
5.LIEN ENTRE VARIABLES

• 2 variables mesurées sur les mêmes objets
• Analyse simultanée des variables
• Au moins une des 2 variables doit être aléatoire
Etude de 2 variables

• Covariance : dispersion de 2 variables quantitatives
• “Variance” de 2 variables simultanées
• Non bornée
• Peut être négative
• Pas d’indication sur l’intensité de la liaison
Etude de la liaison entre 2 variables :
covariance et corrélation

y
x
A
B
Covariances différentes
Avec ν = nombre de ddl (généralement (n - 1))

• Mesure de la liaison linéaire entre 2 variables : corrélation linéaire de Pearson
• Covariance sur données centrées-réduites
• Même signe que la covariance
• Varie entre -1 et 1
rxy = Sxy/(SxSy)
y
x
A
B
Corrélations identiques

• Test de signification de la corrélation
• Variables quantitatives
• Distribution (bi)normale
• Indépendance des observations
• H0 : corrélation nulle dans la population de
référence
• Variables auxiliaires F ou t (test de Student n - 2 ddl)
• On peut tester r par permutations
• Test unilatéral ou bilatéral
• Corrélation ≠ causalité

Test de H0 : r ≠ 0
• Test habituel H0 : r = 0 ; recherche d’un lien
• Parfois, l’hypothèse biologique est différente
• Relations allométriques
• “Lois” métaboliques : BMR vs densité, ...
• Relations prédateurs-proies
• r varie entre -1 et 1 : distribution symétrique autour de 0
• Besoin d’une transformation pour H0 : r ≠ 0

Transformation• Transformation de Fisher
z = 0,5ln((1 + r)/(1 - r)) = tgh-1r
(arc-tangente hyperbolique)
• Distribution de -∞ à +∞
• Opérations sur données transformées puis, si besoin, retour aux vraies valeurs par tgh
• On obtient un intervalle de confiance du r
• Valable pour n > 50 (25 à la rigueur)
• Correction pour les petits échantillons

Test
• Transformation de la valeur observée de r en z
• Transformation du r de l’hypothèse nulle (ρ0) en ζ0
• On construit une statistique-test appelée t∞
t∞ = |(z-ζ0)√(n-3)|
• La statistique-test suit à peu près une distribution normale centrée-réduite

Corrélation non paramétrique
• Quand les données ne suivent pas une distribution binormale
• Pour variables semi-quantitatives
• Basée sur les rangs
• Il existe des corrections pour les ex-aequo

• ρ de Spearman
• Equivalent au r de Pearson calculé sur les rangs des variables originales
• Efficacité (/r) = 0,91
• Varie entre -1 et 1
Avecd = différence entre les rangs d’un même objet pour les deux variablesp = nombre total d’objets
corrélation ρ = 1 -6
p
∑j =1
dj2
p3- p

• Exemple
Objets 1 2 3 4 5
Var 1 5 1 4 2 3
Var 2 5 1 4 2 3
Var 3 5 1 4 2 3
Var 4 2 1 4 5 3
p = 5
ρ (1,2) = 1 - (6(0))/(53 - 5) = 1
ρ (3,4) = 1 - (6(32 + 32))/(53 - 5) = 0,1
↑d = 3
↑d = 3
← rangs← rangs← rangs← rangs

• Il existe une correction pour les ex-aequo (utile seulement si leur nombre est important)
• La corrélation de Spearman peut se tester : on calcule une statistique-test qui obéit à une loi normale (si n est suffisamment grand : 30) sous H0
(pas de corrélation)

• τ de Kendall
• Permet le calcul de corrélations partielles
• Varie entre -1 et 1
corrélation τa= 2 Sp (p - 1)

• Exemple
Objets 1 2 3 4 5
Var 1 5 1 4 2 3
Var 2 2 1 4 5 3
Objets 2 4 5 3 1
Var 1 1 2 3 4 5
Var 2 1 5 3 4 2
Classement des objets en ordre croissant selon la première variable
τ (1,2)= 2(1+1+1+1-1-1-1+1-1-1)/5(5-1)= 0
+1+1
+1
-1-1
etc...-1
+1

• Le τ de Kendall peut se tester
• La statistique-test sous H0 suit une loi
normale pour n > 8

Régression linéaire
• Modèle ≠ corrélation
• Fonction de la forme Y = aX + b, premier ordre
• Pertinent que si r significatif et plutôt élevé
• Variable dépendante Y (= réponse) : dont on cherche à comprendre la variation
• Variable indépendante (= explicative) X : par rapport à laquelle on cherche à expliquer les variations de Y
• Plusieurs variables X : régression multiple

• X contrôlé, Y aléatoire : modèle I
• X et Y aléatoires : modèle II
• Droites passent par X et Y moyens
Types de régression

• Démarche expérimentale/démarche corrélative
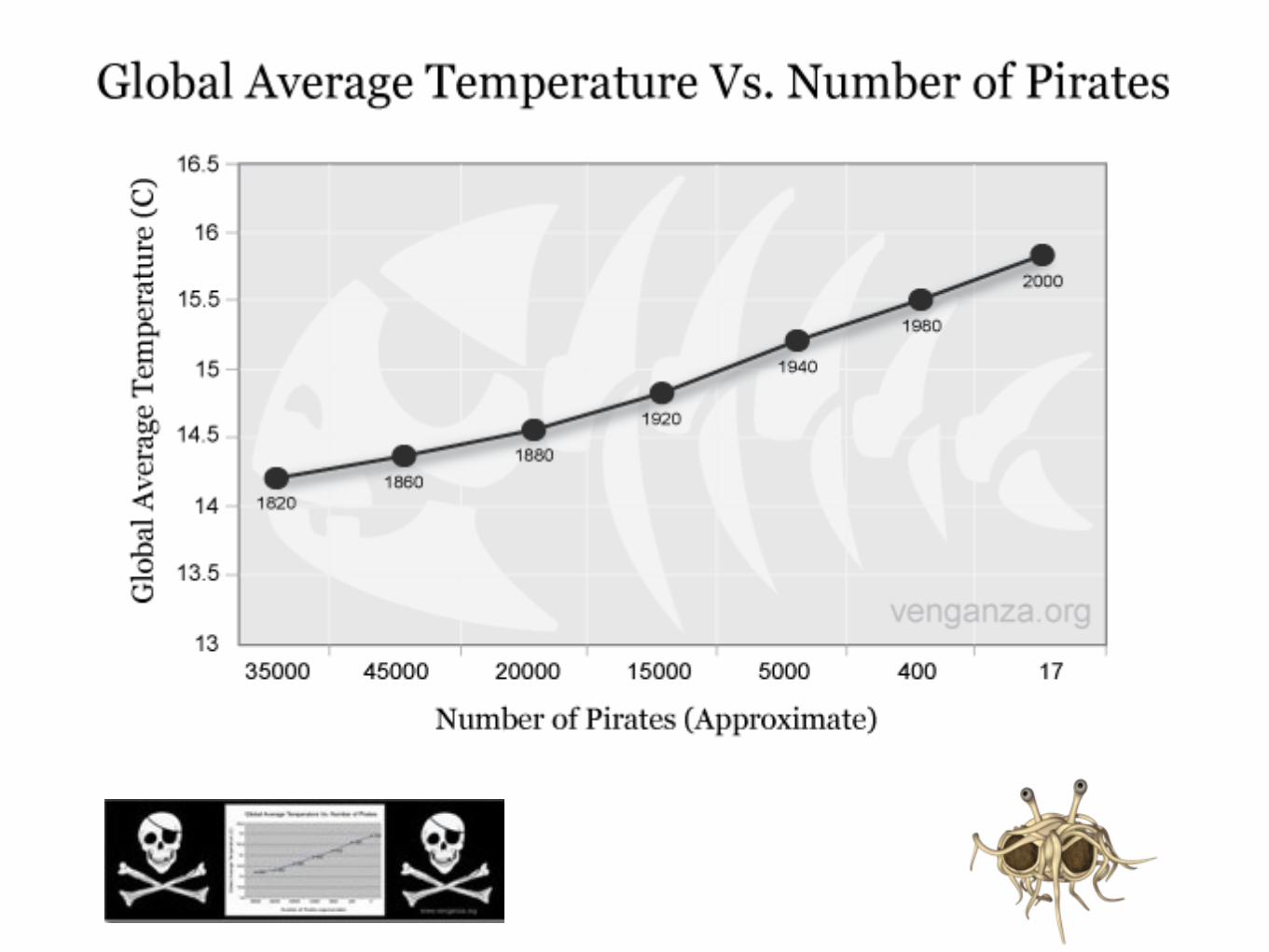
Exemple : dans quelle mesure la température influence-t-elle la croissance d’une espèce ?
• Démarche expérimentale : individus placés à des températures différentes, mesure de la croissance et des processus biologiques liés : test de liens de causalité, élaboration de modèles prédictifs...

