chapitre 4. méthodes de minimisation de l’énergie a...
TRANSCRIPT

96
Chapitre 4. Méthodes de minimisation de l’énergie a posteriori
Maximiser la probabilité a posteriori (3.4.2) est équivalent à minimiser l’énergie aposteriori (appelé aussi critère du MAP) décrite dans l’équation (3.4.4). La minimisationdu critère du MAP est problématique parce que la fonction de potentiel peut être nonconvexe et donc peut admettre des minima locaux.
On peut classer les algorithmes de minimisation en deux catégories avec les sous-catégories correspondantes:
- les algorithmes stochastiques: de type recuit simulé:
- recuit avec dynamique de Metropolis;- échantillonneur de Gibbs avec recuit;
algorithmes génétiques (peu utilisés) [KOZ 93], [CHA 97].- les algorithmes déterministes. Le plus utilisés sont:
- modes conditionnels itérés (ICM = Iterated Conditional Modes);- non-convexité graduelle (GNC = Graduated Non-Convexity);- recuit en champ moyen (MFA = Mean Field Annealing).
Les algorithmes stochastiques assurent la convergence théorique vers un minimumglobal de l’énergie du critère du MAP, mais ont comme défaut d’être très lents. Lesalgorithmes déterministes sont plus rapides, mais peuvent rester piégés dans un minimumlocal de l’énergie MAP.
4.1. Algorithmes stochastiques
Les algorithmes stochastiques d’optimisation (minimisation) sont basés sur uneanalogie avec le procédé de recuit, utilisé par exemple en métallurgie et en verrerie. Pourobtenir la cristallisation la plus parfaite possible (correspondant à un état moléculaire leplus ordonné possible), on porte le matériau à très haute température, puis on le laisse serefroidir très lentement.
Le recuit simulé fait partie d’une classe d’algorithmes de relaxation stochastique detype Monte-Carlo, qui s’appuient sur une recherche partiellement aléatoire dans l’espacedes solutions. A chaque pas de l’algorithme, la solution précédente est vue comme uneperturbation aléatoire. Par rapport aux algorithmes déterministes itératifs basés sur laminimisation du gradient, lesquels évoluent selon la direction de décroissance de lafonction à minimiser, le recuit simulé permet l’exploration de telles solutions dontcertaines peuvent s’éloigner temporairement du minimum, pour éviter la convergence versun minimum local.

97
La probabilité d’accepter une croissance de la fonction à minimiser est contrôléepar un paramètre appelé température. Le principe général des algorithmes de recuit estdonné dans (4.1).
Le système est porté à une température suffisamment grande pour pouvoir acceptertoutes les évolutions possibles du système. Puis la température est diminuée selon une loide refroidissement. A chaque température, le système doit évoluer suffisamment pouratteindre un état d’équilibre. L’algorithme général est de la forme:
(4.1)
La convergence de l’algorithme est strictement liée à la loi de refroidissement. Ladécroissance logarithmique de la température [GEM 84]:
)1ln( +
=i
T τ , i=1,2,..., où τ est une constante et i est l’indice d’itération (4.2)
assure la convergence théorique vers un minimum global de la fonction.Nous décrivons les 2 algorithmes qui permettent de calculer un nouvel état du
système à une température donnée: le recuit simulé avec dynamique de Metropolis etl’échantillonneur de Gibbs avec recuit.
4.1.1. Recuit avec dynamique de Metropolis
Dans le cas de la dynamique de Metropolis (qui est la plus proche du processusphysique du recuit), la variation de température est assez lente pour qu’on puisseconsidérer qu’à une température donnée, le système a le temps d’évoluer jusqu'à un état leplus ordonné possible qui correspond au point d’équilibre thermique à cette température.Cet équilibre est caractérise par le fait que la probabilité pour que le système se trouvedans un état I est [CHA 94]:
( ))(exp1)( IEZ
Ip ⋅−= β , (4.3)
où : ( )∑ ⋅−=I
IEZ )(exp β est la fonction de partition du système. E(I) est
l’énergie du système correspondant à la configuration I. La constante β est: β=1/k·T, où Test la température absolue du système et k la constante de Boltzmann. On remarque quecette équation est similaire à l’équation (3.2.8).
Initialisation à une température Tmax élevée
RépéterCalculer le nouvel état (E) du systèmeDiminuer la température selon la loi de refroidissement (Ti+1=f(Ti))
Jusqu’à atteindre une température Tmin " basse" (voir nulle) qui garantisse la convergence vers un minimum

98
Lorsque la température est élevée, tous les états sont équiprobables. Donc, unebaisse brutale de température risquerait de figer le matériau dans une configuration tropdésordonnée. Lorsque T tend vers 0, la configuration la plus probable est cellecorrespondant à l’énergie minimale. Le matériau est alors un cristal parfait.
Pour l’application de la technique de recuit aux images, on considère que la grilledes pixels représente les atomes du matériau et les niveaux de gris représente leurs étatspossibles. Donc, une image représente une configuration I, à laquelle on associe l’énergieE(I) et une probabilité de réalisation donnée par (4.3). A chaque température, on effectuede petites perturbations du système, jusqu'à ce que celui-ci se trouve dans son étatd’équilibre ”thermique”. En général, la perturbation consiste à modifier légèrement lavaleur d’un pixel en lui ajoutant une valeur aléatoire (appelée grain). Une autre possibilitéconsiste à échanger la valeur de deux pixels.
A chaque pas de l’algorithme on génère une nouvelle solution candidate (uneperturbation), d’une manière aléatoire. Si cette solution conduit à une décroissance del’énergie ∆E<0, la solution est acceptée. Sinon, la solution est acceptée en conformitéavec une distribution exponentielle de probabilité (p):
≤>−
=010)exp(
EsiEsiT
p ,
, ∆∆∆
(4.4)
où T est la température et ∆E représente la variation d’énergie due à laperturbation. Si la température est grande, la probabilité d’accepter une configurationaugmentant l’énergie est plus grande que dans le cas où la température serait faible.
Une description de l’algorithme de recuit simulé utilisant la dynamique deMetropolis est la suivante [MUR 97] (I(k) est la configuration à l’itération k):
(4.5)
1. Initialiser i=0 et T=Tmax. On choisit de manière aléatoire la configurationinitiale I(0);
2. Générer aléatoirement une nouvelle solution candidate (perturbation) I(i+1);3. Calculer : ∆E=E(I(i+1))-E(I(i));4. Calculer la probabilité :
≤>−= 01
0)exp(EsiEsiTp ,
, ∆∆∆
5. Si p=1, on accepte la perturbation. Sinon, on tire aléatoirement unnombre, en conformité avec une distribution uniforme entre 0 et 1. Si cenombre est égal ou plus petit que p, on accepte la perturbation : I(i+1)=I(0).Sinon : I(i+1)=I(i) ;
6. Incrémenter: i=i+1. Si : i≤Nmax, où Nmax est prédéfini, revenir en 2;7. Initialiser: i=0 et I(0)= I(Nmax). On réduit T en conformité avec la loi de
refroidissement. Si : T>Tmin, aller en 2. Sinon, Arrêt.

99
Parce que les perturbations sont générées d’une manière aléatoire, l’algorithmenécessite un grand nombre d’itérations pour converger, quand l’espace d’état est grand,quand I est continu ou quand le nombre des composantes du vecteur inconnu est grand.
Le fait d’accepter des configurations d’énergie supérieures permet d’éviter leproblème des minima locaux de l’énergie E.
4.1.2. Echantillonneur de Gibbs avec recuit
Dans le cas de l’échantillonneur de Gibbs, l’analogie avec le processus physique derecuit et moins directe, parce que même si l’algorithme est bien de la forme (4.1), on nelaisse pas forcement le système se stabiliser à chaque température.
Au lieu de générer les perturbations d’une manière aléatoire et de décider après sielles sont acceptées ou pas, dans le cas d’échantillonneur Gibbs, les perturbations sontgénérées en conformité avec des fonctions de densité de probabilité conditionnelleslocales, qui dérivent d’une distribution de Gibbs. Le nouvel état du système est calculé dela façon suivante: on modifie la valeur de niveau de gris d’un pixel p, en lui affectant lavaleur a, qui dépend des valeurs des voisins de p et d’une variable aléatoire A, ayant unedistribution quelconque (par ex. uniforme). Les sites sont explorés de façon cyclique. Enconsidérant que l’énergie peut se mettre sous la forme d’une somme de potentiels locauxet comme l’image est considérée comme un champ de Markov, on peut écrire:
( )
==−⋅==
TdevoiIaIE
ZaIp p r rpp sin),(|)(exp1))(( (4.6.1)
Ecrire E(I) sous forme de somme de potentiels locaux suppose que le voisinage aitun support de petite taille.
Une description de l’échantillonneur de Gibbs avec recuit est:
(4.6.2)
1. Initialiser: i=0 et T=Tmax. Choisir de manière aléatoire la configurationinitiale (I(0));
2. Scruter chaque pixel p pour perturber la valeur de I(p) correspondante. Laperturbation est calculée de la manière suivante:a) Pour chaque position on calcule la probabilité conditionnelle de I(p) (voir
4.6.1) afin de prendre toutes les valeurs possibles dans l’espace dessolutions, en fonction des valeurs actuelles (données) des voisins de laposition courante.
b) Ensuite, on calcule les probabilités pour tous les éléments de S et oneffectue un tirage d’une nouvelle valeur de I(p) dans cette distribution.
3. Répéter l’étape 2 un nombre de pas suffit à une température donnée, puisfaire décroître la température et répéter 2. On remarque que les probabilitésconditionnelles dépendent de la température.

