clir techniques ver 1
TRANSCRIPT

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 1/40
Introduction
1.1 What is CLIR Techniques? From " Douglas W. Oard and Bonnie J. Dorr. Evaluating Cross-Language Text Filtering
Effectiveness. In Proceedings of the Cross-Linguistic Multilingual Information RetrievalWorkshop, pages 8-14, Zurich,Switzerland, 1996
Techniques to select document in one language based on information need /query Q inanother language.
1.2 Translate document or query? FROMOard and Diekema have identified three basic approaches D. W. Oard and A. R. Diekema. Cross-language informationretrieval. In Annual Review of InformationScience and Technology, volume 33.
to CLIR: query translation, document translation,and interlingual techniques [6].
Translate document or query?
Paper McCarley, J.S.: Should We Translate the Documents or the Queries inCross-Language In-. formation Retrieval? Proceedings of the 37thannual meeting of the Association for ComputationalLinguistics on Computational Linguistics , 1999
HOW,RESULT Oppesit two directions of translations between document and querythe authors try identical data set to investigate IR between English ad
French using MT and they found that hybrids document and querybased systems out perform (better than) depending on query onlyeven human query translation.
Disadvantages inusing MT in querytranslation
-machine translation is Error Prone ,query are short and containkeywords and phrase only once so when t translated to the wrongone the IR engine cant recover while translating long documentsgives better chance to MT in translation.- MT tendency in translation where the output is smaller than theinput vocublary
Fast MT engine Authors argue that translating collection of documents is expesiveand for that they develop fast MT Engine for translting largecollection of documents and quries for IR

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 2/40
on Research and development in information retrieval, 1998 - portal.acm.orgPage 1. The Effects of Query Structure and Dictionary Setups in Dictionary-Based Cross-language Information Retrieval Ari Pirkolaist.org/fileadmin/engage/public_jakarta2006/presentations/A1_02_Adriani.pdf,last visited at Dec2007
Using language models for information retrieval Ph. DD Hiemstra - Thesis University of Twente, Enschede, 2001
1.2.1 Query translation
Advantages
• Less Expensive than document translation from computations point of view
• effective with short quiresApproaches for query translation includes,
• Machine translation• Corpus based Methods
• Dictionary based Methods
1.2.2 Document Translation
Document translation Advantages over query translation
• Able to be done off-line language model
• Ability to give the user high quality preview of the document• More text for disambiguation
Disadvantages
• Needs a lot of memory and Processing
McCarley, J.S.: Should We Translate the Documents or the Queries in Cross-Language In-.formation Retrieval? Proceedings of the 37th annual meeting of the Association for Computational
Linguistics on Computational Linguistics , 1999jakarta2006.engage-
Opposite two directions of translations between document and query the authors try identical data set
to investigate IR between English ad French using MT and they found that hybrids document
and query based systems out perform (better than) depending on query only even human query
translation.
Using language models for information retrieval Ph. D .D Hiemstra - Thesis University of Twente, Enschede, 2001
Its difficult to answer this question –problems and it needs need further research
Problems In query translation approach Problems Document translationapproach
search done in document language Search done in language of query
Must pick one translation and translatethe document.
Can use more than translation fro reachquery term
2

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 3/40
CLIR Techniques Taxonomy
1.3 Previous taxonomy at 1997
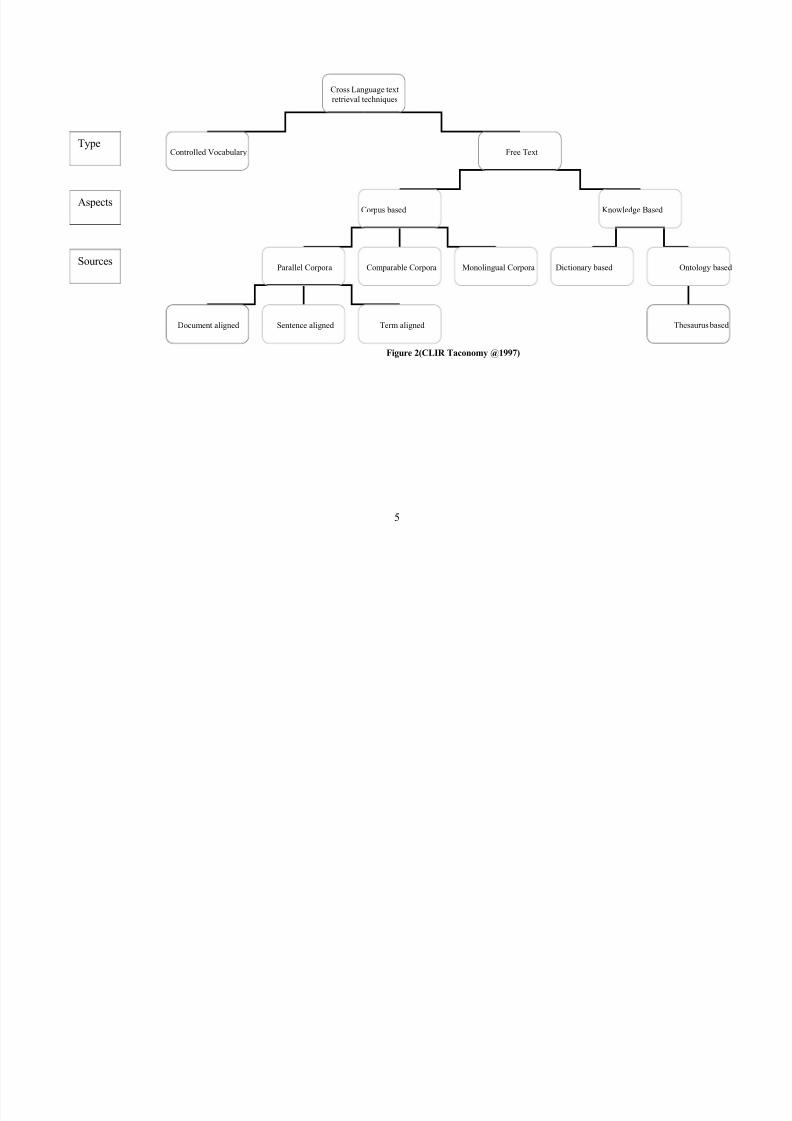
Cross language text retrieval approaches {taxonomy}Oard 1997) Douglas W. Oard, "Alternative Approaches for Cross-Language Text Retrieval," inCross-Language Text and Speech Retrieval , AAAI Technical ReportAs shown in Figure 1 and briefly they will be defined as follow
1.3.1 Controlled Vocabulary
Predetermined vocabulary Used to index documents and the user uses the samevocabulary to form his/her query. Noticing that entering new terms will motivate the needto describe it. This approach different from Concept Identifier match, where multilingualthesaurus applied to relates selected terms from each language to universal set of language
[This method obstacle for 2 decades now as Dr.Oard told in his Email ]
1.4 Free Text
1.4.1 Corpus based
Use Query translation methods to overcome Knowledge based methods restriction. Thus this method is suitable for specific applications.
1.4.1.1 Parallel Corpora
Analyze the text and automatically extract the information needed where thecollection contains the original documents and their translation.
But there are Limited causes of the need to get suitable collection for applying thetechnique where translated documents are expensive to create.
1.4.1.2 Comparable Corpora
The collection composed of documents on similar subjects. BUT written indissimilar languages. It over comes Parallel Corpora disadvantage
But similarity depends on the topics addressed in the document.
1.4.1.3 Monolingual Corpora
"A monolingual corpus would be a collection that is in a single language." Oard –by
Email"
1.4.2 Knowledge Based
1.4.2.1 Dictionary based
Replace each term in the Query Q with suitable term or terms in the wanted language.Noticing that entering new terms will motivate the need to describe it. As in Controlled
Vocabulary.Disadvantages of Dictionary based approachOard 1997) Douglas W. Oard, "Alternative Approaches for Cross-Language Text Retrieval," inCross-Language Text and Speech Retrieval , AAAI Technical Report
1. Many words don’t have unique translation, beside that translation may have
different meaning.1. translation may require additional words to be added because
3

