capturés par la toile - où vont nos données personnelles sur internet
DESCRIPTION
Toutes les entreprises pr´sentes sur Internet tentent de capturer notre information personnelle, qui est un produit commercial de grande valeur. Les données privées peuvent être analysées avec ou sans notre consentement et constituent un matériel "commerciable", que nous le voulions ou non. Nous abordons ici les différents aspects de la capture et de la gestion de ces données, ce que les scientifiques et professionnels peuvent faire avec elles dans cette nouvelle écologie informatique ainsi que nos défenses exigües.TRANSCRIPT

1

Capturés par la toile
Où vont nos données personnelles sur internet
Raymond Colle
L'auteur est docteur en Sciences de l'Information,
professeur pensionné de l'Université Pontificale Catholique
de Santiago du Chili.
Licence Creative Commons
(Reproducción permise seulement dans des textes sans fin de lucre, sans modification et mentionnant la source)
NOTE
Le présent texte est la traduction faite par l'auteur d'une première version écrite enespagnol.
2

Introduction
Dans le monde physique, si nous voulons protéger notre intimité, nous fermons la porteet les rideaux. Dans le monde numérique, il n'en n'est pas de même: nous sommestoujours exposés et nos possibilités de contrôle sont assez limitées. Lorsque nousutilisons la toile et les téléphones et téléviseurs “intelligents”, nous donnons desinformations sur nous-même, tant si nous le voulons comme si nous en le voulons pas.Nous laisson toujours une trace de notre activité sur internet, que nous utilisions ou nonles réseaux sociaux. Et toutes les entreprises qui y sont présentes font leur possible pourcapturer cette information, qui est maintenant un produit commercial de valeur. Et cettesituation croîtra de façon exponentielle avec les gadgets qui feront partie de l'”Internetdes Objets” o IoT (Internet of Things) (Gizmodo, 9/01/2015).
Les données personnelles qui peuvent apparaître quand nous utilisons internet sont dequatre types:
• privées: celles que nous générons et qui «voyagent» grâce à des moyens directs depersonne à personne (comme le courriel et le `chat´); ce peuvent être aussi desdocuments que nous mettons dans le «nuage» (Dropbox, iCloud, etc.) sans lespartager;
• publiques: nos publications sur la toile: pages web personnelles, blogs, articles derevues, documents sur services comme ISSUU, Scribd, etc. ;
• sociales: qui correspondent à nos activités sur les réseaux sociaux (Messagesd'état, photos et vidéos, «likes», etc.);
• «traces» (data trail): laissées involontairement par nos activités (p.ex. le typed'appareil utilisé, l'endroit où nous sommes, les hyperliens suivis, etc.).
Les données publiques et sociales sont des informations révélées volontairement et nousparlerons dans le deuxième chapitre de ce qui peut leur arriver. Les données privéespeuvent être analysées avec ou sans notre consentement si elles ne sont pas encryptées etlaissent toujours des traces utilisables par les fournisseurs de services. Elles constituentde l'information que nous appelleront ici «extraite», et nous l'examinerons dans letroisième chapitre.
Nous parleons ensuite des principaux problèmes liés à l'utilisation de nos données :propriété, protection du privé, sécurité, conservation, et.
La Seconde Partie de ce petit livre aborde plus à fond le thème de la capture et de lagestion de ces données. Nous nous demanderons qu'est-ce qui se fait actuellement et cequi pourra se faire avec eux dans l'avenir. Ceci, évidemment, dépend du type
3

d'utilisateur et de ses objectifs, et nous ne les oublierons pas. Cela dépend aussi desmachines et de leur pouvoir (croissant) de traitement, mais aussi des avancements enmatière d'applications (logiciels), ce qui –de son côté– dépend de la connaissance quel'on ait de ce que signifie l'obtention d'informations et le concept que l'on ait del'intelligence possible dans les machines (sciences cognitives). Nous nous demanderonsaussi dans quelle mesure ces technologies sont disponibles pour des particuliers commeprétendent quelques vendeurs d'applications. Et nous essayerons de voir ce que nousdépare l'avenir si, comme certains croient, tout le contenu de notre cerveau pourrait êtrecopié dans le «nuage» numérique.
4

1. L'environnement des données
Bien quel a forme de base de notre cerveau n'a presque pas changé au cours des derniers40.000 ans, la façon dont nous trouvons, conservons et interprétons l'information,comment nous dirigeons notre attention et employons nos sens, comment nous noussouvenons et comment nous oublions est le produit de milliers d'années d'histoire, avectous les avatars et changements qui ont modelé ls structure physique et lefonctionnement du cerveau et conditionne notre esprit. Les facteurs les plus décisifspour l'intellect ont été le développement de l'écriture et, des siècles plus tard, del'imprimerie. Nous connaissons des tablettes de grès avec des signes graphiques quidatent d'il y a 8.000 ans. L'interprétation de ces signes rendu nécesaire ledéveloppement de nouvelles connections neuronales dans le cerveau de leursutilisateurs, connectant l'écorce visuelle du cerveau à son aire du langage. Des étudesmodernes ont montré que, de ce fait, l'activité mentale est double ou triple dans cescircuits, provoquant une importante évolution culturelle et technologique. Ray Kurzweilen a déduit que nous approchons d'une nouvelle ère, où la technologie s'unira avecl'intelligence humaine, pour mener ensuite –vers la fin de ce siècle– au développementd'un “univers intelligent”.
1.1. Evolution technologique
On peut considérer Charles Babbage (Angleterre, 1792–1877) et son amie Augusta AdaByron (1815–1852) comme les principaux précurseurs de l'informatique vu qu'ils ontconçu un modèle conceptuel de machine appelée “moteur analytique”, qui aurait un“moulin” (“mill”) – qui serait son centre logique (équivalent à l'unité arithmétique desordinateurs actuels) –, une unité de contrôle et une mémoire, et serait capable demanipuler des symboles en suivant des règles définies. Et ils assuraient qu'il n'y avaitaucune raison pour ces symboles en soient que des chiffres et des équations.
Cependant, il a fallu attendre la décade de 1930 pour voir la construction des premièresmachines capables d'opérer réellement de cette façon. Depuis lors, nous sommes passéspar plusieurs “générations” d'ordinateurs: les électromécaniques (avec relais électro-magnétiques), les électroniques basés sur des tubes à vide (comme les anciennes radios),ceux basés sur des transisteurs individuels, et les “intégrés” (avec des puces réunissantde nombreux transisteurs et autres composants dans une seule pièce de silice) qui ontfinalement donné lieu aux ordinateurs personnels.
A la vue de ce que nous avons aujourd'hui à notre disposition, il est facile de voir que latechnologie a évolué de plus en plus rapidement. Le graphique qui suit montre cette
5

évolution, divisée en cinq générations ou “changements de paradigmes”, et montre enparticulier comment a augmenté le pouvoir de calcul. Il faut prêter attention à l'échellede l'axe vertical, qui est logarithmique, c'est-à-dire que chaque nouvelle frangehorizontale est une multiplication de l'antérieure (valeur exponentielle). Le graphique estde Ray Kurzweil (p.74, de sa version en espagnol):
6
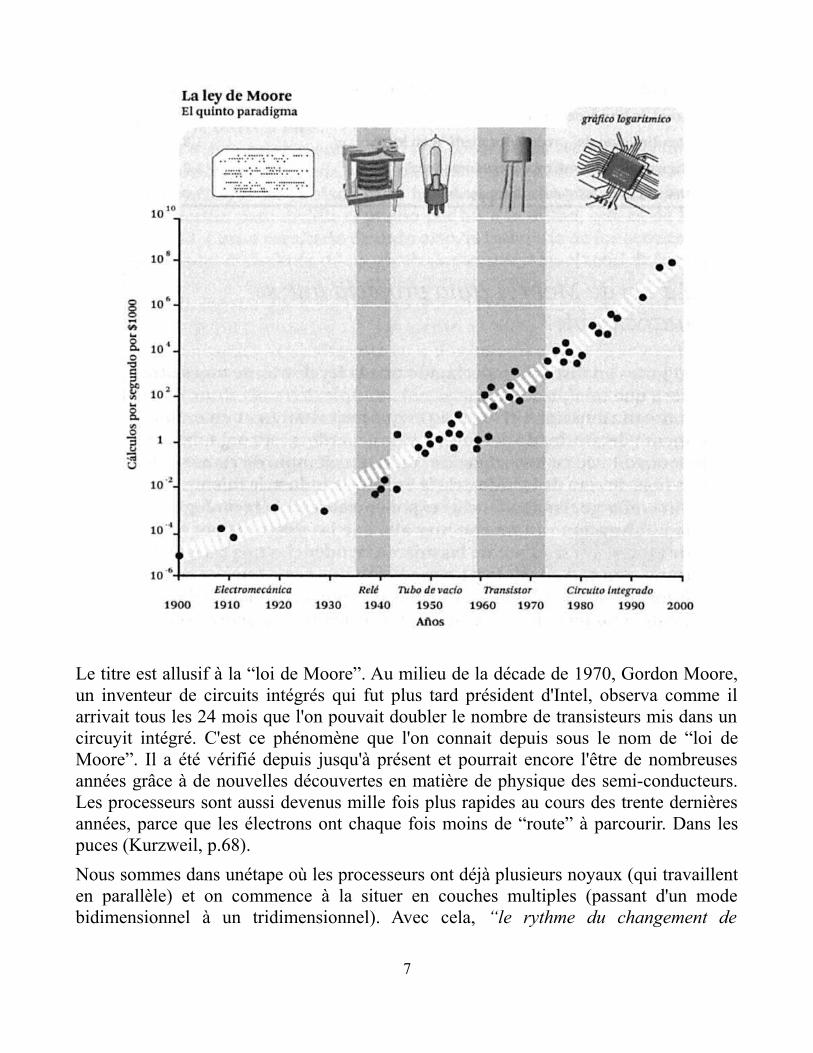
Le titre est allusif à la “loi de Moore”. Au milieu de la décade de 1970, Gordon Moore,un inventeur de circuits intégrés qui fut plus tard président d'Intel, observa comme ilarrivait tous les 24 mois que l'on pouvait doubler le nombre de transisteurs mis dans uncircuyit intégré. C'est ce phénomène que l'on connait depuis sous le nom de “loi deMoore”. Il a été vérifié depuis jusqu'à présent et pourrait encore l'être de nombreusesannées grâce à de nouvelles découvertes en matière de physique des semi-conducteurs.Les processeurs sont aussi devenus mille fois plus rapides au cours des trente dernièresannées, parce que les électrons ont chaque fois moins de “route” à parcourir. Dans lespuces (Kurzweil, p.68).
Nous sommes dans unétape où les processeurs ont déjà plusieurs noyaux (qui travaillenten parallèle) et on commence à la situer en couches multiples (passant d'un modebidimensionnel à un tridimensionnel). Avec cela, “le rythme du changement de
7

paradigme (l'innovation technologique) s'accélère. En ce moment, il se double chaquedécade.” (Kurzweil, p.27)
Ceci, évidemment, affecte la quantité de données qui peuvent être réunies et traitées, cequi explique ce qui arrive actuellement sur internet, comme le developpement du“nuage” (cloud) de conservation massive de données, et la capacité d'entreprises commeGoogle pour conserver et exhiber tout ce qui se publie.
1.2. Internet et la toile
La première connexion à distance entre ordinateurs a eu lieu en 1969 et fut l'origine deARPANET, le réseau d'ordinateurs de l'Agence de Projets de Recherche Avancée deDéfense (DARPA) des Etats-Unis, qui unit les quatre premières universités de ce pays:Stanford, UCLA, Santa Bárbara et Utah. En 1972, Ray Tomlinson, de BBNTechnologies, créa le premier programme de courrier électronique et utilisa pour lapremière fois le symbole @ dans une adresse. La difusion internationale du courriel acommencé l'année suivante. En 1981, pour la première fois, des ordinateurs del'Université de Yale et de l'Université de la Ville de New-York établirent une connexiondirecte, marquant le départ de ce qui serait le grand réseau académique mondialBITNET (Because It's Time NETwork). On annonça alors l'élection du protocole TCP/IPpour tous les serveurs (hosts) de ARPANET, encore en usage aujourd'hui.
Mais il a fallu attendre 1989 pour voir apparaître le lengage HTML et le concept deweb1, de Tim Berners–Lee, et jusqu'à 1991 pour voir le premier logiciel permettant unirplusieurs ordinateurs au moyen de la “toile”. La World Wide Web commença en pratiqueen 1993, quand le CERN rendit officiel dans un document que la technologie quipermettait sa création serait dès lors du domaine public. Et jusqu'en 1995, la toilecontinua à être un privilège des universités, de leurs professeurs et élèves, avec unquantité de serveurs qui arriva cependant à trois millions.
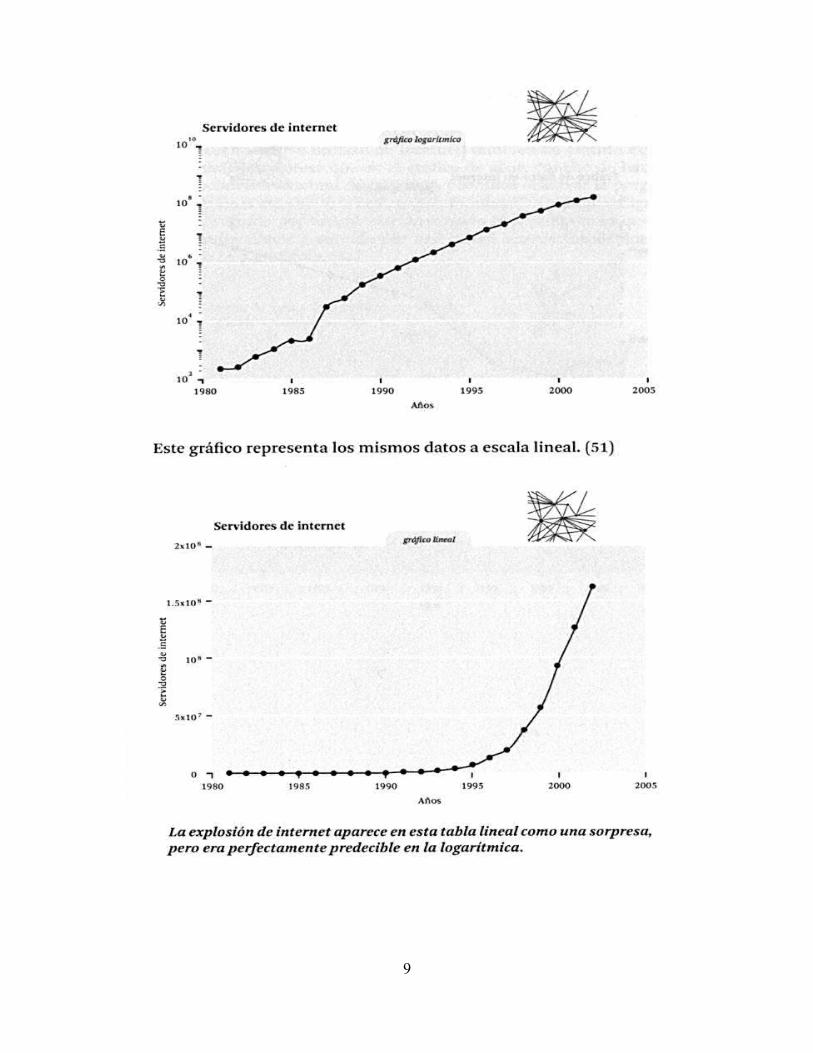
En 2013, il y avait 265 millions de noms de domaines (D.Wallace, 2014) et 1.000millions de serveurs enregistrés par la Société Internet, bien que seulement 183 millionsde sites web se considéraient actifs (Diario TI, 13/05/2014). R. Kurzweil (p.85) montreaussi dans des graphiques comment s'est produite une accélération de la croissance detype exponentiel (voir page suivante).
Le taux de pénétration d'internet, fin 2013, atteignait pratiquement 80% dans les paysdéveloppés et et 30% dans les sous-développés (El País, 26/11/2013). Le traffic dedonnées sur internet a aussi doublé chaque année, ce qui a rendu nécessairel'agrandissement de la bande passante, ç.à.d. De la capacité de transmission simultanée.
1 On lui donna le nom de World Wide Web en 1991.
8
9