• Démarche corrélative : on recherche dans la nature des situations où l’espèce est présente dans des conditions variables de température. On mesure la corrélation entre la taille observée et la température ➡ régression = modèle
• Mise en évidence de corrélations
• Corrélation ≠ causalité !!
• Absence de corrélation ≠ absence de lien

• Description : modèle fonctionnel
• Trouver le meilleur modèle
• Génération d’hypothèses
• Inférence : test d’une hypothèse
• Tests des paramètres
• Lien entre variables
• Prévision et prédiction
• Valeurs de Y pour de nouvelles valeurs de X
• Interpolation (prévision) ≠ extrapolation (prédiction)
Utilisations de la régression

Régression de modèle I• Variation sur Y >> X
• Typiquement utilisée dans un contexte expérimental : X contrôlé
• Méthode des moindres carrés ordinaires MCO (ordinary least-squares : OLS)
• Parfois utilisable quand X et Y sont aléatoires si on ne cherche pas une estimation parfaite des paramètres, ni leur significativité
• Parfois (souvent) le seul type de régression des logiciels
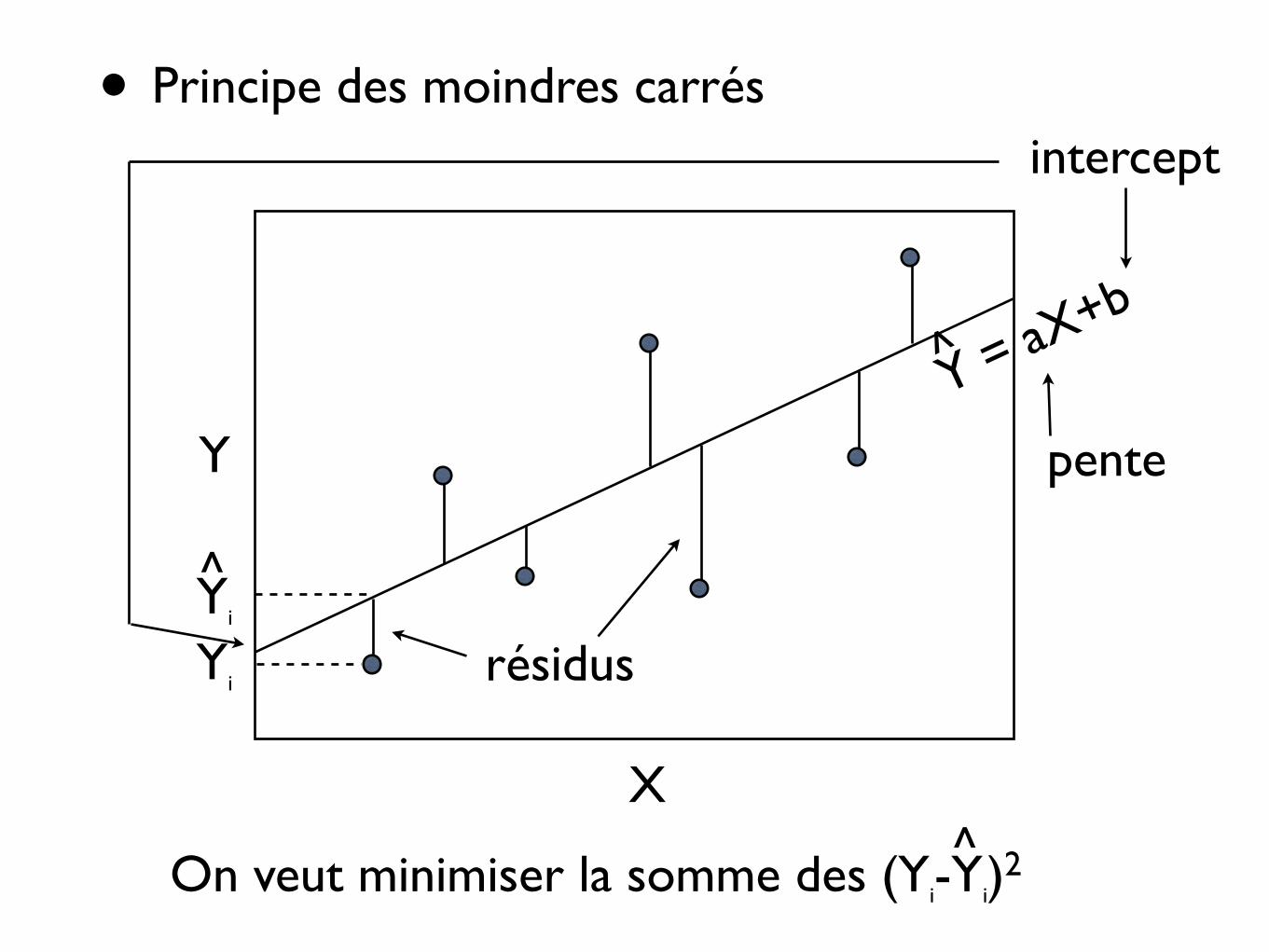
Y
X
• Principe des moindres carrés
Yi
Yi
On veut minimiser la somme des (Yi-Yi)2^
résidus
pente
intercept
Y = aX+b
^

• Après développement mathématique (minimisation de la somme des carrés des résidus), on trouve
a = Sxy/Sx2 = rxy(Sy/Sx)
b = Y - aX
car la droite passe par le centre de gravité du nuage de point (coordonnées = moyennes)
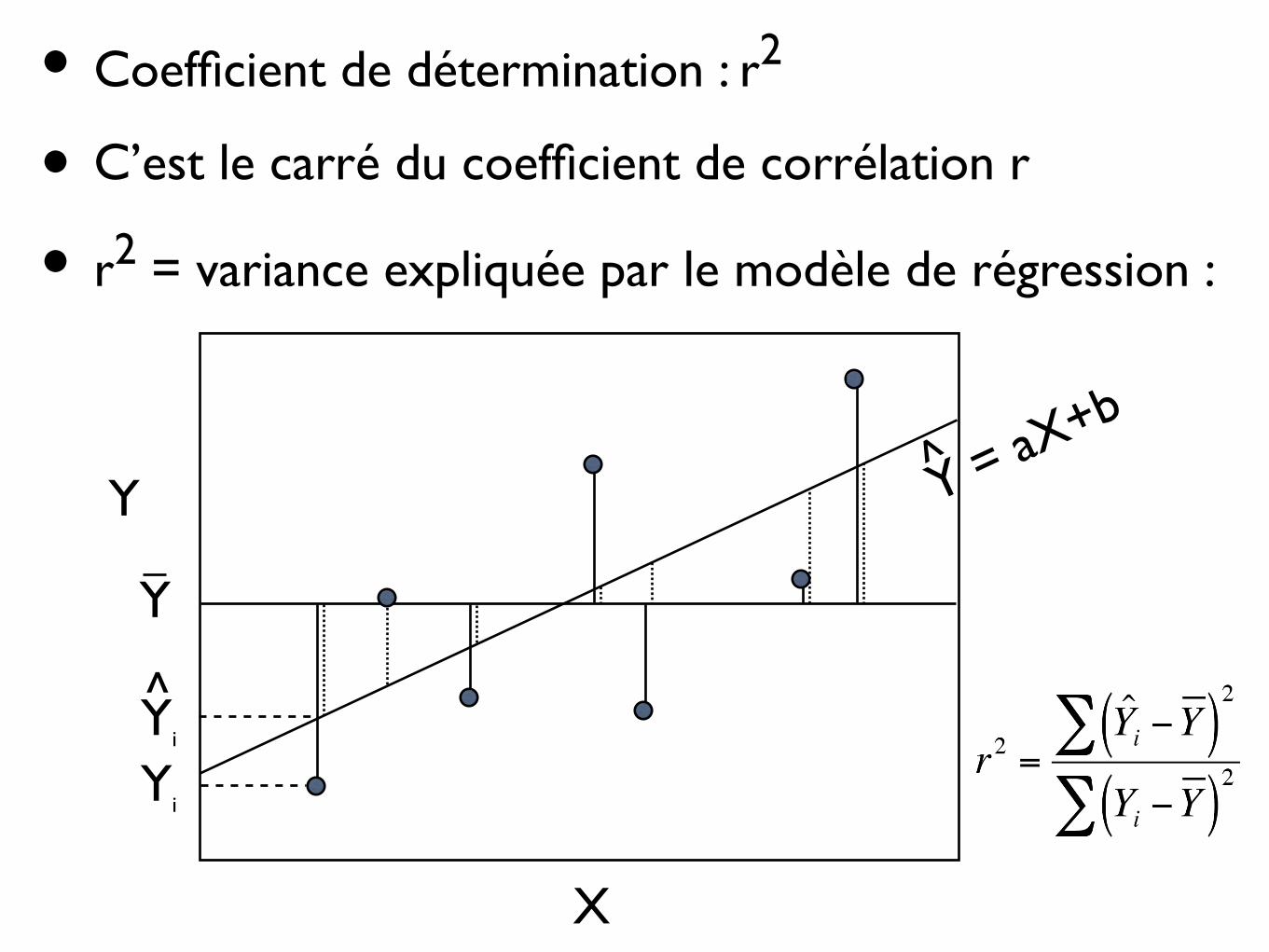
Y
• Coefficient de détermination : r2
• C’est le carré du coefficient de corrélation r
• r2 = variance expliquée par le modèle de régression :
Yi
Yi
Y
X
Y = aX+b
^

