
I
Schedae
Prépublications de l’Université de Caen Basse-Normandie
Colloque InternationalDiscours et Document
International SymposiumDiscourse and Document
Fascicule n° 1 2006
Presses
univers i ta ires
de Caen

II

III
Schedae, 2006
Présidents du colloqueM.-P. PÉRY-WOODLEY, U. Toulouse 2 ;
P. ENJALBERT, U. Caen ;
M. GAIO, U. Pau et Pays de l’Adour.
Comité de programmeJ. BATEMAN, U. Bremen, Allemagne ; D. BATTISTELLI, U. Paris 4, France ; Y. BESTGEN, U. C. Lou-
vain, Belgique ; B. BOGURAEV, IBM T.J. Watson Research Center, USA ; A. BORILLO, U. Tou-
louse 2, France ; N. BOUAYAD-AGHA, U. Pompeu Fabra, Barcelona, Espagne ; F. CERBAH,
Dassault Aviation, France ; M. CHAROLLES, U. Paris 3, France ; D. CRISTEA, U. Iasi, Romania ;
L. DEGAND, U. C. Louvain, Belgique ; D. DUTOIT, Sté Memodata, France ; P. ENJALBERT, U. Caen,
France ; S. FERRARI, U. Caen, France ; O. FERRET, CEA, France ; M. GAIO, U. Pau, France ;
B. GRAU, U. Paris-Sud, France ; N. HERNANDEZ, U. Caen, France ; G. LAPALME, U. Montréal,
Québec, Canada ; A. LE DRAOULEC, U. Toulouse 2, France ; A. LEHMAM, Sté Pertinence
Mining.com, France ; D. LEGALLOIS, U. Caen, France ; N. LUCAS, U. Caen et CNRS, France ;
F. MAUREL, U. Caen, France ; A. MAX, U. Paris-Sud, France ; J.-L. MINEL, U. Paris 4, France ;
M. MOJAHID, U. Toulouse 3, France ; M.-P. PÉRY WOODLEY, U. Toulouse 2, France ; H. SAGGION,
U. Sheffield, Angleterre ; I. SALEH, U. Paris 8, France ; S. SALMON, Alt ATILF-CNRS, France ;
L. SARDA, CNRS, LATTICE, France ; D. SCOTT, Open University, Angleterre.
Comité d’organisationS. FERRARI, Coordinateur ; F. BILHAUT ; N. HERNANDEZ ; A. WIDLÖCHER.
GREYC – Groupe de Recherche en Informatique,Image, Automatique et Instrumentation de CaenStatut : Unité mixte de recherche université, CNRS et ENSICAEN – UMR 6072
Directeur : Régis CARIN
Directeur-adjoint : Étienne GRANDJEAN
Axes de recherches: algorithmique, sécurité, information, langage, interface homme-machine,
image, automatique, instrumentation, capteurs, électronique
Fascicule n° 1
Colloque International : Discours et DocumentInternational Symposium: Discourse and Document Responsable : Patrice ENJALBERT
L’objectif du colloque Discours et Document est de rassembler des chercheurs intéres-
sés par ce qu'on peut appeler le « niveau document » en linguistique du discours, en
TAL ou en ingénierie documentaire. Ce fascicule regroupe les communications pré-
sentées au colloque.

IV

V
Schedae
,
2006
Sommaire
Preface
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
VII
Session 1 : Organisation discursive : études de corpus et modélisation
Marie-Paule J
ACQUES
& Josette R
EBEYROLLE
:Titres et structuration des documents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
Farida A
OULADOMAR
, Leila A
MGOUD
, Patrick S
AINT
-D
IZIER
:
On Argumentation in Procedural Texts
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13Sophie P
IÉRARD
& Yves B
ESTGEN
:Adverbiaux temporels et expressions référentiellescomme marqueurs de segmentation : emploi simultané ou exclusif ? . . . . . 23
Sandrine S
TEIN
-Z
INTZ
:De l’altérité spatiale à l’organisation textuelle :la locution
d’une part… d’autre part
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29Susanne H
EMPEL
& Liesbeth D
EGAND
:
The use of sequencers in academic writing:a comparative study of French and English
. . . . . . . . . . . . . . . . . . . . . . . . . 35
Session 2 : Discours, document, et TAL
Frédérik B
ILHAUT
:Introducteurs intra-prédicatifs d’univers de discourset leur détection automatique. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
Marion L
AIGNELET
:Les titres et les introducteurs de cadres comme indices pour le repéragede segments d’information évolutive . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
Dominique L
EGALLOIS
& Stéphane F
ERRARI
:Vers une grammaire de l’évaluation des objets culturels . . . . . . . . . . . . . . . 57
Nadia Z
ERIDA
, Nadine L
UCAS
, Bruno C
RÉMILLEUX
:Combinaison de descripteurs linguistiqueset de structure pour la fouille d’articles biomédicaux . . . . . . . . . . . . . . . . . . 69
Amanda B
OUFFIER
:Segmentation de textes procéduraux pour l’aide à la modélisationde connaissances : le rôle de la structure visuelle . . . . . . . . . . . . . . . . . . . . . 79
Christophe P
IMM
:Quelle plus-value linguistique pour la segmentation automatique de texte ? 85
Session 3 : Nouveaux types de documents,nouveaux modes d’accès à l’information textuelle
Clara M
ANCINI
& Donia S
COTT
:
Hyper-Document Structure: Maintaining Discourse Coherencein Non-Linear Documents
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91Javier C
OUTO
& Jean-Luc M
INEL
:SEXTANT, un langage de modélisation des connaissancespour la navigation textuelle. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
Birgitta B
EXTEN
:
Hypertext and Plurilinearity: Challenging an Old-fashioned Discourse Model
117
Fascicule n° 1

VI
Thomas K
RECZANIK
:Modélisation de parcours dans des hypertextes pédagogiques :typage des ressources et des liens . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
Olivier L
E
D
EUFF
:Des bons mots au bon document.Comment éduquer à l’usage des mots-clés efficacespour accéder à la pertinence documentaire . . . . . . . . . . . . . . . . . . . . . . . . . 129
Session 4 : Systèmes de TAL, démonstrations
Abderrafih L
EHMAM
:Solutions de traitement du document textuelavec prise en charge de ressources linguistiques . . . . . . . . . . . . . . . . . . . . . 135
Frédérik B
ILHAUT
& Antoine W
IDLÖCHER
:Analyse de structures discursives avec la plate-forme LinguaStream . . . . . . 141
Ágnes S
ÁNDOR
, Aaron K
APLAN
, Gilbert R
ONDEAU
:
Discourse and citation analysis with concept-matching
. . . . . . . . . . . . . . . . 147
Conférence invitée
Simone T
EUFEL
:
Discourse structure in scientific articles: argumentation and citation
(à venir) . . 153

VII
Schedae
,
2006
PrefaceISDD 2006: aims and scope
In connection with the development of digital documents, discourse linguistics, docu-
ment engineering and NLP are increasingly converging: applying corpus analysis methods to
discourse calls for greater use of NLP techniques while new modes of access to the contents
of documents place more emphasis on exploiting discourse structure. This convergence is
manifest in a number of joint studies, and results in cross fertilisation of the disciplines. This is
the analysis which led us, in the call for papers for Discourse and Document 2006, to explicitly
reach out towards researchers concerned with “the document level” in discourse linguistics,
computational linguistics, and document-engineering.
We present in this volume twenty contributions by authors who must have recognised
themselves in this way of setting out the issues. The aim of the symposium is to build on the
convergence of questions and objectives which clearly emerge from these contributions.
Beyond their specific scientific interest, the challenge is to arrive at a usable definition of an
emergent research field, with implications both in discourse linguistic and document engi-
neering areas.
The first two sessions can be described as presenting different takes on document organ-
isation. Each paper tends to focus on a particular view of what may be semantically impor-
tant in discourse processing. One such view is that documents are organised in topics (in the
sense of “what is being talked about”), and can be segmented in terms of this organisation
(whether via automatic procedures to identify breaks in lexical cohesion or via analyses of
reference chains). Other approaches stress argumentative structure, and identify segments
that fulfil particular argumentative or rhetorical functions. In both these views, the organisa-
tion is assumed to be largely implicit: various techniques are brought to bear to identify the
shifts between continuity and discontinuity, to tease out discourse function on the basis of
surface markers. Another take is to consider explicit clues to document organisation, such
as metadiscursive expressions, or elements of the so-called “logical structure”.
These questions are considered in a largely descriptive manner in the first session, while
the second focuses on the design of NLP procedures to identify such structures in text. Indeed
a major field in NLP is the development of systems concerned with facilitating access to the
information stored in documents, and there is a growing awareness of the need to take better
account of the organisation of the documents being processed. Another facet of this evolu-
tion is that researchers into discourse organisation gradually move towards more empirical
methods and require computational instruments to analyse large volumes of data. The third
session provides a very concrete illustration of these trends, through the presentation and
demonstration of NLP systems, originating in both academic and industrial contexts.
Fascicule n° 1

VIII
Finally, new document types - hyper-documents - raise radically new questions about dis-
course organisation and the interaction between semiotic functions. What makes such docu-
ments cohere (or not)? How are they read and understood? How can this reading process
be made easier, more efficient? But further, what new insight into the organisation of “ordi-
nary” text can be gained through the comparison with these new non linear textual forms?
Some of these questions apply equally at the level of document bases - now widely acces-
sible thanks to internet and other electronic devices -, which can be seen as “macro-texts”
through which the user has to wander as s/he scours for relevant information. And the notion
of navigation is also at stake in the case of “classical” texts, with new NLP techniques going
into the design of much needed tools to assist the reader in non-linear text browsing. From
linear document to hyper-document to document bases, and back to non-linear modes of
access to “classical” documents, we've gone full circle… These are some of the stimulating
questions which are addressed in the final session.
Taken as a whole, the twenty papers presented at ISDD'06 provide a rich and accurate
view of a number of complementary aspects of discourse structure in relation with the func-
tional notion of document. A promising area of research is outlined, an area which, as it extends
across discipline boundaries, requires a scientific community to gradually form, with a com-
mon language and common references. The organisers of ISDD 2006 hope this symposium
is a step in the right direction.
We thank the authors for their interest in taking part in this project, and the Programme
Committee members for their precious contribution with formulating the scope of the sympo-
sium and refereeing the papers. We also thank our sponsors: the GREYC laboratory, the Univer-
sity of Caen, the CNRS, the City of Caen and the Council of the Region of Basse-Normandie.
And finally the Organisation Committee whose work allowed ISDD'06 to become reality.
ISDD'06 Chair
Patrice Enjalbert Mauro Gaio Marie-Paule Pery-Woodley

Organisation discursive :études de corpus et modélisation
session 1

II

1
Marie-Paule Jacques & Josette Rebeyrolle« Titres et structuration des documents »
Schedae, 2006, prépublication n°1, (fascicule n°1, p. 1-12).
Schedae, 2006
Titres et structuration des documents
Marie-Paule Jacques & Josette RebeyrolleERSS (UMR5610)/Maison de la Recherche
Université Toulouse-Le Mirail – 5, allées A. Machado – 31058 Toulouse Cedex 9
[email protected], [email protected]
Résumé :
La structuration d’un document peut être assurée, entre autres moyens, par un découpage en
sections et sous-sections, généralement dotées d’un titre. Nous nous focalisons sur ces titres et
sur la façon dont, en plus d’assurer la segmentation et l’organisation visuelle du texte, ils contri-
buent à la construction de son contenu sémantique. Nos travaux antérieurs nous ayant permis de
dégager deux grands types d’implication des titres dans cette construction, la question essen-
tielle est ici de mettre au jour les corrélats formels qui permettent de distinguer ces deux types
d’implication et de montrer que selon le registre de textes l’implication des titres est différente.
Mots-clés : titres, document, linguistique du discours, structuration du texte, analyse de
corpus.
Abstract :
Textual organization of a document includes material characteristics such as sections which usu-
ally have a heading. We are particularly interested in headings and especially in how headings
contribute to the construction of the meaning of a text. In previous work a functional approach of
headings was presented in detail. In the present paper, our study is meant to identify in corpora
linguistic correlates of the two types of heading implication in discourse : referential/thematic. The
final corpus analysis shows how the headings are distributed in the texts of the corpus.
Keywords : headings, document, discourse linguistics, text structure, corpus analysis.
SommairementSans entrer dans la délicate question de définir rigoureusement ce qu’est un docu-
ment1, nous considérerons qu’un document écrit est un texte i. qui forme un tout (même
si l’on peut y repérer une certaine intertextualité et/ou des références et renvois à d’autres
documents), ii. qui présente une organisation interne, notamment dans le cas de ce que
Prépublication n° 1 Fascicule n° 1
1. Voir la réflexion de Roger T. Pédauque (2003), Document : forme, signe et médium, les re-formulations dunumérique, disponible sur http://archivesic.ccsd.cnrs.fr/sic_00000413.html page consultée le 13-05-06.

2
Schedae, 2006, prépublication n°1, (fascicule n°1, p. 1-12).
l’on peut appeler des documents longs tels que rapports, thèses, articles scientifiques,
ouvrages, etc.
Nous proposons ici une analyse descriptive de ce que nous pensons être des consti-
tuants essentiels de cette structuration : les titres de section. La suite explique moins som-
mairement la problématique.
Le document : un tout structuréAux deux caractéristiques formelles du document postulées ci-dessus correspondent
deux propriétés sémantiques : un document présente un niveau de contenu sémantique
et, simultanément, un niveau abstrait de structuration de ce contenu. Nous voulons dire
par là que le document ne délivre pas son contenu sémantique « en vrac », mais comme
contenu organisé, structuré, hiérarchisé. C’est de cet ensemble que le lecteur construit un
discours, c’est-à-dire un modèle mental de ce qui est en train de s’énoncer, au fur et à
mesure qu’il lit le document.
Divers modes de structuration discursive font l’objet de recherches, notamment les
moyens de cohésion lexicale, qui construisent des chaînes référentielles (Cornish 2003) ou
les expressions introductrices de cadres de discours, qui construisent des univers de dis-
cours particuliers, les cadres : « plusieurs propositions apparaissant dans le fil d’un texte
entretiennent un même rapport avec un certain critère et sont, de ce fait, regroupables à
l’intérieur d’unités que nous appellerons des cadres. » (Charolles 1997). À côté de ceux-là,
d’autres moyens de structuration discursive sont encore assez peu étudiés comme tels,
hormis par le même M. Charolles (2002). Il s’agit de la segmentation matérielle du texte
écrit en paragraphes, sections et sous-sections, ces dernières étant généralement dotées
d’un titre.
Ce découpage fournit au lecteur une structuration visuelle du texte qui, avant même
d’entrer dans son contenu, lui permet de commencer à construire la structuration discursive :
le lecteur perçoit des blocs, des enchâssements, qu’il peut utiliser comme autant de « cases
de l’esprit »2 dans lesquelles classer les éléments du discours en train de se construire. Et
si les segments perceptibles visuellement sont titrés, alors les différents blocs ne constituent
plus d’anonymes étagères ou tiroirs pour ordonner le propos, classer et ranger les éléments
du discours, ils tirent aussi de leur titre d’autres éléments pour la structuration, qui sont pré-
cisément l’objet de notre étude.
Nous avons fait remarquer que ces moyens visuels d’organisation du texte n’ont guère
été étudiés en tant que moyens de structuration discursive, ce qui ne veut pas dire qu’ils n’ont
pas été étudiés du tout. Au contraire, le Modèle d’Architecture Textuelle (Luc & Virbel 2001)
est un cadre théorique qui rend compte du fait que, tout texte écrit étant inscrit sur un sup-
port, il possède des caractéristiques matérielles qui peuvent jouer un rôle au plan textuel
(plus récemment, voir aussi le travail de Power, Scott & Bouyad-Agah 2003). Par exemple,
on peut réaliser une énumération de diverses manières, en utilisant des marqueurs lexicaux
du type le premier, le deuxième, le troisième, ou bien en utilisant exclusivement des moyens
visuels : disposition dans l’espace du support, indentation, puces ou numéros… La figure
ci-dessous représente ces deux types d’énumération.
2. Précisons que cette expression ne véhicule aucune hypothèse sur notre conception de l’esprit. Nous lareprenons d’une communication d’Anne Le Draoulec, qui elle-même l’emprunte à Heinrich Weil (1844), Del’ordre des mots dans les langues anciennes comparées aux langues modernes. Question de grammairegénérale. Paris, Didier Érudition, réédition 1991.

3
Schedae, 2006, prépublication n°1, (fascicule n°1, p. 1-12).
En prenant cette matérialité au sérieux, autrement dit en en faisant une composante à
part entière du texte, le Modèle d’Architecture Textuelle définit des objets textuels qui se
caractérisent par un contraste de mise en forme matérielle avec le reste du texte et par une
fonction au sein du texte. Sans développer outre mesure, parmi les objets textuels identi-
fiés dans le cadre de ce modèle, citons dans le désordre les énumérations, les paragraphes,
les titres.
Dans cet ensemble plus vaste que ces quelques exemples, nous nous focalisons sur
les titres de section car ils présentent la particularité d’être un objet à deux faces.
Les titres de section, objet à deux facesL’une de leurs faces est constituée de cette propriété matérielle d’être un objet con-
trastant avec le reste du texte et opérant ainsi une segmentation, une délimitation en sec-
tions, sous-sections, sous-sous-sections, etc. Notons que les séparations ainsi marquées ne
sont pas de simples bornes de segments de textes car les titres sont hiérarchisés – une hié-
rarchie elle aussi marquée par des moyens typo-dispositionnels – et cette hiérarchisation se
répercute sur les sections titrées. De ce fait, nous l’avons déjà souligné, le texte peut être
appréhendé non comme une suite linéaire de blocs de natures diverses, mais comme une
structure faite d’éléments de plus haut niveau englobant d’autres éléments, hiérarchie qui
n’est assurément pas neutre.
Les titres présentent aussi une seconde face, non plus matérielle mais sémantique, liée
au fait que les titres sont composés d’unités lexicales et syntaxiques, porteuses elles-mêmes
d’une signification. Ce qui implique que les titres participent doublement à la construction
de la sémantique du document, non seulement ils segmentent et hiérarchisent, mais leur
propre contenu sémantique interagit avec le contenu sémantique du reste du texte. En un
certain sens, les titres sont à la fois dans et hors du texte. Dans parce que nous allons mon-
trer maintenant qu’ils sont partie prenante du contenu du texte, qu’ils remplissent certaines
fonctions discursives ; hors parce qu’ils ont ce statut particulier de se distinguer du corps
de texte, de jouer ce rôle d’organisateur textuel visuel.
Nous exposons maintenant les modalités pratiques de notre étude : quels textes, quelle
méthodologie ; puis nous indiquerons les résultats actuels de notre analyse. Dans la der-
nière partie, nous abordons un autre aspect de notre problématique : la relation entre forme-
fonction des titres et registre de textes.
Méthodologie, corpus et tout ça…Pour comprendre quel est le rôle des titres sur le plan de la structuration discursive de
documents textuels, il est essentiel de disposer de documents textuels dans lesquels il y a
des titres et d’indicateurs de la fonction discursive des titres. Le premier point qui pourrait
paraître une boutade n’en est qu’à moitié une et nous sert à souligner que nous avons réso-
lument inscrit notre étude dans le cadre d’une analyse de corpus, c’est-à-dire que nous avons
réuni un ensemble de textes authentiques, comportant des titres de sections, nous allons
XXX__________________________________________________________________. Premièrement,
_________________________________________. Deuxièmement,_______________________________
_____________________________________________________________________. Troisièmement, _____
________________________________________________________________________.
XXX___________________________________________________.
1. ___________________________________________________________
2. ___________________________________________________________
3. ___________________________________________________________
Figure 1 : Énumérations discursive et visuelle.

4
Schedae, 2006, prépublication n°1, (fascicule n°1, p. 1-12).
y revenir. Le second point n’est pas plus trivial : analyser les fonctions discursives des titres,
soit, mais avec quels instruments d’analyse ? À quoi s’apprécie le rôle joué par un titre au
niveau discursif ? Les deux choses sont liées dans la mesure où le type de support de l’ana-
lyse détermine en partie le type d’indicateurs.
Nous avons réuni trois ensembles de textes de provenances diverses : articles scienti-
fiques des domaines de l’ingénierie des connaissances et de la géopolitique ; écrits élabo-
rés dans un cadre professionnel de gestion des déplacements : comptes rendus, rapports,
projets, description de tâches… Ce corpus a été constitué de telle manière que chaque
ensemble présente un nombre équivalent de titres de section, pas tout à fait 350 pour cha-
que, avec un total de 1 041 titres.
Si nous avions suivi une façon de faire bien établie dans les études sur le discours, nous
aurions travaillé à l’identification des fonctions des titres à partir d’un petit nombre d’exem-
ples, authentiques ou fabriqués pour nos besoins, dont nous aurions proposé un classement
de nature à illustrer des fonctions discursives. Le nombre considéré ici se prête à une autre
démarche : non un classement global de chaque titre selon l’interprétation que l’on peut en
donner, mais une saisie plus analytique de traits formels. Cette démarche répond à diverses
exigences :
1 plus on s’appuie sur des traits formels, moins on fait entrer en jeu la subjecti-
vité et donc la dépendance d’un jugement à l’égard d’un analyste ;
2 on peut saisir ainsi plus facilement les variations qui ne concernent qu’un ou
deux des traits pris en considération, ce qui n’est guère facile lorsque le classe-
ment repose sur un jugement global ;
3 on obtient une quantification de chaque trait, à partir de laquelle on peut pro-
céder à des traitements statistiques qui permettent de mesurer les phénomè-
nes de corrélation, de co-variation ou d’indépendance ;
4 les fonctions décrites le sont non en terme d’interprétation, mais en terme de
corrélats linguistiques de nature formelle ;
5 il est possible de faire émerger diverses configurations de traits statistiquement
valides et de les mettre en rapport avec le genre de textes, comme on le verra
dans la dernière partie de l’article.
La clé de voûte de la démarche réside alors dans le choix des traits formels à prendre
en considération. Comme notre analyse vise les fonctions discursives des titres et la façon
dont ils contribuent à l’organisation du discours et à la construction de la sémantique du texte,
les traits choisis concernent d’une part des éléments factuels liés au titre indépendamment
de son co-texte, tels que la forme et le niveau du titre (par exemple, SN, SV, SP, niveau 1,
2, 3 ou 4), d’autre part des éléments co-textuels que nous supposons aptes à saisir la façon
dont le titre s’intègre au texte, tels que le fait que le titre ait été préalablement introduit
dans le discours et/ou qu’il fasse l’objet d’une reprise anaphorique.
S’agissant des premiers, outre la catégorie grammaticale (SN, SV, SP, phrase), nous
avons noté si le titre présente une partition interne telle qu’une coordination, par exemple :
Nature des savoirs et type de connaissance
ou une ponctuation, par exemple :
1. Deux grandes approches : l’ouverture ou la substitution aux importations.
Ceci nous permet de distinguer ce que nous avons appelé les titres bipartites des titres
qui sont formés d’un bloc syntaxique unique comme La question agricole ou Penser la guerre
totale.
Pour ce qui est des seconds, notre description la plus aboutie à ce jour porte sur les
reprises. Lorsque le titre fait l’objet d’une anaphore, on note :

5
Schedae, 2006, prépublication n°1, (fascicule n°1, p. 1-12).
– la forme de la reprise :
• strictement identique ;• la totalité du lexique du titre mais pas nécessairement à l’identique ;• une partie seulement du titre ;• un pronom ;• une phrase présentative ou autre (il s’agit…).
– l’« éparpillement de la reprise » : reprise unique ou reprises à des endroits épars ;
– une éventuelle conversion, par ex. comparaison repris par le verbe comparer ;
– la localisation de la reprise :
• 1ère phrase de la section ;• ailleurs dans le paragraphe.
– la position sujet ou non de la reprise ;
– la présence d’un autre titre et une éventuelle reprise dans cet autre titre.
L’annotation de ces modalités de reprise nous permet de construire un modèle théo-
rique des fonctions des titres. Nous exposons maintenant ce modèle tel qu’il s’est élaboré
au fur et à mesure de l’analyse des titres, et dans la section suivante, nous montrerons com-
ment l’analyse statistique corrobore en partie ce modèle.
Modèle des fonctions discursives des titresPour classer les titres, nous nous appuyons sur leur type d’implication dans l’organisa-
tion du contenu textuel (cf. Ho-Dac, Jacques & Rebeyrolle 2004 (classification inspirée de
Halliday 1985)). Et nous distinguons deux grands types d’implication : une implication réfé-
rentielle, c’est-à-dire une contribution du titre à la gestion des référents du discours, et une
implication thématique, c’est-à-dire une délimitation du thème général dans lequel s’inscrit
ce dont on va parler : un domaine d’activité, un domaine de connaissances, un point de vue,
une situation spatio-temporelle, etc., spécifiques. Ces deux pôles renvoient à des processus
interprétatifs différents : il s’agit dans le premier cas, d’attirer l’attention du lecteur sur un ou
des référents du discours particulier(s), dans le second, de canaliser certaines de ses connais-
sances d’arrière-plan.
De l’implication référentielle…
Les titres à implication référentielle constituent un maillon d’une chaîne de référence
dont les éléments s’égrènent au fil du texte, parfois avant, toujours après le titre. Celui-ci
assure généralement la mise en saillance de ce référent. Trois types se dégagent :
1. Titres préparatoires
Le référent exprimé dans le titre fait l’objet d’une introduction, en position saillante, dans
la première (ou éventuellement la seconde) phrase du paragraphe. Ce n’est qu’après cette
introduction, liée souvent à une explicitation ou une justification de ce que le référent a à
voir avec le propos global, que ce référent devient le topic des phrases qui suivent.
5.3. La réutilisation
L’une des techniques proposées pour faciliter le processus de modélisation, en ingénierie des
besoins comme en ingénierie des connaissances, est la réutilisation de modèles. Elle devient un
objectif prépondérant. Il s’agit de réutiliser des modèles (ou des parties de modèles) conçus
sous une forme générique, précédemment développés et stockés dans des bibliothèques spé-
cialisées.
2. Titres focalisateurs
Le titre remet au premier plan de l’attention un référent déjà présent dans le discours,
qui peut éventuellement avoir été introduit plusieurs sections ou paragraphes auparavant.

6
Schedae, 2006, prépublication n°1, (fascicule n°1, p. 1-12).
Mais le Kremlin compte à la fois sur le jugement des dirigeants de ces pays et sur la vigilance
de leurs autres voisins, principalement la Chine et l’Iran. L’avenir décidera de la pertinence de
ces calculs. [deux paragraphes]
La Chine
Quoique de façon moins spectaculaire que la Russie, la République populaire de Chine (RPC)
n’a pas, elle non plus, hésité à se joindre à la Sainte-Alliance. […]
Mais la Chine avait deux raisons principales d’affirmer sa solidarité avec les États-Unis au lende-
main du 11 septembre. D’une part, elle doit faire face à ses propres problèmes de minorité […]
3. Titres installateurs
À la différence du type précédent, le référent n’a pas déjà été introduit dans le discours,
il ne fait pas non plus l’objet d’une introduction en début de section titrée, c’est le titre seul
qui installe le référent dans le discours.
3.3. L’ontologie computationnelle
L’ontologie computationnelle est spécifiée dans le langage DefOnto (Barry et al. [2001]). Elle
est obtenue en codant les propositions semi-informelles en propositions formelles (voir fig. 4).
… à l’implication thématique
Au pôle opposé, les titres à implication thématique ouvrent un espace thématique qui
est ensuite déployé dans la section. D’une certaine manière, ces titres condensent le con-
tenu de la section titrée pour délimiter, canaliser les connaissances et inférences qui devront
être mobilisées par le lecteur pour une interprétation de ce qui suit.
4.2. Adhésion et observance
À l’issue des expérimentations, 70 enregistrements de décision ont été exploitables, corres-
pondant à un total de 236 recommandations […]. En ce qui concerne l’adhésion, elle a été
meilleure […]. Quant à l’observance, les résultats obtenus…
Chacun des éléments du titre est repris dans un introducteur de cadre (Charolles 1997)
qui ponctue la section titrée et permet d’en ordonner le contenu.
Le titre thématique permet aussi de réduire l’univers de discours à un domaine de
connaissance, un point de vue, une situation spatio-temporelle :
4.1 Spécificités du contexte pédagogique
4.1.1. Du point de vue du domaine
[…]
4.1.2. Du point de vue de l’organisation de l’activité
[…]
4.1.3. D’un point de vue technique
Premièrement, l’interface a été conçue pour inciter les étudiants à utiliser certains outils […]
Deuxièmement, l’articulation des outils synchrones et asynchrones ne fait pas l’objet d’un dis-
positif technique, mais de l’intervention d’un des étudiants, rôle attribué par émergence.
Enfin, la circulation des données entre les étapes ne fait pas l’objet d’un dispositif technique ;
elle est gérée par le tuteur, afin que celui-ci soit partie intégrante de l’activité.
Dans ce second exemple, le titre définit littéralement un point de vue à partir duquel les
spécificités du contexte pédagogique sont abordées. Hormis l’adjectif technique qui réap-
paraît deux fois, réaffirmation de ce point de vue, ce titre ne donne pas lieu à une anaphore.
La bipolarité que nous venons d’exposer s’est faite jour lors de l’analyse manuelle des
titres, au fur et à mesure de leur annotation. Elle se fonde sur des corrélats formels qui per-
mettent de fixer des prototypes (au sens d’exemplaires typiques) de chaque extrémité.

7
Schedae, 2006, prépublication n°1, (fascicule n°1, p. 1-12).
Corrélats formelsLa mise au jour de corrélats de l’implication des titres dans le discours servira de base à
la construction de variables permettant la vérification sur corpus des hypothèses théoriques.
Pour caractériser formellement les titres, rappelons que nous disposons de deux grands
types de traits : des traits liés à la forme du titre, des traits liés à ses modalités de reprise.
Du côté de l’implication référentielle se positionnent des titres :
– formés d’un bloc unique ;
– de type SN ;
– donnant lieu à une reprise :
• consistant en une répétition strictement identique du titre ou en uneanaphore pronominale, dans tous les cas une reprise unique ;
• immédiate ;• en position sujet.
Par exemple :
3. Notre méthode
Notre méthode offre un cadre (fig. 1) au sein duquel les choix méthodologiques et techniques
proposés restent ouverts.
2.2.3 SYNTHÈSE DES BOUCHONS
Elle fera l’objet d’une fiche, mentionnant la situation, au moment de la transmission, sur la zone
d’action du CETE du Sud-Ouest.
Du côté de l’implication thématique se positionnent des titres :
– de type SP, SV, SN bipartites ou phrases ;
– donnant lieu à une reprise :
• d’une partie ou de l’ensemble des éléments lexicaux du titre, maiséparpillée dans le texte (reprise multiple) ;
• distante (pas la première phrase de la section) ;• en position autre que sujet.
Par exemple :
3.2. Analyse par scénarios et recueil
Concevoir l’ontologie, c’est d’abord identifier les notions du monde que l’on veut représenter.
Ces notions étant accessibles au travers du langage, il s’agit de recueillir et d’analyser des cor-
pus langagiers en étant guidé par des scénarios d’utilisation. Les corpus que nous avons
recueillis et analysés sont : […]
Soulignons qu’entre ces deux pôles qui représentent deux types d’implication tranchés,
la majorité des titres ne présente qu’une partie de ces caractères formels et se range plutôt
sur une position intermédiaire entre implication référentielle et implication thématique.
Nous éprouvons maintenant la validité de ce modèle bipolaire par des moyens statis-
tiques.
Validation statistique du modèleLe modèle fonctionnel des titres de section tel que nous l’avons présenté est donc un
modèle qui articule divers traits linguistiques formels. Ainsi conçu le modèle présuppose
qu’une fonction donnée n’est pas liée à une variable unique, mais qu’elle dépend de
l’influence conjointe de divers facteurs. Dès lors que l’on envisage de mesurer statistique-
ment une telle influence, c’est une approche multifactorielle qui s’impose. Il s’agit en effet
d’une analyse qui permet de tenir compte non du rôle des variables indépendamment les
unes des autres mais de leur influence conjointe. Ce type d’analyse statistique permet de
8
Schedae, 2006, prépublication n°1, (fascicule n°1, p. 1-12).
confirmer les oppositions posées théoriquement comme pertinentes en validant statisti-
quement ou non la pertinence des traits linguistiques considérés comme déterminants
pour classer les titres et d’interpréter ces classements en termes de fonctions discursives.
Plus précisément, l’analyse statistique sera utilisée ici pour regrouper les titres qui parta-
gent un ensemble de traits communs et pour les opposer à ceux qui partagent d’autres
traits. On pourrait, par exemple, obtenir les regroupements suivants : les titres qui ont la
forme d’un SN pourraient être rassemblés d’un côté, alors que les titres qui ont la forme
d’un SP, d’un SV ou d’un SN bipartite ou encore d’une phrase se trouveraient quant à eux
réunis de leur côté. Ce type de résultat serait un premier pas vers la validation de notre
modèle. Mais voyons maintenant les résultats que nous avons obtenus…
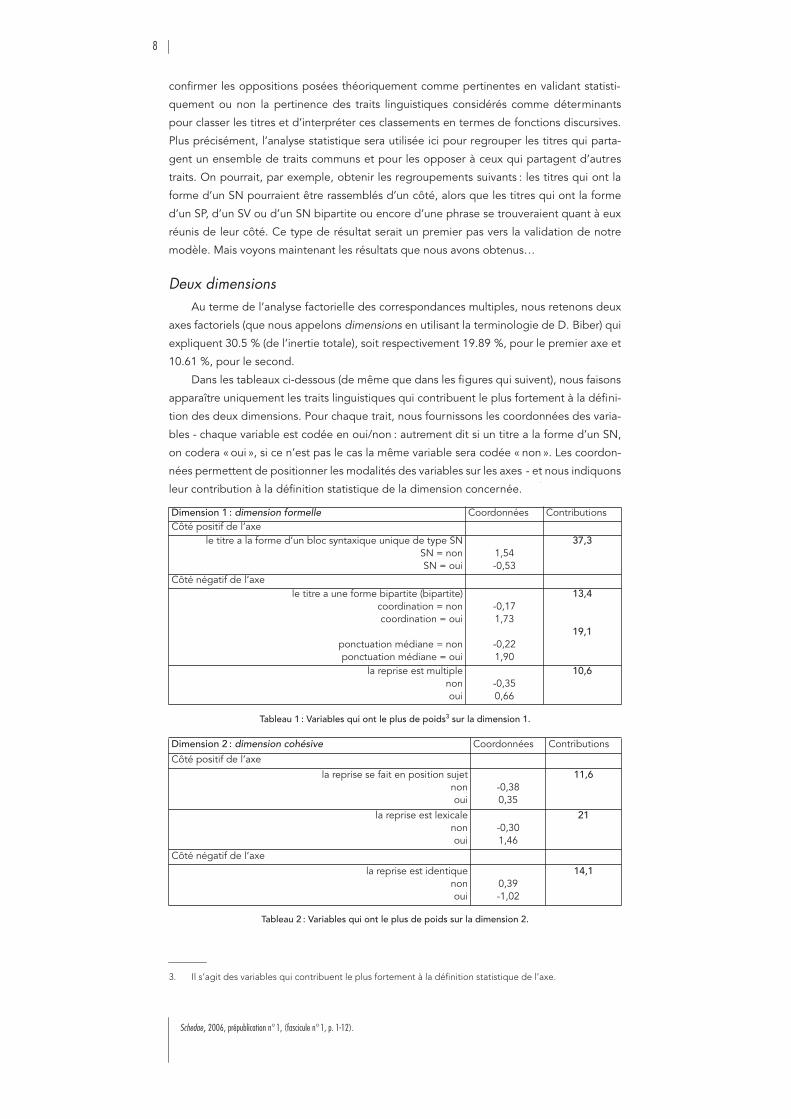
Deux dimensionsAu terme de l’analyse factorielle des correspondances multiples, nous retenons deux
axes factoriels (que nous appelons dimensions en utilisant la terminologie de D. Biber) qui
expliquent 30.5 % (de l’inertie totale), soit respectivement 19.89 %, pour le premier axe et
10.61 %, pour le second.
Dans les tableaux ci-dessous (de même que dans les figures qui suivent), nous faisons
apparaître uniquement les traits linguistiques qui contribuent le plus fortement à la défini-
tion des deux dimensions. Pour chaque trait, nous fournissons les coordonnées des varia-
bles - chaque variable est codée en oui/non : autrement dit si un titre a la forme d’un SN,
on codera « oui », si ce n’est pas le cas la même variable sera codée « non ». Les coordon-
nées permettent de positionner les modalités des variables sur les axes - et nous indiquons
leur contribution à la définition statistique de la dimension concernée. 3
Dimension 1 : dimension formelle Coordonnées ContributionsCôté positif de l’axe
le titre a la forme d’un bloc syntaxique unique de type SNSN = nonSN = oui
1,54-0,53
37,3
Côté négatif de l’axele titre a une forme bipartite (bipartite)
coordination = noncoordination = oui
ponctuation médiane = nonponctuation médiane = oui
-0,171,73
-0,221,90
13,4
19,1
la reprise est multiplenonoui
-0,350,66
10,6
Tableau 1 : Variables qui ont le plus de poids3 sur la dimension 1.
Dimension 2 : dimension cohésive Coordonnées Contributions
Côté positif de l’axe
la reprise se fait en position sujetnonoui
-0,380,35
11,6
la reprise est lexicalenonoui
-0,301,46
21
Côté négatif de l’axe
la reprise est identiquenonoui
0,39-1,02
14,1
Tableau 2 : Variables qui ont le plus de poids sur la dimension 2.
3. Il s’agit des variables qui contribuent le plus fortement à la définition statistique de l’axe.

9
Schedae, 2006, prépublication n°1, (fascicule n°1, p. 1-12).
On peut interpréter le premier axe comme une dimension formelle parce qu’il oppose
les titres en fonction de la forme syntaxique qu’ils revêtent. Les titres placés du côté positif
de l’axe sont les titres qui ont une structure syntaxique qu’on peut analyser comme bipartite
et ceux qui se trouvent réunis du côté négatif sont les titres qui ont la forme d’un syntagme
nominal.
On peut interpréter le second axe comme une dimension cohésive parce qu’il oppose
les titres en fonction de la forme sous laquelle s’opère la reprise. Les titres placés du côté
positif de l’axe sont les titres qui sont repris par le biais d’une reprise lexicale et ceux qui se
trouvent du côté négatif de l’axe sont ceux qui voient leur reprise se faire à l’identique ou
par le biais d’un pronom.
Confirmation de l’oppositionentre titres référentiels et titres thématiques
Rappelons que notre approche de la fonction des titres est une approche classificatoire
qui ordonne les titres sur un continuum allant du tout référentiel d’un côté, au tout théma-
tique de l’autre. Plus précisément, il s’agit d’une catégorisation graduelle qui oppose les
titres maximalement référentiels aux titres maximalement thématiques. Évidemment, la plu-
part des titres ne se trouvent pas au centre de ces deux grandes classes, mais ils se situent
à la périphérie. En d’autres termes, tous les titres ne remplissent pas nécessairement tous
les critères que nous avons définis comme pertinents. C’est cette hypothèse que nous per-
met de vérifier l’analyse multifactorielle. Afin de faciliter la lecture des résultats obtenus, nous
proposons ci-après une figure qui nous permet de visualiser l’opposition entre deux grandes
classes de titres que nous avons posées. Nous obtenons cette figure en croisant nos deux
dimensions. Ce croisement dessine un plan factoriel sur lequel nous pouvons situer les varia-
bles qui ont les plus fortes contributions.
Les cercles dessinés sur la figure nous servent à signaler les rapprochements statistiques
qui s’opèrent entre des sous-ensembles d’indices linguistiques que l’on a théoriquement
considérés comme définitoires de l’implication des titres.
D’un côté, en bas et à gauche, se trouvent réunis les titres qui se réalisent syntaxique-
ment sous la forme d’un syntagme nominal (SN) et qui sont repris dans le texte qui suit sous
une forme en tout point identique (reprise identique) et une seule fois dans la section titrée
(reprise unique). Ces trois éléments sont caractéristiques des titres dont l’implication dans
le texte a été qualifiée de référentielle.
De l’autre côté, en haut et à droite, se trouvent réunis les titres qui partagent les pro-
priétés suivantes : ils se réalisent syntaxiquement sous une forme bipartite, ils sont repris sous
la forme de l’une des unités lexicales qui les composent et cela dans diverses phrases de
la section titrée. Ces trois caractéristiques sont au nombre de celles que nous avons décri-
tes comme définitoires des titres dont l’implication notionnelle dans le texte est de type
thématique.
L’interprétation de l’analyse multifactorielle nous conduit à valider, au moins en partie,
notre modèle théorique. Mais en partie seulement et cela pour deux raisons. D’abord,
parce que certains indices linguistiques n’ont pas participé statistiquement à la définition
des deux dimensions que nous avons présentées. Il s’agit des deux variables suivantes : la
variable « localisation de la reprise » et la variable « le titre est un SV » (cf. § Méthodologie,
corpus et tout ça…). Ensuite, parce que d’autres indices vont dans le sens inverse de notre
modèle. C’est le cas notamment de la variable « position sujet de la reprise ». En outre,
contrairement à ce qu’affirme notre modèle, les reprises qui remplissent la fonction sujet
n’entretiennent pas de lien statistique avec les autres indices linguistiques caractéristiques
de l’implication référentielle.

10
Schedae, 2006, prépublication n°1, (fascicule n°1, p. 1-12).
S’agissant des variables « localisation de la reprise » et « position sujet de la reprise »,
on observe cependant une forte corrélation, comme le montre le tableau suivant (X2 signi-
ficatif à .000) :
Lorsque la reprise s’opère dans la phrase qui suit immédiatement le titre, elle occupe
la position syntaxique de sujet. En revanche, lorsque la reprise est localisée ailleurs dans la
section, elle assumera préférentiellement d’autres fonctions syntaxiques. Ce résultat nous
invite à construire une nouvelle variable combinant la fonction et la localisation afin de faire
entrer dans l’analyse les deux variables conjointes. Nous espérons alors mieux faire appa-
raître le lien entre la fonction syntaxique de sujet et la fonction référentielle du titre.
Titres référentiels ou thématiques :des préférences selon les genres textuels
Les résultats de l’analyse multifactorielle permettent de montrer que les titres n’assu-
ment pas les mêmes fonctions discursives dans tous les textes. Pour s’en convaincre, il suffit
d’observer la place qu’occupent les sous-corpus sur les deux dimensions dégagées. Mais
auparavant une précision s’impose. Pour bien comprendre ce qui est en jeu ici, il faut se
souvenir que les calculs statistiques ont été réalisés à partir d’informations qui décrivent les
titres eux-mêmes (forme, type de reprise, etc.). À ce stade, en revanche, il s’agit uniquement
de projeter les sous-corpus d’où sont extraits les titres analysés sur les axes qui ont été cal-
culés. En d’autres termes, les sous-corpus ne participent pas à l’analyse statistique, il s’agit
d’une information disponible (on connaît pour chaque titre le corpus d’où il est extrait) que
l’on projette sur les axes pour voir si les titres tirés des mêmes sous-corpus se rassemblent
sur l’espace à deux dimensions défini par l’analyse statistique précédente. Ce sont préci-
sément ces regroupements que l’on fait apparaître sur la figure 3 (il s’agit ici de représenter
la place qu’occupe la variable supplémentaire « sous-corpus » dans le plan factoriel obtenu
par le croisement des deux dimensions). Pour interpréter cette figure, il faut observer suc-
cessivement les deux axes :
Figure 2 : Validation de l’hypothèse d’une opposition entre des titres référentiels et des titres thématiques.
Première phrase Ailleurs
nbre d’occ % nbre d’occ %
Non sujet 246 45 77 65 323
Sujet 306 55 41 35 347
Total 552 100 % 118 100 %
Tableau 3 : La fonction syntaxique de la reprise dépend sa localisation.
reprise partielle
position sujet reprise lexicale
reprise multiple
Titre bipartite
reprise identique
reprise unique
Bloc unique : SN
titres référentiels
titres thématiques
Dimension 1 : formelle
Dimension 2 : cohésion

11
Schedae, 2006, prépublication n°1, (fascicule n°1, p. 1-12).
– sur le premier axe (dimension 1), du côté positif, on observe que se trouvent réunis les
titres des articles des domaines géopolitique et ingénierie des connaissances alors
que les titres extraits des textes professionnels sont regroupés sur le côté négatif de
l’axe ;
– sur le second axe (dimension 2), on observe les mêmes regroupements : d’un côté, les
titres tirés de l’ensemble des articles scientifiques et de l’autre les titres extraits des
textes professionnels.
L’observation de la place qu’occupent les corpus sur les deux dimensions nous rensei-
gne sur les relations entre notre classement fonctionnel des titres et le genre des textes et
nous conduisent à la conclusion suivante : l’implication des titres dans le discours fournit un
indice du type de texte.
Conclusion
En appréhendant les documents écrits sous leur aspect matériel, on est conduit à pren-
dre en compte des éléments structurants qui s’imposent visuellement tels que les sections,
paragraphes et leurs titres. Nous nous sommes intéressées au rôle joué par ces derniers dans
la construction de la sémantique du texte et avons dégagé deux fonctions polaires par rap-
port, d’un côté à la gestion des référents, de l’autre à la thématique. Se construit ainsi de
l’une à l’autre un continuum sur lequel se placent les divers titres du corpus, en fonction des
valeurs des différents traits formels utilisés pour les caractériser.
La description précise des indices linguistiques de l’implication des titres dans le dis-
cours suivie de leur codage dans un vaste corpus permet de quantifier les indices considérés
comme théoriquement pertinents. Cette étape de validation empirique d’un modèle théo-
rique a été franchie avec un relatif succès, dans cette étude, puisque les corrélats formels
théoriquement pertinents l’ont été aussi statistiquement. Le travail de description sur la fonc-
tion syntaxique de la reprise doit néanmoins être poursuivi afin de mieux expliquer les résul-
tats contradictoires obtenus. Par ailleurs, l’ensemble des titres ne donnant pas lieu à anaphore
doit être caractérisé par les autres traits annotés. L’une de nos hypothèses actuelles est qu’ils
s’apparentent à des introducteurs de cadre, elle doit être maintenant explorée.
Le second enseignement que l’on peut tirer du travail présenté ici concerne les possi-
bilités de caractérisation du contenu textuel via les titres de section. L’analyse portant sur un
Figure 3 : Projection des sous-corpus sur les axes dégagés par l’analyse multifonctionnelle.
reprise partielle
position sujet reprise lexicale
reprise multiple
Titre bipartite
reprise identique
reprise unique
Bloc unique : SN
titres référentiels
titres thématiquesArticles géopolitique / ingénierie
Textes professionnels

12
Schedae, 2006, prépublication n°1, (fascicule n°1, p. 1-12).
corpus diversifié, on peut en effet affirmer qu’il existe des affinités entre certains types de
titres et certains genres ou registres de discours. Ce résultat ouvre sur une application pos-
sible de ce travail vers le profilage automatique de textes (Habert et al. 2000). Si ce résultat
se confirme sur un plus grand nombre de corpus, on peut imaginer faire entrer les caracté-
ristiques des titres parmi les différents traits de surface qui seraient utilisés pour une caté-
gorisation automatique des textes.
Dans le même genre de perspectives, plusieurs applications concrètes sont envisagea-
bles. Pour une navigation intradocumentaire sélective, le typage des titres s’avérerait fruc-
tueux, ce serait une information supplémentaire que le lecteur pourrait utiliser pour décider
de lire ou non telle ou telle portion de texte. Pour des tâches automatiques telles que la
recherche d’information, il semble de plus en plus nécessaire de cesser de considérer les
textes comme des « sacs de phrases » et de bâtir des systèmes qui prennent en compte leur
structuration. Les applications impliquant un accès au contenu textuel ont tout à gagner d’une
meilleure compréhension du fonctionnement de ces éléments de structuration.
BibliographieBIBER D. (2003), « Variation among University Spoken and Written Registers : a new multi-dimensional
analysis », in Corpus analysis. Language structure and language use, P. Leistyna & C. F. Meyer (éds),
Amsterdam – New York, Rodopi, p. 47-67.
CHAROLLES M. (1997), « L’encadrement du discours : univers, champs, domaines et espaces», Cahier de
Recherche Linguistique, 6, p. 1-73.
CHAROLLES M. (2002), « Organisation des discours et segmentation des écrits», in Actes de la rencontre
Inscription Spatiale du Langage : structures et processus, Toulouse, p. 31-39.
CORNISH F. (2003), « The roles of (written) text and anaphor-type distribution in the construction of
discourse », Text, 23, 1, p. 1-26.
HABERT B., ILLOUZ G., LAFON P., FLEURY, S., FOLCH H., HEIDEN S. & PRÉVOST S. (2000), « Profilage de textes :
cadre de travail et expérience », in JADT (Journées Internationales d’Analyse Statistique des Données
Textuelles), M. Rajman (éd.), Lausanne.
HALLIDAY M.A.K. (1985), An introduction to Functional Grammar, London, Edward Arnold.
HO-DAC M., JACQUES M.-P. & REBEYROLLE J. (2004), « Sur la fonction discursive des titres », in L’unité
texte, S. Porhiel & D. Klingler (éds.), Pleyben, Perspectives, p. 125-152.
LUC C., & VIRBEL J. (2001), « Le modèle d’architecture textuelle Fondements et expérimentation »,
Verbum, 23, 1, p. 103-123.
POWER R., SCOTT D. & BOUYAD-AGAH N. (2003), « Document structure », Computational Linguistics, 29, 2,
p. 211-260.

13
Farida Aouladomar, Leila Amgoud, Patrick Saint-Dizier« On Argumentation in Procedural Texts »
Schedae, 2006, prépublication n°2, (fascicule n°1, p. 13-22).
Schedae, 2006
On Argumentation in Procedural Texts
Farida Aouladomar, Leila Amgoud, Patrick Saint-DizierIRIT-CNRS
118, route de Narbonne – 31062 Toulouse Cedex France
[email protected], [email protected], [email protected]
Abstract :
Procedural texts consist of sequences of instructions designed to reach an objective. The user
must follow step by step the instructions in order to reach the results expected. In this paper, we
explore the different facets of natural argumentation used in such texts that reinforces the plan-
goal structure.
Keywords: procedural texts, plan-goal structure, natural argumentation.
Résumé:
Les textes procéduraux sont composés de séquences d’instructions visant à atteindre un objec-
tif. L’utilisateur doit suivre étape par étape les instructions pour atteindre les résultats souhaités.
Dans cet article, nous explorons les différentes facettes de l’argumentation contenue dans ce
genre textuel servant à renforcer la structure plan-but des textes procéduraux.
Mots-clés: textes procéduraux, structure plan-but, argumentation.
IntroductionProcedural texts consist of a sequence of instructions designed with some accuracy in
order to reach an objective (e.g. assemble a computer). In our perspective, procedural texts
range from apparently simple cooking receipes to large maintenance manuals (whose paper
versions are measured in tons e.g. for aircraft maintenance). They also include documents
as diverse as teaching texts, medical notices, social behavior recommendations, directions
for use, do-it-yourself and assembly notices, itinerary guides, advice texts, savoir-faire guides,
etc.
In most types of procedural texts, in particular social behavior, communication, etc.
procedural discourse has two dimensions: an explicative component, constructed around
rational and objective elements (goals and plans), and a seduction component whose goal
is (1) to encourage the user, (2) to help him revise his opinions, (3) to enrich the goals and
the purposes, by outlining certain properties or qualities or consequences of a certain action
or prevention. This seduction component closely associated with the rational elements,
forms, in particular, the argumentative structure of the procedural text.
Prépublication n° 2 Fascicule n° 1

14
Schedae, 2006, prépublication n°2, (fascicule n°1, p. 13-22).
Another important feature, which is rather implicit, is the way instructions or groups of
instructions are organized and follow each other, and both the logic (objective aspect) and
the connotations (subjective aspects) that underlie this organization (sequential, parallel,
concurrent, conditional, etc.).
In procedural texts, goals are, roughly, reached by means of sequences of instructions.
These sequences are meaningful essentially w.r.t. the goals to reach. Similarly, the argu-
mentative structure supports the execution of the instructions in various ways. Arguments
get also their meaning w.r.t. the goal-sequences of instruction structure.
The diversity of procedural texts, their objectives and the way they are written is the
source of a large variety of natural arguments. We briefly present them in this paper. This
paper basically relates the argumentative structure of procedural texts as they are in French.
This study is based on a extensive corpus study, within a language production perspective.
This approach allows us to integrate logical, linguistic (e.g. Moeschler 1985, Anscombre et
al. 1981) and philosophical views of argumentation. It is basically linguistic and conceptual.
In the remainder of this paper, we briefly outline the theoretical basis of argumentation,
from an AI and cognitive perspective; we then present the structure of procedural texts. Then,
we show the different conceptual and linguistic facets of arguments, as found in our corpora,
and attempt to make explicit and categorize the roles these may play.
Argumentation process and argument typologyA rational agent can express claims and judgments, aiming at reaching a decision, a
conclusion, or informing, convincing, negotiating with other agents. Pertinent information
may be insufficient or conversely there may be too much, but partially incoherent informa-
tion. In case of multi-agent interactions, conflicts of interest are unavoidable. Agents can
be assisted by argumentation, a process based on the exchange and the valuation of inter-
acting arguments which support opinions, claims, proposals, decisions,…
According to Dung (1995), an argumentation framework is defined as a pair consisting of
a set of arguments and a binary relation representing the defeasibility relationship between
arguments.
Definition 1. An argumentation framework is a pair <A, R> where A is a set of arguments
and R is a binary relation representing a defeasibility relationship between arguments, i.e.
R ⊆ A × A. (a, b) ∈ R or equivalently “a R b” means that the argument a defeats b.
Among all the conflicting arguments, it is important to know which arguments will be
kept for inferring conclusions and for making decisions. In (Dung, 1995), different semantics
for the notion of acceptability have been proposed. Let's recall them here.
Definition 2. (Conflict-free, Defence) Let B ⊆ A.
– B is conflict-free iff there exist no ai, aj in B such that ai R aj;
– B defends an argument ai iff for each argument aj ∈ A, if aj R ai, then there exists ak ∈ B
such that ak R aj.
Definition 3. (Acceptability semantics) Let B be a conflict-free set of arguments, and let
F: 2A→ 2A be a function such that F(B) = {a | B defends a}.
– B is admissible iff B ⊆ F(B);
– B is a complete extension iff B = F(B);
– B is a grounded extension iff it is the minimal (w.r.t. set-inclusion) complete extension;

15
Schedae, 2006, prépublication n°2, (fascicule n°1, p. 13-22).
– B is a preferred extension iff it is a maximal (w.r.t. set-inclusion) complete extension;
– B is a stable extension iff it is a preferred extension that defeats all arguments in A\B.
Let E = {E1, …, En} be the set of all possible extensions under a given semantics.
Note that there is only one grounded extension. It contains all the arguments which
are not defeated and also the arguments which are defended directly or indirectly by non-
defeated arguments.
In the above framework, an argument is an abstract entity whose role is only determined
by its relation to other arguments. Then its structure and its origin are not known. However,
in many applications of argumentation, for instance for handling inconsistency in knowledge
bases, arguments take the form of explanations, called in (Amgoud & Prade 2005) explana-
tory arguments. However, recent works on negotiation have argued that argumentation can
play a key role in finding a compromise. Indeed, an offer supported by a `good’ argument
has a better chance to be accepted by another agent. Argumentation may also lead an agent
to change its goals and finally may constrain an agent to respond in a particular way. In
addition to explanatory arguments studied in classical argumentation frameworks, works
on argumentation-based negotiation have emphasized other types of arguments such as
threats, rewards, tips and warnings (see section 5). For example, if an agent receives a threat,
this agent may accept the offer even if it is not really acceptable for him (because otherwise
really important goals would be threatened). The figure below shows clearly the differences
between the four types of arguments.
The Context: Procedural text structure
Under the heading of procedural texts, there is a quite large diversity of texts. Procedural
texts can be grouped into families according to their main objectives and style (Adam 2001).
We have, for example, regulatory texts (Mortara Garavelli 1988), procedural texts (Longacre
1982), ‘programmatory’ texts (Greimas 1983), instructional-prescriptive texts (Werhlich 1975),
injunctive texts (Adam 1987), advice texts (Lüger 1995) and receipe texts (Qamar 1996), etc.
All these views share common structures: specification of goals, description of ingredients/
materials to use, and description of sequences of instructions. Procedural texts obey to a
number of structural criteria which are quite well-defined. They indeed share common sty-
listic forms, e.g. preference for imperative forms, and a number of typographic elements
such as enumerations.
Procedural texts explain how to realize a certain goal by means of actions which are at
least partially temporally organized; they also outline the way these actions can be realized,
Statement: If ‘a’ then ‘b’, where ‘a’ is a potential action of hearer
Is ‘b’ desirable or undesirable for hearer
Is ‘b’ a potential action of speaker ? Is ‘b’ a potential action of speaker ?
desirable undesirable
Tip Reward Threat Warning
no yes yes no

16
Schedae, 2006, prépublication n°2, (fascicule n°1, p. 13-22).
with advices and preferences. The organization of a procedural text is in general made vis-
ible by means of linguistic and typographic marks.
Another feature is that procedural texts tend to minimize the distance between language
and action. The main structure of procedural texts can refer to plans and goals theory in IA
theory. In procedural texts, plans to realize a goal are made as immediate and explicit as
necessary, the objective being to reduce the inferences that the user will have to make before
acting. Texts are thus oriented towards action, they therefore combine instructions with icons,
images, graphics, summaries, preventions, advices, etc.
We based our studies of procedural texts on their discursive aspects in order to identify
and isolate the main informational modules that will be useful for answering procedural ques-
tions on the web in a QA system (see (Aouladomar 2005) for more details).
Instructions may be sequential, or may have a more complex structure including, for
example, options, alternatives or operations to realize in parallel with others. This level also
includes the analysis of markers proper to certain types of instructions and markers that
connect instructions.
The goal-plan structure of procedural texts has been described using a grammar for-
malism that presents the main elements composing procedural texts, that we use for anno-
tating them.
The goals and sub-goals of procedural texts represent the skeletal structure of those
texts. Every structure identified contributes to the realization of those goals.
Methodology The methodology we use to represent the structure of procedural texts is based on
corpora analysis. Our corpus is built following two steps: (1) a user-centred method, (2) an
enhancement of this first corpus when important categories of procedural texts were missing.
First, we collect procedural queries from queries inventories on the web, which we use
to select associated procedural texts. At the end of this stage, we gathered 78 texts from
essentially technical (ex: computer assembly) and communication domains (how to write a
CV). Then, we added 47 procedural texts from important missing categories (recipes, injunc-
tions, etc.). The work presented below corresponds to a manual analysis of procedural texts
in order to describe their organization. The description is based on example/counter exam-
ple method.
A Discursive analysis of procedural textsProcedural texts can be a simple, ordered list of instructions to perform to reach a goal,
but they can also be less linear, outlining different ways to realize something, with arguments,
conditions. They often also contain a number of recommendations, warnings, and comments
of various sorts.
Here is, represented by means of a grammar, the structure we have elaborated for pro-
cedural texts from a corpora analysis.
Structures reported below essentially correspond to the organization of the informational
contents. Elements concerning the layout (e.g. textual organizers such as: titles, enumera-
tions, etc.), and linguistic marks of various sorts are used as triggers or delimiters in the imple-
mentation of this grammar. In what follows, parentheses express optionality, + iteration, {}
express the compulsory character of an element but which is not always realized linguistically,
the comma is just a separator with no temporal connotation a priori, / is an or and the oper-
ator < indicates a preferred precedence. Each symbol corresponds to an XML-tag, allowing
us to annotate procedural texts.