1.3. Les réseaux sociaux et la mobilité
On considère généralement qu'avec les réseaux sociaux, aux alentours de 2005, estapparue une nouvelle “génération”: la “Web 2.0”. Sa caractéristique principale est soncaractère dynamique, avec la possibilité de participation active de tous les usagers. Maisil ne s'agit pas d'une apparition subite ou spontanée: les réseaux sociaux sont héritiersdes “communautés virtuelles”, dont la première fut “Habitat”, qui apparut en19862 etréunit plusireurs milliers d'usagers sur un réseau d'ordinateurs personnels qui utilisaitaussi le protocoloe TCP/IP. Apès sont apparues d'autres communautés, quelques unesvirtuelles (avec des univers fictifs) et d'autres rélles, comme “The VancouverCommunity Network”. Le premier “reseau d'amis”, antécédant Facebook, fut Friendster,en 2002. Facebook s'ouvrit à tous les usagers en 2007, après avoir lancé un premier feedde nouvelles pour amis l'année précédente. En novembre 2007, les réseaux sociauxdépassèrent déjà le courriel en quantité d'heures d'usage. En juillet 2009, ils avaient dejàplus d'utilisateurs que le courriel et en septembre 2010 ils atteignirent 1.000 millionsd'utilisateurs, dont la moitié sur Facebook (Castells, 2014, p.143).
En plus d'être une nouvelle source de données, les réseaux sociaux ont changédrastiquement la façon dont beaucoup obtiennent leurs informations. Une étude récentede Quantcast a révélé qu'ils génèrent 34% des références du traffic web sur dispositifsmobiles. Il s'agit du double de ce que génèrent les appareils de bureau. Le rapport –réalisé avec des données de tout 2013 – réunit les mesures des 250 principales sourcesde nouvelles et inclut le traffic au travers des navigateurs et applications internes deréseaux comme Twitter et Facebook (Clases de Periodismo, 16/05/2014). Cette quantitéd'accès mobile (par smartphones), causée principalement par les réseaux sociaux,provoque déjà que les transmissions deviennent plus lentes dans certaines zones à causede la saturation (Wired, 28/11/2014). Elle change aussi les systèmes de marketing etmême l'information journalistique.
De même, l'omniprésence des appareils mobiles “intelligents” a mené à la formationd'un nouvel environnement, clairement différent de la toile traditionnelle. Comme lemontre un étude de Morgan Stanley, les utilisateurs de mobiles dépassèrent ceuxd'ordinateurs personnels au début de 2014 (voir graphique), ce qui démontrel'importance que prennent les applications (logiciels) mobiles et la raison qui pousse lesgrandes entreprises à s'occuper de plus en plus de cette réalité.
2 Crée par Lucasfilm Games en collaboration avec Quantum Computer Services Inc.
10
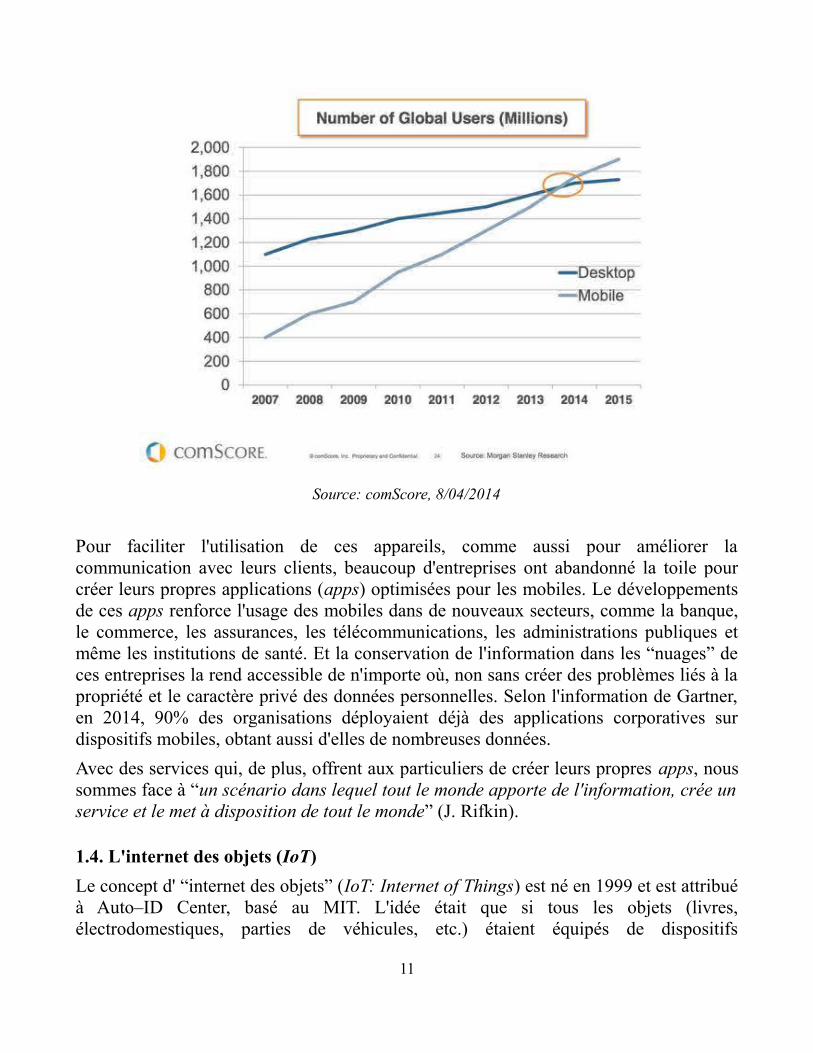
Source: comScore, 8/04/2014
Pour faciliter l'utilisation de ces appareils, comme aussi pour améliorer lacommunication avec leurs clients, beaucoup d'entreprises ont abandonné la toile pourcréer leurs propres applications (apps) optimisées pour les mobiles. Le développementsde ces apps renforce l'usage des mobiles dans de nouveaux secteurs, comme la banque,le commerce, les assurances, les télécommunications, les administrations publiques etmême les institutions de santé. Et la conservation de l'information dans les “nuages” deces entreprises la rend accessible de n'importe où, non sans créer des problèmes liés à lapropriété et le caractère privé des données personnelles. Selon l'information de Gartner,en 2014, 90% des organisations déployaient déjà des applications corporatives surdispositifs mobiles, obtant aussi d'elles de nombreuses données.
Avec des services qui, de plus, offrent aux particuliers de créer leurs propres apps, noussommes face à “un scénario dans lequel tout le monde apporte de l'information, crée unservice et le met à disposition de tout le monde” (J. Rifkin).
1.4. L'internet des objets (IoT)
Le concept d' “internet des objets” (IoT: Internet of Things) est né en 1999 et est attribuéà Auto–ID Center, basé au MIT. L'idée était que si tous les objets (livres,électrodomestiques, parties de véhicules, etc.) étaient équipés de dispositifs
11

d'identification (comme les étiquettes de radio NFC), il n'existerait plus d'objets perdusni hors de stock, parce que nous suarions toujours où ils sont et aussi ce qui seconsomme à chaque endroit. La connexion par internet, cependant, était impossible àcette époque, parce que le protocole d'internet (Ipv4) était au bord de la saruration. Maisle développement du nouveau protocole Ipv6, qui commença à être implanté à la fin de2012, admite 2128 o 340 sextillons d'adresses, ce qui suffirait pour les 1.000 à 5.000objets qui – selon les calculs – pourraient entrourer chaque être humain.
Tant les capteurs personnels (dans les smartphones et les nouveaux wearables) commeles caméras de surveillance et les capteurs publics de tout type (dans les “villesintelligentes”) recueilleront et enverront des informations. Le plus grand rendez-vous dela technologie, la foire CES de Las vegas, en janvier 2015, a confimé que c'est le pariactuel de tout type de fabriquant.
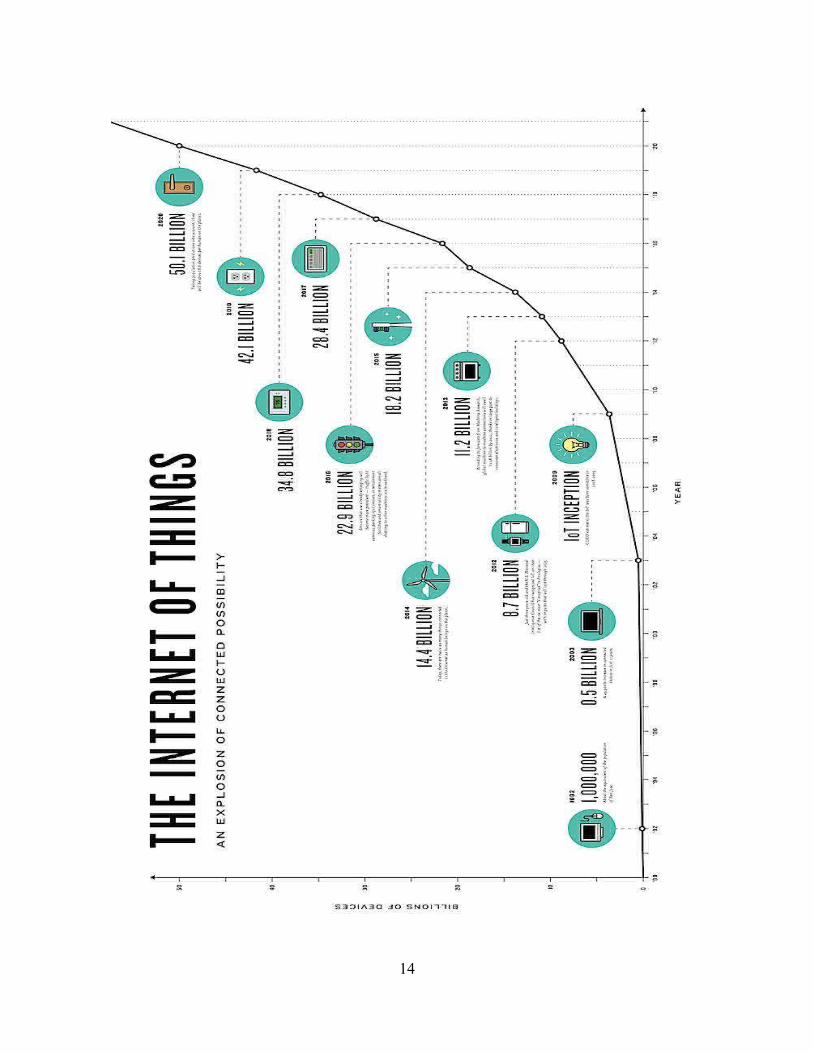
Le graphique de la page suivante illustre les différents types d'objets considérés etcommen ils se connecteront.
Nous vivrons entourés de produits connectés et même “capables de prendre desdécisions” selon ce qu'ils captent. “Notre auto pourra stationner seule, notre maisons'ajustera à la température qu'il nous faut à chaque instant, notre bicyclette seracapable de nous avertir si on la vole” (El Mundo.es, 9/01/2015).
On calcule qu'en 2015 se connecteront à internet 25.000 millions de nouveauxdispositifs liés aux “foyers intelligents”. La FTC (Federal Trade Commission) desEtats-Unis a averti pour cela de la possibilité des vols et mavais usages de l'informationproduite par ces appareils (Gizmodo, 9/01/2015). En 2020, il y aura entre 40 y 50.000millions d'appareils connectés, depuis les téléphones jusqu'aux lampes des maisons. Ils'agit d'une augmentation de 50.000 fois en moins de trois décades (The Connectivist,via Microsiervos, 13/05/2014).
La Corporation EMC a annoncé le 9 avril 2014 les résultats de sa septième étude surl'univers numérique, la seule étude qui qualifie et pronostique la quantité de donnéesproduite annuellement. L'étude, titulée “L'univers numérique des occasions: informationde valeur et augmentation de la valeur de l'internet des objets”, avec l'analyse d'IDC,révèle comment l'apparition des technologies sans fil, les “produits intelligents” et lesaffaires définies para logicial remplissent en rôle fondamental dans la croissanceexponentielle des données numériques dans le monde. A cause, en partie, de l'internetdes objets, l'univers numérique double son extension tous les deux ans et se multiplierapar dix entre 2013 et 2020 (DiarioTI, 09/04/14).
Le second des graphiques qui suivent montre cette évolution avec, à nouveau, la courbeexponentielle, ce qui confirme aussi l'hypothèse évolutive de Ray Kurzweil. (Source:The Future of the Internet of Things, Xively.com, 19/03/2014).
12

Source: Infographic Journal, 26/03/2014 (partie extraite de l'originel)
13
14

“Ce sera une tendance qui transformera tous les marchés et impactera toutes lesindustries”, dit José Manuel Petisco, directeur général de Cisco en Espagne. Jorge Lang,directeur d'Innovation et Solutions de Intel pour le sud de l'Europe, ajoutait: “Noussommes conscients de l'impact qu'aura l'Internet of everything; il sera supéreur à celuide la révolution industrielle su XIXe Siècle”.
1.5. Les “big data”
Les données extraites d'internet par lesentreprises s'accumulent en grandesbases de données que l'on appellemaintenant “big data”. Nous parleronstout spécialement de cela dans laDeuxième Partie. Comme référence, ilfaut tenir compte de ce que signifie untravail important sur la toileaujourd'hui: ainsi, par exemple, Googletraite 3.500 millions de requêteschaque jour et conserve environ 10exaoctets de données (l'équivalent de1.600.000.000.000 livres). Il utiliseplus d'un million de serveurs. Facebookajoute 500 teraoctets chaque jour.Amazon conserve les données des achats de 152 millions de clients, qui font environ 1exaoctet (selon Adeptia, Infographic Journal, 6/03/2015).
Si un moyen de communication numérique a une liste de souscripteurs, ce qui constitueseulement une table dans une base de données, il serait difficle de la considerer “bigdata”. Elle pourrait passer à l'être, à un niveau minimum, s'il enregistre en plus pourchaque souscripteur chaque page lue, avec les données de l'accès (date, heure, appareilutilisé, navigateur ou app, lieu, etc.).
15

Première Partie: Capturés
(La perte du privé)
2. L'identité révélée
Il existe des services que nous choisissons etutilisons pour nous faire connaître commepersonne, comme professionnel ou commeauteur d'une production intelectuelle ouesthétique. De cette façon nous révélonsvolontairement une partie de notre identité et,évidemment, nous ne pouvons nous plaindre siles services utilisés conservent cetteinformation. Mais il est plus discutible qu'ilsl'utilisent à leurs propres fins, et spécialementde les analyser et vendre à des tiers, bien quecela puisse être, justement, la forme depayement que nous devons accepter quand ce genre de service est gratuit.
Nous connaissons évidemment ce que nous publions éventuellement dans des sites web(revues, blogs, etc.) et il n'y a pas grand chose à dire à ce sujet ici. Il est évident que lesadministrateurs de ces sites ont plein accès à ces contenus et aux données personnellesque nous leur avons fournies. Il extraient probablement aussi d'autres données, moinsvisibles, mais nous traiterons cet aspect dans la Deuxième Partie. Les informationspersonnelles les plus communes aujourd'hui, et où les recherches démontre que l'onprend le mois de précautions, sont celles des réseaux sociaux.
2.1. Réseaux sociaux
Notre profil et nos envois (posts) sur notre “mur” sont des données que nous publionslibrement et qui font grossir les bases de données des réseaux auxquels nous participons.Mais, comme nous verrons dans le chapitre suivant, ils obtiennent beaucoup plusd'information sur la base de tous les mouvements que nous effectuons lorsque noussommes connectés. Nous pouvons avoir un certain contrôle sur ce qui est divulgué aumoyen de certaines options que nous offre chaque service. Mais il y a des choses quiéchappent à notre contrôle.
Pour en savoir un peu plus et prendre des décisions informées, il nous faut lire la
16

politique d'information privée de chaque service, ce qui n'est pas toujours facile et peutprendre du temps: elle occupe parfois plusieurs pages et utilise souvent des termes queseuls comprennent les avocats. Lorrie Faith Cranor, directrice du cyberlaboratoire desécurité Carnegie Mellon, a calculé que lire toutes les politiques de confidentialité qu'unutilisateur rencontre au cours d'une année prendrait 76 jours! “Les conditions restentinaccessibles, illégibles, pleines d'hyperliens –entre 40 et 100– et dérivent parfois à despages en anglais” avertit UFC-QueChoisir, la principale association française de défensedes consommateurs (El País, 25/03/2014). En tous cas, il convient de voir ces pages etcelles relatives }a la sécurité (par exemple “Qui peut se emttre en contact avec moi?” et“Quel messages filtrer” sur Facebook). Il est aussi recommendable de désactivertoujours l'option de géolocalisation (à moins que ce soit essentiel, comme pour sedéplacer en automobile suivant une carte), car c'est un moyen puissant pour faire desdéductions en croisant statistiquement les données.
Les firmes de réseaux sociaux sont, sans aucun doute celles qui se bénéficient le plus del'analyse de tout ce que nous publions. Ainsi, par exemple, Facebook possède uninstrument appelé Facebook Audience Insights dont la finalité est d'évaluer les clientsactuels et potentiels pour personnaliser des messages et stratégies de marketing. Il offreà ses clients, sur nous, une information démographique (âge, style de vie, éducation,relations, travail, etc.), pages et messages préférés dans diverses catégories, localisation,langue, activités liées aux achats en ligne et hors de ligne et formes de payement(Wwhat's New, 8/05/2014).
L'information dont dispose Facebook sur un de ses utilisateurs puet dépasser 1.200pages comme a pu constater, Max Scherems, un étudiant de droit autrichien qui enappela en 2011 à la législation européene sur la protection des données pour exiger àFacebook d'être informé de tout ce que l'entreprise savait de lui. Dans ce millier depages figuraient toutes ses données personnelles divisiées en 57 catégories comme pass-temps, goûts, opinion religieuse, etc., ainsi que tout ce qu'il avait publié et “navigué”depuis son inscription, même les chats privés effacés et les demandes d'amitié refusées(L.Zanoni, p.86).
Le site Genbeta a dit que “Facebook a un service de messagerie instantanée, et Twittera étrenné ses messages directs en groupe. Ce sont des formes de communication avecnos amis et connaissances qui ont comme base un réseau social mais qui sontcomplètement privées” (26/02/2015). Mais je demande pardon à Miguel López, qui aécrit cela, car je en suis pas d'accord: ces communications n'ont RIEN de privées! Ellesont tout au plus cachées à nos autres contacts, mais ces deux firmes en enregistrent lescontenus et peuvent les analyser. Il en va de même pour leur conservation des photos,qui pourrait être fermé au public (comme il est aussi possible de le faire dans d'autreservices) mais peuvent aussi être analysées (comme Facebook le fait pour reconnaître et“étiqueter” les visages).
17

2.2. Connaître ce qui est révélé
Nous rappeler ce que publions sur la toile peut être utile dans quelques cas et ce n'est pastoujours facile, surtout quand il en s'agit pas de documents que nous produisons etgardons dans le “nuage” numérique ou que nous publions sans garder copie.
Dans le cas de pages web, nous pouvons enregistrer celles qui nous intéressent avec desapplications comme Evernote ou en garder les références dans une table Excel (fort utilepour cela est l'extension “Citable” pour le navigateur Chrome). Mais même ainsi, nousn'avions pas, jusqu'il y a peu, de système qui nous permette d'enregistrer notrenavigation d'un site web à un autre. C'est l'objectif de Trailblazer(http://www.trailblazer.io/) – une extension pour Chrome –, qui construit une carte dessites visités lorsque nous cliquons sur les liens ou faison une recherche.
Sur Facebook, il est possible de savoir ce que nous accumulons en utilisant l'option deConfiguration, puis “Décharger une copie de vos données”. Cela mènera à une page quipermet de décharger le fichier qui incluirá les messages, photos, vidéos, conversations,information de profil et quelques autres. Cliquer ensuite sur le bouton “Commencer”,écrire la clé d'accès et attendre.
Il est possible de découvrir plus de ce que sait Facebook utilisant Wolfram Alpha(www.wolframalpha.com/facebook) et cliquant sur le bouton “Get Your Report”: onobtiendra là divers graphiques et visualisations qui incluent des informations sur lafréquence de nos publications, les mots les plus souvent écrits, les “Like” envoyés, lesphotos les plus commentées, les commentaires d'amis, et même un groupementdémographique relatif à nos cercles sociaux (PC Magazine, 5/09/2014).
Google, pour sa part, réunit notre information personnelle pour créer un profil quicouvre des détails comme notre âge, genre et intérêts personnels, pour déterminer quelsannonces publicitaires montrer, en plus des options relatives à l'utilisation de ses sites(configuration) et les opérations réalisées avec son navigateur (Chrome) – si nous avonsopté pour celui-çi – et avec les comptes de Gmail et Google+. Les données réuniespeuvent être consultées (et changées) – au moins en partie – dans les options de menu“Paramètres”, “Panneau de contrôle” et la page “Ad Settings”. On trouvera aussi“Historique”, qui permet de voir la liste des pages visitées (à moins qu'on ait bloquécette fonction ou effacé régulièrement son contenu). Tout ce qui est synchronisé peutêtre vu (et contrôlé) en passant au lien “Google Dashboard”. “Sécurité”(https://security.google.com/settings/security/permissions) permet aussi de voir une listede toutes les applications web, mobiles et de bureau, qui peuvent accéder à nosinformations personnelles. Les données utilisées pour déterminer quelle publicité nousmontrer peuvent être vues sur www.google.com/settings/ads/. Toutes les recherchesréalisées avec Google Search sont accumulées et peuvent être consultées surwww.google.com/history/ (fonction qui peut être bloquées). Il en est de même pour
18