• Test de signification : on peut tester r ou a (idem)
• La pente a
• H0 : a = 0
• H1 : a ≠ 0
• Test F (analyse de variance), avec
F = SyR2/Se
2 avec 1 et (n - 2) ddl
=variance expliquée par la régression = SCERvariance due aux erreurs = SCEE/(n - 2)
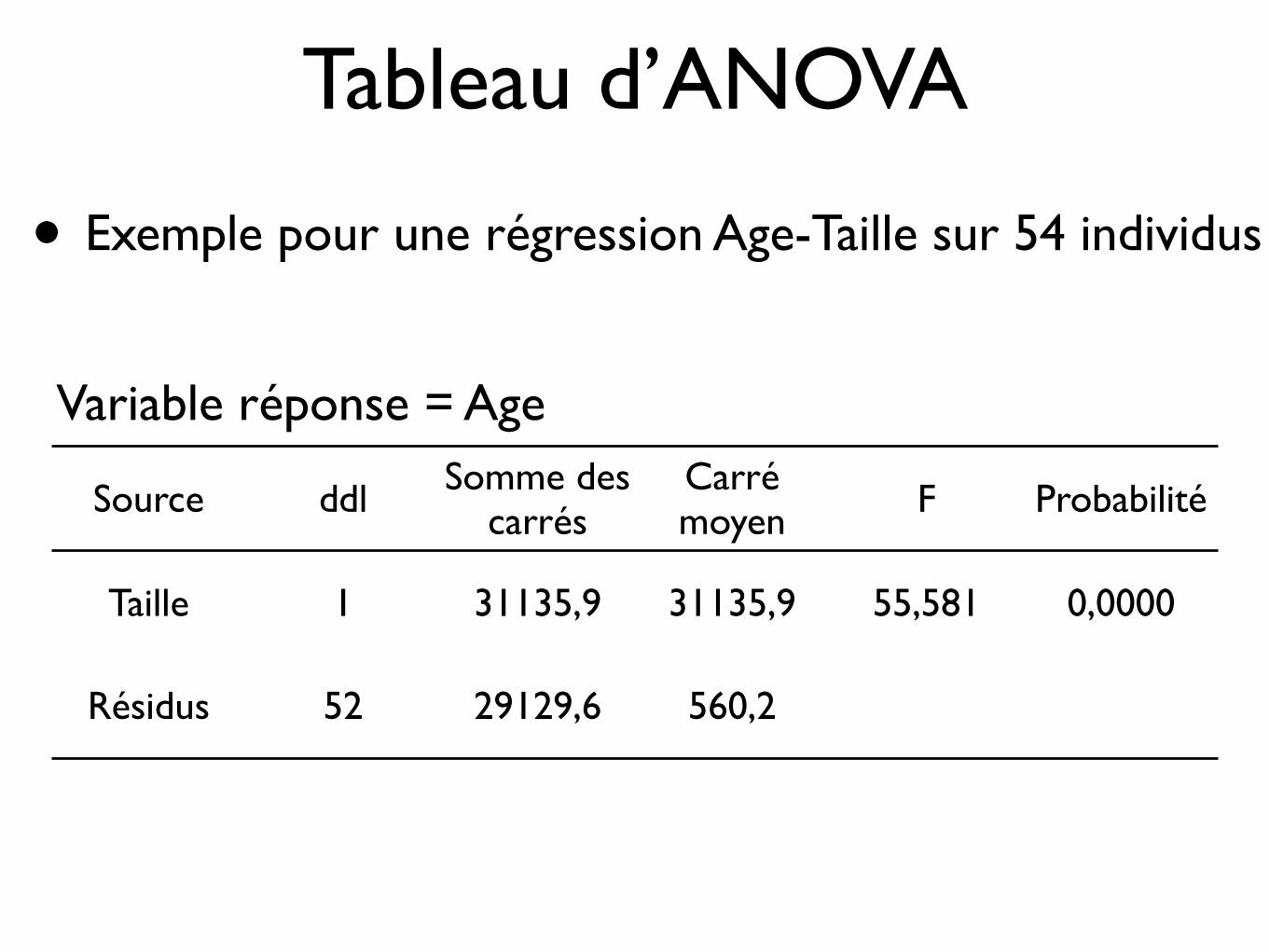
Tableau d’ANOVA
Source ddl Somme des carrés
Carré moyen F Probabilité
Taille 1 31135,9 31135,9 55,581 0,0000
Résidus 52 29129,6 560,2
• Exemple pour une régression Age-Taille sur 54 individus
Variable réponse = Age

• Conditions d’application du test
• Distribution normale des variables explicatives
• Homogénéité des variances
• Indépendance des résidus

• Tester le r2 est équivalent à tester le coefficient de corrélation r
• On emploie la statistique t vue précédemment (ci-dessous, suit une loi de Student), ou la Table donnant le rcritique
t = √F = (r√(n - 2))/(√(1 - r2))
• Test unilatéral ou bilatéral à (n - 2) ddl
• Test réalisable par permutations

Intervalles de confiance
• Pente : relation (0 ?), hypothèse (≠ 0)
• Ordonnée à l’origine (0 ?)
• Estimation : intervalle d’un Yi pour un Xi
• Prédiction d’une estimation : pour une nouvelle observation d’un Yi , intervalle plus large
• Estimation de la moyenne : pour une nouvelle série de valeurs de Y pour une seule valeur de X, intervalle plus étroit
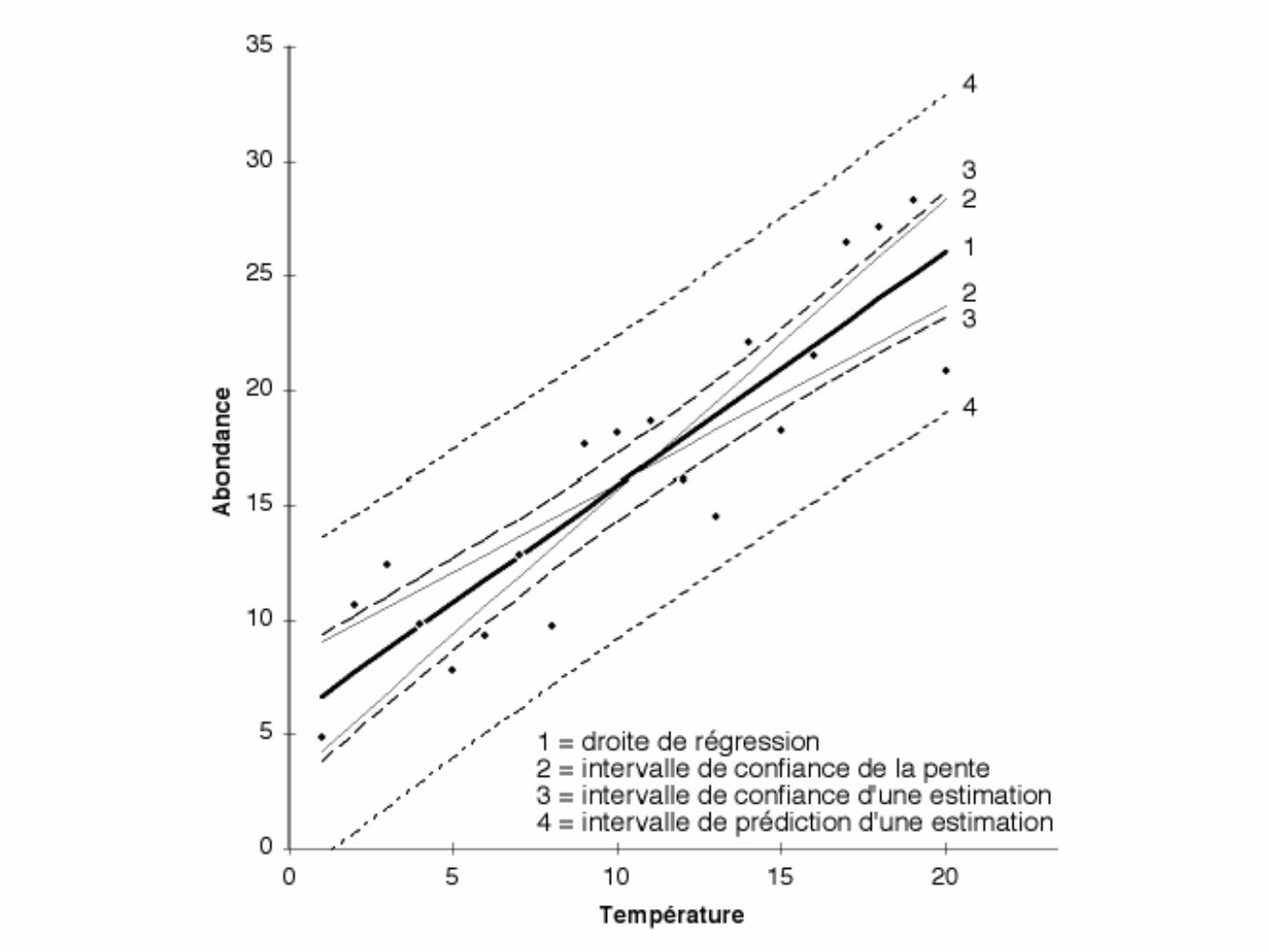

