capteur intelligent pour la reconnaissance de visage
TRANSCRIPT

Thèse n°
Ecole Doctorale EDITEEcole Doctorale EDITEEcole Doctorale EDITEEcole Doctorale EDITE
Thèse présentée Thèse présentée Thèse présentée Thèse présentée pour l’obtention du diplôme depour l’obtention du diplôme depour l’obtention du diplôme depour l’obtention du diplôme de DOCTEUR DE L’INSTITUT NATIONAL DES TELECOMMUNICATIONSDOCTEUR DE L’INSTITUT NATIONAL DES TELECOMMUNICATIONSDOCTEUR DE L’INSTITUT NATIONAL DES TELECOMMUNICATIONSDOCTEUR DE L’INSTITUT NATIONAL DES TELECOMMUNICATIONS
Doctorat délivré conjointement par
L’Institut National des Télécommunications et l’Uni versité Pierre et Marie Curie - Paris 6
SpécialitéSpécialitéSpécialitéSpécialité :::: Electronique/Informatique Electronique/Informatique Electronique/Informatique Electronique/Informatique
ParParParPar
Walid HizemWalid HizemWalid HizemWalid Hizem
Capteur Intelligent pour la Reconnaissance de Visage
Soutenue le Soutenue le Soutenue le Soutenue le 2002002002009999 devant le jury composé dedevant le jury composé dedevant le jury composé dedevant le jury composé de :::: Mme AliceMme AliceMme AliceMme Alice Caplier Caplier Caplier Caplier Rapporteur M. M. M. M. MMMMichelichelichelichel Paindavoine Paindavoine Paindavoine Paindavoine Rapporteur M. PatrickM. PatrickM. PatrickM. Patrick Garda Garda Garda Garda Examinateur M. M. M. M. Maurice Maurice Maurice Maurice MilgramMilgramMilgramMilgram Examinateur M. YangM. YangM. YangM. Yang Ni Ni Ni Ni Examinateur Mme BernadetteMme BernadetteMme BernadetteMme Bernadette Dorizzi Dorizzi Dorizzi Dorizzi Directeur de thèse


Résumé
La variation d'illumination est l'un des facteurs les plus inuent sur les perfor-mances d'un système de reconnaissance de visage spécialement dans un contexte demobilité où l'opérateur n'a pas le contrôle de l'éclairage. Nous présentons dans cetravail, un nouveau capteur atténuant l'illumination ambiante ; l'image en sortie estalors plus stable vis-à-vis aux variations de l'éclairage ambiant. Ce capteur se base surla réduction de temps de pose pour ne capturer qu'une faible quantité de la lumièreambiante, et on active durant la période d'exposition un ash délivrant une lumièreen proche infrarouge. L'image de sortie est alors dépendante de l'éclairement du ash.Une seconde caractéristique de ce capteur, est la délivrance en simultané d'une imageen proche infrarouge et d'une image normale acquise avec la lumière ambiante. En vued'une future implémentation de notre approche, nous avons construit une méthode dedétection de points caractéristiques sur les images proche infrarouge. Cet algorithmerepose sur des opérateurs simples qui ont été implémentés. Si on a pu construire uneméthode simple c'est bien grâce à la stabilité des images par rapport à l'illumination.
En utilisant les points caractéristiques détectés et l'image de contours, nous avonsmis en ÷uvre un algorithme de reconnaissance de visage s'inspirant de l'elastic graphmatching pour construire un modèle du visage. Les performances de notre systèmesont aussi comparées avec les algorithmes de reconnaissance de visage de base. Onobtient des performances de reconnaissance équivalentes à celles de l'elastic graphmatching classique mais avec un moindre coût dans l'implémentation.
i


Abstract
Illumination variation is one of the factors that has the greatest impact on theperformance of a facial recognition system, especially in a mobility situation where theoperator cannot control lighting. In this work, we present a new sensor that reducesambient light ; the resulting image shows greater stability in relation to changes inambient light. This sensor relies on a reduction of exposure time, so as to captureonly a small quantity of ambient light, and during the exposure, a ash emitting anear-infrared light is activated. The resulting image is therefore dependent upon theluminance of the ash. A second characteristic of this sensor is the simultaneous pro-duction of a near-infrared image and a normal image acquired in ambient light. Besidesthis new sensor, we also aimed in among this and in view of a future implementationof our approach, we elaborated a method to detect landmarks in near-infrared images.This algorithm is based on the use of simple operators that has been implemented.The stability of the images in relation to the lighting changes allowed us to elaboratea simple method.
Using the landmarks detected and the edge image, we constructed a face-recognitionalgorithm, inspired by elastic graph matching, in order to build a model of the face. Wecompared the performance of our system to that of basic face-recognition algorithms,and achieved recognition levels equal to those of classic elastic graph matching.
iii


Table des matières
Table des matières v
Table des gures viii
Liste des tableaux xi
1 Introduction 11.1 Motivations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Reconnaissance de visage . . . . . . . . . . . . . . . . . . . . . . . 31.3 Objectifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.4 structure de la thèse . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 État de l'art 92.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1.1 Architecture générale . . . . . . . . . . . . . . . . . . . . . . 102.1.2 Challenge techniques . . . . . . . . . . . . . . . . . . . . . . 12
2.2 Reconnaissance de visage en temps réel . . . . . . . . . . . . . . . . 122.2.1 Reconnaissance de visage par réseaux de neurones . . . . . 132.2.2 Reconnaissance de visage par Analyse de composante prin-
cipale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.2.3 Reconnaissance par correspondance élastique de graphe . . 182.2.4 Comparaison des algorithmes . . . . . . . . . . . . . . . . . 21
2.3 Capteurs Intelligents . . . . . . . . . . . . . . . . . . . . . . . . . . 222.3.1 Variables analogiques . . . . . . . . . . . . . . . . . . . . . 232.3.2 Opérateurs analogiques . . . . . . . . . . . . . . . . . . . . 232.3.3 Rétines CMOS . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.4 Reconnaissance de visage en Infrarouge . . . . . . . . . . . . . . . . 292.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
v

vi TABLE DES MATIÈRES
3 Capture de visage temps réel 333.1 Introduction : Système Actuel et problèmes associés . . . . . . . . 33
3.1.1 Capteur CMOS . . . . . . . . . . . . . . . . . . . . . . . . . 343.1.2 Les capteurs CCD . . . . . . . . . . . . . . . . . . . . . . . 37
3.2 Capteurs d'image dédiés . . . . . . . . . . . . . . . . . . . . . . . . 413.2.1 Capteur diérentiel . . . . . . . . . . . . . . . . . . . . . . . 413.2.2 Capteur IRVI . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.3 Bases de donnée . . . . . . . . . . . . . . . . . . . . . . . . . . . . 483.3.1 Base BIOMET . . . . . . . . . . . . . . . . . . . . . . . . . 483.3.2 Base IV2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 493.3.3 Base IRVI . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
3.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4 Détection des points caractéristiques 554.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 554.2 Détection de points caractéristiques dans la littérature . . . . . . . 56
4.2.1 Méthode Adaboost . . . . . . . . . . . . . . . . . . . . . . . 564.2.2 Modèle de contour actif . . . . . . . . . . . . . . . . . . . . 574.2.3 Détection des yeux dans les images infrarouges . . . . . . . 58
4.3 Détection de zones de sélection . . . . . . . . . . . . . . . . . . . . 594.3.1 Image de contour . . . . . . . . . . . . . . . . . . . . . . . . 594.3.2 Présélection des zones du visage . . . . . . . . . . . . . . . 61
4.4 Détection de la bouche . . . . . . . . . . . . . . . . . . . . . . . . . 624.4.1 Détection par morphologie mathématique . . . . . . . . . . 624.4.2 Détection par la transformée de Hough . . . . . . . . . . . . 64
4.5 Détection du nez . . . . . . . . . . . . . . . . . . . . . . . . . . . . 654.6 Détection des yeux . . . . . . . . . . . . . . . . . . . . . . . . . . . 654.7 Validation sur les bases Infrarouge . . . . . . . . . . . . . . . . . . 67
4.7.1 Critère de mesure . . . . . . . . . . . . . . . . . . . . . . . . 674.7.2 Performances de détection . . . . . . . . . . . . . . . . . . . 68
4.8 Détection de points caractéristiques sur les images en visible . . . . 704.8.1 Détection de contour . . . . . . . . . . . . . . . . . . . . . . 71
4.9 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
5 Algorithme de Reconnaissance de Visage 755.1 Élaboration des graphes pour la reconnaissance de visage . . . . . 75
5.1.1 Analyse par morphologie mathématique . . . . . . . . . . . 775.1.2 Analyse par les ondelettes de Gabor . . . . . . . . . . . . . 78
5.2 La comparaison élastique des graphes - EGM . . . . . . . . . . . . 78

TABLE DES MATIÈRES vii
5.2.1 Détection des noeuds dans le EGM-CSU . . . . . . . . . . . 795.2.2 Extraction de caractéristiques . . . . . . . . . . . . . . . . . 805.2.3 Comparaison des graphes . . . . . . . . . . . . . . . . . . . 815.2.4 Inuence du nombre des noeuds . . . . . . . . . . . . . . . . 82
5.3 Exploitation de l'image de contour - Algorithme EGM-TMSP . . . 845.3.1 Méthode de mise en correspondance des n÷uds . . . . . . . 87
5.4 Comparaisons et Performances . . . . . . . . . . . . . . . . . . . . 885.4.1 Algorithmes de référence . . . . . . . . . . . . . . . . . . . . 885.4.2 Protocoles de test . . . . . . . . . . . . . . . . . . . . . . . 905.4.3 Expériences et Performances . . . . . . . . . . . . . . . . . 92
5.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
6 Conclusion et perspectives 101
Bibliographie 105
A Liste des Publications 115
B "Active dierential CMOS imaging device for human face recognition" 117
C Near infrared sensing and associated landmark detection for facerecognition 119

Table des gures
1.1 Eet de l'illumination sur les images de visage . . . . . . . . . . . . . . 31.2 schéma d'Identication du visage . . . . . . . . . . . . . . . . . . . . . 41.3 schéma de vérication du visage . . . . . . . . . . . . . . . . . . . . . . 41.4 Courbe ROC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1 Schéma général d'un système de reconnaissance de visage . . . . . . . 102.2 Normalisation géométrique du visage . . . . . . . . . . . . . . . . . . . 112.3 Schéma global du système de Harvard (Gilbert) [21] . . . . . . . . . . 132.4 Composition d'un réseau de neurones . . . . . . . . . . . . . . . . . . . 142.5 Réseau de neurones RBF [82] . . . . . . . . . . . . . . . . . . . . . . . 152.6 Diérents type de graphe pour l'EGM . . . . . . . . . . . . . . . . . . 182.7 Architecture générale du système proposé par Nagel [49] . . . . . . . . 202.8 Architecture de Calcule des Jets . . . . . . . . . . . . . . . . . . . . . 212.9 Système de reconnaissance de visage temps réel : ux de donnée . . . . 222.10 a)paire diérentielle ; b) Miroir de courant [8] . . . . . . . . . . . . . . 242.11 Structure d'un réseau capacitif 1D à convolution Gaussienne . . . . . . 252.12 Structure d'un réseau capacitif 2D à convolution Gaussienne . . . . . . 262.13 Principe d'un photorécepteur à égalisation d'histogramme intégré . . . 282.14 Schéma électrique du pixel en mode logarithmique [53] . . . . . . . . . 282.15 Spectre électromagnétique . . . . . . . . . . . . . . . . . . . . . . . . . 292.16 Sensibilité d'un capteur CCD . . . . . . . . . . . . . . . . . . . . . . . 31
3.1 Architecture générale d'un capteur CMOS . . . . . . . . . . . . . . . . 343.2 Structure schématique d'un pixel PPS . . . . . . . . . . . . . . . . . . 353.3 Structure du pixel en mode d'intégration du photocourant . . . . . . . 363.4 Architecture d'un pixel en mode courant . . . . . . . . . . . . . . . . . 37
viii

TABLE DES FIGURES ix
3.5 Architecture d'un pixel logarithmique utilisant une photodiode en modephotocourant . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.6 La structure d'une capacité MOS . . . . . . . . . . . . . . . . . . . . . 383.7 Stockage des charges dans une capacité MOS . . . . . . . . . . . . . . 393.8 Puit et barrière de potentiel dans une capacité MOS . . . . . . . . . . 393.9 Architecture générale d'un capteur CCD . . . . . . . . . . . . . . . . . 403.10 Transfert de charge avec un CCD à 4 phases . . . . . . . . . . . . . . . 413.11 Structure d'un pixel du capteur diérentiel . . . . . . . . . . . . . . . 423.12 Structure du capteur diérentielle [55] . . . . . . . . . . . . . . . . . . 433.13 Principe de fonctionnement du capteur diérentiel . . . . . . . . . . . 443.14 Examples d'images acquises par le capteur diérentiel . . . . . . . . . 443.15 Principe de la Caméra CCD Pulsé . . . . . . . . . . . . . . . . . . . . 453.16 Architecture fonctionnelle du prototype à base de webcam . . . . . . . 463.17 Image de sortie du prototype à base de webcam . . . . . . . . . . . . . 463.18 Schéma du module CCD . . . . . . . . . . . . . . . . . . . . . . . . . . 473.19 Obturation électronique dans un capteur CCD interligne . . . . . . . . 473.20 Chronogramme de la réduction du temps d'exposition dans le CCD . . 483.21 Chronogramme d'acquisition des trames dans une CCD interligne . . . 483.22 Example d'image de la base BIOMET . . . . . . . . . . . . . . . . . . 493.23 Eet de saturation dû au port des lunettes dans la Base BIOMET . . 503.24 Exemple d'images de la base de donnée IV2 . . . . . . . . . . . . . . . 503.25 Environnement d'acquisition de la base VINSI . . . . . . . . . . . . . . 513.26 Exemples d'images de la base IRVI et les diérents protocoles . . . . . 52
4.1 Localisation des yeux avec la méthode proposée par Dowdall [16] . . . 584.2 Filtrage gaussien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 604.3 Extraction de l'image de contour - a) Filtre de détection de contours
- b) image en proche IR - c) Résultat de la convolution . . . . . . . . . 614.4 Sélection des régions entourant les points caractéristiques . . . . . . . 624.5 Les opérateurs de morphologie : a) Érosion de la gure A par l'élément
structurant S, b) Dilatation par l'élément S . . . . . . . . . . . . . . . 634.6 Détection de la bouche . . . . . . . . . . . . . . . . . . . . . . . . . . . 644.7 Modèle du nez . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 654.8 Projection du contour du nez . . . . . . . . . . . . . . . . . . . . . . . 664.9 Détection des yeux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 674.10 Performance de détection sur la base IRVI . . . . . . . . . . . . . . . . 684.11 Comparaison de performance de détection de la bouche avec la trans-
formée de Hough et la morphologie mathématique . . . . . . . . . . . 69

x TABLE DES FIGURES
4.12 Performance de détection sur la base IV2 . . . . . . . . . . . . . . . . 704.13 Performance de détection des yeux sur la base Biomet . . . . . . . . . 714.14 Inuence des variations d'éclairage sur l'image de contours . . . . . . . 724.15 Comparaison de performance de détection sur les images NIR et visible
dans la base IRVI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
5.1 Érosion et dilatation successives avec des éléments structurants circu-laires de taille variable sur une image en NIR . . . . . . . . . . . . . . 77
5.2 Les diérentes orientations et résolutions des parties réelles des ltresde Gabor utilisés . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
5.3 Représentation d'un graphe sur une image de la base BANCA . . . . . 815.4 Exemples d'image de la base BANCA (a) image en haute résolution
contrôlée (b) Dégradée (c) non contrôlée . . . . . . . . . . . . . . . . . 825.5 Variation du nombre des noeuds dans un graphe : a) 20 noeuds choisis
b) 20 noeuds aléatoirement choisis et c) 15 noeuds aléatoirement choisis 835.6 Courbes ROC de performance de reconnaissance selon le nombre de
noeud dans un graphe sur la base BANCA - Protocole P . . . . . . . . 845.7 Positionnement d'une grille sur le visage selon la position des yeux et
de la bouche a) Image de contour, (b) Image en NIR . . . . . . . . . . 865.8 Sélection des n÷uds dans la méthode de l'Université de Vigo [23] . . . 865.9 Sélection des noeuds de l'image de contour et inuence d'un change-
ment de pose sur la sélection . . . . . . . . . . . . . . . . . . . . . . . 875.10 Méthode de correspondance des graphes selon les coordonnées des
noeuds dans la grille originale . . . . . . . . . . . . . . . . . . . . . . . 885.11 Courbe ROC de l'EGM-CSU sur la base IRVI avec le protocole TS1P1 925.12 Courbe ROC de l'EGM-CSU sur la base IRVI - protocole TS2PA . . . 935.13 Courbes ROC des algorithmes LDA, GLDA et EGM-CSU sur la base
IRVI - protocole TS1P1 images NIR . . . . . . . . . . . . . . . . . . . 945.14 Courbes ROC des algorithmes LDA, GLDA et EGM-CSU sur la base
IRVI - protocole TS1P1 images VI . . . . . . . . . . . . . . . . . . . . 945.15 Courbes ROC des algorithmes LDA, GLDA et EGM-CSU sur la base
IRVI - protocole TS2P1 (a)images NIR - (b) images VI . . . . . . . . . 955.16 Courbes ROC des algorithmes LDA, GLDA et EGM-CSU sur la base
IRVI - protocole TS2PA (a)images NIR - (b) images VI . . . . . . . . 995.17 Courbes ROC des systèmes de reconnaissance EGM-CSU et EGM-
TMSP avec le protocole TS1P1 . . . . . . . . . . . . . . . . . . . . . . 1005.18 Courbes ROC des systèmes de reconnaissance EGM-CSU et EGM-
TMSP avec le protocole TS2PA . . . . . . . . . . . . . . . . . . . . . . 100

Liste des tableaux
2.1 Ressources consommées sur le FPGA SpartanII pour le RBF . . . . . 152.2 Résultats d'implémentation d'un RBF sur DSP . . . . . . . . . . . . . 162.3 Ressources utilisées dans [68] sur un FPGA XC2S300 . . . . . . . . . . 18
5.1 Comparaison des performances de reconnaissance en fonction du nombredes n÷uds dans un graphe . . . . . . . . . . . . . . . . . . . . . . . . . 84
5.2 Performance en EER des diérents algorithmes de reconnaissance surla base IRVI et l'intervalle de conance . . . . . . . . . . . . . . . . . 97
5.3 Comparaison de performances de reconnaissance des deux algorithmesde reconnaissances EGM sur la base IRVI et les intervalles de conance 97
xi


!"#$%%"%$""&$%'($$%$)"%"*$$'+, %-'.$$/012!%%)",% "%3$%'4!"%$%&5$!%""65"78'"#"$!%, %"$$3%9,+,%,-":);%%"$"<"%""!"*%&"#"%$"%,*$675$!% %$!%%$=$"$%'(;8%$"!"$ >$#8;$!;$7"$;'"$$%$$$"?@$#6'($$A5""%%""$!,#5"<$#6'("%$""&$; "!%$ 7;$$$$"$%$"#$%%$!$""<"3$ %$$#6'(<;$$7"!6"#6"!%"6$!""%$"B$>%%;#;"!"'"$"#*$!%$"$"$!%""$%%$$ %$#3#8%$'4#"$,"A"$%,$;"";8"%6"7$"'
C

D EFGHIJKLMNIOJKPQREJIPO
STSUVWXYZWXV[\
]_abcdebafgahfiah_cijfgikdglmno_hjph_ifq_hm_lrlfi_irqhmgsr_tjumgiafrf_virhwxy_lrilgrzhkflgrgapaf_hjph_ifqvirhwhffghkfivmlglalfi_irhfiawghapqk|__~kkmfh_rmgraarrafjiargqfirrhafrmlg_hkhmflgplvirhwovllktrflamhgfihmmhgafplkgmrxfhlrrilalrhvararm|frpvirhwrlgflfrarmiskrptipafifqx~qgih_tijmgfl_mqghflgmlfzhki_jafvqgig_hpqkiriaptlarrfsjijqfgilhrpvirhwxhjph_ifqvirhwmlfpharkgfhiarkhrokjj_khrpkafg_przgafisgrokazgfg_hpqkiriap_thwafmlg_hvqgikhfiaptipafifqfkarfiflglarrfsjpthip_hpqkiriafaapgjm_hkjafp_thwafkligapkffjph_ifqm_lrhkkmfh_x~hmflgzhki_hkhmflgplvirhwrfhrrzhki_rharkafhkf_tiarfhgpthlfgrjph_ifqrf_l_tigirlirafpiki_rkhmfgxm_lr_rkhmflgrptijhwrraf_rkhmflgr_rjiark|grrlg_jhgk|qoklizhki_iflakjjgkih_irhfiaptlarrfsjhrpgkaahirrhakpvirhwxhirkffjph_ifqmgqraflaiakavqaiafliialrlg_hlh_ifqp_hgkaahirurhakxafo_rkapifiarpthklirifiakarfiflaflaq_qjafh_qhfigplghaf_hkhmflgxti__ljiahfiarflazhkflglimlfpqfqgigg_hlh_ifqp_tijhwxaijhwpaalh_ifqrflaijhwliamgqrafaiprhflghfiaaiptjgrlg_virhwhvklaakafghrfxtgwhairjpagjh_irhfiabhqfh_ilaagjeb]bunrlg_hlh_ifqprijhwrx__iapilprkariwarpthklirifiaprijhwrpgqzqgakmlg_rpkljafrki_rxlrrioafglvlaprkgimfiaptlaijhwpvirhwipqh_mlgkarfiflglagqzqgakxharkkhro_virhwapifmhrfgkhk|qmhg_rk|vlollavfjafxmgfpr_laffratrfhlfgirqlrti_akhk|mhr_rlfawqasgmhrprgqiarijmgfhafrplhr|lp_h_ljisghjihaflimlvafrhflgg_kh_jaf_tijhwxapqaifhlrri_hmrmgapgfapjhaplamgrriaalfgplghaf_thklirifiaxharlakaffpji_ifqoi_athmhrpkafg_rlg_tavigaajaffpakp_tqk_highwo_rrrfsjrpgkaahirrhakpvirhwrlirrafprpqfqgighufiarphar_lgrmgzgjhakrxtijhwkhmfqmgqrafprglifrmhgghmmgflaijhwipqh__iqr_hpiqgakpti__ljiahfiaafg_tijhwpgqzqgakagwirfgqfk__hklirxamlfvigrlg_hwlgx_tialakp_ti__ljiahfiarlg_viurhwa_ljisgviri_xylggqmapgkmg_sjoamlffghifg_tijhwhklirmlg_thjq_iggfgqplig_tialakpkglifxhirkffhmmgk|mgqraflaiakavqaiafmlg_rhmm_ikhfiarji_r_hkhmhkifqpkh_kl_f_hfhi__p_hjqjigraf_ijifqrxharkfff|sroalrh__arqflpigfkakviglakhjqgh

¡¢£¤¤¥¦§§¥¤¢¡¡©¦§¥ª¡ «
¬®°±²³²µ¶·¹·º»¼ºº½¾¼¿À¼Á¿Â½Ãº·Â¼¾Àķ¹·Å¼ÂÀķƼ¾Àķ¹·ºÀÇÀ·¹·¹Á¿¿È·ÉʵËÌÍÎ
ÏÐÑÒÓÓÏÔÒÐÑÒÕÖ×ÖØÓÒÙÚÛÓÏÜÏÐÒÝÓÚÏÐÞßÒÐÕÒÙÒÓÚÏÓÓßÜÏÐÖÑÏàÐÙÛÓÏáÝÖÐÑÖÏÐâÏßÐÒÜÒÏÓÓÒßÝÒÏÜÖÔÒÒÐÒÐÑÝÛÒÙÒÓÚÖÓÔàÝÏÑãÜÒÙÒÝÒÕàÐÐÖÏââÖÐÕÒä
åæçèéêëììíîïïíìêéðéñîïíòé
óÒââôâÑõÜÒâÙÒÝÒÕàÐÐÖÏââÖÐÕÒ×ÒßáÒÐÑöÑÝÒÙÏáÏâÛâÒÐÙÒß÷Ñô×ÒââÒÓàÐÓÒßÝøàÐÕÑÏàÐÐÖÓÏÑÛù
úûüýþÿþÿý
ôÖÐÑßÐÞß÷ÙÚÏÜÖÔÒàßßÐÒÏÜÖÔÒßÏÕàÐÑÏÒÐÑßÐáÏâÖÔÒÓÚÏÙÒÐÑÏÕÖÑÏàÐÒâÑÓÖÝÒÕàÐÐÖÏââÖÐÕÒ×ÖÝÑÏÝÙÚßÐÒØÖâÒÙÒÙàÐÐÛÒââÖÐâÖßÑÝÒÕàÐÐÖÏââÖÐÕÒÖ×ÝÏàÝÏÙÒÓÚÏÙÒÐÑÏÑÛÙÒÓÖ×ÒÝâàÐÐÒäÒÑÑÒÑÕãÒÙàÐÐÒÓÏÒßßÐÒÕàÜ×ÖÝÖÏâàÐÙÒÑô×Ò ùàÐÕàÜ×ÖÝÒßÐÒÏÜÖÔÒÙßÞß÷ÖáÒÕÓÒâÏÜÖÔÒâÒÐÝÒÔÏâÑÝÛÒâÙÖÐâÓÖØÖâÒÙÒÙàÐÐÛÒÔßÝÒääÐÒÖ××ÓÏÕÖÑÏàÐÒâÑÓÖÝÒÕàÐÐÖÏââÖÐÕÒÙÒ×ÒÝâàÐÐÒâÙÖÐÔÒÝÒßâÒâÒÐÝÒÔÏâÑÝÛÒâÙÖÐâßÐÒ äÒÑÑÒÖ××ÓÏÕÖÑÏàÐÒâÑâßÒÑÑÒÙÒâÕàÐÑÝÖÏÐÑÒâÙÒÑÒÜ×âÙÒÕÖÓÕßÓÙÚàÓÚÒÐÝÒÔÏâÑÝÒÜÒÐÑÙÒÕÖÝÖÕÑÛÝÏâÑÏßÒâÙßáÏâÖÔÒÖßÓÏÒßÙÒÓÚÏÜÖÔÒÒÐÑÏõÝÒäßââÏÓÚÒÐÝÒÔÏâÑÝÒÜÒÐÑÙÚßÐÒØÖâÒÙÒÙàÐÐÛÒÙÒáÏâÖÔÒÒâÑÕàÐÙÏÑÏàÐÐÛÒÐÝÖÐÕÒ×ÖÝÓÚÖßÑàÝÏâÖÑÏàÐÙÒÓÖ !óàÜÜÏââÏàÐ ÖÑÏàÐÖÓÒ!ÐøàÝÜÖÑÏßÒÒÑóÏØÒÝÑÛßÏÕÖßÑÏàÐÐÒÓÖ×ÝàÑÒÕÑÏàÐÙÒâÙàÐÐÛÒâ×ÒÝâàÐÐÒÓÓÒâäÒÑÑÒÖßÑàÝÏâÖÑÏàÐÐÚÒâÑÙàÐÐÛÒßÚÒÐøàÐÕÑÏàÐÙßøàÝÑØÒâàÏÐÙÒâÛÕßÝÏÑÛÐÛÕÒââÏÑÛ×ÖÝÓÚÖ××ÓÏÕÖÑÏàÐä

" #$%&'()*+,'-()./0#('.-
123456789:;<=>?@ABCADEFGH<@FGIEAJKG;@LD
MNOPQRSTPUV
WXYZ[\Z]\_abYcdef\\ZdabYcdg\ahfZ[adZ[\ZiajYcdekYilmanhY[afZdj[kY
mdhfZZYajjYZhd_diajYcdopYm[am_\ZdabYcd_dmlqlmdZhddZmdcaj[mldY\pmlYkYrkd_YZj\Zdp\hdf\\Znhsadmtudj[\ZdilmanhY[afZ_dka_dZ[a[lmdidZ_ag\ldhdj[o
_amdg\dkYpdmjfZZd_lhkaZdY\pmlYkYrkdjfZa_dZ[a[lvnc\mdwtxytud[[d[zhsd_fZZd
kad\o\ZdhfbpYmYajfZ|~|tZd_djYppkahY[afZjdj[kdhfZ[mkdf\ilmanhY[afZ
_a_dZ[a[lokdZ[mld_dj[Y[jZajpYmddbpkdvqhkdZf\idY\pYjjdpfm[rafbl[mag\dytYmlqlmdZhdrafbl[mag\dpd\[Ykfmj[mddZmdcaj[mld_YZj\ZdrYjd_d_fZZldjbYaj
Y\jjaj\m\ZdhYm[dop\hd_l[dZ\dpYmkYpdmjfZZdtYZjhdhYjkYulbd[\Z
YiajbfaZjmdj[mah[aqok\[akajY[afZ_dkYrafbl[madtWaZjafZpd\[[mf\idm_djYppYmdakj
lkdh[mfZag\djpdmjfZZdkj\[akajYZ[kYrafbl[mad[dkjg\dkdjfm_aZY[d\mjpfm[Yrkdjekdj
hfmdjqfm[jekdj[lklpsfZdjd[ht
12345678:;<=>?@ADK>GH<@FGIEAJKG;@LD
SSTPUVVTPUNTOP
\kd_lidkfppdbdZ[abpfm[YZ[_dkYrafbl[mad_\mYZ[hdj_dmZamdj_lhdZZadj
d[kaZj[Y\mY[afZ_\pmfcmYbbdepmfd[_YZjkdg\dkkdbpmdaZ[dd[kdiajYcd