YouTube, sur www.youtube.com/feed/history/search_history.
Si utilisa un dispositif Android, il est probable que sa localisation soit envoyée à Google.On peut vérifier l'historique de localisations surhttps://maps.google.com/locationhistory.
Sur Yahoo, il n'y a pas de mécanisme pour obtenir une copie des données propres, maisFlickr supporte des applications externes de décharge des photos, comme Bulkr.
Sur LinkedIn, il n'est pas plus possible d'obtenir une copie complète de ses données,mais il es possible d'obtenir une copie de la liste de contacts en “Export LinkedInConnections”. (On peut bien sûr aussi imprimer la page web du profil personnel.)
Sur Twitter, à part le profil que l'on peut voir et éditer, nous pouvons obtenir un fichierde tous les twits et RT (une version pour le navigateur et une autre en format CSV, pourune feuille de calcul) dans le menu dépliable de configuration grâce au bouton“Demandez votre fichier”.
19

3. L'identité extraite
Les entreprises – de tout type– se sont rapidement occupées d'essayer de prendre bonparti de toute l'information que nous révélons et aussi des traces que nous laissons sansle savoir. Avec les mobiles et les réseaux sociaux, elles connaissent nos listes d'amis, nosgoûts, où nous allons, et plus encore. Et, en analysant ou vendant ces données, ellespeuvent obtenir de plus grandes bénéfices grâce à toute cette information. Ledéveloppement d'algorithmes d'analyse de la navigation permet aussi de connaître demieux en mieux ce qui se passe dans la société au point de pouvoir en prédire diverscomportements.
3.1. Des équipements “traîtres”
Le simple fait de posséder un appareil capable de se connecter à internet implique que lefournisseur du service non seulement peut le connaître mais aussi l'usage que nous luidonnons, et qu'il peut mettre cela en relationa avec les données personnelles que nous luiavons fourni au moment d'engager le service. Évidemment, les compagnies detéléphonie mobile accumulent les informations sur ceux qui font et reçoivent les appels,leur durée et la localisation des clients. El les fournisseurs d'internet saven quelnavigateur nous utilisons et peuvent enregistrer tout notre historique de navigation.
Si nous utilisons un téléphone “intelligent” ou une tablette, nous devons de plusconsidérer que le fabricant peut en faire le suivi (ce qui dépend de la marque). De plus,toute application peut accéder au numéro de série de l'appareil, à sa localisation, à ladate et heure des connexions. Ce sont là les “metadata”, et elles sont suffisantes pouridentifier l'utilisateur. Les apps sont aussi souvent capables de lire la liste des contacts etextraire diverses autres données, ce qui rend conseillable de vérifier toujours lesautorisations d'accès qu'elles demandent. Sur Android, on peut voir cette liste aumoment d'installer chaque app (et on peut les refuser). Sur iOS, Apple exige maintenantdes développeurs qu'ils indiquent clairement dans un message pour quoi ils désirentavoir accès à telle ou telle donnée et qu'ils permettent à l'utilisateur d'accepter ou derefuser. (Dans les deux cas, refuser une autorisation peut cependant empêcherl'installation ou que le logiciel fonctionne pleinement).
3.2. Navigation
Depuis que furent créées les pages web, il existe la possibilité d'obtenir l'information dessites que nous visitons, des nouvelles que nous y lisons, de ce nous achetons par elles, dela musique que nous écoutons, des films que nous voyons, etc. Les navigateurs gagnentdes millions de dollars grâce à une analyse des habitudes de navigation de leurs
20

utilisateurs, information qu'ils vendent aux annonceurs. Nous pouvons tenter de nousprotéger. Il existe pour cela un standard qui devrait permettre d'utiliser la règle “Do NotTrack” (“ne pas suivre”) pour que notre comportement ne soit pas enregistré. Mais degrandes entreprises comme Yahoo et Facebook ne suivent pas le standard qui suggère derespecter cette option (qui se trouve dans les paramètres de navigateurs) et beaucoupd'autres sites n'en tiennent pas plus compte.
Il existe cependant aussi de bonnes applications,comme Ghostery (www.ghostery.com), quirévèlent qui nous épie et nous permettent debloquer vraiment l'envoi de ces données.
Tous les navigateurs conservent aussi notrehistorique de navigation, au moins pendant quenous sommes en ligne, ce qui nous permet deretrouner rapidement à une page visitéerécemment. Cette liste est normnalementaccessible via le menu du navigateur et il y a une option pour l'effacer (Qui peut êtreautomatisée dans certains navigateurs). Google Analytics collecte cette information (lessites y le temps que nous y passons), mais nous pouvons le bloquer à la pagehttps://tools.google.com/dlpage/gaoptout.
Le service d'information de Google (Google Now) pour teléphones utilise tout ce qu'ilarrive à savoir de nous pour sélectionner les informations qu'il supose “importantes”pour nous en fonction du profil qu'il établit (Il n'y aura rien de vraiment utile si nousbloquons toutes les possibilités de suivi!).
3.3. Réseaux sociaux
S'inscrire dans un réseau social en fait pas seulement que notre information publiqueentre dans ses bases de donnée, elle implique aussi que toutes les opérations que nousréalisons quand nous l'utilisons et tout ce qu'il est possible de savoir au moyen de laconnexion (appareil, navigateur, numéro IP, etc.) est aussi enregistré. Dans tous cesservices, la “politique de intimité” informe que ces données sont captées – au moins –pour “pourvoir, améliorer, essayer et superviser l'efficacité du service”. Bien qu'il espossible de restreindre d'accès de tiers aux contrôles de confidencialité offerts, il n'y aaucune restriction en relation à ce que la firme enregistre et analyse (et vend!). Le cadresuivant montre les données que capturent quatre des principales entreprises de la toile,les métodes utilisées et quelques emplois.
21

Comme les mobiles et les réseaux sociaux, les entreprises connaissent nos listes d'amis,nos goûts, où nous avons été, et bien d'autres choses. Et, en analysant et vendant cela,elles peuvent – grâce à nos soins – obtenir de plus grands bénéfices.
Pour le démonter, Ubisoft a créé une application qui permet de mesurer “l'ombrenumérique” qu'un utilisateur laisse sur Facebook, Twitter et Google+. Ce logicielconsidère les profils des messages, les amis, famille, photos, etc., pour mesurer la“valeur” de cette ombre pour un annonceur ou un pirate qui désirerait obtenir le compte.Ici suit un exemple d'une trace sur Facebook selon un test publié par Forbes(25/04/2014).
22

Facebook apparait fréquemment dans les nouvelles en raison des changements de lapolitique et contrôles de confidencialité, ce qui est probablement la plus grande sourcede méfiance face à ce réseau, surtout parce que le niveau de contrôle réel est fort réduit.Les changements constants ont été commenté par de nombreux média et, de ce fait, on apu observer que 61% de ses utilisateurs ne confient plus aveuglement dans ce système(WebpageFX et The Next Web, novembre 2013).
Des chercheurs des universités de Stanford (Etats-Unis) et de Cambridge (GrandeBretaña) ont démontré que, en moyenne, “il suffit de 10 «like» sur Facebook pour queses algorithmes te connaissent mieux qu'un compagnon de traveil; avec 70 «like»Facebook te connaîtra mieux qu'un ami, avec 150 mieux que ta famille et avec 300mieux que ta femme ou ton mari” (Gizmodo, 13/01/2015).
Facebook utilise tant le profil de chaque membre comme ses envois pour servir sesannonceurs. Si, lorque quelqu'un s'inscrit, il informe de ses films, programmes detélévision ou livres favoris, les annoncuers en seront informés et essayeront d'en tirerprofit. Et s'il efface complètement son compte, plus personne en le vera, maisFacebookconservera et utilisera encore ses données. De plus, ils construisent une“mémoire sémantique” du registre historique des activités de chaque utilisateur etréalisent une analyse exhaustive afin de commercialiser ces données. De fait, en avril2014, ils ont annoncé qu'ils lanceraient leur propre réseau de publicité pour mobiles,dans lequel ils profiteraient de leur base de données pour créer des avis personnalisés,afin de faire la concurrence à Google. En fonction des mouvements et caractéristiques de
23

la navigation des utilisateurs, ils détermineront quels avis publicitaires sont lesmeilleurs, en fonction aussi des plateformes informatiques (appareils et systèmesd'exploitation) et des applications utilisées dans les mobiles (Noticiasdot.com,22/04/2014).
Une étude commandée et communiquée par la Commission de confidencialité de laBelgique a aussi démontré que Facebook viole les lois européennes dans ce domaine,entr'autres extrayant de l'information sur ses utilisteurs pendant qu'ils naviguent sur latoile même lorsqu'ils ont abandonné le site web du réseau social, grâce à des boutonsextra comme les “like” (“J'aime”) et comme les “biscuits” (cookies)3 mis sansautorisation dans l'appareil du lecteur et qui interactuent avec les sites web visités. Ilsobtiennent et conservent même des données de personnes qui n'ont pas de compte dansleur réseau, lorsqu'elles sont citées par les membres (Genbeta, 31/03/2015). Facebook arépondu que cela sert seulement à rendfe sa publicité “plus intéressante”, qu'ilsrespectent les options de ne pas faire de suivi des pages webs visitées et que tout lemonde peut désactiver l'option de que les “actions sociales” soient reflétées dans lapublicité que reçoivent les amis (Genbeta, 10/04/2015).
Selon un étude récente du centre de recherche Pew réalisé aux Etats-Unis, 91% desadultes croient que les consommateurs ont perdu le contrôle sur la façon dont lesentreprises obtiennent de l'information sur leurs clients. 61% n'ont plus confiance dans lapromesse que font les réseaux sociaux, les moteurs de recherche ou les magasins enligne de ce que ces données en servent que pour améliorer leur service. Que ces donnéessoinet rendues anonymes (éliminant le nom): “En croisant diférents points, il est faciled'obtenir un profil unique et réel de n'importe quel utilisateur. Ce que nous en racontonspas sur un site, nous le racontons sur un autre. Nous en dison peut-être pas sur le résausocial où nous avons dîné, mais la photo du plat principal prise avec le mobile a descoordonnées GPS et en laisse aucun doute” dit le journal espagnol El Mundo(20/11/2014).
Si on envoye des vidéos, même sans qu'ils soient géolocalisés, il existe des algorithmesqui peuvent localiser où ils furent pris, au moyen des images et des sons. Le système aété développé par des scientifiques de l'université Ramon Llull de Barcelone, quipublièrent leur étude dans la revue Information Sciences4. Bien qu'il n'était pas encorepublic, il en se passera pas baucoup de temps pour que n'importe quelle entrepriseinformatique en fasse de même (Agence SINC, 11/02/2015).
3 Informations invisibles qui sont «collées» dans la machine et peuvent être lues par le navigateur. On peut les voir en clickant sur la petite page en blanc qui apparaît à gauche de l'adresse URL, au haut de la page (tout au moins avec le navigateur Chrome).
4 Xavier Sevillano, Xavier Valero, Francesc Alías. “Look, listen and find: A purely audiovisual approach to online videos geotagging”. Information Sciences 295: 558–572, 2015.
24

3.4. Téléviseurs intelligents
Tant Samsung que LG et d'autres fabriquants ont inclu dans leurs “téléviseursintelligents” d'importantes fonctions d'espionage des utilisateurs: elles copient l'adresseIP, les identificateurs de dispositifs, les données des transactions réalisées et desapplications et services utilisés.
En plus, ils répondent à des commandes orales et, au moins dans le cas de Samsung,enregistraient TOUT se qui se disait devant l'appareil, en théorie pour connaître lesordres les plus fréquents et, de cette façon améliorer le système dans des modèles futurs.Vu que des millions de personnes envoyent un ordre que son téléviseur en comprendpas, les envoyer à la firme rendrait possible qu'ils soient compris dans l'avenir. Mais laconversation pourrait aussi être interférée et Samsung, au moins, en avertissait sesusagers dans sa web: “Veuillez tenir compte de ce qui si vos paroles incluent desinformations personnelles ou confidentielles, elles feront partie des données capturéeset transmises à un tiers lors de votre utilisation de la fonction de reconnaissance de lavoix”, un avertissement submergé dans le texte sur la politique de confidencialité d'uneextension de 46 pages (Wwwhats´ New, 6/02/2015). Après que cela fut dénoncépubliquement, Samsung répondit qu'ils en conservaient pas les conversations des clientset appliquait “les mesures et pratiques de sécurité standard de l'industrie” pour“protéger l'information personnelle des clients et évitar son obtention ou usage nonautorisé”, alores qu'ils envoyent ces données à la firme nordaméricaine Nuance,spécialisée en reconnaissance de la voix qui les assiste dans ce domaine. Ils avertirentfinalement qu'ils changeaient leur politique et que “les ordres oraux seront enregistrésseulement quand sera demandée la fonction spécifique au moyen du bouton d'activationsur la commande à distance ou sur l'écran et quand on parlera devant le micro de lacommande à distance” (El Mundo.es, 10/02/2015 y ABC.es, 11/02/2015).
Mais ceux qui n'acceptent pas cette spécification en peuvent pas utiliser les commandesorales ni accéder à d'autres services additionnels, tant dans les téléviseurs de Samsungcomme de Toshiba. Dans ceux de Panasonic, dans ce cas, on ne peut accéder ni auxapplications ni au navigateur et avec LG on perd aussi les applications (Xataka,4/11/2014).
Les commandes orales avec Google Chrome, Google Now, Apple Siri, Amazon Echo etles téléphones intelligents sont aussi susceptibles d'êtres écoutées à distance. Bien qu'engénéral cette fonction peut être désactivée, cela peut aussi causer la perte de diversservices.
3.5. L'internet des objets
L'“internet des objets” (Internet of Things, IoT, en anglais) introduira probablementbeaucoup d'objets pratiques dans notre vie, mais il faudra le payer avec une perte encore
25

plus grande de confidancialité de notre vie privée.
“L'ère de l'«internet des objets» se base, précisément, sur cela. Lesélectrodomestiques apprendront et sauront tout de leurs propriétaires, afind'améliorer leur vie et faciliter leur tâche. La transparence à l'heure de montrer cetype de pratique et une plus grande conscience de la part des consommateurs setransforment en frontière de convivialité. Les dispositifs «intelligents» amènent àune perte inévitable du privé? Selon les experts, cette situation est «intrinsèque» àce genre d'appareils.” (ABC.es, 11/02/2015)
L'“internet des objets” sera partout, ce qui signifie que quand il se produira unquelconque changement enregistré par l'un de nos appareils connectés, une entreprise ensera informée, reliant cette donnée aux autres qu'elle aura de nous. “Personne en seracapable d'échapper à son impact, parce qu'on n'utilisera pas la IoT: on vivrá dedanstoute la journée, tous les jours”, dit Geoff Webb, Directeur de Solution Strategy enNetIQ. “Quand nous vivons dans un monde où il y a un nombre infini de senseurs etobjets intelligents autour de nous, tout le temps; quand les vêtements que nous portons,et même des choses à l'intérieur de notre corps, sont intelligents et connectés, alors elconcept de «privé» se transforme en quelque chose de beaucoup plus éphémère.”(Wired, 5/02/2015).
Ce qui arrive déjà avec les cartes de crédit peut nous donner une idée de ce que celasignifie. Une étude dirigée par Yves-Alexandre de Montjoye, du Media Lab de l'Institutde Technologie du Massachusetts (MIT), et publié dans un volume spécial de la revueScience sur le thème de ls sécurité, permit d'identifier 94% des personnes d'une base dedonnées d'acheteurs utilisant seulement l'information de trois achats faits un jour avecchacune de leurs cartes (sans connaître initialement leur nom). L'analyse permit mêmede détecter que tant les femmes comme les personnes avec de plus hautes rentrées sontplus faciles à identifier, car leurs patrons d'achats au cours du temps sont beaucoup plusdéfinis que les autres. “Notre travail démontre comme il est difficile de rendre lesdonnées anonymes”, dit de Montjoye. (El Mercurio, 30/01/2015).
Voyons quelques uns des cas les plus commentés actuellement.
3.5.1. Bracelets de Fitness
Les bracelets destinés a surveiller l'exercice physique sont une excellente sourced'information privée qui, dans bien des cas, envoyent ces données à un serveur central.Ceux qui dominent ce marché sont Fitbit, avec 67% de part de marché en 2014, etJawbone. Fitbit a un programme gratuit pour les entreprises de 1.000 travailleurs auxEtats-Unis (300 en Espagne).
On estime qu'en 2013 les ventes de ces calculateurs à des entreprises dans le cadre deleurs programmes de santé furent de 200.000 unités, et pour 2018 cette quantité pourrait
26

arriver à 13 millions de dispositifs. Beaucoup de grandes entreprises ont ce type deprogramme pour leurs travailleurs (80% de celles qui ont plus de 1.000 employés et 50%de celles qui en ont entre 50 et 999). Selon une étude de la Fondation Kayser Family, cesplans leur permettent d'obtenir une réduction de 35% du coût de leurs assurancesmédicales.
Les assurances assument que si les travailleurs sont plus actifs et dorment mieux, il yaura moins de chances qu'ils utilisent leur assurance (Xataka, 12/02/2015). C'est pouquoibeaucoup de compagnies, comme Google, eBay, BP, Autodesk et presque toutes lesgrandes assurances et celles du secteur de la santé aux Etats-Unis offrent ces braceletsdans leur programmes de bien-être.
Ces firmes installent un serveur spécial qui reçoit les données des bracelets et créentavec elles des statistiques sur les activités physiques et les heures de sommeil destravailleurs. L'administreteur du programme dispose d'un panneau de contrôle où sontreflétés les données des utilisateurs et des dispositifs en opération. Pour leur par, chaquetravailleur peut voir ses propres données sur son navigateur web, avec l'indication –parexemple– des jours où il a atteint ses objectifs, la distance parcourrue, le meilleur jour deson histoire, et un graphique qui compare son rendement à la moyenne du groupe.
Un exemple d'écran de visualisation de Fitbit Corporate Fitness (via Xataka)
27

