une forte incertitude métrologique, devient extrêmement important dans la
prédétermination des quantiles rares (extrapolation en fréquence). De manière générale, il n’est pas
recommandé d’utiliser ces approches pour une extrapolation des distributions de fréquences vers les
valeurs extrêmes, lorsqu’elles sont calées localement [Lang et al., 2013].
Pour réduire les effets de l’échantillonnage, très dommageable pour l’estimation des valeurs
rares et extrêmes, des approches complémentaires ont été développées. Afin de mieux prendre en
compte le poids des valeurs extrêmes, une des solutions est donc d’enrichir l’échantillon des valeurs
observées, pour augmenter sa représentativité. Pour cela, la recherche d’informations sur d’autres
sites de mesure (approche régionale), sur différentes variables caractéristiques (approche multi-
durées), sur des données historiques (approche historique) est réalisée. Un bref aperçu du principe
des approches les plus courantes est donné dans les paragraphes suivants.
A.2.2 Les méthodes régionales
La méthode dite des « années-stations » ou les approches régionales utilisent l'information de
plusieurs stations pour réduire l'influence des erreurs sur les données et l’influence de
l’échantillonnage des valeurs exceptionnelles. Elles peuvent être utilisées pour le traitement
statistique des pluies, comme pour les débits. Il y a la méthode de l’index de crue [Darlymple, 1960]
qui a initié ces approches, largement utilisées actuellement [J.R.M. Hosking and Wallis, 1997; Merz
and Blöschl, 2005; Ribatet et al., 2007; Stedinger and Tasker, 1985]. L’homogénéité spatiale des
données doit être vérifiée par diverses méthodes statistiques [J. R. M. Hosking and Wallis, 1993].
Après « homogénéisation » ou « normalisation », les données de différentes stations de mesure sont
agglomérées et étudiées de façon régionale. L'accroissement de l'effectif permet l'utilisation de

11
façon robuste de lois à 3 paramètres, comme la loi GEV [Neppel et al., 2007a], voire des lois à 4
paramètres comme la loi TCEV présentée par Rossi [1984].
Notons que de nombreuses applications de méthodes régionales conduisent à des valeurs
négatives pour les coefficients de forme de la loi GEV ou GPD utilisées sur des données de pluies
journalières (-0.15 en Espagne [Ferrer, 1992] ; -0.15 en Grèce [Demetris Koutsoyiannis, 2004] ; -
0.13 sur la région Languedoc [Dominguez et al., 2005]), signifiant un comportement asymptotique
plus qu’exponentiel pour cette variable. Les approches régionales sont largement préférables aux
approches locales, à condition de s’assurer de l’indépendance des données agglomérées et de leur
homogénéité.
A.2.3 Les approches multi-variées
Une autre façon d’augmenter la représentativité de l’échantillon des données observées est
d’étudier en même temps plusieurs variables d’un même phénomène. C’est le cas par exemple
lorsque la pluviométrie est étudiée sur l’ensemble de ces durées, à travers l’analyse des courbes
IDF (Intensité-Durée-Fréquence)[Demetris. Koutsoyiannis et al., 1998]. Des approches du type QdF
(Débit-Durée-Fréquence) étudient aussi l’ensemble des durées pour les débits [Pierre Javelle et al.,
1999]. L’hypothèse sous-jacente est que les pluies (ou les débits) de différentes durées sont
dépendantes entre elles et leur dépendance est liée à la durée sur laquelle le phénomène est étudié.
C’est aussi une hypothèse des méthodes multifractales qui considère une certaine invariance
d’échelle du phénomène. Cette hypothèse permet une nette réduction du nombre de paramètres pour
modéliser un phénomène complexe [Burlando and Rosso, 1996].
Les modèles multi-durées présentent un grand intérêt en ingénierie puisque des données
journalières peuvent être utilisées pour estimer des quantiles à des pas de temps plus fins. Ces
données journalières, plus largement disponibles que les données à pas de temps plus fins peuvent
alors améliorer l’estimation des pluies à pas de temps fins. Par exemple, Muller et al. [2009]
montrent, sur une longue chronique de pluies à Marseille, que les enregistrements journaliers sont
de meilleure qualité et présentent moins de lacunes que les enregistrements horaires, en particulier
lors des événements extrêmes. Dans ce cas, les estimations des quantiles de pluies de courtes durées
réalisées par une approche multi-durées sont plus robustes et plus fiables que celles obtenues par
une approche classique par durée de pluie.
A.2.4 Les approches historiques
Leur objectif est d’utiliser une information historique pour consolider la distribution des
valeurs observées avec des valeurs plus anciennes que les données systématiques (chroniques) [J.
Miquel, 1983; J Miquel, 1984]. L'utilisation de l'information historique dans une analyse
fréquentielle permet de mieux intégrer l'information réellement disponible et devrait donc permettre
d'améliorer l'estimation des quantiles de grandes périodes de retour. Ces approches sont surtout
appliquées pour intégrer l’information relative aux grandes crues qui se sont produites avant le
début de la période de mesures systématiques. Des approches bayésiennes sont alors utilisées pour
traiter des informations partielles et souvent associées à de fortes incertitudes [Gaume et al., 2010;

12
Naulet et al., 2005; Neppel et al., 2010; Payrastre et al., 2011]. De façon générale, l'utilisation de
l'information historique conduit à une diminution de l'impact des valeurs singulières dans les séries
d'enregistrements systématiques et à une diminution de l'écart-type des estimations [Ouarda et al.,
1998]. L’incertitude d’échantillonnage sur les quantiles estimés est donc réduite lorsque
l’information historique est exploitée. Une des difficultés de cette approche est peut être
l’estimation des débits de crues historiques, en particulier le passage des hauteurs d’eau (niveaux
historiques atteints) aux débits [Naulet, 2002; Naulet et al., 2005]. Des efforts particuliers sont
réalisés pour centraliser cette information indispensable pour consolider l’estimation des valeurs
extrêmes. A titre d’exemple, la base nationale BDHI recense les crues mémorables observées en
France (http://bdhi.fr/appli/web/welcome), surtout pour les grands cours d’eau traversant les
grandes villes. Les pluies extrêmes sont aussi renseignées par Météo-France pour maintenir la
mémoire des records observés (http://pluiesextremes.meteo.fr/). A noter que la pluviométrie
bénéficie généralement de données systématiques plus longues que les données de débit.
A.2.5 Combinaison de lois ajustées sur différentes variables d’intérêt
La prédétermination des débits peut aussi être approchée par l'étude statistique des pluies.
Généralement, cette étude amène à la détermination d'une pluie de projet liée à une probabilité
d'apparition. Cette pluie de projet peut être établie de deux façons [C.I.G.B., 1992] :
- par une approche probabiliste utilisant les méthodes statistiques locales appliquées sur la
pluie. Dans ce cas, la pluie de projet est liée à une probabilité d'apparition ou une période de retour.
Son élaboration repose sur l'analyse statistique de divers éléments (hauteur, durée, forme) des
événements pluvieux [Sighomnou and Desbordes, 1988].
- par une approche maximaliste ou d'événement maximal probable : la pluie de projet est
alors définie comme la plus forte précipitation physiquement possible sur une surface donnée, pour
un site et une époque donnés [Collier and Hardaker, 1996; Hershfield, 1961; D. Koutsoyiannis,
1999].
La pluie de projet est transformée en crue de projet par une modélisation hydrologique simple.
Cette crue de projet sert alors directement au dimensionnement des ouvrages hydrauliques. Divers
problèmes apparaissent alors, comme le problème d'échantillonnage sous-jacent à l'étude statistique
des pluies servant à l'élaboration de la pluie de projet (problème identique à l'étude statistique des
débits seuls) ou le problème de l'affectation d'une fréquence à une pluie de projet synthétique, puis
celui de l'affectation d'une fréquence à l'hydrogramme qui en résulte.
L'information fréquentielle des pluies peut aussi être utilisée directement pour renseigner le
comportement des débits vers les fréquences rares. C'est le principe de la méthode du Gradex mise
au point par Guillot et Duband [1967]. Dans un diagramme de Gumbel, l'extrapolation de la
distribution de fréquences des débits est réalisée de façon parallèle à la distribution de fréquences
des pluies, en faisant l'hypothèse de la saturation des sols pour les pluies de fréquences rares. Des
variantes à la méthode du Gradex ont été développées en faisant varier progressivement le
comportement asymptotique des débits en fonction de la période de retour étudiée [Margoum et al.,
1994].

13
L'utilisation de l'information pluviométrique améliore la connaissance des quantiles de crues
rares. Cependant, l'absence de chroniques suffisamment longues, les problèmes de métrologie lors
de l'observation de forts événements (pluviomètres qui débordent, stations limnimétriques noyées
ou emportées) et la difficulté d'attribuer une fréquence aux valeurs exceptionnelles observées,
rendent les résultats de ces méthodes statistiques extrêmement sensibles à l'échantillonnage des
valeurs fortes.
Les approches probabilistes directes s’appuient sur des développements théoriques en
statistiques, liés en particulier aux recherches issues de la théorie des valeurs extrêmes. Cet aspect
de l’hydrologie statistique fait l’objet de nombreux travaux à la frontière entre l’hydrologie et les
mathématiques appliquées.
Les méthodes présentées bénéficient donc d’un cadre théorique fort, mais s’appuient aussi
sur des approches plus empiriques essayant de mettre en avant les processus, à l’instar des
méthodes prenant en compte la pluie pour estimer des débits.
La pratique a conduit aussi les hydrologues à essayer de s’affranchir au mieux des problèmes
d’échantillonnage particulièrement importants pour l’estimation de valeurs extrêmes. L’échantillon
des valeurs traitées est donc régulièrement enrichi par de l’information soit historique soit
régionale.
Les méthodes présentées restent cependant strictement liées à l’étude de la variable d’intérêt
et ne permettent pas la prise en compte du phénomène dans sa complexité temporelle. C’est pour
essayer de répondre à cette limitation que les méthodes par simulation ont été développées.

14
A.3 Les « approches par simulation »
Les recherches en milieu non jaugé ont conduit certains chercheurs à introduire, dans
l'estimation des quantiles de crues, l'utilisation de générateurs de pluie couplés à une transformation
de la pluie en débit. Cette approche a été initiée par Eagleson [1972] et utilisée dans de nombreuses
autres études. Les méthodes par simulation sont basées sur deux éléments principaux [Cadavid et
al., 1991]: un modèle probabiliste qui introduit une composante stochastique à travers un modèle de
pluie ; un modèle de transformation de la pluie en débit qui fournit un débit de pointe et une forme
de crue pour une pluie efficace donnée.
Par la combinaison de ces deux éléments, les débits de pointe ou d’autres variables
hydrologiques peuvent être extraits des scénarios de crues simulés, pour déterminer leur distribution
de probabilité de façon empirique. Ces méthodes sont généralement appliquées sur des bassins de
moins de 10 000 km². Au delà, les problèmes d’hétérogénéité climatique et hydrologique
deviennent trop importants, ainsi que les problèmes liés à l’estimation de la dépendance spatiale des
événements extrêmes (problèmes de concomitance des crues).
Ces méthodes par simulation (Continuous Simulation Modelling : CSM) font l’objet d’une
activité de recherche croissante [Li et al., 2014]. En Europe, le projet Européen FloodFreq COST 7
ES0901 Action (http://www.cost-floodfreq.eu/) présente par exemple, différentes méthodes de
prédétermination des crues basées sur des approches par simulation [Willems et al., 2012] : aux
Royaumes Unis [Kjeldsen, 2007], en France [Arnaud and Lavabre, 2002; Paquet et al., 2013], en
Grèce [Loukas, 2002], en République tchèque [Blazkova and Beven, 2002] et en Slovaquie
[Hlavcova et al., 2004].
L’analyse bibliographique de ces méthodes montre de multiples variantes liées au type de
modélisations mises en œuvre, soit au niveau de la prédétermination de la pluie et soit au niveau du
passage au débit. Elle montre que [Willems et al., 2012] :
- Les simulations d’événements de pluies peuvent être « continues » ou « événementielles »,
« ponctuelles » ou « spatiales ». Les modélisations mises en œuvre sont aussi très variées, du
simple tirage aléatoire de pluies journalières à la simulation complète de hyétogrammes
horaires.
- En général les méthodes prennent en compte les effets orographiques de la pluie et certaines
peuvent fonctionner en sites non-jaugés.
- La moitié des méthodes fonctionnent avec une modélisation hydrologique globale, les autres
avec des approches semi-distribuées. Les modèles hydrologiques utilisés sont extrêmement
nombreux et correspondent généralement aux modèles développés par les chercheurs dans le
cadre d’autres utilisations.
- L’incertitude de ces méthodes est difficile à prendre en compte et fait l’objet d’une
recherche active.

15
De même que pour les approches probabilistes directes, il est donc impossible d’être exhaustif
sur les méthodes existantes. La présentation faite ici, regroupe différentes approches de
modélisation de la pluie, en les classant en trois groupes : les approches ponctuelles basées sur des
processus agrégatifs, celles basées sur des processus désagrégatifs et les approches spatiales
générant des champs de pluie. Le passage au débit est présenté en fonction du degré de complexité
modélisé dans la relation pluie-débit.
A.3.1 La simulation des pluies
La pluie résulte de processus physiques naturels dont les principes fondamentaux sont connus.
Les phénomènes énergétiques et mécaniques concernant la physique atmosphérique sont alors à la
base des modèles de prévision météorologique. Mais ces modèles sont associés des échelles souvent
trop grandes pour être utilisés en hydrologie. Le phénomène de précipitation est alors plutôt
considéré comme un phénomène aléatoire qui peut être étudié de façon statistique par le biais
d’approches stochastiques, à la base des générateurs de pluies.
Les modèles de génération de pluies sont plus fréquemment associés à un pas de temps
journalier [Buishand, 1978; Thompson et al., 2007]. La modélisation des pluies au pas de temps
journalier est en effet plus simple car le phénomène est moins complexe qu’aux pas de temps plus
fins. L’information est d’ailleurs bien plus importante au pas de temps journalier, ce qui facilite leur
mise en application. L’étude des crues nécessite souvent d’avoir une information à pas de temps
infra-journalier. Bien que leur développement soit plus réduit qu’au pas de temps journalier, les
modélisations de chroniques de pluies à pas de temps fins ont fait l’objet de nombreuses recherches
à travers différentes approches.
1. Les approches ponctuelles agrégatives
Initiés par les travaux de LeCam [1961], certains modèles sont basés sur des processus
d’agrégation, par la combinaison de deux processus aléatoires : le positionnement de cellules
pluvieuses (en définissant leur occurrence et la durée qui les sépare), puis la détermination de leur
quantile d’eau (en définissant la durée et l’intensité de ces cellules). Les auteurs de ce processus
[Neyman and Scott, 1958] l'élaborèrent pour traiter de façon probabiliste des phénomènes de
cosmologie (représentation de galaxies).
C'est Waymire et Gupta [1981] qui furent les premiers à utiliser ce processus pour décrire
l'occurrence des épisodes pluvieux, ainsi que des cellules pluvieuses qui les composent. Ces cellules
pluvieuses ainsi générées et positionnées, sont affectées d'une durée et d'une intensité. La pluie sur
chaque pas de temps est alors déterminée par la somme des intensités des cellules présentes sur le
pas de temps. Deux approches sont principalement utilisées pour positionner les cellules pluvieuses
dans la chronique : le processus de Neyman-Scott et le processus de Bartlett-Lewis [David
Cameron et al., 2000] (Figure 3).

16
Figure 3 : Principe des modèles basés sur un processus d’agrégation.
Ces modèles fonctionnent en continu. Ils nécessitent un nombre relativement faible de
paramètres pour générer des épisodes pluvieux (5 ou 6), mais qui doivent être déterminés pour
chaque mois (d'où plus de 60 valeurs) ou du moins par saisons.
Le calage de ces paramètres n’est pas directement lié à l’observation du phénomène qu’ils
sont censés représenter (nombre de cellules, leur durée, leur intensité,…) mais plutôt une
adéquation à postériori des résultats de la modélisation avec les caractéristiques statistiques de
pluies observées (valeur moyenne ou variance de pluies de différentes durées, auto-corrélation des
pluies horaires, probabilité de valeurs nulles,…).
Les différents travaux sur ces modèles [Cowpertwait, 1991; Rodriguez-Iturbe et al., 1987]
montrent que cette approche donne des résultats relativement bons. Ces modèles sont capables de
reproduire correctement la distribution des pluies à différents pas de temps. Des développements sur
ces modèles ont porté sur la régionalisation de leurs paramètres [Cowpertwait et al., 1996], sur leur
capacité à reproduire des valeurs extrêmes [David Cameron et al., 2000] et sur l’étude de leur
incertitudes [Favre et al., 2004].
D’autres modèles sont basés sur une simulation « directe » de hyétogrammes, définie à partir
de l’analyse descriptive qui est faite du signal observé. Ces modèles partent aussi du principe que la
pluie peut être assimilée à un processus aléatoire et intermittent (succession d'états secs et
pluvieux). A la différence des approches présentées plus haut, les caractéristiques des
hyétogrammes sont directement déterminées à partir des hyétogrammes observées. L’observation
directe de ces variables permet un calage à priori des lois de probabilité que les caractérisent. Ces
lois serviront alors à reconstruire le signal de pluie. Ces modèles reposent aussi sur l'hypothèse
d'indépendance des variables décrivant les hyétogrammes, ainsi que sur l'hypothèse de stationnarité
Origine de l'épisode (Processus de Poisson)
Durée d'activité des épisodes (loi exponentielle)
( PRO CESSUS DE BARTLETT-LEWIS )
Origine des cellules (Processus de Poisson )
( PRO CESSUS DE NEYMAN-SCO TT )
Nombre de cellules par épisode (loi de Poisson ou loi géométrique)C = 4 C = 3
1 1 22 343
Origine des cellules à partir de l'origine de l'épisode
1 1 22 34 3
A chaque instant, la pluie est égale à la somme
Durée des cellules (loi exponentielle)
(loi exponentielle)
Intensité des cellules (loi exponentielle)
des intensités présentent à cet instant.
temps
temps
temps
temps
temps
temps
temps
temps

17
du phénomène étudié. Ce type de modèle est souvent retrouvé au pas de temps horaire [Patrick
Arnaud and J. Lavabre, 1999; F. Cernesson, 1993; Lebel, 1984; Tourasse, 1981], mais aussi au pas
de temps journalier [Buishand, 1978]. L'élaboration de ce type de modèle se résume donc à trouver
les bonnes variables aléatoires indépendantes décrivant le processus de pluie, ainsi que les lois de
probabilité qui les représentent le mieux. La reconstruction du signal s'effectue grâce à une
hiérarchisation logique du tirage des différentes variables, afin de parvenir à une représentation la
plus fidèle possible du signal de départ, tout en respectant la définition des variables utilisées. La
validation du modèle consiste à étudier sa capacité à reproduire des variables représentatives du
signal simulé, non utilisées lors du calage du modèle. Sur cette base, différents modèles peuvent
être élaborés (comme celui développé dans notre approche), les différences provenant en particulier
du choix des variables descriptives et de leurs lois de probabilité.
2. Les approches ponctuelles désagrégatives
Parmi ces approches, il y a des modèles basés sur la désagrégation de la pluie journalière
[Econopouly et al., 1990; Demetris koutsoyiannis, 1994]. L'élaboration de tels modèles trouve son
intérêt dans la disponibilité plus large des données journalières par rapport aux données horaires.
Une première approche, présentée par Glasbey et al [1995] consiste à simuler des séries de
pluies horaires à partir d'un modèle horaire, qui n’est pas forcément calé, et de les contraindre à
respecter les totaux journaliers observés. La simulation des pluies horaires se fait donc de façon
inconditionnelle, jusqu'à obtenir une séquence ayant des totaux horaires satisfaisants. La méthode
présentée agrège donc des pluies horaires simulées avant de désagréger la pluie journalière observée
ou générée par un modèle journalier. Les résultats sont indépendants du modèle horaire qui peut
être du type de ceux présentés précédemment. Les modèles de génération de chroniques de pluies
journalières ne manquant pas (toute la famille des modèles auto-régressifs ou autres...), leur
couplage avec cette approche de désagrégation fournit une nouvelle méthode d'étude des
distributions des pluies à pas de temps fins.
Des modèles basés sur des processus de cascades multiplicatives, ont aussi été développés
[Gupta and Waymire, 1993; Over and Gupta, 1994] et permettent parfois une désagrégation sur des
pas de temps inférieurs à l’heure [Gaume et al., 2007; Molnar and Burlando, 2005]. Ils exploitent la
propriété d’invariance d’échelle issue de la théorie des fractales, pour répartir la pluie sur un pas de
temps successivement divisé par deux.
D’autres approches visent à désagréger des événements pluvieux simulés sans forme
(uniquement leur durée, leur intensité moyenne et la durée entre deux événements), en leur
appliquant un « profil d’averse ». Ce profil d’averse correspond à une courbe adimensionnelle de
répartition de la pluie en fonction du temps (courbe de Huff [1967]). L’analyse des pluies horaires
observées permet la détermination de plusieurs « profils » qui seront alors tirés aléatoirement pour
produire des pluies horaires [Acreman, 1990; Eagleson, 1972; Heneker et al., 2001]. Les résultats
de ces modèles sont cependant fortement tributaires la dépendance entre les variables modélisant les
cumuls des événements (entre la durée et l’intensité) et la dépendance des « profils » choisis en
fonction du cumul des averses. Pour pallier à ces dépendances, une classification peut être faite sur

18
les événements (par type de perturbation ou par saison) pour prendre en compte une certaine
typologie des événements pluvieux [D. Cameron et al., 2000; Cameron et al., 1999].
Remarque : La désagrégation reste une approche intéressante que nous avons étudiée pour
passer aux pas de temps infra-horaires [cantet, 2014; Fine, 2009]. Dans ce cas, les modèles de
désagrégation utilisés sont différents de ceux pouvant exister pour désagréger la pluie journalière.
3. Les approches spatiales
Les générateurs de champs de pluies, ou générateurs spatiaux, permettent de prendre en
compte la structure spatiale de la pluie, occultée dans les approches ponctuelles, si ce n’est par le
biais du coefficient d’abattement spatial qui permet d’estimer une pluie moyenne sur une surface.
Le développement de ces approches est plus récent car elles nécessitent une information
conséquente sur la pluviométrie pour étudier sa structure spatiale. Cette information devient de plus
en plus disponible à des échelles fines grâce aux développements de l’imagerie radar [Krajewski
and Smith, 2002].
Les générateurs de champs de pluies s’appuient soit sur des approches géostatistiques avec
l’étude de la fonction de covariance spatiale de la pluie [Bouvier et al., 2003; Leblois and Creutin,
2013; Mantoglou and Wilson, 1982], soit sur des approches de type « agrégatives » qui modélisent
la génération de cellules pluvieuses dans l’espace et le temps [Rodriguez Iturbe and Eagleson,
1987; Waymire et al., 1984; Willems, 2001]. Des approches multifractales sont aussi utilisées pour
modéliser des champs de pluies à différentes échelles d’espace (souvent par désagrégation), avec un
nombre de paramètres moins important [Deidda, 1999; Gaume et al., 2007].
Ces générateurs de champs spatiaux présentent des intérêts évidents pour l’étude des
phénomènes courants, mais ils sont peu utilisés dans le cadre de la prédétermination des pluies ou
des crues car ils n’ont pas encore été évalués dans leur capacité à générer des événements extrêmes.
A.3.2 Le passage aux débits
Les pluies simulées par les différentes approches présentées (§ A.3.1) peuvent être
transformées en événements de crues par le biais de modèles hydrologiques. La modélisation
hydrologique est une discipline très « féconde » car il existe une multitude de modélisations plus ou
moins complexes, s’appuyant sur des approches différentes. Ces modèles sont généralement utilisés
pour reconstituer des crues observées. Ils sont aussi utilisés en prévision de crues, pour déterminer
l’évolution des débits dans un futur proche, à partir d’hypothèses sur les pluies à venir. Ici, on
s’intéresse à leur utilisation pour la prédétermination des débits. Une classification de ces modèles
hydrologiques est présentée en fonction de la simplification qui est faite dans la modélisation des
processus. Trois types de modèles sont différenciés :

19
- Les modèles empiriques : en simplifiant au maximum le processus, ils ne s’intéressent qu’à la
réponse du système. Cette réponse est modélisée grâce à une équation ou à un opérateur dont
les paramètres sont déterminés par les résultats expérimentaux. Ces modèles sont assimilés à
une « boite noire » donnant une description purement mathématique du fonctionnement du
système, sans faire appel à une notion liée à la physique du processus. Ces modèles sont très
dépendants des données et donc difficilement extrapolables au-delà de leur condition
d’élaboration. Couplées à l’information de la pluie (caractérisée généralement par un quantile),
il y a par exemple la formulation simple de la méthode rationnelle introduite par Kuichling
[1889], la méthode du Gradex [Guillot and Duband, 1967] et ses dérivées [Margoum et al.,
1994], les méthodes régionales CRUPEDIX et SOCOSE [Ministère de l'Agriculture et al.,
1980], …
- Les modèles conceptuels : ils sont basés sur une conception simple du processus qui ne fait
pas vraiment appel aux processus physiques mis en jeu. Ces processus physiques et leur
interaction sont modélisés par des opérateurs dont les paramètres n’auront pas de significations
physiques réelles. Ces modèles sont surement ceux qui présentent le plus de développements,
surement parce qu’ils présentent un bon compromis entre leur facilité de mise en œuvre et leurs
bonnes performances. Couplés à des générateurs de chroniques de pluies, il y a par exemple le
modèle hydrologique MORDOR [Garcon, 1999] utilisé dans la méthode SCHADEX
développée par EDF [Paquet et al., 2006; Paquet et al., 2013], le modèle GR3H [Yang, 1993]
utilisé dans la méthode SHYPRE développée par Irstea [Arnaud and Lavabre, 2002], des
modèles basés sur l’hydrogramme unitaire couplés avec des générateurs basés sur le processus
de Poisson [Hebson and Wood, 1982; Rodriguez-Iturbe and Valdes, 1979],…
- Les modèles mécanistes : aussi appelés modèles à base physique ou théoriques, ils cherchent à
représenter et à expliquer le fonctionnement du système par la description de ses mécanismes
internes, avec l’utilisation de lois physiques théoriques. Les paramètres de ces modèles sont
censés être mesurables. Les difficultés de la mise en place de ces modèles restent liées à la
complexité des processus hydrologiques et à la disponibilité de données relatives à la mesure de
ses différentes composantes. Couplés à des générateurs de chroniques de pluies, il y a les
modèles basées sur la théorie de l'onde cinématique [Cadavid et al., 1991; Eagleson, 1972;
Shen et al., 1990], le modèle TOPMODEL [Beven and Kirkby, 1979; Blazkova and Beven,
1997],...
Le couplage des modèles hydrologiques aux générateurs de pluies pose des questions
méthodologiques particulières. Quelle que soit la modélisation hydrologique choisie, elle sera
soumise à des pluies simulées, parfois extrêmes, et donc dépassant les conditions de calage des
modèles. Le problème du comportement de la modélisation face à ces pluies extrêmes est lié à la
non-linéarité des processus hydrologiques que la modélisation alors devra prendre en compte. Les
hypothèses faites lors de la conception du modèle auront alors des conséquences importantes pour
la prédétermination des valeurs extrêmes, parfois difficiles à apprécier lors du calage sur des
valeurs observées plus courantes. Se pose alors le problème d’équifinalité des modèles. Ces
modèles devront de plus avoir un paramétrage indépendant de la pluie, pour assurer de leur
utilisation sur toute la gamme de fréquence des pluies simulées.

20
A.4 La démarche scientifique choisie
L’estimation fréquentielle des crues est un véritable sujet de recherche dans le domaine des
sciences de l’environnement, et plus particulièrement dans la discipline « hydrologie ». Comme la
plupart des sciences de l’environnement, l’hydrologie est une discipline en interaction étroite avec
d’autres disciplines. Les flux d’eau sont la conséquence de plusieurs processus liés entre autres à la
météorologie (ou physique de l’atmosphère), à la géologie, la géographie ... Ces flux d’eau
représentent aussi un facteur impactant les écosystèmes terrestres et aquatiques. La connaissance de
la variabilité spatiale et temporelle des flux d’eau sur l’ensemble d’un territoire est donc une
variable d’entrée influant l’étude de nombreux systèmes environnementaux mais aussi anthropiques
(comportement des ouvrages, aménagement du territoire, sécurité des personnes…).
La complexité des processus hydrologiques et leur nature aléatoire fournissent donc des
questionnements qui alimentent la recherche sur le thème de l’estimation fréquentielle de l’aléa
hydrologique. L’état de l’art sur les méthodes disponibles et en développement, a conduit notre
équipe de recherches, à développer une méthode de prédétermination des crues basée sur la
simulation des processus. Cette approche permet de fournir un maximum d’informations sur la
connaissance régionale de l’aléa hydrologique nécessaires à d’autres disciplines.
Les développements initiaux autour de cette approche ont été réalisés par deux travaux de
thèse [Flavie Cernesson, 1993] et [Arnaud, 1997], suivant l’idée de Jacques Lavabre, alors
animateur de l’équipe. Les développements suivants ont été réalisés par une succession de travaux
de thèses pour lesquels j’ai assuré l’encadrement ou le co-encadrement, [Muller, 2006], [Cantet,
2009], [Fouchier, 2010] et [Aubert, 2012].
Au cours de ces années de recherche, la méthode a évolué, mais avec l’objectif affiché de
produire une information temporelle complète sur l’aléa lié aux crues, en tout point d’un territoire.
Cette approche choisie est donc une approche par simulation directe des processus. Elle est basée
sur le développement d’un générateur de pluies au pas de temps horaires (présenté dans la partie B
de ce document) couplé à une modélisation hydrologique simple (présentée dans la partie C de ce
document). Dans un premier temps cette méthode a été développée sur des données
hydrométéorologiques situées en milieu méditerranéen, puis étendue à d’autres contextes
climatiques (tropicaux et tempérés). Le développement des modèles associés à la méthode a été
consciemment contraint par la recherche d’une parcimonie dans la paramétrisation, afin d’éviter la
redondance des paramètres et faciliter ainsi leur régionalisation.
La méthode ainsi développée, présente une certaine complexité contrôlée par un souci de
transposabilité et de performances. Elle a alors été éprouvée dans le cadre d’un projet de recherche
ANR (projet Extraflo) visant la comparaison de méthodes de prédétermination développées en
France, appliquées sur un même jeu de données et confrontées à un panel important de
configurations d’application. Cette méthode, nommée SHYPRE (Simulation d’Hydrogramme pour
la PREdéternimation de crues), a fait l’objet de 80% de mes travaux de recherches et est présentée
dans ce manuscrit.
21
B – SIMULATION DE PLUIES HORAIRES
POUR L’ESTIMATION DE L’ALÉA
PLUVIOGRAPHIQUE

22
L’estimation de l’aléa pluvial permet d’appréhender les risques associés aux pluies plus ou
moins intenses (ruissellement, laves torrentielles, crues plus ou moins rapides, inondations et autres
phénomènes induits tels que le transport solide ou de polluants…). Il permet de déterminer
l’occurrence ou la « gravité » d’un événement pluvieux observé, ou à l’inverse de prédéterminer un
événement pluvieux pour une fréquence d’apparition donnée.
Par exemple, les procédures de classement des événements en CATastrophes NATurelles
(CATNAT) passent par la détermination de la période de retour des pluies liées à ces événements
(classement en CATNAT des événements de période de retour supérieure à 10 ans). Plus
récemment, des méthodes d’alerte aux phénomènes de ruissellements rapides reposent sur la
qualification en période de retour des pluies observées (en plus de celles des débits). C’est le cas de
la méthode AIGA2 qui définit des niveaux d’alertes associés à des seuils sur les périodes de retour
(2, 10 et 50 ans) des pluies maximales observées par les radars météorologiques [Fouchier et al.,
2007; P. Javelle et al., 2012; Lavabre and Gregoris, 2006]. Sur ce principe, Météo-France a mis au
point un service d’Avertissement aux Pluies Intenses à l’échelle des Communes (service APIC) mis
en œuvre en 2012 (https://apic.meteo.fr/).
L’estimation de l’aléa pluvial est aussi nécessaire dans de nombreuses méthodes de
dimensionnement de réseau d’assainissement, ou pour des méthodes d’estimation de l’aléa
hydrologique combinant l’information fréquentielle des pluies à celles des débits (voir § A.2.5).
La prévention des risques hydrologiques nécessite alors d’avoir une connaissance sur l’aléa
pluviométrique, qui s’exprime par :
- une connaissance sur les valeurs extrêmes : nécessité de pouvoir extrapoler l’information
vers les fréquences rares et extrêmes
- une connaissance sur les intensités de pluie, fournie par une information sur des pas de
temps relativement fins (infra-journalier)
- une connaissance régionale, c'est-à-dire disponible sur l’ensemble d’un territoire donné.
Face au problème de la disponibilité de l’information pluviométrique à pas de temps fins
(chroniques trop courtes, lacunes, faible couverture spatiale, …), les générateurs de pluies offrent
une alternative en simulant des chroniques de pluies statistiquement équivalentes aux chroniques de
pluies observées. La modélisation de ces pluies permet alors de générer de multiples scénarios de
pluies probables directement utilisables pour l’étude du risque pluvial, mais aussi comme variables
d’entrée pour différentes modélisations (hydrologique, transport solide, transfert de polluants, …).
L’intérêt de ces modèles est alors de fournir une information temporelle complète sur des
événements pluvieux probables.
C’est dans ce contexte, qu’un générateur stochastique de hyétogrammes horaires a fait l’objet
de développements et d’applications depuis une vingtaine d’année par l’équipe de recherche en
hydrologie d’Irstea - Centre d’Aix-en-Provence. Les recherches associées à ce générateur de pluie
sont présentées dans cette partie du manuscrit.
2 AIGA : Adaptation d’Information Géographique pour l’Alerte en crues (http://www.irstea.fr/la-
recherche/unites-de-recherche/ohax/hydrologie/aiga).

23
B.1 Développement d’un générateur stochastique de pluies horaires.
Ce générateur de pluies horaires a été développé dans le cadre de deux thèses [Arnaud, 1997;
Flavie Cernesson, 1993] et a subit des améliorations dans le cadre de la thèse de Philippe Cantet
[2009]. Il est fortement basé sur l’analyse descriptive du signal de pluie au pas de temps horaire,
permettant de définir des variables directement quantifiables à partir des hyétogrammes horaires
observés. C’est sur ce point particulier que l’approche se distingue des approches plus
« populaires » basées sur les processus d’agrégation du type Neumann-Scott et Bartlett-Lewis qui
définissent une structure à priori de la pluie pour la modélisation, sans l’analyser directement sur les
hyétogrammes observés.
B.1.1 Le principe
Le générateur est basé sur le principe des approches ponctuelles agrégatives (voir § A.3.1) qui
visent la simulation directe de hyétogrammes. C’est un modèle événementiel, c'est à dire qu'il crée
de façon indépendante et discontinue des événements pluvieux au pas de temps horaire. Le nombre
moyen d'événements par saison3 est respecté, ce qui permet de déterminer des probabilités
annuelles, bien que les événements ne soient pas positionnés dans une chronique. La saisonnalité
des pluies est cependant respectée car la mise en œuvre est faite sur des échantillons saisonniers.
Cette mise en œuvre du générateur de pluies horaires implique trois étapes, présentées sur le
schéma de la Figure 4 et détaillées dans les paragraphes suivants.
1. La première étape est l’analyse descriptive des hyétogrammes observés qui déterminera la
structure et le calage du générateur. Elle conduit au choix des variables qui définissent au
mieux la structure temporelle du phénomène et au choix des lois de probabilité qui vont décrire
ces variables (§ B.1.2). L’hypothèse d’indépendance des variables descriptives les unes par
rapport aux autres doit alors être vérifiée (§ B.1.4). Les paramètres des lois de probabilité de
chaque variable sont ensuite estimés à partir d’un ajustement statistique des distributions de
fréquences des valeurs observées.
2. La seconde étape est la simulation d’événements pluvieux : différentes valeurs des variables
définies à l’étape précédente sont générées par une méthode de Monte Carlo, c'est-à-dire par un
tirage aléatoire dans leur loi de probabilité théorique préalablement calée. La génération des
variables est réalisée suivant un ordre dicté par la construction des événements pluvieux (§
B.1.3). L'hypothèse initiale d'indépendance des différentes variables descriptives permet le
3 Deux saisons ont été choisies pour différencier les pluies d’ « été » plutôt intenses et courtes (de juin à
novembre) et les pluies d’ « hiver » plutôt longues et moins intenses (de décembre à mai), bien que ce découpage puisse
être contestable suivant la climatologie des régions étudiées.
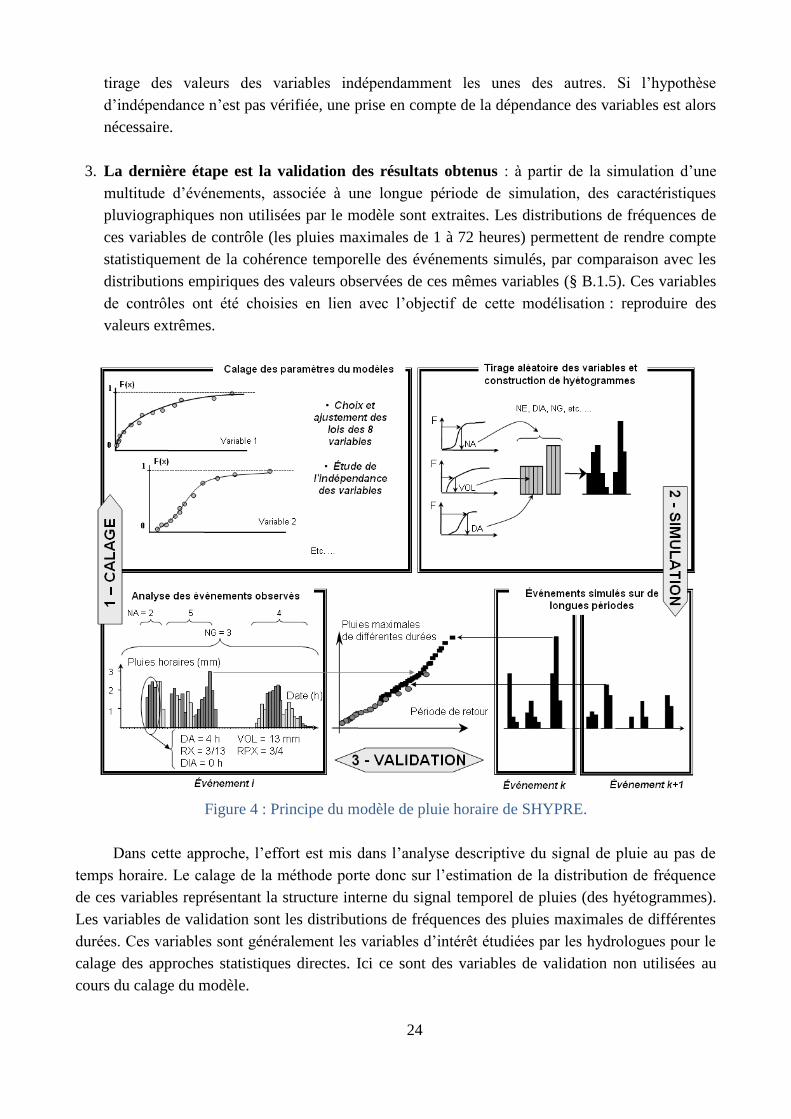
24
tirage des valeurs des variables indépendamment les unes des autres. Si l’hypothèse
d’indépendance n’est pas vérifiée, une prise en compte de la dépendance des variables est alors
nécessaire.
3. La dernière étape est la validation des résultats obtenus : à partir de la simulation d’une
multitude d’événements, associée à une longue période de simulation, des caractéristiques
pluviographiques non utilisées par le modèle sont extraites. Les distributions de fréquences de
ces variables de contrôle (les pluies maximales de 1 à 72 heures) permettent de rendre compte
statistiquement de la cohérence temporelle des événements simulés, par comparaison avec les
distributions empiriques des valeurs observées de ces mêmes variables (§ B.1.5). Ces variables
de contrôles ont été choisies en lien avec l’objectif de cette modélisation : reproduire des
valeurs extrêmes.
Figure 4 : Principe du modèle de pluie horaire de SHYPRE.
Dans cette approche, l’effort est mis dans l’analyse descriptive du signal de pluie au pas de
temps horaire. Le calage de la méthode porte donc sur l’estimation de la distribution de fréquence
de ces variables représentant la structure interne du signal temporel de pluies (des hyétogrammes).
Les variables de validation sont les distributions de fréquences des pluies maximales de différentes
durées. Ces variables sont généralement les variables d’intérêt étudiées par les hydrologues pour le
calage des approches statistiques directes. Ici ce sont des variables de validation non utilisées au
cours du calage du modèle.
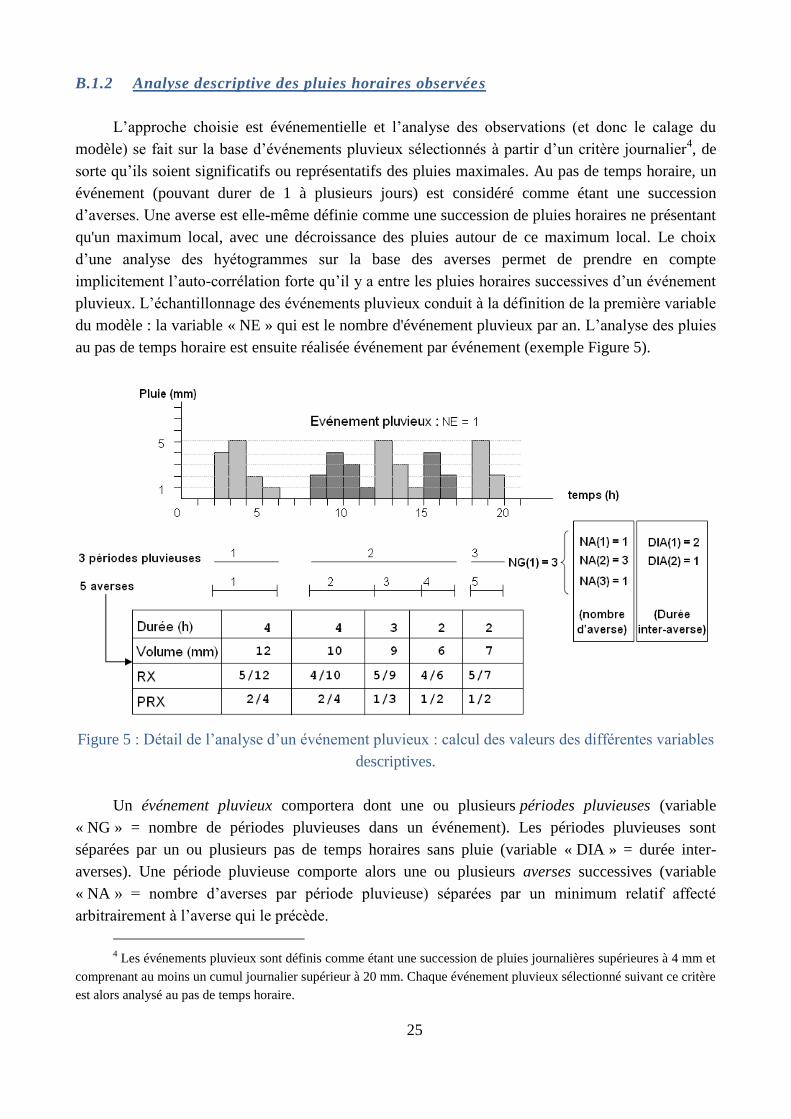
25
B.1.2 Analyse descriptive des pluies horaires observées
L’approche choisie est événementielle et l’analyse des observations (et donc le calage du
modèle) se fait sur la base d’événements pluvieux sélectionnés à partir d’un critère journalier4, de
sorte qu’ils soient significatifs ou représentatifs des pluies maximales. Au pas de temps horaire, un
événement (pouvant durer de 1 à plusieurs jours) est considéré comme étant une succession
d’averses. Une averse est elle-même définie comme une succession de pluies horaires ne présentant
qu'un maximum local, avec une décroissance des pluies autour de ce maximum local. Le choix
d’une analyse des hyétogrammes sur la base des averses permet de prendre en compte
implicitement l’auto-corrélation forte qu’il y a entre les pluies horaires successives d’un événement
pluvieux. L’échantillonnage des événements pluvieux conduit à la définition de la première variable
du modèle : la variable « NE » qui est le nombre d'événement pluvieux par an. L’analyse des pluies
au pas de temps horaire est ensuite réalisée événement par événement (exemple Figure 5).
Figure 5 : Détail de l’analyse d’un événement pluvieux : calcul des valeurs des différentes variables
descriptives.
Un événement pluvieux comportera dont une ou plusieurs périodes pluvieuses (variable
« NG » = nombre de périodes pluvieuses dans un événement). Les périodes pluvieuses sont
séparées par un ou plusieurs pas de temps horaires sans pluie (variable « DIA » = durée inter-
averses). Une période pluvieuse comporte alors une ou plusieurs averses successives (variable
« NA » = nombre d’averses par période pluvieuse) séparées par un minimum relatif affecté
arbitrairement à l’averse qui le précède.
4 Les événements pluvieux sont définis comme étant une succession de pluies journalières supérieures à 4 mm et
comprenant au moins un cumul journalier supérieur à 20 mm. Chaque événement pluvieux sélectionné suivant ce critère
est alors analysé au pas de temps horaire.