17
Schedae, 2006, prépublication n°2, (fascicule n°1, p. 13-22).
– Text title, (summary), (warning)+, (pre-requisites)+, (picture) + < objective;
– Summary title+. “Summary” describes the global organisation of the procedure, it may
be useful when procedures are complex (summary can be a set of hyper-links, often
pointing to titles);
– Warning (picture)+, (pre-requisites), (arguments). “Warnings” represent global precau-
tions or preventions associated with actions or objectives (e.g. switch off electricity prior
to any action);
– Pre-requisites list of objects, (instruction sequences). “Pre-requisites” describe all kinds
of equipments needed to realize the action (e.g. the different constituents of a receipe)
and preparatory actions;
– Picture describes a sequence of charts and/or schemas of various sorts. They often
interact with instructions by e.g. making them clearer;
– Objective {goal} < (warning), (picture), (pre-requisites), instruction sequences+ / objec-
tive. This structure corresponds to the subgoals and sub-plans of procedural texts. It is
the main structure of procedural texts, that we use for the answering process of the QA
system;
– Instruction sequences instseq < {connector} < instruction sequences / instseq;
– Instseq imperative linear sequence / optional sequence / alternative sequence / impe-
rative co-temporal sequence;
– Imperative linear sequence instruction < {temporal mark} < imperative linear sequence /
instruction. (e.g. cook peeled potatoes and reduce them out of mashed potatoes);
– Optional sequence optional expression < imperative linear sequence. (e.g. if you
prefer a stronger flavour, add curry powder and cream);
– Alternative sequence (conditional expression), (argument), imperative linear sequence,
(alternative-opposition mark) < instseq / (conditional expression, instseq). (e.g. peel
potatoes, or leave the peel on if it is thin);
– Imperative co-temporal sequence Imperative linear sequence < co-temporal mark <
imperative co-temporal sequence / instruction. A co-temporal sequence relates ins-
tructions which must be realized at the same time, or more generally non-sequentially
(e.g. mash tomatoes while mixing with garlic and olive oil);
– Instruction (iterative expression), action, (argument)+, (reference)+, (picture)+ (warn-
ing). “Instruction” is the lowest level, instructions can be complex since they may con-
tain their own goals, warnings, pictures, arguments, etc.
Besides this aspect of analysis for QA systems, procedural texts seem of much interest
for other various linguistic analysis: one can explore their layout structure, temporal struc-
ture, rhetorical structure (Kosseim 2000, Vander Linden 1995, Rosner 1992), argumentative
structure, logical structure, etc.
We focus in the rest of this paper on the argumentative aspects of procedural texts.
Argumentation in procedural texts
General considerations
Argumentation is a process used by a person to convince an audience (Oléron 1983).
Procedural texts are a form of argumentation structure since they (1) make interact the instruc-
tions producer and receiver, (2) are also a process that exert an influence on the receiver (the
user must realize the instructions), (3) give justifications or elements that prove the appro-
priateness of the instruction, using rational elements (see our argument typology below).

18
Schedae, 2006, prépublication n°2, (fascicule n°1, p. 13-22).
Procedural texts are specific forms of discourse, satisfying constraints of economy of
means, accuracy, etc. They are in general based on a specific discursive logic, made up of
presuppositions, causes and consequences, goals, inductions, warnings, anaphoric net-
works, etc., and more psychological elements (e.g. to stimulate a user). The goal is to opti-
mize a logical sequencing of instructions and make the user feel safe and confident with
respect to the goal(s) he wants to achieve (e.g. clean an oil filter, learn how to organize a
customer meeting). Procedural texts, from this point of view, can be analyzed not only just
as sequences of mere instructions, but as efficient, one-way (i.e. no contradiction, no nego-
tiation) argumentative discourses, designed to help a user to reach a goal, making the best
decisions (see e.g. Amgoud et al. 2001, 2005).
Producing explanations is a rather synthetic activity whose goal is to use the elements
introduced by knowledge explicitation mechanisms to induce generalizations, subsump-
tions, deductions, relations between objects or activities and the goals to reach. This is par-
ticularly visible in the lexical choices made and in the choice of some constructions, including
typographic. Procedural discourse is basically interactive: it communicates, teaches, justifies,
explains, warns, forbids, stimulates, evaluates. It contains a number of facets, which all are
associated in a way to argumentation.
The author of procedural texts must consider different dimensions (Donin et al. 1992),
among others: (1) cognitive: notions referred to must be mastered and understood by the
target users, (2) epistemic: take into account, possibly to deny them, the beliefs of those
users. The producer of procedural texts starts from a number of assumptions or presuppo-
sitions about potential users, about their knowledge, abilities and skills, but also about their
beliefs, preferences, opinions, ability to generalize and adapt (to adapt instructions to their
own situation, which is never exactly the one described in the procedure), perception of
generic situations, and ability to follow discursive processes.
The producer of procedural texts has then, from this basis, to re-inforce or weaken pre-
suppositions, to specify some extra knowledge and know-how, possibly beliefs or opinions.
He has to convince the reader that his text will certainly lead to the success of the target
goal, modulo the restrictions he includes. Texts are also expected to be locally and globally
coherent, with no contradictions, and no space for hesitation or negotiation.
Given a certain goal, it is also of much interest to compare or contrast the means used
by different authors, possibly for different audiences. Resorting to arguments for the pro-
ducer of procedural texts can thus depend on several factors: the author beliefs, the type
and the complexity of procedural texts (i.e. technical procedural texts are very rich in argu-
ments compared to receipes), or the expertise level of users (i.e. a text designed for experts
may contain less arguments than for non-experts of a domain).
Argumentation in procedural texts is found in the expression of objectives, in the expres-
sion of disjunction, alternatives, warnings, and within instructions (see the grammar above).
Arguments are thus structurally and semantically dependent of the local structures or the
general plans and goals structure they are associated with.
Definitions of arguments
Two families of arguments are found in the logical and psychological literature of argu-
mentation, depending on the involvement of the producer of the argument: advices and
inducements. In procedural texts, those arguments describe the reason why users could,
should or must do the prescribed instructions.
– Inducements are speech acts uttered in an attempt to make another person do, or
refrain from doing some actions (Fillenbaum 1986). They consists of either promises
(rewards) or threats:
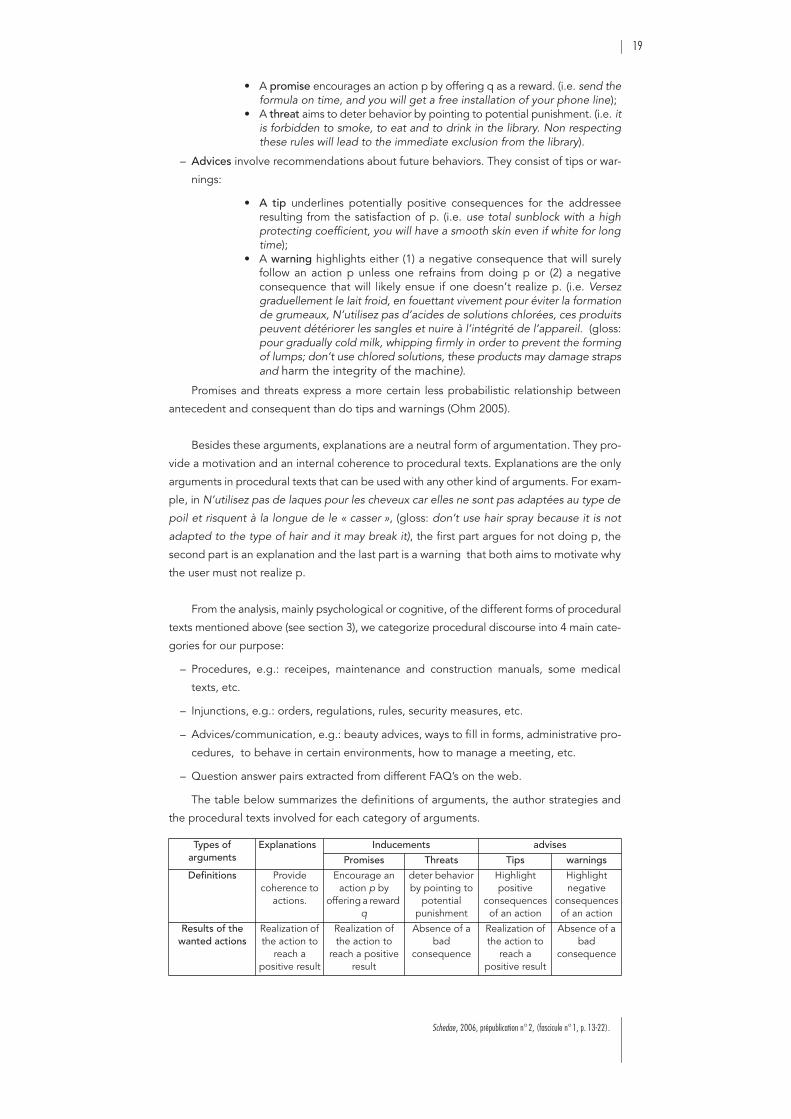
19
Schedae, 2006, prépublication n°2, (fascicule n°1, p. 13-22).
• A promise encourages an action p by offering q as a reward. (i.e. send theformula on time, and you will get a free installation of your phone line);
• A threat aims to deter behavior by pointing to potential punishment. (i.e. itis forbidden to smoke, to eat and to drink in the library. Non respectingthese rules will lead to the immediate exclusion from the library).
– Advices involve recommendations about future behaviors. They consist of tips or war-
nings:
• A tip underlines potentially positive consequences for the addresseeresulting from the satisfaction of p. (i.e. use total sunblock with a highprotecting coefficient, you will have a smooth skin even if white for longtime);
• A warning highlights either (1) a negative consequence that will surelyfollow an action p unless one refrains from doing p or (2) a negativeconsequence that will likely ensue if one doesn’t realize p. (i.e. Versezgraduellement le lait froid, en fouettant vivement pour éviter la formationde grumeaux, N’utilisez pas d’acides de solutions chlorées, ces produitspeuvent détériorer les sangles et nuire à l’intégrité de l’appareil. (gloss:pour gradually cold milk, whipping firmly in order to prevent the formingof lumps; don’t use chlored solutions, these products may damage strapsand harm the integrity of the machine).
Promises and threats express a more certain less probabilistic relationship between
antecedent and consequent than do tips and warnings (Ohm 2005).
Besides these arguments, explanations are a neutral form of argumentation. They pro-
vide a motivation and an internal coherence to procedural texts. Explanations are the only
arguments in procedural texts that can be used with any other kind of arguments. For exam-
ple, in N’utilisez pas de laques pour les cheveux car elles ne sont pas adaptées au type de
poil et risquent à la longue de le « casser », (gloss: don’t use hair spray because it is not
adapted to the type of hair and it may break it), the first part argues for not doing p, the
second part is an explanation and the last part is a warning that both aims to motivate why
the user must not realize p.
From the analysis, mainly psychological or cognitive, of the different forms of procedural
texts mentioned above (see section 3), we categorize procedural discourse into 4 main cate-
gories for our purpose:
– Procedures, e.g.: receipes, maintenance and construction manuals, some medical
texts, etc.
– Injunctions, e.g.: orders, regulations, rules, security measures, etc.
– Advices/communication, e.g.: beauty advices, ways to fill in forms, administrative pro-
cedures, to behave in certain environments, how to manage a meeting, etc.
– Question answer pairs extracted from different FAQ’s on the web.
The table below summarizes the definitions of arguments, the author strategies and
the procedural texts involved for each category of arguments.
Types of arguments
Explanations Inducements advises
Promises Threats Tips warnings
Definitions Provide coherence to
actions.
Encourage an action p by
offering a reward q
deter behavior by pointing to
potential punishment
Highlight positive
consequences of an action
Highlight negative
consequences of an action
Results of the wanted actions
Realization of the action to
reach a positive result
Realization of the action to
reach a positive result
Absence of a bad
consequence
Realization of the action to
reach a positive result
Absence of a bad
consequence

20
Schedae, 2006, prépublication n°2, (fascicule n°1, p. 13-22).
Typology of Arguments in procedural textsLet us review here the 4 major forms of arguments we found frequently in corpora. Verb
classes referred to are in general those specified in WordNet (Fellbaum 1998):
– explanations are the most usual ones. We find them in any kind of procedural texts.
They usually introduce a set of sequences or more locally an instruction implemented
in the “goal” symbol of the grammar.
The abstract schemas are the following: (1) purpose connectors-infinitive verbs, (2) causal
connectors-deverbals and (3) titles.
The most frequently used causal connectors are: pour, afin de, car, c’est pourquoi, etc.
(to, in order to) (e.g. to remove the bearings, for lubrification of the universal joint shafts,
because it may be prematurely worn due to the failure of another component).
– warning arguments embedded mostly either in a “negative” formulation. They are
particularly rich in technical domains.
Their role is basically to explain and to justify. Negative formulation is easy to identify:
there are prototypical expressions that introduce the arguments.
Negative formulation follows the abstract schemas: negative causal connectors-infinitive
risk verbs; negative causal marks-risk VP; positive causal connectors-VP negative syntaxic
forms, positive causal connectors-prevention verbs.
• negative connectors: sous peine de, sinon, car sinon, sans quoi, etc.(otherwise, under the risk of) (e.g. sous peine d'attaquer la teinte du bois);
• risk class verbs: risquer, causer, nuire, commettre etc. (e.g. pour ne pascommettre d'erreur);
• prevention verbs: éviter, prévenir, etc. (e.g. afin d'éviter que la carte sedéchausse lorsqu'on la visse au châssis}, gloss: in order to prevent thecard from skipping off its rack);
• Positive causal mark and negative syntaxic forms: de facon à ne pas, pourne pas, pour que… ne… pas etc. (in order not to) (e.g. pour ne pas lerendre brillant, gloss: in order not to make it too bright).
– Tip arguments: these arguments are less imperative than the other ones, they are
advices, evaluations. They are particularly rich in communication texts.
The corresponding abstract schemas are: causal connectors-performing NP; causal
connectors-performing verbs; causal connectors-modal-performing verbs; performing
proposition.
• performing verbs: e.g. permettre, améliorer, etc. allow, improve;• performing PPs: e.g. Pour une meilleure finition; pour des raisons de
performances;• performing proposition: e.g. Have small bills. It's easier to tip and to pay
your bill that way.
– threatening arguments and reward arguments: these arguments have a strong impact
on the user's intention to realize the instruction provided, the instruction is almost made
compulsory by using this kind of argument. This is the injunctive form.
Involvement of the speaker in the consequences of
an action p
neutrality Involvement Involvement Neutrality Neutrality
Types of procedural texts
involved
Technical texts
Advises textsMedical texts
InjunctionsReceipesQA pairs
QA pairsInjunctions
QA pairsInjunctions
Technical textsAdvises textsMedical texts
InjunctionsReceipesQA pairs
Technical texts
Advises textsMedical texts
InjunctionsReceipesQA pairs

21
Schedae, 2006, prépublication n°2, (fascicule n°1, p. 13-22).
We could not find any of these types of arguments in procedural texts, except in QA
pairs and injunctions texts (e.g. rules) where the author and the adressee are clearly identi-
fied. Therefore, in those arguments we often find personal pronouns like “nous” “vous” (we,
you). For threatening arguments, it follows the following schemas: otherwise connectors-
consequence proposition; otherwise negative expression-consequence proposition:
• otherwise connectors: sinon;• otherwise negative expression: si… ne… pas… (e.g. si vous ne le faites
pas, nous le périmerons automatiquement après trois semaines en ligne).For reward arguments, the schemas associated are the following: personal pronouns –
reward proposition:
• reward proposition: using possession transfer verbs (gagner, donner,bénéficier, etc. (win, give, benefit …)
Besides these four main types of arguments, we found some forms of stimulation-eval-
uation (what you only have to do now...), and evaluation.
ConclusionIn this paper, we have shown the variety of natural argumentation forms found in pro-
cedural texts. To get a more accurate view of the diversity of argumentation in this type of
text, we need to also consider more subtle language forms such as: modalisators, tonality,
opinion marks, evaluation marks, illocutionary force in arguments, etc.
Let us conclude with some interesting observations and remarks that need to be
developed by comparative analysis of different procedural texts.
– Using emphasizing arguments to express the importance of following instructions, can
depend on the nature of procedural texts. Preliminary observations tend to show that
technical procedural texts are richer in argumentation than, for instance, receipes. Argu-
ments in procedural texts seem to depend also on the complexity or “dangerousness”
of the procedure. Further investigations in those directions but also in the existence of
specific syntactic and semantic schemas of arguments proper to different types of pro-
cedural texts would be interesting to carry out;
– Arguments can depend on the user’s expertise or familiarity with the domain. In that
case, arguments are means, for the producer, of adapting his writing strategies accor-
ding to the user.
All these considerations can lead to recommendations for writing assistance tools. Results
can also help to develop different strategies when generating answers to procedural ques-
tions by: (1) adding arguments in the answer of a QA system which is a way to give justifi-
cations to the generated answer; (2) using arguments adapted to user levels.
BibliographyADAM J.-M. (2001), “Types de texts ou genres de discours? Comment classer les textes qui disent de et
comment faire?”, Langages, 141 (Les discours procéduraux), p. 10-27.
ADAM J.-M. (1987), “Types de séquences textuelles élémentaires”, Pratiques, 56.
AMGOUD L. & PRADE H. (2005), “Handling threats, rewards and explanatory arguments, in a unified
setting”, International Journal Of Intelligent Systems, 20, 12, p. 1195-1218.
AMGOUD L., PARSONS S., MAUDET N. (2001), “Arguments, dialogue, and negotiation”, in Proceedings of
the 14th European Conference on Artificial Intelligence, Berlin.
AMGOUD L., BONNEFON J.F., PRADE H. (2005), “An argumentation-based approach to multiple criteria
decision”, in Proceedings of the 8th European Conference on Symbolic and Quantitative Approaches
to Reasoning with Uncertainty (ECSQARU'2005), Barcelona.

22
Schedae, 2006, prépublication n°2, (fascicule n°1, p. 13-22).
ANSCOMBRE J.-C., DUCROT O. (1981), “Interrogation et Argumentation”, Langue française, 52 (L'interro-
gation), p. 5-22.
AOULADOMAR F. (2005), “Towards answering procedural questions”, in Proceedings of IJCAI05 Workshop
on Knowledge and Reasoning for Answering Questions (KRAQ’05), F. Benamara, M.F. Moens, and
P. Saint-dizier (eds), Edinburgh, p. 21-32.
AOULADOMAR F., SAINT-DIZIER P. (2005), “An exploration of the diversity of natural argumentation in
instructional Texts”, in Proceedings of IJCAI05 Workshop on Computational Models of Natural
Argument (CMNA’05), C. Reed (ed), Edinburgh, p. 69-72.
DONIN J., BRACEWELL R. J., FREDERIKSEN C. H., DILLINGER M. (1992), “Students’ strategies for writing
instructions: organizing conceptual information in text”, Written Communication, 9, p. 209-236.
DUONG P. M. (1995), “On the acceptability of arguments and its fundamental role in nonmonotonic
reasoning, logic programming and n-person games”, Artificial Intelligence Journal, 77, p. 321-357.
FELLBAUM C. (1998), WordNet An Electronic Lexical Database, The MIT Press.
FILLENBAUM S. (1986), “The use of conditionals in inducements and deterrents”, in On conditionals,
E.C. Traugott, A.T. Meulen, J.S. Reilly & C.A. Ferguson (eds), Cambridge, Cambridge University Press,
p. 179-195.
GREIMAS A. (1983), “La soupe au pistou ou la conversation d’un objet de valeur”, in Du sens II, Paris, Seuil.
KOSSEIM L., LAPALME G. (2000), “Choosing rhetorical structure to plan instructional texts”, in Computational
intelligence, Boston, Blackwell.
LONGACRE R. (1982), “Discourse typology in relation to language typology”, in Text processing,
proceeding of nobel symposium 51, Sture Allen (ed.), Stocholm, Almquist and Wiksell, p. 457-486.
LUGER H.H. (1995), Pressesprache, Tubingen, Niemeyer.
MOESCHLER J. (1985), Argumentation et conversation, éléments pour une analyse pragmatique du
discours, Paris, Hatier/Credif.
MORTARA GARAVELLI B. (1988), “Tipologia dei testi”, in Lexicon der romanistischen linguisti, G. Hodus et
al. (eds), IV, Tübingen, Niemeyer.
OHM E. (2005), The relationship between formal and informal reasoning, Thesis, University of Saskatchewan,
Saskatoon, Canada.
OLERON P. (1983), L'argumentation, Paris, Presses Universitaires de France.
QAMAR H. (1996), Quand dire c’est: écrire-comment-faire. Un autre type de texte: le RECETTAL, Thesis,
Université Lumière Lyon II.
ROSNER D., STEDE M. (1992), “Customizing RST for the automatic production of technical manual”, in
Proceedings of the 6th International Workshop on Natural Language Generation, R. Dale, E. Hovy, D.
Rösner and O. Stock (eds), Berlin, Springer Verlag, p. 199-214.
VANDER LINDEN K., MARTIN J. (1995), “Expressing local rhetorical relations in instructional Text: a case
study of the purposes relation”, Computational Linguistics, 21, 1, p. 29-57.
WERLICH E. (1975), Typologie der texte, Heidelberg, Quelle and Meyer.

23
Sophie Piérard & Yves Bestgen« Adverbiaux temporels et expressions référentielles comme marqueurs de segmentation : emploi simultané ou exclusif ? »
Schedae, 2006, prépublication n°3, (fascicule n°1, p. 23-28).
Schedae, 2006
Adverbiaux temporelset expressions référentiellescomme marqueurs de segmentation : emploi simultané ou exclusif ?
Sophie Piérard & Yves Bestgen1
Université catholique de Louvain
Place Cardinal Mercier, 10 ; 1348 Louvain-la-Neuve – Belgique
Résumé :
Cette recherche essaye d’éclaircir une question initiée par une recherche de Vonk et al. (1992)
sur l’utilisation simultanée ou non de deux types de marqueurs de la segmentation : les expres-
sions temporelles et les anaphores nominales. Par une analyse de corpus, nous montrons que ces
deux types d’expressions apparaissent simultanément et permettent de confirmer l’intérêt des
recherches de détection automatique des ruptures thématiques basées sur le cumul d’indices.
Mots-clés : adverbiaux temporels, expressions référentielles, nom propre, marqueur de la
structure.
Abstract :
This research tries to answer a question initiated by Vonk et al. (1992) on the simultaneous use or
not of two types of segmentation markers : temporal expressions and nominal anaphora. A corpus
analysis shows that these two types of expressions appear simultaneously to highlight a paragraph
shift. This observations confirm the interest of automatic text segmentation procedures that are
based on the coccurrence of indices.
Keywords : temporal adverbials, referential expressions, proper name, segmentation
markers.
De nombreux moyens linguistiques sont à la disposition de l’auteur d’un texte pour
signaler les ruptures thématiques. Il s’agit par exemple des adverbiaux temporels et des
expressions référentielles (Charolles 1997, Laignelet 2004). D’une manière générale, nos
Prépublication n° 3 Fascicule n° 1
1. Yves Bestgen est chercheur qualifié du Fonds national de la recherche scientifique (FNRS). Cette recher-che est financée par une « Action de Recherche concertée » du Gouvernement de la Communauté fran-çaise de Belgique.

24
Schedae, 2006, prépublication n°3, (fascicule n°1, p. 23-28).
travaux visent à étudier l’emploi de ces marqueurs dans de grands corpus de textes (Piérard &
Bestgen 2005). Sont-ils bien associés à des ruptures thématiques ? Certaines expressions
sont-elles de meilleurs signaux ? Pour identifier les ruptures de thème, nous employons un
indice qui traduit, au moins partiellement, les intentions de l’auteur d’un texte : les change-
ments de paragraphe (Hofmann 1989, Longacre 1979). Nous utiliserons dans cette recher-
che une technique d’analyse qui fait l’objet d’un regain d’intérêt (Hoey 2005).
En plus de répondre à ces questions, la présente étude vise un objectif plus spécifique :
étudier les relations entre deux types de marqueurs de la segmentation d’un texte : les adver-
biaux temporels et les expressions référentielles (nom propre, pronom, nom avec détermi-
nant indéfini, défini, démonstratif et possessif de la 3e personne). La question principale à
laquelle nous voulons répondre trouve son origine dans une recherche de Vonk et al. (1992).
Ces auteurs s’intéressent au rôle des expressions référentielles comme marqueurs de la struc-
ture. En effet, selon ceux-ci, une expression référentielle plus spécifique que nécessaire
indique un changement de thème. Des expressions, telles que le pronom personnel, sont
utilisées dans des situations de continuité de thème. Par contre, des expressions nominales
(comme « Jacky » mais aussi « le pharmacien »), lorsqu’elles sont utilisées alors que l’acces-
sibilité à l’antécédent est forte, indiquent une transition vers une nouvelle unité du discours.
Les expressions nominales sont donc des signaux de changement de thème lorsqu’elles
sont employées alors que le contexte ne le nécessite pas (Fox 1984). Dans une de leurs
expériences, Vonk et al. (1992) ont demandé à leurs participants d’écrire une suite à de
courtes histoires de deux lignes mettant en scène un personnage. Dans l’une des conditions
expérimentales, les chercheurs imposaient aux participants d’écrire une suite en rupture ou
en continuité thématique par rapport au début du texte. Ils ont observé que les ruptures
de thème étaient liées à l’emploi d’anaphores plus spécifiques que nécessaire, c’est-à-dire
d’anaphores nominales. De plus, ils ont observé que lorsqu’il y a un changement de thème
dans une narration, l’auteur a tendance à employer soit une expression temporelle en début
de phrase et un pronom soit un nom seul. Ils expliquent cette observation en soutenant que
la présence d’un marqueur temporel de la segmentation réduit les chances d’observer une
expression référentielle plus spécifique que nécessaire. Ils concluent donc qu’il n’y a pas
d’emploi simultané de ces deux dispositifs qui indiquent un changement de thème.
Ces résultats ont été obtenus au travers d’une tâche relativement artificielle (imposer
aux participants de produire des suites en continuité ou en rupture thématique). Dans la
présente recherche, nous voulons déterminer si ce même emploi exclusif de ces deux types
de marqueurs peut être mis en évidence par une analyse de corpus.
Le corpusLe corpus qui a été utilisé est composé de textes littéraires extraits des bases ABU,
Intratext et Wordthèque. Il contient 67 romans (du XIXe et XXe siècle) et approximativement
4 300 000 mots. Les textes ont été découpés en phrases et lemmatisés au moyen du pro-
gramme TreeTagger de Schmid (1994). Nous avons retiré du corpus les paragraphes qui
contenaient des dialogues afin de focaliser les analyses sur l’emploi des indicateurs de la
structure du discours écrit.
Expressions temporelles et paragrapheDans un premier temps, nous avons employé une procédure d’extraction d’expressions
régulières pour sélectionner de manière automatique les phrases contenant une expression
temporelle comme une date (le 4 janvier), une partie de journée (dès le matin), une indica-
tion d’heure (vers midi), un délai (une heure/semaine/année plus tard), etc. Au total, les
25
Schedae, 2006, prépublication n°3, (fascicule n°1, p. 23-28).
phrases sélectionnées représentent 3 % des phrases de notre corpus. Nous avons classé ces
phrases selon que l’expression temporelle est présente au début, au milieu ou en fin de
phrase. Ensuite, nous nous sommes intéressés au positionnement de ces phrases dans les
paragraphes. Afin d’avoir un point de référence, nous avons calculé le pourcentage de
chance qu’a une phrase, contenant ou non une expression temporelle, d’arriver en tête de
paragraphe : ce pourcentage est de 26 %2. Lorsqu’une phrase contient une expression tem-
porelle, elle apparaît dans 38 % des cas en tête de paragraphe. Ce pourcentage masque
une grande disparité selon la position qu’occupe l’expression temporelle dans la phrase :
51 % des phrases introduites par une expression temporelle sont en début de paragraphe
contre 37 % pour les phrases qui se terminent par ce genre d’expressions et 31 % lorsque
l’expression est au milieu de la phrase. Cette observation confirme l’importance de la posi-
tion initiale dans la phrase pour qu’une expression temporelle signale efficacement un chan-
gement thématique (Costermans & Bestgen 1991, Charolles 1997, Virtanen 1992).
Nous avons également observé des différences entre les types d’expressions tempo-
relles présentes en début de phrase. En effet, certains types de marqueurs apparaissent
beaucoup plus souvent en tête de paragraphe (Chi2(7) = 31.704, p < 0.0001), comme nous
pouvons le constater dans le tableau ci-dessous. 3
Expressions référentielles et paragrapheDans un second temps, nous nous sommes intéressés aux expressions référentielles
présentes dans tous le corpus. Nous avons déterminé, au moyen d’une série d’heuristiques
syntaxiques, quel était le sujet du premier verbe conjugué de chacune des phrases. Puis,
nous avons observé si les phrases dont le sujet est un syntagme avec un article indéfini, un
déterminant possessif, etc. étaient plus souvent en tête de paragraphe ou pas. Les phrases
dont le sujet est un nom propre ont 38 % de chances d’apparaître en début de paragraphe
(contre 26 %, quelle que soit le sujet de la phrase). Les pronoms, à titre de comparaison,
ont 21 % de chances d’apparaître en tête de paragraphe (Chi2 (1) = 1437.2, p < 0.0001).
Nous avons effectué ces mêmes calculs sur un sous ensemble de notre corpus, à savoir,
sur les phrases contenant une expression temporelle. Pour chaque position de l’expression
temporelle dans la phrase (début, milieu, fin), nous avons également observé comment se
distribuaient les phrases selon leur sujet grammatical.
Comme on peut le voir dans le tableau, seul le nom propre est plus souvent le sujet
d’une phrase en tête de paragraphe. Les sujets grammaticaux d’autres catégories appa-
raissent plus souvent dans les phrases qui ne sont pas en tête de paragraphe, et ce, de
2. Cette valeur correspond à des paragraphes d’en moyenne 3,84 phrases.
Exemples des types d’expressions temporelles Nombre de phrases en tête de paragraphe
Nombre de phrases non en tête de
paragraphe
« le 1er juillet »… 41 19
« le lendemain »… 150 87
« le soir », « l’avant-midi »… 200 214
« vers 14 heures »… 79 88
« une heure après », « deux jours après »… 89 114
« une heure/jour/mois plus tard »… 20 31
« en 1975 »,… 7 11
« en été »3… 2 2
3. Comme cette catégorie rassemble peu d’occurrences, nous avons également calculé le Chi2 sans celle-ci ;le Chi2 reste toujours aussi significatif : Chi2(6) = 31.703, p < 0.0001.
26
Schedae, 2006, prépublication n°3, (fascicule n°1, p. 23-28).
manière statistiquement significative (Chi2 (6) = 114.627, p = 0.001). Le nom propre fonc-
tionne donc comme un marqueur de la structure. Cette constatation rejoint les observa-
tions de Hofmann (1989) et de Schnedecker (1997) pour lesquels l’« unité paragraphique »
coïncide avec d’autres traits linguistiques dont les syntagmes nominaux. Ceux-ci apparais-
sent aux points de fracture du texte. 4
Expressions temporelles et expressions référentiellesLa dernière analyse vise à répondre à notre question spécifique : l’emploi de marqueurs
temporels en tête de paragraphe réduit-il l’apparition d’expressions référentielles plus spé-
cifiques comme un nom propre par rapport à un pronom. Selon cette thèse, on devrait obser-
ver moins de noms propres sujets et plus de pronoms sujets lorsque l’expression temporelle
est en tête de phrase et en tête de paragraphe ne vont pas dans ce sens. Lorsque le mar-
queur temporel est en tête de phrase, on observe 175 noms propres sujets de phrases en
tête de paragraphe et 87 noms propres sujets de phrases qui ne sont pas en tête de para-
graphe. D’autre part, on observe 127 pronoms sujets de phrases en tête de paragraphe et
192 pronoms sujets de phrases qui ne sont pas en tête de paragraphe (Chi2 (1) = 41.96, p
< 0.0001). En poussant plus loin l’analyse, on remarque également que le nom propre pré-
sent dans une phrase débutant par un marqueur temporel, est dans 58 % des cas une reprise
d’un nom propre cité dans les 10 phrases qui précédent. Il apparaît que l’utilisation d’un type
de marqueurs de rupture comme les adverbiaux temporels n’empêche pas l’utilisation d’autres
types de marques comme une expression référentielle plus spécifique, tel le nom propre,
contrairement à l’idée avancée par Vonk et al. (1992). Ce résultat est en accord avec les
observations faites par Hofmann (1989) et Schnedecker (1997). Les indices de segmentation
textuelle, comme la marque de paragraphe, induisent le lecteur à conclure le traitement d’un
bloc d’information et à en initialiser un nouveau. Ce nouveau bloc peut débuter par diffé-
rents types d’expressions et parmi celles-ci, nous pouvons citer les marqueurs temporels.
Cette opération implique une accessibilité moins importante des entités contenues dans le
paragraphe qui vient d’être clôturé. Il est donc nécessaire d’utiliser des marqueurs de plus
faible accessibilité, comme les noms propres.
ConclusionCette recherche avait pour objectif d’étudier l’emploi simultané ou exclusif de deux types
d’expression qui signalent une rupture thématique, à savoir les expressions temporelles et
Catégorie grammaticale du sujet du premier verbe conjugué d’une phrase contenant une expression temporelle
Nombre de phrases en tête de paragraphe contenant l’expression
Nombre de phrases qui ne sont pas en tête de paragraphe contenant l’expression
Déterminant défini + syntagme nominal 247 404
Déterminant démonstratif + syntagme nominal 30 56
Déterminant possessif + syntagme nominal 20 47
Déterminant indéfini + syntagme nominal 65 113
Nom propre 368 299
Pronom personnel 307 712
Autre4 271 492
Total 1308 2123
4. Cette catégorie reprend les sujets grammaticaux qui ne sont pas repris dans les autres catégories, commepar exemple, le « on » impersonnel.

27
Schedae, 2006, prépublication n°3, (fascicule n°1, p. 23-28).
les anaphores nominales. Nous avons analysé, au moyen de procédures automatiques, un
corpus de textes littéraires. Nos résultats plaident pour une utilisation combinée de ces deux
types d’indices. Le caractère additif de ce type d’expressions dans le marquage de la seg-
mentation d’un texte confirme l’intérêt de développer de procédures d’identification des
ruptures basées sur l’accumulation d’indices.
BibliographieCHAROLLES M. (1997), « L’encadrement du discours – univers, champs, domaines et espaces », Cahier de
recherche linguistique, 6, p. 1-73.
COSTERMANS J. & BESTGEN Y. (1991), « The role of temporal markers in the segmentation of narrative
discourse », Cahiers de Psychologie Cognitive, 11, p. 349-370.
FOX B.A. (1984), « Anaphora in popular written English narratives », in Coherence and grounding in
discourse, R.S. Tomlin (éd.), 11 (Typological studies in language), Amsterdam, Benjamins.
HOEY M. (2005), Lexical priming : a new theory of words and language, Londres, Routledge.
HOFMANN T.R. (1989), « Paragraphs, & anaphora », Journal of Pragmatics, 13, p. 239-250.
LAIGNELET M. (2004), Les titres et les cadres de discours temporels, Mémoire de DEA en Sciences du
langage, Université de Toulouse 2 – Le Mirail, 196 pages (dactyl.).
LONGACRE R. E. (1979), « The paragraph as a grammatical unit », in Syntax and Semantics, 12 (Discourse
and Syntax), T. Givón (éd.), New York, Academic Press, p. 115-134.
PIÉRARD S. & BESTGEN Y. (2005), « Deux indices pour l’étude des marqueurs de la continuité thématique
dans de grands corpus », Communication présentée aux 4es journées de Linguistique de Corpus,
Université de Bretagne-Sud, Septembre 2005.
SCHMID H. (1994), « Probabilistic Part-of-speech tagging using decision trees », in Proceedings of
International Conference on New Methods in Language Processing.
SCHNEDECKER C. (1997), Nom propre et chaînes de référence, Paris, Klincksieck.
VIRTANEN T. (1992), Discourse functions of adverbial placement in English, Åbo, Åbo Akademi University
Press.
VONK W., HUSTINX L.G. & SIMONS W.H. (1992), « The use of referential expressions in structuring
discourse », Language and cognitive processes, 7, 3/4, p. 301-333.

28
Schedae, 2006, prépublication n°3, (fascicule n°1, p. 23-28).

29
Sandrine Stein-Zintz« De l’altérité spatiale à l’organisation textuelle : la locution d’une part… d’autre part »
Schedae, 2006, prépublication n°4, (fascicule n°1, p. 29-34).
Schedae, 2006
De l’altérité spatialeà l’organisation textuelle :la locution d’une part… d’autre part
Sandrine Stein-ZintzUniversité Paul-Verlaine Metz,
Ile du Saucy – 57000 Metz
Résumé :
La locution adverbiale d’une part… d’autre part dont il est question dans cette étude est très lar-
gement décrite so us l’angle de la série. Dans les faits, un certain nombre d’énoncés sont com-
patibles avec une analyse sérielle. Néanmoins, certaines configurations discursives dans lesquelles
apparaît d’une part… d’autre part échappent à une telle analyse. Sans vouloir totalement remet-
tre en cause le fonctionnement sériel de d’une part… d’autre part, nous aimerions montrer que
cette locution nécessite pourtant un examen qui va au-delà de ce type d’emplois.
Mots-clés : organisateurs textuels, marqueurs d’intégration linéaire, série.
Abstract :
The french adverb d’une part… d’autre part is usually described like a serial adverb. In fact, some
examples seem to be compatible with a serial analysis. However, some discur configurations in
wich appear d’une part… d’autre part can’t be described with the notion of series. We would like
to show that d’une part… d’autre part had to be analysed beyond its serial employements.
Keywords : french adverb, series.
IntroductionA. Auchlin (1981), dans le cadre d’une analyse sur les marqueurs de structuration de la
conversation, est le premier à s’intéresser à la locution adverbiale d’une part… d’autre part
qu’il baptise « marqueur d’intégration linéaire »1. G. Turco et D. Coltier (1988) feront des MIL
une catégorie de marqueurs linguistiques à part entière qui, disent-ils, « accompagnent l’énu-
mération sans fournir de précision autre que le fait que le segment discursif qu’ils introduisent
Prépublication n° 4 Fascicule n° 1
1. Désormais MIL.

30
Schedae, 2006, prépublication n°4, (fascicule n°1, p. 29-34).
est à introduire de façon linéaire dans la série » (1988 : 57). G. Turco et D. Coltier (1988) pro-
posent également un premier inventaire de la catégorie des MIL. Ils en dénombrent quatre :
deux MIL dont l’origine morphosémantique est le lieu (d’une part… d’autre part et d’un
côté… d’un autre côté), un MIL dont l’origine morphosémantique est le temps (d’abord…
ensuite… enfin) et un MIL dont l’origine morphosémantique est la numération (première-
ment… deuxièmement… troisièmement).
L’aspect sériel de d’une part… d’autre part sera par la suite très largement relayé.
M. Nøjgaard (1992) en fait d’ailleurs une caractéristique essentielle, classant cette locution
parmi ce qu’il nomme les « adverbes sériels corrélatifs ». Pourtant, nous n’avons à l’heure
actuelle aucune description précise du type de série encadrée par cette locution. Il s’agira
pour nous de compléter ces travaux en nous interrogeant dans un premier temps sur les
emplois de d’une part… d’autre part dans les configurations discursives sérielles. Dans un
second temps, nous verrons qu’un certain nombre d’emplois de la locution échappent à
une analyse en termes de série 2.
1. Un fonctionnement sériel…
1.1. Taille de la configuration encadrée par d’une part… d’autre partLa locution d’une part… d’autre part encadre au moins deux constituants discursifs. La
présence de d’une part dans un énoncé crée en effet un sentiment d’attente fort. Si cette
attente n’est pas comblée, le résultat est étrange :
(1) ? J’aime bien Pierre. D’une part, il est serviable.
Il suffit de rétablir la deuxième partie de la locution pour rendre cet énoncé acceptable :
(2) J’aime bien Pierre. D’une part, il est serviable. D’autre part, il est généreux.
Il est également possible pour d’une part… d’autre part d’encadrer une configuration dis-
cursive de plus de deux éléments, en entrant en combinaison avec un autre MIL comme enfin.
Dans l’exemple (3), sont énumérées trois raisons à la disparition des costumes folkloriques :
(3) L’essor de la confection industrielle d’une part, celui des communications de masse d’autre part,
enfin la dynamique des styles de vie et des valeurs modernes ont, en effet, entraîné non seule-
ment la disparition des multiples costumes régionaux folkloriques, mais aussi l’atténuation des
différentiations hétérogènes dans l’habillement […] (G. Lipovetsky 1987 dans Frantext)
Les emplois de d’une part… d’autre part répondent donc à une première contrainte
numérique, permettant une analyse sous l’angle de la série : l’encadrement d’au moins deux
constituants discursifs.
1.2. Homogénéité de la configurationencadrée par d’une part… d’autre part
D’une part… d’autre part apparaît dans des configurations caractérisées par une équi-
valence des segments textuels mis en relation. Cette équivalence est le résultat d’un fort
parallélisme syntaxique mais également d’une homogénéité à la fois sémantique et énon-
ciative.
2. Cette étude n’est pas à proprement parler une analyse de corpus. Nous avons néanmoins essayé de traiterun maximum d’exemples dont certains sont issus de la base textuelle Frantext. Par ailleurs, notre travailne s’accompagne d’aucunes données numériques.

31
Schedae, 2006, prépublication n°4, (fascicule n°1, p. 29-34).
Au plan syntaxique d’abord, on observe que les constituants mis en relation par d’une
part… d’autre part relèvent d’une même catégorie grammaticale, par exemple des syntag-
mes prépositionnels dans (4), des syntagmes nominaux dans (5) :
(4) La perception des performances de l’économie japonaise est largement biaisée par la tentation
d’une part, de la référence historique, qui la confronte à ses propres succès passés, et, d’autre
part, de la comparaison géographique, qui la mesure à l’aune de l’insolente prospérité améri-
caine (Le Monde du 09.12.1997)
(5) Elles (les constructions détachées) comprennent d’une part un GN, d’autre part un adjectif, un
GP ou un participe prédicatif (Grammaire méthodique du français p. 192)
Au plan énonciatif, d’une part… d’autre part articule des constituants obligatoirement
dans un rapport monologique. Cette locution ne peut pas encadrer deux constituants pro-
duits par deux énonciateurs différents (cf. Auchlin 1981 à ce propos) :
(6) A : J’aime bien Pierre. D’une part, il est serviable.
?? B : D’autre part, il est généreux
Quant à l’homogénéité sémantique des constituants encadrés par d’une part… d’autre
part, elle peut se manifester de différentes façons. Dans l’exemple suivant, c’est la répéti-
tion du substantif cotisation qui assure l’identité sémantique :
(7) Les charges de la section des salariés sont couvertes, d’une part, par les cotisations propor-
tionnelles à l’ensemble des rémunérations […] et d’autre part, par les cotisations et ressources
affectées aux prestations familiales (La réforme de la sécurité sociale 1968 dans Frantext)
L’homogénéité sémantique peut également être garantie par un élément présent dans
le cotexte gauche de la locution, un élément baptisé classifieur, à l’origine d’une « idée fédé-
ratrice» (Jackiewicz 2003 : 4). Dans l’exemple (8), c’est le substantif raison qui joue le rôle
de classifieur. Accompagné de l’adjectif numéral deux il nous renseigne sur la longueur et
l’homogénéité de la série, composée des deux raisons expliquant pourquoi le locuteur aime
Pierre :
(8) J’aime Pierre pour deux raisons. D’une part il est serviable, d’autre part il est généreux.
2. … partiellement remis en questionPourtant, malgré la compatibilité de d’une part… d’autre part avec les configurations
discursives sérielles, certains éléments nous montrent qu’il faut approfondir l’analyse de cette
locution, dont le fonctionnement est plus complexe qu’il n’y paraît.
2.1. Une configuration dont la longueur est limitéeSi d’une part… d’autre part peut participer à la mise en relation de plus de deux cons-
tituants discursifs, en s’associant avec un autre MIL, ce type de configuration est pourtant
contraint. Les configurations auxquelles participent d’une part… d’autre part semblent en
effet être limitées à trois éléments : nous n’avons trouvé aucun exemple dans lequel d’une
part… d’autre part participe à une configuration discursive composée de quatre éléments
(ou plus). Il s’agit d’une caractéristique qui distingue d’une part… d’autre part des adverbiaux
ordinaux, susceptibles de se « multiplier à l’infini » (Nøjggard 1992 : 246). C. Schnedecker
(2001) note cependant que « dans la pratique, les séries (d’adverbes ordinaux) sont pour-
tant limitées à un maximum de quatre unités […]. Au-delà, il semble qu’on leur préfère les
chiffres » (Schnedecker 2001 :282).

32
Schedae, 2006, prépublication n°4, (fascicule n°1, p. 29-34).
2.2. Une configuration non ordonnéeLes combinaisons entre MIL attestent d’une part d’une souplesse d’emploi, d’autre part
de l’homogénéité de cette catégorie d’organisateurs textuels. Nous l’avons vu supra, d’une
part… d’autre part se combine avec enfin 3. Cette souplesse se manifeste également dans
les possibilités de permutation d’une partie de la locution avec un autre MIL. Par exemple,
d’une part peut être associé, non pas à d’autre part, mais à d’un autre côté :
(9) Si elle manque à ce point d’humour, de tendresse, de poésie, c’est tout bonnement, d’une part,
qu’elle a pour unique objet l’intelligible, et que, d’un autre côté, l’intelligible, n’est ni amusant,
ni émouvant, ni poétique (Brémond 1926 dans Frantext).
Une contrainte pèse cependant sur ces possibilités de permutation : d’une part ne
semble pas pouvoir entrer dans une configuration dans laquelle d’autre part est remplacé
par adverbial ordinal. Cette contrainte pèse également sur d’une part qui permute diffici-
lement avec premièrement :
(10) ? J’aime bien Pierre : premièrement il est serviable, d’autre part il est généreux.
(11) ? J’aime bien Pierre : d’une part il est serviable, deuxièmement il est généreux.
Il s’agit d’une différence importante entre d’une part… d’autre part et les autres MIL :
seuls les MIL premièrement… deuxièmement et d’abord… ensuite… enfin semblent pou-
voir ordonner une configuration discursive. D’une part… d’autre part se rapproche ici d’un
autre MIL, d’un côté… d’un autre côté qui présente les mêmes restrictions d’emploi : on ne
peut pas remplacer d’un côté ou d’un autre côté par un adverbial ordinal.
2.3. Une homogénéité sémantique non imposéeCertains exemples échappent à l’homogénéité sémantique qui caractérisait les énon-
cés (7) et (8). Dans l’exemple suivant, d’une part est associé, non pas à d’autre part, mais à
l’adverbe inversement :
(12) Si, d’une part, le sémiologue est toujours vigilant derrière le chroniqueur d’actualité (dont les
articles sont de véritables travaux de sémiotique qui relèvent de ce que l’on pourrait appeler
une sémiotique militante, engagée), inversement, on voit poindre l’humour concret et l’ironie
caustique du polémiste dans les recherches théoriques du sémiologue (cité par Turco & Coltier
1988 : 69).
Il est difficile d’analyser de type d’exemple sous l’angle de la série : le contenu séman-
tique des constituants encadrés n’est pas dans une relation d’identité, mais plutôt dans une
relation d’opposition : la vigilance du sémiologue opposée à l’humour et l’ironie du polémiste.
Ici, d’une part et inversement permutent facilement avec d’un côté… d’un autre côté, qui
n’impose pas une identité sémantique entre les constituants mis en relation. À l’inverse, d’une
part et inversement ne peuvent pas permuter avec premièrement… deuxièmement.
Cette absence d’homogénéité sémantique s’observe également pour les emplois de
d’une part associé à d’autre part. Dans l’exemple (13), les verbes nourrir et atrophier sont
dans une relation sémantique d’antonymie :
(13) Elle (la culture de masse) fantomalise le spectateur, projette son esprit dans la pluralité des uni-
vers imagés ou imaginaires, fait essaimer son âme dans les innombrables doubles qui vivent
pour lui… D’une part, la culture de masse nourrit la vie, d’autre part, elle atrophie la vie (Lipo-
vetsky 1987 dans Frantext).
3. Nous limitons notre propos à d’une part… d’autre part. Il est cependant important de noter que les pos-sibilités de combinaisons caractérisent tous les MIL (cf. Turco & Coltier 1988)

33
Schedae, 2006, prépublication n°4, (fascicule n°1, p. 29-34).
ConclusionsLa locution adverbiale d’une part… d’autre part peut entrer dans des configurations
discursives sérielles : elle encadre au moins deux constituants discursifs dans une relation
d’équivalence (énonciative, sémantique, syntaxique). Pourtant, ce fonctionnement sériel
soulève un certain nombre de questions. Tout d’abord une question d’ordre numérique : la
longueur de la série à laquelle participe d’une part… d’autre part semble en effet être limi-
tée à un maximum de trois éléments. Ensuite, d’une part… d’autre part n’ordonne pas la
configuration à laquelle cette locution participe : peut-on, dans ce cas, encore parler de
série ? Si l’on se base sur les travaux récents en traitement automatique des textes, l’ordre
est pourtant une caractéristique essentielle des configurations sérielles. L’insertion de la
locution dans une configuration sérielle n’est d’ailleurs pas une contrainte d’emploi. C’est
ce qu’indiquent par exemple les derniers énoncés examinés, qui excluent totalement une
analyse sérielle, l’homogénéité sémantique n’étant pas respectée. Pourtant, dans tous ses
emplois, la locution d’une part… d’autre part témoigne d’un fonctionnement binaire : c’est
seulement sous certaines conditions qu’elle peut participer à des configurations discursi-
ves sérielles.
L’apport sémantique de autre explique ce fonctionnement avant tout binaire : autre
implique l’existence d’un premier élément. Cet aspect rétroactif de autre fonctionne par-
faitement dans d’une part… d’autre part, même s’il s’agit d’une locution figée. D’autre part
est en effet associé à d’une part que l’on retrouve dans le cotexte gauche. Même si les pos-
sibilités de combinaison entre MIL permettent la substitution de d’une part par un autre
MIL, le fonctionnement rétroactif de d’autre part n’est pas remis en question. C’est égale-
ment le cas quand d’autre part est employé de façon isolée, sans d’une part ou un autre
organisateur textuel : le fonctionnement binaire est toujours activé, pour preuve, l’impossi-
bilité pour d’autre part d’initier un énoncé. Mais il ne faudrait pas oublier l’apport séman-
tique de part : part signifiait côté en ancien français. Ce sens originel locatif ne survit que
dans un certain nombre de locutions adverbiales figées, par exemple de toutes parts, de
part en part. Cette origine spatiale explique d’ailleurs la proximité de d’une part… d’autre
part avec la locution d’un côté… d’un autre côté : comme pour d’une part… d’autre part,
l’analyse de d’un côté… d’un autre côté en termes de série pose problème. Mais, alors que
d’une part… d’autre part peut participer à une configuration discursive sérielle, cette pos-
sibilité semble tout à fait exclue pour d’un côté… d’un autre côté, essentiellement à cause
de l’opposition que cette locution exprime, incompatible avec le caractère homogène d’une
série.
BibliographieAUCHLIN A. (1981), « Réflexions sur les marqueurs de structuration de la conversation», Études de linguis-
tique appliquée, 44, p. 88-103.
JACKIEWICZ A. & MINEL J-L. (2003), « L’identification des structures discursives engendrées par les cadres
organisationnels », TALN, 1, p. 155-164.
NØJGAARD M. (1992), Les adverbes du français : essai de description fonctionnelle, Historisk-filosofiske
Meddelelser, 66, 1.
SCHNEDECKER C. (1998), « Les corrélats anaphoriques : une entrée en matière », Recherches linguistiques,
22, p. 3-36.
SCHNEDECKER C. (2001), « Adverbes ordinaux et introducteurs de cadre », Lingvisticae Investigationes, 2,
24, p. 257-287.
TURCO G. & COLTIER D. (1988), «Des agents doubles de l’organisation textuelle, les marqueurs d’intégration
linéaire », Pratiques, 57, p. 57-79.