100
4.1.3. Conclusions
Les algorithmes stochastiques de type recuit convergent en probabilité vers unminimum global du critère du MAP, indépendamment de la configuration initiale. Dans lecas où l’énergie du MAP s’écrirait comme une somme de termes locaux, on peut utiliserl’échantillonneur de Gibbs avec recuit. Dans le cas contraire, on utilise le recuit simuléavec dynamique de Metropolis [CHA 94].
Les algorithmes de recuit ont un coût de calcul important. De plus, même si laconvergence est prouvée en théorie, il n’est pas toujours possible en pratique de se placerdans les bonnes conditions. Par exemple, si l’on veut s’affranchir du problème des minimalocaux, il est nécessaire d’adopter une décroissance logarithmique de la température, cequi peut ne pas être possible en pratique. C’est ce qui fait écrire à Donald Geman, àpropos de l’échantillonneur de Gibbs [GEM 92]: ”nous n’avons aucune garantie d’obtenirun véritable minimum avec une quantité finie de calculs”.
4.2. Algorithmes déterministes
L’énergie issue du critère du MAP est la plupart de temps non convexe. Dans cecas, les algorithmes déterministes sont tous sous-optimaux, dans le sens qu’ils nepermettent d’atteindre qu’un minimum local de l’énergie, la transition d’une configurationà une autre n’étant pas possible que si l’énergie est inférieure.
Les algorithmes déterministes les plus connus, de descente simple du type gradient,gradient conjugué, ou modes conditionnels itérés (ICM=Iterated Conditional Modes)risquent de rester piégés dans des minima locaux éloignés du minimum global, donc lesestimées obtenues risquent d’être de mauvaise qualité. Diverses stratégies ont étéproposées afin d’obtenir des solutions de bonne qualité et les plus connues sont la Non-Convexité Graduelle (GNC=Graduated Non-Convexity) et le recuit en champ moyen(MFA=Mean Field Annealing).
4.2.1. Modes conditionnels itérés (ICM)
L’algorithme ICM a été proposé par Besag [BES 86]. Il est également appelérelaxation de Gauss-Seidel non linéaire à cause du fait que l’algorithme ICM est procheformellement de l’algorithme de relaxation de Gauss-Seidel, utilisé en analyse numériquepour résoudre des systèmes linéaires de grande taille [PER 93].
L’algorithme ICM est appelé aussi recuit gelé (Metropolis gelé ou Gibbs gelé),parce que cet algorithme est un cas particulier de l’algorithme de Metropolis ou del’échantillonneur de Gibbs: dans l’étape 4 de l’algorithme de Metropolis (4.5), laprobabilité d’accepter des perturbations qui augmente l’énergie, est toujours nulle. Besag

101
[BES 86] a appliqué implicitement cette technique à l’échantillonneur de Gibbs: si I est laconfiguration courante, alors la valeur du pixel p est remplacée par un des modes de ladistribution conditionnelle locale (4.6.1) connaissant les valeurs des pixels r voisins de p,d’où le nom de ICM (Iterated Conditional Modes = modes conditionnels itérés) donné àcet algorithme.
Le principe de l’algorithme est le suivant: on parcourt les sites (pixels) d’une façoncyclique. A chaque itération, on modifie la valeur d’un pixel uniquement. En chacun pixelp, on maximise de façon déterministe la probabilité conditionnelle (4.6.1) ou autrementdit, on minimise l’énergie (le critère) du MAP, par rapport à I(p) uniquement. On montrequ’à chaque itération, la probabilité a posteriori (4.6.1) augmente. On peut montrer aussi,que ICM converge vers la solution qui maximise la probabilité conditionnelle en chacunpixel. Il peut donc être implanté de manière similaire avec l’échantillonneur de Gibbs,mais en choisissant pour chaque pixel la valeur (appartenant à l’intervalle de variationpossible) qui maximise la probabilité conditionnelle locale (au lieu de tirer une valeuraléatoire d’une distribution de probabilité conditionnelle). Moyennant une ”bonne”initialisation, l’estimée calculée est de bonne qualité.
La description du principe général de l’algorithme ICM est:
(4.7)
L’algorithme ICM converge beaucoup plus rapidement que les algorithmesstochastiques de type recuit simulé, mais il converge vers un minimum local à cause dufait qu’il n’accepte que les perturbations qui ont comme résultat une variation d’énergie∆E négative. Donc, un problème important dans l’utilisation d’ICM est de choisir uneestimée initiale convenable.
L’avantage de cet algorithme est qu’il est très général et peut être utilisé dans ungrand nombre d’applications. De plus, surtout si le nombre d’états possibles du systèmeest petit (comme par exemple le déplacement maximal en estimation du mouvement ou lenombre d’étiquettes en segmentation), l’ICM est très rapide (1-5 itérations suffisent, engénéral [RAN 91]).
1. Initialisation I(0) ;2. Calcul de I(k+1) à partir de I(k) :
(a) on balaie l’ensemble des pixels p (selon une stratégie devisite des sites) :
( ))(|)(minarg)( )()()1( rpp pp
kkk IIEI =+ , r∈Np
k=k+1;(b) Retour en (a) jusqu'à réalisation d’un critère d’arrêt.
102
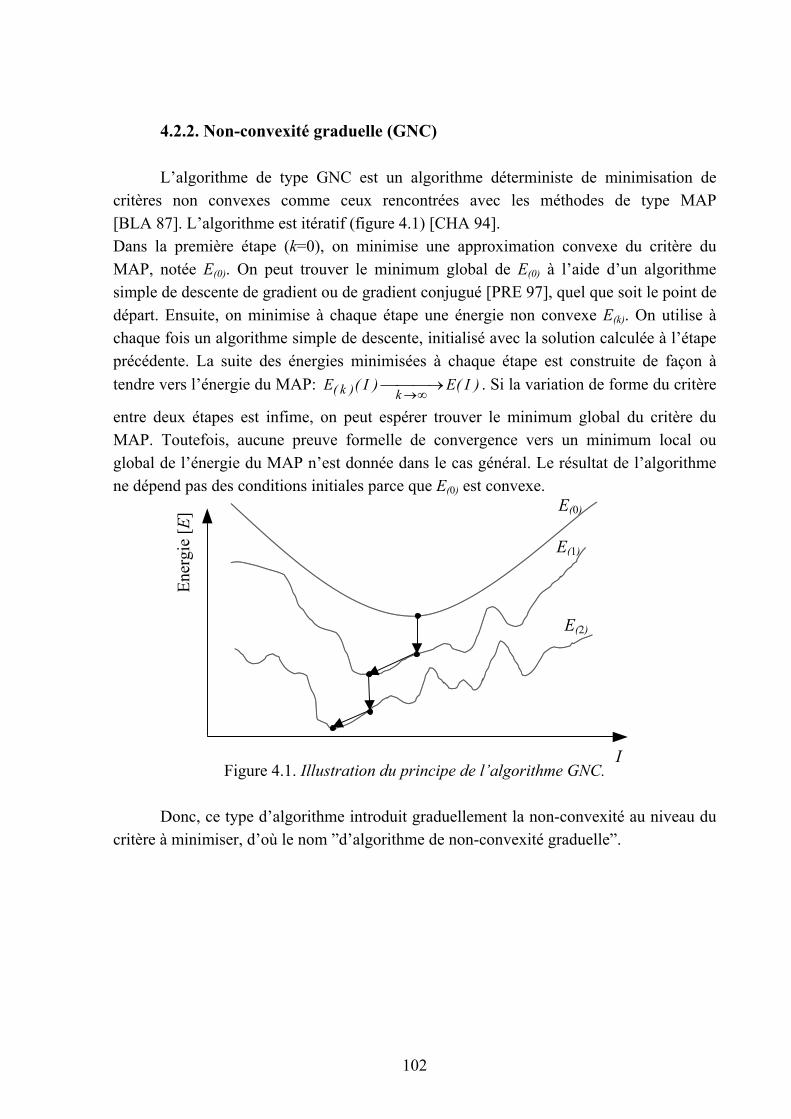
4.2.2. Non-convexité graduelle (GNC)
L’algorithme de type GNC est un algorithme déterministe de minimisation decritères non convexes comme ceux rencontrées avec les méthodes de type MAP[BLA 87]. L’algorithme est itératif (figure 4.1) [CHA 94].Dans la première étape (k=0), on minimise une approximation convexe du critère duMAP, notée E(0). On peut trouver le minimum global de E(0) à l’aide d’un algorithmesimple de descente de gradient ou de gradient conjugué [PRE 97], quel que soit le point dedépart. Ensuite, on minimise à chaque étape une énergie non convexe E(k). On utilise àchaque fois un algorithme simple de descente, initialisé avec la solution calculée à l’étapeprécédente. La suite des énergies minimisées à chaque étape est construite de façon àtendre vers l’énergie du MAP: )I(E)I(E
k)k( →∞→
. Si la variation de forme du critère
entre deux étapes est infime, on peut espérer trouver le minimum global du critère duMAP. Toutefois, aucune preuve formelle de convergence vers un minimum local ouglobal de l’énergie du MAP n’est donnée dans le cas général. Le résultat de l’algorithmene dépend pas des conditions initiales parce que E(0) est convexe.
Figure 4.1. Illustration du principe de l’algorithme GNC.
Donc, ce type d’algorithme introduit graduellement la non-convexité au niveau ducritère à minimiser, d’où le nom ”d’algorithme de non-convexité graduelle”.
I
Ener
gie
[E] E(0)
E(1)
E(2)

