
DEUTSCH-FRANZOumlSISCHE SOMMERUNIVERSITAumlT
FUumlR NACHWUCHSWISSENSCHAFTLER 2011
UNIVERSITEacute DrsquoEacuteTEacute FRANCO-ALLEMANDE
POUR JEUNES CHERCHEURS 2011
CLOUD COMPUTING
DEacuteFIS ET OPPORTUNITEacuteS CLOUD COMPUTING
HERAUSFORDERUNGEN UND MOumlGLICHKEITEN
177 ndash 227 2011
Windows Azure as a Platform as a Service (PaaS)
Jared Jackson Microsoft Research
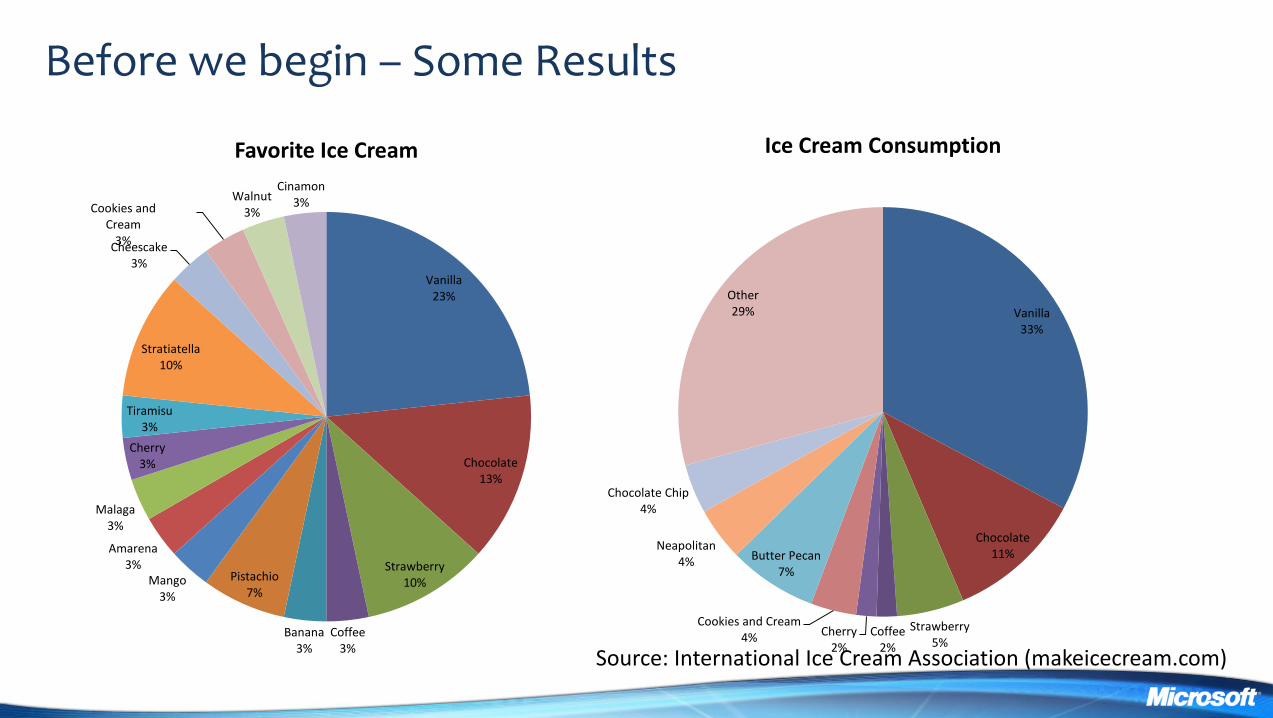
Before we begin ndash Some Results
Vanilla 23
Chocolate 13
Strawberry 10
Coffee 3
Banana 3
Pistachio 7
Mango 3
Amarena 3
Malaga 3
Cherry 3
Tiramisu 3
Stratiatella 10
Cheescake 3
Cookies and Cream
3
Walnut 3
Cinamon 3
Favorite Ice Cream
Vanilla 33
Chocolate 11
Strawberry 5
Coffee 2
Cherry 2
Cookies and Cream 4
Butter Pecan 7
Neapolitan 4
Chocolate Chip 4
Other 29
Ice Cream Consumption
Source International Ice Cream Association (makeicecreamcom)
Windows Azure Overview
4
Web Application Model Comparison
Machines Running IIS ASPNET
Machines Running Windows Services
Machines Running SQL Server
Ad Hoc Application Model
5
Web Application Model Comparison
Machines Running IIS ASPNET
Machines Running Windows Services
Machines Running SQL Server
Ad Hoc Application Model
Web Role Instances Worker Role
Instances
Azure Storage Blob Queue Table
SQL Azure
Windows Azure Application Model
Key Components Fabric Controller
bull Manages hardware and virtual machines for service
Compute bull Web Roles
bull Web application front end
bull Worker Roles bull Utility compute
bull VM Roles bull Custom compute role bull You own and customize the VM
Storage bull Blobs
bull Binary objects
bull Tables bull Entity storage
bull Queues bull Role coordination
bull SQL Azure bull SQL in the cloud
Key Components Fabric Controller
bull Think of it as an automated IT department
bull ldquoCloud Layerrdquo on top of
bull Windows Server 2008
bull A custom version of Hyper-V called the Windows Azure Hypervisor
bull Allows for automated management of virtual machines
Key Components Fabric Controller
bull Think of it as an automated IT department bull ldquoCloud Layerrdquo on top of
bull Windows Server 2008
bull A custom version of Hyper-V called the Windows Azure Hypervisor bull Allows for automated management of virtual machines
bull Itrsquos job is to provision deploy monitor and maintain applications in data centers
bull Applications have a ldquoshaperdquo and a ldquoconfigurationrdquo bull The configuration definition describes the shape of a service
bull Role types
bull Role VM sizes
bull External and internal endpoints
bull Local storage
bull The configuration settings configures a service bull Instance count
bull Storage keys
bull Application-specific settings
Key Components Fabric Controller
bull Manages ldquonodesrdquo and ldquoedgesrdquo in the ldquofabricrdquo (the hardware) bull Power-on automation devices bull Routers Switches bull Hardware load balancers bull Physical servers bull Virtual servers
bull State transitions bull Current State bull Goal State bull Does what is needed to reach and maintain the goal state
bull Itrsquos a perfect IT employee bull Never sleeps bull Doesnrsquot ever ask for raise bull Always does what you tell it to do in configuration definition and settings
Creating a New Project
Windows Azure Compute
Key Components ndash Compute Web Roles
Web Front End
bull Cloud web server
bull Web pages
bull Web services
You can create the following types
bull ASPNET web roles
bull ASPNET MVC 2 web roles
bull WCF service web roles
bull Worker roles
bull CGI-based web roles
Key Components ndash Compute Worker Roles
bull Utility compute
bull Windows Server 2008
bull Background processing
bull Each role can define an amount of local storage
bull Protected space on the local drive considered volatile storage
bull May communicate with outside services
bull Azure Storage
bull SQL Azure
bull Other Web services
bull Can expose external and internal endpoints
Suggested Application Model Using queues for reliable messaging
Scalable Fault Tolerant Applications
Queues are the application glue bull Decouple parts of application easier to scale independently bull Resource allocation different priority queues and backend servers bull Mask faults in worker roles (reliable messaging)
Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
Before we begin ndash Some Results
Vanilla 23
Chocolate 13
Strawberry 10
Coffee 3
Banana 3
Pistachio 7
Mango 3
Amarena 3
Malaga 3
Cherry 3
Tiramisu 3
Stratiatella 10
Cheescake 3
Cookies and Cream
3
Walnut 3
Cinamon 3
Favorite Ice Cream
Vanilla 33
Chocolate 11
Strawberry 5
Coffee 2
Cherry 2
Cookies and Cream 4
Butter Pecan 7
Neapolitan 4
Chocolate Chip 4
Other 29
Ice Cream Consumption
Source International Ice Cream Association (makeicecreamcom)
Windows Azure Overview
4
Web Application Model Comparison
Machines Running IIS ASPNET
Machines Running Windows Services
Machines Running SQL Server
Ad Hoc Application Model
5
Web Application Model Comparison
Machines Running IIS ASPNET
Machines Running Windows Services
Machines Running SQL Server
Ad Hoc Application Model
Web Role Instances Worker Role
Instances
Azure Storage Blob Queue Table
SQL Azure
Windows Azure Application Model
Key Components Fabric Controller
bull Manages hardware and virtual machines for service
Compute bull Web Roles
bull Web application front end
bull Worker Roles bull Utility compute
bull VM Roles bull Custom compute role bull You own and customize the VM
Storage bull Blobs
bull Binary objects
bull Tables bull Entity storage
bull Queues bull Role coordination
bull SQL Azure bull SQL in the cloud
Key Components Fabric Controller
bull Think of it as an automated IT department
bull ldquoCloud Layerrdquo on top of
bull Windows Server 2008
bull A custom version of Hyper-V called the Windows Azure Hypervisor
bull Allows for automated management of virtual machines
Key Components Fabric Controller
bull Think of it as an automated IT department bull ldquoCloud Layerrdquo on top of
bull Windows Server 2008
bull A custom version of Hyper-V called the Windows Azure Hypervisor bull Allows for automated management of virtual machines
bull Itrsquos job is to provision deploy monitor and maintain applications in data centers
bull Applications have a ldquoshaperdquo and a ldquoconfigurationrdquo bull The configuration definition describes the shape of a service
bull Role types
bull Role VM sizes
bull External and internal endpoints
bull Local storage
bull The configuration settings configures a service bull Instance count
bull Storage keys
bull Application-specific settings
Key Components Fabric Controller
bull Manages ldquonodesrdquo and ldquoedgesrdquo in the ldquofabricrdquo (the hardware) bull Power-on automation devices bull Routers Switches bull Hardware load balancers bull Physical servers bull Virtual servers
bull State transitions bull Current State bull Goal State bull Does what is needed to reach and maintain the goal state
bull Itrsquos a perfect IT employee bull Never sleeps bull Doesnrsquot ever ask for raise bull Always does what you tell it to do in configuration definition and settings
Creating a New Project
Windows Azure Compute
Key Components ndash Compute Web Roles
Web Front End
bull Cloud web server
bull Web pages
bull Web services
You can create the following types
bull ASPNET web roles
bull ASPNET MVC 2 web roles
bull WCF service web roles
bull Worker roles
bull CGI-based web roles
Key Components ndash Compute Worker Roles
bull Utility compute
bull Windows Server 2008
bull Background processing
bull Each role can define an amount of local storage
bull Protected space on the local drive considered volatile storage
bull May communicate with outside services
bull Azure Storage
bull SQL Azure
bull Other Web services
bull Can expose external and internal endpoints
Suggested Application Model Using queues for reliable messaging
Scalable Fault Tolerant Applications
Queues are the application glue bull Decouple parts of application easier to scale independently bull Resource allocation different priority queues and backend servers bull Mask faults in worker roles (reliable messaging)
Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Windows Azure Overview
4
Web Application Model Comparison
Machines Running IIS ASPNET
Machines Running Windows Services
Machines Running SQL Server
Ad Hoc Application Model
5
Web Application Model Comparison
Machines Running IIS ASPNET
Machines Running Windows Services
Machines Running SQL Server
Ad Hoc Application Model
Web Role Instances Worker Role
Instances
Azure Storage Blob Queue Table
SQL Azure
Windows Azure Application Model
Key Components Fabric Controller
bull Manages hardware and virtual machines for service
Compute bull Web Roles
bull Web application front end
bull Worker Roles bull Utility compute
bull VM Roles bull Custom compute role bull You own and customize the VM
Storage bull Blobs
bull Binary objects
bull Tables bull Entity storage
bull Queues bull Role coordination
bull SQL Azure bull SQL in the cloud
Key Components Fabric Controller
bull Think of it as an automated IT department
bull ldquoCloud Layerrdquo on top of
bull Windows Server 2008
bull A custom version of Hyper-V called the Windows Azure Hypervisor
bull Allows for automated management of virtual machines
Key Components Fabric Controller
bull Think of it as an automated IT department bull ldquoCloud Layerrdquo on top of
bull Windows Server 2008
bull A custom version of Hyper-V called the Windows Azure Hypervisor bull Allows for automated management of virtual machines
bull Itrsquos job is to provision deploy monitor and maintain applications in data centers
bull Applications have a ldquoshaperdquo and a ldquoconfigurationrdquo bull The configuration definition describes the shape of a service
bull Role types
bull Role VM sizes
bull External and internal endpoints
bull Local storage
bull The configuration settings configures a service bull Instance count
bull Storage keys
bull Application-specific settings
Key Components Fabric Controller
bull Manages ldquonodesrdquo and ldquoedgesrdquo in the ldquofabricrdquo (the hardware) bull Power-on automation devices bull Routers Switches bull Hardware load balancers bull Physical servers bull Virtual servers
bull State transitions bull Current State bull Goal State bull Does what is needed to reach and maintain the goal state
bull Itrsquos a perfect IT employee bull Never sleeps bull Doesnrsquot ever ask for raise bull Always does what you tell it to do in configuration definition and settings
Creating a New Project
Windows Azure Compute
Key Components ndash Compute Web Roles
Web Front End
bull Cloud web server
bull Web pages
bull Web services
You can create the following types
bull ASPNET web roles
bull ASPNET MVC 2 web roles
bull WCF service web roles
bull Worker roles
bull CGI-based web roles
Key Components ndash Compute Worker Roles
bull Utility compute
bull Windows Server 2008
bull Background processing
bull Each role can define an amount of local storage
bull Protected space on the local drive considered volatile storage
bull May communicate with outside services
bull Azure Storage
bull SQL Azure
bull Other Web services
bull Can expose external and internal endpoints
Suggested Application Model Using queues for reliable messaging
Scalable Fault Tolerant Applications
Queues are the application glue bull Decouple parts of application easier to scale independently bull Resource allocation different priority queues and backend servers bull Mask faults in worker roles (reliable messaging)
Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

4
Web Application Model Comparison
Machines Running IIS ASPNET
Machines Running Windows Services
Machines Running SQL Server
Ad Hoc Application Model
5
Web Application Model Comparison
Machines Running IIS ASPNET
Machines Running Windows Services
Machines Running SQL Server
Ad Hoc Application Model
Web Role Instances Worker Role
Instances
Azure Storage Blob Queue Table
SQL Azure
Windows Azure Application Model
Key Components Fabric Controller
bull Manages hardware and virtual machines for service
Compute bull Web Roles
bull Web application front end
bull Worker Roles bull Utility compute
bull VM Roles bull Custom compute role bull You own and customize the VM
Storage bull Blobs
bull Binary objects
bull Tables bull Entity storage
bull Queues bull Role coordination
bull SQL Azure bull SQL in the cloud
Key Components Fabric Controller
bull Think of it as an automated IT department
bull ldquoCloud Layerrdquo on top of
bull Windows Server 2008
bull A custom version of Hyper-V called the Windows Azure Hypervisor
bull Allows for automated management of virtual machines
Key Components Fabric Controller
bull Think of it as an automated IT department bull ldquoCloud Layerrdquo on top of
bull Windows Server 2008
bull A custom version of Hyper-V called the Windows Azure Hypervisor bull Allows for automated management of virtual machines
bull Itrsquos job is to provision deploy monitor and maintain applications in data centers
bull Applications have a ldquoshaperdquo and a ldquoconfigurationrdquo bull The configuration definition describes the shape of a service
bull Role types
bull Role VM sizes
bull External and internal endpoints
bull Local storage
bull The configuration settings configures a service bull Instance count
bull Storage keys
bull Application-specific settings
Key Components Fabric Controller
bull Manages ldquonodesrdquo and ldquoedgesrdquo in the ldquofabricrdquo (the hardware) bull Power-on automation devices bull Routers Switches bull Hardware load balancers bull Physical servers bull Virtual servers
bull State transitions bull Current State bull Goal State bull Does what is needed to reach and maintain the goal state
bull Itrsquos a perfect IT employee bull Never sleeps bull Doesnrsquot ever ask for raise bull Always does what you tell it to do in configuration definition and settings
Creating a New Project
Windows Azure Compute
Key Components ndash Compute Web Roles
Web Front End
bull Cloud web server
bull Web pages
bull Web services
You can create the following types
bull ASPNET web roles
bull ASPNET MVC 2 web roles
bull WCF service web roles
bull Worker roles
bull CGI-based web roles
Key Components ndash Compute Worker Roles
bull Utility compute
bull Windows Server 2008
bull Background processing
bull Each role can define an amount of local storage
bull Protected space on the local drive considered volatile storage
bull May communicate with outside services
bull Azure Storage
bull SQL Azure
bull Other Web services
bull Can expose external and internal endpoints
Suggested Application Model Using queues for reliable messaging
Scalable Fault Tolerant Applications
Queues are the application glue bull Decouple parts of application easier to scale independently bull Resource allocation different priority queues and backend servers bull Mask faults in worker roles (reliable messaging)
Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