26
Chaque averse est ensuite définie par différentes variables que sont :
• la durée de l'averse (en heure) : variable « DA »,
• le volume de l'averse (en mm) : variable « VOL »,
• le rapport entre la pluie horaire maximale de l'averse et son volume : variable « RX »,
• et la position relative de la pluie horaire maximale dans l'averse : variable « RPX ».
L’analyse descriptive des événements pluvieux enregistrés sur une station pluviographique
conduit à étudier plusieurs événements par an, composés de plusieurs périodes pluvieuses ayant
elles-mêmes plusieurs averses. L’effectif des variables étudiées est alors bien supérieur à une valeur
par an, ce qui participera à la robustesse de l’approche (pour trente années d’observation, l’effectif
des échantillons sur lesquels portent l’ajustement des lois de probabilité internes au modèle, varie
entre 100 et 1500 réalisations suivant les variables et le poste étudié).
Les huit variables ainsi définies sont utilisées pour décrire les événements pluvieux observés.
L'étude d'une cinquantaine de postes pluviographiques, situés dans les départements du pourtour
méditerranéen français, a permis de déterminer les lois de probabilités théoriques qui reproduisent
au mieux les distributions de fréquences empiriques des différentes variables [Flavie Cernesson,
1993] : la loi de Poisson est utilisée pour les variables NE et DA ; la loi géométrique est utilisée
pour les variables NG, NA et DIA ; la loi normale, tronquée entre 0 et 1, est utilisée pour la variable
PRX ; la loi uniforme pour la variable RX et une loi exponentielle pour la variable VOL.
L’application de ces lois sur de nouvelles séries de mesures, en climat tempéré et tropical, a aussi
montré leur pertinence, conduisant à les garder quelle que soit la zone d’étude [Arnaud, 1997].
L’analyse quantitative des volumes des averses et de leur durée, a montré la nécessité de
distinguer deux types d’averses. Une typologie des averses a fait l’objet de différents tests. Les
travaux effectués sur le modèle en climat méditerranéen ont conduit à la définition d’averses dites
«principales » et d’averses dites « ordinaires ». Un événement pluvieux comptait une seule averse
principale qui était celle qui apporte la plus grande quantité d’eau lors de l’événement. Toutes les
autres averses étaient alors définies comme étant des averses ordinaires [Cernesson et al., 1996].
Cette typologie s’est avérée insuffisante pour caractériser les pluies extrêmes observées sous
d’autres climats. En effet, l'analyse des hyétogrammes observés sur l’île de la Réunion (records
mondiaux de pluviométrie), a montré la nécessité de considérer plus d’une averse « principale » par
événement [Fine and Lavabre, 2003]. Afin de ne pas alourdir la paramétrisation du modèle, dans
l’objectif de sa régionalisation, la solution retenue a été de définir une typologie des averses basée
sur un critère journalier. Ce critère doit permettre de distinguer les averses responsables des forts
cumuls de pluie. Une averse principale par événement est alors retenue, à laquelle sont rajoutées
autant d’averses principales que de jours où la pluie journalière a dépassé 50 mm. Ce seuil de 50
mm, fixé quelque soit le climat, a été choisi empiriquement pour ne pas donner trop d’importance à
des événements pluvieux longs mais peu intenses [Arnaud and Lavabre, 2010]. Ce seuil conduit à
la détermination d’une neuvième variable qui est le nombre d’averses principales de l’événement
(variable « NAVP »). Cette typologie des averses ne concerne que les variables VOL, DA et RX,
qui seront caractérisées par des lois de probabilité ajustées sur les deux échantillons distincts
d’averses. Pour la variable RPX, la distinction des types d’averses n’est pas nécessaire. Le Tableau
1, issus de [Arnaud and Lavabre, 2010], indique les différentes lois de probabilité et leurs
paramètres associés, pour chaque variable du modèle.
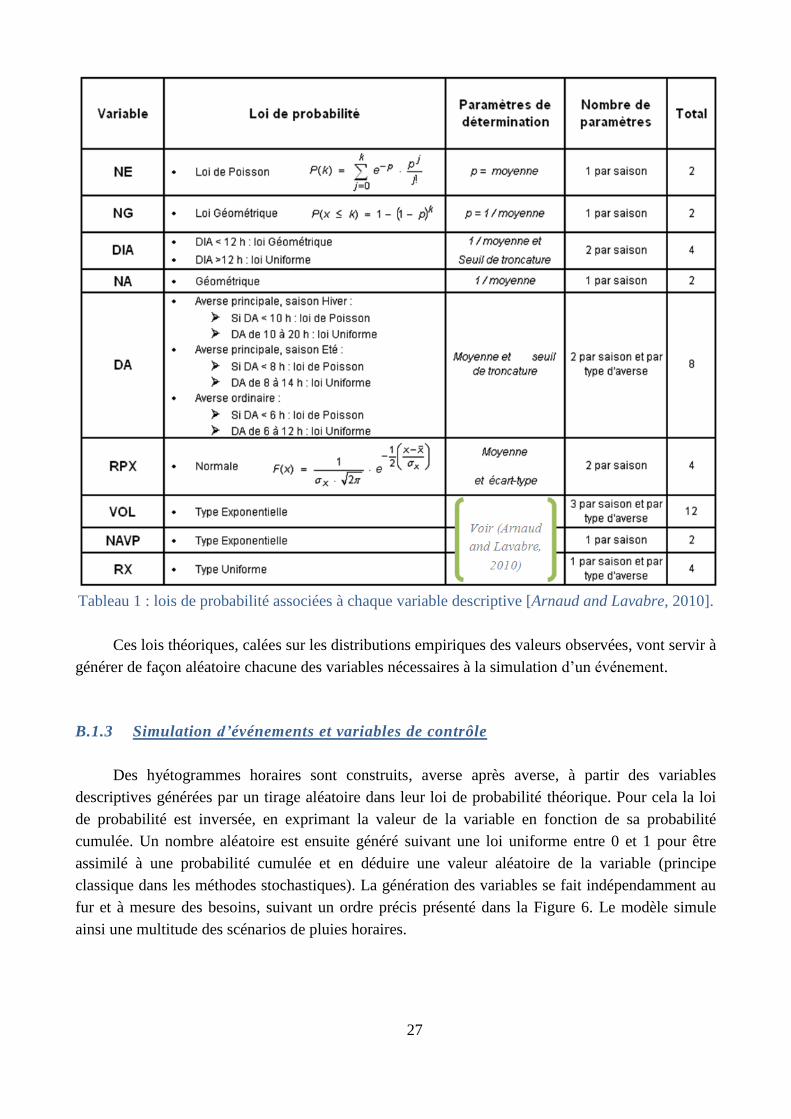
27
Tableau 1 : lois de probabilité associées à chaque variable descriptive [Arnaud and Lavabre, 2010].
Ces lois théoriques, calées sur les distributions empiriques des valeurs observées, vont servir à
générer de façon aléatoire chacune des variables nécessaires à la simulation d’un événement.
B.1.3 Simulation d’événements et variables de contrôle
Des hyétogrammes horaires sont construits, averse après averse, à partir des variables
descriptives générées par un tirage aléatoire dans leur loi de probabilité théorique. Pour cela la loi
de probabilité est inversée, en exprimant la valeur de la variable en fonction de sa probabilité
cumulée. Un nombre aléatoire est ensuite généré suivant une loi uniforme entre 0 et 1 pour être
assimilé à une probabilité cumulée et en déduire une valeur aléatoire de la variable (principe
classique dans les méthodes stochastiques). La génération des variables se fait indépendamment au
fur et à mesure des besoins, suivant un ordre précis présenté dans la Figure 6. Le modèle simule
ainsi une multitude des scénarios de pluies horaires.

28
Figure 6 - Organisation des tirages aléatoires des différentes variables nécessaires à la construction
de hyétogrammes.
Par exemple, pour générer un échantillon d’événements équivalents à 100 ans de données, il
faut générer 100 valeurs de la variable NE suivant sa loi calée sur les observations de la saison « été
» (juin à novembre) et 100 valeurs de cette même variable suivant sa loi calée sur les observations
de la saison « hiver » (décembre à mai). La somme de ces 200 valeurs de NE correspond alors au
nombre total d’événements à générer. Puis pour chacun des événements à générer, les variables
descriptives sont générées en prenant en compte leurs lois de probabilité ajustées sur la saison
appropriée. Pour simuler un événement l’ordre des tirages aléatoires effectués est le suivant :
Tirage du nombre de périodes pluvieuses : NG
Pour chaque période pluvieuse, tirage du nombre d’averses qui la compose et de la durée
sèche qui la sépare de la période pluvieuse suivante. On génère donc NG valeurs de NA et
(NG-1) valeurs de DIA. Par sommation, le nombre total d’averses composant l’événement
peut être calculé.
Tirage du nombre d’averses principales à considérer. Ce nombre sera borné par le nombre
d’averses total déterminé précédemment. On génère ensuite la position des averses
principales dans l’événement.

29
Pour chaque averse, les valeurs des variables DA, VOL sont générées en distinguant les
averses principales et les averses ordinaires. La détermination de la durée de chaque averse
et la connaissance des durées inter-averses permettent alors de positionner les différentes
averses dans le temps, et de déduire la durée totale de l’événement. La quantité de pluie
totale de l’événement est obtenue par sommation de toutes les valeurs de la variable VOL.
Pour chaque averse, les valeurs des variables RX (en distinguant la typologie de l’averse) et
RPX sont générées. Le maximum horaire de chaque averse (le produit de VOL par RX) et sa
position sont alors déterminés.
Il reste alors à répartir la quantité restante, soit (1-RX).VOL, de façon aléatoire de part et
d’autre du maximum horaire, en respectant la décroissance des pluies lorsque l’on s’éloigne
du maximum. La définition d’une averse est alors respectée (succession de pluies horaires
ne présentant qu’un maximum relatif).
Un échantillon d’événements pluvieux au pas de temps horaire est ainsi généré, dont l’effectif
est proportionnel au nombre d’années simulées. Cet échantillon doit être statistiquement équivalent
à l’échantillon des événements observés. Pour vérifier cela, l’échantillon des événements pluvieux
simulés est comparé à l’échantillon des événements pluvieux observés utilisés lors du calage du
générateur. Cette comparaison ne peut être que statistique. Pour juger de la pertinence de la
structure temporelle des événements simulés, différentes durées d’analyse doivent être prises en
compte. Le contrôle de la cohérence statistique et de la structure temporelle des événements simulés
est basé sur l’analyse des distributions de fréquences des pluies de différentes durées (courbes
Intensité Durée Fréquence IDF). Ces variables ne sont pas utilisées lors de la modélisation. Elles
sont déduites des hyétogrammes simulés, de la même façon que pour les hyétogrammes observés.
Les variables de contrôle sont donc les pluies maximales sur des durées de 1 à 72 heures, extraites
des hyétogrammes, qu’ils soient observés ou simulés.
Pour les simulations, les courbes IDF déduites des hyétogrammes simulés, sont issus de
simulations 100 fois plus longues que la plus grande période de retour désirée. On ne s’intéresse
alors qu’à des valeurs de rang supérieur à 100, faiblement influencée par l’échantillonnage des
simulations.
B.1.4 Etude de la dépendance des variables
Une des hypothèses de base des générateurs stochastiques de pluie est l’indépendance des
variables du modèle. Ces variables peuvent ainsi être générées de façon indépendante lors de la
modélisation. Le choix des variables du modèle peut être influencé par cette hypothèse lors de la
conception du modèle. Toutefois, l’étude de la dépendance des variables entre elles reste nécessaire
pour vérifier cette hypothèse.
Notons que cette étude est possible car notre approche est basée sur une réelle analyse
descriptive de la pluie. En effet, l’observation directe des variables composant le modèle et
décrivant la pluie, permet l’observation et l’étude de leurs dépendances. C’est une divergence
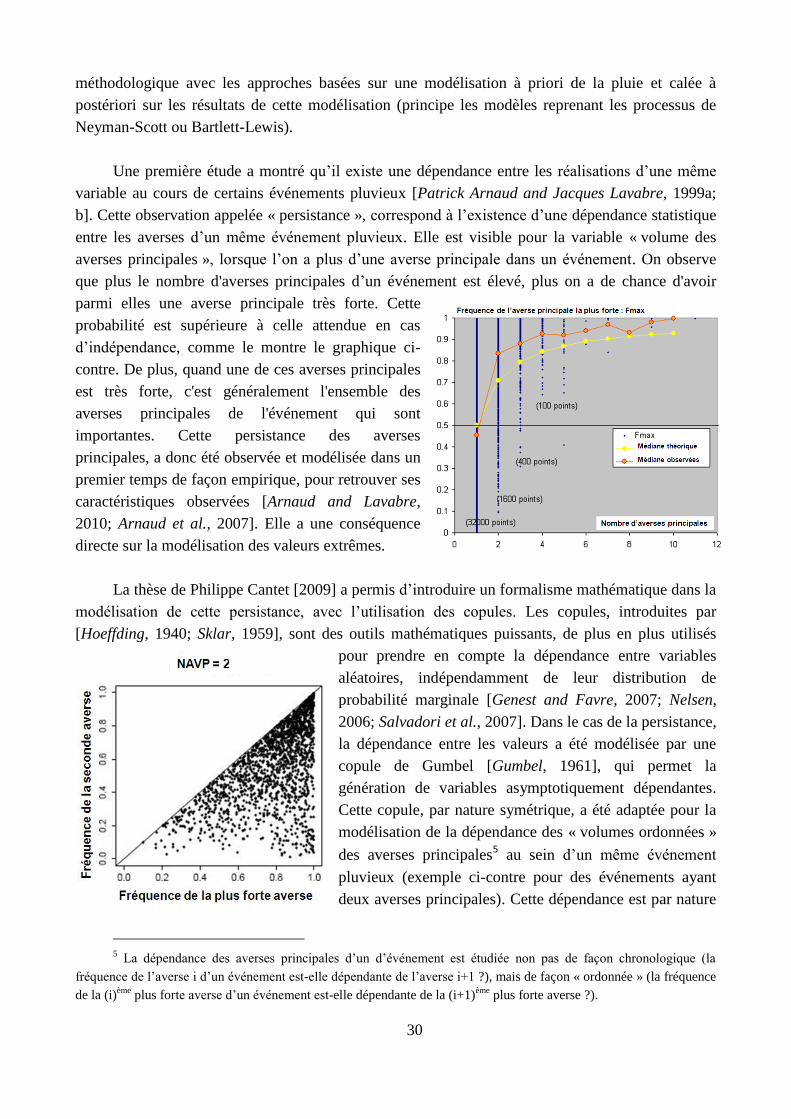
30
méthodologique avec les approches basées sur une modélisation à priori de la pluie et calée à
postériori sur les résultats de cette modélisation (principe les modèles reprenant les processus de
Neyman-Scott ou Bartlett-Lewis).
Une première étude a montré qu’il existe une dépendance entre les réalisations d’une même
variable au cours de certains événements pluvieux [Patrick Arnaud and Jacques Lavabre, 1999a;
b]. Cette observation appelée « persistance », correspond à l’existence d’une dépendance statistique
entre les averses d’un même événement pluvieux. Elle est visible pour la variable « volume des
averses principales », lorsque l’on a plus d’une averse principale dans un événement. On observe
que plus le nombre d'averses principales d’un événement est élevé, plus on a de chance d'avoir
parmi elles une averse principale très forte. Cette
probabilité est supérieure à celle attendue en cas
d’indépendance, comme le montre le graphique ci-
contre. De plus, quand une de ces averses principales
est très forte, c'est généralement l'ensemble des
averses principales de l'événement qui sont
importantes. Cette persistance des averses
principales, a donc été observée et modélisée dans un
premier temps de façon empirique, pour retrouver ses
caractéristiques observées [Arnaud and Lavabre,
2010; Arnaud et al., 2007]. Elle a une conséquence
directe sur la modélisation des valeurs extrêmes.
La thèse de Philippe Cantet [2009] a permis d’introduire un formalisme mathématique dans la
modélisation de cette persistance, avec l’utilisation des copules. Les copules, introduites par
[Hoeffding, 1940; Sklar, 1959], sont des outils mathématiques puissants, de plus en plus utilisés
pour prendre en compte la dépendance entre variables
aléatoires, indépendamment de leur distribution de
probabilité marginale [Genest and Favre, 2007; Nelsen,
2006; Salvadori et al., 2007]. Dans le cas de la persistance,
la dépendance entre les valeurs a été modélisée par une
copule de Gumbel [Gumbel, 1961], qui permet la
génération de variables asymptotiquement dépendantes.
Cette copule, par nature symétrique, a été adaptée pour la
modélisation de la dépendance des « volumes ordonnées »
des averses principales5 au sein d’un même événement
pluvieux (exemple ci-contre pour des événements ayant
deux averses principales). Cette dépendance est par nature
5 La dépendance des averses principales d’un d’événement est étudiée non pas de façon chronologique (la
fréquence de l’averse i d’un événement est-elle dépendante de l’averse i+1 ?), mais de façon « ordonnée » (la fréquence
de la (i)ème
plus forte averse d’un événement est-elle dépendante de la (i+1)ème
plus forte averse ?).

31
représentée dans un domaine « triangulaire » car les couples de valeurs étudiés (Xi, Xi+1) vérifient la
relation Xi > Xi+1 pour i = 1,…,n-1, où Xi est la ième
plus forte valeur [Cantet, 2009].
La persistance des averses a pu être étudiée directement sur l’observation des caractéristiques
des averses. C’est un des atouts que présente cette approche « directe » qui se base sur la
description fine de la structure des événements pluvieux et qui tente de la reproduire au mieux. La
modélisation de la persistance des averses permet la modélisation d’événements pluvieux extrêmes
présentant de forts cumuls, comme par exemple dans les régions cévenoles ou en milieu tropical.
Des copules ont aussi été utilisées pour modéliser la dépendance entre deux variables
différentes. C’est le cas de la relation « Volume-Durée » des averses principales : cette dépendance
a été modélisée par une copule de Frank qui s’est avérée la mieux adaptée aux observations [Cantet
and Arnaud, 2014].
Les observations servant à caler les paramètres des copules sont des fréquences indépendantes
des lois marginales des variables, ce qui permet l’agglomération des données fournies par plusieurs
postes. La dépendance peut donc être modélisée de façon unique pour l’ensemble des postes d’une
même région. C’est donc une composante régionale sur la structure des pluies qui est déterminée à
travers les paramètres des copules. Cette approche est suffisante et permet de garder une certaine
robustesse dans l’estimation de paramètres sensibles influant sur le comportement asymptotique du
modèle.
B.1.5 Application et analyse des performances
Les recherches initiales sur le générateur de pluie ont été réalisées sur les données d’une
cinquantaine de postes pluviographiques situés sur le pourtour méditerranéen français. Dans le
cadre de l’extension de l’approche sur l’ensemble du territoire français, le modèle a été appliqué sur
de nouveaux postes situés sur l’ensemble du territoire métropolitain, ainsi que sur des postes situés
en outre-mer (Îles de la Réunion, de la Martinique et de la Guadeloupe, et la Nouvelle Calédonie).
Au total, le générateur de pluies horaires a été testé sur 407 postes pluviographiques, localisés sur
les cartes de la Figure 7. De façon indicative, ces postes sont regroupés selon leur climatologie.
Quatre types de climats sont définis :
le climat « alpin » : 29 postes sont situés dans le massif alpin, à une altitude moyenne
de 950 mètres, avec 75% des postes à plus de 500 mètres6.
le climat « méditerranéen » : 90 postes sont situés dans les départements des régions
du Sud Est de la France, à proximité de la mer Méditerranée.
6 Le traitement des données de pluies a été réalisé exclusivement sur des données de précipitations liquides. Les
événements pluvieux sont formes neigeuses ont été supprimés de l’analyse pour ne pas influence l’analyse de la
structure des averses au sein d’un événement pluvieux.

32
le climat « tempéré » : 98 postes sont situés sur le reste du territoire métropolitain
français, à une altitude moyenne de 182 m, avec 95% des postes à moins de 500
mètres.
le climat « tropical » : 52 postes sont situés sur l’île de la Réunion, 17 postes sur l’île
de la Martinique, 13 sur l’île de la Guadeloupe et 108 en Nouvelle Calédonie.
Figure 7 : localisation des postes pluviographiques étudiés.
Appliqué sur ces postes horaires, le générateur de pluie présente une bonne restitution des
quantiles de pluie de différentes durées. Cela signifie que les scénarios de pluies générés ont des
caractéristiques temporelles statistiquement équivalentes à celles des observations et que le modèle
s’adapte bien à différents types de climats, en utilisation toujours la même structure [Arnaud et al.,
2007]. La structure du modèle est donc suffisamment pertinente pour que la paramétrisation suffise
à caler le générateur sur des données allant du climat tempéré au climat tropical.
La méthode a aussi été évaluée dans le cadre du projet ANR Extraflo7. Dans le cadre de ce
projet, la comparaison de plusieurs méthodes de prédétermination s’est appuyée sur un cadre
rigoureux permettant d’appliquer chaque méthode sur les mêmes données (associées à des
échantillonnages variés) et les confronter aux mêmes critères d’évaluation suite à des procédures de
calage/validation [B. Renard et al., 2013]. Le paragraphe suivant présente les critères développés
dans le cadre de ce projet et qui seront utilisés dans plusieurs paragraphes de ce document.
7 Le projet ANR Extraflo 2009-2013 (https://extraflo.cemagref.fr/) du programme RiskNat de l’ANR, avait pour
objectif de mieux connaitre les domaines d’application des différentes méthodes d’estimation des pluies et des crues
extrêmes. Ce projet s’est appuyé sur des actions de comparaison des différentes méthodes utilisées en France, soumises
à une procédure commune permettant de qualifier la justesse et la stabilité des estimations suivant différentes
configurations d’application (locale, régionale) et d’échantillonnage.

33
a - Cadre d’évaluation lié au projet ANR Extraflo
Le principe du projet a été de tester différentes méthodes de prédétermination, utilisées dans
des situations différentes. Ces mises en situation sont liées à des échantillonnages réalisés sur les
données, afin de contraindre l’utilisation de certaines observations pour le calage des méthodes et
d’autres pour leur validation. Suivant la nature des méthodes, les échantillonnages peuvent être
différents comme le schématise la Figure 8. Sur ce schéma, chaque « bâton » représente une
chronique de données (pluie ou débit) subdivisés en « carré » qui correspondent à une année de
cette chronique. Les couleurs indiquent dans quels cas ces données sont utilisées : en calage de
paramètres locaux (couleur bleue), en calage de paramètres régionaux (couleur verte) et en
validation (couleur saumon).
Figure 8 : Principe des décompositions en fonction de la nature des approches.
Ce cadre définit aussi des critères d’évaluation permettant de juger les résultats des approches
au regard des observations. La description précise de cette plateforme d’évaluation est donnée par
[B. Renard et al., 2013]. Les critères d’évaluation utilisés sont décrits rapidement ici. Ils évaluent la
« justesse » et la « stabilité » des méthodes.
La justesse d’une méthode de prédétermination est liée à sa capacité à attribuer aux
observations des probabilités d’apparition justes, c'est-à-dire respectant une distribution théorique
bien définie. Deux critères, dont la détermination est illustrée par la Figure 9, ont été définis ainsi :
Le critère NT correspond aux nombres d’observations qui dépassent un certain seuil. Ce
seuil, associé à une période de retour T, est déterminé par la méthode testée (c’est le quantile
de période de retour T). La distribution théorique de ce nombre de dépassement d’un seuil
est alors associée à une loi Binomiale de paramètres n (nombre d’années d’observations) et
1/T (fréquence annuelle de succès) [B. Renard et al., 2013].
Le critère FF, utilisé dans d’autres travaux [England et al., 2003; Garavaglia et al., 2011],
correspond à la fréquence que donne une méthode à la plus forte valeur observée en n
années d’observation. La distribution théorique de cette variable est associée à une loi
Beta(n,1) de paramètre n (nombre d’années d’observation) [Kumaraswamy, 1980].
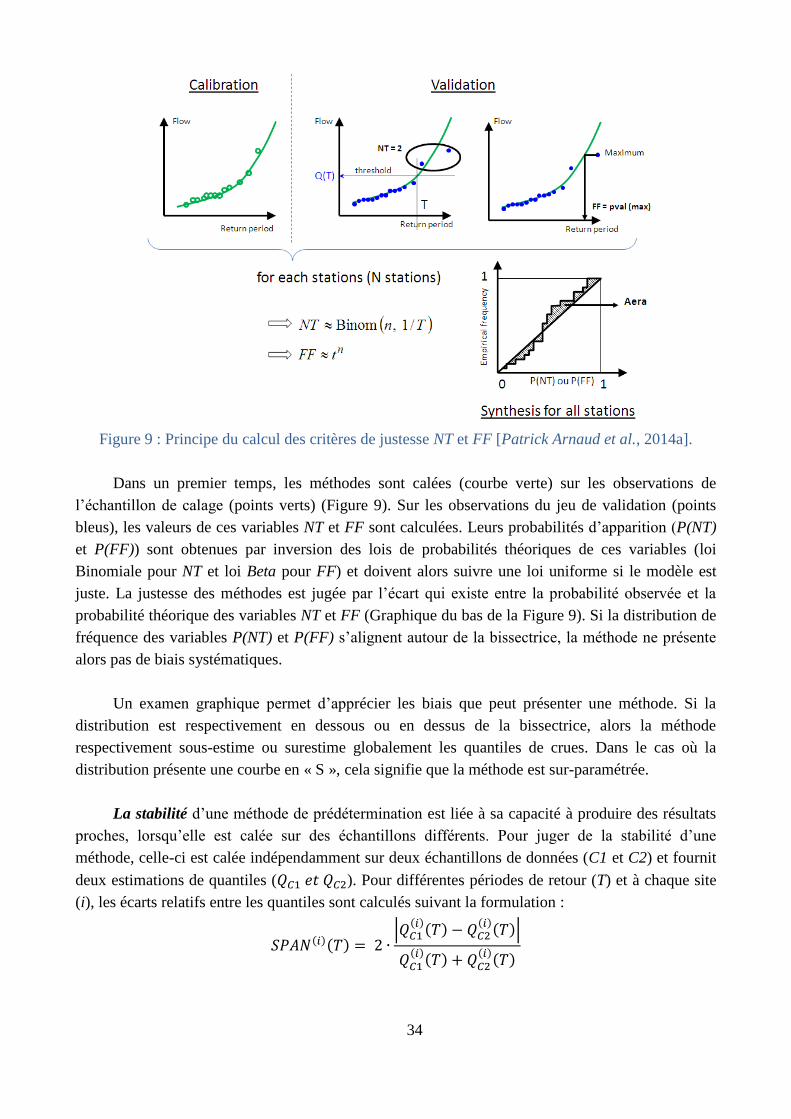
34
Figure 9 : Principe du calcul des critères de justesse NT et FF [Patrick Arnaud et al., 2014a].
Dans un premier temps, les méthodes sont calées (courbe verte) sur les observations de
l’échantillon de calage (points verts) (Figure 9). Sur les observations du jeu de validation (points
bleus), les valeurs de ces variables NT et FF sont calculées. Leurs probabilités d’apparition (P(NT)
et P(FF)) sont obtenues par inversion des lois de probabilités théoriques de ces variables (loi
Binomiale pour NT et loi Beta pour FF) et doivent alors suivre une loi uniforme si le modèle est
juste. La justesse des méthodes est jugée par l’écart qui existe entre la probabilité observée et la
probabilité théorique des variables NT et FF (Graphique du bas de la Figure 9). Si la distribution de
fréquence des variables P(NT) et P(FF) s’alignent autour de la bissectrice, la méthode ne présente
alors pas de biais systématiques.
Un examen graphique permet d’apprécier les biais que peut présenter une méthode. Si la
distribution est respectivement en dessous ou en dessus de la bissectrice, alors la méthode
respectivement sous-estime ou surestime globalement les quantiles de crues. Dans le cas où la
distribution présente une courbe en « S », cela signifie que la méthode est sur-paramétrée.
La stabilité d’une méthode de prédétermination est liée à sa capacité à produire des résultats
proches, lorsqu’elle est calée sur des échantillons différents. Pour juger de la stabilité d’une
méthode, celle-ci est calée indépendamment sur deux échantillons de données (C1 et C2) et fournit
deux estimations de quantiles ( ). Pour différentes périodes de retour (T) et à chaque site
(i), les écarts relatifs entre les quantiles sont calculés suivant la formulation :

35
La distribution de fréquence des valeurs de la variable SPAN doit alors être proche de la
valeur zéro, pour les méthodes les plus stables.
L’analyse graphique de ces différents critères (de justesse et de stabilité) peut être synthétisée
par le calcul de « scores ». Ces « scores » sont basés sur le calcul de l’aire comprise entre la
distribution observée et la distribution théorique de chaque critère. Une normalisation de cette aire
permet de faire varier tous les « scores » entre les valeurs 0 (mauvaise performance) et 1
(performance maximale). Ces scores sont présentés dans diverses publications liées aux projets
(voir paragraphes suivants) et dans la partie C.3 sur l’estimation des débits de crues.
b - Les résultats du projet ANR Extraflo pour la détermination ponctuelle des pluies
extrêmes
Les résultats du projet ANR Extraflo sur les méthodes « locales » d’estimation de l’aléa
pluviométrique sont présentés dans un rapport [Veysseire et al., 2012] qui compare les résultats du
générateur de pluie de la méthode SHYPRE, avec l’utilisation de plusieurs lois de probabilité
sélectionnées (à 2 et 3 paramètres : exponentielle, loi GEV et loi de Pareto généralisée), ainsi que la
loi MEWP (mélanges de lois exponentielles calées par types de temps) développée par EDF/GDF
[Garavaglia et al., 2011]. Dans le cadre de ce projet, les comparaisons ont été faites uniquement sur
l’estimation des quantiles de pluies journalières. Comme la seule information utilisée dans ce projet
est une information journalière (entre 671 et 1568 stations de mesures suivant les échantillonnages
réalisés8), la version de SHYPRE utilisée est une version « journalisée », présentée dans la partie
B.2.1. Des résultats sont aussi disponibles aux pas de temps infra-journaliers et présentés
dans[Cantet and Arnaud, 2014].
Concernant les méthodes d’estimation locale de l’aléa pluvial, le projet ANR Extraflo conclut
que parmi les lois statistiques dites « classiques », les meilleurs résultats sont donnés par
l’utilisation de la loi de Pareto ajustée par les moments pondérés. Cependant le constat est fait que :
« SHYPRE (le générateur de pluie) apparaît comme la méthode la plus juste devant la loi de Pareto
et la loi MEWP. … On constate que la robustesse de la loi de Pareto est inférieure à celles de la loi
MEWP et de SHYPRE» [Veysseire et al., 2012]. On observe les mêmes conclusions lorsque l’on
s’intéresse aux données infra-journalières (217 stations) [Cantet and Arnaud, 2014].
8 Les méthodes sont évaluées sur différentes périodes de calage et validation, permettant de les mettre dans des
configurations différentes : un échantillonnage de 50% (respectivement 33%) des années pour le calage et 50%
(respectivement 67%) des données pour la validation permet de juger de la justesse des méthodes ; un échantillonnage
sans l’année « du record » en calage (pour des séries de 20, 30 et 50 ans d’observation) et avec le « record » en
validation permet de juger de la capacité des méthodes à prédéterminer les valeurs extrêmes ; un échantillonnage de
deux périodes distinctes de calage (de 10, 15 et 25 ans chacune) permet de juger de la stabilité des méthodes.

36
Le générateur stochastique de chronique de pluies horaires qui a été développé est donc basé
sur l’analyse de variables aléatoires décrivant au mieux le signal de pluie au pas de temps horaire.
Ces variables aléatoires sont définies par leur distribution de probabilité, ajustée sur l’échantillon
des valeurs observées. L’observation des variables internes du générateur de pluie permet aussi
d’évaluer directement la pertinence des hypothèses faites sur leur loi de probabilité théorique et sur
la dépendance qui peut exister entre elles. Ce point contribue à la complexité de la méthode qui
tend à modéliser la structure interne des hyétogrammes de pluie à partir de leur observation (car
« on modélise ce que l’on voit …»), mais permet aussi de s’affranchir d’hypothèses de modélisation
souvent présentes dans d’autres types de générateurs de pluies (type Neyman-Scott).
L’ajustement de lois de probabilité sur les variables internes du modèle pourrait laisser
penser que cette modélisation reste soumise aux mêmes difficultés de calage que les « approches
classiques ». Ce n’est pas le cas pour deux raisons :
d’une part l’effectif des valeurs observées sur lequel porte l’ajustement des lois est
nettement plus important que lorsque l’on s’intéresse à une seule observation par événement
(la pluie maximale en 24 heures de l’événement par exemple), voire à une seule observation
par an (échantillonnage des valeurs maximales annuelles). En effet, on a plusieurs
événements par an qui sont composés de plusieurs averses. L’analyse des lois
caractéristiques des averses repose généralement sur des échantillons d’effectif supérieur à
100 voire 1000.
d’autre part, un effort particulier a été fait dans le choix des lois de probabilité utilisées, en
choisissant des lois robustes, c'est-à-dire le plus faiblement paramétrées. Les lois les plus
sensibles sont étudiées de façon adimensionnelle afin d’augmenter la représentativité de
l’échantillon par agglomération des variables (sorte de composante « régionale »). C’est le
cas par exemple de la loi représentant le volume des averses.
La prise en compte de la dépendance entre les variables du modèle est aussi un point
important dans le développement du générateur. Cette dépendance est observée et sa modélisation
a été orientée par cette observation. Cette modélisation a été réalisée par le biais de copules dont le
calage a été réalisé de façon régionale, et dont l’influence reste forte sur la modélisation des
valeurs extrêmes.
Le générateur de pluie développé présente de nombreuses qualités mises en avant lors de sa
comparaison à d’autres approches. Parmi elles, la justesse qui est la qualité primordiale de ce
genre d’approche. En particulier, sa capacité prédictive qui conduit à produire des estimations
justes des valeurs extrêmes malgré leur absence dans les échantillons de calage. La stabilité que
montre la méthode est aussi une qualité importante. De plus, la méthode est par nature une
approche multi-durées, puisqu’elle permet de fournir une information sur les pluies de différentes
durées avec la même modélisation. Les avancées réalisées sur ce modèle nous permettent alors
d’envisager son utilisation pour l’estimation régionale de l’aléa hydrologique. Cependant une
étape préalable de régionalisation est nécessaire pour pouvoir l’utiliser en sites non jaugés.

37
B.2 Estimation de l’aléa pluvial en site non instrumenté
L’objectif énoncé ici est de passer d’une estimation localisée de l’aléa à une estimation
régionalisée. Le générateur de pluies horaires développé a été éprouvé dans les contextes
climatiques très variés que l’on peut rencontrer en France, y compris dans les départements d’outre-
mer. La structure du générateur de pluies est restée la même, avec la même définition des variables,
les mêmes lois de probabilité associées à ces variables et la même procédure de caractérisation des
dépendances. A partir de cette structure unique qui modélise correctement la structure temporelle
des pluies horaires, le modèle s’ajuste au contexte local par le biais du calage de ces paramètres. Ce
calage peut être local (certains paramètres sont déterminés pour chaque station de mesure) ou
régional (certains paramètres sont déterminés pour une région donnée : c’est le cas des paramètres
de dépendance des copules, les seuils pour la loi des durées d’averses ou la sélection des
événements pluvieux à analyser,…).
L’application du générateur de pluie est alors possible si l’on dispose d’informations au pas
de temps horaire pour caler les différents paramètres du modèle. Cependant, cette information
(issue des pluviographes) reste insuffisante pour espérer réaliser une cartographie directe des vingt
paramètres du modèle de pluies horaires, estimés localement à partir de l’information horaire. En
revanche, l’information de pluie au pas de temps journalier (obtenue en plus par le réseau des
pluviomètres) est plus largement disponible sur l’ensemble du territoire français, tant en nombre de
stations de mesure qu’en durée des chroniques observées. C’est pourquoi, une première étape vers
la régionalisation du générateur a été de trouver une paramétrisation issue de l’information des
pluies journalières.
B.2.1 Etude de sensibilité et simplification de la paramétrisation
Le modèle a été initialement calé à partir de l’information pluviographique locale, répartis de
façon relativement homogène sur l’ensemble du territoire français. Un jeu de vingt paramètres
horaires par saison est déterminé pour chacun des 217 postes pluviographiques étudiés. Une analyse
de sensibilité a permis de fixer quinze de ces paramètres par saison, dont la variabilité géographique
n’est pas nécessairement la conséquence d’une particularité climatique [Arnaud, 1997]. Ces
paramètres, permettant de reproduire des hyétogrammes de forme réaliste, sont souvent peu
variables, ou dans une gamme où le modèle est peu sensible. Le fait de les fixer à leur valeur
médiane pour l’ensemble du territoire Français, ou pour un département donné (cas de l’application
aux DOM), ne dégrade pas les performances du modèle [Arnaud and Lavabre, 2010]. Il reste donc
cinq paramètres horaires principaux qu’il faut chercher à expliquer par l’intermédiaire de
l’information journalière. Ces paramètres sont : le nombre d’événement moyen par saison (variable
NE), le volume moyen des averses dites “principales” (produisant les plus forts volumes) (variable
VOLP) et celui des averses dites “ordinaires” (variable VOLO), le nombre moyen d’averses
principales (variable NAVP) et le nombre moyen d’averses dans un événement (variable NA).