Il y a des entreprises qui vont beaucoup plus loin, contrôlant toutes les activités etdéplacements de leurs employés. Ainsi, par exemple, la compagnie de transfert dedevises Intermex leur exige de charger dans leurs téléphones mobiles l'application Xora,de “gestion de centres de travail”, qui suit la localisation 24 heures par jour. Et elle aremercié une employée qui l'avait effacée (employée qui réclama devant les tribunauxpour invasion d'intimité et expulsion injustifiée). (The Guardian, 12/05/2015).
3.5.2. Ton auto te dénonce
Les fabricants d'automobiles “connectées” obtiennent des données de leur conduction etfonctionnement, information qui est envoyée aux serveurs tant du fabriquant commeparfois de tiers. BMW elle même a dénoncé que les firmes technologiques etpublicitaires désirent obtenir toute cette information, avec aussi celle qui concerne lesconducteurs. Et, selon la compagnie allemande, ils pressionnent les fabriquants pourqu'ils y donnent libre accès ou leur vendent ces données. Les entreprises de publicitéoffrent déjà de les utiliser pour leur “donner plus de valeur” en faisant apparaître sur lenavigateur de bord des annonces, par exemple, des restaurants proches où le chauffeurdevrait aller prce que l'annonceur saurait qu'il conduit déjà depuis plusieurs heures etauarit besoin d'une pause pour se restaurer. BMW veut pour cela commencer unecampagne pour assurer que toute l'information de ses véhicules connectés soit bienprotégée et réservée (Xataka, 15/01/2015).
Et de 16 fabriquants consultés par le sénateur Edward Markey, du Massachusetts,seulement deux ont assuré être préparés pour détecter et commencer à affronter lesproblèmes de sécurité associés à cette connectivité. Le client a peu de possibilité dedésactiver cette transmission de données sans que cela suppose une importante perte desprestations de l'auto, spécialement de la navigation par GPS. Le sénateur a aussi accuséles fabriquants d'employer ces informations personnelles pour des fins qui en sont pastoujours propres de la sécurité ou de l'expérience à bord. L'agence officielle de ladéfense, DARPA, a elle-même démontré qu'il est possible de pirater et prendre lecontrôle d'un véhicule en moins d'une heure, pouvant contrôler la mise en route,l'accélérateur et le frein (Xataka, 10/02/2015).
3.5.3 Ton lecteur numérique aussi
Les lecteurs de livres numériques, comme le Kindle d'Amazon (et quelques autresaussi), peuvent aussi nous épier et avertir le fabriquant de ce que nous faisonas avec euxsi nous les maintenons connectés. Le Kindle offre à ses utilisteurs l'option de marquerles parragraphes préférés et de les garder dans l'équivalent d'un chier de notes. MaisAmazon est mise au courant de ce qui est souligné et, si le lecteur ne prend pas laprécaution de refuser l'autorisation correspondante, la firme offrira cette information
28

dans son “nuage” et, chaque mois, rand public le ranking des citations les plussoulignées (BBC Mundo, 19/11/2014).
3.6. Les grandes données (“Big data”)
Toutes les données accesibles sur internet sont réunies para divers acteurs en une masseappelée “big data” conservée dans de grandes bases de données et ensuite analyséespour obtenir une meilleure connaissance de ceux qui les produisent (nous). Il doit êtreclair maintenant que, s'il est déjà difficile de conserver l'information privée, avecl'Internet des Objets nous devrons oublier définitivement cela. Comme a expliqué W.Ben Hunt sur le site de Forbes, comparer l'analyse de big data avec l'analyse que réalisenotre cerveau lorsqu'il considère de nombreuses données serait une grave erreur:
“Le cerveau humain en peut pas comprendre facilement l'immensité de TOUTEl'équation ou ce que signifie regarder TOUT de façon simultanée et en parrallèle[comme le fait un puissant ordinateur]. Cela peut paraître de la magie, et à niveaupurement symbolique cela peut être décrit comme de la magie. Mais au niveaufondamental, je en comprend pas cette magie et aucun autre être humain ne peut lefaire. Ce que je epux dire avec une certitude absolue, cependant, c'est que lamagie existe et qu'il y a un tas de mages, avec plus de gradués du MIT, de Harvardet de Stanford chaque année.[Il faut reconnaître] que des intérêts privés puissants nous quittent les clés de notreconduite sous nos yeux et avec notre coopération. Cet acte simple dereconnaissance changera pour toujours notre comportement d'échange de données,et cette bataille ne pourra pas être gagnée si un nombre suffisant d'entre nous nechangent pas leur comportement pour protéger avec zèle leurs clés.” (W. BenHunt, Forbes.com, 14/02/2015)
Lamentablement, les entitiés de gouvernement qui tentent d'attaquer le problème dansdivers pays luttent dans une guerre obsolète au lieu de faire face à celle qui estréellement à la vue de ceux qui connaissent la vraie situation, ajoute Ben Hunt. PourHodgson, il s'agirait d'assurer une transparence totale dans les deux sens (nous face auxentreprises et elles face à nous) avec notre plein accès à nos propres données et notredroit clair de propriété (Hodgson, 2014). Nous développons ce thème dans le chapitresuivant.
Un autre aspect de l'analyse de big data est que, comme signalé plus haut (étude deYves-Alexandre de Montjoye au MIT), il n'est plus nécessaire que notre nom soitenregistré dans la base de données – pas d'avantage que notre profil d'utilisateur – pourque nous soyons identifiés. Notre identité peut être déterminée sur la base de notrecomportement dans l'utilisation de quelques applications d'achats et payement en ligne,services multimédia et plateformes de communication, même sans notre nom.
29

L'analyse de big data est une ressource importante pour de nombreuses firmes et les“scientifiques de données” capables de réaliser ce travail sont de plus en plus demandés.Nous traiterons cet aspect dans la Deuxième Partie.
30

4. Protection et cession de données
Selon une étude récente du centre de recherche Pew aux Etats-Unis, 91% des adultescroit là que les consommateurs ont perdu le contrôle de la façon dont les entreprisesprivées réunissent leur information sur leurs clients. 61% se méfient de la promesse quefont beaucoup de réseaux sociaux, moteurs de recherche et commerces en ligne den'utiliser ces données que pour offrir un meilleur service (El Mundo, 20/11/2014).
4.1. Droits
Cela met en évidence un problème sérieux: celui de la propriété et confidencialité desdonnées réunies au moyen des “données sociales5” et “traces” laissées par les internautessur la toile. S'il existe dans bien de cas une cession volontaire de données personnelles(généralement comme une façon de rétribuer un service “gratuit”), celle-çi en peut êtreindiscriminée et en devrait pas surgir sans le consentement des intéressés. La principlaeassociation française de défense des consommateurs, UFC-Que Choisir, a dénoncédevant les Tribunaux de Justice Twitter, Facebook et Google+ pour leurs normesd'utilisation de données personnelles de leurs abonnés, considérées “illicites” et“abusives”. “Les conditions continuent à être souvent inaccesibles, illégibles, pleinesd'hyperliens – entre 40 et 100 liens d'hypertexte – et dérivent parfois à des pages enanglais. Pire encore, les réseaux continuent à permettre amplement l'obtention, lamodification, la conservation et l'exploitation des données des utilisateurs et même deleur famille. Sans l'accord explicite des utilisateurs, ils donnen une licence mondialeillimitée pour le fonctionnement et la communication de données à des associésd'affaires” ont-ils déclaré (El País, 25/03/2014). Le président Obama lui-même a abordéle thème il y a peu: “Nous croyons que les consommateurs ont le droit de décider queltype d'information personnelle est prise d'eux et comment elle est utilisée, ou savoir quel'information utilisée par une entreprise avec une fin concr}ete n'est pas utilisée par uneautre entreprise avec une autre fin” (El Mundo.es, 13/01/2015).
La téléphonie mobile, en particulier, a un “côté obscur”, non réglé, qui permet auxporteurs d'enregistrer tous les déplacements de n'importe quel citoyen et ce qu'il faitavec son appareil, p.ex. s'il fait des achats, où, de quel type de produit, etc. (Wired,6/01/2002).
“La confidencialité doit équilibrer le désir du consommateur avec la nécessité del'organisation” dit Fatemeh Khatibloo, analyste sénior de Forrester. La confidencialitédoit être considérée en fonction de cinq aspects:
5 On entend techniquement comme «donnée sociale» l'identification au travers d'un réseau social pour entrer sur un autre site ou service web.
31

• temporel: quand les données peuvent être obtenues et utilisées;
• spatial: où elles peuvent être utilisées;
• fonctionnel: comment elles peuvent être obtenues et utilisées;
• d'identité: qui interviennent dans la relation;
• social: avec qui elles peuvent être partagées (Tierney, 2014).
Le débat de fond est sur la quantité de pouvoir que nous avons pour contrôler le fluxd'information sur nous-mêmes. Si l'anonymat et le contrôle signifient donner aux gens ledroit de cacher ce qu'ils veulent, alors nous avons une bataille difficile à gagner et ilpourrait être trop tard selon David Hodgson, de Computer Associates. Si nous allonsembrasser la transparence et l'assurer d'être totale dans les deux sens, alors nouspourrions être capables de gagner cette guerre. Cela signifie accepter que notre vie est àdécouvert, met en exigeant que tous les emplois des données soient aussi à découvert etque tous se bénéficient de leur utilisation. Bien que pour beaucoup cette idée estdésagréable, il est possible que ce soit la seule façon de nous assurer de ce que nousavançons vers un futur où la personne en soit pas exploitée (Hodgson, 2014).
4.2. Protection
Les citoyens de l'Union Européenne ont – en théorie – la faculté de contrôler leursdonnées personnelle (soit toute information qui permette de les identifier ou rendreidentifiables). L'Agence Espagnole de Protection de Données considère que Google estentre les entreprises “les plus irresponsables” en matière de gestion de la confidencialité,et critique qu'elle profite de tous les “crevasses” légales pour tenter d'éluder sesresponsabilités en Europe (El Mundo.es, 26/11/2014). La Comssion Européenne
“surveille les grandes entreprises comme Facbook et Google, mais des servicesplus petits et récents qui deviennent populaires passent sous le radar ouaccumulent les données des utilisateurs à l'étranger, où le contrôle est plusdifficile. Les applications mobiles supposent un problème supplémentaire.Beaucoup de gratuites le sont parce que les bénéficent proviennent del'information qu'ils sont capables d'obtenir en arrière plan.” (Ángel Jiménez deLuis, El Mundo, 20/11/2014)
Ainsi, il n'est pas facile d'exercer un contrôle, moins encore si les données en sont pasgardées dans des serveurs situés dans les pays de l'UE. Même si l'on obtient que certainscontenus disparaissent, généralement ils ne sont plus visibles pour des tiers mais ne sontpas effacés des serveurs. Le “droit à l'oubli” signifie généralement que les hyperlienssont bloqués sur les moteurs de recherche et directoires, mais il est impossible d'assurer
32

que le contenu est réellement éliminé, car il peut avoir aussi été reproduit et conservéailleurs.
Une étude de l'Université de Leuven pour la Commission de Confidencialité belge aconstaté aussi que la façon dont Facebook utilise les données de ses membres viole leslois europénnes de confidencialité et de protection des données. Ses politiques relativesà la publicité de tiers “ne respectent pas les exigences requises pour un consentementjuridiquement valide” et le réseau social “n'offre pas de mécanismes de contrôleadéquats” en relation à l'emploi des contenus générés par les utilisateurs à finscommerciales, malgré que la compagnie a changé ses politiques en janvier 2015 enréponse aux réclamation de la Commission Européenne. Le rapport signale aussi qu'ilimpossible d'empêcher Facebook de savoir où se trouve chaque utilisateur au moyen deson application pour téléphones mobiles si ce n'est arrêtant le fonctionnement dusystème de géolocalisation au niveau du sustème d'exploitation. (The Guardian,23/02/2015)
Aux Etats-Unis, la Maison Blanche, dans l'espoir de ce que le débat national sur laconfidencialité dépasse les dénonciations liées aux activités de surveillance de l'Agencede Sécurité Nationale et considère les pratiques de compagnies comme Google etFacebook, publia le 1er mai 2014 un rapport qui recommende l'application par legouvernement aux entreprises privées de limites à la manière d'utiliser le torrentd'informations qu'elles obtiennent de leurs clients en ligne. John D. Podesta, auteurprincipal de ce rapport, fait les recommendations suivantes:
• approbation d'une loi nationale sur la violation des données, qui exigerait auxentreprises d'informer quand elles souffrent des pertes de données personnelles etde cartes de crédit après des attaques pirates comme celle qui a exposé l'information des cartes de crédit de 70 millions de clients;
• une législation qui définisse les droits des consommateurs en relation à l'emploides données sur leurs activités;
• augmentation des protections de intimité pour les individus qui en sont pascitoyens des Etats-Unis;
• mesures destinées à garantir que les données obtenues d'étudiants en soientutilisées que pour des fins éducatrices (New York Times, 1/05/2014).
Ce rapport signale aussi que la même technologie qui est souvent si utile pour prédiredes innondations ou diagnostiquer des maladies de bébés difficiles à découvrir a aussi le“potentiel d'éclipser les protections traditionnelles des droits civils, en utilisantl'information personnelle sur le logement, le crédit, l'emploi, la santé, l'éducation et lemarché” (ibidem). Il se centre spécialement sur les “algorithmes d'apprentissage” quisont utilisés fréquemment pour déterminer le genre de publicité en ligne qui sera montrésur l'écran de l'ordinateur de quelqu'un ou pour baser sa recherche d'une nouvelle auto
33

ou d'un plan de voyage – par exemple – sur ses habitudes d'achats. Ces mêmesalgorithmes peuvent créer de lui une “photographie” numérique qui, selon Podesta,permettrait de déduire sa race, son genre ou orientation sexuelle, même si ce n'est pas lepropos du logiciel.
La Haute Commissaire de l'ONU pour les Droits Humains a publié en juin 2014 unrapport titulé “The right to privacy in the digital age” (Le droit à l'intimité à l'âgenumérique), où il est dit: “La surveillance invasive, tout comme la collection etl'enmagasinage de données personnelles dérivées de la communication numérique – sielle fait partie de programmes de surveillance dirigée ou massive – non seulement peutenfreindre le droit à l'intimité mais aussi un certain rang d'autres droits fondamentaux”(Human Rights Council, 30/06/2014).
Quel doit être le chemin de l'industrie?
“Le paradigme reconnu de consentement informé au sujet des données privéespeut encore être très efficace dans le monde des grandes données et leur analyses'il est combiné avec des communications adéquates, avec una analyseexhaustives des risques et bénéfices pour le consommateur et avec la capacité desuspendre l'abonnement à tout moment. La non-adoption de ce genre de point devue pourrait donner lieu à une vague de législation nouvelle et de politiquescoûteuses, à la condamnation publique et à la rétribution financière. Cela sembleêtre une décision simple et le chemin vers le succès.Un consommateur informé puet décider de participerou non, pour vivre ensuite enfonction de sa décision, soit por recueillir les bénéfices offerts soit pour rencontrerdes conséquences imprévues qui peuvent se retourner contre lui pendant desdécades.” (R. Lee, 2014).
Cela impliquerait d'utiliser le format “opt-in”, selon lequel nous choisirions seulementce que nous sommes disposés à partager, au lieu du format “opt-out”, où il faut niermanuellement ce que nous en voulons pas partager, ce qui est le mode dominantaujourd'hui. Ceci est particulièrement urgent dans des doamines qui sont enpleine voiede développement:
“En matière de protection des données, il y a d'importantes aires encore peuexplorées et desquelles l'utilisteurs sait réellement peu ou prou, comme les risquesliés à la croissance du «cloud computing» [6]. Il existe aussi peu d'information surle traitement des données laborales et médicales, et d'autres de type pluspersonnel, comme les goûts, l'orientation politique ou religieuse... tous lesquels,de façon plus ou moins directe, sont susceptibles d'être employés par lesentreprises à des fins publicitaires, donnant lieu ainsi à d'importants débats légaux
6 Traitement dans le nuage numérique.
34

qui, de plus, génèrent des changements de législation à une vitesse peu habituelle7
dans le monde juridique mais nécessaire vu leur lien avec le développementtechnologique.” (TICbeat, 8/02/2015).
Au sujet du “nuage”, l'Organisation Internationale pour la Standarisation (ISO) a établile standard ISO/IEC 27018, développé pour assurer une vision internationale uniformequi permette de protéger l'intimité et la sécurité des données personnelles conservéesdans les “nuages”. Et, en février 2005, Microsoft s'est convertie en premier fournisseurmondial l'ayant adopté (Diario TI, 19/02/2015).
Pour terminer ce sujet, n'oublions pas que nous devons aussi nous occuperpersonnellement de prendre des mesures de protection, vérifiant et ajustant les optionscorrespondantes qui existent dans les services que nous utilisons.
4.3. Droit à l'oubli
En 2012, la Commission Européenne a annoncé une proposition de loi pour défendre le“droit à l'oubli” des utilisateurs d'internet. Cette loi obligerait les fournisseurs du serviceà respecter la normative à moins qu'ils ayent un raison “légitime” de en pas le faire. Enmai 2014, le Tribunal de Justice de l'Union confirma ce “droit à l'oubli” et dictamina queles moteurs de recherche comme Google doivent retirer les liens aux informationspubliées dans le passé s'il est vérifié qu'elles signifient un préjudice pour un citoyen et ensont plus pertinentes.
Jusqu'à quel point cela pourrait-il être employé par des politiciens ou des corporationspour éviter que soit diffusée une information d'intérêt public? La justice europénne a ététrès claire à ce sujet, dit la BBC: “Ce type de demande en sera accpeté quén tenantcompte de la nature de l'information en question, de la façon dont elle affectela vieprivée de l'utilisateur et l'intérêt public qu'il y aurait à disposer de cette information.D'une certaine façon, avec cette décision, l'Europe dit que la limite de la libertéd'information se trouve définitivement dans toute information qui en concerne personned'autre que l'utilisateur lui-même” (BBC, 13/05/2014).
La décision du Tribunal de Justice provoca pas mal de polémique. D'une part, il y a ceuxqui se réjouissent de la décision et ont commencé à demander aux moteurs de recherchede retirer des résultats quelques informations polémiques. D'autre part, il y a ceux quivoient dans ce cas un antécédent dangereux pour l'exercice de la liberté d'opinion dtd'information. Et c'est que dans le thème deu droit à l'oubli convergent la protection desdonnées personnelles, son impact sur l'intimité des utilisateurs d'internet et la libertéd'expression en ligne. Il y a de bons arguments en faveur de chaque élément, mais il estdifficile de s'incliner pour privilégier l'un ou l'autre. Cependant, le problème inmédiat leplus important est que cette décision habilite le moteur de recherche pour résoudre les
7 Malgré la vitesse signalée ici, les changements légaux arrivent encore bien souvent avec pas mal de retard!
35