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 4/40
1.1. query may be talking about a topic that's out the dictionary range1.2. user uses slang or abbreviations that's not in the dictionary
This approach will be discussed in more details later at this report
1.4.2.2 Ontology based
Ontology is a "sophisticated knowledge structure"
Need reading
1.4.2.3 Thesaurus basedBoca Raton, Florida. USA • 2005. A Machine Translation Approach to Cross Language TextRetrieval , -http://www.dissertation.com/book.php?book=1581122675&method=ISBN. University of Glasgow, Glasgow, United Kingdom ,Advisor(s): Mark Sanderson,Degree: Master of Science(M.Sc.),Year: 1997
Multilingual thesaurus organizes terminology from more than one language. It
represents term and concept relationship in understandable way to human. it Can beused manually or automatically And Concept retrieval technique used when conceptadded to thesaurus.
http://www.glue.umd.edu/~oard/teaching/796/spring04/slides/10/
There are Three construction techniques
• from scratch thesauri building
• existing thesaurus Translation
• Merging monolingual thesauri
4
8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 5/40
Type
Cross Language textretrieval techniques
Controlled Vocabulary Free Text
Corpus based Knowledge Based
Parallel Corpora Comparable Corpora Monolingual Corpora Dictionary based Ontology based
Document aligned Sentence aligned Term aligned Thesaurus based
Aspects
Sources
Figure 2(CLIR Taconomy @1997)
5

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 6/40

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 7/40
But this approach is not powerful
Morphological analysis
Lexicaltransfer using
bilingualdictionary
Localreordering
Morphological generation
Target
Language Text
Source
LanguageText
7

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 8/40
From Foundations of Statistical Natural Language Processing. by Christopher D.Manning and Hinrich Schütze. MIT Press, 1999.
2.1.2.2 Word for word disadvantages
• There is no association between one to one words
• Languages have different word order and naïve direct translation usuallywill order words wrong.
• Syntactic ambiguity
From www.stanford.edu/class/linguist180/ , Introduction to ComputationalLinguistics.htm that uses the Jurafsky book MT approaches
2.1.3 Transfer Model
Transfer Models Steps are analysis Transfer Generation
2.1.3.1 Syntactic transfer approaches
Depends on applying contrastive knowledge that is languages differenceknowledge, it also needs bilingual dictionary such in Direct MT.Steps as shown:
• Analysis: parse Source language syntactically
• Transfer: turn the source language into the target language using Rules
•
Generation: Generate Target sentence using parse treeE.g. English to French rule
Such approach is hard to implement and maintain ,From Foundations of Statistical Natural Language Processing. by Christopher D.Manning and Hinrich Schütze. MIT Press, 1999.
2.1.3.1.1 Disadvantages
Syntactic ambiguityUnsuitable semantic e.g. there is no verb adverb construction in English suchin German " I like to eat German phrase" translated to English to " I eat gladly |with pleasure "
TargetSyntacticParse
Syntactic Transfer SourceSyntactic
parse
TargetText
Word for wordSourceText
8

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 9/40
2.1.3.2 Semantic transfer approachesFrom Foundations of Statistical Natural Language Processing. by Christopher D.Manning and Hinrich Schütze. MIT Press, 1999.
Represent Source sentence meaning. By parsing then indicate the meaningfinally generate target language
2.1.3.2.1 Disadvantages
Even if literal | exact meaning is correct it could be unintelligible | making no sensee.g I need one the book talked about Spanish phrase that I cant understand
NEED EXAMPLE
From www.stanford.edu/class/linguist180/ , Introduction to ComputationalLinguistics.htm that uses the Jurafsky book MT approaches
2.1.4 Interlingua
Depends on meaning using Instead of language - to - language rules.
1- Create meaning representation [Knowledge representationformalism, independent from any language literal meaning translation]by translating source sentence to it.2- Use the meaning representation to generate target sentence
Easier to write results this way b useful information lost
From Foundations of Statistical Natural Language Processing. by Christopher D. Manning and Hinrich Schütze. MITPress, 1999.,chapter21
2.1.4.1.1 Disadvantages
Difficult to design efficient knowledge representation ;because of huge
amount of ambiguity in translating from natural language to Interlinguaknowledge representation.
Targetsemanticmeaning
Semantic TransfereSourcesemanticmeaning
؟
9