38
Sur la base de la définition d’un événement pluvieux (succession de pluies journalières
supérieures à 4 mm et possédant au moins une pluie journalière supérieure à 20 mm), trois
paramètres journaliers ont été définis et déterminés pour les deux saisons étudiées :
a. le paramètre µNE est le nombre moyen d’événements analysés par saison. Il traduit
l’occurrence saisonnière des événements pluvieux significatifs d’un poste (plus de 20 mm de
pluie dans une journée). Il correspond d’ailleurs à un des cinq paramètres principaux à
expliquer.
b. le paramètre µPJMAX (en mm) correspond à la moyenne des pluies journalières maximales
de chaque événement pluvieux sélectionné dans une saison. Ce paramètre rend compte de
l’intensité pluviométrique du poste. Il permet d’expliquer le volume moyen des averses et le
nombre d’averses principales.
c. le paramètre µDTOT (en jour) représente la moyenne des durées des événements pluvieux
d’une saison. Cette caractéristique de durée permet d’expliquer le paramètre horaire
caractérisant le nombre d’averses à générer en moyenne dans un événement pluvieux.
Pour des raisons de continuité dans la régionalisation, des relations uniques ont été établies
sur l’ensemble du territoire métropolitain, entre les paramètres horaires et les paramètres
journaliers. Ces relations sont par contre différentes dans les DOM (en climat tropical).
Les paramètres journaliers ont été calculés à partir des séries horaires, sur la plus grande
période d’observation possible de chaque poste. Cela permet d’augmenter leur représentativité,
même si ces périodes peuvent différer d’un poste à l’autre9. Le choix d’une période commune
d’observation a par contre été respecté lors de l’étape de régionalisation des paramètres journaliers
présentée plus loin. Des régressions linéaires simples ont été établies entre les paramètres horaires
et journaliers. Elles présentent des coefficients de détermination (r2) compris entre 0.8 et 0.9
[Arnaud and Lavabre, 2010]. Les résultats du générateur de pluies paramétré par l’information
journalière sont comparés à ceux obtenus par la paramétrisation horaire. Ils montrent des
performances très proches et largement acceptables. On restitue en effet les quantiles biennaux des
pluies de différentes durées avec des écarts relatifs (par rapport aux quantiles “observés”)
généralement compris entre ±5% et rarement en dehors de l’intervalle ±10%.
Cette nouvelle paramétrisation permet d’envisager une mise en œuvre du générateur de pluies
horaires par un calage basé uniquement sur des données journalières. Les performances du modèle
paramétré par l’information journalière, ont été évaluées sur 2812 postes journaliers fournis par
Météo-France (avec au moins 20 ans de mesures sur la période d’observation 1977–2002) [Arnaud
and Lavabre, 2010]. C’est aussi cette version du générateur qui a été testée dans le cadre du projet
ANR Extraflo, ne disposant que d’informations journalières.
9 L’objectif est d’établir ici des régressions entre variables horaires et journalières, et non pas entre les valeurs
des paramètres de postes voisins, ce qui sera fait lors de la régionalisation. Une période commune et homogène n’est
donc pas impérative dans ce cas. Par contre, la période est commune sur un même poste, pour calculer ses paramètres
horaires et journaliers.

39
B.2.2 Cartographie des paramètres
L’utilisation du générateur de pluies horaires est donc possible à partir de la connaissance de
paramètres journaliers. Ces paramètres ont été déterminés sur les données de 2812 stations en
France métropolitaine, mais aussi sur 62 stations sur l’Ile de la Guadeloupe, 56 stations sur l’île de
la Martinique, 93 stations sur l’île de la Réunion et 158 stations sur la Nouvelle Calédonie. En
métropole, la cartographie des paramètres journaliers a été réalisée par Météo-France à partir de
l’information des 2812 pluviomètres [Sol and Desouches, 2005] et à partir d’une approche de type
“Aurelhy” [Benichou and Le Breton, 1987]. Pour cela, la France métropolitaine a été découpée en
onze zones climatiques homogènes au sens des paramètres à régionaliser. Sur chaque zone, une
régression linéaire multiple (appelée “fonction géographique”) a été étudiée entre chaque paramètre
et des variables caractérisant l’environnement géographique. Un découpage plus important aurait
diminué le nombre de postes disponibles pour établir les régressions, et donc les corrélations
obtenues auraient été moins significatives. Les variables environnementales étudiées sont de trois
types :
Altitude : l’altitude moyenne sur 25 km2 a été calculée pour chaque pixel d’un km
2. Le
choix d’un relief lissé permet de ne pas prendre en compte la variabilité fine du relief, sans
signification réelle vis-à-vis de la variabilité de la pluviométrie.
Paysage : le relief autour de chaque pixel (pris en compte sur un carré de 30 km de coté
centré sur le pixel) a fait l’objet d’une analyse en composantes principales. Douze vecteurs
propres issus de cette analyse ont alors été retenus pour expliquer le “paysage” autour du
pixel. Le premier vecteur propre (CP1) représente par exemple une cuvette ou un monticule,
le second (CP2) représente une pente NW/SE, etc.
Distances : des critères de distances aux mers, aux grands fleuves, aux crêtes des grandes
chaînes montagneuses ou encore aux grandes vallées ont aussi été calculés sur les zones
homogènes.
Les variables environnementales retenues, pour les différents paramètres et pour les
différentes zones, sont celles qui apportent une explication significative sur la variabilité des
paramètres journaliers. On retient dans la plupart des cas trois ou quatre prédicteurs, la valeur
médiane du coefficient de détermination des régressions étant de 0.58. Les résidus à la régression,
calculés aux 2812 points d’observation, sont ensuite interpolés par krigeage et ajoutés à la “fonction
géographique” pour obtenir un champ final spatialisé à la résolution d’un km². Pour le krigeage des
résidus, un variogramme sphérique sans effet de pépite a été utilisé. L’exemple de la Figure 10
montre ces différentes étapes de régionalisation, à travers la cartographie du paramètre µPJMAX de
la saison “été” sur la zone alpine. Bien que les caractéristiques de pluies extrêmes soient souvent
corrélées avec l’altitude [Weisse and Bois, 2001], l’altitude n’a pas été retenue comme variable
explicative de la variabilité du paramètre µPJMAX, arrivant en quatrième position après la distance
à la mer, l’effet des grandes vallées (CP1) et de leur orientation (CP2). Le choix de ces variables
n’est pas anodin lors de l’extrapolation des résultats sur les zones de hautes altitudes où
l’information pluviométrique devient plus rare.

40
Figure 10 : Progression dans la cartographie des variables journalières : exemple de la variable
µPJMAX pour la saison « été » sur la zone « Alpine » [Sol and Desouches, 2005].
Les cartes finales sont obtenues par assemblage des cartes calculées sur les onze zones
définies. Chaque zone débordant sur sa voisine sur une distance de 15 km, les variables sont alors
calculées sur les zones de chevauchement par une moyenne des valeurs des deux ou trois zones
superposées, pondérées par l’inverse de la distance à la limite des zones. La Figure 11 présente les
cartes des paramètres journaliers permettant de mettre en œuvre le générateur de pluies horaires en
tout point du territoire métropolitaine français [Arnaud, 2010; Arnaud et al., 2008c].
La répartition spatiale de ces paramètres montre une cohérence climatique qui souligne la
pertinence de la paramétrisation du modèle pour estimer les pluies intenses, sous des climats
variables. Des zones se différencient à travers les valeurs des trois paramètres journaliers. Les
régions méditerranéennes sont caractérisées par de fortes intensités de pluie, conduisant à de forts
cumuls journaliers, d’autant plus marqués sur les reliefs cévenols. Ces régions ne présentent pas
pour autant les plus fortes occurrences de pluie, ni les plus fortes durées. Les régions côtières non-
méditerranéennes (côtes atlantiques, côtes de la Manche et mer du Nord) ainsi que les régions
d’altitude présentent une pluviométrie marquée par des événements plutôt longs mais pas
nécessairement intenses. L’occurrence des événements semble par contre corrélée positivement
avec l’altitude. Les valeurs élevées du paramètre µNE sont présentes sur les régions alpines (Alpes
du nord), le massif central, les Vosges et les Pyrénées. Les plus faibles valeurs pour l’ensemble des
trois paramètres sont observées pour le bassin Parisien et le nord de la France. Ces cartes montrent
aussi la cohérence saisonnière des paramètres. La saison “été” est caractérisée par des paramètres
caractéristiques de pluies plus intenses mais plus courtes que pour la saison “hiver”.
A partir de la cartographie des paramètres journaliers et grâce à la paramétrisation journalière
du générateur de pluies horaires, des simulations de chroniques de pluies horaires peuvent être
faites pour chaque pixel d’un km2. Les courbes intensités–durées–fréquences (courbes IDF)
synthétisant l’information pluviographique sont alors établies à partir de ces simulations pour
obtenir à l’échelle de la France et à la résolution kilométrique, les quantiles des pluies maximales de
1 à 72 h pour des périodes de retour de 2 à 1000 ans (par exemple).
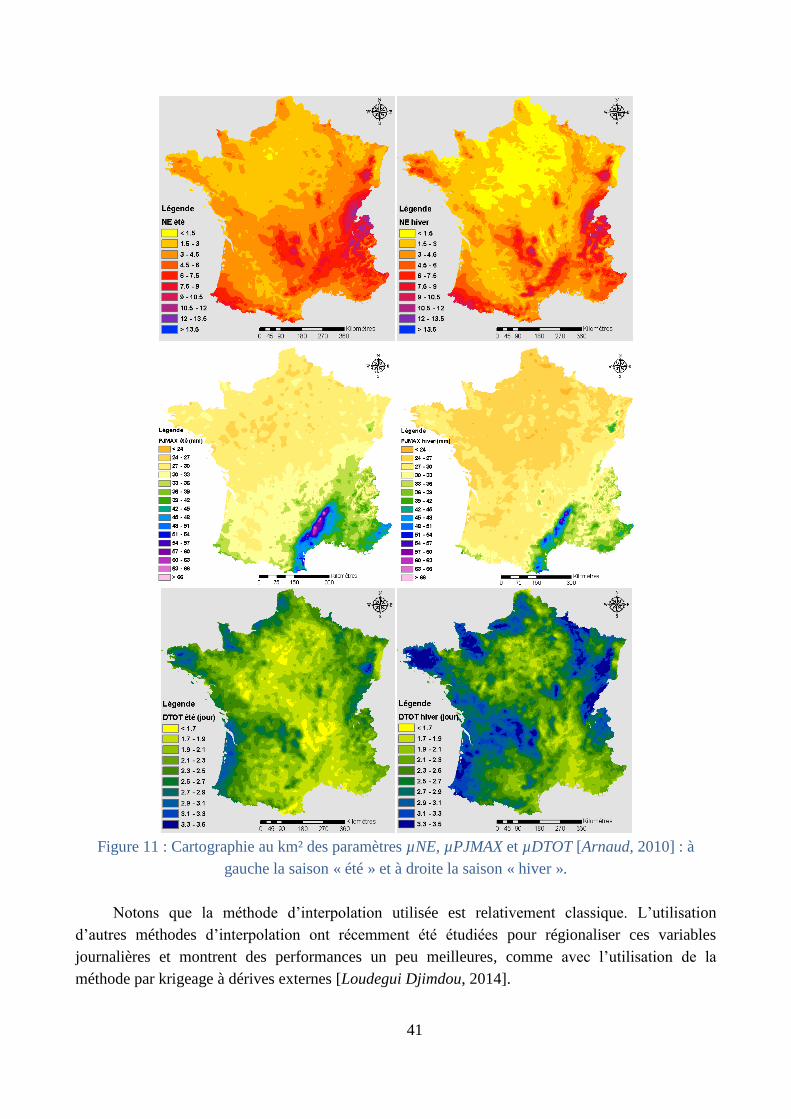
41
Figure 11 : Cartographie au km² des paramètres µNE, µPJMAX et µDTOT [Arnaud, 2010] : à
gauche la saison « été » et à droite la saison « hiver ».
Notons que la méthode d’interpolation utilisée est relativement classique. L’utilisation
d’autres méthodes d’interpolation ont récemment été étudiées pour régionaliser ces variables
journalières et montrent des performances un peu meilleures, comme avec l’utilisation de la
méthode par krigeage à dérives externes [Loudegui Djimdou, 2014].
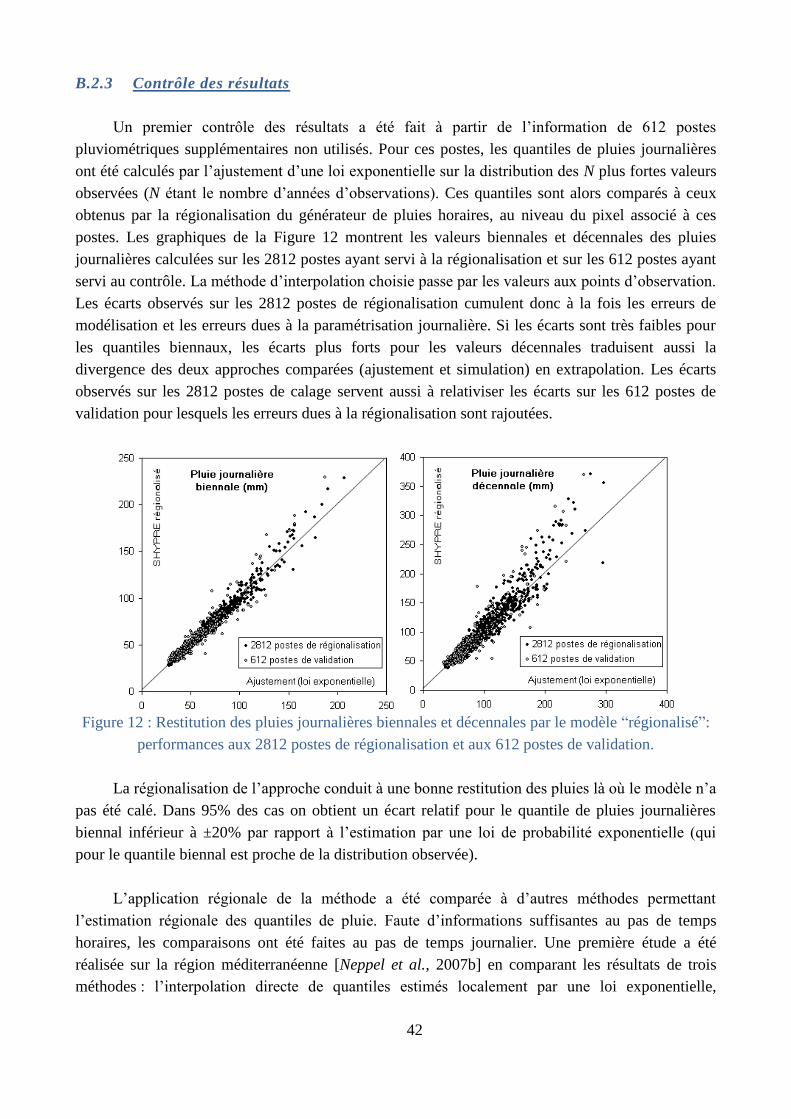
42
B.2.3 Contrôle des résultats
Un premier contrôle des résultats a été fait à partir de l’information de 612 postes
pluviométriques supplémentaires non utilisés. Pour ces postes, les quantiles de pluies journalières
ont été calculés par l’ajustement d’une loi exponentielle sur la distribution des N plus fortes valeurs
observées (N étant le nombre d’années d’observations). Ces quantiles sont alors comparés à ceux
obtenus par la régionalisation du générateur de pluies horaires, au niveau du pixel associé à ces
postes. Les graphiques de la Figure 12 montrent les valeurs biennales et décennales des pluies
journalières calculées sur les 2812 postes ayant servi à la régionalisation et sur les 612 postes ayant
servi au contrôle. La méthode d’interpolation choisie passe par les valeurs aux points d’observation.
Les écarts observés sur les 2812 postes de régionalisation cumulent donc à la fois les erreurs de
modélisation et les erreurs dues à la paramétrisation journalière. Si les écarts sont très faibles pour
les quantiles biennaux, les écarts plus forts pour les valeurs décennales traduisent aussi la
divergence des deux approches comparées (ajustement et simulation) en extrapolation. Les écarts
observés sur les 2812 postes de calage servent aussi à relativiser les écarts sur les 612 postes de
validation pour lesquels les erreurs dues à la régionalisation sont rajoutées.
Figure 12 : Restitution des pluies journalières biennales et décennales par le modèle “régionalisé”:
performances aux 2812 postes de régionalisation et aux 612 postes de validation.
La régionalisation de l’approche conduit à une bonne restitution des pluies là où le modèle n’a
pas été calé. Dans 95% des cas on obtient un écart relatif pour le quantile de pluies journalières
biennal inférieur à ±20% par rapport à l’estimation par une loi de probabilité exponentielle (qui
pour le quantile biennal est proche de la distribution observée).
L’application régionale de la méthode a été comparée à d’autres méthodes permettant
l’estimation régionale des quantiles de pluie. Faute d’informations suffisantes au pas de temps
horaires, les comparaisons ont été faites au pas de temps journalier. Une première étude a été
réalisée sur la région méditerranéenne [Neppel et al., 2007b] en comparant les résultats de trois
méthodes : l’interpolation directe de quantiles estimés localement par une loi exponentielle,

43
l’application d’une loi statistique régionale dont les paramètres ont été régionalisés et la méthode
par simulation (le simulateur de pluie présenté). Les résultats montrent que la loi régionale et le
simulateur de pluies conduisent à des résultats très proches malgré leur forte différence
méthodologique. Les résultats montrent aussi que ces méthodes sont nettement plus stables que
l’interpolation directe de quantiles de pluies ajustés localement.
Les résultats du projet ANR Extraflo vont aussi dans ce sens, avec un panel de méthodes et de
tests supplémentaires, mélangeant entre autres les approches locales et régionales [Neppel et al.,
2014]. Il en résulte que les méthodes « purement statistiques » ayant une composante régionale sont
préférables aux méthodes calées seulement par l’information locale. Pour les méthodes purement
régionales, la comparaison est faite entre une interpolation des paramètres d’une loi GEV (méthode
SIGEV), l’utilisation d’une loi régionale (loi GEV calée sur les pluies normalisées par la moyenne
[index value]) et le simulateur de pluies (méthode SHYPRE). Si la méthode SIGEV est à proscrire,
la loi régionale et le simulateur de pluies présentent des performances équivalentes [Carreau et al.,
2013]. Il est souligné qu’actuellement au niveau national, seul le simulateur de pluies permet
d’obtenir aussi une information régionale sur les pluies à pas de temps infra-journaliers.
Les développements du générateur de pluies horaires ont permis une réelle avancée dans
l’estimation du risque pluvial. Ces travaux de recherche ont conduit à une méthode complète, mise
en œuvre sur de grands territoires et largement documentée en particulier par la rédaction d’un
ouvrage de synthèse [Arnaud and Lavabre, 2010]. Outre les thèses et les publications associées, la
validation et la reconnaissance scientifique de la méthode a été établie suite au projet de recherche
ANR Extraflo, qui a permis de situer les très bonnes performances de la méthode par rapport à de
nombreuses autres méthodes développées par la communauté scientifique.
On propose ainsi, plus qu’une méthode, un véritable outil régionalisé sur l’ensemble de la
France et sur les DOM, permettant la simulation de scénarios de pluies horaires directement
utilisables pour la prédétermination des pluies à pas de temps infra-journalier et destinés à être
transformés en scénarios de crues. L’avantage de cette approche est de se caler sur une
information journalière pour prendre en compte la pluviométrie locale, et de s’appuyer sur une
analyse régionale des pluies horaires pour définir leur structure temporelle, influençant
indirectement le comportement asymptotique du modèle vers les événements extrêmes.
Des recherches supplémentaires ont été réalisées en parallèle du développement du générateur
de pluies et de sa régionalisation. Elles concernent la recherche des incertitudes associées à la
méthode et son application dans un contexte de changement climatique. Ces deux points ayant fait
l’objet d’une thèse chacun, sont rapidement présentés dans les paragraphes suivants.

44
B.3 Etude des incertitudes du générateur de pluie
De façon générale, les incertitudes peuvent être dues aux données ou au modèle. Ces
incertitudes peuvent être attribuées : aux problèmes d’échantillonnage des données ou aux erreurs
de mesures, aux procédures de calage les paramètres, à la structure du modèle utilisé,… Il est
cependant difficile de prendre en compte simultanément l’ensemble des sources d’incertitudes
associées à une méthode.
Lors de l’élaboration du générateur de pluie, l’analyse des performances de la méthode,
qu’elle soit calée localement (§ B.1.5) ou appliquée dans sa version régionalisée (§B.2.3), a montré
qu’elle était juste et stable si l’on reprend les conclusions du projet ANR Extraflo. La justesse de la
méthode s’explique par une modélisation correcte du signal de pluie, avec une prise en compte
pertinente des processus conduisant aux valeurs extrêmes (tels que la persistance des averses au sein
d’un même événement pluvieux ou la dépendance entre certaines variables). La stabilité de la
méthode est liée à sa paramétrisation réalisée par des valeurs moyennes et par une paramétrisation
régionale des paramètres les plus sensibles à l’échantillonnage. Ces points font que malgré sa
complexité et un nombre de paramètres élevé, la méthode ne devrait pas présenter une incertitude
très élevée dans l’estimation des quantiles extrêmes.
Si ce résultat est intuitif, un formalisme plus scientifique sur les incertitudes de la méthode est
nécessaire. C’est dans ce cadre que la thèse de Aurélie Muller a débuté en 2003, sous la direction de
Jean-Noël Bacro, professeur de l’Université de Montpellier II (école doctorale « Information,
Structures et Systèmes ») et que j’ai co-encadré avec Michel Lang (Irstea-Lyon). Ce paragraphe est
une synthèse des recherches menées sur les incertitudes du générateur de pluie dans le cadre de
cette thèse [Muller, 2006; Muller et al., 2009] et qui ont été poursuivi par la suite. L’analyse porte
dans un premier temps sur un exemple associé à l’étude de la longue série de pluie enregistrée à
Marseille. Une comparaison est faite entre les incertitudes liées à l’application du générateur de
pluies et celles liées à l’utilisation d’une loi statistique. L’effet de la taille de l’échantillonnage sur
ces incertitudes est aussi étudié. Une généralisation est ensuite proposée.
B.3.1 La méthode utilisée
Afin d’évaluer les incertitudes sur les quantiles fournis par le simulateur de pluie, une
comparaison a été faite avec les incertitudes fournies par une approche probabiliste directe. Les
incertitudes associées à la loi de probabilité Pareto généralisée (GPD) ajustée par la méthode des
moments pondérés, ont été étudiées. L’analyse de ces incertitudes est menée dans un cadre
Bayésien, en exploitant les données de pluies journalières de la longue série de Marseille (122 ans,
1882-2003) dans le Sud de la France. On considère donc que l’estimation des paramètres d’un
modèle est tributaire des données d'entrée, et en particulier de l'incertitude liée à l'échantillonnage

45
de ces données. La distribution a posteriori des paramètres représente la variabilité aléatoire des
paramètres étant donné les observations avec lesquelles ils ont été estimés.
Dans le cas de l’utilisation du générateur de pluies, paramétré par l’information
journalière, les lois marginales des paramètres sont des lois normales, puisque les
paramètres journaliers sont estimés par des moyennes d’un grand nombre de valeurs. Sur la
série de Marseille, la corrélation estimée entre les paramètres est de 0.22 (r²) entre µPJMAX
et µDTOT, et inférieure à 5% entre µNE et les deux autres paramètres. On modélise alors la
distribution jointe des paramètres par une loi normale en trois dimensions, avec des lois
marginales indépendantes, centrées sur les estimateurs des paramètres et de variances égales
aux variances d’échantillonnage des paramètres. On simule ensuite des pluies par le
générateur, avec différents jeux de paramètres (µNE, µPJMAX et µDTOT) tirés au hasard
dans la loi jointe. On retient alors la médiane et les intervalles de confiance des quantiles
déduits des chroniques de pluies horaires générées.
Dans le cas de la loi GPD10
, la loi a posteriori des paramètres, notée post, est calculée dans
le cadre Bayésien par la relation :
Ckxxvraiskpriorxxkpost nn /),,...,(),(),...,,( 11
où :
- ),( kprior est la distribution a priori des paramètres, elle traduit les connaissances
relatives aux paramètres, sans tenir compte des observations ;
- C est une constante ;
- ),,...,( 1 kxxvrais n désigne la vraisemblance des observations supérieures au
seuil u sous l'hypothèse de la distribution GPD de paramètres , k :
n
i
in kxgkxxvrais
1
1 ),(),,...,(
avec
0//)(exp),(
0//)(1),(1/1
ksiuxkxg
ksiuxkkxgk
La loi a priori utilisée ici est la loi lognormale de paramètres 0 et 100 pour α, uniforme
entre -1 et 1 pour k. Ces distributions a priori sont semblables à celles de [S. Coles et al.,
2003] pour les paramètres de la GEV. L'algorithme utilisé pour simuler la loi a posteriori des
paramètres est un algorithme MCMC combinant 1000 itérations de Gibbs-Metropolis puis
80000 itérations de Metropolis [Muller et al., 2008; Benjamin Renard et al., 2006].
10
Le simulateur génère des événements indépendants, caractérisés par la présence d’une pluie journalière
supérieure à 20 mm, comme pour les événements observés utilisés pour le calage de la méthode. La distribution
empirique résultant de l’analyse des événements pluvieux générés s’apparente donc à une distribution de valeur
supérieure à un seuil. C’est pourquoi la loi GPD est étudiée ici.
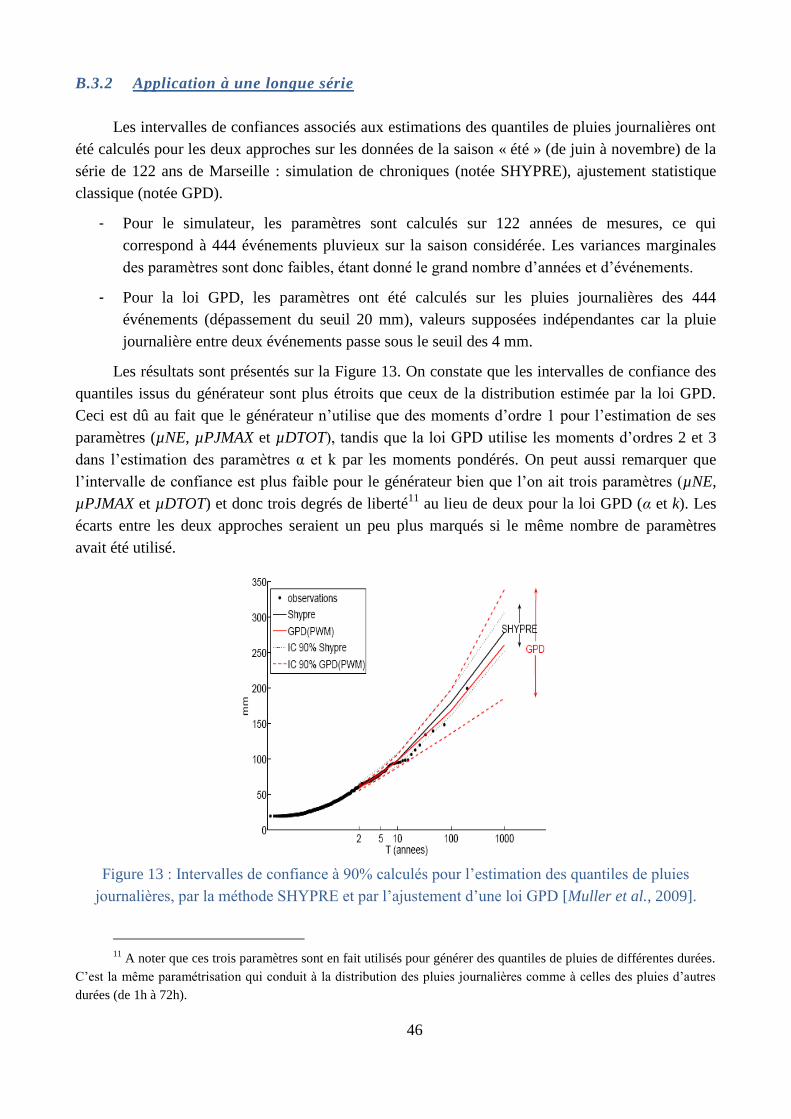
46
B.3.2 Application à une longue série
Les intervalles de confiances associés aux estimations des quantiles de pluies journalières ont
été calculés pour les deux approches sur les données de la saison « été » (de juin à novembre) de la
série de 122 ans de Marseille : simulation de chroniques (notée SHYPRE), ajustement statistique
classique (notée GPD).
- Pour le simulateur, les paramètres sont calculés sur 122 années de mesures, ce qui
correspond à 444 événements pluvieux sur la saison considérée. Les variances marginales
des paramètres sont donc faibles, étant donné le grand nombre d’années et d’événements.
- Pour la loi GPD, les paramètres ont été calculés sur les pluies journalières des 444
événements (dépassement du seuil 20 mm), valeurs supposées indépendantes car la pluie
journalière entre deux événements passe sous le seuil des 4 mm.
Les résultats sont présentés sur la Figure 13. On constate que les intervalles de confiance des
quantiles issus du générateur sont plus étroits que ceux de la distribution estimée par la loi GPD.
Ceci est dû au fait que le générateur n’utilise que des moments d’ordre 1 pour l’estimation de ses
paramètres (µNE, µPJMAX et µDTOT), tandis que la loi GPD utilise les moments d’ordres 2 et 3
dans l’estimation des paramètres α et k par les moments pondérés. On peut aussi remarquer que
l’intervalle de confiance est plus faible pour le générateur bien que l’on ait trois paramètres (µNE,
µPJMAX et µDTOT) et donc trois degrés de liberté11
au lieu de deux pour la loi GPD (α et k). Les
écarts entre les deux approches seraient un peu plus marqués si le même nombre de paramètres
avait été utilisé.
Figure 13 : Intervalles de confiance à 90% calculés pour l’estimation des quantiles de pluies
journalières, par la méthode SHYPRE et par l’ajustement d’une loi GPD [Muller et al., 2009].
11
A noter que ces trois paramètres sont en fait utilisés pour générer des quantiles de pluies de différentes durées.
C’est la même paramétrisation qui conduit à la distribution des pluies journalières comme à celles des pluies d’autres
durées (de 1h à 72h).

47
B.3.3 Application à des sous-séries de 20 ans
En général, l’étude du risque pluviométrique ou hydrologique repose sur l’analyse de séries
chronologiques d’une durée moyenne de vingt à trente ans. Les séries peuvent d’ailleurs être encore
plus courtes pour les valeurs infra-journalières. Par le biais de l’échantillonnage, une chronique de
20 ans peut contenir aucune, une ou plusieurs valeurs extrêmes. C’est cet aspect de
l’échantillonnage qui a été étudié en découpant la série de 122 ans en six sous-séries successives de
20 ans. Les résultats fournis par les deux modèles sont alors comparés. La méthode utilisée est
encore la méthode bayésienne présentée dans le paragraphe précédent, mais appliquée cette fois aux
sous-séries de 20 ans. Le Tableau 2 présente les statistiques associées à chaque sous-série, ainsi que
les valeurs fortes (pluies journalières supérieures à 100 mm). Pour les paramètres, les moyennes
sont présentées avec les valeurs des écarts-types entre parenthèses.
Tableau 2 : Valeurs de paramètres journaliers caractéristiques de six sous-séries de 20 ans du poste
pluviométrique de Marseille [Muller, 2006].
Si chaque sous-série de 20 ans présente un nombre d’événements équivalent (paramètre µNE
peu variable), elles peuvent être sensiblement différentes en termes de hauteur d’eau précipitée et en
termes d’occurrence de valeurs extrêmes. Les intervalles de confiance présentés, sur la Figure 14,
présentent des distributions d’allure symétrique pour le générateur, tandis qu’on trouve des
distributions à forte dissymétrie pour la loi GPD.
La forme de la distribution marginale des quantiles dépend d’une part de la distribution des
paramètres et d’autre part de la sensibilité des modèles à leurs paramètres. Si les distributions des
paramètres sont relativement symétriques pour les deux modèles (moins pour la GPD), la sensibilité
des modèles à leurs paramètres n’est pas la même. La distribution des paramètres (loi normale) et la
loi marginale des quantiles liées au simulateur de pluies sont semblables : la relation entre les
paramètres du générateur et les quantiles fournis par le générateur semble être linéaire. Les résultats
de la loi GPD sont eux par contre très sensibles aux valeurs du paramètre de forme k. Bien que ce
paramètre ait une distribution à faible dissymétrie, la sensibilité de la loi GPD aux valeurs
négative12
de k conduit à une dissymétrie positive forte pour les quantiles rares.
12
Les valeurs négatives de k indiquent un comportement asymptotique supérieur à la loi exponentielle.

48
Figure 14 : Intervalles de confiance à 90% des quantiles de pluies journalières décennales et
millénales des six sous-séries de 20 ans de pluies de Marseille [Muller, 2006].
Les incertitudes des quantiles se révèlent plus fortes avec la GPD qu’avec le générateur au vu
de l’amplitude des intervalles de confiance. La forte incertitude de la GPD sur les séries 5 et 6
conduit à de forts coefficients d’asymétrie (2.4 ; 3.9) et d’aplatissement (10.7 ; 23) sur ces séries.
On peut noter que les intervalles de confiance donnés par la loi GPD peuvent conduire à des valeurs
physiquement irréalistes. En effet la borne de 2500 mm d’eau précipités en un jour est inconcevable
sur la région d’étude. Les valeurs maximales observées sur la région atteignant difficilement les 500
mm. En France le record de pluie journalière observé est de l’ordre de 1000 mm, et au niveau
mondial de l’ordre de 1800 mm (record sur l’île de la Réunion).
Les écarts relatifs entre les estimations médianes des quantiles décennaux des six sous-séries
sont relativement faibles et similaires pour les deux approches. Suivant les sous-séries étudiées, on
estime les pluies journalières décennales entre 80 et 120 mm, avec les deux modèles. Par contre, en
extrapolation, les résultats des deux modèles divergent. L’estimation des valeurs millénales
médianes varient de 100 à 350 mm (rapport de 1 à 3,5) pour la loi GPD et de 220 à 350 mm pour le
générateur de pluie (rapport de 1 à 1,6). L’extrême largeur des intervalles de confiance de la loi
GPD vers les fréquences rares garantit leur recouvrement dans le cas où différentes sous-séries sont
utilisées en entrée, mais ils n’en sont pas plus réalistes et ni informatifs. Cette application illustre le
problème de la sensibilité de la loi GPD appliquées de façon locale, en particulier pour une
utilisation en extrapolation vers les fréquences rares.
Ces résultats montrent aussi la stabilité de l’approche par simulation face à l’échantillonnage.
Ce point est directement lié à la forte stabilité de ces paramètres qui sont estimés par des valeurs
moyennes. L’approche par simulation est donc moins sensible à l’échantillonnage que la loi GPD
calée localement, ce qui rejoint les conclusions du projet ANR Extraflo qui ne recommande pas
l’utilisation d’une loi statistique « locale », mais plutôt l’utilisation d’une loi régionale.
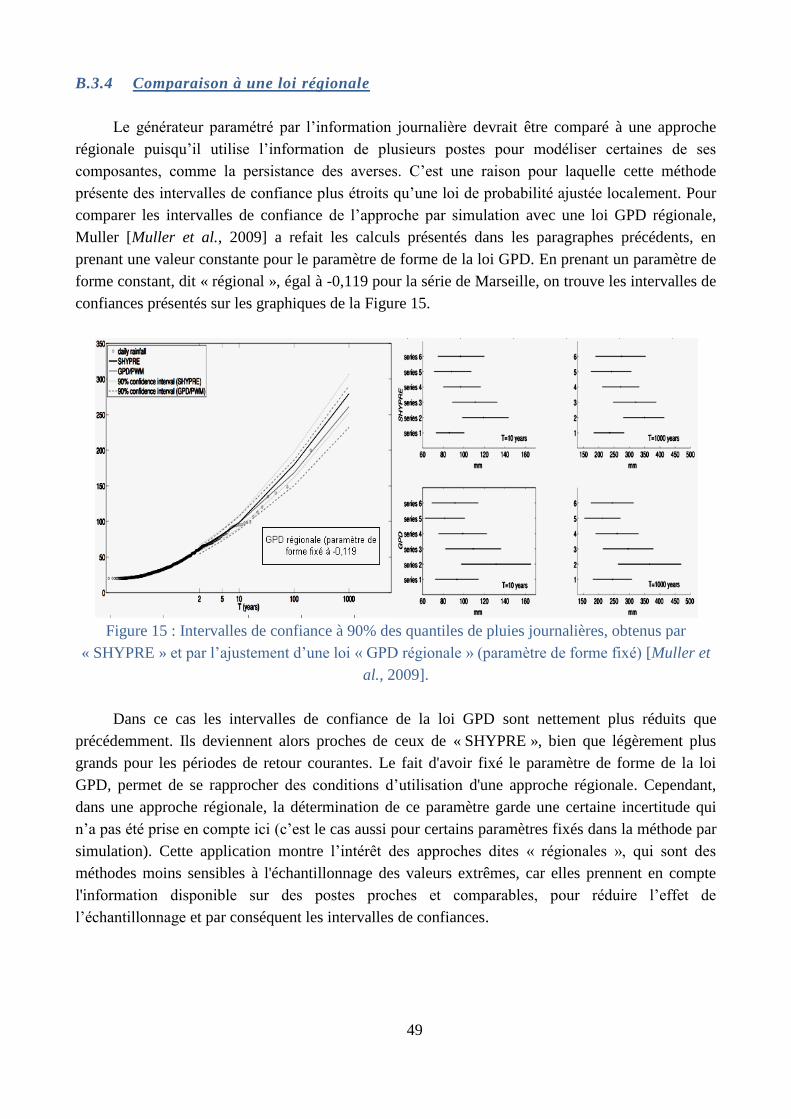
49
B.3.4 Comparaison à une loi régionale
Le générateur paramétré par l’information journalière devrait être comparé à une approche
régionale puisqu’il utilise l’information de plusieurs postes pour modéliser certaines de ses
composantes, comme la persistance des averses. C’est une raison pour laquelle cette méthode
présente des intervalles de confiance plus étroits qu’une loi de probabilité ajustée localement. Pour
comparer les intervalles de confiance de l’approche par simulation avec une loi GPD régionale,
Muller [Muller et al., 2009] a refait les calculs présentés dans les paragraphes précédents, en
prenant une valeur constante pour le paramètre de forme de la loi GPD. En prenant un paramètre de
forme constant, dit « régional », égal à -0,119 pour la série de Marseille, on trouve les intervalles de
confiances présentés sur les graphiques de la Figure 15.
Figure 15 : Intervalles de confiance à 90% des quantiles de pluies journalières, obtenus par
« SHYPRE » et par l’ajustement d’une loi « GPD régionale » (paramètre de forme fixé) [Muller et
al., 2009].
Dans ce cas les intervalles de confiance de la loi GPD sont nettement plus réduits que
précédemment. Ils deviennent alors proches de ceux de « SHYPRE », bien que légèrement plus
grands pour les périodes de retour courantes. Le fait d'avoir fixé le paramètre de forme de la loi
GPD, permet de se rapprocher des conditions d’utilisation d'une approche régionale. Cependant,
dans une approche régionale, la détermination de ce paramètre garde une certaine incertitude qui
n’a pas été prise en compte ici (c’est le cas aussi pour certains paramètres fixés dans la méthode par
simulation). Cette application montre l’intérêt des approches dites « régionales », qui sont des
méthodes moins sensibles à l'échantillonnage des valeurs extrêmes, car elles prennent en compte
l'information disponible sur des postes proches et comparables, pour réduire l’effet de
l’échantillonnage et par conséquent les intervalles de confiances.
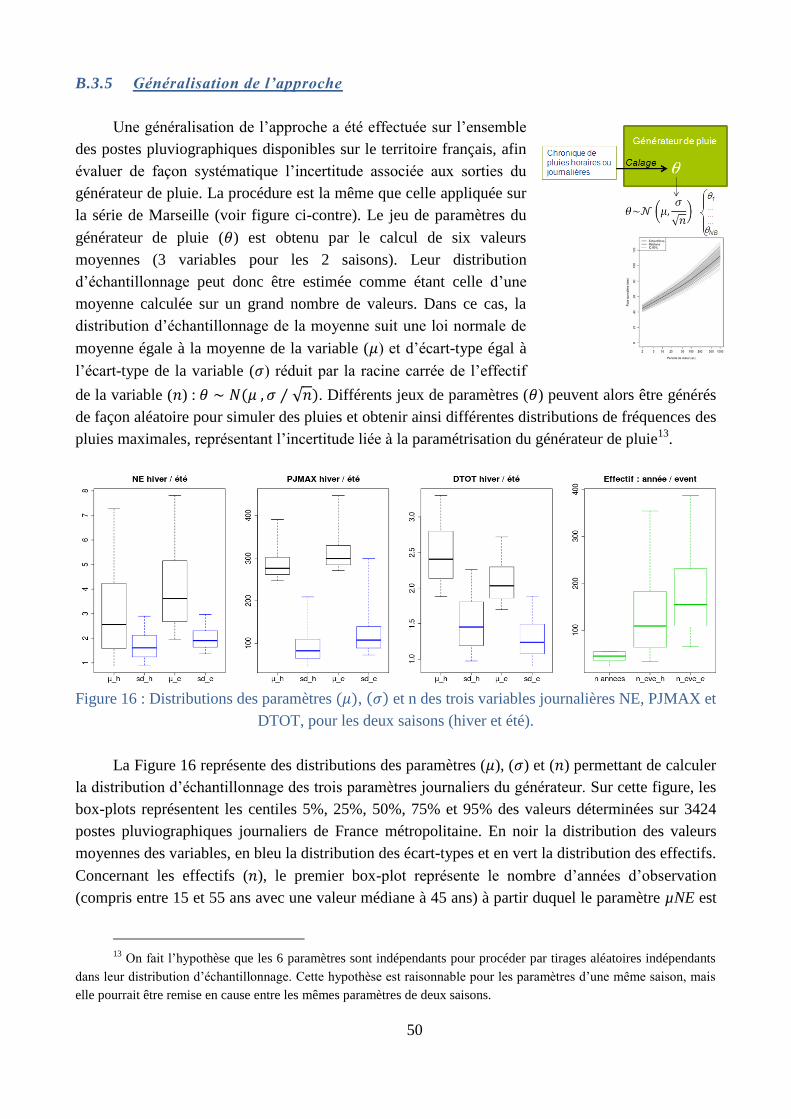
50
B.3.5 Généralisation de l’approche
Une généralisation de l’approche a été effectuée sur l’ensemble
des postes pluviographiques disponibles sur le territoire français, afin
évaluer de façon systématique l’incertitude associée aux sorties du
générateur de pluie. La procédure est la même que celle appliquée sur
la série de Marseille (voir figure ci-contre). Le jeu de paramètres du
générateur de pluie ( ) est obtenu par le calcul de six valeurs
moyennes (3 variables pour les 2 saisons). Leur distribution
d’échantillonnage peut donc être estimée comme étant celle d’une
moyenne calculée sur un grand nombre de valeurs. Dans ce cas, la
distribution d’échantillonnage de la moyenne suit une loi normale de
moyenne égale à la moyenne de la variable ( ) et d’écart-type égal à
l’écart-type de la variable ( ) réduit par la racine carrée de l’effectif
de la variable ( ) : . Différents jeux de paramètres ( ) peuvent alors être générés
de façon aléatoire pour simuler des pluies et obtenir ainsi différentes distributions de fréquences des
pluies maximales, représentant l’incertitude liée à la paramétrisation du générateur de pluie13
.
Figure 16 : Distributions des paramètres , et n des trois variables journalières NE, PJMAX et
DTOT, pour les deux saisons (hiver et été).
La Figure 16 représente des distributions des paramètres ( ), ( ) et ( ) permettant de calculer
la distribution d’échantillonnage des trois paramètres journaliers du générateur. Sur cette figure, les
box-plots représentent les centiles 5%, 25%, 50%, 75% et 95% des valeurs déterminées sur 3424
postes pluviographiques journaliers de France métropolitaine. En noir la distribution des valeurs
moyennes des variables, en bleu la distribution des écart-types et en vert la distribution des effectifs.
Concernant les effectifs ( ), le premier box-plot représente le nombre d’années d’observation
(compris entre 15 et 55 ans avec une valeur médiane à 45 ans) à partir duquel le paramètre µNE est
13
On fait l’hypothèse que les 6 paramètres sont indépendants pour procéder par tirages aléatoires indépendants
dans leur distribution d’échantillonnage. Cette hypothèse est raisonnable pour les paramètres d’une même saison, mais
elle pourrait être remise en cause entre les mêmes paramètres de deux saisons.