103
4.2.3. Recuit en champ moyen (MFA=Mean Field Annealing)
4.2.3.1. Principe
Le recuit en champ moyen s’appuie sur l’idée ”d’approximation par champmoyen” de la mécanique statistique. A chaque température, on calcule de façondéterministe une estimée au sens du champ moyen. Lorsque la température s’annule,l’estimée calculée est une bonne approximation de la solution [CHA 94].
D’autre part, on peut considérer qu’on minimise, comme pour le GNC, une suite defonctionnelles, mais la construction de cette suite est différente. Dans le cas du GNC, lasuite est construite de façon ad-hoc alors que dans le cas du MFA, elle est construitenaturellement en fonction de la température du système.
L’approximation par champ moyen permet le remplacement de chaque variablealéatoire (le champ aléatoire évalué dans un certain site) par la moyenne de sa densité deprobabilité à une température donnée. Alors, le recuit en champ moyen estime cesmoyennes en chaque site (pixel, dans notre cas). L’algorithme de recuit en champ moyenest similaire à l’algorithme de recuit simulé, mais la relaxation stochastique à chaquetempérature est remplacée par une relaxation déterministe pour minimiser ”l’erreur duchamp moyen”, en général, en utilisant un algorithme de descente de gradient ou degradient conjugué.
Les algorithmes de recuit en champ moyen sont, en général, limités à des modèlesde type Ising, décrits par des fonctionnelles qui impliquent un vecteur binaire. Lesexpérimentations montrent que le MFA est valide pour des champs de Markov avec desinteractions locales sur un support de petite taille [MUR 97]. Donc, le calcul desmoyennes et de l’erreur du champ moyen sont faits en utilisant des distributions de Gibbs.
L’approximation qui utilise la théorie du champ moyen consiste à négliger lesfluctuations par rapport à la valeur moyenne du champ, dans le voisinage de chaque pixel.Donc, dans un telle approximation, la valeur qui correspond au pixel s ne dépend pas desvaleurs correspondantes aux pixels voisins, le système résultant ayant le comportementd’un système composé de variables indépendantes [FOR 00].
En fait, l’idée est de supposer que l’effet sur le pixel s, imposé par les interactionsavec ses voisins, peut être approché par l’effet d’un champ moyen qui est le résultat desinteractions avec ces voisins. Donc, au lieu de calculer les interactions d’un pixel avecchacun de ses voisins, on peut calculer le champ moyen généré par ses voisins et estimerl’impact de ce champ sur le pixel s [WEI 99].
Comme le recuit en champ moyen peut donner un résultat très proche du résultatoptimal (obtenu en utilisant le recuit simulé) et comme l’algorithme résultant estparallélisable, il est directement implantable sur des réseaux neuronaux [RAN 91],[GEI 91], [KIM 01]. La suite des travaux portera sur l’étude de l’algorithme de recuit enchamp moyen, utilisé en estimation de mouvement.

104
4.2.3.2. Champ moyen pour l’estimation de mouvement
Soit le champ de déplacement d. On note d le champ moyen estimé sachant unedensité de probabilité Bayesienne p(d):
∑ ⋅−=d
d ddd )()( 2 pVar (4.8)
où ∑d
représente la somme sur toutes les configurations possibles de d et d Var
est la variance de d . En minimisant d Var par rapport à toutes les valeurs possibles de d ,
on obtient:
0Var =∂∂
d d ⇒ ∑ ⋅=
dddd )(p (4.9)
L’équation (4.9) va définir les équations déterministes du champ moyen.
Pour illustrer l’application d’approximation du champ moyen dans l’estimation dumouvement dans le cas discret, on va supposer l’estimation MAP du mouvement avecprise en compte des discontinuités, décrite par l’équation (3.4.4) où, pour simplifier lesnotations, on va noter:
l = (lx,ly) = (H,V) le processus de ligne l, avec les deux composantes H et V;
U(It,It-1,d,l)= U(I,d,l) : énergie totale;
U(It|d,l,It-1) = Ua(I,d) : énergie d’attache aux données;
U(d|l,It-1) = Udl(d,l) = Udl(d,H,V) : énergie a priori sur le champ de déplacement ou terme de régularisation du champ de déplacement;
U(l|It-1) = Ul(l)= Ul(H,V) : énergie a priori sur le champ de lignes ou terme de régularisation du champ de lignes;
αd, αl = constantes de régularisation.
Comme il a été présenté, le processus de ligne a deux composantes (H et V). Leprocessus de ligne horizontal Hij lie le pixel p(i,j) avec le pixel p (i,j-1), c’est à dire lespixels adjacents d’une même ligne, et le processus de ligne vertical Vij lie le pixel (i,j) aupixel (i-1,j), c’est-à-dire aux pixels adjacents d’une même colonne. En utilisant cesnotations, on peut réécrire l’énergie totale MAP (3.4.4) comme l’énergie d’une membraneen mécanique [JIA 99]:
U(I,d,l)= Ua(I,d) + αd ·Udl(d,l) + αl ·Ul(l) (4.10)
Pour l’énergie d’attache aux données Ua(I,d) on peut utiliser le modèle décritdans l’équation (3.4.6) ou (3.4.7). On va donner l’exemple en utilisant le DFD (3.4.6):

105
[ ] [ ]∑∑ =−−= −jiji
tta jiDFDjijiIjiIIU,
2
,
212
1
),()),(),((),(2
1),( ddπσ
(4.11)
Pour l’énergie de régularisation du champ de déplacement (ou a priori sur lechamp de déplacement) Udl(d,l) on peut utiliser le modèle décrit dans l’équation(3.4.13) ou (3.4.17):
∑∈
−⋅−⋅=
prrplrdpdld
NdlU )),(1()()(
2
1),( 222πσ
(4.12.a)
ou, pour le voisinage d’ordre 1:
∑
−⋅−+−⋅−⋅= −−
jijijijijijijidl VHU
,,
2,1,,
2
1,,22
)1()1(2
1),( ddddldπσ
(4.12.b)
où : ( ) ( )2221 11 )j,i(d)j,i(d)j,i(d)j,i(d yyxxj,ij,i −−+−−=− −dd (4.13)
( ) ( )2221 11 )j,i(d)j,i(d)j,i(d)j,i(d yyxxj,ij,i −−+−−=− −dd (4.14)
Les deux termes de l’équation (4.12.b) expriment les interactions entre le champ dedéplacement d=(dx,dy) et le processus de ligne l = (H,V), pour les plus proches voisins.
Pour l’énergie de régularisation du champ de lignes (ou l’énergie a priori sur lechamp de lignes) Ul(l) on peut utiliser le modèle décrit dans l’équation (3.4.20):
( )∑ ⋅+⋅=j,i
j,iVj,iHl VH)(U l αα (4.15)
Pour simplifier, on peut considérer αH=αV=αl :
( )∑ +⋅=j,i
j,ij,ill VH)(U l α (4.16)
L’énergie a priori sur le champ de lignes (ou l’énergie de régularisation du champde lignes) exprime la pénalité accordée à chaque création d’une discontinuité et elle estnécessaire pour prévenir la création de discontinuités partout.

106
4.2.3.3. Calcul de la fonction de partition
Par la mécanique statistique et par la théorie des probabilités, on sait que toutes lesvaleurs moyennes d’un système peuvent être obtenues à partir de la fonction de partitionZ, qui doit donc être calculée. Comme l’image et le champ de déplacement ont étémodélisés par un champ de Markov et comme un champ de Markov est équivalent (voir lethéorème de Hammersley-Clifford, paragraphe 3.2.4) à un champ de Gibbs décrit par sadistribution (3.2.8), on obtient l’équation (3.4.3). On va introduire un paramètre β=1/T,inspiré par la thermodynamique [GEI 91], qui permet d’appliquer des méthodes similairesau recuit simulé. Donc, le modèle a posteriori de l’estimation MAP du mouvement avecprise en compte des discontinuités, va avoir la probabilité a posteriori :
),,I(UeZ1),,I(p ld ld ⋅−= β (4.17)
où:
∑ ⋅−=ld
ld ,,I
),,I(UeZ β est la fonction de partition (4.18)
et l’énergie totale MAP pour l’estimation du mouvement avec prise en compte desdiscontinuités U(I,d,l) est donnée par l’équation (4.10), où chaque terme est décrit par leséquations (4.11), (4.12) et (4.15) ce qui conduit à l’expression globale:
)(),(),(),,( llddld lldlda UUIUIU ⋅+⋅+= αα
∑ +
−−= −
jijitt jiIjiI
,
2,12
1
)),((),(2
1 d πσ
+
−⋅−+−⋅−⋅+ −− )1()1(
2,
2,1,,
21,,2
2jijijijijiji
d VH ddddπσ
α
⋅+⋅+ j,iVj,iH VH αα (4.19.a)
En séparant les termes qui dépendent des deux composantes du processus de ligne:
∑ +
++
−−= −
jiVHjitt jiIjiIIU
,
2,12
1
)),((),(2
1),,( ααπσ
dld
[ ]∑ ⋅−+⋅−+ji
jijijiji GVVGHH,
,,,, )1()1( (4.19.b)
où: Hjid
ji dHGH α∆πσ
α−⋅= ,2
2,
2 et Vji
dji dVGV α∆
πσ
α−⋅= ,2
2,
2 (4.20)
21,,, −−= jijijidH dd∆ et
2,1,, jijijidV −−= dd∆ (4.21)