5
Web Application Model Comparison
Machines Running IIS ASPNET
Machines Running Windows Services
Machines Running SQL Server
Ad Hoc Application Model
Web Role Instances Worker Role
Instances
Azure Storage Blob Queue Table
SQL Azure
Windows Azure Application Model
Key Components Fabric Controller
bull Manages hardware and virtual machines for service
Compute bull Web Roles
bull Web application front end
bull Worker Roles bull Utility compute
bull VM Roles bull Custom compute role bull You own and customize the VM
Storage bull Blobs
bull Binary objects
bull Tables bull Entity storage
bull Queues bull Role coordination
bull SQL Azure bull SQL in the cloud
Key Components Fabric Controller
bull Think of it as an automated IT department
bull ldquoCloud Layerrdquo on top of
bull Windows Server 2008
bull A custom version of Hyper-V called the Windows Azure Hypervisor
bull Allows for automated management of virtual machines
Key Components Fabric Controller
bull Think of it as an automated IT department bull ldquoCloud Layerrdquo on top of
bull Windows Server 2008
bull A custom version of Hyper-V called the Windows Azure Hypervisor bull Allows for automated management of virtual machines
bull Itrsquos job is to provision deploy monitor and maintain applications in data centers
bull Applications have a ldquoshaperdquo and a ldquoconfigurationrdquo bull The configuration definition describes the shape of a service
bull Role types
bull Role VM sizes
bull External and internal endpoints
bull Local storage
bull The configuration settings configures a service bull Instance count
bull Storage keys
bull Application-specific settings
Key Components Fabric Controller
bull Manages ldquonodesrdquo and ldquoedgesrdquo in the ldquofabricrdquo (the hardware) bull Power-on automation devices bull Routers Switches bull Hardware load balancers bull Physical servers bull Virtual servers
bull State transitions bull Current State bull Goal State bull Does what is needed to reach and maintain the goal state
bull Itrsquos a perfect IT employee bull Never sleeps bull Doesnrsquot ever ask for raise bull Always does what you tell it to do in configuration definition and settings
Creating a New Project
Windows Azure Compute
Key Components ndash Compute Web Roles
Web Front End
bull Cloud web server
bull Web pages
bull Web services
You can create the following types
bull ASPNET web roles
bull ASPNET MVC 2 web roles
bull WCF service web roles
bull Worker roles
bull CGI-based web roles
Key Components ndash Compute Worker Roles
bull Utility compute
bull Windows Server 2008
bull Background processing
bull Each role can define an amount of local storage
bull Protected space on the local drive considered volatile storage
bull May communicate with outside services
bull Azure Storage
bull SQL Azure
bull Other Web services
bull Can expose external and internal endpoints
Suggested Application Model Using queues for reliable messaging
Scalable Fault Tolerant Applications
Queues are the application glue bull Decouple parts of application easier to scale independently bull Resource allocation different priority queues and backend servers bull Mask faults in worker roles (reliable messaging)
Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Key Components Fabric Controller
bull Manages hardware and virtual machines for service
Compute bull Web Roles
bull Web application front end
bull Worker Roles bull Utility compute
bull VM Roles bull Custom compute role bull You own and customize the VM
Storage bull Blobs
bull Binary objects
bull Tables bull Entity storage
bull Queues bull Role coordination
bull SQL Azure bull SQL in the cloud
Key Components Fabric Controller
bull Think of it as an automated IT department
bull ldquoCloud Layerrdquo on top of
bull Windows Server 2008
bull A custom version of Hyper-V called the Windows Azure Hypervisor
bull Allows for automated management of virtual machines
Key Components Fabric Controller
bull Think of it as an automated IT department bull ldquoCloud Layerrdquo on top of
bull Windows Server 2008
bull A custom version of Hyper-V called the Windows Azure Hypervisor bull Allows for automated management of virtual machines
bull Itrsquos job is to provision deploy monitor and maintain applications in data centers
bull Applications have a ldquoshaperdquo and a ldquoconfigurationrdquo bull The configuration definition describes the shape of a service
bull Role types
bull Role VM sizes
bull External and internal endpoints
bull Local storage
bull The configuration settings configures a service bull Instance count
bull Storage keys
bull Application-specific settings
Key Components Fabric Controller
bull Manages ldquonodesrdquo and ldquoedgesrdquo in the ldquofabricrdquo (the hardware) bull Power-on automation devices bull Routers Switches bull Hardware load balancers bull Physical servers bull Virtual servers
bull State transitions bull Current State bull Goal State bull Does what is needed to reach and maintain the goal state
bull Itrsquos a perfect IT employee bull Never sleeps bull Doesnrsquot ever ask for raise bull Always does what you tell it to do in configuration definition and settings
Creating a New Project
Windows Azure Compute
Key Components ndash Compute Web Roles
Web Front End
bull Cloud web server
bull Web pages
bull Web services
You can create the following types
bull ASPNET web roles
bull ASPNET MVC 2 web roles
bull WCF service web roles
bull Worker roles
bull CGI-based web roles
Key Components ndash Compute Worker Roles
bull Utility compute
bull Windows Server 2008
bull Background processing
bull Each role can define an amount of local storage
bull Protected space on the local drive considered volatile storage
bull May communicate with outside services
bull Azure Storage
bull SQL Azure
bull Other Web services
bull Can expose external and internal endpoints
Suggested Application Model Using queues for reliable messaging
Scalable Fault Tolerant Applications
Queues are the application glue bull Decouple parts of application easier to scale independently bull Resource allocation different priority queues and backend servers bull Mask faults in worker roles (reliable messaging)
Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
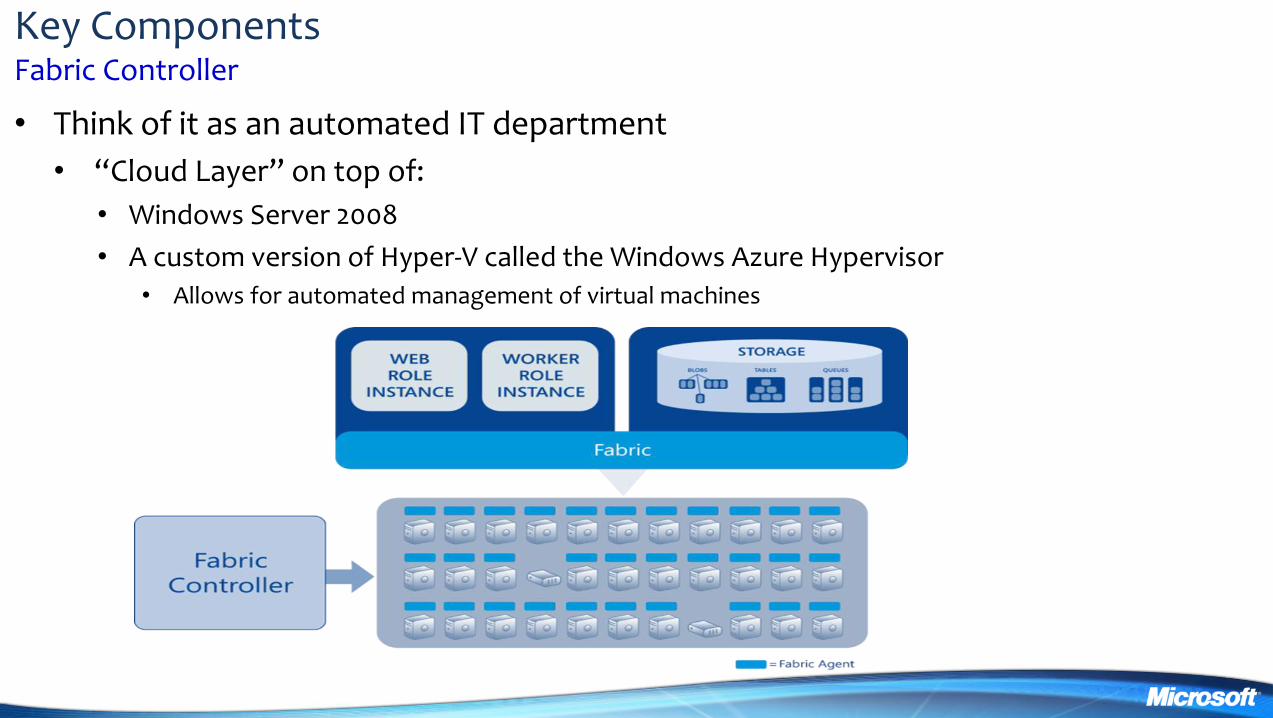
Key Components Fabric Controller
bull Think of it as an automated IT department
bull ldquoCloud Layerrdquo on top of
bull Windows Server 2008
bull A custom version of Hyper-V called the Windows Azure Hypervisor
bull Allows for automated management of virtual machines
Key Components Fabric Controller
bull Think of it as an automated IT department bull ldquoCloud Layerrdquo on top of
bull Windows Server 2008
bull A custom version of Hyper-V called the Windows Azure Hypervisor bull Allows for automated management of virtual machines
bull Itrsquos job is to provision deploy monitor and maintain applications in data centers
bull Applications have a ldquoshaperdquo and a ldquoconfigurationrdquo bull The configuration definition describes the shape of a service
bull Role types
bull Role VM sizes
bull External and internal endpoints
bull Local storage
bull The configuration settings configures a service bull Instance count
bull Storage keys
bull Application-specific settings
Key Components Fabric Controller
bull Manages ldquonodesrdquo and ldquoedgesrdquo in the ldquofabricrdquo (the hardware) bull Power-on automation devices bull Routers Switches bull Hardware load balancers bull Physical servers bull Virtual servers
bull State transitions bull Current State bull Goal State bull Does what is needed to reach and maintain the goal state
bull Itrsquos a perfect IT employee bull Never sleeps bull Doesnrsquot ever ask for raise bull Always does what you tell it to do in configuration definition and settings
Creating a New Project
Windows Azure Compute
Key Components ndash Compute Web Roles
Web Front End
bull Cloud web server
bull Web pages
bull Web services
You can create the following types
bull ASPNET web roles
bull ASPNET MVC 2 web roles
bull WCF service web roles
bull Worker roles
bull CGI-based web roles
Key Components ndash Compute Worker Roles
bull Utility compute
bull Windows Server 2008
bull Background processing
bull Each role can define an amount of local storage
bull Protected space on the local drive considered volatile storage
bull May communicate with outside services
bull Azure Storage
bull SQL Azure
bull Other Web services
bull Can expose external and internal endpoints
Suggested Application Model Using queues for reliable messaging
Scalable Fault Tolerant Applications
Queues are the application glue bull Decouple parts of application easier to scale independently bull Resource allocation different priority queues and backend servers bull Mask faults in worker roles (reliable messaging)
Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Key Components Fabric Controller
bull Think of it as an automated IT department bull ldquoCloud Layerrdquo on top of
bull Windows Server 2008
bull A custom version of Hyper-V called the Windows Azure Hypervisor bull Allows for automated management of virtual machines
bull Itrsquos job is to provision deploy monitor and maintain applications in data centers
bull Applications have a ldquoshaperdquo and a ldquoconfigurationrdquo bull The configuration definition describes the shape of a service
bull Role types
bull Role VM sizes
bull External and internal endpoints
bull Local storage
bull The configuration settings configures a service bull Instance count
bull Storage keys
bull Application-specific settings
Key Components Fabric Controller
bull Manages ldquonodesrdquo and ldquoedgesrdquo in the ldquofabricrdquo (the hardware) bull Power-on automation devices bull Routers Switches bull Hardware load balancers bull Physical servers bull Virtual servers
bull State transitions bull Current State bull Goal State bull Does what is needed to reach and maintain the goal state
bull Itrsquos a perfect IT employee bull Never sleeps bull Doesnrsquot ever ask for raise bull Always does what you tell it to do in configuration definition and settings
Creating a New Project
Windows Azure Compute
Key Components ndash Compute Web Roles
Web Front End
bull Cloud web server
bull Web pages
bull Web services
You can create the following types
bull ASPNET web roles
bull ASPNET MVC 2 web roles
bull WCF service web roles
bull Worker roles
bull CGI-based web roles
Key Components ndash Compute Worker Roles
bull Utility compute
bull Windows Server 2008
bull Background processing
bull Each role can define an amount of local storage
bull Protected space on the local drive considered volatile storage
bull May communicate with outside services
bull Azure Storage
bull SQL Azure
bull Other Web services
bull Can expose external and internal endpoints
Suggested Application Model Using queues for reliable messaging
Scalable Fault Tolerant Applications
Queues are the application glue bull Decouple parts of application easier to scale independently bull Resource allocation different priority queues and backend servers bull Mask faults in worker roles (reliable messaging)
Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Key Components Fabric Controller
bull Manages ldquonodesrdquo and ldquoedgesrdquo in the ldquofabricrdquo (the hardware) bull Power-on automation devices bull Routers Switches bull Hardware load balancers bull Physical servers bull Virtual servers
bull State transitions bull Current State bull Goal State bull Does what is needed to reach and maintain the goal state
bull Itrsquos a perfect IT employee bull Never sleeps bull Doesnrsquot ever ask for raise bull Always does what you tell it to do in configuration definition and settings
Creating a New Project
Windows Azure Compute
Key Components ndash Compute Web Roles
Web Front End
bull Cloud web server
bull Web pages
bull Web services
You can create the following types
bull ASPNET web roles
bull ASPNET MVC 2 web roles
bull WCF service web roles
bull Worker roles
bull CGI-based web roles
Key Components ndash Compute Worker Roles
bull Utility compute
bull Windows Server 2008
bull Background processing
bull Each role can define an amount of local storage
bull Protected space on the local drive considered volatile storage
bull May communicate with outside services
bull Azure Storage
bull SQL Azure
bull Other Web services
bull Can expose external and internal endpoints
Suggested Application Model Using queues for reliable messaging
Scalable Fault Tolerant Applications
Queues are the application glue bull Decouple parts of application easier to scale independently bull Resource allocation different priority queues and backend servers bull Mask faults in worker roles (reliable messaging)
Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
Creating a New Project
Windows Azure Compute
Key Components ndash Compute Web Roles
Web Front End
bull Cloud web server
bull Web pages
bull Web services
You can create the following types
bull ASPNET web roles
bull ASPNET MVC 2 web roles
bull WCF service web roles
bull Worker roles
bull CGI-based web roles
Key Components ndash Compute Worker Roles
bull Utility compute
bull Windows Server 2008
bull Background processing
bull Each role can define an amount of local storage
bull Protected space on the local drive considered volatile storage
bull May communicate with outside services
bull Azure Storage
bull SQL Azure
bull Other Web services
bull Can expose external and internal endpoints
Suggested Application Model Using queues for reliable messaging
Scalable Fault Tolerant Applications
Queues are the application glue bull Decouple parts of application easier to scale independently bull Resource allocation different priority queues and backend servers bull Mask faults in worker roles (reliable messaging)
Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
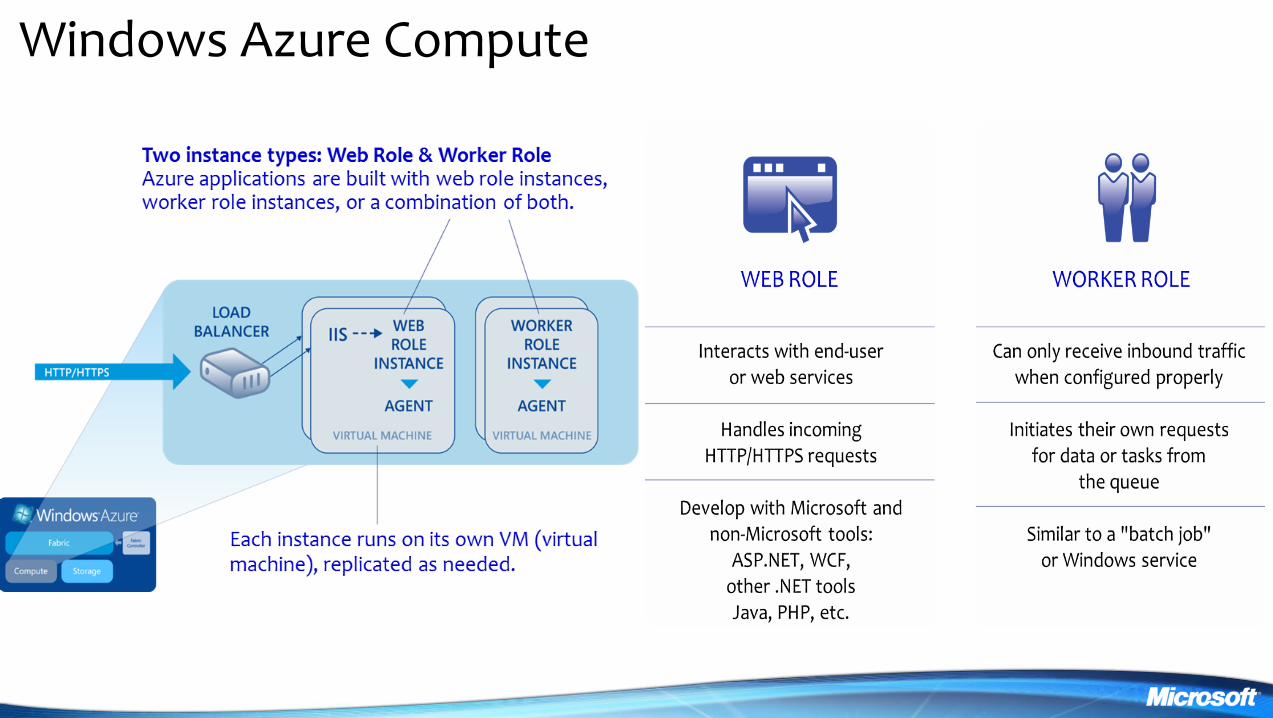
Windows Azure Compute
Key Components ndash Compute Web Roles
Web Front End
bull Cloud web server
bull Web pages
bull Web services
You can create the following types
bull ASPNET web roles
bull ASPNET MVC 2 web roles
bull WCF service web roles
bull Worker roles
bull CGI-based web roles
Key Components ndash Compute Worker Roles
bull Utility compute
bull Windows Server 2008
bull Background processing
bull Each role can define an amount of local storage
bull Protected space on the local drive considered volatile storage
bull May communicate with outside services
bull Azure Storage
bull SQL Azure
bull Other Web services
bull Can expose external and internal endpoints
Suggested Application Model Using queues for reliable messaging
Scalable Fault Tolerant Applications
Queues are the application glue bull Decouple parts of application easier to scale independently bull Resource allocation different priority queues and backend servers bull Mask faults in worker roles (reliable messaging)
Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
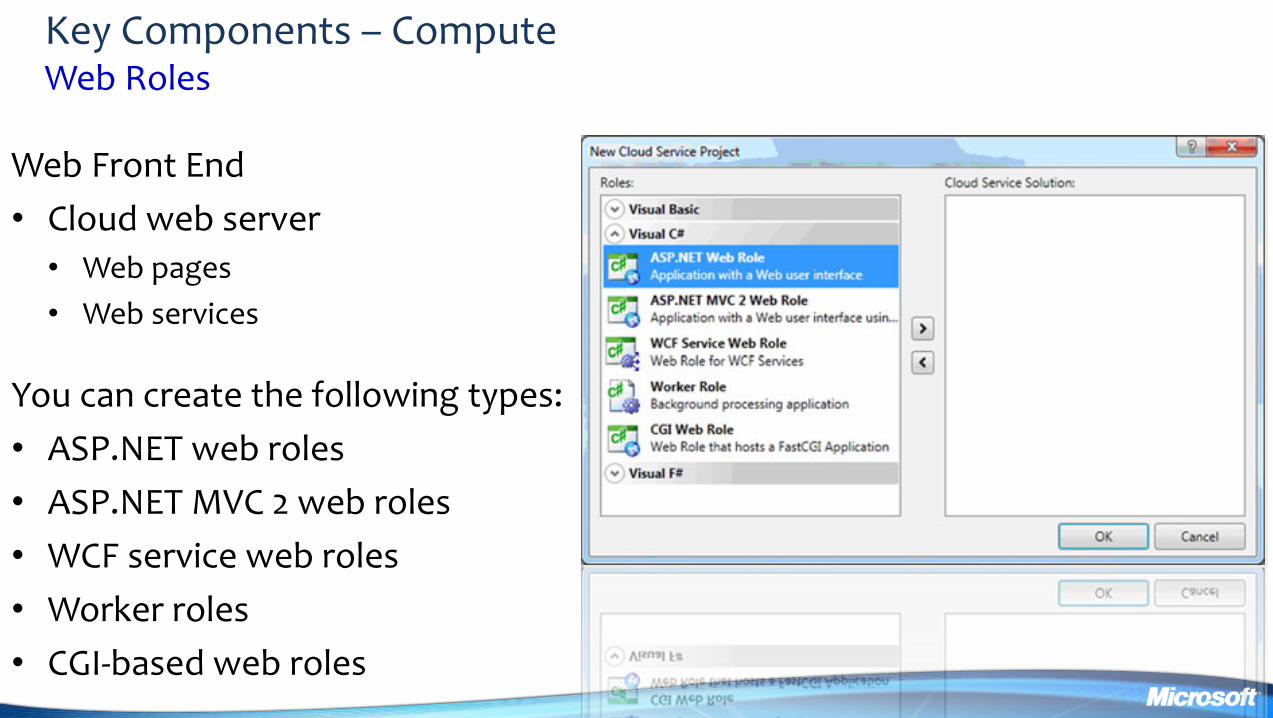
Key Components ndash Compute Web Roles
Web Front End
bull Cloud web server
bull Web pages
bull Web services
You can create the following types
bull ASPNET web roles
bull ASPNET MVC 2 web roles
bull WCF service web roles
bull Worker roles
bull CGI-based web roles
Key Components ndash Compute Worker Roles
bull Utility compute
bull Windows Server 2008
bull Background processing
bull Each role can define an amount of local storage
bull Protected space on the local drive considered volatile storage
bull May communicate with outside services
bull Azure Storage
bull SQL Azure
bull Other Web services
bull Can expose external and internal endpoints
Suggested Application Model Using queues for reliable messaging
Scalable Fault Tolerant Applications
Queues are the application glue bull Decouple parts of application easier to scale independently bull Resource allocation different priority queues and backend servers bull Mask faults in worker roles (reliable messaging)
Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Key Components ndash Compute Worker Roles
bull Utility compute
bull Windows Server 2008
bull Background processing
bull Each role can define an amount of local storage
bull Protected space on the local drive considered volatile storage
bull May communicate with outside services
bull Azure Storage
bull SQL Azure
bull Other Web services
bull Can expose external and internal endpoints
Suggested Application Model Using queues for reliable messaging
Scalable Fault Tolerant Applications
Queues are the application glue bull Decouple parts of application easier to scale independently bull Resource allocation different priority queues and backend servers bull Mask faults in worker roles (reliable messaging)
Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
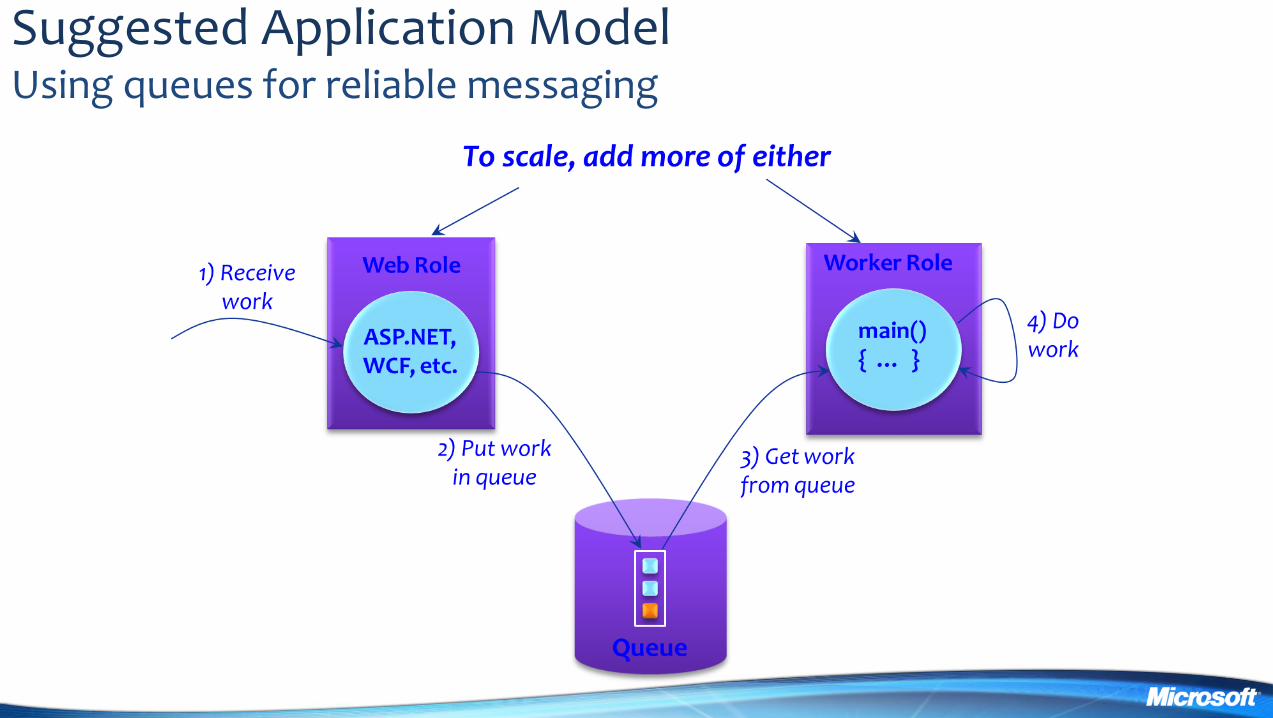
Suggested Application Model Using queues for reliable messaging
Scalable Fault Tolerant Applications
Queues are the application glue bull Decouple parts of application easier to scale independently bull Resource allocation different priority queues and backend servers bull Mask faults in worker roles (reliable messaging)
Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
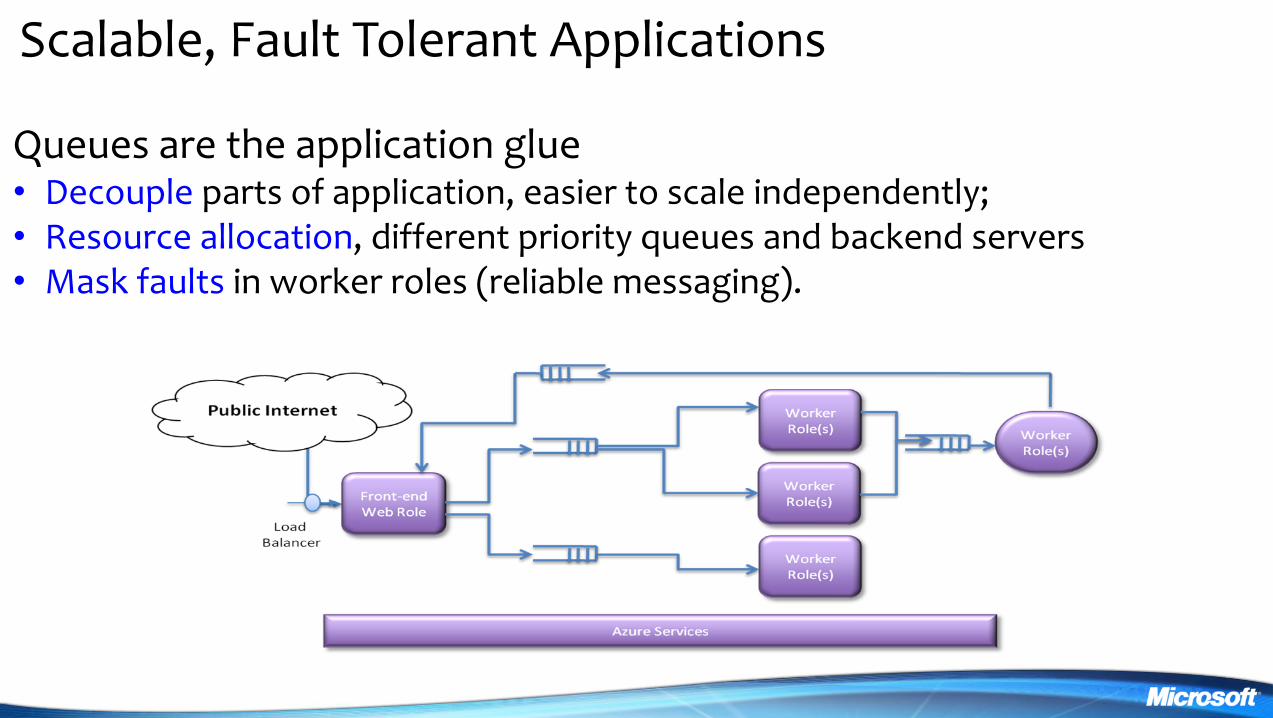
Scalable Fault Tolerant Applications
Queues are the application glue bull Decouple parts of application easier to scale independently bull Resource allocation different priority queues and backend servers bull Mask faults in worker roles (reliable messaging)
Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Key Components ndash Compute VM Roles
bull Customized Role
bull You own the box
bull How it works
bull Download ldquoGuest OSrdquo to Server 2008 Hyper-V
bull Customize the OS as you need to
bull Upload the differences VHD
bull Azure runs your VM role using
bull Base OS
bull Differences VHD
Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Application Hosting
lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