51
calculé, et les deux second box-plots représentent le nombre d’événements (valeurs médianes
respectivement de 110 et 150 pour les saisons « hiver » et « été ») à partir duquel les paramètres
µPJMAX et µDTOT sont calculés. On dispose donc, pour les 6 paramètres, des éléments permettant
de calculer leur distribution d’échantillonnage.
Pour chaque poste, la génération de NB jeux de paramètres conduit à NB distributions de
fréquence des pluies représentant l’incertitude de la méthode. Pour chaque quantile de pluies, les
bornes supérieures et inférieures associées aux probabilités de non dépassement de 95% et
5% ( et ) sont déterminées et leur différence représente l’intervalle de confiance à 90% :
. Pour comparer ces intervalles de confiance, on calcule l’amplitude relative de
l’intervalle de confiance à travers son ratio à la valeur médiane :
. La répartition
spatiale de ce ratio et sa distribution pour différentes périodes de retour sont représentés sur la
Figure 17, pour le quantile de pluies journalières déterminé par le simulateur de pluies.
Figure 17 : Amplitude relative de l’IC90% des quantiles de pluies journalières : à gauche répartition
spatiale pour le quantile T=10 ans, à droite distribution pour différentes périodes de retour.
La Figure 17 montre que :
- Les amplitudes relatives de l’intervalle de confiance sont plus élevées sur les régions
méditerranéennes (présentant des écarts-types de µPJMAX les plus élevés), mais aussi pour
certaines régions du Bassin Parisien et d’Aquitaine où le nombre d’événements est faible.
- Les amplitudes relatives croissent en moyenne avec la période de retour. Ce résultat n’est
pas surprenant, mais il faut noter que cet accroissement de l’amplitude relative est faible
pour des périodes de retour pourtant élevées.
L’étude des incertitudes reste une étape importante. Les résultats présentés peuvent paraitre
triviaux à postériori, mais ils permettent de fixer les idées sur les intervalles de confiance associés à
la méthode par simulation et justifier ainsi l’effort de recherche d’une paramétrisation « robuste ».
Ces résultats permettent aussi d’expliquer la stabilité de la méthode par simulation. Cependant,
certains points doivent encore être étudiés comme l’influence de la paramétrisation de certaines
composantes régionales (comme les copules) sur les incertitudes des estimations.

52
B.4 Etude de la non-stationnarité des pluies extrêmes
Les méthodes actuelles d’estimation de l’aléa reposent sur l’hypothèse de stationnarité des
phénomènes. Ces hypothèses sont mises à rude épreuve avec la mise en évidence du changement
climatique [IPCC, 2007]. Si les observations actuelles montrent une augmentation significative des
températures ou une évolution de la pluviométrie moyenne annuelle, l’avis des experts est plus
mitigé concernant l’occurrence et l’intensité des phénomènes extrêmes. Le problème vient d’une
part du manque de recul dans les chroniques de pluies observées qui ne permet pas d’évaluer une
tendance pour les phénomènes extrêmes, et d’autre part de la difficulté rencontrée par les modèles
climatiques globaux pour modéliser les processus météorologiques extrêmes. Dans ce contexte,
doit-on remettre en cause les méthodes de prédétermination des risques hydrologiques ?
Se posent alors différentes questions :
- l’hypothèse de stationnarité des phénomènes climatiques peut-elle être mise à mal dans le
domaine des valeurs extrêmes ?
- Comment caractériser une éventuelle non-stationnarité « observée » et comment évaluer son
évolution passée et à venir ?
- Quel impact aurait une évolution des caractéristiques climatiques sur l’aléa hydrologique
extrême ?
Ces questions ont été abordées dans la thèse de Philippe Cantet [2009], dirigée par Jean-Noël
Bacro et que j’ai co-encadré. L’idée originale est de s’appuyer sur le générateur des chroniques de
pluies. La mise en évidence d’un changement dans les caractéristiques descriptives des pluies
(occurrence des événements, durée des événements, intensité des averses, …) pourra alors se
traduire en termes d’impact sur les valeurs extrêmes de pluies. Ce paragraphe présente donc les
résultats obtenus dans le cadre de cette thèse [Cantet, 2009; Cantet et al., 2011].
B.4.1 Détection de tendances
Si l’augmentation des températures moyennes a été mise en évidence [IPCC, 2007], on peut
penser que cela a un impact direct sur le cycle de l’eau et par conséquent sur les précipitations. Les
tendances observées sur les précipitations moyennes annuelles concluent à une légère hausse sur la
globalité de la planète, mais avec une forte disparité suivant les régions : à la hausse en Amérique
du Nord et en Europe du Nord et de l’Ouest [Groisman et al., 2001; Schönwiese and Rapp, 1997;
Zhang et al., 2000], mais à la baisse en Chine et sur les régions méditerranéennes [Xoplaki et al.,
2004; Zhai et al., 1999]. Les tendances sur les valeurs extrêmes sont beaucoup plus difficiles à
détecter [Dubuisson and Moisselin, 2006]. De plus les modèles climatiques (Global Climate
Models : GCM) ont des difficultés à modéliser les processus extrêmes [Moberg and Jones, 2004].
Les approches classiques, basées sur l’ajustement de lois de probabilité et sur la détection de
tendances dans l’estimation de leurs paramètres, sont limitées par la représentativité des séries
observées (trop courtes, peu nombreuses) [Pujol et al., 2007; B. Renard, 2006].

53
Le problème de l’échantillonnage lié aux valeurs extrêmes rendant difficile la détection de
tendances, il a été choisi de travailler de façon indirecte sur les paramètres du générateur de pluie.
Bien que basés sur des valeurs moyennes, ces paramètres permettent d’estimer correctement les
valeurs extrêmes (§ B.1.5). De plus, l’usage d’une structure unique du générateur pour tous les
types de climat, permet d’appréhender des processus pluvieux différents (phénomènes convectifs,
frontaux, orographiques, cycloniques, …) uniquement à partir de sa paramétrisation. Les résultats
présentés par la suite sont donc basés sur l’hypothèse que si les processus pluvieux changent, cela
sera visible sur la paramétrisation du générateur, et qu’il n’est pas nécessaire de revenir sur la
structure du modèle.
Les travaux menés sur la détection de tendance ont donc portés sur des variables journalières
permettant de caractériser des pluies fortes et servant à la paramétrisation du générateur de pluies (à
travers leur moyenne)14
, à savoir :
- La variable NE : nombre d’événement pluvieux par saison.
- La variable PJMAX : la pluie journalière maximale d’événement d’une saison donnée.
- La variable DTOT : la durée d’un événement d’une saison donnée.
L’objectif est de déterminer si ces variables présentent une évolution temporelle (cas de
l’instationnarité) ou si elles peuvent être considérées comme stables dans le temps (stationnarité).
Pour cela, un test sur le(s) paramètre(s) des lois décrivant ces variables a été réalisé et appliqué sur
139 stations pluviométriques de références sélectionnées par Météo-France pour leur qualité et leur
période d’observation relativement longue (1960-2003). Le test du rapport du maximum de
vraisemblance a été utilisé [Stuart. Coles, 2001; B. Renard, 2006]. Ce test permet de comparer deux
modèles et (le modèle étant un cas particulier du modèle ). Le modèle est associé
à une hypothèse de stationnarité, c'est-à-dire que ses paramètres sont fixes dans le temps. Le modèle
est associé à une hypothèse d’instationnarité car ses paramètres sont linéairement variables avec
le temps. L’hypothèse nulle considère alors que le modèle est le plus adapté aux données,
contre l’hypothèse alternative qui considère que le modèle est meilleur. Le test est basé sur le
calage de la « déviance statistique » définie par :
où est la log-vraisemblance de l’échantillon des observations suivant le modèle
et le vecteur de paramètres maximisant cette log-vraisemblance. Sous l’hypothèse et avec un
échantillon suffisamment grand, suit une loi du Khi2 de degré de liberté égal à la différence du
nombre de paramètres des deux modèles ( ). Ainsi, l’hypothèse est rejetée avec un risque
de première espèce si avec
14
L’étude directe de la stationnarité des paramètres (et non pas des variables), c'est-à-dire des moyennes des
variables étudiées (soit µNE, µPJMAX et µDTOT) aurait été possible si ces variables suivaient une loi gaussienne. Ce
n’est pas le cas, c’est pourquoi on s’est focalisé sur la distribution des variables et l’évolution des paramètres de leur loi,
pour ensuite revenir à l’estimation de la moyenne de la variable.

54
Ce test a surtout été appliqué sur les deux variables NE et PJMAX. La variable DTOT n’ayant
pas d’impact significatif sur les extrêmes, son traitement n’est pas détaillé ici :
La variable NE représente l’occurrence des événements et peut être assimilé à un
processus de Poisson d’intensité . Dans ce cas, on peut étudier soit le nombre
d’occurrence des événements (qui suit une loi de Poisson d’intensité ), soit la durée entre
les événements ou « temps d’attente » (qui suit une loi exponentielle aussi d’intensité ).
Des tests de stationnarité existent pour ces deux variables. Par simulation il s’est avéré que
le test sur les « temps d’attente » est meilleur [Cantet, 2009]. Dans le cas de ce test, la log-
vraisemblance à calculer est :
avec .
Les deux hypothèses testées sont : et
La variable PJMAX est associée à des événements sélectionnés au dessus d’un seuil u
( = 20 mm). Elle peut être associée à une loi de Pareto généralisée (GPD). Pour des
raisons liées au problème d’échantillonnage, il a été supposé que le paramètre de forme de
la loi GPD ( ) est constant, comme suggéré par Renard [2006]. Ainsi, la non stationnarité
sera caractérisée par un paramètre d’échelle variant avec le temps : . Dans ce cas la
log-vraisemblance à calculer est :
Les deux hypothèses testées sont alors: et
Ce test a été appliqué suivant deux configurations :
- Une approche locale où la tendance des variables est étudiée indépendamment pour chaque
station de mesure.
- Une approche régionale où les valeurs ont été agglomérées sur des zones homogènes pour
déterminer une loi régionale. Dans ce cas, la détermination des zones homogènes a été
réalisée par la méthode hiérarchique ascendante de Ward [Saporta, 2006]15
. Sur les quatre
zones homogènes définies, une loi régionale a été déterminée pour les variables NE et
PJMAX, en prenant en compte de façon originale la dépendance spatiale de valeurs [Cantet
et al., 2011].
15
Cette procédure permet de former des groupes (clusters) tels que la
variance à l’intérieur des groupes soit minimale, de façon à ce que ces groupes
soient les plus homogènes possible. Le regroupement a été réalisé en prenant
en compte l’ensemble des paramètres (µNE, µDTOT et µPJMAX des deux
saisons), ainsi que les coordonnées des postes de mesures. Une information
supplémentaire de 2761 stations non prises en compte pour l’étude des
tendances, a été utilisée pour établir ces quatre zones homogènes, présentées
sur la carte ci-contre [Cantet et al., 2011].

55
Par l’approche locale, les résultats obtenus sont difficilement interprétables en termes
d’évolution temporelle, car localement des postes voisins peuvent avoir des tendances opposées, ce
qui n’est pas compatible avec l’échelle spatiale du processus climatique. On peut cependant
entrevoir des tendances régionales, confirmées par l’approche régionale (Tableau 3).
Par l’approche régionale, les plus gros changements observés ont lieu pour la saison
« Hiver » où le nombre d’événements (NEWinter) augmente significativement sur l’ensemble de la
France, mis à part sur le pourtour méditerranéen où il baisse. Cette hausse touche plus
particulièrement la zone « continentale » qui présente aussi une augmentation du nombre
d’événements pluvieux en saison « Eté » (NESummer). Une augmentation des intensités pluvieuses est
aussi relevée sur les zones « d’altitude ».
Tableau 3 : Résultats des tests de tendances déterminées entre 1960 et 2003 par l’approche
régionale [Cantet et al., 2011]
La stationnarité (ou la non-stationnarité) des paramètres des lois décrivant les variables
journalières (NE, PJMAX et DTOT) a été évaluée suivant une tendance linéaire. Si cette tendance
est significative au vue des tests appliqués, la moyenne de ces variables peut alors être déterminée
au cours du temps. Ces moyennes ont donc été calculées pour l’année 2003 (dernière année des
observations) en prenant en compte d’éventuelles non-stationnarités, puis calculées dans le cadre
d’une hypothèse de stationnarité (moyenne sur toutes les valeurs). Deux jeux de paramètres
utilisables par le générateur de pluies ont été constitués pour produire des quantiles pour différentes
périodes de retour : soit pour les quantiles calculés en prenant en compte la non-
stationnarité et pour les quantiles calculés sous hypothèse de stationnarité. Sur chaque station
pluviométrique, le ratio
est calculé. Le graphique de la Figure 18 présente l’évolution du
ratio pour =5, 10, 100 et 1000 ans en fonction du ratio , obtenus avec l’approche
« locale » de la stationnarité, pour le quantile de la pluie maximale en 24 heures.
Ce graphique permet d’apprécier l’évolution des quantiles pour différentes périodes de retour.
Il permet aussi de visualiser l’impact de la non-stationnarité en fonction de la période de retour.
L’impact de cette non-stationnarité est d’autant plus important que l’on s’intéresse aux événements
extrêmes (de périodes de retour élevées).
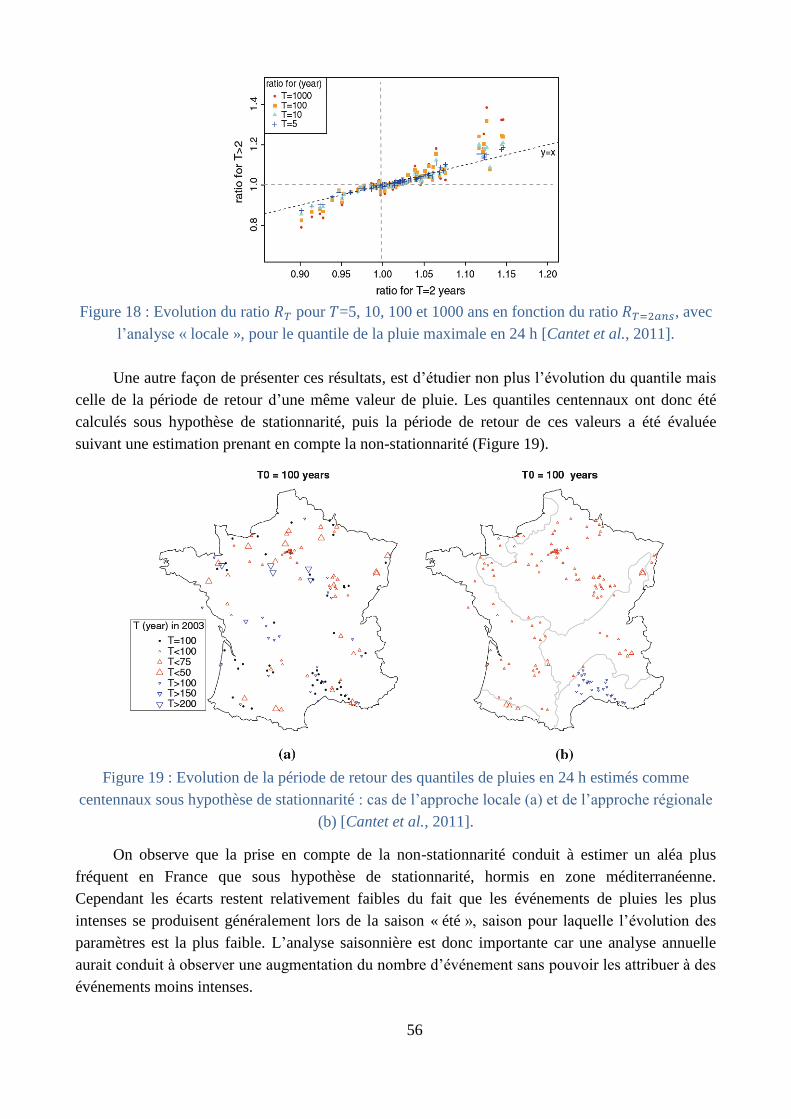
56
Figure 18 : Evolution du ratio pour =5, 10, 100 et 1000 ans en fonction du ratio , avec
l’analyse « locale », pour le quantile de la pluie maximale en 24 h [Cantet et al., 2011].
Une autre façon de présenter ces résultats, est d’étudier non plus l’évolution du quantile mais
celle de la période de retour d’une même valeur de pluie. Les quantiles centennaux ont donc été
calculés sous hypothèse de stationnarité, puis la période de retour de ces valeurs a été évaluée
suivant une estimation prenant en compte la non-stationnarité (Figure 19).
Figure 19 : Evolution de la période de retour des quantiles de pluies en 24 h estimés comme
centennaux sous hypothèse de stationnarité : cas de l’approche locale (a) et de l’approche régionale
(b) [Cantet et al., 2011].
On observe que la prise en compte de la non-stationnarité conduit à estimer un aléa plus
fréquent en France que sous hypothèse de stationnarité, hormis en zone méditerranéenne.
Cependant les écarts restent relativement faibles du fait que les événements de pluies les plus
intenses se produisent généralement lors de la saison « été », saison pour laquelle l’évolution des
paramètres est la plus faible. L’analyse saisonnière est donc importante car une analyse annuelle
aurait conduit à observer une augmentation du nombre d’événement sans pouvoir les attribuer à des
événements moins intenses.

57
B.4.2 Prise en compte de projections climatiques
L’étude des tendances sur les paramètres du générateur de pluies permet de réviser
l’estimation de l’aléa dans un contexte lié au présent. Par exemple, si une tendance à l’augmentation
est observée sur une période, la probabilité d’apparition d’un événement donné sera plus forte en fin
de période (donc dans le présent qui intéresse les aménageurs) qu’en début de période.
L’extrapolation dans un horizon plus lointain sera conditionnée par le maintien de la tendance
observée dans le passé.
L’évolution du climat futur est tributaire des conditions présentes (effet d’inertie) et de
scénarios futurs sur les émissions de gaz à effet de serre (GES) par exemple. Pour se projeter dans
un climat futur, de nombreuses recherches portent sur les modèles climatiques prenant en compte
différents scénarii d’émission de GES jusqu’en 2100 et proposent des scénarios climatiques
associés16
. En France, le modèle ARPEGE-Climat est utilisé par le CNRM (Centre National de
Recherche en Météorologie). L’ensemble des projections climatiques produites sont alors
désagrégées de façon statistique à une résolution plus fine de 8x8 km sur la France et une partie de
la Suisse, grâce aux données SAFRAN [Boé et al., 2006]. Ce sont ces données qui ont été mises à
disposition par le CNRM, pour tester leur utilisation par le simulateur de pluies horaires.
L’objectif de ce travail a consisté à caler le générateur de pluies sur des chroniques de pluies
issues de projections climatiques. La difficulté qu’ont les modèles de climat à générer des valeurs
extrêmes ne leur permet actuellement pas de faire des estimations de l’aléa. De plus, la résolution
temporelle de ces modèles est rarement en dessous du pas de temps journalier et ne permet pas non
plus d’évaluer l’évolution des intensités pluvieuses. Le « filtre » proposé par le générateur de pluie
est alors utilisé pour convertir les informations de pluies journalières issues de projections
climatiques, en information sur l’évolution de l’aléa pluvial.
Les données utilisées correspondent à des chroniques de précipitations journalières (liquides
uniquement) simulées sur différentes périodes de 20 ans (1980-2001 / 2046-2066 / 2081-2100) à
une résolution 8x8 km sur la France. Ces chroniques ont permis de calculer les paramètres
journalières du générateur de pluie (µNE, µPJMAX et µDTOT pour les deux saisons « Hiver » et
« Eté ») sur les trois périodes. A partir de ces nouvelles valeurs de paramètres il est facile de mettre
en œuvre le générateur de pluies et d’extraire des simulations les différents quantiles de pluies.
Une première comparaison est faite sur les quantiles correspondant à la période actuelle, soit
1980-2001. Dans ce cas, on dispose des quantiles issus des « données observées » (résultats
présentés dans le paragraphe B.2.2 issus des pluviomètres) et des quantiles issus des données du
modèle climatique. Les résultats sont présentés sur les graphiques de la Figure 20.
16
Il existe 4 scénarii principaux (A1, A2, B1 et B2) pouvant présenter des variantes, associés à l’évolution
démographique, économique, technologique…
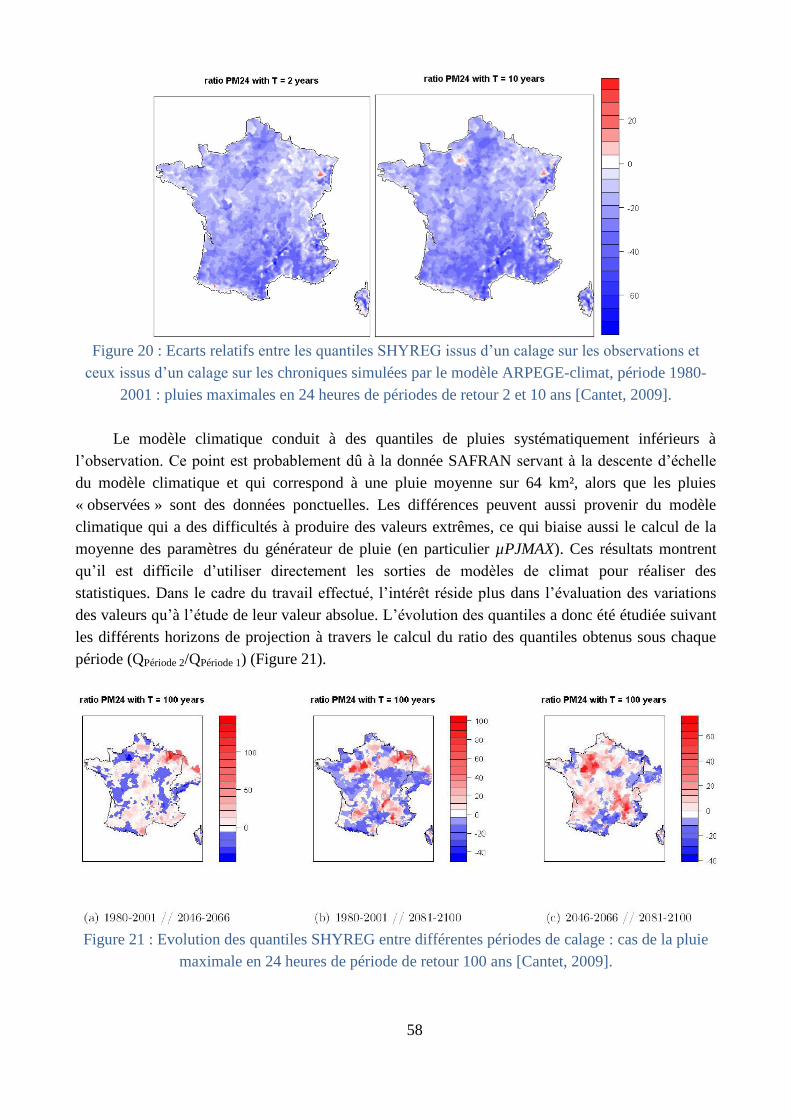
58
Figure 20 : Ecarts relatifs entre les quantiles SHYREG issus d’un calage sur les observations et
ceux issus d’un calage sur les chroniques simulées par le modèle ARPEGE-climat, période 1980-
2001 : pluies maximales en 24 heures de périodes de retour 2 et 10 ans [Cantet, 2009].
Le modèle climatique conduit à des quantiles de pluies systématiquement inférieurs à
l’observation. Ce point est probablement dû à la donnée SAFRAN servant à la descente d’échelle
du modèle climatique et qui correspond à une pluie moyenne sur 64 km², alors que les pluies
« observées » sont des données ponctuelles. Les différences peuvent aussi provenir du modèle
climatique qui a des difficultés à produire des valeurs extrêmes, ce qui biaise aussi le calcul de la
moyenne des paramètres du générateur de pluie (en particulier µPJMAX). Ces résultats montrent
qu’il est difficile d’utiliser directement les sorties de modèles de climat pour réaliser des
statistiques. Dans le cadre du travail effectué, l’intérêt réside plus dans l’évaluation des variations
des valeurs qu’à l’étude de leur valeur absolue. L’évolution des quantiles a donc été étudiée suivant
les différents horizons de projection à travers le calcul du ratio des quantiles obtenus sous chaque
période (QPériode 2/QPériode 1) (Figure 21).
Figure 21 : Evolution des quantiles SHYREG entre différentes périodes de calage : cas de la pluie
maximale en 24 heures de période de retour 100 ans [Cantet, 2009].

59
Les résultats obtenus ne montrent pas une évolution générale et uniforme à l’échelle de la
France. Les régions soumises à une augmentation de la pluviométrie seraient la vallée du Rhône,
l’Ouest de la région parisienne et le Nord-est. A l’inverse, la région des Pyrénées, la Bourgogne et
la Bretagne seraient moins touchées par les événements extrêmes.
Ces résultats n’ont pas vocation à être interprétés car ils sont totalement tributaires des
résultats des projections climatiques et des modèles qui les produisent. Il faudrait répéter ces calculs
avec d’autres modèles et d’autres scénarios d’évolution. Ils illustrent juste une application possible
de l’utilisation du générateur de pluies horaires dans la recherche de l’évaluation des pluies
extrêmes en contexte de changement climatique.
Le travail mené au cours de la thèse de Philippe Cantet [2009] et dirigé par Jean-Noël Bacro
du département de Mathématiques Appliquées de l’Université Montpellier II a bénéficié de forts
développements méthodologiques, en particulier dans la mise en place et le choix de tests
appropriés à la problématique de la paramétrisation du générateur de pluie. Le recours à des
simulations a permis le choix des approches les plus pertinentes, la détermination des tests les plus
significatifs et la détermination de seuils associés à ces tests.
Les résultats présentés ont montré qu’une approche de détection de tendance régionale était
plus pertinente qu’une approche locale.
Les résultats sur la non-stationnarité montrent que le générateur de pluies est un outil
original permettant de traduire une connaissance abordable sur l’évolution des pluies journalières
moyennes en estimation des pluies extrêmes à pas de temps fins. Il a été montré que l’observation
de tendances sur des valeurs moyennes peut se traduire par des tendances accentuées sur les
valeurs extrêmes. Cette non linéarité est importante pour l’estimation des pluies extrêmes et est
difficilement prise en compte par les modèles climatiques.
Dans le cadre de l’estimation de l’impact du changement climatique sur l’aléa hydrologique,
l’utilisation d’une information sur l’évolution de la pluie reste particulièrement pertinente. Les
tendances observées sur les pluies sont moins tributaires des problèmes de stationnarité que les
données hydrologiques, qui elles sont plus tributaires à la métrologie ou à des impacts
anthropiques d’occupation des sols, indépendants du changement climatique [B. Renard, 2006].

60
B.5 Conclusion et perspectives
Les travaux de recherche présentés dans cette partie sont directement liés au développement
d’un générateur de pluies horaires destiné à produire de l’information sur l’aléa pluvial. Cette
approche par simulation de scénarios de pluies est originale par rapport aux approches statistiques
classiques. L’intérêt de cette approche est lié à sa nature. La modélisation de scénarios de pluies et
leur simulation sur de très longues périodes permet d’aborder la prédétermination de l’aléa dans
toute sa complexité temporelle à partir d’une seule modélisation, et de s’affranchir par exemple de
la construction de pluies de projet dont on ne maitrise pas l’occurrence réelle.
L’intérêt lié à la nature de l’approche n’a de sens que si l’information qu’elle produit est juste.
Ce point essentiel a été évalué tout le long du développement de la méthode. Cette évaluation
systématique a permis la recherche de points d’amélioration pour augmenter la justesse de
l’approche. Des améliorations notables ont été réalisées avec l’étude de la dépendance des variables
du modèle et en particulier l’observation du phénomène dit de « persistance » qui conditionne la
génération d’une même variable. L’usage des copules a permis la prise en compte de façon
régionale de ces dépendances observées. Les améliorations progressives du générateur de pluie ont
abouti à un modèle qui a été testé et évalué sur un très grand nombre de stations de mesures (plus de
3000) présentant une forte variabilité climatique. Les résultats de son évaluation, menée dans le
cadre de son développement et dans le cadre de comparaison à d’autres approches, ont montré sa
justesse et particulièrement sa stabilité, qui la place parmi les méthodes de prédétermination
recommandées en France pour l’estimation des valeurs extrêmes. En particulier, il a été montré que
la méthode avait une « capacité prédictive » forte car elle conduisait à une bonne estimation de
valeurs « record » sans que celles-ci ne fassent partie des observations lors du calage de la méthode.
Malgré sa complexité, la force de l’approche réside aussi dans l’analyse descriptive
importante qui est faite du signal de pluie. Peu d’hypothèses sont faites sur sa modélisation. Chaque
variable est observée, de même que sa dépendance avec les autres variables. Les lois de probabilité
choisies et les tirages aléatoires effectués lors de la génération des pluies sont directement orientés
par leur observation sur les chroniques de pluies enregistrées. Les performances de la méthode sont
donc liées à la pertinence de la modélisation mise en œuvre, mais aussi au choix délibéré d’une
paramétrisation peu sensible à l’échantillonnage. La prise en compte de façon régionale de certaines
composantes, l’analyse de variables abondamment observées (sur la base d’averses) et une
paramétrisation essentiellement basée sur des moyennes, lui confèrent ses propriétés de stabilité.
Localement, le générateur de pluie peut être calé à partir de données horaires. Une
paramétrisation basée sur une information journalière a été mise en place et a permis le calage du
générateur de pluies à partir d’une information plus largement disponible. La régionalisation de la
méthode est alors possible et a été réalisée sur l’ensemble du territoire national. La comparaison
avec l’utilisation de lois statistiques régionales a montré des capacités équivalentes en termes de

61
justesse et stabilité, avec en plus la capacité de fournir une information multi-durée à partir d’une
même paramétrisation, là où les lois régionales doivent être ajustées pour chaque durée de pluie.
L’outil développé présente un grand intérêt pour la connaissance régionale de l’aléa
pluviographique. La base de données à laquelle le développement de ces recherches a abouti,
fournit une information précieuse mise à disposition dans le cadre d’études hydrologiques. Les
applications sont nombreuses, en particulier pour fournir une information pertinente dans
l’estimation de l’aléa hydrologique (voir partie suivante) ou qualifier des événements (méthode
AIGA et service APIC).
La non-stationnarité des pluies extrêmes a aussi été étudiée. Elle repose sur l’hypothèse que,
le générateur de pluies développé est capable de reproduire de multiples configurations climatiques
(du climat tempéré continental au climat tropical) grâce à la même structure et uniquement
paramétré par une information journalière. Cette modélisation est alors capable, par le biais d’une
paramétrisation journalière basée sur des valeurs moyennes, de reproduire des chroniques de pluies
horaires statistiquement équivalentes aux chroniques observées. De ces chroniques simulées on peut
alors facilement extraire une information fréquentielle des pluies maximales de différentes durées
(de 1 heure à plusieurs jours) pertinente pour l’étude des pluies extrêmes. Des tendances sur des
valeurs moyennes sont alors plus facilement détectables et directement traduites en termes
d’évolution des valeurs extrêmes.
Les avantages liés à sa nature et ses performances, donne à cette approche un intérêt qui nous
pousse à poursuivre son développement. Des questions restent donc en suspens et doivent faire
l’objet de recherches et développements plus poussés. Ces questions reprises dans la partie D
concernent par exemple :
- la prise en compte d’une typologie des événements en lien avec les configurations
météorologiques qui les génèrent, pourrait être plus pertinente qu’une analyse par saison,
- l’application de la méthode sur des climats plus secs est envisagée,
- l’étude d’une modélisation à pas de temps fins a déjà fait l’objet de pistes de recherches sur
la base de méthodes de désagrégation de l’information horaire vers des pas de temps plus
fins,
- la recherche de méthodes de régionalisation plus performantes,
- la modélisation de pluies de bassins par la prise en compte de l’abattement,
- la poursuite des recherches sur l’évaluation de l’impact du changement climatique,
- la poursuite des recherches sur l’évaluation des incertitudes, avec par exemple la prise en
compte des incertitudes sur la détermination des paramètres régionaux des copules, …
Ces recherches sur l’estimation de l’aléa pluvial sont importantes en soi. Elles présentent
surtout un grand intérêt pour l’estimation de l’aléa hydrologique qui résulte des pluies extrêmes. Ce
travail de recherche est présenté dans la partie suivante. Il est abordé par la simulation de
chroniques de crues issues d’une transformation hydrologique des pluies modélisées par le
générateur de pluies horaires.

62
C - ESTIMATION DE L’ALÉA
HYDROLOGIQUE PAR LA SIMULATION
DES CRUES
Saint Pargoire (34) 29/09/2014 - Source Midi-
Libre
Montagnac (34) le 29/09/2014 - Source Midi-Libre

63
La prédétermination d’aléa hydrologique consiste à associer une grandeur hydrologique à sa
période de retour (§ A.1). Elle passe par l’analyse statistique des observations disponibles sur un
bassin versant donné. Les méthodes employées passent souvent par l’ajustement de lois de
probabilités théoriques sur les distributions de fréquences empiriques des valeurs observées. La
non-linéarité des processus hydrologiques, liée à la saturation progressive des bassins versants, a
conduit certaines méthodes à s’appuyer sur la connaissance des pluies pour extrapoler les
distributions de fréquences des débits. Par nature, c’est le cas des méthodes par simulation des
processus qui tentent de modéliser le signal de pluie et la relation pluie-débit, afin de simuler des
scénarios de crues d’où sont tirées les distributions de fréquence des débits maximums.
Le besoin d’une connaissance de l’aléa hydrologique sur des bassins non instrumentés,
nécessite des méthodes de transposition de l’information. Deux approches sont possibles : passer
soit par l’interpolation spatiale directement de la grandeur hydrologique [Cipriani et al., 2012], soit
par l’interpolation spatiale des paramètres des modèles/méthodes (statistiques ou non) pour pouvoir
les appliquer en sites non-jaugés (c’est le cas des méthodes par simulation). En hydrologie, quelle
que soit la méthode, l’interpolation spatiale vise le transfert de l’information observée sur certains
bassins versants, vers des bassins versants non-jaugés. Différentes méthodes de transfert peuvent
être utilisées : les méthodes basées sur le voisinage, les méthodes déterministes basées sur des
régressions avec les caractéristiques physiques des bassins, les méthodes géostatistiques, ou la
combinaison de ces différentes méthodes [Merz and Blöschl, 2005].
La méthode par simulation développée dans le cadre de mes recherches et présentée dans ce
manuscrit permet d’estimer l’aléa hydrologique par couplage d’un générateur de pluie à une
modélisation hydrologique. Cette approche fournit une information temporelle complète sur l’aléa,
elle prend en compte la non-linéarité du processus hydrologique et sa régionalisation porte sur sa
paramétrisation. La méthode complète est donc présentée dans cette partie, suivant différentes
configurations de mise en œuvre liées à l’information disponible (« locale » ou « régionale », voir
Figure 22).
Figure 22 : Les différents modes de fonctionnement de la méthode par simulation développée.
Le développement du générateur de pluie (présenté dans la partie B de ce manuscrit) permet
d’estimer l’aléa pluvial, par la simulation de chroniques de pluies horaires. Le passage aux débits
consiste donc à « brancher » un modèle hydrologique à la sortie de générateur de pluie pour

64
modéliser des chroniques de crues. On parlera alors de la méthode « SHYPRE » [Arnaud, 1997;
Arnaud and Lavabre, 2002; Flavie Cernesson, 1993] qui couple le générateur de pluie au modèle
hydrologique GR3H. Dans ce cas, la mise en œuvre de la méthode nécessite : d’une part la
connaissance locale des pluies horaires sur le bassin pour caler le « simulateur de pluies horaires
ponctuel » et déterminer d’un coefficient d’ « abattement de la pluie » et d’autre part la
connaissance des débits à l’exutoire pour le calage du modèle hydrologique « GR3H ».
Des adaptations ont été réalisées pour simplifier l’approche initiale, en vue de faciliter sa
régionalisation [Yoann Aubert et al., 2014; Organde et al., 2013], un des objectifs de la méthode
étant son utilisation pour la connaissance régionale (donc aussi en sites non-jaugés) des débits de
crue extrêmes. Dans ce cas, on parlera de la méthode « SHYREG » (SHYpre REGionalisé) et les
adaptations apportées sont :
La régionalisation du générateur de pluies horaires (B.2). Ce travail a nécessité la
paramétrisation du générateur de pluie par une information journalière plus abondante. Sur cette
base, la régionalisation a gagné en précision (plus d’informations) sans dégradation notable des
performances du générateur [Arnaud et al., 2008b]. On parlera de « simulateur de pluies
horaires régional ».
La simulation pixélisée et la régionalisation du modèle hydrologique. Il a été choisi de
réaliser une transformation des pluies horaires simulées en débits de crue simulés, sur des pixels
d’un km² pour lesquels on dispose des valeurs des paramètres du générateur de pluie. Ce passage
au pixel est imposé par la nature ponctuelle des pluies modélisées par le générateur. Il nous
permet aussi de simplifier le modèle hydrologique (nommé « GR simple »). Deux étapes sont
nécessaires. Dans un premier temps, les pluies horaires générées à chaque pixel sont
transformées en scénarios de crues par le modèle hydrologique simplifié. La simplification du
modèle conduit à le paramétrer par un seul paramètre. Les scénarios de crue permettent d’obtenir
des quantiles de débits au km² (débits spécifiques). Ces quantiles de débits spécifiques sont
ensuite agglomérés à l’échelle des bassins versants. L’agrégation de cette information est réalisée
en prenant en compte, de façon indifférenciée, l’abattement spatial lié aux pluies et l’abattement
spatio-temporel lié à l’hydraulique (« Abattement Pluvio-Hydro : FTS ») [Fouchier, 2010]. Pour
cela une fonction d’abattement des débits agglomérés est utilisée et dépend seulement de la
surface du bassin et de la durée étudiée. Cette fonction est unique sur un territoire donné. Le
calage de la méthode (« SHYREG local ») porte alors sur un seul paramètre, optimisé de façon à
respecter au mieux l’information connue sur les débits. La régionalisation de l’approche porte
alors sur ce seul paramètre de calage [Organde et al., 2013] qui sera alors utilisé dans l’approche
« SHYREG régional » (Figure 22).
Les paragraphes suivants présentent les travaux de recherches effectués pour mettre en œuvre
ces différents modes de fonctionnement de la méthode : couplage du générateur de pluie avec une
modélisation hydrologique, simplification de l’approche, agrégation des quantiles de crues et
régionalisation de la méthode sur l’ensemble du territoire français.

