centre génie industriel et informatique (g2i) tatiana … · 2 une présentation de trois...
TRANSCRIPT

TATIANA : UN LODES INTERACTIONS
PAR ORDDE LA SPECIFICATION
G. DYKE, C. LUN
Décem
RAPPORT DE2008-4
GICIEL POUR L’ANALYSE HUMAINES MEDIATISEES
INATEUR ; A L’IMPLEMENTATION
D, J.J. GIRARDOT
bre 2008
RECHERCHE 00-005
Centre Génie Industriel et Informatique (G2I)


Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
Tatiana : un logiciel pour l’analyse des interactions humaines médiatisées par ordinateur, de la spécification à l’implémentation
Gregory Dyke*, Kristine Lund°, Jean-Jacques Girardot*
*Département RIM, Ecole Nationale Supérieure des Mines de St. Etienne,158, cours Fauriel F-42023 Saint-Étienne, France
°Laboratoire de Recherche ICAR, CNRS, University of Lyon, 15 parvis René Descartes, 69700 Lyon, France Email {Gregory.Dyke, Jean-Jacques.Girardot}@emse.fr
Email [email protected] ABSTRACT The analysis of multimodal computer-mediated human interaction data is difficult. The diverse nature of this data and its sheer quantity is formidable, but a further obstacle is introduced by the complex ways in which the different data sources are related to one another (e.g. video, audio, interaction trace log files). Indeed, creating an object of study that gives the most complete, faithful and pertinent view possible of observed data for the research questions being addressed is a challenge. In this paper, we present Tatiana (Trace Analysis Tool for Interaction Analysts) as an environment to assist researchers in managing, synchronising, visualising and analysing their data by iteratively creating artefacts that exhibit researchers’ current understanding of their data or otherwise build upon it. In order to motivate our design choices, we present three analytical contexts of on-going research projects and compare Tatiana's features with those of a number of existing tools. Finally, we show how we plan to extend Tatiana for wider applicability in terms of data import and export, transformation and formatting, visualisation and analysis. RÉSUMÉ L’analyse de données d’interactions médiatisées par ordinateur est difficile. La variété et la quantité des ces données sont en elles-mêmes impressionnantes, mais un obstacle supplémentaire est introduit par la complexité des liens qui lient entre elles ces données (p.ex. vidéo, audio, traces d’interaction). En effet, la création d’un objet d’étude qui fournisse une vision la plus complète, fidèle et pertinente possible de ces données dans l’optique d’une question de recherche posée constitue un véritable défi. Dans ce papier, nous présentons Tatiana (Trace Analysis Tool for Interaction Analysts), un environnement destiné à aider les chercheurs à gérer, synchroniser, visualiser et analyser leur données en créant de manière itérative des artefacts qui expriment la compréhension que ces chercheurs ont acquis de ces données, ou qui s’appuient sur celles-ci pour créer de nouvelles représentations. Afin de justifier les choix de conception, nous présentons trois contextes d’analyse, issus de projets de recherche en cours, et comparons les traits de Tatiana avec ceux d’autres outils. Enfin, nous expliquons comment Tatiana peut être étendu en termes d’applicabilité à de nouveaux types de données, en importation, exportation, transformation, formatage, visualisation et analyse.
1 Introduction L’étude socio-cognitive des interactions humaines supportées par ordinateur peut s’effectuer au travers de
l’enregistrement de ces activités, en particulier si elles ne sont pas limitées aux seules traces produites par les outils, mais incluent également des enregistrements audio et vidéo de ces activités (Avouris, Fiotakis, Kahrimanis, Margaritis, & Komis 2007). Cox (2007) encourage les chercheurs à utiliser l’ordinateur et les diverses techniques qu’il propose (visualisation, data mining, etc.) pour effectuer leurs analyses des interactions dans ce qu’il appelle « traitement du processus » (« process data »). Cependant, les corpus d’interaction, en particulier lorsque ces interactions médiatisées se déroulent en face à face, sont difficiles à gérer d’un point de vue technique, et compliquées à appréhender du fait de la multiplicité et de la diversité des sources de données. Il ne suffit pas en effet d’analyser des flots de données séparés ; ces flots de données doivent être combinés pour permettre une compréhension globale des interactions qui ont eu lieu (Goodman, Drury, Gaimari, Kurland, & Zarrella, 2006). Qui plus est, ces analyses doivent souvent être effectuées en équipe, que ce soit pour valider la méthode d’analyse au travers de la méthode des juges (De Wever, Schellens, Valcke, & Van Keer, 2006), pour répartir la charge de travail (Goodman et al., 2006), pour étendre l’applicabilité d’une méthode analytique à un nouveau domaine (Lund, Prudhomme, Cassier, 2007), ou pour combiner les perspicacités de plusieurs chercheurs (Prudhomme, Pourroy & Lund, 2007).
Les difficultés décrites ci-dessus suggèrent le besoin d’utiliser des outils qui non seulement sont capables de gérer cette quantité et cette variété de données, mais également permettent l’analyse et la visualisation au sein d’un cadre commun, qui autorise le partage avec d’autres chercheurs (c.f. Reffay, Chanier, Noras, & Betbeder, 2008 sur le travail de structuration des corpus d’apprentissage à des fins de partage).
Dans cet article, nous présentons le logiciel Tatiana (Trace Analysis Tool for Interaction ANAlysts), destiné aux chercheurs qui souhaitent analyser, dans une perspective d’interaction socio-cognitive, des situations d’enseignement ou de travail collaboratif médiatisé par ordinateur. Nous présenterons d’abord trois exemples
Centre G2I / Laboratoire CNRS ICAR
1

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
typiques de situations d’analyse, puis décrirons brièvement les outils comparables à Tatiana. Nous comparerons ensuite les caractéristiques de Tatiana avec celles de ces outils, et montrerons leur utilité à la lumière des exemples décrits. Nous présenterons enfin les aspects principaux de l’architecture de Tatiana, et décrirons comment cet outil permet la création itérative et interactive d’artefacts montrant comment le chercheur appréhende le corpus, et l’aidant à approfondir sa compréhension de ce dernier.
2 Une présentation de trois contextes d’analyse Afin de justifier certains de nos besoins – et de nos choix techniques – pour un logiciel d’analyse des
interactions médiatisées par ordinateur, mais se déroulant en présentiel, nous allons présenter quelques exemples extraits de trois corpus différents que nous analysons actuellement, ainsi que les questions de recherche liées à ces trois corpus. Ces exemples peuvent également servir d’indicateurs à des concepteurs d’outils d’analyse, pour estimer l’applicabilité de leurs outils aux contextes que nous allons décrire.
2.1 Prise de notes partagée durant des séances de monitorat Dans le cadre du projet de recherche européen LEAD1 (LEAD, 2006), nous avons observé neuf dyades sur une série de cinq rendez-vous avec leur encadrant dans le contexte de projets de programmation proposés en application d’un cours d’introduction à l’informatique. Ces réunions avaient lieu en face-à-face, l’enseignant et les deux étudiants ayant tous trois accès, sur des portables, à un “chat” et un éditeur de texte partagé. Ces “trilogues2” ne reposaient pas sur un scénario pédagogique formel ; au contraire, un parallèle pourrait être établi avec des réunions de revue de projet industriel, dans lesquelles l’enseignant jouait, selon les circonstances, le rôle du donneur d’ordre, du consultant pédagogue ou de l’expert en programmation, et les étudiants se trouvaient dans la position d’une équipe de développement. Les points abordés, au cours de ces réunions, concernaient la compréhension du travail à faire ou les choix possibles dans la conception et la programmation (spécification fonctionnelle, implémentation). Les étudiants prenaient des notes, définissaient les tâches à accomplir pour la prochaine réunion, et discutaient de la mise en forme du rapport et de la présentation finale. Les données recueillies consistaient en un enregistrement audio multi-pistes (une par participant), une vidéo d’ensemble, les fichiers de trace informatique (chat et éditeur de texte partagé, deux outils implémentés sur notre plate-forme collaborative DREW3), ainsi que des notes prises par le chercheur observant l’expérience. Les conditions expérimentales variaient selon les dyades : deux tuteurs différents étaient impliqués, gérant trois projets différents. Les dyades utilisaient l’une ou l’autre des versions de l’éditeur de texte partagé, la première faisant appel à un jeton pour gérer l’autorisation d’écrire, la seconde permettant l’accès libre à n’importe quel participant.
Nous explorons grâce à ce corpus trois questions de recherche. La première concerne la distribution des diverses modalités : comment les participants organisent-ils les modes de communication en fonction de leurs objectifs, comment leurs activités (dialogue, chat, prise de notes) se recouvrent-elles, et comment pouvons nous mettre en évidence les effets de ces tâches simultanées ? La seconde s’intéresse aux relations entre les formes de collaboration et les caractéristiques des outils, par exemple l’influence du type de l’éditeur de texte (accès libre ou régulé par jeton) sur les contributions des participants et la forme finale du texte. La dernière, enfin, s’intéresse au contenu pédagogique, par exemple à la manière dont les étudiants reformulent dans leurs notes ce qui est dit par l’enseignant, ou à l’influence de l’outil sur l’activité pédagogique de l’encadrant, puisque celui-ci peut voir en temps réel les notes prises par les étudiants.
Pour répondre à ces questions, il est essentiel de pouvoir visualiser la transcription du dialogue multimodal en conjonction avec les traces d’interaction (chat, éditeur de texte), et de comprendre comment le texte a été composé dans l’éditeur partagé. Cette dernière tâche est compliquée par la représentation des traces d’interactions produites par l’éditeur partagé : chaque seconde (lorsqu’il y a interaction), un événement est enregistré, comportant le texte complet, le nom du participant ayant modifié le contenu, et la position du curseur au moment de l’intervention. Cette information est suffisante pour permettre l’implantation de l’éditeur partagé,
1 Le projet Européen LEAD (Technology-enhanced learning and problem-solving discussions: Networked learning environments in the classroom) est financé par le 6ème PCRD, Information Society Technology LEAD IST-028027. http://www.lead2learning.org/ 2 Le terme “dilogue” est utilisé par Kerbrat-Orecchioni (2004) pour faire référence à un échange entre deux personnes (le préfix grec “dia”, comme dans “dialogue”, ne signifie pas “deux”, mais plutôt “à travers”). En conséquence, “tri” signifiant “trois”, “trilogue” est utilisé pour désigner un échange entre trois personnes. 3 Le logiciel DREW (Dialogical Reasoning Educational Web tool) fut conçu et développé au sein du projet SCALE (Internet-based intelligent tool to Support Collaborative Argumentation-based LEarning in secondary schools), financé par le 5ème PCRD, Information Societies Technology SCALE IST-1999-10664.
Centre G2I / Laboratoire CNRS ICAR
2