107
Le calcul de la fonction de partition est fait en calculant la somme (4.18) pourtoutes les configuration possibles {I,d,l} du système. Le calcul de la fonction de partitionest équivalent à calculer une intégrale multi-dimensionnelle à variables dépendantes. Leproblème est résolu en utilisant des techniques de champ moyen, le système résultantayant le comportement d’un système à variables indépendantes [FOR 00].
La fonction de partition joue un rôle très important, parce qu’elle permet le calculde toutes les valeurs moyennes du système. Conformément à sa définition (4.18), lafonction de partition correspondant au modèle choisi, c’est à dire à l’énergie décrite dansl’équation (4.19.a) et (4.19.b), est:
[ ]×= ∑
∑
++−−⋅− −
d
d
,
)),((),(2
1,
2,12
1
I
jiIjiIji
VHjitteZ
ααπσ
β
[ ] [ ]∑∑
∑∑ ⋅−⋅−⋅−⋅−××
ldld
ji,ji,
,
)1(
,
)1( ,,,, jijijiji GVVGHHee
ββ (4.22)
4.2.3.4. Calcul des valeurs moyennes du processus de ligne
La contribution du processus de ligne dans la fonction de partition peut êtrecalculée exactement. Selon la théorie de champ moyen, la fonction de partition duprocessus de ligne, décrite par l’équation (4.22) correspond à la fonction de partition dedeux systèmes indépendants (H et V) dans 2 champs externes (GH et GV) sansinteractions entre les positions voisines. Alors, chaque système contribueindépendamment à la fonction de partition, la contribution du champ horizontal (resp.
verticale) de ligne étant
+
⋅− jiGHe ,1 β (resp. )1( , jiGVe
⋅−+
β), d’après (4.22). La
fonction de partition peut s’écrire:
[ ]×= ∑
∑
++−−⋅− −
d
d
,
)),((),(2
1,
2,12
1
I
jiIjiIji
VHjitteZ
ααπσ
β
∏
+⋅
+×
⋅−⋅−
ji
GVGH jiji ee,
,, 11 ββ (4.23)
Pour pouvoir quantifier la contribution du processus de ligne, dans l’équation(4.23) on identifie les termes où interviennent effectivement les deux composantes duprocessus de ligne:
Z = Za+Zeff (4.24)

108
avec:[ ]
∑∑
−−⋅− −
=d
d d
,
)),((),(2
1,
2,12
1),(I
jiIjiI
aji
jitteIZ πσ
β
(4.25)
et :[ ]
∑∑ ++⋅−+⋅−⋅−
=ld
ji,ld
,
)1()1( ,,,,),(
VHjijijiji GVVGHH
eff eZααβ
∏
++
+⋅
+=
⋅−⋅−
jiVH
GVGH jiji ee,
,, 11 ααββ (4.26)
Zeff peut être vue comme la contribution effective du processus de ligne à lafonction de partition du système entier, quand les autres variables sont ”gelées”.
Les énergies correspondant à ces fonctions de partition sont Ua(⋅) et Ueff(⋅):
[ ]∑∑ =
−−= −
jijijitta jiDFDjiIjiIIU
,
221,
2,12
1
),(2
1)),((),(2
1),(πσπσ
dd (4.27)
Ua(⋅) correspond à l’énergie d’attache aux données.
∑
++
+⋅
+⋅−=
⋅−⋅−
jiVH
GVGHeff
jiji eeU,
,, 11ln1),( ααβ
ββld (4. 28)
Ueff (d,l) exprime l’interaction effective entre le processus de ligne l et le champ dedéplacement d aux instants t-1 et t.
La fonction de partition (4.24) correspond au système d’énergie suivant:
U(I,d,l)= Ua(I,d) + Ueff (d,l) (4.29)
L’introduction de l’énergie effective Ueff permet d’obtenir un ensemble d’équationsdéterministes à partir de l’équation (4.33). En mécanique statistique, la somme del’énergie d’attache aux données et de l’énergie effective représente l’énergie libre dusystème et les solutions des équations du champ moyen sont obtenues en minimisant cetteénergie libre. L’ensemble des équations déterministes est obtenu après résolution del’équation:
( ) 0),(),(),,(=+
∂∂
=∂
∂ ldddd
ldeffa UIUIU (4.30)
avec: ( ) 0=+∂∂ ),(U),I(Ud effa
xldd (4.31)
( ) 0=+∂∂ ),(U),I(Ud effa
yldd (4.32)

109
Le calcul de la fonction de partition (4.22) ou (4.23) est très complexe parce qu’ilnécessite le calcul pour toutes les configurations possibles, du champ composé (I,d,l).Pour éviter cette difficulté, on peut faire une approximation, en approximant la fonctionde partition Z par sa valeur maximale. Plus précisément, on néglige les fluctuationsstatistiques du champ composé et on considère seulement la contribution du termemaximal de Z. Cette approximation, dite ”du point-selle”, implique aussi le remplacementde la variable (dans notre cas d) par sa valeur moyenne d [GEI 91], [BOU 00]. On a alors:
),,( ld IUeCZ ⋅−⋅≅ β (4.33)où C est une constante et d vérifie l’équation (4.30):
0),,(=
∂
∂
dldIU (4.34)
On peut obtenir l’expression de la valeur moyenne du processus de ligne enremplaçant l’équation (4.27), resp. (4.28) dans l’équation (4.29) (ou directement enremplaçant l’équation (4.25), resp. (4.26), dans l’équation (4.24)), en introduisant cerésultat dans l’équation (4.33) et en utilisant ce résultat dans l’équation (A.1.9), resp.(A.1.10), Annexe 1. On obtient:
−⋅−⋅⋅−
−
+
=+
=2
1,,,
1
1
1
1,
jijiHji
ee
HGH
jidd µαββ
, où:222πσ
αµ d= (4.35)
−⋅−⋅⋅−
−
+
=+
=2
,1,,
1
1
1
1,
jijiVji
ee
VGV
jidd µαββ
(4.36)
Les équations (4.35) et (4.36), peuvent être obtenues aussi en utilisant la théorie duchamp moyen et ”l’approximation du champ moyen” et pas l’approximation du point-selle(voir l’annexe 2).
La signification des équations (A.2.4) et (A.2.5) est que si le champ d est fixé(”gelé”), la valeur moyenne du processus de ligne peut être obtenue à partir de l’équation(4.26) en utilisant les équations (A.1.9) et (A.1.10), simplement en remplaçant la valeurdu champ de déplacement d par sa valeur moyenne d .
Conclusion:Pour obtenir une solution déterministe pour le processus de ligne, on doit faire une
approximation: l’approximation du champ moyen ou l’approximation du point-selle.L’essence de l’approximation du champ moyen est qu’on néglige les fluctuationsstatistiques du champ et on remplace la valeur du champ d dans l’équation (4.30) et (4.31)par sa valeur moyenne d . Dans la cas de l’approximation du point-selle, la fonction departition Z est approchée par sa valeur maximale et le champ d est remplacé par sa valeurmoyenne d .

110
4.2.3.5. L’algorithme MFA monorésolution
L’estimation du champ de déplacement peut être obtenue en minimisant l’énergieMAP (4.19.a). D’après (4.19.a) et (3.4.7), on obtient l’énergie MAP à minimiser [YU 94]:
∑ +
+⋅+⋅=
ji
tyy
xx jiIjiIjidjiIjidIU
,
221
),(),(),(),(),(2
1),,(
ldπσ
+
−⋅−+−⋅−⋅+ −− )1()1(
2,
2,1,,
21,,2
2jijijijijiji
d VH ddddπσ
α
⋅+⋅+ j,iVj,iH VH αα (4.37)
c’est à dire qu’on doit trouver la solution de l’équation (4.30):
0),,(=
∂∂
dldIU (4.38)
ou plus précisément les solutions des équations (4.31) et (4.32):
0),,( =∂∂ ldIUd x
(4.39)
0),,( =∂
∂ ldIUd y
(4.40)
En considérant les relations (4.13), (4.37), (4.39) et (4.40), on peut écrire:
( ) +⋅+⋅+⋅ xj,i
tj,iy
yj,ix
xj,i II)j,i(dI)j,i(dI
( ) ( ) ( ) ( ){ +−+⋅−−−−⋅−+ + )j,i(d)j,i(dH)j,i(d)j,i(dH xxj,ixxj,i 1111 122
21
σ
σ
( ) ( ) ( ) ( )} 01111 1 =−+⋅−−−−⋅−+ + )j,i(d)j,i(dV)j,i(d)j,i(dV xxj,ixxj,i (4.41)
( ) +⋅+⋅+⋅ yj,i
tj,iy
yj,ix
xj,i II)j,i(dI)j,i(dI
( ) ( ) ( ) ( ){ +−+⋅−−−−⋅−+ + )j,i(d)j,i(dH)j,i(d)j,i(dH yyj,iyyj,i 1111 122
21
σ
σ
( ) ( ) ( ) ( )} 01111 1 =−+⋅−−−−⋅−+ + )j,i(d)j,i(dV)j,i(d)j,i(dV yyj,iyyj,i (4.42)

111
Pour obtenir des deux composantes du champ de déplacement )j,i(d x et
)j,i(d x , en fonction de les deux composantes du champ de lignes j,iH et j,iV , on doit
résoudre le système d’équations 4.41+4.42 (voir l’annexe 3). Les solutions itératives de cesystème sont [YU 94]:
⋅−=+ kji
xjikx
ki,jkx aIjidjid ),(,1 ),(1),(
l
(4.43)
⋅−=+ kji
yjiky
ki,jky aIjidjid ),(,1 ),(1),(
l
(4.44)
où:( ) ( )2,
2,),(
),(,,,),(
),(),(
yji
xjikji
kjit
jikyy
jikxx
jiji
II
IjidIjidIa
k++⋅
⋅+⋅+⋅=
l
l
λ (4.45)
où k est l’indice d’itération.Pour obtenir l’estimation du champ de déplacement, on suppose que les
discontinuités de déplacement coïncident avec les discontinuités d’intensité. Le principede l’algorithme MFA monorésolution [YU 94] peut être décrit comme dans (4.46).
(4.46)
1. Calculer les gradients spatiaux, I x, I y, et le gradient temporel, I t ;2. Initialiser le processus de ligne H (resp. V) (par exemple en utilisant
l’opérateur de Canny [DER 87]);3. Calculer la valeur moyenne locale du processus de ligne et du champ de
déplacement, kji ),(l , kx )j,i(d , ky )j,i(d , en utilisant les équations (A.3.1),
(A.3.2) et (A.3.3);
4. Calculer la nouvelle estimation du champ de déplacement, 1+kx )j,i(d et
1+ky )j,i(d , en utilisant les équations (4.43), (4.44) et (4.45);
5. Calculer les nouvelles approximations du processus de ligne, H et V, enutilisant les équations (4.35) et (4.36);
6. Calculer une erreur relativement à la dernière itération (par exemple lavaleur de la différence moyenne entre l’estimation courante et l’estimationprécédente du champ de déplacement, pour tous les pixels de l’image);
7. Tester la condition d’arrêt. Si l’erreur ou le nombre d’itérations est plus petitqu’un seuil prédéfini, l’algorithme est fini ;
8. Actualiser le champ de déplacement et le champ de lignes avec les nouvellesvaleurs estimées et retour à l’étape 3.