Calculs
• Intervalle de confiance de la pente
• La vraie pente (α) se situe entre
a ± tα/2√(Sa2); où √(Sa
2) est l’erreur type de a
Sa2 = Se
2/(n - 1)Sx2 = SCEE/((n - 2)(n - 1)Sx
2)
(rappel : SCEE = Σ(Σ(yi - yi)2)
• t suit une loi de Student à (n - 2) ddl

• Intervalle de confiance de l’ordonnée à l’origine
• Le vrai intercept (β) se situe entre
b ± tα/2√(Sb2); où √(Sb
2) est l’erreur type de b
Sb2 = (Se
2ΣXi2)/(nΣ(Xi - X)
2)
• t suit une loi de Student à (n - 2) ddl

• Intervalle de confiance d’une estimation
• Une estimation de y, y, se situe entre
y ± tα/2√(Sy2); où √(Sy
2) est l’écart type de y
Sy2 = Se
2(1/n + (Xi - X)2/Σ(Xi - X)
2)
• t suit une loi de Student à (n - 2) ddl

• On utilise également la régression de modèle I
• Quand on a une raison claire de postuler quelle variable influence l’autre
• Quand on veut simplement faire de la prévision
• Quand seulement le r2 est important

Régression de modèle II
• X et Y aléatoires, erreurs de même ordre
• En modèle I : la régression de Y sur X ≠ X sur Y
• Cas typique des relations dans la nature
• Relation poids-longueur, entre abondances, ...
• Plusieurs méthodes
• Axe majeur AM
• Axe majeur réduit AMR
• Axe majeur sur données cadrées AMDC
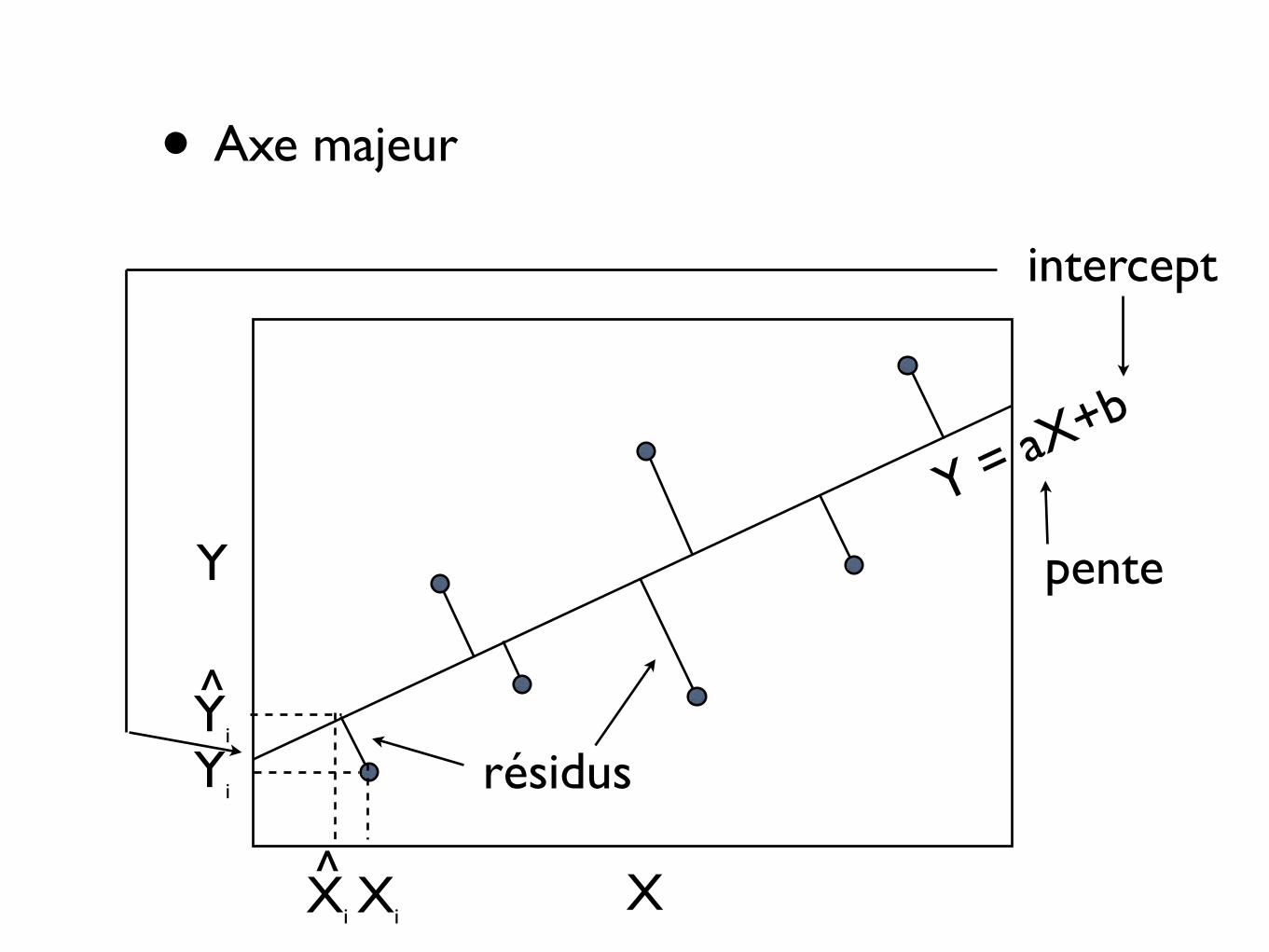
• Axe majeur
Y
X
résidus
Y = aX+b
pente
intercept
Yi
Yi
Xi Xi

• Axe majeur : plus grande variabilité du nuage de points = première composante principale
• Plus complexe à calculer
• Sensible aux échelles des variables (contrairement au modèle I basé sur la corrélation)
• On transforme souvent les variables en ln
• Axe majeur réduit : sur données centrées-réduites
• Nécessite une forte corrélation (r significatif) entre les variables et un grand nombre d’observations
• Pente non testable

• Si les données ne sont pas exprimées dans les mêmes unités
• Axe majeur sur données cadrées
• Cadrage
Xi’ = (Xi - Xmin)/(Xmax - Xmin)
Yi’ = (Yi - Ymin)/(Ymax - Ymin)
• Avec un minimum à 0, la transformation devient
Xi’ = Xi/Xmax
Yi’ = Yi/Ymax

• Les données varient ainsi entre 0 et 1
• A éviter en cas de valeurs aberrantes

• Pente de l’axe majeur : am
am = (d ± √(d2 + 4))/2 ; (± suivant le signe de r)
avec d = (a2 - r2)/(ar2)
où a = pente de la droite MCO
et r = coefficient de corrélation
• Ordonnée à l’origine
bm = Y - amX
• Intervalle de confiance laborieux à calculer