lsquoGrokkingrsquo the service model
bull Imagine white-boarding out your service architecture with boxes for nodes and arrows describing how they communicate
bull The service model is the same diagram written down in a declarative format
bull You give the Fabric the service model and the binaries that go with each of those nodes
bull The Fabric can provision deploy and manage that diagram for you
bull Find hardware home
bull Copy and launch your app binaries
bull Monitor your app and the hardware
bull In case of failure take action Perhaps even relocate your app
bull At all times the lsquodiagramrsquo stays whole
Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Automated Service Management Provide code + service model
bull Platform identifies and allocates resources deploys the service manages service health
bull Configuration is handled by two files
ServiceDefinitioncsdef
ServiceConfigurationcscfg
Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Service Definition
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
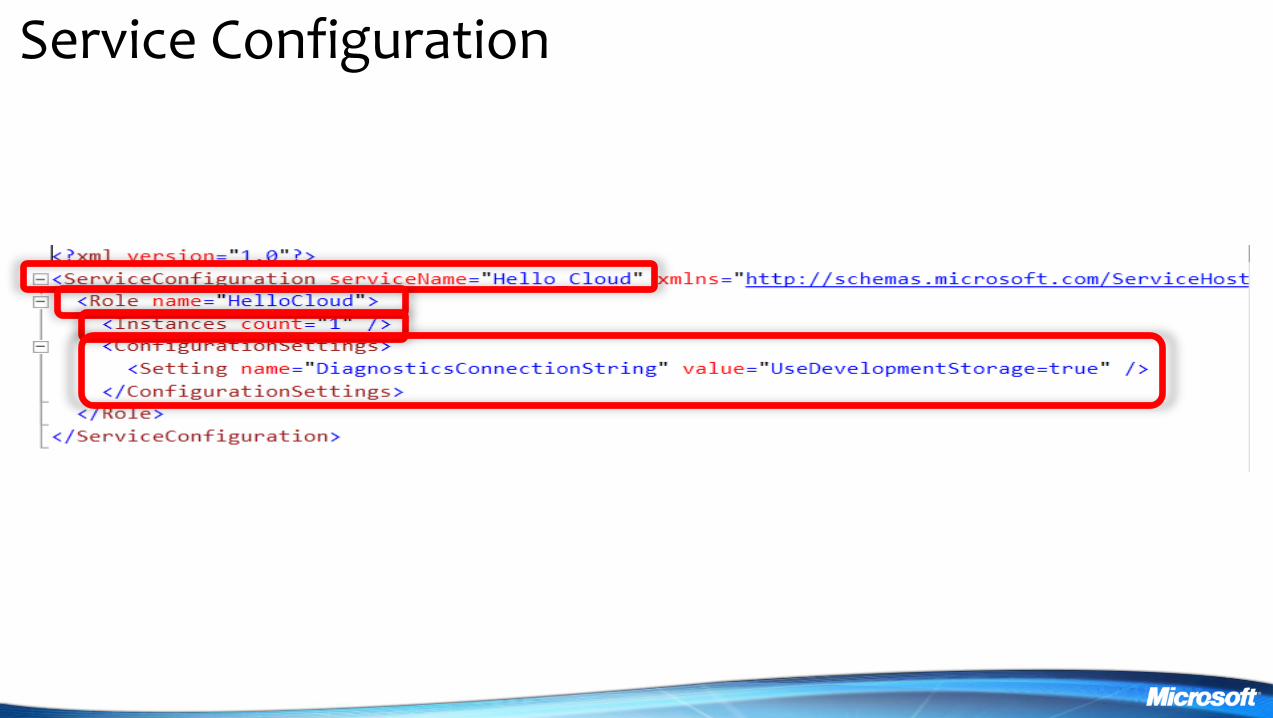
Service Configuration
GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

GUI
Double click on Role Name in Azure Project
Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Deploying to the cloud
bull We can deploy from the portal or from script
bull VS builds two files
bull Encrypted package of your code
bull Your config file
bull You must create an Azure account then a service and then you deploy your code
bull Can take up to 20 minutes
bull (which is better than six months)
Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Service Management API
bullREST based API to manage your services
bullX509-certs for authentication
bullLets you create delete change upgrade swaphellip
bullLots of community and MSFT-built tools around the API
- Easy to roll your own
The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