112
4.2.3.6. L’algorithme MFA multirésolution
Algorithme homogène
L’utilisation de l’équation de contrainte du mouvement (3.3.10) comme termed’attache aux données [GRA 01] ne permet d’estimer que les petits déplacements (d’ordreà 1-2 pixels) à cause de la validité du développement en série Taylor et de l’utilisationd’équations différentielles qui sont approchées, dans le cas discret, par des différencesd’ordre 1. Si la vitesse v dans une séquence d’images est plus grande que le rapport entrela résolution spatiale (∆x) et la résolution temporelle (∆t) v=∆x/∆t, celle ci ne peut pas êtreestimée correctement. Pour pouvoir estimer les déplacements plus grands et obtenir uneréduction du temps de calcul, on peut utiliser une version multirésolution de l’algorithmedécrit dans le paragraphe 4.2.3.5 [YU 96].
L’approche multirésolution (voir le paragraphe 1.5.6.2) fait appel à unereprésentation hiérarchique d’images sous la forme d’une pyramide de Laplace [BUR 93].Ce principe peut s’appliquer de la même façon à l’estimation du mouvement [PER 93],[GAO 00]: il permet l’estimation de déplacements de plus grande amplitude que dans lecas monorésolution, avec une précision plus grande.
Dans le cas de l’estimation MFA multirésolution, le mouvement est estimé enutilisant le principe MFA décrit dans (4.46), successivement à chaque niveau, encommençant par le niveau de résolution le plus faible, situé au sommet de la pyramide(figure 1.5.7). L’estimation au niveau de résolution faible (niveau supérieur dans lareprésentation pyramidale) est transmise par un héritage selon un arbre quaternaire auniveau de résolution supérieure (niveau immédiatement inférieur dans la représentationpyramidale) où elle est utilisée comme initialisation pour l’estimation du mouvement.Cette initialisation est ensuite raffinée par l’application de la méthode MFA (cf. 4.46),avec les paramètres correspondants au niveau donnée de résolution, le processus étantrepris pour le niveau suivant (figure 1.5.8).
L’algorithme d’estimation multirésolution du mouvement basé sur le recuit enchamp moyen, est décrit dans (4.47).
Cet algorithme est homogène, en ce sens que l’estimation à chaque niveau esttransmise intégralement au niveau suivant, quel que soit le niveau. Dans une séquenced’images, plusieurs vitesses peuvent exister. Une vitesse est estimée de manière optimalepour un certain rapport entre la résolution spatiale et temporelle. La résolution temporelle(c’est à dire la distance en temps entre deux images successives) étant constante dans uneséquence donnée, il en résulte que la vitesse sera estimée de façon optimale en chaquepixel à une certaine résolution spatiale, correspondant donc à un niveau particulier de lapyramide. Ce niveau sera différent pour chaque pixel selon sa vitesse [BAT 91]. Parconséquent, l’algorithme multirésolution homogène (4.69) qui propose de manièreidentique l’estimation d’un niveau à l’autre, risque de détériorer une estimation optimaleobtenue à un niveau intermédiaire.

113
(4.47)
En plus, dans la représentation multirésolution d’une image, les composantesspatiales haute fréquence sont atténuées aux résolutions faibles, où les gradients spatiauxet temporaux peuvent être estimés avec une bonne précision. A faible résolutionapparaissent des erreurs de discrétisation. A haute résolution, les erreurs de discrétisationdiminuent, mais les erreurs de dérivation augmentent et les gradients spatiaux ettemporaux ne seront donc pas estimés avec une bonne précision.
Il en résulte que pour pallier les désavantages de l’algorithme multirésolutionhomogène et déterminer le niveau de résolution optimal pour l’estimation de la vitesse,qui correspond au minimum des erreurs cumulées de dérivation et de discrétisation, ondoit utiliser un algorithme multirésolution adaptatif. Dans ce cas, les paramètresdépendent du niveau de résolution [PER 93] et l’estimation optimale ne correspond pasforcément au dernier niveau [BAT 91].
Algorithme adaptatif
Une des possibilités d’implantation d’un algorithme multirésolution localementadaptatif est de calculer à chaque niveau de résolution et pour chaque pixel, une erreurrelative qui englobe les erreurs de dérivation et celles de discrétisation. Un exemple d’unetelle erreur est [BAT 91]:
( ) ( ) ( )[ ]( ) ( ) ( )222
2222
113
2
IIIIIIe
tyxyxt
∆∆∆∆∆∆
σ
π+
++−−
⋅= (4.48)
où: ∆xI=2·I x·∆x, ∆yI=2·I y·∆y, ∆tI=2·I t·∆t;∆x, ∆y, ∆t sont les pas d’échantillonnage spatial et temporel;I x, I y, I t sont les gradients spatiaux et temporel.
1. Construction d’une pyramide Laplace [BUR 93]:− l’image initiale, de résolution maximale, constitue la base de la pyramide;− les images situées à un niveau supérieur sont obtenues à partir du niveau
inférieur, par filtrage passe-bas, suivi d’un sous échantillonnage d’unfacteur 2 du niveau supérieur, dans les directions horizontale et verticale;
− le nombre de niveaux nécessaires dans la représentation pyramidaledépend du déplacement maximal qui doit être estimé;
2. Application de l’algorithme (4.46) à l’image au niveau courant de résolution;3. Transmission par interpolation de l’estimation obtenue au niveau courant au
niveau immédiatement inférieur de la pyramide. Le champ interpolé constituel’estimation initiale du niveau inférieur, qui devient le niveau courant;
4. Reprise de l’algorithme à partir de l’étape 2, jusqu’à la base de la pyramide(niveau de résolution maximale) qui fournit l’estimation finale.

114
σ est la déviation standard de la densité de probabilité de l’intensité des pixels.Dans l’équation (4.48), le premier terme correspond aux erreurs de dérivation et le
deuxième aux erreurs de discrétisation. L’algorithme multirésolution localement adaptatifeffectue le calcul de l’erreur e donnée en chaque pixel à chaque niveau de résolution.L’estimation du mouvement est alors calculée seulement pour les pixels actifs ayant uneerreur relative e supérieure à un seuil prédéfini Te.
Pour les pixels ayant une erreur relative e inférieure ou égale au seuil Te, onconserve l’estimation obtenue au niveau optimal. Cette estimation sera transmise auxpixels correspondants du niveau de résolution supérieure. Pour ces pixels l’estimation demouvement est terminée.
L’algorithme MFA multirésolution localement adaptatif, peut être décrit par (4.49).
(4.49)
1. Construction d’une pyramide de Laplace [BUR 93]:− l’image initiale, de résolution maximale, constitue la base de la pyramide;− les images situées à un niveau supérieur obtenues à partir du niveau
inférieur, par filtrage passe-bas, suivi d’un sous échantillonnage d’unfacteur 2 du niveau supérieur, dans les directions horizontale et verticale;
− le nombre de niveaux nécessaires dans la représentation pyramidaledépend du déplacement maximal qui doit être estimé;
2. Initialisation à 0 d’un champ binaire de marqueurs (0=non-marqué,1=marqué), correspondant à chacun pixel de l’image;
3. Application de l’algorithme (4.46) pour les pixels non-marqués dans l’imageau niveau courant de résolution (le premier niveau de résolution la plusfaible, au sommet de la pyramide);
4. Calcul (pour chaque pixel non-marqué au niveau courant de résolution), del’erreur relative e, conformément à l’équation (4.48). Test: e<Te;
5. Marquer par 1 les pixels pour lesquels e<Te , ainsi que les pixels „enfants” depixels déjà marqués;
6. Transmission par interpolation de l’estimation obtenue au niveau courant auniveau immédiatement inférieur (de résolution supérieure) de la pyramide. Lechamp interpolé va constituer l’estimation initiale à ce niveau inférieur, quidevient le niveau courant;
7. Reprise de l’algorithme à partir de l’étape 2, jusqu’à la base de la pyramide,c’est à dire jusqu’au niveau de résolution maximale. L’estimation résultantereprésente l’estimation finale.

115
4.3. Résultats expérimentaux
Dans le paragraphe 3.3, on a présenté le modèle Markovien MAP classiqued’estimation de mouvement et dans le paragraphe 3.4, le modèle avec prise en compte desdiscontinuités. Le chapitre 4 concerne les méthodes de minimisation utilisées dans cecadre.
On illustre les résultats d’estimation de mouvement obtenus pour des séquencesd’images classiques: les séquences ”rubic-cube” et ”taxi” (images 192×256, sur 8 bits),dans lesquelles on retrouve des combinaisons des mouvements de translation et derotation. On présente également, des résultats obtenus dans le cas de séquences médicalesRX et IRM:• séquence d’images représentant une coupe de thorax animé respirant (images
256×256, sur 8 bits). L’image initiale est fournie par le Laboratoire d’Electronique etTraitement d’Information (LETI), du Commissariat d’Energie Atomique (CEA),Grenoble;
• séquence IRM d’images cardiaques (images 256×312, sur 8 bits), obtenue à l’hôpitalcardiologique de Lyon [CHR 99].
Figure 4.3.2.a et 4.3.2.c on présente les résultats obtenus pour la séquence ”rubic-cube”, avec la méthode MAP classique d’estimation du mouvement, décrite dans leparagraphe 3.3, en minimisant l’énergie MAP (3.3.5) et en utilisant comme méthode deminimisation l’algorithme ICM, décrit dans le paragraphe 4.2.1, pour α=0,05. On a utilisécomme modèle a priori du champ de déplacement, l’énergie décrite par l’équation 3.3.12et comme énergie d’attache aux données, l’équation DFD décrite par l’équation 3.3.10.Figure 4.3.2.b et 4.3.2.d on présente les résultats obtenus avec la méthode MAP avec priseen compte des discontinuités dans le champ de déplacement, décrite dans le paragraphe3.4, en minimisant l’énergie MAP (4.50) et en utilisant comme méthode de minimisationl’algorithme multirésolution de recuit simulé en champ moyen (MFA), décrit dans leparagraphe 4.2.3.2, diagramme 4.71. Pour pouvoir comparer les différentes méthodesentre elles, on présente les résultats de l’algorithme MAP+MFA obtenus en pleinerésolution.