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
mais n’est pas pertinente pour le chercheur, en ce sens que la vision qu’elle fournit est trop granulaire, tout en associant bien trop de détails à chaque événement. Nous explorons actuellement différentes méthodes de visualisation pour permettre au chercheur de mieux appréhender les évolutions du texte (p.ex. Kollberg, 1996).
2.2 Conception collaborative en ingénierie mécanique L’un des objectifs du projet COSMOCE4 était d’étudier le processus de la conception collaborative en
ingénierie mécanique. Dans ce contexte, nous avons mis en place une situation similaire à une étude industrielle, impliquant trois étudiants de l’université (niveau Master). La finalité pour les étudiants était de choisir une des trois solutions proposées, ou d’en imaginer une nouvelle, pour la réalisation d’une “poutre à pneus de téléphérique”. Ce travail s’est déroulé en trois étapes :
• un travail individuel préliminaire, destiné à les préparer à la phase collective de revue de projet ;
• une phase de travail collaboratif de revue de projet, ayant pour but de permettre l’argumentation ;
• une phase finale individuelle, faisant suite à la confrontation collective et à la prise de décision.
Au cours de l’étape de travail collaboratif, les étudiants ont discuté à distance de leurs solutions, en utilisant le chat et un éditeur partagé de graphes argumentatifs sur la plateforme collaborative DREW. Une fois parvenus à un accord, ils avaient pour mission d’utiliser l’éditeur de texte partagé pour décrire les différentes contraintes que leur solution prenait en compte. Les données recueillies au cours de l’expérience étaient constituées des traces construites par le logiciel (chat, grapheur d’argumentation, éditeur collaboratif), ainsi que des documents manuscrits et des dessins réalisés par les étudiants au cours des phases un et trois.
Les analyses initiales de ce corpus, extensives, illustrèrent la dynamique des connaissances des apprentis concepteurs, sous la forme de schémas d’argumentation, basées sur les propositions successives de solutions et de critères destinés à les évaluer (Prudhomme, Pourroy & Lund, 2007). Ces analyses combinèrent les expertises de trois chercheurs spécialistes de quatre domaines : les interactions socio-cognitives, l’argumentation, la conception collaborative et l’ingénierie mécanique. La nécessité de faire appel à différentes formes d’expertises pour aboutir à un consensus sur l’interprétation de l’implicite dans la mise en oeuvre des connaissances en mécanique des étudiants constituait l’un des défis de cette analyse. Parmi les questions de recherche actuelles sur ce corpus se pose le problème de découvrir comment la construction (écrite) de connaissances individuelles des étudiants aux étapes un et trois se retrouve dans les constructions collectives dans le chat et le grapheur d’argumentation de l’étape deux (Lund, Andriessen, Prudhomme, van Amelsvoort, en préparation), ainsi que la description de phénomènes interactionnels au travers de la construction de visualisations sémantiques et temporelles de l’argumentation (Lund, Cassier, Prudhomme, en préparation). Bien que le travail sur les schémas argumentatifs lors des premières analyses n’ait pas bénéficié de l’usage de Tatiana, notre objectif est de mettre en oeuvre ce logiciel pour les recherches suivantes.
2.3 Apprentissage collaboratif médiatisé en face à face au moyen du débat Nos partenaires5 du projet LEAD ont recueilli, ou sont en train de recueillir, des données de plusieurs
expérimentations menées en situation d’enseignement avec de petits groupes (discussions ou résolutions de problèmes), conduites en présentiel et médiatisées par ordinateur. La conception de ces observations varie selon les partenaires, mais les données obtenues se composent habituellement d’enregistrements vidéo et de traces d’interactions produites par la plate-forme collaborative CoFFEE6 (De Chiara, Di Matteo, Manno, & Scarano, 2007), qui comporte différents outils (chat, chat structuré, grapheur argumentatif, éditeur de texte, outil de vote, etc.). Notre objectif était de nous assurer que Tatiana était capable de gérer la diversité des données et d’assister nos partenaires du projet, en dépit de la variété des analyses qu’ils désiraient effectuer.
Nous avons été confrontés à deux types de problèmes, liés à l’outil utilisé: 1) le format de représentation des traces rend extrêmement difficile l’accès à certaines informations ; 2) il est très compliqué d’établir un lien entre les données disponibles et une intervention d’un participant dans le chat structuré ou le grapheur d’argumentation, du fait de la nature non linéaire de ces médias.
En plus des deux contextes de recherche présentés antérieurement, ces situations, impliquant des dialogues entre étudiants, des traces d’interactions médiatisées par ordinateur et des interventions de l’enseignant,
4 Le projet COSMOCE (Conception, Outils, Supports, Médias, Organisation pour la Collaboration des Entreprises) a été financé par la région Rhône-Alpes. 5 Universités de Bari, Nottingham, Paris, Salerno, Tilburg et Utrecht. 6 CoFFEE (Cooperative Face2Face Educational Environment) a été conçu et développé dans le cadre du projet LEAD. Centre G2I / Laboratoire CNRS ICAR
3
Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
constituent un autre exemple de données complexes d’interactions multimédia et multimodales entre individus.
2.4 Un support au travail des chercheurs en interaction humaine Nous sommes donc confrontés à la difficulté de créer un objet d’étude — à partir des différentes sources
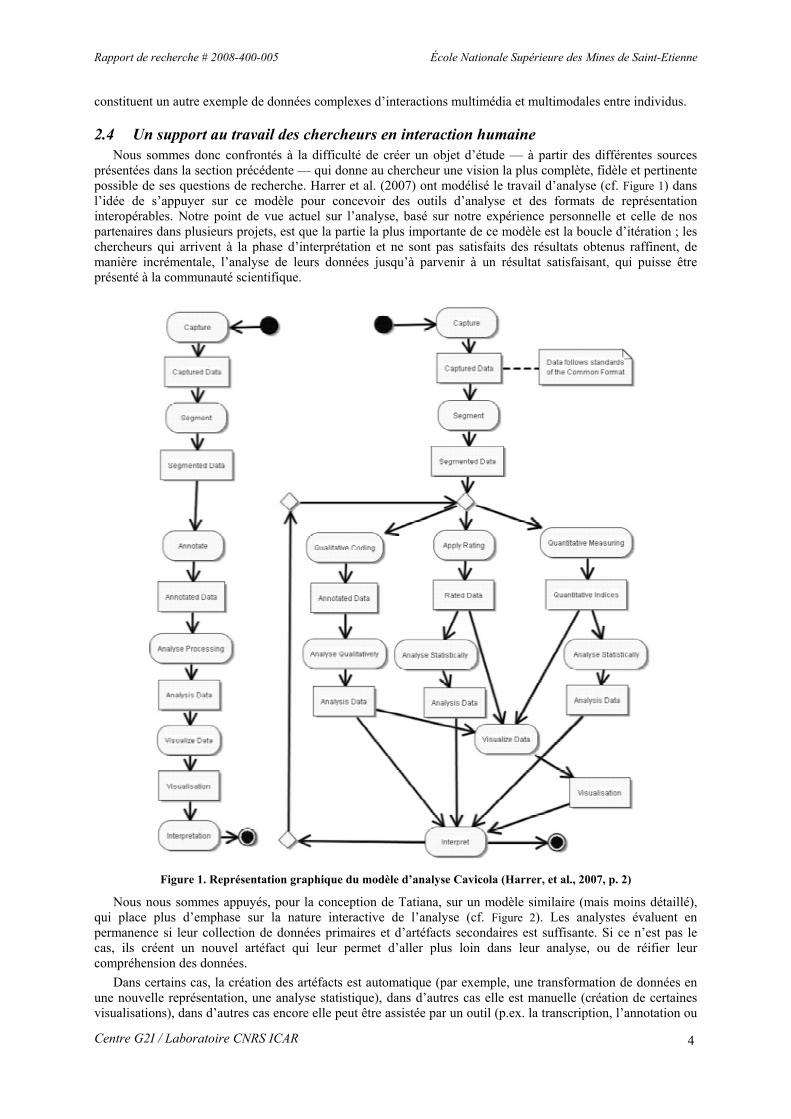
présentées dans la section précédente — qui donne au chercheur une vision la plus complète, fidèle et pertinente possible de ses questions de recherche. Harrer et al. (2007) ont modélisé le travail d’analyse (cf. Figure 1) dans l’idée de s’appuyer sur ce modèle pour concevoir des outils d’analyse et des formats de représentation interopérables. Notre point de vue actuel sur l’analyse, basé sur notre expérience personnelle et celle de nos partenaires dans plusieurs projets, est que la partie la plus importante de ce modèle est la boucle d’itération ; les chercheurs qui arrivent à la phase d’interprétation et ne sont pas satisfaits des résultats obtenus raffinent, de manière incrémentale, l’analyse de leurs données jusqu’à parvenir à un résultat satisfaisant, qui puisse être présenté à la communauté scientifique.
Figure 1. Représentation graphique du modèle d’analyse Cavicola (Harrer, et al., 2007, p. 2)
Nous nous sommes appuyés, pour la conception de Tatiana, sur un modèle similaire (mais moins détaillé), qui place plus d’emphase sur la nature interactive de l’analyse (cf. Figure 2). Les analystes évaluent en permanence si leur collection de données primaires et d’artéfacts secondaires est suffisante. Si ce n’est pas le cas, ils créent un nouvel artéfact qui leur permet d’aller plus loin dans leur analyse, ou de réifier leur compréhension des données.
Dans certains cas, la création des artéfacts est automatique (par exemple, une transformation de données en une nouvelle représentation, une analyse statistique), dans d’autres cas elle est manuelle (création de certaines visualisations), dans d’autres cas encore elle peut être assistée par un outil (p.ex. la transcription, l’annotation ou
Centre G2I / Laboratoire CNRS ICAR
4