34
Schedae, 2006, prépublication n°4, (fascicule n°1, p. 29-34).

35
Susanne Hempel & Liesbeth Degand« The use of sequencers in academic writing: a comparative study of French and English »
Schedae, 2006, prépublication n°5, (fascicule n°1, p. 35-40).
Schedae, 2006
The use of sequencers in academic writing: a comparative study of French and English
Susanne Hempel & Liesbeth DegandUniversité catholique de Louvain
Abstract:
This paper presents the results of a parametric and frequency analysis of discourse structuring
devices in written texts. We present a typology of organisational metadiscourse markers and
examine one specific category of these markers – sequencers - in more detail (Jackiewicz 2002,
2003). A manual corpus analysis, allying descriptive and quantitative analyses, gives a detailed
picture of how sequencers are used in the specific genre of academic writing by native authors
of French and English.
Keywords: comparative study, organisational metadiscourse markers, corpus analysis,
text production.
Résumé:
Ce travail présente les résultats d’une analyse paramétrique et fréquentielle d’éléments linguis-
tiques structurant des textes écrits. Nous établissons une typologie de marqueurs organisation-
nels métadiscursifs, ainsi qu’une description détaillée d’une catégorie de ces marqueurs – les
séquenceurs (Jackiewicz 2002, 2003). Par une analyse de corpus manuelle, alliant analyse descrip-
tive et quantitative (Degand & Bestgen 2004), nous réalisons une étude comparative de l’emploi
des séquenceurs en anglais et en français dans le genre spécifique des textes académiques.
Mots-clés: étude comparative, marqueurs organisationnels métadiscursifs, analyse de
corpus, production de texte.
The primary objective of our paper is to analyse how textual organisation works on the
metadiscourse level. To do this, we present a descriptive corpus analysis of one specific
type of text structuring devices, namely sequencers, in two different languages (French and
English) and their actual use in the genre of academic writing.
Consider the following examples:
1 “Les sentiments ont été classés selon deux critères. D'une part, leur structure
actantielle: ego passif, réflexif, actif sur un ou plusieurs congénères ou objets;
d'autre part, le taxème où ils sont indexés.” (French_Academic)
2 “Since the union organisations are part of PRI, they have a dual function: firstly,
as a pressure group lobbying for a greater share of social benefits for labour;
secondly, as an apparatus of political control of the working class.” (BNC World
Edition)
Prépublication n° 5 Fascicule n° 1

36
Schedae, 2006, prépublication n°5, (fascicule n°1, p. 35-40).
In both examples, the ideational content of the text is structured by linguistic items (d’une
part/ d’autre part; firstly/ secondly). These sequencing devices are items belonging to the
domain of textual metadiscourse, whose function is to allow the understanding of the primary
message by making explicit the organisational structure of the propositional content (Hyland
1998). Building our conception of metadiscourse on Hyland’s typology 1, we focus on his
category of frame markers as they best represent what we call organisational metadiscourse
markers. A further categorisation of these markers has been developed: Our new subdivi-
sion consists of sequencers (elements used to introduce a sequence in the discourse), topi-
calisers (elements indicating the introduction of a new subject), illocution markers (elements
indicating the illocutionary act the writer has been realising in the discourse) and reviews/
previews (elements anticipating or repeating a stage in the discourse).
Our understanding of sequencers is based on the theoretical framework of discourse and
cognition proposed by Charolles (1997) and on the methodological outline of MIL (marqueurs
d’intégration linéaires) described by Jackiewicz (2002). Following these authors’ approach,
sequencers can be classified into three types: spatial sequencers (linguistic elements relative
to space), temporal sequencers (introducing a temporal sequence) and numerical sequencers
(elements relative to enumeration).
The series of a sequence follow certain structural parameters. We defined a reference
structure of a sequence, drawing both on the analysis of some instances of these structures and
on the study of different theoretical models, notably the one by Jackiewicz & Minel (2003).
– A typical sequence has to be introduced by an introductory phrase, clearly stating the
main federative idea with the help of a quantifier and a classifier. The introductory phrase
can be a separate phrase before the organisational frame, it can be a proposition at the
head of the same phrase containing the sequencer, or it can be situated after the several
series of the sequence;
– Each series constitutes an organisational frame, and each organisational frame has to
be opened explicitly by a sequencer, or implicitly by another linguistic item which sign-
posts the beginning of its series;
– The sequencers are organised as follows: the first sequencer is the ‘indicator’, followed
by the ‘intermediate’ sequencer and the ‘closing sequencer’. If there are only two sequen-
cers in a sequence, the last sequencer automatically makes up the ‘closing sequencer’;
– A sequence should preferentially be homogeneous; it is not homogeneous if it contains
constituents belonging to two different series, if the sequence is incomplete or not expli-
citly closed, or if the sequence presents a certain variability concerning the classifier;
– A minimal sequence should be two-fold, but there is no restriction as to a maximum of
series in a sequence;
– The sequencers are independent of the propositional content of the phrase, and as such
are supposed to be mostly placed at the beginning of the sentence, either without or
before a punctuation marker;
– The scope of the individual sequencers can be on an intra-sentential level, or on an inter-
sentential level;
– Another sequence can be embedded in the main sequence, and if this is the case, the
same structural parameters apply to it.
Ideally, following these parameters, a sequence should look like this:
1. Hyland’s taxonomy of textual metadiscourse is five-fold, containing transitions, frame markers, endophoricmarkers and code glosses (Hyland 1998).
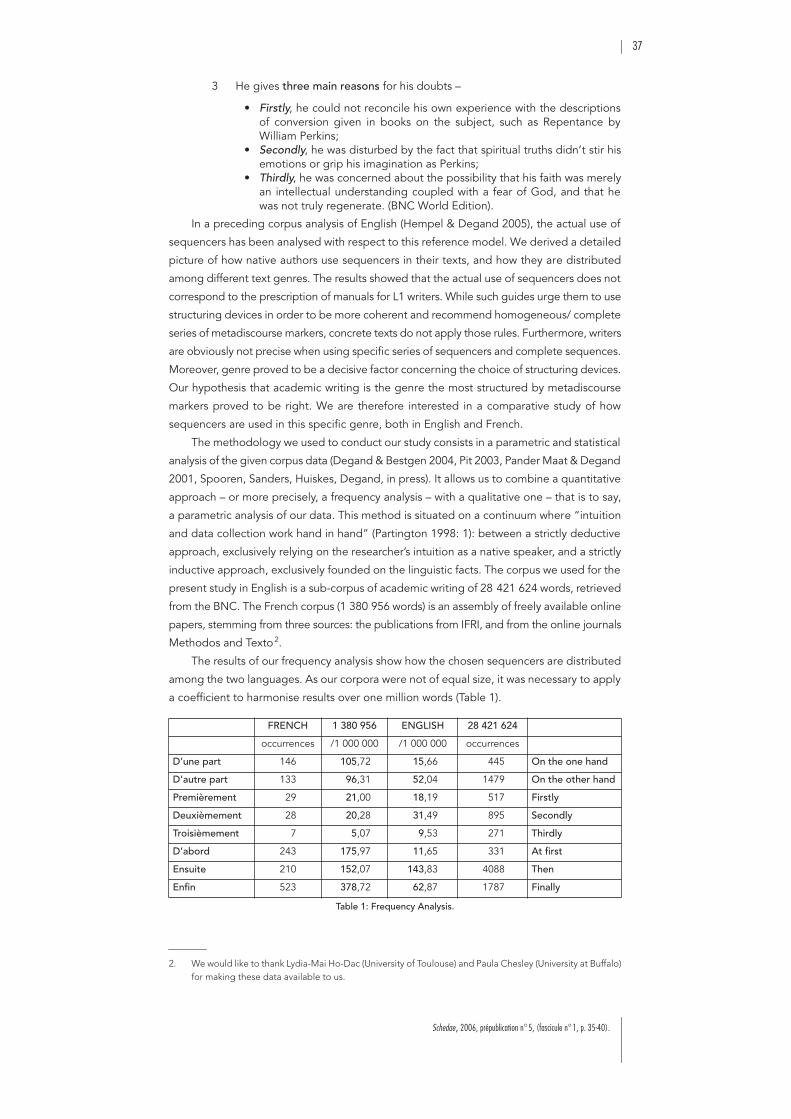
37
Schedae, 2006, prépublication n°5, (fascicule n°1, p. 35-40).
3 He gives three main reasons for his doubts –
• Firstly, he could not reconcile his own experience with the descriptionsof conversion given in books on the subject, such as Repentance byWilliam Perkins;
• Secondly, he was disturbed by the fact that spiritual truths didn’t stir hisemotions or grip his imagination as Perkins;
• Thirdly, he was concerned about the possibility that his faith was merelyan intellectual understanding coupled with a fear of God, and that hewas not truly regenerate. (BNC World Edition).
In a preceding corpus analysis of English (Hempel & Degand 2005), the actual use of
sequencers has been analysed with respect to this reference model. We derived a detailed
picture of how native authors use sequencers in their texts, and how they are distributed
among different text genres. The results showed that the actual use of sequencers does not
correspond to the prescription of manuals for L1 writers. While such guides urge them to use
structuring devices in order to be more coherent and recommend homogeneous/ complete
series of metadiscourse markers, concrete texts do not apply those rules. Furthermore, writers
are obviously not precise when using specific series of sequencers and complete sequences.
Moreover, genre proved to be a decisive factor concerning the choice of structuring devices.
Our hypothesis that academic writing is the genre the most structured by metadiscourse
markers proved to be right. We are therefore interested in a comparative study of how
sequencers are used in this specific genre, both in English and French.
The methodology we used to conduct our study consists in a parametric and statistical
analysis of the given corpus data (Degand & Bestgen 2004, Pit 2003, Pander Maat & Degand
2001, Spooren, Sanders, Huiskes, Degand, in press). It allows us to combine a quantitative
approach – or more precisely, a frequency analysis – with a qualitative one – that is to say,
a parametric analysis of our data. This method is situated on a continuum where “intuition
and data collection work hand in hand” (Partington 1998: 1): between a strictly deductive
approach, exclusively relying on the researcher’s intuition as a native speaker, and a strictly
inductive approach, exclusively founded on the linguistic facts. The corpus we used for the
present study in English is a sub-corpus of academic writing of 28 421 624 words, retrieved
from the BNC. The French corpus (1 380 956 words) is an assembly of freely available online
papers, stemming from three sources: the publications from IFRI, and from the online journals
Methodos and Texto2.
The results of our frequency analysis show how the chosen sequencers are distributed
among the two languages. As our corpora were not of equal size, it was necessary to apply
a coefficient to harmonise results over one million words (Table 1).
2. We would like to thank Lydia-Mai Ho-Dac (University of Toulouse) and Paula Chesley (University at Buffalo)for making these data available to us.
FRENCH 1 380 956 ENGLISH 28 421 624
occurrences /1 000 000 /1 000 000 occurrences
D’une part 146 105,72 15,66 445 On the one hand
D’autre part 133 96,31 52,04 1479 On the other hand
Premièrement 29 21,00 18,19 517 Firstly
Deuxièmement 28 20,28 31,49 895 Secondly
Troisièmement 7 5,07 9,53 271 Thirdly
D’abord 243 175,97 11,65 331 At first
Ensuite 210 152,07 143,83 4088 Then
Enfin 523 378,72 62,87 1787 Finally
Table 1: Frequency Analysis.
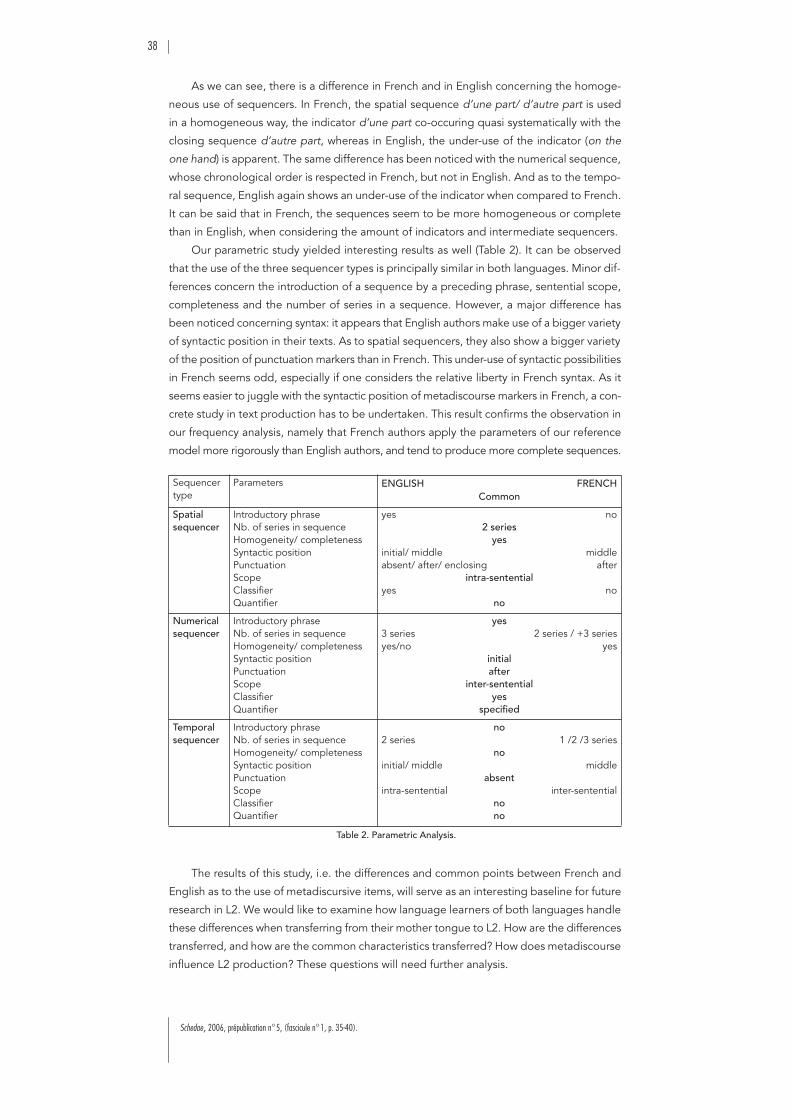
38
Schedae, 2006, prépublication n°5, (fascicule n°1, p. 35-40).
As we can see, there is a difference in French and in English concerning the homoge-
neous use of sequencers. In French, the spatial sequence d’une part/ d’autre part is used
in a homogeneous way, the indicator d’une part co-occuring quasi systematically with the
closing sequence d’autre part, whereas in English, the under-use of the indicator (on the
one hand) is apparent. The same difference has been noticed with the numerical sequence,
whose chronological order is respected in French, but not in English. And as to the tempo-
ral sequence, English again shows an under-use of the indicator when compared to French.
It can be said that in French, the sequences seem to be more homogeneous or complete
than in English, when considering the amount of indicators and intermediate sequencers.
Our parametric study yielded interesting results as well (Table 2). It can be observed
that the use of the three sequencer types is principally similar in both languages. Minor dif-
ferences concern the introduction of a sequence by a preceding phrase, sentential scope,
completeness and the number of series in a sequence. However, a major difference has
been noticed concerning syntax: it appears that English authors make use of a bigger variety
of syntactic position in their texts. As to spatial sequencers, they also show a bigger variety
of the position of punctuation markers than in French. This under-use of syntactic possibilities
in French seems odd, especially if one considers the relative liberty in French syntax. As it
seems easier to juggle with the syntactic position of metadiscourse markers in French, a con-
crete study in text production has to be undertaken. This result confirms the observation in
our frequency analysis, namely that French authors apply the parameters of our reference
model more rigorously than English authors, and tend to produce more complete sequences.
The results of this study, i.e. the differences and common points between French and
English as to the use of metadiscursive items, will serve as an interesting baseline for future
research in L2. We would like to examine how language learners of both languages handle
these differences when transferring from their mother tongue to L2. How are the differences
transferred, and how are the common characteristics transferred? How does metadiscourse
influence L2 production? These questions will need further analysis.
Sequencertype
Parameters ENGLISH FRENCHCommon
Spatialsequencer
Introductory phraseNb. of series in sequenceHomogeneity/ completenessSyntactic positionPunctuationScopeClassifierQuantifier
yes no2 series
yesinitial/ middle middleabsent/ after/ enclosing after
intra-sententialyes no
no
Numericalsequencer
Introductory phraseNb. of series in sequenceHomogeneity/ completenessSyntactic positionPunctuationScopeClassifierQuantifier
yes3 series 2 series / +3 seriesyes/no yes
initialafter
inter-sententialyes
specified
Temporalsequencer
Introductory phraseNb. of series in sequenceHomogeneity/ completenessSyntactic positionPunctuationScopeClassifierQuantifier
no2 series 1 /2 /3 series
noinitial/ middle middle
absentintra-sentential inter-sentential
nono
Table 2. Parametric Analysis.

39
Schedae, 2006, prépublication n°5, (fascicule n°1, p. 35-40).
BibliographyCHAROLLES M. (1997), “L’encadrement du discours – Univers, champ, domaines et espace”, Cahier de
recherche linguistique, 6.
DEGAND L. & BESTGEN Y. (2004), “Connecteurs et analyse de corpus: de l’analyse manuelle à l’analyse
automatisée”, in L’Unité Texte, S. Porhiel and D. Klingler (eds), France, Perspective, p. 49-73.
HEMPEL S. & DEGAND L. (2005), “Qualitative analysis of sequencers in three text genres: academic writing,
journalese and fiction” (submitted).
HYLAND K. (1998), “Persuasion and Context: The pragmatics of academic discourse”, Journal of Pragmatics,
30, p. 437-455.
HYLAND K. & TSE P. (2004), “Metadiscourse in Academic Writing: A Reappraisal”, Applied Linguistics, 25, 2,
p. 156-177.
JACKIEWICZ A. (2002), “Repérage et délimitation des cadres organisationnels pour la segmentation
automatique des textes”, in Actes de CIFT’02, Hammamet, Tunisia, p. 95-105.
JACKIEWICZ A. & MINEL J. (2003), “L’identification des structures discursives engendrées par les cadres
organisationnels”, in Actes de la 10e Conférence Traitement Automatique du Langage Naturel (TALN 2003),
Batz-sur-Mer, p. 155-164.
PANDER MAAT H. & DEGAND L. (2001), “Scaling causal relations and connectives in terms of Speaker
Involvement”, Cognitive Linguistics, 12, p. 211-245.
PIT M. (2003), How to express yourself with a causal connective – Subjectivity and causal connectives in
Dutch, German and French, Amsterdam – New York, Rodopi – USL&C.
SPOOREN W., SANDERS T., HUISKES M. & DEGAND L. (to appear), “Subjectivity and Causality: A Corpus Study
of Spoken Language”, in Empirical and Experimental Methods in Cognitive/Functional Research, S. Rice
and J. Newman (eds), CSLI Publications.
TURCO G. & COLTIER D. (1988), “Des agents doubles de l’organisation textuelle, les marqueurs d’intégration
linéaire”, Pratiques, 57, p. 57-79.

40
Schedae, 2006, prépublication n°5, (fascicule n°1, p. 35-40).

Discours, document et TAL
session 2

II

41
Frédérik Bilhaut« Introducteurs intra-prédicatifs d’univers de discours et leur détection automatique »
Schedae, 2006, prépublication n°6, (fascicule n°1, p. 41-50).
Schedae, 2006
Introducteurs intra-prédicatifs d’universde discours et leur détection automatique
Frédérik BilhautGREYC (CNRS – UMR 6 072) – Université de Caen Basse-Normandie
Résumé :
Cet article concerne le modèle de l’encadrement du discours et plus particulièrement les univers
de discours. En nous basant sur des exemples, nous questionnons l’existence d’introducteurs
d’univers qui ne seraient pas détachés syntaxiquement, mais qui joueraient sous certaines con-
ditions un rôle analogue aux introducteurs tels que considérés habituellement. Dans un second
temps, nous envisageons différents critères susceptibles de conduire à leur détection automati-
que dans le cadre de l’analyse thématique du discours.
Mots-clés: encadrement du discours, analyse thématique, analyse automatique du discours.
Abstract :
This paper relates to the discourse framing theory, and more precisely to discourse universes.
Basing on excerpts, we call into question the existence of universe introducers that would not
be syntactically detached, but that would play, under some circumstances, a similar role. In a
second time, we consider the various criteria that may pertain to their automatic analysis in the
context of thematic analysis of discourse.
Keywords : discourse framing, thematic analysis, automatic discourse analysis.
IntroductionAu sein des récents travaux visant l’annotation automatique de structures discursives,
l’hypothèse de l’encadrement du discours de Michel Charolles (1997) a souvent été mise à
contribution (Jackiewicz 2003, Ferret 2001, Bilhaut et al. 2003), généralement avec des visées
applicatives telles que la recherche d’information ou le résumé automatique. Rappelons
que ce modèle décrit des segments dits « cadres de discours », homogènes par rapport a
un critère sémantique (par exemple une localisation spatiale ou temporelle) spécifié par une
expression détachée en initiale de phrase dite « introducteur de cadre » (dorénavant IC). Les
IC sont présentés comme des marqueurs d’indexation « permettant de répartir les contenus
propositionnels dans des blocs homogènes relativement à un critère spécifié par le contenu
de l’introducteur » (Charolles 1997 p. 24).
Prépublication n° 6 Fascicule n° 1

42
Schedae, 2006, prépublication n°6, (fascicule n°1, p. 41-50).
On peut dire que la reconnaissance par la communauté du TAL de l’intérêt majeur de
l’encadrement du discours dans les contextes applicatifs qui sont les siens constitue une cer-
taine forme de validation de ce modèle. Ou du moins les premiers résultats obtenus par les
différents travaux mentionnés plus haut laissent-ils à penser que l’évaluation qualitative extrin-
sèque (auprès d’utilisateurs réels) des systèmes qui en découleront pourra contribuer, outre les
expérience psycho-linguistiques proprement dites, à affirmer l’hypothèse de l’encadrement.
En contrepartie, la formalisation rigoureuse que requiert le développement de systèmes
d’annotation automatique des cadres sur corpus, et surtout le processus d’observation et
d’évaluation des résultats obtenus fournissent une opportunité non négligeable de constituer
des observables susceptibles de faire évoluer le modèle lui-même.
Le travail ici présenté relève de cette démarche. Dans la perspective de l’analyse auto-
matique de thèmes discursifs, nous avons été amené à nous essayer à l’analyse automati-
que de cadres temporels dans les documents géographiques (Bilhaut et al. 2003), en nous
appuyant sur des travaux portant plus précisément sur cette composante de l’organisation
discursive (Le Draoulec & Péry-Woodley 2001, Ho-Dac et al. 2001). Nous avons par la suite
élargi notre étude à d’autres structures discursives et d’autres domaines de spécialité, ce
qui nous a conduit à introduire les notions de « thème composite » et d’« axe sémantique »
(Bilhaut & Enjalbert 2005). C’est ainsi que nous avons été amené à considérer différentes
structures semblant fonctionner comme des cadres de discours, sans pour autant se con-
former strictement à la définition de M. Charolles.
Nous allons ici nous concentrer sur un type particulier de structure, qui nous apparaît
comme un « cadre » dont l’introducteur serait bien en position initiale, mais pas détachée, et
faisant même partie de la prédication principale au sein de la phrase qui l’héberge. À partir
d’exemples, nous nous efforcerons dans un premier temps de mettre en lumière certaines
propriétés de ces pseudo-introducteurs que nous appellerons ici introducteurs d’univers
intra-prédicatifs (dorénavant IUIP). Dans un second temps, nous montrerons comment cer-
taines de ces propriétés peuvent être exploitées en combinaison avec des connaissances de
domaine pour reconnaître ces introducteurs automatiquement, et si possible évaluer leur
portée. Précisons que nous nous limitons ici aux cadres particuliers dits «univers de discours »
(temporels, spatiaux, praxéologiques, etc.).
Introducteurs intra-prédicatifsComme nous le rappelions plus haut, l’hypothèse de M. Charolles procède tout d’abord
à la caractérisation de ce qui peut constituer des introducteurs de cadres, syntagmes pré-
positionnels particuliers car susceptibles d’introduire un cadre, c’est à dire d’avoir une portée.
Il s’agit typiquement de constituants extra-prédicatifs détachés en initiale de phrase, éven-
tuellement précédés d’un connecteur de discours. Voici un exemple présentant deux cadres
successifs :
§ [ {Dans l’enseignement primaire, on assiste à une forte diminution du taux de retard scolaire.
Cette baisse est en partie attribuable à la réduction du nombre d’élèves par classe, qui […]}S1
{Dans le secondaire, on assiste au contraire à une augmentation sensible du taux de retard.
Celle-ci est principalement imputable à […]}S2] S0
Nous sommes ici en présence d’introducteurs « typiques », répondant bien à la descrip-
tion que nous venons de mentionner. Ils introduisent deux univers de discours liés à deux
niveaux du système éducatif, correspondant aux deux segments S1 et S2, le segment S0 dans
son ensemble étant quant à lui relatif au thème du « retard scolaire ».
On rencontre toutefois des structures qui paraissent analogues bien que ne présentant
pas toujours des cadres « prototypiques » comme les précédents. Il semblerait, pour des

43
Schedae, 2006, prépublication n°6, (fascicule n°1, p. 41-50).
raisons que l’on peut supposer liées à des contraintes d’ordre stylistique, que les successions
de cadres comme la précédente cèdent fréquemment la place à des structures plus hété-
rogènes. Voici par exemple une version légèrement différente de l’exemple précédent :
§ { {L’enseignement primaire (P1) a connu une forte diminution du taux de retard scolaire ces
dernières années.}U1 Cette baisse est en partie attribuable à la réduction du nombre d’élèves
par classe, qui […]}S1 {Dans le secondaire (P2), on assiste au contraire à une augmentation sen-
sible du taux de retard. Celle-ci est principalement imputable à […]}S2
Dans cette version, le segment S1 n’est plus introduit par un introducteur de cadre stricto
sensu : « l’enseignement primaire » apparaît ici comme sujet de la prédication, et n’est donc
plus syntaxiquement détaché. Il est toutefois évident que, tout comme dans l’exemple pré-
cédent, P1 fait ici écho à P2, et que l’ensemble du passage reste organisé pour opposer ces
deux niveaux scolaires. La fonction discursive de P1 paraît analogue à celle du premier intro-
ducteur de la version précédente, dans la mesure où il spécifie bien un critère d’interpréta-
tion s’appliquant au propos central du discours (« le retard scolaire »), et que ce critère vaut
pour plusieurs propositions sans être explicitement repris.
Tout se passe donc comme si P1 bénéficiait d’une portée comparable à celle d’un intro-
ducteur syntaxiquement détaché, et nous le considérons donc ici comme un IUIP. Notre hypo-
thèse est que nous sommes ici en présence d’une structure discursive fonctionnellement
équivalente à la précédente, et que P1 y joue bien un rôle équivalent à un introducteur. Diffé-
rents facteurs semblent pouvoir expliquer ce phénomène.
i) Il convient tout d’abord de considérer avec attention l’antécédent du syntagme pro-
nominal « cette baisse » : il est clair dans ce cas qu’il ne reprend pas seulement le référent de
la « forte diminution du retard scolaire », mais bien l’ensemble du contenu propositionnel
de l’énoncé qui précède U1, qui pourrait s’exprimer par « la diminution du retard scolaire
dans le primaire ». De ce fait, on peut considérer que l’objet sémantique auquel se rapporte
la chaîne de référence du segment S1 est bien une structure complexe, centrée sur la « forte
diminution », mais emportant avec lui « le primaire ».
ii) La forme même du contenu propositionnel de U1 est particulière. En effet, l’accep-
tion ici employée du verbe « connaître » correspond ici à un méta-prédicat, c’est à dire un
prédicat dont le second argument est lui-même un prédicat. Celui-ci est exprimé par la nomi-
nalisation du verbe « diminuer », et son argument est spécifié sous la forme du complément
du nom « le taux de retard scolaire ». Or, ce méta-prédicat est neutre, et la structure séman-
tique résultante peut être « réduite » sans perte d’information, comme nous l’avons repré-
senté dans la figure 1, en une autre structure dont la formulation la plus immédiate serait
« le taux de retard scolaire a diminué dans le primaire ».
Vraisemblablement, le choix par le scripteur d’une construction du type « X a connu Y »
dans un cas comme celui-ci vise la topicalisation de X, qui apparaît ainsi en initiale. Toute-
fois, du fait de son rôle sémantique qui demeure « périphérique », il semble que cette topi-
calisation ne suffise pas ici à définir l’à propos de l’énoncé, tout comme un adverbial détaché
ne définit pas à lui seul le thème au sens de l’à propos, comme le remarque Charolles (2004).
Ainsi, dans notre exemple, « l’enseignement primaire» est topicalisé sans pour autant consti-
tuer le noyau thématique du segment S1 ce qui nous semble caractéristique de cette fonc-
tion discursive. On peut donc voir ici une forme de pseudo-détachement que l’on pourrait
qualifier de « détachement sémantique ».
iii) Il est également possible de faire apparaître ce phénomène de pseudo-détachement
à l’aide de la théorie du centrage (Grosz et al. 1995) augmentée de la notion de « coût »

44
Schedae, 2006, prépublication n°6, (fascicule n°1, p. 41-50).
introduite par Strube et Hahn (1999). Pour argumenter ce point, annotons ainsi le début de
notre exemple :
§ {L’enseignement primaire (P1) a connu une forte diminution du taux de retard scolaire (P2) ces
dernières années.}U1 {Cette baisse (P3) est en partie attribuable à la réduction du nombre d’élè-
ves par classe, qui […]}U2 Dans le secondaire (P4), on assiste au contraire à […]
Soit E1 l’entité réalisée par le syntagme P1, E2 l’entité réalisée par les syntagmes P2 et
P3 (E2 est bien l’élément le plus central de l’antécédent de P3, même si, comme nous l’avons
remarqué en (i), il ne s’y réduit pas), et E3 l’entité réalisée par P4. Dans les termes posés par la
théorie du centrage, l’ensemble des centres anticipateurs de l’énoncé U1 est Ca (U1) = {E1, E2}.
D’autre part, si l’on s’autorise à appliquer au Français la règle d’ordonnancement donnée
dans (Grosz et al. 1995) pour déterminer le centre préféré (sujet > objet(s) > autres) 1, le cen-
tre préféré de U1 est Cp (U1) = E1. Enfin, considérant que l’énoncé U1 n’est précédé d’aucun
autre, son centre rétroactif est indéterminé : Cr (U1) =. Pour l’énoncé U2, le centre rétroactif est
Cr (U2) = E2, et pour les même raisons que précédemment, son centre préféré est Cp (U2) = E2.
Nous nous trouvons donc dans la situation suivante : Cp (U2) = Cr (U2) et Cr (U1) =. Selon
les critères donnés dans (Walker et al. 1998), il s’agit d’un cas de continuation, qui corres-
pond en l’occurrence à l’instauration de E2 comme noyau thématique. Toutefois, on ne pourra
que convenir du statut particulier de l’entité E1 qui constitue, du point de vue du centrage
d’attention, le centre préféré de U1. Or un centre préféré constitue par définition « une pré-
diction sur le centre rétroactif de l’énoncé suivant » (Ibid.), prédiction ici contrariée par le fait
que E1 n’est pas repris dans l’énoncé U2 : Cr (U2) - Cp (U1).
Cette configuration, qui nous intéresse ici particulièrement, n’est pas explicitement envi-
sagée dans (Grosz et al. 1995), mais est en revanche examinée dans (Strube & Hahn 1999)
autour de la notion de coût attribuée aux relations entre énoncés. Les auteurs considèrent une
transition <Un, Un + 1> comme peu coûteuse si Cr (Un + 1) = Cp (Un), et avancent que les rela-
tions peu coûteuses seront généralement préférées. Or nous observons ici une continuation
sur E2 dont la particularité est justement d’être initiée par une relation <U1, U2> coûteuse.
Ceci implique que l’interprétation de cette transition nécessite un effort cognitif particulier,
qui nous semble renforcer l’effet de pseudo-détachement de P1, comme le figure le schéma
de la figure 2, que l’on pourrait cette fois qualifier de « détachement référentiel ».
Figure 1 : Transformations de la structure sémantique associée au méta-prédicat « X a connu P ».
1. Cette règle n’est pas donnée comme complète ni universelle, mais paraît suffisante dans le cas simple quinous occupe, et les autres règles formulées par la suite aboutiraient ici à la même conclusion.

45
Schedae, 2006, prépublication n°6, (fascicule n°1, p. 41-50).
iv) Enfin, la portée de P1 nous semble également explicable en recourant à la notion
d’univers « virtuel » proposée par Charolles. Il se trouve en effet que le syntagme « dans le
secondaire », dont on ne peut douter du statut d’introducteur, projette un univers parent
implicite lié à l’ensemble des niveaux scolaires du système éducatif français (pré-élémentaire,
primaire, secondaire, supérieur). Or il se trouve que « le primaire » est bien un univers dérivé
de cet univers parent, ce qui nous incite probablement à le considérer de façon équivalente
à l’univers du « secondaire ». Et le fait que l’introducteur au sens strict apparaisse après celui
que nous qualifions d’intra-prédicatif ne semble pas problématique si l’on adopte comme
Charolles une approche incrémentielle, qui prévoit « des possibilités de réanalyse a poste-
riori avec mise à jour des interprétations construites » (1997 p. 3).
Nous rejoignons ici la notion d’écho entre ces deux univers, déjà mentionnée plus haut.
Les connaissances de domaine semblent ici jouer un rôle important, puisque la familiarité
supposée du lecteur avec les niveaux du système scolaire interviennent dans la reconnais-
sance de la structure discursive du passage comme quasi-énumérative.
Considérons maintenant deux autres exemples qui nous semblent relever du même phé-
nomène. Le premier est en tout point semblable au précédent, mais fait cette fois intervenir
des univers temporels :
À la fin des années 80, Ullman estimait que ces deux modèles étaient même incompatibles, ce
que confirmaient les faits puisque jusqu’alors les bases de données avaient été soit déclaratives
mais orientées-valeur, soit orientées-objet mais non-déclaratives. Cependant, les années 90 ont
vu apparaître plusieurs tentatives de conciliations, que nous présentons brièvement dans cette
synthèse avant d’en développer deux plus longuement dans le reste de ce chapitre. Ces ten-
tatives peuvent être réparties en deux domaines : les bases de données (monde système) et les
bases de connaissances (monde IA). Au risque d’une simplification excessive, on dira que ces
domaines se distinguent par le fait que le premier privilégie les aspects pratiques et l’efficacité,
et le deuxième les aspects théoriques et l’expressivité.
Source : Systèmes d’information logiques, un paradigme logico-contextuel pour interroger, naviguer et appren-dre, Sébastien Ferré
Le second se distingue des précédents par le fait qu’il ne recours pas au procédé du méta-
prédicat et que l’IUIP apparaît ici sous la forme d’une extension prépositionnelle dans le syn-
tagme sujet :
§ Pour ce qui est du transport ferroviaire, la législation en matière de transport de marchandi-
ses dangereuses par rail a été renforcée et, à la suite de la scission de la société nationale des
chemins de fer en 5 sociétés au début de 1999, la restructuration du secteur ferroviaire a été
poursuivie en 2000. […]
§ Les activités dans le domaine de la navigation intérieure ont fort souffert du blocage du Danube
dû à la crise du Kosovo, ce qui a eu pour conséquence de priver ce secteur des ressources finan-
cières nécessaires à son adaptation à l’acquis de l’UE. Les aspects pratiques concernant la con-
formité des navires roumains aux normes de l’UE pourraient poser problème pour des motifs
d’ordre économique, eu égard à l’objectif des autorités roumaines d’accès au Rhin. Un décret
ministériel a été adopté afin de transposer les règles de l’UE relatives à l’accès à la profession
de transporteur de marchandises par voie navigable. […]
Source : Synthèse d’un rapport de la communauté européenne sur les transports en Roumanie
Figure 2 : Cas de « détachement référentiel ».

46
Schedae, 2006, prépublication n°6, (fascicule n°1, p. 41-50).
Il est remarquable ici que malgré sa faible saillance au niveau de la phrase qui l’héberge
(Ariel 2001), le syntagme « le domaine la navigation intérieure» ait bien une portée significa-
tive. Alors que dans les précédents exemples le phénomène de pseudo-détachement sem-
blait jouer un rôle non négligeable dans la perception du rôle des syntagmes concernés, cet
IUIP apparaît ici dans une position « syntaxiquement profonde » a priori peu favorable à lui
conférer une portée. Il semble pourtant que cette portée soit bien réelle, puisque si le champ
lexical lié à la navigation est significativement présent dans texte qui suit, il n’y a aucune
reprise du qualitificatif « intérieure », qui est pourtant persistant. D’autre part, il est clair que
cet IUIP possède bien une fonction d’indexation au même titre que « le transport ferroviaire »
auquel il répond 2. On peut raisonnablement supposer que dans ce cas l’apparition en ini-
tiale de paragraphe joue un rôle important, mais là encore la relation sémantique entre plu-
sieurs introducteurs successifs et comparables au sein d’une structure plus globale semble
à prendre sérieusement en considération.
Nous risquons l’hypothèse que c’est essentiellement la relation sémantique forte et
supposée connue entre ces introducteurs qui autorise l’un (ou même plusieurs) d’entre eux à
apparaître dans une position qui n’est pas explicitement détachée. Comme nous le verrons
dans la seconde partie, c’est ce dernier critère qui agira de façon prédominante dans la détec-
tion automatique de ces structures discursives particulières.
Segmentation automatiqueexploitant les « cadres » introduits par des IUIP
La détection des cadres de discours est d’un intérêt considérable dans le domaine de
l’analyse automatique du discours. En particulier, si l’on adopte une perspective thématique
à même de servir les besoins d’indexation dans le domaine de la recherche d’information,
l’analyse fine de la répartition du contenu informationnel nécessite la prise en compte de ce
type de structure.
La notion d’univers du discours nous paraît particulièrement intéressante dans ce con-
texte, car elle fait très clairement apparaître un phénomène thématique totalement inac-
cessible aux méthodes d’indexation « classiques », qui ne font pas ou peu intervenir de
considérations linguistiques. Du point de vue de l’à propos, le rôle des introducteurs est en
effet très particulier dans la mesure où il ne consiste pas à définir le thème proprement dit,
mais vient seulement situer un thème instauré par ailleurs. Pourtant, il paraît inadéquat de
négliger leur rôle dans l’instauration d’un thème discursif, puisqu’ils participent clairement
à l’introduction en discours de « ce dont on parle ». Nous considérons donc qu’un IU joue
bien un rôle thématique au sens de l’à propos, même si ce rôle n’est pas central et doit être
rapporté à un thème « principal ».
C’est ce mode d’organisation thématique en discours sur lequel repose l’idée de « thème
composite » présentée dans (Bilhaut & Enjalbert 2005). Nous visons ainsi à exprimer certains
thèmes discursifs sous la forme d’une structure composée d’un noyau thématique et d’un
certain nombre de satellites thématiques, le premier étant relatif au thème d’un segment,
et les seconds aux univers de discours associés. Nous avons identifié une certaine variété de
configurations discursives susceptibles d’instaurer ces thèmes composites, et développé une
méthode de segmentation automatique du discours se basant sur ces principes, qui permet
in fine d’obtenir une indexation intra-documentaire fine des passages concernés par ce type
de structures.
2. Nous considérons bien ici ce dernier comme un IU et non comme un introducteur de cadre thématique,puisqu’il ne définit pas réellement le thème du cadre qu’il introduit, mais constitue pour nous un « satellitethématique » au sens que nous préciserons plus loin.

47
Schedae, 2006, prépublication n°6, (fascicule n°1, p. 41-50).
Les cadres de discours figurent bien-sûr en bonne place parmi les structures discursives
que nous repérons ainsi, dans la mesure où il semblent constituer la forme préférentielle
d’établissement de thèmes composites en discours. Il a toutefois été nécessaire de prendre
en considération d’autres structures analogues de ce point de vue, parmi lesquelles les cadres
introduits par des IUIP. Mais si la détection automatique des introducteurs détachés est rela-
tivement aisée et peut être réalisée avec une très bonne précision (Ferrari et al. 2005), la détec-
tion des IUIP est plus complexe dans la mesure où ils sont par définition dans une position
beaucoup moins caractéristique que les premiers.
Parmi les divers critères évoqués dans la section précédente, se pose la question de
ceux qui sont à la fois suffisamment généraux et applicables automatiquement. Sur ce point,
les détachements « sémantique » et « référentiel » ne sont pas nécessairement de bons can-
didats, d’une part parce qu’ils sont difficiles à reconnaître automatiquement (car impliquant
respectivement une analyse sémantique profonde et une détection fiable des chaînes de
référence), mais surtout parce qu’ils ne semblent pas systématiquement associés aux IUIP
même s’il on les observe fréquemment. Il nous semble préférable dans ce contexte de con-
sidérer que la présence d’une relation sémantique avec d’autres constituants comparables
dans le discours environnant constitue un indice à la fois plus fiable et plus facilement repéra-
ble automatiquement. C’est bien ce qui se produit (certes parfois en conjonction avec d’autres
phénomènes) dans les trois exemples que nous avons reproduit plus haut : chacun des IUIP
que nous avons rencontrés font bien écho à une autre entité apparaissant dans le co-texte
(droit ou gauche) sous la forme d’un introducteur syntaxiquement détaché.
Il semble que dans ce cas, la fonction d’indexation d’un référent du discours puisse appa-
raître très clairement au lecteur sans que sa textualisation fasse l’objet d’aucun détachement,
qu’il soit syntaxique, sémantique ou référentiel. Notre hypothèse est donc que cette situation
est suffisante à l’apparition d’un IUIP (même si elle n’est pas nécessaire dans la mesure où
l’on peut trouver des exemples analogues ne faisant intervenir aucun introducteur au sens
strict).
Cette hypothèse est effectivement mise en œuvre dans notre système d’analyse thé-
matique automatique, qui permet quand cela est nécessaire de tenir compte de connais-
sances d’ordre ontologique. Celles-ci sont formalisées sous forme d’axes sémantiques, qui
correspondent à des espaces notionnels susceptibles de participer à l’indexation de l’informa-
tion dans les textes considérés. Il pourra s’agir d’axes génériques comme le temps ou espace,
ou d’axes plus spécifiques à un domaine ou à une pratique (axe des niveaux scolaires, des
types de transports, etc.). Les axes sont fournis au système par différentes méthodes selon
les cas : il s’agit le plus souvent d’entrées lexicales simples, mais des ressources plus com-
plexes sont parfois nécessaires, comme pour les expressions temporelles ou spatiales.
Dans le cas où des ressources lexicales sont jugées suffisantes, les axes sont représentés
par des ensembles structurés : les termes qui composent un axe donné sont organisés de
façon à pouvoir faire état d’un éventuel degré d’équivalence ou de recouvrement entre deux
items. En pratique, chaque axe sera représenté par une structure arborescente, même si
d’autres modes de représentation pourraient facilement être intégrés au système.
Dans le cas où une analyse syntagmatique des expressions concernées est nécessaire,
nous faisons appel à des méthodes d’analyse sémantique compositionnelle. Le procédé de
comparaison entre deux items dépend alors de la forme des représentations symboliques
effectivement utilisées pour représenter lesdites expressions. Concernant l’analyse des
expressions spatiales et temporelles, nous faisons appel à des grammaires locales d’unifi-
cation (Charnois 2003), et les expressions sont représentées in fine par des intervalles à une
ou deux dimensions, sur lesquels on peut aisément procéder à des calculs d’intersection.
À l’aide de ces ressources, le système est capable de reconnaître non seulement des
entités apparaissant comme introducteurs d’univers syntaxiquement détachés (ceux-ci sont

48
Schedae, 2006, prépublication n°6, (fascicule n°1, p. 41-50).
détectables relativement facilement, à l’aide de critères essentiellement positionnels), mais
aussi des entités qui leur sont comparables sans pour autant apparaître dans des positions
caractéristiques, comme des IUIP. Dès lors qu’un introducteur explicite est détecté, des enti-
tés appartenant au même axe sémantique sont recherchées dans les co-textes droit et gau-
che, ce qui permet dans de nombreux cas de détecter des IUIP qui seraient pas accessibles
en tant que tels à l’analyse automatique. À partir des différents introducteurs détectés, le
système peut alors procéder à la phase de segmentation qui se limite pour l’heure, la ques-
tion de l’analyse automatique de leur portée étant loin d’être résolue en toute généralité,
à fermer un cadre lorsqu’un nouveau cadre du même type est ouvert, ou que la fin de para-
graphe est rencontrée. On notera que ce procédé de segmentation s’inscrit dans un système
d’analyse thématique du discours plus général, qui procède à l’analyse d’autres types de
structure discursives, et qui vise aussi bien la segmentation proprement dite que la descrip-
tion des thèmes des segments (cf. Bilhaut & Enjalbert 2005). L’ensemble du système a été
élaboré sous LinguaStream (Bilhaut & Widlöcher 2006).
ConclusionNous défendons ici l’hypothèse que des constituants non détachés syntaxiquement peu-
vent dans certains cas constituer des introducteurs d’univers dotés d’une réelle portée, et spé-
cifier à ce titre des critères d’interprétation portant sur plusieurs propositions sans faire appel
aux mécanismes référentiels. Nous avons montré à travers plusieurs exemples que des méca-
nismes de pseudo-détachement peuvent intervenir (détachement « sémantique » ou « réfé-
rentiel »), mais aussi que la saillance présupposée de certaines relations sémantiques avec
un autre introducteur semble autoriser une absence de marque de détachement explicite.
Il nous semble que cette approche « assouplie » de ce qui peut constituer un introduc-
teur d’univers est particulièrement intéressante si l’on considère ces derniers du point de vue
de l’à propos, en cherchant à évaluer leur fonction thématique au niveau textuel en tant que
complément d’un thème « principal ». Ce point de vue amène en effet à considérer avec
attention ce qui peut constituer, pour reprendre les termes de Hutchins (1977), des « points
de contact » entre le texte et les connaissances propres du lecteur. Il peut alors être intéres-
sant de considérer que le pouvoir d’indexation des introducteurs d’univers est d’autant plus
fort que les référents impliqués apparaissent clairement comme « connus » ou « donnés » au
lecteur, même s’ils n’apparaissent pas comme « thématiques » ou « topicaux » au sens propre,
ce qui peut être pris en considération en conjonction avec le degré de détachement.
BibliographieARIEL M. (2001), « Accessibility Theory : Overview », in Text Representation : Linguistic and Psycholinguistic
Aspects, T. Sanders, J. Schilperoord & W. Spooren (éds), Amsterdam, Benjamins.
CHAROLLES M. (1997), « L’encadrement du dicours – Univers, champs, domaines et espace », Cahiers de
recherche linguistique, 6.
CHAROLLES M. (2003), « De la topicalité des adverbiaux détachés en tete de phrase », in Adverbiaux et
topiques, M. Charolles et S. Prevost (éds), Travaux de Linguistique (47), Louvain la Neuve.
BILHAUT F., HO-DAC L.-M., BORILLO A., CHARNOIS T., ENJALBERT P., LE DRAOULEC A., MATHET Y., MIGUET H.,
PERY-WOODLEY M.-P. et SARDA L. (2003), « Indexation discursive pour la navigation intradocumentaire: cadres
temporels et spatiaux dans l’information géographique», in Actes de la 10e Conférence Traitement Auto-
matique du Langage Naturel (TALN’03), Batz-sur-Mer, France.
BILHAUT F. et ENJALBERT P. (2005), «Discourse Thematic Organisation Reveals Domain Knowledge Structure»,
in Proceedings of the 2nd Indian International Conference on Artificial Intelligence (IICAI’05), Pune, India.
BILHAUT F. & WIDLÖCHER A. (2006), «LinguaStream: An Integrated Environment for Computational Linguistics
Experimentation », in Proceedings of the 11th Conference of the European Chapter of the Association of
Computational Linguistics, Trento, Italy.

49
Schedae, 2006, prépublication n°6, (fascicule n°1, p. 41-50).
CHARNOIS T., MATHET Y., ENJALBERT P., BILHAUT F. (2003). « Geographic Reference Analysis for Geographic
Document Querying», Workshop on the Analysis of Geographic References, Human Language Technology
Conference (NAACL-HLT), Edmonton, Alberta, Canada.
FERRARI S., BILHAUT F., WIDLÖCHER A. & LAIGNELET M. (2005), « Une plate-forme logicielle et une démarche
pour la validation de ressources linguistiques sur corpus : application à l’évaluation de la détection auto-
matique de cadres temporels », in Actes des 4es Journées de linguistique de corpus, G. WILLIAMS (éd.), à
paraître aux Presses Universitaires de Rennes.
FERRET O., GRAU B., MINEL J.-L. & PORHIEL S. (2001), «Repérage de structures thématiques dans des textes»,
in Actes de la 8e Conférence Traitement Automatique du Langage Naturel (TALN’01), Tours, France.
GROSZ B. J., JOSHI A. K., & WEISTEIN S. (1995), « Centering : A framework for modelling the local coherence
of discourse », Computational Linguistics, 21 (2).
HO-DAC L.-M., LE DRAOULEC A. & PERY-WOODLEY M.-P. (2001), « Cohabitation des dimensions temps,
espace et « phénomènes » dans un texte géographique », Cahiers de Grammaire, 26.
HUTCHINS W. (1977), « On the Problem of Aboutness in Document Analysis », Journal of Informatics, 1, 1.
LE DRAOULEC A. & PERY-WOODLEY M.-P. (2001), « Corpus-based identification of temporal organisation in
discourse », in Proceedings of the Corpus Linguistics 2001 Conference, P. Rayson, A. Wilson, T. McEnery,
A. Hardie & S. Khoja (éds.), Lancaster.
JACKIEWICZ A. & MINEL J.-L. (2003), « L’identification des structures discursives engendrees par les cadres
organisationnels », in Actes de la 10e Conférence Traitement Automatique du Langage Naturel (TALN’03),
Batz-sur-Mer, France.
STRUBE M. & HAHN U. (1999), « Functional Centering : Grounding Referential Coherence in Information
Structure », Computational Linguistics, 25 (3).
WALKER M. A., JOSHI A. K., & PRINCE E. (1998), Centering theory in discourse, Oxford, Oxford University Press.

50
Schedae, 2006, prépublication n°6, (fascicule n°1, p. 41-50).

51
Marion Laignelet« Les titres et les introducteurs de cadres comme indices pour le repérage de segments d’information évolutive »
Schedae, 2006, prépublication n°7, (fascicule n°1, p. 51-56).
Schedae, 2006
Les titres et les introducteurs de cadres comme indices pour le repéragede segments d’information évolutive
Marion LaigneletERSS – Université Toulouse 2 – Le Mirail, Toulouse
et Société INITIALES, Montpellier
Résumé :
Nous supposons que la combinaison d’une analyse discursive à une analyse linguistique plus
locale peut permettre le repérage automatique de segments textuels contenant de l’information
susceptible d’évoluer dans le temps dans le cas de textes encyclopédiques. Dans cet article, nous
présentons comment l’hypothèse de l’encadrement du discours ainsi que le rôle des titres apporte
un gain qualitatif non négligeable pour l’objectif visé. Cet objectif s’inscrit dans un projet indus-
triel visant la création d’une application ayant pour but l’aide à la mise à jour de l’information de
fiches encyclopédiques en français pour le domaine de l’édition.
Mots-clés : navigation intra-documentaire, information évolutive, encadrement du discours,
titres.
Abstract :
The purpose of this paper is to find methods to automatically highlight text segments containing
information that could evolve in time. In order to do this, we hypothesize that combining a dis-
course analysis with a more local linguistic analysis is a possible method to follow. More precisely
we are going to present how a discourse framing hypothesis as well as the role of headings could
be a significant qualitative solution to reach our objective. This objective is part of an industrial
project developing an application that assists human users in updating encyclopedia file infor-
mation in French for publishing companies.
Keywords : intra-document navigation, evolving information, discourse framing hypothesis,
headings.
Le rôle des marqueurs de discours au sein des textes est aujourd’hui au centre de nom-
breux travaux linguistiques. Nous souhaitons montrer dans cet article que la prise en compte
du niveau discursif peut être utile à un système de TAL visant une application industrielle
précise. Cet article ne présente qu’un aspect spécifique d’un projet plus global : nous visons
la création d’un prototype logiciel d’aide à la mise à jour de l’information des documents
Prépublication n° 7 Fascicule n° 1

52
Schedae, 2006, prépublication n°7, (fascicule n°1, p. 51-56).
encyclopédiques pour le domaine de l’édition 1. Nous cherchons à déterminer des méthodes
et techniques (linguistiques et informatiques) pour le repérage de « SEgments de DIScours
contenant de l’information évolutive (ε) » ou SEDIS-ε. Déterminés et définis par rapport à
un usage concret et réel (la mise à jour éditoriale), les SEDIS-ε sont des portions textuelles
contenant une ou plusieurs information(s) susceptible(s) d’évoluer dans le temps 2. Nous ne
nous situons pas dans une problématique d’extraction d’information mais plutôt dans celle
de la navigation intra-documentaire : nous cherchons à signaler au rédacteur des zones
pertinentes pour la tâche de mise à jour de l’information dans le but de l’assister et non de
le remplacer. La mise à jour de l’information proprement dite lui incombe entièrement.
Pour répondre à cet objectif de repérage automatique des SEDIS-ε, nous prenons le
parti de nous baser essentiellement sur des connaissances linguistiques, et notamment sur
les notions de marqueurs textuels et discursifs comme les « mots-repères » ou les « mots-
titres », notions déjà envisagées par Edmundson (1969), les cue phrases (Grosz & Sidner
1986) ou encore les éléments participant de l’analyse de la structure de texte (Marcu 2000).
Dans cet article, nous focalisons notre analyse sur les aspects discursifs des documents à
travers deux types de marqueurs : les titres et les introducteurs de cadre de discours (Cha-
rolles 1997). Nous souhaitons montrer que ces deux niveaux de structuration « à gros grain »
occupent une place importante dans la description et le repérage des SEDIS-ε.
Corpus, indices et marqueurs (textuels et discursifs)
Méthodologie généraleComme nous l’avons précisé en introduction, si nous sommes capable de définir un
SEDIS-ε relativement à l’usage (des segments contenant une information susceptible d’évo-
luer dans le temps), notre objectif est d’en donner une description linguistique et formelle
suffisamment fine et précise dans le but d’automatiser leur repérage. La méthodologie
adoptée a été décrite avec précision dans (Laignelet 2006).
Nous travaillons sur un corpus préliminaire constitué de 38 fiches encyclopédiques 3
dans lesquelles nous avons annoté manuellement les SEDIS-ε (718 SEDIS-ε de longueurs
variables, de l’expression locale à la phrase ou à un ensemble de phrases). Sur ce corpus
préalablement annoté, nous projetons un certain nombre d’indices textuels et discursifs 4
(id.) et observons leur distribution au sein du document (à l’intérieur d’un SEDIS-ε annoté
manuellement ou non). Nous parlons d’indices du fait de leur caractère multi-fonctionnel 5
et nous supposons que leur aptitude à délimiter un SEDIS-ε est liée au fait qu’ils vont appa-
raître ensemble, de manière conjointe et non isolée. Ainsi, ces indices ne deviennent des
marqueurs de SEDIS-ε que dans des conditions particulières et spécifiques que nous cher-
chons à déterminer.
1. Contrat CIFRE entre le laboratoire ERSS, Toulouse, et la Société INITIALES, Montpellier.2. La mise à jour de l’information est ici entièrement liée à des objectifs de ré-édition des fiches encyclopé-
diques qui ont été éditées une première fois en 2001-2003 et qui doivent être rééditées en 2006-2007 ouplus tard.
3. Les documents constituant notre corpus présentent cette caractéristique commune d’être ancrés dans unesituation spécifique, l’édition encyclopédique, et d’être inscrits sur un support précis, le fascicule, supportqui leur confère des caractéristiques matérielles particulières orientant leur usage et leur signification. Ils’agit de fiches fonctionnant sous forme d’abonnement ; le client s’abonne à un moment T et pendant unedurée déterminée, il reçoit un nombre déterminé de fiches tous les mois. Ce type d’édition dure en généralentre 5 et 7 ans voire plus si la collection fonctionne bien.
4. Pour le moment, les indices pris en compte sont : des adverbiaux temporels, des argumentatifs, des mar-queurs aspecto-verbaux, des adverbes de temps, des indices discursifs (titres, introducteurs de cadres).
5. Les indices pris en compte ont plusieurs fonctions dans les textes, nous supposons qu’ils peuvent aussi êtrepertinents pour le repérage des SEDIS-ε.

53
Schedae, 2006, prépublication n°7, (fascicule n°1, p. 51-56).
Le repérage des indices textuels et discursifs se fait de manière automatique à l’aide de
LinguaStream. Cette « plateforme générique pour le TAL » (Widlöcher & Bilhaut 2005) nous
a permis, entre autres, de construire des ressources linguistiques spécifiques (notamment
des lexiques) et d’écrire des grammaires Prolog pour le repérage des adverbiaux temporels
tout en leur associant un certain nombre de traits sémantiques renseignant sur leur nature
déictique ou non, leur référence temporelle, etc. Elle nous permet également de récupérer
des informations sur la structure logique du document grâce au formalisme XML et ainsi de
travailler sur les éléments titres. Nous supposons pour la présente étude que le repérage de
ces indices est acquis (Laignelet 2006) et nous nous focalisons sur le gain qualitatif que peut
représenter la prise en compte d’une analyse discursive pour l’objectif du projet (repérer
automatiquement des SEDIS-ε et, d’un point de vue ergonomique, satisfaire l’utilisateur final).
Définitions et délimitation : les indices de nature discursive
L’hypothèse de l’encadrement du discours définit un cadre de discours comme un regrou-
pement de plusieurs propositions sous un critère sémantique véhiculé par une expression
introductrice de cadre (IC). Un IC est un adverbial situé à l’initiale d’une proposition, géné-
ralement en position détachée. Nous nous focalisons exclusivement sur les cadres de dis-
cours temporels («En 2003…», «Actuellement…»). Les titres peuvent être de natures diverses.
La raison pour laquelle nous traitons précisément ces deux éléments de discours est
qu’ils participent des mêmes métafonctions telles que définies par Halliday & Hasan (1976)
(Charolles et al. 2005, Laignelet 2004). En effet, il est possible de dire que les cadres de dis-
cours et les segments titrés revêtent :
– une fonction textuelle : des segments discursifs (les parties titrées ou les cadres) sont
mis en évidence par la présence de titres ou d’introducteurs de cadres qui ont pour
fonction de regrouper des segments tels que les propositions, les paragraphes ou les
cadres ;
– une fonction idéationnelle : les titres et les introducteurs de cadre posent un critère
sémantique suivant lequel les propositions suivantes sont à interpréter.
Le rôle des titres et des segments titrés nous semble similaire à celui des IC et des
cadres de discours au sein des textes, à ceci près qu’ils fonctionnent au sein d’une structure
à « gros grain ».
Intérêt pour l’application : typer les SEDIS-ε
Nous pouvons d’ores et déjà définir deux types de SEDIS-ε (réactualisation vs. mise à
jour) ainsi que deux niveaux de granularité (SEDIS-ε minimal vs. segment d’interprétation).
Les SEDIS-ε à réactualiser sont des segments dans lesquels l’information restera vraie
dans l’absolu mais, en vue d’une ré-édition et d’une diffusion, les événements et dates
associés doivent être modifiés pour faire référence à un moment plus proche du moment
de lecture/réédition.
L’organisation mondiale de la santé (OMS) estime, en effet, à 160 millions le nombre annuel de
nouveaux cas dans le monde en 2002.
Dans cet exemple, le SEDIS-ε minimal correspond à la valeur chiffrée et à la date (expres-
sions soulignées). A noter que ce genre d’expressions est à la fois indice et SEDIS-ε. Cepen-
dant, visant une application d’aide à la mise à jour, nous pensons que le contexte de la
phrase dans laquelle un SEDIS-ε apparaît est le segment minimal requis pour que la per-
sonne chargée de mettre à jour l’information ait un contexte d’interprétation suffisant.