116
0
50
100
150
200
250
50 100 150 200 250
50
100
150
200
0
50
100
150
200
250
50 100 150 200 250
50
100
150
200
(a) (b)
-100
-50
0
50
100
50 100 150 200 250
50
100
150
200
(c)
Figure 4.3.1. (a) Image 1 de la séquence ”rubic-cube”;(b) Image 2 de la séquence ”rubic-cube”;
(c) Image de différence entre les images 1 et 2 de la séquence”rubic-cube”: (min=-118, max=120, moyenne=-0.73, ecart_type =5.24).
50 100 150 200 250
50
100
150
200
50 100 150 200 250
50
100
150
200
(a) (b)

117
-60
-40
-20
0
20
40
50 100 150 200 250
50
100
150
200
-60
-40
-20
0
20
40
50 100 150 200 250
50
100
150
200
(c) (d)
Figure 4.3.2. Champ de vecteurs déplacement, entre les images 1 et 2 de la séquence”rubic-cube”, obtenu:
(a) en utilisant l’algorithme MAP+ICM et l’énergie d’attache aux données (3.3.10);(b) en utilisant l’algorithme MFA multirésolution (4.73);
(c) Image de différence entre l’image compensée, en utilisant le champ de déplacement(a) et l’image 2 de la séquence ”rubic-cube”
(min=-69, max=59, moyenne=0.01, ecart_type =2.39);(d) Image de différence entre l’image compensée, en utilisant le champ de déplacement
(b) et l’image 2 de la séquence ”rubic-cube”(min=-129, max=127, moyenne =-0.05, ecart_type =3.32).
Dans le tableau 4.3.1 sont présentés les résultats obtenus pour la séquence ”rubic-cube”, d’estimation de mouvement par des méthodes classiques et par des algorithmes detype MAP, en utilisant différentes méthodes de minimisation.
Méthoded’estimation
du mouvement
Valeurmaximale
dmax_e
Valeurminimale
dmin_e
Valeurmoyenne
dmed_e
Ecarttype σ
Paramètres desalgorithmes
HS -125 102 -0.74 3.32 Nit=50, γ=200MCB -231 211 -1.02 11.86 D = 4, B = 5SEA -231 211 -1.02 11.86 D = 4, B = 5
MFA_1 -200 124 -0.07 3.42MFA_3 -130 127 -0.08 3.35
MFA_3_f -129 127 -0.05 3.32
Nit=50,β=5.0,σ1=3.75,σ2=0.71,GH=7.0,GV=7.0, S=0.3
ICM_DFD -219 188 -0.37 7.09 D = 4, B = 5ICM_ECM -69 59 0.01 2.39 Nit=2,α=0.05
Tableau 4.3.1. Résultats obtenus pour la séquence ”rubic-cube”.

118
On observe qu’on obtient les résultats les plus précis en utilisant l’algorithme MFA. Dans le tableau 4.3.1 on a utilisé les notations suivantes, pour les différents algorithmes:- HS= méthode de Horn et Schunck;- MCB= mise en correspondance de blocs, avec recherche exhaustive;- SEA= mise en correspondance de blocs, avec recherche par élimination successive;- MFA_1= MAP avec recuit simulé, monorésolution;- MFA_3= MAP avec recuit simulé, multirésolution (avec 3 niveaux), homogène;- MFA_3_f=MAP avec recuit simulé, multirésolution (avec 3 niveaux), adaptatif;- ICM_DFD= MAP avec modes itérés conditionnel, en utilisant comme énergie
d’attache aux données, l’équation DFD décrite par la relation (3.3.9);- ICM_ECM= MAP avec modes itérés conditionnel, en utilisant comme énergie
d’attache aux données, l’équation ECM décrite par la relation (3.3.10).- les notations pour les paramètres des algorithmes sont similaires aux notations
utilisées dans le tableau 2.2, respectivement dans les relations 4.11, 4.17, 4.20 et 4.72.Figure 4.3.3 représente les images 1 et 2 de la séquence ”taxi” et l’image de
différence.
0
50
100
150
200
250
50 100 150 200 250
20
40
60
80
100
120
140
160
180
0
50
100
150
200
250
50 100 150 200 250
20
40
60
80
100
120
140
160
180
(a) (b)
-150
-100
-50
0
50
100
150
50 100 150 200 250
20
40
60
80
100
120
140
160
180
(c)
Figure 4.3.3. (a) Image 1 de la séquence ”taxi”; (b) Image 2 de la séquence ”taxi”;(c) Image de différence entre les images 1 et 2 de la séquence ”taxi”:
(min=-170, max=157, moyenne=-0.34, ecart_type =5.97).

119
Figure 4.3.4.a et 4.3.4.c on présente les résultats obtenus pour la séquence ”taxi”avec la méthode MAP classique d’estimation du mouvement, décrite dans le paragraphe3.3, en minimisant l’énergie MAP (3.3.5) et en utilisant comme méthode de minimisationl’algorithme ICM, décrit dans le paragraphe 4.2.1, pour α=0,05. On a utilisé commemodèle a priori du champ de déplacement, l’énergie décrite par l’équation 3.3.12 etcomme énergie d’attache aux données, l’équation DFD décrite par l’équation 3.3.10.Figure 4.3.2.b et 4.3.2.d on présente les résultats obtenus avec la méthode MAP avec priseen compte des discontinuités dans le champ de déplacement, décrite dans le paragraphe3.4, en minimisant l’énergie MAP (4.50) et en utilisant comme méthode de minimisationl’algorithme multirésolution de recuit simulé en champ moyen (MFA), décrit dans leparagraphe 4.2.3.2, diagramme (4.71). Pour pouvoir comparer les différentes méthodesentre elles, on présente les résultats de l’algorithme MAP+MFA obtenus en pleinerésolution.
50 100 150 200 250
20
40
60
80
100
120
140
160
180
50 100 150 200 250
20
40
60
80
100
120
140
160
180
(a) (b)
-80
-60
-40
-20
0
20
40
60
80
100
50 100 150 200 250
20
40
60
80
100
120
140
160
180
-80
-60
-40
-20
0
20
40
60
80
100
50 100 150 200 250
20
40
60
80
100
120
140
160
180
(c) (d)Figure 4.3.4. (a) Champ de vecteurs déplacement, entre les images 1 et 2 de la séquence
”taxi”, obtenu en utilisant l’algorithme MAP+ICM_ECM; (b) Champ de vecteursdéplacement entre les images 1 et 2 de la séquence ”taxi”, obtenu en utilisant
l’algorithme MFA multirésolution (4.73); (c) Image de différence entre l’imagecompensée, en utilisant le champ de déplacement représenté sur la figure 4.3.4.a et
l’image 2 de la séquence ”taxi”; (d) Image de différence entre l’image compensée, enutilisant le champ de déplacement représenté sur la figure 4.3.4.b et l’image 2 de la
séquence ”taxi”.

120
Dans le tableau 4.3.2. on présente les résultats obtenus pour la séquence ”taxi”dans le cas des méthodes classiques d’estimation du mouvement, respectivement dans lecas des algorithmes MAP, avec différentes méthodes de minimisation.
Méthoded’estimation
du mouvement
Valeurmaximale
dmax_e
Valeurminimale
dmin_e
Valeurmoyenne
dmed_e
Ecarttype σ
HS -92 129 -0.14 2.34MCB -183 208 -0.24 5.80SEA -183 208 -0.24 5.80
MFA_1 -136 139 -0.099 2.45MFA_3 -117 139 -0.098 2.44
MFA_3_f -117 139 -0.11 2.32ICM_DFD -196 184 -0.23 4.22ICM_ECM -95 105 -0.19 2.11
Tableau 4.3.2. Résultats obtenus pour la séquence ”taxi”.
Dans le tableau 4.3.2 on a utilisé les mêmes notations que dans le tableau 4.3.1.On observe que les résultats les plus précis sont obtenus en utilisant l’algorithme
MFA.Sur la figure 4.3.5.a et 4.3.5.c, on présente les mêmes résultats présentés sur la
figure 4.3.4, mais dans le cas de la séquence ”taxi” sur laquelle on a superposé un bruitgaussien de moyenne nulle et un écart type σ, correspondant à un rapport signal-bruit de40 dB, calculé en utilisant la formule (1.6.3).
50 100 150 200 250
20
40
60
80
100
120
140
160
180
50 100 150 200 250
20
40
60
80
100
120
140
160
180
(a) (b)