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
le codage). Ces artéfacts sont souvent des représentations de données faisant intervenir une dimension temporelle : la séquence des événements enregistrés au cours d’une observation est présentée au chercheur soit par un rejoueur (le chercheur utilise une télécommande pour se déplacer au travers des données, c.f. § “Outils de rejouage”), soit encore sous la forme d’une représentation graphique (avec un axe temporel représenté horizontalement ou verticalement).
Figure 2. Représentation graphique du modèle d’analyse dans Tatiana
Nous proposons que ces deux types d’objets, qui conservent la dimension temporelle de l’ordonnancement des événements et des interactions, soient baptisés rejouables. Ils peuvent être rejoués, synchronisés et analysés. Une analyse consiste ainsi en une création itérative de rejouables qui témoignent de la compréhension par le chercheur des données qu’il manipule, ou qui autorisent un approfondissement de cette compréhension au travers de la création de nouveaux rejouables. Chaque étape de cette itération comporte des transformations telles que : transcription, annotation, codage, visualisation, filtrage, synchronisation, fusion, etc.
Dans la section suivante, nous présentons rapidement des outils qui font appel à certaines de ces transformations, dans un cadre similaire ou différent.
3 Quelques outils d’analyse des interactions humaine Le logiciel Tatiana a été conçu et développé en réponse à des besoins effectifs d’analyse (c.f. § sur les
contextes d’analyse), tout en tenant compte de l’existence d’outils antérieurs. En décrivant, dans les prochaines sections, les raisons d’être des différentes caractéristiques de Tatiana, nous ferons souvent référence à d’autres outils, et à la manière dont ceux-ci implémentent des caractéristiques similaires. Nous débutons donc par un bref tour d’horizon de ces outils.
Elan (EUDICO Linguistic ANnotator, où EUDICO signifie European DIstributed Corpora Project) (http://www.lat-mpi.eu/tools/elan/) est un outil permettant d’effectuer des transcriptions et des annotations d’enregistrements audio et vidéo. Il est principalement destiné à l’analyse de phénomènes linguistiques.
Videograph® (http://www.ipn.uni-kiel.de/aktuell/videograph/enhtmStart.htm) est un lecteur de vidéo (p.ex. d’enregistrements réalisés en classe) destiné à l’évaluation de séquences. Le programme permet la construction de catégories d’observations et d’échelles de notation, que le chercheur peut utiliser comme “instrument de mesure” pour analyser le contenu de la vidéo.
Anvil (http://www.anvil-software.de/) est un logiciel libre d’annotation de vidéo (Kipp, 1996), qui permet la création, dirigée par des schémas que peut définit l’utilisateur, d’annotations hiérarchisées et temporellement très précises. Un tableau d’annotation permet la création d’éléments (codés par des couleurs), placés sur plusieurs pistes synchronisées. Entre autres caractéristiques, l’outil permet la création de liens entre éléments et d’objets non liés au temps, et offre un outil de gestion des annotations multiples. Développé à l’origine pour l’étude des gestes, Anvil s’est également avéré utile pour les recherches sur les interactions homme-machine, la linguistique, l’éthologie, l’anthropologie, la psychothérapie, l’animation par ordinateur et bien d’autres domaines.
CLAN (Computerized Language ANalysis) est un programme spécifiquement conçu pour l’analyse de données transcrites dans le format CHILDES (Child Language Data Exchange System). CLAN permet d’effectuer un grand nombre d’analyses sur les données : recherche de mots, comptage de fréquences, analyse des co-occurences, calcul des tailles moyennes des interventions (MLU, Mean Length of Utterance), analyses interactionnelles, transformations de texte, analyse morphosyntaxique.
NXT, ou “Nite XML Toolkit” (http://groups.inf.ed.ac.uk/nxt/) est un outil de création d’annotations complexes de corpus multimodaux de langue écrite ou parlée (Carletta et al., 2003). NXT est utilisé sur une très large variété de corpus, allant de la représentation de la structure du texte de la Bible à l’analyse des relations entre gestes et expressions déictiques dans les expressions de désignation multimodales. Son architecture extensible permet aussi de l’utiliser pour l’analyse des traces d’interaction.
ABSTRACT (Analysis of Behaviour and Situation for menTal Representation Assessment and Cognitive acTivity modelling; Georgeon et al., 2007; Georgeon, Mille, & Bellet, 2006) est un environnement d’aide à la compréhension des activités humaines à partir d’enregistrements effectués sur ordinateur de ces activités. Il comporte un langage d’interrogation et de transformation de données, permettant d’augmenter le niveau
Centre G2I / Laboratoire CNRS ICAR
5

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
d’abstraction des éléments et de visualiser ces éléments sous forme de symboles graphiques. Replayer (Morrison, Tennent, & Chalmers, 2006) est un outil initialement conçu pour aider à l’évaluation
des applications mobiles. Il permet de synchroniser de nombreux types de données, comme une vidéo ou des traces d’applications, et de visualiser ces données (sous forme graphique, tabulaire, superposées à une carte géographique, etc.)
DRS (Digital Replay System, Greenhalgh, French, Humble, & Tennent, 2007) est destiné à l’analyse de champs dans le domaine des “e-social sciences”7, intégrant des données telles que l’audio, la vidéo, les traces logicielles, l’eye-tracking, etc. Tout comme Replayer, il permet la synchronisation des représentations de ces données. Il offre également la possibilité d’effectuer différents types d’annotations des données.
ActivityLens (Fiotakis, Fidas, & Avouris, 2007) est un outil destiné à la base à l’évaluation de la “facilité d’utilisation” (usability) des logiciels éducatifs. Il permet de synchroniser la vidéo, les traces logicielles, les images, les notes, et offre une interface pour les annotations, les analyses statistiques et les analyses en théorie des activités. Cet outil est une évolution d’une réalisation antérieure, ColAT (Collaboration Analysis Toolkit, Avouris et al, 2007).
SAW (Synchronised Analysis Workspace, Goodman et al., 2006) est un outil d’analyse et de visualisation destinée à aider à la navigation au travers de flots de données multiples et synchronisés, et à faciliter l’analyse de ces flots. Il permet (entre autres possibilités) de représenter les événements par des symboles graphiques, de filtrer ces événements, et de partager tout ou partie des résultats avec d’autres chercheurs.
Nous nous intéresserons également à des outils tels que DREW (Corbel, Girardot, & Jaillon, 2002 ; Corbel et al., 2003), Digalo8 (Lotan-Kochan, 2006) ou CoFFEE (De Chiara et al., 2007), qui comportent tous un mécanisme de rejouage (qui correspond à un mode particulier d’utilisation du logiciel, dans lequel celui-ci lit des traces d’interactions qu’il a lui-même antérieurement générées, et reconstitue, de manière synchrone, son état interne ainsi que ses affichages sur l’interface utilisateur ; le rejouage d’une session permet au chercheur d’observer l’activité d’un étudiant telle qu’elle s’est déroulée, et lui donne ainsi certaines indications sur ce que cet étudiant tentait de faire à ce moment).
4 Caractéristiques et Logique de Tatiana Nous pouvons ranger les caractéristiques de Tatiana dans cinq grandes catégories :
1. Gestion des données : import, export et modélisation des données depuis le logiciel ;
2. Synchronisation : alignement temporel des différentes sources, et descriptions des éléments de l’interface utilisateur permettant de naviguer le long de l’axe temporel ;
3. Visualisation : transformation et visualisation des données comme aide au chercheur dans sa tâche d’analyse ;
4. Analyse : possibilités d’analyse offertes par l’outil ;
5. Extensibilité : manipulation de nouveaux types de données, personnalisation des visualisations et des analyses.
4.1 Données importées et produites Tout outil d’aide à l’analyse doit manipuler deux types de données : 1) celles qu’il est conçu pour analyser, et
2) celles qu’il produit lui-même. Elan, Anvil et Videograph, par exemple, s’intéressent principalement aux sources de données audio et vidéo, et permettent de créer des transcriptions et des annotations dans un format qui leur est propre. Les formats audio et vidéo sont relativement standardisés, et peuvent en général être gérés par les bibliothèques logicielles disponibles. Ces médias sont pris en charge dans tous les outils que nous avons présentés, y compris Tatiana. Cependant, les outils utilisés dans les activités médiatisées par ordinateur génèrent des traces d’interactions dans des formats qui leur sont propres. Les concepteurs des outils utilisés pour l’analyse des interactions doivent dès lors faire des choix, afin que la représentation de leurs données internes soit à la fois assez complète pour répondre aux divers besoins des analyses, mais également assez souple pour permettre la
7 Intégration de ressources informatiques hétérogènes dans le but de favoriser les activités de recherche distribuées et collaboratives. 8 Digalo, un outil pour la discussion et l’argumentation à base de graphes, fut conçu et développé au sein du projet DUNES (Dialogic and argumentative negotiation educational software), financé par le 5ème PCRD Information Society Technology et continue à être utilisé dans le projet ARGUNAUT (An Intelligent Guide to Support Productive Online Dialogue) financé par le 6ème PCRD Information Society Technology. Centre G2I / Laboratoire CNRS ICAR
6

