data mining
TRANSCRIPT

Département d’informatiqueSidi Bel Abbes

Introduction :Data mining (fouille de données , forage de données …) apparait dans les années 1990 aux Etats-Unis comme une nouvelle discipline a l’interface de la statistique et des technologies de l’information exemple : base de donnée , intelligence artificielle …
Le data mining est devenu aujourd'hui un domaine très en vogue adapter et utiliser dans un large
nombre de domaines d'activités. Dans les plus connus on peut mentionner: 1/ Médical / pharmaceutique: ** Explication ou prédiction de la réponse d'un patient à un traitement. ** Etude des corrélations entre le dosage dans un traitement et l'apparition d'effets secondaires . 2/ Assurance et santé : ** Détection d'association de comportements pour la découverte de clients à risque. ** Découverte d'associations des demandes de remboursements 3/ Banques / Finances : ** Crédit scoring - évaluer le risque de non remboursement (technique data mining la plus déployée). ** Prédiction - prévoir quels clients seront intéressés par une offre. 4/ Marketing : ** déterminer ce qui caractérise un groupe particulier de clients . ** déterminer le prix "optimal" pour un produit.

Définition : Le datamining est un processus d’extractions automatique d’informations prédictives à partir de grandes bases de données. L’objectif est de: ** Développer des techniques et systèmes efficaces et extensibles pour l’exploration de BD larges et multidimensionnelles et des Données distribuées.** Représentation simple de la connaissance.Il existe deux type d’apprentissage : apprentissage supervisé et apprentissage non supervisé. 1/ Apprentissage supervisé :l'apprenant considère un ensemble d'exemples, et infère l'appartenance d'un objet à uneclasse en considérant les similarités entre l'objet et les éléments de la classe . Les classes sont étiquetées préalablement. EX : arbre de décision , 1-R , KNN … 2/ Apprentissage non supervisé :Construction d'un modèle et découverte des relations dans les données sans référence à d'autres données. On ne dispose d'aucune autre information préalable que la description des exemples. EX : K-means .
Les données en datamining :Dans un problème de Datamining, les informations caractérisant une étude sont présentées sous la forme d’attributs et d’instances.

Attributs :• Un attribut est un descripteur d’une entité. On l’appelle égalementvariable, champs, caractéristiques ou observations.Instances :• Une instance est une entité caractérisant un objet et est donc constitué d’attributs.Types de données : • numérique continue : la valeur de la variable peut prendre une valeurdans R (par exemple : le montant du compte en banques). • numérique discrète : la valeur de la variable appartient à Z ou N • catégorie : avec ou sans relation d’ordre (par exemple : { rouge, vert,bleu }). • binaire • Chaînes de caractères (par exemple : un texte) • Arbre : (par exemple Page XML) • Données structurées : graphe, enregistrement
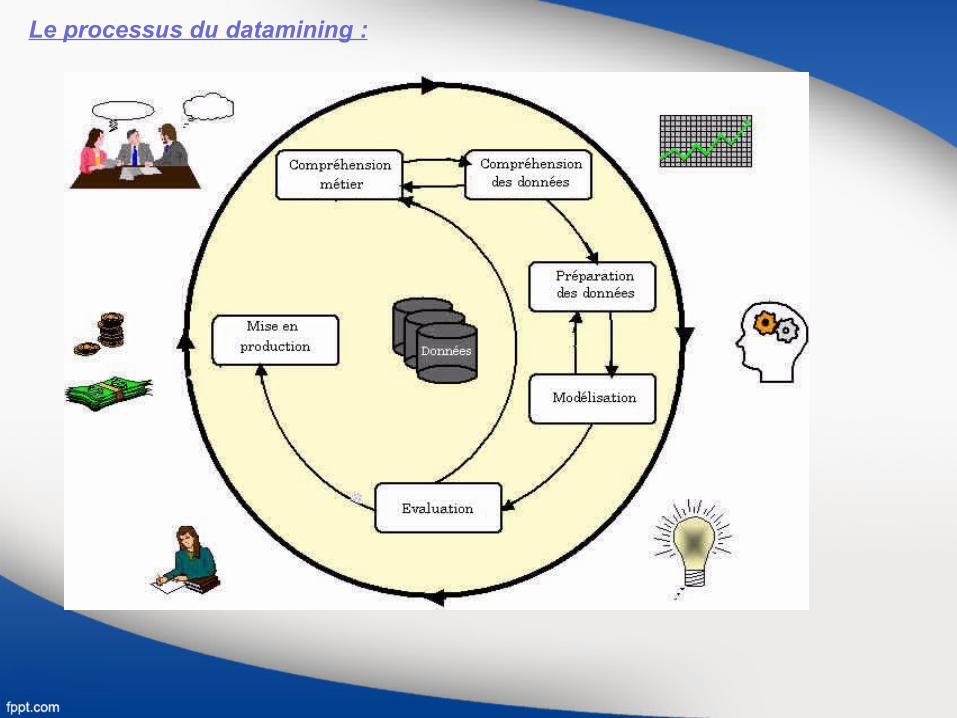
Le processus du datamining :