The Secret Sauce ndash The Fabric
The Fabric is the lsquobrainrsquo behind Windows Azure
1 Process service model
1 Determine resource requirements
2 Create role images
2 Allocate resources
3 Prepare nodes
1 Place role images on nodes
2 Configure settings
3 Start roles
4 Configure load balancers
5 Maintain service health
1 If role fails restart the role based on policy
2 If node fails migrate the role based on policy
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
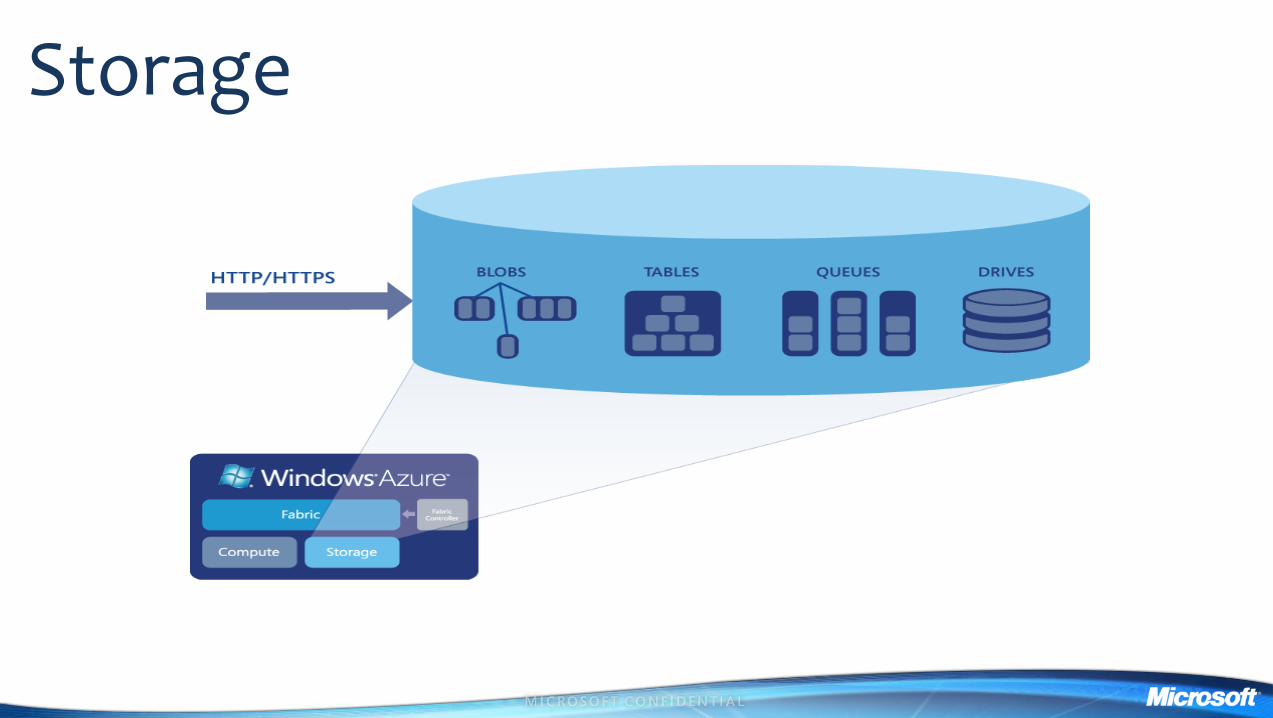
Storage
Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Durable Storage At Massive Scale
Blob
- Massive files eg videos logs
Drive
- Use standard file system APIs
Tables - Non-relational but with few scale limits
- Use SQL Azure for relational data
Queues
- Facilitate loosely-coupled reliable systems
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
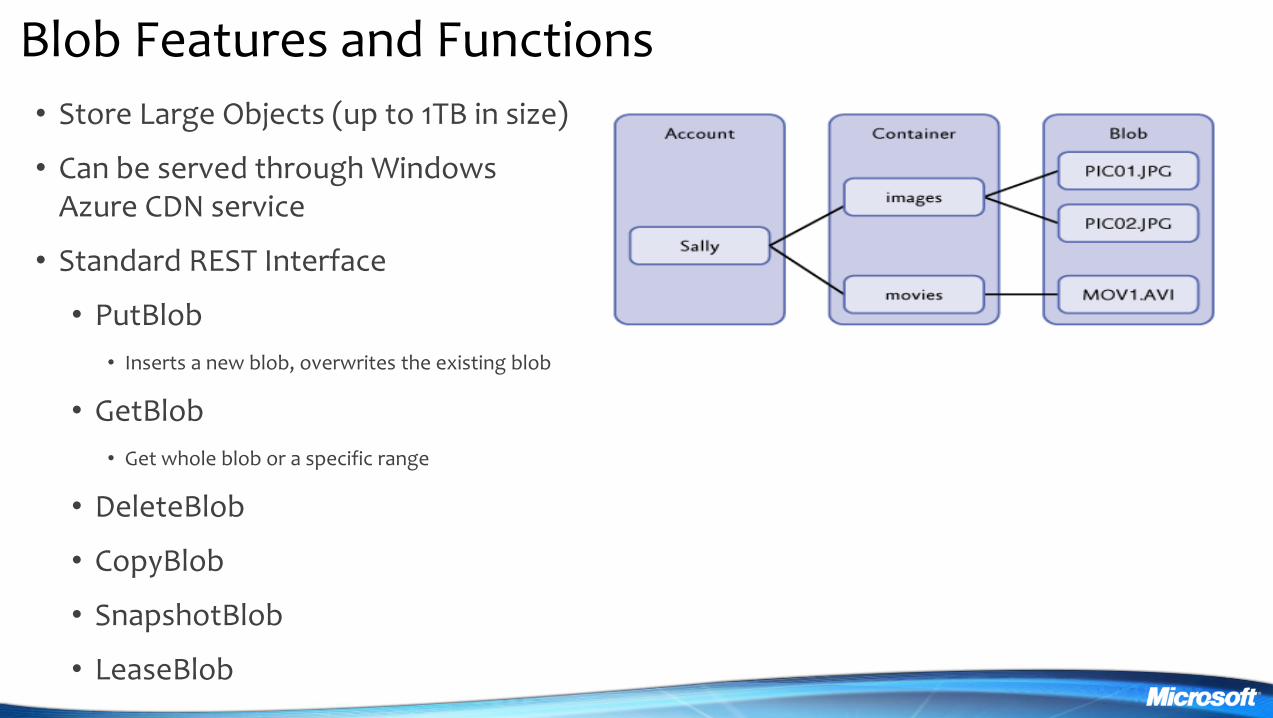
Blob Features and Functions
bull Store Large Objects (up to 1TB in size)
bull Can be served through Windows Azure CDN service
bull Standard REST Interface
bull PutBlob
bull Inserts a new blob overwrites the existing blob
bull GetBlob
bull Get whole blob or a specific range
bull DeleteBlob
bull CopyBlob
bull SnapshotBlob
bull LeaseBlob
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
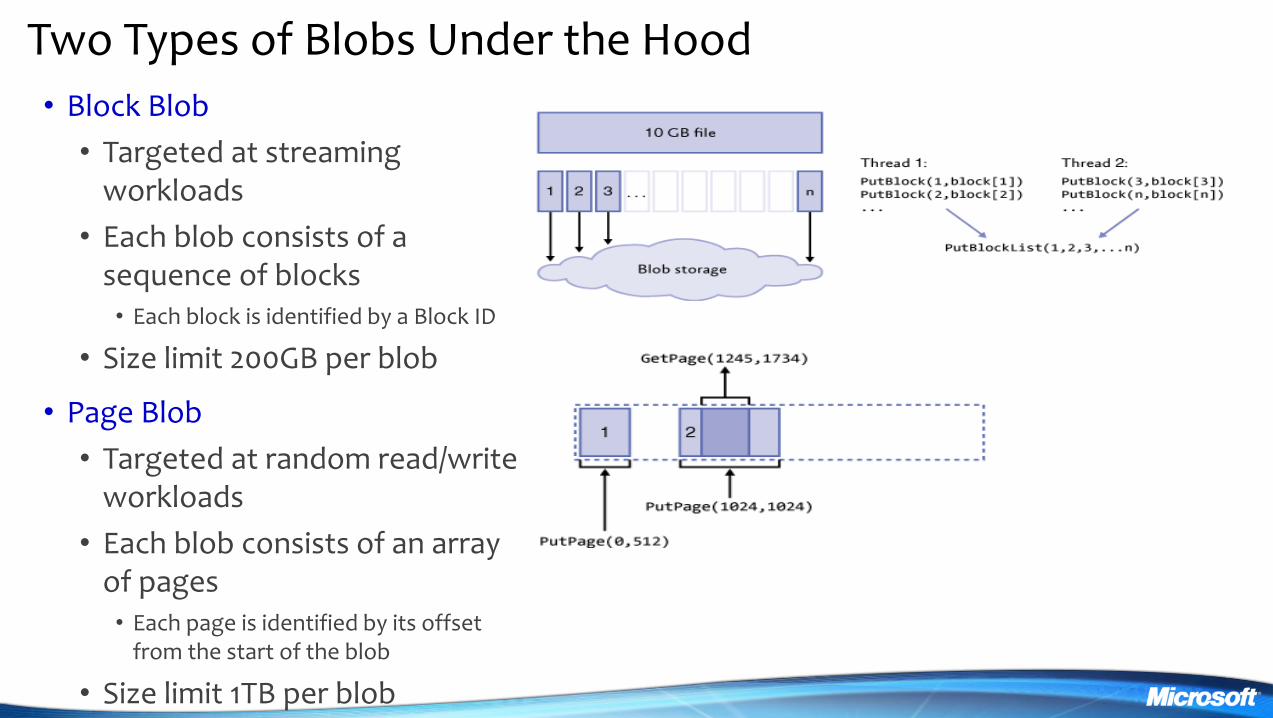
Two Types of Blobs Under the Hood
bull Block Blob
bull Targeted at streaming workloads
bull Each blob consists of a sequence of blocks bull Each block is identified by a Block ID
bull Size limit 200GB per blob
bull Page Blob
bull Targeted at random readwrite workloads
bull Each blob consists of an array of pages bull Each page is identified by its offset
from the start of the blob
bull Size limit 1TB per blob
Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Windows Azure Drive
bull Provides a durable NTFS volume for Windows Azure applications to use
bull Use existing NTFS APIs to access a durable drive bull Durability and survival of data on application failover
bull Enables migrating existing NTFS applications to the cloud
bull A Windows Azure Drive is a Page Blob
bull Example mount Page Blob as X bull httpltaccountnamegtblobcorewindowsnetltcontainernamegtltblobnamegt
bull All writes to drive are made durable to the Page Blob bull Drive made durable through standard Page Blob replication
bull Drive persists even when not mounted as a Page Blob
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
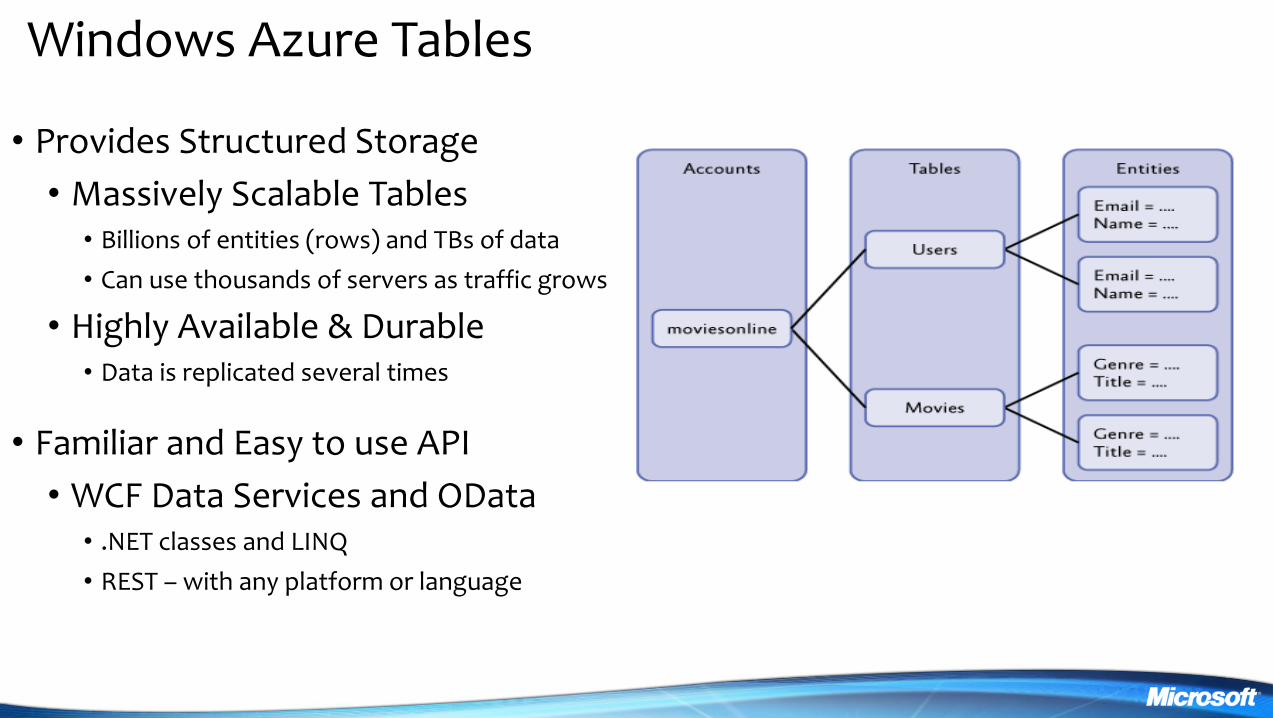
Windows Azure Tables
bull Provides Structured Storage
bull Massively Scalable Tables bull Billions of entities (rows) and TBs of data
bull Can use thousands of servers as traffic grows
bull Highly Available amp Durable bull Data is replicated several times
bull Familiar and Easy to use API
bull WCF Data Services and OData bull NET classes and LINQ
bull REST ndash with any platform or language
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
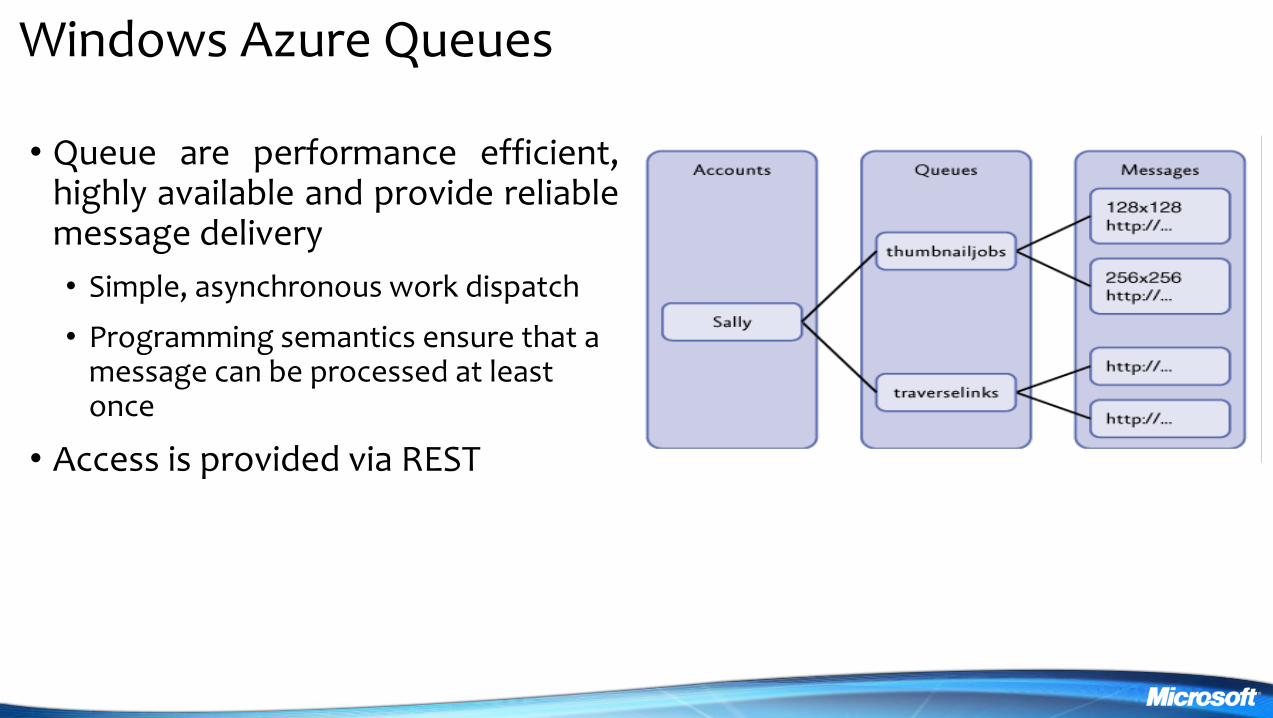
Windows Azure Queues
bull Queue are performance efficient highly available and provide reliable message delivery
bull Simple asynchronous work dispatch
bull Programming semantics ensure that a message can be processed at least once
bull Access is provided via REST
Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Storage Partitioning
Understanding partitioning is key to understanding performance
bull Different for each data type (blobs entities queues) Every data object has a partition key
bull A partition can be served by a single server
bull System load balances partitions based on traffic pattern
bull Controls entity locality Partition key is unit of scale
bull Load balancing can take a few minutes to kick in
bull Can take a couple of seconds for partition to be available on a different server
System load balances
bull Use exponential backoff on ldquoServer Busyrdquo
bull Our system load balances to meet your traffic needs
bull Single partition limits have been reached Server Busy
Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Partition Keys In Each Abstraction
bull Entities w same PartitionKey value served from same partition Entities ndash TableName + PartitionKey
PartitionKey (CustomerId) RowKey (RowKind)
Name CreditCardNumber OrderTotal
1 Customer-John Smith John Smith xxxx-xxxx-xxxx-xxxx
1 Order ndash 1 $3512
2 Customer-Bill Johnson Bill Johnson xxxx-xxxx-xxxx-xxxx
2 Order ndash 3 $1000
bull Every blob and its snapshots are in a single partition Blobs ndash Container name + Blob name
bullAll messages for a single queue belong to the same partition Messages ndash Queue Name
Container Name Blob Name
image annarborbighousejpg
image foxboroughgillettejpg
video annarborbighousejpg
Queue Message
jobs Message1
jobs Message2
workflow Message1
Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Scalability Targets
Storage Account
bull Capacity ndash Up to 100 TBs
bull Transactions ndash Up to a few thousand requests per second
bull Bandwidth ndash Up to a few hundred megabytes per second
Single QueueTable Partition
bull Up to 500 transactions per second
To go above these numbers partition between multiple storage accounts and partitions
When limit is hit app will see lsquo503 server busyrsquo applications should implement exponential backoff
Single Blob Partition
bull Throughput up to 60 MBs
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
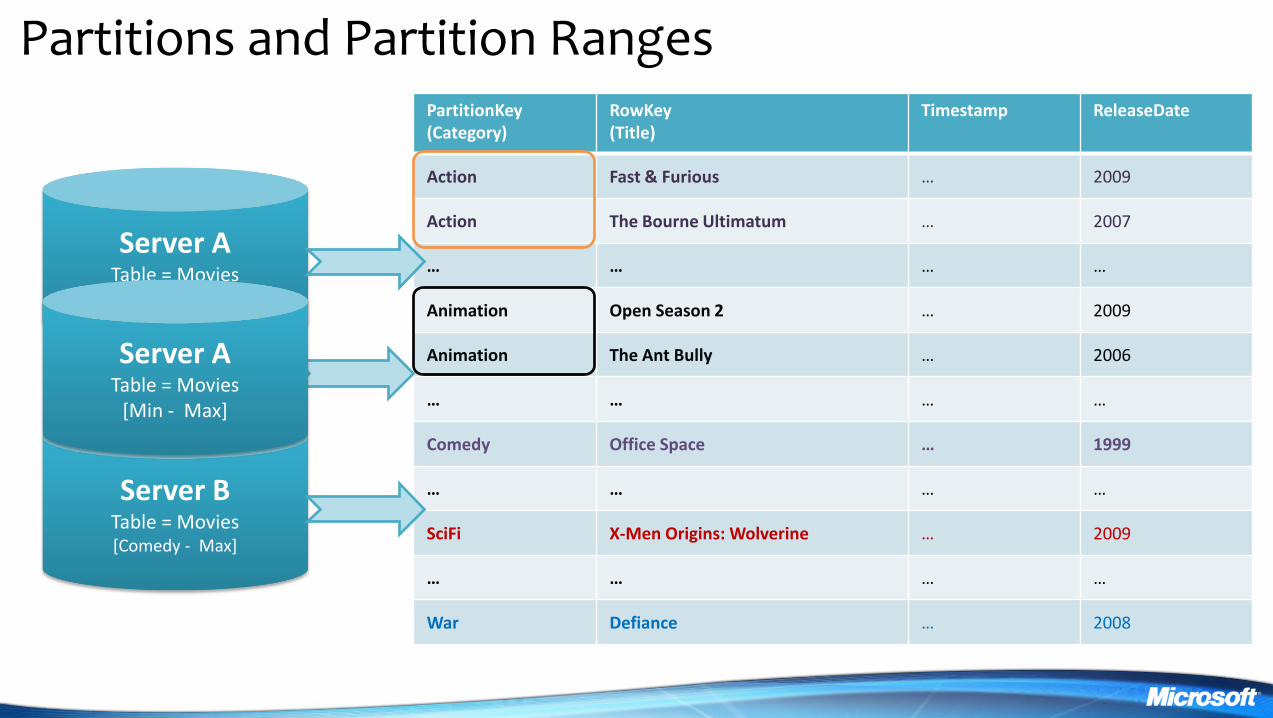
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
PartitionKey (Category)
RowKey (Title)
Timestamp ReleaseDate
Action Fast amp Furious hellip 2009
Action The Bourne Ultimatum hellip 2007
hellip hellip hellip hellip
Animation Open Season 2 hellip 2009
Animation The Ant Bully hellip 2006
hellip hellip hellip hellip
Comedy Office Space hellip 1999
hellip hellip hellip hellip
SciFi X-Men Origins Wolverine hellip 2009
hellip hellip hellip hellip
War Defiance hellip 2008
Partitions and Partition Ranges
Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Key Selection Things to Consider
bullDistribute load as much as possible bullHot partitions can be load balanced bullPartitionKey is critical for scalability
See httpwwwmicrosoftpdccom2009SVC09 and httpazurescopecloudappnet for more information
bull Avoid frequent large scans bull Parallelize queries bull Point queries are most efficient
bullTransactions across a single partition bullTransaction semantics amp Reduce round trips
Scalability
Query Efficiency amp Speed
Entity group transactions
Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Expect Continuation Tokens ndash Seriously
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 1000 rows in a response
At the end of partition range boundary
Maximum of 5 seconds to execute the query
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
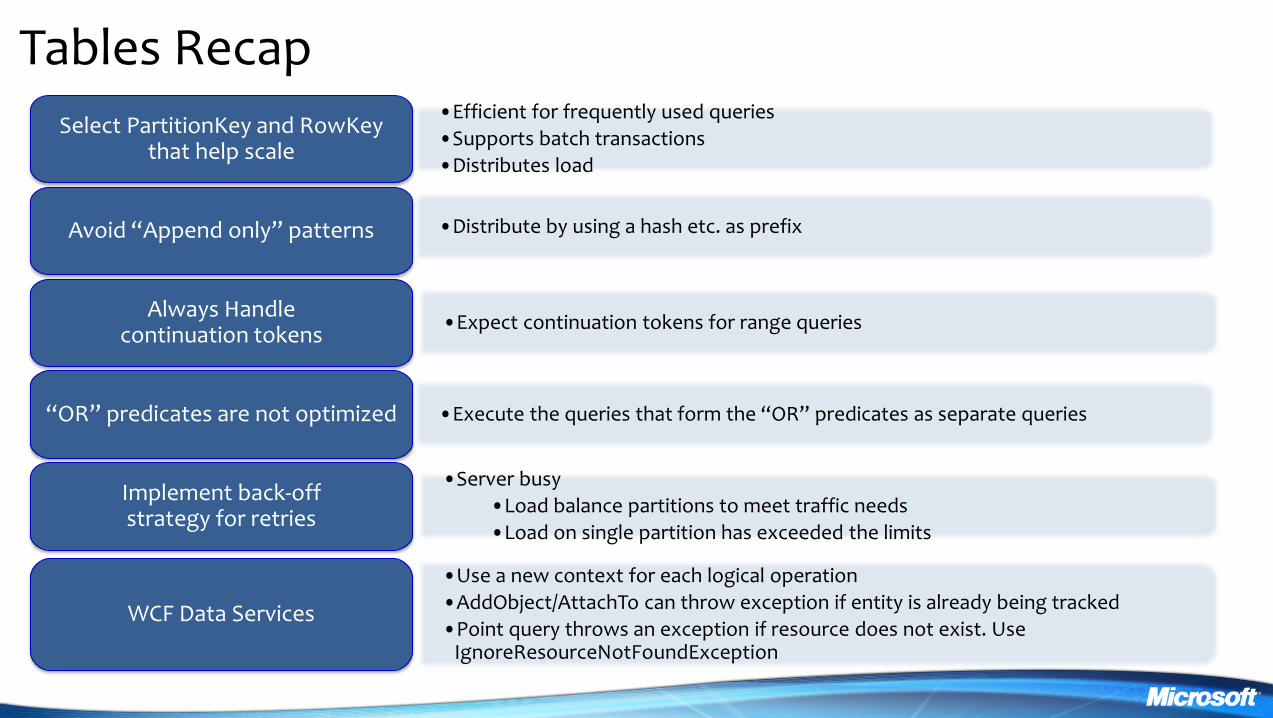
Tables Recap bullEfficient for frequently used queries
bullSupports batch transactions
bullDistributes load
Select PartitionKey and RowKey that help scale
Avoid ldquoAppend onlyrdquo patterns
Always Handle continuation tokens
ldquoORrdquo predicates are not optimized
Implement back-off strategy for retries
bullDistribute by using a hash etc as prefix
bullExpect continuation tokens for range queries
bullExecute the queries that form the ldquoORrdquo predicates as separate queries
bullServer busy
bullLoad balance partitions to meet traffic needs
bullLoad on single partition has exceeded the limits
WCF Data Services
bullUse a new context for each logical operation
bullAddObjectAttachTo can throw exception if entity is already being tracked
bullPoint query throws an exception if resource does not exist Use IgnoreResourceNotFoundException
Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Queues Their Unique Role in Building Reliable Scalable Applications
bull Want roles that work closely together but are not bound together bull Tight coupling leads to brittleness
bull This can aid in scaling and performance
bull A queue can hold an unlimited number of messages bull Messages must be serializable as XML
bull Limited to 8KB in size
bull Commonly use the work ticket pattern
bull Why not simply use a table
Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Queue Terminology
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
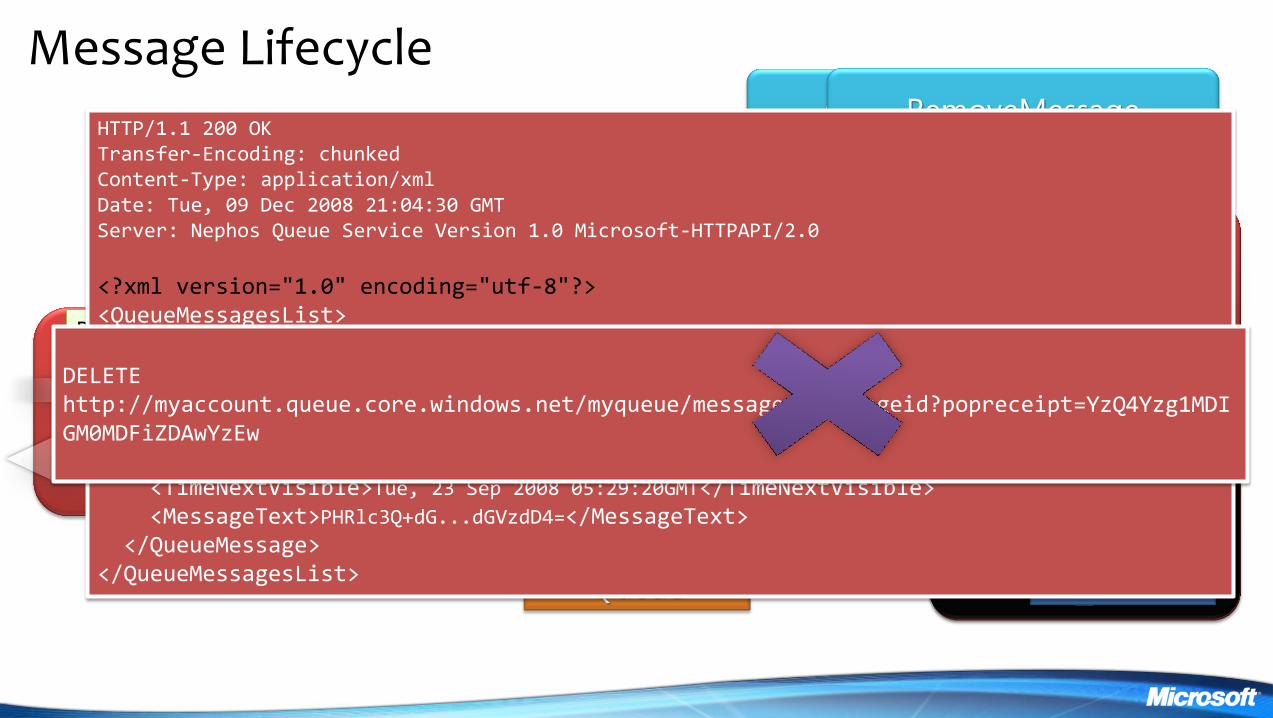
Message Lifecycle
Queue
Msg 1
Msg 2
Msg 3
Msg 4
Worker Role
Worker Role
PutMessage
Web Role
GetMessage (Timeout) RemoveMessage
Msg 2 Msg 1
Worker Role
Msg 2
POST httpmyaccountqueuecorewindowsnetmyqueuemessages
HTTP11 200 OK Transfer-Encoding chunked Content-Type applicationxml Date Tue 09 Dec 2008 210430 GMT Server Nephos Queue Service Version 10 Microsoft-HTTPAPI20
ltxml version=10 encoding=utf-8gt ltQueueMessagesListgt ltQueueMessagegt ltMessageIdgt5974b586-0df3-4e2d-ad0c-18e3892bfca2ltMessageIdgt ltInsertionTimegtMon 22 Sep 2008 232920 GMTltInsertionTimegt ltExpirationTimegtMon 29 Sep 2008 232920 GMTltExpirationTimegt ltPopReceiptgtYzQ4Yzg1MDIGM0MDFiZDAwYzEwltPopReceiptgt ltTimeNextVisiblegtTue 23 Sep 2008 052920GMTltTimeNextVisiblegt ltMessageTextgtPHRlc3Q+dGdGVzdD4=ltMessageTextgt ltQueueMessagegt ltQueueMessagesListgt
DELETE httpmyaccountqueuecorewindowsnetmyqueuemessagesmessageidpopreceipt=YzQ4Yzg1MDIGM0MDFiZDAwYzEw
Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Truncated Exponential Back Off Polling
Consider a backoff polling approach Each empty poll
increases interval by 2x
A successful sets the interval back to 1
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
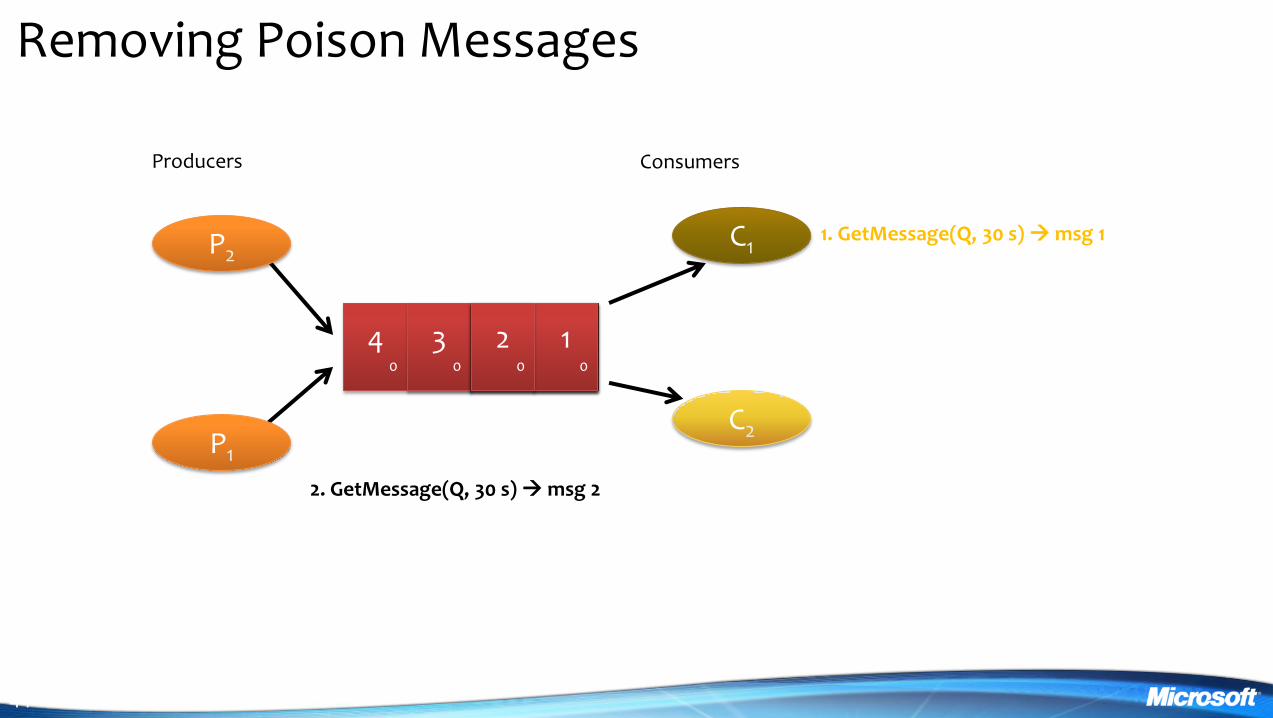
44
2 1
1 1
C1
C2
Removing Poison Messages
1 1
2 1
3 4 0
Producers Consumers
P2
P1
3 0
2 GetMessage(Q 30 s) msg 2
1 GetMessage(Q 30 s) msg 1
1 1
2 1
1 0
2 0
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
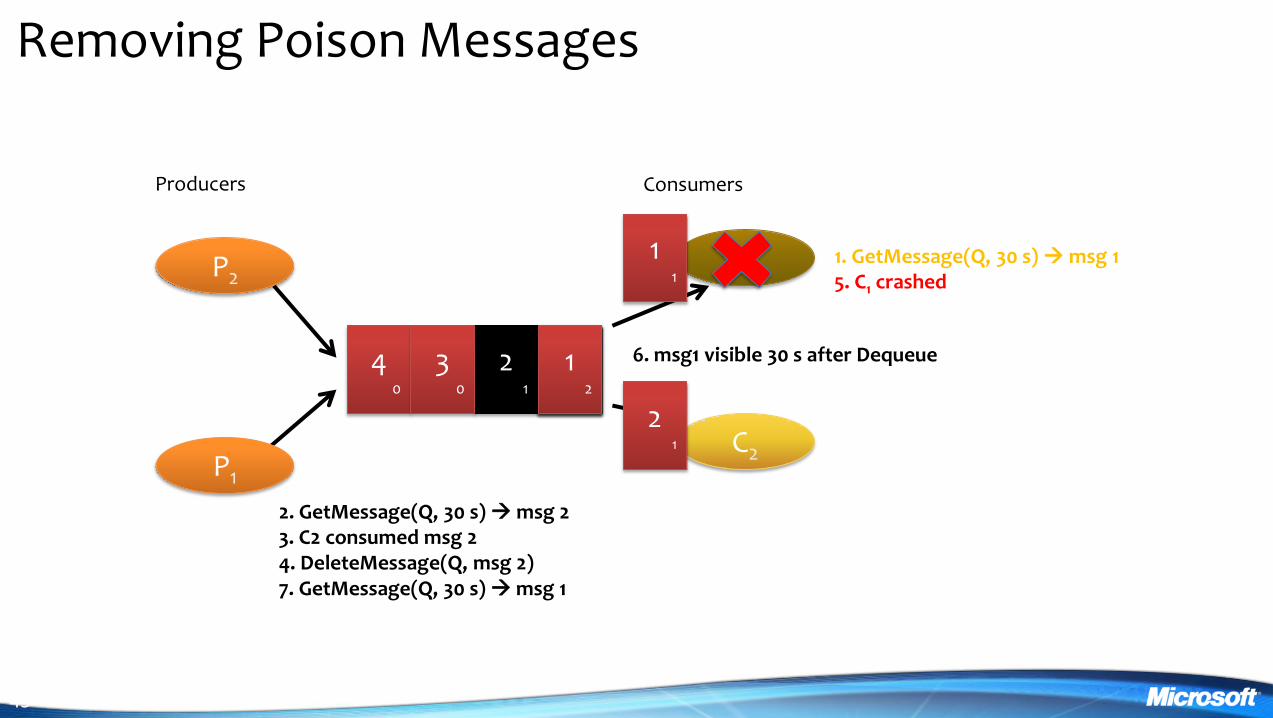
45
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 1
2 1
2 GetMessage(Q 30 s) msg 2 3 C2 consumed msg 2 4 DeleteMessage(Q msg 2) 7 GetMessage(Q 30 s) msg 1
1 GetMessage(Q 30 s) msg 1 5 C1 crashed
1 1
2 1
6 msg1 visible 30 s after Dequeue 3 0
1 2
1 1
1 2
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
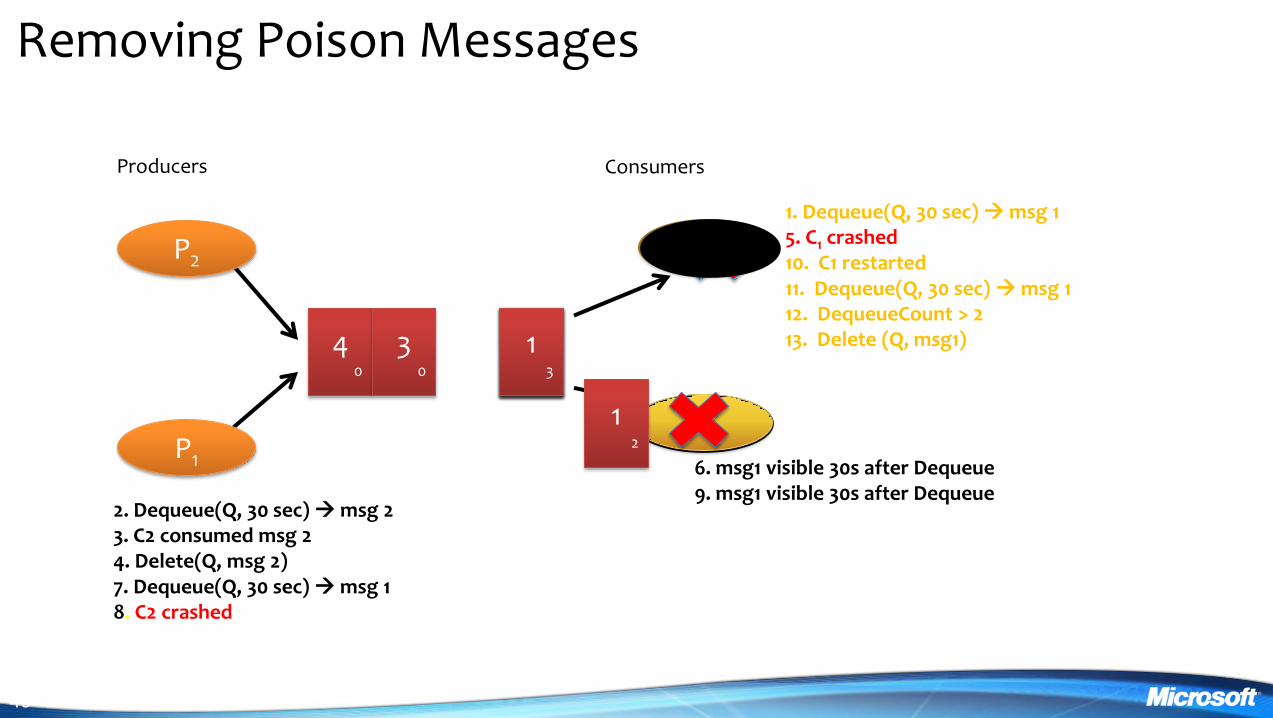
46
C1
C2
Removing Poison Messages
3 4 0
Producers Consumers
P2
P1
1 2
2 Dequeue(Q 30 sec) msg 2 3 C2 consumed msg 2 4 Delete(Q msg 2) 7 Dequeue(Q 30 sec) msg 1 8 C2 crashed
1 Dequeue(Q 30 sec) msg 1 5 C1 crashed 10 C1 restarted 11 Dequeue(Q 30 sec) msg 1 12 DequeueCount gt 2 13 Delete (Q msg1) 1
2
6 msg1 visible 30s after Dequeue 9 msg1 visible 30s after Dequeue
3 0
1 3
1 2
1 3
Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Queues Recap
bullNo need to deal with failures Make message
processing idempotent
bullInvisible messages result in out of order Do not rely on order
bullEnforce threshold on messagersquos dequeue count Use Dequeue count to remove
poison messages
bullMessages gt 8KB
bullBatch messages
bullGarbage collect orphaned blobs
bullDynamically increasereduce workers
Use blob to store message data with
reference in message
Use message count to scale
bullNo need to deal with failures
bullInvisible messages result in out of order
bullEnforce threshold on messagersquos dequeue count
bullDynamically increasereduce workers
Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Windows Azure Storage Takeaways
Blobs
Drives
Tables
Queues
httpblogsmsdncomwindowsazurestorage
httpazurescopecloudappnet
49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