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
prise en charge d’un grand nombre de formats de données. ActivityLens a fait le choix de n’importer que des données représentées dans le format commun proposé par
le groupe de travail CaviCola (Computer-based Analysis and Visualisation of Collaborative Learning Activities) au sein du SIG CSCL du réseau Kaleidoscope (Kahrimanis, Papasalouros, Avouris, & Retalis, 2006). Ce format permet à ActivityLens de prendre en charge les notions d’utilisateur, de groupe, d’outil, d’étape, en imposant une certaine vision des données. Il demeure cependant assez générique, permettant l’ajout de nouveau champs pour en élargir l’usage.
ABSTRACT décrit les données importées au travers d’ontologies rédigées en OWL/RDF, et nécessite des analyseurs pour permettre l’import des données (ce travail a été poursuivi par Settouti, Prié, Mille & Marty, 2006). ABSTRACT n’est capable d’interpréter les données qu’après description d’une ontologie noyau. NXT et DRS fournissent des afficheurs pour différents types de données. NXT peut importer toute donnée assimilable à une transcription (ce qui exclut certaines traces d’interaction complexes). DRS comporte un assistant à l’importation de données susceptibles d’être structurées en tables, et permet l’écriture de classes spécialisées pour l’importation de données plus complexes.
4.1.1 Les données dans Tatiana Nous avons choisi d’aborder le problème d’une autre manière dans Tatiana, en partant du principe qu’un
outil d’analyse devait pouvoir lire n’importe quel format de fichier de données (avec cette réserve que, hormis pour les fichiers audio et video, les fichiers devaient être au format XML et qu’une description de leur structure devait être disponible), et que le coût de l’intégration d’une nouvelle représentation devait être minimal. Nous supposons également qu’il n’est pas nécessaire que l’outil interprète la sémantique des informations contenues dans le fichier (sauf pour les informations de repérage et de synchronisation, c.f. ci-dessous), mais qu’il est suffisant de présenter l’information au chercheur pour que celui-ci puisse lui trouver un sens. Dans cette approche, nous avons choisi une représentation très générique. L’ensemble du corpus est conservé sous sa forme originale, mais Tatiana ajoute une représentation interne qui permet le repérage des événements, et, ultérieurement, leur structuration en graphes. La structure interne des données dans Tatiana (dite “format Display”) constitue un format pivot, et consiste en une séquence d’événements, dont chacun comporte un certain nombre de facettes. Chaque facette représente une donnée nommée et typée. L’importation de données extérieures et la conversion de ces données vers la représentation interne sont effectuées par des scripts écrits en XQuery (W3C, 2007). Ces scripts peuvent être combinés au moyen d’un langage de définition de filtre, qui permet la personnalisation de leurs fonctions (ces filtres sont décrit dans la section consacrée aux visualisations). De manière générale, un script d’importation a pour but de sélectionner un sous-ensemble du fichier à importer, tel que le “chat” au sein d’une trace DREW complète, ou la transcription des interactions (effectuée grâce au logiciel Elan), et à créer les facettes de chaque événement du format Display au moyen des informations contenues dans le fichier à importer. Un filtre générique de fusion permet enfin de combiner l’ensemble des extractions ainsi obtenues. À partir de ce format pivot, il est possible d’exporter relativement aisément vers d’autres représentations (si les informations attendues par ces représentations sont disponibles dans le format en entrée) ; jusqu’à présent, ExcelTM est le seul format très largement répandu pour lequel nous ayons implémenté des fonctions d’importation et d’exportation, dans la mesure où certains travaux d’analyses avaient été antérieurement effectués au sein de cette application.
Dans les deux corpus LEAD décrits ci-dessus, il est nécessaire de créer un rejouable qui combine des données d’interaction (issues des traces d’un logiciel collaboratif) et des transcriptions réalisées à partir de fichiers audio ou vidéo. Grâce à l’approche décrite ci-dessus, nous avons pu importer des données à partir de fichiers de traces de logiciels très différents (CoFFEE et DREW), et des fichiers de transcription au format Elan (ce logiciel ayant été utilisé pour les transcriptions). À une époque où le rejoueur CoFFEE n’était pas encore disponible, il avait été nécessaire de proposer une méthode temporaire pour visualiser les interactions produites au moyen de l’éditeur de graphes argumentatifs de ce logiciel. Nous avons atteint ce but en important la trace CoFFEE au sein de Tatiana, puis en l’exportant au format DREW, vérifiant ainsi que le format interne de Tatiana constituait un format pivot acceptable. Il avait de la sorte été possible de visualiser les traces de CoFFEE au moyen du rejoueur de DREW.
4.2 Synchronisation de différents flots de données simultanés Tous les outils décrits ci-dessus permettent la synchronisation entre différents types de rejouables, que ce
soient de simples fichiers vidéo, des transcriptions ou des annotations (Elan), ou des données de divers types (SAW, Replayer, DRS). La nécessité, pour l’analyste, de la synchronisation des différentes sources de données et rejouables est évidente : les événements observés sont situés temporellement, et doivent être replacés dans le même contexte de co-occurrence. De plus, différentes vues (p.ex. vidéo et transcription) des mêmes données sont très complémentaires lorsqu’elles sont synchronisées. La nécessité d’obtenir cette synchronisation est en fait d’ordre scientifique ; la validation d’une assertion passe par la découverte de preuves de cette assertion dans les
Centre G2I / Laboratoire CNRS ICAR
7

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
données. Les chercheurs créent et utilisent très fréquemment des rejouables qui présentent le corpus sous une forme telle qu’il est plus simple à comprendre, à explorer ou à analyser (c’est le cas, par exemple, d’une transcription par rapport à la séquence audio ou video correspondante). Cependant, lorsque l’on formule une hypothèse en se basant sur un tel artefact “secondaire”, il est indispensable de vérifier que la preuve se trouve également dans le document original. La synchronisation des sources et des documents secondaires fournit un moyen très simple de se référer au document original chaque fois qu’une telle confirmation est nécessaire.
On trouve essentiellement deux méthodes d’alignement temporel des données. La première consiste à supposer que les informations temporelles avaient été correctement estampillées au moment de la capture, et que l’ensemble des données est dès lors temporellement aligné et qu’il est simple de les synchroniser (p.ex. SAW ou NXT). La seconde consiste à fournir des indications temporelles d’alignement du corpus lors de sa construction (DRS et ActivityLens proposent des interfaces graphiques dans ce but).
Une fois les données alignées, il est intéressant de comparer les méthodes de navigation au sein des corpus. Des outils comme Replayer (c.f. Figure 3) et SAW proposent une fonction de type "brush and link" (Becker & Cleveland, 1987) : sélectionner n’importe quel élément ou collection d’éléments dans l’une des vues sélectionne et affiche les éléments correspondants (du point de vue temporel) dans les autres vues. Disposer de ce type de navigation nous semble crucial, en particulier lorsqu’il s’agit d’effectuer la liaison entre des représentations graphiques abstraites et les données à partir desquelles ces représentations sont élaborées. Un autre outil de navigation classique est basé sur la métaphore de la télécommande de magnétoscope (voir, dans la Figure 3, en bas à droite), qui permet de naviguer le long de l’axe temporel, et offre des fonctions comme “jouer”, “pause”, etc.
Figure 3. Dans cet exemple d’affichage de Replayer, les événements sélectionnés dans la vue de gauche sont également
mis en évidence sur la vue d’avion et dans les afficheurs vidéo de droite (http://www.dcs.gla.ac.uk/%7Emorrisaj/Replayer.html).
4.2.1 Synchronisation dans Tatiana Tatiana utilise la seconde méthode de synchronisation, celle dans laquelle les informations d’alignement
temporel sont fournies lors de la création du corpus. Le format pivot de Tatiana comporte donc, pour chaque événement, une facette temporelle obligatoire ; chaque fichier du corpus comporte une date relative de début, une date relative de fin, et la valeur du décalage permettant d’obtenir, par addition de ce décalage, une valeur se traduisant en un “estampillage temporel” Unix (valeur exprimée en millisecondes écoulées depuis le 1er janvier 1970). Les scripts d’importation tiennent compte de cette contrainte, ce qui permet, par exemple, de fusionner sans problème une transcription et des données issues de la trace d’interaction d’un outil. Tatiana utilise également la stratégie “brush and link” entre les divers rejouables : ainsi, lorsque le chercheur clique sur le nom d’un élément du graphe d’argumentation dans la fenêtre présentant les événements par ordre chronologique, le rejoueur (voir §Rejoueurs) se positionne à l’instant où la boîte avait reçu sa dénomination dans le graphe argumentatif. Nous maintenons également un lien entre les constructions du chercheur et les données originales à partir desquelles ces constructions ont été élaborées (p.ex. les schémas d’argumentation découverts dans le corpus COSMOCE). L’outil de “télécommande” s’avère précieux (en particulier, du fait de sa fonction “avance rapide”) pour explorer rapidement une longue session, afin d’en identifier les périodes intéressantes. Par exemple, pour le graphe d’argumentation, il devient simple d’identifier les périodes d’activité intense ou faible, les problèmes d’interface, les constructions qui ont conduit à des dialogues abondants, etc.
4.3 Visualisation des données d’interactions humaines multimodales Il y a trois finalités dans le fait d’enregistrer les données d’une session pour une analyse ultérieure. En
premier, trop d’événements se produisent simultanément pour que l’analyse en temps réel soit possible (bien que la prise de notes par un observateur apporte souvent un éclairage qui autrement aurait été perdu). Ensuite, la quantité et la complexité des données sont effrayantes. Enfin, le processus d’analyse nécessite que les données constituent à la fois un artefact de travail (p.ex. un document ou une video qui puisse être annotés) et une preuve à laquelle on puisse se référer, afin que les hypothèses puissent être vérifiées de manière indépendante. De fait,
Centre G2I / Laboratoire CNRS ICAR
8