54
Schedae
,
2006, prépublication n°7, (fascicule n°1, p. 51-56).
D’autre part, nous définissons des
SEDIS-
ε
« à mettre à jour »
: dans ce cas, l’information
n’est potentiellement plus vraie au moment de lecture/réédition ou alors, étant une prédic-
tion sur l’avenir de la part du rédacteur, elle s’est ou non vérifiée.
La découverte du virus a permis la mise au point d’une méthode de dépistage […]. On peut
ainsi savoir qu’une personne est infectée longtemps avant que la maladie ne se déclare. Il
n’existe pas à l’heure actuelle de vaccin contre le sida. Si les thérapies actuelles permettent
d’améliorer sensiblement la durée et les conditions de vie du malade, aucune n’est capable
d’éliminer le virus.
À cette distinction basée sur la nature des segments recherchés, nous supposons l’impor-
tance de la notion de
segment d’interprétation
au sein desquels IC et titres vont avoir un
rôle central. Nous distinguons donc les
SEDIS-
ε
qui sont de l’ordre de l’expression locale de
ceux qui correspondent à des segments d’interprétation, et qui nécessitent un cadre corres-
pondant au moins à la phrase.
Exemples et Résultats
Nous avons montré dans (Laignelet 2006) que prendre en considération les indices de
manière isolée est insuffisant pour déterminer si le segment (
a minima
la phrase) dans laquelle
l’indice est présent peut être considéré comme un
SEDIS-
ε
. Même si le test du CHI
2
a montré
que les indices que nous prenons en compte apparaissent de manière significative dans les
SEDIS-
ε
annotés manuellement, il semble incontournable de les traiter en configurations,
i.e.
de définir des schémas d’indices.
Dans cette optique, la prise en compte des IC et des titres nous semble être un gain
(qualitatif) pour le repérage (automatique) des
SEDIS-
ε
dans la mesure où ils semblent per-
mettre l’ouverture de
segments d’interprétation.
C’est ce que nous pouvons observer dans
les deux exemples suivants.
Dans le premier exemple (
Texte 1
), le
SEDIS-
ε
s’ouvre sur un introducteur de cadre tem-
porel. Dans ce cas, il est important de noter que toutes les informations contenues dans ce
Texte 1 : Exemple de
SEDIS-
ε
introduit par un IC temporel.
Texte 2 : Exemple de SEDIS-
ε
chapeauté par un titre.

55
Schedae, 2006, prépublication n°7, (fascicule n°1, p. 51-56).
segment ne sont pas à mettre à jour et notamment les propositions soulignées (en ondulé),
pour lesquelles une référence temporelle différente est explicitement signalée. L’intérêt de
considérer l’IC temporel « En 2003 » (dans l’encadré) est que le critère sémantique (la réfé-
rence temporelle « 2003 ») qu’il véhicule est valable pour l’ensemble du paragraphe. Ainsi,
les deux valeurs chiffrées dans les ovales ont une relation (temporelle) à travers l’expression
« En 2003 ». Les deux éléments dans les encadrés arrondis sont également des informations
à mettre à jour du fait de leur proximité temporelle.
Dans le second exemple (Texte 2), le segment titré en entier constitue un SEDIS-ε. Cepen-
dant, comme cela apparaît à travers le jeu des encadrés, un certain nombre d’indices per-
mettent de délimiter cinq SEDIS-ε de granularité inférieure (de longueur d’une phrase chacun).
Le titre « Perspective », qui est de niveau 1 et qui, par sa sémantique, oriente une interpré-
tation vers quelque chose situé dans le futur, influe sur l’ensemble de la section. Enfin, il est
important de noter que la position en fin de document, en position de conclusion dans la
fiche, confère à cet élément titre un rôle et une fonction particulière au sein du document
(Marcu 2000).
Quantitativement, environ 50 % des IC temporels sont inclus dans un SEDIS-ε, ce qui
est loin d’être négligeable étant donné qu’en nombre de phrases, la proportion de SEDIS-ε
au sein de notre corpus est d’environ 9 % du corpus. Environ 1/3 des IC présents dans un
SEDIS-ε ont une portée couvrant plus de deux phrases 6. Concernant les titres, leur propor-
tion à apparaître avant une série de SEDIS-ε est de 9 % environ et parmi eux, 25 % sont en
position de conclusion dans la fiche.
Le segment d’interprétation : un apport plus qualitatif que quantitatif ?Les IC étant des adverbiaux, et ces derniers étant, comme les valeurs chiffrées, à la fois
des indices et des SEDIS-ε minimaux 7, c’est le critère positionnel de ces expressions à l’ini-
tiale de la proposition qui va permettre l’ouverture d’un cadre d’interprétation. La portée de
l’IC fonctionne généralement vers l’avant (cf. le sens des flèches sur nos segments). Concer-
nant les titres, leur fonctionnement est sensiblement différent. Ainsi, sauf dans quelques cas
bien précis, l’expression contenue dans le titre n’est pas un SEDIS-ε à proprement parler et
n’est pas non plus inclus dans le SEDIS-ε. D’un côté, le rôle de certains titres est de prédire
la présence d’un ou plusieurs SEDIS-ε. De l’autre, lorsque plusieurs SEDIS-ε apparaissent
en série dans une même partie, et lorsque le titre appartient à une classe sémantique spé-
cifique8, alors, par propagation (vers l’arrière), l’ensemble de la partie titrée peut être définie
comme un segment d’interprétation. Dans tous les cas, dans un segment d’interprétation,
il peut se trouver des segments qui ne nécessitent pas de mise à jour (cf. ce qui est souligné
en ondulé dans Texte 1).
Conclusion et PerspectivesLa notion de cadre d’interprétation nous semble intéressante, à la fois dans une optique
linguistique à travers la description du fonctionnement des IC et des titres, mais également
pour l’objectif applicatif visé. Il nous semble en effet qu’un accès à des mises à jour de grains
différents (SEDIS-ε minimaux vs. segments d’interprétation) peut améliorer l’utilisation d’un
tel outil d’aide à la mise de l’information. Il sera néanmoins incontournable de procéder à
une évaluation de cette distinction auprès d’utilisateurs finaux. Nous projetons le traitement
6. La portée a été observée et calculée manuellement.7. Généralement, la valeur de la référence temporelle doit être modifiée.8. Un travail de typage des expressions pouvant occuper la position titre est en cours.

56
Schedae, 2006, prépublication n°7, (fascicule n°1, p. 51-56).
des IC médiatifs (« Selon une étude du Ministère… ») et des IC spatiaux (« En France… »), car
il semble qu’ils ont également cette capacité à ouvrir un cadre d’interprétation :
Selon une enquête du Ministère du travail, sur 13,5 millions de salariés, 21,3 % déclarent ne pas
entendre une personne qui leur parle normalement, […]. 27 % seraient même exposés à des
bruits supérieurs à 85 dB, […]. Ces affections représentent actuellement près de 33 % des ren-
tes […].
Enfin, une étude sur un corpus encyclopédique différent est prévu, ainsi qu’une éva-
luation de nos analyses.
BibliographieCHAROLLES M. (1997), « L’encadrement du discours, univers, champs, domaine et espaces », Cahiers de
Recherche linguistique, 6.
CHAROLLES M., LE DRAOULEC A., PÉRY-WOODLEY M.-P., SARDA L. (2005), « Temporal and spatial dimensions
of discourse organisation », Journal of French Language Studies, 15, 2, p. 203-218.
EDMUNDSON H. (1969), « New methods in automatic abstracting », Journal of ACM, 16, 2, p. 264-285.
GOSSELIN L. (2005), Temporalité et modalité, Bruxelles, Éditions Duculot.
GROSZ J. & SIDNER A. (1986), « Attention, intentions, and the structure of discourse », Computational
linguistics, 3, 12, p. 175-204.
HALLIDAY M.A.K. & HASAN R. (1976), Cohesion in English, Londres, Longman Group Limited.
HO-DAC M., JACQUES M.-P. & REBEYROLLE J. (2004), « Sur la fonction discursive des titres », in L’unité texte,
S. Porhiel et D. Klingler (éds.), Pleyben, Perspectives, p. 125-152.
LAIGNELET M. (2006), «Repérage de segments d’information évolutive dans des documents de type encyclo-
pédique», in Actes de la 13e conférence sur le Traitement Automatique des Langues Naturelles (RECITAL),
P. Mertens, C. Fairon, A. Dister et P. Watrin (éds.), Presses universitaires de Louvain, Belgique, p. 690-699.
LAIGNELET M. (2004), Les titres et les cadres de discours temporels – Structuration des discours et orga-
nisation de l’information, Mémoire de DEA, Université Toulouse 2 – Le Mirail.
MARCU D. (2000), «The rhetorical parsing of unrestricted texts : A surface-based approach», Computational
Linguistics, 26, 3, p. 395-448.
WIDLÖCHER A. & BILHAUT F. (2005), « La plate-forme LinguaStream : un outil d’exploration linguistique sur
corpus », in Actes de la 12e Conférence Traitement Automatique du Langage Naturel (TALN), M. Jardino
(éd.), France, ATALA LIMSI, p. 517-522.

57
Dominique Legallois & Stéphane Ferrari« Vers une grammaire de l’évaluation des objets culturels »
Schedae
, 2006, prépublication n°8, (fascicule n°1, p. 57-68).
Schedae
,
2006
Vers une grammairede l’évaluation des objets culturels
Dominique Legallois
CRISCO (CNRS – FRE 2 805) – Université de Caen Basse-Normandie
Stéphane Ferrari
GREYC (CNRS – UMR 6 072) – Université de Caen Basse-Normandie
Résumé :
Cette étude traite de l’identification des formes linguistiques destinées à l’expression de l’évalua-
tion des objets culturels. À partir d’un corpus, nous dégageons trois niveaux coordonnés et com-
plémentaires qui, une fois formalisés et implémentés, constituent
une grammaire de l’évaluation
à partir de laquelle le phénomène peut être abordé (au moins partiellement) automatiquement.
Ces trois niveaux sont : le niveau expérientiel, le niveau lexico-grammatical, le niveau énonciatif.
Nous présentons une expérimentation informatique montrant la faisabilité de l’implémentation, et
ouvrant la voie à un type d’analyse discursive automatisée traitant du phénomène de l’évaluation.
Mots-clés : expression de l’évaluation, grammaire locale, expérimentation sur corpus.
Abstract :
This paper focuses on the identification of the linguistics objects used to express evaluation. On
the basis of a corpus study, we draw three coordinated and complementary levels of rules which
constitute a grammar of evaluation once formalized and implemented. These levels are the expe-
riential, the lexico-grammatical and the enunciative ones. We present a computer experimentation
proving the feasibility of an implementation, and leading to further developments for an automatic
discourse analyzer taking the evaluation phenomenon into account.
Keywords : formulation of evaluation, local grammar, corpus experimentation.
Introduction
Les sites
amazon.fr
et
fnac.fr
offrent la possibilité pour les lecteurs de déposer leurs
avis sur les livres lus, afin de les recommander ou de les déconseiller aux consommateurs
internautes. Quelques-unes de ces critiques, réunies dans un corpus restreint à 51 092 mots
(représentant approximativement 400 critiques, essentiellement de romans, mais aussi de
Prépublication n° 8 Fascicule n° 1

58
Schedae, 2006, prépublication n°8, (fascicule n°1, p. 57-68).
BD, de poésie et d’essais) constituent un objet d’observation et d’analyse précieux et com-
plexe pour un travail d’identification des formes linguistiques destinées à l’expression de
l’évaluation dans les discours. Évaluation est ici entendu dans une acception large, d’ailleurs
assez difficile à circonscrire : appréciation des qualités esthétiques, pratiques d’un objet, mais
aussi réaction affective, comportementale, voire somatique face aux qualités des choses,
des personnes et des événements, ou encore jugement d’ordre moral ou éthique. Notre
objectif à terme, est l’élaboration d’une grammaire de l’évaluation des objets culturels (livres,
films, théâtre, etc.) implémentable à des fins d’extraction automatique, pour l’analyse de
comparaison entre textes : devant la complexité et la permanence du phénomène évaluatif,
nous nous attendons à des mises en discours fortement différentes de son expression selon
les objets évalués et les stratégies évaluatives.
Notre approche est donc fondée sur l’usage discursif 1, plutôt que sur la description lexi-
cologique entreprise, par exemple, par certains travaux sur le lexique des sentiments (cf. le
numéro 105 de Langue Française, ou Mathieu 2000) ; elle diffère également des analyses
thématiques (Rastier 1995), fondée sur l’étude lexicométrique, en privilégiant les propriétés
lexico-grammaticales et énonciatives d’expressions routinières. En effet, notre corpus com-
prend nombre de textes largement stéréotypés, dans lesquelles les expressions dédiées à
l’évaluation sont souvent préconstruites, prédonnées : le langage évaluatif portant sur les
livres est en partie formulaire.
Nous reconnaissons à l’évaluation une portée considérable sur des champs linguistiques
entiers : au niveau lexical 2, un grand nombre de lexèmes, quelle que soit leur catégorie, sont
par nature évaluatifs : tragédie, succès, splendide, échouer, réussir, heureusement, etc. ; au
niveau des constructions, le système comparatif et superlatif constitue une expression gram-
maticalisée de l’évaluation ; au niveau énonciatif, la pragmatique linguistique inspirée par
Ducrot et Anscombre place la fonction évaluative au cœur même du dispositif argumentatif :
c’est un bon livre ne constitue pas d’emblée un énoncé informatif, c’est d’abord un énoncé
argumentatif fondé sur une évaluation 3 ; les marqueurs enclosifs 4 (une espèce de/un vrai/
un véritable N) sont employés dans des énoncés évaluatifs ; enfin, un certain type de méta-
phores nominales, parmi les plus répandues et acceptant les modifications enclosives, est
essentiellement évaluatif (Sophie est une vipère). Mais ces champs ne seront pas étudiés
ici pour eux-mêmes ; notre point de départ reste les discours avérés et leur complexité, et
l’évaluation sera considérée comme phénomène textuel plutôt que phénomène inhérent à
la langue elle-même.
Nous présentons dans ce qui suit, les caractéristiques des niveaux fonctionnels dégagés
par l’observation et l’étude du corpus ; nous donnons ensuite, avant d’exposer la méthode
d’implémentation employée, l’exemple d’une analyse d’un texte qui illustre l‘enchevêtrement
des niveaux à la base de notre grammaire.
Analyse du corpusÀ l’issu de l’examen de notre corpus, nous avons considéré trois niveaux fonctionnels
complémentaires et interactifs pour la constitution de la grammaire de l’évaluation :
1. L’analyse linguistique de l’acte d’évaluation a fait récemment l’objet d’un certain nombre d’études« corpus driven approach » dans le domaine anglo-saxon : par exemple, l’ouvrage collectif sous la responsa-bilité de S. Hunston et G. Thompson (2000) dont les contributions montrent des traitements sémantiqueset grammaticaux possibles de l’évaluation ; et, de façon encore plus substantielle, le travail de J. Martin etP. White (2005) sur la notion d’appraisal, dans la perspective de la grammaire fonctionnelle systémique.
2. C. Kerbrat-Orecchioni 1997.3. On pourra lire O. Galatanu (2002) pour l’analyse des valeurs intrinsèques au lexique et leurs effets en discours.4. Cf. Legallois 2002.

59
Schedae, 2006, prépublication n°8, (fascicule n°1, p. 57-68).
– Niveau des cadres expérientiels ;
– Niveau des séquences lexico-grammaticales ;
– Niveau des configurations énonciatives.
Ces trois niveaux correspondent aux méta-fonctions que distinguent Halliday (1996) :
fonction idéationnelle (pour nous, cadre expérientiel), fonction textuelle (niveau lexico-
grammatical), fonction interpersonnelle (niveau énonciatif).
I Les cadres expérientielsLe premier niveau identifie les aspects de l’objet évalué. Une analyse de l’évaluation d’un
livre est vite confrontée à un problème inhérent à la constitution de l’objet même : on peut
évaluer différents aspects ou qualia ; par exemple, le contenu, le style, la satisfaction ou la
déception par rapport à des attentes, etc. L’évaluation peut porter également sur l’auteur du
livre, sur l’histoire. Autrement dit, la forme de l’expression d’un jugement est naturellement
configurée par rapport à ce que nous avons nommé des cadres expérientiels. Quelques exem-
ples de cadres :
L’emprise du livre sur le lecteur : On ne peut plus le lâcher, jusqu’à la fin/Comme beaucoup
d’entre vous, je suis tombée sous le charme de la douceur du récit de Philip Roth.
Les attentes satisfaites ou non du lecteur : Je reste de loin sur ma faim/Je m’attendais à mieux
de K. DICK/J’ai été surprise par le style de ce livre/Vivement la suite !
L’effort investi pour sa lecture : Lisez le livre, il en vaut la peine/Le livre se lit facilement et rapi-
dement/Il faut s’accrocher au début
Son impact affectif sur le lecteur : On pleure un peu, on rit, on s’émeut !…
Sa valeur axiologique : L’Aliéniste est avant tout un EXCELLENT roman.
La prescription ou la proscription du livre (recommander un livre est une façon indirecte mais
implacable de l’évaluer positivement) : A conseiller pour ceux qui aiment les thrillers.
Ces cadres, même s’ils sont identifiés à partir d’un corpus précis, sont suffisamment
généraux pour être appliqués à l’évaluation d’autres objets culturels ; en effet, l’observation
d’avis portant sur des CD musicaux, des jeux vidéos ou des films permet de constater la
présence de cadres identiques. Ce phénomène s’explique ainsi : l’évaluation porte rarement
sur les propriétés intrinsèques de l’œuvre, mais sur les rapports que les sujets ont avec cette
œuvre. De ce fait, les aspect jugés par la critique livresque sont facilement transposables à
d’autres objets : efforts, impacts affectifs, prescriptions, attentes, mais aussi style, effets hédo-
niques (par ex. passer un agréable moment : Voici le plus beau recueil de lettres au collège
de pataphysique. Un réel moment de bonheur de découvrir ce monde inexploré (à propos
de Je voudrais pas crever de B. Vian)), etc. sont autant de cadres communs à l’expérience
des objets culturels.
II Séquences lexico-grammaticalesLe second niveau est celui des séquences lexico-grammaticales ; c’est ainsi que nous
proposons une articulation du phénomène phraséologique à l’analyse de l’évaluation. À
condition de ne pas voir dans la phraséologie un ensemble de formes radicalement figées,
il est possible de concevoir des séquences lexico-grammaticales récurrentes, bien que
polymorphes, dédiées ici à l’évaluation. Autrement dit, notre tâche a été de recenser les
expressions « préfabriquées », de la simple collocation (par ex. conseiller vivement) aux
configurations plus larges. Par exemple :
on n’a jamais aussi bien rendu l’amour réciproque/Aucun livre de ma connaissance n’a jamais
si bien démontré […] les dégâts […] que peuvent occasionner la vie

60
Schedae, 2006, prépublication n°8, (fascicule n°1, p. 57-68).
ce « pattern » [ne jamais (aus)si bien + verbe de représentation/explication] est ici consi-
déré comme une construction relativement ouverte, mais constituant malgré tout une unité
prédonnée, directement disponible dans la compétence linguistique du locuteur. Les séquen-
ces lexico-grammaticales ont en partie été repérées grâce au logiciel « Collocates5 » qui per-
met d’identifier les n-grams du corpus ; nous procédons à une vérification afin de nous assurer
que les répétitions collocatives sont porteuses d’évaluation ou en sont des indices.
Parmi ces séquences, certaines sont entièrement dédiées à un cadre expérientiel, d’autres
sont beaucoup plus indépendantes et peuvent s’actualiser dans plusieurs cadres. Nous don-
nons quelques exemples parmi les dizaines répertoriées (à noter que l’évalué renvoie à l’objet
évalué, l’évaluatème à la valeur accordée à l’évalué, le siège à la personne qui «expérimente»
l’évalué – le siège peut être ou non l’évaluateur) :
[à lire absolument] : cette séquence figée, employées 16 fois dans le corpus, s’actualise dans
le cadre « prescription », comme la collocation [[Évaluateur [conseiller vivement] [Évalué]]
[siège] [ne pas pouvoir lâcher avant/jusque] : cette séquence (11 occurrences) s’actualise dans
le cadre « emprise », et connaît plusieurs réalisations :
Pas question de lâcher le bouquin avant la fin.
Je n’ai pas pu le lâcher avant de l’avoir terminé.
On ne peut plus le lâcher, jusqu’à la fin.
On ne parvient à lâcher le roman qu’à la dernière page.
(enfin/voilà/voici) un [évalué] qui [évaluatème] : il s’agit d’une construction à phrase averbale
particulièrement récurrente dans le corpus (22 fois). Cette séquence s’actualise dans plusieurs
cadres possibles : un livre qui donne à rêver (cadre «hédonique») ; un livre qui fait réfléchir (cadre
« valeur intellectuelle ») ; un roman qui tiraille le lecteur entre notamment l’humour, l’amour, les
rejets, les situations grotesques (cadre « emprise »).
Det ([enclosure]) [évaluatème] : cette séquence s’actualise principalement dans le cadre «valeur» :
Dix petits nègres est un vrai petit bijou ; un vrai petit Jules Vernes ou Barjavel ; la présence de
l’enclosure ici, est un indice imparable de la fonction évaluative du terme subséquent. Ainsi,
Jules Vernes/Barjavel sont-ils étiquetés évaluatèmes.
Nous recensons ainsi près d’une trentaine de séquences évaluatives ou introductrices
d’évaluation dont les rôles thématiques sont étiquetées non pas à partir de catégories géné-
rales (par ex. agent, bénéficiaire, etc.), mais à partir de rôle propres à l’expression de l’éva-
luation. Ces séquences sont de dimensions et de natures hétérogènes : du syntagme récurrent
à la phrase figée. Là encore, une projection sur d’autres textes (projection qui n’est pas encore
systématisée à l’heure actuelle) permet de voir des constructions fort apparentées séman-
tiquement et grammaticalement ; par exemple, au sujet de l’audition du requiem de Mozart :
Cette interprétation du requiem k626 est un véritable feu d’artifice. J’en suis resté scotché sur
mon fauteuil. Bravo ! (amazon.fr)
Ou à propos du jeu vidéo Morrowind :
Ce jeu est tout simplement magnifique : si vous avez une x-box, Morrowind est incontournable.
Les graphismes sont superbes et l’ambiance vous immerge totalement dans l’univers. Les quêtes
sont très variées et le joueur ne s’ennuie jamais : il y a toujours quelque chose à faire !!! Je suis
resté scotché sur ce jeu pendant toute une semaine et je suis même pas au 1/4 du jeu ! Je le
recommande même à ceux qui ne sont pas spécialement fan du genre : vous ne serez pas déçu !
(amazon.fr)
Ainsi, dans la perspective d’une implémentation rendant compte de l’évaluation de tout
objet culturel, il est important d’assigner aux deux séquences ne pas pouvoir lâcher/rester
5. Conçu par Michael Barlow.

61
Schedae, 2006, prépublication n°8, (fascicule n°1, p. 57-68).
scotcher une catégorie subsumant les diverses réalisations. C’est par ce travail de généra-
lisation que pourra être établie une systématicité valant pour l’ensemble des objets culturels.
III Configurations énonciatives
Le niveau énonciatif est fondamental pour une analyse générale du discours évaluatif de
l’objet culturel6. Les évaluations, en tant qu’acte de discours, doivent être mesurées selon leur
force illocutoire. C’est à ce niveau que s’articulent et se construisent les stratégies argumenta-
tives : il s’agit, pour le locuteur, de se mettre en scène pour faire partager son avis : premier
plan, engagement, retrait, prise en charge faible, etc. Cette mise en scène, dans notre corpus,
est relativement normée dans la mesure où le genre est lui-même partiellement stéréotypé ;
mais là encore, la formalisation du niveau énonciatif devra permettre toute projection vers
d’autres objets afin d’élaborer des points de comparaisons et de différences.
Ainsi, par exemple :
Les marqueurs restreignant au seul énonciateur la validation de l’énoncé : À mon goût, à mon
avis, selon moi.
Les marqueurs délimitant le public intéressé : une mine d’informations pour tous ceux qui s’inté-
ressent à la psychologie en général.
Les verbes d’attitude propositionnelle (impliquant la modalité épistémique) : Je crois que Philip
Roth a atteint le sommet avec Opération Shylock.
Les tournures concessives : Ce bouquin est certes intéressant au début, mais il devient très vite
rébarbatif.
Les adverbes intensifs (marquant explicitement le degré d’engagement de l’énonciateur) : Vrai-
ment, véritablement, absolument, impérativement, totalement, etc.
Pronoms personnels (l’évaluateur peut s’effacer devant l’expérimentateur, attribuer le juge-
ment à une instance collective, projeter une évaluation du destinataire, etc.) : Plus vous avan-
cerez dans la lecture, plus vous serez dégoûtés par ce simili d’érudition prétentieux et bourré
de fautes !
Les interjections : Vraiment, beurk…
Ce niveau est le plus complexe des trois à formaliser dans la mesure où les formes sont
extrêmement hétérogènes, de dimensions parfois larges, dépassant le simple énoncé. La
«stratégie» consiste en fait à s’appuyer le plus possible sur les séquences lexico-grammaticales,
qui constituent à notre avis, le niveau intermédiaire entre niveau des cadres expérientiels
et niveau des configurations énonciatives. Nous voudrions illustrer ce phénomène par un
exemple.
IV Exemple d’un traitement d’un avis
L’exemple tiré du corpus est le suivant (à propos de Le sang du temps de Maxime
Chattam) :
je suis déçu par ce livre, on regrette la fameuse trilogie. Malgré cela on se laisse quand même
entraîner dans notre lecture mais pas jusqu’à l’envoûtement.
On voit ici les divers niveaux enchevêtrés dont nous donnons les éléments dans un
tableau pour faciliter la lecture :
6. Cf. Charaudeau 1988.
62
Schedae, 2006, prépublication n°8, (fascicule n°1, p. 57-68).
L’illustration par ce simple exemple montre la difficulté mais aussi l’intérêt de la tâche.
Dans le même texte, figurent plusieurs cadres expérientiels ; chaque cadre est cependant
marqué par des indices lexicaux et grammaticaux propres qui suffisent à identifier la nature du
cadre. De même, les valeurs énonciatives accordées aux pronoms sont inférées d’une part,
de la forme même du pronom (je – on), et, d’autre part, de la combinaison entre le pronom et
le verbe, voire de la valeur intrinsèque de l’adjectif (fameux, dans cet emploi, est un adjectif
médiatif indicateur d’une jugement collectif). On notera que la notion d’évaluateur collectif
ne renvoie pas à une instance énonciative, ni à une source évaluative effective : il s’agit d’une
construction – d’une stratégie – de la part du locuteur afin de minimiser son engagement per-
sonnel, mais aussi de l’inscrire dans une participation collective certes factice mais efficiente.
L’étiquetage des séquences lexico-grammaticales s’appuie sur les données d’un analy-
seur syntaxique (Tree Tagger) ; les données de Tree Tagger doivent pourtant être reconfigurée
dans un format plus « sémantique » dans lequel figurent, par exemple, les rôles thématiques
propres à l’évaluation, ou encore la fonction de connecteur à portée énonciative.
Ni le tableau, ni l’analyse implémentée ne donnent directement l’interprétation globale
de la nature évaluative ; plutôt, ils fournissent les indices discursifs généralisés nécessaires à
l’interprétation « humaine », et conduisent à une factorisation des données utiles au balisage
de parcours interprétatifs.
Expérimentation informatiqueAfin d’expérimenter le modèle sur corpus, nous utilisons LinguaStream 7, une plate-
forme de TAL qui permet notamment l’utilisation dans une même chaîne de traitements de
différents formalismes (Widlöcher & Bilhaut 2005, Enjalbert 2005, chap. 10). L’objectif est
pour nous de réaliser un outil informatique facilitant l’observation des régularités lexico-
grammaticales précédentes, tant sur le corpus d’étude original que sur de nouvelles don-
nées. Nous visons à plus long terme la possibilité d’apprécier de manière semi-automatisée
la variation de l’expression de l’évaluation selon les textes.
Une expérimentation comme celle que nous proposons ici suppose de reformuler
l’ensemble de nos hypothèses précédentes, à caractère plutôt descriptif, en un modèle opé-
ratoire, à caractère prescriptif, comme montré par Ferrari et al. (2005). Les formalismes mis
FORMES CADRES EXPERIENTIELS
SÉQUENCES LEXICO-GRAMMATICALES
CONFIGURATIONS ÉNONCIATIVES
je suis déçu par ce livre Attente (déçue) [Évalué] [décevoir] [Évaluateur]
Je = Évaluateur Énonciateur
on regrette la fameuse trilogie
Attente (déçue) [Évaluateur] [regretter] [Évaluer]
On = Évaluateur collectif
la fameuse trilogie Renommée [adj. Évaluatème] [Évalué]
Évaluateur collectif
on se laisse quand même entraîner dans notre lecture
Emprise [Siège de l’expérience][se laisser entraîner/envoûter/prendre] [dans/par Évalué]
On = Évaluateur collectif
Malgré Connecteur argumentatif
concession
quand même Connecteur argumentatif
concession
mais pas jusqu’à l’envoûtement
Emprise [jusqu’à Évaluatème] Force de l’évaluation
7. http://www.linguastream.org/

63
Schedae, 2006, prépublication n°8, (fascicule n°1, p. 57-68).
à disposition dans LinguaStream laissent une grande liberté dans l’expression du modèle
opératoire, qui peut être mis en œuvre tant à l’aide d’automates de type expressions régu-
lières que de grammaires de type Prolog. Nous avons tiré parti de cette offre, certains types
d’analyse étant mieux adaptés à la mise en œuvre des patrons lexico-grammaticaux, d’autres
à la « remontée» d’informations sémantiques depuis un lexique jusqu’à des éléments textuels.
Cependant, ni les formalismes exploités ni les composants développés ne sont le reflet direct
de l’analyse précédente, car les trois niveaux de la grammaire proposée sont en réalité dis-
persés dans de multiples composants, réalisés à l’aide de formalismes différents, d’une part,
et certains cohabitent quelquefois au sein d’un même composant, d’autre part. Enfin, le
corpus d’origine a été préalablement transcodé en XML, selon les méthodes préconisées
par Habert et al. (1998). Il contient désormais des informations sur les éléments logiques
des avis, selon leur disponibilité : titre, date, lecteur diffusant l’avis, titre et auteur du livre
visé… L’extrait de la figure 1 permet d’apprécier ces différents éléments.
Chaîne de traitements pour observer l’expression de l’évaluationParmi les trois niveaux de la grammaire précédente, nous proposons une première mise
en œuvre particulièrement adaptée pour les niveaux I et II, c’est-à-dire le niveau expérientiel
et le niveau lexico-grammatical. Nous donnons quelques pistes pour permettre une prise en
considération du niveau III de l’énonciation.
La chaîne LinguaStream de la figure 2 montre les différents composants utilisés pour
l’expérimentation. Chaque boîte y représente un composant ou une ressource, les flèches
entre les boîtes représentent la transmission d’information entre composants. La première
colonne de composants consiste en quelque sorte en une préparation du corpus aux analyses
suivantes. La première boîte représente une ressource : la version XML du corpus (CCL pour
corpus de Critiques de Livres). La boîte suivante, CCL XML Marker, est un composant Lingua-
Stream permettant de sélectionner les éléments XML pertinents d’une ressource structurée
pour les analyses ultérieures, et, le cas échéant, de les typer ; dans notre cas, nous concen-
trons les analyses sur le titre et le corps des avis, les informations concernant par exemple les
dates et les auteurs des avis seront ignorées des analyses menées ultérieurement. Les deux
boîtes suivantes représentent une segmentation en mots (Tokenizer) et la catégorisation
grammaticale à l’aide du tree tagger (Schmid 1994). À l’issue de cette première colonne de
composants, la chaîne d’analyse se poursuit avec la transmission de deux informations en
parallèles : une version du document d’origine enrichi au fur et à mesure d’ancres permettant
d’y repérer les différents éléments analysés, et les résultats des analyses, transmis en paral-
lèle et codés dans un fichier indépendant lors d’une sauvegarde. Cette première colonne
de composants influence la qualité des résultats des composants dédiés à la mise en œuvre
de notre modèle, dans la mesure où ils exploitent une partie des informations qui y ont été
produites.
Figure 1 : extrait du corpus en version structurée XML. (L’affichage est réalisé à l’aide d’unefeuille de style CSS qui différencie visuellement les éléments de structure XML. Les avis ysont regroupés par œuvre, tels que collectés.)

64
Schedae, 2006, prépublication n°8, (fascicule n°1, p. 57-68).
La deuxième colonne de composants est celle qui représente le plus la partie des ana-
lyses qui concerne notre modèle. La boîte RE – Idiom Regexp exploitent des automates pour
une amorce de l’analyse des formes lexico-grammaticales, fondée sur la présence de cer-
tains mots dans un certain ordre, avec vérification de la catégorie grammaticale si besoin.
Ainsi, la structure Aucune comparaison avec [comparant] s’y traduit par la règle déclarative
suivante :
<idiom> privatif () %[0-2] {lemma : comparaison} </idiom>
/sem {synt : SPpost_avec, sem : aucunecomp, eval : idiom}
et une règle intitulée « privatif » exploitée par la précédente et disponible pour d’autres :
(« pas » « de » | « plus » « de » | « guère » « de » | {lemma : aucun} | {lemma : nul})
La première règle permet de marquer comme élément idiom un mot dont le lemme
est « comparaison » et qui est précédé d’un privatif, un ou deux mots supplémentaires pou-
vant s’intercaler. L’information qui est associée à l’élément découvert est une structure de trait
renseignant sur la nature de l’élément repéré et/ou précisant quelle analyse mener ensuite
pour compléter le patron : eval : idiom permet de caractériser ici un type de résultat de l’ana-
lyse de l’évaluation, sem: aucunecomp précise quel patron a été employé, synt : SPpost_avec
sera utilisé par un composant ultérieur pour associer le syntagme prépositionnel suivant
l’expression repérée. La deuxième règle a pour objectif de généraliser le patron initialement
observé, afin de permettre une certaine variabilité lexicale lors de la confrontation à de nou-
veaux corpus.
La deuxième boîte SN DCG Marker représente un composant d’analyse de syntagmes
nominaux. Il s’agit d’une grammaire Prolog8 dans laquelle nous avons injecté une partie de
l’information lexicale liée à notre modèle. Les clauses suivantes illustrent la notion pour les
noms présents dans notre lexique :
nom (lem : L..E) -- > ls_lookupToken (_,tag : nom..lemma : L,_), ls_lexicon (eval, E, lemma).
nom (lem : L) -- > ls_token (_,tag : nom..lemma : L).
La première clause, appliquée en priorité lors de l’appel du prédicat nom (), permet de
récupérer le lemme issu des premières analyses (tree tagger), sans consommer le mot analysé,
Figure 2 : chaîne de composants d’analyse dans LinguaStream.
8. Composant réalisé en collaboration avec T. Charnois, GREYC – CNRS UMR 6 072. Travail en cours. Plusprécisément, les clauses exploitent le formalisme GULP, proposé par Covington (1994), pour permettre lamanipulation en Prolog des structures de traits.

65
Schedae, 2006, prépublication n°8, (fascicule n°1, p. 57-68).
et de combiner à cette information celle présente dans un lexique de formes lemmatisées.
Si le mot analysé n’est pas dans le lexique, la deuxième clause s’appliquera alors, se con-
tentant de récupérer le lemme du nom.
Dans cette phase, toute information lexico-sémantique susceptible de concerner l’ex-
pression de l’évaluation est exploitée. Pour le niveau I, on retrouve par exemple le cadre
expérientiel de la valeur axiologique, avec des adjectifs comme bon, mauvais, superbe,
extraordinaire… Pour le niveau III, on retrouve des informations sur les adverbes intensifs, les
interjections… Pour le niveau II, l’analyse effectue directement le repérage des structures pré-
construites comme Det ([enclosure]) vrai/véritable/pur [évaluatème]. Il s’agit à cette étape
de l’analyse de fournir aux modules suivants toute information lexicalisée susceptible d’être
exploitée pour un niveau ou pour un autre de la grammaire.
Les deux dernières boîtes de la deuxième colonne de composants représentent un
complément d’analyse lexicale permettant de compléter l’information précédente notam-
ment pour la catégorie verbale, qui n’est pas actuellement exploitée par le module d’analyse
des syntagmes. Ce découpage temporaire des premiers modules reste quelque peu artifi-
ciel, il est destiné à terme à être remplacé par l’utilisation d’un analyseur syntaxique robuste
et d’une analyse lexicale unique
L’exploitation de tous les résultats précédents se fait par les composants représentés par
les deux premières boîtes de la troisième colonne, qui consistent en un filtrage des informa-
tions précédemment associées aux syntagmes pour ne conserver que celles en rapport avec
notre étude. En effet, sur le corpus de critiques de livres, conserver l’ensemble des informa-
tions de cette analyse conduit à un fichier de 30 Mo pour l’affichage dans un navigateur
(présence de nombreuses divisions HTML cachées contenant les informations associées aux
syntagmes). Mais ces derniers composants dédiés ont pour objectif essentiel de limiter la
taille du fichier destiné à l’affichage ; rien n’empêche de stocker par ailleurs la totalité des
informations pour une autre exploitation. Les autres composants représentés dans la troi-
sième et la dernière colonne consiste en une préparation à l’affichage, conduisant aux exem-
ples présentés dans la section suivante.
Exemples de résultats
Les multiples analyses précédentes permettent d’associer et de combiner différentes
informations à différentes unités textuelles. Le résultat consiste la plupart du temps en l’asso-
ciation d’une structure de traits comme celles de la figure 3 à une unité textuelle particulière.
Dans ces exemple, le groupe nominal « un vrai petit bijou » est repéré comme pertinent
pour notre analyse, c’est-à-dire exprimant l’évaluation ou en rapport direct avec un autre
Figure 3 : 2 exemples de structures de traits et tolérance à l’agrammaticalité.

66
Schedae, 2006, prépublication n°8, (fascicule n°1, p. 57-68).
élément l’exprimant. En consultant la structure de traits associés, on remarque la présence
d’un adjectif marquant une enclosure, issu du niveau II de notre grammaire. Les analyses
menées permettent de repérer aussi cette structure lorsque l’accord est incorrect, comme
dans le deuxième extrait de la figure 3, « une vrai perle ». En effet, les règles Prolog d’ana-
lyse locale n’exploitent que la catégorie grammaticale principale, sans vérifier ni tenir compte
de l’accord en genre et en nombre. Le filtrage des informations permet d’obtenir des résul-
tats comme celui de la figure 4, où un des verbes associé au cadre expérientiel de l’emprise
est suivi de groupes prépositionnels pour lesquels l’information syntaxico-sémantique est
conservée.
Les résultats obtenus à l’heure actuelle permettent essentiellement de valider les motifs
initialement proposés et d’envisager leur exploitation sur un autre corpus. Les structures
de traits qui sont construites à ce stade d’avancement de nos travaux et la nature des élé-
ments sur lesquels elles portent n’ont pas de fait un caractère définitif. Il reste notamment
à mener une réflexion sur le type d’information que nous désirons y faire figurer, cela en
rapport avec un éventuel cadre applicatif particulier. Dans leur état actuel, il est toutefois
déjà possible de remonter par exemple sur des unités telles la phrase ou des éléments de
structure logique (paragraphe, section et avis dans ce corpus) une information quantifiée
indiquant combien d’éléments de chaque niveau de notre grammaire ont été employés au
sein de telles unités, ou encore quels cadres expérientiels.
Conclusion générale et perspectives
Nous avons proposé une grammaire locale de l’évaluation s’articulant sur trois niveaux :
expérientiel, lexico-grammatical et énonciatif. Une première expérimentation a montré la
faisabilité de la mise en œuvre pour les deux premiers niveaux de cette grammaire. Cette
expérimentation exploite une chaîne de traitements fondés sur des formalismes différents ;
cette chaîne utilise de multiples composants linguistiques déjà développés par ailleurs et
pour d’autres besoins. Le dernier niveau, celui de l’énonciation, présente cependant un
degré de difficulté supérieur. Il nécessite selon nous la manipulation d’unités discursives
diverses pour lesquels les formalismes actuellement exploités (automates, grammaire Pro-
log) ne sont pas les mieux adaptés. Aussi, nous envisageons un nouveau composant con-
sacré à ce niveau, qui permette l’expression de contraintes sur des unités variées, sans tenir
compte nécessairement de l’ordre entre ces unités ni de l’ordre dans leur traitement, en
s’appuyant sur un formalisme tel celui proposé par Widlöcher (2006).
Nous visons une implémentation possédant plusieurs champs d’applications possi-
bles. Ainsi, nous voudrions examiner les éléments généraux communs à l’évaluation
d’objets culturels différents, afin d’extraire les éléments constitutifs du genre. Les différen-
ces spécifiques de chaque objet devront bien sûr être théorisées (par exemple, une criti-
que cinéma peut porter sur le jeu des acteurs, aspect qui n’a pas sa contrepartie dans la
Figure 4 : filtrage pour affichage.

67
Schedae, 2006, prépublication n°8, (fascicule n°1, p. 57-68).
critique livresque). Une observation des différences de modalités évaluatives selon les genres
des livres devra être menée (intuitivement, une critique d’un roman paraît différente d’une
critique d’un essai ou d’une BD).
La projection du système pourra permettre également de mesurer sur corpus proximi-
tés et différences entre critiques « amateurs » et critiques professionnelles (par exemple, au
niveau des cadres expérientiels) dans l’espoir d’analyser les modes d’institutionnalisation
de la critique. D’autres types de textes devront également être pris en compte ; nous pen-
sons à la publicité des objets culturels (encart publicitaire pour tel livre dans tel quotidien) : on
perçoit des liens évidents entre le langage formulaire des internautes et ceux des publici-
taires, par exemple dans la construction averbale très récurrente : un livre qui + évaluatème.
Enfin, l’implémentation d’une grammaire de l’évaluation peut apporter un outil appré-
ciable pour procéder à une comparaison entre types de textes différents, mais qui partagent
tous la mise en discours des valeurs individuelles et collectives propres à une société : dis-
cours épidictiques 9, politiques et idéologiques. Construire en discours l’évaluation, c’est tou-
jours construire sa propre subjectivité (et son ethos) pour l’orienter dans le champ des valeurs
sociales.
BibliographieCHARAUDEAU P. (1988), « La critique cinématographique : faire voir et faire parler », in La presse : produit,
production, réception, Didier érudition (Langages Discours et Sociétés), p. 47-70.
COVINGTON M. A. (1994), GULP 3.1 : An Extension of Prolog for Unification-Based Grammar. Research
Report AI – 1994 – 06, The University of Georgia, Artificial Intelligence Center, Athens, Georgia, USA.
DOMINICY M. & FREDERIC M. (éds.) (2001), La mise en scène des valeurs : la rhétorique de l’éloge et du
blâme, Lausanne, Delachaux et Niestlé.
ENJALBERT P. (dir.) (2005), Sémantique et traitement automatique du langage naturel, Hermès Sciences,
Traité IC2.
FERRARI S., BILHAUT F., WIDLÖCHER A. & LAIGNELET M. (2005), « Une plate-forme logicielle et une démarche
pour la validation de ressources linguistiques sur corpus: application à l’évaluation de la détection auto-
matique de cadres temporels », in Actes des 4es Journées de la Linguistique de Corpus, G. WILLIAMS
(éd.), à paraître aux Presses Universitaires de Rennes.
GALATANU O. (2002), « Le concept de modalité : les valeurs dans la langue et dans le discours », in Les
valeurs : séminaire Le lien social, Nantes, 11 et 12 juin 2001/organisé par le CALD-GRASP; coord. scienti-
fique et présentation Olga Galatanu, Maison des Sciences de l’Homme Ange Guépin.
GROSS M. (1995), «Une grammaire locale de l’expression des sentiments», Langue Française, 105, p. 70-87.
HABERT B., FABRE C. & ISSAC F. (1998), De l’écrit au numérique : constituer, documenter, normaliser un
corpus électronique, Paris, InterEditions.
HALLIDAY M. A. K. (1996), An introduction to functional grammar, Sydney, Arnold.
HUNSTON S. & THOMPSON G. (éds) (2000), Evaluation in Text. Authorial Stance and the Construction of
Discourse, Oxford, Oxford University Press.
KERBRAT-ORECCHIONI C. (1997), L’énonciation : de la subjectivité dans le langage, Paris, A. Colin.
LEGALLOIS D. (2002), « Incidence énonciative des adjectifs vrai et véritable en antéposition nominale »,
Langue Française, 136.
MARTIN J. & WHITE P. (2005), The Language of Evaluation : Appraisal in English, Palgrave Macmillan
Hardcover.
MATHIEU Y.Y. (2000), Les verbes de sentiment : de l’analyse linguistique au traitement automatique,
Paris, CNRS Éditions.
RASTIER F. (dir.) (1995), L’analyse thématique des données textuelles : l’exemple des sentiments, Paris,
Didier érudition.
9. Dominicy & Frédéric 2001.

68
Schedae, 2006, prépublication n°8, (fascicule n°1, p. 57-68).
SCHMID H. (1994), « Probabilistic Part-of-Speech Tagging Using Decision Trees », International Conference
on New Methods in Language Processing, Manchester, UK.
WIDLÖCHER A. (2006), « Analyse par contraintes de l’organisation du discours », in Actes de la Conférence
Traitement Automatique du Langage Naturel (TALN 2006), Louvain, Presses universitaires de Louvain,
Belgique, p. 367-376.
WIDLÖCHER A. & BILHAUT F. (2005), « La plate-forme LinguaStream : un outil d’exploration linguistique
sur corpus », in Actes de la 12e Conférence Traitement Automatique du Langage Naturel (TALN),
M. Jardino (éd.), ATALA LIMSI, Dourdan, France, p. 517-522.

69
Nadia Zerida, Nadine Lucas, Bruno Crémilleux« Combinaison de descripteurs linguistiques et de structure pour la fouille d’articles biomédicaux »
Schedae, 2006, prépublication n°9, (fascicule n°1, p. 69-78).
Schedae, 2006
Combinaison de descripteurs linguistiques et de structure pour la fouilled’articles biomédicaux
Nadia Zerida, Nadine Lucas, Bruno CrémilleuxGREYC (CNRS – UMR 6 072) – Université de Caen Basse-Normandie
[email protected], [email protected], [email protected]
Résumé :
Ce travail propose une combinaison originale de descripteurs linguistiques et de descripteurs de
structure avec une méthode de fouille de données. L’objectif est de montrer l’apport de ces des-
cripteurs prenant en compte la structure des documents pour caractériser trois types de textes
biomédicaux : articles de recherche, articles de synthèse et articles de clinique. La description du
texte est faite à différents niveaux, du global au local. Nous montrons que l’utilisation du plan et
de différents contextes permet de mener à bien la tâche de caractérisation de ces trois classes.
Nous donnons une évaluation quantitative de la caractérisation grâce aux capacités des techni-
ques de fouille de données basées sur les motifs émergents.
Mots-clés : caractérisation, descripteurs linguistiques, descripteurs de plan, fouille de
données.
Abstract :
This work proposes an original combination of linguistic and structural descriptors with one of data
mining methods. The objective is to show the effectiveness of descriptors taking into account the
structure of documents to characterise three kinds of biomedical texts (reviews, research and clini-
cal papers). The description of the text is made at various levels, from the global level to the local
one. The use of the plan and various contexts makes it possible to characterise the three classes.
The characterisation of the textual resources is carried out quantitatively by using the discrimina-
ting capacity of techniques of data mining based on emerging patterns.
Keywords : characterisation, linguistic descriptors, plan descriptors, data mining.
IntroductionLa confrontation à la masse des documents électroniques textuels biomédicaux est un
grand défi. Ce travail exploite d’une part, un ensemble de descripteurs linguistiques et de
structure, et d’autre part, une méthode efficace de fouille de données pour la caractérisation.
Il est réalisé dans le cadre du projet Bases de données INductives et données GénOmiques,
Prépublication n° 9 Fascicule n° 1

70
Schedae, 2006, prépublication n°9, (fascicule n°1, p. 69-78).
Bingo1 qui a entre autres pour but d’extraire des connaissances biomédicales à partir de res-
sources textuelles pour mieux exploiter les résultats issus de l’extraction de connaissances
de données d’expression de gènes. L’objectif à moyen terme de notre travail est de cibler
le contenu des textes biomédicaux pour pouvoir faire émerger de nouvelles connaissances.
Dans cet article, nous présentons les résultats obtenus lors du processus de fouille de textes
mis en place.
Dans ce travail, nous considérons les propriétés linguistiques et structurelles des docu-
ments comme des critères de base. Un savoir de nature linguistique est exploité, à partir de
travaux théoriques tels que (Parsons 1990). On en a dérivé une grammaire du texte, dans une
approche comparable à celle de Kando (1999) ou Karlgren (2005). Nous avons opté pour
l’exploitation de l’article en entier pour pouvoir gérer des espaces d’observation différents,
tels que le corps de texte, les parties, les sections, les paragraphes, les phrases et les virgu-
lots2, ces unités servent ensuite de fenêtres d’observation multi-échelle. Il ne s’agit pas d’une
simple utilisation de mots clés ou d’une analyse distributionnelle des mots, mais d’une ana-
lyse qui met en jeu la notion de contexte à travers la hiérarchie de mise en forme matérielle.
C’est en ce sens que nous cherchons à donner à nos descripteurs une valeur sémantique.
La pertinence des associations entre ces descripteurs est automatiquement extraite par une
technique performante de fouille de données, les motifs émergents (Dong & Li 1999). Nous
montrons que la combinaison d’associations extraites réussit à caractériser les trois princi-
paux types d’articles biomédicaux (synthèse, recherche et clinique). Ces types d’articles sont
les plus utilisés. Les articles intéressant prioritairement les biologistes dans le projet sont les
synthèses. Les expérimentations fournissent une quantification des résultats et montre la
pertinence de l’approche adoptée.
Cet article est organisé de la façon suivante. La section 2 présente les différentes
familles de descripteurs, les grandes lignes de notre approche sont décrites à la section 3
et la méthode de fouille de données utilisée à la section 4. Finalement, les expériences à
la section 5 montrent l’efficacité de cette approche.
Les différentes familles de descripteursLa fouille de textes de spécialité est un domaine de recherche qui a récemment gagné
l’attention de nombreux chercheurs car il fait appel à des techniques capables de manipu-
ler efficacement un très grand volume de données textuelles. Mais la plupart des travaux
ont pour trait commun l’exploitation des titres et des résumés proposés par PubMed 3 et de
considérer que le texte n’est qu’un simple sac de mots sur lequel on peut appliquer l’une
des techniques de fouille de données classiques faisant référence à des ressources thésau-
rales telles que MeSH 4 (Hersh et al. 2003, Dayanik et al. 2003). Pour pouvoir extraire de la
nouvelle connaissance, la majorité de ces travaux se sont orientés plutôt vers l’évaluation
des techniques de représentation du mot dans le document (Wilcox & Hripcsak 1995), ou
l’étude de la variation des concepts (Ruch et al. 2003). Sinon, parmi le peu de travaux qui se
sont intéressés naturellement à l’utilisation de la notion de structure et du contenu, quel-
ques uns ont travaillé au niveau des propositions Mesh (Rosario & Hearst 2005), d’autres
1. http://www.info.unicaen.fr/~bruno/bingo/2. Espace ponctué par une virgule.3. http://ncbi.nih.gov/entrez/query.fcgi.4. Medical Subject Heading.

71
Schedae, 2006, prépublication n°9, (fascicule n°1, p. 69-78).
sur l’exploitation de la location de l’information et la fréquence des mots dans les phrases
des résumés (Blott 2003, Kayaalp et al. 2003), et plus rarement l’exploitation de l’article en
entier enrichi par des connaissances linguistiques (Ruch et al. 2003).
Dans ce travail, nous formulons l’hypothèse que les différentes catégories d’articles
(recherche, synthèse, clinique) sont susceptibles d’avoir une certaine organisation de l’écrit et
un contenu spécifiques. La construction des descripteurs de plan et de style vise à exploiter
ces spécificités portant sur l’organisation textuelle de l’article. Dans cette section, nous com-
mençons par présenter ces descripteurs. Puis, nous indiquons rapidement les descripteurs
métriques et lexicaux. Ceux-ci nous seront utiles pour comparer l’apport des descripteurs de
plan et de style par rapport à ces deux dernières familles, les descripteurs lexicaux corres-
pondant à une approche classique.
Les descripteurs au niveau globalUn premier jeu de descripteurs concerne l’organisation textuelle de l’article, il s’agit des
descripteurs de plan (cf. tableau 1). L’idée sous-jacente est que chaque article est constitué
d’un ensemble de parties qui sont établies pour jouer chacune une fonction bien détermi-
née, mais elles sont aussi reliées logiquement entre elles. Cette relation, exprimée par le plan
de l’article, permet de construire une structure logique de ce dernier. Cette constatation nous
a conduit à préserver l’unité globale de l’article de façon à présenter une information struc-
turée logiquement. Ainsi les intitulés des parties constituant le plan ont été utilisés comme
descripteurs au niveau « article ».
Les descripteurs stylistiques multi-échelleLes études linguistiques (voir par exemple Parsons 1990) sont à la base de cette
deuxième famille de descripteurs. Plusieurs études se sont intéressées aux descripteurs de
texte, la plupart de ces études se basent sur les mots (Ahmed et al. 2005), quelques recher-
ches sur les styles et les relations ont été établies par Karlgren (2005). Ses expérimentations
montrent que selon certains scénarios, une polarisation claire vers certains types ou genres
de textes peut être trouvée. Partant de l’hypothèse que la variation dans le choix lexical
reflète une variation intéressante dans la variation du style global, il a défini deux types de
descripteurs statistiques. Le premier type comprend des statistiques au niveau du mot telles
que le nombre de mots les plus longs, la longueur moyenne des mots, nombre de pronoms
etc. Un deuxième type de descripteurs est établi au niveau de la phrase ; il s’agit entre autres
de la longueur de la phrase, de la moyenne maximale de la profondeur d’un arbre syntaxi-
que d’une phrase, du nombre de skips dans les phrases, d’un indicateur propositionnel tel
que la moyenne de TextTiles5, le nombre de chaque type pronoms pour prédire le registre6
du texte, la présence ou absence des contractions (isn’t, does’nt), liste des adverbes pour
renforcer l’assertion des propositions textuelles, la fréquence relative des verbes modaux
(seem, appear) utilisés en début de texte.
AbstractIntroductionMaterials & MethodsResultsFootnotes
References DiscussionAknowledgmentsConclusionKeywordsLearn obj
Tableau 1 : Exemples de descripteurs de plan.
5. Nombre de segments compris comme subtopic, par Hearst 1997.6. Par exemple familier ou soutenu « formal », par Biber 1988.

72
Schedae, 2006, prépublication n°9, (fascicule n°1, p. 69-78).
À la différence de ces derniers, les descripteurs de style que nous proposons sont établis
pour six niveaux mis en relation avec la mise en forme matérielle. Ils sont définis à travers
des classes définies pour chaque niveau, et qui comprennent non seulement des mots mais
aussi des traits discontinus (notion de portée des marqueurs discursifs). Notre hypothèse est
que chaque type d’article comporte une variation stylistique propre à ce dernier, l’idée fon-
datrice de ces descripteurs et que l’information pertinente pour l’utilisateur peut se localiser
dans plusieurs fenêtres d’observation. Cette famille de descripteurs s’appuie essentiellement
sur deux notions de base qui sont respectivement : la notion de position et celle de l’héritage
du contexte (Lucas et al. 2003).
Ces descripteurs (cf. tableau 2) peuvent s’organiser implicitement selon une certaine
hiérarchie qui représente le modèle logique du document. La combinaison de descripteurs
de plusieurs niveaux de la hiérarchie permet de multiplier le poids des descripteurs de plus
haut niveau. Ainsi, les mots n’auront pas le même rôle, ni la même importance, suivant leur
place dans le document (titre, résumé, introduction, etc.). Leur importance varie aussi suivant
leur position dans une fenêtre d’observation (partie, paragraphe, section, etc.). Par exemple
parmi les coordinations de phrase, and et but – qui sont fréquents – seront renforcés au niveau
du paragraphe, qui comprend des coordinations comme moreover., qui est plus significatif
lorsqu’il se trouve en début de phrase. Les indicateurs les plus fréquents se retrouvent dans
le niveau le plus fin pour minimiser l’héritage dans le niveau au dessous. La position relative,
en début ou en fin d’une fenêtre change dans la hiérarchie d’une fenêtre à une autre. Pour
tenir compte des inclusions, le début ou la fin d’une fenêtre se traduisent respectivement
par la première (ou la dernière) sous-fenêtre d’une fenêtre donnée, par exemple, le début et
la fin d’un paragraphe sont respectivement la première et la dernière phrase du paragraphe.
Descripteurs métriques
Les descripteurs métriques portent sur la longueur des différentes unités textuelles obte-
nues lors de la segmentation : la longueur du corps de texte (exprimée en nombre de parties),
Niveau Descripteurs
<corps> Temporel : Now, Present, Past, Future, Ever, Current, Often. Superpersonnel : we,us, I, our, Think, thought, believe, believed, suggest, suggested, that, to, is, are,as Mode : can, may, should, would
</parties> Appel : Appels aux références bibliographiques ou aux figures Penser : think,thought, believ (e|ed), suggest, suggested Voix : is, was, were, are, edNegationList : do not, no FuturList : will, would Passé : ed, had, were, might,could Aspect : do, has, ed Determinants : these, this, those, that, the, a, anConnecteurs adverbiaux : moreover, thus, therefore, indeed, in fact, ly Anaphore :this, these, those, that, the, thus Conjonctions : Because, if, whether, how, for thisreason, although, though, as, as well as, as well, due to, however
</section> Conjonctions : why, because, if, how for this reason, although, though, as well,due to, however, while, when, which, where Evaluation_Comparaison : even, they,it is, one, most, some, all, a number, several, few, first, second, third, its, their,such, only, other, otherwise, same
</paragraphes> Prepositions : In, At, For, From, to, with, by, of, by contrast, among, withinAdverbiaux : inside, outside, through, after, before, mean, while, despite, Indeed,in fact, in spite of Evaluation quantifiée : one, most, some, all, a number, several,few, first, second, third, fourth, fifth, it, they Négation : do not, no Determinants :this, that, the, a, an Coordination : and, but, also, or, instead, moreoverPonctuation : … ; : , Adverbes : generally, particularly, specifically, clearly,obviously, interestingly, accordingly
</phrases> Coordination : and, but Reflexif : sel (f|ves)
</virgulots> Passé : ed, ould, ought Forme « ing » : ing Adverbes : ly Forme « s » : sDeterminants : the, a, an Déictique : this, these, those, that, there, thus, therefore,there is, there are, the other
Tableau 2 : Descripteurs stylistiques (extrait).