121
-100
-80
-60
-40
-20
0
20
40
60
80
100
50 100 150 200 250
20
40
60
80
100
120
140
160
180
-100
-80
-60
-40
-20
0
20
40
60
80
100
50 100 150 200 250
20
40
60
80
100
120
140
160
180
(c) (d)Figure 4.3.5. (a) Champ de vecteurs déplacement, entre les images 1 et 2 de la séquence
”taxi” avec de bruit gaussien, obtenu en utilisant l’algorithme MAP+ICM_ECM;(b) Champ de vecteurs déplacement entre les images 1 et 2 de la séquence ”taxi” avec de
bruit gaussien, obtenu en utilisant l’algorithme MFA multirésolution (4.73);(c) Image de différence entre l’image compensée, en utilisant le champ de déplacement
représenté sur la figure 4.3.4.a et l’image 2 de la séquence ”taxi” avec un bruit gaussien(min=-118, max=112, moyenne=-0.24, ecart_type =1.28);
(d) Image de différence entre l’image compensée, en utilisant le champ de déplacementreprésenté sur la figure 4.3.2.b et l’image 2 de la séquence ”taxi” avec un bruit gaussien
(min=-126, max=128, moyenne =-0.10, ecart_type =1.27).
Comme on peut l’observer, MFA_3_f est plus sensible au bruit que ICM_ECM.Dans le tableau 4.3.3. on présente les résultats obtenus dans le cas de la séquence
”taxi” avec de bruit gaussien, dans le cas des méthodes classiques d’estimation dumouvement, respectivement dans le cas des algorithmes de type MAP, avec différentesméthodes de minimisation.
Méthoded’estimation
du mouvement
Valeurmaximale
dmax_e
Valeurminimale
dmin_e
Valeurmoyenne
dmed_e
Ecarttype σ
HS -94 128 -0.11 1.17MCB -197 205 -0.39 4.22SEA -197 205 -0.39 4.22
MFA_1 -195 128 -0.12 1.57MFA_3 -126 128 -0.108 1.32
MFA_3_f -126 128 -0.100 1.27ICM_DFD -204 198 -0.06 4.11ICM_ECM -118 112 -0.24 1.28
Tableau 4.3.3. Résultats obtenus dans le cas de la séquence ”taxi”, avec un bruit gaussien.

122
Les résultats les plus précis sont obtenus, dans ce cas aussi, en utilisantl’algorithme MFA.
Dans le tableau 4.3.3 on a utilisé les mêmes notations que dans le tableau 4.3.1.Pour la séquence ”taxi”, dans le cas des algorithmes testés on a obtenu les temps de
calcul comparatifs suivants (sur une même machine):
HS MCB SEA MFA_1 MFA_3 MFA_3_f ICM_DFD ICM_ECMTemps decalcul [s]
0.7 1.36 0.31 1.4 33.64 32.5 27.52 52.92
Tableau 4.3.4. Temps de calcul obtenu dans le cas de la séquence ”taxi”.
Comme on peut observer par les résultats présentés figures 4.3.2, 4.3.4 et 4.3.5,ainsi que par les tableaux 4.3.1÷4.3.4, les algorithmes MAP avec prise en compte desdiscontinuités offrent des résultats plus précis que les algorithmes classiques (HS, MCB,SEA), en termes de valeur moyenne et d’écart type de l’erreur. Mais ce plus de précisionest obtenu avec un temps de calcul plus grand. Pour un usage ”temps réel” on doit doncprévoir des techniques d’accélération de ces méthodes, en utilisant des structures”hardware” de calcul parallèle, dédiées. Suite aux résultats obtenus, on observe quel’utilisation dans l’énergie MAP de l’équation du flux optique comme terme d’attache auxdonnées, donne des résultats meilleurs, pour les séquences étudiées. Les algorithmesICM_ECM et MFA_3_f donnent des résultats meilleurs que les autres algorithmesétudiés. ICM_ECM diffère de ICM_DFD par l’énergie d’attache aux données.
L’algorithme MFA_3_f (4.73) représente une amélioration de l’algorithme MFA_3(4.71), qui lui-même représente une amélioration de l’algorithme MFA_1 (4.70). Lechamp des lignes (ou des discontinuités) est initialisé à partir de l’image de gradienttemporel (calculé en utilisant les deux images de la séquence) sur lesquelles on a calculéle gradient spatial en direction horizontale (pour obtenir les discontinuités en directionhorizontale) et le gradient spatial en direction verticale (pour obtenir les discontinuités endirection verticale). On suppose que les discontinuités des images d’intensitécorrespondent aux discontinuités du mouvement. Pour obtenir une initialisation binaire,on applique un seuillage des deux images de gradient spatial, calculés sur l’image degradient temporel. Le seuil (S) peut être calculé comme un pourcentage prédéfini sur ladynamique des deux images, comme par exemple:
−⋅≥−⋅<
=)(,1)(,0
minmax
minmaxHHSHsiHHSHsi
H
(4.72)
Figure 4.3.6 on présente les champs binaires des discontinuités, avec lesquels a étéinitialisé le champ des lignes, pour les algorithmes de type MFA.

123
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
50 100 150 200 250
20
40
60
80
100
120
140
160
180
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
50 100 150 200 250
20
40
60
80
100
120
140
160
180
(a) (b)Figure 4.3.6. Champs de lignes avec lesquels ont été initialisés les algorithmes de type
MFA, pour la séquence ”taxi”: (a) champ de lignes verticales; (b) champ de ligneshorizontales.
Figure 4.3.7 on présente deux images d’une séquence de synthèse, proches d’uncas réel. Les deux images représentent une coupe d’un thorax, qui simulent unmouvement respiratoire (séquence qui sera nommée par la suite ”pair”). L’image initiale aété fournie par le LETI-CEA et la deuxième image a été obtenue à partir de la premièreimage, en appliquant une déformation de type FFD (en anglais FFD=Free FormDeformation) [SED 86], [LAV 00], dont les paramètres sont choisis afin de simuler unmouvement respiratoire avec un déplacement maximal de 4 pixels. Par conséquent, pourcette séquence on connaît le champ théorique de déplacement.
0
50
100
150
200
250
50 100 150 200 250
50
100
150
200
250
0
50
100
150
200
250
50 100 150 200 250
50
100
150
200
250
(a) (b)

124
-100
-80
-60
-40
-20
0
20
40
60
80
100
50 100 150 200 250
50
100
150
200
250
50 100 150 200 250
50
100
150
200
250
(c) (d)
Figure 4.3.7. (a) Image 1 de la séquence ”pair”; (b) Image 2 de la séquence ”pair”;(c) Image de différence entre les images 1 et 2 de la séquence ”pair”:
(min=-108, max=117, moyenne=1.10, ecart_type =4.58);(d) Champ théorique de vecteurs déplacement entre les images 1 et 2 de la séquence
”pair”, obtenu en utilisant une déformation de type FFD de la première image.
Sur la figure 4.3.8.a et 4.3.8.c, on présente les résultats obtenus pour la séquence”pair” avec la méthode MAP_ICM_ECM, pour α=0.05. Figure 4.3.8.b et 4.3.8.d onprésente les résultats dans le cas de la méthode MAP_MFA_3_f.
50 100 150 200 250
50
100
150
200
250
50 100 150 200 250
50
100
150
200
250
(a) (b)

125
-20
-10
0
10
20
30
40
50
60
70
80
50 100 150 200 250
50
100
150
200
250
-20
-10
0
10
20
30
40
50
60
70
80
50 100 150 200 250
50
100
150
200
250
(c) (d)
Figure 4.3.8. (a) Champ de vecteurs déplacement, entre les images 1 et 2 de la séquence”pair”, obtenu en utilisant l’algorithme MAP+ICM_ECM;
(b) Champ de vecteurs déplacement entre les images 1 et 2 de la séquence ”pair”, obtenuen utilisant l’algorithme MAP+MFA_3_f;
(c) Image de différence entre l’image compensée, en utilisant le champ de déplacementreprésenté sur la figure 4.3.8.a et l’image 2 de la séquence ”pair”
(min=-27, max=83, moyenne=0.29, ecart_type =1.99);(d) Image de différence entre l’image compensée, en utilisant le champ de déplacement
représenté sur la figure 4.3.8.b et l’image 2 de la séquence ”pair”(min=-59, max=58, moyenne =0.11, ecart_type =1.20).
Dans ce cas aussi, le champ de lignes (ou des discontinuités), est initialisé à partirde l’image de gradient temporel (calculée en utilisant les deux images de la séquence) surlaquelle on a calculé le gradient spatial en direction horizontale (pour obtenir lesdiscontinuités en direction horizontale) et le gradient spatial en direction verticale (pourobtenir les discontinuités en direction verticale). Sur l’image résultante on applique unseuillage, afin d’obtenir un champ binaire de lignes.
Figure 4.3.9 on présente les champs des lignes (discontinuités) initialescorrespondent aux 3 niveaux de résolution de l’algorithme MFA_3_f, dans le cas de laséquence ”pair”.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
10 20 30 40 50 60
10
20
30
40
50
60
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
20 40 60 80 100 120
20
40
60
80
100
120
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
50 100 150 200 250
50
100
150
200
250
Figure 4.3.9. Champs des lignes (discontinuités) initiales correspondent aux 3 niveaux derésolution de l’algorithme MFA_3_f, dans le cas de la séquence ”pair”.
126
Dans le tableau 4.3.5. on présente les résultats obtenus pour la séquence ”pair”,dans le cas des méthodes classiques d’estimation du mouvement, respectivement dans lecas des algorithmes de type MAP, avec différentes méthodes de minimisation.
Méthoded’estimation
du mouvement
Valeurmaximale
dmax_e
Valeurminimale
dmin_e
Valeurmoyenne
dmed_e
Ecarttype σ
HS -57 58 0.19 1.33MCB -135 136 1.06 4.97SEA -135 136 1.06 4.97
MFA_1 -65 138 0.14 1.67MFA_3 -59 58 0.12 1.22
MFA_3_f -59 58 0.11 1.20ICM_DFD -92 90 0.40 1.97ICM_ECM -27 83 0.29 1.99
Tableau 4.3.5. Résultats obtenus dans le cas de la séquence ”pair”.
Dans le tableau 4.3.6. on présente les résultats pour la séquence ”pair” sur laquelleon a superposé un bruit gaussien de moyenne nulle et d’écart type σ, correspondant à unrapport signal/bruit de 40 dB, calculé en utilisant la formule (1.6.3).
Méthoded’estimation
du mouvement
Valeurmaximale
dmax_e
Valeurminimale
dmin_e
Valeurmoyenne
dmed_e
Ecarttype σ
HS -73 147 0.32 1.34MCB -185 168 1.22 3.92SEA -185 168 1.22 3.92
MFA_1 -94 140 0.31 1.48MFA_3 -73 126 0.30 1.30
MFA_3_f -73 126 0.26 1.27ICM_DFD -150 165 0.88 1.80ICM_ECM -63 111 0.57 1.79
Tableau 4.3.6. Résultats obtenus dans le cas de la séquence ”pair”, avec un bruit gaussien.
Comme on peut l’observer dans le cas de la séquence ”pair” et ”pair” avec un bruitgaussien, les résultats les plus précis sont obtenus en utilisant la méthodeMAP+MFA_3_f, mais avec un temps de calcul plus élevé. Pour illustrer le comportementet la robustesse au bruit de cette méthode, sur la figure 4.3.10 on représente la variation del’erreur moyenne entre l’image compensée et la deuxième image de la séquence ”pair”,pour plusieurs valeurs du rapport signal/bruit (RSB). Les résultats numériquescorrespondants sont présentés dans le tableau 4.3.7.