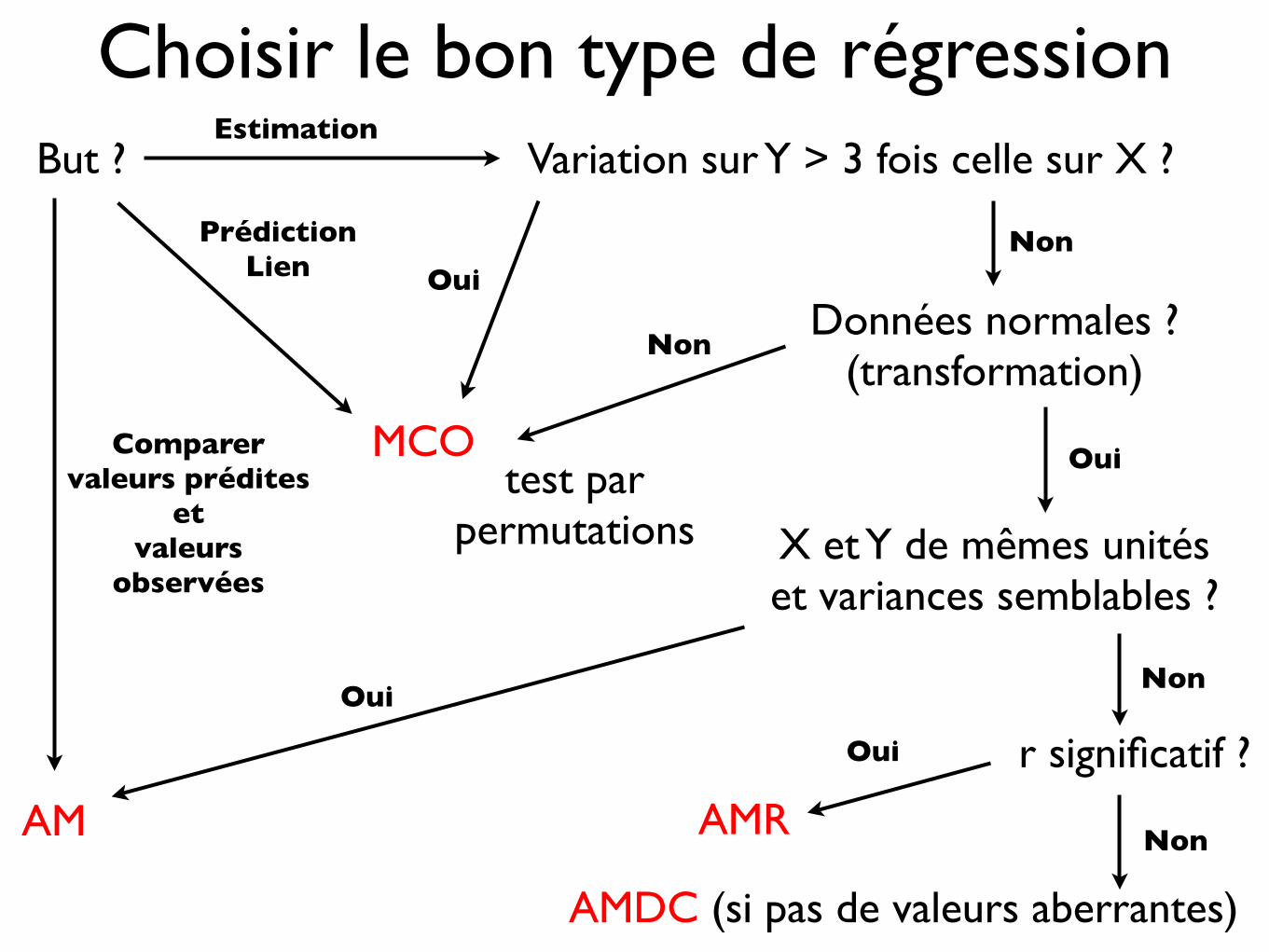
Choisir le bon type de régressionVariation sur Y > 3 fois celle sur X ?
X et Y de mêmes unitéset variances semblables ?
AM
r significatif ?
MCO
Oui
Données normales ?(transformation)
Non
Non
Oui
OuiNon
Oui
AMR
AMDC (si pas de valeurs aberrantes)
Non
test par permutations
But ?
PrédictionLien
Estimation
Comparervaleurs prédites
etvaleurs
observées

Lien entre 2 variables qualitatives :
test du χ2
• Etude d’un tableau de fréquences : tableau de contingence
• Plusieurs utilisations du test
• Liaison entre 2 variables qualitatives
• Comparer plusieurs groupes décrits par une variable qualitative
• Conformité distribution observée vs théorique (ex : distribution mendélienne en génétique)

• Les variables qualitatives comportent différents états : modalités
• Exemple : variable = couleur ; modalités : rouge, bleu, vert
• Les fréquences (absolues ou relatives) sont les nombres d’objets caractérisés par une modalité de chaque variable
• Exemple (couleur et forme) : 35 carrés et rouges, 20 triangles et rouges, ...
• Les chiffres sur lesquels se fait l’analyse ne sont pas les mesures d’une variable mais des fréquences
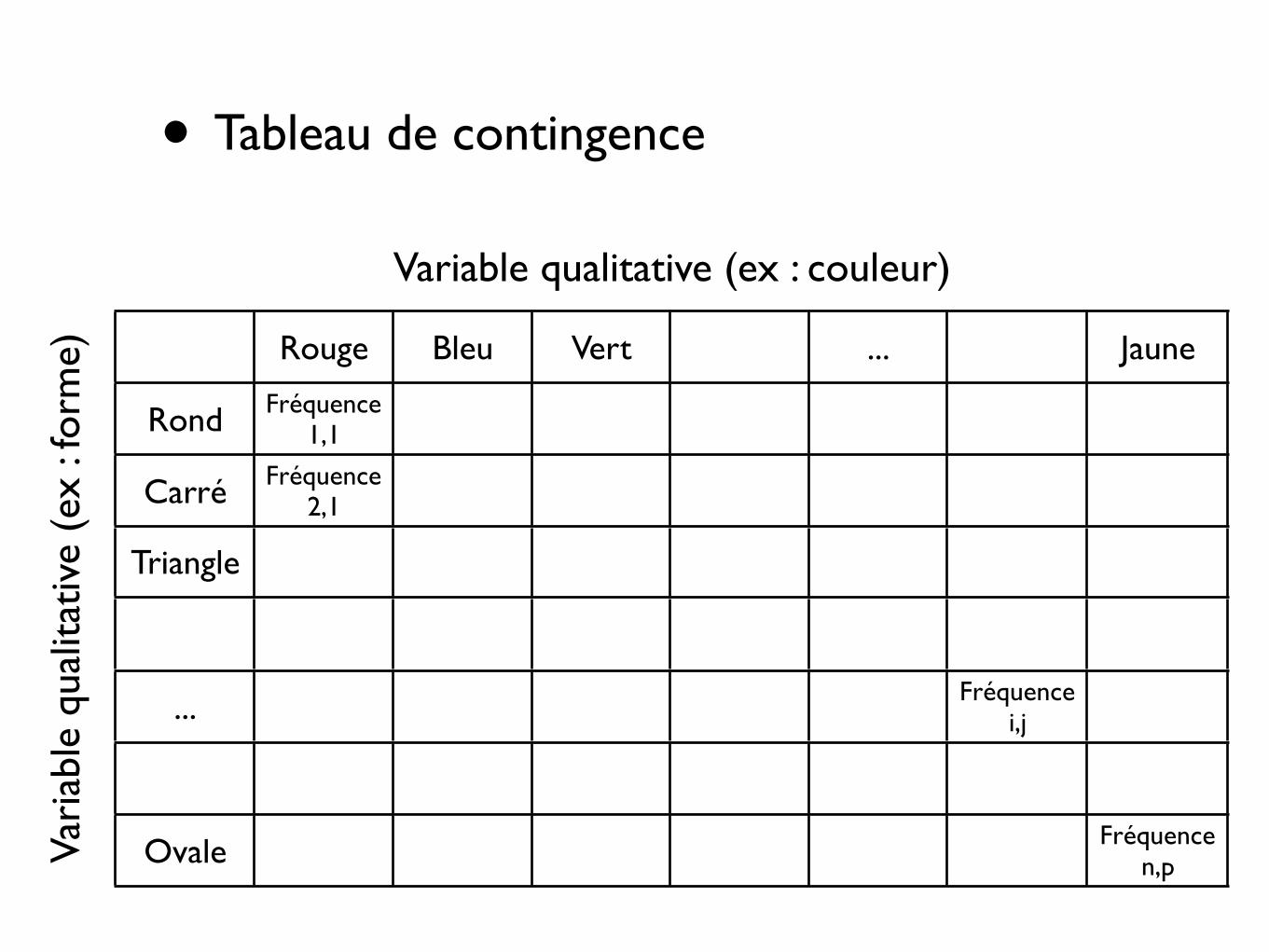
• Tableau de contingence
Rouge Bleu Vert ... Jaune
Rond Fréquence 1,1
Carré Fréquence 2,1
Triangle
... Fréquence i,j
Ovale Fréquence n,p
Variable qualitative (ex : couleur)
Vari
able
qua
litat
ive
(ex
: for
me)

• Principe
• Mesurer les écarts entre la distribution observée (O) et la distribution théorique (E : espérée sous hypothèse d’indépendance)
• Comparaison à une statistique-test : χ2
• χ2 = corrélation pour variables qualitatives
• Cette statistique suit une distribution particulière sous H0
• Les écarts observés sont-ils assez petits pour être dus au hasard ?