49
A Quick Exercise
hellipThen letrsquos look at some code and some tools
50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

50
Code ndash AccountInformationcs public class AccountInformation private static string storageKey = ldquotHiSiSnOtMyKeY private static string accountName = jjstore private static StorageCredentialsAccountAndKey credentials internal static StorageCredentialsAccountAndKey Credentials get if (credentials == null) credentials = new StorageCredentialsAccountAndKey(accountName storageKey) return credentials
51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

51
Code ndash BlobHelpercs public class BlobHelper private static string defaultContainerName = school private CloudBlobClient client = null private CloudBlobContainer container = null private void InitContainer() if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudBlobClient() container = clientGetContainerReference(defaultContainerName) containerCreateIfNotExist() BlobContainerPermissions permissions = containerGetPermissions() permissionsPublicAccess = BlobContainerPublicAccessTypeContainer containerSetPermissions(permissions)
52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

52
Code ndash BlobHelpercs
public void WriteFileToBlob(string filePath) if (client == null || container == null) InitContainer() FileInfo file = new FileInfo(filePath) CloudBlob blob = containerGetBlobReference(fileName) blobPropertiesContentType = GetContentType(fileExtension) blobUploadFile(fileFullName) Or if you want to write a string replace the last line with blobUploadText(someString) And make sure you set the content type to the appropriate MIME type (eg ldquotextplainrdquo)
53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

53
Code ndash BlobHelpercs
public string GetBlobText(string blobName) if (client == null || container == null) InitContainer() CloudBlob blob = containerGetBlobReference(blobName) try return blobDownloadText() catch (Exception) The blob probably does not exist or there is no connection available return null
54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