demandes des personnes qui veulent un “effacement”. Quel critère emploiera-t'il pourdécider si une pétition est valide ou non? Cela est opposé à la politique généralementdéfendue selon laquelle les intermédiaires (fournisseurs d'internet, moteurs de recherche,etc.) en devraient jamais pouvoir décider sur les contenus.
4.4. Se cacher?
Pouvons-nous cacher nos données pour nous protéger? Nous avons déjà mentionnéquelques unes des mesures que nous pouvons appliquer pour réduire le suivi queréalisent les navigateurs, et aussi l'existence d'applications et d'extensions qui bloquentles suiveurs (“trackers”), comme c'est le cas de l'excellent Ghostery(www.ghostery.com), qui nous révèle qui tente de nous épier et nous permet de bloquerl'envoi de ces données.
Il existe aussi des applications de courriel plus privées que les classiques Outlook, Gmailet Yahoo, comme Peerio (www.peerio.com/), une suite de productivité decommunications chiffrées qui inclu la messagerie instantanée et le courriel, en plus del'enmagasinage d'archives dans le “nuage” avec une encryptation d'extrême à extrême oùseul le destinataire final peut voir ce qui est envoyé.
Pour cacher totalement nos transmissions, ou même paraître être situé dans un autrepays, on peut utiliser un réseau privé virtuel (VPN) qui cache (remplace) notre numéroIP et chiffre les transmissions, comme c'est le cas de Faceless.me. Les contenus enpeuvent être interprétés que par l'expéditeur et le destinataire, mais la VPN doit vérifierl'authenticité de l'identité des deux.
Nous pouvons aussi obtenir une connexion à internet sûre et anonyme sur des réseauxpublics WiFi en utilisant Hotspot Shield (www.hotspotshield.com), qui opère sur unréseau VPN.
Pour terminer, nous pouvons “déménager” vers le “réseau profond” (deep net) et utiliserTOR, “The Onion Router” (www.torproject.org/), qui est né au Laboratoire deRecherche Navale des Etats-Unis comme une forme de créer des communications sûrespour les militaires, mais est ouvert à tous parce que sa finalité principale est de faciliterles communications libres dans les régions où elles peuvent être restreintes (par exemplepour les dissidents et journalistes). TOR est structuré en noyaux et couches (son symboleest un oignon), de telle façon que l'utilisateur “saute” de l'uneà l'autre, protégé par une couche de chiffrement qui empêcheque le serveur final connaisse son numérp IP. En Europe, Torest employé chaque jour para 80 de chaque 10.000utilisateurs d'internet, surtout en Italie, qui est le second paysoù on l'utilise le plus, après les Etats-Unis (Microsiervos,24/06/2014). L'organisation Internet Engineering Task Force
36

(IETF) ha proposé de convertir la technologie du réseau Tor en standard d'internet. Sicette proposition prosp}ere, la toile pourrait entrer dans une nouvelle étape de sonhistoire, où le caractère privé serait propre de l'essence même d'internet (Genbeta,30/11/2013).
4.5. (In)Sécurité
Le plus grand problème lié aux grandes données (big data), à part la perte d'intimité, estla pauvre sécurité de ces bases de données, comme il a été révélé par une enquêteréalisée par Unisphere Research et patrocinée par Oracle8. Le quart seulement despersonnes consultées a indiqué qu'ils chiffraient toutes les donnée et 56% chiffrent uamoins une partie des copies de sécurité. 81% citent les erreurs humaines comme leurprincipale préoccupation, suivie en 65% par les possibles ataques internes, et 54% sontpréoccupés par l'abus de privilèges d'accès de leur propre personnel. 51% reconaissentqu'ils n'ont pas de garanties et 21% en savent pas s'ils ont des garanties pour prévenirqu'un administrateur ou développeur puisse éliminer accidentellement une table ouprovoquer intentionnellement des dommages à des bases de données critiques (Hispasec,18/11/2014).
Il faut aussi tenir compte de ce que le réseau public d'aujourd'hui n'est pas fiable pouroffrir un niveau consistent de service, fiabilité, sécurité et flexibilité pour lescommunications de machine à machine, comme dans le cas de l'internet des objets. On aproposé pour celui-çi divers protocoles mais il n'existe pas encore de standard communmalgré que croît de plus en plus la demande pour une connectivité plus sûre (DiarioTI,1/12/2014).
La police britanique a averti que des milliers d'hyperliens à des images de caméras devidéo, de surveillance et même de moniteurs de bébés, dans des dizaines de pays etterritoires, sont apparus sur un site web administré en Russie. Ce sont 4.591 camérasaux Etats-Unis, 2.059 en France, 1.576 en Hollande, 500 en Grande-Bretagne et 378 enEspagne. Et ces liens sont classés par pays et par marque de la caméra (El Mundo.es,20/11/2014).
Il faut aussi tenir compte de ce que les pirates (hackers) tendent à abandonner lesattaques individuelles (comme par courriel), préférant attaquer directement les serveursd'entreprises –spécialement du domaine financier– pour voler las bases de donnéescomplètes. Ainsi par exemple, dans l'“Opération High Roller”, 60 entités financières dumonde entier ont été affectées, victimes d'une cyberattaque qui en a extrait 60 millionsd'euros (El Mundo, 21/06/2014). Kaspersky Lab a aussi découvert comment plus de 100banques de 30 pays furent affectés par un vol électronqiue massif au moyen d'uneopération sophistiquée en plusieurs étapes. Les pirates arrivèrent à s'introduire dans les
8 “DBA – Security Superhero: 2014 IOUG Enterprise Data Security Survey”
37

ordinateurs d'employés de banque en Russie, Suisse, Japon, Hollande et Etats-Unis,observer leur façon de travailler et ensuite imiterles patrons de leurs transactions pourtranférer de l'argent à de faux comptes aux Etats-Unis et en Chine, et même faire que desdistributeurs de billets en dispensent aux complices qui y attendaient (The NewYorkTimes, 15/02/2015).
Les histoires médicales semblent aussi un matériel intéresant }a voler: près de 80millions, de citoyens du monde entier, ont été volés d'une importante compagnied'assurances (Hipertextual, 5/02/2015).
38

Deuxième Partie: Espions
(Que font-ils avec nos données et comment)
5. Qui nous épie
Les capteurs de données personnelle, dans le monde d'internet, en sont pas touséquivalents et n'ont pas les mêmes objectifs. Les entreprises peuvent informer sur elles-mêmes, leurs activités, produits ou services sur la toile, et presque toutes essayentd'utiliser les contacts obtenus sur la toile ou leurs apps pour miuex connaître leurspossibles clients et rentabiliser la relation. Les gouvernements offrent et captent desinformations pour orienter leur gestion et améliorer leurs services... et réalisent desactivités d'espionage pour protéger leur sécurité. Les politiciens sont intéressés parl'opinion publique en tentent de l'influencer. Et n'oublions pas les pirates (hackers) quiessayent d'accéder à des informations réservées, services financiers, infrastructure, etc.avec les intentions les plus obscures. Les institutions académiques, en plus de se faireconnaître, offrent de plus en plus souvent des alternatives d'enseignement à distance etpublient les résultats de leurs projets de recherche mais, dans ce sens, elles peuvent êtreconsidérées dans la même catégorie que les autres entreprises qui tentent de mieuxconnaître leur public-objectif.
5.1. Les entreprises
On en conçoit aujourd'hui aucune entreprise qui en soit presente sur le net, au moins aumoyen d'une page web. Dans ce sens, toute affaire est –au moins en principe– un“émetteur” de données, au moins avec de l'information sur elle-même mais, surtout,comme un important canal de vente, comme découvrirent rapidement celles qui“entrèrent” à la toile quand elle s'ouvrit au commerce en 1995. Elle permettait nonseulement offrir produits et services et établir des contacts avec des clients: el permettaitque les ventes se fassent aussi directement “en ligne”, ce qui pouvait transformer lecommerce local en commerce mondial. Elle permettait aussi d'offrir une plus grandediversité de produits et obtenir des bénéfices de produits vendus en moindre quantité (lephénomène de la “longue queue” décrit par Chris Anderson). Ainsi est né le commerceélectronique ou e-commerce, qui a crû de 400% entre 1999 et 2009. Et il a continué àcroître, comme montre le dernier rapport de la Internet Society:
39
Une étude récente a découvert que 27% des consommateurs ont fait leur dernier achar enligne. Bien que le dernier recensement des Etats-Unis a montré que 5,8% seulemementdes ventes au détail se fait électroniquement, une étude de McKinsey a déterminé queses marges opératives pourraient augmenter de cette façon de 60% (Forbes, 5/04/2014).
Opérations en ligne détectées en 60 secondes par Ever Merchant
Source: Ever Merchant.com, 10/07/2014, 18h30 (registre d'1 minute en temp real)
40

L'avenir de beaucoup d'entreprises dépend de ce qu'elles se rendent compte de ce que leclient est maintenant le principal protagoniste et se concentrent sur sa satisfaction. Leplus important pour elles est d'offrir au client une expérience agréable, pour qu'il la fasseconnaître à son réseau de contacts. Et cela implique aussi prendre conscience del'importance des réseaux sociaux. 75% du commerce électronique reposait sur lesréseaux sociaux (en particulier Facebook, Twitter et Pinterest) en 2013 y 74% desacheteurs se basent sur les opinions données sur ces réseaux selon Forrester Research etBusiness Insider (Socialmedia Today, 11/04/2014).
Alors qu'Amazon est devenu leader de commerce électronique, facturand plus de 67.000millions de dollars en 2013 (Applesfera, 7/05/2014), un autre secteur a vu naître desfirmes spécialisées dans l'utilisation du réseau. A part Amazon, celles qui dominent sontprincipalement Facebook, Google, Yahoo, Twitter et eBay. Facebook, Google et Yahoosont celles qui accumulèrent le plus de bénéfices en 2013 selon Business Insider. Googlerepresentait 25% de tout le traffic d'internet en 2013 (PC World, 22/07/2013).
Evidemment, les réseaus sociaux sont les “grands” de la toile. Mais ils en sont pas en soides générateurs de données: ce sont essentiellement des moyens de diffusionpersonnalisés... et des “requins” qui dévorent d'énormes quantités de donnéessecondaires associées aux activités de leurs utilisateurs. Facebook, Google+, Twitter etYoutube sont les plateformes les plus utilisées, avec 77% de l'audience active en ligne, etles deux tiers de ceux-çi se connectent avec des mobiles, selon le rapport “Social Media2014” de la Online Business School (El Mercurio, 12/05/2014). Il n'existe rien decomparable aux bases de données de Google, Facebook, Amazon et eBay dans l'histoiredu commerce traditionnel non numérique (Xataka, 9/01/2015).
“Pour Facebook, cela se traduit en ce que chaque utilisateur du réseau social a unevaleur de 1,60 euros par trimestre. Twitter peut arriver à extraire des centainesd'euros par an en valeur de ses profils les plus actifs. Ce en sont pas des quantitéssurprenantes, mais en les multipliant par les centaines de millions d'utilisateurs deces services, les comptes sont ronds.” (Ángel Jiménez de Luís, El Mundo.es,20/11/2014)
La possibilité de réaliser des opérations financières en ligne, après avoir intéressé lesbanques, a aussi amené de nouveaux “joueurs”, dédiés à s'offrir comme intermédiairespour réaliser es payements, comme PayPal, née en 1998. Avec l'apparition destéléphones “intelligents”, ce type d'opération s'étend et l'on progresse vers lagénéralisation des “payements mobiles”, généralement administrés par de grandesentreprises déj}a établies sur la toile (Apple Pay, Google Wallet, Amazon Coin, etc.).Selon l'étude “Mobile Payment Strategies: Remote, Contactless & Money Transfer2014-2018”, de la firme Jupiter Research, en 2014 le marché des payements mobilesaurait pu croître de 40% en relation à l'année antérieure, arrivant à un montant de
41

507.000 millions de dollars (El Mercurio, 28/04/2014). “Les banques qui en seront paspréparées pour de nouveaux concurrents comme Google, Facebook ou Amazon devrontfaire face à mort sûre” écrivit dans le Financial Times Francisco González, conseillerdélégué de la BBVA (The Next Web, 14/04/2014).
5.2. Les gouvernements
Les organismes internationaux et les gouvernements n'ont pas tardé à se rendre comptede l'intérêt qu'ils auraient à opérer de façon intégrée avec les grandes quantités dedonnées qu'ils peuvent accumuler. La quantité des applications et emplois possibles n'apas laissé indifférente la Commission Européenne. Elle a demandé aux gouvernementsnationaux d'”ouvrir les yeux face à la révolution des Big Data” et, en plus d'établir unesérie de superordinateurs et de créer une incubatrice de données ouvertes, a proposé deréaliser une cartographie de normes sur les données, identifiant les possibles lacunes etproposant de nouvelles règles au sujet de la “propriété des données” et de laresponsabilité de leur offre (TICbeat, 5/07/2014).
Comme le signalent les analystes de l'Union Internationale des Télécommunications:
“Les «big data» renferment de grandes possibilités de contribuer à générer uneinformation nouvelle et révélatrice, et il existe un débat de plus en plus intense surla façon dont les entreprises, les gouvernements et les citoyens peuvent maximiserles bénéfices qu'elles apportent. Si le secteur privé fut le premier à employer les«big data» pour améliorer son efficience et augmenter ses revenus, la pratiques'est étendue à la communanuté statistique mondiale. La Commission deStatistiques des Nations Unies et les bureaux nationaux de statistiques analysentdes façons d'utiliser les sources de «big data» pour élaborer des statistiquesofficielles et accomplir au mieuxleur mandat e faciliter ponctuellement lesprueves qui soutiennent la formulation des politiques publiques.
Les inquiétudes les plus urgentes sont en relation à la normalisation etl'interfonctionnement des analyses de «big data», et aussi avec l'intimité, lasécurité et la continuité. Il est fondamental de résoudre les problèmes relatifs àl'échange et l'utilisation des données et, de ce fait, il est important que lescréateurs et utilisateurs de «big data» coopèrent étroitement dans ce domaine,entr'autres faisant connaître l'importance et les perspectives de nouvellesréflexions en créant des associations publiques-privées pour profiter pleinementdes possibilités qu'offrent les«big data» en faveur du développement.” (UIT,2014b, p.40)
42

Cités intelligentes
La croissance des villes fait surgir de plus en plus de problèmes et de conflitscomplexes, l'administration devenant un défi énorme pour les gouvernements, surtoutpour les services de transport,la sécurité, l'éducation, les communications et les espacespublics, les solutions devant compter sur la participation du secteur privé et des citoyens.La technologie des détecteurs et de l'analyse de big data se présente, maintenant, commeune alliée fondamentale et indispensable pour trouver ces solutions. De cette façon, onpeut développer des “cités intelligentes” (Smart Cities).
“Une ville intelligente est la gestion créative des villes avec la dernière technologie tantdans le design et la planification comme dans l'optimisation de tout le processus pourles rendre plus productives et écologiques”, explique Anthony Townsend, spécialiste deplanification urbaine et directeur de recherche de l'Institute for the Future (L.Zanoni,p.130).
Selon le rapport “Smart Cities: Estrategias, energía, emisiones y ahorro de costes 2014-2019”, publié par Juniper, les systèmes de gestion intelligente du traffic réduiront lesbouchons et les émissions correspondantes de pollution par les véhicules. La réductiontotalle d'émission de CO2 pourrait atteindre 164 millions de tonnes en 2019.L'illumination des voies publiques, la distribution de l'energie et les services de transporten commun pourraient être radicalement améliorés selon les experts de la firme(PCWorld.es, 15/01/2015).
A la fin de 2015, les villes intelligentes auront utilisé 1.100 millions d'objets connectéset, cinq ans plus tard, ce chiffre atteindrait 9.700 millions (TICbeat, 20/03/2015).
Selon le IV Rapport sur l'IoT (Internet des Objets) de l'Institut VINT de Sogeti(nov.2014):
“Les Smart Cities supposeront un investissement de 87.000 millions d'euros entre201 et 2020. L'évolution rapide des villes intelligentes est poussée par le fait de ceque, si la moitié de la population mondiale vit actuellement dans des villes, en2050 cette proportion sera de 75%. D'autre part, actuellement, 80% des émissionsde CO2 et 75% de la consommation d'énergie se produit dans les villes et ellesgénèrent 80% de la richesse économique.” (NetworkWorld, 9/12/2014).
Le gouvernement de Paris, par exemple, a approuvé le projet “Paris Smart City 2050”, àcharge de la la firme d'ingénieurs Setec Bâtiment y de l'architecte Vincent Callebaut.Son principal objectif esra de transformer la capitale française en “ville verte” et réduireles émissions polluantes jusqu'à 75% pour cette date. Le projet intégre des éléments quitransformeront fortement le paysage urbain, avec –par exemple– de grandes toursrésidencielles capables de produire leur propre électricité grâce à leurs cellules solaireset boucliers thermiques (Xataka, 21/01/2015).
43