• E11 = x1.x.1/n
• χ2 = Σ(E - O)2/E
Modalité 1 Modalité 2 Modalité k
Modalité 1 x11
Modalité 2 x22
Modalité r xr1 xrk
Variable 1
Vari
able
2
Variable 1Modalité 1 Modalité 2 Modalité k
Modalité 1 E11 x1.
Modalité 2 E22 x2.
Modalité r Er1 Erk xr.
x.1 x.2 x.k x.. (=n)
Vari
able
2

• Plus l’écart entre les valeurs observées et
théoriques augmente, plus la valeur de χ2 augmente
• Plus cet écart augmente, plus le numérateur de la statistique-test augmente, quel que soit le signe de cette différence : test unilatéral
• Le nombre de degrés de liberté est associé au nombre de (E - O)2/E calculés : il y en a autant que de cases dans le tableau, soit (r x k)
• En retirant le nombre de paramètres estimés, il reste (r - 1)(k - 1) ddl

Recherche des correspondances
• Quelles sont les associations entre modalités (cases du tableau) responsables de la relation éventuelle ?
• Ce sont les cases ou E est la plus différente de O : correspondances entre les modalités
• Il est possible de visualiser les correspondances par une analyse factorielle des correspondances (AFC)

Conditions d’application
• 2 variables qualitatives, ou 1 variable qualitative et des variables quantitatives ou semi-quantitatives divisées en classes
• Indépendance des observations
• Fréquences absolues
• E pas trop petites, n assez grand (n > (5 x r x k))
• Pour petits effectifs : Test Exact de Fisher (tableaux 2 X 2)

Plusieurs variables indépendantes :
régression multiple
• But : expliquer une variable dépendante par plusieurs variables indépendantes
• Permet la prise en compte de l’effet de variables confondantes
Y = f(X1, X2, ..., Xn)

• Y = b + a1X1 + a2X2 + ... + akXk
• 2 variables indépendantes : plan ; au-delà : hyperplan
• ai (coefficient de régression partielle) : contribution de
la variable Xi à l'explication de la variable Y, quand les
variables explicatives sont tenues constantes
Régression linéaire multiple
• 2 variables indépendantes (explicatives) : plan

• R2 global = coefficient de détermination multiple : donne la proportion de variance expliquée par toutes les variables
• r2 partiels = coefficients de détermination partielle : donne la proportion de variance expliquée par chacune des variables en contrôlant l’effet des autres
• Les deux peuvent être testés (mêmes conditions que pour la régression simple)

Test du coefficient de détermination multiple R2
FRM = R2(n - p)/((1 - R2)(p - 1))
• où p est le nombre total de variables (incluant Y), et n celui des observations
• FRM suit une loi de F à (p - 1) et (n - p) ddl

R2 ajusté
• Problèmes du R2 : augmente avec le nombre de variables, même aléatoires
• Comparaison difficile des équations de régressions multiples avec des nombres différents de variables indépendantes
• Le R2 ajusté tient compte du nombre de variables et diminue d’autant la valeur du R2
R2 ajusté = 1 - ((n - 1)/(n - p))(1 - R2)

Calcul des paramètres de régression
• Calcul des coefficients de régression et de l’ordonnée à l’origine
• Il faut connaître
• Coefficients de corrélation linéaire simple entre toutes les paires de variables (Y, X1, X2, ...) :
rX1X2, rYX1, ...
• Ecarts types de toutes les variables
• Moyennes de toutes les variables

• Exemple pour Y = b + a1X1 + a2X2 + a3X3
• Calcul des coefficients de régression centrés-réduits (ai’) à l’aide des équations normales
rYX1 = a1’ + rX1X2a2’ + rX1X3a3’
rYX2 = rX2X1a1’ + a2’ + rX2X3a3’
rYX3 = rX3X1a1’ + rX3X2a2’ + a3’
• Système de 3 équations à 3 inconnues : on trouve les ai’

• On revient aux coefficients de régression originaux (non centrés-réduits)
a1 = a1’SY/SX1
a2 = a2’SY/SX2
a3 = a3’SY/SX3
• On trouve l’ordonnée à l’origine
b = Y - a1X1 - a2X2 - a3X3
• Cela permet également de calculer R2, car
R2 = Σai’riy où y est la variable dépendante

• Colinéarité entre les variables X : besoin de procédures de sélection des variables significatives
• Elimination descendante (backward elimination)
• Toutes les variables sont incluses dans le modèle et les paramètres de régression partiels calculés
• Si une ou plusieurs variables ne sont pas significatives, la moins significative est retirée du modèle et les paramètres de régression sont recalculés
• Et ainsi de suite jusqu'à ce que toutes les variables restantes soient significatives
Sélection des variables X

• Sélection ascendante (forward selection)
• Même chose mais en ajoutant les variables une à une d’après leur corrélations partielles avec Y, en commençant par la plus significative individuellement
• Procédure pas à pas (stepwise procedure)
• Mélange des deux procédures précédentes : chaque étape de sélection ascendante est suivie d’une élimination descendante pour voir si une des variables incluse jusque là n’est plus significative

• Effet de deux variables X1 et X2 sur une variable Y
• Exemple : effet de la température (X1) et de l’humidité
(X2) sur la croissance (Y) d’un organisme
• La température et l’humidité ont chacune une influence sur la croissance
• La température et l’humidité sont corrélées : redondance dans l’explication de la variation
Partitionnement de la variation

100 % de la variation de Y
Variation expliquée par X1 = R21
Variation expliquée par X2 = R22
Variation inexpliquée
da b c
Avec a+b+c+d = 100 %
a, b, c, et d sont déduits par soustraction
= a+b
= b+c
= a+b+c
= d
Variation expliquée à la fois par X1 et X2 = R21,2