54
Application Code - Blobs private void SaveToCloudButton_Click(object sender RoutedEventArgs e) StringBuilder buff = new StringBuilder() buffAppendLine(LastNameFirstNameEmailBirthdayNativeLanguageFavoriteIceCreamYearsInPhDGraduated) foreach (AttendeeEntity attendee in attendees) buffAppendLine(attendeeToCsvString()) blobHelperWriteStringToBlob(SummerSchoolAttendeestxt buffToString())
The blob is now available at httpltAccountNamegtblobcorewindowsnetltContainerNamegtltBlobNamegt Or in this case httpjjstoreblobcorewindowsnetschoolSummerSchoolAttendeestxt
55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

55
Code - TableEntities using MicrosoftWindowsAzureStorageClient public class AttendeeEntity TableServiceEntity public string FirstName get set public string LastName get set public string Email get set public DateTime Birthday get set public string FavoriteIceCream get set public int YearsInPhD get set public bool Graduated get set hellip
56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

56
Code - TableEntities public void UpdateFrom(AttendeeEntity other) FirstName = otherFirstName LastName = otherLastName Email = otherEmail Birthday = otherBirthday FavoriteIceCream = otherFavoriteIceCream YearsInPhD = otherYearsInPhD Graduated = otherGraduated UpdateKeys() public void UpdateKeys() PartitionKey = SummerSchool RowKey = Email
57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

57
Code ndash TableHelpercs public class TableHelper private CloudTableClient client = null private TableServiceContext context = null private DictionaryltstringAttendeeEntitygt allAttendees = null private string tableName = Attendees private CloudTableClient Client get if (client == null) client = new CloudStorageAccount(AccountInformationCredentials false)CreateCloudTableClient() return client private TableServiceContext Context get if (context == null) context = ClientGetDataServiceContext() return context
58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

58
Code ndash TableHelpercs private void ReadAllAttendees() allAttendees = new Dictionaryltstring AttendeeEntitygt() CloudTableQueryltAttendeeEntitygt query = ContextCreateQueryltAttendeeEntitygt(tableName)AsTableServiceQuery() try foreach (AttendeeEntity attendee in query) allAttendees[attendeeEmail] = attendee catch (Exception) No entries in table - or other exception
59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

59
Code ndash TableHelpercs public void DeleteAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return AttendeeEntity attendee = allAttendees[email] Delete from the cloud table ContextDeleteObject(attendee) ContextSaveChanges() Delete from the memory cache allAttendeesRemove(email)
60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

60
Code ndash TableHelpercs public AttendeeEntity GetAttendee(string email) if (allAttendees == null) ReadAllAttendees() if (allAttendeesContainsKey(email)) return allAttendees[email] return null
Remember that this only works for tables (or queries on tables) that easily fit in memory This is one of many design patterns for working with tables
61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

61
Pseudo Code ndash TableHelpercs public void UpdateAttendees(ListltAttendeeEntitygt updatedAttendees) foreach (AttendeeEntity attendee in updatedAttendees) UpdateAttendee(attendee false) ContextSaveChanges(SaveChangesOptionsBatch) public void UpdateAttendee(AttendeeEntity attendee) UpdateAttendee(attendee true) private void UpdateAttendee(AttendeeEntity attendee bool saveChanges) if (allAttendeesContainsKey(attendeeEmail)) AttendeeEntity existingAttendee = allAttendees[attendeeEmail] existingAttendeeUpdateFrom(attendee) ContextUpdateObject(existingAttendee) else ContextAddObject(tableName attendee) if (saveChanges) ContextSaveChanges()
62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

62
Application Code ndash Cloud Tables private void SaveButton_Click(object sender RoutedEventArgs e) Write to table tableHelperUpdateAttendees(attendees)
Thatrsquos it Now your tables are accessible using REST service calls or any cloud storage tool
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
63
Tools ndash Fiddler2
Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Best Practices
Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Picking the Right VM Size
bull Having the correct VM size can make a big difference in costs
bull Fundamental choice ndash larger fewer VMs vs many smaller instances
bull If you scale better than linear across cores larger VMs could save you money
bull Pretty rare to see linear scaling across 8 cores
bull More instances may provide better uptime and reliability (more failures needed to take your service down)
bull Only real right answer ndash experiment with multiple sizes and instance counts in order to measure and find what is ideal for you
Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Using Your VM to the Maximum
Remember bull 1 role instance == 1 VM running Windows
bull 1 role instance = one specific task for your code
bull Yoursquore paying for the entire VM so why not use it
bull Common mistake ndash split up code into multiple roles each not using up CPU
bull Balance between using up CPU vs having free capacity in times of need
bull Multiple ways to use your CPU to the fullest
Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Exploiting Concurrency
bull Spin up additional processes each with a specific task or as a unit of concurrency
bull May not be ideal if number of active processes exceeds number of cores
bull Use multithreading aggressively
bull In networking code correct usage of NT IO Completion Ports will let the kernel schedule the precise number of threads
bull In NET 4 use the Task Parallel Library
bull Data parallelism
bull Task parallelism
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
Finding Good Code Neighbors
bull Typically code falls into one or more of these categories
bull Find code that is intensive with different resources to live together
bull Example distributed network caches are typically network- and memory-intensive they may be a good neighbor for storage IO-intensive code
Memory Intensive
CPU Intensive
Network IO Intensive
Storage IO Intensive
Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Scaling Appropriately
bull Monitor your application and make sure yoursquore scaled appropriately (not over-scaled)
bull Spinning VMs up and down automatically is good at large scale
bull Remember that VMs take a few minutes to come up and cost ~$3 a day (give or take) to keep running
bull Being too aggressive in spinning down VMs can result in poor user experience
bull Trade-off between risk of failurepoor user experience due to not having excess capacity and the costs of having idling VMs
Performance Cost
Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Storage Costs
bull Understand an applicationrsquos storage profile and how storage billing works
bull Make service choices based on your app profile
bull Eg SQL Azure has a flat fee while Windows Azure Tables charges per transaction
bull Service choice can make a big cost difference based on your app profile
bull Caching and compressing They help a lot with storage costs
Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Saving Bandwidth Costs
Bandwidth costs are a huge part of any popular web apprsquos billing profile
Sending fewer things over the wire often means getting fewer things from storage
Saving bandwidth costs often lead to savings in other places
Sending fewer things means your VM has time to do other tasks
All of these tips have the side benefit of improving your web apprsquos performance and user experience
Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Compressing Content
1 Gzip all output content
bull All modern browsers can decompress on the fly
bull Compared to Compress Gzip has much better compression and freedom from patented algorithms
2Tradeoff compute costs for storage size
3Minimize image sizes
bull Use Portable Network Graphics (PNGs)
bull Crush your PNGs
bull Strip needless metadata
bull Make all PNGs palette PNGs
Uncompressed
Content
Compressed
Content
Gzip
Minify JavaScript
Minify CCS
Minify Images
Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Best Practices Summary
Doing lsquolessrsquo is the key to saving costs
Measure everything
Know your application profile in and out
Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Research Examples in the Cloud
hellipon another set of slides
Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Map Reduce on Azure
bull Elastic MapReduce on Amazon Web Services has traditionally been the only option for Map Reduce jobs in the web bull Hadoop implementation bull Hadoop has a long history and has been improved for stability bull Originally Designed for Cluster Systems
bull Microsoft Research this week is announcing a project code named Daytona for Map Reduce jobs on Azure bull Designed from the start to use cloud primitives bull Built-in fault tolerance bull REST based interface for writing your own clients
76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

76
Project Daytona - Map Reduce on Azure
httpresearchmicrosoftcomen-usprojectsazuredaytonaaspx
77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

77
Questions and Discussionhellip
Thank you for hosting me at the Summer School
BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

BLAST (Basic Local Alignment Search Tool)
bull The most important software in bioinformatics
bull Identify similarity between bio-sequences
Computationally intensive
bull Large number of pairwise alignment operations
bull A BLAST running can take 700 ~ 1000 CPU hours
bull Sequence databases growing exponentially
bull GenBank doubled in size in about 15 months
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
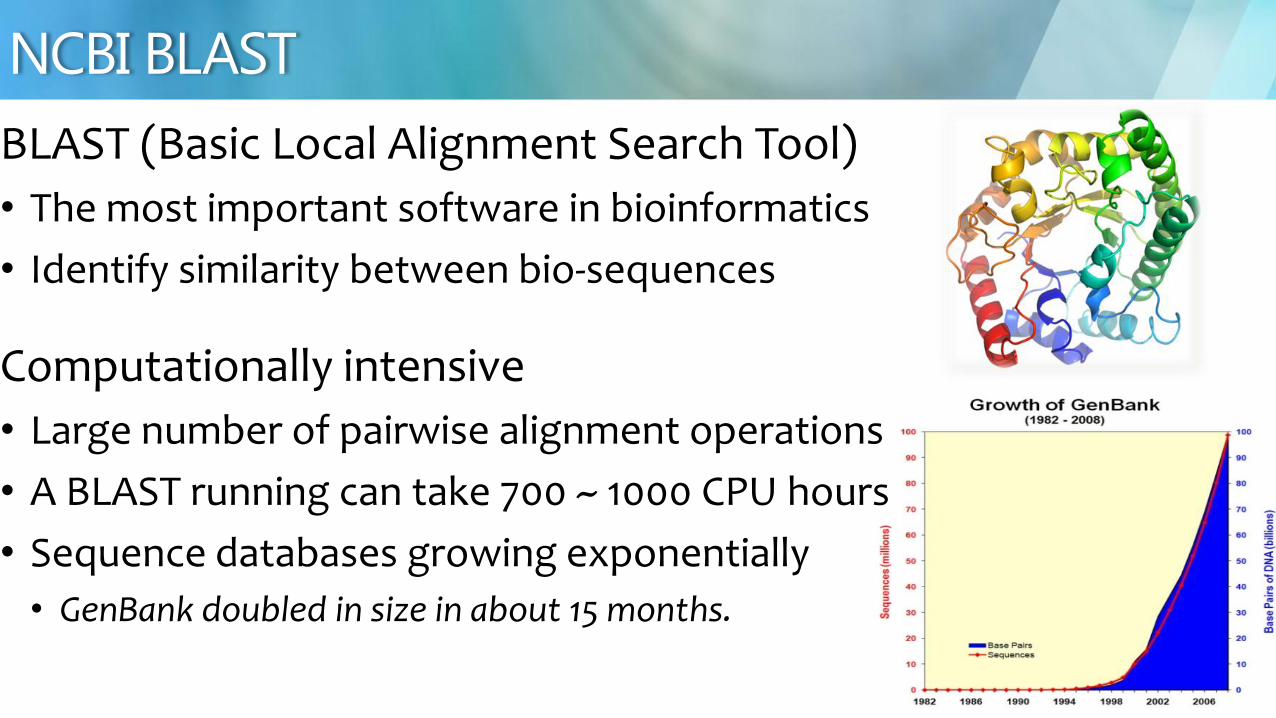
It is easy to parallelize BLAST
bull Segment the input
bull Segment processing (querying) is pleasingly parallel
bull Segment the database (eg mpiBLAST)
bull Needs special result reduction processing
Large volume data
bull A normal Blast database can be as large as 10GB
bull 100 nodes means the peak storage bandwidth could reach to 1TB
bull The output of BLAST is usually 10-100x larger than the input
bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

bull Parallel BLAST engine on Azure
bull Query-segmentation data-parallel pattern bull split the input sequences
bull query partitions in parallel
bull merge results together when done
bull Follows the general suggested application model bull Web Role + Queue + Worker
bull With three special considerations bull Batch job management
bull Task parallelism on an elastic Cloud
Wei Lu Jared Jackson and Roger Barga AzureBlast A Case Study of Developing Science Applications on the Cloud in Proceedings of the 1st Workshop
on Scientific Cloud Computing (Science Cloud 2010) Association for Computing Machinery Inc 21 June 2010
A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

A simple SplitJoin pattern
Leverage multi-core of one instance bull argument ldquondashardquo of NCBI-BLAST
bull 1248 for small middle large and extra large instance size
Task granularity bull Large partition load imbalance
bull Small partition unnecessary overheads bull NCBI-BLAST overhead
bull Data transferring overhead
Best Practice test runs to profiling and set size to mitigate the overhead
Value of visibilityTimeout for each BLAST task bull Essentially an estimate of the task run time
bull too small repeated computation
bull too large unnecessary long period of waiting time in case of the instance failure Best Practice
bull Estimate the value based on the number of pair-bases in the partition and test-runs
bull Watch out for the 2-hour maximum limitation
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
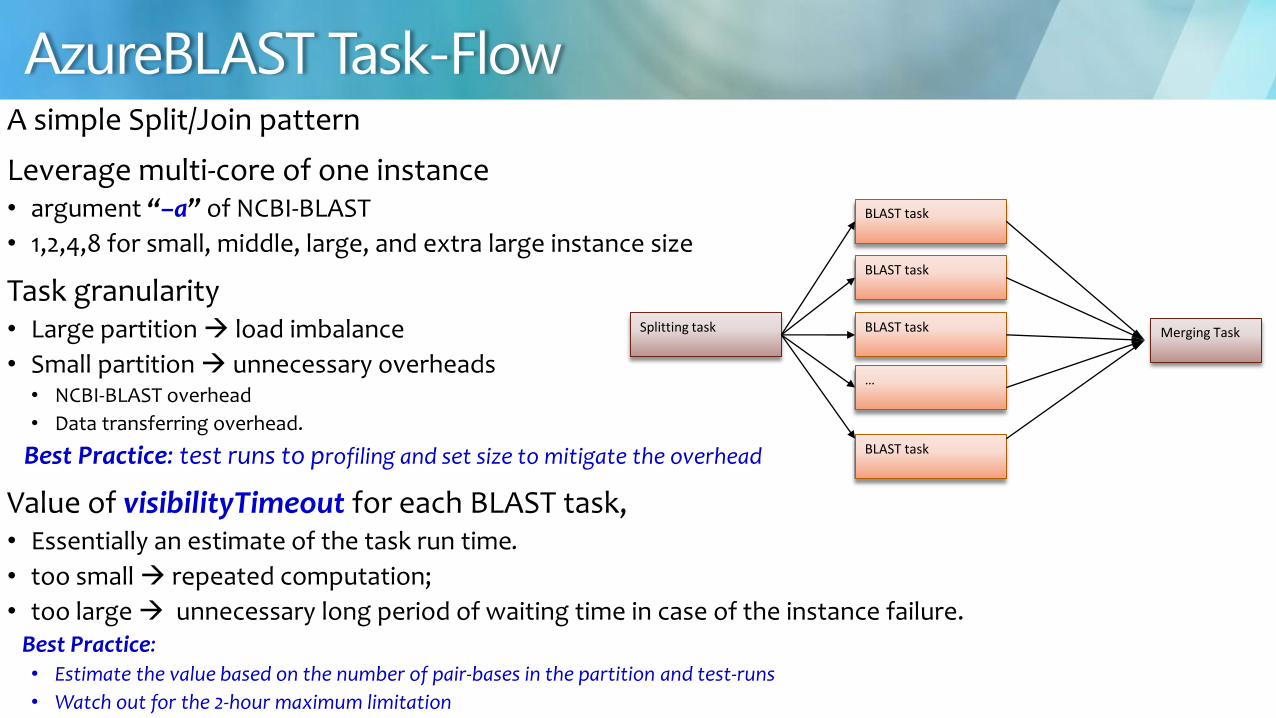
Task size vs Performance
bull Benefit of the warm cache effect
bull 100 sequences per partition is the best choice
Instance size vs Performance
bull Super-linear speedup with larger size worker instances
bull Primarily due to the memory capability
Task SizeInstance Size vs Cost
bull Extra-large instance generated the best and the most economical throughput
bull Fully utilize the resource
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
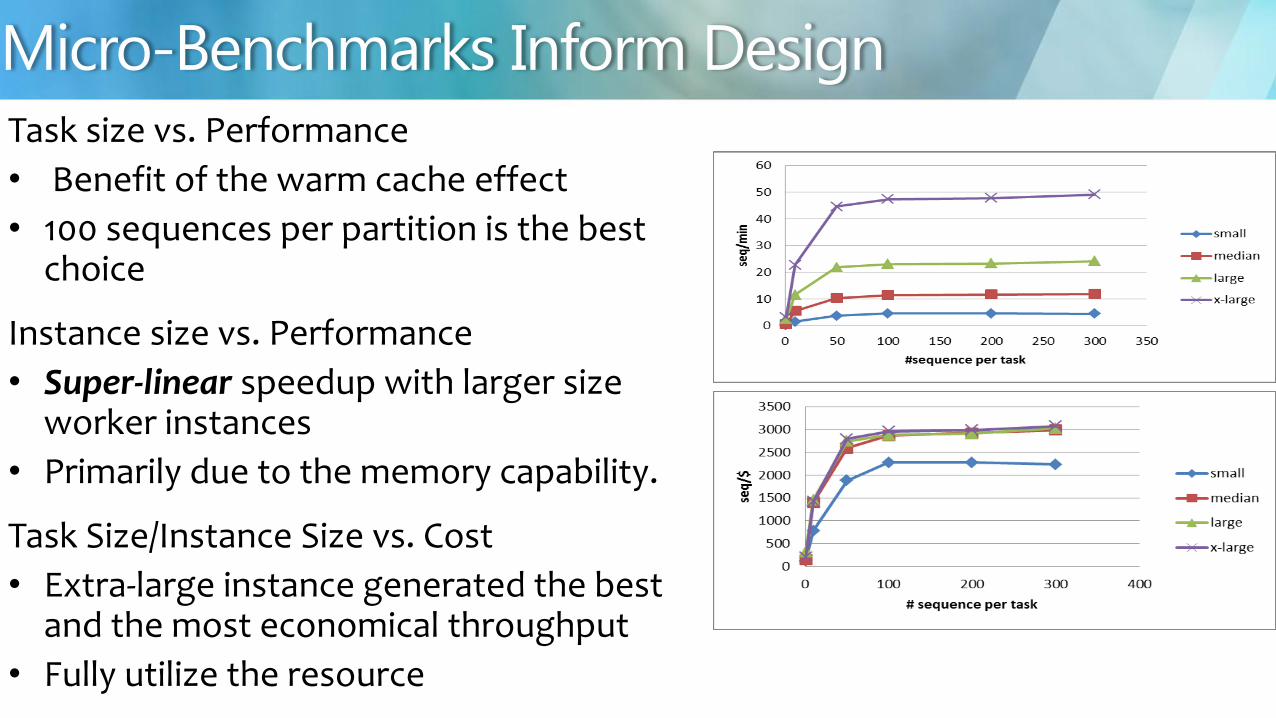
Web
Portal
Web
Service
Job registration
Job Scheduler
Worker
Worker
Worker
Global
dispatch
queue
Web Role
Azure Table
Job Management Role
Azure Blob
Database
updating Role
hellip
Scaling Engine
Blast databases
temporary data etc)
Job Registry NCBI databases
BLAST task
Splitting task
BLAST task
BLAST task
BLAST task
hellip
Merging Task
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
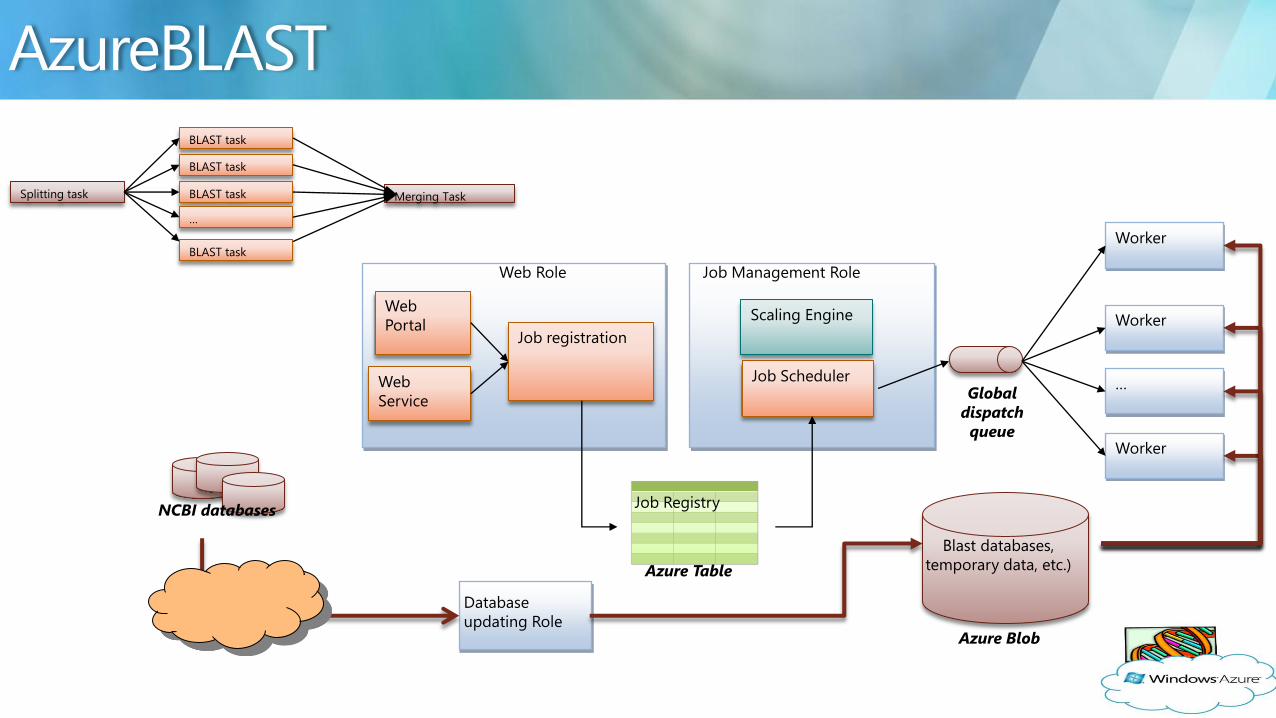
ASPNET program hosted by a web role instance bull Submit jobs
bull Track jobrsquos status and logs
AuthenticationAuthorization based on Live ID
The accepted job is stored into the job registry table bull Fault tolerance avoid in-memory states
Web Portal
Web Service
Job registration
Job Scheduler
Job Portal
Scaling Engine
Job Registry
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
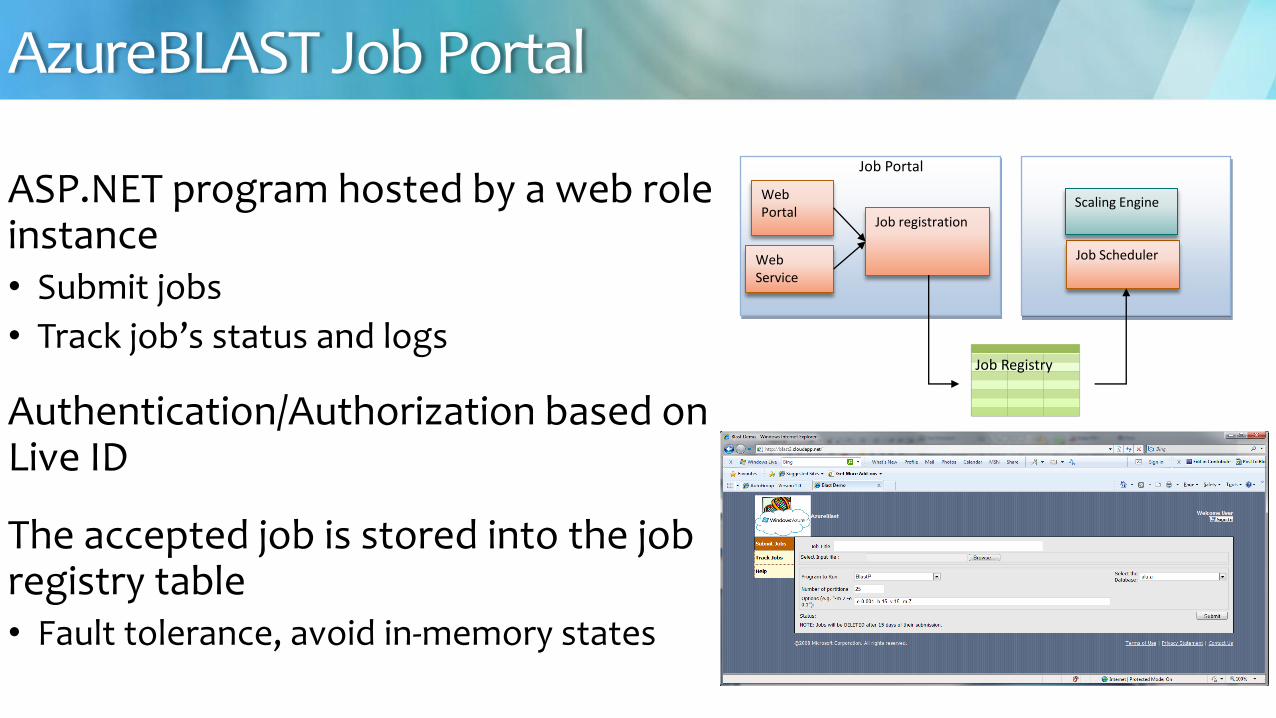
R palustris as a platform for H2 production Eric Shadt SAGE Sam Phattarasukol Harwood Lab UW
Blasted ~5000 proteins (700K sequences) bull Against all NCBI non-redundant proteins completed in 30 min
bull Against ~5000 proteins from another strain completed in less than 30 sec
AzureBLAST significantly saved computing timehellip
Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