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
rendre les corpus plus simples à partager et à analyser de manière indépendante dans les domaines du CSCL et du CSCW relève de la nécessité scientifique (Betbeder, Ciekanski, Greffier, Reffay, & Chanier, 2008). La contrepartie de cette approche est que nous disposons dès lors d’un ensemble de documents, qui non seulement sont impressionnants du simple fait du volume de leurs données, mais aussi dont le lien est difficile à établir avec ce qui s’est passé durant l’observation, en particulier dans le cas des traces brutes d’interaction (les vidéos posent d’autres problèmes, liés par exemple aux angles de prises de vue, à la qualité du son, etc.). Le premier réflexe du chercheur, lorsqu’il est confronté au problème, est de créer des rejouables qui éliminent nombre de données, réduisant ainsi la complexité de l’information et simplifiant l’établissement de liens avec les événements observés. L’un des dangers de cette approche est le risque d’aboutir à une fausse interprétation de ces données du fait de la perte de leur contexte. Le défi consiste à créer un ensemble de rejouables synchronisés, tel que chacun ne reflète qu’une portion réduite de l’information disponible, mais qui tous ensemble brossent un tableau global qui permet au chercheur de disposer à tout instant du contexte. Nous allons présenter les différentes formes de visualisation des rejouables, et de quelle manière ces rejouables peuvent être construits, transformés et formatés avant leur affichage.
4.3.1 Les Visualisations existantes L’un des outils les plus simples de CSCL est le chat. Les logs qu’il produit peuvent aisément s’afficher sous
une forme tabulaire, avec une ligne par événement, et des colonnes pour les différentes données de cet événement : date, utilisateur, intervention. De fait, des outils comme ExcelTM sont souvent utilisés. C’est aussi le type de visualisation adopté par ActivityLens, et l’un de ceux proposés par Elan, DRS, etc. Un autre mode d’affichage, que l’on retrouve dans nombre d’outils d’analyse de vidéo, comme Elan, et également présent, par exemple, dans DRS (c.f. Figure 4) est la partition, une ligne temporelle horizontale sur laquelle les événements sont représentés proportionnellement à leur durée, complétés par une description textuelle.
Figure 4. Dans DRS, la plupart des types de données peuvent être affichés dans le visualisateur de piste. Ici, la
transcription est présentée, complétée par un code couleur représentant les catégories assignées à la transcription (http://www.mrl.nott.ac.uk/research/projects/dress/software/DRS/Home.html)
Figure 5. Représentation graphique symbolique dans ABSTRACT des événements enregistrés lors d’un changement
de file sur une autoroute (http://liris.cnrs.fr/abstract/)
Une forme très similaire de visualisation est la représentation graphique ponctuelle des événements sur une ligne horizontale. Ce mode de présentation se retrouve dans SAW, ABSTRACT (c.f. Figure 5), Replayer, DRS et d’autres. Le reproche principal que l’on peut adresser à cette représentation, qui fournit une information appréciable, est sa faible adaptativité. Il manque presque toujours la possibilité de modifier l’affichage, et en particulier la représentation graphique des événements (sauf intervention dans le code source de l’application). D’autres formes de visualisation s’effectuent au travers d’un graphe (le temps étant représenté sur l’axe horizontal, une autre information sur l’axe vertical), d’une carte ou d’une image vue d’avion (cf. Figure 3) pour des données GPS.
Centre G2I / Laboratoire CNRS ICAR
9

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
4.3.2 Rejoueurs Une dernière méthode utilisée pour appréhender le sens d’un fichier de traces consiste à synchroniser un
ensemble de rejouables (p.ex. un affichage tabulaire et une vidéo) avec une représentation sur l’écran du chercheur de ce que les sujets observés avaient sur leur propre écran. Cette situation est similaire à la synchronisation d’une transcription avec une vidéo, mais l’affichage est directement effectué (en mode rejouage) par l’outil utilisé pour la médiation des activités. Bien que ce rôle puisse être en partie joué par de simples captures d’écrans, nous militons pour l’utilisation d’un rejoueur (en plus, ou à la place, de telles captures d’écran). Un rejoueur lit le fichier de traces, et interprète chaque événement comme l’aurait fait un client supplémentaire durant l’observation. L’inconvénient est que ce fichier de traces ne comporte pas toujours certains événements se déroulant sur le poste client (déplacements du curseur, utilisation des ascenseurs, sélections, clicks de la souris, frappe clavier). De ce fait, il n’est jamais garanti que le chercheur voit sur son écran exactement ce que l’utilisateur voyait sur le sien (le contraire étant plus que probable), mais la similitude reste suffisamment élevée pour que le chercheur puisse comprendre la signification d’une description d’événement dans le format tabulaire, et soit capable de relier cet événement à un contexte plus général.
Les avantages, d’un autre côté sont multiples, et, de notre point de vue, compensent largement cet inconvénient. Le premier s’exprime en terme d’encombrement de la mémoire : les fichiers vidéos sont encombrants, les captures d’écran ou de fenêtres sont difficiles à effectuer de manière systématique. De plus, une capture ne montre que ce qui était visible à l’écran, et non les autres objets ne se trouvant pas dans la partie visible affichée par la fenêtre ; il conviendrait alors de réaliser des captures sur tous les postes de travail, ou de garder à l’esprit que le chercheur ne voit que ce que voyait un intervenant particulier, mais pas nécessairement tous les intervenants. Le problème peut être contourné grâce à l’enregistrement d’événements liés au poste de travail. Ainsi, dans CoFFEE, l’utilisation des ascenseurs peut être capturée sur chaque poste de travail, avec un rejoueur capable de représenter les positions des ascenseurs des divers participants (c.f. Figure 6). De manière générale, les rejoueurs permettent de manipuler les interfaces utilisateur, en assurant une qualité constante de l’affichage (contrairement à une vidéo, qui devient floue lorsqu’elle agrandie), et permettant de se déplacer jusqu’à des objets non visibles à un moment donné (par exemple, un nouveau message dans le chat apparaissant hors de la zone actuellement visible).
Figure 6. L’ascenseur du chercheur est coloré en bleu, et lui permet de naviguer au sein de l’espace de travail. A
chaque instant de l’expérimentation, Ann et Bob ne peuvent voir de cet espace de travail que la partie affichée sur leur écran. Si le chercheur place son ascenseur dans la même position que celui d’Ann, par exemple, il peut avoir la
même vision que cette dernière à ce moment de l’expérimentation.
Le principal avantage d’un rejoueur, qui s’avère crucial pour l’analyse, est donc la possibilité de consulter l’état interne du logiciel utilisé, état que le rejoueur reconstruit, afin de montrer au chercheur une information non visible dans l’interface utilisateur originelle, ou de montrer l’information disponible sous une forme différente. Ainsi, dans l’éditeur de texte partagé de DREW, à des fins de prise de conscience (“awareness”), les textes récemment insérés par les participants sont brièvement affichés dans la couleur associée à ce participant, avant de virer au noir. Dans le rejoueur correspondant, il est possible de laisser les couleurs subsister, ce qui permet au chercheur de comprendre qui a écrit quoi (c.f. Figure 7, extraite d’une expérimentation décrite dans Lund, Rossetti, and Metz, 2007).
Les corpus dans lesquels on a recueilli des traces d’interventions dans les éditeurs de graphes argumentatifs d’outils comme DREW ou CoFFEE sont difficiles à analyser, du fait des manipulations permanentes, par les intervenants, des objets affichés. Une boîte peut être créée, ultérieurement éditée, déplacée à plusieurs reprises, puis finalement détruite. Durant toutes ces manipulations, il faut pouvoir fournir au chercheur l’information suffisante pour qu’il se rende compte que ces événements concernent la même boîte, et qu’il puisse consulter les propriétés de cet objet. Comme nous le verrons en abordant la discussion du formatage (c.f. §Extensibilité), nous avons choisi d’associer un numéro à ces objets. Mais quelle boîte est la numéro 6 ? Comme nous l’avons
Centre G2I / Laboratoire CNRS ICAR
10

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
mentionné plus haut, nous avons pu utiliser Tatiana pour transformer des traces CoFFEE en traces DREW, en attendant la disponibilité d’un rejoueur CoFFEE. Il a ainsi été possible d’ajouter l’identification unique des boîtes dans l’affichage de l’outil (cf. Figure 8), tout en gardant à l’esprit que cette représentation n’est pas celle qui s’affichait dans l’interface des participants.
Figure 7. Rejouage dans DREW du chat et de l’éditeur de texte collaboratif : alors que les couleurs associées aux
participants sont rémanentes dans le chat, le texte de l’éditeur partagé apparaît noir pour les intervenants. Le rejoueur peut colorer ce texte, afin de faciliter les comparaisons des origines des interventions dans les deux outils.
Figure 8. Lors du rejouage dans DREW des traces de l’éditeur collaboratif de CoFFEE — rejouage piloté par Tatiana
— nous affichons à la fois les contenus des boîtes, visibles par les utilisateurs (p.ex. "UV-straling"), et les identifications de ces boîtes dans Tatiana. Dans cet exemple, Pieter vient de créer un lien entre les boîtes 1 et 3, auquel
a été associée l’identification 100003.
Notons, sur le plan pratique, que Tatiana a été conçu pour interagir avec des rejoueurs externes, qui peuvent ainsi être synchronisés avec les afficheurs internes, au moyen d’un protocole XML-RPC relativement simple. Ce protocole a été implémenté pour les outils DREW et CoFFEE, et les afficheurs video VLC et MPlayer.
4.3.3 Les visualisations dans Tatiana Tatiana fournit deux types d’affichage : une vision tabulaire classique (avec une ligne pour chaque
événement, une colonne pour chaque type d’information que l’on choisit d’afficher), et une vue graphique symbolique, avec un axe des temps horizontal. Tatiana affiche des données représentées dans son format pivot Display. L’affichage tabulaire est très largement paramétrable au moyen d’une description indiquant pour chaque colonne les informations à afficher (de quelles facettes elles sont extraites) et sous quelle forme (formatage et présentation). Ceci permet d’éviter l’affichage de colonnes qui n’intéressent pas le chercheur, de regrouper entre elles des colonnes presque toujours vides, etc. Ainsi, une même colonne peut présenter les identifications des objets graphiques (boîtes, liens) bien que ces informations apparaissent dans des facettes différentes (cf. Figure 8). Le chercheur peut aussi modifier cette disposition. Dans la vue graphique, différentes propriétés (forme, taille, couleur, position verticale) sont associées à chaque événement. La largeur et la position sur l’axe horizontal sont calculées à partir de l’estampillage temporel et de la durée de l’événement. Les autres paramètres sont calculés d’après diverses facettes, en suivant des règles définies par le chercheur au sein de
Centre G2I / Laboratoire CNRS ICAR
11