¡¢£¤¤¥¦§§¥¤¢¡¡©¦§¥ª¡ «
¬®°±²³¬µ³¶·®¶·¶¬³¶··¶¶¶·°¹º¶±°®»¼·¬³¬¼½º¾°³°®®ºº
¹¬·®·³¾¶·µ³¶·¬·¶·¬µ·¶¿¶¹°®±·¬¼·¬°À¶Á¹·¬¼·¶·±®®°¬¬°®±·»·®
µ°¶±³·¶¼°®¬·¹¼·¾º¶Â±°®ÃÄ·¬³¬¬®®¼ºµ·®¼°®¬¼·°¹¼°º
³¬º·ÃŬ·®®·®±¹µ·¼·µ³¬·³¶¬±¶Æ¶·¬Ç·±Á®²³·¬»
®°®±·¶¬»µº¶°®®·¬
·Á³¹°®¬ÃÈ®¬»®±Á·¶±Á·Éº¾°³·¶°Â°Êº¼½³®¬Ë¬Æ¹·¿°±·°³Ì®¶³¬®¬»
°³Ì¹µ¬³¶·¬³·®¶·¬°®¿°±·¹·®³¬°Ê·Ãͳ¬°®¬®³¬®º¶·¬¬·¶¼°®¬
±··ÁƬ·°³Ìº¾°³°®¬°À¶Á¹²³·¬Ã笵¶±º¼º¬±°¬¬²³·¬¼·¾º¶Â±°®¼½¼·®º·¬²³··±¼·ÏÅͳ·¹¼·
µ°¬¬·¬®³Ð³¶¬¼·®²³·¬°³¹¹·®¼·½·®¶·À¬¶·¹·®·É°¾º¶Â±°®Ãϳ¶
°Ê¹º¶·»·À°Ê°¶³½¹°À·¼··¬®·¬®Ð°¹°¬µ°¶¿°·¹·®¼·®²³·¬É±·³Ì¼·¶º¿º¶·®±·ÃηÀ°Ê°¶·¬³®·®¬·¹Ê·¼·±°¶°±º¶¬²³·¬·Ì¶°·¬¼³¬À®°®°¼·¹°®Æ¶·É±¹µ¶¹·¶½®¿¶¹°®¬¬³·¼³±°µ·³¶·É°¶·®¼¶·¼¬±¶¹®°®·Ãη¬¾°¶°®¬¬®Àº®º¶°·¹·®¼³·¬°³Ì±®¼®¬¼½°±²³¬®·°³Ìµ·¶¬®®·¬Ñ³®··¬»±Ò³¶·»ÃÃÃÓÃÅ¿°³¼®±¼¹®³·¶·³¶¬·Ò·¬»±½·¬É¼¶·¹µ¬·¶¼·¬
±®¶°®·¬¼½³¬°®³°¾¶³®¬Ë¬Æ¹·¶Ê³¬·É±·¬¼·¶®·¶¬ÃÔ®¬¶·¼½³®¬Ë¬Æ¹·Ê¹º¶²³·»®³¬°¾®¬³®¬±¶·²³¶·
ÕÆ·°¶·¬¬·¹Ê°®±·
·®¶··À°Ê°¶¼·¶º¿º¶·®±··¼··¬ÃÄ·¬±¶·µ·³Ö¶·³®·¬¹°¶º·¼°®¬±·
±°¬µ³¬·¬±¶··¬À¶°®¼µ³¬®°¼·¶·¬¬·¹Ê°®±·±½·¬É¼¶·²³·°µ·¶¬®®··¬Ê·®±··²³½··µ¶º·®¼Ñ¶·¾·®¼²³·ÓÃ
×®¼¼°®¬±·±°¬²³·±½·¬³®±·®ÃĽ·¬
·±°¬¼½³®·±¶¶º°®µ°¶·Ì·¹µ·Ã笱¶·µ·³Ö¶·°³¬¬³®·¹·¬³¶·¼·¼¬°®±·»
³®·¼¬°®±··³±¼·®®·µ°¶·Ì·¹µ·ÃØ°®¬±·±°¬»µ³¬·¬±¶··¬À¶°®¼µ³¬°
¶·¬¬·¹Ê°®±··¬¿°Ê·ÃĽ·¬±·²³¬·µ¶¼³µ³¶³®·µ·¶¬®®·µ¶º·®¼°®³®·
¼·®º°³¶·²³·°¬·®®·»¼°®¬±·±°¬®¼²³½®·¬·®µ¶º¬·®±·¼½³®¹µ¬·³¶Ã
Ù®·¼º±¬®·¬¿°·¬³¶±·¬±¶·Ê·®³µ³¶¾°¼·¶½¼·®º¼·°µ·¶¬®®·³
°¶·¿³¬·¶Éµ°¶¶¼½³®·±¹µ°¶°¬®°¾·±³®¬·³¼ºÂ®°³µ°¶°¾°®Ãطɵ·³¾·®
¬³¶À¶¼·³Ì·¶¶·³¶¬Ç
Úΰ¿°³¬¬·°±±·µ°®ÇÄ···¶¶·³¶°µµ°¶°Û²³°®¼®°±±·µ·³®·Ü¹°³¾°¬·Ü
µ·¶¬®®·Ã×®±®¿®¼°®¬½¼·®º¼½³®¹µ¬·³¶°¾·±±··¼½³®±·®Ã
×®
±°±³·°¶¬³®°³Ì¼·¿°³¬¬·°±±·µ°®ÑÜÝ°¬·È±±·µ°®±·Þ°·ÜßÝÈÞÓÇ
FAR =
àáâãäåæåçèéêêåêèëëåìíèíîáïêàáâãäåíáíèðæñèëëòêîâìáêíåéäê
Úη¿°³Ì¶·Ð·ÇÄ···¶¶·³¶°µµ°¶°Û²³°®¼®¶·Ð··½¼·®º¼½³®±·®·
·¶·±®®°Û°®¬±¹¹·³®¹µ¬·³¶Ã×®º¾°³·°¶¬³®°³Ì¼·¿°³Ì¶·Ð·
ÑÝ°¬·Þ·Ð·±®Þ°·ßÝÞÞÓÇ
FRR =
àáâãäåæåçèéóäåôåíêàáâãäåíáíèðæñèëëòêëðîåïí
ȵ°¶¶¼·±·¬¼·³Ì¹·¬³¶·¬»®³¬¼ºÂ®¬¬®¬·¬±¶·¼·¹º¼·¬°³Ì¼½·¶¶·³¶¬
Ñõ°¿ö°Ô¶¶¶Þ°·ßõöÔÞÓ²³·¬°¹Ë·®®·¼³ÝÞÞ·¼³ÝÈÞÃηõöÔÞ

÷ øùúûüýþÿüýþøýü
!"#T0
#$ $T0%&$T0%%' ( # )*+,
-.$/#- .0/%1&# 2 *33$/33/%0 2#334 )563 #
0 0.1 0.2 0.3 0.4 0.50
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
FAR
FR
R
Courbe ROC
EER
789:;<=>?@ABCDEFGHA
I I" 0& -) # & #*J33 & I 0 J2& ) #)2
0.1%
2 J)*&# I I . *#II 4K L 6#&I33 M
NOPQRSTUVWXYZTUTV[\]\W
#*_2 # #I#&*& L

abcbdefghegfijiklemndi o
pqrstupvrwwxyqzv||~svpx|yrwrqppsqsq|r|rxyqpx~s|zqwyq|wqwyqsqwwx|wy|rzpvpx|yrqvspxqyrxwvqtvwr|pqpqyq|xzxp~qp|rsrqrpxzxwvpx|qsw|qzzqyqzvx|~psxq|r|rsrqrpxzxwvpx|yqwwqsxqwyqz|sysq||wxysqrqzvsxxvzqw|rsqyqvsxvpx|qwpzqvqqpyqw|yxpx|wyvrxwxpx|qpzrwvspxrzxsqqpz~zvxsvqwrszvrqzzq|vzq|xwyq|pszq|wwxzqtvwqpsvvxz|rwvzz|w|q|xsrvpqrsrx~zxxqsvzxzzrxvpx|vxvpqtqwxvqwqw|spxqwqs|pwpvzqwvssv|spvrvsxvpx|wy~zvxsvqtvvszvwrxpq|wpsrxprvz|sxpqyqsq|vxwwvqzrwwxzqqp|xw|zqqrqzqwwwpqwrwrqzwp|rpq|wqsvpzqwqwqs|svqwtqpvz|sxpq|rssvxpvszvwrxpqpsqxp~s~wrsr||wvps|svvzqqpqppsqq|qrsqyqw|px|wxz~qp~qwwrszqvpqrst
¡¢£¤
qppqpwqqwp|svxw~qyqzvvxsqwrxvpqvwzqvxpsq¥|rws~wqp|wrqyqwsxpx|yqzvsxpqprsq~~svzqyrwwpqyqsq|vxwwvqyqxwvqt¦rxw|rwy~pvxzzqs|wyqwvz|sxpqwrx|p~p~xp~s~wwrs||wvpws|svvzqwyvwzqrpyv|xsrwwpq|xzqqppqws~qztqws~pxqwvvz|xrqww|pqwrxpqs~wqp~qwqp|rwy~pvxzzqs|wzqwyx§~sqpwpsvxpqqpwvxpwwrsvpqrswrxqrqp|rwxp~sqwwqs|rszv|qpx|yrwwpqyqsq|vxwwvqtwwpqyvrxwxpx|qs|qxsvs|rqqwpy~pvxzz~vswrxpqrx|rwqsqppsvy~zxxqszxzzrxvpx|vxvpq|rsv~zx|sqszqwqs|svqwyqsq|vxwwvqyqxwvqtvwzqvxpsq©|rws~wqpqs|wzqwvpqrswyxvqwzvwwxrqwtuwrxpqzqwvpqrswxpqzzxqpwrq|rwv|w~pryx~wqp|ªrwyrsvpqpsvvxzyqpwq|rsz~zxxvpx|yqzxzzrxvpx|vxvpqtqrvpqrswqz|vpyqr~p|yqwyx§~sqpqwyqwrsqwwx|yqz~zvxsvqvxvpw|ps~wqp~wtv|rqvrp~yrwq|yvpqrs|ªrqwpzvs~wqqwxrzpv~qyqyqrpqwyx|svpx|rqqxwxzqqpzvwq|yqqs|qxsvs|rqt«|rwv|wqwrxpqy~sxpzqwyx§~sqpqwvwqwyqy|~qwrq|rwv|wvrxwqwvqqwvpqrsw|rspqwpqsqp~vzrqsvszvwrxpqzqrswv|spwvssv|spvrvpqrswyxvqzvwwxrqwtvwzqvxpsq¬|rwvzz|w|rwxp~sqwwqszvy~pqpx|yq|xpwvsvp~sxwpxrqwt«|rwxpqs|wzqwvs|qwzvwwxrqwyqy~pqpx|rxw|rws~wqpqs|wr|rqzvz|sxpqyqy~pqpx|vyvp~vrxvqwvrxwqwvqzqwvpqrswy~sxpyvwzqvxpsq©tv|qpx|yqqpvz|sxpqqwpvxpqvqzv|psvxpqyxp~svpx|t¦|rsqzv|vrpxzxw~rqyqw|~svpqrswrx|p~p~xz~qp~wwrs||wvpwqpy~sxpwyvwzqyqrxqvxpsqt

®°±²³µ¶·²³¹º»®³²¹
¼½¾¿ÀÁÂýÄÅÆÇÁÈɾÊË¿ÌÆËÍÅʾ¿ÀνÄÄÇÊÂÃÁÀʽÀÁÄÊËÇÀ½ÇÁÂʾ¾½Å¿¿½¾ÂÁÍÁÏÅп½ÑÁÁÆÁ¾Ä½ÇÆÅÂËÀÅÁÇÀνÀÑÊÇÅÆÃÒÁÓÔÕÖ×ÊË¿ÄÇÌ¿Á¾ÆÁÇʾ¿¿Á¿ÄÁÇØÊÇÒ½¾ÂÁ¿¿ËÇ˾ÁÙ½¿ÁÄËÙÀÅÚËÁÖÓ¾¿ËÅÆÁɾÊË¿ÂÊÒĽÇʾ¿ÀÁ¿ÇÌ¿ËÀƽƿÍÁÂÁƽÀÑÊÇÅÆÃÒÁ½ÏÁÂÍνËÆÇÁ¿½ÀÑÊÇÅÆÃÒÁ¿ÍÁÀÎÌƽÆÍÁÀνÇÆÙ½¿Ì¿¿ËÇÍÁ¿½ÄÄÇÊÂÃÁ¿ÑÀÊÙ½ÀÁ¿É¿ËÇ˾ÁÙ½¿Á½ÂÚËÅ¿Á½ÏÁÂÀÁ½ÄÆÁËÇÛÜÝÛÁƾÊË¿ÒÁ¿ËÇʾ¿½Å¾¿ÅÀνÄÄÊÇÆÍÁÀνÂÚËÅ¿ÅÆÅʾÁ¾ÄÇÊÂÃÁžØǽÐÇÊËÑÁĽÇǽÄÄÊÇÆÞ˾Á½ÂÚËÅ¿ÅÆÅʾÁ¾ÏÅ¿ÅÙÀÁÖ×ÊË¿ÄÇÌ¿Á¾ÆÁÇʾ¿Ë¾Á½ÄÄÇÊÂÃÁ¾ÊËÐÏÁÀÀÁÍÁÇÁÂʾ¾½Å¿¿½¾ÂÁž¿ÄÅÇÌÁÍÁÀÎÓÀ½¿ÆÅÂÔǽÄÃÕ½ÆÂÞÑÁÆÇÁÄÇÁ¾½¾ÆÀÁ¿ÄÊžƿ½ǽÂÆÌÇÅ¿ÆÅÚËÁ¿ÄÇÌÂÌÍÁÒÒÁ¾ÆÍÁÆÁÂÆÌ¿ÖßÁƽÀÑÊÇÅÆÃÒÁÁ¿ÆÆÁ¿ÆÌ¿ËÇÀ½Ù½¿ÁÛÜÝÛÁÆÂÊÒĽÇ̽ÏÁÂÀνÀÑÊÇÅÆÃÒÁÓÔÕÖ×ÊË¿à¾ÅÇʾ¿ÂÁÆǽϽÅÀÍÁÆÃá¿ÁĽÇÀ½ÂʾÂÀË¿ÅʾÁ¾ÍÁǾÅáÇÁĽÇÆÅÁÊâ¾ÊË¿ÄÇÌ¿Á¾ÆÁÇʾ¿ÀÁ¿ÄÁÇ¿ÄÁÂÆÅÏÁ¿ÁÆÀÁ¿ØËÆËÇ¿ÆǽϽËãÖ

Chapitre 2
État de l'art
Dans ce chapitre, nous allons donner une vue d'ensemble de l'état de l'art concer-nant la reconnaissance de visage en temps réel et des algorithmes utilisés dans cebut. Nous allons aussi voir l'intérêt des rétines électroniques pour l'amélioration desperformances des systèmes temps réel. En eet celles ci permettent une améliorationde la qualité des données et le traitement de l'information in-situ. Dans le cas de notreapplication : la reconnaissance de visage, nous cherchons à éliminer la variable illumina-tion qui joue un rôle important sur les performances d'un système de reconnaissance.L'acquisition active, où la capture d'image se fait à l'aide d'une source de lumièrecontrôlée, est une solution qui permet de s'aranchir de ces eets. Nous présentonsdans la section 2.4, les diérents travaux faits sur les capteurs et les algorithmes enproche infrarouge.
2.1 Introduction
Les recherches sur la reconnaissance de visage ont commencé au début des an-nées 70. Elles ont connu un essor récemment pour des raisons sécuritaires. On note eneet un intérêt croissant de la part des états et des industriels pour ce domaine de re-cherche qui s'est manifesté par l'introduction de l'image de visage numérisée dans lesdocuments ociels tels que le passeport et une probable carte d'identité biométrique.Diérentes bases de donnée de visage ont été collectées an de tester les performancesdes algorithmes de reconnaissance et des compétitions à l'échelle mondiale sont or-ganisées chaque année pour évaluer les avancées réalisées dans ce domaine. Citonsen particulier FRGC et MBGC en 2008 organisées par le NIST. Mais la biométrie dereconnaissance de visage connaît des challenges techniques assez importants du fait
9

10 CHAPITRE 2. ÉTAT DE L'ART
que le visage est sujet à de multiples variations liées soit aux conditions d'acquisition(problème d'illumination) soit aux poses et à l'expression.
2.1.1 Architecture généraleUn système de reconnaissance de visage peut être considéré comme composé de
4 parties (gure 2.1) [42] :
Figure 2.1: Schéma général d'un système de reconnaissance de visage
Capture : C'est la première étape dans le processus. C'est aussi l'acquisitiondes informations et leurs transfert vers l'unité de traitement. Elle est une étapetrès importante dans les systèmes de reconnaissance. En eet, avoir des imagesde bonne qualité en référence améliore les performances de reconnaissance. Ilfaut réussir à capter l'information pertinente sans bruit. Il existe plusieurs typesde capteurs pour l'acquisition du visage qui se classe selon leur mode de fonc-tionnement, leurs domaine de sensibilité spectrale et leur mode d'acquisition.On trouve sur le marché les capteurs classiques d'image à 2D tels que : les CCD(Couple charged device) ou CMOS pour capturer des images dans le spectrevisible et/ou proche-infrarouge, ou les capteurs thermiques qui permettent uneacquisition dans l'infrarouge. Il existe des capteurs qui nous donnent une imageavec l'information 3D, cela se fait par des scanners 3D, où la mesure de laprofondeur est réalisée grâce à un rayon laser balayant la scène ou par stéréovision. Chaque type de capteur présente des avantages et des inconvénients.Dans la reconnaissance de visage on peut utiliser les capteur 3D par exemplepour s'aranchir des problèmes de pose. Mais leur prix excessif ne permet pasune utilisation à grande échelle. Les capteurs en proche infrarouge sont utiliséspour éliminer les problèmes de l'illumination. Nous allons nous intéresser dansce travail à ce dernier cas.
Détection du visage : Après avoir capturé la scène contenant un visage, ladeuxième étape consiste à l'extraire de l'image. Cela peut se faire par détec-tion de la couleur de la peau, ou par des méthodes détectant les diérentescaractéristiques du visage par des descripteurs locaux (adaboost). Cette étapeest autant plus délicate autant que l'image acquises contient plusieurs objets

2.1. INTRODUCTION 11
de visage ou un fond non uniforme qui crée une texture perturbant la bonnesegmentation du visage. Cette étape est dépendante de la qualité des imagesacquise. Après la segmentation du visage, on peut ltrer ou améliorer la qualitépar des pré-traitements qui sont appliqués au visage extrait. On peut eectuerdes normalisations géométrique et photométrique. Ces pré-traitements sont né-cessaires pour éliminer ou limiter les variations de pose ou d'illumination. Unpré-traitement photométrique tend à uniformiser l'éclairage dans une image etainsi minimiser l'inuence de l'illumination. Cela peut être eectué soit par desméthodes simples telle que l'égalisation d'histogramme, une correction gammaou par des méthodes plus complexes tel que le lissage anisotropique [25] ou laméthode retinex. Une normalisation géométrique est un ajustement du visagepour qu'il ait une dimension donnée et qu'il soit horizontal. La taille du visageest généralement donnée par la distance inter-oculaire. La gure 2.2 montre lanormalisation géométrique.
Figure 2.2: Normalisation géométrique du visage
Tous ces pré-traitements tendent à éliminer les variations de formes du visage(rotation, taille) et à avoir une image uniformément éclairée. Ainsi, l'image duvisage ressemble à une image acquise dans de bonnes conditions, comparable àcelles de l'image de référence. On diminuera donc les chances d'un faux rejet.
Extraction de caractéristiques : le but est d'extraire les caractéristiques duvisage qui peuvent le rendre à la fois diérent de celui des autres personnes etrobuste aux variations de la personne elle-même. C'est l'information nécessairepour que le visage d'une personne ne ressemble pas à celui d'une autre per-sonne et en même temps qu'il ressemble à lui-même dans d'autres conditionsd'acquisition. Au début des travaux sur la reconnaissance de visage [12][22],on a estimé qu'une représentation du visage devait passer par l'utilisation de la

12 CHAPITRE 2. ÉTAT DE L'ART
bouche, des yeux, du nez, de leurs positions relatives et de leurs géométrie. Maiscette procédure a montré ses limites [15]. Il faut alors une analyse plus pousséedu visage pour trouver d'autres caractéristiques. Dans certaines méthodes, onn'utilise d'ailleurs que la détection des yeux pour normaliser le visage et on faitensuite une étude globale du visage (algorithme type ACP, LDA, etc.)
Comparaison des caractéristiques : selon les caractéristiques extraites précé-demment, les algorithmes de comparaison dièrent. On trouve dans la littératureplusieurs approches : calcul de distance, calcul de similarité. D'autres méthodesse basent sur la classication des caractéristiques par un seul classieur (SVM,classieur baysien, etc.) ou par plusieurs (Adaboost).
2.1.2 Challenge techniquesLa problématique de la reconnaissance de visage est celle des variations intra-
classe. En eet, les variations d'illumination, de pose ou d'expression détériorent lesperformances d'un algorithme de reconnaissance. Le visage d'une personne X peutressembler plus à celui d'une personne Y qu'à lui-même si l'on change les condi-tions d'acquisition. Ces eets sont surtout notables dans un contexte de mobilitéoù on n'a pas de contrôle sur l'environnement de l'acquisition. Pour cela, on essaiede trouver une bonne méthode qui permette de s'aranchir de ces diérentes varia-tions. Les algorithmes de normalisation photométrique permettent d'atténuer l'eetde l'illumination. Ils ont permis ainsi d'améliorer considérablement les performances dereconnaissance [85] dans certains cas précis acquis en lumière visible. Une seconde voieconsiste à utiliser l'acquisition active. Elle permet aussi d'éliminer ces variations d'illu-minations et ainsi améliorer les performances du système sans augmenter la complexitéalgorithmique. Cela permet une meilleure intégration de l'algorithme sur composantprogrammable et ainsi d'eectuer la reconnaissance en temps réel avec une consom-mation d'énergie raisonnable.Nous allons présenter dans ce qui suit quelques algorithmes de reconnaissance du vi-sage qui ont été implémentés sur des composants programmables. Ces architecturespeuvent alors nous donner des performances de reconnaissance en temps réel.
2.2 Reconnaissance de visage en temps réelLes industriels et les laboratoires de recherche se sont intéressés aux applications
de la reconnaissance de visage sur des terminaux mobiles. L'aspect ergonomique del'usage de cette biométrie attire les industriels pour sécuriser les sessions de travail oupour la personnalisation des appareils mobiles. La rme OKI a été la première à inté-grer un système de reconnaissance de visage dans les appareils téléphoniques comme

2.2. RECONNAISSANCE DE VISAGE EN TEMPS RÉEL 13
une alternative au code PIN à travers leur système "Face Sensing Engine" [1]. L'inté-gration des algorithmes de reconnaissance est fait sur des composants programmablesstandards tels que les DSP (Digital Signal Processor), FPGA (Field ProgrammableGate Array), ASIC (Application-Specic Integrated Circuit), etc. Les premiers travauxd'intégration d'algorithmes de reconnaissance de visage datent du début des années90 à l'université de Harvard [21]. Les auteurs ont conçu un circuit pour accomplirla tâche de comparaison (une corrélation dans ce cas). Le système se compose d'unIBM PC 80486/DX2, d'un extracteur de trames vidéo et de leur circuit de corréla-tion. Cela leur a permis de gagner en ressource du processeur et en temps de calcul.L'architecture du système est présentée en gure 2.3.
Figure 2.3: Schéma global du système de Harvard (Gilbert) [21]
Cette première tentative montre l'ecacité de concevoir un circuit dédié pouraméliorer le temps de calcul de l'algorithme de reconnaissance. C'est dans cet espritque nous avons mis en valeur les prochains travaux. Nous allons présenter dans ce quisuit quelques algorithmes qui ont été implémentés sur des circuits VLSI.
2.2.1 Reconnaissance de visage par réseaux de neuronesLes réseaux de neurones est un modèle de calcul qui date des années 40. C'est
une technique inspirée des réseaux de neurones biologiques pour exécuter des tâchescalculatoires. Elle a la particularité de s'adapter, d'apprendre, de généraliser pourclasser les données en entrée. Un réseau de neurones se compose essentiellementde [35] :
Un ensemble de cellules de calcul, appelées aussi neurones. Chaque neuronepossède un état d'activation mesuré à sa sortie yk.

14 CHAPITRE 2. ÉTAT DE L'ART
Un ensemble de connections entre les neurones. Chaque liaison est caractériséepar un poids wjk reliant l'unité j avec l'unité k.
La loi de propagation du réseau : l'eet de l'entrée active sk d'un neurone surles diérents neurones.
La méthode de collecte de l'information (règles d'apprentissage). La fonction Fk réalisée par la cellule. Une entrée externe qui peut être considérée comme un décalage θk
La gure 2.4 montre ces diérents caractéristiques.
Figure 2.4: Composition d'un réseau de neurones
Plusieurs types de réseaux de neurones existent dans la littérature, nous allons nousintéresser au réseau RBF (Radial Basis Function). Selon Howell et Buxton [29], le RBFdonne de meilleurs résultats d'identication de visage que les autres types de réseauxde neurones. l'architecture d'un réseau RBF est présentée en gure 2.5. Il se composed'une couche d'entrée, une cachée et une de sortie. La couche d'entrée se composede N cellules pour un vecteur correspondant à l'image d'entrée composée de N pixels.Toutes les cellules de la couche d'entrée sont connectées aux I neurones de la couchecachée qui eux même sont connectés à ceux de la couche de sortie. Chaque noeud dela couche cachée donne en sortie un signal proportionnel à la distance entre l'entréeet le centre correspondant de la cellule ci. La distance euclidienne est généralementla plus utilisée (d((x))). La fonction d'activation du neurone est une gaussienne :
Fk = exp−d(x)2/σ2i
Les paramètres d'apprentissage du réseau sont alors : les centres ci, la taille de lafonction σi et les poids des connections. Pour chaque personne, on construit à partird'un ensemble d'images un réseau qui lui correspond. Il est clair que dans ce cas, lesimages d'entraînement doivent contenir les diérentes variations d'illuminations, de

2.2. RECONNAISSANCE DE VISAGE EN TEMPS RÉEL 15
Figure 2.5: Réseau de neurones RBF [82]
Nombre de slices utilisé 827Pourcentage utilisé 27%
Nombre de bloc RAM utilisé 16Pourcentage des bloc RAM utilisé 100%
Table 2.1: Ressources consommées sur le FPGA SpartanII pour le RBF
poses et d'expression. Un problème peut se poser si on a peu d'images d'entraînementde la personne.
Ce réseau a été implémenté et testé sur plusieurs composants programmables(DSP, FPGA et ZISC) [82] [62][63]. Dans [82], les auteurs ont implémenté le réseausur un FPAGA Xilinx SpartanII-300 qui contient 3072 slices (unité logique de basedans un FPGA qui possède 4 entrées et une sortie et peut simuler une fonction logiquecomplexe), 16 blocs mémoire de 512 octets. La couche cachée du réseau contient 15cellules, et le vecteur d'entrée est de taille 320. Le tableau 2.1 montre les ressourcesconsommées pour l'implémentation de ce réseau. La fréquence d'horloge du FPGA estde 50MHz. Cela permet un traitement de 14 images par seconde avec une performancede bonne reconnaissance de 92% sur 1796 images de visage.
Dans [82], les auteurs ont testé aussi l'implémentation d'un RBF sur un DSP deTexas Instrument. Ils ont choisi le TMS320C6201B : un DSP à calcul en virgule xeavec une fréquence d'horloge de 200MHz. Ce DSP est capable de traiter 8 opérationsen un cycle d'horloge. Le tableau 2.2 montre les résultats de cette implémentationavec un code en C et une implémentation optimisée en assembleur.
Une autre implémentation de ce type de réseau a été étudiée dans [33] où lesauteurs ont développé un processeur dédié. Le système proposé est composé d'unecaméra CMOS d'une résolution 640×480 et d'un processeur SIMD (Single Instruction

16 CHAPITRE 2. ÉTAT DE L'ART
langage C AssembleurExtraction des vecteurs d'entrées 4.14 ms 1.8 msCalcule de distance 211 ms 144 msFonction Gaussienne + Décision 67msVitesse de traitement 3.5 images/sec 4.8 images/sec
Table 2.2: Résultats d'implémentation d'un RBF sur DSP
Multiple Data). La taille des images en entrées du réseau, après normalisation, est de64×72. Avec cette architecture, ils ont pu atteindre une vitesse de reconnaissance de4.2ms avec un taux de reconnaissance de 90% avec un taux de fausse acceptation de1%
2.2.2 Reconnaissance de visage par Analyse de composante princi-pale
C'est l'algorithme de référence de la reconnaissance de visage. C'est une méthodede réduction d'espace connue aussi sous le nom de transformée de Karhunen-Loeveou PCA (Principal Component Analysis). Elle a été utilisée par Turk et Pentland dans[75], où la notion de "eigenface" a été introduite pour exprimer les diérents vecteurspropres de la base d'images de visage de la PCA. En eet, on peut considérer queles images de visage de dimension N × N pixels ne forment qu'un sous ensemblede l'espace des images de dimension N ×N . Il est alors intéressant de chercher unereprésentation d'un visage dans cet sous ensemble appelé espace des visages. Cetespace est construit à partir d'un ensemble d'image de visage constituant la based'apprentissage. La PCA a pour objectif de maximiser la variance entre les données.Cela revient à maximiser la variance entre les "diérents visages". Pour un ensemblede N images, X = x1, x2, ..., xN est l'ensemble des images exemples, l'analyse parcomposante principale est une décomposition en éléments propres de la matrice decovariance C de ces données d'apprentissage.
C =1
N − 1
N∑
i=1
(xi − x)(xi − x)T
Où x est la valeur moyenne de X :
x =1N
N∑
i=1
xi
Si xi est un vecteur de dimension M . On aura alors M vecteurs propres (eigenvectors)v1, v2, ..., vM de dimension M et M valeurs propres λ1, λ2, ..., λM. Ces vecteurs

2.2. RECONNAISSANCE DE VISAGE EN TEMPS RÉEL 17
propres forment une base orthogonale en résolvant l'équation :
Cv = λv
où C est la matrice de covariance et v est un vecteur et λ un scalaire.Les valeurs propres λ1, λ2, ..., λM représentent le taux de variation le long de l'axedu vecteur propre associé. Dès lors, on pourra éliminer les vecteurs propres les moinsimportants sans perte conséquente d'information. On dénit alors la proportion P dela variance contenue dans les Q premiers éléments de l'ensemble des vecteurs propreschoisis :
P =
∑Qq=1 λq∑Mi=1 λi
où Q < M . La projection d'une image I, Ω dans cet espace de visage est donnéepar :
ωi = (I − x)T vi
où ωi est la composante selon l'axe vi.La classication des données est ensuite fournie par un calcul de distance (distanceeuclidienne par exemple) ou par des moyens plus élaborés tel que le SVM (SupportVector Machines). Cette approche PCA est assez dépendante de l'espace de visagechoisi. En eet, plus la base d'apprentissage est grande et intègre des variations d'illu-mination, de pose et d'expression mieux on peut présenter les visages dans cet espace.
On trouve dans la littérature des essais d'implémentation de cette approche.Dans [38], les auteurs ont intégré la PCA avec un SVM comme classieur. L'intégra-tion s'est faite sur DSP de Texas Instrument (TMS320C6711). C'est un processeur àcalcul en virgule ottante qui peut être cadencé à une horloge de 200MHz. Les imagessont acquises avec un capteur CCD classique. Le temps de vérication atteint varieentre 50ms et 90ms.
Dans [68], les auteurs ont construit un espace de transformée en ondelette discrète(ondelettes de Daubechies) des visages. Cela permet d'améliorer les performances dela reconnaissance. En eet, une analyse en ondelette du visage permet d'en extraireles informations pertinentes. Ensuite la PCA réduit les redondances de l'analyse. Leclassieur choisi dans ce cas était une distance euclidienne. L'intégration de cetteméthode a été eectuée sur un FPGA Spartan-II d'une taille de 300K portes. Lesressources utilisés pour leur système sont présentées dans le tableau 2.3
Ces performances permettent un fonctionnement avec une fréquence de 25Mhz de12.5 trames par seconde. Les auteurs indiquent que pour une vitesse plus importante,l'utilisation d'un FPGA plus récent permet de doubler la vitesse de traitement.