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 10/40
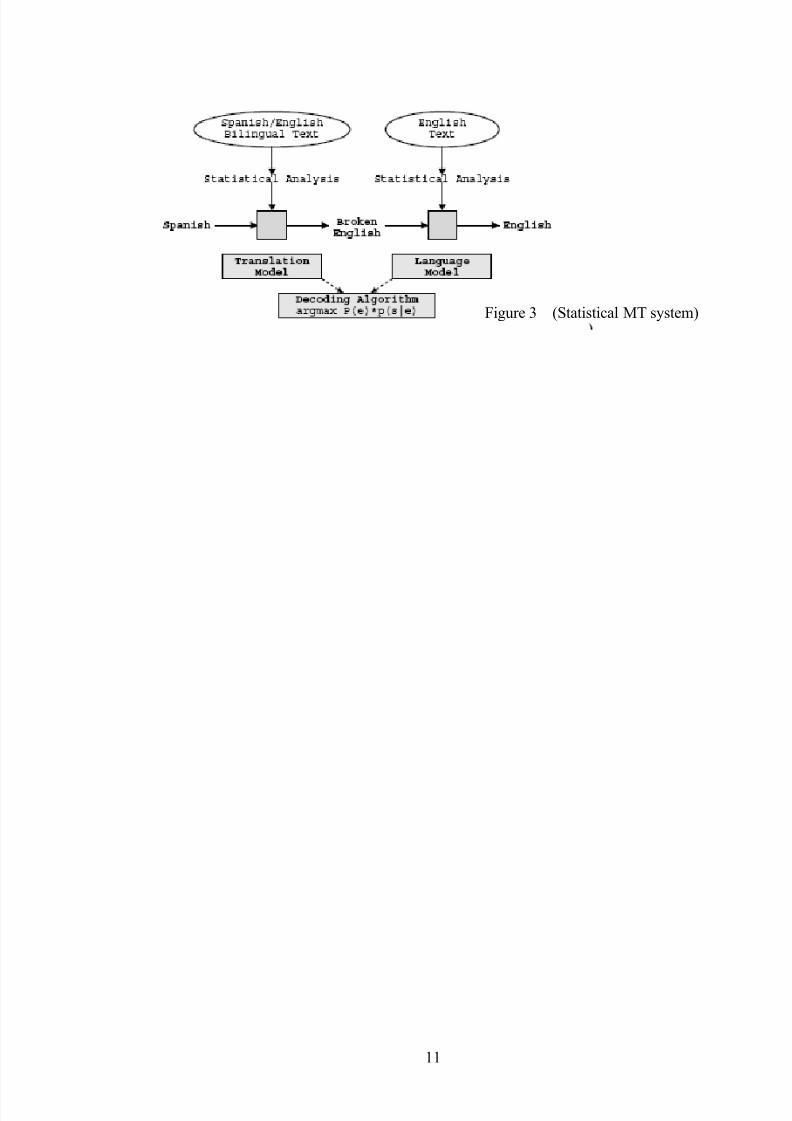
2.2 Modern statistical Machine Translation (SMT)approaches; focus on results
2.2.1.1 Statistical MT systemESSLLI Summer Course on SMT (2005), day1, 2, 3, 4, 5 by Chris Callison-Burch andPhilipp Koehn , http://www.statmt.org/
Get most accepted English sentence [target language] given foreign languagesentence [source language] .
e^ = argmax P(e) P(f | e)
Where e^ best translationP(e) fluency
P(f | e) faithfulnessFrom Foundations of Statistical Natural Language Processing. by Christopher D.
Manning and Hinrich Schütze. MIT Press, 1999.,chapter13SMT compromises due to languages culture and parallel constructions, tenseand metaphor are differ so SMT do what translators do compromise to beaccepted in both languages.
To do so we need three things
• Quantify fluency ; language model
• Quantity faithfulness; translation model
• Create algorithm to find best translation ;that maximize the product of P(e) P(f | e) .Decoding algorithm
From SMT Tutorial (2003) by Kevin Knight and Philipp Koehn Information SciencesInstitute
University of Southern California , http://www.statmt.org/
Figure 2 (Statistical MT system)
10
8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 11/40
Figure 3 (Statistical MT system)
11

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 12/40
ESSLLI Summer Course on SMT (2005), day1, 2, 3, 4, 5 by Chris Callison-Burch andPhilipp Koehn , http://www.statmt.org/
2.2.2 Language model
Tries to make sure that words are in right order P (e) , it gives higherprobability to fluent / grammatical sentence . It is estimated throughmonolingual corporaCalculation done using standard trigram language model
Trigram is a specialization of N-gram models where n=3 words
2.2.2.1 Language Model – n-gram
For N-grame models
P (wn-1,wn) = P(wn | w n-1) P(wn-1)
Language model – Tri gram
E.g. Trigram example
P(I want to eat Chinese food) = P(I | <S><S>) * P( want | I <S> ) * P ( to | I want )*P(eat | want to) * P (Chinese | to eat) * P( food | eat Chinese )* P(</s> | food Chinese ) *P(</s> | Chinese </s>)
Calculating probabilities done as shown below• Uni-gram probability P(w1)= count w1 / total words• Bi-gram probability P (w2 | w1) = count (w1w2) /count w1• Tri-gram probability P (w3 | w1 w2 ) = count (w1 w2 w3 ) / count (w1 w2 )
Increasing N increases accuracy but needs larger corpus to train back off Proceed from
ESSLLI Summer Course on SMT (2005), day1, 2, 3, 4, 5 by Chris Callison-Burch andPhilipp Koehn , http://www.statmt.org/
Calculate Language model – Probabilistic Context Free Grammars PCFG
2.2.2.2 Language model – Probabilistic Context Free
Grammars PCFG
Also it could be calculated using Probabilistic Context Free Grammars PCFGthat defines sentence probability according to grammar GFromhttp://umiacs.umd.edu/~resnik/programming/assignments/project1/project1.html ,last visited January2008http://en.wikipedia.org/wiki/Stochastic_context-free_grammar , last visited January
2008
Probabilistic context-free grammar PCFG stochastic context-free grammar CFGis a context free grammar where each production[possible right hand side \terminal symbols ] has a probability , and the parse / derivation is the productof the probabilities of the use production in the derivation but summation of right hand side probabilities to calculate the non terminal symbol probability ismore consistent .E.g.S -> NP VP [1.0]NP -> Det N [0.6]
NP -> Det Adj N [0.2]NP -> John [0.1]
12

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 13/40
NP -> Mary [0.1]VP -> Vi [0.3]VP -> Vt NP [0.7].. and so on.
13

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 14/40
2.2.3 Translation model P(f | e)
From Foundations of Statistical Natural Language Processing. by Christopher D.Manning and Hinrich Schütze. MIT Press, 1999.,chapter21
Bilingual dictionary doesn’t tell what word is equal to another in differentlanguage but parallel corpus do that, but to use it problems must be solved firstthose problems includealignment
Word alignment or Melamed Pear / EM methods.
ESSLLI Summer Course on SMT (2005), day1, 2, 3, 4, 5 by Chris Callison-Burch andPhilipp Koehn , http://www.statmt.org/
Gives higher probability to sentence that have related meaning. It is
estimated through bilingual corpora .training corpus used to estimateparameters.It is impossible to calculate p(f |e) for a sentence so sentences broken intosmaller chunks andP( f | e ) = sum a P(a, f| e) where a is an alignment between word and the sentenceP(a, f| e) =|--| j=1 m [from j=1 to m ] t(f j | e i)t(f j | e i) = count (f j | e i) / count (e i)
14