Le processus du datamining comporte 6 phases :1- Compréhension métier :· Énoncer clairement les objectifs globaux du projet et les contraintes de l’entreprise.· Traduire ces objectifs et ces contraintes en un problème de data mining.· Préparer une stratégie initiale pour atteindre ces objectifs.
2- Compréhension des données :· Recueillir les données.· Utiliser l’analyse exploratoire pour se familiariser avec les données, commencer à les comprendre et imaginer ce qu’on pourrait en tirer comme connaissance.· Évaluer la qualité des données.· Éventuellement, sélectionner des sous-ensembles intéressants.
3- Préparation des données :· Préparer, à partir des données brutes, l’ensemble final des données qui va être utilisé pour toutes les phases suivantes.· Sélectionner les cas et les variables à analyser.· Réaliser si nécessaire les transformations de certaines données.· Réaliser si nécessaire la suppression de certaines données.Cette phase fait suite à la compréhension des données. Celle-ci a mis au jour les corrélations, les valeurs aberrantes, les valeurs manquantes : on peut donc faire la préparation.

4- Modélisation:· Sélectionner les techniques de modélisation appropriées (souvent plusieurs techniques peuvent être utilisées pour le même problème).
5- Evaluation : · Pour chaque technique de modélisation utilisée, évaluer la qualité (la pertinence, la signification) des résultats obtenus.· Déterminer si les résultats obtenus atteignent les objectifs globaux identifiés pendant la phase de compréhension du métier.· Décider si on passe à la phase suivante (le déploiement) ou si on souhaite reprendre l’étude en complétant le jeu de données.
6- Déploiement :· Prendre les décisions en conséquences des résultats de l’étude de data mining· Préparer la collecte des informations futures pour permettre de vérifier la pertinence des décisions effectivement mis en œuvre.

1.Apprentissage supervisé
One Rule :
-Règle de classification qui travaille sur un attribut indépendamment de l’autre. -le modèle étant constitue sur la base d’un seul attribut.
ID3 :
ID3 construit un arbre de décision de façon récursive en choisissant l’attribut qui maxime le gain d’information selon l’entropie de Shannon. Cet algorithme fonctionne exclusivement avec des attributs catégoriques et un nœud est créé pour chaque valeur des attributs sélectionnés.

C4.5:
C4.5 est une amélioration d’ID3 qui permet de travailler à la fois avec des données discrètes et des données continues. Il permet également de travailler avec des valeurs d’attribut manquantes.
Naïve bays:
Modélisation statistique; tout les attributs constituent dans le modèle de façon équitable et indépendante mais la pratique a montré que la méthode bien simple et plutôt efficace.
K-NN:
C’est un fainéant algorithme , consiste à prendre en compte (de façon identique) les k échantillons d'apprentissage dont l’entrée est la plus proche de la nouvelle entrée x, selon une distance à définir.