Paris 2050. Source: vincent.callebaut.org
New York, pour sa part, prétend transformer la Rue 42, une des plus utilisées deManhattan, en incorporant un système de transport électrique, des dispositifs derécolection de la pluie, le recyclage des résidus életroniques, des cellulesphotovoltaiques, des points WiFi, des jeux pour enfants et un parc dont la communautélocale serait responsable (Xataka, 20/01/2015).
Nueva York. Fuente: Xataka, janvier 2015
44

5.3. Les politiciens
Si grâce à l'analyse de données les entreprises peuvent obtenir des informations utilessur leur public objetif, les politiciens peuvent aussi utiliser ces instruments pourconnaître les comportements, goûts et préférences de leurs électeurs et planifier leurscampagnes politiques.
“De cette façon l'a compris l'équipe de campagne de Barack Obama pour utiliserles Big Data en bénéfice du candidat démocrate, qui arriva à la présidence desEtats-Unis en 2008. La stratégie, expliquée avec le maximum de détail parl'espagnol Diego Beas dans le livre «La reinvención de la política», a consisté enréunir la plus grande quantité possible d'utilisteurs, de croiser les bases dedonnées, extraire toute l'information possible et l'employer pour maintenir lecontact avec l'électorat de chaque Etat, acheter de la publicvité dans les réseauxsociaux et, fondamentalement, réunir des fonds. «Nous mesurerons tout», a dit lechef de campagne, Jim Messina, qui forma une équipe dédie seulement à la dataanalytics.” (L.Zanoni, pp.83-84)
5.4. Les pirates (hackers)
Les cyberdélinquants migrent aussi vers l'obtention et l'analyse des grandes données(Big Data) et ont développé de nouvelles capacités pour tenter de voler du matérielsensible de façon massive. Les gouvernements, les cartes de crédit, les donnée médiclaeset les appareils de l'Internet des Objets seront le centre principal de leur attention en2015, dit le journal ABC (ABC.es, 9/01/2015). Les dispositifs mobiles seront aussi deplus en plus objets d'attaques pour en voler l'identification et clé d'accès, qui serontutilisés comme porte d'entrée aux applications et données des entreprises basées dans le“nuage” (cloud computing).
Le président Obama a rappelé que “dans les cyberattaques récentes, plus de 100millions de nordaméricains ont vu compromise leur information personnelle, commecelle de leurs cartes de crédit” et a annoncé une loi qui obligera les banques à avertirleurs clients si les données de leur carte de crédit ont été volées. D'autres msures seraientdirtigées à pénaliser la vente de logiciels d'espionnage et les réseaux “zombis” ou“botnets” utilisés pour voler de l'information financière, transmettre des messages depublicité non désirée et mener des attaques de dénégation de service contre des sites web(El Mundo.es, 13/01/2015).
A mesure que croîtra l'Internet des Objets (IoT, Internet of Things), elle sera une autresource apétécible d'information, laquelle – pour le moment – est très mal protégée. Ettous ces objets peuvent être la porte d'entrée pour “pirater” les maisons et les véhiculesou, au travers d'eux, pénétrer les systèmes des entreprises qui leur prètent service.
45

Un autre secteur qui intéressera de plus en plus les criminels sera celui de la santé.“Probablement, 2015 sera l'année où nous verrons apparaître les attaques auxcompagnies de santé et à celles qui enregistrent las données médicales de leurs affiliés”,assurent les experts. Et la raison en est que les histoires médicales contiennent unegrande quantité d'information personnelle qui peut être utilisée dans une multituded'attaques et de types de fraudes(ABC.es, 9/01/2015). “Avec la prolifération desdispositifs connectés à internet dans les hôpitaux, le risque de ce que les informationsqui y sont contenues dispparaissent est chaque fois plus grand”, avertit McAfee dans unrapport de sécurité. Ces données “ont plus de valeur que celle des cartes de crédit” auxyeux des pirates informatiques, estime cette firma spécialisée (DePerú.com, 9/12/2014).
46

6. Pour quoi?
6.1. Le marketing
Dans l'emploi, chaque fois plus intensif, de l'information numérique, la plupart desentreprises se limite à l'information relative à ses propres processus y les donnéesappelées “structurelles”, relatives à leur personnel et leurs clients, ç-à-d. les donnéestypiques d'identification (noms, adresse, fonction), les produits acquis, les payements,etc. qui s'obtiennent facilement et directement au moyen de formulaires web. Mais,comme nous le savons, chaue contact électronique génère un autre type de données, quine sont pas toujours colectées et analysées, auxquelles on peut encore ajouter lesinformations publiques et privées que les clients ont publié sur la toile et les réseauxsociaux. Et tout cela peut être accumulé de façon structurée (en fonction de variablesprédéfinies) ou non-structurée (comme les commentaires, les “changements d'état” dansles réseaux sociaux, et les listes de “suiveurs”), formant ainsi les big data. Dans lemonde corporatif, on estime que près de 80% des données disponibles sont ces non-structurées, qui rendent nécessaires des technqiues d'analyse complexes.
Selon TICbeat, “Il y a peu d'exemples d'entreprises qui mettent complètement en marcheaujourd'hui des projets de Big Data et il y en a encore moins qui en voient la valeur. Defait, dans un rapport de Gartnet, seulement 8% des entreprises enquêtées ont développéun projet de Big Data en 2014 et 57% d'elles reconnaissent n'être encore qu'aux étapesde recherche et planification” (TICbeat, 14/01/2015). Le principal probl}eme est lemanque de professionnels adéquatement préparés: les “scientifiques de données”. Selonun étude divulguée par Diario TI, 86% des directeurs considèrent même que pourprofiter vraiment des données dont ils disposent, il serait nécessaire que tout leurpersonnel soit capable de les gestionner, mais 91% que les meilleures analyses sontcelles faites par des scientifiques de donnéesspécialement formés (DiarioTI, 5/11/2014).Connaissant comme il le font l'avantage de compter avec les meilleures analyses pourprendre des décisions et augmenter l'efficience de leurs entreprises, il sont à la recherchetant de spécialistes comme de solutions informatiques d'application plus facile.
Queles sont les usages que les entreprises donnent aux instrments d'analyse de données ?Principalement (48%) l'analyse du comportement des consommateurs (Betanews,21/11/2014).
47
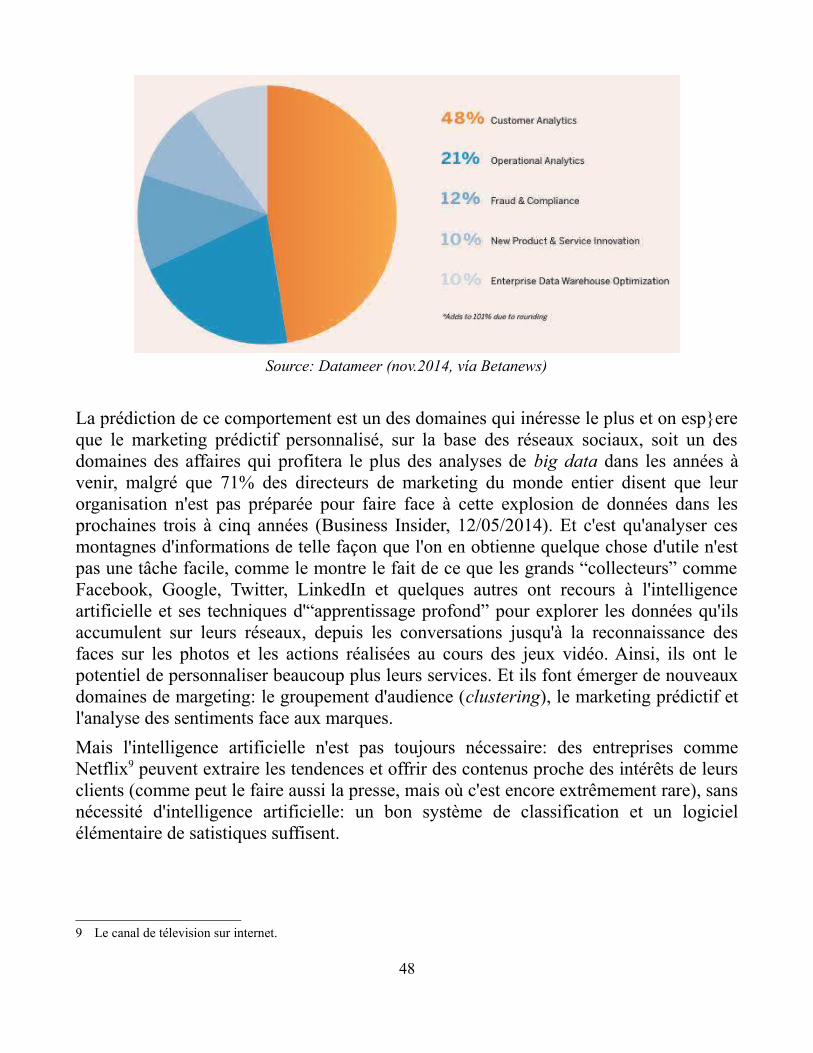
Source: Datameer (nov.2014, vía Betanews)
La prédiction de ce comportement est un des domaines qui inéresse le plus et on esp}ereque le marketing prédictif personnalisé, sur la base des réseaux sociaux, soit un desdomaines des affaires qui profitera le plus des analyses de big data dans les années àvenir, malgré que 71% des directeurs de marketing du monde entier disent que leurorganisation n'est pas préparée pour faire face à cette explosion de données dans lesprochaines trois à cinq années (Business Insider, 12/05/2014). Et c'est qu'analyser cesmontagnes d'informations de telle façon que l'on en obtienne quelque chose d'utile n'estpas une tâche facile, comme le montre le fait de ce que les grands “collecteurs” commeFacebook, Google, Twitter, LinkedIn et quelques autres ont recours à l'intelligenceartificielle et ses techniques d'“apprentissage profond” pour explorer les données qu'ilsaccumulent sur leurs réseaux, depuis les conversations jusqu'à la reconnaissance desfaces sur les photos et les actions réalisées au cours des jeux vidéo. Ainsi, ils ont lepotentiel de personnaliser beaucoup plus leurs services. Et ils font émerger de nouveauxdomaines de margeting: le groupement d'audience (clustering), le marketing prédictif etl'analyse des sentiments face aux marques.
Mais l'intelligence artificielle n'est pas toujours nécessaire: des entreprises commeNetflix9 peuvent extraire les tendences et offrir des contenus proche des intérêts de leursclients (comme peut le faire aussi la presse, mais où c'est encore extrêmement rare), sansnécessité d'intelligence artificielle: un bon système de classification et un logicielélémentaire de satistiques suffisent.
9 Le canal de télevision sur internet.
48

6.2. Le commerce de données
Si bien Google, Facebook et Twitter déclarent utiliser les “traces” que nous laissonsavec nos activités chez eux pour “améliorer leur service”, ils le font aussi pour obtenirdes rentrées extra grâce }a la vente de ces informations. Ainsi,
“Au lieu de lancer un message en se basant sur des estimations d'audience, lesannonceurs peuvent maintenant segmenter leurs communications à un niveau dedétail imprensable il y a seulement une décade.
Si, par exemple, je désire que mon annonce arrive seulement à des jeunescélibataires du quartier de Salamanca à Madrid, je peux maintenant le faire. Si jepréfère des femmes de plus de 60 ans avec des petits-enfants à Bilbao, aussi. Monrestaurant peut montrer de la publicité sur la navigateurs de ceux qui se ont descodes postaux proches ou mon magasin de vêtements peut annoncer les dernièresnouveautés à côté des résultats de recherche aux foyers qui ont une rente de plusde 80.000 euros.
Pour Facebook, cela se traduit en ce que chaque utilisateur de ce réseau social àune valeur proche de 1,60 euros par trimestre. Twitter peut arriver à exprimer descentaines d'euros par an en valeur de ses perfils les plus actifs. Ce en sont pas desvaleurs surprenantes, mais en les multipliant par les centaines de millions d'utilisateurs de ces services, les comptes sont ronds.” (El Mundo.es, 20/11/2014)
Si bien ces données, en général, sont rendues anonymes, nous savons qu'il est facile decroiser diverses sources pour obtenir un profil unique et réel (qui en serait plusanonyme) de n'importe quel utilisateur. Il n'y a pas le moindre moyen de nous caccher, }a part abandonner les communications numériques. C'est pourquoi notre identité et nosdonnées sont le prix que nous devons payer pour les utiliser:
“Le prix, c'est toi-même.”
49

Les réseaux sociaux ne sont pas lesseuls à coleccioner et vendre nosdonnées. Toutes les applications(“apps”) que nous déchargeons etinstallons sur nos mobiles demandentdes autorisations pour utiliser diversesressources du système d'exploitation“pour fonctionner correctement” etainsi exécuter les tâches propres deleur fonctionnement (A côté, le cas deFacebook). Mais pas toutes sont“propres”. Dans le cas d'Android,chaque app signale avant de s'installerles autorisations qu'elle désire obtenir(on peut aussi les consulter sur lemenu Ajustes/Applications)10. Dans lecas du iPhone et du iPad, il n'y a pasde demande avant l'installation maisbien après (aussi visible sur le menu d'Ajustes). Quelques exemples sont lapossibilité de lire l'état du téléphone,modifier le stockage, accéder à lalocalisation, lire et modifier(!) la listede contacts, lire le registre des appelset prendre des photos. Bien de ces casne se justifient aucunement mais, encas de refus, le logiciel enfonctionnera pas.
Un des thèmes les plus délicats est celui des informations médicales, un problème quicroît en même temps que se multiplient les apps relatives à l'état physique (fitness) etl'usage des moteurs de recherche par les patients qui veulent en savoir plus sur leursmalaises. A ce sujet, un cherceur de Pennsylvanie, Tim Libert, a créé un logiciel pouranalyser les pages web en vue de savoir vers où allaient les recherches et l'a appliqué àla médecine. Il découvrit que 91% des pages faisient des appels (et envois de données) àdes tiers lorsqu'on faisait une demande. C'est-à-dire que lorsqu'on cherchait uneinformation sur une maladie et on clicquait sur un lien, il était très probable quel'information de ce fait soit communiqué à une autre entreprise. Selon Libert, la firmeExperian (de commerce de données), par exemple, est présente dans 5% des pages
10 Avec la nouvelle version M de Android, il serait posible d'administrer ces autorisations de façon individuelle.
50

relatives à la médecine mais personne en sait quelles donnés elle conserve ni commentelle le fait (Xataka, 24/02/2015).
Il y a deux ans, un canadien s'est surpris quand il commença à recevoir de la publicitésur des appareils de ventilation continue durant le sommeil, après avoir cherché del'information sur les appareils pour traiter l'apnée du sommeil. L'enquête révéla que sarecherche avait provoqué l'installation sur son ordinateur d'un “biscuit” (cookie11) quiprovoquait cette sélection de publicité chaque fois qu'il visitait des sites web abonnés auservice de publicité de Google. Le régulateur public canadien a averti Google del'illégalité de ce procédé et la firme a répondu que cela était contraire à sa politique maisque quelques annonceurs en suivaient pas la règle. Une supervision plus rigoureuse luifut recommendée (Commissariat à la Protection de la Vie Privée du Canadá,15/01/2014).
Une multitude d'éditeurs et annonceurs contineunt à gagner des millions de dollars (oueuros) grâce à l'analyse des coutumes de navigation des utilisateurs.
Il existe de plus, souvent, un interconnection de données entre associés, ce qui peutmener à un désordre total, faisant que notre information termine en des lieux que nousne désirons pas du tout. Ainsi, par exemple, Instagram envoye à trois associésl'information sur la marque et modèle du mobile, le pays, la résolution de l'image, laversion d'Android, le nom de l'utilisateur et sa clé d'accès (qui, de plus, n'est pas chiffréepour la transmission, ce qui extrêmement périlleux). Et un jeux comme Angry Bird vabeaucoup plus loin: il informe du navigateur prédeterminé, du type de connectionlorsqu'on joue, de l'opérateur mobile, la liste des capteurs, la version d'Android, lamarque et le modèle du téléphone, son identification de fabrication, le type d'audio, lepays, le numéro IP, le type d'alimentation électrique, la résolution d'écran et autresdonnées techniques de l'appareil, le tout étant envoyé à sept sites différents sans aucuneprotection de sécurité (Xataka, 3/04/2014).
Pour comble, il existe des entreprises, comme l'italienne Hacking Team, qui ontdéveloppé des “solutions” supposées légales qui permettraient de contrôler depuis lesappels téléphoniques jusqu'aux messages de Viber, Whatsapp ou Skype (ABC.es,7/07/2014). Et pour les éditeurs de média est apparu Reverb Insights, qui offred'analyser les intérêts de chaque lecteur et les comparer à ceux des autres, pour rendrecompte de leurs intérêts et permettre l'offre “d'autres textes qui pourraient les intéresser”(TechCrunch, 24/02/2015). Une autre startup, Crystal, analyse à la demande toutel'information disponible sur une personne sur le réseau mondial et la synthétise pourdéterminer le type de personnalité (elle en en a défini 54 types) et conseiller ensuite sur
11 La plupart des sites web commerciaux installent ces petits blocs d'information dans la mémoire des ordinateurs pour «suivre la piste» de leurs visteurs. Les navigateurs ont généralement une option de leurs «Préférences» pour les bloquer, mais quelques sites refusent de se montrer sion les bloque.
51

la meilleure façon de rédiger un courriel dirigé à cette personne (pour lui offrir quoi quece soit).
6.3. Études sociales
Facebook profite aussi de ses millions de membres et des données qu'ils accumulentpour faire des études sur leur comportement sans les en avertir. En mars 2014, la revueProceedings of the National Academy of Sciences (PNAS) a publié une de ces études,réalisée en 2012 avec la participation de sociologues de l'Université de Cornell. Ilsanalysèrent comment se produit la contagion des émotions en fonction de mots positifsou négatifs contenus dans les notes de nouvelles (feeds) de 689.003 membres du réseauélus au hasard. Le plus questionnable fut qu'ils implantèrent un algorithme qui omettaitle contenu positif ou negatif des feeds pour étudier la contagion émotionnelle du type decontenu, observant qu'à peu de mots positifs les interlocuteurs recourraient à plus demots négatifs et, à peu de mots négatifs, répondaient avec plus de mots positifs. Mais lesmessages réels étaient ainsi changés sans que les “enquêtés” le savaient, altérant leursrelations! Légalement, Facebook a droit de réaliser ce type d'étude depuis qu'unutilisateur crée son compte, car il l'accepte dans les conditions d'usage qui lui sontsignalées. Mais faire des expériences sans en informer les utilisateurs n'est près éthique.Et ce cas est un clair appel d'attention sur la manipulation dont n'importe qui peut êtreobjet sur les réseaux et communautés numériques (BBC Mundo, 30/06/2014).
52