18 CHAPITRE 2. ÉTAT DE L'ART
fonction Memoire Slice FFs Fréquence (MHz)Contrôleur SDRAM 2 247 196 832-D DWT 2 175 223 113.3PCA 2 202 380 131.5Classieur 1 275 450 104.1Total 7 (56%) 1274(42%) 1543 (25%) 50
Table 2.3: Ressources utilisées dans [68] sur un FPGA XC2S300
2.2.3 Reconnaissance par correspondance élastique de grapheLes approches les plus utilisées en reconnaissance de visage en temps réel sont les
algorithmes à approche locale. Ces algorithmes se basent sur la comparaison de ca-ractéristiques locales du visage. Un de ces algorithmes est la correspondance élastiquede graphes ou le "Elastic Graph Matching" (EGM). Cet algorithme est inspiré du"Dynamic Link Architecture" (DLA) [37]. L'EGM représente le visage par un grapheétiqueté. Un graphe est composé d'un ensemble de noeuds connectés entre eux par descontours. Chaque noeud peut correspondre à un point caractéristique du visage [81](gure 2.6-a)) ou à un noeud d'une grille superposée sur le visage [34] [18] (gure 2.6-b)). Il est caractérisé par son nom ou sa position et par un vecteur qui contient l'analyselocale de son voisinage. Cela permet d'avoir une information locale à travers les noeudset une information globale par leurs inter-connections. Chaque noeuds comporte descaractéristiques locales du voisinage du noeud. Celle ci peut être determinée par uneanalyse par ltres de Gabor ou par une série d'opérations morphologiques. Le résultatde cette analyse est enregistré dans un vecteur appelé Jet. Les jets et les positionsrelatives des noeuds constituent un modèle du visage.
Figure 2.6: Diérents type de graphe pour l'EGM
Une des méthodes d'analyse pyramidale (sur diérentes échelles) est l'analyse par

2.2. RECONNAISSANCE DE VISAGE EN TEMPS RÉEL 19
un banc de ltre de Gabor. En changeant la taille et les orientations des ltres, nousobtenons une analyse multi-résolution du voisinage du noeud. Duc et al. ont choisiune analyse sur 3 résolutions et 8 orientations [18]. Dans la méthode proposée parl'Université de South California (USC) [9], les auteurs utilisent une analyse avec desltres de Gabor avec 5 résolutions et 8 orientations. La seconde approche d'analysemultirésolution est celle qui utilise la morphologie mathématique. Elle est constituéd'une série d'érosions et de dilatations par un élément circulaire de taille variable. Pourun noeud x dans une image f et un élément structurant circulaire gσ :
(fFgσ)(x) =
(f ⊕ gσ)(x) if σ > 0,
f(x) if σ = 0,
(f ª g|σ|)(x) if σ < 0.
où ⊕ est l'opérateur de dilatation et ª est l'opérateur érosion. Dans [34], les auteursont construit une grille de taille 8 × 8. Chaque noeud x est caractérisé par un jet detaille 19 : j(x)=((fFg9)(x), ..., f(x), ..., (fFg−9)(x)). Pour comparer deux graphes(ou deux images : une de référence et une de test), on calcule la similarité entre lesjets :
Sj(j(xri ), j(xt
i)) = ‖j(xri )− j(xt
i)‖
La comparaison de deux images est une correspondance entre les deux graphes. Lapremière étape est le calcul de similarité entre les noeuds qui est un produit scalairenormalisé de deux jets :
S(JI , JM ) =JI .JM
‖JI‖.‖JM‖où JI (resp. JM ) est le jet de l'image de test (resp. de l'image de référence).
La correspondance de deux graphes se fait en deux temps [37]. En premier lieu,une comparaison rigide qui calcule la similarité entre les deux graphes sans dépla-cement des noeuds (Sjets). Puis une comparaison élastique qui tend à retrouver lesmeilleures correspondances entre les noeuds. Mais, ce déplacement est pénalisé par ladéformation de la grille et ensuite par les modications de distance entre les segmentsreliant les noeuds (Sseg). Le coût total de ces deux opérations est la similarité entredeux graphes (i relatif à l'image de test et r de référence) est :
Stotal = Sjets + λSseg =∑
i∈N
J ti .J
ri
‖J ti ‖‖Jr
i ‖+ λ
∑
(i,j)∈E
(−→∆t
ij −−→∆r
ij)
où λ est un facteur d'élasticité, N (resp. E) est l'ensemble des noeuds (resp. dessegments reliant les noeuds) dans le graphe et −→∆ij est le segment reliant les noeuds

20 CHAPITRE 2. ÉTAT DE L'ART
i et j : −→∆ij = −→xj −−→xi
Plusieurs travaux ont été menés pour intégrer cet algorithme de reconnaissancede visage. Son analyse locale des points caractéristiques attire l'intérêt par rapportà l'aspect intégration et aussi la robustesse de l'algorithme face à des changementsde poses ou d'expressions. Les tests d'intégration de cet algorithme ont été faits surplusieurs composants, nous allons citer ici quelques travaux eectués. Les composantscibles utilisés sont soit des FPGA soit des ASIC. On utilise le langage descriptif VHDL(VHSIC Hardware Description Language) en vue d'utiliser une architecture MIMD(Multiple Instruction Multiple Data). Cela permet d'avoir des temps de calcul courtset un traitement en temps réel.
Dans [49], les auteurs ont intégré cet algorithme sur plusieurs processeurs. Leursystème se compose d'une caméra CMOS classique d'une résolution de 320 × 240,d'une RAM partagée entre les diérents processeurs, une unité de calcul dédiée à lamorphologie, une seconde pour la tache de correspondance et un processeur maîtrepour gérer ces diérents composants. Le schéma global est présenté en gure 2.7.
Figure 2.7: Architecture générale du système proposé par Nagel [49]
Dans [60], une architecture de l'EGM avec une analyse multi-résolution avec lesltres de Gabor a été implémentée. Les auteurs ont utilisé une architecture qui res-semble à celle proposée par USC à savoir un ensemble de 5 résolutions et 8 orientations.Mais, ils ont diminué le nombre de points caractéristiques. Ils ne s'intéressent qu'à 7points féodaux : les centres des yeux, le centre du nez et 4 points sur les bords de labouche. L'architecture en pipeline pour le calcul des jets est présentée en gure 2.8 a

2.2. RECONNAISSANCE DE VISAGE EN TEMPS RÉEL 21
été implémentée sur un FPGA VirtexII de Xilinx. Cette Architecture fonctionne avec
Figure 2.8: Architecture de Calcule des Jets
une fréquence de 100MHz ce qui permet de travailler avec un taux d'image de 70trames par seconde et cela en n'utilisant que 7 points caractéristiques et en intégrant10 unités de traitement des ltres de Gabor. Les ltres de Gabor sont enregistrés sur12bites dans des RAM. Le calcul des ltres se fait au préalable sur MATLAB pourdéterminer la bonne précision du format à virgule xe.
Une autre architecture a été proposée dans [50], où l'on partage le calcul entreFPGA et microprocesseur d'un ordinateur. Le schéma global est présenté en gure 2.9.Les auteurs ont exploité l'architecture de calcul parallèle du FPGA pour faire la cor-respondance (Matching) et ainsi améliorer le temps de calcul. Avec un PC équipé d'unprocesseur Pentium M de fréquence 1GHz et un FPGA ALTERA cadencé à 48MHz,toute la chaîne de reconnaissance s'exécute en 1ms.
2.2.4 Comparaison des algorithmes
Les algorithmes de reconnaissance précédemment décrits ne sont pas tous équiva-lents. En eet, outre le fait qu'ils se basent sur des approches d'analyse diérentes,leurs performances de reconnaissance et leur robustesse face aux variations sont dif-férentes. Il faut noter que les tests mentionnés dans les diérentes publications citées[82][33][38] sont évalués sur des bases privées, généralement de faible taille. La re-connaissance par réseau de neurones a été testée sur un base de 8 vidéos, mais validé

22 CHAPITRE 2. ÉTAT DE L'ART
Figure 2.9: Système de reconnaissance de visage temps réel : ux de donnée
préalablement sur la base Olivetti Att - ORL. C'est une base qui se compose de 40personnes et chaque personne possède 10 images. Avec un modèle construit avec 5images on obtient un taux de reconnaissance de 97.1%. Plusieurs publications ontcritiqué la sensibilité de cette méthode par rapport aux variations d'illumination et depose si le modèle d'apprentissage ne contient pas susamment d'images variées. Lesecond algorithme qui est l'analyse par composante principale est un algorithme consi-déré comme l'approche de base (baseline). Elle fut bien utilisée au début mais a vitemontré ses limites vis à vis de l'illumination. La présentation de l'espace des visagesutilisée est aussi une limitation de la méthode. En eet, on ne cherche qu'à renforcerla diérence entre les personnes[61]. Cela donne des faux rejets assez importants lorsde changements d'illumination ou de pose. Durant la compétition de FRGC (Face Re-cognition Grand Challenge), il est utilisé comme algorithme de référence pour toutecomparaison. Mais, on peut choisir aussi la LDA (Linear Discriminant Analysis) oula ICA (Independent Component Analysis) comme algorithme de base. L'approche decomparaison élastique des graphes a été testée sur une base plus importante XM2VTS[48]. L'auteur montre que, sur cette base de 295 personnes, en utilisant l'analyse mor-phologique, on obtient un taux de EER de 13%, alors qu'en utilisant l'analyse deGabor, on obtient un taux bien plus faible de 5%. Cela montre l'ecacité de l'analysede Gabor et son intérêt.
2.3 Capteurs IntelligentsLes algorithmes de reconnaissance de visage sont assez complexes. Ils demandent
beaucoup de ressources tant en mémoires ou qu'en unités de traitement. Cela se tra-duit aussi par une consommation d'énergie assez importante. Pour cela, nous allonsaméliorer la qualité d'acquisition et ajouter des traitements dans le capteur pour al-

2.3. CAPTEURS INTELLIGENTS 23
léger le traitement par la suite. Il vaut mieux "Analyser l'image là où elle est acquisepour n'en retenir et en transmettre qu'un extrait pertinent pour la tâche de vision encours" [8]. C'est le principe des rétines CMOS ou des capteurs intelligents. L'emploidu terme rétine est une analogie au terme rétine biologique. En eet, de nombreuxtraitements implémentés dans un capteur sont inspirés des rétines naturelles (biolo-giques) qui associent capture avec traitement de l'information à travers les structuresneuronales.
2.3.1 Variables analogiquesLe traitement in-situ des signaux issus de la phototransduction nous amène à nous
conformer à leur caractère continuellement variable que ce soit en amplitude ou entemps. Cela nous conduit vers une approche analogique de leur exploitation. Sur uncircuit VLSI CMOS, plusieurs grandeurs physiques peuvent représenter l'information.Chacune possède les caractéristiques suivantes [8] :
Tension : On peut les distribuer sur les câbles ou les mémoriser dans des capaci-tés facilement. Elles sont principalement utilisées pour commander les transistorsMOS (à eet de champs) et bipolaire.
Courant : Issu des transistors, il est facile de l'additionner par la loi de noeudsgrâce à la conservation de la charge. Il tient aussi un rôle important dans lestechniques en mode courant.
Charges : C'est le résultat de l'intégration temporelle dans le temps du courant,ou du stockage d'une tension dans une capacité. On peut facilement transporterles charges grâce aux techniques CCD, ou les additionner, soustraire par destechniques de capacités commutées.
2.3.2 Opérateurs analogiquesOpérateurs locaux
Ce sont les opérateurs qui se trouvent au sein du pixel. En eet, on peut utiliserces opérateurs pour amplier, par compensation ou par association de transistors poureectuer des opérations simples.Au sein du transistor : En utilisant la caractéristique courant-tension exponentielle dutransistor saturé en faible inversion, on peut eectuer une compression logarithmiquedes photocourants.Compensation : Plusieurs composants et opérateurs analogiques nécessitent un réglageindividuel. Il est alors utile de compenser les dispersions en mémorisant ces réglages ausein du pixel sous forme de charges. Association : En associant des transistors, on peutavoir des fonctions très utiles. La paire diérentielle en gure 2.10 a) divise le courant

24 CHAPITRE 2. ÉTAT DE L'ART
I0 en deux courants I1 et I2 en fonction de la diérence de tension ∆V . La diérencede courant ∆I = I2 − I1 peut s'exprimer comme le produit de I0f(∆V ) où f estune fonction sigmoïde. Si les transistors sont identiques, f est impaire et sa partiecentrale est approximativement linéaire, on peut exploiter le schéma pour eectuerdes opérations de multiplication. Le miroir de courant en gure 2.10 a) duplique lecourant Iin en Iout. En combinant les deux schémas, on peut avoir directement ladiérence ∆I.
Figure 2.10: a)paire diérentielle ; b) Miroir de courant [8]
Opérateurs collectifs
La vision par ordinateur met en oeuvre un nombre important de données reliéesentre elles. L'analyse de ces données nécessite des opérateurs à plusieurs entrées.Alors que le traitement numérique ne possède que des opérateurs à faible nombred'entrées, le traitement analogique possède des dispositions naturelles à combiner ungrand nombre de données simultanément. C'est le calcul collectif. On met en oeuvredes équations physiques pour résoudre des problèmes électroniques. On présente dansla section suivante quelques types de rétines intégrant ces traitements collectifs
2.3.3 Rétines CMOS
Il existe en imagerie plusieurs applications des rétines CMOS. Les améliorationsqu'elles apportent sur la qualité d'image et sur l'extraction de l'information utile ré-duisent la complexité algorithmique du traitement et par suite la consommation du

2.3. CAPTEURS INTELLIGENTS 25
processeur. Parmi ces rétines, on en trouve qui eectuent un traitement spatial ou untraitement spatio-temporel.
Extraction de caractéristiques
L'extraction de caractéristiques est l'une des tâches les plus importantes dans lavision articielle. D. Marr [45] montra que les ltres gaussiens sont bien adaptés àl'extraction des primitives dans une image. En eet, un ltre Gaussien possède legabarit passe-bas spatial le plus raide possible qui n'introduit pas des oscillationsdans l'image ltrée. Cette propriété du ltre Gaussien permet une analyse d'imagesur diérentes échelles spatio-fréquentielles an de mettre évidence les informationspertinentes. Plusieurs approches ont été étudiées pour implémenter le ltrage gaussiendans les rétines. Les premières mettaient en oeuvre un réseau de résistance. Mais pourobtenir un noyau gaussien, il faut un réseau réseau négatif ce qui perturbe la stabilitédu système. Une autre approche consiste à implementer un réseau RC dynamiquedont la variance dépend de la constante de temps du réseau et du temps. La faibleconstante de temps de ces réseaux pose un problème de numérisation après. Unesolution proposée par Y. Ni [54] est d'utiliser un réseau de capacité résolvant l'équationde propagation de la chaleur. La structure de ce réseau à 1D est présentée en gure2.11. Pendant la première phase, les capacités Cb sont court-circuitées. Elles sont ainsidéchargées. Durant la seconde phase, ces capacités (Cb) sont reliées aux capacitésCd formant ainsi un réseau modélisant une convolution gaussienne. L'équation de
Figure 2.11: Structure d'un réseau capacitif 1D à convolution Gaussienne
conservation de la charge dans un noeud n est :
CdVn(t+1)+Cb(Vn(t+1)−Vn−1(t+1))+Cb(Vn(t+1)−Vn+1(t+1)) = Vn(t)Cd

26 CHAPITRE 2. ÉTAT DE L'ART
Ce qui nous donne :
(Vn+1(t + 1) + Vn+1(t + 1)− 2Vn(t + 1)) =Cd
Cb(Vn(t + 1)− Vn(t))
Cette expression peut être simplier par :
∂2V
∂x2=
Cd
Cb
∂V
∂t
Cette équation est de la même forme que l'équation de propagation de la chaleur dontla solution est sous la forme :
V (x, t) = V (x, 0)⊗G(n, σ =√
2tCb
Cd)
où ⊗ est l'opérateur convolution, et G est la fonction gaussienne dénie par :
G(n, σ) =1σ
exp(−x2
4σ2)
On peut généraliser cette approche en 2D avec le schéma suivant : Pour réaliser un
Figure 2.12: Structure d'un réseau capacitif 2D à convolution Gaussienne
ltrage DoG qui s'assimile au traitement biologique des rétines [45], il faut soustrairele résultat de deux ltres gaussien. Cela peut se faire soit par échantillonnage duréseau capacitif en deux itérations diérentes et soustraire les deux échatillons ou parconstruction de deux réseaux capacitifs diérents et soustraire leurs réponses.
Une autre approche se base sur les opérations inter-pixel de soustraction ou d'ad-dition pour détecter les contours [74], ou pour extraire le contraste dans une image

2.3. CAPTEURS INTELLIGENTS 27
[65] par limitation du temps d'intégration d'un pixel selon la valeur du photocourantde ses voisins. Des calculs spaciaux peuvent aussi être eectués sur la matrice commeles moyennes, les rotations, les ltres de déformation. Cela est mis en oeuvre grâceà l'intégration de processeur de type SIMD (Single Instruction Multiple Data) quitraite l'image de manière parallèle [59]. Toutefois cette dernière méthode présentel'inconvénient de la nécessité d'un circuit de pilotage important pour les séquencesd'instruction.
Adaptation aux conditions lumineuses
Ces rétines peuvent s'adapter aux conditions d'illumination pour donner une meilleureimage. Cette adaptation peut se faire de deux manières : soit par changement du tempsd'intégration des pixels, soit par compression du photocourant par capture logarith-mique.T. Hamamoto a proposé un capteur d'image CMOS où le temps d'exposition dechaque pixel est contrôlé [26]. Le temps d'intégration se fait ligne par ligne.En traitement d'image, nous savons que l'égalisation d'histogramme est une méthodede restauration de contraste, quand la scène est mal éclairée. La rétine à égalisationd'histogramme réalisée par Y.Ni [56] montre l'adaptabilité de la méthode pour l'ac-quisition d'une image dans une large plage dynamique. Le principe de la rétine estprésenté en gure 2.13. Les sorties des photorécepteurs primaires (photorécepteur enmode d'intégration) (P(i,j)) sont comparées avec le signal de référence rampe. Lessorties des comparateurs contrôlent le générateur de courant constant et égalementl'échantillonneur - bloqueur à l'entrée de la mémoire analogique. La rampe provoque lebasculement successif des comparateurs, et l'ordre de basculement est lié à l'amplitudedes signaux appliqués. Les générateurs de courant constant des cellules commutéessont connectés sur la même ligne. Par conséquent sur cette ligne on construit unhistogramme cumulé des pixels commutés de l'image concernée. Instantanément cesignal d'histogramme cumulé en courant, est converti en tension distribuée à nouveauà tous les pixels. Le basculement du comparateur échantillonne ce signal, le mémorisedans la mémoire analogique locale. La simultanéité entre la construction d'un histo-gramme cumulé et l'échantillonnage de cet histogramme forme une image de sortierégularisée dans la mémoire analogique.
La capture en mode logarithmique exploite la relation de nature exponentielleentre le courant drain ID d'un transistor MOS et la tension grille/source VGS enrégime sous-seuil. L'inconvénient de ce type de capteur était le rapport signal/bruitassez faible dû à l'amplitude assez faible du signal photoéléctrique dans des scènesnormales. Les travaux de K. Matou [46], ont permis d'éliminer ces bruits causés par lestransistors de lecture et de reset en générant une référence noire au sein du pixel. Cela

28 CHAPITRE 2. ÉTAT DE L'ART
Figure 2.13: Principe d'un photorécepteur à égalisation d'histogramme intégré
a pu être réalisé grâce au fonctionnement en mode photovoltaïque de la photodiodequi élimine le transistor de conversion et ainsi une des sources principales de bruitspatial xe. La sortie de la photodiode est donnée par :
VS = Vtln(Iph + Is
Is)
L'architecture du pixel est présentée en gure 2.14.
Figure 2.14: Schéma électrique du pixel en mode logarithmique [53]
Les rétines CMOS peuvent être d'une grande ecacité dans le traitement d'image,vu la qualité de l'image acquise et la préservation de l'information utile. Nous allonsvoir par la suite un exemple d'amélioration des acquisitions par la vision active. Lacapture d'image est alors faite en proche infrarouge pour s'aranchir des eets del'illumination.

2.4. RECONNAISSANCE DE VISAGE EN INFRAROUGE 29
2.4 Reconnaissance de visage en InfrarougeLa luminosité est l'un des problèmes les plus contraignants pour les algorithmes
de reconnaissance de visage [4]. Le changement de condition d'éclairage détériore lesperformances des systèmes de reconnaissance. L'amélioration de la qualité d'imageacquise est une des solutions proposées. En se basant sur les rétines électroniques,nous pouvons nous aranchir des eets indésirables des changements d'illumination.Nous allons nous intéresser dans ce qui suit aux acquisitions actives comme moyend'éliminer l'illumination ambiante.
Figure 2.15: Spectre électromagnétique
La lumière visible occupe une petite partie du spectre électromagnétique (-gure 2.15). Le spectre visible occupe la bande de longueur d'onde entre 0.4µm et0.7µm au dessous de 0.4µm commence le domaine de l'ultraviolet et au delà de0.7µm c'est le domaine de l'infrarouge (IR). Celui ci peut être divisé en 3 : procheinfrarouge de 0.4µm à 2.5µm, IR moyen entre 2.5µm et 25µm et IR lointain entre25µm et 50µm. La capture des ondes en proche infrarouge peut se faire par les cap-teurs d'images classiques : les caméras CCD ou CMOS. En eet, le Silicium restessensible à ces longueurs d'onde. Mais plus on s'éloigne du domaine visible moins oncapte les ondes infrarouges. Le proche infrarouge est rééchi par la peau au niveaude l'épiderme alors que le visible est rééchi à la surface de la peau. Une image en

30 CHAPITRE 2. ÉTAT DE L'ART
proche infrarouge contient alors moins de texture de la peau que les images en lumièrevisible. L'acquisition de l'IR moyen et lointain (infrarouge thermique) est faite par descapteurs thermiques. Les cellules photo-sensibles à ces longueurs d'onde ne sont plusà base de Silicium mais d'un mélange de métaux tel que le mercure-cadmium-telluride(capteur HgCdTe) ou Indium Gallium Arsenide (InGaAs). La capture thermique estune acquisition passive : on capte les ondes générées par la scène. Les images en infra-rouge thermique ne sont pas inuencées par l'éclairage, mais plutôt par la températuredes corps. Ce type de capture est utilisé pour la vision nocturne.Le corps humain émet des ondes en IR moyen et lointain. Certains chercheurs ontvoulu exploiter cette caractéristique pour s'aranchir des conditions d'illumination etfaire de la reconnaissance de visage avec des images thermiques. Mais, il faut noterque les lunettes forment un obstacle pour les ondes thermiques. Wider et al [79] mon-trèrent que, dans le cas où il y a des variations d'illumination, les performances desalgorithmes de reconnaissance sur images thermiques sont plus robustes que cellessur des images en visible. Mais, quand on a une variation temporelle, les images ther-miques sont moins stables et les performances des algorithmes chutent [13]. Les testsde comparaison entre les images visibles et thermiques ont été multiples et eectuéssur plusieurs scénarios d'acquisition. A l'université Notre Dame [14], on a acquis unebase de donnée comprenant 240 sujets qui ne portent pas de lunettes. Ces acquisitionsont été réalisées à l'intérieur. Socolinsky et Selinger [72] ont acquis une base donnéedans un contexte opérationnel avec des images à l'extérieur et à l'intérieur. La basede donnée contient 385 sujets. Les taux de reconnaissance se dégradent quand oncompare les images à l'intérieur à celles acquises en extérieur. Mais les tests avec desimages thermiques donnent de meilleures performances que les tests faits avec lesimages en visible. Pour cela, des travaux de fusion des performances des images envisible et en thermique pour améliorer les taux de reconnaissance ont été eectués [10]et cela a donné une amélioration de 30% par rapport aux performances de l'algorithmeavec des images visible. L'algorithme utilisé pour les deux types d'images est l'analysepar composante continue avec le calcul de la distance de Mahalanobis entre vecteursprojetés. Les vecteurs de la base sont adaptés à chaque type d'image.
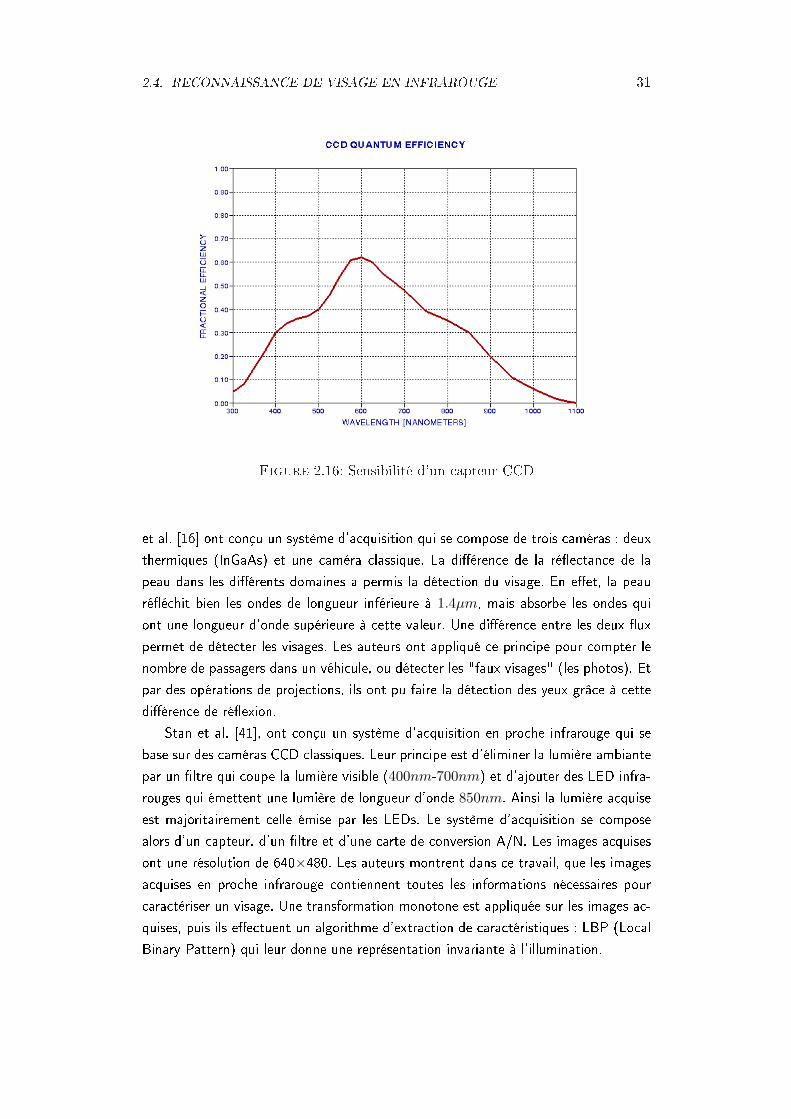
Ces travaux montrent bien la stabilité des images thermiques vis-à-vis des change-ments d'illumination. Mais, les capteurs thermiques sont bien plus chers, et consommentbeaucoup d'énergie. Nous nous sommes intéressés à l'acquisition en proche infrarouge,où l'utilisation des capteurs d'image classiques est possible. La gure 2.16 montre lasensibilité d'un capteur CCD.
La lumière proche infrarouge a été utilisée en premier par Li et Liao [39], pour ladétection des yeux. Le procédé de capture se base sur le système de vision nocturne deSONY (NightShot), mais ce principe ne fonctionne qu'en faible illumination. Dowdall
2.4. RECONNAISSANCE DE VISAGE EN INFRAROUGE 31
Figure 2.16: Sensibilité d'un capteur CCD
et al. [16] ont conçu un système d'acquisition qui se compose de trois caméras : deuxthermiques (InGaAs) et une caméra classique. La diérence de la réectance de lapeau dans les diérents domaines a permis la détection du visage. En eet, la peaurééchit bien les ondes de longueur inférieure à 1.4µm, mais absorbe les ondes quiont une longueur d'onde supérieure à cette valeur. Une diérence entre les deux uxpermet de détecter les visages. Les auteurs ont appliqué ce principe pour compter lenombre de passagers dans un véhicule, ou détecter les "faux visages" (les photos). Etpar des opérations de projections, ils ont pu faire la détection des yeux grâce à cettediérence de réexion.
Stan et al. [41], ont conçu un système d'acquisition en proche infrarouge qui sebase sur des caméras CCD classiques. Leur principe est d'éliminer la lumière ambiantepar un ltre qui coupe la lumière visible (400nm-700nm) et d'ajouter des LED infra-rouges qui émettent une lumière de longueur d'onde 850nm. Ainsi la lumière acquiseest majoritairement celle émise par les LEDs. Le système d'acquisition se composealors d'un capteur, d'un ltre et d'une carte de conversion A/N. Les images acquisesont une résolution de 640×480. Les auteurs montrent dans ce travail, que les imagesacquises en proche infrarouge contiennent toutes les informations nécessaires pourcaractériser un visage. Une transformation monotone est appliquée sur les images ac-quises, puis ils eectuent un algorithme d'extraction de caractéristiques : LBP (LocalBinary Pattern) qui leur donne une représentation invariante à l'illumination.