2. Apprentissage non-supervisé:
Clustering:
est une méthode statistique d’analyse de données qui a pour but de regrouper un ensemble de données en différents groupes homogènes Chaque sous-ensemble regroupe des éléments ayant des caractéristiques communes qui correspondent à des critères de proximité.
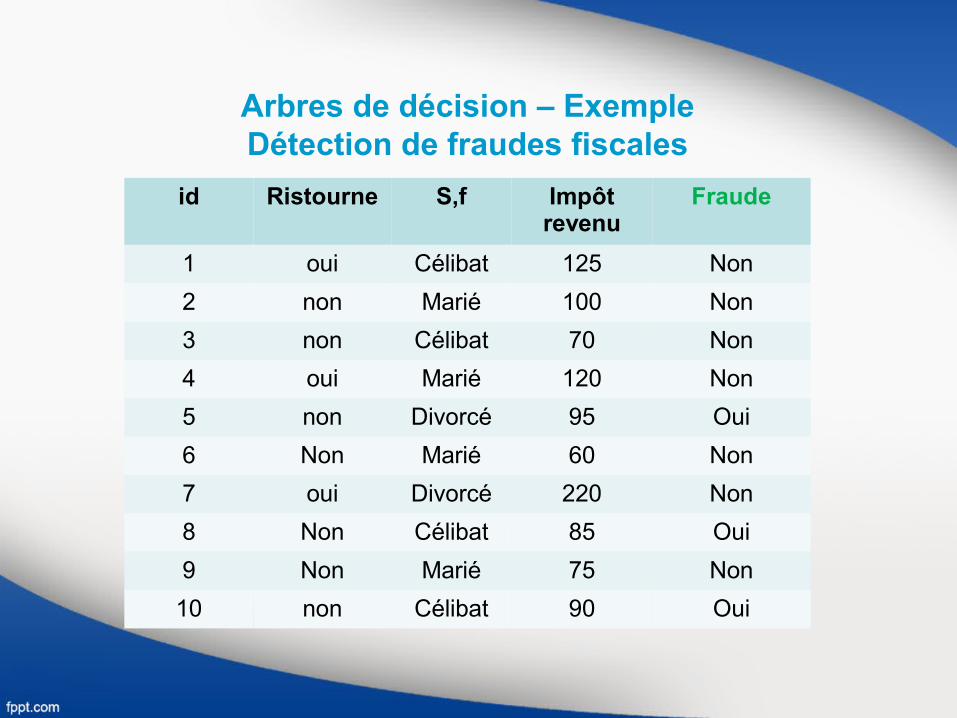
Arbres de décision – Exemple Détection de fraudes fiscales
id Ristourne S,f Impôt revenu
Fraude
1 oui Célibat 125 Non
2 non Marié 100 Non
3 non Célibat 70 Non
4 oui Marié 120 Non
5 non Divorcé 95 Oui
6 Non Marié 60 Non
7 oui Divorcé 220 Non
8 Non Célibat 85 Oui
9 Non Marié 75 Non
10 non Célibat 90 Oui
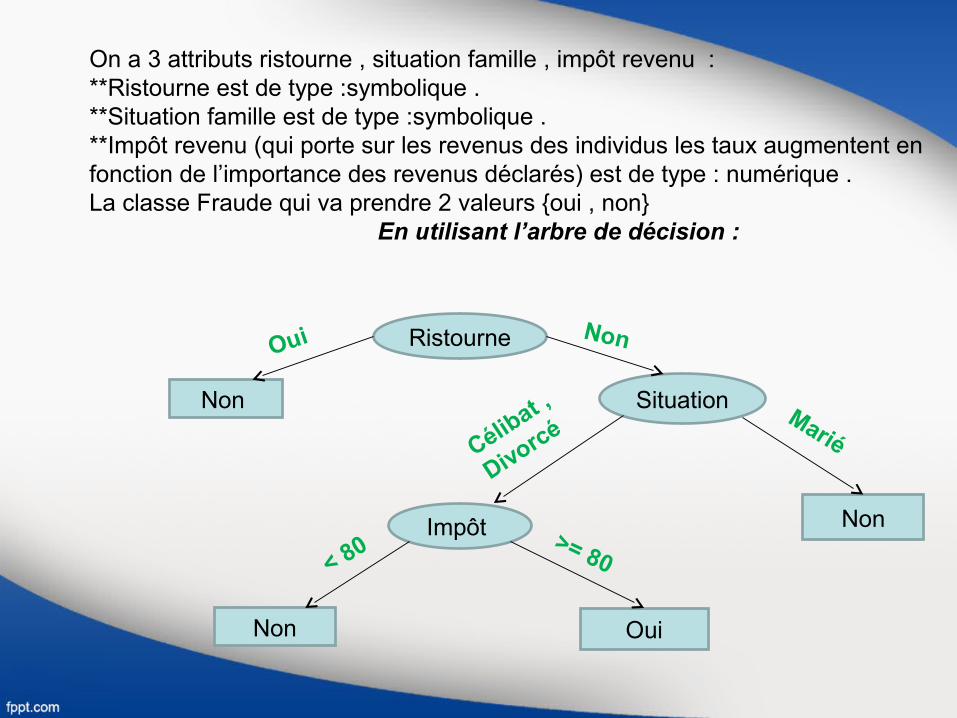
On a 3 attributs ristourne , situation famille , impôt revenu :**Ristourne est de type :symbolique .**Situation famille est de type :symbolique .