• Etude de l’effet d’une variable X1 sur une autre, X2,
tout en contrôlant l’effet d’une troisième, X3 (la
covariable)
• Consiste à régresser X2 sur X3 puis à étudier ensuite
le lien entre les résidus de cette régression (la variation de X2 qui n’est pas expliqué par X3) et X1
• Cela revient à tenir X3 constante
• Exemples : contrôle de l’effet de l’échantillonnage, de la taille des hôtes, du temps, ...
Régression partielle
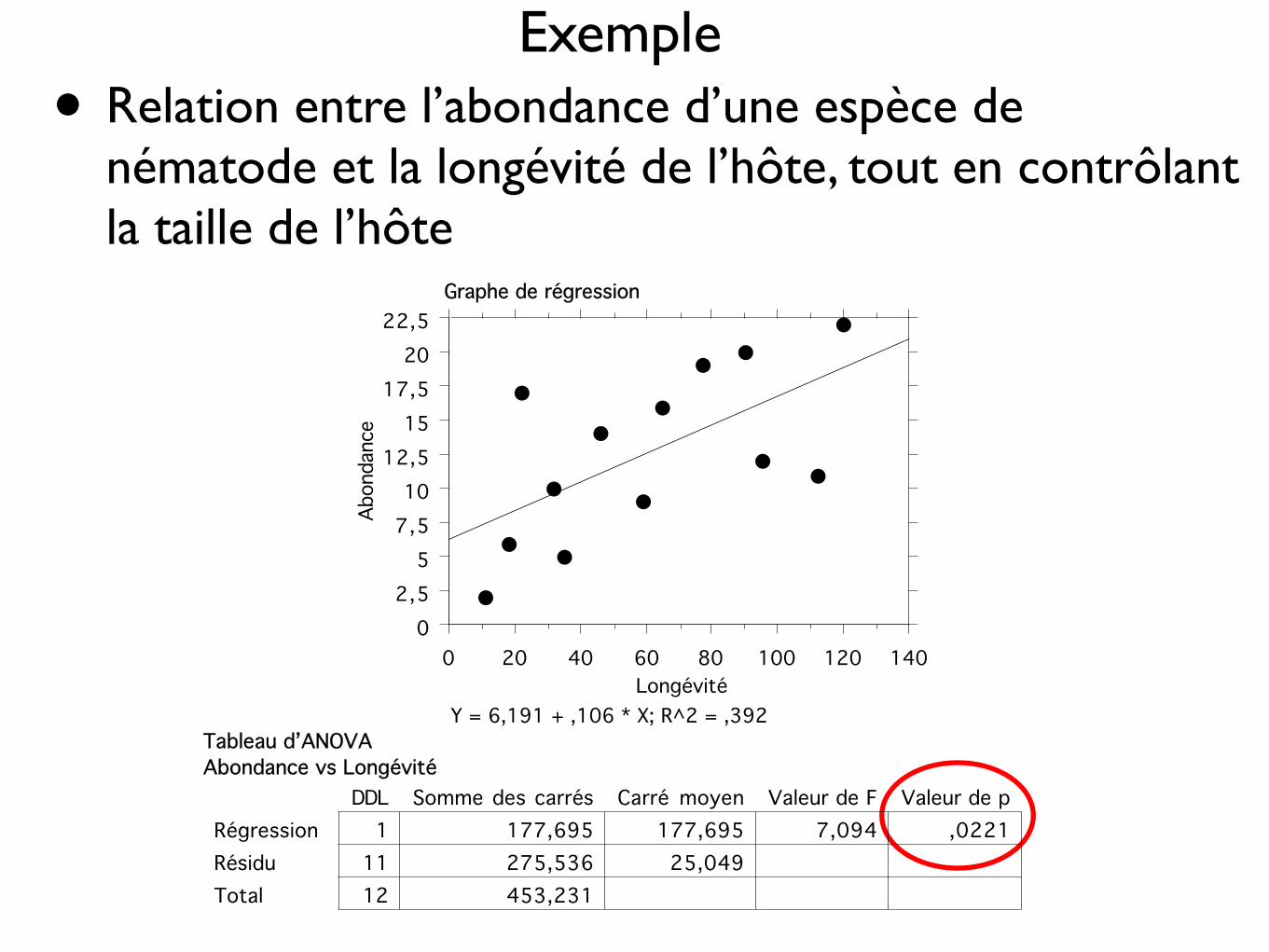
Exemple• Relation entre l’abondance d’une espèce de
nématode et la longévité de l’hôte, tout en contrôlant la taille de l’hôte
02,5
57,510
12,515
17,520
22,5
Abon
danc
e
0 20 40 60 80 100 120 140Longévité
Y = 6,191 + ,106 * X; R^2 = ,392
Graphe de régression
1 177,695 177,695 7,094 ,022111 275,536 25,04912 453,231
DDL Somme des carrés Carré moyen Valeur de F Valeur de pRégression Résidu Total
Tableau d’ANOVAAbondance vs Longévité

0
20
40
60
80
100
120
140
Long
évité
25 50 75 100 125 150 175 200 225 250Taille
Y = -16,966 + ,563 * X; R^2 = ,892
Graphe de régression
02,5
57,510
12,515
17,520
22,5
Abon
danc
e
-30 -25 -20 -15 -10 - 5 0 5 10 15 20Résidus Longévité
Y = 12,538 - ,05 * X; R^2 = ,009
Graphe de régression
1 4,246 4,246 ,104 ,753111 448,984 40,81712 453,231
DDL Somme des carrés Carré moyen Valeur de F Valeur de pRégression Résidu Total
Tableau d’ANOVAAbondance vs Résidus Longévité

Régression polynomiale
• Permet d’ajuster des courbes de formes variées, non linéaires, entre une variable dépendante Y et une ou plusieurs variables explicatives X
• 1 variable X : courbe
• 2 variables X : surface (plan) plus ou moins “bosselée”
• > 2 variables X : hyperplan “bosselé”

• Variante de la régression multiple : ajout de variables supplémentaires par l’intermédiaire des variables originales élevées à différents ordres (carré, cube, ...)
• Exemple avec une variable X : ajout de X2, X3, ...
Y = b + a1X + a
2X2 + a
3X3 +...
• Les variables à différents ordres sont sélectionnées par les procédures habituelles
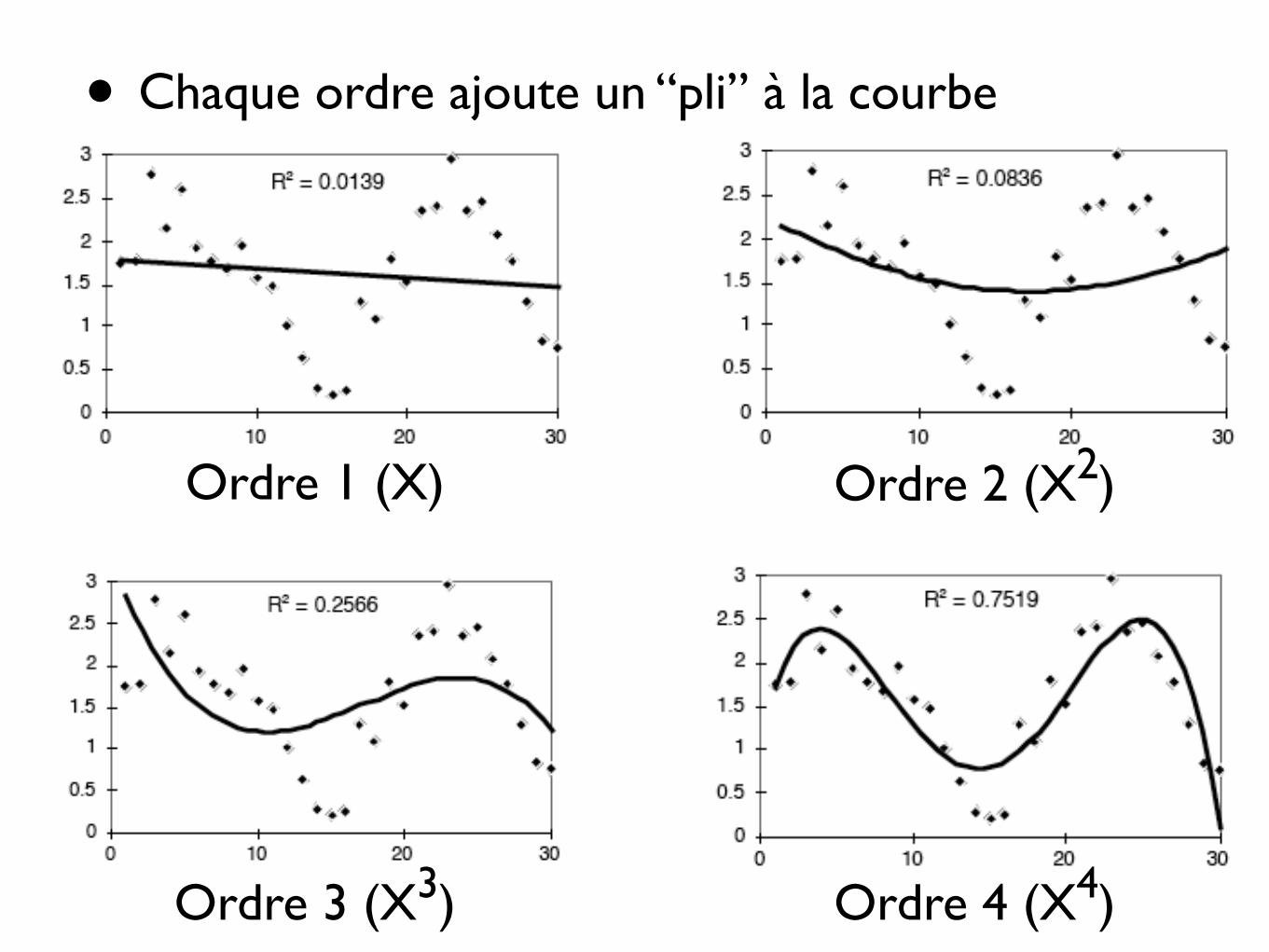
• Chaque ordre ajoute un “pli” à la courbe
Ordre 2 (X2)
Ordre 3 (X3) Ordre 4 (X4)
Ordre 1 (X)