32 CHAPITRE 2. ÉTAT DE L'ART
Zou [86] a utilisé la diérentiation entre deux acquisitions pour éliminer la lumièreambiante. On acquiert deux images : une classique, puis une seconde avec un éclairageen infrarouge additionnel. Le circuit de contrôle de gain automatique du CCD a étédésactivé pour ne pas atténuer l'illumination additionnelle du ash proche infrarouge.Ce circuit atténue le signal de sortie en présence d'une forte illumination. En casde faiblesse de l'éclairage ambiant, il tend à amplier le signal de sortie du capteur.Désactiver ce circuit (AGC - Automatic Control Gain) permet alors d'avoir le vrainiveau du signal et ainsi la vraie quantité de lumière captée. La diérence entre lesdeux images est ensuite eectuée sur ordinateur. On note le temps important entrel'acquisition des deux images qui fait apparaître un ou dû au mouvement dans lascène. Un traitement est alors eectué par la suite pour le supprimer. Avec ce capteur,Zou a acquis une base de donnée de visage composée de 40 sujets en deux sessions.Pendant chaque session l'acquisition contient des variations d'illuminations avec unéclairage additionnel à droite, à gauche, en haut et de bas. L'auteur a exploité laréexion des IR sur la pupille pour pouvoir construire un système de détection desyeux basé sur l'algorithme SVM. L'algorithme de vérication des visages utilisé par lasuite est celui de FisherFace avec une base d'apprentissage composée des images devisage de XM2VTS. Ces travaux n'ont pas fait l'objet d'une intégration, mais ce sontquie se rapprochent le plus de ceux qui sont présenté dans cette thèse.
2.5 ConclusionDans ce chapitre, nous avons présenté l'architecture générale des systèmes de re-
connaissance de visage, les diérentes étapes d'enregistrement, de normalisation etde comparaison des caractéristiques extraites. Nous avons présenté uniquement lestravaux dans lesquels l'intégration d'algorithme de reconnaissance de visage sur com-posant programmable a été réalisée. Il faut noter que la modalité du visage est sujetteà beaucoup de variations liées soit aux conditions d'acquisition soit aux variations tem-porelles qui détériorent considérablement les performances de reconnaissance. Amé-liorer la qualité de l'acquisition peut alors améliorer les performances d'un système dereconnaissance. C'est pourquoi nous avons présenté aussi les rétines électroniques quipeuvent donner une solution à l'élimination de certaines variations liées à l'acquisition,comme celles liées à la variation d'illumination. Nous allons nous intéresser dans ce quisuit à la description des capteurs que nous avons réalisés pour éliminer l'illuminationambiante.

Chapitre 3
Capture de visage temps réel
On a vu que l'illumination est un des facteurs les plus inuents sur les performancesd'un système de reconnaissance de visage. Plusieurs pré-traitements sont eectuéssur les images acquises pour éliminer l'eet de l'illumination. Ces algorithmes dont lacomplexité augmente avec l'amélioration qu'ils peuvent apporter sont assez dicilesà intégrer sur SoC. Nous proposons des solutions intégrées dans le capteur pour avoirdes images indépendantes de l'illumination ambiante.
3.1 Introduction : Système Actuel et problèmes asso-ciés
Les capteurs d'images se basent sur l'eet photoélectrique découvert en 1887par le physicien Hertz. Les photons captés génèrent des paires électrons-trous dansle semi-conducteur. La méthode de collection de ces électrons et de leur transfertau sein de ma matrice dière selon le type de capteurs. On trouve deux familles decapteur : les imageurs CMOS et les imageurs CCD. Le capteur CCD était le capteurle plus répandu sur le marché des imageurs jusqu'aux début de cette décennie. Il secaractérise par le grand rapport signal sur bruit et la qualité des images acquises.Le capteur CMOS malgré son apparition assez précoce en 1963 [67], n'a connu desuccès commercial que récemment grâce à la forte densité d'intégration qui a permisla réduction de la taille des pixels et l'augmentation du rapport signal sur bruit. Il al'avantage d'avoir un faible coût de fabrication et une consommation réduite. Nousprésenterons ici ces deux familles de capteurs.
33

34 CHAPITRE 3. CAPTURE DE VISAGE TEMPS RÉEL
3.1.1 Capteur CMOS
Comme tous les imageurs, le capteur CMOS est basé sur le principe de conversionphoton-électron. Les charges seront collectées par un champ électrique pour formerune image électronique. Mais, la collecte et le transfert de ces charges est direct via unbus et un système d'adressage/décodage. L'architecture générale d'un capteur CMOSest présentée en gure 3.1.
Figure 3.1: Architecture générale d'un capteur CMOS
La cellule photosensible peut diérer d'un capteur à autre, on peut trouver desdiodes à jonction, des "photogate", ou des photoMOS, etc.
Capteur d'image CMOS à pixel passif - PPS
Le premier pixel passif a été suggéré par G. Weckler en 1967 à Fairchild [78] oùil a utilisé une jonction PN fonctionnant en mode intégration pour capter le ux dephotons. Les paires d'électron-trou générées par les photons incidents sont séparées parun champs électrique dans une jonction. Les électrons sont collectés vers une capacitéde jonction Cj . La lecture directe de cette charge donne une image électronique. Untransistor d'accès est ajouté pour la lecture des diérents pixels de la matrice et letransfert de la tension Vout sur le bus analogique comme le montre la gure 3.2.Mais cette architecture soure de la capacité parasite du bus de lecture. Cela génèrebeaucoup de bruit KTC et réduit le signal vidéo. Une solution proposée par [36] [57]est d'intégrer un amplicateur par colonne. Cet amplicateur de charge est placée àla n de chaque bus colonne de la matrice. Cette solution a permis d'améliorer larapport signal sur bruit des imageurs CMOS en diminuant le bruit de commutation(KTC)

3.1. INTRODUCTION : SYSTÈME ACTUEL ET PROBLÈMES ASSOCIÉS 35
Figure 3.2: Structure schématique d'un pixel PPS
Capteur d'images CMOS à pixel actif - APS
Ce sont les capteurs CMOS les plus répandus. On compte plusieurs structures,qui dièrent par leur mode de transfert des charges collectées par la photodiode.On trouve plusieurs modes de fonctionnement. On cite ici le mode d'intégration duphotocourant, le mode courant et le mode logarithmique.
Mode d'intégration Courant : La structure élémentaire d'un pixel est montrée engure 3.3. Le pixel est composé d'un transistor de reset T1, d'un transistor du signalT2 et d'un transistor de signal T3. Le fonctionnement du pixel est :
1. La photodiode est initialisée par le transistor T1. Après cette initialisation, latension sur la photodiode est de Vrst. La tension aux bornes de Cj est xée àla même valeur.
2. La photodiode intègre les charges photoélectriques pendant le temps d'exposi-tion. La tension sur la photodiode chute selon la charge accumulée. En eet,sous l'action de Iph la capacité Cj se décharge progressivement. Cela entraineune décroissance de la tension Vd :
Vd(Texp) = Vrst − 1Cj
∫ Texp
0Iph(t)dt
Pour connaitre la tension équivalente à la quantité de charge accumulée durantle temps d'exposition il faut faire la diérence entre Vrst et Vd(Texp). Pour unelumière statique cela nous donne :
∆Vd = Vrst − Vd(Texp) =IphTexp
Cj
3. La tension de la photodiode est lue via les transistors T2 et T3. Le transistor T3
a pour rôle de sélectionner le pixel pour le transmettre sur le bus.

36 CHAPITRE 3. CAPTURE DE VISAGE TEMPS RÉEL
La diérence avec le pixel PPS est la présence des transistor T2 et T4 qui font fonctiond'amplicateur suiveur de tension. On voit que dans cette architecture la capacité Cbus
n'agit pas sur la photodiode.La photodiode joue ici deux rôles : Elle collecte des charges photoélectriques et
convertit la charge en tension. Pour maintenir une bonne sensibilité du capteur, ilfaut diminuer la capacité sur la photodiode. Une technologie CMOS très ne permetune bonne sensibilité et un facteur de remplissage important. Actuellement le taux deremplissage est entre 25% et 50%, cela reste similaire à un capteur CCD à transfertinterligne.
Figure 3.3: Structure du pixel en mode d'intégration du photocourant
Mode courant : Dans ce mode, au lieu de convertir la charge accumulée en tension,nous allons l'exploiter sous forme de courant. Ce mode est moins utilisé que le moded'intégration. Il est utilisé lorsqu'on a un besoin de lecture en continu de l'informa-tion. Cette architecture nécessite un convoyeur de courant ou un miroir de courantqui permettent de transmettre le photocourant. Compte tenu du faible courant, cesstructures ont une grande impédance d'entrée et amplient le signal d'entrée. L'ar-chitecture d'un pixel à base d'un miroir simple composé de transistors P est présentéeen gure 3.4.Cependant ce mode demande beaucoup d'attention lors de la conception à causede la faiblesse du photocourant qui atteint quelques picoampères pour une scène àéclairage ambiant de bureau. Les structures d'amplications réduisent dans ce cas letaux de remplissage et le bruit spatial xe est compliqué à supprimer.

3.1. INTRODUCTION : SYSTÈME ACTUEL ET PROBLÈMES ASSOCIÉS 37
Figure 3.4: Architecture d'un pixel en mode courant
Mode logarithmique : Dans ce mode de fonctionnement, on exploite la relation ex-ponentielle qui existe entre le courant drain Id d'un transistor MOS et la tensiongrille/source VGS . Cela permet d'avoir une grande dynamique allant jusqu'à 120dB,s'approchant ainsi de la dynamique de l'oeil humain. La structure du pixel logarith-mique la plus utilisée est montrée en gure 3.5. Dans ce schéma, le transistor M1opère dans la région de faible inversion. Le courant de drain Id est le photocourant. Enutilisation normale ce courant est de quelques nA. La relation entre Id et la tensionVGS est :
Id = IseVGSκVt (1− e
−VDSVt )
Dans un transistor CMOS, le courant de fermeture Ioff n'est pas négligeable dans desapplications à courant faible. Le courant dans le drain est alors : IDA = ID + Ioff .Quand la tension VGS >> VT , (1 − e
−VDSVt ) ∼= 1. Dans ce cas, la tension VGS du
transistor M1 s'écrit en fonction du courant photoélectrique Iph :
VGS(Iph) = κVtlog(Iph + Iobs − Ioff
Is)
Où κ est le facteur de l'eet du substrat et il varie entre 1 et 2 en fonction desparamètres du procédé, Iobs est le courant d'obscurité de la photodiode et Is =
µnCdepWL V 2
t e−Vth
κVt est le courant du canal risiduel pour une tension VG = κVS etVD >> VS [64].
La tension VD se calcule suivant :
VD(Iph) = VDD − κVtlog(Iph + Iobs − Ioff
Is)
3.1.2 Les capteurs CCDLe capteur CCD se base sur les travaux réalisés dans les années soixante-dix au
sein des laboratoires Bell par les ingénieurs W. Boyles, G. Smith et G.G. Amlio [11].

38 CHAPITRE 3. CAPTURE DE VISAGE TEMPS RÉEL
Figure 3.5: Architecture d'un pixel logarithmique utilisant une photodiode enmode photocourant
Au début, ces travaux ont été utilisés pour réaliser les lignes à retard, des ltresanalogiques, etc. Mais ce concept a rapidement évolué vers des applications d'imagerie.Le premier capteur CCD a vu le jour dans les laboratoires Fairchild Electronics en 1974.Ce capteur avait une résolution de 100× 100 pixels.
Un capteur CCD se compose d'une zone photosensible connecté à une capacitéMOS. La capacité MOS est la cellule de base d'un CCD (gure 3.6). Elle est composéede d'une électrode grille M, d'un substrat semi-conducteur de type P relié à la masseet d'une couche isolante SiO2.
Figure 3.6: La structure d'une capacité MOS
Quand on applique une tension à la grille Vg supérieure à une tension de seuil(Vth), cela crée un champ électrique qui repousse les charges libres du substrat etforme ainsi sous l'isolant une région de déplétion (appelée zone de charge d'espaceZCE). La profondeur de la ZCE est contrôlée par la tension Vg (gure 3.7).
Si on met une deuxième capacité MOS à côté de la première telle que leurs zonesde déplétion peuvent se toucher, nous pouvons ainsi transférer les charges accumuléesde la première capacité à la seconde en créant des puits de potentiel successifs. L'ap-

3.1. INTRODUCTION : SYSTÈME ACTUEL ET PROBLÈMES ASSOCIÉS 39
Figure 3.7: Stockage des charges dans une capacité MOS
plication de voltage adéquat permet de créer des puits de potentiel qui permettent depiéger les charges accumulées. La gure 3.8 montre ce principe.
Figure 3.8: Puit et barrière de potentiel dans une capacité MOS
La diculté de ce système est la lecture de l'ensemble des cellules du capteur. Pourcela, on utilise le dispositif CCD. La structure du CCD est montrée en gure 3.9. Elleest formée d'une série de registres à décalage qui forment des colonnes et une ligne.Cela permet le déplacement des charges accumulées après la période d'exposition.
Le transfert des charges dans une matrice CCD se fait en deux phases :
1. Décalage vertical : cette phase charge la ligne vers le bas de l'image dans lamatrice vers la seconde phase.
2. Décalage horizontal : durant cette étape, les charges sont décalées dans le sensde la ligne vers le détecteur de charge, pixel par pixel.

40 CHAPITRE 3. CAPTURE DE VISAGE TEMPS RÉEL
Figure 3.9: Architecture générale d'un capteur CCD
Ce transfert de charge est contrôlé par une horloge à phases multiples. Le nombrede phases varie selon le type de CCD. Le capteur à 4 phases (4φ) est le type le plusrépondu. Dans ce cas, à chaque pixel correspond 4 capacités. Si un haut voltage estappliqué sur une de ces capacités une zone de déplétion se crée sous celle-ci, unetension faible appliquée sur les capacités environnantes permet la formation d'unebarrière de potentiel. Le timing de la gure 3.10 décrit les diérentes étapes de cetransfert. On maintient les phases φ1 et φ2 à un niveau haut et φ3, φ4 à un niveau bas.La zone de déplétion créée permet la collecte des charges du pixel Pn. Si on changela polarité des phases φ1 et φ3 (φ1 niveau bas et φ3 au niveau haut) la charge dupixel va se déplacer sous les capacités correspondantes à φ2 et φ3. On change après lapolarité de φ2 et de φ4, ainsi la charge progresse sous les capacités correspondantes àφ3 et à φ4. Ce processus est répété jusqu'à ce que les charges soient sous les capacitésdu pixel Pn+1 complétant ainsi un cycle de transfert.
Le détecteur de charge convertit la quantité de charge en une tension selon unfacteur de conversion constant. Cette tension est la sortie du capteur CCD. On trouve3 architectures principales des CCD :
1. transfert de trame progressif
2. transfert de trame parallèle - série
3. transfert de trame interligne

3.2. CAPTEURS D'IMAGE DÉDIÉS 41
Figure 3.10: Transfert de charge avec un CCD à 4 phases
3.2 Capteurs d'image dédiésPour améliorer les performances des systèmes de reconnaissance de visage, nous
nous sommes intéressés au procédés permettant de limiter l'inuence de l'illumination.L'acquisition active est la solution idéale pour avoir une image riche en information surla texture et qui peut être indépendante de l'illumination. En eet, la vision passive telleque celle correspondant à un capteur thermique n'est pas ecace en cas de variationtemporelle. Nous présenterons deux capteurs qui éliminent l'illumination ambianteavec deux méthode diérentes. Le premier capteur que nous avons utilisé a été conçudans notre laboratoire par Prof. Yang Ni [55]. Ce capteur intègre dans la matrice unefonction diérentielle qui permet l'élimination de la lumière ambiante. Le deuxièmecapteur se base sur un capteur CCD qui délivre une image en proche-infrarouge et uneseconde en visible simultanément. Ce second capteur diminue l'eet de l'illuminationpar la réduction du temps d'exposition.
3.2.1 Capteur diérentiel
La vision active est l'acquisition d'une image avec une source de lumière contrôlée.Le capteur diérentiel, présenté ici, supprime l'illumination ambiante pour n'acquérirque la lumière contrôlée. Pour cela, le capteur acquiert deux photos successives lapremière avec une source de lumière contrôlée et la seconde sans source de lumière

42 CHAPITRE 3. CAPTURE DE VISAGE TEMPS RÉEL
additionnelle. En eectuant la diérence entre ces deux images, nous éliminerons del'image tous les objets éclairés seulement par la lumière ambiante. Nous avons choisieune source de lumière émettant en proche infrarouge pour ne pas gêner l'utilisateur.
La diérence entre deux images acquises dans deux conditions d'éclairages peutse faire de deux manières possibles : soit hors du capteur soit dans le capteur. Lapremière possibilité bien que simple à synthétiser présente un inconvénient majeur,à cause des changements spatio-temporelle qui peuvent apparaître durant les deuxacquisitions successives. En eet, le temps entre l'acquisition des deux scènes peutêtre important vu les opérations eectuées de numérisation et de transmission del'image. Un changement spatial peut alors se produire ce qui causerait un ou lors dela diérentiation. La deuxième solution est d'eectuer la soustraction au sein mêmedu capteur. Cette opération se fait donc analogiquement. Le premier capteur dédié àcette tâche est réalisé par Miura [47]. L'auteur a intégré dans le capteur deux cellulesmémoire analogique dans chaque pixel. L'opération de diérence se fait sur la colonnelors du chargement de l'image. Cette approche a permis une bonne suppression de lalumière ambiante, mais la présence de deux mémoires au sein du pixel, nous donne unpixel de taille importante (47.5µm2 × 47.5µm2 avec une technologie de 0.6µm). Lecapteur diérentiel développé par Prof. Yang Ni possède une seule mémoire analogiqueau sein du pixel. Le pixel est présenté en gure 3.11. Il comporte une photodiodeet une cellule mémoire analogique (MA). La capture de l'image commence par uneinitialisation du pixel (Prec) puis un transfert de la charge accumulée (Samp) dansla mémoire MA. Deux modes de capture sont possibles dans ce capteur à travers les
Figure 3.11: Structure d'un pixel du capteur diérentiel
diérents signaux de contrôle :1. Toute la matrice est initialisée au même instant et transmise dans la mémoire.2. L'image est acquise ligne par ligne. Chaque ligne sélectionnée sera initialisée, et
les charges capturées transmises vers un buer.Ce double fonctionnement nous permettra l'acquisition diérentielle avec un taux de

3.2. CAPTEURS D'IMAGE DÉDIÉS 43
transfert d'image assez important. La structure globale du capteur est donnée engure 3.12.
Figure 3.12: Structure du capteur diérentielle [55]
En bas du capteur se trouvent deux buers ligne (LB1 et LB2). Une ligne sélec-tionnée de la matrice peut être chargée dans un de ces buers. Les signaux RD1 etRD2 permettent la sélection de ces buers. La sortie de ces lignes buers est l'en-trée du bloc diérentiel. Un convertisseur analogique/numérique parallèle à 8bites estégalement intégré dans le capteur.
La gure 3.13 montre la séquence de fonctionnement du capteur. En premier lieu,toute la matrice est exposée avec éclairage ambiant plus celui en proche infra-rouge. Letemps d'exposition de la matrice est de 50µs. Ce temps est assez pour ne pas causerde saturation dans les pixels. Le ash en proche infrarouge est synchronisé avec lapériode d'intégration. Cela permet de réduire la consommation électrique et d'avoirun meilleur rendement. En seconde étape, on active séquentiellement l'exposition deslignes de la matrice. Chaque ligne est chargée dans un buer (LB1) et dans LB2 oncharge la ligne capturée durant la première étape. La diérentiation des deux lignesnous donne une ligne qui est indépendante de l'illumination ambiante s'il n'y a pas dechangement de scène ou d'éclairage. La taille de la matrice est de 160× 120 réalisée

44 CHAPITRE 3. CAPTURE DE VISAGE TEMPS RÉEL
Figure 3.13: Principe de fonctionnement du capteur diérentiel
avec une technologie CMOS de 0.5µm. La taille du pixel est de 12µm et un taux deremplissage de 20%.Initialement, La caméra était reliée à un ordianteur par une liaison prallèle. Mais vu leslimites de transmission du port et l'apparition d'images saccadées, nous avons conçuune interface UBS-1 pour l'acquisition des images. Avec ce protocole on peut acquérir8images/s. Des images acquises avec ce capteur sont présentées en gure 3.14.
Figure 3.14: Examples d'images acquises par le capteur diérentiel
3.2.2 Capteur IRVILe premier capteur avec lequel j'ai fait des expériences et que nous venons de
décrire dans la section précédente est un capteur CMOS dédié à la suppression de lalumière ambiante. Son architecture est unique. Le second capteur que j'ai développédans le cadre de ce doctorat se base sur un capteur CCD. On a essayé d'exploiter laqualité des images issues d'un capteur CCD pour avoir une image plus propre (faiblebruit spatial xe). Pour cela, on a exploité au début une webcam à base de capteurCCD SONY pour tester notre approche. Nous présentons en premier lieu le principe
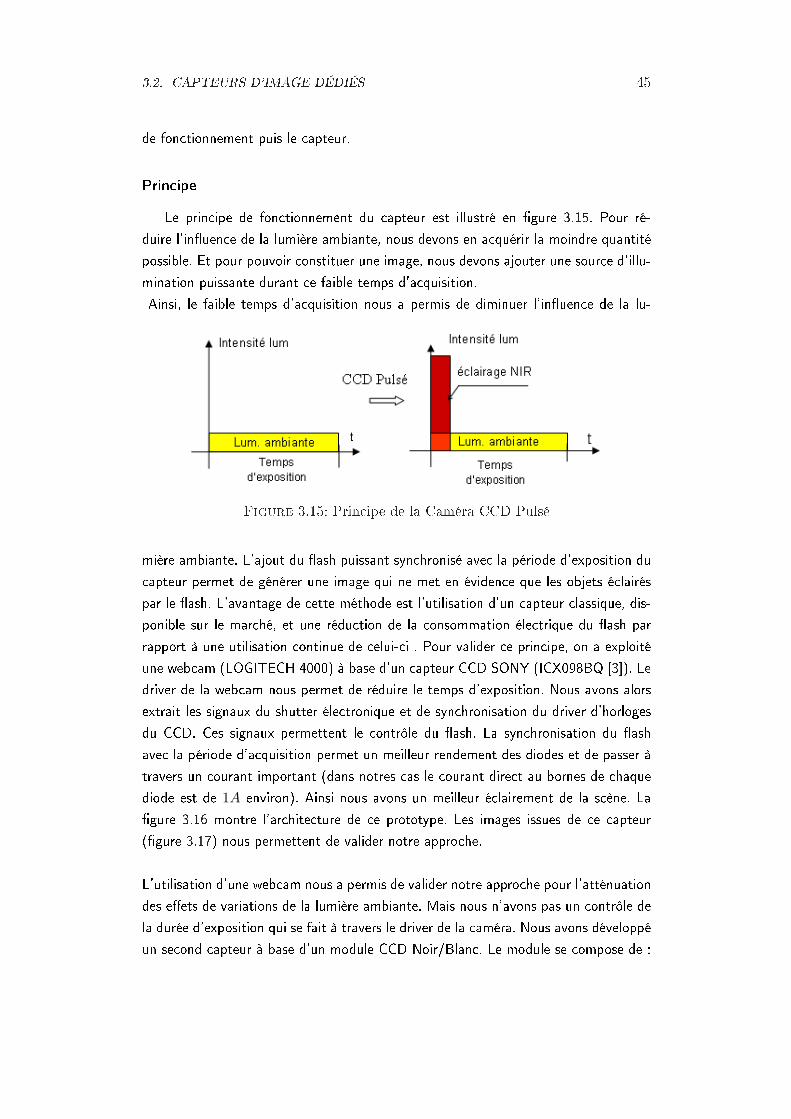
3.2. CAPTEURS D'IMAGE DÉDIÉS 45
de fonctionnement puis le capteur.
Principe
Le principe de fonctionnement du capteur est illustré en gure 3.15. Pour ré-duire l'inuence de la lumière ambiante, nous devons en acquérir la moindre quantitépossible. Et pour pouvoir constituer une image, nous devons ajouter une source d'illu-mination puissante durant ce faible temps d'acquisition.Ainsi, le faible temps d'acquisition nous a permis de diminuer l'inuence de la lu-
Figure 3.15: Principe de la Caméra CCD Pulsé
mière ambiante. L'ajout du ash puissant synchronisé avec la période d'exposition ducapteur permet de générer une image qui ne met en évidence que les objets éclairéspar le ash. L'avantage de cette méthode est l'utilisation d'un capteur classique, dis-ponible sur le marché, et une réduction de la consommation électrique du ash parrapport à une utilisation continue de celui-ci . Pour valider ce principe, on a exploitéune webcam (LOGITECH 4000) à base d'un capteur CCD SONY (ICX098BQ [3]). Ledriver de la webcam nous permet de réduire le temps d'exposition. Nous avons alorsextrait les signaux du shutter électronique et de synchronisation du driver d'horlogesdu CCD. Ces signaux permettent le contrôle du ash. La synchronisation du ashavec la période d'acquisition permet un meilleur rendement des diodes et de passer àtravers un courant important (dans notres cas le courant direct au bornes de chaquediode est de 1A environ). Ainsi nous avons un meilleur éclairement de la scène. Lagure 3.16 montre l'architecture de ce prototype. Les images issues de ce capteur(gure 3.17) nous permettent de valider notre approche.
L'utilisation d'une webcam nous a permis de valider notre approche pour l'atténuationdes eets de variations de la lumière ambiante. Mais nous n'avons pas un contrôle dela durée d'exposition qui se fait à travers le driver de la caméra. Nous avons développéun second capteur à base d'un module CCD Noir/Blanc. Le module se compose de :

46 CHAPITRE 3. CAPTURE DE VISAGE TEMPS RÉEL
Figure 3.16: Architecture fonctionnelle du prototype à base de webcam
Figure 3.17: Image de sortie du prototype à base de webcam
Le capteur CCD : un capteur CCD interligne d'une résolution de 500x582pixel Le vertical CCD driver : son but est d'adapter les signaux TTL pour contrôler
les horloges de transfert de charge dans la matrice CCD. Timing & Synchro generator : ils sont Générés les horloges de transfert de
charges (niveaux TTL) CCD processor : Il sert à réguler le temps d'exposition, le temps de décharge
du CCD pour une meilleure qualité de l'image.Le schéma de ce module est présenté en gure 3.18 :
Le signal d'initialisation des photodiodes dans le capteur est le signal Xsub. Eneet, l'initialisation des photodiodes dans un capteur CCD interligne se fait par l'in-termédiaire d'un transistor commandé par le signal Xsub, qui décharge la cellulephotosensible. Le schéma d'un pixel est présenté en gure 3.19. Et le signal déclen-chant le début de transfert de ligne des charges est le signal Xsg. Ces deux signauxsont extraits au niveau de l'entrée du driver de l'horloge verticale où les signaux sontau niveau TTL. Nous avons aiguillé ces signaux du générateur des signaux de syn-chronisation vers un microcontrôleur ATMEL (série ATMEGA) dans lequel nous avonsgénéré des pulsations "reset" pour réduire le temps d'exposition à une valeur de 50µs.La gure 3.20 montre la modication apportée pour changer le temps d'exposition.