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
Tatiana. La nécessité de cette souplesse d’approche nous est apparue après de laborieux efforts de création de diverses représentations au sein d’un prototype. Ainsi, la Figure 9 est une représentation de l’usage des différentes modalités dans notre situation de prises de notes de réunion ; mais cette représentation particulière, regroupant les modalités par utilisateur, peut sembler moins claire qu’une autre qui aurait regroupé les intervenants par modalités, ou aurait affiché une seule ligne représentant les dialogues, avec une couleur par utilisateur, etc. Il nous semble important que le chercheur puisse, au travers d’essais successifs, choisir la représentation des rejouables (ici, leur visualisation graphique) la plus appropriée, tout en conservant la synchronisation de ces rejouables avec le reste du corpus (Lund, et al. 2008). Nous travaillons actuellement sur la création et la représentation de liens entre les objets graphiques qui apparaissent dans cette forme de visualisation.
Figure 9. Distribution de la communication à travers les médias et les modalités.
Lors de l’analyse du corpus COSMOCE, les chercheurs ont créé de nouveaux graphes d’arguments à partir de réarrangement des contributions des étudiants dans le graphe argumentatif, et en ajoutant les contributions effectuées dans le chat, ainsi que les liens, implicites ou explicites, de ces contributions avec les éléments du graphe. Nous pensons possible d’implémenter ce genre de visualisation graphique dans Tatiana à des fins d’analyse, tout en conservant la possibilité de “brush and link” (c.f. Figure 10). Ceci permettrait aux chercheurs de visualiser la logique temporelle inhérente à un graphe qui n’est pas en lui-même organisé selon la dimension temporelle.
Figure 10. Une maquette montrant l’intérêt de la synchronisation entre un graphe créé par un chercheur décrivant une solution proposée dans le cadre une expérimentation en ingénierie mécanique et les interventions effectivement
recueillies.
4.3.4 Transformation des données en vue de leur visualisation dans Tatiana Afin de préparer la visualisation des données dans Tatiana, nous faisons à nouveau appel à des scripts
XQuery, et à des filtres génériques pour combiner ces scripts. Ainsi, le script qui extrait la nouvelle position d’une boîte qui a été déplacée dans le grapheur de DREW crée également une nouvelle facette pour cet événement, avec un contenu significatif pour le chercheur, tel que “Ann a placé la boîte n°3 à la position 456,324”. Un autre script pourrait transformer cette phrase en “Ann a déplacé la boîte à gauche et vers le haut” si cette information était jugée plus pertinente pour le chercheur. Un filtre Tatiana pourrait combiner ces deux opérations, l’une qui extrait l’information, l’autre qui la réécrit, pour créer le fichier destiné à l’affichage. De même, des scripts ont été utilisés pour filtrer les données (p.ex. extraire les informations relatives à un seul groupe d’élèves dans CoFFEE), créer de nouveaux événements, en regrouper, etc.
A titre d’exemple, dans notre corpus relatif à la prise de notes en réunion, nous n’avions pas de ressources financières suffisantes pour assurer la transcription de la totalité du corpus, mais souhaitions disposer, au minimum, des dialogues échangés durant la phase de prise de notes dans l’éditeur partagé. Du fait de la représentation des interactions de l’éditeur de texte dans le fichier de trace, l’identification des phases de
Centre G2I / Laboratoire CNRS ICAR
12

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
rédaction n’était pas aisée, pas plus qu’il n’était faisable de regarder la vidéo et de tenter de repérer les périodes où les intervenants utilisaient leur clavier. Pour résoudre le problème, nous avons créé un filtre qui identifiait les périodes d’inactivité dans un outil, et créait un rejouable comportant des événements de début et de fin d’écriture d’un bloc de texte précédant et suivant cette période d’inactivité. La combinaison de ces différents scripts produit un filtre réutilisable (cf. Figure 11) pour identifier les périodes d’activité et d’inactivité dans l’éditeur partagé. Ceci permet de résumer une session complète, contenant des centaines d’événements relatifs à l’éditeur, en quelques séquences actives (la durée d’une période d’inactivité ayant été arbitrairement fixée à 60 secondes au minimum). Nous pouvons dès lors effectuer la transcription des seules périodes qui nous intéressent. Ce script peut être utilisé comme “maquette” d’outil pour le regroupement manuel d’événements élémentaires (insertion ou destruction d’un petit nombre de caractères) en blocks plus significatifs en termes d’édition. Nous développons actuellement une interface graphique de création et d’édition de filtres, permettant au chercheur de combiner des scripts prédéfinis, afin de créer les rejouables dont il a besoin pour ses travaux.
Figure 11. Un filtre Tatiana qui combine trois scripts, prenant comme paramètres un fichier de trace DREW et la
durée d’une période d’inactivité, et produisant un rejouable enrichi de deux nouveaux types d’événements, textboard-begin-write, textboard-end-write, en plus des événements textboard. Le rejouable est ici affiché sous forme tabulaire.
5 Analyse des données d’interaction humaine multimodales Une fois les données transformées en rejouables visualisables et compris du chercheur, le processus
d’analyse se poursuit par la création de nouveaux rejouables susceptibles d’améliorer la compréhension, comportant des artéfacts créés par le chercheur (sens supplémentaire, abstraction) pour décrire ce qui s’est passé durant l’observation, et proposer des hypothèses de nature qualitative ou quantitative. Nous baserons cette description des besoins du chercheur sur une étude de certains outils (dont nous supposons qu’ils satisfont à ces besoins) et sur notre propre expérience.
5.1 Les pratiques d’analyse et les besoins correspondants Parmi les outils destinés à l’analyse qui ont été présentés (NXT, DRS, SAW, Elan, ActivityLens), presque
tous permettent de traduire cette analyse par des annotations libres, applicables à des segments du corpus (décrits par une date de début et de fin, mais sans liaison à un média spécifique), ou à des événements isolés. Bien que les pratiques de catégorisation soient distinctes de celles des annotations, elles peuvent s’implémenter au travers de la même technologie : les annotations peuvent être restreintes à un ensemble (ouvert ou fermé) de mots clefs, ce qui, par essence, permet la catégorisation. Pour annoter des segments, il faut les créer au préalable. Ce processus est disponible dans tous les outils d’analyse de vidéo. La transcription équivaut (sur le plan technologique) à une segmentation suivie d’une annotation ; tout outil permettant ces deux opérations peut donc permettre d’effectuer des transcriptions. Le cas des annotations effectuées à partir d’une liste de mots clefs (donc, la catégorisation) présente un intérêt particulier : dans NXT, par exemple, ces catégories peuvent être décrites par des ontologies complexes, ce qui permet d’utiliser des catégories comme base pour une recherche de données (un exemple typique est la recherche de paires adjacentes).
La catégorisation est aussi utilisée comme prélude à l’analyse quantitative ; dans ce cas, la possibilité de segmenter le corpus devient cruciale du fait qu’il est nécessaire, lorsque l’on recense des objets, qu’ils soient de même nature. La possibilité de resegmenter un corpus (par exemple, en regroupant des éléments) nous permettrait, dans l’exemple du corpus de prises de notes, de grouper les interactions enregistrées dans les traces en “séquences d’écritures” significatives. Les traces produites par le grapheur de DREW sont très prolixes : la seule création d’une boîte nouvelle se traduit par un événement de création suivi d’une action de déplacement, qui correspond en fait au positionnement initial de la boîte. Selon les perspectives de l’analyse et le type d’actions que l’on souhaite recenser, cette création peut être comptée comme deux événements distincts, ou comme un seul. ABSTRACT propose un moyen de regrouper automatiquement des événements : le chercheur écrit des requêtes constituées de règles lui permettant de construire, par itérations successives, des entités sémantiques plus abstraites et plus riches. Ainsi, les données capturées par l’instrumentation du volant d’une voiture peuvent se traduire en événements “faire tourner le véhicule”, qui peuvent à leur tour se regrouper en événements de type “changement de file”. Ils peuvent dès lors être combinés avec des données issues de
Centre G2I / Laboratoire CNRS ICAR
13