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 15/40
From http://www.stanford.edu/class/linguist180/
2.2.4 Decoding Algorithm
Given translation model language model and a new sentence translate it by
maximizing P(e) P(f | e).Kevin knight refer to t as generative story it has three steps1) Construct phrase by Grouping words2) Translate every phrase3) Reorder translated phrases with distortion probability that
1) measure distance between positions in the two languages2) parameterized using two parameters
1) ai => the start position of the foreign phrasegenerated by the ith English phrase ei 2)3) bi-1 => is the end position of the foreign generated
by the I-1th source phrase ei-1
2.3 SMT evaluationFrom Adam Lopez, A Survey of Statistical Machine Translation.
Statistical machine translation methods consider many of human formedtranslation samples then SMT algorithms automatically learn how to translate,SMT described by the use translation a machine learning methods.SMT accuracy system depends on
• Data accuracy
• Data quantity
• Data quality
• Data domainFrom "Machine Translation in the Year 2004", (K. Knight, D. Marcu), Proc. ICASSP,2005.
MT System Evaluation is subjective process since translation is generationprocess not a classification process, evaluating the system is unclear, howcould distance between human translation and MT be measuredE.g. from Chinese to English "from the paper"
At least 12 people were killed in the battle last weekAt least 12 people lost their lives in the last week fightLast week fight took at least 12 lives ….etc it has 11 differenttranslations.
From "INEED THE BOOK CALLED of Jurafsky and Martin. 2007. Speech and LanguageProcessing. CHAPTER 25 "From C:\Documents and Settings\XPPRESP3\Desktop\MT\LINGUIST 180 Introductionto Computational www.stanford.edu/class/linguist180/ .htm that uses the Jurafskybook MT approaches
Good translation depends on
• Faithfulness : how close the target meaning to the source translated text" does the translation cause the reader to draw the same inferences asthe original would have"
And
• Fluency: how natural is the translation taking in account the fluency in
the target language.
15

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 16/40
3 Corpus based Methods
Translate the query by finding association between query and document (implicit
dependency and co-occurrence ) independent of language differences.We have collection C1 in language A
and collection 2 C2 in language B
and collection of translated documents C3 that contain translated documents from
language A to B , C3 can be observed in both spaces related to C1 and C2 , If query Q in
language B submitted the C3 related documents will retrieved and used to retrieve related
documents from C1 that uses language A.
So Query translation And Expansion done using basis of multilingual terminology
(terms ?"is terms right word??" ) Derived from parallel or comparable corpora
(Ari Pirkola,1998) opinion in corpus based methods where query translated andexpanded depending on comparable document collection or parallel corpora ,Varity of
methods used and some of them pointed that their results near to monolingual quires .
But such approaches that report near to monolingual quires A training sample to be
representative of the full data and sufficient parallel or comparable corpora to be
available.( we don’t have it in our data set )
16

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 17/40
4 Dictionary based Methods
4.1 Problems of Dictionary based MethodsDictionary-Based Cross-Language Information Retrieval: Problems,. Methods, and ResearchFindings. Inf. Retr. 4(3-4): 209-230 (2001). ... www.waset.org/pwaset/v4/v4-44.pdf -
•Untranslatable search key that wont be found in general dictionary ; newcompound words ,names ,spelling variants and special terms { I think thisrelated to medical in special terms }
o Where compound words are easier to decompose thanphrase identification.o Proper names and spelling variants ,to translate spellingvariants Varity of methods could be used such as
n- gram based matching or
approximate string matching or
Transliteration based on phoneticكت بحروف لغة أخريsimilarity . BUT n-gram shows that its effective comparablewith poor results of the other two methods, for that theytest n gram method and query structuring both togetherthey claim it could be used in mono or cross languageretrieval.
Special terms transition prob. can be solved by theuse of general and domain specific dictionary . it ispossible to combine limited content dictionaries to covergeneral language and many specific domains. Noticing thatspecial dictionary reduce translation ambiguity problem. Pirkola 1998 used this combination to translatehealth documents and he summarized his experience inusing sequential translation where special dictionary getsmore weight is appropriate for scientific text.
o Inflected طع- نث – فرص فر words
Stemming used to deal with inflected words and the output is root or stem. Also morphological analysis used where wordsnormalized into base form and split compound words. Stemmingproblem is that different headwords can be belong to one stem;and if index terms stemmed dictionary output words have to be
stemmed. Morphological effectiveness is limited to morphologicallexicon size its impossible to list all language words in lexicon.Noticing that when depending on stemming recall improved sincemore documents retrieved on the other hand precisionimprovement depends on the language experiments on ArabicEnglish French show that.
o Phrase
Identified using
• collection statistics tor exognize sub phrases in phrases<!?>
• Part of speech tagging POS
17

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 18/40
Phrase translation if phrase are not defined and translated correctly then the effect may be fatal on quires. phrase translationmay be done by
• Phrase dictionary where its impossible to list all phrases or
•
Based on word collection statistics<???>o Translation ambiguity, CLIR dictionary based technique to handleambiguity involves
Part of speech tagging ,had different effective on differentlanguages Corpus based disambiguation ,includes query e Pirkola)……<I didn’t complete the paper MISSSSSSSSSSS >
18
8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 19/40
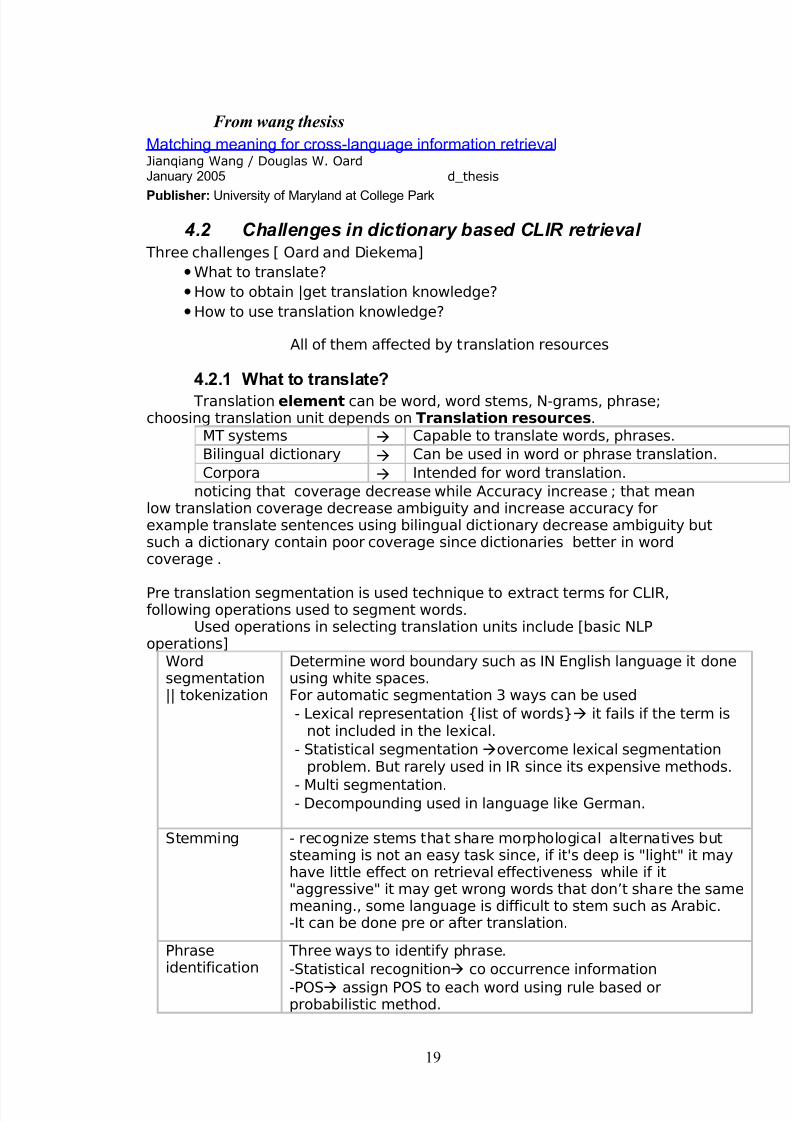
From wang thesiss
Matching meaning for cross-language information retrieval Jianqiang Wang / Douglas W. OardJanuary 2005 d_thesis
Publisher: University of Maryland at College Park
4.2 Challenges in dictionary based CLIR retrieval Three challenges [ Oard and Diekema]
•What to translate?
•How to obtain |get translation knowledge?
•How to use translation knowledge?
All of them affected by translation resources
4.2.1 What to translate?
Translation element can be word, word stems, N-grams, phrase;choosing translation unit depends on Translation resources.
MT systems Capable to translate words, phrases.
Bilingual dictionary Can be used in word or phrase translation.
Corpora Intended for word translation.
noticing that coverage decrease while Accuracy increase ; that meanlow translation coverage decrease ambiguity and increase accuracy forexample translate sentences using bilingual dictionary decrease ambiguity butsuch a dictionary contain poor coverage since dictionaries better in wordcoverage .
Pre translation segmentation is used technique to extract terms for CLIR,following operations used to segment words.
Used operations in selecting translation units include [basic NLPoperations]
Wordsegmentation|| tokenization
Determine word boundary such as IN English language it doneusing white spaces.For automatic segmentation 3 ways can be used
- Lexical representation {list of words} it fails if the term isnot included in the lexical.
- Statistical segmentation overcome lexical segmentationproblem. But rarely used in IR since its expensive methods.
- Multi segmentation.- Decompounding used in language like German.
Stemming - recognize stems that share morphological alternatives butsteaming is not an easy task since, if it's deep is "light" it mayhave little effect on retrieval effectiveness while if it"aggressive" it may get wrong words that don’t share the samemeaning., some language is difficult to stem such as Arabic.-It can be done pre or after translation.
Phraseidentification
Three ways to identify phrase.
-Statistical recognition co occurrence information
-POS assign POS to each word using rule based orprobabilistic method.
19