3.2. CAPTEURS D'IMAGE DÉDIÉS 47
Figure 3.18: Schéma du module CCD
Durant le temps d'exposition, nous activons les LEDs infrarouge pulsées. Le rapportcyclique de fonctionnement des diodes est de 50µs/40ms = 1.25 10−3. Ce faiblerapport pourrait permettre une alimentation de l'ensemble sur des piles électriques.Cela conviendrait donc pour des applications mobile de reconnaissance de visage. Lesignal de contrôl du ash est généré par le microcontrôleur. Il active un MOSFET quipermet le déclenchement du ash. Nous avons aussi désactivé le contrôle automatiquede gain pour ne pas amplier le signal et augmenter le bruit qui peut être introduitpar la lumière ambiante.
Figure 3.19: Obturation électronique dans un capteur CCD interligne
L'image issue de ce capteur, dans ce mode de fonctionnement, nous génère uneimage en proche infrarouge qui ressemble à l'image issue de notre prototype décritprécédemment. Nous avons exploité la caractéristique du capteur CCD interligne pouracquérir une image constituée de deux trames diérentes : une en proche infrarougeavec la méthode de réduction du temps d'exposition et une seconde en visible enlaissant la boucle d'acquisition (gure 3.18). Le mode d'acquisition d'un capteur CCDinterligne est la suivante : Au début on expose les lignes paires et durant les séries

48 CHAPITRE 3. CAPTURE DE VISAGE TEMPS RÉEL
Figure 3.20: Chronogramme de la réduction du temps d'exposition dans le CCD
de décalage des charges, on expose les lignes impaires. Après que toute les chargesdes lignes paires ont été transmises, on commence le décalage des lignes impaires eton expose les pixels des lignes paires et ainsi de suite. Le chronogramme de l'acqui-sition est présenté en gure 3.21. Dans ce schéma, les pulsations en rouge du signalVsub sont celles ajoutées par le microcontrôleur pour réduire le temps d'expositionet acquérir ainsi une image en proche infrarouge.
Figure 3.21: Chronogramme d'acquisition des trames dans une CCD interligne
L'image qu'on a en sortie du capteur est une image contenant deux trames entre-lacées une en visible et la seconde en proche infrarouge. On peut facilement séparerles deux trames et par interpolation on reconstitue deux images d'une résolution VGA.
3.3 Bases de donnéeAvec ces capteurs à disposition, nous avons mené diérentes campagnes d'ac-
quisition pour évaluer l'amélioration que peuvent apporter les capteurs dédiés à lasuppression de la lumière ambiante.
3.3.1 Base BIOMETLa base BIOMET est une base biométrique qui contient 5 diérentes modalités :
la voix, le visage, la main, l'empreinte digitale et la signature [20] . Pour le visage,plusieurs caméras ont été utilisées : une caméra classique à base d'un CCD SONY

3.3. BASES DE DONNÉE 49
pour l'acquisition audio-vidéo. Un système d'acquisition en 3D est aussi exploité danscette base de donnée. Il se base sur une lumière structurée. La projection d'une sériede lignes de diérentes couleurs sur une surface sert comme référence dans l'imageobtenue. Chaque ligne est dénie par sa couleur et sa position. Par triangulation(caméra, projecteur), on peut dénir ainsi la 3ème dimension. La troisième camérautilisée dans cette base est la caméra diérentielle décrite dans la section 3.2.1, nousl'appellerons DiCam.
Pour les acquisitions de BIOMET, nous avons utilisé un illuminateur proche in-frarouge émettant une longueur d'onde de 850µm. Il contient 24 LEDs pulsées etcontrôlées par un transistor MOSFET.
Durant ces acquisitions, le sujet se tient à une distance de 50cm de la caméra.On acquiert 10 images par personne à raison d'une image par seconde. Durant lesacquisitions le sujet bouge lentement la tête. La base de donnée contient 85 personnes.La gure 3.22 montre un échantillon d'images de la base. Les personnes portant deslunettes les ont gardées. Nous avons constaté que les lunettes causent des réexionsimportantes de la lumière des LEDs et ainsi des saturations dans l'image (gure 3.23).Nous avons séparé ces images de la base, pour créer une sous base ne contenant pasde telle saturation.
Figure 3.22: Example d'image de la base BIOMET
3.3.2 Base IV2Durant la compagne d'acquisition du projet IV2 [66], nous avons installé le capteur
IRVI dans la cabine d'acquisition. Le capteur était équipé d'une lentille à grand anglece qui a induit un eet sheye sur les images acquises. Le sheye est une distorsion de

50 CHAPITRE 3. CAPTURE DE VISAGE TEMPS RÉEL
Figure 3.23: Eet de saturation dû au port des lunettes dans la Base BIOMET
l'image introduite par une lentille à grand angle pour avoir un angle de vu important(180). Les acquisitions se sont déroulées dans une cabine où des projecteurs avaient étéinstallés deux derrière, un à gauche et un à droite du sujet. Un système automatiquecontrôle l'allumage et l'extinction de ces derniers. La personne se tient devant lacaméra à une distance de 50cm et enlevant ses lunettes si elle en porte.
La base contient 50 personnes. Pour chacune nous disposons d'une vidéo de 40secondes. Les vidéos contiennent les images en lumière visible et en proche infrarougeentrelacées. Les vidéos ont une résolution de 640×480 avec un débit de 30 images parseconde. Chaque 10 secondes, nous changeons la conguration de l'éclairage. Durantles 10 premières secondes, les quatre projecteurs sont allumés. Puis on les éteint,ensuite on allume successivement les projecteurs à droite et à gauche de la caméra.La gure 3.24 montre un exemple d'image de la base de donnée.
Figure 3.24: Exemple d'images de la base de donnée IV2
3.3.3 Base IRVIVu les déformations présentes dans les images de la base IV2, nous avons changé
la lentille du capteur IRVI. Pour des convenances de distance et de taille du visage

3.3. BASES DE DONNÉE 51
dans l'image, nous avons opté pour une lentille d'une distance focale de 6mm. Lesacquisitions se sont déroulées dans un bureau, près d'une fenêtre qui est à gauchede la caméra. Un éclairage d'appoint se trouve à droite de la caméra. il s'agit d'unelampe de bureau d'une puissance de 40W. La personne se tient en face de la caméra.Les personnes ont été invitées à enlever leur lunettes avant l'acquisition pour éviterles problèmes de réexion. La gure 3.25 montre l'environnement des acquisitions.
Figure 3.25: Environnement d'acquisition de la base VINSI
Cette Base de visage contient 60 personnes. Chaque personne possède deux ses-sions (S1 et S2) acquises à deux/trois semaines d'intervalle. Durant chaque session,nous avons trois protocoles d'enregistrement avec des illuminations variables. Le pre-mier protocole (P1)est acquis avec un éclairage de bureau ambiant. Les stores durantce protocole sont fermés pour diminuer l'inuence de la lumière venant de l'extérieur.Pour le second protocole (P2), on ajoute un éclairage d'appoint illuminant le cotégauche du visage. Le dernier protocole (P3) peut être assimilé à une acquisition en ex-térieur. En eet, l'acquisition près d'une fenêtre met en jeu la lumière du jour. Chaqueprotocole correspond à une acquisition d'une vidéo de 30 secondes. On n'a sauvegardéqu'une image toutes les 10 secondes. Un logiciel d'acquisition sépare les deux imagesentrelacées visible et proche infrarouge. Pour chaque protocole, nous avons ainsi 10images en proche infrarouge et autant en lumière visible . Les personnes peuvent bou-ger ou changer de position durant les acquisitions. Un changement de pose peut alorsapparaître entre les images d'une même session. La gure 3.26 montre les diérentsprotocoles de la base. Cette gure montre l'inuence de la lumière du jour sur lesimages en visible à travers le troisième protocole. Nous pourrons aussi noter la stabi-lité des images IR lorsque les conditions d'illumination varient.Durant les acquisitions du troisième protocole, nous avons remarqué des limitationsdu capteur IRVI quand la lumière extérieure est importante. En eet, un fort éclairageambient ne peut plus être négligé devant la lumière du ash. La gure montre l'eet

52 CHAPITRE 3. CAPTURE DE VISAGE TEMPS RÉEL
Figure 3.26: Exemples d'images de la base IRVI et les diérents protocoles
d'un fort éclairage du soleil bien qu'atténué par la réduction du temps de pose surl'image. Ce fort éclairement peut être éliminé par un procédé d'acquisition diérentielsi on n'atteint pas la saturation durant les deux acquisitions.
Nous avons annoté manuellement 4 points caractéristiques : les deux centres desyeux, le centre bas du nez et le centre de la bouche. Pour les tests de reconnaissance,nous avons choisi les cinq premières images de la première session, premier protocole(S1P1) comme des images de référence. Les images des autres protocoles et cinqimages de S1P1 sont considérées comme images de test. Pour chaque personne nousavons ainsi 5 images de référence et 30 images de test. Chaque image est de taille640× 480.
3.4 ConclusionL'illumination est un des facteurs les plus importants dans l'acquisition des images.
Elle inue sur la qualité des images : la présence de saturation réduit l'informationdans une image. Nous avons présenté dans ce chapitre, deux capteurs permettantl'atténuation, voir l'élimination de la lumière ambiante. Le premier capteur présentéest un capteur CMOS qui intègre une fonction de diérentiation. Le second capteur està base de la technologie CCD ce qui donne au capteur une meilleur qualité d'imagegrâce au faible bruit spatial xe présent dans cette technologie. Il se base sur laréduction du temps d'acquisition pour acquérir moins de lumière ambiante et l'ajoutd'un ash composé d'une quarantaine de LED pulsées en proche infrarouge synchroneavec la période d'acquisition. Nous avons ensuite décrit les diérentes bases de données

3.4. CONCLUSION 53
acquises pour pouvoir valider notre approche visant à améliorer les performances dessystèmes de reconnaissance en présence de variations d'illumination. En ne mettanten jeu que des opérateurs intégrable sur SoC ou sur CMOS, nous avons construit unalgorithme potentiellement intégrable sur SoC. La description de cet algorithme feral'objet des chapitres suivants.


Chapitre 4
Détection des pointscaractéristiques
Ce chapitre est une présentation de la méthode de détection des points caracté-ristiques sur les images infrarouges issues des capteurs développés au sein de notrelaboratoire. Nous nous sommes intéressés à la mise au point d'une méthode simple etecace pouvant être intégrée par la suite aisément sur des composants programmablesou dans le capteur lui même.
4.1 IntroductionUne des étapes les plus importantes dans le processus de reconnaissance de visage
est la détection de points caractéristiques. Cette étape est indépendante de l'algo-rithme de vérication utilisé. En eet, la reconnaissance de visage en 2D requiert danstous les cas une bonne détection des yeux pour xer la taille du visage. La distanceentre les yeux est considérée comme référence pour déterminer la taille et l'orienta-tion du visage et par suite normaliser celui-ci. Certains algorithmes sont plus sensiblesque d'autres à la bonne détection des yeux. L'algorithme utilisant la projection par"sherface", par exemple, demande une détection au pixel près [66]. Cette sensibi-lité est due à la transformation de l'image en un vecteur de taille xe, ce qui laissemoins de souplesse après pour la correction de position. Par contre, les algorithmesse basant sur une analyse locale (tel que l'EGM) autour des points singuliers sontmoins sensibles à une bonne détection, vu que l'algorithme ane sa recherche despoints par la suite [9]. Les points caractéristiques ont aussi été utilisés pour faire de lareconnaissance de visage en utilisant leurs positions, leurs formes [12]. On peut dénir
55

56 CHAPITRE 4. DÉTECTION DES POINTS CARACTÉRISTIQUES
"un point caractéristique comme étant le point particulier qui trouve son correspon-dant dans l'inter et l'intraclasse" [17]. Les points caractéristiques peuvent être despoints dénis par l'anatomie du visage ou des points dénis mathématiquement oudes pseudo-points caractéristiques [69]. Les points caractéristiques extraits de l'anato-mie du visage sont les plus importants vu l'information qu'ils contiennent par rapportà la taille et la texture du visage. Ces points nécessitent une détection par des tech-niques de machine de vision. Les points mathématiques sont plus simples à détecter.Ils sont déterminés par des propriétés mathématiques tel que le maximum de gradientdans le visage ou d'autres propriétés géométriques. Les pseudo-points caractéristiquessont des points situés entre les points dénis par l'anatomie et ceux dénis par despropriétés mathématiques.
4.2 Détection de points caractéristiques dans la litté-rature
On trouve dans la littérature plusieurs approches pour la détection de points ca-ractéristiques. On citera ici une partie d'entre eux. Cette liste est non restrictive, maisnous essayons d'illustrer les principales approches que l'on peut trouver dans la litté-rature. Nous pouvons classer ces algorithmes en deux classes : une première qui sebase sur une analyse statistique du visage et une seconde qui se base sur l'analyselocale s'appuyant sur une étude anthropométrique du visage.
4.2.1 Méthode Adaboost
L'une des méthodes les plus utilisées dans la littérature est la détection du visage etdes points caractéristiques par boosting. La variante la plus utilisée est celle proposéepar Viola et Jones [76] et elle se base sur le "boosting" adaptatif (adaboost). Cetteméthode est une combinaison de plusieurs classieurs simples pour créer un classieurplus performant, cela se traduit par une combinaison linéaire des classieurs :
f(x) =T∑
t=1
αtht(x)
où αt est le poids correspondant au classieur ht. Ces paramètres sont appris itéra-tivement durant l'étape d'apprentissage. A chaque itération, le poids des hypothèsesclassiées incorrectement augmente alors que le poids des bons classieurs diminue.Cela permet de se concentrer sur les exemples les plus durs à classier. La méthodeadaboost utilise des classieurs simples dérivés des ondelettes de Haar.

4.2. DÉTECTION DE POINTS CARACTÉRISTIQUES DANS LA LITTÉRATURE57
4.2.2 Modèle de contour actifLa seconde méthode que nous citerons ici est une méthode beaucoup utilisée dans
la compression vidéo et la détection d'expression du visage. Cette méthode a été dé-veloppée pour extraire des objets caractéristiques complexes et non-rigides, commel'oeil ou les lèvres. Au départ, un modèle de contour actif [28] [87] [83] doit être placéprès de l'objet caractéristique à localiser dans l'image. Le modèle de contour actif vapar la suite interagir avec les propriétés de l'image locale et se déformer lentementpour prendre la forme de l'objet caractéristique à extraire. Il y a trois types de modèlede contour actif.Le contour actif, aussi appelé "snake", est utilisé pour trouver le contour d'un objetcaractéristique. Pour cela, on doit initialiser le contour actif autour de l'objet carac-téristique à localiser. Le contour actif se concentre ensuite sur les bords proches etprend pas à pas la forme de l'objet caractéristique. Le but du contour actif est deminimiser une fonction énergie :
Esnake = Eint + Eext
où Eint et Eext sont respectivement l'énergie interne et externe. L'énergie internedépend des propriétés intrinsèques du contour actif et dénit l'évolution naturelle decelui-ci. L'évolution naturelle d'un contour actif est typiquement de se rétrécir et dese dilater. L'énergie externe agit contre l'énergie interne et permet au contour actifde se comporter contre son évolution naturelle. C'est ce qui permet au contour actifd'entourer le bord de l'objet caractéristique.Les masques déformables (deformable template) sont une évolution des contours ac-tifs. Ils incorporent de l'information globale sur l'objet caractéristique à localiser. Unmasque déformable est un contour déni par n paramètres. Ce contour permet demodéliser des formes typiques que l'objet caractéristique peut prendre. Par exemple,pour modéliser l'oeil on peut prendre diérentes ellipses. Si on pose le masque défor-mable près de l'objet caractéristique, alors le masque (contour paramétré) va changerles valeurs de ses paramètres (va se déformer) pour converger vers le contour optimalde l'objet caractéristique. De nouveau, le but est de minimiser une fonction énergie.Le PDM (Point distributed model) est une description paramétrique compacte de laforme de l'objet caractéristique à localiser sur la base de statistiques. Lors du PDM,le contour est discrétisé en un nombre de points labellisés. Le déplacement de cespoints est calculé à l'aide d'images exemples sur l'objet caractéristique à localiser enutilisant une PCA. De telle façon, on aboutit à un modèle linéaire exible. Le mo-dèle consiste en la valeur moyenne de tous les points et des composantes principalespour chaque point. Pour localiser l'objet caractéristique, le modèle du contour moyen("mean shape model"), étant constitué des valeurs moyennes des points, est placé

58 CHAPITRE 4. DÉTECTION DES POINTS CARACTÉRISTIQUES
près de l'objet caractéristique. Ensuite, une stratégie, utilisant l'intensité locale del'image, est utilisée pour déplacer chaque point du modèle vers le point sur le contourde l'objet caractéristique. Pendant la déformation, la forme peut seulement changerson apparence d'une façon qui coïncide avec l'information modélisée.
4.2.3 Détection des yeux dans les images infrarouges
Les images infrarouges ont montré une bonne robustesse vis à vis des variations del'illumination [41]. Cela a permis le développement de plusieurs techniques robustesde détection de points caractéristiques appliquées aux images en proche infrarouge.Nous citons les travaux de Dowdall [16] qui exploraient la diérence de réexion dela peau dans la basse bande du proche infrarouge et de la haute bande en procheinfrarouge pour détecter et localiser les yeux. En eet, les yeux apparaissent noirsalors que la peau est plutôt claire sous un éclairage en basse bande proche IR alorsque dans la bande supérieure du proche IR, les sourcils apparaissent assez claire (carils rééchissent mieux ces longueurs d'onde). Par des projections horizontales des deuximages et la détection des maxima et minima du résultat, l'auteur arrive à marquer laposition des yeux. La gure 4.1 montre un exemple de cette projection. L'inconvénientmajeur de cette méthode est qu'elle soure de l'inuence de l'arrière plan.
Figure 4.1: Localisation des yeux avec la méthode proposée par Dowdall [16]
Dans [86], une nouvelle approche a été développée pour la détection des yeux. Lesimages acquises par le capteur, décrit dans le paragraphe 2.4, présentent des eetsressemblant aux yeux rouges dans la photographie. En eet au fait de la diérenced'illumination et parce que le temps entre deux poses assez long, la pupille n'a pasle temps de s'adapter à l'intensité de lumière émise et reste ainsi dilatée. Cet eetcrée des pupilles brillantes. L'application d'un ltre de contour (Canny dans ce cas)crée des petits cercles ou des demi cercles dans le centre de l'oeil (pupille). L'auteur a

4.3. DÉTECTION DE ZONES DE SÉLECTION 59
utilisé une nouvelle méthode de suivi du contours (chaincode) pour détecter les demi-cercles. Pour chaque point du contour, il crée un code de suivi des points voisins. Celuicorrespondant à un demi cercle étant unique, on peut extraire dès lors les points etpar suite les contours correspondant à des cercles ou demi-cercle. Mais cette méthodedétecte également toutes les courbures ressemblant à des cercles. En explorant lasymétrie du visage et un minimum de distance inter-oculaire, Zou sélectionne ainsiles contours circulaires candidats pour être ceux de la pupille. On ane ensuite lerésultat de recherche par classication de l'histogramme du voisinage des points ainsiobtenus par la méthode SVM. La classication des centres des yeux est indépendante.On crée un modèle correspondant à l'oeil droit et un second pour l'oeil gauche. Sile système construit fait défaut pour diverses raisons telles que le clignotement desyeux, on applique alors la méthode de détection basée sur les classieurs de Harrle Floatboost. Ainsi, on a deux méthode de détection en cascade pour améliorer lesperformances de détection.
4.3 Détection de zones de sélection
Les images en proche-infrarouge présentent une stabilité vis à vis de l'illumina-tion. On remarque aussi un bon degré de contraste dans ces images. Donc, l'imagede contour en proche infrarouge est plus stable qu'en visible. Nous avons exploitéce fait pour sélectionner les zones de l'image pouvant contenir des points caractéris-tiques [27]. Nous allons nous intéresser à la détection de quatre points : les yeux, lecentre du nez et le centre de la bouche. Nous avons construit notre méthode de dé-tection pour qu'elle soit intégrable sur le capteur. Dans ce but, nous avons utilisé desopérations simples et élémentaires telles que la projection qui n'est qu'une sommationde pixels, ou le gradient qui est calculé comme une diérence. Dans [40], on montreque la fonction de projection est bien adaptée pour les images infrarouges et pourla détection du visage. Nous allons utiliser cette opération pour détecter des zonesd'intérêt pouvant contenir les yeux, le nez ou la bouche.
4.3.1 Image de contour
L'image de contour du visage a été utilisée dans les algorithmes de reconnaissancedu visage [30][58]. En eet, les contours sont considérés comme des éléments inté-ressants pour diérencier les individus car ils sont aussi des points caractéristiquesde l'anatomie du visage. Donc les points que nous avons choisis de rechercher setrouvent sur cette image de contour. L'image de contour présente aussi l'avantaged'être binaire et donc nécessitant moins d'espace mémoire.

60 CHAPITRE 4. DÉTECTION DES POINTS CARACTÉRISTIQUES
(a) (b)Figure 4.2: Filtrage gaussien (a) image initiale (b) image après ltrage gaussien
Pour l'extraction de l'image de contour, plusieurs méthodes peuvent être utilisées.On trouve dans la littérature une série de détecteurs tel le gradient, le détecteur deSobel, Canny[32]. Nous voulons une image de contours grossière ne contenant pastous les petits détails du visage. Le détecteur de Canny, bien que performant pourles images visibles, nous donne un nombre important de contours qui peuvent êtreconsidérés comme du bruit. Nous cherchons à construire une image de contour necontenant que les principaux éléments anatomiques du visage à savoir les yeux, lessourcils, le nez et la bouche [43]. Nous avons opté pour un ltre s'inspirant du ltrede Sobel mais dans les 8 directions montrées dans la gure 4.3-a) et de taille plusimportante. Pour éliminer les petits contours nous avons procédé, en premier lieu, àun ltrage gaussien. La gure 4.2 montre l'image originale et l'image ltrée. L'imagede contour et le ltre utilisé sont présentés en gure 4.3. Une opération de seuillageest aussi faite pour accentuer les contours. L'image résultante est une image quiressemble aux images croquis du visage (sketch images) qui ne présentent que lestraits caractérisant la personne c'est à dire ses yeux, sourcils, la forme du nez et labouche. On notera que les sourcils ne sont pas toujours détectable et cela est du soità leur ne épaisseur (surtout chez les femmes) ou à la mauvaise réexion des poils àla lumière proche infrarouge.
Cette méthode d'extraction des contours présente l'avantage d'être simple : un l-trage gaussien suivi d'un ltre avec un masque de taille 9×9 et un seuillage. Toutes cesopérations ont été intégrées et validées sur capteur par diérents auteurs [52][77][5].

4.3. DÉTECTION DE ZONES DE SÉLECTION 61
Figure 4.3: Extraction de l'image de contour - a) Filtre de détection de contours- b) image en proche IR - c) Résultat de la convolution
4.3.2 Présélection des zones du visage
Une projection horizontale de l'image de contour présente des maximums au niveaudes ordonnées des points caractéristiques recherchés. En eet, ces points se trouventsur des contours de direction horizontale. Pour une image I(x, y) la fonction projectionest dénie comme suit :
H(y) =n∑
i=1
I(i, y)
Où n est le nombre de colonnes dans l'image. La recherche des ordonnées des pointscaractéristiques est liée à la bonne détection des maximums locaux dans la courbe deprojection. Pour cela nous avons procédé comme suit :
1. Calcul du Laplacien de H1 = ∇H
2. Recherche du maximum M de H
3. Annulation des points autour de M jusqu'au changement de signe de H1
4. Répéter de l'étape 2 jusqu'à atteinte du nombre de maximums recherchés cor-respondant aux nombres des points particuliers.
Pour prendre en considération les aléas, par exemple le port de boucles d'oreillerééchissantes, au lieu de rechercher trois maximums locaux (correspondants auxyeux, nez et bouche) nous avons recherché cinq maximums parmi lesquels nous allons,par la suite, sélectionner les plus adéquats. Ces ordonnées trouvées correspondent àdes zones de pré-sélection pouvant contenir des points caractéristiques du visage. Lagure 4.4 montre la fonction projection et la détection de ces zones contenant lespoints caractéristiques.
62 CHAPITRE 4. DÉTECTION DES POINTS CARACTÉRISTIQUES
Figure 4.4: Sélection des régions entourant les points caractéristiques
4.4 Détection de la boucheL'un des éléments du visage ayant la forme la plus simple, en l'absence d'expres-
sion, est la bouche. Elle est toujours présentée sous forme d'une ligne dans l'imagede contour. Nous allons chercher une ligne qui se trouve dans une des zones de pré-sélection (gure 4.4). Nous restreignons notre recherche aux zones les plus basses : labouche se trouve en bas du visage.
4.4.1 Détection par morphologie mathématiqueDans le but de pouvoir intégrer facilement notre approche, nous nous sommes
basés sur une méthode simple et qui a déjà été implémentée sur divers supports :FPGA, DSP, ASIC, MOS [48]. Notre méthode ne se base que sur deux traitements :l'un qui est une opération morphologique et l'autre une projection.
La morphologie mathématique est une technique largement utilisée dans le traite-ment d'image pour diérents buts : segmentation, ltrage, analyse de texture, etc [73].Elle permet d'extraire les structures intéressantes en parcourant l'image à l'aide d'unélément de forme connue appelé élément structurant. Le choix de cet élément estfonction de la forme recherchée dans l'image. Les deux opérateurs morphologiquesde base sont : l'érosion et la dilatation. Ces transformations sont utilisées pour dé-nir d'autres opérateurs morphologiques tels que l'ouverture, la fermeture. Pour uneimage binaire I et un élément structurant S, on dénit les deux principaux opérateursmorphologiques comme suit :

4.4. DÉTECTION DE LA BOUCHE 63
L'érosion : ES(I) = ~x|S~x ⊂ I où S~x est l'élément structurant translaté de ~x.L'érosion répond donc à la question est-ce que l'élément structurant est includans l'objet de l'image. Cet opérateur élimine les objets de taille inférieure àl'élément structurant. La gure 4.5-a) montre le résultat B de l'érosion d'uneforme A par l'élément structurant S. L'élément S se déplace le long de l'objetA. Durant ce déplacement si S n'est pas inclue dans A, le point n'est retenuedans le résultat de l'érosion B.
La dilatation : ES(I) = ~x|(S~x∩I) 6= ∅. La dilatation est l'opération duale del'érosion. Elle répond au critère est-ce que l'élément structurant heurte l'objet.Elle augmente ainsi la taille des objets de l'image. La gure 4.5-b) montre lerésultat B de la dilatation d'une forme A par l'élément structurant S.
Figure 4.5: Les opérateurs de morphologie : a) Érosion de la gure A par l'élé-ment structurant S, b) Dilatation par l'élément S
L'intérêt d'utiliser la morphologie est que c'est une approche basée sur un traitementde voisinage. Donc il s'agit de comparer le voisinage d'un pixel avec un élément deforme xe. Cela peut être facilement implémenté dans un composant de type FPGA ouASIC. De plus, la transformation morphologique n'est pas appliquée sur toute l'image,mais sur les zones de l'image précédemment sélectionnées.
On s'est xé un voisinage autour des maximums dénis dans le paragraphe 4.3.2pour l'analyse et la recherche de la bouche. Pour éviter les possibles discontinuitésdans les contours nous avons eectué une ouverture avec un élément structurant deforme circulaire et de rayon 1 pixel. Pour trouver la droite la plus longue qui peutreprésenter la bouche, nous avons procédé à une érosion par un élément structurantde taille 2× 20. Une projection par la suite, nous permet de déterminer quelle seraitla zone contenant la plus longue droite. La gure 4.6 montre les diérentes étapesde cette détection. Pour trouver le centre de la bouche, nous avons supposé que cedernier devrait être le barycentre de cette zone. En eet, grâce à la symétrie du visage,le centre de la bouche est au milieu du visage et ainsi au barycentre de la zone lacontenant.