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
l’observation des regards du conducteur et des autres indicateurs instrumentés dans la voiture, afin d’identifier des événements de haut niveau tels que “changement de file anticipé” ou “changement de file non anticipé”.
L’une des activités d’analyse qu’aucun des outils que nous avons étudiés ne semble offrir est la description de relations entre événements. Dans les paragraphes précédents, nous avons montré qu’il était souhaitable de rendre explicites certaines relations entre objets ou événements : par exemple il est utile (analyse du corpus en ingénierie mécanique) de montrer en quoi une solution est en fait une évolution d’une autre solution, qui retient certains aspects de la précédente tout en incorporant des modifications qui la rendent acceptables selon de nouveaux critères (cf. Figure 10). Ces relations peuvent alors être utilisées pour créer un graphe, ou rechercher des types différents de paires adjacentes (par exemple, deux interventions successives dans le chat de type “question”, dont l’une a été décrite comme une reformulation de l’autres).
Une dernière nécessité des analyses consiste (pour les raisons mentionnées dans l’introduction de ce document) à pouvoir conserver à la fois les corpus et les analyses de ces corpus.
5.2 Implementation de l’analyse dans Tatiana Nous avons ainsi identifié trois larges aspects de l’activité d’analyse : l’annotation, les regroupements et
segmentations et la création de liens. Tatiana offre ces trois possibilité au travers d’un mécanisme voisin de celui qui est utilisé dans NXT, que nous avons baptisé ancre et lien. Une ancre est une désignation spécifique dans un corpus (un “point du corpus”), et un fichier d’analyse décrit chaque action d’analyse comme une série de liens entre différentes ancres (Corbel, Girardot, & Lund, 2006). Un lien regroupe des ancres et/ou des annotations. Ainsi :
• Une annotation est un lien associé avec un texte, tandis qu’une catégorisation est un lien entre deux ancres (l’une désigne une catégorie, l’autre un point du corpus). Par exemple, l’événement de création d’une boîte dans le grapheur pourrait être annoté “C’est la seconde fois que l’utilisateur crée cette boîte”. L’ancre du lien désignerait l’événement correspondant du fichier trace (très précisément, l’élément XML décrivant cet événement). De même, l’application de la catégorie “critère d’affirmation” à la création d’une flêche dans le grapheur d’argumentation aurait pour effet de créer un lien avec une ancre sur l’événement du fichier trace, et une autre vers le fichier XML contenant l’énumération des catégories.
• La segmentation ou le regroupement d’événements est une création de lien : le regroupement de cinq événements dans l’éditeur de texte (au motif qu’ils représentent une “unité d’édition”) consiste à créer un lien regroupant les cinq ancres sur ces événements.
• La création d’une relation entre deux événements est également une création de lien — ainsi, affirmer que l’envoi d’un message dans le chat est une réponse à la création d’une boîte dans le grapheur consiste à créer un lien associant les ancres de ces deux événements ; l’identification de ce lien comme représentant une relation de “réponse” se fait en ajoutant une annotation ou une ancre vers le fichier décrivant les catégories de liens.
Grâce à ces informations (une ancre désignant de manière non ambiguë un point du corpus, tout comme un événement dans le format pivot), un fichier d’analyse peut être fusionné à un rejouable. Le résultat de cette opération est d’ajouter des facettes supplémentaires aux événements annotés, facettes qui, à leur tour, peuvent être visualisées.
Les représentations dans le format Display pivot sont susceptibles d’évoluer au cours de l’analyse (l’application de filtres permet d’éliminer, de modifier, de rajouter des facettes ou des événements), mais il est important qu’une liaison existe entre un élément d’un tel fichier et le point du corpus qui est à l’origine de cet élément. Pour ce faire, les scripts d’importation associent à chaque événement une facette “ancre source” qui fait référence au point du corpus d’où l’événement a été extrait. Différents scripts peuvent importer (en créant des facettes différentes) le même événement, mais l’ancre source sera identique, et toutes les transformations (filtrage, fusion, etc) conservent cette ancre source. En d’autres termes, celle-ci constitue une “référence universelle” sur le point du corpus.
Les possibilités d’analyse actuellement implémentées dans Tatiana se limitent aux annotations et aux catégorisations. L’interface de définition d’une ontologie de catégorisation est assez rudimentaire. Nous espérons l’améliorer, dans un futur proche, et travailler aussi sur une interface de segmentation/regroupement et de création de liens. Nous sommes cependant confiants sur la capacité de représenter ces opérations et leurs résultats au moyen du format pivot, qui devrait également permettre sans difficulté le partage d’analyses entre chercheurs utilisant Tatiana (ou tout outil interopérable avec Tatiana).
6 Extensibilité Différents chercheurs ont différents besoins. Bien qu’il soit impossible d’offrir un outil qui satisfasse tous les
Centre G2I / Laboratoire CNRS ICAR
14

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
besoins de tous les chercheurs, nous avons mis en évidence certains aspects des questions d’analyse pour lesquels il est utile de rendre l’outil extensible : import et export de données, transformation et formatage, visualisation et analyse des données. DRS, Replayer et NXT offrent diverses visualisations des données, ainsi que la possibilité de créer de nouvelles vues. Ils autorisent également la création de scripts pour importer de nouveaux formats et pour décrire l’affichage de ces formats. Aucun de ces outils, cependant, ne semble fournir de moyen simple pour manipuler les données sous des formes non prévues à l’avance. De plus, il est important de définir ce que l’on entend par “extensible”. Ainsi, Tatiana est disponible sous une licence open source, ce qui veut dire que toute personne peut se procurer le logiciel et le modifier. Cependant, la mise en place de l’environnement de développement du logiciel ainsi que son appropriation par un programmeur sont lourdes en temps et en ressources, et de tels développements aboutissent à des versions incompatibles du même système. Nous préférons proposer un mécanisme d’extensibilité basé sur des plugins, ce qui permet à des tiers de faire des développements indépendants et d’étendre les possibilités de Tatiana sans même avoir à le recompiler.
L’architecture que nous mettons en place pour Tatiana (cf. Figure 12) prévoit plusieurs possibilités d’extension par des tiers, afin de leur permettre de manipuler des rejouables au sein de Tatiana. En nous souvenant que les chercheurs font appel à une grande variété d’outils, nous avons rendu possible l’importation de données dans le logiciel par le simple fait de coder de nouveaux scripts en XQuery. De nouveaux scripts peuvent être ajoutés, pour coder toutes sortes de nouvelles transformations. Tous les scripts peuvent être combinés pour constituer des filtres puissants. Des scripts peuvent aussi servir à exporter des données vers n’importe quel format XML. Pour rendre disponible un script, il suffit de le placer dans le répertoire des scripts de Tatiana.
Trois types de scripts peuvent donc être utilisés avec Tatiana: 1. Les scripts d’importation produisent du XML au format Display. Ils traduisent un fichier de log en
créant, pour chaque événement (ou pour les seuls événements sélectionnés), un item contenant les facettes obligatoires "time" et "source anchor", et toute autre facette permettant de décrire l’événement.
2. Les filtres de transformation des données lisent et produisent des fichiers XML au format Display. Tout en préservant (ou modifiant, ou agrégeant les facettes obligatoires), ils peuvent filtrer des éléments, créer, modifier ou supprimer des facettes, etc.
3. Les scripts d’exportation lisent des fichiers au format Display, et produisent du XML (ou du texte pur) au format attendu.
Figure 12. Schéma de l’architecture de Tatiana, montrant 1) les dépendances entre composants, 2) les composants
conçus dans une optique d’extension, et 3) les développements futurs.
Comme nous l’avons indiqué dans la section consacrée aux visualisations, Tatiana fournit une API9 pour les rejoueurs externes. Un tel rejoueur doit, après son lancement, créer un serveur de XML-RPC qui accepte les requêtes suivantes :
• OpenFile(filename) – ouvrir le fichier spécifié du corpus. • Goto(timestamp) – positionner le rejoueur au moment indiqué. • Mark(timestamp) – conserver en mémoire la position correspondant au moment indiqué.
9 Application Programming Interface Centre G2I / Laboratoire CNRS ICAR
15

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
• End() – fermer le rejoueur. • Accepts(command) – demander au rejoueur s’il implémente la commande correspondante. • GetEvents() – rendre les estampilles temporelles des événements présents dans le fichier.
Avec ce protocole de communication, Tatiana est capable de piloter un rejoueur externe et de le synchroniser avec les autres rejouables, en envoyant des requètes de type “Goto” lorsque nécessaire (en se basant sur la liste des événements reconnus par le rejoueur). A l’heure actuelle, deux rejoueurs implémentent ce protocole : le rejoueur de DREW, et un prototype du rejoueur CoFFEE (dont la version publique doit être disponible fin 2008).
Enfin, Tatiana a été porté sur la plateforme Eclipse (www.eclipse.org), afin de tirer parti de l’architecture des plugins Eclipse (Bolour, 2003). Pour installer un plugin Eclipse compilé, il suffit de le copier dans le répertoire de plugins de l’application, et de relancer celle-ci. Une prochaine étape consistera à définir l’interface permettant d’implanter des afficheurs écrits par de tierces parties. L’interface destinée à la gestion de l’analyse, cependant, n’est pas encore stabilisée. Une fois ceci terminé, nous réimplémenterons l’afficheur de table et l’afficheur de partition sous forme de plugins, qui serviront d’exemples et valideront notre API.
En fournissant ces trois possibilités d’extensions (i.e. les scripts, l’interface avec des rejoueurs externes, et les plugins de visualisation, cf. Figure 12), nous espérons élargir la variété de questions de recherches auxquelles Tatiana est susceptible de s’appliquer, tout en gardant une infrastructure de développement raisonnable, qui permette aux chercheurs de résoudre nombre de questions de recherche au prix d’un investissement minimal.
7 Conclusions et développements futurs Dans ce document, nous avons présenté un outil, Tatiana (Trace Analysis Tool for Interaction Analysts),
destiné aux chercheurs s’intéressant aux situations de CSCL ou CSCW, et qui souhaitent analyser les processus des interactions humaines. Nous avons signalé que Tatiana avait été conçu en réponse à des besoins précis d’analyse de situations d’interactions médiatisées par ordinateur en présentiel. Nous avons décrit les principales caractéristiques du logiciel, en termes de gestion des données, de synchronisation, de visualisation et d’analyse, et montré comment ce logiciel pouvait s’adapter à des situations pour lesquelles il n’avait pas été conçu. En comparant ces caractéristiques avec celles d’autres outils, et en expliquant comment elles contribuaient à résoudre certaines questions de recherche, nous en avons montré les aspects innovateurs, et avons justifié ces innovations.
Tatiana répond aux besoins intrinsèquement itératifs et divers d’analyses relatives au CSCL et CSCW, en fournissant des méthodes très flexibles de transformation et d’affichage de données, en particulier grâce à des passerelles permettant d’étendre le logiciel pour répondre à de nouveaux besoins. La difficulté de faire revivre, à partir des données enregistrées, ce que les participants éprouvaient lors du recueil du corpus trouve des réponses au travers des visualisations multiples de données synchronisées, en particulier grâce à l’utilisation de rejoueurs externes. Enfin, du fait de la possibilité de sauvegarder et de partager des analyses, Tatiana permet aux chercheurs en sciences humaines et sociales de travailler en équipe, et d’intégrer et de comparer leurs analyses.
Nos travaux futurs devraient porter d’une part sur l’amélioration de notre compréhension des besoins et des méthodologies d’analyse des chercheurs, d’autre part sur le développement de Tatiana en tant qu’environnement de gestion de rejouables (et des autres artéfacts des analyses). Tatiana permet la création automatique des rejouables grâce à des filtres. Il reste à généraliser et rendre plus cohérent l’environnement de travail, afin de donner aux chercheurs la possibilité de créer de nouvelles formes de visualisation, et de permettre la création et la transformation itératives de rejouables (tel que suggéré par la maquette de la Figure 10).
Nous envisageons de développer Tatiana pour en faire un outil permettant la gestion des artéfacts que les chercheurs désirent créer pendant leurs analyses. Nous espérons ainsi leur offrir une meilleure approche de leur corpus, tout en leur permettant de partager cette création de sens avec d’autres collègues. Nous espérons également aboutir à une meilleure compréhension du processus d’analyse des interactions socio-cognitives, ce qui rendrait plus facile l’évaluation et le partage des méthodologies au sein de la communauté du CSCL.
Remerciements Nous souhaitons remercier ici nos collègues du projet LEAD, qui ont collaboré avec nous en termes d’échanges de données, de méthodes analytiques, et d’expertise en programmation, nous permettant de faire aboutir la communication entre Tatiana et CoFFEE.
Références Centre G2I / Laboratoire CNRS ICAR
16