65
C.1 Modélisation hydrologique parcimonieuse
Il existe une multitude de modèles hydrologiques qui permettraient de transformer les
chroniques de pluies simulées en chroniques de débits. Le choix s’est porté sur un modèle
conceptuel simple et parcimonieux issu de la famille des modèles à réservoirs GR
(http://webgr.irstea.fr/). L’intérêt de ces modèles est de présenter un très bon rapport
« performances/paramètres ». En effet, avec un faible paramétrage ces modèles conduisent à de très
bonnes performances [Perrin et al., 2001], ce qui est un atout dans une optique de régionalisation
de l’approche.
C.1.1 Utilisation du modèle GR3H
Dans sa version « SHYPRE », l’approche utilise le modèle GR3H [Yang, 1993]. Ce modèle
fonctionne au pas de temps horaire, il est composé de 2 réservoirs et de 2 hydrogrammes unitaires.
Sa structure est identique à celle du modèle journalier GR3J présenté par Edijatno et Michel [1989].
Le schéma de la Figure 23 présente sa structure.
Pluie : P
Structure
du modèle
GR3H
Ps = (1-(S/A)²).P
S
Débit : Q = Qr + Qd
Pr
B R
Qd
0,9Pr 0,1Pr
C
Transfert
Pr = (S/A)².P
Production
Réservoir A
Réservoir
HU1
R
S
HU2
C 2C
Qr (t) = R(t)5/4B
4
S0/A
R0= f(Q0)
Initialisation
Figure 23 : Structure du modèle GR3H
Le modèle a trois paramètres (A, B, C) liés à sa structure et deux paramètres liés à son
initialisation (en mode événementiel). Généralement dans une utilisation continue du modèle,
l’initialisation ne fait pas l’objet d’une optimisation car les états initiaux sont déterminés par une
période de « chauffe » ou « d’initialisation » suffisante pour que les valeurs initiales imposées
n’aient plus d’impact sur les résultats produits au-delà de cette période. Dans le cas d’une utilisation
en mode « événementiel », la période de « chauffe » n’est pas possible et l’initialisation fait l’objet

66
d’une optimisation. Le calage du modèle GR3H en mode événementiel se ferait donc sur 5
paramètres au lieu de 3. Une étude de sensibilité du modèle à ses paramètres a permis de réduire à
trois le nombre de paramètres importants pour le calage du modèle hydrologique fonctionnant en
mode événementiel [Arnaud, 1997; Arnaud and Lavabre, 2000]. Ces trois paramètres sont S0/A (le
taux de remplissage du réservoir A) B (la capacité maximal du réservoir de transfert) et C (le temps
de montée des deux hydrogrammes unitaires). Le paramètre A est imposé à une valeur fixe17
et le
niveau de remplissage du réservoir B (R0) est déduit du débit initial de chaque crue (Q0).
Sur un bassin versant, présentant des observations de pluies horaires et des chroniques de
débits, le calage du modèle hydrologique est possible. Un pluviomètre représentatif est choisi, sur
lequel portera le calage du générateur de pluie. La relation pluie-débit (via le calage du modèle
GR3H) se fera entre les pluies observées sur ce pluviomètre et les débits observés à l’exutoire.
Dans une première version de la méthode [Arnaud, 1997], les trois paramètres ont été
optimisés pour chaque crue observée, ce qui permet d’en déduire leur distribution de fréquence. En
simulation, un jeu de paramètres (S0/A, B et C) doit alors être généré par un tirage aléatoire dans
leur loi de probabilité respective : la loi normale tronquée entre 0 et 1 pour S0/A et la loi log normale
pour B et C. La valeur de Q0, servant à initialiser le réservoir B, est fixée à la valeur médiane
observée sur les crues du bassin versant considéré.
L'examen de l'indépendance des paramètres a aussi été réalisé. Les paramètres sont
linéairement indépendants de la pluie (coefficients de corrélation non significatifs), ce qui permet de
les générer de façon aléatoire quel que soit l'événement de pluie généré. Le paramètre C est
indépendant des deux autres paramètres, ce qui permet aussi de le générer aléatoirement. Une
liaison linéaire a par contre été constatée entre les valeurs du logarithme népérien de B et les valeurs
de S0/A. Cette liaison a alors été intégrée lors de la génération des paramètres B et S0/A par
l'intermédiaire du coefficient de détermination de la régression entre S0/A et Ln(B). La valeur de
S0/A est générée de façon aléatoire, et la valeur de B en est déduite en tenant compte à la fois des
paramètres de la régression entre S0/A et Ln(B) et de la dispersion observée autour de cette
régression [Arnaud and Lavabre, 1997]. Des essais ultérieurs ont montré que la prise en compte de
cette dépendance entre ces deux paramètres et la prise en compte de la variabilité des paramètres via
un tirage aléatoire dans leur loi, n’avait pas un réel impact sur les résultats de l’approche, permettant
finalement de ne considérer ces paramètres qu’à travers leur valeur médiane saisonnière.
Des applications du couplage de ce modèle avec le générateur de pluie sont présentées dans
différents travaux [Arnaud and Lavabre, 2000; 2002; Arnaud et al., 1997], en particulier sur des
bassins méditerranéens présentant une forte variabilité dans les débits. Il a été montré que par
rapport aux méthodes classiques de prédétermination, la méthode développée est beaucoup moins
sensible aux problèmes d'échantillonnage en particulier des valeurs extrêmes, comme le montre
l’exemple présenté sur les graphiques de la Figure 24.
17
Dans un premier temps la valeur du paramètre A a été fixée à 330 mm [Arnaud and Lavabre, 2000] puis
imposée par une valeur fonction de l’hydrogéologie du bassin versant [Aubert, 2012], permettant ainsi de modéliser des
bassins versants ayant des capacités de stockages plus ou moins importantes liées à des échanges forts (en perte) avec le
milieu souterrain (bassin parisien, régions landaises, …).
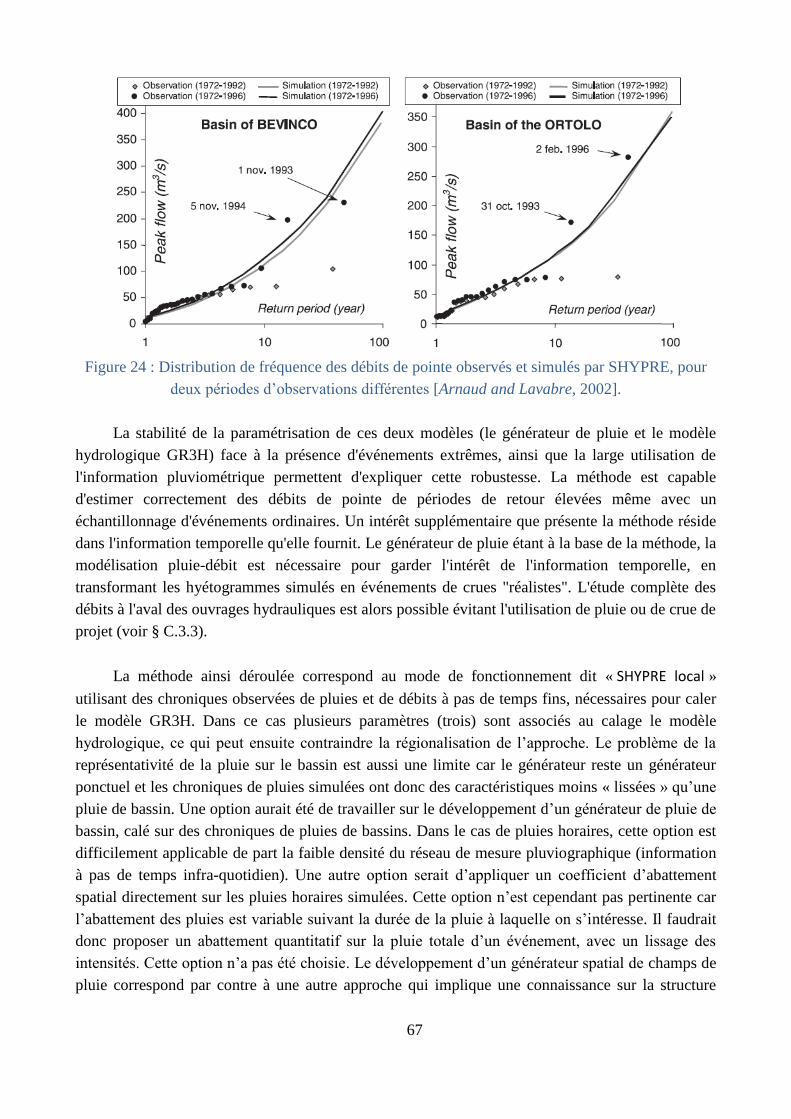
67
Figure 24 : Distribution de fréquence des débits de pointe observés et simulés par SHYPRE, pour
deux périodes d’observations différentes [Arnaud and Lavabre, 2002].
La stabilité de la paramétrisation de ces deux modèles (le générateur de pluie et le modèle
hydrologique GR3H) face à la présence d'événements extrêmes, ainsi que la large utilisation de
l'information pluviométrique permettent d'expliquer cette robustesse. La méthode est capable
d'estimer correctement des débits de pointe de périodes de retour élevées même avec un
échantillonnage d'événements ordinaires. Un intérêt supplémentaire que présente la méthode réside
dans l'information temporelle qu'elle fournit. Le générateur de pluie étant à la base de la méthode, la
modélisation pluie-débit est nécessaire pour garder l'intérêt de l'information temporelle, en
transformant les hyétogrammes simulés en événements de crues "réalistes". L'étude complète des
débits à l'aval des ouvrages hydrauliques est alors possible évitant l'utilisation de pluie ou de crue de
projet (voir § C.3.3).
La méthode ainsi déroulée correspond au mode de fonctionnement dit « SHYPRE local »
utilisant des chroniques observées de pluies et de débits à pas de temps fins, nécessaires pour caler
le modèle GR3H. Dans ce cas plusieurs paramètres (trois) sont associés au calage le modèle
hydrologique, ce qui peut ensuite contraindre la régionalisation de l’approche. Le problème de la
représentativité de la pluie sur le bassin est aussi une limite car le générateur reste un générateur
ponctuel et les chroniques de pluies simulées ont donc des caractéristiques moins « lissées » qu’une
pluie de bassin. Une option aurait été de travailler sur le développement d’un générateur de pluie de
bassin, calé sur des chroniques de pluies de bassins. Dans le cas de pluies horaires, cette option est
difficilement applicable de part la faible densité du réseau de mesure pluviographique (information
à pas de temps infra-quotidien). Une autre option serait d’appliquer un coefficient d’abattement
spatial directement sur les pluies horaires simulées. Cette option n’est cependant pas pertinente car
l’abattement des pluies est variable suivant la durée de la pluie à laquelle on s’intéresse. Il faudrait
donc proposer un abattement quantitatif sur la pluie totale d’un événement, avec un lissage des
intensités. Cette option n’a pas été choisie. Le développement d’un générateur spatial de champs de
pluie correspond par contre à une autre approche qui implique une connaissance sur la structure

68
spatiale de la pluie à pas de temps horaire, disponible uniquement depuis quelques années avec le
développement des radars météorologiques. Cette approche spatiale reste cependant difficile à
appliquer pour l’estimation des valeurs extrêmes et nécessiterait de plus d’utiliser une modélisation
hydrologique spatialisée (bien qu’une approche globale soit aussi utilisable).
Le choix fait a été de travailler sur une modélisation au pixel, permettant de fournir des
quantiles de débits spécifiques qui feront l’objet d’un abattement spatial global, attribué à la fois à
la pluie et à l’hydraulique. Cette approche développée par la suite a permis une simplification de la
modélisation hydrologique, réalisée sur une même maille de calcul, le kilomètre carré. Cette
modélisation est, comme dans la plupart du temps, orientée par la question qui est posée… et qui
concerne ici la connaissance des caractéristiques des crues extrêmes en sites dépourvus
d’information.
C.1.2 Simplification du modèle GR3H pour un fonctionnement pixélisé
Afin de proposer des modifications et une simplification dans la structure du modèle GR3H
pour modéliser les crues sur des mailles élémentaires de un km², le modèle GR3H a été appliqué sur
une douzaine de petits bassins versants de superficie voisine du km² (entre 0,64 et 16 km², médiane
à 1,5 km², moyenne à 3,7 km²) [Arnaud, 2005]. Ces bassins sont présents sous différents climats : 6
bassins en zones méditerranéennes pluvieuses, 3 bassins alpins (Suisse) et 3 bassins tropicaux (Île
de la Martinique). La capacité du premier réservoir (A) reste fixée comme pour le modèle GR3H.
Une première simplification du modèle GR3H a été de supprimer les deux hydrogrammes
unitaires caractérisés par le paramètre C, pour les remplacer par un hydrogramme unitaire simple
placé au début de la modélisation. Cet hydrogramme unitaire répartit la pluie suivant deux pas de
temps horaires : 70% au pas de temps de la pluie et 30% au pas de temps suivant. Cet opérateur
permet un lissage des intensités horaires de pluie et ne fait pas l’objet d’une optimisation. Cette
simplification n’a pas d’impacts notables sur la capacité du modèle à restituer les crues observées,
d’une part parce que le paramètre B permet de compenser légèrement, mais aussi parce que
l’application sur des petits bassins versants ne conduisait pas à des valeurs du paramètre C très
variables.
Une seconde simplification a été apportée au niveau réservoir de transfert B, dont la capacité a
été fixée (à 50 mm), de même que sa valeur initiale de remplissage (initialisé à 30%). Le débit
initial Q0 est simplement ajouté à l’hydrogramme simulé et ne sert plus à l’initialisation de B. Cette
simplification, possible lorsque l’on veut modéliser des bassins versants sur une taille identique et
élémentaire, peut être compensée par le calage du dernier paramètre S0/A. En effet, le transfert étant
finalement supposé unique sur tous les bassins (d’un km²), la variabilité des écoulements va
provenir de la pluie et de la production du bassin. Les calages ont montré que cette hypothèse était
raisonnable et que le modèle ainsi simplifié conduisait à des résultats très satisfaisants sur des petits
bassins versants, en respectant la pointe des hydrogrammes et leur volume. Une
« désynchronisation » entre les hydrogrammes observés et modélisés est cependant possible, mais si
ce point peut être gênant en prévision des crues, il n’a pas d’importance en prédétermination.

69
La version simplifiée de GR3H (Figure 25) présente différents avantages. Sans dégrader
notablement les performances du modèle en restitution des crues, on réduit l'impact des paramètres
C et Q0 sur les résultats du modèle. En effet, ces deux paramètres avaient respectivement un rôle de
transfert et de production qui pouvait influencer les valeurs prises par les deux paramètres
principaux du modèle (B et S0/A), rendant ainsi difficile la maîtrise du comportement du modèle.18
Pluie : P (i)
Structure
simplifiée du
modèle GR3H
Ps = (1-(S/A)²).P
S
Débit : Q = Qr + Q0
B = 50 mm R
Pr = (S/A)².P
Réservoir A Réservoir
R
S
Qr (t) = R(t)5/4B
4
S0/A
Initialisation
R0/B = 0,3
P = 0,7P(i) + 0,3P(i-1)
Figure 25 : Structure du modèle GR3H simplifié : GRsimple
Cette version du modèle présente des caractéristiques intéressantes pour son utilisation en
prédétermination des crues :
parcimonie : on fait le gain d’un paramètre (C) en supprimant les deux hydrogrammes
unitaires de GR3H. En effet, le décalage temporel entre les pluies et les débits ne présente
aucun intérêt en prédétermination. En restitution des crues (calage du modèle), les erreurs de
synchronisme peuvent être évitées par un décalage temporel de la pluie observée (décalage
non utilisé en simulation). Ce décalage temporel est alors neutre dans la modélisation par
rapport à l’utilisation d’un hydrogramme unitaire qui introduit un étalement de la pluie dans
le temps. Cependant dans le cadre des petits bassins versants étudiés, aucun décalage n’est
nécessaire. Le paramètre B et son état initial ont aussi été fixés.
indépendance des paramètres : la suppression des hydrogrammes unitaires et le fait de
fixer le taux de remplissage du réservoir B conduit à une meilleure distinction des
paramètres entre eux en réduisant les effets compensatoires de paramètres ayant le même
rôle. Ce point est particulièrement intéressant pour aider à la régionalisation des paramètres.
Le calage du modèle hydrologique à l’échelle du km² est donc porté sur un seul paramètre
de production (S0/A) les autres paramètres étant fixés.
18
Notons que cette structure a été reprise dans le cadre de l’élaboration d’une version distribuée (spatiale) du
modèle GR3H, appelée GRD (GR Distribué), utilisée pour réaliser une modélisation hydrologique adaptée à la
prévision des crues (Arnaud et al, 2011). Cette structure permet alors de modéliser la contribution de chaque pixel du
bassin versant soumis à l’information pluviométrique pixellisée apportée par la mesure des radars météorologiques
(Javelle et al, 2010).

70
Le comportement de la modélisation vers les fréquences rares a aussi été étudié en soumettant
la modélisation hydrologique réalisée, aux pluies extrêmes simulées par le générateur de pluies
horaires. On a alors mis en évidence le problème de l’équifinalité des paramètres, posant le
problème du choix de la modélisation à retenir. En effet, un dilemme se présente. Il existe plusieurs
solutions (sur la structure et sur la paramétrisation) qui permettent de conduire à une restitution
équivalente des crues observées, par l’effet de compensations. Cependant, si ces modélisations sont
équivalentes pour la restitution des crues observées, leur utilisation avec des pluies de fréquences
exceptionnelles conduit parfois à des résultats très différents. Le choix et la validation de la
modélisation à retenir sont alors très difficiles. La réduction du nombre de paramètres permet en
partie de résoudre ce problème important.
Cette question s’est posée en particulier pour la valeur du paramètre A dont la valeur fixée a
une influence non négligeable sur le comportement asymptotique du modèle vers les valeurs
extrêmes. Ce point a été abordé dans le cadre de la thèse de Yoann Aubert [2012] et a conduit a un
choix pertinent pour le paramètre A utilisé dans le cadre de l’application régionale de la méthode
[Yoann Aubert et al., 2014] présentée dans le paragraphe suivant.
Le couplage du générateur de pluie avec une modélisation hydrologique permet d’étudier
l’aléa hydrologique dans toute sa composante temporelle, de la même façon que pour les pluies. Le
modèle hydrologique a été choisi pour être performant tout en étant parcimonieux. Avec seulement
trois paramètres, le modèle GR3H répond à ces critères. Le couplage avec le générateur de pluies a
nécessité l’étude de la dépendance des paramètres avec la pluie ainsi que de leur dépendance entre
eux (le modèle étant événementiel, plusieurs jeux de paramètres sont déterminés pour un même
bassin), afin d’être éventuellement pris en compte lors de la simulation.
Dans l’objectif de régionalisation de l’approche, destinée aussi a été utilisable en sites non-
jaugés, la transformation pluie-débit a été simplifiée au maximum. Cette simplification est justifiée
par la résolution spatiale sur laquelle est faite la transformation des pluies simulées en débits. A
cette résolution spatiale, c’est la production du modèle qui présente le plus de variabilité, le
transfert pouvant être supposé invariant d’un pixel à l’autre, en première approximation. La
réduction du nombre de paramètres est guidée par une limite imposée par la capacité du modèle à
restituer les débits de pointe et les volumes de crues sur des bassins de l’ordre de un km². Une
structure simple, basée sur le modèle GR3H dont certaines composantes sont simplifiées et certains
paramètres fixés, permet de répondre à cet objectif en ne gardant qu’un paramètre de calage.
A cette étape, la simplification permet aussi de supprimer le problème de la dépendance des
paramètres entre eux (puisqu’il n’en reste plus qu’un) mais qu’il faut prendre en compte dans une
approche plus complète.
Les simplifications réalisées à cette étape restent un préalable « pour dérouler » la méthode
jusqu’à son utilisation finale en sites non-jaugés, sur des bassins de toutes tailles. La recherche
effectuée a consisté à trouver les hypothèses simplificatrices les plus pertinentes pour ne pas nuire
à la justesse des résultats sur des petits bassins. L’analyse des résultats sur l’approche complète
permettra ensuite de revenir sur certaines hypothèses simplificatrices en étudiant les zones
géographiques et les types de bassins où l’approche est mise en défaut.

71
C.2 Mise en œuvre régionale de l’approche par simulation
Cette partie présente la version régionale de la méthode « SHYPRE ». Cette version nommée
« SHYREG » est développée pour une application régionale (estimation en sites non jaugés). Elle
s’appuie fortement sur la connaissance régionale de la pluviométrie pour estimer les quantiles de
crues courants à extrêmes. Cette information pluviométrique est estimée suite au travail de
cartographie des paramètres du générateur de pluies horaires.
C.2.1 Rappel sur la mise en œuvre régionale du générateur de pluies horaires
Ce paragraphe rappelle de façon synthétique les étapes présentées dans le paragraphe B.2, qui
ont abouti à la production de la base de données SHYREG-pluie utilisée pour l’estimation des crues
et présentée en détail dans un guide méthodologique [Arnaud and Lavabre, 2010]. L’élaboration de
cette base est passée par différentes étapes représentées sur la Figure 26 :
Figure 26 : Principe de l’élaboration de la base SHYREG-pluie

72
1 - Le calage d’un générateur de pluie. Le principe est de décrire les chroniques de pluies
horaires par l’intermédiaire de différentes variables aléatoires. Ces variables sont au nombre de
9 (nombre d’événements pluvieux par an, nombre d’averses par événement, durées des averses,
volumes des averses, etc.). Elles sont toutes associées à une loi de probabilité adaptée qui
permet le tirage aléatoire des valeurs nécessaires pour simuler des chroniques de pluies horaires
(Cernesson, Lavabre et al. 1996). La dépendance entre certaines variables a été mise en
évidence et modélisée (Cantet 2009). Le calage du modèle, effectué pour deux saisons, a été
réalisé sur 217 postes horaires de référence et les résultats contrôlés sur 207 autres postes.
2 - La paramétrisation du générateur par une information journalière. Par le biais de
corrélations linéaires, les paramètres les plus importants du générateur de pluie sont facilement
déterminés par des caractéristiques journalières de la pluie. D’autres paramètres sont fixés à des
valeurs régionales. L’intérêt de cette paramétrisation par l’information journalière est de
disposer d’une information pluviométrique nettement plus dense au pas de temps journalier
qu’au pas de temps horaire. Cette paramétrisation, basée sur des caractéristiques moyennes,
garantit la stabilité de la méthode face aux problèmes d’échantillonnage des observations.
3 - La régionalisation des paramètres journaliers. Les trois paramètres journaliers permettant de
mettre en œuvre le générateur de pluie horaire ont été déterminés sur 2812 chroniques de pluies
journalières observées sur la période 1977-2002. Ces trois paramètres caractérisant
l’occurrence, la durée et l’intensité des pluies, ont alors été régionalisés à une maille de 1x1 km
en utilisant une méthode de type AURELHY (Benichou and Le Breton 1987) par Météo-France
(Sol and Desouches 2005).
4 - La simulation de chroniques de pluies. A partir des trois paramètres journaliers régionalisés
sur une maille d’un km², la génération d’un échantillon d’événements pluvieux indépendants
est réalisée au pas de temps horaire. Cet échantillon est alors statistiquement équivalant à un
échantillon de plusieurs milliers d’années d’observation, sous hypothèse de stationnarité.
5 - Extraction des quantiles de pluies (courbes IDF). Les événements pluvieux simulés sont
analysés comme des observations en extrayant les valeurs de pluies maximales de différentes
durées. Ces valeurs sont ensuite classées pour déterminer des distributions empiriques d’où
sont extraits directement les quantiles empiriques de pluies de différentes durées, sans
ajustement de lois. On obtient ainsi une base de données de courbes Intensité-Durée-Fréquence
à la maille de un km², représentant la pluie ponctuelle.
La régionalisation du générateur de pluie permet son utilisation sur l’ensemble du territoire
d’étude. Elle fournit une information pixélisée robuste et pertinente de l’aléa pluvial, prenant en
compte l’information pluviométrique régionale et une information topographique. La
paramétrisation régionalisée du générateur permet dont de générer en tout point du territoire des
chroniques synthétiques de pluies horaires qui seront alors utilisées par le modèle hydrologique
GRsimple.

73
C.2.2 Principe et calage de la méthode SHYREG
Le calage de la méthode SHYREG consiste à trouver une paramétrisation du modèle
hydrologique qui permette de se caler sur la distribution de fréquence empirique des débits
maximums observés aux stations jaugées. Cette phase correspond au mode de fonctionnement
appelé « SHYREG local » de la Figure 22 et comprend deux étapes.
Figure 27 : principe du calage de la méthode SHYREG
Ces étapes de calage décrites dans la Figure 27 sont :
Etape 1 : une simulation au pixel :
La première étape consiste à générer des quantiles de débits de crue à la maille du pixel (un
km²). Pour cela, des événements indépendants de pluies horaires sont simulés à chaque maille, à
partir des paramètres régionalisés du générateur de pluie. Ces événements de pluies sont
transformés en événements de crues indépendants par le modèle hydrologique simplifié (§ C.1.2).
Des simulations sont réalisées pour différentes valeurs de l’unique paramètre S0/A. Finalement, pour

74
chaque valeur de S0/A, et à chaque pixel, des événements de crues sont simulés avec la pluie locale.
Les quantiles de crues sont extraits de façon empirique de ces événements simulés. A l’ensemble
des débits générés, on rajoute un débit de base (noté Q0). Le débit de base utilisé correspond à une
estimation du débit spécifique mensuel moyen, fourni par une méthode régionale d’estimation de la
ressource en eau (la méthode LOIEAU : [Folton and Lavabre, 2006; 2007]). Bien que cette valeur
soit souvent négligeable face aux débits de crues simulés, il est important de la prendre en compte
lors du calage de la méthode. En effet, elle permet de distinguer la partie « ruissellement » de la
partie « écoulement de base » qui ne dépend pas directement des pluies générées au cours de la
crue. Cette prise en compte permet d’éviter un biais dans le calage [Aubert, 2012].
La variabilité spatiale des débits, pour une même durée, une même période de retour et une
même valeur de S0/A, est assurée principalement par la pluviométrie (variabilité des paramètres du
générateur), mais aussi par la taille du réservoir A et à moindre échelle par le débit de base Q0. La
notion de durée caractéristique du bassin versant a été, sinon éludée sur cette modélisation au km²,
tout au moins considérée comme identique pour tous les pixels. Le paramétrage local ne porte donc
que sur le rendement des pluies, à travers le calage du paramètre S0/A. Lors de son calage, ce
paramètre doit alors compenser les hypothèses faites sur les autres paramètres qui ont été fixés. La
méthode n’étant pas continue, on suppose que les événements pluvieux, générés de manière
indépendante, se produisent toujours sur un système dont l’état initial est un état moyen, toujours le
même, et est donné par le paramètre S0/A. Les deux saisons sont cependant prises en compte en
optimisant une valeur du paramètre S0/A pour chaque saison.
Comme pour les pluies, les événements de crues générés sont associés à une période de
simulation et sont analysés empiriquement pour calculer des valeurs de quantiles de crue
directement lus sur la distribution empirique. Seuls les quantiles de périodes de retour 100 fois plus
faibles que la durée de simulation sont retenus pour garantir une stabilité de la fréquence empirique.
Pour obtenir des quantiles millénaux on simule donc l’équivalent de 100 000 ans d’événements
pluvieux que l’on transforme en crues et on retient les caractéristiques de rang 100. Ce travail est
effectué en chacun des 550 000 pixels recouvrant le territoire de la France métropolitaine.
Etape 2 : le calcul aux exutoires des bassins versants
La seconde étape consiste à calculer pour les différentes valeurs du paramètre S0/A, les
quantiles de débits de crues aux exutoires des bassins versants jaugés. Ainsi, pour chaque bassin
versant et pour chaque valeur de S0/A, les débits spécifiques sont moyennés sur les pixels
appartenant au bassin. On calcule donc la grandeur
qui est la moyenne des
débits de durée (pour le débit de pointe, ) et de période de retour des pixels de un km²
contenus dans le bassin, notés pour à . Ces débits moyennés sont ensuite
réduits par une fonction d’abattement qui dépend de la surface du bassin (km²) et de la durée du
débit moyen. Cette fonction sert à prendre en compte simultanément l’abattement des pluies avec la
surface, mais aussi un abattement de nature hydraulique [Aubert, 2012; Fouchier, 2010]. Elle

75
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
1 10 100 1000 10000
f1(S)
f2(S)
s’exprime par le biais de deux équations dépendant de la durée sur
laquelle le débit moyen est calculé :
avec
Les paramètres 1, 2, 1, 2, et ont été optimisés de façon unique sur un échantillon de
1291 bassins versants en France et sont considérés comme constants sur l’ensemble de la France
Métropolitaine19
. On obtient alors pour chaque bassin versant les quantiles de débits de différentes
durées : . Le calage consiste alors à trouver la valeur du paramètre qui minimise
les écarts entre la distribution empirique et la distribution fournie par la méthode. En pratique un
écart relatif est calculé entre six quantiles issus des observations (débits de pointe et débits moyens
journaliers de périodes de retour 2, 5 et 10 ans) et les six mêmes quantiles fournis par la méthode
SHYREG. Les quantiles issus des observations sont obtenus par l’ajustement d’une loi de
probabilité GEV dont le paramètre de forme a été borné (sa valeur doit être comprise entre 0 et 0,4).
Le choix de cette loi a relativement peu d’importance tant que l’on reste dans le domaine des
fréquences courantes (T<10 ans), nécessaire au calage de la méthode20
. Ainsi, pour chaque bassin
versant jaugé, la méthode peut-être calée en optimisant un seul paramètre. C’est sur ce paramètre
que portera la régionalisation nécessaire pour pouvoir appliquer la méthode tout le long du réseau
hydrographique (et donc en milieu non jaugé). C’est dans cette configuration que la méthode a été
évaluée et comparée à l’usage des méthodes statistiques classiques. Les résultats sont présentés dans
le paragraphe C.3.
C.2.3 Régionalisation de la méthode
La méthode choisie repose sur la recherche de régressions entre le paramètre optimisé sur
chaque bassin versant de calage et des variables environnementales, puis sur l’interpolation spatiale
des résidus à ces régressions [Hydris, 2009].
19
Ces paramètres prennent respectivement les valeurs 0,01 / 0,25 / 0,24 / 10 / 5 et 0,9, avec de faibles variations
lorsque l’on fait varié l’échantillon de calage lors de procédures de calage/validation. 20
Un poids est affecté aux différents quantiles dans le calcul du critère d’écart. Les quantiles de période de retour
2 et 5 ans ont un poids de 2 et le quantile de période de retour 10 ans a un poids de 1, afin de limiter l’impact de
l’échantillonnage sur le calage de la méthode.
Surfa
ce (km²)

76
Figure 28 : Principe de la régionalisation du paramètre du modèle hydrologique.
Comme le présente le schéma de la Figure 28, cette régionalisation passe par plusieurs étapes :
1. La détermination des valeurs optimales du paramètre. Cette valeur est issue de l’étape
de calage présentée au paragraphe précédent. Dans ce cas, le paramètre est considéré comme
constant pour l’ensemble des pixels d’un même bassin versant.
2. La recherche de variables explicatives consiste à trouver des corrélations entre les valeurs
optimales du paramètre à régionaliser et des valeurs de variables environnementales
moyennées sur les bassins versants. Dans le cas de la régionalisation de notre paramètre, les
variables disponibles qui permettent d’expliquer au mieux sa variabilité sont la densité du
réseau de drainage21
, l’hydrogéologie22
[Moulard, 2010] et une variable de bilan hydrique.
On détermine alors une carte du paramètre dite « S0/A expliqué », avec un coefficient de
détermination de l’ordre de 40%.
3. Cartographie des résidus. Les corrélations trouvées précédemment permettent d’expliquer
une partie de la variabilité spatiale du paramètre. Les résidus à cette régression sont alors
calculés pour chaque bassin versant. Ces résidus sont ensuite cartographiés en attribuant à
chaque pixel de la zone, la valeur du résidu du bassin le plus petit présent sur ce pixel (cas
21
La densité de drainage a été calculée à partir de la BDCarthage (référentiel sur le réseau hydrographique en
France http://www.sandre.eaufrance.fr), permettant le calcul d’un indice correspondant au pourcentage de pixels de
100x100 m traversés par le réseau hydrographique, sur une surface de 1 km². 22
L’information hydrogéologique a été obtenue par digitalisation d’une carte élaborée par Margat en 1978. Cette
information a été classifiée par grands types d’aquifères (Moulard, 2010).

77
de bassins emboités). Une interpolation simple du type IDW (inverse de la distance au carré)
est réalisée pour prendre en compte les tendances régionales à la surestimation ou la sous-
estimation de la valeur optimale du paramètre. Une carte dite des « résidus » obtenue et
éventuellement lissée. La carte dite « S0/A régionalisée » est alors la somme des cartes
« S0/A expliqué » et « résidus ».
4. Intégration de zones spécifiques. A partir de l’information issue de la base de données
d’occupation des sols (Corine Land Cover : http://www.eea.europa.eu), des pixels ont été
définis dont la valeur du paramètre est imposée. Ces pixels de un km² sont ceux concernés
majoritairement par la présence de zones urbaines, périurbaines et plans d’eau que l’on
considère comme fortement ou totalement imperméable. A noter que sur ces pixels la valeur
de S0/A était alors imposée dès la première étape d’optimisation.
5. Le contrôle consiste à vérifier la concordance entre les valeurs optimales du paramètre et
celles fournies par la régionalisation. La présence de bassins emboités et la procédure
adoptée, ne permet pas de retrouver exactement les valeurs des paramètres optimums même
en prenant en compte les résidus.
Cette procédure a été testée sur différents échantillons de calage/validation pour déterminer la
meilleure procédure à adopter : choix des variables explicatives à retenir, méthode d’interpolation
des résidus et lissage à appliquer [Organde et al., 2013]. C’est cette procédure optimale en
validation qui a ensuite été appliquée sur l’échantillon complet de bassins jaugés. D’autres
procédures de régionalisation sont encore à tester, comme les méthodes de voisinage, pour essayer
d’améliorer la régionalisation du paramètre hydrologique. Ces recherches sont en cours dans le
cadre de la thèse de Jean Odry (2015-2017).
La régionalisation du paramètre S0/A permet de mettre en œuvre la méthode sur l’ensemble
des pixels de la zone d’étude. Le déroulement complet de la méthode est alors possible en tout point
du réseau hydrographie. Ce mode de fonctionnement correspond à celui appelé « SHYREG régional »
dans la Figure 22. Sa mise en œuvre opérationnelle a été réalisée sur l’ensemble du territoire
national Français et a conduit à une base de données nationale sur l’aléa hydrologique équivalente à
celle produite sur l’aléa pluvial (Figure 29). Notons que cette base de données est associée à la
procédure d’agglomération et d’abattement des quantiles estimés dans un premier temps à l’échelle
des pixels kilométriques. La procédure d’agglomération et d’abattement est alors réalisée en
utilisant les directions d’écoulement, nécessaires pour déterminer numériquement le contour de tout
bassin versant. Pour la mise en œuvre nationale de la méthode, les directions d’écoulement à une
résolution de 50 m fournies par le SCHAPI (Service Central d’Hydrométéorologie et d’Appui à la
Prévision des Inondations) ont été utilisées. Cette base des directions d’écoulement a été travaillée
pour retrouver le réseau hydrographique de la BD Carthage et les bassins des stations
hydrométriques. Elle peut être considérée comme une base de référence nationale pour la
délimitation des bassins versants topographiques. Un calcul automatique des contours de bassin
versant a d’ailleurs été réalisé et a conduit à l’élaboration d’une base de près de 140 000 contours de
bassins associés à des tronçons hydrographiques [Patrick Arnaud et al., 2014b; Organde et al.,
2013].

78
Figure 29 : Création des bases de données SHYREG-débit.
Les bases SHYREG-débit (Figure 29) sont donc le résultat de l’application de la méthode
SHYREG sur le territoire national. C’est une approche régionale qui résulte de l’utilisation d’une
information hydrométéorologique la plus exhaustive possible, disponible sur les bases de données
nationales. Elle intègre la variabilité spatiale des statistiques sur les pluies. C’est une approche qui
présente aussi l’avantage d’être homogène sur l’ensemble du territoire et qui propose, en une seule
régionalisation, l’estimation de l’ensemble des caractéristiques des crues (débit de pointe, volumes,
durées, …).
D’un point de vue scientifique, cette base est le résultat de nombreuses recherches produites
par des travaux de thèses et des projets scientifiques pour répondre à des questions liées à la
connaissance des processus complexes à partir d’informations incomplètes. La problématique à
résoudre est liée d’un part à l’extrapolation en fréquence d’un phénomène dont les réalisations
sont observées de façon très limitée par rapport aux fréquences que l’on désire connaitre
(probabilité de dépassement annuelle de 10-2
à 10-4
), et d’autre part à l’extrapolation dans l’espace
d’un phénomène observé très partiellement malgré sa forte variabilité spatiale. La méthode
développée et choisie permet de répondre au mieux à cette problématique tout en essayant de
produire des résultats les plus justes possibles. L’évaluation des performances de la méthode est
donc un point important pour justifier son développement.

79
C.3 Evaluation des performances de la méthode et applications
La méthode développée a fait l’objet d’une évaluation de ses performances à travers différents
travaux synthétisés dans ce paragraphe. Ces travaux sont relatifs à des études propres au
développement de la méthode et à des études réalisées dans le cadre du projet ANR Extraflo
(https://extraflo.cemagref.fr/) de comparaison de méthodes de prédétermination de crues.
Les études propres à la mise en place de la méthode SHYREG-débit sur le territoire national
s’appuient sur un jeu de données de 1605 bassins versants, jugés non influencés par les
gestionnaires (information banque HYDRO), non spécifiques (par exemple non fortement
karstiques) et présentant au minimum dix ans de données et une surface inférieure à 10 000 km².
Dans le cadre du projet Extraflo, la base de données des bassins versants étudiés est variable en
fonction des tests effectués (de 508 stations à 1172 stations extraites de la base des 1605 bassins
précédents).
C.3.1 Evaluation de la méthode appliquée localement (SHYREG Local)
Une première évaluation des résultats a été réalisée lors du développement de la méthode sur
des bassins versants méditerranéens [Arnaud, 1997; Arnaud and Lavabre, 1998; 2000; 2002], puis
étendu sur des régimes hydrologiques plus variés, sur 1290 bassins versants français [Fouchier,
2010; Organde et al., 2013]. Les derniers résultats, appliqués sur 1605 bassins versants, montrent
qu’à partir de la détermination d’un seul paramètre la méthode restitue correctement les quantiles de
fréquences courantes (périodes de retour < 10 ans) ajustés par une loi GEV sur les observations.
Pour les quantiles plus extrêmes (périodes de retour > 10 ans), différents critères ont été utilisés
pour juger de la pertinence de la méthode : la bonne adéquation avec les distributions empiriques
issues de longues chroniques, la saturation progressive du modèle hydrologique et la stabilité des
quantiles estimés [Aubert, 2012; Yoann Aubert et al., 2014].
Une évaluation plus approfondie a été réalisée au cours du projet ANR Extraflo dont le cadre
méthodologique [B. Renard et al., 2013] et les critères d’évaluation ont été présentés rapidement
dans le paragraphe B.1.5. Pour l’évaluation des approches dites « locales », les méthodes ont été
testées par des procédures de calage/validation sur différents échantillons. La Figure 30 présente
une synthèse de certains résultats. Elle présente les valeurs des « scores » de justesse et stabilité
calculés pour les estimations de quantiles issus de la méthode SHYREG calée localement (courbe
noire). Les mêmes critères ont été calculés pour les estimations de quantiles issus de l’usage de lois
de probabilité classiques telles que la distribution de Gumbel (courbes rouge et bleu), la
distribution GEV (courbe verte et turquoise) et la distribution GEV « bornée » (courbe rose).