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 20/40
-Syntactic Parsingconstruct syntactic structure e.g. verbphrase.
Stop wordremoval
Pre translation stop word removal is worthy since theyincorrectly could be translated into high term weight words.
20

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 21/40
4.2.2 How to get translation knowledge?
Require tow steps1. Acquire /get translation resource that contains theknowledge.
Where each resource type has its own advantages and disadvantages.Resources to get translation knowledgeHuman Human construct the most truthful and confident translation, but for
automatic IR system it's impractical.
Parallel /comparablecorpora
Sentence aligned parallel corpora can be used to develop term toterm translation model [since it contain the same sentence welltranslated in the two languages] on the other hand sentence alignparallel corpora is rare to find.Comparable corpora [same subject but not same sentencestranslated], extracting translation knowledge is a challengeabletask.
Mt systems For building Mt system often require more language resources andhuman power.
Bilingualdictionary
Cover pair of languages more than other resources
Despite Translation Knowledge Resources Out-of-Vocabulary (OOV) terms if translated such as names and geo locations; decrease the CLIR system
effectiveness.
2. Extract the knowledge from the resource.
How to do 1, 2 (acquire and extract knowledge using) following resources.
Bilingual dictionary. Acquired by
- web Searching- -universities- Research institutes- Non prophet organizations
-printed bilingual dictionary
Bilingual corpora , Acquired by Parallel corpora fromInternational organization e.g. (UN) for example rules published in several languages,European union publications, the Bible.
Web for both parallel and comparable corpora [a previous study shows that parallel pages can be found using web page anchor related text. Also mining the web to find parallel ages I promising technique.
These dictionariesoften low coverage
and don’t covermost languages
D e p e n d s o n d i c t i o n a r y s t r u c t u r e
( b o l d , i t a l i c , e n t r i e s . . ) a n d
p e r f o r m w a r s t h a n w e b d i c t i o n a r y
21

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 22/40
Bilingual corpora used techniques to extract translation knowledge could be
• Statistical MT , GIZA++ tool kit let the user to select a model and change parameters.
• Cross language latent semantic Indexing CL-LSI
4.2.3 How to Use translation knowledge?
Two interrelated views
1-Translation disambiguation2-Weighting translation choices
1-Translation disambiguation
When more than one translation available [Polysemy = term have more than one
meaning] ambiguity shall be resolved.How does ambiguity solved in Bilingual DictionaryEarly First method depends on selecting one best translation, but no guarantee that’sthe first translation is the most appropriate and if it’s the right translation it may notfit in the specific sentence being translated, beside that not al dictionaries put themost equivalent translation as first one.Second approach is to depend on more than one dictionary to find the translation andit seems logically true to take the one that appears in most of them.The third and most efficient method depends on phrase translation rather than wordtranslation it identify and translate phrases .but phrase covering in bilingualdictionaries are limited.How does ambiguity solved in Corpora-Davis and his colleagues use POS for each English query and select its equivalentpart of speech tagging POS in Spanish text that matches, this done on TREC 5collection and improve CLIR effectiveness more than 70%.but conflicting resultsobtained when disambiguation used independently it decrees effectiveness .-term statistics also used, simplest method is to calc unigram frequency in the targetcorpus and choose the highest one BUT no study differentiate between synonymousambiguity and polysemous ambiguity that seems to have more bad influence onCLIR.- Co occurrence phrase translation to dictionary translation improves CLIReffectiveness.-other study uses word co occurrence e information to translate and resolve
ambiguity but this improves CLIR effectiveness slightly and researchers point to thesmall training set or domain as arson for that slight improve .
22

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 23/40
How to deal with out of vocabulary terms (OOV)
Three major techniques1-TranslationIf the languages share similar alphabets translation can be
A)Orthographic ئاجهmapping :-use rules to transform language A spelling tolanguage B spelling .e.g. treat English word as misspelled French word and considerbest suits an translation.But if no share in alphabet between the two languages then B) considered
B) Phonetic ظل) ص )mapping can where OOV words converted to phoneticversion that converted to target language using phonetic rules[derived by expert orstatistic approaches] finally transformed to character sequence2- Backoff اتخإ translation [it shows improvement in retrieval - CLEF collection2000]Oard develop a Backoff translation technique that enhances CLIR retrievaleffectiveness the technique the experiment as shown below
• Term by term translation technique.
•Require lexicon [dictionary], where each French F word associated with rankedlist of English translations {e1, e2, e3…}.A) Match input document term surface [English] form with source language
surface forms In the translation dictionary. If it fails go to B).B) Match input term stem ذ with source language surface forms In the
translation dictionary. If it fails go to C).C) Match input term surface form with term stems forms of the source In
thetranslation. If it fails go to D).
D) Match input term stem with term stems forms of the source In thetranslation
dictionary.3-Pre translation expansion
[Query expansion]
Query expansion can be before OR after translation.If before pre-translation If After Post-Translation
• First monolingual retrievalperformed on comparable documentcollection.
• A new query created by addingterms from top ranked documents.
• The new query set translated .
• Search target collection using thenew translated set.
AdvantagesUseful words translated to targetlanguage. This method very effective inshort queries
• Expand translated query.
• By adding top terms from topranked retrieve documents usingtranslated query.
AdvantagesVary according to experiment, some
peppermints shows that its affectpositively retrieve when long queriesused and when poor translationresources used too.
[Document expansion]For CLIR done as follow
• Translate documents to query language
• Use translated document as query to search the comparable collection
• Select top ranked terms fro top ranked documents and expand the translated
document (expansion). This shows light small improvement in retrieval.
23
8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 24/40
Using the webFollowing method might be true for un cognate character set languages, the methoddepends on observing Particular technical terms that stay as it's when borrowed fromanother language.
24