7. Comment on nous étudie
7.1. La science des données
La “science des données” (data science) se diférencie de la science statistiquetraditionnelle en particulier par la considération de grandes quantité de données non-structurées, ce qui implique la nécessité de dominer de nouveaux instrumentsinformatiques en plus des connaissances traditionnelles. Un “scientifique de données”doit dominer le calcul multivariable, l'algèbre linéal y matriciel, la programmation enPython et R et les méthodes de vidualisation de données (graphique).
Au moyen de la “minerie de données” (data mining), avec les instruments adéquats, peutdécouvrir des patrons de grande valeur cachés dans la masse des données et, à partird'eux, formuler une ou plusieurs hypothèses utiles pour les opérations de son entrepriseet la mettre à l'épreuve. Ensuite ou en parallèle, il utilise des instruments analytiques quiopèrent sur l'ensemble des données pour obtenir une nouvelle information (“donnéesagrégées”) plus significative que si on considère ces données de façon séparée. Ainsi,par exemple, on peut définir de nouvelles catégories de clients, “croiser” celles-çi avecleur géolocalisation -obtenue de leur téléphone mobile- et, de cette façon, segmenter lapublicité mobile selon le type de client et l'endroit où ils se trouvent. On peut mieuxconnaître ce que désirent les clients, obtenant que leur expérience s'améliore en leuroffrant ce qui les attire. L'industrie du tourisme utilise ce système “pour former unecarte avec photos selon les iamges que prennent les touristes avec leurs smartphones, endéterminant l'endroit. Si nous entrons à Google Mas, par exemple, nous verons à Parisdes centaines de photos différentes de la Tour Eiffel prises par des personnes que nousne connaissons pas” (Zanoni, p.69).
Toutes les données ne sont pas équivalentes et n'ont pas la même valeur ou la mêmequalité, et l'entreprise doit définir celles qui peuvent lui être utiles. Cela significe aussique le scientifique de données doit très bien connaître l'entreprise et ses fins, et travailleren étroite collaboration avec ceua qui définissent les objectifs des divers projets.Certaines données peuvent être utiles pour un projet déterminé mais être inutiles pour unautre. Ainsi, les opérations d'analyse peuvent aussi varier selon les objectifs.
Les variables de base que considère la science des données sont le volume de celles-çi,la vitesse d'analyse requise (en “temps réel” ou en différé), la variété (type de fichiers etde contenus), la valeur et la véracité de l'information. Cela implique, comme déjàsignalé, différentes méthodes de traitement et différentes interfaces (visualisation). (UIT,2014b, p.39).
Un des principaux objectifs de la science des données est de prédire le résultat de
53

certaines actions ou situations et offrir d'avance des suggestions sur ce qui peut être faitdans chaque cas.
“Il ne s'agit pas uniquement de prendre de meilleures décisions sinon aussi deréduire la charge du travail nécessaire pour prendre ces décisions. Ces capacitésreconnaissent la complexité inhérente à l'analyse Big Data mais font que lessolutions soient accesibles aux utilisateurs. Cela s'obtient en analysant les donnéesavec un point de vue scientifique rigoureux et offre aux utilisateurs uneexplication de la raison pour laquelle une décision est plus recommendable dansdes termes qui peuvent être universellement compris. Il est vital que la solutionsoit intuitive et accessible. Sinon, on ne l'utilisera pas. La data science doit tenircompte, de plus, de ce que la solution finale nécessite évoluer. C'est-à-dire que,non seulement, elle doit avoir une valeur mesurable (et reportable) pour l'affaire,mais aussi avoir des métriques internes qui servent comme source d'informationpour l'autoamélioration. Sinon, même la meilleure solution finira par êtreobsolète.” (Juan Miró, TICbeat, 15/01/2015)
Le logiciel adéquat peut faciliter une augmentation significative de la vitesse d'obtentiondes résultats. Ainsi, par exemple, “une compagnie globale de produits de consommationpeut réduire l'obtention de rapports de 6 minutes à 736 microsecondes en temps réel;une entreprise de fabrication peut réduire la présentation de rapports aux clients deplusieurs jours }a quelques secondes; et une entreprise financière a réduit les calculsd'un modèle de vente de 45 minutes à 5 secondes” (Schoenborn, p.9).
Il existe quatre types d'analyse de données:
• descriptif: “Utilise une statistique de base ou visualisation pour caractériser unensemble de donnée. Les résultats peuvent montrer des moyennes, totaux,fréquences et peut-être aussi une relation causale. La majorité de l'analytiquefaite aujourd'hui tombre dans cette catégorie.”
• prédictif: Aide à voir ce que peur déparer l'avenir. On employe des modèlesstatistiques pour pronostiquer une condition comme les rentrées, bénéfices, quotede marché ou résultat opérationnel. L'analyse prédictive se base sur une raltionmodelée entre un ensemble de variables indépendantes et s'utilise souvent pour laplanification.
• prescriptif: Porte l'analyse prédictive à un nouveau niveau au moyen del'optimisation des meilleurs résultats d'une prédiction. Il tient compte desnouvelles entrées ou restrictions spécifiques d'une situation donnée.
• cognitif: Utilise des technqiues et une infrastruture de haut rendement pourextraire les relations entre divers ensembles de données. (Schoenborn, p.8)
54

Les scientifiques de données peuvent utiliser l'analyse de sept façons différentes selonWilliam Chen:
1. pour préparer et interpréter des expériences pour informer de décisions sur desproduits
2. pour construire des modèles qui prédisent un signal et non un bruit
3. pour transformer les big data en une grande image (visualisation)
4. pour comprendre la participation des utilisateurs, la rétention, la conversion et lesclients potentiels
5. pour donner à leurs utilisateurs ce qu'ils désirent
6. pour faire des estimations intelligentes
7. pour raconter l'histoire avec des données. (Dataconomy.com, 28/11/2014)
Le plan de l'analyse doit pointer vers:
• l'habilitation d'un accès partagé et sûr à une information riche et fiable, capabled'absorber des volumes croissants de données, plus variés et à plus grande échelle
• construire de l'intelligence dans les transactions opératives au moyen d'analysesrapides et de l'optimisatio de la pile de solutions pour différentes charges de trvaild'analyse
• maximiser la disponibilité et les connaissances au moment adéquat pour fairefront à plus d'utilisateurs et plus de concurrence, au changement de la demande età la capacité de récupération au point d'impact. (Schoenborn, p.13)
7.2. Machines et applications
7.2.1. Ordinateurs
A moins que l'on ait recours à un service en ligne (“dans le nuage”), il faut uneimporante infrastructure pour pouvoir conserver les données (disques de mémoire) et lestraiter avec rapididté (processeurs). L'infrastructure doit être construite spécialementpour obtenir de nouveaux niveaux de connaissance à partir de l'exploitation de toutes lesdonnées disponibles. La plateforme requise doit être fluide pour tous les types defichiers, données et analyses. Elle doit être escalable et hautement flexible, toujoursouverte au grand milieu de données d'aujourd'hui et capable de tirer parti de l'intégrationdes technologies sociales, mobiles et en “nuage” (Schoenborn, p.13).
La capacité d'un système est escalable lorsqu'il peut réaliser una quantité toujourscroissante de travail. “Bien pensée, il sera relativement facile d'ajouter de la puissancede processeur et de conservation. Les besoins de machinerie se dérivent des nombres
55

relatifs à l'utilisation actuelle de données, leur croissance prévue, la complexité desanalyses et algorithmes sous-jacents, et les objectifs de l'affaire.” (Schoenborn, p.17). Ilexiste divers moyens d'analyse qui peuvent aider à prédire l'équipement qui pourrarépondre à ces exigences.
Quelques exemples sont les “System X” et “System Z” d'IBM, qui sont basés sur lesprocesseurs de noyaux multiples IBM NextGeneration POWER8, optimisés pour manierdes applications frientes de données. Les System Z offrent un écosystème de typeouvert (open server) qui permet d'opérer avec les système d'exploitation Linux standardou avecAIX UNIX, alors que les System X supportent Red Hat Linux ou WindowsServer. Ces plateformes permettent de choisir l'apparence pour satisfaire une grandegamme de nécessités des centres de données. Mais les applications et les dépôts dedonnées s'offrent aussi de plus en plus souvent comme service “dans le nuage” (cloudcomputing), ce qui peut être pluséconomique dans bien des cas. Amazon, Microsoft etGoogle, entre autres, offrent ce type de service.
7.3.2. Applications (Logiciels)
Il existe de multiples alternatives d'applications spécialisées, de divers niveaux decomplexité, tant instalables dans des serveurs propres comme opérant “dans le nuage”,Certaines sont de code ouvert (open source) et beaucoup fonctionnent sur desordinateurs avec système Linux et serveur web Apache. C'est le cas de Hadoop, qui estsans aucun doute le système le plus courant.
Hadoop a été créé par Yahoo avec la finalité de faire fonctionner des programmesd'analyse simultanément sur de grands ensembles d'ordinateurs. Comme son code estouvert, n'importe quel programmateur peut le modifier et développer un code-sourcepropre, ce qui a assuré l'existence d'une communauté de développeurs qui leperfectionnent et partagent constamment. Il a rapidement été adopté comme une dessolutions préférées en matière d'“intelligende d'affaires” basée sur l'analyse de big data.Il se compose d'un système d'archive (dépôt de données) auto-organisé, distribué etredondant, et d'un système de traitement distibué qui peut opérer avec des donnéesstructurées et non-structurées. Les utilisateurs peuvent introduire les données à partir demultiples sources (blogs, mails, réseaux sociaux, etc.) et ensuite effectuer desconsultations (obtenir des résultats d'analyse)au moyen d'une application cliente (cfr.R.Peglar -dans la bibliographie finale- pour plus de détails).
Dans la majorité des cas, l'utilisteur doit recourrir à la ligne de commande, une choseque seuls les programmeurs dominent. Peu à peu, cependant, apparaissent des interfacesgraphiques qui rendent le système plus “aimable”. Ainsi, Amazon a créé une interfacegraphique appelée Hue, basée sur le navigateur, mais introduit -semble-t'il- un problèmede sécurité (Gigaom, 7/12/2014). IBM a aussi abordé ce probl}eme et offre Alteryx
56

Designer Desktop, un système avec interface de bureau très intuitive, dessinée pourfaciliter le travail de l'analyste sans nécessité de dominer des habilités informatiquesavancées. Microsoft, dans sa plateforma Azure, offre aussi Stream Analytics et MachineLearning, un moteur d'analyse avancé avec plus de 200 algorithmes.
Pour des entreprises moyennes, il y a de multiples applications alternativesd'“intelligence d'affaires” sur internet, entre lesquelles Pentaho, SiSense, RJMetrics,Board, et Looker, avec différentes possibilités de maniement des données (SmallBusiness Trends, 18/03/2015). (Nous n'avons pas vérifé leur adéquation pour uneanalyse réelle de big data et il est possible qu'ils soient inférieurs à ce qu'offrent IBM etMicrosoft).
Nous devons rappeler que les grands du réseau, comme Google, Facebook, Twitter etd'autres, commencent à utiliser des techniques d'intelligence artificielle pour développerleur capacité d'apprentissage “profond” à partir des données qu'ils accumulent de leursconnexions, depuis les conversations jusqu'à la reconnaissance des visages sur lesphotos et les activités de jeux. Ainsi, l'intelligence artificielle sera de plus en plus partieintégrante des systèmes d'analyse de big data. IBM investit des billions de dollars danssa division dédiée à ce qu'ils appellent “computation cognitive”, un terme que lacompagnie utilise pour désigner les techniques d'intelligence artificielle qui opèrentaavec son ordinateur Watson et qu'ils mettent aussi à disposition des grandes entrepriseset des gouvernement qui désirent analyser leurs big data pour prendre de meilleuresdécisions.
57

8. Notre avenir
8.1. Big data pour tous?
Quelques publications d'affaires sur la toile recommandent d'utiliser les big data dansn'importe quelle antreprise. Face à l'excès de données numériques, qui peuvents'accumuler et sont diffcile d'interpréter, elles prétendent que la solution est simplementde visualiser (graphiquer) et “historier” (storify, donner forme de conte). Mais cela nevaut généralement que pour la présentation des résultats d'une analyse : il n'est paspossible de manipuler visuellement toutes les données (surtout parce que se mélangentdes structurées et non-structurées). Un bon outil de visualisation n'élimine nullement lanécessité de scientifiques de données pour les analyser correctement et générer lesrésultats. Malgré que ces publications tentent parfois de nous convaincre de ce que cesexperts ne sont pas nécessaires, après de nombreuses lectures et après avoir expérimentéavec la minerie de données (data mining) il y a une décade12, nous sommes arrivés à laconviction de ce qu'il n'est pas possible aujourd'hui à quiconque de réaliser une analysede big data comme il se doit. Dominer les statistiques tout comme la programmation etun système comme Hadoop est indispensable.
Alors, il n'est pas possible de travailler sans des scientifiques de données? Pour desentreprises qui ne sont pas en condition de financer une telle équipe de spécialistes etl'infrastructure requise, il est nécessaire, sans auncun doute, de penser à engager unefirme qui offre ce type de service, et celles-çi commencent }a se multiplier sur internet.Quelques unes offrent un “paquet” de base gratuit – à décharger ou sur le nuage, avecinterface web –, utile pour de petites entreprises (qui comptent au moins avec unprofessionnel qui comprenne le sujet) et ensuite divers tarifs selon la quantité decontenus et usage de leur nuage. (Seulement à titre d'exemple et sans que ce soit unerecommendation, nous pouvons signaler RapidMiner et Rhiza, bien qu'il seraitconvenable d'évaluer d'abord Alteryx, l'offre d'IBM). Et évaluer ces offres n'est pasfacile non plus, car il est généralement difficle de savoir si elles sont à jour et incluent,par exemple, l'apprentissage de machine. L'“état de l'art” dans ce domaine évolue trèsrapidement.
Pour un média qui désirerait prioriser le “journalisme de données” ou voudrait analyserle comportement de son audience en ligne, il faudra sans doute recourrir à ce genre deservice. Il est possible que les chercheurs universitaires, avec l'appui de leursinstitutions, doivent faire de même, à moins qu'ils ne comptent avec un puissantlaboratoire d'informatique. Et les experts signalent aussi qu'il convient aujourd'hui de
12 Cfr. Colle, R (2002).: Explotar la información noticiosa – Data mining aplicado a la documentación periodística. Université Complutense de Madrid.
58

former les futurs professionnels en matière de concepts et utilisations de ces outils, aumoins pour en connaître l'utilité et savoir comment faire des consultations pour obtenirdes résultats intéressants (cfr. S.C. Lewis).
Alos, comment commencer? Que peut faire pour son compte un professionnel? Nous enparlons à continuation en pensany surtout aux journalistes.
8.2. Big data pour professionnels
“Commencer en grand c'est commencer la maison par le toit” nous dit Matti Keltanen,un expert en planification de services numériques. Il faut d'abord savoir quels sont lesdonnées importantes à accumuler, étudier les outils adéquats pour leur analyses, réunirune première quantité – suffianste pour una première analyse – et tirer une leçon del'expérience.
Il est essentiel de savoir si l'on va travailler avec des données structurées (comme lesbases de données relationnelles) ou non-structurées. Le graphique qui suit montre enpremière file (en orange) des exemples typiques de données structurées, et ensuite (enbleur) de données non-structurées. Les application pour big data se justifiente seulementsi le second cas doit être inclus.
Le plus probable est que l'on dispose déjà d'instruments adéquats (par exemple pourclasser des nouvelles accumulées dans une base de données et extraire des statistiques).“Le petit secret du Big data est qu'aucun algotithme ne peut te dire ce qui est importantou te révéler son sens. Les données se convertissent alors en un autre problème qu'ilfaut résoudre. Partir abordant peu de données (Lean Data) suppose commencer avecdes questions relevantes pour l'affaire et trouver la façon de leur répondre au moyen desdonnées, au lieu de passer notre temps à criber d'incomptables ensembles de données”ajoute Keltanen (TicBeat, 19 de mayo 2013).
Les journalistes, comme aussi la majorité des enseignants du domaine des
59

communications sociales, peuvent travailler avec certaines quantités de données qu'ilsobtiennent soit de sources externes soit de leurs propres recherches. Souvent cesdonnées peuvent être inclues et traitées sur des tables Excel. De plus, Microsoft offre unplugin pour Excel 2010 appelé PowerPivot, qui permet de traiter plus efficacement desensembles massifs de données (des millions de files). Si l'on a besoin de fonctionsstatistiques plus avancées (Régression, fonctions non-linéales, séries temporelles,simulations, etc.), on peut utiliser le SPSS de IBM, qui a maintenant un excellent moteurgraphique. Evidemment, plus on saura de statistiques, meilleur pourra être l'analyse.Mais l'époque est déjà passée où cela était suffisant pour réaliser une véritable analysede big data, spécialement parce que le big est beaucoup plus grand et complexe qu'il y acinq ans (ce qui ne veut pas dire qu'une analyse plus simple ne puisse pas avoir devaleur).
Pour la visualisation des résultats, bien l'on recommande le langage R pour manipulerles bases de données afin de les graphiquer et les feuilles d'Excel et SPSS peuvent êtrespassées au format requis par R, si toutes les données sont en Excel il n'y a aucunenécessité de connaître et utiliser R. Pour obtenir des graphiques supérieurs à ceuxd'Excel, on peut utiliser Tableau, qui a une version libre(Tableau Public:https://public.tableau.com/s/) et même un app pour tablettes qui rend les images tactileset interactives: Elastic (http://www.tableau.com/be-elastic).
8.3. Vivre dans le nuage
D'une certaine façon, nous sommes en train de créer un double de notre mémoire dans lenuage digital:
“Nous enmagasinons nos mémoires dans les énigmatiques serveurs d'internet. Il ya la chronologie de Facebook qui enregistre les moments les plus significatifs denotre vie, le compte d'Instagram où nous gardonsnos portraits, le plateau d'entréede Gmail qui documente nos conversations et le canal de Youtube qui transmetcomment nous nous mouvons, parlons ou chantons. Nous coleccionnons etconservons nos souvenirs de façon beaucoup plus exhaustive qu'auparavent,tentant d'obtenir dans chaque cas une certaine forme d'immortalité.” (BBCMundo, 8/02/2015)
Si nous utilisons le nuage pour garder aussi nos fichiers – ce qui peut être une bonnemesure de sécurité mais très mauvaise du point de vue de l'intimité si nous en leschifrrons pas –, nous agrandissons encore plus ce “double” de notre histoire personnelle.
Et si cela en nous parait pas suffisant, on a créé un nouveau service d'internet – appeléEterni.me – qui prétend assurer que les souvenirs d'une personne soient conservés enligne après sa mort. Dans ce cas, il faut autoriser en vie le service pour qu'il aie acc}esaux comptes personnels de Twitter, Facebook et courriel, copie des photos, données de
60