73
Schedae, 2006, prépublication n°9, (fascicule n°1, p. 69-78).
des parties (exprimée en nombre de sections ou de paragraphes), des sections (exprimée
en nombre de paragraphes), des paragraphes (exprimée en nombre de phrases) et des phra-
ses (exprimée en nombre de virgulots). Nous avons également pris comme descripteur la
longueur du titre et des sous titres de l’article (exprimée en nombre de caractères).
Descripteurs lexicauxEnfin, dans le but de comparer notre travail avec une approche classique, nous avons
utilisé les 47 résumés des articles pour extraire les mots clés caractérisant ces articles. Les
descripteurs lexicaux forment une base de comparaison avec les descripteurs de plan, dis-
cursifs et métriques.
Le processus de fouilleCette expérience est conçue dans le but de comparer les résultats obtenus par les diffé-
rentes familles de descripteurs. La figure 1 synthétise le processus général de notre appro-
che, il s’agit de comparer des descripteurs linguistiques et de structure versus une simple
approche sac de mots représentée par descripteurs lexicaux.
La première étape concerne le choix des classes d’articles utilisées, qui tiennent compte
des attentes des biologistes : l’information qui intéresse prioritairement les spécialistes se
trouve dans ces trois classes. La première classe correspond aux articles de synthèse qui
représentent une revue très complète et exhaustive, commençant par l’historique jusqu’aux
connaissances actuelles sur un sujet très précis ; la deuxième classe contient des articles de
recherche qui présentent un travail personnel effectué par rapport à l’état des connaissances
actuelles ; enfin, la classe des articles de clinique qui décrivent une observation particulière
par rapport à sa rareté ou son caractère démonstratif. On a exclu dans cette expérience par
exemple les éditoriaux, qui peuvent contenir des hypothèses non démontrées.
D’autre part, suite à des attentes plus spécifiques de biologistes au sein du projet Bingo,
le sujet des articles est le cancer du cerveau ou de la prostate. Les articles ont été collectés
à partir d’une recherche documentaire classique par mots-clés MeSH sur la base documen-
taire en ligne PubMed.
La deuxième étape concerne la récupération des résumés du corpus et l’application
des différentes étapes des approches sac de mots, telles que la lemmatisation (stemming)
et l’élimination des mots vides. Pour chaque article on garde les dix premiers mots les plus
Figure 1 : Les grandes lignes de l’approche.

74
Schedae, 2006, prépublication n°9, (fascicule n°1, p. 69-78).
fréquents (seuil > = 2), pour ce jeu de données, une ligne représente un article et une
colonne représente la présence ou l’absence d’un mot dans l’article.
La troisième étape consiste à segmenter le corpus en unités textuelles telles que le titre,
les sous titres, les parties, les sections, les paragraphes, les phrases et les virgulots en utili-
sant une méthode de découpage qui s’appuie sur la mise en forme matérielle du HTML, puis
sont extraits les différents descripteurs linguistiques et structuraux de chaque niveau en uti-
lisant des expressions régulières. Un jeu de données par niveau est ainsi obtenu. Schéma-
tiquement, pour chaque jeu de données, une ligne peut être vue comme un segment du
texte (exemple : virgulots, phrases etc.) et une colonne code la présence ou l’absence d’un
descripteur pour chaque segment.
La caractérisation des articles est finalement obtenue en utilisant une méthode de fouille
de données, les motifs émergents (cf. section 4).
Des contraintes externes portant sur l’accessibilité des articles de PubMed ont influencé
la taille du corpus. En effet, la majorité des articles en accès libre sont au format PDF, ce qui
rend la tâche de prétraitement très complexe. Dans ce travail, nous nous sommes limités au
format HTML. Le sous-ensemble de textes ainsi obtenu rassemble 47 articles. Nous sommes
conscients que cet échantillon est restreint. Cependant, nous verrons à la section 5 que cette
échantillon va contenir 20 237 unités à explorer.
Fouille de données de motifs contraintsLa fouille de données a pour but la découverte d’information nouvelle utile aux utilisa-
teurs. Les méthodes typiques de fouille de données extraient tous les motifs vérifiant certaines
propriétés. Dans ce travail, les motifs sont des associations de descripteurs (e.g., stylistiques,
métriques) présents dans les articles. Du point de vue du processus de fouille, les propriétés
recherchées sont traduites par des contraintes qui expriment ainsi le point de vue de l’utili-
sateur et on parle de fouille de données sous contraintes (Bayardo 2005). Une contrainte est
une restriction devant être satisfaite par un motif. Considérons par exemple la table 3 qui
est un extrait d’un ensemble de données notée D contenant trois types d’articles (Cc pour
clinique, Cs pour synthèse et Cr pour recherche). Chaque ligne est un article décrit par les titres
des quatre parties Introduction, Material & Methods, Conclusion. Par exemple, « {Introduction,
Material & Methods} » est un motif composé de deux descripteurs qui vérifie la contrainte
«être présent au moins 3 fois dans D », en effet 4 segments contiennent ce motif, il s’agit des
segments 1, 2, 3 et 6. On dit que la fréquence de ce motif est 4. Il est possible d’exprimer
des contraintes très variées, comme le motif possède (ou ne possède pas) un descripteur, le
motif vérifie une certaine longueur, l’aire d’un motif (i.e., le produit de sa longueur par sa
fréquence) dépasse un seuil, etc. Une caractéristique importante de la fouille de données
sous contraintes est qu’on veut obtenir tous les motifs satisfaisant la contrainte. Cette complé-
tude de la réponse à la requête est nécessaire pour obtenir toute l’information des données.
Elle exige des stratégies efficaces de fouille de données afin de ne pas avoir à parcourir tout
l’espace des motifs potentiels.
Dans ce travail, nous cherchons à caractériser des collections de données (i.e., les types
d’articles) les unes par rapport aux autres. Pour cela, nous nous intéressons aux « motifs
émergents ».
Segment Classe Items
1 CC Introduction, Material & Methods
2 CC Introduction, Material & Methods
3 CS Introduction, Material & Methods, Conclusion

75
Schedae, 2006, prépublication n°9, (fascicule n°1, p. 69-78).
Ces motifs sont des motifs dont la fréquence varie fortement entre deux ou plusieurs
classes (Soulet et al. 2005), une classe correspondant ici à un type d’articles. Soit Di (i : 1..3)
l’ensemble des articles d’un même type. La fréquence F (X, D) d’un motif X dans D est le
nombre d’articles contenant X dans D. Par exemple, F ({Introduction, Material & Methods},
D) = 4. Le concept de motif émergent est relié à la notion de différence de fréquence entre
classes. La quantification du contraste entre une classe i et les autres classes est mesurée
par le taux de croissance (ou « growth rate ») et noté GRi :
GRi (X) = [(|D| – |Di|)/|Di|] × [F (X, Di)/ (F (X, D) – F (X, Di))]
On dit que X est un motif émergent de D\Di dans Di, si GRi (X) > = ρ avec ρ > 1. Par
exemple le motif {Introduction, Material & Methods} est un motif émergent de D\Cc dans
Cc car le GR1 ({Introduction, Material & Methods}) = 2.5
Résultats et discussion
La segmentation des articles en unités textuelles (le corps de texte, les parties, les sec-
tions, les paragraphes, les phrases et les virgulots) est une des tâches initiales de notre tra-
vail. Il s’agit d’un traitement de surface pour découper le texte en unités que l’on supposera
élémentaires et qui serviront de fenêtres d’observation. En ce qui concerne le corpus utilisé
dans cet article, on obtient 12 246 virgulots, 5 404 phrases, 1 767 paragraphes, 416 sections,
310 parties et 47 corps de texte ainsi que 47 résumés, soit au total 20 237 unités.
Les tableaux 4 et 5 donnent les résultats pour les meilleurs motifs émergents (EP) résul-
tant de l’utilisation des descripteurs lexicaux et métriques. Le processus est effectué trois
fois : on caractérise la classe Clinique par rapport aux Synthèse et Recherche et on donne
le meilleur motif émergent EP1, on caractérise la classe Synthèse par rapport aux Clinique
et Recherche et on donne le motif émergent EP2, et on fait la même chose pour la classe
Recherche et on donne le motif émergent EP3. Pour chaque motif émergent on associe son
GR et sa fréquence relative dans une classe donnée (représentée par la ligne). Par exemple
11,76 % est la fréquence relative de EP3 = {high} dans la classe « articles de recherche ». Ces
tables montrent que les descripteurs lexicaux et métriques sont uniformément distribués dans
les trois classes et le contraste exprimé par le GR est très faible. Ces descripteurs seuls ne
permettent pas de caractériser les trois classes.
4 CS Introduction, Conclusion
5 CS Conclusion
6 CR Introduction, Material & Methods, Conclusion
7 CR Material & Methods
Tableau 3 : Extrait d’un ensemble de données.
Classe Motifs Emergents (ρ = 2) GR Fréquences relatives
Clinique Synthèse Recherche
Clinique vs. Synthèse et Recherche
EP1 = {tumor, treat} 2.0588 30,00 % 25,88 % 23,52 %
Synthèse vs. Recherche et Clinique
EP2 = {combination} 2.0461 13,00 % 15,88 % 16,38 %
Recherche vs. Synthèse et Clinique
EP3 = {high } 2.1025 13,29 % 10,96 % 11,76 %
Tableau 4 : Exemples des meilleurs résultats des descripteurs lexicaux.
76
Schedae, 2006, prépublication n°9, (fascicule n°1, p. 69-78).
Les tableaux 6 et 7 montrent les résultats en employant les descripteurs de plan et les
descripteurs stylistiques. Le motif {Discussion, Footnotes}{Abstract, Introduction, Material
& Methods} est un des motifs émergents mis en évidence avec les descripteurs de plan : sa
fréquence est 100 % pour les articles de recherche et 88,23 % pour les articles de clinique.
En revanche, il n’est pas présent dans les articles de synthèse. Cela signifie que la présence
de ce motif dans un article exclut qu’il s’agisse d’un article de synthèse. Nous disons alors
que la caractérisation des articles de synthèse est négative (par absence de ce motif dans
un article). Cela signifie que les articles de synthèse sont organisés différemment des arti-
cles de recherche et des articles de clinique.
On observe un résultat similaire avec les descripteurs stylistiques. On remarque qu’au
niveau du corps du texte, il existe des motifs émergents présents jusqu’à 82 % dans les arti-
cles de recherche et 69 % des articles de synthèse, mais 0 % des cliniques. La caractérisation
des articles de clinique est alors aussi négative. On note également que les résultats sont
conformes avec les résultats des descripteurs de plan, car c’est au niveau des parties que
les articles de synthèse sont discriminés.
Classe Motifs Emergents (ρ = 2) GR Fréquences relatives
Clinique Synthèse Recherche
Clinique vs. Synthèseet Recherche
EP1 = {longueur_Titre_Article ∈ [35,195]} 2.000 91,00 % 83,12 % 88,23 %
Synthèse vs. Rechercheet Clinique
EP2 = {longueur Crps_txt < 6} Inf. 00,00 % 46,16 % 00,00 %
Recherche vs. Synthèseet Clinique
EP3 = {longueur_Section ∈ ]5,10]} 2.016 78,37 % 100 % 89,05 %
Tableau 5 : Exemples des meilleurs résultats des descripteurs métriques.
Classe Motifs Emergents (ρ = 2) GR Fréquences relatives
Clinique Synthèse Recherche
Clinique vs. Synthèseet Recherche
EP1 = {Footnotes, Aknowledgement} {Abstract, Introduction, Material & Methods, Results}
2.7451 82,35 % 00,00 % 100 %
Synthèse vs. Rechercheet Clinique
EP2 = {Conclusion, abstract} 10.4615 05,88 % 61,53 % 05,88 %
Recherche vs. Synthèseet Clinique
EP3 = {Discussion, Footnotes} {Abstract, Introduction,Material & Methods, Results}
2.0000 88,23 % 00,00 % 100 %
Tableau 6 : Exemples des meilleurs résultats des descripteurs de plan.
Classe Niveau Motifs Emergents (ρ = 2) GRFréquences relatives
Clinique Synthèse Recherche
Clinique vs. Synthèseet Recherche
EP1 = {TEMP_Début, SUPPERS_Fin} 2.1176 35,29 % 15,38 % 17,64 %
Synthèse vs. Rechercheet Clinique
Corpsde
texte
EP2 = {MOD_Fin, SUPPERS_Fin} Inf. 00,00 % 53,84 % 00,00 %
Recherche vs. Synthèseet Clinique
EP3 = {SUPPERS_Début, SUPPERS_Fin} 2.7451 82,00 % 69,23 % 35,00 %
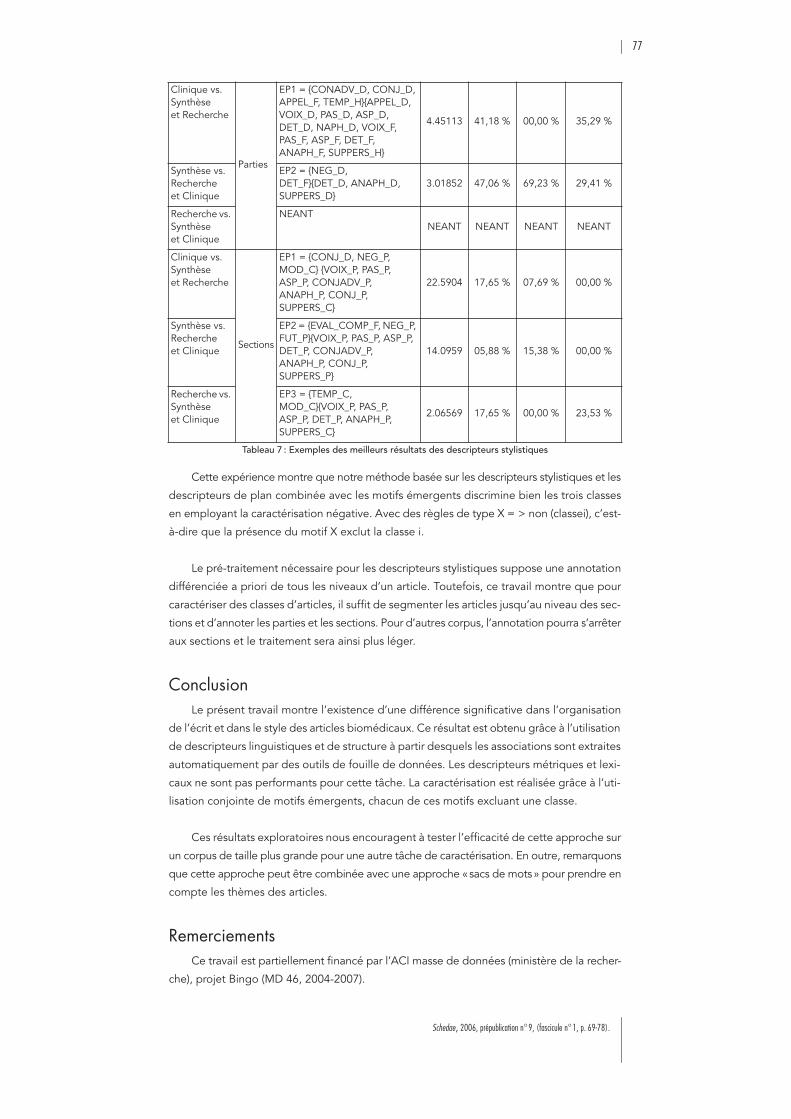
77
Schedae, 2006, prépublication n°9, (fascicule n°1, p. 69-78).
Cette expérience montre que notre méthode basée sur les descripteurs stylistiques et les
descripteurs de plan combinée avec les motifs émergents discrimine bien les trois classes
en employant la caractérisation négative. Avec des règles de type X = > non (classei), c’est-
à-dire que la présence du motif X exclut la classe i.
Le pré-traitement nécessaire pour les descripteurs stylistiques suppose une annotation
différenciée a priori de tous les niveaux d’un article. Toutefois, ce travail montre que pour
caractériser des classes d’articles, il suffit de segmenter les articles jusqu’au niveau des sec-
tions et d’annoter les parties et les sections. Pour d’autres corpus, l’annotation pourra s’arrêter
aux sections et le traitement sera ainsi plus léger.
ConclusionLe présent travail montre l’existence d’une différence significative dans l’organisation
de l’écrit et dans le style des articles biomédicaux. Ce résultat est obtenu grâce à l’utilisation
de descripteurs linguistiques et de structure à partir desquels les associations sont extraites
automatiquement par des outils de fouille de données. Les descripteurs métriques et lexi-
caux ne sont pas performants pour cette tâche. La caractérisation est réalisée grâce à l’uti-
lisation conjointe de motifs émergents, chacun de ces motifs excluant une classe.
Ces résultats exploratoires nous encouragent à tester l’efficacité de cette approche sur
un corpus de taille plus grande pour une autre tâche de caractérisation. En outre, remarquons
que cette approche peut être combinée avec une approche «sacs de mots» pour prendre en
compte les thèmes des articles.
RemerciementsCe travail est partiellement financé par l’ACI masse de données (ministère de la recher-
che), projet Bingo (MD 46, 2004-2007).
Clinique vs. Synthèseet Recherche
Parties
EP1 = {CONADV_D, CONJ_D, APPEL_F, TEMP_H}{APPEL_D, VOIX_D, PAS_D, ASP_D, DET_D, NAPH_D, VOIX_F, PAS_F, ASP_F, DET_F, ANAPH_F, SUPPERS_H}
4.45113 41,18 % 00,00 % 35,29 %
Synthèse vs. Rechercheet Clinique
EP2 = {NEG_D, DET_F}{DET_D, ANAPH_D, SUPPERS_D}
3.01852 47,06 % 69,23 % 29,41 %
Recherche vs. Synthèseet Clinique
NEANTNEANT NEANT NEANT NEANT
Clinique vs. Synthèseet Recherche
Sections
EP1 = {CONJ_D, NEG_P, MOD_C} {VOIX_P, PAS_P, ASP_P, CONJADV_P, ANAPH_P, CONJ_P, SUPPERS_C}
22.5904 17,65 % 07,69 % 00,00 %
Synthèse vs. Rechercheet Clinique
EP2 = {EVAL_COMP_F, NEG_P, FUT_P}{VOIX_P, PAS_P, ASP_P, DET_P, CONJADV_P, ANAPH_P, CONJ_P, SUPPERS_P}
14.0959 05,88 % 15,38 % 00,00 %
Recherche vs. Synthèseet Clinique
EP3 = {TEMP_C, MOD_C}{VOIX_P, PAS_P, ASP_P, DET_P, ANAPH_P, SUPPERS_C}
2.06569 17,65 % 00,00 % 23,53 %
Tableau 7 : Exemples des meilleurs résultats des descripteurs stylistiques

78
Schedae, 2006, prépublication n°9, (fascicule n°1, p. 69-78).
BibliographieAHMED S., CHIDAMBARAM D., DAVULCU H., BARAL C. (2005), Intex : A syntactic role driven proteinprotein
interaction extractor for bio-medical text, in Proceedings ISMB/ACL Biolink, p. 54-61.
BAYARDO R. (2005), « The Hows, Whys, and Whens of Constraints in Itemset and Rule Discovery», in
Proceedings of the workshop on Inductive Databases and Constraint Based Mining.
BLOTT S., GURRIN C., JONES G.J.F., SMEATON A.F. & SODRING T. (2003), « On the Use of MeSH Headings to
Improve Retrieval Effectiveness », in NIST Special Publication 500-255 : The Twelfth Text REtrieval Confe-
rence (TREC 2003), E. M. Voorhees et L. P. Buckland (éds), USA., NIST, p. 215-224.
DAYANIK A., NEVILL-MANNING C.G., OUGHTRED R. (2003), « Partitioning a graph of sequences, Structures
and Abstracts for Information Retrieval », in NIST Special Publication 500-255 : The Twelfth Text REtrieval
Conference (TREC 2003), E. M. Voorhees et L. P. Buckland (éds), USA, NIST, p. 522-531.
DONG G. & LI J. (1999), « Efficient Mining of Emerging Patterns : Discovering Trends and Differences »,
in 5th ACM SIGKDD Int’l Conf. On knowledge Discovery and Data Mining (KDD’99), San Diego,
Californie, USA, p. 43-52.
HERSH W., BHUPATIRAJU R.T., PRICE S. (2003), « Phrases, Boosting, and Query Expansion Using External
Knowledge Resources for Genomic Information Retrieval», in NIST Special Publication 500-255: The Twelfth
Text REtrieval Conference (TREC 2003), E. M. Voorhees et L. P. Buckland (éds), USA., NIST, p. 503-509.
KANDO N. (1999), « Text Structure Analysis as a Tool to Make Retrieved Documents Usable», in Proceedings
of the 4th International Workshop on Information Retrieval with Asian Languages, Taipei, Taiwan, p. 126-
135.
KARLGREN J. (2005), « Meaningful models for information access systems », in Inquiries into Words,
Constraints and Contexts : Festschrift in the Honour of Kimmo Koskenniemi on his 60th Birthday, CSLI
Studies in Computational Linguistics, CSLI Publications, Stanford, Californie, p. 241-248.
KAYAALP M., ARONSON A.R., HUMPHREY S.M., IDE N.C., TANABE L.K., SMITH L.H., DEMNER D., LOANE R.R.,
MORK J.G., BODENREIDER O., DEMNER D. (2003), « Methods for Accurate Retrieval of MEDLINE Citations
in Functional Genomics », in NIST Special Publication 500-255 : The Twelfth Text REtrieval Conference
(TREC 2003), E. M. Voorhees et L. P. Buckland (éds), USA, NIST, p. 441-450.
LUCAS N., CRÉMILLEUX B., TURMEL L. (2003), Signalling well-written academic articles in an English corpus by
text-mining techniques, UCREL technical papers, 16 (Special issue Proceedings Corpus Linguistics 2003),
p. 465-474.
PARSONS G. (1990), Cohesion and coherence: Scientific texts. A comparative study, Nottingham, Angleterre,
Department of English Studies, University of Nottingham.
ROSARIO B. & HEARST M. (2005), « Multi-way Relation Classification : Application to Protein-Protein Inter-
action », in Proceedings of the HLT-NAACL’05, Vancouver (à paraître).
RUCH P., BAUD R. & GEISSBHLER A. (2003), « Learning-free Text Categorization », in Proceedings of the 9th
Conference on Artificial Intelligence in Medicine Europe AIME 2003, M. Dojat, E. Keravnou & P. Barahona
(éds), Springer, p. 199-208.
RUCH P., CHICHESTER C., COHEN G., CORAY G., EHRLER F., GHORBEL H., MÜLLER H. & PALLOTTA V. (2003), «Report
on the TREC 2003 Experiment : Genomic Track », in NIST Special Publication 500-255 : The Twelfth Text
REtrieval Conference (TREC 2003), E. M. Voorhees et L. P. Buckland (éds), USA, NIST, p. 756-761.
SOULET A., CRÉMILLEUX B., RIOULT F. (2005), « Condensed Representation of EPs and Patterns Quantified by
Frequency-Based Measures», in Post-proceedings of the International Workshop on Knowledge Discovery
in Inductive Databases (KDID'04) co-located with the ECML-PKDD'04, B. Goethals et A. Siebes (éds.),
Springer (Lecture Notes in Computer Science 3370), p. 173-190.
WILCOX A. & HRIPCSAK G. (2000), « Medical text representations for inductive learning », in Proceedings of
the American Medical Informatics Association Fall Symposium, USA, AMIA.

79
Amanda Bouffier« Segmentation de textes procéduraux pour l’aide à la modélisation de connaissances : le rôle de la structure visuelle »
Schedae, 2006, prépublication n°10, (fascicule n°1, p. 79-84).
Schedae, 2006
Segmentation de textes procéduraux pour l’aide à la modélisation de connaissances : le rôle de la structure visuelle
Amanda BouffierLaboratoire d’Informatique de Paris-Nord
99 avenue Jean-Baptiste Clément – 93 430 Villetaneuse
Résumé :
Dans cet article, nous étudions le rôle de la structure visuelle pourla segmentation automatique
de textes procéduraux. Nous nous focalisons sur un type de textes procéduraux particulier : les
Guides de Bonnes Pratiques médicales. Une étude linguistique effectuée sur ce corpus montre
la pertinence ainsi que les limites des indices visuels, pour délimiter des ensembles conditions-
actions, qui forment des unités sémantiques de base pour la segmentation.
Mots-clés : aide à la modélisation, linguistique textuelle, textes procéduraux.
Abstract :
In this paper, we study the role of the visual organization (paragraphs, headings, lists…) for a seg-
mentation task of procedural texts. We focus on a particular type of procedural texts : medical
pratice guidelines. A linguistic study shows the relevancy and the limits of the structural clues to
delimit the condition-action units, which form the basic semantic units for the segmentation task.
Keywords : modelling support tool, text linguistics, procedural texts.
Les textes procéduraux sont des textes qui ont pour objectif de prescrire des actions
au vu de certaines conditions. Ils reçoivent une attention croissante en entreprise car ils ont
des conséquences importantes en termes de sécurité et en termes légaux. Ils sont pourtant
souvent peu lus ou peu adaptés aux conditions de travail effectives (situations d’urgence,
habitudes de travail difficiles à modifier). Dès lors, le développement de systèmes facilitant
l’accès aux instructions présentes dans les textes de manière adaptée aux situations de travail
représenterait un bénéfice incontestable.
Pour construire ces systèmes, les textes ont besoin d’être modélisés. Or, le passage du
texte brut au modèle reste une étape le plus souvent manuelle, donc coûteuse. Fort de ce
constat, l’objectif de notre travail est de fournir une aide à la modélisation en proposant une
première représentation structurée de ces textes. La structuration consiste à isoler les unités
textuelles qui correspondent aux conditions et aux actions et à remettre en correspondance
Prépublication n° 10 Fascicule n° 1

80
Schedae, 2006, prépublication n°10, (fascicule n°1, p. 79-84).
ces unités entre elles. Des phénomènes de portée étendue concernant les unités exprimant
une condition rendent la tâche complexe. La difficulté est de calculer la portée de ces unités.
La portée étant représentée par un cadre (Charolles1997)1. L’étape de structuration doit donc
être précédée d’une étape de segmentation, qui consiste à délimiter les cadres engendrés
par les unités. De nombreux indices dans le texte suggèrent la fermeture ou la continuation
d’un cadre. Nous concentrons ici sur le rôle que peuvent jouer les indices relatifs à la struc-
ture visuelle des textes (découpage en paragraphes, titres, structures énumératives etc.).
1 Des phénomènes de portée
Un cadre représente la portée d’une unité-condition appelée introducteur de cadre. Le
fait, pour une unité-condition, d’avoir une portée étendue (i. e supérieure à sa propre phrase),
peut se réaliser de différentes manières sur le plan linguistique. Dans un premier cas, l’intro-
ducteur de cadre est un titre ou une expression non intégrée syntaxiquement à la phrase,
comme dans l’exemple de la figure 1 (sur le corpus étudié, voir la section 3).
Cet exemple montre trois cadres introduits par des expressions détachées en début de
phrase.
Dans d’autres cas, la portée d’un introducteur s’établit par le biais de liens anaphoriques
(parfois doublés de phénomènes complexes d’ordre temporel).
Pour délimiter la fin de ces cadres (de types différents) de nombreux indices peuvent
intervenir. Nous nous concentrons ici sur le rôle des indices relatifs à la structure visuelle des
textes.
2 Segmenter en cadres : le rôle de la structure visuelle
Nous faisons l’hypothèse que les indices relatifs à la structure visuelle sont un ensemble
d’indices très pertinents pour les textes procéduraux. En effet, parce qu’ils doivent être lus
rapidement et efficacement, ces textes sollicitent fortement ce type de structuration.
Pour tester cette hypothèse, nous avons effectué une étude sur un corpus de recomman-
dations médicales : les Guides de Bonnes Pratiques. Ces textes sont écrits par des autorités
en matière de santé et sont adressés aux médecins afin d’uniformiser leurs pratiques. Suite
au constat que leur simple diffusion avaient peu d’impact sur les pratiques des médecins, de
nombreux travaux ont vu le jour, avec l’objectif de contribuer au développement d’outils
d’aide à la décision fondés sur ces guides (Séroussi 2003).
Cette étude a utilisé 18 Guides de Bonnes Pratiques (environ 120 000 mots, disponibles
sur http://www.anaes.fr) portant sur la prise en charge de diverses pathologies. 500 expressions
1. Nous lui empruntons les notions de portée et de cadre. Néanmoins, notre définition est plus vaste : la por-tée d’une unité peut se réaliser de différentes manières sur le plan linguistique. On inclut notamment lescas où celle-ci s’établit à partir de relations anaphoriques remontantes. Voir section 1
Figure 1 : Exemples de cadres introduits par des expressions détachées.

81
Schedae, 2006, prépublication n°10, (fascicule n°1, p. 79-84).
de condition introductrices de cadre ont été isolées (titres, expressions détachées ou inté-
grées). Pour chaque introducteur, le cadre qu’il engendre a été délimité avec l’aide d’un
expert (Catherine Duclos du laboratoire LIM & Bio de l’université Paris 13). Plusieurs para-
mètres, en relation avec la structure visuelle, jugés comme indices potentiellement pertinents
pour la segmentation ont été retenus : la portée de l’introducteur par rapport au découpage
en paragraphes, la position de celui-ci dans le paragraphe, la relation qu’il entretient avec le
titre de la section dont il fait partie, et quand il fait également partie d’une structure énumé-
rative, la relation avec cette dernière. Pour chaque introducteur, la valeur de chaque para-
mètre a été relevée. Pour tester la corrélation entre certains paramètres, un chi carré a été
calculé.
Le principal résultat obtenu montre que les indices relatifs à la structure visuelle sont très
discriminants, en particulier en ce qui concerne la structuration en paragraphes, les titres
ainsi que les structures énumératives.
Nous avons notamment observé que 60 % des expressions détachées engendrent un
cadre qui se ferme à la fin du paragraphe. Ce résultat montre que le découpage logique en
paragraphes est un indice très discriminant.
En revanche, il a également été observé, de manière inattendue, que 6,8 % des expres-
sions détachées engendrent un cadre qui inclut des paragraphes de même niveau que l’intro-
ducteur. Ces cas sont liés à une redondance entre le titre et l’expression détachée, ce qui
entraîne une confusion de leurs portées respectives. Ce résultat est surprenant car ce qui était
attendu est un fonctionnement exclusif entre les titres et les expressions détachées, autre-
ment dit qu’ils ne puissent pas assumer la même fonction au même moment. Cependant,
dans notre corpus, dans 51 % des cas, le premier introducteur de type expression détachée
présent après le titre est redondant totalement ou partiellement avec celui-ci, comme en
témoigne l’exemple de la figure 2.
Dans cet exemple, l’introducteur initié par en cas de colite chronique a une portée qui
dépasse le paragraphe dont il fait partie. Ceci est lié à une redondance entre l’introducteur
et une partie du titre initié par IV.1 Surveillance. Cette redondance provoque une confusion
de leurs portées respectives.
Dans ce type de cas, la similarité entre le titre et l’expression détachée est alors un indice
pertinent pour calculer la portée de cette dernière.
Enfin, 14,6 % des expressions détachées sont inclus dans une structure énumérative,
comme l’illustre l’exemple de la figure 3 où l’introducteur joue le rôle d’amorce de l’énu-
mération.
Figure 2 : Un cas de redondance entre le titre et l’expression détachée.

82
Schedae, 2006, prépublication n°10, (fascicule n°1, p. 79-84).
Dans ce type de cas, il est nécessaire de pouvoir repérer les structures énumératives
pour calculer la portée des introducteurs se trouvant dans ce type de configuration.
Si une segmentation basée sur des indices visuels est donc pertinente, elle a néanmoins
des limites : c’est le cas notamment 18 % des expressions détachées où le cadre se ferme
entre la phrase de l’introducteur et la fin du paragraphe ainsi que 11,5 % d’expressions inté-
grées qui ont une portée dépassant leur propre phrase. Pour les cas non résolus par les indi-
ces relatifs à la structure visuelle, d’autres classes d’indices ont été isolés. Dans le cas des
expressions détachées, des marqueurs de relations sémantico-rhétoriques sont pertinents :
notamment des marqueurs de relations de contraste (cependant, en revanche) ou des mar-
queurs de relations de justification (en effet, en fait). Dans le cas des expressions détachées,
des marqueurs de relations anaphoriques sont de bons indices, comme en témoigne l’exem-
ple de la figure 4.
Dans cet exemple, Dans les deux cas, qui est un marqueur anaphorique, renvoie le lec-
teur aux deux conditions énoncées auparavant (lorsque l’HbA1c est > 8 %/lorsque l’HbA1c
est comprise entre 6,6 % et 8 %) et indique que l’action qui suit tombe sous la portée de ces
deux conditions.
3 Vers une automatisation de la segmentation
Cette étude linguistique sur corpus nous a permis de définir une architecture modulaire
exploitant les indices présentés dans la section précédente pour segmenter et structurer les
textes. Un premier module est dédié au repérage des introducteurs de cadre qui sont des
expressions de condition. Un deuxième module a pour charge de repérer les différents indi-
ces pertinents pour délimiter la fin des cadres. Un troisième module, enfin, est dédié au calcul
de la délimitation des cadres sur la base d’heuristiques exploitant les indices. De manière
générale, une segmentation par défaut est fixée au paragraphe courant dans le cas des
expressions détachées et à la phrase courante dans le cas des expressions intégrée. Cette
segmentation par défaut est remise en question lorsqu’apparaissent d’autres types d’indi-
ces. Dans le cas d’indices conflictuels (i. e amenant à des segmentations divergentes), des
heuristiques ont été écrites afin de gérer certaines priorités.
Figure 3 : Un introducteur amorce d’une énumération.
Figure 4 : Un anaphorique comme indice de continuation.

83
Schedae, 2006, prépublication n°10, (fascicule n°1, p. 79-84).
Les modules sont écrits en Perl et XSLT. Tous les modules prennent en entrée un fichier
XML et produisent en sortie les mêmes fichiers XML modifiés.
Cette architecture, en cours d’implémentation, a été validée sur certains aspects (démar-
che générale, repérage des introducteurs et des énumérations) avec l’aide d’experts du
domaine. Une fois l’implémentation terminée, l’outil sera évalué sur un autre corpus de textes
procéduraux, afin de mettre à l’épreuve et évaluer la généricité de la méthode.
4 Positionnement de l’approcheL’analyse de textes de spécialité est un des champs applicatifs du TAL qui a connu un
grand succès ces dernières années : des travaux se sont concentrés sur les méthodes d’ex-
traction de termes ou de relations entre ces termes. Leur objectif étant d’aider à modéliser,
nous nous inscrivons pleinement dans la lignée de ces travaux. Néanmoins, nous nous en
distinguons par la prise en compte d’un niveau d’analyse différent. En effet, les travaux sus-
mentionnés s’appliquent à un niveau interne à la phrase tandis que notre niveau d’analyse
est le texte en lui-même.
Dans la mesure où l’objet de notre étude est le texte et sa structure, nous intéressons
naturellement aux travaux en linguistique textuelle. Les travaux fondateurs de Halliday, sur la
notion de cohérence textuelle constituent l’arrière plan de notre étude. Nous nous inspirons
fortement de la théorie de l’encadrement du discours de Charolles (1997), dont nous repre-
nons en partie la notion de cadre et de portée. Nous empruntons également aux travaux
de Virbel et Luc (2001), qui étudient le fonctionnement de la structure visuelle d’un texte.
Nous portons enfin une attention toute particulière aux travaux de Pascual et Péry-Woodley
(Péry-Woodley 1998) qui a notamment travaillé sur l’interaction entre différentes structures
textuelles.
Au-delà de l’analyse linguistique, nous nous démarquons des travaux précédents en
visant le développement d’un outil permettant le repérage de ces structures et leur exploita-
tion dans le cadre d’une tâche d’aide à la modélisation. La description est donc faite avec un
souci d’opérationnalisation qui oblige à fonder l’analyse linguistique sur des indices repé-
rables automatiquement en corpus.
Cet objectif d’opérationnalisation nous inscrit dans le cadre des systèmes d’accès à
l’information qui exploitent la structure du texte – qu’elle soit de nature thématique ou rhé-
torique – ou des structures spécifiques comme les cadres de discours.
5 ConclusionNous nous sommes concentrés dans cet article sur le rôle de la structure visuelle pour la
segmentation. Une étude linguistique, effectuée sur un corpus de textes de recommandations
médicales, a montré la pertinence ainsi que les limites de ce type d’indices.
L’enjeu principal consiste désormais à étudier la portée de ce travail et sa généricité.
Chaque texte procédural est spécifique et, si l’on espère qu’une partie de ce travail (mar-
queurs, indices visuels…) est réutilisable, une autre partie devra être adapté. Nous travaillons
actuellement sur d’autres corpus, afin de déterminer des stratégies d’adaptation efficaces
en fonction des textes et de la tâche envisagée.
BibliographieCHAROLLES M. (1997), « L’encadrement du discours-univers, champs, domaines et espaces », Cahier de
recherche linguistique, 6, p. 1-73.

84
Schedae, 2006, prépublication n°10, (fascicule n°1, p. 79-84).
PÉRY-WOODLEY M-P. (1998), « Modes d’organisation et de signalisation dans des textes procéduraux »,
Langages, 141, p. 28-46.
SÉROUSSI B., GEORG G. & BOUAUD J. (2003), « Dérivation d’une base de connaissances à partir d’une
instance GEM d’un guide de bonnes pratiques médicales textuel », in Actes des 14es Journées
Francophones sur l'Ingénierie des Connaissances (IC' 2003), Dieng-Kuntz (éd.).
VIRBEL J-L. & LUC C., (2001), « Le modèle d’Architecture Textuelle : fondements et expérimentation »,
Verbum, 23, 1, p. 103-123.

85
Christophe Pimm« Quelle plus-value linguistique pour la segmentation automatique de texte ? »
Schedae, 2006, prépublication n°11, (fascicule n°1, p. 85-90).
Schedae, 2006
Quelle plus-value linguistiquepour la segmentation automatique de texte?
Christophe PimmERSS, Université de Toulouse-le-Mirail
5 Allées Antonio Machado – 31058 Toulouse Cedex 9
Résumé :
Cet article s’inscrit dans le domaine de l’analyse du discours. Dans cet article se focalise sur une
partie de mon travail de thèse qui vise à la description de mécanismes complexes de structura-
tion du discours. Elle se base sur la description de l’interaction de plusieurs mécanismes complé-
mentaires dans la construction de la cohérence discursive. Le but de cette étude sur corpus est
d’utiliser ces descriptions pour la réalisation d’un module de segmentation automatique.
Mots-clés : Analyse du discours, TAL, RST, MAT, Encadrement du discours, cohérence,
organisation hiérarchique du discours, segmentation statistique, segmentation du discours.
Abstract :
This paper situates itself in the field of discourse analysis. It focuses on a part of my work for my
PhD aiming to describe complex mechanisms in the structuration of discourse. It is based on the
description of the interaction between various complementary mechanisms for the construction
of discourse coherence. The goal of this corpus-based study is to build an automatic segmenta-
tion module based on these descriptions.
Keywords : Discourse analysis, computational linguistics, RST, Text Architecture Model,
Discourse Framing, coherence, hierarchical organization of discourse, statistical segmenta-
tion, discourse segmentation.
Au sein du TAL, le domaine de la segmentation automatique de texte s’est considéra-
blement développé depuis quelques années répondant à des besoins et aux avancées de
l’informatique.
Dans cet article qui s’inscrit dans le domaine de l’analyse du discours, je me propose
de revenir sur des méthodes de traitement automatique statistiques (basées sur la notion
de cohésion lexicale) en soulignant leurs caractéristiques et leurs limites et d’évaluer la plus-
value que pourrait leur apporter l’utilisation de modèles et théories de l’analyse du discours
(qui étudient les mécanismes de cohérence du discours). Mon but n’est pas de totalement
rejeter les approches statistiques, qui ont quand même des qualités, au profit de modélisa-
tions purement linguistiques mais plutôt de proposer une approche hybride statistique et
Prépublication n° 11 Fascicule n° 1

86
Schedae, 2006, prépublication n°11, (fascicule n°1, p. 85-90).
linguistique de segmentation automatique permettant de dégager des segments de dis-
cours cohérents et pertinents. Je présenterai enfin les applications envisagées qui guident
le choix des modèles utilisés.
1. Cadre de l’étude – l’analyse du discoursCette étude s’inscrit dans le domaine du TAL mais également dans le domaine de l’ana-
lyse du discours. En effet, si ce travail a des visées applicatives et utilise des outils et des
méthodes de TAL, une grande partie du travail précédant l’étape de l’automatisation est
un travail de description linguistique sur les textes constituant le corpus. Je vais maintenant
brièvement présenter chaque méthode et modèle utilisés avant de montrer en quoi il est
pertinent de considérer ces modèles ensembles dans une tâche d’observation des phéno-
mènes de cohérence en vue de leur utilisation dans un système de segmentation automati-
que. La cohérence est une notion centrale de l’analyse du discours. En effet, un discours n’est
pas une simple succession de phrases mises à la suite les unes des autres mais bien un tout
cohérent dans lequel tous les segments sont liés les uns aux autres de façon hiérarchique.
Un grand nombre de théories et modèles de la cohérence existent à l’heure actuelle et j’ai
choisi pour mon étude d’en utiliser trois, leur choix étant motivé à la fois par leur complé-
mentarité et par les applications de TAL visées.
1.1. Trois théories et modèles de la cohérence discursiveL’Encadrement du discours de Charolles (1997) décrit l’organisation et le fonctionne-
ment de segments discursifs appelés cadres de discours. Les cadres sont définis par Cha-
rolles (1997) comme des unités contenant « plusieurs propositions apparaissant dans le fil
d’un texte [et qui] entretiennent un même rapport avec un certain critère » ce dernier étant
souvent marqué par une expression détachée en tête de phrase et initiant le cadre : l’intro-
ducteur de cadre (IC). Sa portée dépasse la proposition et peut s’étendre sur plusieurs phra-
ses. Charolles (1997) a ainsi dégagé quatre grands types de cadres, chacun étant introduit
par un type d’IC 1. Participant à la construction de la cohérence discursive, les cadres ne sont
pas des segments isolés mais peuvent être liés entre eux par des relations de deux types :
la subordination ou la coordination. L’Encadrement du discours offre des perspectives inté-
ressantes dans la description de la cohérence car même si il ne peut être appliqué à l’ensem-
ble d’un texte, il permet une description de phénomènes au fonctionnement particulier et
qui complète bien (comme nous allons le voir) la description d’autres segments et relations
du discours.
La RST (Rhetorical Structure Theory) est une théorie développée Mann & Thompson
(entre autres Mann & Thompson 1988 & 2001). Elle décrit l’interaction entre des segments
de discours à l’aide d’un jeu ouvert de relations rhétoriques. Dans la RST, les relations occu-
pant une place centrale sont définies par un ensemble de contraintes sur la relation et sur les
segments liés par cette relation. La RST distingue entre deux types de relations : les relations
noyau-satellite (où le noyau est le segment principal) et les relations multinucléaires (liant
plusieurs noyaux). Un des avantages de la RST est la variété des relations proposées. Elle
permet également de rendre compte de la structure hiérarchique du discours. Par contre,
faire une analyse RST d’un texte n’est jamais aisé car le jeu des relations n’est pas fixe et il
n’est parfois pas évident de décider quelle relation convient le mieux pour relier deux seg-
ments.
1. Les univers de discours temporels et spatiaux, les cadres thématiques, les domaines qualitatifs et lesespaces de discours.

87
Schedae, 2006, prépublication n°11, (fascicule n°1, p. 85-90).
Le MAT (Modèle de l’Architecture Textuelle) est un modèle décrivant la mise en forme
matérielle (MFM) des textes comme participant à la construction de la cohérence du discours.
On peut en trouver des descriptions dans Luc (2000) et Luc & Virbel (2001). Selon ce modèle,
chaque élément de formatage des textes peut être exprimé par un métalangage. Les titres
ou les énumérations sont des exemples d’objets textuels qu’il est possible de décrire à l’aide
du MAT et repérables grâce à des marqueurs (par exemple, l’alignement du texte ou des
caractères en gras). Le MAT est un modèle pertinent quand on travaille sur des textes écrits
car les aspects de MFM des textes sont des indicateurs précis des intentions de l’auteur et
facilitent la construction de la cohérence du discours du lecteur à partir du texte. Il est inté-
ressant d’utiliser ce modèle lorsqu’on travaille dans une optique de segmentation automa-
tique car la MFM la facilite et les marqueurs de formatage sont relativement faciles à repérer
de façon automatique.
1.2. Une étude sur les titresPour compléter l’utilisation de ces modèles, j’ai entrepris une étude sur les titres au sein
des documents de mon corpus 2 (présenté en section 2). Ce choix se justifie car les textes
de mon corpus sont très fortement structurés et notamment avec des titres. Pour l’identifi-
cation de segments et la segmentation, les titres fournissent un certain nombre d’indices. Si
le discours est une entité hiérarchique, cette hiérarchie est aussi véhiculée par les titres. Dans
l’étude des titres de section, les travaux de Ho-Dac, Jacques & Rebeyrolle (Rebeyrolle 2003,
Ho-Dac et al. 2004) nous éclairent sur le rôle et la fonction des titres et nous donnent égale-
ment des pistes pour leur étude. Les titres organisent doublement le discours car ils orga-
nisent les thèmes abordés dans un texte mais aussi le texte lui-même.
Pour le présent travail, certains indices sont particulièrement intéressants. Tout d’abord,
la forme des titres. Rebeyrolle (2003) avait constaté que les titres de section étaient majori-
tairement des SN mais pouvaient aussi par exemple être réalisés par des SP, des SN coor-
donnés ou des phrases. Un autre indice lié à l’organisation hiérarchique du texte est le niveau
de hiérarchie du titre qui permet de situer le titre dans la hiérarchie du document et ainsi de
voir ses relations avec les autres titres de ce document. Enfin, un dernier type d’indices dans
les textes concerne la reprise des titres dans le segment titré (lieu et forme de la reprise).
Combinée aux théories et modèles évoqués plus haut, cette étude des titres a le potentiel
de faciliter le repérage et l’utilisation de certains segments de discours.
2. Présentation du corpusMon étude est une étude sur un corpus bilingue français/anglais de textes écrits longs
et structurés appartenant à trois types de texte différents. Travailler sur des textes longs a
été un choix qui se justifie par le besoin de les traiter efficacement mais aussi et surtout par
la nécessité de disposer de textes assez longs pour observer les phénomènes de construc-
tion de la cohérence, ce qui est plus difficile à faire sur des textes courts, en particulier en ce
qui concerne les titres qui doivent être nombreux si on veut observer leur fonctionnement.
Un second critère qui a été retenu est qu’ils devaient être structurés sur le plan visuel et orga-
nisationnel, par l’utilisation de titres (avec au moins trois niveaux de titre) mais également par
l’utilisation de la MFM comme des puces ou du gras. Les trois types de textes que j’ai retenus
pour mon corpus sont des textes procéduraux (des manuels de logiciel – 172 000 mots), un
2. Cette étude a été initiée dans le cadre du projet « Visualisation dynamique de texte : extraction sélective,affichage spatial multi-échelle et observation des stratégies de lecture » (voir http://www.limsi.fr/Individu/jacquemi/COGNITIQUE02/).

88
Schedae, 2006, prépublication n°11, (fascicule n°1, p. 85-90).
texte institutionnel (le Traité établissant une constitution pour l’Europe – 320 000 mots) et
des textes argumentatifs (des articles de presse spécialisée – 36 000 mots).
Pour mon étude, le corpus a subi un certain nombre de pré-traitements : les formats
des textes étant variés (Word, PDF, RTF, PS, etc.), je les ai d’abord tous convertis au format
XML en leur donnant une DTD commune et je les ai également étiquetés à l’aide du Tree-
Tagger, ce qui était nécessaire, notamment pour le traitement des textes par le TextTiling.
3. Avantages et limites des méthodes statistiquesUne étude préliminaire a été effectuée sur les méthodes statistiques de traitement auto-
matique de textes. Il a d’abord été question de savoir si la LSA 3 étaient une méthode qui
pouvait potentiellement être utilisée pour la segmentation automatique. Le plus grand pro-
blème que j’ai constaté est que la LSA est une méthode statistique basée sur des calculs de
similarité qui dépend beaucoup trop de l’espace sémantique dans lequel a lieu la compa-
raison. De plus, la LSA ne permet pas de déterminer les segments à comparer pour la seg-
mentation nécessitant donc trop de pré-traitements.
Le TextTiling Algorithm de Hearst (1994, 1997) a également été considéré. Cette
méthode de segmentation thématique est robuste et donne de bons résultats pour certai-
nes applications. Mais elle a aussi des limites quand on travaille sur des textes structurés :
un trop grand nombre de titres et des paragraphes trop courts entraînent des problèmes
de découpage qui faussent la segmentation thématique. De plus, le TextTiling Algorithm
utilise des pseudo-paragraphes des pseudo-phrases pour la segmentation, ce qui rajoute
de l’« à peu près » dans la segmentation. Pour l’instant, j’ai évalué cet algorithme sur mon
corpus à partir de son implémentation en Perl que j’ai réalisée. Cela ne suffit néanmoins pas
et un protocole expérimental est en train d’être mis en place pour son évaluation plus en
profondeur par rapport aux tâches finales qui sont présentées en conclusion de cet article.
4. Une combinaison des modèles servant l’applicationLes différents modèles, théories et études présentés permettent de décrire chacun un
aspect de la cohérence, cette description étant toujours motivée par des objectifs précis. Avec
le développement des applications de TAL et le besoin de plus en plus grand de prendre
en compte des informations linguistiques d’un côté et pour aboutir à une description plus
poussée de la cohérence d’autre part, certains auteurs ont commencé à considérer conjoin-
tement plusieurs théories et modèles pour décrire des phénomènes complexes et répondre
à ces besoins. C’est le cas de Luc (2000) et Luc & Virbel (2001) qui envisagent la complémen-
tarité entre le MAT et la RST. De la même façon, Power et al. (2003) font le lien entre la struc-
ture du document et la structure rhétorique pour le développement d’outils de génération
automatique de texte. Des travaux font cohabiter méthodes statistiques et méthodes linguis-
tiques, la linguistiques complétant les méthodes statistiques. C’est le cas des travaux de
Ferret et al. (2001) qui font cohabiter une segmentation à la Hearst et l’utilisation de l’Enca-
drement du discours en vue d’une application de résumé automatique 4. Ces auteurs con-
cluent que les méthodes statistiques sont performantes quand il y a des cassures franches
entre les segments mais que dans le cas contraire, le repérage de marqueurs linguistiques
donne de meilleurs résultats. La combinaison de méthodes statistiques et linguistiques peut
3. Voir Landauer et al. (1998) pour une présentation de la LSA.4. Les auteurs utilisent également une troisième méthode faisant appel à des données externes au texte : un
réseau de collocations construit à partir d’un corpus d’articles de journaux.

89
Schedae, 2006, prépublication n°11, (fascicule n°1, p. 85-90).
donc fournir un bon compromis entre efficacité et précision. Les théories et modèles pré-
sentés en section 1 sont très complémentaires dans le sens où certains pallient des manques
des autres. Par exemple, déterminer les indices de fermeture des cadres (souvent problé-
matique), il est possible d’utiliser la MFM, les titres ou les relations RST. Après avoir observé
le fonctionnement conjoint de ces modèles sur un corpus de textes procéduraux et argu-
mentatifs lors de mon DEA (Pimm 2003), j’en ai conclu qu’ils se complétaient et interagis-
saient les uns avec les autres5 et permettaient de dégager des macro-segments discursifs
récurrents et propres à un type de texte particulier.
Une première étude sur mon corpus m’a permis de dégager des macro-segments récur-
rents dans les textes procéduraux et le texte institutionnel. Ces segments mettent en jeu tou-
jours la même configuration de marqueurs. Ces configurations ont été implémentées en
Perl pour repérer automatiquement ces segments et relations. Ce programme constitue un
squelette pour le programme de segmentation qui, une fois couplé avec un programme de
segmentation statistique, permettra d’identifier ces macro-segments pour leur utilisation
ultérieure dans des systèmes de TAL.
5. En conclusion – les applications considéréesGrâce à la combinaison de plusieurs modèles de l’analyse du discours combinés à une
étude sur les titres, j’ai pu mettre à jour des configurations récurrentes de marques au sein
de textes de types différents. Cette étude était motivée en partie par les applications pou-
vant tirer partie d’une segmentation discursive basée sur des indices de la cohérence dis-
cursive. L’une de ces applications est la visualisation et la navigation multi-échelle de textes
pour laquelle on doit avoir la possibilité de visualiser le texte à des niveaux de grain plus ou
moins fins et donc, de tirer partie de la structure hiérarchique du document, ce qui n’est pas
possible avec une méthode statistique. Une deuxième application envisagée est l’aide à la
rédaction. Un système d’aide à la rédaction de manuels procéduraux ou de textes institution-
nels pourrait fournir un patron à remplir par le rédacteur contenant déjà toutes les relations
et les types de segments à utiliser pour assurer une bonne compréhension des textes par les
lecteurs. Dans ces deux exemples d’applications, il semble que la combinaison de méthodes
statistiques et linguistiques est un compromis efficace.
6. BibliographieCHAROLLES M. (1997), « L’encadrement du discours : univers, champs, domaines et espaces», Cahier de
Recherche Linguistique, 6, p. 1-73.
FERRET O., GRAU B., MINEL J.-L. & PORHIEL S. (2001), «Repérage de structures thématiques dans des textes»,
in Actes de la conférence Traitement Automatique du Langage Naturel (TALN’01), ATALA, p. 163-172.
HEARST M. (1994), « Multi-paragraph segmentation of expository text», in Proceedings of the 32nd Annual
Meeting of the Association for Computational Linguistics, Las Cruces, p. 9-16.
HEARST M. (1997), « TextTiling : Segmenting text into multi-paragraph subtopic passages», Computational
Linguistics, 23, 1, p. 33-64.
HO-DAC L.-M., JACQUES M.-P. & REBEYROLLE J. (2004), «Sur la fonction discursive des titres», in L’unité texte,
S. Porhiel & D. Klingler (éds), Pleyben, Perspectives, p. 125-152.
LANDAUER T., FOLTZ P. & LAHAM D. (1998), « Introduction to Latent Semantic Analysis », Discourse
Processes, 25, p. 259-284.
5. Il faut bien sûr garder à l’esprit que la cohérence discursive est un phénomène très complexe et même sion utilise conjointement plusieurs théories et modèles, nous sommes encore très loin de la décrire com-plètement.

90
Schedae, 2006, prépublication n°11, (fascicule n°1, p. 85-90).
LUC C. (2000), Représentation et composition des structures visuelles et rhétoriques du texte, Thèse de
Doctorat, IRIT, Université Paul Sabatier – Toulouse III (dactyl.).
LUC C. & VIRBEL J. (2001), « Le modèle de l’architecture textuelle – fondements et expérimentations »,
Verbum, 23 (Cohérence et relations de discours à l’écrit), 1.
MANN W.C. & THOMPSON S. (1988), Rhetorical Structure Theory : Toward a functional theory of text organi-
zation, Text, 8, 3, p. 243-281.
MANN W.C. & THOMPSON S. (2001), «Deux perspectives sur la Théorie de la Structure Rhétorique (RST)»,
Verbum, 23 (Cohérence et relations de discours à l’écrit), 1.
PIMM C. (2003), Une étude sur corpus de textes anglais et français de cinq relations rhétoriques proches
(la conséquence, la cause, la condition, la temporalité et le but), leurs réalisations, leur place, leur rôle
et les liens qui les unissent dans les textes à consignes, Mémoire de DEA, Université de Toulouse-le-
Mirail, Toulouse II (dactyl.).
POWER R., SCOTT D. & BOUAYAD-AGHA N. (2003), « Document Structure », Computational Linguistics, 29,
2, p. 211-260.
REBEYROLLE J. (2003), «Forme linguistique et fonction discursive des titres de sections», in Actes du
Colloque de l’Association for French language studies (AFLS) : Le français aujourd’hui : Problèmes et
méthodes, Université de Tours, France.