Discovering Homologs bull Discover the interrelationships of known protein sequences
ldquoAll against Allrdquo query bull The database is also the input query
bull The protein database is large (42 GB size) bull Totally 9865668 sequences to be queried
bull Theoretically 100 billion sequence comparisons
Performance estimation bull Based on the sampling-running on one extra-large Azure instance
bull Would require 3216731 minutes (61 years) on one desktop
One of biggest BLAST jobs as far as we know bull This scale of experiments usually are infeasible to most scientists
bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

bull Allocated a total of ~4000 instances bull 475 extra-large VMs (8 cores per VM) four datacenters US (2) Western and North Europe
bull 8 deployments of AzureBLAST bull Each deployment has its own co-located storage service
bull Divide 10 million sequences into multiple segments bull Each will be submitted to one deployment as one job for execution
bull Each segment consists of smaller partitions
bull When load imbalances redistribute the load manually
5
0
62 6
2 6
2 6
2 6
2 5
0 62
bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

bull Total size of the output result is ~230GB
bull The number of total hits is 1764579487
bull Started at March 25th the last task completed on April 8th (10 days compute)
bull But based our estimates real working instance time should be 6~8 day
bull Look into log data to analyze what took placehellip
5
0
62 6
2 6
2 6
2 6
2 5
0 62
A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

A normal log record should be
Otherwise something is wrong (eg task failed to complete)
3312010 614 RD00155D3611B0 Executing the task 251523
3312010 625 RD00155D3611B0 Execution of task 251523 is done it took 109mins
3312010 625 RD00155D3611B0 Executing the task 251553
3312010 644 RD00155D3611B0 Execution of task 251553 is done it took 193mins
3312010 644 RD00155D3611B0 Executing the task 251600
3312010 702 RD00155D3611B0 Execution of task 251600 is done it took 1727 mins
3312010 822 RD00155D3611B0 Executing the task 251774
3312010 950 RD00155D3611B0 Executing the task 251895
3312010 1112 RD00155D3611B0 Execution of task 251895 is done it took 82 mins
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
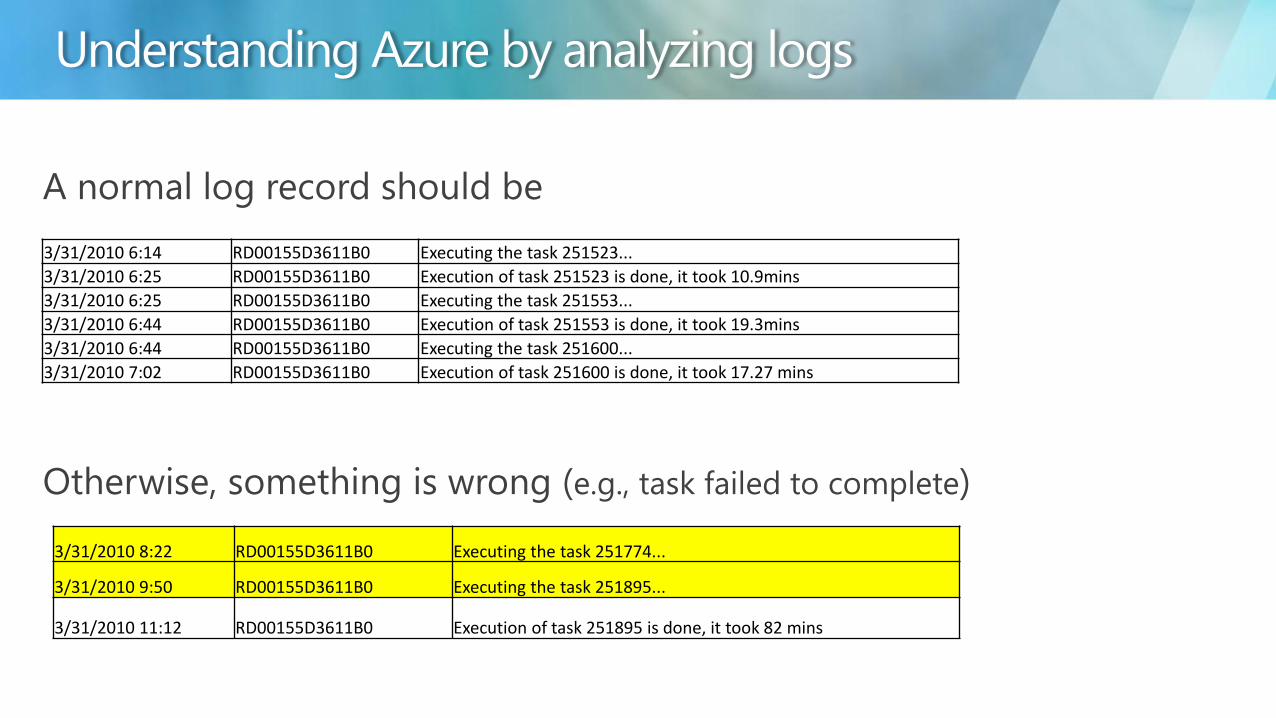
North Europe Data Center totally 34256 tasks processed
All 62 compute nodes lost tasks
and then came back in a group
This is an Update domain
~30 mins
~ 6 nodes in one group
35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

35 Nodes experience blob
writing failure at same
time
West Europe Datacenter 30976 tasks are completed and job was killed
A reasonable guess the
Fault Domain is working
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
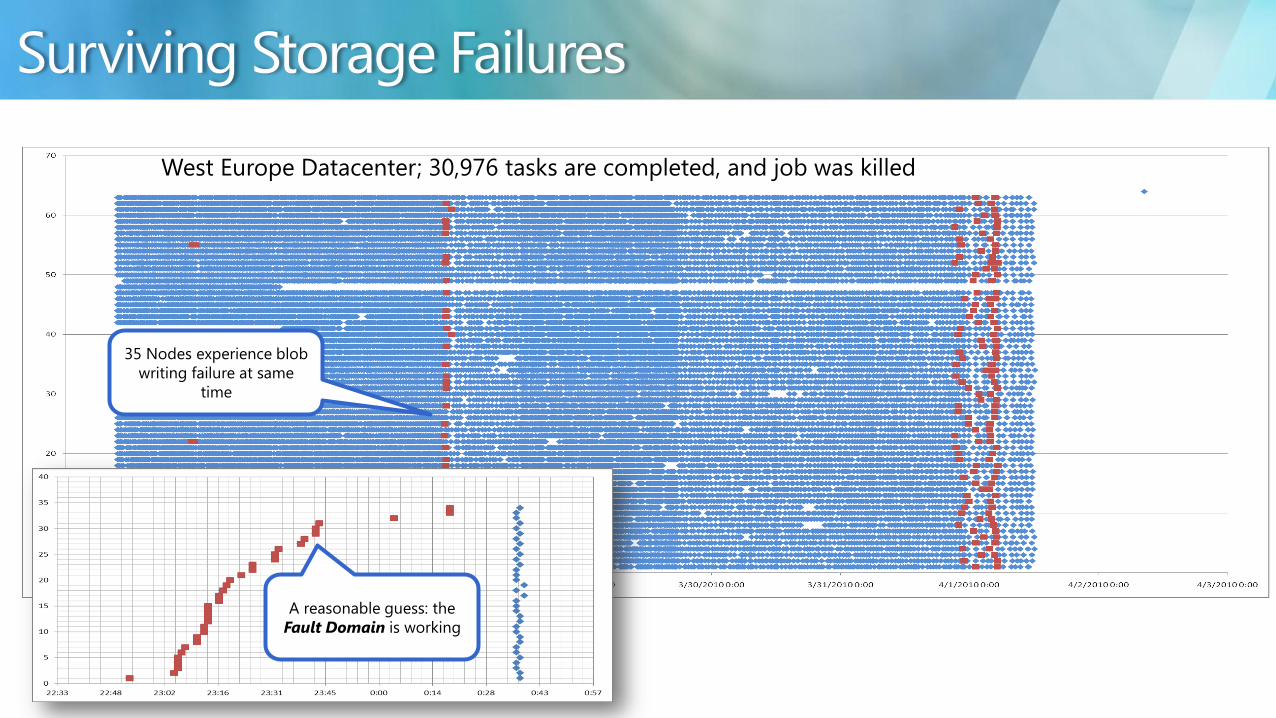
MODISAzure Computing Evapotranspiration (ET) in The Cloud
You never miss the water till the well has run dry Irish Proverb
ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

ET = Water volume evapotranspired (m3 s-1 m-2)
Δ = Rate of change of saturation specific humidity with air temperature(Pa K-1)
λv = Latent heat of vaporization (Jg)
Rn = Net radiation (W m-2)
cp = Specific heat capacity of air (J kg-1 K-1)
ρa = dry air density (kg m-3)
δq = vapor pressure deficit (Pa)
ga = Conductivity of air (inverse of ra) (m s-1)
gs = Conductivity of plant stoma air (inverse of rs) (m s-1)
γ = Psychrometric constant (γ asymp 66 Pa K-1)
Estimating resistanceconductivity across a
catchment can be tricky
bull Lots of inputs big data reduction
bull Some of the inputs are not so simple
119864119879 = ∆119877119899 + 120588119886 119888119901 120575119902 119892119886
(∆ + 120574 1 + 119892119886 119892119904 )120582120592
Penman-Monteith (1964)
Evapotranspiration (ET) is the release of water to the atmosphere by evaporation from open water bodies and transpiration or evaporation through plant membranes by plants
NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-