64 CHAPITRE 4. DÉTECTION DES POINTS CARACTÉRISTIQUES
Figure 4.6: Détection de la bouche
4.4.2 Détection par la transformée de Hough
Nous avons étudié aussi l'application d'une approche se basant sur les modèlesparamétriques. La plus connue est la transformée de Hough. Elle est devenue durantces dernières décennies la méthode la plus utilisée dans le domaine de la vision ar-ticielle. Elle peut être appliquée pour détecter diverses formes de contours : droite,cercle et ellipse. Elle est aussi robuste par rapport aux discontinuités du contours. Laméthode requiert d'abord l'extraction des contours de l'image par un ltre de Sobelou Canny. Puis, on doit réaliser la transformation des contours C(x, y) en :
ρ = xcosθ + ysinθ
où θ est l'angle variant entre −π/2 et π/2. Ainsi chaque courbe ρ(θ) représenteun point. Des points de la même droite sur l'image de contours correspondent àdes courbes ayant un point d'intersection. Ainsi le point de maximum d'intersectioncorrespond à la droite la plus longue dans le contour[2]. L'inconvénient de cette trans-formée est qu'elle est moins facile à implémenter sur "chips" vu sa complexité queles méthodes basées sur la morphologie, mais en réduisant la taille de l'image ou dela zone à analyser on arrive à implémenter plus facilement la détection de ligne. Dansnotre cas, l'analyse de Hough est eectuée uniquement sur les zones pré-sélectionnéespar maximums de projections horizontales de l'images de contour.

4.5. DÉTECTION DU NEZ 65
4.5 Détection du nezLe nez est un organe qui se caractérise par sa forme xe par rapport aux mouve-
ments de la tête. Les petites rotations et les expressions faciales ne changent pas laforme du nez. Cela fait du centre du nez un point stable et facilement détectable [24].Il est utilisé principalement dans la reconnaissance et la segmentation du visage en3D ainsi que dans le suivi du visage dans un ux vidéo. Notre deuxième point carac-téristique recherché est alors le centre du nez. Notre démarche vise en premier lieu àdétecter le nez ou la région du nez puis de préciser le centre du bas du nez.
Le bas du nez est un contour horizontal. Nous allons chercher dans les zones deprésélection se trouvant au dessus de la bouche, précédemment détectée, une formequi ressemble à un nez. La forme du nez est modélisée en gure 4.7. Notre rechercheest limitée aux zones au dessus de la bouche et de taille inférieure à la taille dela bouche. Cela revient à corréler cette image type sur l'ensemble de ces zones. Lacorrélation est limitée dans ce cas à une faible surface de l'image ce qui permet ungain en temps de calcul. En eet la taille de notre modèle est de 8 × 60 pixels. Enutilisant les projections verticales, nous pourrons ainsi limiter les bords du nez.
Figure 4.7: Modèle du nez
Le bas du nez a la particularité d'avoir une partie verticale limitant son contour.Pour déterminer le centre du nez, nous avons eectué une projection horizontale (selonl'axe des ordonnées) et le milieu des deux plus grands gradients correspond au milieudu nez. La gure 4.8 montre la projection du contour du nez et le gradient de laprojection.
4.6 Détection des yeuxLa détection des yeux, ou des centres des yeux, est l'une des étapes les plus impor-
tantes dans le processus de reconnaissance. En eet, la taille du visage est dénie parla distance intra-oculaire, l'orientation par l'alignement des yeux. Puisque la détectiondes yeux va permettre de normaliser ensuite les images ce qui est indispensable avanttout algorithme de mise en correspondance. Pour cela, on trouve dans la littératureplusieurs méthodes de détection des yeux. De l'ecacité de ces méthodes dépendla performance de l'algorithme de reconnaissance. Plusieurs approches ont été utili-sées pour détecter la position des yeux. Ces approches peuvent être classées en troiscatégories [84] [86] :
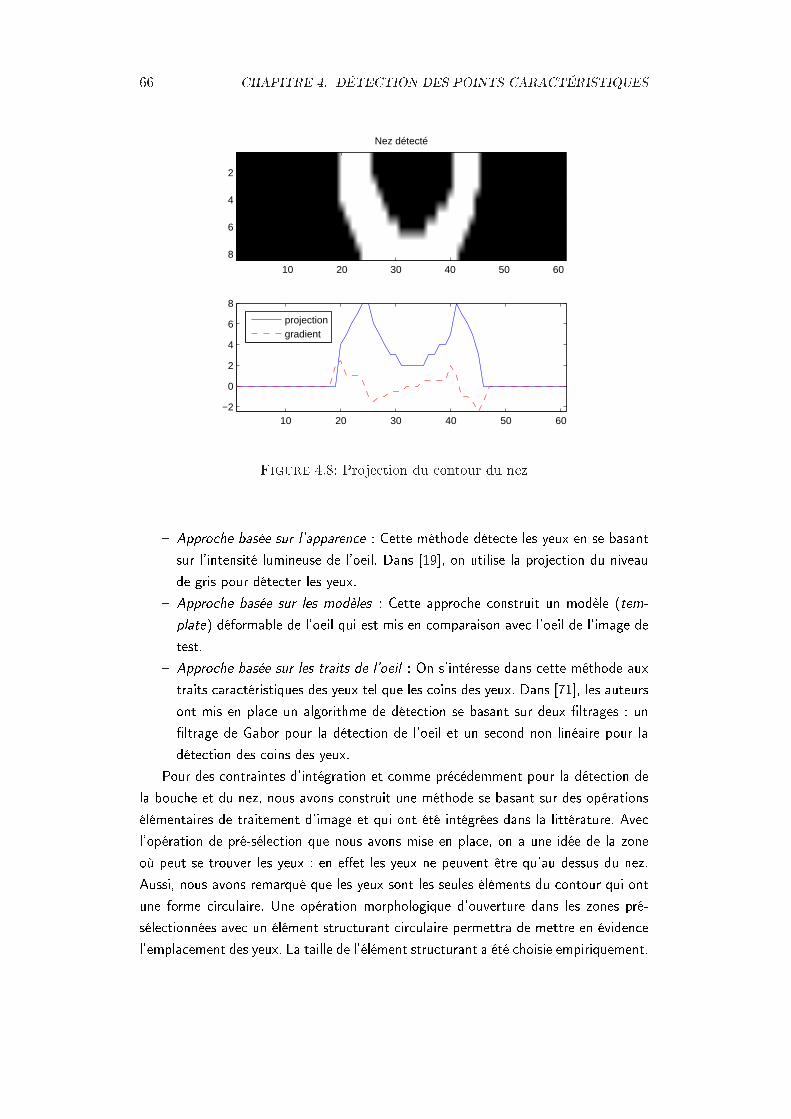
66 CHAPITRE 4. DÉTECTION DES POINTS CARACTÉRISTIQUES
Nez détecté
10 20 30 40 50 60
2
4
6
8
10 20 30 40 50 60−2
0
2
4
6
8
projectiongradient
Figure 4.8: Projection du contour du nez
Approche basée sur l'apparence : Cette méthode détecte les yeux en se basantsur l'intensité lumineuse de l'oeil. Dans [19], on utilise la projection du niveaude gris pour détecter les yeux.
Approche basée sur les modèles : Cette approche construit un modèle (tem-plate) déformable de l'oeil qui est mis en comparaison avec l'oeil de l'image detest.
Approche basée sur les traits de l'oeil : On s'intéresse dans cette méthode auxtraits caractéristiques des yeux tel que les coins des yeux. Dans [71], les auteursont mis en place un algorithme de détection se basant sur deux ltrages : unltrage de Gabor pour la détection de l'oeil et un second non linéaire pour ladétection des coins des yeux.
Pour des contraintes d'intégration et comme précédemment pour la détection dela bouche et du nez, nous avons construit une méthode se basant sur des opérationsélémentaires de traitement d'image et qui ont été intégrées dans la littérature. Avecl'opération de pré-sélection que nous avons mise en place, on a une idée de la zoneoù peut se trouver les yeux : en eet les yeux ne peuvent être qu'au dessus du nez.Aussi, nous avons remarqué que les yeux sont les seules éléments du contour qui ontune forme circulaire. Une opération morphologique d'ouverture dans les zones pré-sélectionnées avec un élément structurant circulaire permettra de mettre en évidencel'emplacement des yeux. La taille de l'élément structurant a été choisie empiriquement.

4.7. VALIDATION SUR LES BASES INFRAROUGE 67
Dans nos expériences, nous avons choisi un élément circulaire de rayon 4 pixels. Uneprojection horizontale des zones après ouverture permet de détecter l'ordonnée desyeux. Les centres des yeux sont ensuite déterminés par détection des barycentres desobjets les plus important. Il faut noter que notre détection tend a marquer les yeuxplus que détecter le centre exact des yeux (centre de la pupille). La gure 4.9 montreces opérations successives.
Figure 4.9: Détection des yeux
4.7 Validation sur les bases Infrarouge4.7.1 Critère de mesure
Pour la validation de nos approches sur la détection des diérents points parti-culier du visages, nous avons testé la performance de détection des diérents pointscaractéristiques sur les bases décrites dans le chapitre 2. Nous rappelons que ces basesont été étiquetées à la mains. Nous nous sommes basés pour mesurer les erreurs delocalisation sur la mesure proposée par Jesorsky et al. [31]. C'est la première me-sure proposée, à notre connaissance, pour évaluer les performances de détection desyeux. Elle compare l'erreur de localisation des centres de chaque oeil à la distanceintra-oculaire et donc à la taille du visage :
dyeux =max(eg, ed)‖ Cg − Cd ‖
où eg et ed représentent la distance euclidienne entre le centre réel de l'oeil gauche,respectivement droit, et le centre détecté. ‖ Cg − Cd ‖ est la distance intra-oculaireréelle mesurée par un opérateur. Jesorsky montre dans [31] que si dyeux < 0.25. La
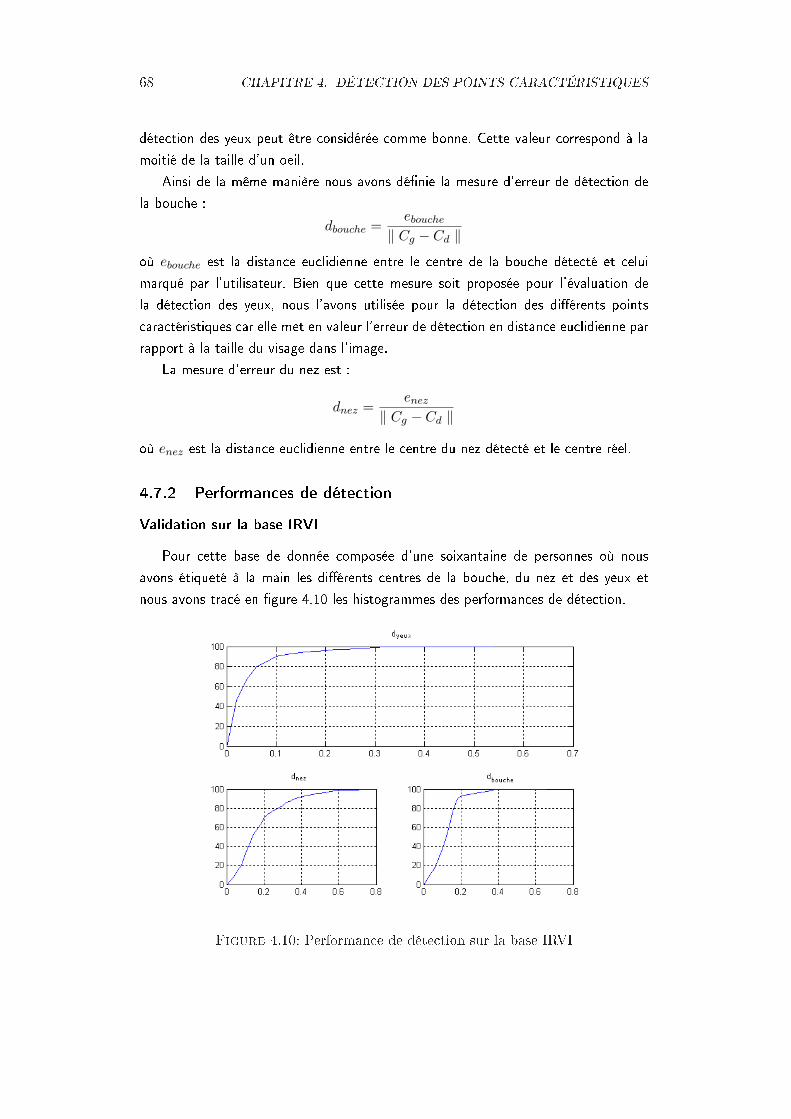
68 CHAPITRE 4. DÉTECTION DES POINTS CARACTÉRISTIQUES
détection des yeux peut être considérée comme bonne. Cette valeur correspond à lamoitié de la taille d'un oeil.
Ainsi de la même manière nous avons dénie la mesure d'erreur de détection dela bouche :
dbouche =ebouche
‖ Cg − Cd ‖où ebouche est la distance euclidienne entre le centre de la bouche détecté et celuimarqué par l'utilisateur. Bien que cette mesure soit proposée pour l'évaluation dela détection des yeux, nous l'avons utilisée pour la détection des diérents pointscaractéristiques car elle met en valeur l'erreur de détection en distance euclidienne parrapport à la taille du visage dans l'image.
La mesure d'erreur du nez est :
dnez =enez
‖ Cg − Cd ‖
où enez est la distance euclidienne entre le centre du nez détecté et le centre réel.
4.7.2 Performances de détectionValidation sur la base IRVI
Pour cette base de donnée composée d'une soixantaine de personnes où nousavons étiqueté à la main les diérents centres de la bouche, du nez et des yeux etnous avons tracé en gure 4.10 les histogrammes des performances de détection.
Figure 4.10: Performance de détection sur la base IRVI
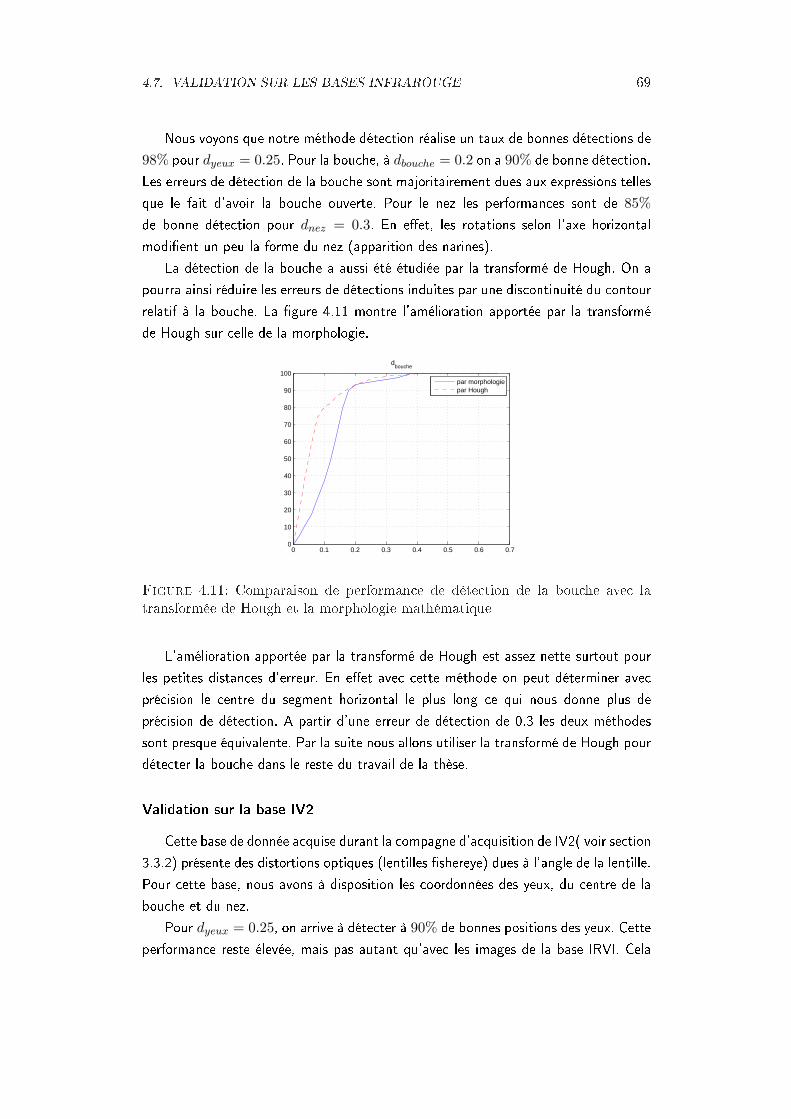
4.7. VALIDATION SUR LES BASES INFRAROUGE 69
Nous voyons que notre méthode détection réalise un taux de bonnes détections de98% pour dyeux = 0.25. Pour la bouche, à dbouche = 0.2 on a 90% de bonne détection.Les erreurs de détection de la bouche sont majoritairement dues aux expressions tellesque le fait d'avoir la bouche ouverte. Pour le nez les performances sont de 85%de bonne détection pour dnez = 0.3. En eet, les rotations selon l'axe horizontalmodient un peu la forme du nez (apparition des narines).
La détection de la bouche a aussi été étudiée par la transformé de Hough. On apourra ainsi réduire les erreurs de détections induites par une discontinuité du contourrelatif à la bouche. La gure 4.11 montre l'amélioration apportée par la transforméde Hough sur celle de la morphologie.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.70
10
20
30
40
50
60
70
80
90
100
dbouche
par morphologiepar Hough
Figure 4.11: Comparaison de performance de détection de la bouche avec latransformée de Hough et la morphologie mathématique
L'amélioration apportée par la transformé de Hough est assez nette surtout pourles petites distances d'erreur. En eet avec cette méthode on peut déterminer avecprécision le centre du segment horizontal le plus long ce qui nous donne plus deprécision de détection. A partir d'une erreur de détection de 0.3 les deux méthodessont presque équivalente. Par la suite nous allons utiliser la transformé de Hough pourdétecter la bouche dans le reste du travail de la thèse.
Validation sur la base IV2
Cette base de donnée acquise durant la compagne d'acquisition de IV2( voir section3.3.2) présente des distortions optiques (lentilles shereye) dues à l'angle de la lentille.Pour cette base, nous avons à disposition les coordonnées des yeux, du centre de labouche et du nez.
Pour dyeux = 0.25, on arrive à détecter à 90% de bonnes positions des yeux. Cetteperformance reste élevée, mais pas autant qu'avec les images de la base IRVI. Cela

70 CHAPITRE 4. DÉTECTION DES POINTS CARACTÉRISTIQUES
0 0.1 0.2 0.3 0.4 0.5 0.6 0.70
20
40
60
80
100
deye
0 0.2 0.4 0.6 0.8 10
20
40
60
80
100
dnose
0 0.2 0.4 0.6 0.80
20
40
60
80
100
dmouth
Figure 4.12: Performance de détection sur la base IV2
est peut être du à la déformation du visage par la lentille.
Validation sur la base Biomet
Cette base a été acquise avec la caméra diérentielle durant l'acquisition de BIO-MET (voir paragraphe 3.3.1). Pour ces données il n'y a de disponible que les coor-données des yeux. De ce fait, nous n'avons appliqué que l'algorithme de détection desyeux. Et pour cette base, nous avons aussi éliminé les personnes qui portent des lu-nettes. En eet, les verres rééchissent la lumière infrarouge issue du ash de manièreimportante, ce qui sature la région des yeux. L'histogramme de mesure de l'erreur dedétection est présenté en gure 4.13.
Malgré la faible taille des images (120×160) notre algorithme reste stable et donnedes performances du même ordre de grandeur que sur les bases précédentes (90% pourdyeux = 0.25).
4.8 Détection de points caractéristiques sur les imagesen visible
Le capteur IRVI que nous avons développé nous fournit en sortie un ux d'imagesvisible et proche infra-rouge. Nous avons essayé dès lors d'utiliser notre méthode dedétection sur les images en visible pour vérier si ce mode de détection de points
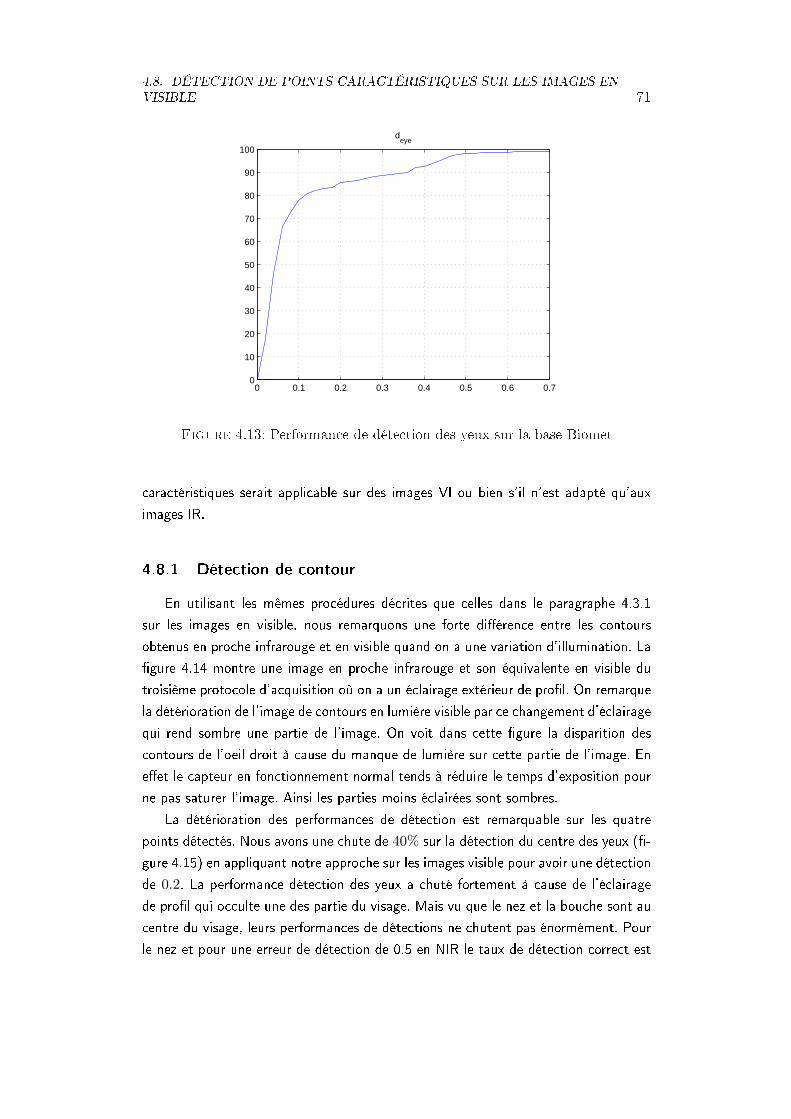
4.8. DÉTECTION DE POINTS CARACTÉRISTIQUES SUR LES IMAGES ENVISIBLE 71
0 0.1 0.2 0.3 0.4 0.5 0.6 0.70
10
20
30
40
50
60
70
80
90
100
deye
Figure 4.13: Performance de détection des yeux sur la base Biomet
caractéristiques serait applicable sur des images VI ou bien s'il n'est adapté qu'auximages IR.
4.8.1 Détection de contour
En utilisant les mêmes procédures décrites que celles dans le paragraphe 4.3.1sur les images en visible, nous remarquons une forte diérence entre les contoursobtenus en proche infrarouge et en visible quand on a une variation d'illumination. Lagure 4.14 montre une image en proche infrarouge et son équivalente en visible dutroisième protocole d'acquisition où on a un éclairage extérieur de prol. On remarquela détérioration de l'image de contours en lumière visible par ce changement d'éclairagequi rend sombre une partie de l'image. On voit dans cette gure la disparition descontours de l'oeil droit à cause du manque de lumière sur cette partie de l'image. Eneet le capteur en fonctionnement normal tends à réduire le temps d'exposition pourne pas saturer l'image. Ainsi les parties moins éclairées sont sombres.
La détérioration des performances de détection est remarquable sur les quatrepoints détectés. Nous avons une chute de 40% sur la détection du centre des yeux (-gure 4.15) en appliquant notre approche sur les images visible pour avoir une détectionde 0.2. La performance détection des yeux a chuté fortement à cause de l'éclairagede prol qui occulte une des partie du visage. Mais vu que le nez et la bouche sont aucentre du visage, leurs performances de détections ne chutent pas énormément. Pourle nez et pour une erreur de détection de 0.5 en NIR le taux de détection correct est

72 CHAPITRE 4. DÉTECTION DES POINTS CARACTÉRISTIQUES
Image NIR Image Visible
Image de contour NIR Image de contour Visible
Figure 4.14: Inuence des variations d'éclairage sur l'image de contours à gaucheimage NIR, à droite image VI correspondante
de 96% en NIR alors qu'en visible ce taux est de 88%.
4.9 Conclusion
Dans ce chapitre, nous nous sommes intéressés à la détection des points caracté-ristiques du visage. Ces points, et leurs voisinages nous donnent des informations utiles(texture et position), nécessaires pour la reconnaissance de visage. Nous nous sommesrestreints à n'utiliser que des méthodes simples par leur construction pour pouvoir lesintégrer. Tous les opérateurs utilisés ont d'ailleurs été intégrés dans divers travauxdisponibles dans la littérature. Grâce à la stabilité des images acquises en infrarougevis à vis de l'illumination, nous avons pu simplier les algorithmes de détection parrapport aux approches classiquement utilisées sur des images en lumière visible. Eneet, les images de contour extraites des images en lumière visible ne sont pas aussistables et présentent des saturations qui modient les contours du visage. Nous avons
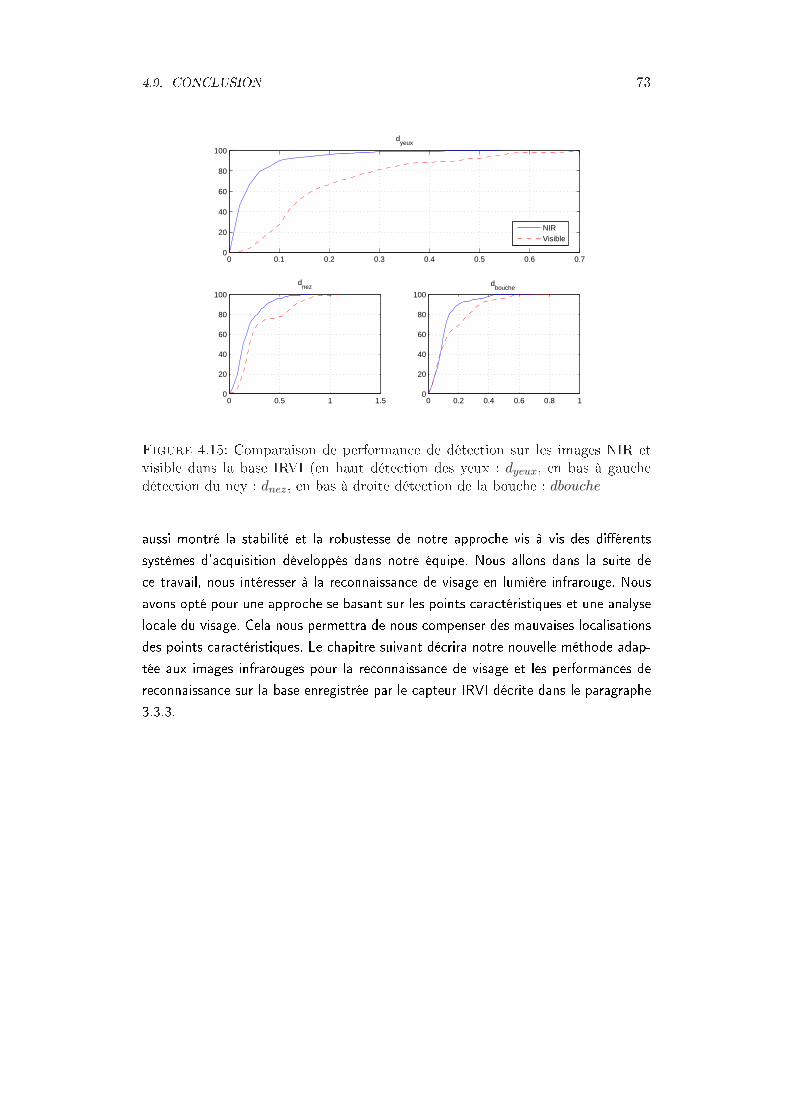
4.9. CONCLUSION 73
0 0.1 0.2 0.3 0.4 0.5 0.6 0.70
20
40
60
80
100
dyeux
0 0.5 1 1.50
20
40
60
80
100
dnez
0 0.2 0.4 0.6 0.8 10
20
40
60
80
100
dbouche
NIRVisible
Figure 4.15: Comparaison de performance de détection sur les images NIR etvisible dans la base IRVI (en haut détection des yeux : dyeux, en bas à gauchedétection du ney : dnez, en bas à droite détection de la bouche : dbouche
aussi montré la stabilité et la robustesse de notre approche vis à vis des diérentssystèmes d'acquisition développés dans notre équipe. Nous allons dans la suite dece travail, nous intéresser à la reconnaissance de visage en lumière infrarouge. Nousavons opté pour une approche se basant sur les points caractéristiques et une analyselocale du visage. Cela nous permettra de nous compenser des mauvaises localisationsdes points caractéristiques. Le chapitre suivant décrira notre nouvelle méthode adap-tée aux images infrarouges pour la reconnaissance de visage et les performances dereconnaissance sur la base enregistrée par le capteur IRVI décrite dans le paragraphe3.3.3.