Nouveaux types de documents,nouveaux modes d’accèsà l’information textuelle
session 3

II

91
Clara Mancini & Donia Scott« Hyper-Document Structure: Maintaining Discourse Coherence in Non-Linear Documents »
Schedae, 2006, prépublication n°12, (fascicule n°1, p. 91-104).
Schedae, 2006
Hyper-Document Structure:Maintaining Discourse Coherencein Non-Linear Documents
Clara Mancini & Donia ScottCentre for Research in Computing
The Open University, Milton Keynes, MK7 6AA, UK
[email protected], [email protected]
Abstract :
The passage from linear text to hypertext poses the challenge of expressing discourse coherence
in non-linear text, where linguistic discourse markers no longer work. While hypertext introduces
new possibilities for discourse organisation, it also requires the use of new devices which can sup-
port the expression of coherence by exploiting the technical characteristics and expressive richness
of the medium. In this paper we show how in hypertext the notion of abstract document structure
encompasses animated graphics as a form of meta-language for discourse construction.
Keywords: hypertext, discourse coherence, cognitive coherence celations, document
structure, visual meta-discourse.
Résumé:
Le passage du texte linéaire à l’hypertexte pose le problème d’exprimer la cohérence du discours
dans une texte non-linéaire ou le marques linguistiques du discours ne fonctionnent pas. Pendant
que l’hypertexte introduit des nouvelles possibilités d’organisation du discours, il aussi nécessite
d’utiliser des nouveaux dispositifs qui peuvent supporter l’expression de la cohérence par l’exploi-
tation des caractéristiques techniques et des capacités expressives du médium. Dans cet article
nous montrons comment, dans l’hypertexte, la notion de structure abstraite de document inclut
graphiques animés en tant qu’une forme de métalangage pour la construction du discours.
Mots-clés: hypertexte, cohérence du discours, relations de cohérence cognitive, structure
de document, métadiscours visuel.
Introduction: possibilities and limitations of a mediumThere is a long and well-established literature on textual devices that signal the coherence
structure of a discourse to the reader, within both theoretical (e.g., van Dijk 1977, Halliday &
Hasan 1976, Grimes 1975, Brown & Yule 1983) and computational (e.g., Hobbs 1985, Mann &
Thompson 1988, Schiffrin 1987, Knott & Mellish 1996) linguistics. However, most of the work
Prépublication n° 12 Fascicule n° 1

92
Schedae, 2006, prépublication n°12, (fascicule n°1, p. 91-104).
so far addresses the traditional conceptualisation of text as a two dimensional array on a
physical page, traversed in a set pattern (e.g., left to right, top to bottom in the Western
tradition).
Hypertext is very different from traditional text: it is electronic, in that it can only be read
on a computer screen, and it is non-linear, in that there are several paths available through
the document. Instead of following a set path, the reader of a hypertext document moves
from node to node in her chosen path by mouse-clicking on links. A node can be the equiv-
alent of a traditional text page or can contain just a few sentences. A link can be a word in
the text or a graphical element in the node. As nodes contain multiple links, the author can
only partially control the order in which the reader will access them. In other words, hyper-
text introduces a new conceptualisation of text: as a three-dimensional array on a computer
screen, which can be traversed in any number of ways.
The well-understood discourse markers of the traditional notion of text e.g., cue- words,
cue-phrases, and punctuation do not work well (if at all) for this new medium. Since the com-
prehension of a text relies on the reader’s construction of its underlying coherence structure,
for which discourse markers are a key resource, this poses problems for the easy compre-
hension of hypertext documents.
To overcome this, a new set of devices is needed to function as markers of discourse
structure, together with formation rules to govern their usage, and supported by sound
theoretical frameworks.
We are exploring new possibilities for signalling coherence in non-linear, hypertextual,
documents. Precisely because discourse in non-linear documents is organised as a network
of self-standing units rather than as a hierarchy of interdependent segments, our analysis
of discourse coherence departs from the tradition whereby text is described as a hierarchi-
cal structure (e.g., Mann & Thompson 1988). Instead, we take a cognitive approach where
coherence is a characteristic of the mental representation that the reader constructs during
the process of text interpretation (see, e.g., Johnson-Laird 1983).
Coherence representation in linear text
Text comprehension depends on the reader’s ability to construct a coherent represen-
tation of what (he thinks that) the text is conveying (Sanders & Spooren 2001). To do so the
reader needs to be able to identify the conceptual relations (he thinks to be) holding between
the set of discourse elements (whether these are sentences, paragraphs or entire text sec-
tions). Conceptual relations are primarily identified on the basis of the content of the related
discourse elements, but in linear text their identification is facilitated by a number of cohe-
sive formal elements.
Over the years, the study of text coherence has concentrated on two types of cohesive
element: those which function at the level of discourse structure and those which function at
the level of document structure. A lot of work has focussed on discourse structure. Whether
data driven (Halliday & Hasan 1976, Martin 1992, Knott & Dale 1994) or theory driven (Hobbs
1985, Kamp & Ryle 1993, Mann & Thompson 1988, Sanders et al. 1993), this work has mainly
studied the use of discourse markers (in particular, cue-words and -phrases) and referring
expressions. For instance, in the sentence
Lucia arrived at work late because she had missed her train.
the two clauses are related through the connective because and through the pronouns
she and her, whose semantic content facilitates the interpretive work of the reader. It also
contributes to the fluency of the text.

93
Schedae, 2006, prépublication n°12, (fascicule n°1, p. 91-104).
Other work, on the other hand, has highlighted the role played by graphical features
such as punctuation and layout in text organisation. In particular, Nunberg (1990) distinguishes
text structure from syntactic structure. For Nunberg, text structure can be realised, by punc-
tuation and other graphical marks such as parentheses, dashes, white-space etc., which are
concrete features of abstract, logical categories such as paragraph, text-sentence or text-
clause. For instance, in the sentence
Lucia arrived at work late: she had missed her train.
the same causal relation previously expressed by the connective “because” is now
expressed by a colon. This distinction between abstract and concrete textual features has
been extended by Power, Scott and Bouayad-Agha (2003) to yet another graphical feature
of text, namely layout. For example, in the text segment
To fix this house, I have to
• repair the roof;
• re-plaster the walls;
• replace the floors.
the conjunctive relation between the second, third and fourth clause is laid out as a
bulleted, vertical list.
In addition to layout, the abstract features also include other text categories whose
graphical features define the general formatting of a document e.g., titles, chapter and
section headings, emphasis, etc. In the example above, for instance, the words roof, walls
and floors could be highlighted as the parts of the house that need fixing with the use of
bold face.
Elsewhere (Power et al. 2003) we propose that layout and formatting features deserve
a separate descriptive level in the analysis and generation of written texts, which we term
abstract document structure and which constitutes an extension to Nunberg’s ‘text-grammar’
(Nunberg 1990). The distinction between document structure and discourse structure is, we
argue, equivalent to the distinction between semantics and syntax. Although document struc-
ture is an intrinsic part of text structure, its constituents work differently from the way in which
both discourse markers and concrete textual features work, because they have different
semiotic characteristics: whereas discourse markers and punctuation are textual, devices
like layout and formatting are visual (Piwek et al. 2005).
Abstract discourse structure: visual vs. textual
In written text, the minimal linguistic unit is the character, a non-signifying differential
element, whose combination generates words, successively articulated to produce phrases,
clauses, sentences, etc (Saussure 1922). As the character is a symbolic element, in written
text the association between signifier and signified is non-motivated: the correspondence
between them is conventional. Because of this, in written text abstract concepts can be
explicitly expressed for example, as we saw earlier, by using adverbial connectives like
“because” to signal CAUSALITY.
Its symbolic nature also implies that text can deploy along a single line, which can be
articulated using punctuation, dashes, parentheses and the like (i.e., concrete textual fea-
tures). These are purely graphical symbols, which signal different types of textual articula-
tion and inflection, and whose use is also regulated by strict conventions. For instance, a
period marks the end of a text-sentence, while a semicolon marks the end of a text-clause.
Substantially different from both cue-phrases and punctuation, abstract features transform

94
Schedae, 2006, prépublication n°12, (fascicule n°1, p. 91-104).
the line of text into a visual configuration capable of conveying discourse structure on the
space of the page.
In visual configurations the association between a sign and its meaning is characterised
by a degree of isomorphism, which makes this association partially motivated. For instance,
in the following example of a horizontal list
I had a busy morning: I had a work meeting, I went shopping, I picked up the children.
the text segments in the list play an equivalent role within the sentence (Pander Maat
1999). This rhetorical equivalence could be expressed as a vertical (e.g., bulleted) list, in
which the segments are given the same visual rendering: each segment starts on a new line
with a bullet. Likewise, the title of the sections in a text will be visually more prominent than
the title of the subsections in order to signal their places in the hierarchy of the text struc-
ture, just as emphasis is visually expressed through a format that stands out.
Unlike textual representations, visual representations tend to be regulated by conven-
tions that are less strict and more dependent on the context of use. For instance, a list of
clauses could be indented or not, bulleted, numbered or scored; whatever the chosen con-
figuration, it is important that all listed clauses are rendered in the same way (i.e. with par-
allel syntax) and occupy the same horizontal position under the first (introductory) clause.
Even though they respond to flexible conventions, however, visual features can express
discourse connections so effectively that the use of cue phrases or punctuation becomes
redundant. So, in a bulleted list the use of connectives (e.g., “and”) and commas is super-
fluous, as the conventions at work in the visual configuration of the list override the conven-
tions that regulate the use of cue-words and punctuation.
Coherence representation in non-linear text
The devices described above constitute cohesive elements that can be used to express
discourse coherence in linear text, either on paper or in electronic documents that maintain
linearity. However, discourse markers such as relational and referential connectives can only
be effectively used when discourse units are arranged in a predefined sequence, so that they
are accessed in a univocal order. But because hypertext is a network of interconnected nodes,
the order in which discourse parts will be accessed can only be partly controlled. Order can
be established locally (a node can be linked to another node), but it is hardly possible to
establish it globally through extended structures (unless one resorts to constrained paths,
which would defeat the purpose of using a non-linear medium).
So, relational and referential connectives cannot be used to signal the discourse rela-
tion between nodes, because each node is accessible in more than one way and thus the
context in which it appears is not constant. As a result, hypertext nodes tend to be written
as self-standing units of text: a hypertext node typically will not use pronouns or referential
phrases to refer to the content of another node; instead, any information contained in the
latter that would need to be referred to in the former has to be repeated. In fact, text sen-
tences or paragraphs that are strongly related (for instance, by causality) will normally be
kept within the same node: since they constitute strongly inter-dependent discourse parts,
the writer is reluctant to put them in different nodes, because the reader might miss one or
the other. However, it is less problematic to separate into different nodes, discourse parts
that are less strongly related (for instance, by elaboration or background) and therefore less
inter-dependent. They can more easily be put into different nodes, their connection being
expressed paratactically via a link (Mancini & Buckingham Shum 2004). Finally, the same
limitations that apply to discourse connectives also apply to punctuation and the like, which

95
Schedae, 2006, prépublication n°12, (fascicule n°1, p. 91-104).
usually only work within nodes and do not facilitate the transition between link words and
their target nodes (for example, it is no longer effective to introduce with a colon, a node
containing the items of a list).
If the non-linearity of hypertext does not lend itself to the use of discourse markers and
concrete features, however, things are different for abstract document features, because
they are visual and work in space. Because of its technical characteristics, hypertext is a
spatial medium, and indeed numerous proposals that tackle the issue of non-linearity seek
to compensate for the lack of control on discourse order by exploiting the spatial nature of
hypertext. Some have proposed spatial metaphors as a way of describing discourse struc-
ture (Landow 1991, Bolter 1991, Kolb 1997); others propose the use of maps, schemas,
outlines (Carter 2000) or navigational patterns (Bernstein 1998) to return to the author’s
hands as much control as possible on the way in which discourse takes shape before the
reader’s eyes and coheres in their mind. But it is also a temporal medium, in which spatial
structures have a temporal dimension and realisation (Luesebrink 1998). So, both space
and time can be exploited in hypertext to express discourse coherence and, we contend,
in hypertext the notion of abstract document structure consists of both spatial and tempo-
ral configurations working in a three-dimensional space.
From text to hypertext via abstract document structureIf coherence is a cognitive phenomenon, then it is possible to express coherence rela-
tions not only through linguistic markers, but also through visual patterns. And if this can
be done by using spatial abstract features in linear documents, then it can also be done by
using spatial and temporal abstract features in non-linear documents. In particular, we pro-
pose that graphics and animation could be used to express discourse coherence in hyper-
text (see Mancini & Buckingham Shum 2004).
At present, most hypertexts (especially on the web) make no use of graphical features
to signal rhetorical relations between nodes, and nodes often consist of long text pages
with a few links targeting other pages, from where the source page can no longer be seen.
However, we believe that the non-linear medium could be used in a far more expressive
and articulated way, if graphic features were exploited as discourse markers to support
coherence. Our work precisely aims at identifying visual devices that can play the role of
discourse markers in the non-linear, three dimensional space of hypertext.
One of these devices could consist of creating much smaller hypertext nodes and using
the screen as a visual field across which they can distribute as links are clicked and new nodes
appear, composing meaningful patterns. The appearance and distribution of the nodes
should signify the rhetorical role that their content plays within the discourse. To achieve
that, rhetorical relations could be used as document structuring principles during discourse
construction to define hypertext links. These could then be dynamically rendered during
navigation through the consistent and concurrent use of the medium’s spatial and temporal
graphic features.
In this respect, having established a parallel between textual and visual processing
(Riley & Parker 1998), Gestalt theory has proposed useful principles of document design
(Campbell 1995). Furthermore, a number of representational rules for visually expressing dis-
course relations between hypertext nodes could be derived from the semiology of graphics,
according to which graphic features can be employed to express conceptual relationships
of similarity, difference, order and proportion exploiting the properties of the visual image, in
a bi-dimensional static space (Bertin 1967) as well as in a three-dimensional dynamic space
(Koch 2001). Using these rules, we have designed and begun testing a series of prototype
visual patterns expressing coherence relations in non-linear discourse (Mancini 2005).

96
Schedae, 2006, prépublication n°12, (fascicule n°1, p. 91-104).
Visualising and testing rhetorical patternsBased on cognitive parameterisations of coherence relations (Sanders et al. 1993, Pander
Maat 1999, Louwerse 2001), we selected a set of relations for experimental rendering and
evaluation. The set included: CAUSALITY, CONDITIONALITY, SIMILARITY, CONTRAST, CONJUNCTION,
DISJUNCTION, ELABORATION and BACKGROUND 1. Here we report on one example: CAUSALITY.
The graphical renderings of the relations were designed based on their parametrical descrip-
tion. In our descriptions of reference, the bipolar parameters defining CAUSALITY were: basic
operation, according to which a relation can be causal or additive, and polarity, according to
which a relation can be positive or negative. The values of each cognitive parameter defining
the relations were rendered through graphical features. As a result, each relation was visually
defined by the sum of the graphical features rendering the cognitive values that define it.
The representation of CAUSALITY was defined by the features rendering the values causal and
positive.
To reify the relation renderings, examples of argumentative passages were taken from
a history of science text. Short passages were isolated, each passage consisting of a pair or
a triple of sentences. The sentences of each pair or group held with each other one of the
eight selected relations, all signaled by appropriate connectives. Finally, each pair or triple
of related sentences was represented on screen respectively within a pair or triple of related
text windows, and those windows were attributed certain graphical properties expressing
the relation holding between the content of one sentence and the content of the other. On
screen, all connectives were removed from the text within the windows, and the connective
function between the text spans was entirely delegated to the windows’ graphical proper-
ties. In order to be as differentiated as possible, each representation had to be kept as min-
imalist as possible, making use of no more formal elements than strictly necessary. A small
number of graphical variables (Koch 2001) were used following specific rules of graphics 2.
Below is the description of the pattern designed for CAUSALITY.
The text spans selected to reify the relation were:
A. Galileo ignored Kepler’s demonstration of the elliptical orbits of planets and continued
to believe that planetary revolutions were a “natural” motion requiring no external mover.
B. Galileo failed to see that the actual geometry of the heavens contradicted any spherical
model.
C. Galileo missed the problem of how planets were retained in their elliptical orbits.
The three windows respectively containing the three text spans were arranged one under
the other, the second sliding down from behind the first as soon as the first had appeared,
and the third sliding down from behind the second as soon as it had reached its position.
They all shared the same width, while the height of each was determined by the quantity
of text contained in each window. The value of the windows’ background became increas-
ingly darker from the first to the third, and the ratio of increment was the same from the first
to the second and from the second to the third, that is, they were equidistant, as far as the
value was concerned. In this configuration, the order of the events was rendered by the
arrangement of the text windows, while the fact that the second and the third windows
appeared by sliding down from the previous one rendered the fact that the second and the
third events followed, and were brought about, respectively by the first and the second
event. At the same time, the darkening of the background rendered the idea of progression
in the forging of a logical chain. Finally, the cohesion between the three events was rein-
forced by the fact that the three windows had the same width (Figure 1).
1. For the criteria of selection and for the discussion of all the renderings, see Mancini (2005).2. For a detailed discussion of the design process for all the relational renderings see (Mancini, 2005).

97
Schedae, 2006, prépublication n°12, (fascicule n°1, p. 91-104).
The whole set of relations was rendered with the purpose of testing the renderings and
their impact on users. In particular we wanted to find out whether the concurrent and con-
sistent use of visual features according to certain perceptual principles and design criteria
would determine the expressiveness of the configurations designed to represent the selected
sub-set of discourse relations and whether people would discriminate the relational expres-
siveness of different visual configurations.
As a first form of verification, we designed and conducted an empirical study with a
group of 24 participants. We asked them to choose from three different representations the
one that in their judgement best expressed each relational concept: the one that had been
designed to represent that particular relation, plus two alternative representations originally
designed to express different relations.
One at the time, the participants were given the original text that had been used to
reify each relation, as well as an abstract definition of the relation in question, then were
shown the three animations associated with it, from which they had to choose what they
thought to be its most expressive representation. They were asked to go through a second
round, in which they were allowed to modify, one way or the other, the choices made in the
first round.
For each given relation, the great majority of participants converged on the same option,
which in fact corresponded to the animated pattern that had been specifically designed to
render that particular relation. For six of the relations CAUSALITY, CONJUNCTION, SIMILARITY,
CONTRAST, ELABORATION and BACKGROUND the results were statistically significant (Table 1).
In brief, albeit not conclusive, the results of this first study suggest that people did rec-
ognize a particular expressiveness in the options that had been designed to render the
subset of discourse coherence relations. In other words, there is positive evidence that the
concurrent and consistent use of graphical elements, according to certain perceptual prin-
ciples and design criteria, can support the visual expression of relational concepts.
The fact that for two of the relations CONDITIONALITY and DISJUNCTION the renderings did
not obtain the same consensus obtained by the others could be explained with the fact that
both conditionality and disjunction are characterized by a greater degree of cognitive com-
plexity. From a cognitive point of view, CAUSALITY, CONJUNCTION, SIMILARITY, CONTRAST, ELABO-
RATION and BACKGROUND hold within a space-temporal continuity, or along one possible line
Figure 1: Two screen shots from the animated graphic rendering of causality(the letters beside the text boxes are for illustration purposes only).
R Caus. Cond. Conj. Disj. Sim. Cont. Back. Elab.
1st 19 10 18 12 16 20 21 20
2nd 22 13 21 12 18 20 21 21
χ2 37 4.750 32.25 3.25 19.75 28 32.25 27.25
p <0.001 N/S <0.001 N/S <0.001 <0.001 <0.001 <0.001
Table 1: Results of the experiment conducted with 24 participants, showing the renderings designed torespectively express each relation. 1st and 2nd = votes obtained by each rendering respectively in the firstand in the second round.

98
Schedae, 2006, prépublication n°12, (fascicule n°1, p. 91-104).
of events. However, conditionality and disjunction hold across two possible lines of events.
That is, they implicate the cognitive projection into an alternative space-temporal dimension
(or narrative axis), before the conditioned or disjuncted situations can be presented. Such an
abstraction is easy to express in natural language, but it is not as easy to express in visual
languages.
This work is still in progress and we are still exploring ways of presenting hypertext which
employ the graphical features of the medium in a systematic and principled way. We have not
implemented a system yet, but that is our goal, and the experimental results that we have
obtained so far are encouraging.
Applying visual rhetorical patterns to hypertextNow let us illustrate an example of how in non-linear text the expression coherence could
be supported by visualising rhetorical patterns. Consider the following text passage:
Some animals are 'nice' to each other, especially those who live on the edge.
For example, vampire bats have been shown to share meals. If a bat fails to find a meal it
is often unable to survive until the next evening's hunting. A bat that has fed well, though,
has more than enough to survive, and could easily spare some of its meal. So sometimes
a full bat will regurgitate some of its meal to another that is starving.
These animals are showing behaviour known as 'reciprocal altruism', which simply means that they
lend each other favours in the expectation that the favours will be repaid some time in the future.
[For example] A bat which one day might be bloated by a great meal, might on another
evening be less lucky and be in need of help itself. By being generous one day at little cost
to itself, it might be saved from starvation the next by another bat returning the favour.
This process can be explained with a game called 'Prisoner's Dilemma'. In the game, two
suspects have been arrested for a crime and the police question them in separate
rooms. The police offer them each a deal. If they don't co-operate with each other (i.e.
they give the police evidence that the other person is guilty) then they will be rewar-
ded and the other person will be put away for the crime. If they both fail to co-ope-
rate, and give evidence against each other then they will both get locked up (although
they will get a lesser sentence), but if they both co-operate with each other by kee-
ping quiet then the police have no evidence and they will eventually both be released.
[Going back to our example] For the bats the risk of starvation if they do not feed is very
high, while the cost of co-operating is low, so it should be no surprise to us that they have
come to co-operate with each other, with every bat benefiting from the arrangement.
This sort of situation faces animals all the time, and by understanding what the rewards and
costs are to them in each case, we can understand the way they behave.
This is composed of four paragraphs, each of which is made up of two or three sentences.
As far as the content is concerned, three different narrative levels marked by the indentation
of the layout can be identified, whose relations are expressed by connective or referential
phrases (in bold) or simply by paratactic juxtaposition (in bold and square brackets). The author
explains an animal behaviour known as ‘reciprocal altruism’, at one level as an abstract con-
cept, at another level with an example from the animal kingdom, and at yet another level
with a metaphor from a game. Now let us consider the case in which the linear text passage
is turned into a hypertext.
In the hypertext version, the underlined words or clauses constitute links and the num-
bers in brackets next to them indicate their target node (nodes are numbered for illustration
purposes). Each node has at least two links, which means that each node can be accessed
at least from two other nodes. Because of that, none of the nodes here contain connectives or
referential phrases that relate to other nodes: each one is a self-standing fragment, no matter
from where it is accessed. If connectives and referential phrases are not used to express the

99
Schedae, 2006, prépublication n°12, (fascicule n°1, p. 91-104).
rhetorical relations holding between nodes, however, these relations could be expressed
through graphic features. Following the rules of graphics visual attributes could be used con-
sistently and concurrently to render relations of order between nodes in a three-dimensional
space, marking the rhetorical relations holding between the discourse parts contained in the
nodes.
Let us hypothesise that one reader follows the path that leads from node 1, to node 2,
to node 3, by following first the link ’nice’ to each other in node 1 and then the link repaid
some time in the future in node 2.
Node 1, the starting point in the hypertext, expresses in a nutshell the concept of ‘recipro-
cal altruism’, which is the subject of the passage. Node 2 elaborates the concept and, on the
basis of that elaboration, node 3 comes to a conclusion. At first, node 1 is on the screen on
its own, but, when the reader clicks on the link ‘nice’ to each other, node 2 appears (A). The
relation of elaboration holding between nodes 1 and 2 could be expressed as follows: node 2
overlaps on the lower edge of node 1, projecting a small shadow. That is, through the slight
overlapping and projected shadow of node 2, this configuration aims to reflect the fact that
the two units do not belong to the same discourse level: the first one, higher up and more
in depth in the visual field, states the basic concept that the second one, lower and more
to the forefront in the visual field, restates and expands. At this point, when the reader clicks
on the link repaid some time in the future, node 3 slides down from behind node 2, greyed
out at first (A). As it positions itself under node 2, node 3 becomes readable and node 1 greys
out instead, leaving the other two both in evidence (B). The relation holding between the
[1] Some animals are 'nice' to each other (>2), especially those who live life on the edge (>4).
[4] Vampire bats have been shown to share meals (>5). If a bat fails to find a meal it is often unable to survive until the next evening's hunting. A bat that has fed well, though, has more than enough to survive, and could easily spare some of its meal. So sometimes a full bat will regurgitate some of its meal to another (>6) that is starving. [2] Certain animals show a behaviour
known as 'reciprocal altruism‘ (>5),which simply means that they lend each other favours (>6) in the expectation that the favours will be repaid some time in the future (>3).
[3] Situations in which reciprocal altruism (>2) is necessary face animals all the time, and by understanding what the rewards and costs are to them in each case, we can understand the way they behave (>1).
[5] A bat which one day might be bloated by a great meal, might on another evening be less lucky and be in need of help (>4) itself. By being generous one day at little cost to itself, it might be saved from starvation the next by another bat returning the favour. For the bats the risk of starvation if they do not feed is very high, while the cost of co-operating is low, so it should be no surprise to us that they have come to co-operate with each other (>6), with every bat benefiting from the arrangement (>3).
[6] In the game 'Prisoner's Dilemma', two suspects have been arrested for a crime and the police question them in separate rooms. The police offer them each a deal. If they don't co-operate with each other (i.e. they give the police evidence that the other person is guilty) then they will be rewarded and the other person will be put away for the crime. If they both fail to co-operate, and give evidence against each other then they will both get locked up (although they will get a lesser sentence), but if they both co-operate (>5) with each other by keeping quiet then the police have no evidence and they will eventually be both released (>2).
Situations in which reciprocal altruismis necessary face animals all the time, and by understanding what the rewards and costs are to them in each case, we can understand the way they behave.
Some animals are 'nice' to each other, especially those who live life on the edge.
Certain animals show behaviour known as 'reciprocal altruism‘, which simply means that they lend each other favours in the expectation that the favours will be repaid some time in the future.
Situations in which reciprocal altruismis necessary face animals all the time, and by understanding what the rewards and costs are to them in each case, we can understand the way they behave.
Some animals are 'nice' to each other, especially those who live life on the edge.
Certain animals show behaviour known as 'reciprocal altruism‘, which simply means that they lend each other favours in the expectation that the favours will be repaid some time in the future.
A B

100
Schedae, 2006, prépublication n°12, (fascicule n°1, p. 91-104).
nodes - conclusion - is a pragmatic form of causality. This is expressed by the origin and tra-
jectory of node 3, which physically descends from node 2 and by the fact that the background
of node 3 has a darker value. Moreover, the fact that node 2 and 3 have the same width and
are aligned closely one under the other aims to express the fact that they constitute the inter-
connected parts of a larger unit. Finally, by the greying out of node 1 the presentation under-
lines the unity of node 2 and 3.
Now let us hypothesise that another reader follows a different path, going from node 1,
to node 6, to node 5, to node 3, by respectively following the links live life on the edge, regur-
gitate some of it’s meal to another, both co-operate and benefiting from the arrangement.
This second reading constitutes a different navigational experience, to which corresponds a
different visual experience.
At first, node 1 is on its own on the screen, but as soon as the reader clicks on the link
live life on the edge, node 4 appears (A). The content of node 4 is an exemplification of the
concept stated in node 1, and since exemplification is a form of conceptual elaboration, the
visual relationship between node 1 and 4 is represented in the same way as the visual rela-
tionship between node 1 and 2 in the previous path, except that the background colour of
node 4 is different from that of node 2 in the previous path. As the reader now clicks on the
link regurgitate some of its meal to another, node 6 enters the screen from the right hand
side (A) to position itself right next to node 4 (B). As it gets into place, the background colour
of node 6 turns the same as the background colour of node 4.
This is how the conceptual similarity holding between the content of node 4 and the
content of node 6 is rendered through a graphic similarity: node 6 moves in towards node 4,
it has the same height as node 4, it positions itself next to it and it changes its original back-
ground colour (which signals a different domain from which the comparison is drawn) to match
that of node 4. As the reader clicks on the link both co-operate, node 5 enters the screen
from the left hand side to position itself where node 4 was before, so that it gets into the
same position as node 4 with respect to node 6 (C).
Some animals are 'nice' to each other, especially those who live life on the edge.
Vampire bats have been shown to share meals. If a bat fails to find a meal it is often unable to survive until the next evening's hunting. A bat that has fed well, though, has more than enough to survive, and could easily spare some of its meal. So sometimes a full bat will regurgitate some of its meal to another that is starving.
In the game 'Prisoner's Dilemma', two suspects have been arrested for a crime and the police question them in separate rooms. The police offer them each a deal. If they don't co-operate with each other (i.e. they give the police evidence that the other person is guilty) then they will be rewarded and the other person will be put away for the crime. If they both fail to co-operate, and give evidence against each other then they will both get locked up (although they will get a lesser sentence), but if they both co-operate with each other by keeping quiet then the police have no evidence and they will eventually be both released.
A
In the game 'Prisoner's Dilemma', two suspects have been arrested for a crime and the police question them in separate rooms. The police offer them each a deal. If they don't co-operate with each other (i.e. they give the police evidence that the other person is guilty) then they will be rewarded and the other person will be put away for the crime. If they both fail to co-operate, and give evidence against each other then they will both get locked up (although they will get a lesser sentence), but if they both co-operate with each other by keeping quiet then the police have no evidence and they will eventually be both released.
Some animals are 'nice' to each other, especially those who live life on the edge.
Vampire bats have been shown to share meals. If a bat fails to find a meal it is often unable to survive until the next evening's hunting. A bat that has fed well, though, has more than enough to survive, and could easily spare some of its meal. So sometimes a full bat will regurgitate some of its meal to another that is starving.
B

101
Schedae, 2006, prépublication n°12, (fascicule n°1, p. 91-104).
This is to represent that the same conceptual similarity that holds between nodes 4 and 6
also holds between nodes 6 and 5. Consistently with that, node 5 has the same height and
background colour as node 4, as well as ending up in the same position.
Conclusions
If a reader is to understand a text, their mental representation of its content has (at least
to some degree) to reflect the coherence structure intended by the writer. In linear documents,
a number of textual devices facilitate this process of reconstruction by signalling the coher-
ence structure of discourse. However, these devices only work within a linear structure and
they are no longer helpful in the interpretation of non-linear documents. When it comes to
non-linear media, such as hypertext, a different set of signalling devices is required, which
we claim are visual rather than textual. These visual elements constitute the abstract docu-
ment structure in traditional text, where they work within the bi-dimensional space of the page.
However, in hypertext they have to work in a three-dimensional space as well as in time, which
pushes the boundaries of the notion of abstract document structure.
As we have argued, there is a fundamental semiotic difference between visual configu-
rations and textual expressions: since it is a symbolic code, text can express relational con-
cepts with degrees of precision and subtlety that are not easily available in the visual medium.
However, although visual languages do not have the same semiotic capabilities of abstrac-
tion, there is theoretical ground and some preliminary evidence to suggest that they can
express at least the most basic relational concepts (for instance, CAUSALITY, CONJUNCTION,
SIMILARITY). The condition for that is the consistent and concurrent use of the properties of
the image according to specific rules, in order to establish a linguistic context in which dif-
ferent configurations become recognisable as having different meaning. Of course, the use
of visual patterns to express coherence relations in hypertext could be associated with other
devices (Kress & van Leeuwen 2001). For instance, exploiting text generation capabilities,
hybrid representational forms could be used, in which symbolic connectives are used in
addition as soon as two nodes appear on the screen. However, our aim is to identify ways of
presenting hypertext discourse which employ graphical features in a systematic and princi-
pled way, extending the notion of abstract document structure, so that it applies to hyper-
text as well as linear text, by making articulate use of the space-temporal dimensions of the
electronic medium, fully exploiting its expressive potential.
Still in its infancy, this work is at this stage more concerned with identifying the right
questions than with presenting the right answers. We have not yet implemented a system,
but that is our goal, and the experimental results obtained so far are encouraging. As a next
step we will be carrying out further tests on the visual renderings of rhetorical relations. For
example, we intend to test the same relational renderings with a larger number of partici-
pants from different backgrounds, carrying out a qualitative analysis of their responses. We
In the game 'Prisoner's Dilemma', two suspects have been arrested for a crime and the police question them in separate rooms. The police offer them each a deal. If they don't co-operate with each other (i.e. they give the police evidence that the other person is guilty) then they will be rewarded and the other person will be put away for the crime. If they both fail to co-operate, and give evidence against each other then they will both get locked up (although they will get a lesser sentence), but if they both co-operate with each other by keeping quiet then the police have no evidence and they will eventually be both released.
Some animals are 'nice' to eachother, especially those who live life on the edge (>4).
4. Vampire bats have been shown to share meals. If a bat fails to find a meal it is often unable to survive until the next evening's hunting. A bat that has fed well, though, has more than enough to survive, and could easily spare some of its meal. So sometimes a full bat will regurgitate some of its meal to another that is starving.
A bat which one day might be bloated by a great meal, might on another evening be less lucky and be in need of help itself. By being generous one day at little cost to itself, it might be saved from starvation the next by another bat returning the favour. For the bats the risk of starvation if they do not feed is very high, while the cost of co-operating is low, so it should be no surprise to us that they have come to co-operate with each other, with every bat benefiting from the arrangement.
C

102
Schedae, 2006, prépublication n°12, (fascicule n°1, p. 91-104).
have also started to construct hypertext mock-ups using our set of coherence relations to
define the links between nodes and rendering the connections through their corresponding
visual patterns. These are to be tested with users: as they navigate and visual patterns take
shape on the screen, they will be asked to identify the relations holding between nodes, which
will be indicated solely by the graphical clues. Further tests will also be designed.
Our long-term goal is the application of this work to a larger effort in natural language
generation, whereby the same semantic content is rendered differently for different reader-
ships. In particular, we are generating paraphrases that vary not just along the traditional
dimensions (discourse, syntax, lexicalisation) but also in terms of graphical presentation, for
example, as textual reports in different styles including linear vs. non-linear or as slides for
a presentation.
AcknowledgmentsWe would like to thank Richard Power and the reviewers of ISDD’06 for their helpful
feedback.
BibliographyBERNSTEIN M. (1998), “Patterns of Hypertext”, in Proceedings of ACM Hypertext'98, Pittsburgh, PA,
New York, ACM Press, p. 21-29.
BERTIN J. (1967), Sémiologie Graphique, Paris – La Haye, Mouton – Gauthier-Villars; English translation
(1983), Semiology of Graphics: Diagrams, Networks, Maps, Madison, University of Wisconsin Press.
BOLTER J.D. (1991), Writing Space: The Computer, Hypertext, and the History of Writing, Cambridge MA,
Eastgate Systems.
BROWN G. & YULE G. (1983), Discourse Analysis, New York, Cambridge University Press.
CAMPBELL K.S. (1995), Coherence, Continuity, and Cohesion. Theoretical Foundations for Document
Design, Hillsdale (NJ), Lawrence Erlbaum Associates Publishers.
CARTER L.M. (2000), Arguments in Hypertext: A Rhetorical Approach, in Proceedings of ACM Hypertext ‘00,
New York, ACM Press, p. 87-91.
DIJK van T.A. (1977), Explorations in the Semantics and Pragmatics of Discourse, London – NY, Longman.
GRIMES J.E. (1975), The Thread of Discourse, Berlin – New York – Amsterdam, Mouton Publishers.
HALLIDAY M.A.K. & HASAN R. (1976), Cohesion in English, New York, Longman.
HOBBS J.R. (1985), On the Coherence and Structure of Discourse, Stanford, CSLI (Technical Report 85-37).
JOHNSON-LAIRD P. N. (1983), Mental models: Towards a cognitive science of language, inference, and
consciousness, Cambridge MA, Harvard University Press.
KAMP H. & RYLE U. (1993), From Discourse to Logic, Dordrecht, Kluwer.
KNOTT A., DALE R. (1994), “Using Linguistic Phenomena to Motivate a Set of Coherence Relations”,
Discourse Processes, 18, 1, p. 35-62.
KNOTT A., MELLISH C. (1996), “A feature-based account of the relations signalled by sentence and
clause connectives”, Language and Speech, 39, 2/3, p. 142-183.
KOCH W.G. (2001), “Jaques Bertin’s Theory of Graphics and its Development and Influence on
Multimedia Cartography”, Information Design Journal, 10, 1, p. 37-43.
KOLB D. (1997), “Scholarly Hypertext: Self-Represented Complexity”, in Proceedings of ACM Hypertext'97,
New York, ACM Press, p. 29-37.
KRESS G. & VAN LEEUWEN T. (2001), Multimodal discourse: the modes and media of contemporary
communication, London, Arnold.
LANDOW G.P. (1991), “The Rhetoric of Hypermedia: Some Rules for Authors”, in Hypermedia and Literary
Studies, P. Delany and G.P. Landow (eds.), Cambridge MA, MIT Press, p. 81-104.
LOUWERSE M. (2001), “An Analytic and Cognitive Parametrization of Coherence Relations”, Cognitive
Linguistics, 12, 3, p. 291-315.
LUESEBRINK M. (1998), “The Moment in Hypertext”, in Proceedings of ACM Hypertext'98, New York,
ACM Press, p. 106-112.

103
Schedae, 2006, prépublication n°12, (fascicule n°1, p. 91-104).
MANCINI C. (2005), Cinematic hypertext. Investigating a new paradigm, Amsterdam, IOS Press.
MANCINI C. & BUCKINGHAM SHUM S. (2004), “Towards Cinematic Hypertext“, in Proceedings of ACM Hyper-
text'04, New York, ACM Press, p. 115-124.
MANN W.C., THOMPSON S.A. (1988), “Rhetorical Structure Theory: Toward a Functional Theory of Text
Organisation”, Text, 8, 3, p. 243-281.
MARTIN J.R. (1992), English Text. System and Structure, Amsterdam, John Benjamins Publishing Co.
NUNBERG G. (1990), The Linguistics of Ponctuation, Stanford, USA, CSLI.
PANDER MAAT H. (1999), “The Differential Linguistic Realisation of Comparative and Additive Coherence
Relations”, Cognitive Linguistics, 10, p. 147-184.
PIWEK P., POWER R., SCOTT D., VAN DEEMTER K. (2005), “Generating multimedia presentations: from
plain text to screenplay Intelligent Multimodal Information Presentation”, Text Speech and Language
Processing, 27, O. Stock and M. Zancanaro (eds.), Dordrecht, Kluwer, p. 203-226.
POWER R., SCOTT D., BOUAYAD-AGHA N. (2003), “Document Structure”, Computational Linguistics, 29,
4, p. 211-260.
RILEY K., PARKER F. (1998), “Parallels between visual and textual processing”, IEEE Transactions on
Professional Communication, 41, p. 175-185.
SANDERS T.J.M., SPOOREN W.P.M., NOORDMAN L.G.M. (1993), “Coherence Relations in a Cognitive
Theory of Discourse Representation”, Cognitive Linguistics, 4, 2, p. 93-133.
SANDERS T.J.M, SPOOREN W. (2001), “Text Representation as an Interface Between Language and its Users”,
in Text Representation. Linguistic and psycholinguistic aspects, T.J.M. Sanders, J. Schilperoord, W. Spooren
(eds.), University of Utrecht, University of Tilburg, Free University of Amsterdam Press, p. 1-26.
SAUSSURE F. (1922), Cours de Linguistique Générale, Paris, Éditions Payot.
SCHIFFRIN D. (1987), Discourse Markers, New York, Cambridge University Press.

104
Schedae, 2006, prépublication n°12, (fascicule n°1, p. 91-104).

105
Javier Couto & Jean-Luc Minel« SEXTANT, un langage de modélisation des connaissances pour la navigation textuelle »
Schedae
, 2006, prépublication n°13, (fascicule n°1, p. 105-116).
Schedae
,
2006
SEXTANT, un langage de modélisationdes connaissancespour la navigation textuelle
Javier Couto
Universidad de la República – Facultad de Ingeniería – Instituto de Computación
J. Herrera y Reissig 565– Montevideo – Uruguay
Jean-Luc Minel
MoDyCO, UMR 7 114 CNRS- Université Paris X Nanterre
200 Avenue de la République – 92001 Nanterre
Résumé :
Nous présentons tout d’abord notre conception de la navigation textuelle conçue comme un pro-
cessus cognitif qui convoque des connaissances qui sont propres à la finalité de la navigation. Nous
formulons l’hypothèse que ces connaissances peuvent être, en partie, modélisées sous une forme
déclarative avec le langage SEXTANT que nous décrivons. Enfin, nous présentons deux applica-
tions qui utilisent la plate-forme NaviTexte dans laquelle le langage SEXTANT est implémenté.
Mots-clés : navigation textuelle assistée, langage de modélisation des connaissances.
Abstract :
In this paper, we present our approach to text navigation conceived like a cognitive process, which
exploits navigation specific knowledge. We draw up the hypothesis that such knowledge can be
designed in a declarative way with our language SEXTANT. Finally, two applications are described.
Keywords : assisted navigation of texts, knowledge management language.
Conceptions de la navigation textuelle
Le terme de navigation textuelle reçoit de multiples interprétations. La plus commune
renvoie inévitablement au processus mis en oeuvre par les outils de navigation utilisés pour
circuler dans les documents hypertextes, c’est-à-dire la possibilité d’activer un lien pour dépla-
cer le point de lecture ; ce déplacement pouvant être intra ou intertextuel. Plusieurs points
Prépublication n° 13 Fascicule n° 1

106
Schedae, 2006, prépublication n°13, (fascicule n°1, p. 105-116).
sont à souligner dans ce type de navigation hypertextuelle. Tout d’abord, l’activation du lien
est « aveugle », plus précisément aucune signalétique (en dehors d’un titre ou de l’adresse
Url qui est en général peu significative) ou instructions de navigation ne sont associées au
lien. Deuxièmement cette navigation est linéaire, c’est-à-dire qu’une seule voie de naviga-
tion est offerte au lecteur quand celui-ci active le lien. Autrement dit, pour chaque nœud
source il existe un seul nœud cible. De notre point de vue, cela constitue une contrainte trop
restrictive vis-à-vis des fonctionnalités offertes à l’utilisateur. Troisièmement, l’orientation de
la navigation n’est pas indiquée explicitement ; le lecteur ne sait pas si le déplacement se
fait vers l’amont ou vers l’aval 1 du texte lu, ce qui entraîne entre autre des phénomènes de
désorientation cognitive (Edwards & Hardman 1989, Cotte 2004). Dans certains systèmes,
l’affichage d’une carte représentant l’ensemble du site et la localisation du point de lecture
sont utilisés pour résoudre en partie ce problème (Danielson 2002). Enfin et surtout, les liens
sont placés dans le corps même du texte, ce qui implique qu’il n´est pas possible d’adapter les
parcours dans ce texte au lecteur. En d’autres termes aucune information ou connaissances
complexes ne peuvent être associées à la navigation.
Notre conception de navigation textuelle se démarque de ce type de navigation car nous
considérons que circuler ou naviguer dans un texte est l’expression d’un processus cognitif
qui convoque des connaissances qui sont propres à la finalité de la navigation (Minel 2003,
Couto & Minel 2004). Ainsi, comme nous l’illustrerons en présentant différentes applications
(section 4), un documentaliste qui doit écrire un résumé d’un texte (Endres-Niggemeyer et al.
1995) ne navigue pas de la même façon qu’un lecteur intéressé par l’évolution des sentiments
d’un des personnages d’un roman (Mathieu 2004) ou qu’un linguiste qui explore les anno-
tations placées par un système automatique (Pery-Woodley 2004). Ainsi, le fait qu’un texte soit
maintenant numérisé et qu’il soit présenté au lecteur sur un écran peut être considéré, de
notre point de vue, comme une nouvelle mutation qui place le lecteur devant de nouvelles
possibilités qui restent à explorer :
Le texte […] offre en effet une richesse sémiotique particulière, qui fournit de multiples objets
d’interprétation et de multiples pistes d’actions […] les lecteurs n’ont pas la même démarche
envers l’objet ni la même définition de cet objet, ils ne « voient » pas la même chose (Souchier
et al. 2003).
Nous formulons l’hypothèse que la démarche du lecteur peut être assistée par l’exploi-
tation de connaissances qui peuvent être, en partie, modélisées sous une forme déclarative.
En conséquence, nous proposons le langage SEXTANT2 pour exprimer ces connaissances
(section 3).
Du point de vue du lecteur, la navigation textuelle que nous proposons est très diffé-
rente de la navigation hypertextuelle au sens ou nous considérons que le lecteur, qui active lui
aussi des connaissances d’interprétation (Kintsch 2003, Baccino 2004) doit pouvoir interagir
en choisissant la voie de navigation qui lui semble la plus appropriée pour sa tâche de lecture.
Il est néanmoins évident que cette interaction est actuellement très limitée, car la navigation
proposée reste dans les limites posées par le concepteur des modules de navigation (sec-
tion 3). En ce sens, il serait peut-être plus précis de parler de « navigation textuelle assistée ».
Afin de proposer une approche systématisée à la navigation textuelle, quatre éléments
sont nécessaires :
– une représentation du texte pouvant décrire différents phénomènes linguistiques ;
1. L’orientation n’a de signification que dans le cas d’une navigation intratextuelle.2. Par analogie avec les navigateurs du XVIIIe siècle qui ont parcouru le monde en s’orientant sur les mers
avec un sextant.

107
Schedae, 2006, prépublication n°13, (fascicule n°1, p. 105-116).
– la possibilité de pouvoir isoler les connaissances de visualisation et de navigation ;
– un agent (une personne, une équipe d’experts, un système, etc.) capable d’encoder ces
connaissances ;
– un système qui interprète ces connaissances.
Nous n’aborderons pas dans cet article la modélisation des connaissances de visualisa-
tion, que l’on peut brièvement définir comme l’ensemble des opérations qui spécifient
comment un texte est représenté sur l’écran (voir (Couto 2001, 2006) pour une présenta-
tion détaillée). Dans la section suivante nous présentons le modèle de texte que requiert
cette conception de la navigation.
Représentation du texte
La représentation du texte, décrite dans un format standard XML, se divise en deux
parties ; le Corps, où les unités textuelles, significatives pour la tâche sont délimitées, et la
Tête, où s’expriment les relations non hiérarchiques entre ces mêmes unités.
Le Corps
Dans le Corps, l’élément de base de notre modèle est l’Unité Textuelle (UT) typée, ce qui
permet d’incorporer de nouveaux éléments textuels de manière simple. Ces principes d’anno-
tation sur lequel s’appuie NaviTexte sont classiquement ceux proposés par les standards tels
que ceux de la TEI (Text Encoding Initiative).
Concrètement, dans le Corps, une unité textuelle (UT) est balisée, avec la balise <Chaine>,
et des attributs, en nombre illimité, peuvent lui être attribués. Chaque UT est typée et possède
optionnellement un rang. Le type peut aussi bien dénoter la fonction structurelle de l’unité
en question, sa caractéristique syntaxique, sa fonction discursive. On peut remarquer que ce
type d’annotation laisse une marge de liberté très grande, notamment dans la répartition
des valeurs d’annotation entre le type de l’UT et les attributs de cette UT (Couto et al. 2005).
La Tête
Néanmoins ce type de délimitation des unités est insuffisant pour traiter certains phéno-
mènes linguistiques, tel que la discontinuité ou le recouvrement. Plusieurs solutions ont été
proposées qui reposent généralement sur les fonctionnalités offertes par X-Link et XPointer.
Mais la généricité et la relative complexité de ces approches associées à l’absence d’outils
d’éditions sophistiqués rendent leur utilisation plutôt difficile dans le cadre du Traitement
Automatique du Langage (TAL). C’est pour répondre à ce besoin, l’annotation des structure
complexes rencontrées en TAL, que quatre structures, qui sont déclarées dans la Tête, ont été
définies (Couto 2006). Ces quatre structures sont nommées Ensemble, Séquence, Référence
et Graphe et elles permettent de déclarer de nouveaux éléments composés d’unités textuel-
les du Corps du texte. De plus, pour chacune de ces structures, des opérations de visualisa-
tion et de navigation prédéfinies sont en cours de développement.
Un Ensemble déclare un ensemble non ordonné d’UT pour lesquelles existe, du point de
vue de l’annotateur, une relation d’équivalence. Par exemple, des UT avec des étiquettes
morpho-syntaxiques différentes peuvent exprimer un même thème.
Une Référence décrit une relation orientée entre deux UT et une opération de navigation
prédéfinie est associée à cet objet. Cette opération va du référé au référent. Typiquement
une Référence permet de représenter le lien entre une anaphore et son référent discursif. Un
autre exemple d’utilisation est la représentation des relations rhétoriques entre deux propo-
sitions comme le propose la Rhetorical Structure Theory (Thompson & Mann 1988).

108
Schedae, 2006, prépublication n°13, (fascicule n°1, p. 105-116).
Une Séquence permet de décrire des éléments discontinus dans un texte. Plus formel-
lement, une Séquence est une suite ordonnée d’éléments à laquelle l’annotateur attribue
une cohésion. L’intérêt de ce type de structure peut être illustré sur différents exemples.
Le premier exemple est illustré par le besoin d’annoter un syntagme verbal dont la con-
tinuité est par exemple brisée par la négation. Ainsi, il n’est pas possible dans le Corps d’indi-
quer que dans la suite « ne sont pas stockées », le syntagme verbal composé de « sont » et
de « stockées » constitue une seule unité, sans y inclure la marque de la négation. En effet,
il est tout à fait possible de déclarer les unités indépendamment et de les inclure dans une
autre unité, mais ce choix de segmentation ne correspond pas à la description linguistique
visée. Or, l’objectif est de visualiser, avec une même couleur de fond par exemple, ces deux
unités et de pouvoir déclencher la même opération de navigation à partir d’une de ces unités.
La déclaration d’une Séquence composée de deux éléments : « sont » et « stockées », offre
cette possibilité.
Les cadres thématiques (Porhiel 2003) constituent un deuxième exemple de l’intérêt de
cette structure puisqu’elle permet de déclarer les introducteurs de cadre comme apparte-
nant à une même unité.
Le dernier exemple concerne les chaînes de référence lexicales. Une chaîne de référence
lexicale est constituée par l’ensemble des syntagmes nominaux qui réfèrent à un même objet.
Ainsi, dans un article de presse (Le Figaro, le 16 juillet 2004) sur l’amnistie fiscale3, on trouve
pour référer à « La taxe sur les fonds rapatriés en France », dix-sept corrélats linguistiques
qui réfèrent au même référent dont par exemple « La taxe sur les fonds rapatriés en France »,
«une taxe sur les fonds placés à l’étranger et rapatriés en France », «une telle mesure», «elle»,
etc. La déclaration d’une Séquence composée de toutes ces unités textuelles, et qui con-
crétise la chaîne de référence lexicale, permet d’offrir au lecteur un parcours entre ces élé-
ments en utilisant la même opération de navigation décrite précédemment.
Comme l’illustrent ces trois exemples, l’objet Séquence qui combine une structure avec
une opération de visualisation et une opération de navigation offre les moyens de traiter
simplement des phénomènes linguistiques très fréquents.
Le dernier type d’objet, Graphe est utilisé pour construire des relations multiples entre
des UT. Il correspond exactement à la notion mathématique d’un graphe (Berge 1958) où les
nœuds, qui représentent des UT sont liés par des arcs qui représentent les relations entre
ces nœuds. Un Graphe permet ainsi de représenter un index comme on en trouve par exem-
ple en fin d’ouvrage et permet ainsi de mettre en œuvre une autre conception de la naviga-
tion, plus figée que celle que nous proposons, comme celle que propose Nazarenko (2004).
Ainsi, chaque entrée générique de l’index est un nœud du Graphe, les relations entre les
entrées génériques et spécifiques sont représentées par les arcs et feuilles du graphe sont
les UT du texte dont la chaîne lexicale a pour valeur une occurrence du terme indexé.
Le langage SEXTANTLe langage SEXTANT a pour finalité d’offrir des fonctionnalités à la fois suffisamment
génériques tout en proposant une sémantique qui se focalise sur l’essentiel du processus de
visualisation et de navigation dans les textes, à l’inverse de langages de transformation ou
de programmation comme, par exemple, XSLT (EXtensible Stylesheet Language) ou XPATH.
Notre langage est donc de type déclaratif et propose des opérations prédéfinies4.
3. Ce texte fait partie des textes recueillis et analysés par Lita Lundquist.4. Voir (Couto 2006) pour une description détaillée du langage de modélisation.

109
Schedae, 2006, prépublication n°13, (fascicule n°1, p. 105-116).
Les vues d’un texteLe fait de pouvoir afficher un texte de manières différentes, et que chaque manière (vue
du texte) comporte des indications précises sur les différentes options d’affichage (opérations
de visualisation) et sur les interactions que l’utilisateur peut effectuer (opérations de navi-
gation) constitue l’épine dorsale de notre approche. De plus, une vue d’un texte ne montre
pas nécessairement tous les constituants d’un texte ; il peut s’agir d’une vue partielle se foca-
lisant sur certains aspects spécifiques ou phénomènes présents dans celui-ci. Cela constitue,
en quelque sorte, la vue d’un filtrage du texte.
Afin de présenter une approche systématisée des différentes vues, nous proposons une
classification selon leur type et leur contenu. Les types possibles sont : linéaire, arborescente
et graphe tandis que les contenus possibles sont : les chaînes lexicales et les annotations.
Il en résulte qu’il existe six combinaisons possibles.
Certes, d’autres types de vues à ceux présentés ici sont envisageables, comme les vues
basées sur la technique « Focus + Context» (Lamping & Rao 1996) (Dieberger & Russell 2002),
par exemple ; ou d’autres plutôt ad-hoc comme la vue « docball » (Crestani et al. 2002), qui
montre la structure hiérarchique d’un document. Néanmoins, le choix des types linéaire,
arborescente et graphe correspond à la représentation de texte proposée, et constitue, de
notre point de vue, un bon point de départ, pouvant s’enrichir des propositions et des
développements postérieurs.
Modules de connaissances et descriptions de vueLes éléments constitutifs d’une vue sont spécifiés dans une description de vue. Plusieurs
descriptions de vue peuvent être rassemblées dans une entité cohérente d’après l’encodeur
des connaissances, nommée module de connaissances. Nous pouvons concevoir la création
d’une vue comme l’application d’une description de vue à un texte déterminé. Par analogie,
l’application d’un module de connaissances à un texte implique la création d’un ensemble
de vues. En conséquence, toute vue est liée à un texte, à une description de vue et, indi-
rectement, à un module de connaissances.
Une description de vue est identifiée dans le module par son nom. Afin de la définir,
l’encodeur doit indiquer :
– le type de vue selon les types de vue disponibles : linéaire, arborescente et graphe ;
– le contenu de la vue selon les contenus disponibles : chaînes lexicales et annotations ;
– ses paramètres, selon le type de représentation ;
– ses contraintes de création (i.e. des conditions d’appartenance à la vue, à vérifier par les
unités textuelles du texte) ;
– un ensemble d’opérations de visualisation ;
– un ensemble d’opérations de navigation ;
– un ensemble d’opérations de coordination.
Le fait de pouvoir créer des vues partielles d’un texte introduit le besoin de contraintes.
Il s’agit de conditions sur les UT.
Le langage de conditionsUne partie importante de SEXTANT est le langage de conditions. Par exemple, on utilise
une condition pour exprimer des contraintes d’appartenance d’une UT à une vue, pour indi-
quer les UT sur lesquelles une mise en relief s’applique, ou bien pour préciser la cible et la
source dans la description d’une opération de navigation. Le langage de conditions est com-
posé de conditions simples, de conditions d’existence sur les éléments des UT et de con-
ditions sur la hiérarchie.

110
Schedae, 2006, prépublication n°13, (fascicule n°1, p. 105-116).
Les conditions simples portent sur les attributs et sur les annotations des UT. Pour ce
type de conditions, nous utiliserons une notation proche de la notion de patron. On définit
un opérateur UT comportant cinq opérandes qui correspondent aux propriétés suivantes
d’une UT : le Type, le Numéro, le Rang, les Annotations et la chaîne lexicale. Avec les trois
premiers opérandes on dénote des contraintes d’égalité, d’inégalité, d’ordre (inférieur et
supérieur), de préfixe, de suffixe et de sous-chaîne par rapport à des valeurs. De même pour
le cinquième opérande. Le quatrième opérande est utilisé pour indiquer l’existence ou non-
existence d’annotations, que ce soit un nom d’annotation, une valeur ou un couple nom
d’annotation – valeur.
Pour les conditions d’existence UT, un opérateur sans arguments est défini pour chaque
élément (cf. tableau ci-après).
Pour les conditions où se joue le rapport entre les UT dans la hiérarchie, des opérateurs
unaires spécifiques sont définis. Ces opérateurs prennent comme argument une condition
simple. Le tableau ci-dessus montre les opérateurs définis pour tester des conditions sur le
rapport hiérarchique des UT.
Les conditions peuvent se combiner en utilisant les opérateurs classiques OU, ET et NON,
de la logique. Voici un exemple d’expression du langage qui exprime la condition suivante :
« Les UT de type SN comportant une annotation de nom Référent discursif, tel qu’il existe
dans les ascendants une UT de type Paragraphe qui ne comporte pas une annotation de
nom Étiquette Sémantique et valeur Conclusion »
Les opérations de SEXTANT
Des trois types d’opérations possibles (visualisation, navigation et coordination), nous
nous focalisons sur les opérations de navigation. La navigation est conceptualisée comme
une opération reliant une UT source avec une UT cible. La manière dont ces deux UT sont
liées est fonction de quatre paramètres :
existeAnnotations : teste si l’ensemble d’annotations d’une UT n’est pas vide ;existeChaîneLexicale : teste si la chaîne lexicale d’une UT est définie ;existeTitre : teste si le titre d’une UT n’est pas vide ;existeParent : teste si une UT a une UT parent ;existeFils : teste si la suite d’UT filles d’une UT n’est pas vide.
Tableau 1 : Opérateurs d’existence sur les éléments des UT.
estParent : teste si une UT est le parent dans la hiérarchie d’UT d’une UT décrite en utilisantune condition simple ;estFils : teste si une UT est le fils dans la hiérarchie d’UT d’une UT décrite en utilisant unecondition simple ;estFrère : teste si une UT est le frère dans la hiérarchie d’UT d’une UT décrite en utilisant unecondition simple ;estAscendant : teste si une UT est l’ascendant dans la hiérarchie d’UT d’une UT décrite enutilisant une condition simple ;estDescendant : teste si une UT est le descendant dans la hiérarchie d’UT d’une UT décriteen utilisant une condition simple ;contientDansTitre : teste si une UT contient dans les UT du titre une UT décrite en utilisantune condition simple ;estDansTitreDe : teste si une UT appartient aux UT du titre d’une UT décrite en utilisant unecondition simple ;
Tableau 2 : Opérateurs portant sur le rapport hiérarchique des UT.
UT (Type = SN, *,*,{(Référent discursif, *)},*)ET
estDescendant (UT (Type = Paragraphe,*,*,{ ¬∃(Étiquette Sémantique, Conclusion)},*))
Tableau 3 : Exemple d’utilisation du langage de conditions.