NASA MODIS
imagery source
archives
5 TB (600K files)
FLUXNET curated
sensor dataset
(30GB 960 files)
FLUXNET curated
field dataset
2 KB (1 file)
NCEPNCAR
~100MB
(4K files)
Vegetative
clumping
~5MB (1file)
Climate
classification
~1MB (1file)
20 US year = 1 global year
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
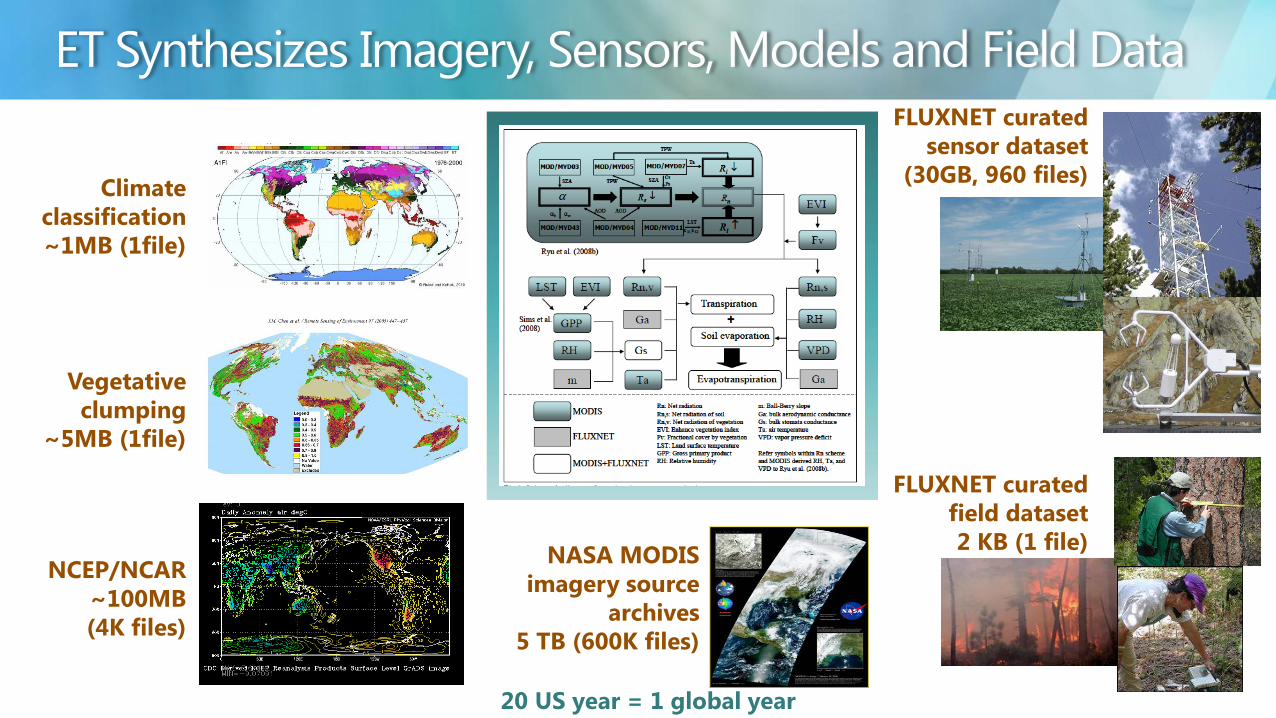
Data collection (map) stage
bull Downloads requested input tiles
from NASA ftp sites
bull Includes geospatial lookup for
non-sinusoidal tiles that will
contribute to a reprojected
sinusoidal tile
Reprojection (map) stage
bull Converts source tile(s) to
intermediate result sinusoidal tiles
bull Simple nearest neighbor or spline
algorithms
Derivation reduction stage
bull First stage visible to scientist
bull Computes ET in our initial use
Analysis reduction stage
bull Optional second stage visible to
scientist
bull Enables production of science
analysis artifacts such as maps
tables virtual sensors
Reduction 1
Queue
Source
Metadata
AzureMODIS
Service Web Role Portal
Request
Queue
Scientific
Results
Download
Data Collection Stage
Source Imagery Download Sites
Reprojection
Queue
Reduction 2
Queue
Download
Queue
Scientists
Science results
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
httpresearchmicrosoftcomen-usprojectsazureazuremodisaspx
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
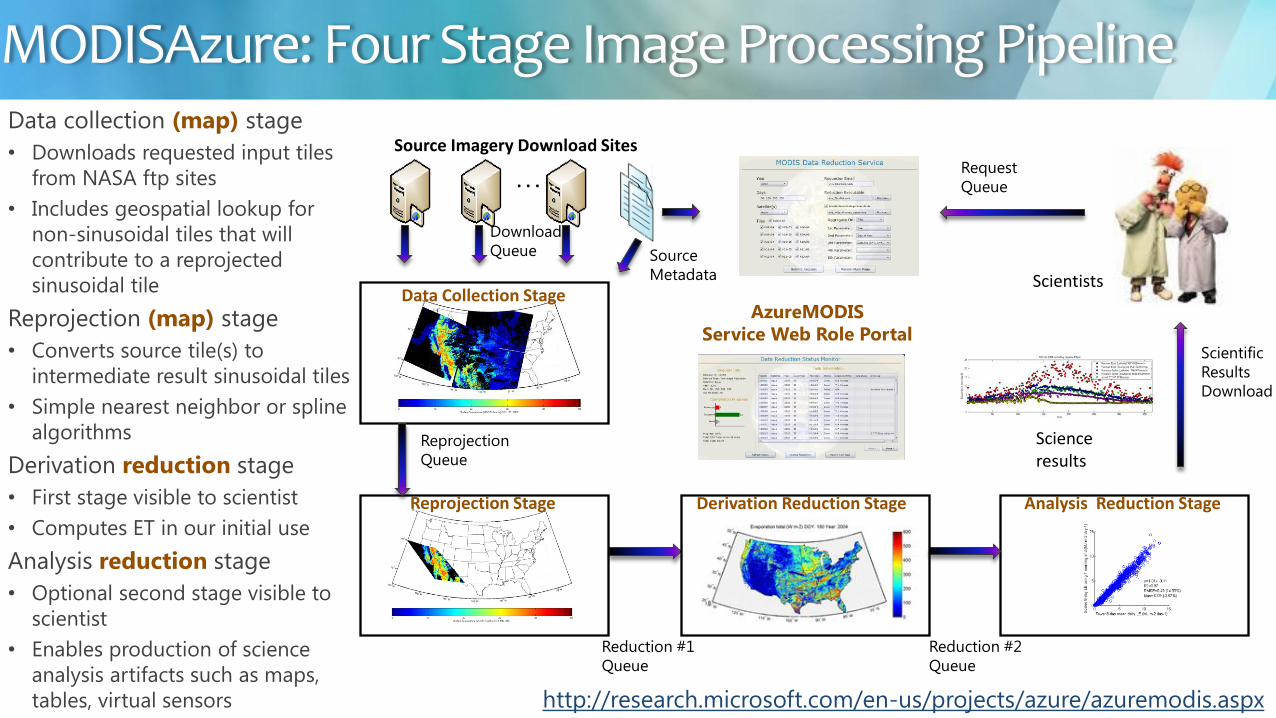
bull ModisAzure Service is the Web Role front door bull Receives all user requests
bull Queues request to appropriate Download Reprojection or Reduction Job Queue
bull Service Monitor is a dedicated Worker Role bull Parses all job requests into tasks ndash
recoverable units of work
bull Execution status of all jobs and tasks persisted in Tables
ltPipelineStagegt
Request
hellip ltPipelineStagegtJobStatus
Persist ltPipelineStagegtJob Queue
MODISAzure Service
(Web Role)
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
hellip
Dispatch
ltPipelineStagegtTask Queue
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
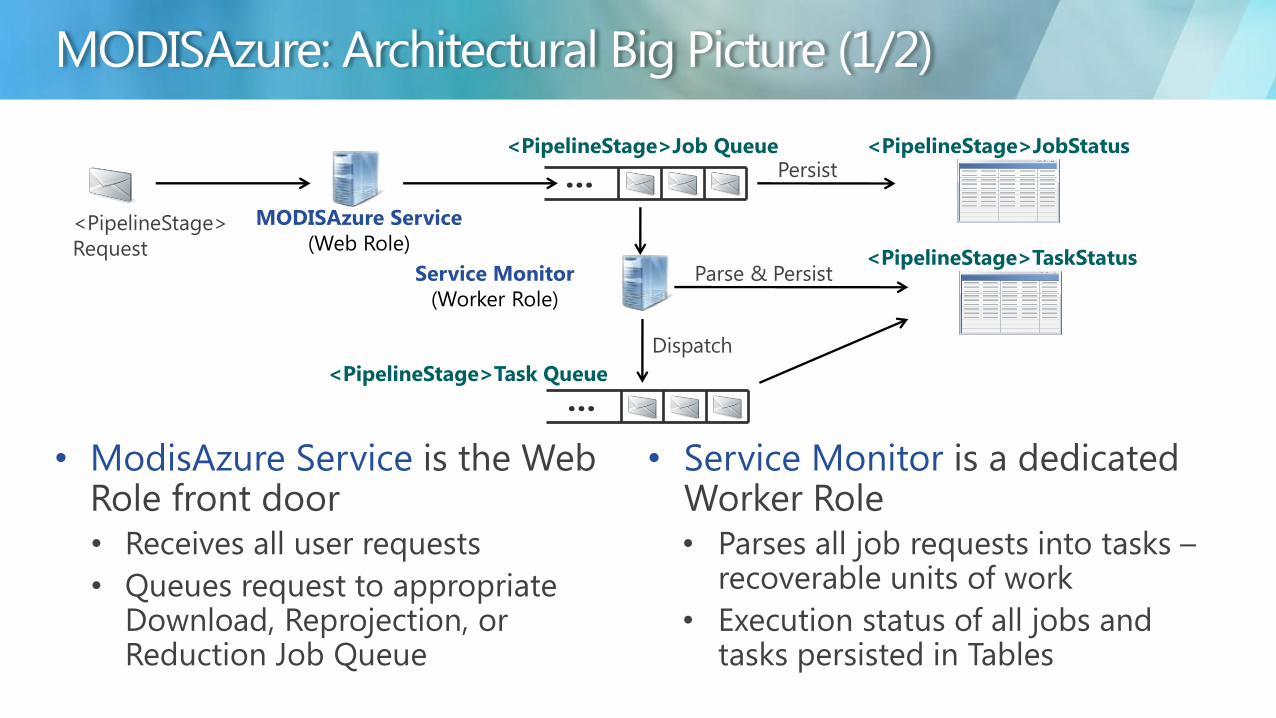
All work actually done by a Worker Role
bull Sandboxes science or other executable
bull Marshalls all storage fromto Azure blob storage tofrom local Azure Worker instance files
Service Monitor
(Worker Role)
Parse amp Persist ltPipelineStagegtTaskStatus
GenericWorker
(Worker Role)
hellip
hellip
Dispatch
ltPipelineStagegtTask Queue
hellip
ltInputgtData Storage
bull Dequeues tasks created by the Service Monitor
bull Retries failed tasks 3 times
bull Maintains all task status
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
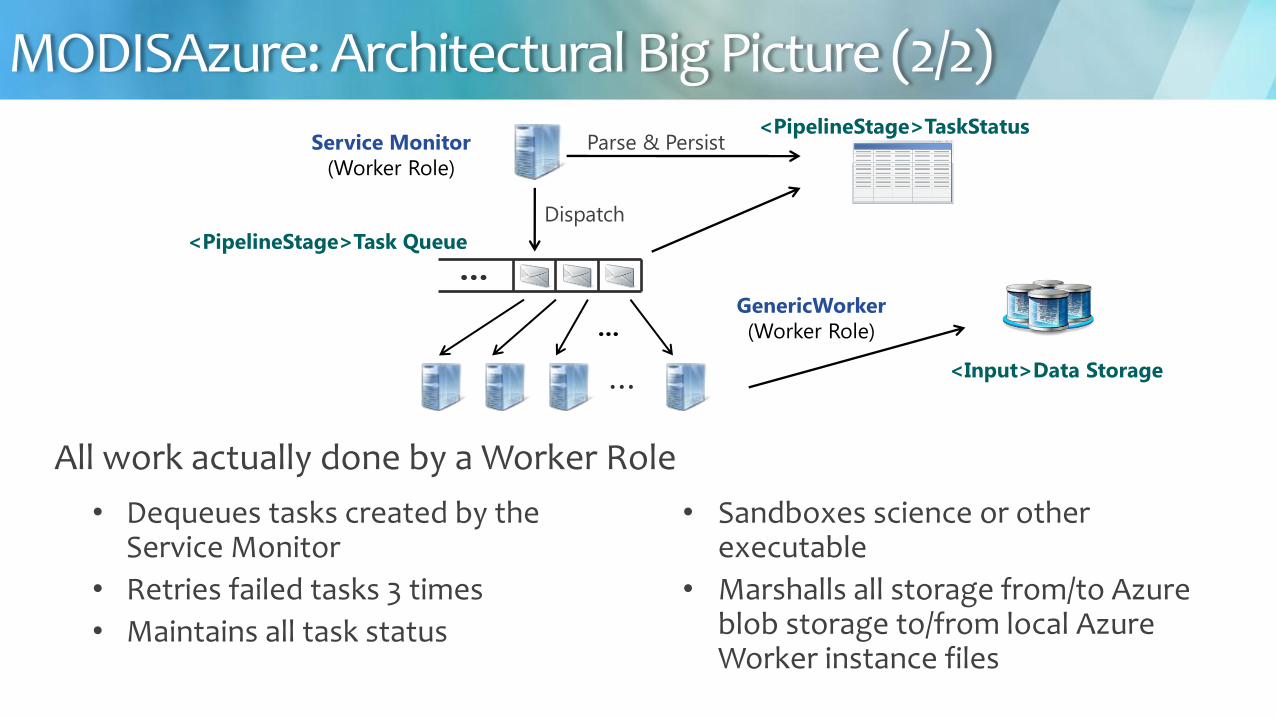
Reprojection Request
hellip
Service Monitor
(Worker Role)
ReprojectionJobStatus Persist
Parse amp Persist ReprojectionTaskStatus
GenericWorker
(Worker Role)
hellip
Job Queue
hellip
Dispatch
Task Queue
Points to
hellip
ScanTimeList
SwathGranuleMeta
Reprojection Data
Storage
Each entity specifies a
single reprojection job
request
Each entity specifies a
single reprojection task (ie
a single tile)
Query this table to get
geo-metadata (eg
boundaries) for each swath
tile
Query this table to get the
list of satellite scan times
that cover a target tile
Swath Source
Data Storage
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
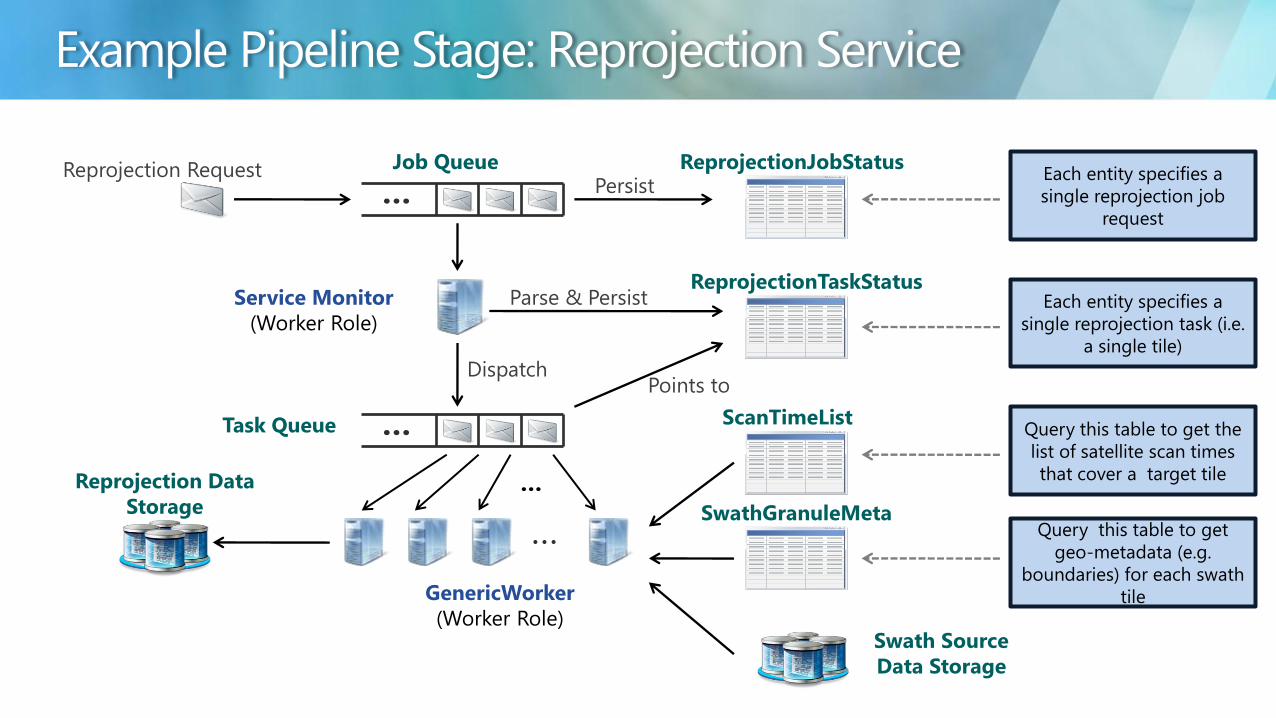
bull Computational costs driven by data scale and need to run reduction multiple times
bull Storage costs driven by data scale and 6 month project duration
bull Small with respect to the people costs even at graduate student rates
Reduction 1 Queue
Source Metadata
Request Queue
Scientific Results Download
Data Collection Stage
Source Imagery Download Sites
Reprojection Queue
Reduction 2 Queue
Download
Queue
Scientists
Analysis Reduction Stage Derivation Reduction Stage Reprojection Stage
400-500 GB
60K files
10 MBsec
11 hours
lt10 workers
$50 upload
$450 storage
400 GB
45K files
3500 hours
20-100
workers
5-7 GB
55K files
1800 hours
20-100
workers
lt10 GB
~1K files
1800 hours
20-100
workers
$420 cpu
$60 download
$216 cpu
$1 download
$6 storage
$216 cpu
$2 download
$9 storage
AzureMODIS
Service Web Role Portal
Total $1420
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-
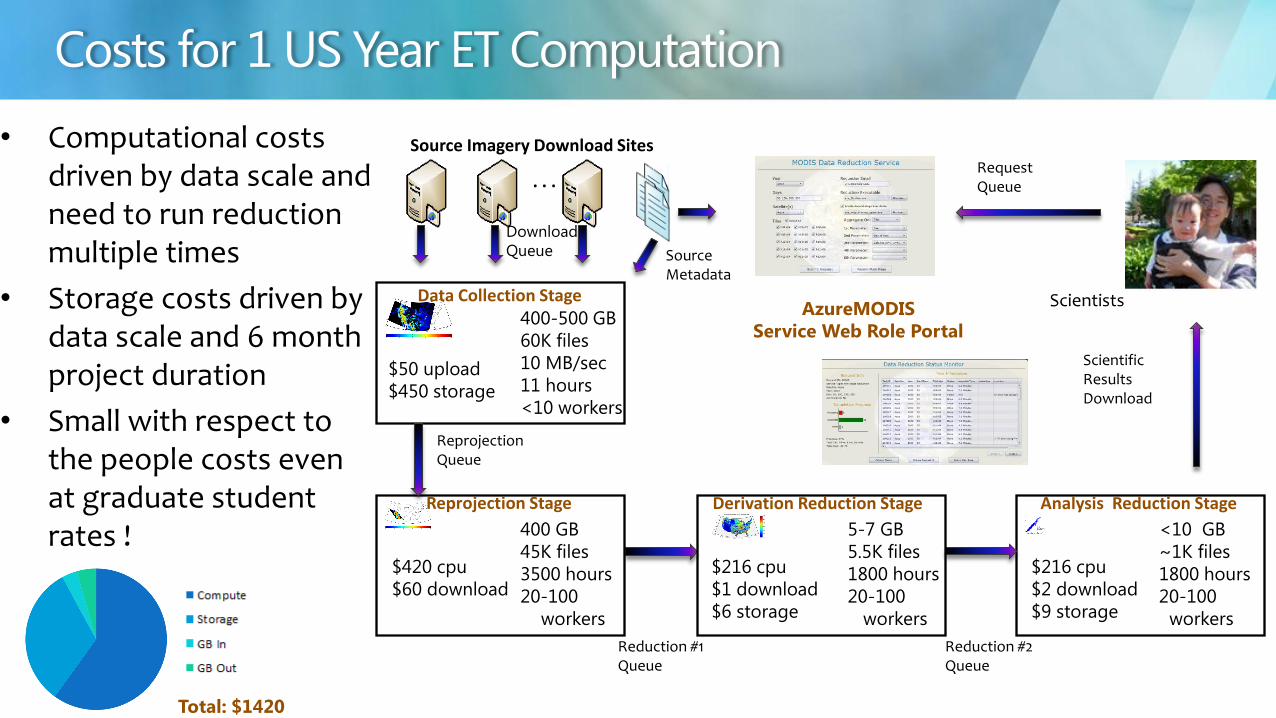
bull Clouds are the largest scale computer centers ever constructed and have the
potential to be important to both large and small scale science problems
bull Equally import they can increase participation in research providing needed
resources to userscommunities without ready access
bull Clouds suitable for ldquoloosely coupledrdquo data parallel applications and can
support many interesting ldquoprogramming patternsrdquo but tightly coupled low-
latency applications do not perform optimally on clouds today
bull Provide valuable fault tolerance and scalability abstractions
bull Clouds as amplifier for familiar client tools and on premise compute
bull Clouds services to support research provide considerable leverage for both
individual researchers and entire communities of researchers
- Day 2 - Azure as a PaaS
- Day 2 - Applications
-