géolocalisation et même enregistrements faits avec les lunettes Google Glass. Cesdonnées, filtrées et analysées, sont transférées à un avatar d'intelligence artificielle quiessaye d'émuler l'apparence et la personnalité du client. “Il s'agit de créer un légatinteractif, une forme d'éviter d'être complètement oublié dans l'avenir”, dit MariusUrsache, un des créateurs d'Eterni.me. “Tes arrière-arrières enfants utiliserons cela aulieu du moteur de recherche ou une chronologie pour accéder à l'information sur toi,depuis les photos d'événememts familiers jusqu'à tes opinions sur certains thèmes, enpássant par les chansons que tu as écrites et n'as jamais fait connaîtres”, ajoute-t'il(BBC Mundo, 8/02/2015). Quelle manière de renoncer à l'intimité!
8.4. La Cinquième Ere
Ray Kurzweil nous avertit que la technologie avance à un rythme croissant, car lechangement technologique est exponentiel. La “Cinquième Ere” de l'évolutionuniverselle commencera quand la technologie prendra le contrôle de sa propreprogression, ce qui – selon son calcul – aura lieu au cours de siècle actuel. Lacinquième ère
“Sera la résultat de la fusion entre l'énorme connaissance logée dans nos cerveauxet la capacité énormement supérieure, la vitesse et l'agilité pour partagerl'information de notre technologie. La cinquième ère permettra que notrecivilisation humaine-machine transcende les limitations des seulement centbillions de connexions extrêmement lentes du cerveau humain.” (p.22)
Cela ser le produit des avancements dans trois domaines: en biologie (spécialementl'étude du cerveau), la nanotehcnologie et la robotique.
Nous voyons déjà comment les téléphones et les bracelets “intellugents”, les processeurset les détecteurs commencent à entrer dans nos vêtements. ET la médecine commence àles implanter dans le cerveau pour solutionner des problèmes graves d'épilepsie et deParkinson. Elle aborde aussi le cas de l'Alzheimer, une voie qui pourrait nous ouvrir àl'ampliation de notre mémoire de façon artificielle au moyen d'implants de puces demémoire.
En même temps, nous voyons comment avancent les systèmes qui permettent nonseulement le contrôle mental par le cerveau de nouvelles prothèses et même lacommunication de cerveau à cerveau. EN mars de 2014, une équipe de scientifiques aobtenu que deux personnes communiquent mentalement avec un “hello” et un “ciao” àplus de 7.000 kilomètres de distance, entre la France et l'Inde. Cela fut possible grâce àun bonnet de dernière génération qui lisait l'activité cérébrale du seujet indien et envoyaces mots à un récepteur français qui avait d'un dispositif de neurostimulation(Transcraneal Magnetic Stimulation; grafique suivant).13
13 Plos One, "Conscious Brain-to-Brain Communication in Humans Using Non-Invasive Technologies", 19/08/2014
61

Source: Plos One, 19/08/2014
Mais, selon Kurzweil, la cinquième ère ´va encore plus loin. Durant la décade de 2020,nous pourrions commencer à disposer de machines capables de conserver une copie ducontenu de faire un duplicatat complet de notre cerveau. En 2045, nous serions capablesde garder cette copie dans le nuage d'internet. “Il y a déjà des ingénieurs qui travaillentà la technologie qui permettra de créer des copies complètes de notre esprit et dessouvenirs qui persisteront après que nos corps soient enterrés ou brûlés” nous avertit laBBC (BBC Mundo, 8/02/2015). Et l'union de ce type de progrès avec ceux de lananotechnologie et de la robotique feront que le cerveau humain multiplie des milliersou millions de fois sa capacité et même qui soit reproduit dans les clones artificiels.
“Des nanorobots plus sophistiqués serviront d'interfaces avec nos neuronesbiologiques pour améliorer nos sens, apportant ainsi une réalité virtuelle etaugmentée provenant de l'intérieur du système nerveu. Ils aideront aussi notremémoire et réaliseront d'autres tâches routinières. Nous serona alors des cyborgs,et à aprtir de ce point d'appui à l'intérieur de nos cerveaux, la partie nonbiologique de notre intelligence étendra exponentiellement ses capacités.
En dernier terme, les humains basés sur du logiciel dépasseront amplement leslimitations humaines telles que nous les connaissons aujourd'hui. Ils viviront dansla toile, projetant leurs corps quand ils le désirent ou nécessitent, ce qui incluira
62

des corps virtuels dans différents domaines de réalité virtuelle, des corps projetésholographiquement, des corps projetés au moyen de foglets14 et des corpsphysiques qui contiendront des essaims de nanorobots et d'autres formes denanotechnologie. Au milieu du XXIe siècle, les humains pourront étendre leurpensée sans limite.” (Kurzweil, p.372)
A moins que l'on n'arrive à un certain moment à créer un double artificiel complet(clone), l'identité en changera pas. Ce double serait évidemment un autre être, qui semodifiera progressivement selon ses patrons. Sera-ce alors aussi un être humain, unrobot ou un autre type d'entité intelligente? Voilà une question pour le moment sansréponse. Mais s'il était totalement numérique, ce serait une réalité virtuelle qu'il seraitdifficile de considérer humaine.
8.5. Questions de sécurité
L'“explosion” de données qui se transmettront avec les “vestibles” et autres appareils del'internet des objets, ajoutées aux données et traces que nous laissons déjà en utilisantnos téléphones “intelligents” pose d'importants problèmes de sécurité, en plus de ceuxrelatifs à la confidentialité et propriété des données personnelles. Ce qu'oublient lesoptimistes comme Kurzweil c'est que tout ce qui est connecté et sujet au risque del'intervention de tiers non autorisés. Nous avons mentionné que les pirates ou hackerssont très intéressés par les données personnelles et trouvent des avantages là où nouspensons le moins, comme l'accès aux fiches médicales, et trouveront aussi comment tirerprofit des connexions de innombrables objets de l'internet des objets (IoT). Il n'est pasfacile d'être optimiste quean on a lu que, depuis 2012, une erreur dans le protocole desécurité OpenSSL (le HTTPS visible dans la barre d'adresse du navigateur) permettait àn'importe quel pirate d'accéder à la mémoire d'un serveur et obtenir les données de sesutilisateurs, ce qui incluait leurs noms et clés d'accès, mais qu'aucune compagnieimportante n'a pris le problème en compte avant que la situation en soit rendue publiquesur la toile au début de 2014(ABC, 9/04/2014).
Il est facile d'imaginer les dommages qu'il serait possible de causer en accédantdirectement à des cerveaux – tant naturels qu'artificiels – qui soient unis à internet, sil'on en prend pas de mesures de sécurité beaucoup plus puissantes que les actuelles.Voici un nouveau domaine où beaucoup plus de recherche et de développement estnécessaire avant de se risquer à connecter des cerveaux humains. Et il faut aussi descampagnes beaucoup plus puissantes de sensibilisation des utilisateurs en matière deprotection de leurs données et équipement personnels.
14 Ensembles de nanorobots qui s'unissent comme un nuage (fog).
63

Conclusion
“Il y a les optimistes sur le thème, qui croient que grâce à la récolte et à l'analysedes données la société obtiendra une amélioration substancielle de sa capacité defaire des diagnostics et des pronostics confiables dans de multiples domaines denos vies. Cette amélioration se traduit, soutiennent-ils, en un monde meilleur, plusefficient et avec ses problèmes résolus. Duncan Watts, scientifique de MicrosoftResearch et auteur du livre «Everything is Obvious», croit que la `datification´ esttrès utile pour prendrede meilleures décisions. Son opinion est que«Si nousdevions choisir entre un monde dans lequel tout ce que nous faisons se base surdes instincts, traditions, ou une certaine sagesse vague, ou faire quelque chosesur la base d'évidences, je dirais que le second chemin est le meilleur». […]
Mais sur le trottoir d'en face sont assis les pessimistes ou, pour mieux dire, lesméfiants. Ce groupe suppose, en grandes lignes, que l'usage massif de donnés etd'information apporte }a la fois des dangers dont les conséquences peuventrésulter très graves pour tous.” (L.Zanoni, p.98)
Nous croyons qu'il n'est pas possible d'être optimiste aujourd'hui quando on observe cequi est fait – de façon supposée légale – avec nos données sans notre consentement et cequi arrive dans le camp illégal (L'entreprise Sophos a détecté plus de 250.000 menacesuniques chaque jour, selon ce qu'à informé son conseiller délégué, Kris Hagerman, aujournal El Mundo.es le 25/05/2014). La protection des données n'est pas seulement unproblème légal, ce l'est aussi de technologie. Les risques à futur sont trop grands pourlaisser tout se poursuivre comme aujourd'hui15.
Mais, comme avertit la revue Wired, la rébellion des consommateurs a commencé: 76%des utilisteurs (nordaméricains) vérifie les sceaux de confidentialité en ligne, et 89%renonce à opérer avec une compagnie qui en protège pas bien leur intimité (Wired,23/03/2015).
La recommendation pour les utilisteurs est celle-çi: vérifier les autorisations qu'on leurdemande et refuser les services qui en justifient pas bien celles qu'ils demandent. Pourles entreprises, elles doivent les justifier clairement, collecter seulement les donnéesindispensables et en pas les vendre à des tiers.
Si nous en cherchons pas “l'immortalité numérique”, réduisons à un minimum
15 Et ils pourraient même augmenter si les Etats-Unis réussissent à signer un nouvea traité de coopération avec l'Union Européenne qui éliminera les restrictions sur la communication des données personnelles que celle-çi maintient pour le moment.
64

indispensable ce que nous révélons sur nous-même, déchargeons les fichiers que nousavons mis dans le nuage (Dropbox et autres) – ou, au moins, encryptons-les – eteffaçons tout ce qui n'est pas utile (comme les vieux messages de e-mail, que beaucoupconservent sans aucune nécessité).
Bibliographie
Anderson, Ch. (2007): La economía Long Tail, Barcelona, Urano.
Bengio, Y. (2009): "Learning Deep Architectures for AI", en Foundations and Trends in Machine Learning, Vol. 2, No. 1 (2009) 1–127. Descargado el 8/01/2015 de http://www.iro.umontreal.ca/~bengioy/papers/ftml_book.pdf
Brownlee, J. (2014): How to Become a Data Scientist, Machine Learning Mastery, descargado el 18/11/2014 de http://machinelearningmastery.com/become-data-scientist/
Burrus, D. (2014): The Internet of Things Is Far Bigger Than Anyone Realizes, en Wired, 26/11/2014, descargado ese día de http://www.wired.com/2014/11/the-internet-of-things-bigger/ y http://www.wired.com/2014/11/iot-bigger-than-anyone-realizes-part-2
Castells, M. (2014): El impacto de internet en la sociedad, en BBVA, “C@mbio. Cómo internet está cambiando nuestras vidas”, Madrid, OpenMind BBVA
Colle, R. (2002): Explotar la información noticiosa – Data mining aplicado a ladocumentación periodística, Madrid, Depto. De Biblioteconomía y Documentación,Universidad Complutense. Visible en http://issuu.com/raymondcolle/docs/librodmdp
- (2013): “Prensa y Big Data: El desafío de la acumulación y análisis de datos”, Revista Mediterránea de Comunicación, vol. 4, nº 1. http://www.mediterranea-comunicacion.org/Mediterranea/article/view/65/133
- (2014): Internet ayer, hoy y mañana, auto-edición, en ISSUU: http://issuu.com/raymondcolle/docs/universointernet
-(2015): ¿Ser digital o ser humano?, (en preparación)
Dull, T. (2015): “A Big Data Cheat Sheet: What Executives Want to Know”, SocialMedia Today 25/05/2015, http://www.socialmediatoday.com/technology-data/tamaradull/2015-05-25/big-data-cheat-sheet-what-executives-want-know
Fisher, D. (2015): Why exploring big data is hard, OpenVisConf 2015,
65

https://youtu.be/UP5412nU2lI
Haikus, E. (2014): Informe sobre Medición de la Sociedad de la Información Resumen Ejecutivo, IUT, En línea en http://www.slideshare.net/eraser/informe-sobre-medicin-de-la-sociedad-de-la-informacin-resumen-ejecutivo
Hodgson, D. (2014): “The Internet of Things — Total Transparency or Total Control?”, blog Computer Associated, descargado el 28/04/2014 de http://blogs.ca.com/mainframe-voice/2014/04/23/the-internet-of-things-total-transparency-or-total-control/
Hope, B. (2014): "A la caza de los datos que valen millones", en Economía y Negocios, El Mercurio, 28/11/2014.
Jaokar, A. (2014): Implementing Tim Berners-Lee’s vision of Rich Data vs. Big Data, descargado el 9/12/2014 de http://www.opengardensblog.futuretext.com/archives/2014/12/implementing-tim-berners-lees-vision-of-rich-data-vs-big-data.html
Jiménez de Luís, A. (2014): “Internet nos ha convertido en la generación transparente”, El Mundo.es, Descargado el 21/11/2014, de http://www.elmundo.es/tecnologia/2014/11/20/546dfb
Kihn, M. (2014): “What do marketers need to know about Hadoop?”, FirstBiz, 29/11/2014, descargado el 2/12/2014 de http://firstbiz.firstpost.com/biztech/marketers-need-know-hadoop-110723.html
Kurzweil, R. (2012): La singularidad está cerca, Lola Books (Original: The Singularity is Near, Viking Press, 2005)
Lee, R. (2014): “Privacy, big data and analytics: A perfect storm”, IBM Big Data & Analytics Hub, 6/06/2014, descargado el 18/06/2014 de http://www.ibmbigdatahub.com/blog/privacy-big-data-and-analytics-perfect-storm
Lewis, Seth C. (2014): “Journalism in an era of big data: Cases, concepts, and critiques”,en Franklin, B. & col.: Digital Journalism, Londres, Routledge, descargado el 16/12/2014 de http://culturedigitally.org/2014/12/journalism-in-an-era-of-big-data-cases-concepts-and-critiques/
Mortier, R. & col. (2014): Human-Data Interaction: The Human Face of the Data-DrivenSociety, Cornell University Library, descargado el 6/02/2015 de http://arxiv.org/pdf/1412.6159v1.pdf
Nielsen, M. (2013): “Big data: ¿a quién pertenece?”, en C@mbio: Cómo Internet está cambiando nuestras vidas, OpenMind BBVA, pp.83-102.
Peglar, R. (2012): Introduction to Analytics and Big Data - Hadoops, Education SNIA, descargado el 5/02/2015 de
66

http://www.snia.org/sites/default/files2/ABDS2012/Tutorials/RobPeglar_Introduction_Analytics%20_Big%20Data_Hadoop.pdf
Rifkin, J. (2014): La sociedad de coste marginal cero, Paidós.
Schoenborn, B. (2014): Big Data Analytics Infrastructure For Dummies, IBM Limited Edition, John Wiley & Sons, disponible en http://newsroom.roularta.be/static/19092014/XBM03004USEN-%20BD&%20A%20for%20dummies.pdf
Tierney, J. (2014): “Customer Data Privacy has Become an Everyman Problem”, Loyalty36org, 14/03/2014, descargado ese día de http://loyalty36.org/resources/article/customer-data-privacy-has-become-an-everyman-problem
UIT (2014a): The World in 2014. Facts and figures, Ginebra, UIT, descargado el 25/11/2014 de http://www.itu.int/go/mis2014
UIT (2014b): Informe sobre Medición de la Sociedad de la Información 2014 - ResumenEjecutivo, Ginebra, UIT, descargado el 1/12/2014. de http://www.itu.int/en/ITU-D/Statistics/Documents/publications/mis2014/MIS_2014_Exec-sum-S.pdf
Wessler, M. (2013): Big Data Analytics For Dummies, Alteryx Special Edition, John Wiley & Sons, disponible en http://www.mosaic.geo-strategies.com/wp-content/uploads/2013/10/Big-Data-for-Dummies.pdf
Zanoni, L. (2014): Futuro inteligente, Autoedición, descargado el 13/01/2015 dehttp://www.futurointeligente.com.ar/ (Disponible en varios formatos)
67

Table des matières
Introduction p.31. L'environnement des données1.1. Evolution technologique p.51.2. Internet et la toile p.81.3. Les réseaux sociaux et la mobilité p.101.4. L'internet des objets (IoT) p.111.5. Les “big data” p.15
Première Partie
2. L'identité révélée2.1. Réseaux sociaux p.162.2. Connaître ce qui est révélé p.18
3. L'identité extraite3.1. Des équipements “traîtres” p.203.2. Navigation p.203.3. Réseaux sociaux p.213.4. Téléviseurs intelligents p.253.5. L'internet des objets p.253.6. Les grandes données (“Big data”) p.29
4. Protection et cession de données4.1. Droits p.314.2. Protection p.324.3. Droit à l'oubli p.354.4. Se cacher? p.364.5. (In)Sécurité p.37
Deuxième Partie
5. Qui nous épie5.1. Les entreprises p.395.2. Les gouvernements p.425.3. Les politiciens p.455.4. Les pirates (hackers) p.45
68

6. Pour quoi?6.1. Le marketing p.476.2. Le commerce de données p.496.3. Études sociales p.52
7. Comment on nous étudie7.1. La science des données p.537.2. Machines et applications p.55
8. Notre avenir8.1. Big data pour tous? p.588.2. Big data pour professionnels p.598.3. Vivre dans le nuage p.608.4. La Cinquième Ere p.618.5. Questions de sécurité p.63
Conclusion p.64Bibliographie p.65
69