111
Schedae, 2006, prépublication n°13, (fascicule n°1, p. 105-116).
– la condition à vérifier par l’UT source ;
– la condition à vérifier par l’UT cible ;
– le type d’opération de navigation ;
– le rapport existant entre l’UT source et l’UT cible.
Une opération de navigation est définie comme une opération qui cherche l’UT cible à
partir de l’UT source, en vérifiant les différentes conditions et en suivant l’orientation relative
au type d’opération. La source est définie en utilisant une condition sur les UT. Implicitement,
une opération de navigation est disponible pour une UT déterminée si celle-ci vérifie la con-
dition exprimée par la source. La cible est déterminée à partir de deux paramètres : une
condition à vérifier pour l’UT cible et le type d’opération de navigation. Une fois la source
déterminée, plusieurs UT peuvent vérifier la condition de la cible, et c’est le type d’opéra-
tion qui indique laquelle choisir d’entre elles. Chaque opération est donc typée avec une
valeur qui appartient à l’ensemble {premier, dernier, suivant [i], précédent [i]}, i étant un
nombre entier positif. Ces valeurs spécifient d’une part l’orientation, c’est-à-dire dans quel
sens (avant ou après l’UT source) doit être effectué la recherche de l’UT cible, et d’autre part
le référentiel, absolu (premier, dernier), ou relatif (suivant [i], précédent [i]), par rapport à la
source. Dans le cas d’un référencement relatif, l’index i permet de spécifier le rang de la
cible recherchée. Par exemple, le type « Suivant [3] » s’interprète comme la recherche, dans
les UT vérifiant les conditions spécifiées pour la cible (i.e. les cibles potentielles), de la troi-
sième unité textuelle située après l’unité textuelle source.
Dans sa première version, la puissance d’expression du langage était limitée par la néces-
sité d’exprimer de manière absolue les conditions sur les valeurs des attributs des UT. Cette
limitation avait par exemple pour conséquence l’obligation d’écrire une opération de naviga-
tion différente pour naviguer entre chaque anaphore et son référent discursif. Dernièrement,
nous avons enrichi le langage de conditions par la possibilité d’exprimer des relations entre
les valeurs des attributs des UT de la source et de la cible, ce qui entraîne qu’une seule
opération de navigation suffit pour traiter la navigation évoquée ci-dessus Les opérations
de coordination, que nous ne détaillerons pas, ont pour finalité de synchroniser les dépla-
cements du point de lecture dans les différentes de vue d’un même texte. Quant aux opé-
rations de visualisation, elles permettent de spécifier les attributs visuels (police, couleur,
espacement, etc.) de chaque vue.
Implémentation dans NaviTexteUne première version développée en langage Java nous a permis de vérifier la validité de
nos hypothèses. La plate-forme est ainsi composée de différents sous-systèmes. Un premier
sous-système se charge de construire à partir d’un texte annoté, la représentation décorée
du texte ; un deuxième sous-système gère les interactions avec l’utilisateur en chargeant et en
interprétant à la demande les modules de navigation (écrits dans le langage SEXTANT). Le
résultat de l’interprétation est un graphe de parcours qui est projeté sur la représentation
opérationNavigation → OpNav (nomOpérationNavigation,typeOpérationNavigation,source,cible)
nomOpérationNavigation → valeurtypeOpérationNavigation → premier | dernier | suivant [valeur] |
précédent [valeur]source → conditioncible → condition
Tableau 4 : Grammaire correspondant aux opérations de navigation.
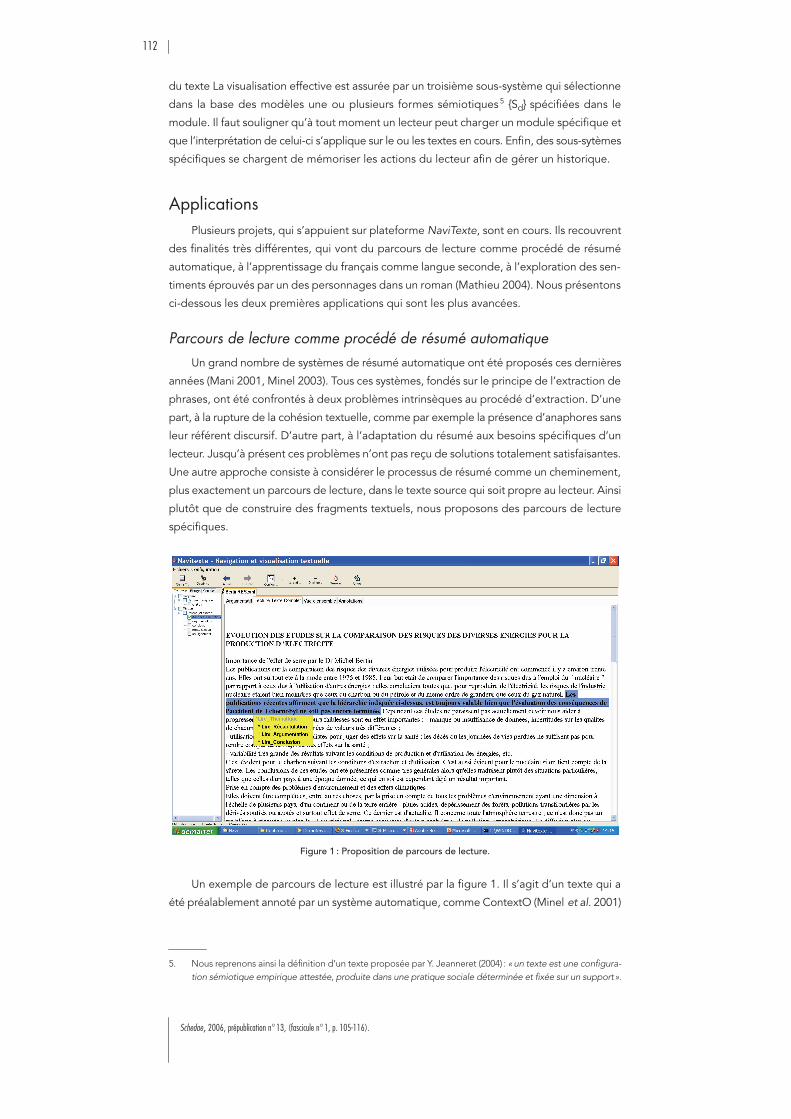
112
Schedae
,
2006, prépublication n°13, (fascicule n°1, p. 105-116).
du texte La visualisation effective est assurée par un troisième sous-système qui sélectionne
dans la base des modèles une ou plusieurs formes sémiotiques
5
{S
d
}
spécifiées dans le
module. Il faut souligner qu’à tout moment un lecteur peut charger un module spécifique et
que l’interprétation de celui-ci s’applique sur le ou les textes en cours. Enfin, des sous-sytèmes
spécifiques se chargent de mémoriser les actions du lecteur afin de gérer un historique.
Applications
Plusieurs projets, qui s’appuient sur plateforme
NaviTexte
, sont en cours. Ils recouvrent
des finalités très différentes, qui vont du parcours de lecture comme procédé de résumé
automatique, à l’apprentissage du français comme langue seconde, à l’exploration des sen-
timents éprouvés par un des personnages dans un roman (Mathieu 2004). Nous présentons
ci-dessous les deux premières applications qui sont les plus avancées.
Parcours de lecture comme procédé de résumé automatique
Un grand nombre de systèmes de résumé automatique ont été proposés ces dernières
années (Mani 2001, Minel 2003). Tous ces systèmes, fondés sur le principe de l’extraction de
phrases, ont été confrontés à deux problèmes intrinsèques au procédé d’extraction. D’une
part, à la rupture de la cohésion textuelle, comme par exemple la présence d’anaphores sans
leur référent discursif. D’autre part, à l’adaptation du résumé aux besoins spécifiques d’un
lecteur. Jusqu’à présent ces problèmes n’ont pas reçu de solutions totalement satisfaisantes.
Une autre approche consiste à considérer le processus de résumé comme un cheminement,
plus exactement un parcours de lecture, dans le texte source qui soit propre au lecteur. Ainsi
plutôt que de construire des fragments textuels, nous proposons des parcours de lecture
spécifiques.
Un exemple de parcours de lecture est illustré par la figure 1. Il s’agit d’un texte qui a
été préalablement annoté par un système automatique, comme ContextO (Minel
et al.
2001)
5. Nous reprenons ainsi la définition d’un texte proposée par Y. Jeanneret (2004) :
« un texte est une configura-tion sémiotique empirique attestée, produite dans une pratique sociale déterminée et fixée sur un support».
Figure 1 : Proposition de parcours de lecture.

113
Schedae, 2006, prépublication n°13, (fascicule n°1, p. 105-116).
ou Linguastream (Bilhaut 2003). Les annotations sont du type « Annonce Thématique », «Con-
clusion», « Soulignement Auteur », etc6. On peut voir sur la figure, que le système propose
au lecteur quatre parcours de lecture différents, suivant que celui-ci s’intéresse plutôt aux
thèmes de l’article, à son argumentation ou à ses conclusions. Ainsi, dans la continuité de sa
lecture du texte, le lecteur se voit proposer, par une signalétique spécifique, des parcours
spécifiques sans rupture de la cohésion textuelle puisqu’il voir à tout instant le texte complet,
ce qui lui permet entre autre d’assurer la continuité référentielle (Battistelli & Minel 2006).
Enseignement du français en langue secondeL’utilisation de la navigation textuelle a des fins pédagogiques est en cours à travers le
projet NaviLire, fruit d’une collaboration entre Lita Lundquist et nous-mêmes (Couto et al.
2005, Lundquist et al. 2006). En conséquence, nous reprenons brièvement ci-dessous les
principaux concepts et résultats exposés dans les deux articles cités.
Par ce procédé, par lequel le lecteur apprend à naviguer dans un texte en suivant ses
différentes pistes de cohérence – basées sur la référence, sur la prédication et sur les con-
necteurs – nous attaquons des problèmes cognitifs cruciaux pour lire, comprendre et inter-
préter correctement un texte, ainsi que pour apprendre par les textes. Le premier problème
consiste à identifier les référents discursifs d’un texte et d’établir les relations correctes entre
les SN qui y réfèrent.
Le second problème cognitif consiste à identifier le « où veut en venir l’émetteur » du
texte. Cette orientation – expressive, argumentative, et d’autre – a été qualifiée de « pro-
gramme d’interprétation » (Lundquist 1990, 1993), étant donné qu’il s’agit d’une orientation
marquée dès le début du texte, qui agit tel un « programme » qui fonctionne du général au
particulier, et qui permet d’identifier des marques suivantes dans le texte, c’est-à-dire du
spécifique au générique, qui «vont dans le même sens» (voir macrostructure et microstructure,
Kintsch 1998). Cette identification de l’orientation, apportée entre autres par les prédications,
est primordiale pour un déchiffrage correct de la cohérence sémantique et pragmatique du
texte.
Finalement, les connecteurs soulignent les relations rhétoriques à établir entre des pro-
positions ou autres séquences du texte, ce qui contribue, évidemment, de manière essen-
tielle à établir les relations nécessaires pour construire la représentation mentale correcte du
texte, c’est-à-dire, de son contenu et de son acte illocutoire prédominant, tel informer, per-
suader, convaincre, narrer, décrire, etc.
Dans le cadre du projet NaviLire, pour naviguer dans l’objet texte, nous avons isolé des
unités textuelles qui permettent de spécifier des opérations de navigation, ce qui équivaut à
établir des liens de cohérence entre des unités de même nature. Comme les éléments textuels
appartiennent à des types différents, la navigation permet d’une part de suivre des pistes de
cohérence différentes dans un même texte, et d’autre part d’en identifier les réalisations
linguistiques dans une langue donnée (ici et pour le moment, le français). Plutôt que de
manipuler des structures textuelles hiérarchiques (Couto & Minel 2004), nous distinguons
ici des pistes parallèles de marques textuelles qui chacune contribue à un type particulier
de cohérence.
Ces types de cohérence sont fondés, grosso modo, sur les principes exposés dans les
nombreux travaux de Lita Lundquist selon lesquels on peut distinguer dans les textes une
cohérence référentielle, une cohérence prédicative et une cohérence pragmatique, fondée
respectivement sur les trois actes de langage : la référence, la prédication et l’illocution qui
entrent dans l’énonciation de chaque phrase (Searle 1969).
6. Voir (Minel et al. 2001) pour plus de détails.
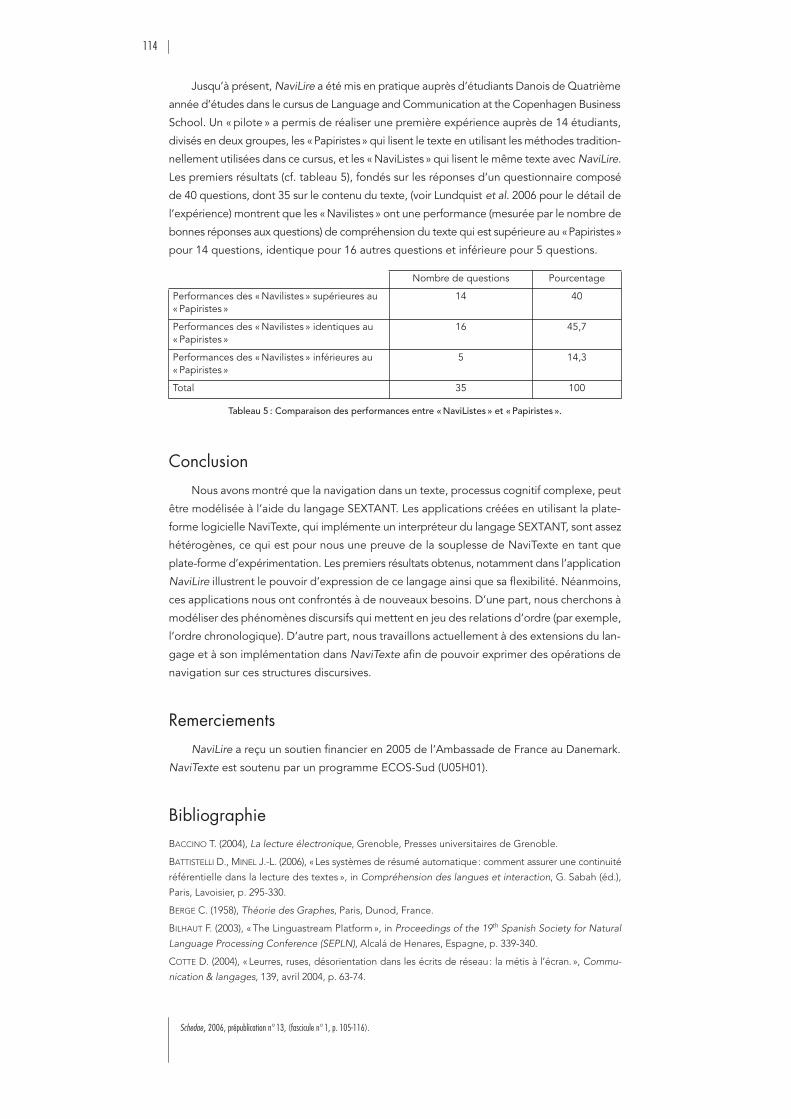
114
Schedae, 2006, prépublication n°13, (fascicule n°1, p. 105-116).
Jusqu’à présent, NaviLire a été mis en pratique auprès d’étudiants Danois de Quatrième
année d’études dans le cursus de Language and Communication at the Copenhagen Business
School. Un « pilote » a permis de réaliser une première expérience auprès de 14 étudiants,
divisés en deux groupes, les «Papiristes» qui lisent le texte en utilisant les méthodes tradition-
nellement utilisées dans ce cursus, et les « NaviListes » qui lisent le même texte avec NaviLire.
Les premiers résultats (cf. tableau 5), fondés sur les réponses d’un questionnaire composé
de 40 questions, dont 35 sur le contenu du texte, (voir Lundquist et al. 2006 pour le détail de
l’expérience) montrent que les « Navilistes » ont une performance (mesurée par le nombre de
bonnes réponses aux questions) de compréhension du texte qui est supérieure au «Papiristes»
pour 14 questions, identique pour 16 autres questions et inférieure pour 5 questions.
Conclusion
Nous avons montré que la navigation dans un texte, processus cognitif complexe, peut
être modélisée à l’aide du langage SEXTANT. Les applications créées en utilisant la plate-
forme logicielle NaviTexte, qui implémente un interpréteur du langage SEXTANT, sont assez
hétérogènes, ce qui est pour nous une preuve de la souplesse de NaviTexte en tant que
plate-forme d’expérimentation. Les premiers résultats obtenus, notamment dans l’application
NaviLire illustrent le pouvoir d’expression de ce langage ainsi que sa flexibilité. Néanmoins,
ces applications nous ont confrontés à de nouveaux besoins. D’une part, nous cherchons à
modéliser des phénomènes discursifs qui mettent en jeu des relations d’ordre (par exemple,
l’ordre chronologique). D’autre part, nous travaillons actuellement à des extensions du lan-
gage et à son implémentation dans NaviTexte afin de pouvoir exprimer des opérations de
navigation sur ces structures discursives.
Remerciements
NaviLire a reçu un soutien financier en 2005 de l’Ambassade de France au Danemark.
NaviTexte est soutenu par un programme ECOS-Sud (U05H01).
BibliographieBACCINO T. (2004), La lecture électronique, Grenoble, Presses universitaires de Grenoble.
BATTISTELLI D., MINEL J.-L. (2006), «Les systèmes de résumé automatique: comment assurer une continuité
référentielle dans la lecture des textes », in Compréhension des langues et interaction, G. Sabah (éd.),
Paris, Lavoisier, p. 295-330.
BERGE C. (1958), Théorie des Graphes, Paris, Dunod, France.
BILHAUT F. (2003), « The Linguastream Platform », in Proceedings of the 19th Spanish Society for Natural
Language Processing Conference (SEPLN), Alcalá de Henares, Espagne, p. 339-340.
COTTE D. (2004), « Leurres, ruses, désorientation dans les écrits de réseau: la métis à l’écran.», Commu-
nication & langages, 139, avril 2004, p. 63-74.
Nombre de questions Pourcentage
Performances des « Navilistes » supérieures au « Papiristes »
14 40
Performances des « Navilistes » identiques au « Papiristes »
16 45,7
Performances des « Navilistes » inférieures au « Papiristes »
5 14,3
Total 35 100
Tableau 5 : Comparaison des performances entre « NaviListes » et « Papiristes ».

115
Schedae, 2006, prépublication n°13, (fascicule n°1, p. 105-116).
COUTO J. (2001), ContextO, Los sistemas de exploracion contextual de cara al usuario, Mémoire de
Master, Université de la République, Uruguay (dactyl.).
COUTO J., (2006), Modélisation des connaissances pour une navigation textuelle assistée. La plate-forme
logicielle NaviTexte, Thèse en cours, Université Paris-Sorbonne.
COUTO J., MINEL J.-L (2004), « Outils dynamiques de fouilles textuelles», in Actes de RIAO 2004, Avignon,
p. 420-430.
COUTO J., LUNDQUIST L., MINEL J.-L (2005), «Naviguer pour apprendre», in Actes de EIAH 2005, Montpellier,
p. 45-56.
CRESTANI F., DE LA FUENTE P., VEGAS J. (2002), « Experimenting with graphical user interface structured
document retrieval », in Proceedings of the SIGIR’02, Tampere, Finlande.
DANIELSON D.R. (2002), « Web navigation and the behavioral effects of constantly visible site maps »,
Interacting with Computers, 14, 5, p. 601-618.
DIEBERGER A., RUSSELL D.M. (2002), « Exploratory navigation in large multimedia documents using Context
Lenses », in Proceedings of the 35th Hawaii International Conference on System Sciences, Hawaii.
EDWARDS D.M., HARDMAN L., (1989), «Lost in hyperspace: cognitive mapping and navigation in a hypertext
environment », in Hypertext : Theory and Practice, R. McAleese (éd.), Oxford, Intellect Books, Angleterre,
p. 105-125.
ENDRES-NIGGEMEYER B., MAIER E., SIGEL A. (1995), «How to implement a naturalistic model of abstracting:
four core working steps of an expert abstractor», Information Processing & Management, 31, 5, p. 631-674.
KINTSCH W. (1998), Comprehension. A Paradigm for Cognition, Cambridge, Cambridge University
Press, 1998/2003.
JEANNERET Y. (2004), « Le procès de la numérisation de la culture », Protée, 32, 2.
LAMPING J., RAO R. (1996), « The Hyperbolic Browser : A Focus + Context technique for visualizing large
hierarchies», in Readings in Information Visualization : Using Vision to Think, Morgan Kaufmann Publishers,
1999, p. 382-408.
LUNDQUIST L. (1990), L’analyse textuelle. Méthode, exercices, Copenhague, Nordisk Forlag.
LUNDQUIST L. (1993), « La Cohérence textuelle argumentative, illocution, intention et engagement de
consistance », Revue québécoise de linguistique, 22, 2, p. 109-138.
LUNDQUIST L., MINEL J.L., COUTO J. (2006), « NaviLire, Teaching French by Navigating in Texts », accepté à
IPMU 2006, Paris, Juin 2006.
MANI I. (2001), Automatic Summarization, Amsterdam, John Benjamins Publishing Company.
MATHIEU Y. Y. (2004), « Linguistic Knowledge and Automatic Semantic Representation of Emotions and
Feelings. », in Proceedings of the International Conference on Information Technology (ITCC 2004),
IEEE Computer Society, p. 314-318.
MINEL J.-L., CARTIER E., CRISPINO G., DESCLÉS J.-P., BEN HAZEZ S., JACKIEWICZ A., (2001), «Résumé automatique
par filtrage sémantique d’informations dans des textes, Présentation de la plate-forme FilText», Technique
et Science Informatiques, 3, p. 369-396.
MINEL J.-L. (2003), Filtrage sémantique. Du résumé à la fouille de textes, Paris, Hermès, France.
NAZARENKO A. (2005), « Sur quelle sémantique reposent les méthodes automatiques d’accès au contenu
textuel », in Sémantique et Corpus, A. Condamines (éd.), Paris, Hermès, France, p. 211-239.
PERY-WOODLEY M.-P. (2005), « Discours, corpus, traitements automatiques », in Sémantique et Corpus,
A. Condamines (éd.), Paris, Hermès, France, p. 177-205.
PORHIEL S (2003), « Les introducteurs de cadre thématique », Cahiers de Lexicologie, 83, 2, p. 1-36.
SEARLE J. (1969), Speech Acts, An Essay in the Philosophy of Language, Cambridge, Cambridge University
Press.
SOUCHIER E., JEANNERET Y., LE MAREC J. (2003), Lire, écrire, récrire : objets signes et pratiques des médias
informatisés, Paris, Bibliothèque publique d’information.
THOMPSON S., MANN W. (1988), « Rhetorical structure theory, a framework for the analysis of texts », IPRA
Papers in Pragmatics, p. 79-105.

116
Schedae, 2006, prépublication n°13, (fascicule n°1, p. 105-116).

117
Birgitta Bexten« Hypertext and Plurilinearity: Challenging an Old-fashioned Discourse Model »
Schedae
, 2006, prépublication n°14, (fascicule n°1, p. 117-122).
Schedae
,
2006
Hypertext and Plurilinearity:Challenging an Old-fashionedDiscourse Model
Birgitta Bexten
Leiden University Center for Linguistics (LUCL)
Departement for German Studies – University of Leiden – Leiden, The Netherlands
Abstract :
Hypertexts are special. Particularly their network structure is a challenge for discourse linguists to
describe. In this paper, I demonstrate how we can accept this challenge using an old-fashioned
but exceptional text model, namely Roland Harweg's (1974) concept of plurilinearity. This model
allows describing the main hypertext features: text bifurcations, simultaneously existing text strings,
and text combinations from a discourse linguistic point of view.
Keywords: global discourse structure, discourse organising model, hypertext.
Résumé :
Les hypertextes sont particuliers. Notamment, leur structure en réseau est un défi pour les lin-
guistes étudiant le discours. Dans cet article, je montre comment relever ce défi en utilisant un
modèle de texte démodé, mais exceptionnel: le concept de
plurilinéarité
de Roland Harweg (1974).
Ce modèle permet de décrire les principales propriétés de l'hypertexte: les bifurcations de texte,
l'existence simultanée de chaînes textuelles, et les combinaisons de textes du point de vue de la
linguistique du discours.
Mots-clés: structure globale du discours, modèle d'organisation du discours, hypertexte.
The starting point
While traditional texts in principle form a single reading sequence, texts in a hypertext
environment split up, recombine and provide simultaneously existing reading paths. Even
if the reader re-linearises (parts of) the hypertext while reading it, the text structurally remains
a network. Obviously, this does not apply to lexicon-like hypertexts. Lexicons consist of sev-
eral linked, but independent texts. Therefore, they are less interesting here. Only hypertexts
that present a single text, e.g. hypernovels, entail the challenge of structurally concatenating
all text parts in a single network.
Prépublication n° 14 Fascicule n° 1

118
Schedae, 2006, prépublication n°14, (fascicule n°1, p. 117-122).
But how special really are those non-linear texts? Many discourse linguists have already
argued that no text is a purely linear phenomenon (e.g. Petöfi 1971, Rieser 1980, van Dijk 1978).
The linear text surface is based on an underlying non-linear semantic structure. In addition, the
thematic text progression is not linear but rather hierarchic (Harweg 2001). Especially longer
texts tend to be thematically segmented into hierarchic units like chapters or paragraphs.
Considering these conditions, it seems worth looking for an existing theory which is able
to deal with the global, network-like hypertext structure. But – and this ‘but’ is crucial – this
model should not only account for the underlying semantics, because in terms of their global
meaning structure, hypertexts hardly differ from any other texts. What really differs is the sur-
face. Therefore, the linguistic model should be applicable to a non-linear surface structure.
Harweg’s model of plurilinearityOne theory that plays to this requirement is the concept of plurilinearity which Harweg
(1974) introduces in his article “Bifurcations de textes”, and which has been augmented by
Tschauder (1989). Harweg points out that the traditional assumption of structurally linear texts
is incomplete. He argues that not even traditional texts are necessarily unilinear; even though
this applies to most of them. Oral discourses (e.g. discussions between more than three peo-
ple) as well as written discourses (e.g. texts with footnotes) can bifurcate and thus become
plurilinear. The only condition is that all resulting text strings are connected with the same
initial text part by means of usual text-building devices. Two different text strings can even
be recombined if someone refers to both of them in the same utterance.
The mere possibility of plurilinearity becomes a presupposition in hypertext: without
text bifurcations and recombinations, there would be no network.
In the reminder, I show to what extend the features of plurilinear texts and texts in a hyper-
text environment match and of what use Harweg’s model can be for describing the global
structure of hypertext.
Text bifurcationsConsider the following example: imagine that this text were a lecture I would be pre-
senting. Imagine that the moment I start reading “Hypertexts are special” one of the listeners
would inform his neighbour under his breath: “That’s completely nonsense! I just read the
other day…” In this case, That would directly refer to my statement. In a normal conversa-
tion I would most likely react immediately and we would get a normal linear oral text. But in
the current case, what we get are two different text strings which both refer to one and the
same preceding unilinear part. Both strings textually continue this unilinear part, and there-
fore, both parts belong to the same text. Only that this text is not unilinear any more, instead
it has bifurcated and has become plurilinear: due to the bifurcation we get two simultaneously
continuing text strings.
The same is true for texts with footnotes. In the following example from Halliday (2004,
71), the initial text string is connected simultaneously with the pronouns This in the main text
and It in the footnote.
“If I say what the duke did was give my aunt that teapot, the nominalization what the
duke did carries the meaning 'and that's all he did, in the context of what we are tal-
king about'.* This is also the explanation of the marked form […].
*It further indicates […] something about the role of the duke […]”
Figure 1: Text bifurcation in print texts.

119
Schedae, 2006, prépublication n°14, (fascicule n°1, p. 117-122).
Now consider the following (translated and slightly shortened) extracts from Berken-
heger’s (1997) hypernovel “Zeit für die Bombe”.
Here, too the initial text continues without a break in the first unit and at the same time is
proceeded in the link’s target unit.
Both, texts with footnotes just as well as hypertexts, confront the reader with a dilemma:
the text splits up at the word which is followed by a footnote marker or functions as a hyper-
text link. The reader has to decide whether to read on in the current hypertext node or whether
to branch off and pursue the link’s target node. He has to follow one of the two simultaneously
existing reading paths. Both subsequent text strings are textually connected with the pre-
ceding text part and, thus, offer just two different versions of the proceeding story.
Main strings vs. side strings
The explanations above show why hypertexts sometimes are referred to as generalised
footnotes (e.g. Nielsen 1995, 2). Even though, there is a fundamental difference between
footnote texts and hypertext units. For footnotes, just as remarks during a lecture, only sup-
plement the main text. The text does not become incomprehensible without them. Nielsen
(ibd.) explains in a footnote “I guess you decided to read the footnote this time. But you could
just as easily have skipped it.“ In hypertext on the other hand, especially in fictional hyper-
texts, most units are part of the main text. Even if some hypertext units do have footnote
character, the main text itself would be incomplete without interconnected units. Describing
hypertext as a generalised footnote means overlooking this fact.
Therefore, to really get a grip on the global structure of hypertext, it would be useful to
find plurilinear texts without side strings. And, indeed, plurilinear texts can do without side
strings, too.
Consider the following macrotext1 example (Harweg 1974, 57f):
“The fourth doctor told about his case.
One of his most talented students just
has been taken to the psychiatry. ‘And
guess, why? He didn’t want to drop his
suitcase.’
The doctor’s hands […].”
“The walls murmured that Iwan shouldn’t
open somebody else’s suitcase, Vero-
nika’s least of all.”
Figure 2: Text bifurcation in hypertext.
(Situation: Mother and two suns sitting in the living room. Father enters.)
Father: Look, darling, I bought something for you, a vase.
(All four talk about the vase for a while. … Several weeks later.)
Peter: I broke the vase.
Paul: What vase?
Peter: The vase father
lately bought for mother.
Mother: Darling, the vase is gone.
Father: What vase?
Mother: The vase you gave to me
several weeks ago.
Figure 3: Text bifurcation in plurilinear macrotexts.
1. Macrotexts, as Harweg (1970) describes them, usually are not recognised as single texts by the intuition of thenormal language user. They consist of at least two different disconnected microtexts, i.e. texts that couldroughly be characterised as normal texts. Several microtexts form one macrotext if they are connected bynormal text building devices as is the case in the example given above.

120
Schedae, 2006, prépublication n°14, (fascicule n°1, p. 117-122).
Both subsequent dialogues are connected to the initial text string by the same anaphoric
expression the vase, but none of the two dialogues can be regarded as more important than
the other.
Text combinations
Except from text bifurcations, a hypertext network cannot do without text combinations.
In the following example two different hypertext units are linked with the same target node.
And in both cases the target text seamlessly follows the preceding text parts.
With Harweg’s model, we can trace the same possibilities in traditional texts. Imagine
four people sitting in a bar discussing the last Olympic doping scandal. At one point, the
conversation splits up into two dialogues (e.g. because somebody directly addresses one
person and asks his opinion while the other two just continue talking). Now imagine that an
alert listener addresses the whole group by saying: “Hey, what you just said is a brilliant argu-
ment against what we said in the beginning.” He thereby reintegrates the one discussion
into the other. His remark not only picks up one of the conversations (what you just said) but
reconnects it to the initial text part (what we said in the beginning). Most likely, all four will
rejoin a single discussion again. The only difference with the hypertext example is that here the
bifurcation as well as the combination are a question of text production. In hypertext, they
are structural phenomena which are independent of both text production and reception.
Conclusions
Many features of hypertexts and plurilinear texts match. Both start with an initial text
string and bifurcate at one or more places. Both consist of simultaneously existing text strings
that are connected to an initial string by text building devices. Both might but do not need
to have side strings. And both can provide text combinations.
The final question, I want to answer here therefore is: Are hypertexts plurilinear texts? The
answer is: No, ideally they are not. Even though, many hypertexts rather have a tree- than a
network-structure, and therefore are plurilinear. But ideal hypertexts structurally are not linear;
not even plurilinear. They present network-like texts: a single information unit can occur at
various places in different reading sequences. What, nevertheless, makes the model of plurilin-
earity worth using, is that it provides discourse linguistic devices to describe the decisive fea-
tures of hypertext networks, namely text bifurcations, text combinations and simultaneously
existing text strings.
Harweg's concept of plurilinearity is based on a comprehensive analysis of discourse
relations. It can be used to approach not only the hypertext's global but also its local struc-
ture. Discussing to what extent this model contributes to a discourse linguistic description
“The fourth doctor told about his
case. One of his most talented stu-
dents just has been taken to the
psychiatry. ‘And guess, why? He
didn’t want to drop his suitcase.’ ”
“ ‘I hope Veronika has it cold’, he
wished with a glance at her piece of
luggage, which he now started to
open. Perhaps only because there
wasn’t anything else to do.”
“The walls murmured that Iwan shouldn’t
open somebody else’s suitcase, Vero-
nika’s least of all.”
Figure 4: Text combination in hypertext.

121
Schedae, 2006, prépublication n°14, (fascicule n°1, p. 117-122).
of network-structured text, therefore, is the first step to constructing a coherent model of
discourse in hypertext.
BibliographyBERKENHEGER S. (1997), Zeit für die Bombe. http://www.wargla.de/zeit.htm.
HALLIDAY M. A. K. (2004), An Introduction to Functional Grammar, London, Arnold.
HARWEG R. (1970), “Zur Textologie des Vornamens: Perspektiven einer Großraumtextologie”, Linguistics,
61, p. 12-28.
HARWEG R. (1974), “Bifurcations de textes”, Semiotica, 12, p. 41-59.
HARWEG R. (2001), “Perspektiven der Textlinguistik”, in Harweg (2001a), p. 19-37.
HARWEG R. (2001a), Studien zur Textlinguistik, Aachen, Shaker Verlag (Bochumer Beiträge zur Semiotik;
Neue Folge 7).
NIELSEN J. (1995), Multimedia and Hypertext: the Internet and Beyond, Boston, Ap Professional.
PETÖFI J. S. (1971), Transformationsgrammatiken und eine ko-textuelle Texttheorie. Grundfragen und
Konzeptionen, Frankfurt a.M., Athenaeum Verlag.
RIESER H. (1980), Aspekte einer partiellen Texttheorie. Untersuchungen zur Textgrammatik mit “nicht-
linear“ festgelegter Basis unter besonderer Berücksichtigung der Lexikons- und des Fachsprachen-
problems, Hamburg, Buske (Papiere zur Textlinguistik; 22).
VAN DIJK T. A. (1978), Tekstwetenschap. Een interdisciplinaire inleiding, Utrecht, Uitgeverij Het Spectrum
(Het wetenschappelijke boek; 633).
TSCHAUDER G. (1989), Textverbindungen. Ansätze zu einer Makrotextologie, auch unter Berücksichti-
gung fiktionaler Texte, Bochum, Brockmeyer.

122
Schedae, 2006, prépublication n°14, (fascicule n°1, p. 117-122).

123
Thomas Kreczanik« Modélisation de parcours dans des hypertextes pédagogiques : typage des ressources et des liens »
Schedae, 2006, prépublication n°15, (fascicule n°1, p. 123-128).
Schedae, 2006
Modélisation de parcoursdans des hypertextes pédagogiques : typage des ressources et des liens
Thomas KreczanikERSICOM – Université Jean Moulin Lyon 3
Résumé :
Comment aiguiller le parcours hypertextuel d’apprenants replacés en situation d’autonomie face à
un ensemble de ressources pédagogiques électroniques? Dans le cadre de notre thèse de doctorat,
nous abordons cette question sous l’angle de la caractérisation des ressources pédagogiques et des
liens qui les associent. Nous détaillons ici les premiers éléments de la modélisation de parcours de
formation : le typage des ressources et des articulations pédagogiques. Pour cela, nous prenons
appui sur une analyse du standard LOM et sur une analyse des pratiques d’enseignants concep-
teurs de ressources dans la plateforme SPIRAL de l’université Lyon 1.
Mots-clés : E-learning, EIAH, ressource pédagogique, articulation, situation, hypertexte,
typage, LOM.
Abstract :
How could we lead the hypertextual path of students who work alone with electronic pedagogic
stuff? In our PHD, we analyse this question with the characterization of the pedagogic resources and
their links. In this paper, we describe the first elements that concern the modeling of pedagogic
paths : the classification of the pedagogic links and resources. For that, we base ourselves on a
study of the LOM standard, and on a study of the practices of teachers that use SPIRAL, the LCMS
of the university Lyon 1 for producing courses.
Keywords: E-learning, Pedagogic Stuff, Link, Pedagogic Resource, Hypertext, Classification,
LOM.
1. IntroductionLes établissements du supérieur se dotent progressivement de plateformes e-learning,
qui fournissent aux enseignants, aux apprenants et aux gestionnaires des moyens pour con-
cevoir, stocker et utiliser diverses ressources pédagogiques. Le défi actuel consiste à faciliter
l’appropriation de ces outils et ressources par les enseignants et par les apprenants. Dans le
cadre de notre thèse de doctorat en Sciences de l’Information et de la Communication, nous
Prépublication n° 15 Fascicule n° 1

124
Schedae, 2006, prépublication n°15, (fascicule n°1, p. 123-128).
abordons cette problématique sous l’angle de la caractérisation des ressources pédagogi-
ques et des liens qui les associent. Nous modélisons un système dans lequel les enseignants
construiraient des enchaînements entre ressources pédagogiques. En aval, le système redon-
nerait de la liberté et de l’autonomie aux apprenants en les laissant piloter, sur la base d’un
ensemble de ressources, leur propre cheminement hypertextuel. Notre modèle projette de
rendre compatible la logique du parcours de l’apprenant avec l’intentionnalité pédagogique
de l’enseignant.
Après avoir pris appui sur une analyse du standard LOM (Learning Object Metadata), et
sur une analyse des pratiques d’enseignants auteurs de cours dans la plateforme SPIRAL de
l’université Lyon 1, nous détaillerons les premiers éléments de la modélisation de parcours
de formation : la classification des liens et des ressources pédagogiques.
2. Typologie des ressources pédagogiques : généralitésLe passage au numérique, la mise en réseau et la reconfiguration des systèmes d’accès
à l’information sont autant de facteurs qui brouillent les frontières du concept de document.
Ces perturbations se repèrent, entre autre, par la perte de stabilité du document en tant
qu’objet matériel, le document étant de plus en plus recomposé en fonction des besoins
des utilisateurs. Dans la continuité du RTP-DOC (Pedauque 2003), qui envisage à la fois le
document comme une forme, comme un contenu et comme un medium, Sylvie Lainé-Cruzel
(Lainé 2004) distingue le document de la ressource : le document perdrait en plasticité ce que
la ressource gagnerait en souplesse d’usage. C’est l’acception que nous retiendrons du mot
ressource, et nous nous focaliserons sur celles utilisées à des fins d’apprentissage – ne per-
dant pas de vue que l’origine documentum du mot document signifie enseignement.
Avant de modéliser des parcours de formation, il convient d’associer une typologie aux
ressources pédagogiques qui en constituent la base. Daniel Peraya, cherchant à caractériser
les paratextes, explique que ces derniers doivent être déduits d’une cohérence théorique ;
pour cela, il distingue la nature, qui dépend du degré d’iconicité, de la fonction, qui dépend
du fonctionnement discursif (Peraya 1995). De plus, la principale difficulté de distinction des
ressources pédagogiques tient au jeu complexe par lequel elles s’imbriquent les unes dans
les autres. Nous posons les trois critères suivants de catégorisation des ressources : granu-
larité, nature, fonction.
3. Un standard de description des ressources pédagogiques : le LOM
Ces dernières années, de nombreux standards ont été développés pour rationaliser la
description des ressources pédagogiques au sein des plateformes e-learning. Le plus utilisé,
mais aussi le plus critiqué de ces standards est celui élaboré par l’IEEE : le Learning Object
Metadata ou LOM1. À la base du LOM-IEEE se trouve un schéma de neuf catégories de méta-
données ayant trait à des aspects variés de la ressource : «1 : General », « 2 : Life Cycle », « 3 :
Meta-metadata », « 4 : Technical », « 5 : Educational », « 6 : Rights », « 7 : Relation », « 8 : Anno-
tation », « 9 : Classification ». Bien qu’il existe dorénavant des interfaces d’aide à l’indexation,
tels que Metalab, en pratique, aucun établissement n’utilise intégralement le LOM. Celui-ci
est habituellement exploité à travers des profils d’application, qui peuvent à la fois le res-
treindre et l’enrichir. Le profil LOM-FR, inspiré du profil ManUeL, est depuis 2005 passé au
rang de norme expérimentale AFNOR.
1. http://ltsc.ieee.org/wg12/ (consulté le 15/05/2006).

125
Schedae, 2006, prépublication n°15, (fascicule n°1, p. 123-128).
Dans le schéma du LOM-IEEE, nous identifions les dix sous-catégories suivantes comme
relatives à la modélisation des parcours de formation : « 1.7 : Structure », « 1.8 : Aggregation
Level », « 5.1 : Interactivity Type », « 5.2 : Learning Ressource Type », « 5.3 : Interactivity level »,
« 5.4 : Semantic Density », « 5.5 : Intended End User Role », « 7.1 : Kind », « 7.2 : Ressource »,
« 9.1 : Purpose ». En effet, ces dix sous-catégories fournissent des éléments pour définir la
structure organisationnelle de la ressource, sa granularité, le mode d’enseignement qu’elle
supporte, sa nature, sa densité sémantique, ses utilisateurs, les liens qu’elle peut établir avec
d’autres ressources et enfin, l’expression à l’aide de langages documentaires de son contenu,
de ses prérequis ou de ses objectifs.
Dans (Kreczanik 2004), nous avons mis en évidence la tendance de l’indexation des res-
sources pédagogiques à s’effectuer suivant des « strates successives », prises en charge tour
à tour par les informaticiens, les enseignants et les documentalistes. Nous avons d’autre part
relevé que les enseignants étaient peu enclins à l’indexation, cette tâche leur paraissant trop
éloignée de leur métier. L’indexation deviendra efficiente lorsqu’elle sera perçue par les ensei-
gnants comme dégageant du sens pour leur activité. Et elle leur paraîtra d’autant plus légi-
time à exécuter, qu’elle vise à développer l’autonomie des apprenants. Une première piste
serait de faire de l’indexation une aide à la structuration et à la programmation des cours. Or,
la limite du LOM est de considérer les dix sous-catégories se rapportant à notre modèle
comme des objectifs finis de caractérisation : on les renseigne isolément (ce qui n’a guère de
sens, ni pour l’enseignant, ni pour l’apprenant), et définitivement (ce qui en restreint usage,
donc l’appropriation). Une deuxième piste serait de remanier ces sous-catégories en des cri-
tères, dépendant les uns des autres, et participant d’un nouvel objectif global : la conception
de parcours de formation pour l’apprenant.
4. Typologie des articulations pédagogiqueset fonctionnalité des ressources
Pour modéliser des parcours de formation, nous prévoyons également d’associer une
typologie aux liens ou articulations qui peuvent s’établir entre les ressources pédagogiques.
Nous définissons l’articulation pédagogique comme l’action de lier entre elles, dans une
intentionnalité précise, deux ressources à la typologie définie. C’est du point de vue de la
fonctionnalité, que nous distinguerons les articulations : les types d’articulations correspon-
dront à des fonctions pédagogiques. Car le lien nous semble porteur d’une fonctionnalité
spécifique, différente de celle portée par la ressource. Et toute tentative de cloisonner la
fonctionnalité dans la ressource ne peut que restreindre l’usage de cette ressource. L’intérêt
de notre modèle est qu’une même ressource pourra se voir attribuer des fonctions en partie
différentes, suivant le parcours par lequel l’apprenant la retrouve. La principale difficulté sera
de situer précisément la frontière entre la fonctionnalité, proprement spécifique à la ressource,
de celle spécifique à l’articulation.
Des dix métadonnées que nous avons repérées dans le LOM-IEEE, la plus en rapport
avec l’articulation est « 7.1 : Kind », appartenant à la catégorie « 7 : Relation ». Cette méta-
donnée définit la nature de la relation, et est instanciée à l’aide d’un vocabulaire issu du
standard Dublin Core, regroupant les 6 connecteurs binaires suivants : is part of/has part ;
requires/is required by ; is based on/is based for ; references/is referenced by ; is format of/
has format ; is version of/has version. On remarque que ce vocabulaire s’en tient à des con-
sidérations de fonctionnement technique, ce qui est insuffisant pour notre modèle. Nous
proposons donc les quelques connecteurs suivants, suite à une synthèse bibliographique
portant sur la rhétorique et la didactique : introduire, définir, exposer, décrire, argumenter,
exemplifier, conclure, illustrer, s’entraîner, se noter, compléter, poursuivre, historiser.

126
Schedae, 2006, prépublication n°15, (fascicule n°1, p. 123-128).
5. Les pratiques enseignantes de structuration de cours :les situations
Peu de travaux ont étudié (à notre connaissance) comment les TICE accompagnent les
enseignants-chercheurs dans la structuration et la programmation de leurs cours. Nous procé-
dons donc à des interviews d’enseignants-chercheurs du domaine des Sciences expérimen-
tales, pour la plupart auteurs de cours dans la plateforme SPIRAL de l’université Lyon 12.
SPIRAL est une plateforme de type LCMS (Learning Content Management System) qui per-
met à la fois de produire et de gérer des ressources pédagogiques, mais également de suivre
des cours en ligne. Par l’analyse de ces interviews nous mettons en évidence des situations
pédagogiques, non spécifiques aux disciplines, desquelles dépend fortement la nature des
parcours et enchaînements produits par l’enseignant. Nous proposons provisoirement les
quelques situations suivantes, qui pourrait remplacer avantageusement le vocabulaire ratta-
ché à la métadonnée « 5.1 : Interactivity Type » du LOM :
– La situation « expérimentale » : l’enseignement s’organise autour d’une manipulation,
dont les moments forts sont mode opératoire, observation, interprétation, conclusion ;
– La situation « rhétorique » : l’enseignement s’organise autour d’un ou de plusieurs mes-
sages forts, que l’on cherche à faire passer ;
– La situation « archéologique » : l’enseignement s’organise autour d’un phénomène, dont
on analyse les apparitions possibles dans le temps ;
– La situation « modélisante » : l’enseignement s’organise autour d’un modèle théorique
ou abstrait, que l’on représente et que l’on discute ;
– La situation « évaluative » : l’enseignement s’organise autour d’un savoir (faire), que l’on
met en évidence par l’activité.
Le schéma 1 montre comment l’articulation entre une ressource de départ et une res-
source d’arrivée se replace toujours dans le plan d’une situation déterminée. La détermination
par l’enseignant de la situation pédagogique dans laquelle il souhaite produire un enchaî-
nement entre ressources, pourrait lui servir d’indication et donc d’aide au repérage du con-
necteur adéquat. 3
2. http://spiral.univ-lyon1.fr (consulté le 15/05/2006).
Schéma 1 : Les situations de l’articulation entre ressources pédagogiques.
3. Sur le schéma, les informations inscrites en italique sont celles que nous envisageons de caractériser.
Ressource d’arrivée
Ressource de départ
Situation
- Granularité- Nature- Fonction
Articulation
- Granularité- Nature- Fonction

127
Schedae, 2006, prépublication n°15, (fascicule n°1, p. 123-128).
6. Classification des ressources pédagogiques
Nous avons précédemment proposé trois critères ou facettes de la caractérisation des
ressources pédagogiques : la granularité, la nature et la fonction. Nous allons ici lister quel-
ques valeurs admissibles par ces facettes.
– Pour ce qui concerne la facette granularité, nous relevons le vocabulaire associé à la
métadonnée « 1.8 : Aggregation Level » du LOM-IEEE, qui prévoit quatre niveaux de
granularité de la ressource : fragment, leçon, cours, parcours. Les parcours contiennent
les cours, contenant eux-mêmes les leçons, composées à base de fragments ;
– Pour ce qui concerne la facette nature, la métadonnée « 5.2 : Learning Ressource Type »
du LOM-IEEE propose le vocabulaire suivant : exercice, simulation, questionnaire, dia-
gramme, figure, graphique, index, diapositive, tableau, texte narratif, examen, expé-
rimentation, énoncé d’un problème, autoévaluation, exposé. Le LOM-FR ajoute la
métadonnée «1.10 : Type documentaire», instanciée à l’aide du vocabulaire suivant : col-
lection, ensemble de données, évènement, image, ressource interactive, image en mou-
vement, objet physique, logiciel, son, image fixe, texte. D’autre part, sur une échelle allant
du plus iconique au plus arbitraire, Daniel Peraya distingue les natures de paratextes
pédagogiques suivantes : photos, schémas, ILEIS (Icône de Logiciels et d’Environnements
Informatiques), graphiques, tableaux, listes, langage verbal, langage mathématique ;
– Pour ce qui concerne la facette fonction, le LOM-FR ajoute au LOM-IEEE la métadonnée
« 5.12 : Activité induite », instanciée à l’aide du vocabulaire suivant : animer, apprendre,
collaborer, communiquer, conduire, coopérer, créer, échanger, observer, organiser, pro-
duire, publier, rechercher, s’autoformer, s’exercer, se documenter, se former, simuler,
s’évaluer.
Nous construisons actuellement une classification à facettes des ressources pédagogi-
ques, sur la base de ces typologies, et en tenant compte des dépendances entre la granu-
larité, la nature et la fonction.
7. Poursuite et conclusion
Dans la continuité de ces travaux, et une fois que nous aurons affiné nos classifications
des ressources, des articulations et des situations, nous utiliserons la plateforme SPIRAL pour
simuler et tester auprès des enseignants et des apprenants notre modèle de parcours de
formation. Ceci nous permettra de vérifier la pertinence et la dépendance des valeurs que
nous aurons attribuées.
Bibliographie
ANNOT E., FAVE-BONNET M.-F. (dirs) (2004), Pratiques pédagogiques dans l’enseignement supérieur :
enseigner, apprendre, évaluer, Paris, l’Harmattan.
ARNAUD M., (2002), « Normes et standards de l’enseignement à distance : enjeux et perspectives », in
Technologies de l’Information et de la Communication dans les Enseignements d’ingénieurs et dans
l’industrie, Villeurbanne, Institut National des Sciences Appliquées de Lyon, p. 57-69.
DE LA PASSARDIERE B., JARRAUD P. (2004), «ManUeL, un profil d’application de LOM pour C@mpuSciences»,
Sciences et technologies de l’information et de la communication pour l’éducation et la formation, vol. 11,
p. 11-57.
KRECZANIK T. (2004), Vers une rationalisation de l’indexation des ressources pédagogiques électroniques,
Mémoire de DEA, Sciences de l’information et de la communication, Université Lyon 3, disponible sur
http://memsic.ccsd.cnrs.fr/mem_00000163.html (consulté le 15/05/2006).

128
Schedae, 2006, prépublication n°15, (fascicule n°1, p. 123-128).
LAINE-CRUZEL S. (2004), « Documents, ressources, données : les avatars de l’information numérique »,
Information Interaction Intelligence, vol. 4, n° 1.
MERMET J.-M., CARRERE C. (2003), « ARPEM : une expérience concrète de mutualisation sur le campus
grenoblois », Document numérique, vol. 7, p. 141-156.
MICHEL C., ROUISSI S. (2003), « Caractérisation des documents numériques avec LOM et IMS-QTI pour
l’acquisition et l’évaluation des connaissances », Document numérique, vol. 7, p. 157-178.
PEDAUQUE R. T. (2003), Document : forme, signe et médium, les re-formulations du numérique, disponible
sur http://archivesic.ccsd.cnrs.fr/sic_00000511.html (consulté le 15/05/2006).
PERAYA D., NYSSEN M.-C. (1995), «Les paratextes dans les manuels scolaires de biologie : une étude compa-
rative», Cahier de la Section des Sciences de l’Éducation, n° 078, Pratiques et Théorie.
PERNIN J.-P., LEJEUNE A. (2004), « Dispositifs d’apprentissage instrumentés par les technologies : vers une
ingénierie centrée sur les scénarios», in Technologies de l’Information et de la Connaissance dans l’Ensei-
gnement Supérieur et de l’Industrie, Compiègne, Université de Technologie de Compiègne, p. 407-414.
PERRIAULT J. (2002), L’accès au savoir en ligne, Paris, Odile Jacob.

129
Olivier Le Deuff« Des bons mots au bon document. Comment éduquer à l’usage des mots-clés efficaces pour accéder à la pertinence documentaire »
Schedae, 2006, prépublication n°16, (fascicule n°1, p. 129-134).
Schedae, 2006
Des bons mots au bon document.Comment éduquer à l’usage des mots-clés efficaces pour accéder à la pertinence documentaire
Olivier Le DeuffCersic-Erellif, Université Rennes 2
Résumé :
La diversité des types de discours utilisés sur Internet entraîne une confusion chez l’élève qui ne
parvient pas toujours à optimiser sa recherche. La formation à la maîtrise et à la production de
l’information permet l’acquisition d’habiletés essentielles.
Mots-clés : document, recherche documentaire, mots-clés, information literacy, élève,
documentaliste, négligences.
Abstract :
The diversity of speeches used on Internet involves a confusion for the pupil who always does
not succeed in optimizing his research. Information literacy increase documentary skills.
Keywords : document, information literacy, keywords, student, negligences.
IntroductionLes stratégies de recherche des élèves sur Internet suscitent parfois interrogations et
débats. L’apprentissage des mots-clés s’avère difficile car il s’agit pour l’élève de réfléchir et
de catégoriser afin de convertir des idées en mots-clés. Ce processus n’est pas naturel et
implique des capacités d’abstraction qui font souvent défaut d’autant plus que sur Internet
nous sommes confrontés à des types de discours fort variées selon les sites visités et les appli-
cations utilisées. Les élèves rencontrent des difficultés pour effectuer la distinction entre tous
ces discours et ne parviennent pas toujours à savoir quel langage employer au bon moment
à bon escient. Ces confusions expliquent également les négligences et autres erreurs de
lecture commises fréquemment.
Ces difficultés sont à rapprocher des représentations erronées de l’Internet qu’ont sou-
vent les élèves. Notre propos vise à démontrer que la capacité à utiliser des mots-clés pour
Prépublication n° 16 Fascicule n° 1

130
Schedae, 2006, prépublication n°16, (fascicule n°1, p. 129-134).
effectuer une recherche s’acquiert progressivement et que la production de contenus sur
Internet par l’élève augmente ses capacités notamment grâce aux possibilités offertes par le
Web 2.0. Nos observations et expériences ont été principalement établies dans un collège du
sud Manche avec des élèves ayant entre 10 et 16 ans et montrent la nécessité d’une réelle
formation à la recherche et la production d’informations (information literacy). Nos travaux
cherchent à étudier les relations entre le document et les usagers et les problèmes commu-
nicationnels qui demeurent en dépit des avancées des traitements automatisés.
1. La médiation des moteursLa recherche de documents évolue et n’est pas uniquement axée sur les moteurs de
recherche. En effet de nouvelles stratégies documentaires voient le jour opérant une « redocu-
mentarisation » comme le nomme le dernier document du RTP-Doc (RTP-Doc 2006). Ainsi ce
« nouvel âge de la navigation » inclut les possibilités de s’abonner à des flux d’informations
notamment. Malgré tout les moteurs de recherche demeurent très nettement le moyen le plus
fréquemment utilisé par les élèves pour rechercher de l’information. Les bases de données
sont peu usitées par ces derniers qui demeurent bien souvent aux portes du Web invisible
mais bon nombre d’enseignants n’échappent pas non plus à la règle. De fait les difficultés
pour accéder à la pertinence documentaire1 sont relativement élevées dans ce cadre. La
recherche documentaire sur Internet recèle quelques complexités et l’usage des élèves tend
au contraire vers une simplicité proche du guichet unique de l’information. Nous songeons
évidemment à Google mais certains élèves tapent parfois leur recherche dans la barre d’adres-
ses ce qui les renvoie à la page par défaut dans Internet Explorer.
L’usage des moteurs étant désormais le moyen utilisé par les plus jeunes pour accéder
à l’information, les documents papiers sont souvent évités voire ignorés (Six Degrés 2006).
De même la tentation de « foncer » sans réflexion est omniprésente. Les documentalistes
de collège peuvent en témoigner. Il faut sans cesse rappeler l’importance d’une réflexion
préalable. La domination du moteur Google se trouve d’autant plus forte que les notions
abstraites de l’Internet sont peu maîtrisées. Nous avons pu constater cet état de fait dans la
formation et l’évaluation dans le cadre du B2I (Brevet informatique et internet). La confusion
des discours commence avant même que l’usager ne soit connecté. Il s’avère que pour beau-
coup il existe une forte confusion entre les mots « navigateur », « moteur de recherche »,
« logiciel », « fournisseur d’accès ». Mais il est clair qu’un seul mot ressort de ce désordre
sémantique : « Google ». Après plusieurs séances de travail sur Internet, des élèves de Cm2
avaient tous retenu le nom « Google », même si d’autres moteurs avaient été présentés, au
point que certains le voyaient également comme un « navigateur» ! Le moteur américain sem-
ble être parvenu à incarner Internet. D’ailleurs la supériorité du moteur Google est même
approuvée par de nombreux professionnels de l’information 2puisque près de 84 % plébis-
citent Google.
Google devient ainsi le port à partir duquel beaucoup d’élèves avancent en pays inconnu.
Dès lors, il est fort logique que les stratégies de recherche des élèves manquent de cohé-
rence. Cette ignorance de l’objet technique Internet, de son histoire et de ses évolutions
explique beaucoup les erreurs commises par les élèves. Ces derniers ne sont pas des Chris-
tophe Colomb et la serendipité (Ertzscheid 2003) n’est de fait guère fréquente. Il leur faut
1. Nous utilisons ici le terme pertinence dans son sens premier et non dans le sens que le moteur Google luia attribué en le faisant devenir synonyme de popularité.
2. Sondage effectué sur « le guide des égarés ». Résultats à la date du 14 mai 2006 (http://gde.jexiste.fr/joomla/Joomla_1.0.4-Stable-fr/component/option,com_poll/task,results/id,15/).