80
La notation de la Figure 30 correspond à la combinaison d’un score et d’un échantillonnage :
- les scores sont issus des critères SPAN (critère de stabilité des estimations, calculé pour les
quantiles 10, 100 et 1000 ans), NT (critère de justesse des estimations, calculé pour les
périodes de retour T=10 ans et 100 ans) et FF (critère de justesse sur la valeur maximale de
l’échantillon). Ils ont été calculés pour la méthode SHYREG, pour les lois de Gumbel et GEV
ajustées par le maximum de vraisemblance (respectivement Gum_MV et GEV_MV) et par les
L-moments (respectivement Gum_LM et GEV_LM) et pour la loi GEV dont le coefficient de
forme est borné entre les valeurs 0 et 0,4 et ajustée par le maximum de vraisemblance
(GEVB_MV).
- les échantillonnages sont composés de la manière suivante pour les critères de justesse (NT
et FF) : 50% des années pour le calage et 50% des années pour la validation (noté « _50% »),
33% des années pour le calage et 67% des années pour la validation (noté « _33% »),
échantillon de 15 ans, 30 ans et 40 ans tronqué de leur valeur record pour le calage et avec la
valeur record pour la validation (notés respectivement « _x15 », « _x30 » et « _x40 »). Pour
le critère de stabilité (SPAN), les deux périodes de calage sont de 10, 15 et 20 ans chacune
(notées « _10 », « _15 » et « _20 »).
Figure 30 : résultats issus du projet ARN Extraflo, méthodes de prédétermination de crues locales :
comparaison de la méthode SHYREG avec des méthodes statistiques classiques (ajustement de lois
de Gumbel et GEV).
Sur ce graphique, présentant la valeur des scores calculés sur les échantillons de validation,
plus la courbe est excentrée plus les résultats de la méthode sont bons. Dans l’ensemble, la méthode
SHYREG montre largement les meilleures valeurs pour le critère de stabilité. Ses critères sont
particulièrement insensibles à la période de retour, alors que pour les méthodes d’ajustement
SHYREG

81
classiques (loi de Gumbel ou GEV) la stabilité devient très mauvaise pour les grandes périodes de
retour, en particulier pour les lois à trois paramètres (GEV). En termes de justesse, la méthode
SHYREG présente aussi de meilleurs résultats que les ajustements de loi de probabilité, sur les
échantillons de validation. Dans sa version locale, la méthode SHYPRE présente donc des
performances meilleures que les méthodes d’ajustement classiquement utilisées en hydrologie, pour
estimer les valeurs de débits extrêmes.
Ces résultats ont été détaillés dans [Patrick Arnaud et al., 2014a]. Ils montrent que la méthode
SHYREG est très stable. Cette caractéristique est liée à deux points. D’une part la méthode s’appuie
sur une information statistique régionale de la pluie, et d’autre part sur une modélisation
hydrologique simple (calage réalisé par un seul paramètre, les autres sont fixés de façon régionale à
priori et indépendamment de l’information hydrologique disponible sur le bassin considéré). La
méthode présente aussi de très bons critères de justesse, supérieurs à ceux trouvés avec les
méthodes statistiques classiques testées. Une étude complémentaire a montré que pour obtenir des
critères de justesse équivalents à la méthode SHYREG, l’utilisation de loi statistique régionale est
nécessaire [Kochanek et al., 2013] et [Lang et al., 2014]. La justesse de la méthode est liée à la
nature de l’approche qui propose une estimation des débits extrêmes conditionnée par l’information
régionale des pluies extrêmes. Cette information pluviométrique fournie par la méthode a d’ailleurs
aussi été jugée juste et stable [Carreau et al., 2013]. Il a aussi été montré que la méthode permet de
fournir des estimations « prédictives » pertinentes, en attribuant par exemple des périodes de retour
correctes à des valeurs « record » absentes des données de calage, ce qui est surement la qualité la
plus importante d’une méthode de prédétermination des valeurs extrêmes...
C.3.2 Evaluation de la méthode appliquée régionalement : SHYREG régional.
L’évaluation de la méthode a été réalisée en la calant et en la régionalisant sur un premier jeu
de bassins versants (parmi 1290 disponibles) et en contrôlant sa mise en œuvre régionale sur le jeu
de bassins versants de validation. Pour cela, deux types de découpages ont été réalisés :
« 50/50 » : 50% des bassins choisis au hasard sont utilisés pour le calage et les 50% restant
servent à contrôler la méthode.
« GB/PB » : les bassins les plus grands sont choisis pour le calage (872 bassins de surface >
100km²) et les bassins les plus petits (418 bassins restant de surface < 100km²) sont gardés
pour la validation.
Afin de relativiser les résultats obtenus par la méthode, une comparaison à la méthode
Crupedix [CTGREF et al., 1980-1982] a été réalisée (actuellement la seule méthode régionale
établie sur l’ensemble du territoire français). La méthode Crupedix initialement établie pour estimer
les débits de pointe décennaux (QP10) est appliquée ici sur les débits de pointe, mais aussi sur les
débits journaliers décennaux (QJ10). Un recalage des coefficients de la formule est réalisé dans les
deux cas. Les coefficients a, b, c et d de la relation suivante sont ajustés sur les bassins de calage :
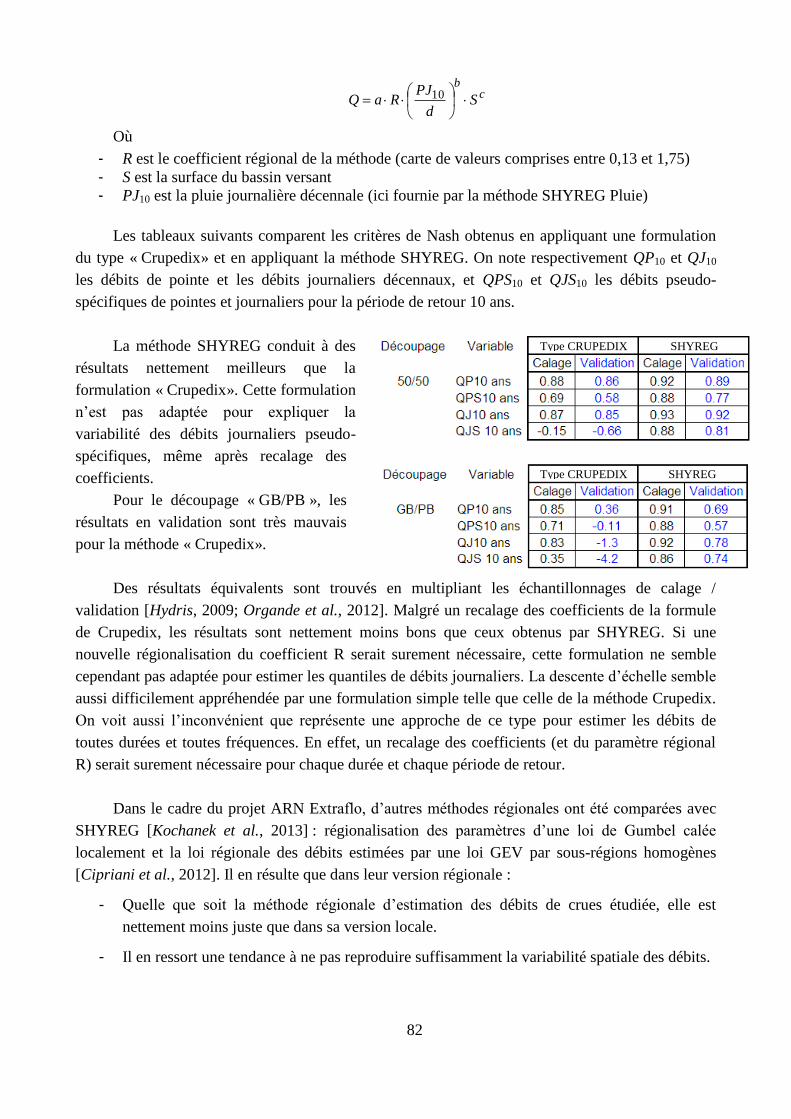
82
cb
Sd
PJRaQ
10
Où
- R est le coefficient régional de la méthode (carte de valeurs comprises entre 0,13 et 1,75)
- S est la surface du bassin versant
- PJ10 est la pluie journalière décennale (ici fournie par la méthode SHYREG Pluie)
Les tableaux suivants comparent les critères de Nash obtenus en appliquant une formulation
du type « Crupedix» et en appliquant la méthode SHYREG. On note respectivement QP10 et QJ10
les débits de pointe et les débits journaliers décennaux, et QPS10 et QJS10 les débits pseudo-
spécifiques de pointes et journaliers pour la période de retour 10 ans.
La méthode SHYREG conduit à des
résultats nettement meilleurs que la
formulation « Crupedix». Cette formulation
n’est pas adaptée pour expliquer la
variabilité des débits journaliers pseudo-
spécifiques, même après recalage des
coefficients.
Pour le découpage « GB/PB », les
résultats en validation sont très mauvais
pour la méthode « Crupedix».
Des résultats équivalents sont trouvés en multipliant les échantillonnages de calage /
validation [Hydris, 2009; Organde et al., 2012]. Malgré un recalage des coefficients de la formule
de Crupedix, les résultats sont nettement moins bons que ceux obtenus par SHYREG. Si une
nouvelle régionalisation du coefficient R serait surement nécessaire, cette formulation ne semble
cependant pas adaptée pour estimer les quantiles de débits journaliers. La descente d’échelle semble
aussi difficilement appréhendée par une formulation simple telle que celle de la méthode Crupedix.
On voit aussi l’inconvénient que représente une approche de ce type pour estimer les débits de
toutes durées et toutes fréquences. En effet, un recalage des coefficients (et du paramètre régional
R) serait surement nécessaire pour chaque durée et chaque période de retour.
Dans le cadre du projet ARN Extraflo, d’autres méthodes régionales ont été comparées avec
SHYREG [Kochanek et al., 2013] : régionalisation des paramètres d’une loi de Gumbel calée
localement et la loi régionale des débits estimées par une loi GEV par sous-régions homogènes
[Cipriani et al., 2012]. Il en résulte que dans leur version régionale :
- Quelle que soit la méthode régionale d’estimation des débits de crues étudiée, elle est
nettement moins juste que dans sa version locale.
- Il en ressort une tendance à ne pas reproduire suffisamment la variabilité spatiale des débits.
Type CRUPEDIX
Type CRUPEDIX
SHYREG
SHYREG

83
- Une analyse fine des critères de justesse montre que les méthodes d’ajustement de lois sur
les débits de crue conduisent à estimer certaines valeurs maximales comme « impossibles »
(probabilité de 1 pour la fréquence du FF), alors que la méthode SHYREG ne le fait pas. Ce
point est probablement lié à l’utilisation, par la méthode SHYREG, de l’information des
pluies pour extrapoler les distributions des débits.
- La méthode SHYREG reste nettement plus stable que les méthodes régionales basées sur
l’ajustement de lois de probabilité.
Le développement de la méthode de prédétermination des crues par simulation de scénarios
représente un effort de recherche important pour mon équipe et pour moi-même. En partant d’un
besoin très opérationnel (besoin d’outils permettant la prédétermination régionale des débits de
crues, nécessaires pour les questions d’ingénierie liées au dimensionnement d’ouvrages, à la
détermination de zones inondables, à la qualification des événements extrêmes, …), nous avons pris
le partie de développer une méthode à priori complexe pour répondre à la complexité du problème :
estimer des phénomènes rares et extrêmes en site non instrumentés, par des méthodes justes et
stables…
La spécificité de ces recherches réside dans l’effort d’extrapolation de connaissances sur les
processus, à partir d’une observation restreinte. Une extrapolation en fréquence vers des valeurs
extrêmes par nature rarement observées, est un premier point de blocage qui concerne largement la
communauté des hydrologues. Ce point est généralement abordé par des méthodes statistiques
parfois très théoriques. L’intégration de notions plus proches des processus (comme la modélisation
de la structure de la pluie et la modélisation de la transformation des pluies en débits) apporte un
réel intérêt aux méthodes de prédétermination des crues. L’extrapolation (ou interpolation) spatiale
vise à étendre la connaissance au-delà des sites de mesures. Cette extrapolation fait appel à des
méthodes communes à de multiples disciplines des sciences de l’environnement, comme les
géostatistiques. Ces méthodes sont relativement bien adaptées à des variables dont la variabilité
spatiale est relativement structurée. C’est le cas de la pluie. En hydrologie, la variabilité spatiale
des caractéristiques de fonctionnement des bassins versant est fortement influencée par les
caractéristiques de sols et par la continuité topographique des bassins (relation amont-aval), qui
rend plus difficile l’application des méthodes classiques. L’intérêt d’une approche basée sur la
relation pluie-débit est qu’une partie de la variabilité des débits est estimée par la variabilité de la
pluie, et une autre partie de la variabilité des débits est estimée par la variabilité de la relation
pluie-débit. Ces deux composantes ayant des structures spatiales totalement différentes, elles
peuvent alors être traitées séparément.
La méthode développée présente dont un « angle » de recherche relativement original et
complet sur les processus caractérisant les phénomènes hydrologiques extrêmes, dont la pertinence
est justifiée par les bonnes performances obtenues lors de son évaluation.

84
C.3.3 Simulation d’hydrogrammes
Les approches stochastiques permettent d’intégrer une composante aléatoire dans un
processus déterministe. Dans le cas de la prédétermination des crues, les approches stochastiques
permettent d’intégrer une composante aléatoire dans le processus hydrologique de la transformation
pluie-débit. Cette composante aléatoire est fournie par la génération de scénarios de pluies dans le
cas de l’approche que nous avons présenté jusque là.
Les résultats présentés dans les paragraphes précédents (C.1 et C.2)
montrent que la méthode développée apporte une information pertinente sur
l’aléa hydrologique en site jaugé comme en site non-jaugé. La mise en œuvre
régionale de la méthode par simulation nous a progressivement conduits à des
simplifications, afin de diminuer le nombre de paramètres et faciliter la
régionalisation. Pour cela, la modélisation hydrologique couplée à la simulation
de pluies a été réalisée sur des pixels d’un km². A l’échelle du bassin versant, une
agrégation de l’information statistique obtenue sur chacun de ses pixels est
réalisée. Cette approche nous fait cependant perdre la notion de simulation
d’hydrogrammes sur un bassin versant, nécessaire à un couplage avec une
modélisation hydraulique. Un quatrième mode de fonctionnement de l’approche
(voir schéma ci-contre) est alors envisagé pour bénéficier des résultats sur la
méthode SHYREG, dont le comportement asymptotique a été éprouvé et jugé comme juste et
stable. Ce quatrième mode de fonctionnement nécessite la recherche d’une paramétrisation du
modèle GR3H permettant de retrouver les quantiles de crues extrêmes fournis par la méthode
SHYREG locale ou régionale.
La recherche d’une paramétrisation dite « équivalente » a été réalisée sur 334 bassins versants
de climatologie très contrastée et a montré qu’il était facile de trouver un jeu de paramètre
permettant de retrouver les distribution de fréquences de la méthode SHYREG, tout en générant des
hydrogrammes de crues représentatifs du fonctionnement du bassin versant [Aubert, 2008]. Il est
donc possible de caler la méthode SHYPRE sur des quantiles SHYREG dont les performances ont
été largement étudiées.
La génération d’hydrogrammes de crues représentatifs du fonctionnement d’un bassin versant
peut donc être utilisée pour l’étude du comportement hydraulique des ouvrages face au risque de
crues. Comme cela a été vu au paragraphe A.3, ces approches par simulation présentent un intérêt
croisant de la part des scientifiques, car elles permettent d’appréhender au mieux un processus
complexe présentant une très forte variabilité. Ces scénarios de crues dont on maitrise les
caractéristiques statistiques peuvent alors être soumis au fonctionnement d’ouvrages hydrauliques et
permettent d’étudier directement la distribution de fréquence de la réponse de l’ouvrage à cet aléa.
La réponse de l’ouvrage dépend de son fonctionnement propre, de sa gestion et de sa probabilité de
défaillance, que l’on peut facilement modéliser. L’approche par simulation permet donc d’étudier
de façon relativement intégrée, l’ensemble des scénarios de fonctionnement d’un ouvrage, couplé à
l’ensemble des scénarios de crues possibles.

85
Une première application a été présentée pour la simulation du fonctionnement hydrologique
d’une retenue pour la gestion de son barrage [Arnaud and Lavabre, 1995; 1997]. D’autres
applications entrent dans le cadre du dimensionnement d’organes évacuateurs de crues de grands
barrages. Ce dimensionnement est lié à la cote atteinte par le plan d’eau en cas de fortes crues
[Carvajal et al., 2009a; Carvajal et al., 2009b; Lavabre et al., 2010]. Dans ce cas, l’hypothèse
réductrice de la notion de crue de projet peut être supprimée. En effet, la crue de projet est
généralement construite autour d’une seule caractéristique de crues (souvent un quantile du débit de
pointe) et d’une hypothèse sur la forme de la crue (et donc souvent sur son volume). On fait ainsi
l’hypothèse d’équivalence entre la période de retour de cette crue et celle de la caractéristique qui a
servi à sa construction, ainsi que d’équivalence entre cette période de retour et la période de retour
de l’impact que la crue de projet produit sur l’ouvrage (par exemple, la cote atteinte par le plan
d’eau). L’approche par simulation permet par contre la détermination d’une distribution de
fréquence de la cote atteinte par le plan d’eau soumis aux multiples scénarios de crues. Cette
distribution peut alors être comparée à la distribution des cotes observées. L’approche permet aussi,
d’attribuer une fréquence d’apparition à une cote donnée et de tester différentes hypothèses de
dimensionnement des ouvrages.
Dans la cadre du projet ANR Extraflo, deux méthodes par simulation développées en France
ont été appliquées sur un bassin versant, avec un même jeu de données pour être comparées : la
méthode SCHADEX développée par EdF [Paquet et al., 2013] et la méthode SHYPRE développée
à Irstea. Les résultats concernant ces deux méthodes par simulation montrent des convergences pour
les fréquences d’occurrence extrêmes, à la fois sur l’estimation de l’aléa hydrologique mais aussi
sur l’estimation de la distribution des cotes du plan d’eau [Paquet et al., 2014]. Ces distributions de
cotes simulées, par les deux approches, montrent une bonne cohérence par rapport aux observations.
Ce point est important car les deux méthodes ne se calent à aucun moment sur les cotes maximales
annuelles observées. Cela montre que l’ensemble de la chaine de modélisation est représentative la
réalité : la simulation des pluies, leur transformation en débits et la modélisation hydraulique du
comportement de l’ouvrage. La comparaison avec l’approche classique (hydrogramme de référence
et hypothèse sur la cote initiale) montre l’intérêt de l’approche par simulation qui fournit des
scénarios diversifiés et évite que les valeurs « dimensionnantes » ne dépendent trop d’hypothèses
lourdes [Arnaud et al., 2015]. Les résultats présentés dans ces études sont évidemment très liés au
contexte hydrologique du bassin, aux types d’organes hydrauliques testés et aux caractéristiques de
l’aménagement étudié, et ne sauraient être généralisés.
Ces approches permettent aussi l’étude de la défaillance possible des ouvrages [Arnaud and
Aubert, 2014]. Des modifications dans les lois hydrauliques des ouvrages peuvent être introduites
pour modéliser cette défaillance. Cette défaillance peut alors être considérée comme aléatoire ou
conditionnelle (par exemple, plus les crues sont importantes plus le risque d’embâcles est probable
et la défaillance possible). La Figure 31 montre par exemple, la distribution de fréquence des cotes
atteintes sur une retenue d’eau fictive, soumise à l’aléa hydrologique caractéristique de son bassin
amont. Cette distribution est variable suivant les hypothèses faites sur la cote initiale de la retenue
avant l’arrivée de la crue (cette cote étant tributaire soit des épisodes précédents, soit des règles de
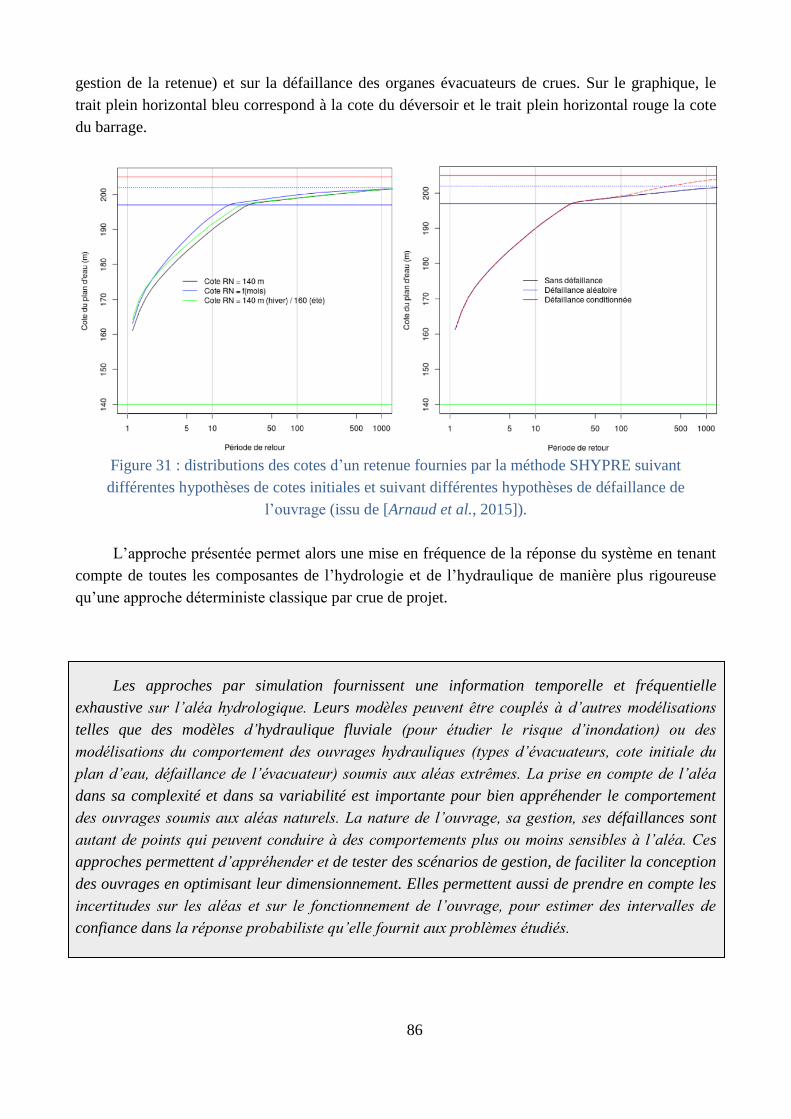
86
gestion de la retenue) et sur la défaillance des organes évacuateurs de crues. Sur le graphique, le
trait plein horizontal bleu correspond à la cote du déversoir et le trait plein horizontal rouge la cote
du barrage.
Figure 31 : distributions des cotes d’un retenue fournies par la méthode SHYPRE suivant
différentes hypothèses de cotes initiales et suivant différentes hypothèses de défaillance de
l’ouvrage (issu de [Arnaud et al., 2015]).
L’approche présentée permet alors une mise en fréquence de la réponse du système en tenant
compte de toutes les composantes de l’hydrologie et de l’hydraulique de manière plus rigoureuse
qu’une approche déterministe classique par crue de projet.
Les approches par simulation fournissent une information temporelle et fréquentielle
exhaustive sur l’aléa hydrologique. Leurs modèles peuvent être couplés à d’autres modélisations
telles que des modèles d’hydraulique fluviale (pour étudier le risque d’inondation) ou des
modélisations du comportement des ouvrages hydrauliques (types d’évacuateurs, cote initiale du
plan d’eau, défaillance de l’évacuateur) soumis aux aléas extrêmes. La prise en compte de l’aléa
dans sa complexité et dans sa variabilité est importante pour bien appréhender le comportement
des ouvrages soumis aux aléas naturels. La nature de l’ouvrage, sa gestion, ses défaillances sont
autant de points qui peuvent conduire à des comportements plus ou moins sensibles à l’aléa. Ces
approches permettent d’appréhender et de tester des scénarios de gestion, de faciliter la conception
des ouvrages en optimisant leur dimensionnement. Elles permettent aussi de prendre en compte les
incertitudes sur les aléas et sur le fonctionnement de l’ouvrage, pour estimer des intervalles de
confiance dans la réponse probabiliste qu’elle fournit aux problèmes étudiés.

87
C.4 Etude des incertitudes de la méthode par simulation
L’étude des incertitudes est relativement complexe dans les approches couplant plusieurs
étapes de modélisation et multipliant ainsi les facteurs d’incertitudes. Dans l’approche par
simulation présentée jusque là, une première étape a été réalisée par l’étude des incertitudes du
générateur de pluie. Cette étude (cf. § B.3) a été réalisée lors de la thèse de Aurélie Muller [Muller,
2006; Muller et al., 2009] sur quelques stations pluviométriques, et récemment complétée sur
l’ensemble des postes du territoire métropolitain français. Il est montré que pour les pluies, la
méthode SHYREG produit des intervalles de confiances plus étroits que ceux produits par
l’ajustement d’une loi à trois paramètres (loi GEV). Concernant les incertitudes liées à la seconde
étape, la modélisation pluie-débit, on peut s’appuyer sur des travaux menés sur l’estimation des
incertitudes liées au paramétrage des modèles hydrologiques, dans un contexte de simple simulation
[Bourgin, 2014; Coron, 2013]. Bien que réalisés en simple simulation, la méthodologie peut être
transposée au contexte de la prédétermination des crues.
Cette partie présente un travail sur l’estimation des incertitudes des quantiles fournis par la
méthode SHYREG, incertitudes dues à la modélisation hydrologique. Ce travail reste exploratoire
et ne traite que les incertitudes liées au calage du modèle hydrologique sur les données de bassins
versants jaugés, tout en prenant en compte la propagation des incertitudes liées à la pluie.
C.4.1 Procédure pour estimer les incertitudes dues au calage de l’approche
Le travail présenté ici vise à estimer les incertitudes de la méthode calée avec des
observations. Ces observations sont des chroniques de pluies (horaires ou journalières) pour caler le
jeu de paramètres du générateur de pluies ( ) et une chronique de débits (ou par défaut les valeurs
maximales annuelles permettant l’estimation de quantiles courants de crues) pour caler le paramètre
hydrologique . Cela représente un jeu de huit paramètres (trois pour la pluie et un pour le
pluie-débit, pour les deux saisons), les autres paramètres de la méthode étant constants quel que soit
le bassin versant étudié23
. La prise en compte de l’incertitude liée à la détermination des paramètres
et est réalisée de façon très différente pour les deux modélisations mises en jeu.
Pour le générateur de pluies :
On procède comme cela a été présenté dans le paragraphe B.3.5. Le jeu de paramètre ( ) est
obtenu par le calcul de six valeurs moyennes (3 variables x 2 saisons) dont les distributions
d’échantillonnage suivent une loi normale de moyenne égale à la moyenne de la variable ( ) et
d’écart-type égal à l’écart-type de la variable ( ) réduit par la racine carrée de l’effectif de la
variable ( ).
23
Notons cependant que leur détermination reste aussi soumise à une incertitude de second ordre, qu’il faudra
prendre en compte ultérieurement dans l’approche régionale.

88
Pour le modèle hydrologique :
Le paramètre est calé de façon à respecter les quantiles de crues courants (périodes de
retour 2, 5 et 10 ans) des débits de pointe et des débits moyens journaliers estimés par l’ajustement
une loi de probabilité24
. La distribution de fréquence de ce paramètre n’a pas connue à priori. Pour
estimer la variabilité de ce paramètre, son calage va être réalisé en faisant varier de façon aléatoire
l’échantillon des observations en utilisant des procédures de Bootstrap. Dans ce cas, les années
d’observations sont supposées indépendantes et les variables que l’on en extrait (les valeurs
maximales par exemple) sont identiquement distribuées (iid). Des échantillons sont alors générés
par un tirage aléatoire avec remise des années d’observation (ou maximums annuels). La procédure
d’évaluation est donc la suivante :
Pour un bassin versant disposant de N années
d’observations, un échantillon de N années issues d’un
tirage aléatoire avec remise des années est généré.
Les valeurs maximales de cet échantillon servent à caler la
loi GEVB pour déterminer les quantiles de périodes de
retour 2, 5 et 10 ans, qui serviront au calage de , mais
aussi l’ensemble de la distribution des débits pour estimer
l’intervalle de confiance associé à la loi GEVB. La loi de
Gumbel sera aussi calée pour comparaison.
La valeur de est alors calée pour fournir la
distribution de fréquences des débits estimée par la
méthode SHYREG.
Les points précédents sont répétés NB fois (NB étant le
nombre d’échantillonnage Bootstrap).
A partir des NB distributions obtenues, les intervalles de confiance 90% et de la distribution
médiane sont calculés.
Ces deux procédures permettent donc de déterminer les incertitudes associées au calcul des
paramètres de la méthode. Ces incertitudes sur les paramètres sont alors directement traduites en
incertitudes sur les quantiles de pluies et de crues fournis par la méthode SHYREG.
Tests effectués :
Les sources d’incertitudes étudiées sont celles du paramétrage du générateur de pluie et de la
modélisation hydrologique. Différents tests ont été effectués pour étudier le poids de chaque source
d’incertitude sur les incertitudes des résultats du modèle, de façon indépendante ou combinée. Ces
cas sont :
24
La loi de probabilité choisie est une loi GEV dont le paramètre de forme est optimisé tout en étant contraint à
être compris entre 0 et 0,4 : cette loi est notée GEVB (pour GEV Bornée) et présente de bons résultats selon les critères
calculés dans le projet ARN Extraflo (C.3.1).

89
Cas 1. : Incertitudes liées au paramétrage du générateur de pluie. Ce cas permet d’évaluer
l’incertitude liée à l’information de pluie en fournissant des distributions de pluies accompagnées
d’un intervalle de confiance (IC) (voir § B.3.5). Il permet ici d’évaluer la propagation de cette
incertitude sur les distributions de débits de la méthode, sans modifier la paramétrisation du modèle
hydrologique.
Cas 2. : Incertitudes liées à l’échantillonnage des débits. Ce cas permet d’évaluer uniquement
l’incertitude liée à l’observation des débits, en considérant toujours la même source d’information
sur les pluies. Ce cas conduit a des intervalles de confiance uniquement sur la distribution des
débits.
Cas 3. : Incertitudes liées aux pluies et aux débits pris indépendamment. Dans ce cas, les
incertitudes sur les paramètres du générateur de pluie et les incertitudes sur la paramétrisation du
modèle hydrologique sont considérées comme indépendantes. Un échantillon de pluies ( ) est
généré à partir d’un jeu de paramètres ( ), puis il est transformé en débit par un paramètre
qui a été déterminé à partir des débits ré-échantillonnés mais en considérant les pluies non ré-
échantillonnées (paramètres initiaux de calage). Dans ce cas, il y a bien une indépendance entre les
incertitudes prises en compte aux niveaux des deux modélisations.

90
Cas 4. : Incertitudes liées aux pluies et aux débits en prenant en compte leur dépendance dans
les observations25
. Contrairement au cas 3, le paramètre est déterminé en prenant en
compte la nouvelle paramétrisation des pluies. Ce cas part du principe qu’il y a une dépendance
entre la pluie (et son ré-échantillonnage) et le calage de la relation pluie-débit. En effet, l’incertitude
sur la pluie peut être compensée par le paramètre de la relation pluie-débit lors de son calage.
C.4.2 Application et résultats
Le travail a été réalisé sur les données des bassins
versants jaugés répertoriés dans la base de données HYDRO
(http://www.hydro.eaufrance.fr/ ). Ces données correspondent à
1162 bassins versants localisés sur la carte ci-contre. Leur
surface est comprise entre 1 et 2000 km², avec une médiane à
180 km². Ces stations de mesure ont été critiquées lors de
l’étude de régionalisation de la méthode SHYREG [Yoann
Aubert et al., 2014; Organde et al., 2013]. Ces stations
présentent une information hydrométrique de plus de 20 ans
(avec une médiane à 40 ans).
Les données de pluie utilisées sont les données SAFRAN qui nous ont permis d’estimer un
écart-type pour les différents paramètres du générateur de pluie ainsi que l’effectif des échantillons
sur lesquels ont été calculés les paramètres (exemple sur la Figure 32). La valeur moyenne des
paramètres de pluie est par contre la même que celle qui a servi à calculer la base de données
SHYREG-Pluie [Arnaud and Lavabre, 2010]. Pour simuler les pluies associées aux bassins
versants, les valeurs des paramètres utilisés sont les valeurs déterminées aux centroïdes des bassins
versants. Cette approximation a été faite pour des raisons de temps de calculs, et influence peu les
résultats par rapport à une utilisation de l’ensemble des pixels du bassin versant.
25
Lors du calage d’un modèle hydrologique (relation pluie-débit), on ne dissocie généralement pas les années
d’observation des pluies et les années d’observation des débits. En effet, des années de faible pluviométrie vont
généralement être associées à des années de faibles écoulements, et inversement. La relation pluie-débit devrait alors
être indépendante de cette variabilité temporelle.
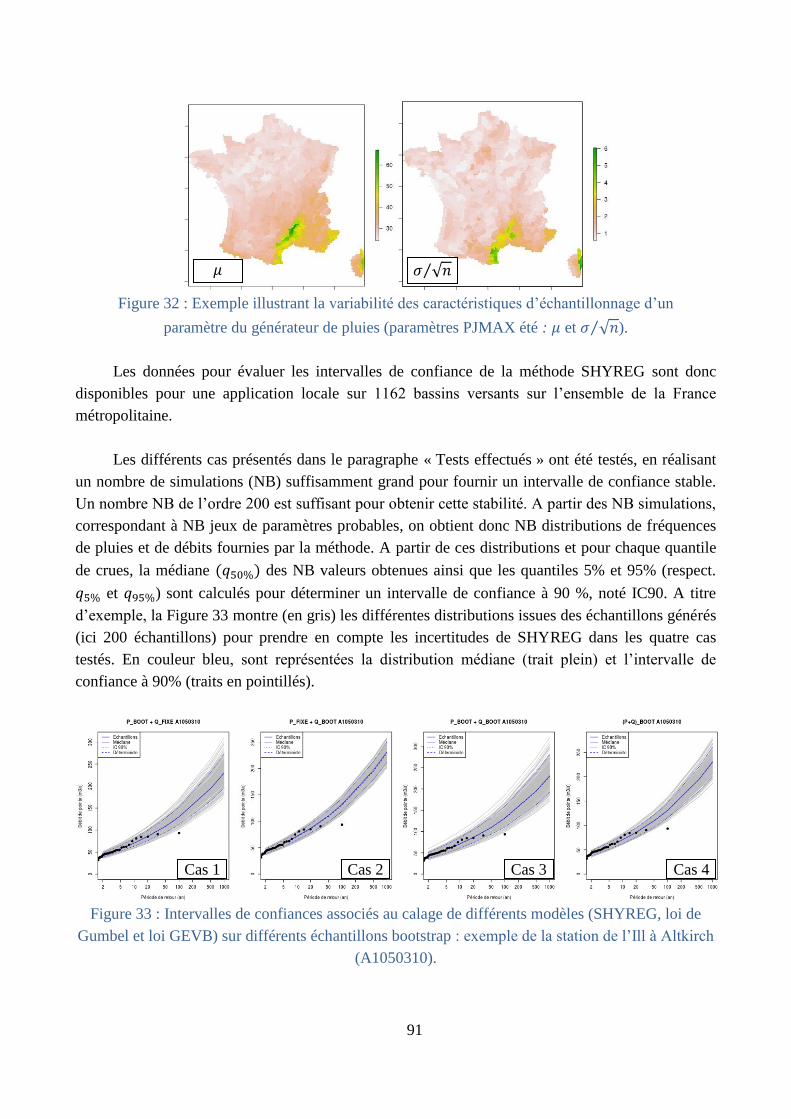
91
Figure 32 : Exemple illustrant la variabilité des caractéristiques d’échantillonnage d’un
paramètre du générateur de pluies (paramètres PJMAX été : et ).
Les données pour évaluer les intervalles de confiance de la méthode SHYREG sont donc
disponibles pour une application locale sur 1162 bassins versants sur l’ensemble de la France
métropolitaine.
Les différents cas présentés dans le paragraphe « Tests effectués » ont été testés, en réalisant
un nombre de simulations (NB) suffisamment grand pour fournir un intervalle de confiance stable.
Un nombre NB de l’ordre 200 est suffisant pour obtenir cette stabilité. A partir des NB simulations,
correspondant à NB jeux de paramètres probables, on obtient donc NB distributions de fréquences
de pluies et de débits fournies par la méthode. A partir de ces distributions et pour chaque quantile
de crues, la médiane des NB valeurs obtenues ainsi que les quantiles 5% et 95% (respect.
et ) sont calculés pour déterminer un intervalle de confiance à 90 %, noté IC90. A titre
d’exemple, la Figure 33 montre (en gris) les différentes distributions issues des échantillons générés
(ici 200 échantillons) pour prendre en compte les incertitudes de SHYREG dans les quatre cas
testés. En couleur bleu, sont représentées la distribution médiane (trait plein) et l’intervalle de
confiance à 90% (traits en pointillés).
Figure 33 : Intervalles de confiances associés au calage de différents modèles (SHYREG, loi de
Gumbel et loi GEVB) sur différents échantillons bootstrap : exemple de la station de l’Ill à Altkirch
(A1050310).
Cas 1 Cas 2 Cas 3 Cas 4
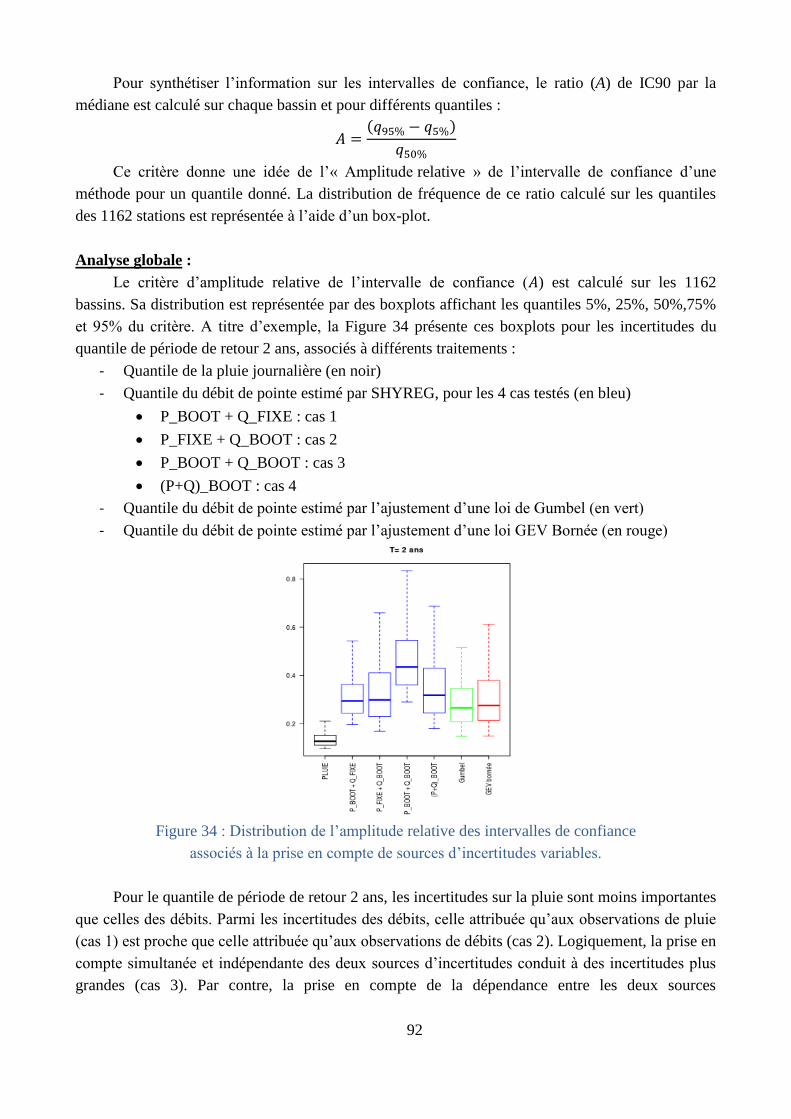
92
Pour synthétiser l’information sur les intervalles de confiance, le ratio (A) de IC90 par la
médiane est calculé sur chaque bassin et pour différents quantiles :
Ce critère donne une idée de l’« Amplitude relative » de l’intervalle de confiance d’une
méthode pour un quantile donné. La distribution de fréquence de ce ratio calculé sur les quantiles
des 1162 stations est représentée à l’aide d’un box-plot.
Analyse globale :
Le critère d’amplitude relative de l’intervalle de confiance ( ) est calculé sur les 1162
bassins. Sa distribution est représentée par des boxplots affichant les quantiles 5%, 25%, 50%,75%
et 95% du critère. A titre d’exemple, la Figure 34 présente ces boxplots pour les incertitudes du
quantile de période de retour 2 ans, associés à différents traitements :
- Quantile de la pluie journalière (en noir)
- Quantile du débit de pointe estimé par SHYREG, pour les 4 cas testés (en bleu)
P_BOOT + Q_FIXE : cas 1
P_FIXE + Q_BOOT : cas 2
P_BOOT + Q_BOOT : cas 3
(P+Q)_BOOT : cas 4
- Quantile du débit de pointe estimé par l’ajustement d’une loi de Gumbel (en vert)
- Quantile du débit de pointe estimé par l’ajustement d’une loi GEV Bornée (en rouge)
Figure 34 : Distribution de l’amplitude relative des intervalles de confiance
associés à la prise en compte de sources d’incertitudes variables.
Pour le quantile de période de retour 2 ans, les incertitudes sur la pluie sont moins importantes
que celles des débits. Parmi les incertitudes des débits, celle attribuée qu’aux observations de pluie
(cas 1) est proche que celle attribuée qu’aux observations de débits (cas 2). Logiquement, la prise en
compte simultanée et indépendante des deux sources d’incertitudes conduit à des incertitudes plus
grandes (cas 3). Par contre, la prise en compte de la dépendance entre les deux sources
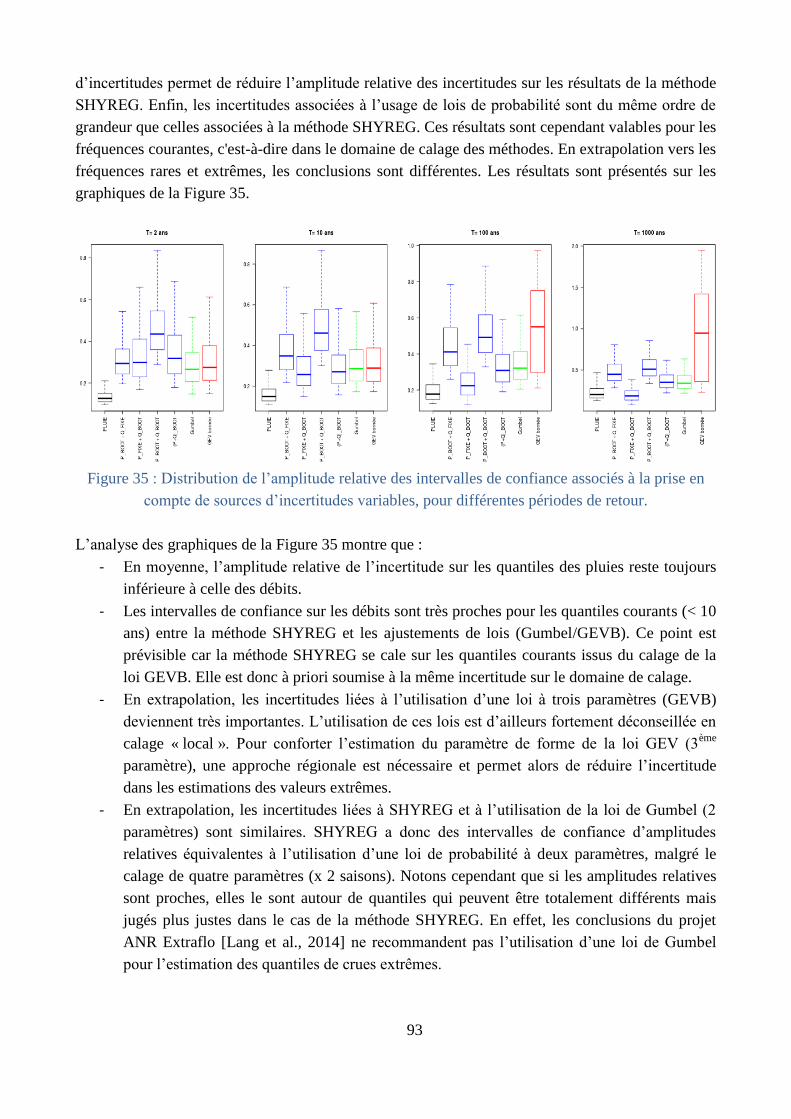
93
d’incertitudes permet de réduire l’amplitude relative des incertitudes sur les résultats de la méthode
SHYREG. Enfin, les incertitudes associées à l’usage de lois de probabilité sont du même ordre de
grandeur que celles associées à la méthode SHYREG. Ces résultats sont cependant valables pour les
fréquences courantes, c'est-à-dire dans le domaine de calage des méthodes. En extrapolation vers les
fréquences rares et extrêmes, les conclusions sont différentes. Les résultats sont présentés sur les
graphiques de la Figure 35.
Figure 35 : Distribution de l’amplitude relative des intervalles de confiance associés à la prise en
compte de sources d’incertitudes variables, pour différentes périodes de retour.
L’analyse des graphiques de la Figure 35 montre que :
- En moyenne, l’amplitude relative de l’incertitude sur les quantiles des pluies reste toujours
inférieure à celle des débits.
- Les intervalles de confiance sur les débits sont très proches pour les quantiles courants (< 10
ans) entre la méthode SHYREG et les ajustements de lois (Gumbel/GEVB). Ce point est
prévisible car la méthode SHYREG se cale sur les quantiles courants issus du calage de la
loi GEVB. Elle est donc à priori soumise à la même incertitude sur le domaine de calage.
- En extrapolation, les incertitudes liées à l’utilisation d’une loi à trois paramètres (GEVB)
deviennent très importantes. L’utilisation de ces lois est d’ailleurs fortement déconseillée en
calage « local ». Pour conforter l’estimation du paramètre de forme de la loi GEV (3ème
paramètre), une approche régionale est nécessaire et permet alors de réduire l’incertitude
dans les estimations des valeurs extrêmes.
- En extrapolation, les incertitudes liées à SHYREG et à l’utilisation de la loi de Gumbel (2
paramètres) sont similaires. SHYREG a donc des intervalles de confiance d’amplitudes
relatives équivalentes à l’utilisation d’une loi de probabilité à deux paramètres, malgré le
calage de quatre paramètres (x 2 saisons). Notons cependant que si les amplitudes relatives
sont proches, elles le sont autour de quantiles qui peuvent être totalement différents mais
jugés plus justes dans le cas de la méthode SHYREG. En effet, les conclusions du projet
ANR Extraflo [Lang et al., 2014] ne recommandent pas l’utilisation d’une loi de Gumbel
pour l’estimation des quantiles de crues extrêmes.
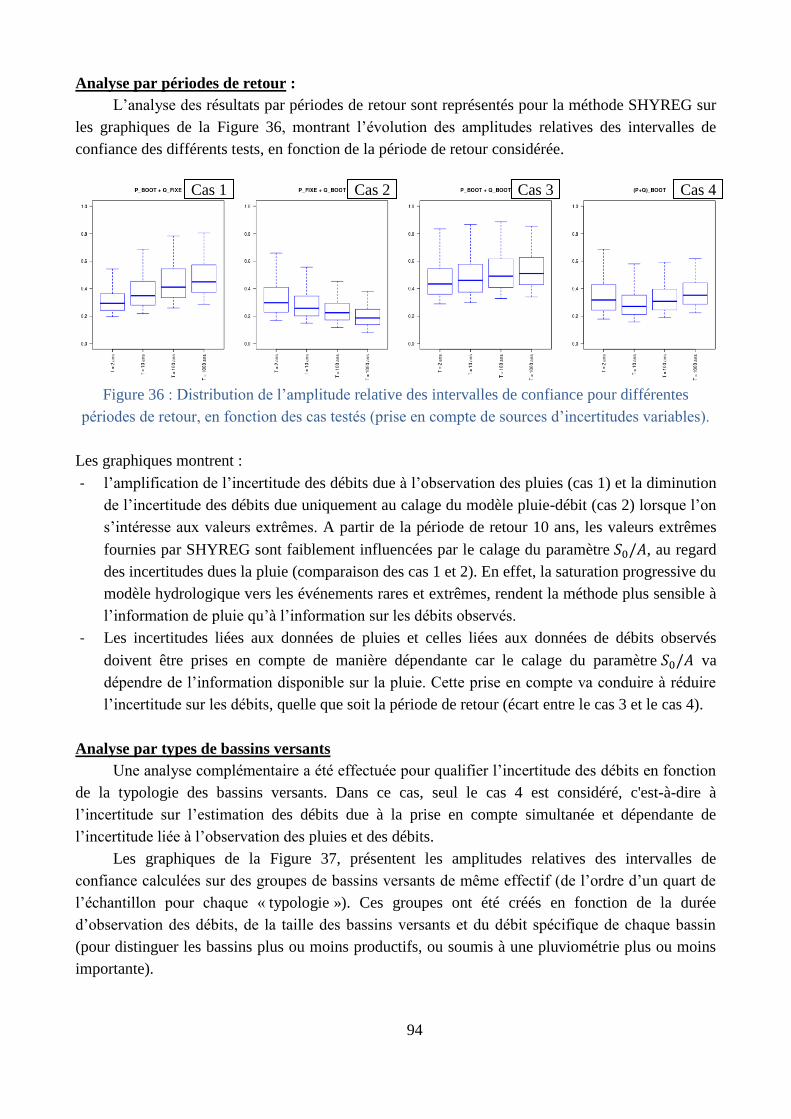
94
Analyse par périodes de retour :
L’analyse des résultats par périodes de retour sont représentés pour la méthode SHYREG sur
les graphiques de la Figure 36, montrant l’évolution des amplitudes relatives des intervalles de
confiance des différents tests, en fonction de la période de retour considérée.
Figure 36 : Distribution de l’amplitude relative des intervalles de confiance pour différentes
périodes de retour, en fonction des cas testés (prise en compte de sources d’incertitudes variables).
Les graphiques montrent :
- l’amplification de l’incertitude des débits due à l’observation des pluies (cas 1) et la diminution
de l’incertitude des débits due uniquement au calage du modèle pluie-débit (cas 2) lorsque l’on
s’intéresse aux valeurs extrêmes. A partir de la période de retour 10 ans, les valeurs extrêmes
fournies par SHYREG sont faiblement influencées par le calage du paramètre , au regard
des incertitudes dues la pluie (comparaison des cas 1 et 2). En effet, la saturation progressive du
modèle hydrologique vers les événements rares et extrêmes, rendent la méthode plus sensible à
l’information de pluie qu’à l’information sur les débits observés.
- Les incertitudes liées aux données de pluies et celles liées aux données de débits observés
doivent être prises en compte de manière dépendante car le calage du paramètre va
dépendre de l’information disponible sur la pluie. Cette prise en compte va conduire à réduire
l’incertitude sur les débits, quelle que soit la période de retour (écart entre le cas 3 et le cas 4).
Analyse par types de bassins versants
Une analyse complémentaire a été effectuée pour qualifier l’incertitude des débits en fonction
de la typologie des bassins versants. Dans ce cas, seul le cas 4 est considéré, c'est-à-dire à
l’incertitude sur l’estimation des débits due à la prise en compte simultanée et dépendante de
l’incertitude liée à l’observation des pluies et des débits.
Les graphiques de la Figure 37, présentent les amplitudes relatives des intervalles de
confiance calculées sur des groupes de bassins versants de même effectif (de l’ordre d’un quart de
l’échantillon pour chaque « typologie »). Ces groupes ont été créés en fonction de la durée
d’observation des débits, de la taille des bassins versants et du débit spécifique de chaque bassin
(pour distinguer les bassins plus ou moins productifs, ou soumis à une pluviométrie plus ou moins
importante).
Cas 1 Cas 2 Cas 3 Cas 4
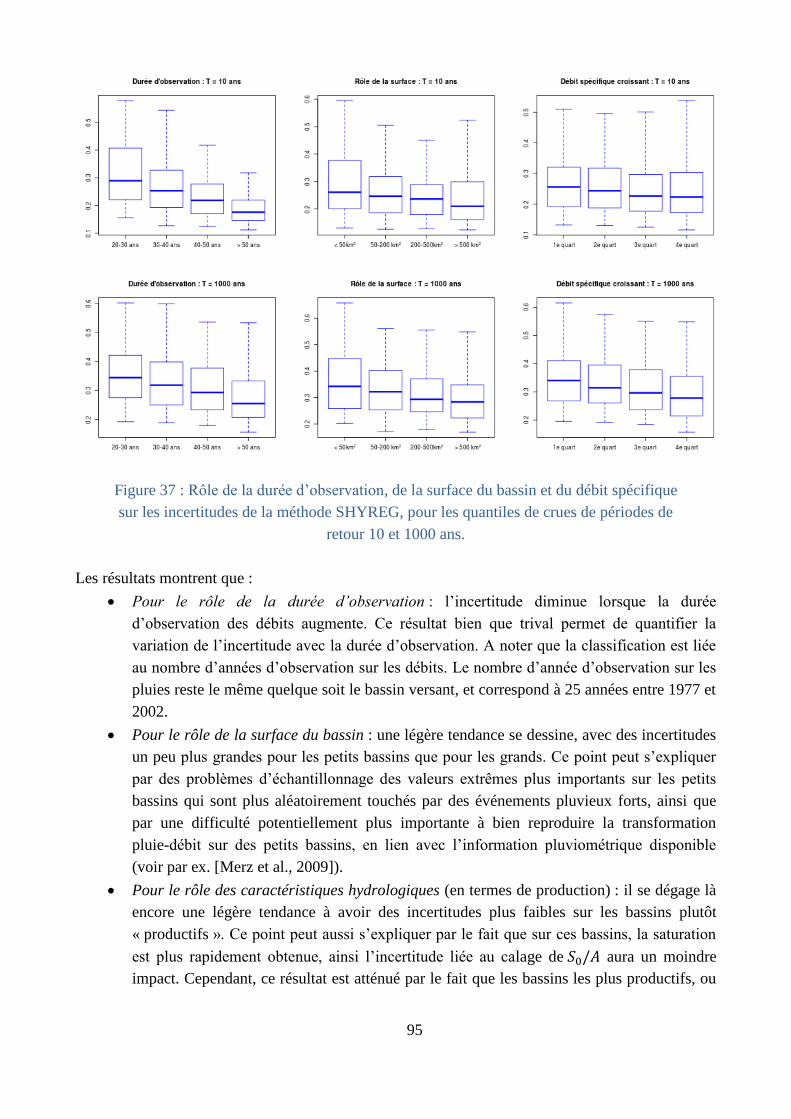
95
Figure 37 : Rôle de la durée d’observation, de la surface du bassin et du débit spécifique
sur les incertitudes de la méthode SHYREG, pour les quantiles de crues de périodes de
retour 10 et 1000 ans.
Les résultats montrent que :
Pour le rôle de la durée d’observation : l’incertitude diminue lorsque la durée
d’observation des débits augmente. Ce résultat bien que trival permet de quantifier la
variation de l’incertitude avec la durée d’observation. A noter que la classification est liée
au nombre d’années d’observation sur les débits. Le nombre d’année d’observation sur les
pluies reste le même quelque soit le bassin versant, et correspond à 25 années entre 1977 et
2002.
Pour le rôle de la surface du bassin : une légère tendance se dessine, avec des incertitudes
un peu plus grandes pour les petits bassins que pour les grands. Ce point peut s’expliquer
par des problèmes d’échantillonnage des valeurs extrêmes plus importants sur les petits
bassins qui sont plus aléatoirement touchés par des événements pluvieux forts, ainsi que
par une difficulté potentiellement plus importante à bien reproduire la transformation
pluie-débit sur des petits bassins, en lien avec l’information pluviométrique disponible
(voir par ex. [Merz et al., 2009]).
Pour le rôle des caractéristiques hydrologiques (en termes de production) : il se dégage là
encore une légère tendance à avoir des incertitudes plus faibles sur les bassins plutôt
« productifs ». Ce point peut aussi s’expliquer par le fait que sur ces bassins, la saturation
est plus rapidement obtenue, ainsi l’incertitude liée au calage de aura un moindre
impact. Cependant, ce résultat est atténué par le fait que les bassins les plus productifs, ou