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 25/40
2- Weighting translation choices Techniques developed to weight choices these techniques include thefollowingWeighted Boolean Model (translation probability knowledge are not available)
• Based on independent assumption
•User query constructed like in monolingual Boolean model where termslinkded by conjunction (or and not0 ,this model perform better than vectorspace model when using manual query processing.
•Noticing that d = document , ti(i=1,2..n) query term
P(A and B) = P(A^B)=P(A)*P(B) weighting function P(t1 And …And tn|d)=P(A OR B) –p(AV B) = P(A)+P(B)-P(A)*P(B) =1-[1-P(A)]*[1-P(b)]
weighting function P(t1 AOR…OR tn|d)=
P( NOT A) =1-P(A) weighting function 1-P(ti }d)
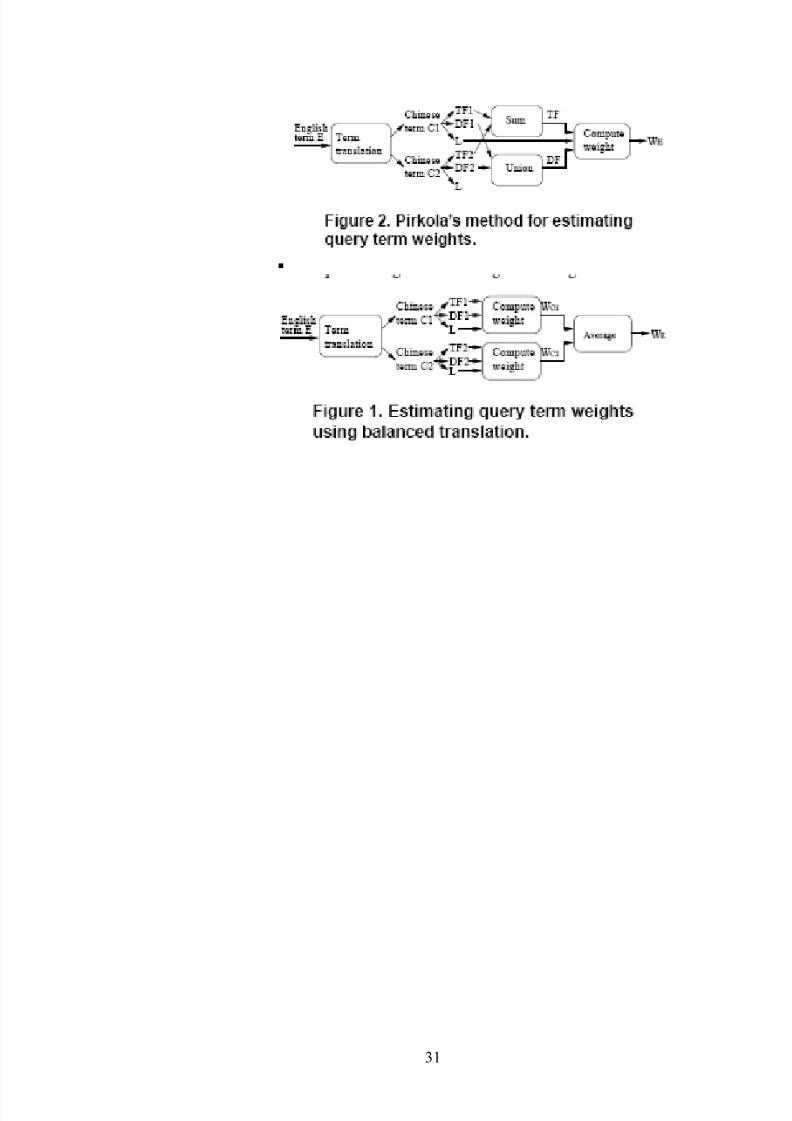
Balanced translation(Levow and Oard, 2002) (translation probability knowledge are not available)
Where source term is the arithmetic mean of its translations weight.Balanced translation problem is that it gives more weight for Rare Terms
This is logical if the rare term translation was correct.But kill rare terms when no information about translation probability AND othercommon alternative be present is generally Good.Structured Queries "Pirkola approach "(translation probability knowledge are not available)
{why not applying it for Med img ret. …?}Compute source term TF, DF based on its translation TF, DF.Queries are structured via the synonym operator of the InQuery retrieval system
{InQuery's synonym operator} that basically designed for monolingual retrieval bythesaurus expansion.Pseudo | artificial term are grouped with synonym operator ant TF,DF computed by
TF normalized to DF are calculated as the summation of TF of each translation
alternative found in the document. = DF = number of documents where at least one of its translation alternative found= union from i=1 to n {d|ti €d}.Where both TD , DF pre-computed for each possible query at indexing time.
-When no translation prob. is known the most effective approach is structuredquery SQ.Later on Kawokss simplified Pirkola method by replacing union with sum in the DFequation without harmful in retrieval effectiveness so DF becomes = sum of Df of each its translation alternative . conservativeNOTICING that In SQ translation appear in many documents takes low weight; sinceDF will be high for that its term rate will be low. But Balanced translation is moresensitive for rare translation than SQ. also as in Chinese if word segmentation has alot of errors that will lead to rare translation and poor results using balancedtranslation. Weighted IDF "(translation probability knowledge are available)
Translation probability knowledge are available throughUsing more thatn bilingual dictionary
25

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 26/40
Use of bilingual corpora This method depends on use translation probability to modifying inverse documentfrequency IDF for many translation alternatives.Balanced translation approach considered a special case of Weighted IDF.Probabilistic Structured Query PSQ {why not applying it for Med img ret. …?}
where P(ti|c) is probability of query term c translating into document term ti .PSQ could be better than structured query if the number of alternatives increase
Language Modeling approach {why not applying it for Med img ret. …?}Hiemstra divide the experiment into 3 sections
• Use one translation for source language.
• Translate query using unstructured query [bag of words] of all possibletranslation for source query term.
• Use structured query in query translation of all possible translation for sourcequery term.
Hiemstra proved that structured query consistently outperform one best translationand untructured query .but less effective than monolingual retrieval , Hiemstraexperiment with on small Dutch- English collection and has some limitation s likeusing 24 topics that makes tests less reliable.KRAJJ developed CLIR model of probabilistic query translation, document translationand document plus query translation where both document and query translated tothird language using language modeling approach , he founds that all of them
performed like structured queryHe notice that poor performance of structured query result of
• Large number of translation alternatives
• Translation property not usedBidirectional TranslationMerge document and query translation more than study showes imrovmetn in CLIR if this method used, [ I will not go through this mainly I want to depend onquery ; at least now ]
26