**Impôt revenu (qui porte sur les revenus des individus les taux augmentent en fonction de l’importance des revenus déclarés) est de type : numérique .La classe Fraude qui va prendre 2 valeurs {oui , non} En utilisant l’arbre de décision :
Ristourne
Non Situation
Impôt Non
Non Oui
Oui Non
MariéCélibat ,
Divorcé
>= 80< 80
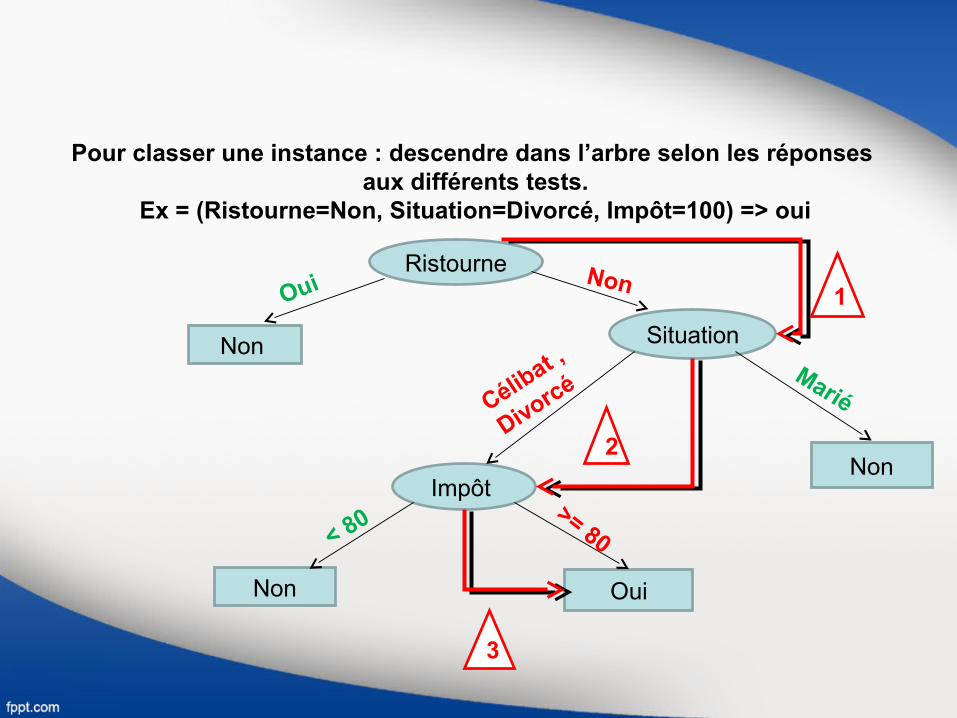
Pour classer une instance : descendre dans l’arbre selon les réponses aux différents tests.
Ex = (Ristourne=Non, Situation=Divorcé, Impôt=100) => oui
Ristourne
Non Situation
Impôt Non
Non Oui
Oui Non
MariéCélibat ,
Divorcé
>= 80< 80
1
2
3

Pour bien mener un projet de DM •Identifier et énoncer clairement les besoins.
•Créer ou obtenir des données représentatives du problème •Identifier le contexte de l’apprentissage
•Analyser et réduire la dimension des données •Choisir un algorithme et/ou un espace d’hypothèses.
•Choisir un modèle en appliquant l’algorithme aux données prétraitées. •Valider les performances de la méthode.