• Plus l’ordre est élevé, plus on perd de degrés de liberté, plus l’explication biologique est difficile
• Il faut trouver un bon compromis
• Pour les biologistes, la régression du deuxième ordre (parabole) est souvent utile
• Les organismes ont souvent des préférences situées autour d’un optimum : distribution unimodale
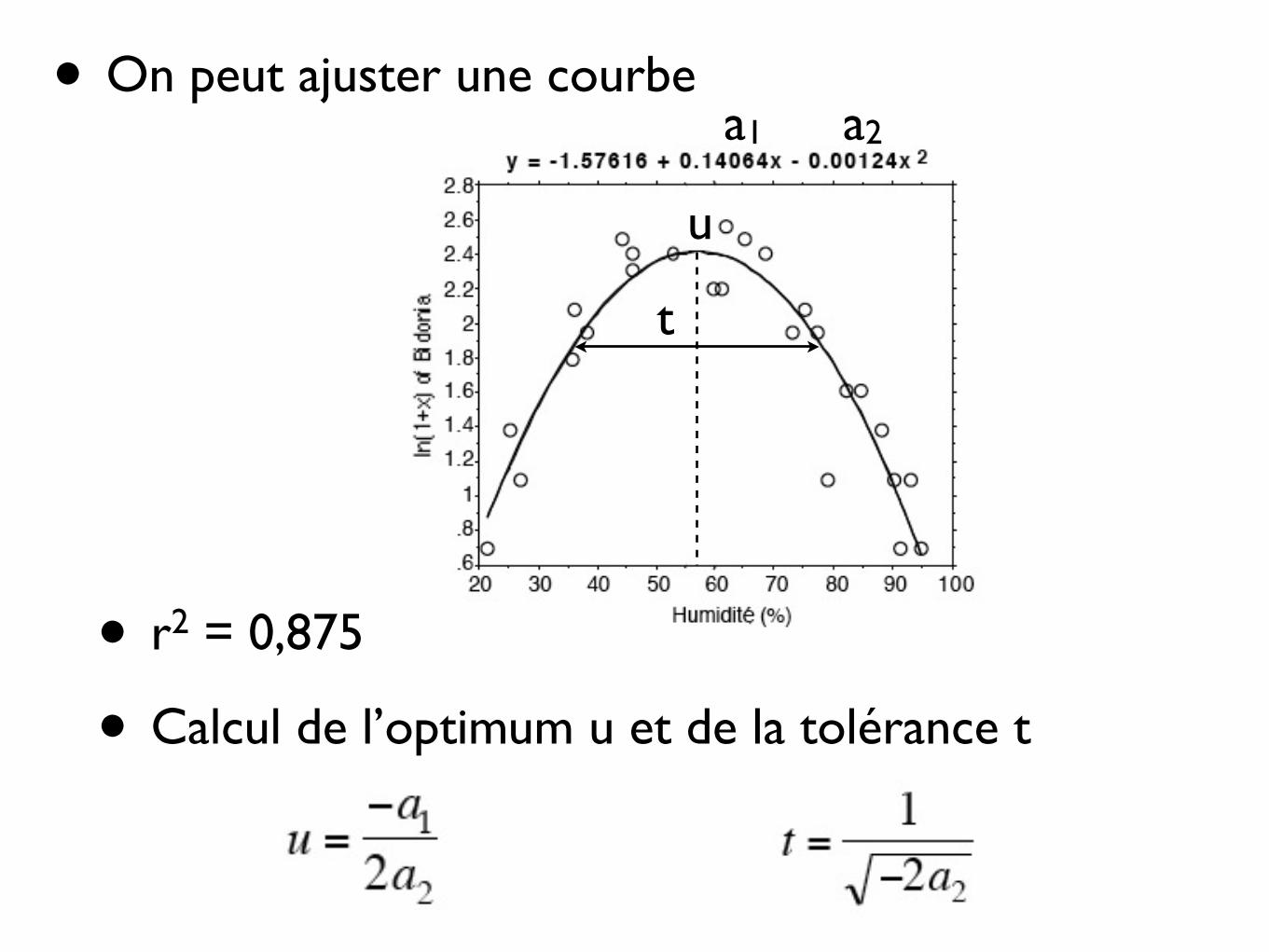
• On peut ajuster une courbe
• r2 = 0,875
• Calcul de l’optimum u et de la tolérance t
a1 a2
u
t

Relation régression et analyse de variance : utilisation de
variables muettes
• En ANOVA, les variables indépendantes sont qualitatives (facteurs)
• Il est possible de les recoder afin de les utiliser dans une régression : variables muettes (dummy variables)
• Le tableau d'ANOVA de la régression donne ainsi le même résultat qu'une ANOVA

• Le recodage se fait avec des 0 et 1
• Exemple : Mâle = 0 ; Femelle = 1
• On pourrait estimer : Taille = f(Poids, Âge, Sexe)
• Taille = 152,03 + 0,43Poids - 0,07Âge - 10,90Sexe
• Une personne de 30 ans pesant 70 Kg mesurera 180 cm si c'est un homme, et 169 cm si c'est une femme
Taille Poids Âge Sexe162 54 25 1185 83 32 0178 65 22 0157 62 43 1175 63 39 1189 91 31 0168 72 27 1
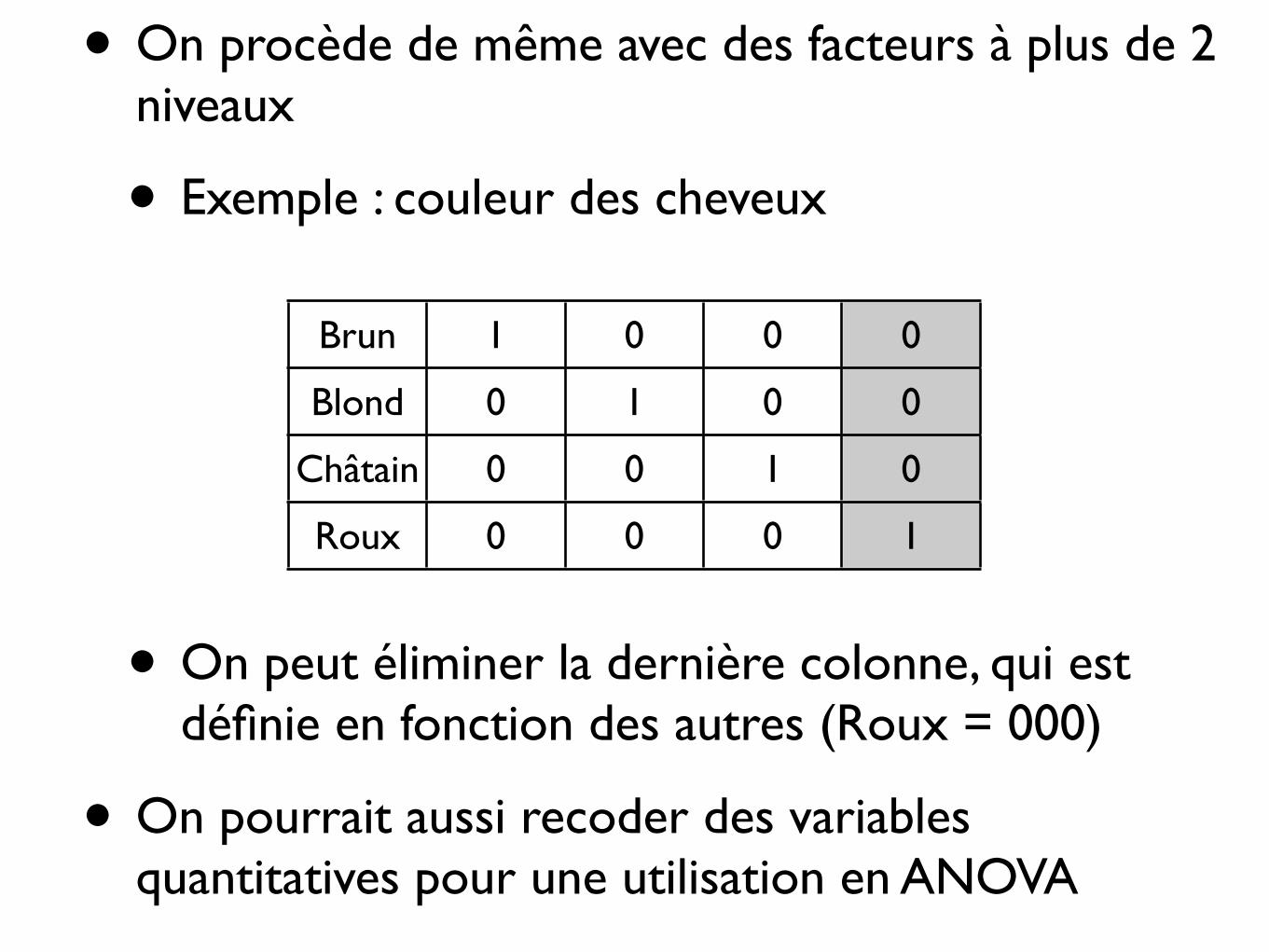
• On procède de même avec des facteurs à plus de 2 niveaux
• Exemple : couleur des cheveux
• On peut éliminer la dernière colonne, qui est définie en fonction des autres (Roux = 000)
• On pourrait aussi recoder des variables quantitatives pour une utilisation en ANOVA
Brun 1 0 0 0
Blond 0 1 0 0
Châtain 0 0 1 0
Roux 0 0 0 1