96
du moins associés aux plus grands débits spécifiques sont aussi associés aux pluviométries
les plus intenses (régions méditerranéennes) qui présentent les plus fortes incertitudes sur
la pluie (voir la carte de écart-types de la Figure 32).
Enfin, les graphiques de la Figure 38 présentent la répartition spatiale de ces amplitudes
relatives des incertitudes des quantiles SHYREG. Les pluies présentent des incertitudes plus fortes
sur la région méditerranéenne, alors que les débits présentent des incertitudes d’ampleurs plus
aléatoires sur l’ensemble du territoire.
Figure 38 : Localisation de l’amplitude relative des incertitudes sur les quantiles de pluie
SHYREG et sur les quantiles de débits SHYREG, pour la période de retour 100 ans.
Le travail présenté sur les incertitudes est un travail prospectif pour appréhender les
intervalles de confiance liés à la méthode SHYREG. Effectué dans un premier temps sur la mise en
œuvre locale de la méthode (calée sur des données), il prend en compte les deux principales
composantes à l’origine des incertitudes : l’échantillonnage des pluies et l’échantillonnage des
débits observés servant aux calages des paramètres de la méthode.
Les incertitudes sur les quantiles de pluies sont plus faibles que les incertitudes sur les
quantiles de crues. Cependant, malgré une paramétrisation basée sur 4 paramètres par saison,
l’amplitude des incertitudes sur les quantiles de crues fournis par la méthode SHYREG sont de
l’ordre de grandeur de ceux associés à l’utilisation d’une loi statistique à deux paramètres (loi de
Gumbel) et sont nettement inférieurs à ceux associés à l’utilisation d’une loi à trois paramètres calée
localement (loi GEV).
Les intervalles de confiance de la méthode SHYREG sont donc relativement faibles au regard
de la complexité de la méthode qui pouvait laisser présager de fortes incertitudes dues à la
paramétrisation de deux modélisations couplées. La prise en compte de la dépendance dans le
calage de ces deux modèles est nécessaire pour ne pas surévaluer les incertitudes.
Des analyses supplémentaires de la méthode régionalisée sont prévues pour estimer les
incertitudes associées à l’estimation des paramètres fixés régionalement et associées à la méthode
de régionalisation choisie.

97
D – CONCLUSIONS ET PERSEPCTIVES
SCIENTIFIQUES
Les développements présentés dans les paragraphes précédents montrent l’intérêt des
approches par simulation pour l’estimation de l’aléa hydrologique, et plus particulièrement les
avancées et les performances liées la méthode SHYPRE/SHYREG développée par Irstea depuis
quelques années. Les recherches associées à cette approche ont permis de répondre aux besoins de
connaissances sur l’aléa hydrologique, les plus justes, fiables et exhaustives possibles en terme
d’information temporelle et fréquentielle, et disponibles en tout point d’un territoire.
Des avancées notables ont été réalisées dans le domaine de la génération stochastique des
pluies à pas de temps fins : modélisation de régimes pluviométriques très contrastés, prise en
compte des dépendances statistiques entre certaines variables, contrôle du comportement
asymptotique, études des incertitudes, … La recherche d’une modélisation hydrologique
parcimonieuse et qui prenne en compte la non-linéarité des processus impliqués dans la relation
pluie-débit a été un autre objectif important. Enfin, la régionalisation de ces modèles est essentielle
pour appliquer les méthodes au contexte du non jaugé. Pour effectuer ces recherches, des jeux de
données exhaustifs ont été utilisés, garantissant que la méthode développée pouvait être largement
utilisées dans des contextes très variables.
Les performances de l’approche par simulation développée, ont été reconnues suite à une
étude comparative d’envergure entre différentes méthodes de prédétermination des pluies et des
crues extrêmes développées par différents laboratoires de recherches en France et souvent étudiées
par l’ensemble de la communauté scientifique travaillant sur l’estimation fréquentielle de l’aléa.
Suite à ces travaux, la méthode est actuellement recommandée pour les atouts qu’elle présente dans
l’estimation de l’aléa hydrologique, et commence à faire référence pour de nombreuses applications
telles que l’élaboration de PPRi, le dimensionnement d’ouvrages hydrauliques, l’estimation de
l’occurrence des événements,…
La nature de l’approche, qui vise à reproduire au mieux les phénomènes observés, son large
spectre d’application et sa paramétrisation robuste et parcimonieuse sont autant d’atouts pour
envisager son utilisation pour l’estimation de l’aléa hydrologique en contexte de changement
global. En effet dans l’approche développée, les phénomènes extrêmes sont modélisés par des
paramètres moyens, plus facilement maitrisables, et les processus conduisant aux crues extrêmes
sont étudiés séparément.
Il n’en demeure pas moins que des améliorations sont attendues et que des perspectives de
recherches supplémentaires sont déjà en projet pour améliorer la méthode et élargir son champ
d’application. Ces perspectives concernent trois champs de recherches présentés ci-après:
- La modélisation des processus, en lien direct avec l’amélioration de la méthode.
- L’étude de l’impact du changement global sur la prédétermination de l’aléa hydrologique.
- La prise en compte de scénarios dans la modélisation de processus sensibles aux crues.

98
D.1 Modélisation des processus
Les travaux de recherches concernant la modélisation des processus visent à élargir le
domaine d’application de la méthode développée. Les résultats sur les performances de la méthode
appliquée de façon semi-automatique sur les données du territoire national [Patrick Arnaud et al.,
2014a] et les limites liées aux hypothèses simplificatrices émises pour cette mise en œuvre [Arnaud
et al., 2013; Patrick Arnaud et al., 2014b] donnent des pistes d’améliorations possibles.
Certaines d’entre elles concernent la modélisation des processus de pluies, d’autres
concernent la modélisation des processus hydrologique. Enfin d’autres pistes d’améliorations plus
transversales concernent les deux composantes de la méthode à travers la recherche de méthodes de
régionalisation plus pertinentes et la détermination complète des incertitudes associées directement
à la méthode ainsi qu’à sa régionalisation.
Perspectives concernant le générateur de pluies :
- Typologie des perturbations : Une analyse des configurations météorologiques qui
génèrent les événements pluvieux (types de perturbations, périodes liées à l’ENSO,…)
peut être plus pertinence qu’une analyse par saison pour différencier des
échantillons. Cette question a commencé à être étudiée et semble apporter des
améliorations en régime tropical [Y. Aubert et al., 2014]. Le calage par type de temps a
d’ailleurs été adopté dans le cadre de l’ajustement de la loi MEWP [Garavaglia et al.,
2011]. La pertinence de la typologie des événements simulés peut d’ailleurs être un atout
dans l’étude de l’impact du changement climatique, pour coupler le générateur avec des
projections climatiques plus « phénoménologiques ». En effet, l’évolution climatique peut
être induite par un changement du type de perturbations (plus d’orages, moins de
phénomènes frontaux, plus de cyclones dans certaines zones,…) plus que par une simple
variation de l’occurrence ou des intensités des événements actuels. Cette analyse par type
de perturbations plutôt que par saisons devrait aussi faciliter la transposition de la méthode
à d’autres régions/pays aux climats encore plus variés (climats plus secs par exemple).
- Descente d’échelle temporelle : le passage à des pas de temps infra-horaires a déjà fait
l’objet de pistes de recherches [cantet, 2014] à travers l’étude de modèles de
désagrégation de l’information horaire vers des pas de temps fins (jusqu’à 5 minutes).
Cette information sera précieuse pour l’étude des phénomènes de ruissellement en zones
urbaines ou sur les petits bassins versants montagnards pour lesquels les temps de réponse
sont très courts. La difficulté actuelle reste de respecter l’ensemble des caractéristiques de
la pluie à ces pas de temps (quantiles, auto-corrélation, intermittences,…). La disponibilité
des données à pas de temps fins reste aussi un obstacle à ces études, en particulier la
profondeur temporelle des observations. Pour entreprendre ce travail, Météo-France a mis
à notre disposition les pluies observées au pas de temps 6 minutes sur 1179 postes
pluviographiques de la France Métropolitaine, mais dont la durée d’observation débute en

99
2005, soit moins de 10 ans d’observation. Si cette information n’est pas assez « longue »
pour une étude statistique des valeurs extrêmes, elle est suffisante pour commencer à
étudier la structure des pluies infra-horaires et élaborer des modèles de désagrégation.
- Modélisation spatiale de la pluie : le générateur de pluie développé reste un générateur
ponctuel. Il permet d’appréhender correctement les valeurs de pluies extrêmes.
L’intégration de l’information spatiale peut se faire par le biais de coefficients
d’abattement. Ces coefficients ont été déterminés sur la France, suite à une analyse des
pluies SAFRAN26
et des réanalyses des radars météorologiques27
(Maire 2011). Ils
présentent une variabilité qui dépend de la zone étudiée, mais aussi de la durée de pluie
considérée et de sa période de retour. Une comparaison avec les résultats d’un générateur
de champs de pluie tel que celui développé par l’équipe d’Irstea-Lyon [Leblois and
Creutin, 2013] est envisagé. Un couplage des deux modélisations pourrait aussi consolider
le comportement asymptotique du générateur de champs pluvieux vers les valeurs
extrêmes, par celui validé par le générateur ponctuel.
• Perspectives concernant la modélisation hydrologique : l’application locale de la méthode a
montré des performances inégales suivant les zones géographiques étudiées. Ce point vient en
partie du fait que l’on ne s’autorise pas à multiplier les paramètres de calage, afin de faciliter
l’étape de régionalisation. En particulier certaines hypothèses sont relativement fortes comme
celle d’imposer pour certains paramètres une valeur unique et d’imposer une régionalisation
globale sur tout le territoire national. Une amélioration de la méthode dans des contextes
hydrologiques variés doit être abordée dans un premier temps par :
- Etude des paramètres constants de la méthode : un calage par grandes zones
hydrologiques (Hydro-Eco-Région par exemple [Wasson et al., 2002]) de certains
paramètres actuellement fixés sur l’ensemble du territoire français, doit permettre d’affiner
la méthode. L’intégration de connaissances nouvelles sur l’abattement spatial des pluies
peut être intéressante à introduire dans la paramétrisation à priori de la fonction
d’abattement spatial de la méthode. Une typologie sur les bassins versants devrait aussi
permettre d’imposer certains paramètres en fonction de certaines caractéristiques des
bassins (classe de pente, nature des sols ou de la végétation,…). Ce travail consistera donc
à effectuer une paramétrisation régionale à priori, fixée par grandes zones ou par grands
types de bassins versants, avant d’effectuer le calage local de la méthode.
26
SAFRAN/France est un système d’analyse à méso échelle de variables atmosphériques près de la surface. Il
utilise des observations de surface, combinées à des données d’analyse de modèles météorologiques pour produire des
paramètres horaires (température, humidité, vent, précipitations solides et liquides, rayonnement solaire et infrarouge
incident), qui sont analysés par pas de 300m d’altitude. Ils sont ensuite interpolés sur une grille de calcul régulière (8 x
8 km) (Sources Météo-France : http://www.cnrm.meteo.fr/ ) 27
Réanalyse Radar : les données COMEPHORE (COmbinaison en vue de la Meilleure Estimation de la
Précipitation HOraiRE) combinent l’information du réseau de pluviographes et l’information des radars
météorologiques pour fournir une lame d’eau au pas de temps horaire sur une grille de un km² sur la France sur la
période de 1997 à 2006.

100
- Modélisation des bassins versants particuliers : certains bassins versants sont plus
difficiles à modéliser, de part une relation pluie-débit marquée par des phénomènes plus
singuliers : c’est le cas des bassins versants karstiques, mais aussi de certains bassins où les
écoulements en période de crues ne sont pas essentiellement attribués au ruissellement (cas
des bassins avec de forts échanges avec les nappes ou ceux fortement impactés par la fonte
nivale). Ces phénomènes actuellement trop occultés en période de crue, doivent être mieux
appréhendés dans notre approche.
• Perspectives concernant la régionalisation :
- Régionalisation des paramètres du générateur de pluie : la régionalisation des paramètres
du générateur de pluie a été réalisée par une méthode qui pourrait être améliorée. De
premiers essais ont été réalisés pour améliorer la régionalisation d’un des paramètres du
générateur de pluies [Loudegui Djimdou, 2014]. Parmi les différentes techniques de
spatialisation (méthodes barycentriques, triangularisation, régression, krigeage simple,
ordinaire et universel,…) c’est la méthode par krigeage à dérives externes, choisies selon la
méthode proposée par Cantet [2012] qui présente les meilleures performances. La
poursuite de ces travaux est dont à réaliser pour l’ensemble des variables du générateur.
- Amélioration des techniques de régionalisation des paramètres hydrologiques : la
régionalisation de l’approche représente surement la plus grande marge de progression. Les
améliorations des performances locales devraient déjà se traduire aussi par des
améliorations au niveau de l’application régionale, surtout si l’effort a été fait de ne pas
introduire une paramétrisation supplémentaire. La dégradation en mode régional est liée à
la perte d’information locale lors de la régionalisation de la méthode. De nouvelles
techniques de régionalisation doivent permettre de nettement améliorer les performances
de l’approche régionale. La première consistera à traiter le problème des bassins versants
emboités qui crée actuellement un biais dans notre approche28
. Une approche permettant de
respecter les valeurs optimales des bassins de calage lors de la régionalisation, doit être
étudiée. Des développements ont déjà étaient initiés en ce sens mais doivent être finalisés.
De plus, la méthode de régionalisation mise en œuvre doit permettre la prise en compte des
dépendances amont-aval qui existent dans la paramétrisation des modèles hydrologiques.
Des techniques géostatistiques comme le topkriging [Sauquet et al., 2000; Skoien et al.,
2006] seront testées et comparées à des méthodes plus simples, comme des méthodes par
voisinage qui donnent actuellement de meilleurs résultats que les méthodes géostatistiques
telles que le krigeage pour la régionalisation des paramètres du modèle hydrologique.
28
Le problème provient du fait que le calage de la méthode nécessite l’hypothèse d’uniformité du paramètre
hydrologique sur l’ensemble du bassin. Dans le cas de bassins emboités, un pixel peut alors être associé à plusieurs
valeurs de paramètre optimal. Le choix a été fait d’en calculer une valeur « moyenne » qui est alors forcément différente
de la valeur optimale.

101
- Recherche de descripteurs pertinents pour la descente d’échelle spatiale : le passage à
des pas de temps plus fins que l’heure et la pertinence de l’information produite sur des
petits bassins non jaugés, nécessite de résoudre le problème de descente d’échelle spatiale.
L’objectif est de trouver les règles de passage d’une information généralement connue sur
des bassins versants plutôt grands, vers des bassins versants plus petits où l’observation
devient rare29
. Actuellement il est pratiquement impossible de contrôler la variabilité
spatiale des processus hydrologiques à l’échelle des petits bassins sur l’ensemble d’un
territoire, avec l’observation disponible (de l’ordre de 150 bassins versants jaugés de moins
de 10 km²). La descente d’échelle est alors réalisée par un paramétrage déduit de
corrélations avec des variables environnementales, ou par une hypothèse d’homogénéité
des paramètres sur le bassin. Cependant, l’observation du comportement de certains petits
bassins versants limitrophes (cas des bassins de recherche du Réal Collobrier ou de Draix)
présentant des caractéristiques environnementales et climatiques très proches, mais dont le
comportement hydrologique est extrêmement variable (quantiles de crues pouvant passer
de 1 à 10 sur deux bassins voisins de même taille), montre qu’il est difficile de trouver des
explications à la variabilité des écoulements à des échelles fines. Cette problématique est
un véritable défi pour espérer fournir une connaissance pertinente de l’aléa hydrologique
sur les petits bassins versants de moins de 10 km².
• Perspectives concernant l’estimation des incertitudes : pour les méthodes purement
statistiques, la détermination d’un intervalle de confiance est relativement aisée. Elle est basée
sur les développements mathématiques à partir des formulations des lois de probabilités
étudiées, que ce soit des lois locales ou régionales [Sveinsson et al., 2003]. Pour les méthodes
par simulation, la détermination d’un intervalle de confiance est moins immédiate. Elle passe
généralement par des approches bayesiennes [Cameron et al., 1999; Gaume et al., 2010]. La
poursuite des études déjà initiées sur la méthode SHYREG doit maintenant porter sur la prise
en compte des incertitudes liées à la détermination des paramètres régionaux, que ce soit pour
le générateur de pluies, comme dans la modélisation hydrologique.
L’ensemble de ces points de recherche vise à améliorer la méthode développée et à étendre
son domaine d’application, afin de réduire les limites d’application définies actuellement [Arnaud
et al., 2013]. Certaines de ces perspectives sont en cours de réalisation, en partie dans le cadre de la
thèse de Jean Odry débutée en décembre 2014, et en partie dans des travaux de recherches en
cours.
29
En France, les 2430 bassins versants instrumentés de taille inférieure à 1000 km² couvrent 54 % du territoire et
les 1025 bassins versants de moins de 100 km² couvrent 7% du territoire. Seulement 150 bassins versants instrumentés
ont une surface inférieure à 10km².

102
D.2 Impact du changement global sur les extrêmes hydrologiques
Les recherches sur le changement climatique et sur ces impacts, représentent une activité
forte en sciences de l’environnement. Cette problématique est largement étudiée par la
communauté scientifique locale (par exemples par le Centre Européen de Recherche et
d’Enseignement des Géosciences de l’Environnement, CEREGE, https://www.cerege.fr/ ou par le
Labex-OTMed http://www.otmed.fr/ ) ce qui nous pousse à poursuivre nos travaux de recherche
sur ce thème.
De part sa structure reposant sur la modélisation de la pluie et sur la modélisation de la
relation pluie-débit, la méthode par simulation (SHYPRE/SHYREG) permet d’appréhender de
façon originale l’impact du changement global (changement climatique et changement
d’occupation des sols) sur les crues extrêmes. Les travaux menés jusqu’ici ont montré que la
méthode par simulation des processus peut prendre en compte les tendances observées sur les
pluies [Cantet, 2009; Cantet et al., 2011] pour les traduire en évolution des valeurs extrêmes. Des
travaux menés en 2013 [Cantet, 2013] ont montré l’impact de l’évolution des pluies sur les
quantiles de crues. Un premier travail prospectif a été réalisé sur l’impact que peut avoir une
modification de la relation pluie-débit sur l’estimation des crues. Cependant, ces modifications (de
la pluie et de la relation pluie-débit) ont été étudiées de façon indépendante. La poursuite de ce
travail nécessite d’aborder les points suivants :
L’étude de l’interaction entre l’évolution climatique et les processus générateurs de
crues : les processus liés au cycle de l’eau sont nombreux mais certains peuvent être
négligés lors de la modélisation des crues. C’est le cas de l’évaporation par exemple ou de
certains écoulements lents. Si ces processus sont négligés lors de la crue, ils conditionnent
fortement l’état de saturation hydrique dans lequel se trouve un bassin versant au début d’un
épisode pluvieux. L’objectif affiché ici est de déterminer les phénomènes intervenant sur la
saturation des sols, qui elle, influence la relation pluie-débit lors des crues. Par exemple, une
saturation plus élevée des sols peut provenir soit d’une occurrence plus marquée des pluies,
soit d’une modification de la nature des précipitations (pluie/neige), soit d’une évolution du
phénomène l’évaporation,…
L’estimation du débit de base sur lequel s’ajoutent les ruissellements peut aussi avoir
son importance dans l’estimation des quantiles courants sur lesquels se base la calage de la
méthode. A ce titre, une modification des écoulements liés à la fonte de la neige peut
modifier l’estimation des débits de crues courants ou leur saisonnalité. Ces processus
doivent être étudiés et modélisés pour proposer une initialisation plus pertinente de la
méthode par simulation. Une modélisation en continue de l’approche est aussi envisagée, ou
bien son couplage à une modélisation continue journalière [Arnaud and Lavabre, 1997].

103
L’étude de l’évolution de l’occupation du sol : le changement climatique peut avoir des
conséquences fortes sur l’occupation du sol. A titre d’exemple, un climat plus sec pourrait
modifier la végétation voire augmenter la fréquence des incendies dans certaines régions, ce
qui modifierait la relation pluie-débit (modification de la demande hydrique, de
l’interception végétale, de la vitesse de propagation des ruissellements, de l’érosion des
sols,…).
Indépendamment du changement climatique, l’aménagement du territoire peut
introduire des modifications dans l’occupation des sols impactant les écoulements de
versants (imperméabilisation) et les écoulements de réseaux (endiguements,…). Ces
évolutions de l’occupation des sols doivent être étudiées et intégrées dans les approches
d’analyse fréquentielle des crues. L’approche par simulation, modélisant la relation pluie-
débit est alors adaptée pour répondre à cette problématique. Pour cela, il faut trouver les
relations pertinentes entre la paramétrisation des modèles hydrologiques et les modifications
de l’occupation des sols.
L’évaluation des incertitudes : les travaux sur les projections climatiques montrent certes
des tendances, mais avec de fortes incertitudes associées. C’est pourquoi les résultats seront
exprimés de façon relative, pour montrer la sensibilité de l’approche aux variations possibles
du climat, plus que pour proposer des projections sur l’évolution l’aléa hydrologique. Le
travail sur les incertitudes de l’approche est donc à approfondir et à coupler avec les
incertitudes liées aux projections climatiques.
L’évaluation des incertitudes sur les projections climatiques passe aussi par
l’utilisation de scénarios climatiques provenant de plusieurs modèles climatiques.
Actuellement les tests ont été effectués uniquement sur les sorties du modèle ARPEGE-
Climat, d’autres résultats de modèles étant disponibles.
D.3 Ouverture vers d’autres thématiques.
Une des particularités de l’approche de prédétermination des crues par simulation
développée, est de proposer des scénarios de pluies et de crues au pas de temps horaire, dont les
caractéristiques statistiques des valeurs courantes à extrêmes sont maitrisées. Ces scénarios, utilisés
pour en déduire des caractéristiques statistiques sur l’aléa hydrométéorologique (quantiles de pluies
et de débits), peuvent aussi être utilisés comme données d’entrée d’un modèle hydraulique pour
effectuer des statistiques sur la réponse du modèle plutôt que de soumettre le modèle à une crue de
projet théorique.
Sur ce principe, le couplage à de nombreuses modélisations est possible, avec des
applications multiples : modèles hydrauliques pour le dimensionnement d’ouvrages, pour la

104
cartographie de zones inondables, pour le test de scénarios d’aménagement,… des modèles
mécanistes de transport de matières solides pour évaluer le charriage, modéliser les laves
torrentielles, … des modèles de transfert de polluants…
Les applications sont nombreuses mais nécessitent l’aménagement de la méthode :
L’échantillonnage des événements simulés : la simulation de milliers de scénarios de crues
n’est peut être pas assimilable par toutes les modélisations pour lesquels un couplage est
envisagé. La recherche d’un échantillon de scénarios de crues « type », suffisamment
représentatif de l’ensemble des scénarios possibles est alors à rechercher pour limiter la
multiplication des calculs [Helms et al., 2012]. Ce travail sur l’échantillonnage a été abordé
dans le cas d’une étude pour le dimensionnement des évacuateurs de crues d’un barrage. La
forme d’un hydrogramme dit « équivalent » a été déterminée, dont les conséquences sur
l’ouvrage est proche de la conséquence moyenne de plusieurs hydrogrammes fournis par la
méthode de simulation. Ce genre de démarche simplificatrice peut avoir son utilisé pour le
couplage de la méthode avec d’autres modélisations plus complexes.
Passage à une modélisation en continue journalière : le positionnement des événements
pluvieux dans une chronique a déjà abordée par le couplage d’une approche continue
journalière avec la modélisation événementielle horaire [Arnaud, 1997; Arnaud and
Lavabre, 1995; 1997]. Ce positionnement présente l’intérêt de pouvoir attribuer une
saisonnalité aux événements pluvieux mais aussi aux conditions de saturation ou aux débits
de base à prendre en compte au moment où un événement pluvieux est modélisé. Cela
permet aussi de mieux prendre en compte l’impact du changement de régime hydrologique
que peut engendrer le changement climatique. Ce point déjà évoquer plus haut parait
important pour multiplier les applications et couplage possibles de la méthode.
Remarque : les approches par simulation permettent de confronter certaines modélisations à
des données d’entrée simulées (sur les pluies ou sur les débits) qui peuvent dépasser le champ des
valeurs observées sur lequel ces modèles sont généralement conçus (cas des valeurs extrêmes par
exemple). Une attention particulière doit être faite pour réaliser des modélisations prenant en
compte l’éventuelle non linéarité des processus ou du moins restant valides dans une gamme
d’application large.
Des interactions fortes existent aussi entre les recherches effectuées sur la méthode SHYREG
et les autres recherches développées par l’équipe Hydrologie. Ces interactions concernent :
La prévision des crues en sites non-jaugées : l’équipe développe un modèle d’alerte de
crues basé sur la détermination en temps réel de la période de retour des événements
observées : c’est le principe de la méthode brevetée AIGA
[P. Javelle et al., 2012; Lavabre
and Gregoris, 2005]. Cette approche est développée sur l’ensemble du territoire national.
Les quantiles SHYREG servent de base pour qualifier les événements, que sont les pluies
observées sur différentes durées (obtenues par les radars météorologiques) ou les débits
modélisés par un modèle hydrologique distribué (GRD, [Arnaud et al., 2011; Diss, 2009]),

105
dont la structure et la paramétrisation sont proches de celles utilisées pour la méthode
SHYREG. Un lien étroit existe donc en ces deux méthodes, au-delà des techniques
transversales présentées plus loin.
L’étude de la ressource en eau : l’équipe développe aussi un modèle hydrologique
fonctionnant en continu au pas de temps mensuel, et actuellement à l’étude pour un
fonctionnement au pas de temps journalier : c’est la méthode LOIEAU [Folton and Lavabre,
2006; 2007]. Cette approche, développée pour la prédétermination de la ressource en eau,
présente des liens forts avec la méthode de prédétermination SHYREG. C’est aussi une
méthode de prédétermination régionalisée basée sur la modélisation hydrologique. Certains
résultats de cette méthode fournissent une information sur les états hydriques des bassins et
les débits avant les périodes pluvieuses, pouvant être utilisée pour initialiser les modèles de
crues. Un couplage plus fort entre les deux méthodes SHYREG et LOIEAU est envisagé.
Des recherches transversales : les méthodes développées dans l’équipe ont en commun
plusieurs points de recherches liés à leur objectif et leur nature. Ce sont des méthodes qui
visent à étudier les phénomènes hydrologiques dans la gamme complète des événements
courants à extrêmes, par la modélisation des processus, et destinées à être régionalisées pour
pouvoir être appliquées en sites non-instrumentés. Ces points de recherches communs
concernent :
o La modélisation hydrologique : la relation pluie-débit recherchée doit faire un
compromis entre justesse et parcimonie, l’objectif de régionalisation étant un point
important. Cet objectif commun à l’ensemble des méthodes développées permet
d’échanger sur les structures des modèles les plus adaptées (actuellement modèles à
réservoir de type GR), sur les procédures de calage (réflexions sur les critères et
techniques d’optimisation, sur les procédures de calage/validation,…), sur les processus
les plus importants à prendre en compte, l’analyse critique des données, etc.
o La régionalisation : elle porte dans tous les cas sur des variables climatiques ou sur les
paramètres des modèles hydrologiques. Les descripteurs utilisés sont mis en commun
ainsi que les méthodes d’interpolation. La problématique de la régionalisation des
paramètres de modèle est essentielle, et doit faire appel à des techniques particulières à
développer. En effet si les méthodes géostatistiques sont adaptées à la spatialisation des
variables climatiques, voire à des grandeurs hydrologiques (fortement influencées par les
variables climatiques), ça semble moins évident pour les paramètres des modèles
hydrologiques. En effet, dans ce cas, la composante climatique a été enlevée, et la
variabilité spatiale des paramètres ne provient plus que de la nature des bassins versants,
pouvant présenter des discontinuités fortes et une structure spatiale particulière (deux
exutoires très proches mais sur des versants différents auront peut-être plus de différences
qu’avec des exutoires avals plus éloignés). Actuellement, les méthodes simples par
voisinage semblent conduire à de meilleurs résultats.
o Les approches distribuées : la disponibilité croissante de l’information spatiale sur les
pluies, mais aussi sur les autres composantes du cycle de l’eau (Neige, ETP,

106
température,…) pousse à vouloir les utiliser pour prendre en compte la variabilité spatiale
des processus. L’objectif est alors de développer des approches distribuées qui ne
complexifient pas la structure des modèles ou du moins le nombre de paramètres à caler.
L’objectif serait alors de « dé-biaiser » la paramétrisation des approches globales qui tend
à compenser la perte d’information sur la variabilité spatiale des données [Arnaud et al.,
2011; Fouchier, 2010].
o Les incertitudes : l’étude des incertitudes fait partie des attentes de plus en plus présentes
dans le développement des modèles. La complexité des modèles nécessite l’utilisation de
techniques adaptées, souvent liées à des processus d’échantillonnage et de simulations.
Ces recherches de techniques sont communes aux différentes approches hydrologiques
développées. Les techniques développées en prévision d’ensemble sont aussi testées pour
étudier les incertitudes.
o Le changement global : le développement d’approches basées sur la modélisation
hydrologique, avec comme données d’entrée des variables climatiques, permet d’étudier
l’impact de la non stationnarité du climat sur la ressources en eau ou sur les risques
d’inondation. La recherche de liaison entre les paramètres hydrologiques et des variables
environnementales pour la régionalisation des approches, fournie une liste d’indicateurs
permettant d’étudier l’impact du changement d’occupation des sols sur les écoulements.
Ces recherches sont aussi transversales ou mutualisables entre les méthodes.
Les développements futurs sur les recherches en hydrologie développées par notre équipe, en
lien étroit avec les hydrologues de l’établissement, sont nombreux. Notre projet est aussi d’apporter
nos compétences particulières en hydrologie appliquée, au collectif des hydrologues de la nouvelle
université Aix-Marseille.
Outre les projets et conventions actuels liés à la poursuite de nos recherches sur les méthodes
développées, des projets sont en cours de montage sur les thèmes suivants :
- La modélisation des crues sur les petits bassins de montagnes, passage à pas de temps fins :
projet FASEP avec le Brésil, projet FEDER avec la région de l’Ile de la Réunion, et les
suites du projet RHYTMME en PACA.
- L’étude de la ressource en eau en contexte de changement climatique en région PACA,
montage d’un projet CPER Recherche 2014-2020, sur le volet « Climat ».
- L’exploitation d’informations sur les dégâts pour introduire la notion d’exposition et de
vulnérabilité dans les déclanchements d’alerte (projet ANR Jeune chercheur porté par
l’Université d’Avignon, partenariat : Ifsttar, Cerema, CCR, Irstea et projet PORTE).
- …
Autant de projets en construction qui nous permettent d’envisager la poursuite de nos
recherches en hydrologie appliquée aux valeurs extrêmes (basses et hautes) en site non jaugés.