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
Avouris N., Fiotakis G., Kahrimanis G., Margaritis M., & Komis V. (2007). Beyond logging of fingertip actions: analysis of collaborative learning using multiple sources of data. Journal of Interactive Learning Research JILR. vol. 18(2), pp.231-250.
Becker R. A., & Cleveland W. S. (1987). Brushing scatterplots. Technometrics, 29:127-142.
Betbeder, M.-L., Ciekanski, M., Greffier, F., Reffay, C. & Chanier, T (forthcoming, 2008). Interactions. Interactions multimodales synchrones issues de formations en ligne : problématiques, méthodologie et analyses [Multimodal synchronous interactions issued from on-line learning : motivation of approach, methodology and analyses]. In Basque, J. & Reffay, C. (dirs), numéro spécial EPAL (échanger pour apprendre en ligne), Sciences et Technologies de l'Information et de la Communication pour l'Education et la Formation (STICEF), vol. 15.
Bolour A. (2003). Notes on the Eclipse Plug-in Architecture. Retrieved April 10, 2008 from http://www.eclipse.org/articles/Article-Plug-in-architecture/plugin_architecture.html
Carletta, J., Evert, S., Heid, U., Kilgour, J., Robertson, J., and Voormann, H. (2003). The NITE XML Toolkit: flexible annotation for multi-modal language data. Behavior Research Methods, Instruments, and Computers, special issue on Measuring Behavior, 35(3), 353-363.
Cox, Richard (2007). Technology-enhanced research: educational ICT systems as research instruments. Technology, Pedagogy and Education, 16 (3), 337-356.
Corbel, A., Girardot, J.J., & Jaillon, P. (2002). DREW: A Dialogical Reasoning Web Tool, ICTE2002, International Conference on ICT's in Education. Badajoz, Spain.
Corbel, A., Jaillon, P., Serpaggi, X., Baker, M., Quignard, M., Lund, K., & Séjourné, A., (2003). DREW : Un outil Internet pour créer des situations d’apprentissage coopérant [DREW : An internet tool for creating cooperative learning situations]. In Desmoulins, Marquet & Bouhineau (Eds.) EIAH2003 Environnements Informatiques pour l’Apprentissage Humain, Actes de la conférence EIAH 2003, Strasbourg, 15-17 avril 2003, Paris : INRP, p. 109-113.
Corbel, A, Girardot, J.J., & Lund�K. (2006). A method for capitalizing upon and synthesizing analyses of human interactions, In (eds) W. van Diggelen & V. Scarano, Workshop proceedings Exploring the potentials of networked-computing support for face-to-face collaborative learning. EC-TEL 2006 First European Conference on Technology Enhanced Learning, Crete, pp. 38-4
De Chiara, R., Di Matteo, A., Manno, I., Scarano, V. (2007). CoFFEE: Cooperative Face2Face Educational Environment. Proceedings of the 3rd International Conference on Collaborative Computing: Networking, Applications and Worksharing (CollaborateCom 2007), New York, USA.
De Wever, B., Schellens, T., Valcke, M. & Van Keer, H. (2006). Content analysis schemes to analyse transcripts of online asynchronous discussion groups: A review. Computers & Education, 46(1) 6-28.
Georgeon, O, Mille, A, & Bellet, B.T. (2006). ABSTRACT: un outil et une méthodologie pour analyser une activité humaine médiée par un artefact technique complexe. Ingéniérie des Connaissances. Semaine de la connaissance. Rémi Lehn, Mounira Harzallah, Nathalie Aussenac-Gilles, Jean Charlet ed. Nantes, France.
Georgeon, O., Mathern, B., Mille A., Bellet, T., Bonnard, A., Henning & N., Trémaux, J.-M. (2007). ABSTRACT Analysis of Behavior and Situation for menTal Representation Assessment and Cognitive acTivity modelling, Retrieved April 10, 2008 from http://liris.cnrs.fr/abstract/abstract.html.
Fiotakis, G., Fidas, C. & Avouris, N (2007). Comparative usability evaluation of web systems through ActivityLens, Proc. PCI 2007, Patras, Greece
Goodman, B. A., Drury, J. Gaimari, R. D., Kurland, L., & Zarrella, J (2006) Applying User Models to Improve Team Decision Making. Retrieved April 10, 2008 from http://mitre.org/work/tech_papers/tech_papers_07/06_1351/
Greenhalgh, C., French, A., Humble, J. and Tennent, P. (2007) Engineering a replay application based on RDF and OWL, Online Proceedings of the UK e-Science All Hands Meeting 2007, September 10-13, Nottingham: NeSC/JISC.
Harrer, A. Zeini, S. Kahrimanis, G. Avouris, N. Marcos, J. A. Martinez-Mones, A. Meier, A. Rummel, & N. Spada, H (2007) Towards a Flexible Model for Computer-based Analysis and Visualisation of Collaborative Learning Activities, Proc. CSCL 2007, New Jersey, USA
Kahrimanis G., Papasalouros A., Avouris N., & Retalis S. (2006), A Model for Interoperability in Computer-Supported Collaborative Learning. Proc. ICALT 2006 - The 6th IEEE International Conference on Advanced
Centre G2I / Laboratoire CNRS ICAR
17

Rapport de recherche # 2008-400-005 École Nationale Supérieure des Mines de Saint-Etienne
Learning Technologies. IEEE Publ., July 5-7, 2006 – Kerkrade , Netherlands, p. 51-55.
Kerbrat-Orecchioni, C. (2004). Introducing polylogue. Journal of Pragmatics. 36, 1-24.
Kipp, M. (2001) Anvil - A Generic Annotation Tool for Multimodal Dialogue. Proceedings of the 7th European Conference on Speech Communication and Technology (Eurospeech), pp. 1367-1370.
Kollberg P. (1996). S-notation as a tool for analysing the episodic structure of revisions. European writing conferences, Barcelona.
LEAD (2006). Problem solving through face to face networked interaction in the classroom, Retreived April 10, 2008 from http://www.lead2learning.org
Lotan-Kochan E. (2006). Analysing Graphic-Based Electronic Discussions: Evaluation of Students' Activity on Digalo. EC-TEL 2006, Crete, Greece: 652-659.
Lund, K., Rossetti, C., & Metz, S. (2007). Do internal factors of cooperation influence computer-mediated distance activity? Proceedings of the international conference CSCL 2007, July 16-21, New Brunswick, New Jersey, USA.
Lund, K., Prudhomme, G., & Cassier, J.-L. (2007). Using analysis of computer-mediated synchronous interactions to understand co-designers’ activities and reasoning. Proceedings of the International Conference On Engineering Design, ICED’07, 28 - 31 august 2007, Cité des Sciences et de l'Industrie, paris, France.
Lund, K., van Diggelen, W., Dyke, G., Overdijk, M., Girardot, J.J., & Corbel, A (forthcoming, 2008). A researcher perspective on the analysis and presentation of interaction log files from CSCL situations within the LEAD project. ICLS 2008, Utrecht, The Netherlands.
Lund, Cassier, Prudhomme (in preparation). Performing Interaction analysis by constructing semantic and temporal visualizations of argumentation.
Lund, Andriessen, Prudhomme, van Amelsvoort (in preparation). The varying influences of collective debating tasks on individual knowledge construction.
Morrison A., Tennent P., & Chalmers M. (2006). Coordinated Visualisation of Video and System Log Data. Proceedings of 4th International Conference on Coordinated & Multiple Views in Exploratory Visualisation. London, 91-102.
Prudhomme, G., Pourroy, F., & Lund, K. (2007). An empirical study of engineering knowledge dynamics in a design situation. Journal of Design Research, 3, 333-358.
Reffay, C, Chanier, T., Noras, M. & Betbeder, M.-L. (forthcoming 2008). Contribution à la structuration de corpus d'apprentissage pur un meilleur partage en recherche [Contribution to the structuring of learning corpora for better sharing of research]. In Basque, J. & Reffay, C. (dirs), numéro spécial EPAL (échanger pour apprendre en ligne), Sciences et Technologies de l'Information et de la Communication pour l'Education et la Formation (STICEF), vol. 15, forthcoming.
Settouti, L.-S., Prié, Y., Mille, A., Marty, J.-C. (2006) Système à base de traces pour l'apprentissage humain. [Trace-based system for human learning] Colloque international TICE 2006 «Technologies de l’Information et de la Communication dans l’Enseignement Supérieur et l’Entreprise».
W3C (2007). XQuery 1.0: An XML Query Language, Retrieved April 10, 2008 from http://www.w3.org/TR/xquery/
Centre G2I / Laboratoire CNRS ICAR
18


Ecole Nationale Supérieure des Mines de Saint-Etienne Centre G2I
158, Cours Fauriel 42023 SAINT-ETIENNE CEDEX 2
www.emse.fr