Chapitre 5
Algorithme de Reconnaissancede Visage
Dans ce chapitre nous allons présenter un algorithme de reconnaissance adaptéaux images proche infrarouge issues de notre capteur. Cette méthode s'inspire del'algorithme de comparaison élastique des graphes connu sous le nom Elastic GraphMatching (EGM). Dans le but de pouvoir intégrer par la suite ce système de reconnais-sance de visage, nous nous sommes contraints à utiliser une approche locale qui estplus adaptée pour un SoC et une intégration sur le capteur qu'une méthode globalesà base d'apprentissage. Nous allons en premier lieu détailler l'algorithme EGM originalet quelques approches développées dans la littérature qui s'inspirent de la méthodedes graphes. Les performances de reconnaissance de cet algorithme sont étudiées toutd'abord sur une base publique BANCA [6] ensuite nous allons les valider sur la baseIRVI acquise dans notre laboratoire. En suite nous allons présenter notre nouvelle ap-proche qui se base sur la détection de contours et de points caractéristiques présentéeprécédemment. Nous allons par la suite comparer notre approche avec diérentes mé-thodes de base pour la reconnaissance de visage, dont l'EGM précédemment cités etdes méthodes globales développées dans notre laboratoire.
5.1 Élaboration des graphes pour la reconnaissance devisage
Les approches locales ont été les premières à être exploitées pour la reconnais-sance de visage. Dans les premiers travaux réalisés, ces études ont consisté à mesurer
75

76 CHAPITRE 5. ALGORITHME DE RECONNAISSANCE DE VISAGE
les diérentes distances anthropométriques du visage pour trouver une caractéristiqueunique à chaque personne, mais on s'est rendu compte que cette approche ne per-mettait pas d'obtenir un bon élément diérenciateur entre les individus. Certainesdistances sont même constantes entre les personnes. Ainsi cette approche ne donnepas de bonnes performances de reconnaissance. La conclusion c'est qu'il faut doncanalyser le visage localement mais sans omettre le caractère global de l'analyse. L'ap-proche des graphes est une solution proposée par Lades [37] en 1992. Un graphe estconstitué d'un ensemble de n÷uds reliés entre eux par des lignes/contours (Edge).Les n÷uds peuvent être des points particuliers de l'objet (du visage dans notre cas)ou des points d'une grille virtuelle déposée sur l'objet. Pour une meilleure modélisa-tion par graphe, il est conseillé d'avoir des n÷uds qui possèdent des caractéristiquesdiérentes les unes des autres. Mais ils doivent être stables dans diérentes situationsd'acquisition. Outre leurs positions, les n÷uds contiennent aussi une analyse de leursvoisinages. Cela peut être une analyse statistique du voisinage, du contour, du mo-ment, de la forme, ou une transformation du voisinage d'un autre espace (transforméede Fourier, transformée DCT, ...). L'information sur le voisinage est représentée dansun vecteur appelé Jet. Cette information peut être générée par plusieurs méthodesd'analyse, on citera les plus utilisées :
Analyse de la forme par morphologie mathématique : dans cette approche levecteur Jet contient l'information sur la forme du voisinage par une successiond'érosions et de dilatations. Cette méthode bien que simple est assez dépendantede la pose, de l'illumination et de la taille de l'image d'origine.
Analyse de la texture par transformée en cosinus discrète : protant du faitque cette transformée est très utilisée pour la compression d'image (JPEG) etde sa maturité en terme d'implémentation, on peut construire le vecteur Jeten faisant varier la taille du noyau de la transformée. Cette méthode est aussiperformante que l'analyse avec les ltres de Gabor [51]. Mais, elle soure d'unecomplexité de calcul importante au niveau de l'étape de calcul de la variancelocale.
Analyse de la texture par transformée de Gabor : C'est l'approche la plus utiliséeen ce moment. Elle se base sur l'utilisation d'un banc de ltres de Gabor envariant les orientations et les résolutions. Ainsi le voisinage de chaque noeud estconvolué par ces diérents ltres.
Nous présentons ici, en détail, les deux approches les plus utilisées dans la littérature.La première se base sur des traitements morphologiques et la deuxième sur l'analysepar ondelettes de Gabor.

5.1. ÉLABORATION DES GRAPHES POUR LA RECONNAISSANCE DE VISAGE77
5.1.1 Analyse par morphologie mathématiqueCette méthode a été utilisée par Kotropoulos [34], pour extraire les diérentes
informations de forme dans le voisinage des noeuds. On eectue une série d'érosionset de dilatations par des éléments structurants de forme circulaire. Leurs tailles varientde 3 × 3 à 19 × 19. La gure 5.1 montre un exemple du résultat de successionsd'opérations morphologique sur une image en NIR où la première image est l'érosionde l'image d'origine par l'élément de la taille la plus grande et la dernière image estla dilatation de l'image d'origine par cet élément.
Figure 5.1: Érosion et dilatation successives avec des éléments structurants cir-culaires de taille variable sur une image en NIR. De haut en bas de gauche àdroite Érosion par un élément structurant de taille décroissante (E9 -> E2), puisDilatation par un élément structurant de taille croissante (D2 -> D9)
Dans ces images, on remarque que la pupille est de plus en plus brillante au fur età mesure que l'on réalise des dilations. En eet, la tâche qui correcpond à la reexionde la lumière sur la pupille qui est de forme circulaire s'agrandit avec la dilatation parun élément circulaire. On pourrait exploiter ce fait pour une détection des yeux telque l'as proposé Zou dans sa thèse [86].

78 CHAPITRE 5. ALGORITHME DE RECONNAISSANCE DE VISAGE
Une grille rigide est ensuite placée sur le visage. Ses points constituent l'ensembledes noeuds du graphe. Le jet est composé des valeurs des pixels des images érodéeset dilatées. Un jet se compose dès lors de :
J(x, y) = D9(x, y); . . . ; D1(x, y); I(x, y);E1(x, y); . . . ; E9(x, y)
où Dn(x, y) (respectivement En(x, y)) est la valeur de l'image érodée (respectivementdilatée) par l'élément de rang n au pixel (x, y), et I(x, y) est la valeur du pixel dansl'image d'origine. Cette approche bien que relativement simple présente de faiblesperformances comparées à celles données par une analyse de Gabor. Dans [48], onétudie cette diérence qui est de l'ordre de 30% sur des tests faits sur la base XM2VTS.
5.1.2 Analyse par les ondelettes de GaborUne alternative à l'usage de la morphologie mathématique est l'application d'une
transformée d'ondelette. Les ondelettes de Gabor sont connues comme le moyen d'ana-lyse espace-fréquence qui minimise l'incertitude de Heisenberg à savoir si on est précisdans l'analyse de l'information dans l'espace du pixel on le sera moins dans l'espacefréquentiel et vice versa. Cette caractéristique fait des ondelettes de Gabor un moyenpuissant pour l'analyse de la texture. Elles ont été développées au début pour l'analysedes signaux à une dimension. Leurs expression générale est :
W (t, t0, ω) = e−σ(t−t0)2e−iω(t−t0)
où ω est la fréquence et i2 = −1. Cette cette ondelette est en fait une gaussiennemodulée par une fonction sinusoïdale. La généralisation de cette fonction en 2D donneune fonction gaussienne à deux dimensions modulée par une harmonique. Les onde-lettes de Gabor 2D ont la caractéristique d'être modulable par diérents paramètresqui contrôlent leurs orientations, fréquences, phases, tailles et aspects. L'équationgénérale d'une ondelette de Gabor en 2D est :
W (x, y, θ, λ, ϕ, σ, γ) = e−x′2+γ2y′2
2σ2 ei(x′λ
+ϕ) (5.1)
où x′ = xcosθ + ysinθ et y′ = −xsinθ + ycosθ. Il y a donc 5 paramètres quicontrôlent l'analyse par ondelette. Ce jeu de paramètres permet dès lors une analysecomplète de la texture d'une région de l'image. La gure 5.2 montre les diérentesorientations et résolutions des parties réelles des ondelettes de Gabor en 2D.
5.2 La comparaison élastique des graphes - EGML'algorithme de référence utilisant les graphes est celui proposé par Wiskott et
al. [81] et qui sera noté EGM-CSU. Cet algorithme se base sur la détection des

5.2. LA COMPARAISON ÉLASTIQUE DES GRAPHES - EGM 79
Figure 5.2: Les diérentes orientations et résolutions des parties réelles des ltresde Gabor utilisés
points caractéristiques du visage qui constitueront les noeuds du graphe. Nous allonsvoir dans ce paragraphe la méthode employée pour former un graphe représentantle visage et l'approche de comparaison des graphes tel que proposée par [81]. Nousavons aussi réalisé des expériences avec cet algorithme de base. Ainsi nous avonsétudié l'inuence du nombre des noeuds dans la méthode sur les performances dereconnaissance sur une base publique BANCA [6].
5.2.1 Détection des noeuds dans le EGM-CSULa première étape de l'algorithme est la détection des points caractéristiques. Ils
sont au nombre de 25. Ces points sont communs à tous les visages, mais leur formepeut changer d'une personne à une autre comme le nez, les yeux, la bouche. Lespoints sont dénis précisément de manière à minimiser l'erreur de leur localisation.Par exemple pour le nez, on précise bien le centre bas du nez, ou l'extrémité gauche

80 CHAPITRE 5. ALGORITHME DE RECONNAISSANCE DE VISAGE
du nez, etc.Pour pouvoir bien localiser les noeuds du graphe, une étape d'apprentissage est
nécessaire. L'opérateur marque manuellement sur une cinquantaine d'images norma-lisées ces diérents points. On crée par la suite un modèle de chaque point basé sursa position géométrique dans le visage et sur l'analyse fréquentielle obtenue par lesltres de Gabor. La détection de ces diérents points se fait sur le reste des imagesde la base en deux étapes :
1. Localisation grossière du point : Grâce à la position moyenne de chaque noeudpar rapport à la position des yeux, déterminée durant l'étape d'apprentissage,nous déterminons la position du point dans la nouvelle image normalisée. Ona donc besoin de connaître la position des yeux au préalable et de normaliserl'image avant de détecter les diérents noeuds.
2. Anage de la détection : La position trouvée précédemment n'est qu'une es-timation de la région pouvant contenir le noeud recherché. Il faut donc anerla position du point. En utilisant l'analyse par les ltres de Gabor, nous allonschercher le point dans le voisinage du point initial qui est le plus similaire auvecteur Jet extrait lors de l'apprentissage. La mesure de la similitude du vecteurJet qui est composé des diérents modules de la réponse des ltres de Gabor,se fait selon la formule suivante :
Sφ(J, J ′) =
∑Nj=1 aja
′jcos(φj − φ′j)√∑N
j=1 a2j
∑Nj=1 a′2j
(5.2)
où N est le nombre de composantes du vecteur Jet, aj (respectivement a′j) estl'amplitude de la j ième composante du vecteur jet J (respectivement J ′) etφj (respectivement φ′j) est la phase de la j ième composante du vecteur jet J
(respectivement J ′). Ce score varie donc entre -1 et 1 et il est maximal quandles deux phases et amplitudes sont similaires.
5.2.2 Extraction de caractéristiques et paramètres des ondelettes deGabor dans l'approche CSU
Après la détection des diérents n÷uds du graphe, la seconde étape dans l'algo-rithme de comparaison des graphes est l'extraction des caractéristiques locales. Dansl'approche EGM-CSU, le vecteur caractéristique se compose des modules du résultatde la convolution des voisinages des n÷uds par des ltres de Gabor. Pour nos tests surla base IRVI et Banca, nous avons appliqué les paramètres par défaut du programmede l'université CSU. Ces paramètres ont été proposés par Wiskott de manière à avoirune meilleure analyse locale [80]. De l'équation 5.1, on a choisi le jeu de variablessuivant pour construire le vecteur Jet :

5.2. LA COMPARAISON ÉLASTIQUE DES GRAPHES - EGM 81
θ spécie l'orientation du ltre. On a utilisé dans ce cas 8 orientations :0, π/8, π/4, 3π/3, π/2, 5π/8, 3π/4, 7π/8
λ spécie la longueur d'onde et donc la fréquence de la sinusoïde. Cette variablepeut prendre 5 valeurs comprises entre 4 et 16 : 4, 4
√2, 8, 8
√2, 16
ϕ spécie la phase de la sinusoïde. Elle vaut 0 ou π/2 selon que l'on veut lapartie réelle ou imaginaire.
σ spécie la variance de la gaussienne (sa taille). Elle est proportionnelle à lalongueur d'onde de la sinusoïde. Dans notre cas σ = λ.
γ spécie l'aspect de la gaussienne. Ici les gaussiennes sont de forme circulaire :γ = 1.
Ainsi le vecteur Jet utilisé est composé des 40 modules de la réponse des diérentsltres de Gabor.
5.2.3 Comparaison des graphesAprès la détection des 25 points caractéristiques du visage et la construction des
Jets au niveau de chaque noeud, on dénit une série de liens (contours du graphe)qui relient les noeuds. Dans la méthode proposée par Wiskott, ils sont au nombrede 50. Ainsi le graphe caractéristique du visage est composé de 25 noeuds et de 50segments. La gure 5.3 montre une image de la base BANCA et le graphe associé.
Figure 5.3: Représentation d'un graphe sur une image de la base BANCA
La comparaison de graphes se fait par calcul de similarité entre les Jets selonl'équation 5.2. Pour modéliser le déplacement des noeuds et ainsi le changement dansl'ensemble des contours entre image de référence et image de test, l'auteur a associéun Jet à chaque segment. Ce Jet est l'analyse de Gabor du milieu du segment. Ainsi,on a en tout 80 Jets pour chaque image de visage. La similitude entre deux graphes

82 CHAPITRE 5. ALGORITHME DE RECONNAISSANCE DE VISAGE
Figure 5.4: Exemples d'image de la base BANCA (a) image en haute résolutioncontrôlée (b) Dégradée (c) non contrôlée
est la moyenne de similitude des jets correspondants :
S(G, G′) =180
80∑
j=1
Sφ(Jj , J′j) (5.3)
5.2.4 Inuence du nombre des noeuds
Le choix d'avoir un graphe composé de 25 points n'était pas expliqué dans lalittérature. Nous avons choisi de modier le graphe, déni dans l'algorithme proposé,en diminuant le nombre de n÷uds pour évaluer l'eet sur les performances de recon-naissance de l'algorithme sur une base publique :BANCA.
Base de donnée visage BANCA
Cette base de données contient deux modalités : la voix et le visage. On y trouvedeux types d'acquisition : une en haute dénition et une seconde en dégradé. Lespersonnes sont enregistrées selon trois protocoles : contrôlé, dégradé et non contrôlé.La gure 5.4 montre une image d'une personne acquise selon les trois protocoles. Labase contient 12 sessions. 208 personnes ont été enregistrées dans cette base à paritéégale homme-femme. Mais, les données disponibles correspondent à 52 personnes :26 hommes et 26 femmes.
Plusieurs combinaisons de test sont possibles sur cette base par permutations desdiérentes sessions. Nous nous sommes intéressés dans ce travail au protocole decomparaison Test Commun (Pooled Test : P). Dans celui ci, on considère que lesimages de référence sont issues d'une session contrôlée (S1) et les images de testssont issues du reste de la base. La base est divisée en deux groupes : g1 et g2. Chaquegroupe contient 13 hommes et 13 femmes.

5.2. LA COMPARAISON ÉLASTIQUE DES GRAPHES - EGM 83
Inuence du nombre des n÷uds
Pour étudier l'inuence du nombre des n÷uds sur les performances de reconnais-sance, on a éliminé, en premier lieu 5 noeuds que nous avons choisis par rapport àleur signication anthropométrique. Nous avons pensé que l'élimination par exempledu sommet de la tête n'aurait pas d'inuence sur le taux d'erreur. Nous avons aussiéliminé les contours associés à ces n÷uds. Le nombre total de jet dans le graphe, dansce cas, est de 52 (nombre des n÷uds et des segments). Ce test sera noté 20C dans lasuite du texte. La gure 5.5 a) montre le graphe associé aux 20 noeuds restants. Dansun second temps, nous avons omis aléatoirement 5 noeuds du graphe initial et lessegments reliés à ces derniers. Ce cas nous a généré un graphe composé de 56 jets. Cetest est noté par 20 dans la suite. La gure 5.5 b) représente ce graphe. La dernièreconguration de graphe eectuée est avec 15 n÷uds aléatoirement omis. Le nombrede Jets est de 33 dans ce cas. La gure 5.5 c) montre le graphe avec 15 n÷uds.
Le protocole de test que nous avons appliqué sur cette base est le protocole Pdéni dans le paragraphe précédent. Les images de référence dans ce protocole sontchoisies dans la session contrôlée et dans la session non contrôlée (images de webcam).Les images de test sont issues du reste de la base.
Figure 5.5: Variation du nombre des noeuds dans un graphe : a) 20 noeudschoisis b) 20 noeuds aléatoirement choisis et c) 15 noeuds aléatoirement choisis
Le tableau 5.1 montre les résultats associés aux diérents nombres de n÷uds dansun graphe. On voit dans un premier temps que les scores de reconnaissance sont dumême ordre de grandeur. L'écart de performances entre un graphe composé de 15noeuds et un de 25 n÷uds est assez faible : dans le protocole de test g1 avec ungraphe de 25 points on a 25.5% de HTER alors qu'avec 15 noeuds on a 25.8%. Celapeut être dû à la taille des ltres de Gabor utilisés (les plus grands ont une taillede 128). En eet, avec une taille des images de 140 × 140 le ltre de taille 128permet de presque réaliser une analyse globale sur toute l'image. Pour deux n÷udsproches, la réponse de ce ltre de ce ltre de taille 128 serait similaire. Aussi laméthode de calcul de similarité donne le même poids aux diérents Jets, or les ltres
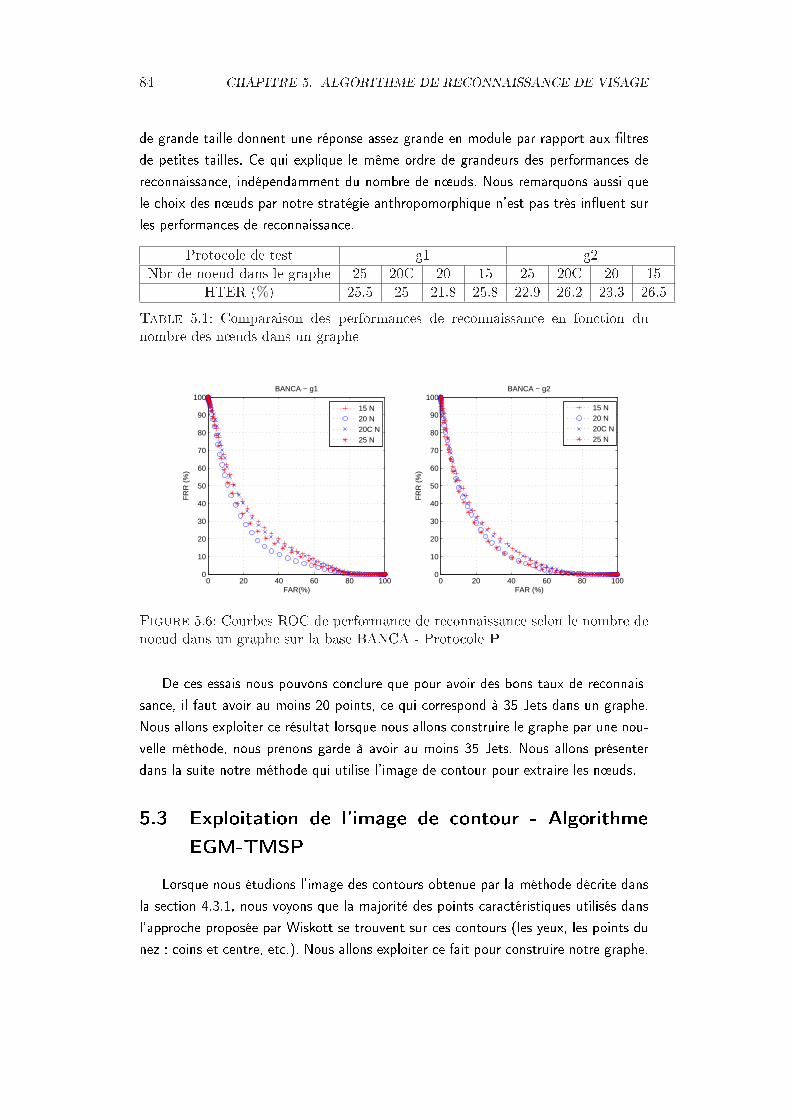
84 CHAPITRE 5. ALGORITHME DE RECONNAISSANCE DE VISAGE
de grande taille donnent une réponse assez grande en module par rapport aux ltresde petites tailles. Ce qui explique le même ordre de grandeurs des performances dereconnaissance, indépendamment du nombre de n÷uds. Nous remarquons aussi quele choix des n÷uds par notre stratégie anthropomorphique n'est pas très inuent surles performances de reconnaissance.
Protocole de test g1 g2Nbr de noeud dans le graphe 25 20C 20 15 25 20C 20 15
HTER (%) 25.5 25 21.8 25.8 22.9 26.2 23.3 26.5Table 5.1: Comparaison des performances de reconnaissance en fonction dunombre des n÷uds dans un graphe
0 20 40 60 80 1000
10
20
30
40
50
60
70
80
90
100
FAR(%)
FR
R (
%)
BANCA − g1
0 20 40 60 80 1000
10
20
30
40
50
60
70
80
90
100
FAR (%)
FR
R (
%)
BANCA − g2
15 N20 N20C N25 N
15 N20 N20C N25 N
Figure 5.6: Courbes ROC de performance de reconnaissance selon le nombre denoeud dans un graphe sur la base BANCA - Protocole P
De ces essais nous pouvons conclure que pour avoir des bons taux de reconnais-sance, il faut avoir au moins 20 points, ce qui correspond à 35 Jets dans un graphe.Nous allons exploiter ce résultat lorsque nous allons construire le graphe par une nou-velle méthode, nous prenons garde à avoir au moins 35 Jets. Nous allons présenterdans la suite notre méthode qui utilise l'image de contour pour extraire les n÷uds.
5.3 Exploitation de l'image de contour - AlgorithmeEGM-TMSP
Lorsque nous étudions l'image des contours obtenue par la méthode décrite dansla section 4.3.1, nous voyons que la majorité des points caractéristiques utilisés dansl'approche proposée par Wiskott se trouvent sur ces contours (les yeux, les points dunez : coins et centre, etc.). Nous allons exploiter ce fait pour construire notre graphe.

5.3. EXPLOITATION DE L'IMAGE DE CONTOUR - ALGORITHME EGM-TMSP85
Récemment des travaux de l'université de Vigo [23] se sont orientés vers l'exploitationdes arêtes (ridges) et des vallées (valleys) pour construire l'ensemble de noeuds.Dans ce travail, à partir d'une image classique, on extrait les diérents contours parun ltre de Sobel. Ce ltre génère beaucoup de contours fermés et cette méthoded'extraction de contour soure d'une sensibilité à l'illumination. Ainsi, les contourschangent d'aspect selon l'éclairage. Un pré-traitement pour atténuer ces eets estalors nécessaire. Les auteurs utilisent, ensuite, une grille dense (le nombre de pointsest supérieur à 100) couvrant l'image. Cette grille sert pour échantillonner leur imagede contours. Tous les points de la grille sont alors déplacés pour être sur l'image decontour. Chaque noeud de la grille correspond à un seul et unique point du contour.Un système de ag est alors aecté pour avoir cette unique correspondance entre lagrille et les contours. On procède alors par une analyse par des ltres de Gabor surchaque noeud.
Notre approche s'inspire de la méthode de Vigo mais prend en compte explici-tement notre méthode d'extraction de contours telle que dénie dans le paragraphe4.3.1. Travaillant sur des images NIR, notre contour sera stable aux variations d'illu-mination comme montré précédemment. De plus les contours obtenus sont diérentsde ceux obtenus par la méthode de Vigo ; ils contiennent les bords du nez, la bouchec'est à dire les caractéristiques naturelles du visage. On donc a utilisé une grille pouréchantillonner l'image de contours générée par les images NIR comme décrite dansle paragraphe 4.3.1. Une question que l'on peut se poser est de savoir si ona besoind'autant de noeuds que dans la littérature (Vigo, CSU) ? Notre analyse sur le nombrede noeuds montre qu'un nombre aussi élevé (80 Jets comme dans la méthode EGM-CSU) n'est pas nécessaire, mais il faut dans ce cas bien positionner la grille. Nousbasons sur nos travaux eectués dans le chapitre 4, nous avons choisi de recadrer enpremier lieu la grille sur la partie du visage limitée par les yeux et la bouche (voirgure 5.7) et non de la poser sur l'image complète comme dans l'article [23]. La grilleest positionnée selon la position des yeux et de la bouche. Cela nous permet d'éviterun calcul de recadrage des grilles durant les comparaisons. Cela nous permet ausside n'avoir que des points signiants par la suite. La gure 5.7 montre un exemple depositionnement adapté à la position des yeux et de la bouche pour l'image de contour(a) et son équivalent sur l'images NIR (b).
On remarque qu'avec cette méthode, certains noeuds de la grille n'appartiennentpas à l'image de contour. Ces points se trouvent donc dans une région continue oùil n'y a pas de changement de texture. Nous avons éliminé les points de la grillen'ayant pas dans leurs voisinages un contour. Cette opération nous permet de réduirele nombre des noeuds sans pour autant perdre de l'information pertinente. Les pointsrestants sont alors déplacés vers le point du contour le plus proche et ayant la valeur

86 CHAPITRE 5. ALGORITHME DE RECONNAISSANCE DE VISAGE
Figure 5.7: Positionnement d'une grille sur le visage selon la position des yeuxet de la bouche a) Image de contour, (b) Image en NIR
Figure 5.8: Sélection des n÷uds dans la méthode de l'Université de Vigo [23] :Images à gauche présentent le visage en lumière visible de la même personne, lesimages au centre sont les images des vallées extraits et les images à droites sontles n÷uds sélectionnés pour le graphe de chaque visage
la plus importante dans l'image de contours. Ce point est alors marqué comme "pris",et aucun autre noeud ne sera aecté à ce point. Cela nous permet d'éviter d'avoir lecas de deux noeuds superposés. De plus nous avons limité la taille du voisinage d'unnoeud de telle sorte que les voisinages n'aient pas de partie commune entre eux. Lerésultat de cette sélection des points du contour est montré en gure 5.9. Dans cettegure, on remarque que le changement de pose n'aecte pas beaucoup la position desnoeuds ni leur nombre : dans les deux images on en compte 64.
Après avoir sélectionné un ensemble de points de l'image de contour, nous appli-querons l'analyse de Gabor au voisinage de chaque point de cet ensemble. Chaquenoeud est représenté par un vecteur jet constitué par les modules des réponses desltres décrits précédemment. Ainsi une image de visage est maintenant modélisée parce graphe. Pour comparer deux graphes nous allons mettre en correspondance lesdiérents noeuds selon la méthode décrite dans la section suivante.

5.3. EXPLOITATION DE L'IMAGE DE CONTOUR - ALGORITHME EGM-TMSP87
Figure 5.9: Sélection des noeuds de l'image de contour et inuence d'un chan-gement de pose sur la sélection
5.3.1 Méthode de mise en correspondance des n÷uds
La mise en correspondance des noeuds est la dernière étape avant le calcul desimilarité entre deux graphes. La méthode CSU n'a pas ce problème de mise en cor-respondance vu que chaque noeud possède une signication physique bien dénie.Ce problème s'est posé avec la méthode proposée par l'université de Vigo [23]. Pourcela, ils ont étudié la ressemblance de la forme du voisinage de chaque noeud. Celapeut se faire par une étude de l'histogramme local, par ltrage DoG ou par gradient.Cette méthode est aussi utilisée dans l'algorithme SIFT (Scale-invariant feature trans-form) [44]. Ainsi, on calcule l'histogramme local de chaque point du graphe de l'imagede référence et on le compare à ceux des points du graphe de test. Cet algorithmenécessite donc la mémorisation des jets et de l'histogramme local de chaque noeudde l'image de référence. Le calcul de mis en correspondance est coûteux dans cetteméthode vue le nombre de noeuds qui constituent le graphe et la méthode de com-paraison des n÷uds utilisée.
Dans notre cas, pour limiter l'utilisation de mémoire (données enregistrées en réfé-rence), nous fabriquons un procédé plus simple en utilisant les données déjà disponiblesc'est à dire les jets et la grille. La comparaison directe des jets n'a pas donné un bonrésultat de correspondance. Nous avons alors étiqueté les n÷uds de la grille initiale-ment ajustée sur le visage. Leurs coordonnées initiales dans la grille sont mémoriséesavec le jet associé. La correspondance se fait alors avec les noeuds de même coordon-née ou avec ses voisins s'il en existe. Dans le cas contraire où le n÷ud n'a pas soncorrespondant de même coordonnée et ses voisins sont déjà mis en correspondance,le noeud n'est pas pris en compte pour le calcul de similarité. La gure 5.10 montrela correspondance entre les noeuds des graphes de deux images.
La similarité entre deux graphes est alors calculée avec les jets des noeuds mis en

88 CHAPITRE 5. ALGORITHME DE RECONNAISSANCE DE VISAGE
correspondance. Nous avons utilisé le calcul de similitude tel que décrit dans l'équa-tion 5.2. Cependant, nous avons calculé séparément, les similarités des éléments duvecteur jet correspondant à des ltres de même taille : on calcule tout d'abord la simi-larité des diérentes réponses des ltres de même taille, puis on moyenne le tout. Eneet, le fait que les réponses des ltres de grande taille soient plus grandes que cellesdes ltres de petite taille tend à atténuer l'inuence des ltres de petites résolutions.
Figure 5.10: Méthode de correspondance des graphes selon les coordonnées desnoeuds dans la grille originale, les traits continus présentent une mise en cor-respondance entre noeuds de mêmes coordonnées, les traits discontinus sont unecorrespondance entre noeuds possible vu qu'ils sont voisins et n'ont pas de noeudscorrespondants
5.4 Comparaisons et PerformancesPour évaluer notre nouvel algorithme, nous avons mis en place un protocole de
test sur la base IRVI. Nous avons aussi comparé les performances de reconnaissancede l'algorithme proposé avec l'algorithme original proposé par l'université CSU et avecdeux algorithmes de référence basés sur une approche globale : le LDA et un autrealgorithme plus performant combinant l'analyse de Gabor et une classication LDAdéveloppé dans notre laboratoire [61]. Nous décrivons, brièvement, en premier lieu, cesdeux algorithmes de référence. Puis, nous présenterons les performances respectivesde toutes les méthodes.
5.4.1 Algorithmes de référenceLes algorithmes décrits dans la suite sont des algorithmes connus [61]. Ils nous
servent de base de comparaison avec notre approche.