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 27/40
Key issues in dictionary-based CLIR "bilingualdictionary" ,fromGina-Anne Levow, Douglas W. Oard, Philip Resnik, "Dictionary-Based Techniques forCross-Language Information Retrieval," Information Processing and Management , to
appear, 2004
"The first approach is often referred to as “query translation” if done at querytime andas “document translation” if done at indexing time, but in practice bothapproaches require that document-language evidence be used to computequery-language term weights that can then be combined as if the documentshad been written in the query language" THE "Authors focus on" Focus onmachine readable bilingual dictionary list for its simplicity
1. Document processing document for IR system consists of terms for example term1 term 2 andterm 3 can ,so categorizing those helps is the issue when they or one of them inquiry . This process consists of..
•Extraction of indexing terms
• Document expansion
1.1. Extraction of indexing terms Differ from a language to the other, but extracting terms using
white spaces is so simple and can be done
By 1) automatically segmenting the text stream into a singlechain (string) of non-overlapping words, which might then be an issue tofurther processing such as stemming
2) Indexing overlapping character sequences
27

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 28/40
{NOTE} "in hemistra thesis (phd) when he talk about toknizationhe says justleave digits and alphas and remove other symbols and replace them with space"
language MethodEnglish andFrenchtokenization,clitic splitting, andstemming
- Both written using space delimiter.A) tokenization
- Simple pattern based {what are they, such as ??}approaches to separate words and punctuation- Clitic splitting done using apostrophe. And a usedtechnique is twofold process by separating the clitic andthen expanding it. For example "you're you re then youare".
B) for the result word MORPHOLOGICAL analysis or STEMMERused
- Morphological analysis: that maps verbs to theirroot.
- Stemming : involve removing prefixes or suffixes orboth ,widely used one is Porter (1980)
Stemming increase match when using normalized document andquery ,since stemming collapse part of speech not preserve them
as morphologicalGerman:decompounding
- German uses white-space delimiter for wordsseparation.- Morphological Can be done using the sameapproaches I English and French.
28

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 29/40
1.2. Document expansion
This method first proposed by Singhal and Pereira (1999) in the context of spoken document retrieval. And can be applied in CLIR to find words thatthe author possibly have used, Authors used this method on news stories toexpand each document by terms related in other documents as follow
•
Extract document terms• Weigh all terms equally such as in query
• Use the collection as comparable corpora "collection" thatsearched for terms to enrich the document
• Rank the collection and select top5 without the original one
• Select terms from the collection by ranking terms based on IDF
• Instance of each term added to the original document
• Till document length doubled
1. Query processing "in Dictionary based CLIR" Like in document it depends on extracting terms, query expansion could be
used too to augment the representation.
1.1. Query Pre-translation processing "term extraction" The same techniques as in document but the important different is that
Query terms are not used for matching but it's used as translation base,authors apply the greedy longest match technique since translating multi-word expressions as a unit is well be useful for CLIR {Authors mention thatpaper about multi word as unit CLIR (Ballesteros & Croft, 1997) } .
1.2. Query Pre-translation expansion
• Short length of query can result ambiguity => that reduces
precision OR• Non-inclusion /omission of document authors usedterms=>that reduces recall BUT
Query Expansion generally increase effectiveness.
• Authors mentioned also that an English-Spanish studyfound that query expansion pre and post translation enhancedprecision and recall. Where pre improves recall and percsion butpost increase recall only.
• Authors perform query expansion as in the followingsteps…
o Construct initial query to INQUERYo
Then Obtain expansion Using INQUERY relevancefeed back from top ranked 10 documentso Concatenate expansion set with the original queryand uses it as translation base.
29

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 30/40
2. Translation knowledge and query translation
2.1. Bilingual term lists and optimizing coverage
Easily found .BUT they constructed for various purposes and may be takenfrom various resources too beside that they vary also in
• Number of entries
• Source, number of multi-word entries
• Degree of ambiguity
• And mix of surface or root form entriesNoticing that in their experiment construction of "an English–Arabic term listdone by sending each unique word found in a large collection of English newsstories to two Internet-accessible English-to-Arabic translation services andmerging the results."
2.2. Weight mapping
previous used technique in dictionary-based querytranslation
Includes all translations for all query words when used with "bagof terms retrieval" such as vector space model where termstreated independently / separately So unnecessary query termsthat have many translations on focus. =>and this is not a desirefor IR system Where terms with fewer translations usually givemore better results when applied.
Better recent technique Authors called it "balancedtranslation"
Average the weight for each query term translation
Balanced translation problem is that it gives more weight for Rare Terms.This is logical if the rare term translation was correct.But kill rare terms when no information about translation probabilityAND other common alternative be present is generally Good.
2.3. Evidence mapping
Pirkola (1998) / balanced query translation method is analternative to Balanced translation ., INQUERY synonymoperator used by Pirkola to implement SQ
Authors used in their experiment INQUERY synonymoperator in query time its expensive but as they claim " butefficient indexing-time techniques are available for use whenquery-time efficiency is a concern (Oard & Ertunc, 2002). " use when query-time efficiency is a concern (Oard & Ertunc,2002). "
30
8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 31/40
31

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 32/40
Previous Work
Medimage 2007
FromGrubinger, Paul Clough, Allan Hanbury, Henning Müller, Overview of the ImageCLEF2007
Medical Retrieval and Annotation Tasks
MRIM–LIG, Grenoble, France;2.6.7 LIGMRIM–LIG submitted 6 runs, all of them textual runs. Besides the best textual results,this wasalso the best overall result in 2007. {looking for the paper}
Already used methods at CLEF
Paper Paul McNamee, James Mayfield: Cross-Language Retrieval Using HAIRCUTat CLEF 2004. CLEF 2004: 50-59
Usedmethods
• Character n-gram tokenization• Pre-Translation• Query Expansion• Statistical Translation• Aligned Parallel corpora
Aligned Parallel corporaThey translate n-gram characters directly.They believe that the relationship between translation and coverageand performance is approximately linear.
32