131
Schedae, 2006, prépublication n°16, (fascicule n°1, p. 129-134).
apprendre un nouveau langage car le moteur effectue la médiation entre l’usager et le docu-
ment, la traduction entre les intentions de recherche de l’usager et le document potentiel-
lement adéquat. L’entremise du moteur entre l’usager et le document implique donc des
usages performants et notamment l’emploi de mots-clés efficaces. Il y aurait donc un parler
«moteur » pour ne pas dire un discours moteur combinant mots-clés et opérateurs booléens.
Or ces pratiques ne sont pas naturelles et guère évidentes pour les jeunes usagers qui ont
beaucoup de mal à définir ou à catégoriser. Les mots-clés impliquent une réflexion, une ten-
tative pour résumer et définir une question en quelques mots. Il s’agit d’un langage différent
du naturel. Or le langage naturel est présent, sous des formes certes parfois évoluées, dans
d’autres applications sur Internet, notamment dans la messagerie ou les dialogues en direct.
2. La confusion des discours et les négligences
L’Internet n’est pas uniforme, par conséquent les discours rencontrés diffèrent forte-
ment suivant les actions effectuées. La communication médiatisée par Ordinateurs génère
de nouveaux modèles d’interactions. Nous n’évoquerons pas ici les langages informatiques
de l’internet même s’il nous apparaît important d’en montrer l’existence aux élèves. L’usage
de l’affichage du code source peut s’avérer en effet riche en informations. Les discours et
documents sur Internet connaissent de fortes variations suivant qu’il s’agit de « dialogues en
directs », de blogs de type « journal intime », de sites d’informations, de messageries ou bien
encore de flux de type Rss.
Les grilles élaborées par des documentalistes tentent de donner des pistes d’analyse de
sites web aux élèves. Elles sont de plus en plus affinées et peuvent constituer un exercice
intéressant. Bien souvent les élèves ne font pas attention à la validité d’une information car
ils ne lisent pas tout (ce que les enseignants nomment parfois « l’effet zapping ») et surtout
ils passent outre certaines indications. Ces mauvaises pratiques de lecture et d’identification
font partie de ce que nous avons appelé les négligences.
Nous avons observé toutes les actions qui font que la liaison document-élève n’aboutit
pas toujours au résultat escompté. Pour cela nous avons utilisé le concept de « négligences »
qui définit tous ces phénomènes de non-lecture ou de mauvaise lecture. Cela nous a permis
de définir une catégorisation des risques d’échec de la relation élève-document.
Le mot négligence vient du latin negligentia qui a un sens proche de l’acception actuelle.
Negligentia vient de negligere qui se décompose en neg-legere qui signifie « ne pas lire »
Nous avons trouvé cette origine chez Régis Debray (Debray 1993) Les négligences sont donc
par extension toutes ces actions de non-lecture, refus de lecture ou de « mauvaise » lecture.
Ces actions négligentes produisent de nombreux effets néfastes que sont par exemple la
mauvaise interprétation ou identification du document. Le faux ou l’erreur n’est donc pas ici
intrinsèque au document mais extrinsèque. Le document qu’il soit numérique ou matériel
voit son existence et sa distinction liées au fait qu’il faut que l’individu soit à même de le déchif-
frer et de le comprendre. Or c’est bien souvent là que commencent les difficultés pour les
élèves. L’emploi du mot « document » suscite déjà des difficultés. L’élève ne fait pas toujours
nettement la différence entre un document et un documentaire. En clair, il ne perçoit pas
souvent les limites du document qu’elles soient physiques ou sémantiques. Une difficulté
d’appréhension du document d’autant plus complexe quand il s’agit d’effectuer des recher-
ches sur Internet.
Toutes ces relations de négligences ne sont donc pas neutres et sans effet pour le docu-
ment numérique. Nous avons dénombré six situations qui démontrent que la multiplication
des sources d’information et les facilités d’accès qui l’accompagnent ne sont pas garants de
la réussite documentaire :

132
Schedae, 2006, prépublication n°16, (fascicule n°1, p. 129-134).
– Le document est ignoré ;
– Le document est plagié ;
– Le document n’est pas pertinent ;
– Le document est mal compris ou mal interprété ;
– Le document est incompréhensible ;
– Le document est inaccessible.
Nous sommes face à des processus communicationnels qui sont sources d’incompré-
hension. Alors que le principe de base d’Internet repose sur les possibilités offertes par
l’hypermédia, nous remarquons un manque de lien entre l’usager et le document. Le risque
d’entropie n’est donc pas seulement lié à la multiplication des sources mais aussi à des barriè-
res sémantiques voire techniques. Ces risques d’échec dans l’accès à la pertinence docu-
mentaire demeurent sont présents avec l’évolution constante des NTIC. Il en résulte des
mutations documentaires qui compliquent l’identification des discours.
3. Information literacy et maîtrise de l’informationIl faut se poser la question du devenir des médiateurs dans cette redocumentarisation.
Ils vont de moins en moins constituer d’intermédiaires entre l’usager et le document avec les
difficultés évidentes qui en résultent. Le travail du RTP-Doc souligne bien que cette facilité
d’accès apparente nécessite des savoirs et de nouveaux savoirs. La question mérite d’être
posée : qui va se charger de la transmission de ces savoirs ? Cette tâche impliquerait une
redéfinition des tâches professorales et un développement de la maitrise de l’information au
sein des systèmes éducatifs. Ou bien doit-on laisser l’usager s’auto-former avec le risque d’une
formation d’une « caste d’initiés » comme ils le sont qualifiés par Pédauque. L’« information
literacy » apparaît alors comme une thérapie (Watzlawick 1979) pour résoudre le problème
des négligences. Un travail important au niveau de l’évaluation de l’information numérique
mérite d’être approfondi et organisé afin de donner aux usagers les capacités d’analyse et
de critiques face aux flux rencontrés. Finalement il semble qu’il faille plaider pour un méta-
discours, un discours de la méthode qui permettrait aux usagers d’acquérir leurs habiletés
documentaires (« information literacy skills »). Les travaux et les réflexions sur ce sujet se mul-
tiplient à l’international. D’ailleurs l’IFLA (International Federation of Libraries Associations)
vient de mettre en place une base de données qui regroupe les sites et travaux sur le sujet 3.
Cette volonté de prôner un discours méthodique et rigoureux s’observe dans la sémantique
appliquée au sujet. Ainsi les anglosaxons n’hésitent pas à employer les termes de « grammar
of the internet ».
Les stratégies des schémas heuristiques (mindmapping) constituent des pistes à exploi-
ter en ce qui concerne l’éducation à la réflexion et à l’abstraction. Cela peut constituer de
bons moyens pour que l’élève utilise les mots-clés avec efficacité. D’ailleurs certains moteurs
comme Exalead offrent la possibilité de relancer la recherche à partir d’autres mots-clés affi-
chés à partir d’une requête. Nous songeons aussi au métamoteur Kartoo qui par sa vision
cartographique sort des habituelles démarches linéaires rejoignant quelque peu le mind-
mapping. L’élève prend ainsi l’habitude de travailler aussi sur les liaisons entre les concepts,
les idées et les mots-clés. Il doit donc créer du lien avant même d’être connecté. Ces démar-
ches « cognitives » vont dans le sens de l’augmentation de l’intellect via l’interaction Homme-
Machine (Englebart 1963) Pour combattre les négligences et afin que l’élève puisse mieux
3. International Information Literacy Ressources Directory, http://www.uv.mx/usbi_ver/unesco/.

133
Schedae, 2006, prépublication n°16, (fascicule n°1, p. 129-134).
appréhender les diverses formes de discours une voie semble devoir être développée : celle
de la production de contenu par l’élève lui-même. La maîtrise des différents discours ne peut
pas s’apprendre que par la lecture. Il faut donc inciter les élèves à devenir producteurs d’infor-
mations et à utiliser les folksonomies avec l’indexation par « tags » afin de mieux comprendre
l’importance des mots-clés. C’est d’ailleurs tout le sens de l’Internet comme hypermedia et
média «all-to-all ». Dès lors la réactivité face à l’information est préconisée et engendre échan-
ges, commentaires, critiques et débats.
ConclusionLes possibilités offertes par les TAL, les systèmes de résumés automatiques ou bien
encore de traduction de document ne sont pas suffisants pour garantir une pertinence docu-
mentaire. La relation usager-document aboutit à des échecs communicationnels du fait de
négligences ou de discours non maîtrisés. La difficulté ne va faire que s’accroître avec l’hybri-
dation des types de discours rencontrés sur une même page web. De ce fait l’accès à la per-
tinence documentaire ne peut se faire sans collaboration. Nous y voyons trois conditions
pour que l’accès au document soit efficace :
1 La formation à l’« information literacy » doit se développer et être accessible à
tous les usagers ;
2 Les technologies doivent continuer à progresser afin que les robots puissent
indexer de manière plus performante les différentes données. Les moteurs
doivent évoluer notamment de manière à distinguer pertinence et popularité ;
3 L’hybridation des deux premières conditions trouve son prolongement dans le
développement de la troisième condition : mieux intégrer l’interaction avec
l’usager ;
4 Dès lors le cercle vertueux peut se mettre en place mais ce succès ne peut avoir
lieu sans rapprochement des techniques et des usages. Des métadonnées
efficaces pourront être émises et le projet de web sémantique pourra peut-être
dès lors voir le jour. Il faut pour cela que tout le monde travaille dans le même
sens. Par conséquent le rôle de médiation des professionnels de l’information
doit s’accroître au niveau de la formation ce qui implique sans doute des
mutations professionnelles.
BibliographieDEBRAY R. (1993), Vie et mort de l’image. Une histoire du regard en occident, Paris, Gallimard.
DUMAS P. (2005), « Google au quotidien : le googling ou les habitudes de recherche de l’internaute
ordinaire », Communication au workshop Le Monde selon Google, Université de Bucarest, http://
archivesic.ccsd.cnrs.fr/sic_00001577.html.
ENGLEBART D. (1963), A Conceptual Framework for the Augmentation of Man’s Intellect, in The Augmen-
tation of Man’s Intellect by Machine, vol. 1, Howerton et Week (éds), Washington DC, Spartan Books,
p. 1-27.
ERTZSCHEID O. & GALLEZOT G. (2003), « Chercher faux et trouver juste : sérendipité et recherche d’informa-
tion», in Actes de CIFSIC03 1ère conférence internationale francophone en Sciences de l’Information et de la
Communication 10e colloque bilatéral Franco-Roumain, Bucarest, Juillet 2003, http://archivesic.ccsd.cnrs.fr/
documents/archives0/00/00/06/89/sic_00000689_02/sic_00000689.html
PROULX S. (2001), «Usages des technologies d’information et de communication: vers une reconsidération
du champ d’étude », conférence à Inforcom 2001, Congrès de la Société des sciences de l’information et
de la communication, Paris, http://grm.uqam.ca/textes/proulx_SFSIC2001.pdf.
RTP CNRS 33 < RTP-DOC > (2005-2006), Documents et contenu : création, indexation, navigation, Plate-
forme d’échange du Réseau thématique pluridisciplinaire sur le document numérique, http://rtpdoc.
enssib.fr.

134
Schedae, 2006, prépublication n°16, (fascicule n°1, p. 129-134).
SERRES A. (2005), Évaluation de l’information sur Internet: Le défi de la formation, Bulletin des Bibliothèques
de France (BBF), 6, p. 38-44, http://bbf.enssib.fr.
SIX DEGRÉS (2006), « Les usages d’internet dans l’enseignement supérieur : “de la documentation au
plagiat” », enquête menée pour Six degrés, Compilatio.net et Le Shinx, Compilatio.net, http://
www.compilatio.net/files/sixdegres-sphinx_enquete-plagiat_3fev06.pdf.
WATZLAWICK P. (1979), Une logique de la communication, Paris, Le seuil (Points essais).

Systèmes de TAL, démonstrations
session 4

II

135
Abderrafih Lehmam« Solutions de traitement du document textuel avec prise en charge de ressources linguistiques »
Schedae, 2006, prépublication n°17, (fascicule n°1, p. 135-140).
Schedae, 2006
Solutions de traitementdu document textuel avec prise en charge de ressources linguistiques
Abderrafih LehmamPertinence Mining SARL
82, avenue Jean Jaurès – 94 400 Vitry sur Seine, France
http://www.pertinence-mining.com
Résumé :
Dans cette article nous avons choisi de présenter quelques solutions de traitement du document
utilisant la technologie du text mining. Nous avons toutefois insisté sur celle du résumé de texte
automatique. Après avoir défini le text mining nous avons d’abord exposé une architecture cons-
truite informatiquement autour de ressources et de techniques linguistiques. L’avenir des solutions
en text mining ne fait que commencer avec l’avènement Internet et la profusion du document
électronique.
Mots-clés : résumé automatique de texte, résumé automatique, plate-forme de veille,
intelligence économique, outil de veille, cartographie de l’information
Abstract :
The paper presents some solutions in text mining, with special focus on automatic summarization
and applications to Arabic. After providing a definition of text mining, we describe a software
architecture based on linguistic resources and techniques, and give an overview of several sum-
marization techniques. This is only a beginning in the future of text mining technologies, with the
growing prevalence of the Internet.
Keywords : summarizer, automatic summarization, text summarization, document summa-
rization, watch platform, information mapping
IntroductionDans le monde professionnel il est important de mettre à disposition des technologies
de traitement de l’information permettant d’aller rapidement à l’essentiel dans un document
textuel. Le but étant d’assister l’utilisateur, par des outils, afin qu’il puisse passer moins de
temps à chercher l’information et davantage à en exploiter le contenu essentiel. Le traitement
automatique du langage (TAL), de plus en plus, remplacé par le concept « Text Mining » chez
Prépublication n° 17 Fascicule n° 1

136
Schedae, 2006, prépublication n°17, (fascicule n°1, p. 135-140).
les professionnels, offre des possibilités réelles pour répondre aux besoins exprimés au
niveau du traitement de document électronique.
En effet, au vu du flot d’information que nous connaissons ; accéder aujourd’hui à l’infor-
mation textuelle utile est devenu un vrai « casse-tête » pour l’utilisateur en quête d’informa-
tion textuelle réutilisable. Le Text Mining répond, en parti, à cette problématique. L’étude
du text mining repose particulièrement sur des liens très étroits entre des recherches en lin-
guistique textuelle et sur les formalisations adéquates en vue d’une réalisation informatique.
L’enjeu est ici de pouvoir d’un côté valider la pertinence des recherches théoriques entre-
prises en linguistique et de l’autre de pouvoir les rendre utiles pour la réalisation de logiciels
efficaces en discernant entre ce qui peut être « informatisable» et ce qui ne peut pas l’être. Le
but est de produire des technologies réellement utilisées dans le monde professionnel telles
que le résumé de texte automatique, les plates-formes de veille (technologique, sanitaire,
intelligence économique…), la cartographie de l’information textuelle issue de l’actualité ou
encore les moteurs et les métamoteurs de recherche sur Internet. Nous nous proposons dans
cet article, d’abord d’exposer des technologies en ce domaine développées par la société
Pertinence Mining et ensuite de les illustrer par des exemples illustrant des situations con-
crètes d’utilisation. Nous nous focaliserons, toutefois, par manque de place, que sur la tech-
nologie du résumé de texte automatique. Dès lors, nous ne présenterons que rapidement les
autres solutions sachant que ses technologies intègrent, toutes, la fonctionnalité de résumé
de texte automatique. La méthode utilisée est initiée des travaux introduits par Edmundson
(1968). Cette même méthode a été améliorée par plusieurs chercheurs, chacun y apportant
une «valeur ajoutée» dans ses écrits et dans ses réalisations (Paice 1990, Lehmam 1995-2006,
Radev 2000).
Avec l’avènement du document textuel électronique suite au développement fulgurant
de l’informatique, des besoins réels se posent maintenant au niveau de l’extraction de l’infor-
mation utile noyée dans des gigaoctets voire des téraoctets de données textuelles véhiculées
dans les différents supports et infrastructures numériques. Devant les besoins naissant pro-
voqués par cette réalité préoccupante, nous avons tout naturellement choisi d’axer nos
recherches et développements, dans le cadre de la société Pertinence Mining, dans ce qu’on
appelle aujourd’hui le text mining. Ce domaine de recherche propose de répondre au besoin
d’extraction, de filtrage et d’exploitation d’un flot d’informations textuelles toujours plus
abondant par des solutions liant les deux disciplines la linguistique et l’informatique pour
apporter des réponses à un besoin qui sera de plus en plus problématique et forcément
tendant à s’accroître dans l’avenir. Les solutions que nous développons visent la résolution
des problèmes liés à la surabondance d’information. On peut définir le text mining comme
ce processus qui permet d’analyser le texte pour extraire les informations efficientes en vue
d’une réutilisation bénéfique pour des buts précis. Des outils s’appuyant sur des méthodes
principalement linguistiques, et parfois, faisant appel aux techniques des réseaux neuronaux,
de la statistique ou du datamining, traduites dans des codes informatiques pour permettre de
« comprendre » (mining) artificiellement le texte (text) en vue d’extraire une quantité d’infor-
mation limitée mais pertinente afin de répondre au besoin recherché qui est principalement
le gain de temps pour une meilleure productivité mais aussi l’aide à la prise de décision.
Dans le cadre du colloque ISDD’06, nous proposons de faire des démonstrations d’appli-
cations conçues de façon à permettre le traitement intelligent de l’information documentaire,
en puisant dans des ressources linguistiques multilingues, pour l’analyse, la recherche et l’ex-
traction de l’information pertinente pour une meilleure utilisation. Ces solutions œuvrent dans :
– Le résumé de texte automatique multilingue ;
– La veille multilingue : collecte, traitement, visualisation, diffusion et exploitation ;

137
Schedae, 2006, prépublication n°17, (fascicule n°1, p. 135-140).
– La cartographie de l’information textuelle avec mesure de visibilité (baromètre) ;
– La méta-recherche avec filtrage des résultats des moteurs de recherche classiques.
Nous nous contentons dans cet écrit à décrire rapidement la solution de résumé auto-
matique.
La solution Pertinence Summarizer (http://www.pertinence.net/ps) identifie les phrases
les plus pertinentes d’un texte en vue de leur extraction pour la constitution d’un résumé,
paramétrable dynamiquement. Cette application tient compte de la spécificité du texte et de
sa thématique (domaines) en se fondant exclusivement sur des techniques d’analyse linguis-
tique du discours.
Quelques points précisant ce qui est pris en charge lors du traitement :
– reconnaissance d’éléments phrastiques pour évaluer la pertinence de la phrase en vue
de sa sélection pour la constitution du résumé ;
– traitement morpho-syntaxique, dictionnaire morphologique spécifique ;
– base synonymique spécifique, terminologie du domaine, personnalisation par utilisateur ;
– structuration de la base des marqueurs selon les domaines ;
– spécialisation par domaine en vue de produire des résumés tenant compte du thème
du texte ;
– Intégrations de thésaurus pour appuyer en pertinence les résumé produits ;
– prise en compte des termes pour les besoins d’utilisateur, ce dernier est invité à entrer
des termes/expressions en vue d’aiguiller le résultat du résumé par rapport son besoin ;
– aide à la lecture rapide par coloration nuancée des phrases au moyen la couleur choisie ;
– navigation sur les termes d’un domaine donné avec possibilité d’extraction des syno-
nymes, d’antonymes ainsi que d’autres relations sémantiques mais aussi des entités
nommés trouvées dans le texte.
Dans l’exemple de copie d’écran de Pertinence Summarizer ci-dessous (figure 1), il est
montré une extraction des termes descripteurs du domaine juridique avec reconnaissance des
termes non-descripteurs et descripteurs, en couleur jaune. En couleur rouge sont indiqués les
termes non-descripteur exprimant la relation de synonymie (sanction pénale → condamnation).
Figure 1 : Extraction des termes d’un domaine avec mise en relief de la relation de synonymie.

138
Schedae, 2006, prépublication n°17, (fascicule n°1, p. 135-140).
Cette fonctionnalité montre le degré d’intelligence artificielle avancée du logiciel dans la
mesure où l’utilisateur a accès, en plus du résumé automatique, à la connaissance par l’acqui-
sition, la compréhension et l’enrichissement de son capital lexique d’un domaine donné grâce
aux relations sémantiques explicitées automatiquement.
Cette solution d’accès rapide à l’information textuelle est intégrée d’office dans tous les
outils 1 de Pertinence Mining. Ces derniers sont tous testables en ligne sur Internet.
La prise en compte de ressources linguistiques va nous permettre la réalisation de fonc-
tionnalités avancées dans Pertinence Summarizer : il est possible, par exemple, de naviguer
sur les termes d’un domaine donné avec possibilité d’extraction de différentes relations sé-
mantiques, à la demande : synonymes, antonymes, homonymes, sigles, entités nommés, etc.
Une aide à la lecture rapide par coloration nuancée des phrases est aussi possible. L’interface
de soumission du document textuel à résumer propose diverses possibilités pour non seu-
lement pouvoir extraire l’information importante mais aussi pouvoir aider l’utilisateur à exploi-
ter cette dernière par la lecture rapide ou la lecture en diagonale du texte source. D’autres
fonctionnalités purement pragmatico-informatiques vont elles permettre la récupération des
références anaphoriques orphelines. Pertinence Summarizer va non seulement, permettre de
résumer des documents issus d’un support matériel (disque dur, disquette, clefs USB, etc.),
d’une URL Internet ou intranet, d’un copié/collé mais aussi de résumer automatiquement
l’ensemble des documents d’un dossier ou d’un répertoire et ceci en un seul clic. C’est cette
dernière fonctionnalité que nous avons choisie de montrer comme seconde illustration pour le
traitement de la langue arabe. Par exemple, en imaginant que l’utilisateur se trouve confronté
à la réalisation d’un rapport ou d’un mémoire de thèse de doctorat ou autre, une solution
pouvant résumer automatiquement un dossier de documents ne peut que lui faire gagner
du temps quant à leur exploration. Dans ce cas précis, les résumés automatiques pourront
rapidement lui fournir suffisamment d’informations pertinentes pour l’aiguiller vers le texte
utile parmi un nombre important de documents présents dans un dossier. Le traitement de
plusieurs dossiers ne peut que l’assister dans sa productivité. Nous donnons ci-dessous un
exemple traitant un dossier contenant de nombreux textes en langue arabe (figure 2).
1. Pertinence Information Network : plate-forme de veille (http://www.pertinence.net/pin). PODoo : méta-moteur de recherche (http://www.podoo.net) – Connivences : cartographie intelligente de l’actualité(http://www.connivences.info)
Figure 2 : Résumé automatique à la volée de nombreux documents contenus dans un répertoire.

139
Schedae, 2006, prépublication n°17, (fascicule n°1, p. 135-140).
Cette fonctionnalité permet l’exploration rapide de l’information pertinente qui est ici
facilitée devant un gros volume de textes. Les résumés automatiques produits par Pertinence
Summarizer à partir d’un dossier ou d’un répertoire vont donner suffisamment d’informations
efficientes pour que l’utilisateur puisse décider de porter son choix sur les textes les plus
intéressants à dépouiller. Ensuite, le bouton « Résumé avancé » va lui permettre d’explorer en
dynamique le texte source afin de récupérer rapidement l’information quêtée. L’intégration
de terminologies ou de thesaurus par domaines thématiques va permettre des fonctionna-
lités intelligentes de text mining ou de fouille de texte comme montré plus haut.
ConclusionLa technologie du text mining est une discipline qui tendra à ce développer dans l’avenir
car les documents textuels électroniques sont devenus d’un usage vulgarisé et ce dans une
proportion toujours croissante. Comme le résumé automatique de texte, nous verrons de
plus en plus apparaître des solutions innovantes qui proposeront des outils de traitement du
document textuel pour faciliter l’accès à l’information. Pour notre part, nous continuons à
réfléchir à d’autres applications qui se fonderont strictement sur des ressources et des tech-
niques linguistiques en vue de répondre à un problème crucial : la maîtrise de l’information.
La difficulté à résoudre reste toutefois l’élaboration de bonnes formalisations qui permet-
traient de faire collaborer en bonne intelligence les deux disciplines à savoir la linguistique
et l’informatique.
BibliographieEDMUNDSON H.P. (1968), « New methods in automatic extraction», Journal of the ACM, 16 (2), p. 264-285.
LEHMAM A. (1999), « Text structuration leading to an automatic summary system», Information Processing
and Management, 35, p. 181-191, 1999, Elsevier Science, New York, USA.
LEHMAM A (2002), « Résumé de texte automatique : vers des solutions professionnelles », Journée ATALA
sur le résumé de texte automatique initiée et organisée par A. Lehmam (Pertinence Mining, Paris) avec
l’aide du laboratoire du Pr. J.-P. Desclés (LaLICC – FRE 2520 CNRS – Paris IV) ENST Paris, décembre 2002.
LEHMAM A. (2006a), « Solutions de Text Mining pour l’intelligence économique, vers la veille
intelligente », Congrès TELMI 06 organisé par l’ARIST Nord-Pas de Calais et l’Université de Lille 3
(Master GIDE-PRISME – UFR IDIST) « Les Outils de Veille Stratégique », 30 mars 2006, Lille, France.
LEHMAM A. (2006b), « Technologie textuelle multilingue », AAFD’06 2e Journées Thématiques « Appren-
tissage Artificiel et Fouille de Données », Université Paris 13, Institut Galilée, 27-28 avril, Paris, France.
LEHMAM A., BOUVET P. (2004a), « Watch application, summarization and syndication in Arabic », in Pro-
ceedings of the conference nemlar '04 « arabic language resources and tools conference », p. 157-163,
22-23 Septembre 2004, Le Caire, Égypte.
LEHMAM A., BOUVET P. (2004b), « Un résumeur automatique de textes multilingues intégré dans une
plate-forme de veille ; application à la langue arabe », in Actes de la conférence JEP-TALN-RECITAL
2004, p. 111-122, Fès, Maroc.
PAICE C.D. (1990), «Constructing literature abstracts by computer techniques and prospects», Information
Processing and Management, 1, New York, Elsevier Science, p. 171-186.
RADEV D (2000), « Summarization of multiple documents : clustering, sentence extraction », ANLP-NAACL
Workshop on Automatic Summarization, April 2000, Seattle, USA.

140
Schedae, 2006, prépublication n°17, (fascicule n°1, p. 135-140).

141
Frédérik Bilhaut & Antoine Widlöcher« Analyse de structures discursives avec la plate-forme LinguaStream »
Schedae, 2006, prépublication n°18, (fascicule n°1, p. 141-146).
Schedae, 2006
Analyse de structures discursivesavec la plate-forme LinguaStream
Frédérik Bilhaut & Antoine WidlöcherGREYC (CNRS – UMR 6 072) – Université de Caen Basse-Normandie
[email protected], [email protected]
Résumé :
À travers la présentation de la plate-forme LinguaStream, nous décrivons certains principes métho-
dologiques et différents modèles d’analyse pouvant permettre l’articulation de traitements sur
corpus et leur inscription dans un processus plus général d’observation, d’élaboration et d’évalua-
tion de modèles linguistiques, à des fins de recherche ou d’enseignement. Nous envisageons en
particulier les besoins nés de perspectives liées à l’analyse du discours.
Mots-clés : linguistique de corpus, TAL, plate-forme logicielle, analyse du discours.
Abstract :
By presenting the LinguaStream platform, we introduce different methodological principles and
analysis models, which make it possible to build hybrid experimental NLP systems by articulating
corpus processing tasks. More especially, we show how they can support the elaboration of auto-
matic discourse analysis processes.
Keywords: corpus linguistics, NLP, software platform, automatic discourse analysis.
IntroductionLinguaStream1 a été initialement développée pour faciliter la réalisation d’expériences
sur corpus en TAL, ainsi que le cycle d’évaluation/ajustement qui en découle. Sans outil
adapté, le coût de mise en œuvre induit par chaque nouvelle expérience devient en effet
un frein considérable à l’approche expérimentale, ainsi qu’à toute application pédagogique
où l’on souhaite se concentrer sur les modèles et règles linguistiques. Pour répondre à cette
problématique, LinguaStream permet de mettre en œuvre de procédés non triviaux tout en
requérant des compétences informatiques minimales. Elle facilite la conception et l’évalua-
tion de chaînes de traitements complexes, par assemblage visuel de modules d’analyse de
types et de niveaux variés : morphologique, syntaxique, sémantique, discursif… Chaque palier
Prépublication n° 18 Fascicule n° 1
1. http://www.linguastream.org

142
Schedae, 2006, prépublication n°18, (fascicule n°1, p. 141-146).
de la chaîne de traitement se traduit par la découverte et le marquage de nouvelles informa-
tions, sur lesquelles pourront s’appuyer les analyseurs subséquents.
Un environnement de développement intégré (cf. figure 1) permet de construire visuel-
lement ces chaînes de traitement, à partir d’une « palette » de composants (une cinquantaine
est intégrée en standard, cet ensemble étant extensible si besoin). Certains sont spécifique-
ment dédiés à des traitements d’ordre linguistique, et d’autres permettent de résoudre diffé-
rents problèmes liés à la gestion des documents électroniques (traitements XML en particulier).
D’autres peuvent être utilisés pour effectuer des calculs sur les annotations produites par
les analyseurs, pour générer des diagrammes, etc. D’autres encore permettent de visualiser
les documents analysés et leurs annotations. Chacun dispose d’un ou plusieurs points d’entrée
et/ou de sortie que l’on relie pour obtenir la chaîne voulue, celle-ci étant représentée par
un graphe où les divers composants apparaissent sous forme de « boîtes » reliées entre elles.
Chaque composant propose un nombre variable de paramètres permettant d’adapter son
comportement. Les marquages produits par chacun sont organisés en couches indépendan-
tes, supportant enchâssements et chevauchements. La plate-forme se base systématique-
ment sur les standards XML, et peut traiter tout fichier de ce type en préservant sa structure
originelle.
Principes fondamentauxEn premier lieu, la plate-forme recourt systématiquement à des représentations décla-
ratives pour spécifier les différents traitements, ainsi que leur enchaînement. Les différents
formalismes disponibles permettent ainsi de transcrire directement l’expertise linguistique à
mettre en œuvre, l’appareil procédural qui en résulte étant pris en charge par la plate-forme.
Les règles données ont donc une valeur tant descriptive, en tant que représentations formelles
d’un phénomène linguistique, que prescriptive, en tant qu’instructions de traitement four-
nies à un processus informatique.
La plate-forme exploite par ailleurs la complémentarité des modèles d’analyse, plutôt
que de privilégier un hypothétique modèle « omnipotent ». Nous faisons en effet l’hypothèse
qu’un analyseur complexe doit adopter successivement plusieurs regards sur le même maté-
riau linguistique, auxquels répondront des formalismes distincts. On pourra par exemple com-
biner, au sein d’un même traitement, des expressions régulières au niveau morphologique,
une grammaire locale d’unification au niveau syntagmatique, un transducteur déterministe
au niveau phrastique et une grammaire de contraintes au niveau discursif. L’interopérabilité
de ces différents modules est garantie par l’usage d’une représentation unifiée des marqua-
ges et des annotations. Ces dernières sont uniformément représentées par des structures
de traits, modèle communément utilisé en TAL et en linguistique, et permettant de repré-
senter des annotations riches et structurées. Tout composant d’analyse pourra produire son
propre marquage en s’appuyant sur les analyses précédentes, les formalismes proposés per-
mettant de spécifier des contraintes sur les annotations existantes. La plate-forme favorise
ainsi l’abstraction progressive des formes de surface : chaque palier d’analyse pouvant accé-
der simultanément aux annotations produites par tous les paliers antérieurs, les analyseurs
de plus haut niveau peuvent s’abstraire progressivement du matériau textuel pour ne plus
reposer que sur des représentations symboliques antérieurement calculées.
Parmi les composants susceptibles de prendre part à une chaîne de traitement, on peut
distinguer deux familles. La première regroupe les analyseurs « prêts à l’emploi », dédiés à
une tâche précise. Il s’agira par exemple de l’étiquetage morpho-syntaxique, une interface
avec TreeTagger (Schmid 1994) étant intégrée par défaut, ou syntaxique en s’appuyant sur les
résultats de Syntex (Bourigault et Fabre 2000). Ces composants sont paramétrables, mais il
n’est pas possible de modifier fondamentalement leur fonctionnement. D’autres au contraire

143
Schedae, 2006, prépublication n°18, (fascicule n°1, p. 141-146).
(EDCG, MRE, CDML, LSL,…) proposent un modèle d’analyse, c’est-à-dire un formalisme de
représentation de contraintes linguistiques, éventuellement associé à un modèle opéra-
toire, par lequel l’utilisateur peut spécifier intégralement le traitement à opérer en écrivant ses
propres règles. Ils permettent d’exprimer des contraintes tant sur les formes de surface que
sur les annotations insérées par les analyseurs précédents.
La modularité des chaînes de traitements favorise quant à elle la réutilisabilité des compo-
sants dans des contextes différents : un module d’analyse développé au sein d’une première
chaîne pourra être réutilisé dans d’autres chaînes. De façon similaire, toute chaîne pourra
être réutilisée en tant que constituant d’une chaîne de plus haut niveau, sous forme de «macro-
composant ». Pour une chaîne donnée, on pourra également substituer à un composant tout
autre composant fonctionnellement équivalent. Pour une sous-tâche donnée, un prototype
rudimentaire pourra être remplacé in fine par un équivalent pleinement opérationnel. Ceci
rend possible la mise en comparaison des traitements, en soumettant ces derniers à des con-
textes rigoureusement identiques, condition sine qua non d’une confrontation pertinente.
Exemple d’application :analyse des cadres de discours temporels
Afin de donner une idée plus concrète des principes méthodologiques présentés, envi-
sageons à présent une configuration linguistique particulière, assez représentative des pro-
blèmes posés par l’analyse discursive, en abordant la question de l’encadrement du discours
(Charolles 1997), et plus particulièrement celle de la détection automatique des cadres tem-
porels. Rappelons que l’auteur qualifie ainsi des segments textuels homogènes du point de
vue d’un critère d’interprétation fixé dans une expression en position détachée en début
de phrase, dite introducteur de cadre. L’opérationnalisation en TAL de ce modèle psycho-
linguistique impose la résolution de deux problèmes principaux : détection des introducteurs,
puis évaluation de leur portée, c’est-à-dire détermination de la borne droite du cadre intro-
duit. Bien que cette dernière tâche soit très problématique dans la mesure où les critères
formels de clôture des cadres sont difficiles à établir, un certain nombre d’indices ont toutefois
pu être dégagés dans le cas précis des cadres temporels (Bilhaut et al. 2003). La figure 2 repré-
sente la chaîne de traitement complète, ainsi que les principales règles d’analyse décrites
ci-dessous.
Le problème de la détection des introducteurs temporels se décline lui-même en deux
sous-problèmes : l’analyse des expressions temporelles, et celle des introducteurs s’appuyant
sur elles. Les principes de modularité évoqués trouvent ici leur justification, puisque nous
souhaiterons généralement traiter ces problèmes indépendamment. L’analyse sémantique des
expressions temporelles fait l’objet d’une grammaire locale d’unification (EDCG), exprimant
des contraintes sur les résultats d’une analyse morpho-syntaxique préliminaire, et associant
aux expressions reconnues une représentation de leur « sens » sous forme de structures de
traits.
Sur cette base, la détection des introducteurs peut être mise en place à l’aide de critères
essentiellement positionnels. Les contraintes exprimées sont fondamentalement séquen-
tielles : nous recherchons des zones de texte vérifiant des motifs imposant la présence, dans
un ordre fixé, d’éléments immédiatement successifs. Ces règles sont donc simplement expri-
mables à l’aide de « macro-expressions régulières » MRE (outre les expressions temporelles,
nous exploitons ici le marquage des phrases et des connecteurs de discours). Les contraintes
sur les structures de traits produites en amont, ainsi que sur les formes de surface (la virgule
en fin de motif) permettent de délimiter l’introducteur. Nous recherchons les éléments précé-
dés d’un début de phrase et composés d’un éventuel connecteur de discours et d’une expres-
sion temporelle. Le reste de l’expression correspond au marquage et à l’annotation produits

144
Schedae, 2006, prépublication n°18, (fascicule n°1, p. 141-146).
en sortie. L’élément reconnu aura le type « introducteur» et sera associé à l’annotation séman-
tique qui lui fait suite. Précisons que la variable $t permet de faire « remonter » l’information
contenue dans la structure de traits associée à l’expression temporelle, pour un usage ultérieur.
Pour la détermination de la portée de l’introducteur, la méthode présentée dans (Bilhaut
et al. 2003) s’appuie sur des critères énonciatifs tels que la cohésion des temps verbaux, sur
la structuration en paragraphes, et sur des calculs sémantiques de cohérence entre l’intro-
ducteur et les autres expressions temporelles. La nature de ces contraintes diffère radicale-
ment des précédentes. D’une part, nous pouvons désormais nous abstraire de la linéarité
du texte : contrairement à une approche par expressions régulières, nous pouvons ici ignorer
un certain nombre d’éléments du flot textuel. D’autre part, s’il existe bien des contraintes
interprétatives entre l’introducteur et certains éléments de la zone introduite, il n’est pas
souhaitable de concevoir ces contraintes comme imposant un ordre strict entre ces éléments.
Pour l’expression de telles contraintes à la fois non linéaires et non séquentielles, nous dis-
posons du formalisme CDML (Widlöcher 2006) et pouvons formuler la « grammaire » repro-
duite en figure 2 : nous recherchons une unité textuelle composée de phrases complètes,
commençant par un élément identifié comme introducteur et ne comportant pas d’autre
élément de ce type, dont tous le verbes sont au même temps, et au sein de laquelle les
expressions temporelles portent sur une plage comprise dans l’intervalle fixé par l’introduc-
teur, en ne retenant que le plus long des candidats partageant un même introducteur.
Il est ainsi possible, à l’aide des principes méthodologiques promus par la plate-forme,
et en nous appuyant sur la complémentarité des modèles d’analyse, de mettre en place un
analyseur de cadres temporels, certes encore imparfait, mais ne faisant usage que de forma-
lismes purement déclaratifs propices à la capitalisation de l’expertise linguistique mise en
œuvre.
ConclusionLes principes fondamentaux ici présentés rendent l’usage de la plate-forme pertinent
dans différents contextes, tels que l’expérimentation en TAL, la linguistique de corpus ou
encore l’enseignement de ces disciplines. La dissimulation de l’appareil procédural, au profit
des formalismes d’expression de règles, permet en particulier la mise en lumière de l’exper-
tise linguistique jugée pertinente. Les principes de modularité permettent pour leur part
d’isoler un problème singulier, de nature (morphologique, syntaxique…) et de grain (mot,
phrase, discours…) variable, sans perdre le bénéfice des analyses préalables éventuellement
nécessaires, en considérant simplement leur apport comme une « donnée » accessible. Les
différents modes de visualisation proposés permettent enfin de rendre les phénomènes étu-
diés à la fois « observables » et « tangibles ».
BibliographieBILHAUT F., HO-DAC L.-M., BORILLO A., CHARNOIS T., ENJALBERT P., LE DRAOULEC A., MATHET Y., MIGUET H.,
PÉRY-WOODLEY M.-P. & SARDA L. (2003), « Indexation discursive pour la navigation intradocumentaire :
cadres temporels et spatiaux dans l’information geographique », in Actes de la 10e Conference
Traitement Automatique du Langage Naturel (TALN’03), Batz-sur-Mer, France, p. 315-320.
BILHAUT F. & WIDLÖCHER A. (2006), « LinguaStream : An Integrated Environment for Computational
Linguistics Experimentation », in Proceedings of the 11th Conference of the European Chapter of the
Association of Computational Linguistics, Trente, Italie, p. 95-98.
BOURIGAULT D. & FABRE C. (2000), « Approche linguistique pour l’analyse syntaxique de corpus », Cahiers
de grammaire, 25, p. 131-151.
CHAROLLES M. (1997), « L’encadrement du dicours – Univers, champs, domaines et espace », Cahiers de
recherche linguistique, 6.

145
Schedae, 2006, prépublication n°18, (fascicule n°1, p. 141-146).
FERRARI S., BILHAUT F., WIDLÖCHER A. & LAIGNELET M. (2005), « Une plate-forme logicielle et une
démarche pour la validation de ressources linguistiques sur corpus : application à l’évaluation de la
détection automatique de cadres temporels », in Actes des 4es Journées de linguistique de corpus,
G. WILLIAMS (éd.), à paraître aux Presses universitaires de Rennes.
SCHMID H. (1994), « Probabilistic Part-of-Speech Tagging Using Decision Trees », in Proceedings of the
Conference on New Methods in Language Processing, Manchester, UK.
WIDLÖCHER A. & BILHAUT F. (2005), « La plate-forme LinguaStream : un outil d’exploration linguistique
sur corpus », in Actes de la 12e Conférence Traitement Automatique du Langage Naturel (TALN),
Dourdan, p. 517-522.
WIDLÖCHER A. (2006), « Analyse par contraintes de l’organisation du discours », in Actes de la Conférence
Traitement Automatique du Langage Naturel (TALN 2006), Leuven, Belgique, p. 367-376.
Annexes
Figure 1 : l’environnement d’expérimentation intégré.
Figure 2 : chaîne de traitement des cadres de discours temporels.

146
Schedae, 2006, prépublication n°18, (fascicule n°1, p. 141-146).

147
Ágnes Sándor, Aaron Kaplan, Gilbert Rondeau« Discourse and citation analysis with concept-matching »
Schedae, 2006, prépublication n°19, (fascicule n°1, p. 147-152).
Schedae, 2006
Discourse and citation analysiswith concept-matching
Ágnes Sándor, Aaron Kaplan, Gilbert RondeauXerox Research Centre Europe
6, chemin Maupertuis – 38240 Meylan, France
[email protected], [email protected], [email protected]
Abstract :
We present here two natural language processing systems for highlighting passages in scientific
texts in order to help researchers to rapidly access relevant knowledge. The first system detects
sentences containing expressions fulfilling discourse functions in scientific argumentation like back-
ground knowledge, summary sentence, contrast with past findings, etc. The second system detects
sentences containing bibliographical references and characterizes the relationship that the authors
describe between their work and the work they refer to. The systems are implemented in the Xerox
Incremental Parser.
Keywords: discourse functions, citation, concept-matching, robust syntactic parsing.
Résumé :
Nous allons présenter deux outils de traitement automatique de langues naturelles qui surlignent
des passages dans des textes scientifiques pour accélérer l’accès aux connaissances. Le premier
système détecte des phrases qui contiennent des expressions véhiculant des fonctions discursives
dans l’argumentation scientifique comme connaissance de base, phrase-résumé, contraste avec
des résultats précédents, etc. Le deuxième système détecte des phrases qui contiennent des
références bibliographiques et caractérise la relation décrite par les auteurs entre leur travail et
l’œuvre auquel ils se référent. Les systèmes sont implémentés avec le Xerox Incremental Parser.
Mots-clés: fonctions discursives, citation, concept-matching, parsing syntaxique robuste.
1. IntroductionThe growing number of scientific research publications makes it difficult for researchers
to keep up with the state of the art even in their own domain. Since most research publications
are available electronically, natural language processing tools might provide useful support.
We propose two tools that are intended to help researchers assimilate the contents of scien-
tific research papers. The first one highlights and types expressions that fulfill relevant dis-
course functions in scientific argumentation, and the second highlights and types expressions
that qualify the relationship between the articles and other articles that they refer to. Both
Prépublication n° 19 Fascicule n° 1

148
Schedae, 2006, prépublication n°19, (fascicule n°1, p. 147-152).
systems are based on detecting expressions with the concept-matching framework. In sec-
tions 2 and 3 we will describe our motivations and the functionalities of both tools. Section 3
explains the concept-matching framework and section 4 our development software and the
architecture of the systems.
2. Tool for discourse analysisScientific articles are highly structured and follow argumentative patterns that guide the
reader in the comprehension of the train of thought described (Hyland 2005, Lewin et al. 2001,
Mizuta & Collier 2004, Ravelli & Ellis 2004, Teufel 1998, Teufel & Moens 2002, Tognini-Bonelli &
Del Lungo Camiciotti 2005). The overall structure of the argumentation is articulated through
the formal division of publications into sections, and the finer structure through meta-discourse
expressions that make the argumentative discourse functions of the smaller units (sentences
or passages) explicit. Often, especially in the domain of experimental research, the titles of
the sections are not related to the topics discussed but instead they refer to their discourse
functions: introduction, background, methods, result, conclusion, etc. In many domains, these
section titles are becoming templates used by a great number of authors, and sometimes
even required by the publishers.
However, this formal structuring is insufficient: On the one hand, within one section that
is supposed to fulfill the discourse function referred to by its title, the authors very often include
digressions fulfilling different discourse functions. For example, a section on results often con-
tains sentences of background knowledge or methods, which also have sections of their own.
On the other hand, the diversity of the relevant discourse functions is greater than that of
section types. For example an important way of convincing the readers is contrasting one's
results with other results. “Contrast”, however, is not a usual title for a section.
The tool we present marks particular discourse function types of sentences in order to
provide the reader with additional support for representing scientific work in a structured
way. In its present state our system identifies the following expressions fulfilling relevant
discourse functions in scientific argumentation: background knowledge, logical contradic-
tion, an element insufficiently or not known, research trend, summary sentence, contrast
with past findings and substantially new finding.
The system has been implemented for processing biomedical literature in the Pubmed
repository (Lisacek et al. 2005). The user enters a Pubmed query and an additional list of
important keywords that is used for relevance ranking. The output is the list of the retrieved
abstracts ranked according to the frequency of the desired keywords, and the sentences
containing the above-mentioned content types are highlighted.
2. Tool for citation analysisWhereas the first tool we presented guides readers in following the train of thought of
one article, citation analysis yields help for awareness of “inter-article” relationships.
Widely used citation analysis tools are Google Scholar and CiteSeer whose main function
is to link citer and citee. Whereas Google Scholar returns a list of publications with the links
of the citations, Citeseer also extracts the passage that includes a reference, and thus indi-
cates its context.
Our tool marks the context of citations according to the type of relationship between
citer and cite (Trigg 1983). At its present state the system extracts sentences where the cita-
tion is made, and does not consider further sentences that refer to that one, although they
might obviously contain important elements. We intend to elaborate wider contexts at a
later stage. The system identifies now four kinds of relationships: background knowledge

149
Schedae, 2006, prépublication n°19, (fascicule n°1, p. 147-152).
(general knowledge, knowledge that helps the reader to understand the article or the topic
of the article, but that is not linked to the details of the article), based-on (the citing article
builds is based in some sense on the article cited, i.e. the cited article has had some effect
on the citing article), comparison (the cited article is compared to the citing article (differ-
ences or resemblances), but no direct link between the two articles is mentioned, contrary
to “based-on”) and assessment (the cited work is assessed, either positively or negatively).
3. MethodologyThe discovery of the expressions fulfilling the above-mentioned discourse functions is
carried out by the implementation of the concept-matching framework (Sándor 2005). The
particular difficulty is the high variability of these expressions both from structural a lexical
points of view. In contrast to expressions conveying propositional contents, they do not follow
identifiable structural patterns and do not have a single conceptual centre that could serve as
an anchor for their identification. The following three sentences illustrate these observations.
They all include bibliographic references in order to provide background knowledge:
(1) Semantic Gossiping [3, 4] is a semantic reconciliation method that can be applied to foster
semantic interoperability in decentralized settings.
(2) Consequently the necessity of a visual syntax for knowledge representation (KR) languages
has been argued frequently in the past [7, 14].
(3) Many other possible approaches to negotiation exist ([4], [13]).
The relevant expressions conveying the concept “background knowledge” are the fol-
lowing:
(1) Semantic Gossiping [3, 4] is a… method that can be applied.
(2) … has been argued frequently in the past [7, 14].
(3) … other … approaches… exist ([4], [13].
In order to establish a common underlying representation of the target expressions, we
break down the target concepts into “constituent concepts”. In the case of the above target
concept, i.e. “background knowledge”, we have identified three constituent concepts: Previ-
ous work[OTHER] provides general[GEN] (background) knowledge[IDEA]. To each constituent
concept we assign a list of keywords or expressions. The concept-matching framework is
based on the co-occurrence of the expressions of all or a subset of the constituent concepts
within the sentences under two types of constraints. The first constraint is the presence of a
direct syntactic dependency relationship between pairs of concepts. The second constraint is
the application of rules that define the co-occurrence of the subset of the constituent con-
cepts in the sentences that are necessary for matching the target concept. The above sen-
tences are matched due to the fact that the necessary constituent concepts are present and
moreover, they are pairwise in syntactic dependency relationships with one another:
(1) DEPENDENCY(Semantic Gossiping[OTHER],is[GEN])
DEPENDENCY(Semantic Gossping[OTHER],[3,4][OTHER])
DEPENDENCY(is[GEN],method[IDEA])
DEPENDENCY(method[IDEA],can be[GEN])
DEPENDENCY(can be[GEN],applied[IDEA])
(2) DEPENDENCY(has been[GEN],argued[IDEA])
DEPENDENCY(argueed[IDEA],frequently[GEN])

150
Schedae, 2006, prépublication n°19, (fascicule n°1, p. 147-152).
DEPENDENCY(argued[IDEA],past[GEN])
DEPENDENCY([7,14][OTHER])
(3) DEPENDENCY(other[OTHER],approaches[IDEA])
DEPENDENCY(approaches[IDEA],exist[GEN])
DEPENDENCY([4],[13][OTHER])
As for the status of our method among content detection methods, we note that it detects
more precise content than search based on bags of words in that it requires the presence
of direct syntactic dependencies between classes of keywords. On the other hand, it covers a
larger variety of patterns than search based on the detection of precise predicate-argument
structures due to two reasons: our keywords in the same class are highly heterogeneous in
nature (in the same class we may find verbs, prepositions or adverbs), and matching particular
dependency types is not required. We can say that our method is between bag-of-words
approaches and bag-of-phrases approaches; we may call it a bag-of-dependency-pairs
approach.
4. Development software and architectureOur systems have been developed with the Xerox Incremental Parser (XIP) (Aït-Mokhtar
et al. 2002). XIP is a natural language analysis tool designed for extracting dependency func-
tions between pairs of words within the sentences. The concept-matching grammars are built
on top of a general rule-based robust dependency grammar that has been developed in Xerox
Research Centre Europe in the XIP formalism. The following schema illustrates the architecture
of the system:
6. AcknowledgementThe development of the tool for citation analysis is funded by the Vikef European
project: http://www.vikef.net/.
Architecture of the concept-matching systems.

151
Schedae, 2006, prépublication n°19, (fascicule n°1, p. 147-152).
BibliographyAIT-MOKHTAR S., CHANOD J.-Pierre & ROUX C. (2002), “Robustness beyond shallowness: incremental
dependency parsing”, Natural Language Engineering, 8, 2/3, p. 121-144.
HYLAND K. (2005), Metadiscourse, Continuum.
LEWIN B. A., FINE J. & YOUNG L. G. (2001), Expository Discourse, Continuum.
LISACEK F., CHICHESTER C., KAPLAN A. & SÁNDOR Á., (2005), “Discovering Paradigm Shift Patterns in Bio-
medical Abstracts: Application to Neurodegenerative Diseases”, in Proceedings of the First International
Symposium on Semantic Mining in Biomedicine (SMBM), p. 41-50.
MIZUTA Y. & COLLIER N. (2004), “Zone Identification in Biology Articles as a Basis for Information Extraction”,
in Proceedings of the Joint Workshop of Natural Language Processing in Biomedicine and Its Applications
(JNLPBA) at the COLING International Conference, p. 19-35.
RAVELLI L. J. & ELLIS R. A. (eds.) (2004), Analyzing Academic Writing, Continuum.
SÁNDOR Á. (2005), “A framework for detecting contextual concepts in texts”, in Proceedings of the Electra
Workshop at the SIGIR-2005 Conference, p. 15-19.
TEUFEL S. (1998), “Meta-discourse markers and problem-structuring in scientific articles”, in Proceedings
of the Workshop on Discourse Relations and Discourse Markers at the 17th International Conference on
Computational Linguistics, p. 43-49.
TEUFEL S. & MOENS M. (2002), “Summarizing Scientific Articles: Experiments with Relevance and Rhetorical
Status”, Computational Linguistics, 28(4), p. 409-445.
TOGNINI-BONELLI E. & DEL LUNGO CAMICIOTTI G. (eds.) (2005), Strategies in Academic Discourse, John
Benjamins Publishing Company.
TRIGG R. (1983), A Network-Based Approach to text Handling for the Online Scientific Community, PhD
Thesis, University of Maryland, Department of Computer Science (typed).

152
Schedae, 2006, prépublication n°19, (fascicule n°1, p. 147-152).

Liste des auteurs
AMGOUD Leila (IRIT-CNRS) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
AOULADOMAR Farida (IRIT-CNRS) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
BESTGEN Yves (Université catholique de Louvain) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
BEXTEN Birgitta (Leiden University Center for Linguistics) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
BILHAUT Frédérik (GREYC, CNRS – Université de Caen Basse-Normandie) . . . . . . . . . . . . . . . . 41, 141
BOUFFIER Amanda (Laboratoire d’Informatique de Paris-Nord) . . . . . . . . . . . . . . . . . . . . . . . . . 79
COUTO Javier (Instituto de Computación, Facultad de Ingeniería, Universidad de la República) . . . 105
CRÉMILLEUX Bruno (GREYC, CNRS – Université de Caen Basse-Normandie) . . . . . . . . . . . . . . . 69
DEGAND Liesbeth (Université catholique de Louvain). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
FERRARI Stéphane (GREYC, CNRS – Université de Caen Basse-Normandie) . . . . . . . . . . . . . . . 57
HEMPEL Susanne (Université catholique de Louvain) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
JACQUES Marie-Paule (ERSS, Université Toulouse 2 – Le Mirail). . . . . . . . . . . . . . . . . . . . . . . . . 1
KAPLAN Aaron (Xerox Research Centre Europe). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
KRECZANIK Thomas (ERSICOM – Université Jean Moulin Lyon 3) . . . . . . . . . . . . . . . . . . . . . . . . . . 123
LAIGNELET Marion (ERSS, Université Toulouse 2 – Le Mirail) . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
LE DEUFF Olivier (Cersic-Erellif, Rennes 2) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
LEGALLOIS Dominique (CRISCO, CNRS – Université de Caen Basse-Normandie) . . . . . . . . . . . 57
LEHMAM Abderrafih (Pertinence Mining SARL) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
LUCAS Nadine (GREYC, CNRS – Université de Caen Basse-Normandie) . . . . . . . . . . . . . . . . . . 69
MANCINI Clara (Centre for Research in Computing, The Open University) . . . . . . . . . . . . . . . . . 91
MINEL Jean-Luc (MoDyCO, CNRS – Université Paris X Nanterre) . . . . . . . . . . . . . . . . . . . . . . . 105
PIMM Christophe (ERSS, Université Toulouse 2 – Le Mirail) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
REBEYROLLE Josette (ERSS, Université Toulouse 2 – Le Mirail) . . . . . . . . . . . . . . . . . . . . . . . . . . 1
RONDEAU Gilbert (Xerox Research Centre Europe) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
SAINT-DIZIER Patrick (IRIT-CNRS) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
SÁNDOR Ágnes (Xerox Research Centre Europe) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 147
SCOTT Donia (Centre for Research in Computing, The Open University). . . . . . . . . . . . . . . . . . . 91
SOPHIE Piérard (Université catholique de Louvain) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
STEIN-ZINTZ Sandrine (Université Paul-Verlaine Metz). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
TEUFEL Simone (Computer Laboratory, University of Cambridge) . . . . . . . . . . . . . . . . . . . . . . . 153
WIDLÖCHER Antoine (GREYC, CNRS – Université de Caen Basse-Normandie) . . . . . . . . . . . . . 141
ZERIDA Nadia (GREYC, CNRS – Université de Caen Basse-Normandie). . . . . . . . . . . . . . . . . . . 69