107
E - RÉFÉRENCES BIBLIOGRAPHIQUES
CITÉES
(WRC), W. R. C. (1967), A uniform technique for determining flow frequencies, Water Resour. Council Bull., 15. Acreman, M. C. (1990), A simple stochastic model of hourly rainfall for Farnborough, England., Hydrological
Sciences Journal, 35(2), 119-148. Aldrich (1997), R.A. Fisher and the Making of Maximum Likehood 1912-1922, Statistical Science, 17(3), 162-176. Arnaud, P. (1997), Modèle de prédétermination de crues basé sur la simulation. Extension de sa zone de validité,
paramétrisation du modèle horaire par l'information journalière et couplage des deux pas de temps. , in Thèse de l'Université Montpellier II. , edited, p. 258 p. + annexes.
Arnaud, P. (2005), Simplification de gr3h pour la prédétermination des crues. Application sur des petits bassins versants., in Note interne., edited, p. 26 p.
Arnaud, P. (2010), Estimation de l’aléa « ruissellement » par la méthode SHYREG. Éléments de réflexions sur la difficulté d’estimation de l’aléa ruissellement., Rapport d'étude, 22 pages.
Arnaud, P., and J. Lavabre (1995), Simulation du fonctionnement hydrologique d'une retenue d'eau., paper presented at Comité National Suisse des Grands Barrages, Research in the Field Dams, , Crans-Montana, Suisse, 7-9 septembre 1995.
Arnaud, P., and J. Lavabre (1997), Simulation du fonctionnement hydrologique d'un bassin versant : application à la conception et à la gestion d'un barrage., Ingénierie EAT, n° 120, 43-54.
Arnaud, P., and J. Lavabre (1998), Flood determination model based on hourly rainfalls stochastic generation., paper presented at XXIII General assembly, E.G.S. (European Geophysical Society), Nice, 20-24 avril 1998
Arnaud, P., and J. Lavabre (1999a), Using a stochastic model for generating hourly hyetographs to study extreme rainfalls., Hydrological Sciences Journal, 44((3)), 433-446.
Arnaud, P., and J. Lavabre (1999b), Nouvelle approche de la prédétermination des pluies extrêmes., in Compte Rendu à l'Académie des Sciences, Sciences de la Terre et des planètes, Géosciences de surface, hydrologie-hydrogéologie, edited by A. d. Sciences, pp. 615-620.
Arnaud, P., and J. Lavabre (1999), Using a stochastic model for generating hourly hyetographs to study extreme rainfalls., Hydrological Sciences Journal, 44(3), 443-445.
Arnaud, P., and J. Lavabre (2000), Using a stochastic model for generating hourly rainfall and a rainfall-runoff transformation model for flood frequency estimation Revue des sciences de l'eau, 13(4), 441-462.
Arnaud, P., and J. Lavabre (2002), Coupled rainfall model and discharge model for flood frequency estimation., Water Resources Research, 38(6).
Arnaud, P., and J. Lavabre (2010), Estimation de l'aléa pluvial en France métropolitaine, edited, p. 158 pages, QUAE, Paris. Update Sciences & Technologies.
Arnaud, P., and Y. Aubert (2014), Prise en compte de l’aléa hydrologique dans le dimensionnement et la gestion des ouvrages hydrauliques (conférence invité), Fiabilité des matériaux et des structures. Analyse des risques et fiabilités des systèmes dans leur environnement., JFMS 2014 - ISTE Editions, 171-183.
Arnaud, P., J. Lavabre, and J.-M. Masson (1999), Amélioration des performances d'un modèle stochastique de génération de hyétogrammes horaires : application au pourtour méditerranéen français., Revue des Sciences de l’Eau, 12(2), 251-271.
Arnaud, P., J.-A. Fine, and J. Lavabre (2007), An hourly rainfall generation model adapted to all types of climate., Atmospheric Research, 85(2007), 230-242.
Arnaud, P., P. Cantet, and Y. Aubert (2014a), Relevance of an at-site flood frequency analysis method for extreme events based on stochastic simulation of hourly rainfall, Accepted Hydrological Sciences Journal., 20 pages.
Arnaud, P., S. Picard, J. Lavabre, and A. Douguedroit (1997), Modélisation stochastique des pluies horaires. Application à la région méditerranéenne française., paper presented at 10è colloque international de climatologie, Québec, 9-12 sept. 1997.
Arnaud, P., J. Lavabre, B. Sol, and C. Desouches (2006), Cartographie de l'aléa pluviographique de la France La houille blanche, 5, 102-111.
Arnaud, P., J. Lavabre, B. Sol, and C. Desouches (2008a), Regionalization of an hourly rainfall generating model over metropolitan France for flood hazard estimation., Hydrological Sciences Journal, 53 (1) 34-47.

108
Arnaud, P., J. Lavabre, B. Sol, and C. Desouches (2008b), Regionalization of an hourly rainfall generating model over metropolitan France for flood hazard estimation, Hydrological Sciences Journal, 53(1), 34-47.
Arnaud, P., J. Lavabre, B. Sol, and C. Desouches (2008c), Regionalization of an hourly rainfall model in French territory for rainfall risk estimation., Hydrological Sciences Journal, 53(1), 21p.
Arnaud, P., Y. Eglin, B. Janet, and O. Payrastre (2013), Bases de données SHYREG-débit : méthode, performances et limites, Notice utilisateurs - Publication Irstea, 35 pages.
Arnaud, P., J. Lavabre, C. Fouchier, S. Diss, and P. Javelle (2011), Sensitivity of hydrological models to uncertainties in rainfall input, Hydrological Sciences Journal, 56(3), 397-410.
Arnaud, P., P. cantet, C. Perrin, F. Bourgin, and G. Thirel (2014), Détermination des incertitudes de la méthode SHYREG calée localement., Rapport Convention SNRH -Irstea 2014, 20.
Arnaud, P., Y. Aubert, D. Organde, P. Cantet, C. Fouchier, and N. Folton (2014b), Estimation de l’aléa hydrométéorologique par une méthode par simulation : la méthode SHYREG – Présentation – Performances – Base de données., la Houille Blanche - Revue Internationale de l'Eau, 2(2014), 20-26.
Arnaud, P., E. Paquet, Y. Aubert, P. Royet, J.-A. Fine, and M. Lang (2015), Estimation de la distribution de cotes de retenue par simulation stochastique pluie-débit. Cas d'un barrage fictif, paper presented at Vingt cinquième congrés des grands barrages, Norvège, juin 2015.
Aubert, Y. (2008), Recherche d’une modélisation équivalente pour générer des hydrogrammes de crue pour le dimensionnement d’ouvrage., in Mémoire de Master SAGE "systèmes aquatiques et gestion de l'eau". ENPC., edited, p. 69 p.
Aubert, Y. (2012), Estimation des valeurs extrêmes de débit par la méthode SHYREG : réflexions sur l'équifinalité dans la modélisation de la transformation pluie en débit, thesis, 317 pp, Université Paris VI, Paris.
Aubert, Y., P. Arnaud, J. A. Fine, and P. Cantet (2014), Rainfall frequency analysis using a hourly rainfall model calibrated on weather patterns : application on Reunion Island, paper presented at EGU General Assembly 2014-7220, Geophysical Research Abstracts, Viennes (Austria).
Aubert, Y., P. Arnaud, P. Ribstein, and J.-A. Fine (2014), La méthode SHYREG débit - application sur 1605 bassins versants en France Métropolitaine, Hydrological Sciences Journal., 59(5), 993-1005.
Beirlant, J., Y. Goegebeur, J. Segers, and J. Teugels (2004), Statistics of Extremes: Theory and Applications, 522 pp., John Wiley & Sons.
Benichou, P., and O. Le Breton (1987), Prise en compte de la topographie pour la cartographie des champs pluviométriques statistiques., La Météorologie, 7ème série(19), 23-34.
Beven, K., and M. J. Kirkby (1979), A physically based variable contributing area model of basin hydrology., Hydrological Sciences Bulletin, 24(1), 43-69.
Blazkova, S., and K. Beven (1997), Flood frequency prediction for data limited catchments in the Czech Republic using a stochastic rainfall model and TOPMODEL., Journal of Hydrology, 195, 256-278.
Blazkova, S., and K. J. Beven (2002), Flood frequency estimation by continuous simulation for a catchment treated as ungauged (with uncertainty), Water Resources Research, 38(8), 14-11–14-14.
Boé, J., L. Terray, F. Habets, and E. Martin (2006), A simple statistical-dynamical downscaling scheme based on weather types and conditional resampling., Journal of Geophysical Research-Atmospheres, 111(D23), D23106.
Bouvier, C., L. Cisneros, R. Dominguez, J.-P. Laborde, and T. Lebel (2003), Generating rainfall fields using principal components (PC) decomposition of the covariance matrix: A case study in Mexico City, Journal of Hydrology, 278(1-4), 107-120.
Buishand, T. A. (1978), Some remarks on the use of daily rainfall models., Journal of Hydrology, 36, 295-308. Burlando, P., and R. Rosso (1996), Scaling and multiscaling models of depth-duration-frequency curves for storm
precipitation, Journal of Hydrology, 187(1-2), 45-64. C.I.G.B. (1992), Choix de la crue de projet. Méthodes actuelles. , Bulletin 82 de la Commission Internationale des
Grands Barrages, 233. Cadavid, L., J. T. B. Obeysekera, and H. W. Shen (1991), Flood frequency derivation from kinematic wave., Journal
of Hydraulic Engineering, 117(4), 489-510. Cameron, D., K. Beven, and J. Tawn (2000), Modelling extreme rainfalls using a modified random pulse Bartlett-
Lewis stochastic rainfall model (with uncertainty), Advances in Water Resources, 24(2), 203-211. Cameron, D., K. Beven, and J. Tawn (2000), An evaluation of three stochastic rainfall models, Journal of
Hydrology, 228(1-2), 130-149. Cameron, D. S., K. J. Beven, J. Tawn, S. Blazkova, and P. Naden (1999), Flood frequency estimation by continuous
simulation for a gauged upland catchment (with uncertainty), Journal of Hydrology, 219(3–4), 169-187. Cantet, P. (2009), Impacts du changement climatique sur les pluies extrêmes par l'utilisation d'un générateur
stochastique de pluies, thesis, 230 pp, Université de Montpellier II - I3M, Montpellier.

109
Cantet, P. (2012), Spatialisation de normales climatiques : méthodes et résultats sur la Martinique, Convention de recherche et développement partagés DEAL Martinique / Météo-France DIRAG.
Cantet, P. (2013), Impacts du changement climatique sur les crues : utilisation de projections climatiques dans l'estimation de débits extrêmes par la méthode SHYREG., Rapport d'étude Irstea - Convention multirisque Irstea-DGPR 2013, 26 pages.
cantet, P. (2014), Base SHYREG pour les quantiles de pluies infra-horaires, Rapport d'étude Irstea, Projet CPER RHYTMME, 25 pages.
Cantet, P., and P. Arnaud (2014), Extreme rainfall analysis by a stochastic model: impact of the copula choice on the sub-daily rainfall generation, Stochastic Environmental Research and Risk Assessment, 28(6), 1479-1492.
Cantet, P., J.-N. Bacro, and P. Arnaud (2011), Using a rainfall stochastic generator to detect trends in extreme rainfall, Stoch Environ Res Risk Assess, 25(3), 429-441.
Carreau, J., L. Neppel, P. Arnaud, and P. Cantet (2013), Extreme rainfall analysis at ungauged sites in the South of France : comparison of three approaches, Journal de la Société Française de Statistique, 154(2), 119-138.
Carvajal, C., L. Peyras, P. Arnaud, and P. Royet (2009a), Probabilistic Modelling of Flood Water Level for Dam Reservoirs, Journal of Hydrologic Engineering, 14(3), 223-232.
Carvajal, C., L. Peyras, P. Arnaud, D. Boissier, and P. Royet (2009b), Assessment of Hydraulic Load Acting on Dams including Filling Variability and Stochastic Simulations, European Journal Of Environmental and Civil Engineering, 13(4), 399-411.
Cernesson, F. (1993), Modèle simple de prédétermination des crues de fréquences courante à rare sur petits bassins versants méditerranéens., in Thèse de doctorat de l'Université Montpellier II, edited, p. 240 p + annexes.
Cernesson, F. (1993), Modèle simple de prédetermination des crues de fréquences courantes à rares sur petits bassins versants méditéranéens, Université Montpellier II thesis.
Cernesson, F., J. Lavabre, and J.-M. Masson (1996), Stochastic model for generating hourly hyetographs. , Atmospheric Research, n° 42, 149-161.
Chow, V. T., D. R. Maidment, and L. W. Mays (1988), Applied Hydrology., Mc Graw-Hill book compagny, 572 pages.
Cipriani, T., T. Toilliez, and E. Sauquet (2012), Estimation régionale des débits décennaux et durées caractéristiques de crue en France, La Houille Blanche, 1, 16-20.
Coles, S. (2001), An introduction to Statistical Modeling of Extreme Values, ed. Springer-Verlag, Heidelberg, Germany.
Coles, S., L. R. Pericchi, and S. Sisson (2003), A fully probabilistic approach to extreme rainfall modeling., Journal of Hydrology, 273(1-4), 35-50.
Collier, C. G., and P. J. Hardaker (1996), Estimating probable maximum precipitation using a storm model approach., Journal of Hydrology, 183(3-4), 277-306.
Cowpertwait, P. S. P. (1991), Further developments of the Neyman-Scott clustered point process for modelling rainfall., Water Resources Research, 27(7), 1431-1438.
Cowpertwait, P. S. P., P. E. O'Connell, A. V. Metcalfe, and J. A. Mawdsley (1996), Stochastic point process modelling of rainfall. II. Regionalisation and disaggregation, Journal of Hydrology, 175(1-4), 47-65.
CTGREF, SRAE, and D. S.-H (1980-1982), Synthèse nationale sur les crues des petits bassins versants. Fascicule 3 : la méthode Crupedix., Information technique n°8-2 (juin 1980).
Darlymple, T. (1960), Flood-frequency analysis, Water Supply Pap., 1543A - US Geol Surv. Deidda, R. (1999), Multifractal analysis and simulation of rainfall fields in space, Physics and Chemistry of the
Earth, Part B: Hydrology, Oceans and Atmosphere, 24(1–2), 73-78. DGPR, M.-. (2004), Les inondations - Dossier d'information, Edition Ministère de l'Ecologie et du Développement
Durable, 20 pages. Diss, S. (2009), Apport de l’imagerie radar pour la connaissance spatio-temporelle des champs de pluie.
Utilisation pour une modélisation prédictive des crues, Université Paris 6 thesis, 259 pp, Paris. Dominguez, R., C. Bouvier, L. Neppel, and H. Niel (2005), Approche régionale pour l’estimation des distributions
ponctuelles des pluies journalières dans le Languedoc-Roussillon (France) / Regional approach for the estimation of low-frequency distribution of daily rainfall in the Languedoc-Roussillon region, France, Hydrological Sciences Journal/Journal des Sciences Hydrologiques, 50(1), 17-29.
Dubuisson, B., and J. Moisselin (2006), Evolution des extrêmes climatiques en France à partir des séries observées, La Houille Blanche, 6, 42-47.
Eagleson, P. S. (1972), Dynamics of flood frequency., Water Resources Research, 8(4), 878-898. Econopouly, T. W., D. R. David, and D. A. Woolhiser (1990), Parameter transferability for a daily rainfall
disaggregation model., Journal of Hydrology, 118, 209-228. Edijatno, and C. Michel (1989), Un modèle pluie-débit à trois paramètres., La Houille Blanche, 2, 113-121.

110
England, J. F., R. D. Jarrett, and J. D. Salas (2003), Data-based comparisons of moments estimators using historical and paleoflood data, Journal of Hydrology, 278(1–4), 172-196.
Favre, A.-C., A. Musy, and S. Morgenthaler (2004), Unbiased parameter estimation of the Neyman-Scott model for rainfall simulation with related confidence interval, Journal of Hydrology, 286(1-4), 168-178.
Ferrer, J.-P. (1992), Analyse statistique de pluies maximales journalières - Comparaison de différentes méthodes et application au bassin Guadalhorce (Espagne), Hydrologie continentale, 7(1), 23-31.
Fine, J.-A. (2009), SHYPRE, désagrégation au pas de temps 5 minutes : modèle pluie-débit, Rapport d'étude Hydris.
Fine, J.-A., and J. Lavabre (2003), Synthèse des débits de crue sur l'Ile de la Réunion. Phase I : la pluviométrie. Éléments pour la régionalisation du modèle de simulation. , edited, p. 24 p.
Fisher, R. A., and L. H. C. Tippett (1928), Limiting forms of the frequency distribution of the largest and smallest member of a sample, Proc. Cambridge Phil. Soc., 24, 180-190.
Folton, N., and J. Lavabre (2006), Regionalization of a monthly rainfall-runoff model for the southern half of France based on a sample of 880 gauged catchments, IAHS Publication Large Sample Basin Experiments for Hydrological Model Parameterization: Results of the Model Parameter Experiment - MOPEX, vol. 4, 264-277.
Folton, N., and J. Lavabre (2007), Approche par modélisation pluie-débit pour la connaissance régionale de la ressource en eau: application à la moitié du territoire français, Houille-Blanche, n° 03-2007, 64-70.
Fouchier, C. (2010), Développement d’une méthodologie pour la connaissance régionale des crues, thesis, 231 pp, Université Montpellier II Sciences et techniques du Languedoc,, Montpellier.
Fouchier, C., P. Arnaud, J. Lavabre, and J.-P. Mizzi (2007), AIGA: an operational tool for flood warning in southern France. Principle and performances on Mediterranean flash floods. , paper presented at Assemblée générale de l'EGU, 15-20 avril 2007.
Fréchet, M. (1927), Sur la loi de probabilité de l'écart maximun., Ann. Soc. Polonaise Math., 6, 93-116. Garavaglia, F., M. Lang, E. Paquet, J. Gailhard, R. Garcon, and B. Renard (2011), Reliability and robustness of
rainfall compound distribution model based on weather pattern sub-sampling, Hydrology and Earth System Sciences, 15(2), 519-532.
Garcon, R. (1999), Modèle global pluie-débit pour la prévision et la prédétermination des crues, La Houille Blanche, 7-8, 88-95.
Gaume, E., N. Mouhous, and H. Andrieu (2007), Rainfall stochastic disaggregation models: Calibration and validation of a multiplicative cascade model, Advances in Water Resources, 30(5), 1301-1319.
Gaume, E., L. Gaál, A. Viglione, J. Szolgay, S. Kohnová, and G. Blöschl (2010), Bayesian MCMC approach to regional flood frequency analyses involving extraordinary flood events at ungauged sites, Journal of Hydrology, 394(1–2), 101-117.
Genest, C., and A. Favre (2007), Everything you always wanted to know about copula modeling but were afraid to ask, Journal of Hydrologic Engineering, 12, 347-368.
Glasbey, C. A., G. Cooper, and M. B. McEchan (1995), Disagregation of daily rainfall by conditional simalution from a point-process model., Journal of Hydrology, 165, 1-9.
Groisman, P. Y., R. W. Knight, and T. R. Karl (2001), Heavy Precipitation and High Streamflow in the Contiguous United States: Trends in the Twentieth Century, Bulletin of the American Meteorological Society, 82(2), 219-246.
Guillot, P., and D. Duband (1967), La méthode du Gradex pour le calcul de la probabilité des crues à partir des pluies., I.A.S.H., Publication, 84.
Gumbel, E. J. (1935), Les valeurs extrêmes des distributions statistiques., Annales de l'I.H.P., 5(2), 115-158. Gumbel, E. J. (1961), Bivariate logistic distributions, Journal of the American Statistical Association the American Statistical Associatio, 1005, 335-349. Gupta, V., and E. Waymire (1993), A statistical analysis of mesoscale rainfall as a random cascade, Journal of
Applied Meteorology, 32, 251-267. Hansen, E. M. (1987), Probable maximum precipitation for design floods in the United States, Journal of
Hydrology, 96(1987), 267-278. Hebson, C., and E. F. Wood (1982), A derived flood frequency distribution using Horton order ratios., Water
Resources Research, 18(5), 1509-1518. Helms, M., J. Ihringer, and M. R. (2012), Hydrological simulation of extreme flood scenarios for operational flood
management at the Middle Elbe river, Advances in Geosciences, 32, 41-48. Heneker, T. M., M. F. Lambert, and G. Kuczera (2001), A point rainfall model for risk-based design. Journal of
Hydrology, Journal of Hydrology, 247(1-2), 54-71. Hershfield, D. M. (1961), Estimating the Probable Maximum Precipitation., Proc. American Society of Civil
Engineers, Journal Hydraulics Division, 87, 99-106.

111
Hlavcova, K., S. Kohnová, J. Szolgay, and M. Zvolensky (2004), Estimation of rainfall flood risk on the Torysa river, J. Hydrol. Hydromec., 52(3), 141-155.
Hoeffding, W. (1940), Masstabinvariante korrelationstheorie, Schrijtfen Math. Inst. Inst, Angew. Math. Univ. Berlin.(5), 179-233.
Hosking, J. R. M., and J. R. Wallis (1993), Some statistics useful in regional frequency analysis., Water Resour. Res., 29(2), 271-281.
Hosking, J. R. M., and J. R. Wallis (1997), Regional frequency analysis: an approach based on L-moments, Cambridge University Press.
Hubert, P. (2005), La prédétermination des crues, Comptes Rendus Geoscience, 337(1–2), 219-227. Huff, F. A. (1967), Time distribution of rainfall in Heavy storms, Water Resources Research, 3(4), 1007-1019. Hydris (2009), Cartographie des débits de crue en Métropole. Régionalisation du modèle pluie-débit.
Détermination des débits de crues de référence par l’application de la méthode SHYPRE régionalisée sur la métropole. 2. Calibration du modèle de transformation de la pluie en débit, recherche de variable explicatives et régionalisation du modèle, in Rapport d'étude, edited, p. 32 p.
IPCC (2007), Climate change 2007: the physical science basis. Contribution of working group I to the fourth assessment report of the intergovernmental panel on climate change, Cambridge University Press, Cambridge.
Javelle, P., J.-M. Grésillon, and G. Galéa (1999), Modélisation des courbes débit-durée-fréquence en crues et invariance d'échelle, Comptes Rendus de l'Académie des Sciences - Series IIA - Earth and Planetary Science, 329(1), 39-44.
Javelle, P., J. Pansu, P. Arnaud, Y. Bidet, and B. Janet (2012), The AIGA method: an operational method using radar rainfall for flood warning in the south of France, in Weather Radar and Hydrology, edited by R. J. Moore, S. J. Cole and A. J. Illingworth, pp. 550-555, Int Assoc Hydrological Sciences, Wallingford.
Jenkinson, A. F. (1955), The frequency distribution of the annual maximum (or minimum) values of meteorological elements., Quarterly Journal of the Royal Meteorological Society, 81, 158-171.
Kjeldsen, T. R. (2007), The revitalised FSR/FEH rainfall-runoff method - a user handbook., Centre for Ecology ans Hydrology - Wallingford, UK.
Kochanek, K., B. Renard, P. Arnaud, Y. Aubert, M. Lang, T. Cipriani, and E. Sauquet (2013), A data-base comparison of flood frequency analysis methods used in France, Accepted Natural Hazards and Earth System Sciences, 20 pages.
koutsoyiannis, D. (1994), A stochastic disaggregation method for design storm and flood synthesis, Journal of Hydrology, 156(193-225).
Koutsoyiannis, D. (1999), A probabilistic view of hershfield's method for estimating probable maximum precipitation., Water Resources Research, 35(4), 1313-1322.
Koutsoyiannis, D. (2004), Statistics of extremes and estimation of extreme rainfall: II. Empirical investigation of long rainfall records, Hydrological Sciences Journal, 49(4), 591-610.
Koutsoyiannis, D., D. Kozonis, and A. Manetas (1998), A mathematical framework for studying rainfall intensity-duration-frequency relationships., Journal of Hydrology, 206(1-2), 118-135.
Krajewski, W. F., and J. A. Smith (2002), Radar hydrology: rainfall estimation, Advances in Water Resources, 25(8-12), 1387-1394.
Kuichling, E. (1889), The relation between the rainfall and the discharge of sewers in populous districts, Transactions of the American Society Civil Engineers, 20, 1-56.
Kumaraswamy, P. (1980), A generalized probability density function for double-bounded random processes, Journal of Hydrology, 46(1-2), 79-88.
Lang, M., and J. Lavabre (2007), Estimation de la crue centennale pour les plans de prévention des risques d'inondations, edited, p. 232 p, QUAE, Paris.
Lang, M., et al. (2013), Domaines d’application des méthodes de prédétermination des pluies et crues extrêmes - Rapport V., Projet ANR-08-RISK-03-01 - Extraflo.
Lang, M., et al. (2014), Résultats du projet ExtraFlo (ANR 2009-2013) sur l’estimation des pluies et crues extrêmes, La Houille Blanche, 2, 5-13.
Lavabre, J., and Y. Gregoris (2005), AIGA : un dispositif d'alerte des crues sur l'ensemble du réseau hydrographique., In Ingénieries(n° 44), 3-12.
Lavabre, J., and Y. Gregoris (2006), AIGA : un dispositif d'alerte des crues. Application à la région méditerranéenne française, paper presented at FRIEND 2006. Water Resource Variability : analyses and impacts, AISH Publications, La Havane (Cuba), 27/11 au 1/12/2006.
Lavabre, J., P. Arnaud, P. Royet, J.-A. Fine, S. Delichère, Z.-X. Fang, and F. Foussard (2009), Crue de projet ou cote de projet ? Exemple des barrages écrêteurs de crue du département du Gard. , paper presented at Colloque CFBR-SHF: «Dimensionnement et fonctionnement des évacuateurs de crues», Lyon, 20-21 janvier 2009.

112
Lavabre, J., P. Arnaud, P. Royet, J.-A. Fine, S. Delichère, F. Zhong-Xue, and F. Foussard (2010), Crues de projet ou cotes de projet ? Exemple des barrages écrêteurs de crue du département du Gard, La Houille Blanche, n° 2-2010, 58-64.
Lebel, T. (1984), Moyenne spatiale de la pluie sur un bassin versant : estimation optimale, génération stochastique et gradex des valeurs extrêmes., Thèse INPG, Grenoble, 350 pages.
Leblois, E., and J.-D. Creutin (2013), Space-time simulation of intermittent rainfall with prescribed advection field: Adaptation of the turning band method, Water Resources Research, 49(6), 3375-3387.
LeCam, L. (1961), A stochastic description of precipitation., Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, edited by J. Neyman, 165-186.
Li, J., M. Thyer, M. Lambert, G. Kuczera, and A. Metcalfe (2014), An efficient causative event-based approach for deriving the annual flood frequency distribution, Journal of Hydrology, 510(0), 412-423.
Llamas, J. (1993), Hydrologie générale principes et applications., 2° édition, Gaëtan Morin éditeur, Paris, 527 pages.
Loudegui Djimdou, M. (2014), Comparaison de méthodes de spatialisation pour régionaliser un paramètre d'un générateur de pluies, Rapport de stage - Université de Caen - Basse Normandie, 57 pages.
Loukas, A. (2002), Flood frequency estimation by a derived distribution procedure, Journal of Hydrology, 255(1–4), 69-89.
Mantoglou, A., and J. L. Wilson (1982), The turning bands method for simulation of random fields using line generation by a spectral method, Water Resources Research, 18(5), 1379-1394. Margoum, M., G. Oberlin, M. Lang, and R. Weingartner (1994), Estimation des crues rares et extrêmes : principes
du modèle AGREGEE., Hydrologie continentale, 9(1), 85-100. Merz, R., and G. Blöschl (2005), Flood frequency regionalisation—spatial proximity vs. catchment attributes,
Journal of Hydrology, 302(1–4), 283-306. Merz, R., J. Parajka, and G. Bloschl (2009), Scale effects in conceptual hydrological modeling., Water Resources
Research, 45(W09405). Ministère de l'Agriculture, Services Régionaux de l'Aménagement des Eaux (S.R.A.E.), Direction de
l'Aménagement Service de l4hydraulique (D.A.S.H.), and C.T.G.R.E.F. (1980), Synthèse nationale sur les crues des petits bassins versants. Fascicule 2, la méthode SOCOSE (janvier 1980) - Fascicule 3, la méthode CRUPEDIX (juillet 1980), 38.
Miquel, J. (1983), Crue : un modèle d'estimation des probabilités des débits de crue., La houille blanche, 2, 95-103.
Miquel, J. (1984), Guide pratique d'estimation des probabilités de crues, Eyrolles ed., 160 pp., EDF, Paris. Moberg, A., and P. D. Jones (2004), Regional climate model simulations of daily maximum and minimum near-
surface temperature across Europe compared with observed station data 1961-1990, Climate Dynamics, 23, 695-715. Molnar, P., and P. Burlando (2005), Preservation of rainfall properties in stochastic disaggregation by a simple
random cascade model, Atmospheric Research, 77, 137-151. Moulard, C. (2010), Apport de l’information hydrogéologique pour la régionalisation de deux modèles
hydrologiques de surface, MASTER « Hydrogéologie, Sol et Environnement », université d'Avignon, 60 pages. Muller, A. (2006), Analyse du comportement asymptotique de la distribution des pluies extrêmes en France.,
thesis, 246 pp, Université Montpellier II - I3M, Montpellier. Muller, A., J.-N. Bacro, and M. Lang (2008), Bayesian comparison of different rainfall depth-duration-frequency
relationships., Stochastic Environmental Research and Risk Assessment, 22(1), 33-46. Muller, A., P. Arnaud, M. Lang, and J. Lavabre (2009), Uncertainties of extreme rainfall quantiles estimated by a
stochastic rainfall model and by a generalized Pareto distribution., Hydrological Sciences Journal, 54(3), 417-429. Musy, A., and C. Higy (2004), Hydrologie - Tome 1 : Une science de la nature., Presses Polytechniques et
Universitaires Romandes, 1, 314. Myers, V. A. (1967), Estimation of extreme precipitation for spillway design floods., Tech. Mem. WBTM HYDRO-5,
U.S. Weather Bur., Washington, D.C., 29 pages. Naulet, R. (2002), Utilisation de l’information des crues historiques pour une meilleure prédétermination du
risque d’inondation. Application au bassin de l’Ardèche à Vallon-Pont-d’Arc et St-Martind’Ardèche. Thèse, Université Joseph Fourier Grenoble, Université du Québec, Cemagref Lyon, Inrs-Ete Québec, (2002), 322p, Thèse, Université Joseph Fourier, Grenoble - Université du Québec, 322 pages.
Naulet, R., M. Lang, T. B. M. J. Ouarda, D. Coeur, B. Bobée, A. Recking, and D. Moussay (2005), Flood frequency analysis on the Ardèche river using French documentary sources from the two last centuries., Journal of Hydrology, Special Issue “Applications of palaeoflood hydrology and historical data in flood risk analysis »(312), 58-78.
Nelsen, R. B. (2006), An introduction to copulas, Springer Verlag.

113
Neppel, L., P. Arnaud, and J. Lavabre (2007a), Cartographie des pluies extrêmes - Comparaison de deux approches appliquées en milieu méditerranéen., Comptes-rendus de l'Académie des sciences Paris Sciences de la terre et des planètes, 339(2007), 820–830.
Neppel, L., P. Arnaud, and J. Lavabre (2007b), Cartographie des pluies extrêmes ; comparaison de deux approches appliquées en milieu méditerranéen, edited, pp. 820-830, Compte rendu à l'Académie des Sciences.
Neppel, L., B. Renard, M. Lang, P.-A. Ayral, D. Coeur, E. Gaume, N. Jacob, O. Payrastre, P. K., and F. Vinet (2010), Flood frequency analysis using historical data: accounting for random and systematic errors. , Hydrological Sciences Journal, 52(2), 192-208.
Neppel, L., P. Arnaud, F. Borchi, J. Carreau, F. Garavaglia, M. Lang, E. Paquet, B. Renard, J. M. Soubeyroux, and J. M. Veysseire (2014), Résultats du projet Extraflo sur la comparaison des méthodes d'estimation des pluies extrêmes en France, La Houille Blanche - Revue Internationale de l'Eau, 2(2014), 14-19.
Neyman, J., and E. Scott (1958), Statistical approach to problems of cosmology., Journal of Royal Statistical Society, seris b (methodological), 20(1), 1-43.
Organde, D., P. Arnaud, and J.-A. fine (2012), Régionalisation d'une méthode de prédétermination de crue sur l'ensemble du territoire français : la méthode SHYREG, Revue des Sciences de l’Eau, in press.
Organde, D., P. Arnaud, J.-A. Fine, C. Fouchier, N. Folton, and J. Lavabre (2013), Régionalisation d'une méthode de prédétermination de crue sur l'ensemble du territoire français : la méthode SHYREG, Revue des Sciences de l’Eau, 26(1), 65-78.
Ouarda, T. B. M. J., P. F. Rasmussen, B. Bobée, and J. Bernier (1998), Utilisation de l'information historique en analyse hydrologique fréquentielle, Revue de Sciences de l'Eau, 11(n° spécial), 41-49.
Over, T., and V. K. Gupta (1994), Statistical analysis of mesoscale rainfall : dependence of a random cascade generator on large scale forcing, Journal of Applied Meteorology, 33, 1526-1542.
Paquet, E., J. Gailhard, and R. Garçon (2006), Evolution de la méthode du Gradex : approche par type de temps et modélisation hydrologique, La houille blanche, 5(2006).
Paquet, E., F. Garavaglia, R. Garçon, and J. Gailhard (2013), The SCHADEX method: A semi-continuous rainfall–runoff simulation for extreme flood estimation, Journal of Hydrology, 495(0), 23-37.
Paquet, E., Y. Aubert, P. Arnaud, P. Royet, and J.-A. Fine (2014), Prédétermination des crues et côtes de projet par les méthodes SHYPRE et SCHADEX – Application à un aménagement fictif sur le Tech, La Houille Blanche - Revue Internationale de l'Eau, 5(2014), 61-68.
Payrastre, O., E. Gaume, and H. Andrieu (2011), Usefulness of historical information for flood frequency analyses: developments based on a case study., Water Resources Research, 47(W08511).
Perrin, C., C. Michel, and V. Andreassian (2001), Does a large number of parameters enhance model performance? Comparative assessment of common catchment model structures on 429 catchments, Journal of Hydrology, 242(3-4), 275-301.
Pickands, J. (1975), Statistical inference using extreme order statistics, Ann. Stat., 3, 119-131. Pujol, N., L. Neppel, and R. Sabatier (2007), Regional tests for trend detection in maximum precipitation series in
the French Mediterranean region, Hydrol. Sci. J, 52(5), 956-973. Renard, B. (2006), Détection et prise en compte d'éventuels impacts du changement climatique sur les extrêmes
hydrologiques en France, thesis, INP Grenoble. Renard, B., V. Garreta, and M. Lang (2006), An application of Bayesian analysis and Markov chain Monte Carlo
methods to the estimation of a regional trend in annual maxima., Water Resources Research, 42(W12422, doi:10.1029/2005WR004591), 17 pages.
Renard, B., et al. (2013), Data-based comparison of frequency analysis methods: A general framework, Water Resources Research, 49(2), 825-843.
Ribatet, M., E. Sauquet, J.-M. Grésillon, and T. B. M. J. Ouarda (2007), A regional Bayesian POT model for flood frequency analysis., Stochastic Environmental Research and Risk Assessment, 21(4), 327-339.
Rodriguez-Iturbe, I., and J. B. Valdes (1979), The Geomorphologic structure of Hydrologic Response., Water Resources Research, 15(6), 1409-1420.
Rodriguez-Iturbe, I., D. R. Cox, and F. R. S. e. V. Isham (1987), Some models for rainfall based on stochastic point processes., Proc. Royal Society London, A410, 269-288.
Rodriguez Iturbe, I., and P. S. Eagleson (1987), Mathematical methods of rainstorm events in space and time, Water Resources Research, 23(1), 181-190.
Rossi, F., M. Fiorentino, and P. Versace (1984), Two component extreme value distribution for flood frequency analysis., Water Resources Research, 20(7), 847-856.
Salvadori, G., C. De Michele, N. T. Kottegoda, and R. Rosso (2007), Extremes in nature : an approach using copulas, Springer.
Saporta, G. (2006), Probabilites, analyse des donnees et statistique.

114
Sauquet, E., L. Gottschalk, and E. Leblois (2000), Mapping average annual runoff: a hierarchical approach applying a stochastic interpolation scheme, Hydrological Sciences Journal, 45, 799-815.
Schönwiese, C. D., and J. Rapp (1997), Climate Trend Atlas of Europe Based on Observations, 1891-1990, Kluwer Academic Pub.
Shen, H. W., G. J. Koch, and J. T. B. Obeysekera (1990), Physically based flood features and frequencies., Journal of Hydraulic Engineering, 116(4), 494-514.
Sighomnou, D., and M. Desbordes (1988), Recherche d'un modèle de pluie de projet adapté aux précipitations de la zone tropicale africaine., Hydrologie continentale, 3(2), 131-139.
Sklar, A. (1959), Fonctions de répartition à n dimensions et leurs marges0, Publ. Inst, Statistics Univ. Paris(8), 229-231.
Skoien, J. O., R. Merz, and G. Bloschl (2006), Top-kriging – geostatistics on stream networks, Hydrology and Earth System Sciences, 10(2006), 277-287.
Sol, B., and C. Desouches (2005), Spatialisation à résolution kilométrique sur la France de paramètres liés aux précipitations. , Rapport d’étude Météo-France., Convention Météo-France DPPR n°03/1735., 41 pages.
Stedinger, J. R., and G. D. Tasker (1985), Regional hydrologic analysis: 1. Ordinary, weighted and genaralized least squares compared., Water Resources Research, 21(9), 1421-1432.
Sveinsson, O. G. B., J. D. Salas, and D. C. Boes (2003), Uncertainty of quantile estimators using the population index flood method, Water Resources Research, 39(8), SWC2.1-SWC2.20.
Tchiguirinskaia, I., P. Arnaud, J. Lavabre, and D. Schertzer (2008), Intercomparison of two stochastic methods to simulate heavy rains and floods. Résumé, paper presented at 2nd International HyMeX Workshop, 2-4 juin 2008. , Ecole Polytechnique, Palaiseau, France.
Thompson, C. S., P. J. Thomson, and X. Zheng (2007), Fitting a multisite daily rainfall model to New Zealand data, Journal of Hydrology, 340(1-2), 25-39.
Tourasse, P. (1981), Analyses spatiales et temporelles des précipitations et utilisation opérationnelle dans un système de prévision de crues. Application aux régions cévenoles., Thèse INPG, Grenoble, 190 pages.
UNISDR (2009), Terminologie pour la prévention des risques de catastrophe, 39. Veysseire, J. M., J. M. Soubeyroux, P. Arnaud, F. Garavaglia, F. Borchi, and R. Fantin (2011), Inter-comparaison
des méthodes probabilistes : comparaison des méthodes locales pour l’estimation des pluies extrêmes, in Projet ANR-08-RISK-03-01, edited, p. 44.
Veysseire, J. M., J. M. Soubeyroux, P. Arnaud, F. Garavaglia, F. Borchi, and R. Fantin (2012), Inter-comparaison des méthodes probabilistes. Rapport III.1 comparaison des méthodes locales pour l’estimation des pluies extrêmes, in Projet ANR-08-RISK-03-01, edited, p. 44.
Wasson, J. G., A. Chandesris, H. Pella, and L. Blanc (2002), Définition des hydro-écorégions françaises métropolitaines., Rapport final Cemagref-MEDD.
Waymire, E., and V. K. Gupta (1981), The mathematical structure of rainfall representations : a review of the stochastic rainfall models., Water Resources Research, 17(5), 1261-1272.
Waymire, E., V. K. Gupta, and I. Rodriguez Iturbe (1984), A Spectral Theory of Rainfall Intensity at the Meso-β Scale, Water Resources Research, 20(10), 1453-1465.
Weibull, W. (1951), A statistical distribution function of wide applicability, J. Appl. Mech.-Trans. ASME, 18(3), 293-297.
Weisse, A. K., and P. Bois (2001), Topographic effects on statistical characteristics of heavy rainfall and mapping in the French Alps, J. Appl. Meteor., 40(4), 720-740.
Willems, P. (2001), A spatial rainfall generator for small spatial scales, Journal of Hydrology, 252(126-144). Willems, P., et al. (2012), Rewiew of European simulation methods for flood-frequency-estimation. WG3: Flood
frequency analysis using rainfall-runoff methods., Report of Cost Action ES0901., 66 pages. Xoplaki, E., l.-R. J. F. Gonz\'a, J. Luterbacher, and H. Wanner (2004), Wet season Mediterranean precipitation
variability: influence of large-scale dynamics and trends, Climate Dynamics, 23(1), 63-78. Yang, X. (1993), Mise au point d'une méthode d'utilisation d'un modèle pluie-débit conceptuel pour la prévision
des crues en temps réel, thesis, 205 pp, Ecole Nationale des Ponts et Chaussées, CERGRENE. Zhai, P., A. Sun, F. Ren, X. Liu, B. Gao, and Q. Zhang (1999), Changes of Climate Extremes in China, Climatic
Change, 42(1), 203-218. Zhang, X., L. A. Vincent, W. D. Hogg, and A. Niitsoo (2000), Temperature and Precipitation Trends in Canada
During the 20th Century, Atmosphere-Ocean, 38(3), 395-429.