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 33/40
Paper Julien Gobeill, Henning Müller, Patrick Ruch, Query and Document Translation by Automatic TextCategorization: A Simple Approach to Establish a Strong Textual Baseline for ImageCLEFmed 2006, workingnotes of the Cross Language Evalutation Forum (CLEF 2006), Alicante, Spain, 2006
Methodfeatures
- Can be applied with any controlled vocabulary {the experiment uses MeSh}- No need for training data
Result This approach competitive with CLIR effective approaches
Experiment design
Automatic textcategorizer
Categorizer {Can be done using byes , k-nearest –boosting –rule based ….} this categorizer relly on poor data so theycatogrize MeSh terms as if they are documents and input documents
Each Document All uires
Annotated using
Automatic text categorizer that contain MeSh in English French and German
Annotated documents indexed using standard. engine
Annotated by 3 MeSh categoriesCate ories var 3 , 5 , 8
33

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 34/40
UsedClassifiers and
their combination
for thecategorizer Applied on Canonic MeSH augmented (increased) with MeSh thesaurus, the system moves a Window along the
abstract and cuts the abstract into 5 tokens phrase, the distance calculated between these 5 tokens and Each MeShterm where insertion costs one and deletion costs 2. And ranking of terms done bas using this distance measure
Based on genral IR engine with tf.idf "SMART representation" -and list of 544 stop words-for weighting factor cosin normalization used "for its effective results in documents with similer length" -even in controlled vocabularythe idf was able to discriminate between content and non content bearing رهظم-ةبسن features such as yndrome ةمزلتن ضارعأ and disease
The pattern matcher gives better results then vector space engine-combination (non linear)between the first two classifiers done as follow=> returned list from extor space engine used as refrence list RL and RegExp list as boosting(enhance)ززع listBL , Beside that long and compound terms favoured than short and single terms .=>combined retrieval status value cRSV done as follow for each concept t in the RL list cRSVt {"equation……!!!}Categorizer and indexingTo translate quries and document English French and germen of Mesh merged in the categorizer, each language stop wordlist merged.
Results Textual retreival results ---runs genrated automaticlly ,english retreival results was the second best froup
Visual and mixed runs-all visual run ar not good as textual ones. Need further investigation.
Regular Expression pattern matcher
Vector space
component
Visual retrieval
using GIFT
34

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 35/40
MIRACLE
MIRACLE submitted 36 runs in total and thus most runs of all groups. The text retrievalrunswere among the best, whereas visual retrieval was in the midfield. The combined runs wereworse
than text alone and also only in the midfield.
35

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 36/40
Appendix A , Definitions
1.1. Polysemy Polysemy = multiple meaning. A word is judged to be polysemous if it has two senses of the
word whose meanings are relatedhttp://en.wikipedia.org/wiki/Polysemy
1.2. Medical Literature Analysis and Retrieval System Online (MEDLINE)
" is an international literature database of life sciences and biomedical information. It covers
the fields of medicine, nursing, pharmacy, dentistry, veterinary medicine, and health care.
MEDLINE covers much of the literature in biology and biochemistry, and fields with no
direct medical connection, such as molecular evolution. Listing of an article in MEDLINE
does not mean endorsement of that article.
Compiled by the U.S. National Library of Medicine (NLM), MEDLINE is freely availableon the Internet and searchable via PubMed and NLM's National Center for Biotechnology
Information's Entrez system."http://en.wikipedia.org/wiki/MEDLINE
1.3. Medical Subject Headings ( MeSh )"Is a huge controlled vocabulary (or metadata system) for the purpose of indexing journal
articles and books in the life sciences. Created and updated by the United States National
Library of Medicine (NLM),"
MeSh structure
o 1.1 Descriptors
Hierarchy arranged, descriptor may appear in many places at the Hierarchy , a descriptor can carry several tree numbers and each descriptor has a unique ID.
o 1.2 Description
Explanatory text for each entry
o 1.3 Qualifiers [ subheadings]
Can be added to the descriptor to narrow down the topic
o 1.4 Supplements [Concept Records]
It Enlarge the thesaurus and have links to the closest fitting descriptor.
http://en.wikipedia.org/wiki/Medical_Subject_Headings
36

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 37/40
37
8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 38/40
SMART
" The SMART (Salton’s Magic Automatic Retriever of Text) Information Retrieval System is aninformation retrieval system developed at Cornell University in the 1960s. Many importantconcepts in information retrieval were developed as part of research on the SMART system,
including the vector space model and relevance feedback "
http://en.wikipedia.org/wiki/SMART_Information_Retrieval_System
StemmingFor stemming algorithms as inhttp://www.dissertation.com/book.php?book=1581122675&method=ISBNsee
Porter (1980) and Frakes (1992)
-what charctrize a word to be indexed is the fulfillment (requiermetn) of the followingrequirement
Generating index in 4 languagte Pelissier and others at 86 Merging thesoursn different languages discussed by Kalachkina at 87.
Clitichttp://www.thefreedictionary.com/clitic
"An unstressed word, typically a function word, that is incapable of standing on its own and attaches inpronunciation to a stressed word, with which it forms a single accentual unit. Examples of clitics are the
pronoun 'em in I see 'em and the definite article in French l'arme, "the arm." "
38

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 39/40
INQUERY "" J. P. Callan, W. B. Croft, and S. M. Harding. The INQUERY retrieval system. In Proceedings of the
Third International Conference on Database and Expert Systems Applications, pages 78--83,
Valencia, Spain, 1992. Springer-Verlag. "Well known system…
-retrieval system based on probabilistic retrieval model (Bayesian inference net)-support complicated indexing and multipart /complex query
INQUERY Architecture Based on document retrieval inference network (type of Bayesian network) .Inference net consists of two networks first one for documents {that represent them indifrenttechniques }
and the second for queries {that nodes are always rue} query nodes related to document nodesthrough concept and content nodes and this may done within more than one concept or singlenode /not one to one mapping .
Nodes has the value true or false and arcs have between and 1 belief value ,if document node rpresetnthe query of the useitgets value of true .Mapping {parsing } done using five components
1- Lexical analyzer That provides lexical tokens .to the syntactic analyzer.2- Syntactic analyzer
Ensure that the document is in the expected format3- Concept identificationIdentify high level concept such as datea and names of persons, companies … also
define sentence and paragraph boundaries at the documents4- Dictionary storageFirst Stored in B tree then hash table used so when needed the word or sentence
replaced within its entry in the dictionary .5- Transaction generation
1.4. What is language modeling A Bit of Progress in Language Modeling Extended VersionJoshua T. Goodman Machine Learning and Applied Statistics GroupMicrosoft Research One Microsoft Way Redmond, WA 98052 [email protected] August 2001 Technical Report MSR-TR-2001-72
"Language modeling is the art of determining the probability of a sequence of words." "
39

8/2/2019 CLIR Techniques Ver 1
http://slidepdf.com/reader/full/clir-techniques-ver-1 40/40
AbbreviationsIR ------------------------------------------------------- Information retrievalCL-LSI------------------------------------------------------- Cross Language Latent Semantic Indexing
I have to find also + mt bok Introducing Speech and Language ProcessingSeries: Cambridge Introductions to Language and Linguistics
John Coleman
From ord lecture Natural Language Processingfor Information RetrievalDouglas W. Oard