127
10 20 30 40 50 60 700
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
Erre
ur m
oyen
ne [p
ixel
s]
RSB [dB]
Figure 4.3.10. Variation de l’erreur moyenne entre l’image compensée et l’image 2 de laséquence ”pair”, en fonction du rapport signal-bruit (RSB), pour l’algorithme
MAP+MFA_3_f.
RSB [dB] 10 20 30 40 50 60 70L’erreur
moyenne [pixels]1.69 0.78 0.24 0.17 0.12 0.12 0.08
Tableau 4.3.7. Erreur moyenne entre l’image compensée et l’image 2 de la séquence”pair”, en fonction du rapport signal-bruit (RSB), pour l’algorithme MAP+MFA_3_f .
Sur la figure 4.3.11 on présente les résultats expérimentaux des méthodesd’estimation du mouvement, décrites précédent, dans le cas d’une séquence d’imagesréelles, pour voir si les conclusions de jusqu’ici se confirment ou pas. On présente lesrésultats dans le cas d’une séquence de deux images, nommé par la suite ”irm”, quireprésente un cœur en mouvement [CHR 99]. Les images sont acquises en utilisant latechnique spécifique IRM [CHR 99].
0
50
100
150
200
50 100 150 200 250 300
50
100
150
200
250
50 100 150 200 250 300
50
100
150
200
250
(a) (b)

128
-40
-30
-20
-10
0
10
20
30
50 100 150 200 250 300
50
100
150
200
250
-40
-30
-20
-10
0
10
20
30
50 100 150 200 250 300
50
100
150
200
250
(c) (d)
Figure 4.3.11. (a) Image 1 de la séquence ”irm”; (b) Champ de vecteurs déplacement, entre l’image 1 et l’image 2 de la séquence ”irm”,
obtenu en utilisant l’algorithme MAP+MFA_3_f;(c) Image de différence entre l’image 1 et l’image 2 de la séquence ”irm”
(min=-50, max=40, moyenne=0.26, ecart_type =2.49); (d) Image de différence entre l’image compensée en utilisant le champ de déplacement
représenté sur la figure 4.3.11.b. et l’image 2 de la séquence ”irm”(min=-48, max=37, moyenne=-0.10, ecart_type =1.11).
Dans le tableau 4.3.8. sont présentés les résultats obtenus pour la séquence ”irm”dans le cas des méthodes classiques d’estimation du mouvement, respectivement dans lecas des algorithmes de type MAP, avec différentes méthodes de minimisation.
Méthoded’estimation
du mouvement
Valeurmaximale
dmax_e
Valeurminimale
dmin_e
Valeurmoyenne
dmed_e
Ecarttype σ
HS -48 35 -0.14 1.17MCB -237 165 0.122 4.17SEA -237 165 0.122 4.17
MFA_1 -63 106 -0.126 1.17MFA_3 -48 50 -0.103 1.02
MFA_3_f -48 37 -0.106 1.11ICM_DFD -235 232 0.12 3.26ICM_ECM -33 39 -0.11 1.05
Tableau 4.3.8. Résultats obtenus dans le cas de la séquence ”irm”.
Comme on peut l’observer dans ce cas aussi, les algorithmes les plus précis sontaussi les algorithmes de type MAP+MFA multirésolution, ce qui confirme les conclusionsprécédentes.

129
4.4. Conclusions
Cette deuxième partie de la thèse décrit les méthodes d’estimation du mouvementqui permettent la préservation des discontinuités dans le champ de mouvement. Notreobjectif est d’identifier les particularités de ces méthodes et de proposer des solutions pourl’implantation de tout ou partie des algorithmes, sur des structures de calcul parallèle, detype réseaux neuronaux cellulaires.
Dans le paragraphe 3.2 on décrit les concepts et les définitions de base des champsde Markov. Ce modèle probabiliste permet l’incorporation dans le processus d’estimationdu mouvement, des informations a priori disponibles sur le mouvement.
Dans le paragraphe 3.3 on rappelle les bases du modèle markovien MAP(Maximum A Posteriori) classique d’estimation de mouvement, avec l’énergie d’attacheaux données et les modèles a priori les plus utilisés en pratique.
Dans le paragraphe 3.4 on décrit l’estimation MAP du mouvement, avec prise encompte des discontinuités dans le champ de mouvement. Les modèles a priori utiliséspour le champ de déplacement qui permettent l’incorporation des informations disponiblesa priori concernant le champ de déplacement sont présentés. Une de ces informations apriori peut être les discontinuités du champ de mouvement, qui sont décrites par le champdes discontinuités, connu aussi comme ”processus de ligne”.
Dans le chapitre 4, on décrit les méthodes les plus utilisées pour la minimisationdes fonctionnelles issues du MAP: l’algorithme des modes itérés conditionnel (ICM), lanon-convexité graduelle (GNC) et le recuit en champ moyen (MFA). Le recuit en champmoyen étant le plus aisément ”parallélisable”, il est donc particulièrement intéressant pourêtre implanté sur des réseaux neuronaux. C’est pourquoi nous avons présenté les détailsd’implantation de la version monorésolution, ainsi que de la version multirésolution del’algorithme.
Le paragraphe 4.3 présente les résultats expérimentaux obtenus en utilisant lesméthodes markoviennes d’estimation du mouvement, implantées par l’auteur etappliquées à des séquences d’images test.
Comme on peut l’observer à partir des résultats expérimentaux, en utilisantl’estimation MAP classique du mouvement et l’algorithme ICM, on obtient les meilleursrésultats en utilisant le terme d’attache aux données décrit dans l’équation (3.3.10), maisavec des erreurs résiduelles aux endroits où il y a discontinuités de mouvement.
Pour éviter ces erreurs, on a mis en œuvre une méthode d’estimation MAP dumouvement avec prise en compte des discontinuités (3.4.4), avec le terme d’attache auxdonnées décrit dans l’équation (3.3.10), en utilisant l’algorithme de recuit en champmoyen. Comme on peut l’observer à partir des résultats présentés, les erreurs sont plusfaibles (en valeur moyenne et en écart type), mais on obtient encore des erreurs auxendroits où il y a des discontinuités de mouvement. Ces erreurs sont dues à au moins deux

130
causes. La première cause provient de la complexité de régler de façon optimale tous lesparamètres qui interviennent dans l’algorithme. La deuxième cause est le terme d’attacheaux données utilisé, qui n’est autre que l’équation de contrainte du mouvement (ECM) oude flux optique (EFO) [HOR 81]. En effet, les dérivées partielles, qui sont approchéesdans le cas discret par des différences finies entre les voisins d’ordre 1, limitent ledéplacement maximal qui peut être estimé à environ 1-2 pixels.
Par conséquent, afin d’obtenir des résultats plus précis on doit essayer d’éliminerou de minimiser l’effet de ces deux sources d’erreurs. Pour éliminer la première cause, ondoit faire une étude exhaustive des paramètres utilisés dans l’algorithme, pour trouver lesparamètres adaptés quel que soit la séquence d’images. Afin d’éliminer l’effet du termed’attache aux données et donc pour pouvoir estimer des déplacements plus grands, on peututiliser l’approche multirésolution de l’algorithme, décrit dans le paragraphe 4.2.3.1.
En termes de temps de calcul, l’algorithme ICM converge en 2 à 4 itérations, dufait que le nombre d’états possibles qui correspond aux valeurs possibles du déplacementestimé, est relativement faible [RAN 91]. Pour une image 256×256 et un déplacementmaximal de D=5 pixels, on obtient un temps de calcul compris entre 1 et 3 minutes, sur unPC 800 MHz (jusqu’à une minute par itération, sans optimisation de l’algorithme). Dansle cas de l’algorithme de minimisation du recuit en champ moyen, pour une image256×256, on a obtenu un temps de calcul d’environ 1 minute (55 secondes) pour 200itérations.
Pour obtenir un temps de calcul plus faible (temps-réel) nous allons étudier dansles chapitres suivants, l’implantation de ces algorithmes et des opérations quiinterviennent dans l’estimation du mouvement (interpolation des images, compensation demouvement) sur un réseau neuronal cellulaire RNC, qui est en fait un réseau deprocesseurs analogiques dédié pour le traitement d’images [SZI 00], [MIL 00], qui estdécrit dans le chapitre 5.