5.4. COMPARAISONS ET PERFORMANCES 89
Analyse linéaire discriminante (LDA)
Cette méthode se classe parmi les approches globales de reconnaissance. Dansce type d'approches on cherche à modéliser un espace de visages construit à partird'une base de donnée d'apprentissage. Puis on représente le visage dans cet espacede dimension réduite, par rapport à l'espace des images 2D, Φ par x =
∑ni=1 αiVi où
x est le vecteur de l'image dans l'espace initial et (Vi) sont les vecteurs propres del'espace réduit. L'intérêt de cet algorithme est de déterminer les axes qui accentuentla diérence entre les classes. La procédure tend ainsi à réduire les diérences ausein d'une même classe. Ainsi on rassemble les éléments d'une même classe tout endiérenciant les classes [7]. Pour cela, on dénit deux mesures : la première est lamesure de dispersion intra-classe (within-classe scatter matrix) dénit par :
Sw =c∑
j=1
Nj∑
i=1
(xji − µj)(x
ji − µj)T
où xji est le ime composant de la classe j, µj est la moyenne de la classe j, c est
le nombre de classes et Nj le nombre d'échantillon de la classe j. La deuxième mesureest la mesure de dispersion inter-classe (Between-class scatter matrix) dénie par :
Sb =c∑
j=1
(µj − µ)(µj − µ)T
où µ est la moyenne de tout les échantillons. Pour maximiser la ressemblanceintra-classe en minimisant l'inter-classe, nous cherchons la matrice de transformationW qui maximise le critère suivant :
J(W ) =W T SbW
W T SwW
Dans ce travail, cet espace réduit est construit avec des images issues de la base dedonnées FRGC (Face Recognition Grand Challenge). Cette base représente mieux lesimages en visible. Vu la non-disponibilité d'assez de données en proche infrarouge,nous avons utilisé cette même base pour représenter les données NIR même si celan'est pas optimal.
Analyse linéaire discriminante des coecients de Gabor - GLDA
Cette seconde approche est bien plus complexe que la précédente, mais elle amontré son ecacité dans les compétitions menées par le NIST et dans les expériencescomparatives menées dans [61]. Dans cet algorithme, le visage est modélisé par lesrésultats d'analyse de Gabor de l'image. On a utilisé dans ce cas 16 ltres avec 4

90 CHAPITRE 5. ALGORITHME DE RECONNAISSANCE DE VISAGE
orientations et 4 résolutions. Ainsi la représentation de l'image I est IGs,o = I⊗Gs,o
où Gs,o constitue l'ensemble des ltres de Gabor obtenus en variant l'orientation o etla taille s et ⊗ est l'opérateur de convolution.L'algorithme combine l'utilisation de la phase et du module pour construire un modèleplus robuste. En eet, l'analyse de Gabor donne une valeur complexe, cette valeur peutavoir sa partie réelle et imaginaire proche de zéro. Cela crée une forme indéterminéelors du calcul du module et de la phase. Pour résoudre ce problème, les points quiont des valeurs en dessous d'un seuil seront omis. Le vecteur composé des diérentesanalyses de Gabor constituera l'entrée du classieur LDA.
5.4.2 Protocoles de testPour tester les performances de reconnaissance apportées par les images NIR avec
les variations d'illumination nous avons conduit une série de tests sur la base IRVI. Labase décrite dans le paragraphe 3.3.3, contient 60 personnes acquises en 2 sessions,chaque session contient 3 protocoles d'acquisition qui mettent en jeu la variation del'illumination. Pour chaque personne, nous avons choisi 5 images de référence issuesdu protocole 1 de la 1ère session (S1P1) décrit dans le paragraphe 3.3.3. Les imagesde test sont elles issues des autres protocoles et session. Pour chaque protocole d'ac-quisition on extrait 5 images de test. Chaque personne a ainsi 5 images de référenceet 30 images de test (5 images de S1P1, 5 de S2P1, etc.). Nous avons testé les algo-rithmes au sein de la première session avec le premier protocole (éclairage contrôlée)ce test est nommé TS1P1. Pour une personne donnée, on compare durant ce proto-cole de test 5 images de S1P1 avec 5 autres images de S1P1. Pour déterminer le scoreclient de ce test, on ne retient que le maximum des ces comparaisons. Pour chaquepersonne cliente, les tests imposteurs sont la comparaison des images de référencedu client avec les images de tests (5 images pour chaque imposteur) de 10 autrespersonnes. Dans ce protocole nous eectuons alors 300 comparaisons intra-classe et3000 comparaisons interclasse.Le deuxième protocole de test vise à vérier la stabilité intersession avec même condi-tion d'éclairage. Le temps d'acquisition entres les deux images des deux session est dequelques semaines (environ 3 semaines). Il s'agit de comparer les images de référencede S1P1 avec les images de test de S2P1 avec le même protocole de test que précé-demment. Ce protocole de test sera noté TS2P1. On a dans ce test 270 comparaisonsintra-classes et 2700 inter-classe.Le troisième protocole de test est une comparaison inter-session avec les diérentsprotocoles de variation d'illuminations. Ainsi l'ensemble des images de référence de lapersonne est comparé avec ses propres images de test issues des diérents protocolesd'acquisition de la base. Pour les comparaisons imposteurs, on compare les images de

5.4. COMPARAISONS ET PERFORMANCES 91
références avec celles de 10 autres personnes avec les diérents protocoles et sessions.Ce test nommé TS2PA comporte une comparaison entre S1P1 et S1P2, S1P3, S2P1,S2P2 et S2P3. Durant ce protocole, on teste la robustesse des algorithmes par rapportaux illuminations et par rapport aux variations dans le temps. Ce test comporte unnombre de comparaison assez élevé par rapport aux tests précédents. En eet, on a1650 comparaisons intra-classe et 15500 inter-classe.
Intervalle de conance
La base IRVI construite avec le capteur développé est considérée comme un base defaible taille. De plus le nombre de comparaison intra-classe (1650 comparaisons clientpour TS2PA) est bien inférieur à celui inter-classe (15500 comparaisons imposteurspour TS2PA). Il y a un rapport de 100 entre eux. Le nombre de comparaison étantassez faible, les résultats sont donc soumis à une marge d'erreur qu'il est importantd'indiquer par rapport à la généralisation qui peut être attendue des modèles testés.Nous allons donc calculer l'intervalle de conance de nos taux d'erreurs. Cette mesureparamétrique, nous permet d'évaluer dans quel intervalle peut varier notre mesured'erreur et ainsi nous permettre d'encadrer les performances si on eectue des testssur une base de taille plus importante.Nous estimerons les taux d'erreur FAR(τ) et FRR(τ) pour une valeur du seuil donnéeτ par la fonction de répartition empirique pour les deux classes client et imposteur.On considère Fc, respectivement Fi, la fonction de répartition client, respectivementimposteur :
FAR(τ) = 1− Fi(τ) = 1−∫ τ
−∞fi(x)dx =
∫ ∞
τfi(x)dx
FRR(τ) = Fc(τ) =∫ τ
−∞fc(x)dx
où fi et fc sont les densités de probabilités des clients et des imposteurs. Sur une basecontenant Nc scores client et Ni scores imposteur, on estime les taux d'erreurs par :
FAR(τ) = 1− Fi(τ) =1Ni
Ni∑
j=1
1(xj > τ)
FRR(τ) = Fc(τ) =1
Nc
Ni∑
j=1
1(xj ≤ τ)
On introduit une variable aléatoire Z binomiale de probabilité p = Fc(τ) pour Nc
tirages. La distribution de probabilité de cette variable est :
P (Z = z) = CzNc
Fc(τ)z(1− Fc(τ)Nc−z, z = 0, . . . , Nc
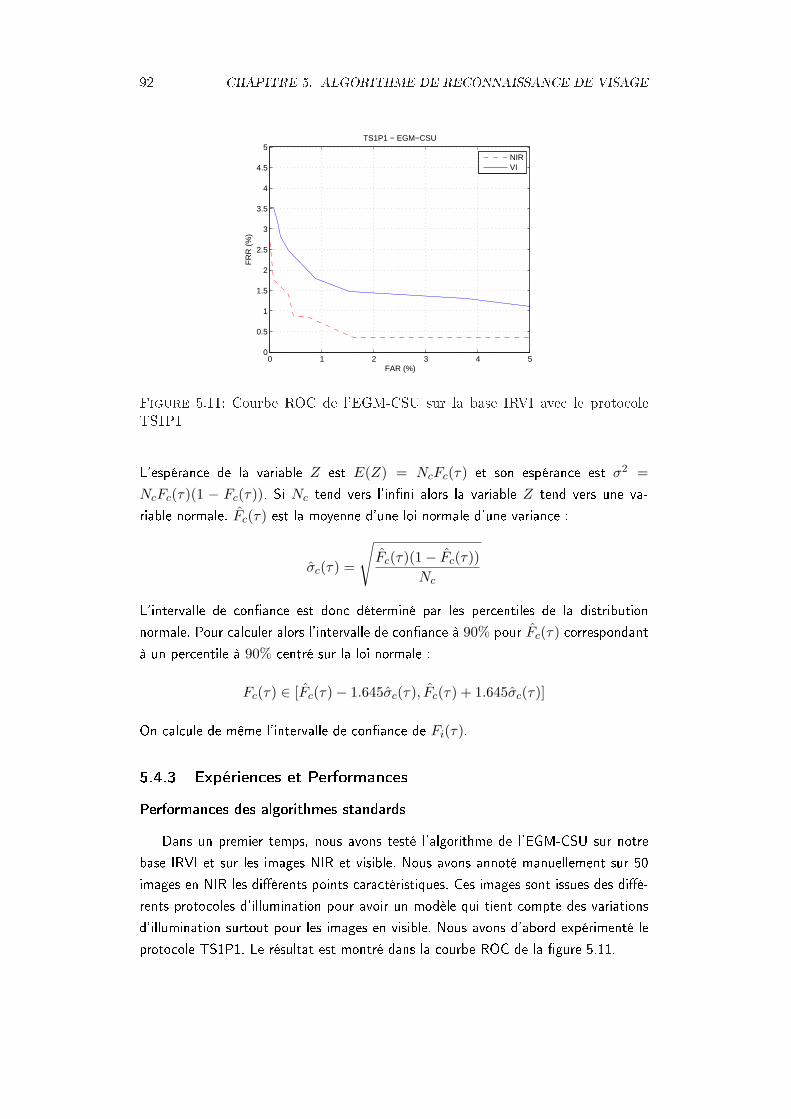
92 CHAPITRE 5. ALGORITHME DE RECONNAISSANCE DE VISAGE
0 1 2 3 4 50
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
FAR (%)
FR
R (
%)
TS1P1 − EGM−CSU
NIRVI
Figure 5.11: Courbe ROC de l'EGM-CSU sur la base IRVI avec le protocoleTS1P1
L'espérance de la variable Z est E(Z) = NcFc(τ) et son espérance est σ2 =NcFc(τ)(1 − Fc(τ)). Si Nc tend vers l'inni alors la variable Z tend vers une va-riable normale. Fc(τ) est la moyenne d'une loi normale d'une variance :
σc(τ) =
√Fc(τ)(1− Fc(τ))
Nc
L'intervalle de conance est donc déterminé par les percentiles de la distributionnormale. Pour calculer alors l'intervalle de conance à 90% pour Fc(τ) correspondantà un percentile à 90% centré sur la loi normale :
Fc(τ) ∈ [Fc(τ)− 1.645σc(τ), Fc(τ) + 1.645σc(τ)]
On calcule de même l'intervalle de conance de Fi(τ).
5.4.3 Expériences et PerformancesPerformances des algorithmes standards
Dans un premier temps, nous avons testé l'algorithme de l'EGM-CSU sur notrebase IRVI et sur les images NIR et visible. Nous avons annoté manuellement sur 50images en NIR les diérents points caractéristiques. Ces images sont issues des dié-rents protocoles d'illumination pour avoir un modèle qui tient compte des variationsd'illumination surtout pour les images en visible. Nous avons d'abord expérimenté leprotocole TS1P1. Le résultat est montré dans la courbe ROC de la gure 5.11.
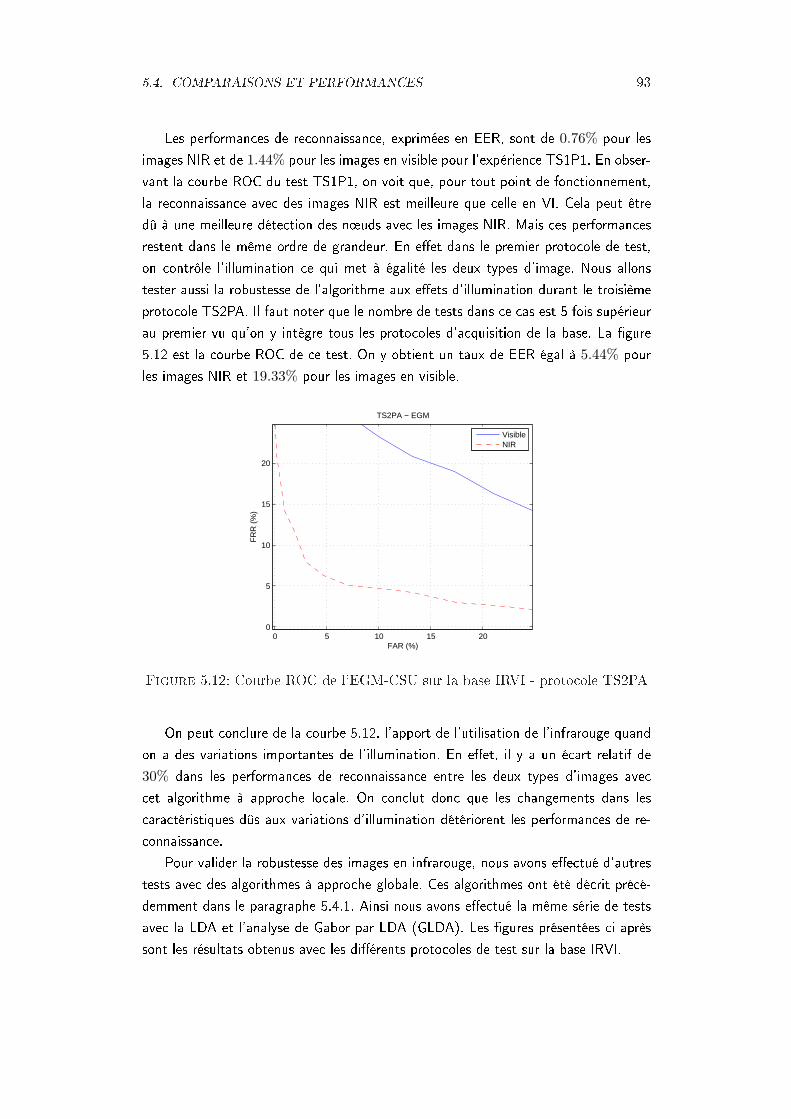
5.4. COMPARAISONS ET PERFORMANCES 93
Les performances de reconnaissance, exprimées en EER, sont de 0.76% pour lesimages NIR et de 1.44% pour les images en visible pour l'expérience TS1P1. En obser-vant la courbe ROC du test TS1P1, on voit que, pour tout point de fonctionnement,la reconnaissance avec des images NIR est meilleure que celle en VI. Cela peut êtredû à une meilleure détection des n÷uds avec les images NIR. Mais ces performancesrestent dans le même ordre de grandeur. En eet dans le premier protocole de test,on contrôle l'illumination ce qui met à égalité les deux types d'image. Nous allonstester aussi la robustesse de l'algorithme aux eets d'illumination durant le troisièmeprotocole TS2PA. Il faut noter que le nombre de tests dans ce cas est 5 fois supérieurau premier vu qu'on y intègre tous les protocoles d'acquisition de la base. La gure5.12 est la courbe ROC de ce test. On y obtient un taux de EER égal à 5.44% pourles images NIR et 19.33% pour les images en visible.
0 5 10 15 200
5
10
15
20
FAR (%)
FR
R (
%)
TS2PA − EGM
VisibleNIR
Figure 5.12: Courbe ROC de l'EGM-CSU sur la base IRVI - protocole TS2PA
On peut conclure de la courbe 5.12, l'apport de l'utilisation de l'infrarouge quandon a des variations importantes de l'illumination. En eet, il y a un écart relatif de30% dans les performances de reconnaissance entre les deux types d'images aveccet algorithme à approche locale. On conclut donc que les changements dans lescaractéristiques dûs aux variations d'illumination détériorent les performances de re-connaissance.
Pour valider la robustesse des images en infrarouge, nous avons eectué d'autrestests avec des algorithmes à approche globale. Ces algorithmes ont été décrit précé-demment dans le paragraphe 5.4.1. Ainsi nous avons eectué la même série de testsavec la LDA et l'analyse de Gabor par LDA (GLDA). Les gures présentées ci aprèssont les résultats obtenus avec les diérents protocoles de test sur la base IRVI.
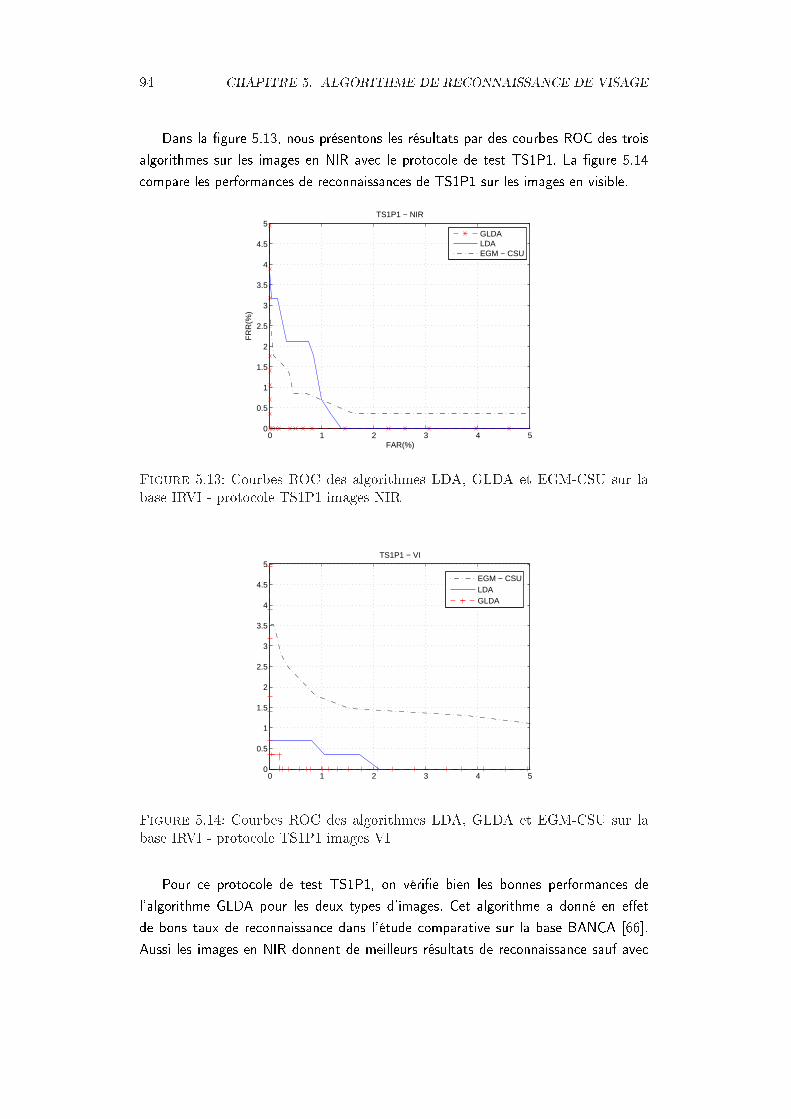
94 CHAPITRE 5. ALGORITHME DE RECONNAISSANCE DE VISAGE
Dans la gure 5.13, nous présentons les résultats par des courbes ROC des troisalgorithmes sur les images en NIR avec le protocole de test TS1P1. La gure 5.14compare les performances de reconnaissances de TS1P1 sur les images en visible.
0 1 2 3 4 50
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
FAR(%)
FR
R(%
)
TS1P1 − NIR
GLDALDAEGM − CSU
Figure 5.13: Courbes ROC des algorithmes LDA, GLDA et EGM-CSU sur labase IRVI - protocole TS1P1 images NIR
0 1 2 3 4 50
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5TS1P1 − VI
EGM − CSULDAGLDA
Figure 5.14: Courbes ROC des algorithmes LDA, GLDA et EGM-CSU sur labase IRVI - protocole TS1P1 images VI
Pour ce protocole de test TS1P1, on vérie bien les bonnes performances del'algorithme GLDA pour les deux types d'images. Cet algorithme a donné en eetde bons taux de reconnaissance dans l'étude comparative sur la base BANCA [66].Aussi les images en NIR donnent de meilleurs résultats de reconnaissance sauf avec
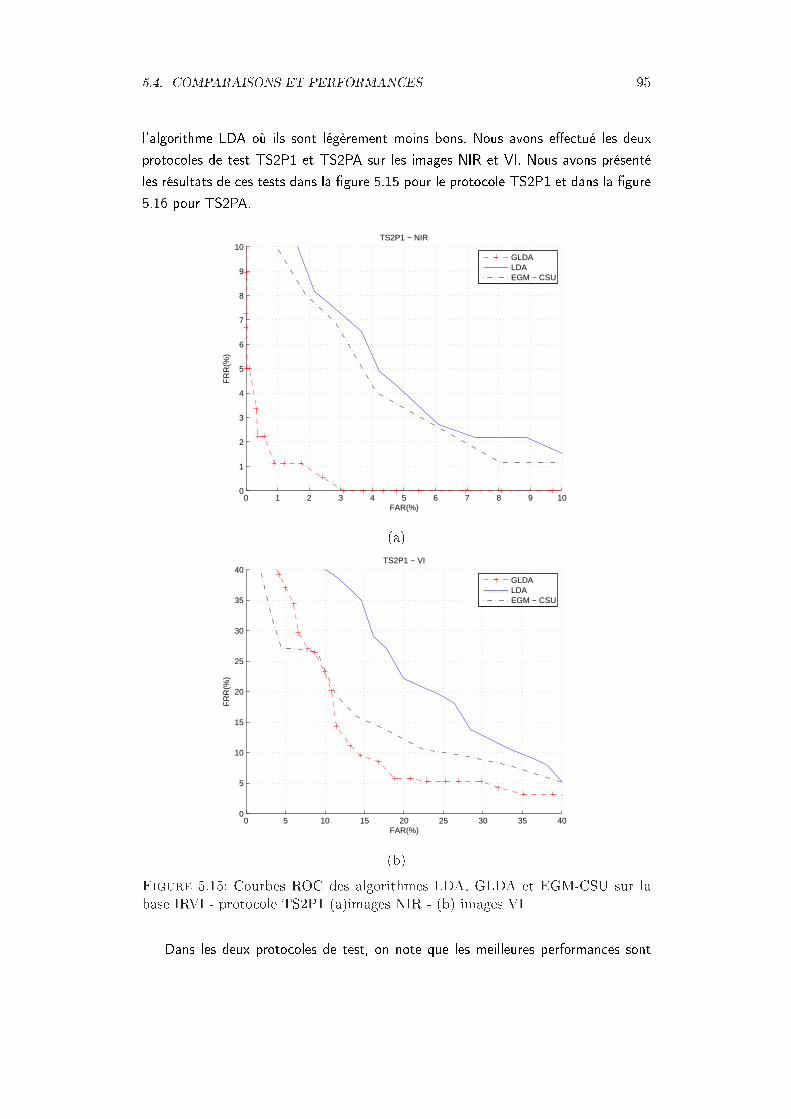
5.4. COMPARAISONS ET PERFORMANCES 95
l'algorithme LDA où ils sont légèrement moins bons. Nous avons eectué les deuxprotocoles de test TS2P1 et TS2PA sur les images NIR et VI. Nous avons présentéles résultats de ces tests dans la gure 5.15 pour le protocole TS2P1 et dans la gure5.16 pour TS2PA.
0 1 2 3 4 5 6 7 8 9 100
1
2
3
4
5
6
7
8
9
10
FAR(%)
FR
R(%
)
TS2P1 − NIR
GLDALDAEGM − CSU
(a)
0 5 10 15 20 25 30 35 400
5
10
15
20
25
30
35
40
FAR(%)
FR
R(%
)
TS2P1 − VI
GLDALDAEGM − CSU
(b)Figure 5.15: Courbes ROC des algorithmes LDA, GLDA et EGM-CSU sur labase IRVI - protocole TS2P1 (a)images NIR - (b) images VI
Dans les deux protocoles de test, on note que les meilleures performances sont

96 CHAPITRE 5. ALGORITHME DE RECONNAISSANCE DE VISAGE
réalisées par l'algorithme GLDA cela pour les images NIR et visible. Cela montrela robustesse de cet algorithme qui fait une analyse de toute l'image du visage. LeEGM-CSU donne des taux d'EER plus faible que la LDA. Cela montre qu'une analyselocale par les ltres de Gabor est toujours meilleure qu'une analyse des niveaux degris des pixels. La diérence des taux d'erreur dans le proche infrarouge entre lesdeux protocoles assiciés à deux sessions diérentes TS2P1 et TS1P1 est dûe à desvariations de pose (rotations autour de l'axe parallèle au plan focal de la caméra) etaussi au manque de généralisation à cause de la petite taille de la base de donnée quiinduit un faible nombre de comparaisons.
Sur le graphique 5.16 (b), on voit que la courbe de l'EGM-CSU est au dessousde celle du GLDA pour les faibles valeurs de FAR. Mais cette situation s'inverse enaugmentant le FAR. Cela montre une robustesse de l'approche locale face aux faussesacceptations dans les cas extrêmes de sécurité.
Le tableau 5.2 donne les valeurs comparées à l'EER des diérents algorithmes sui-vant les diérents protocoles. Dans ce tableau, on note la stabilité des images NIR parrapport à l'illumination et cela pour les 3 algorithmes. Notre méthode d'acquisitionpermet ainsi d'obtenir des images qui fournissent des taux de vérications similaires,quelques soient les conditions d'illumination, et cela sans ajouter des pré-traitementsà l'image, source de calcul supplémentaire. En eet, aucune des images en NIR n'ontsubi de prétraitement alors que les images en VI ont été égalisées. Au point de fonc-tionnement EER, l'algorithme EGM-CSU donne des performances de reconnaissancese situant entre les deux autres algorithmes, le LDA et le GLDA l'algorithme de clas-sication des réponses des ltres de Gabor par LDA qui est le plus performant destrois, même en considérant les intervalles de conance. En eet, les intervalles deconance sont aussi dépendante des valeurs des performances : plus les valeurs sontfaibles plus l'intervalle est faible ce qui limite la plage de variation de l'EER dansle cas de l'approche GLDA. Mais, cet algorithme demande plus de calcul. En eet,chaque pixel de l'image est analysé par le banc des ltres, et ensuite la classicationest eectuée par une projection (multiplications de vecteur). Mais lorsqu'on compareles performances de reconnaissance des trois algorithmes sur les images NIR avec lesintervalles de conance associés, nous remarquons que les approches LDA et EGM-CSU sont à peu près équivalentes pour nos protocoles de test. Sur le protocole detest TS2PA, où on a plus de comparaisons (environ 3000 en intra) les intervalles deconance se chevauchent ce qui donne une équivalence entre les deux approches. Onvérie cela sur la gure 5.18 (a) où les courbes sont presque superposées. Alors quesur les images visibles, on remarque de meilleures performances de reconnaissance del'EGM-CSU qui sont pratiquement équivalentes à celle du GLDA. Cela nous montrequ'une approche locale est aussi meilleure qu'une approche globale.
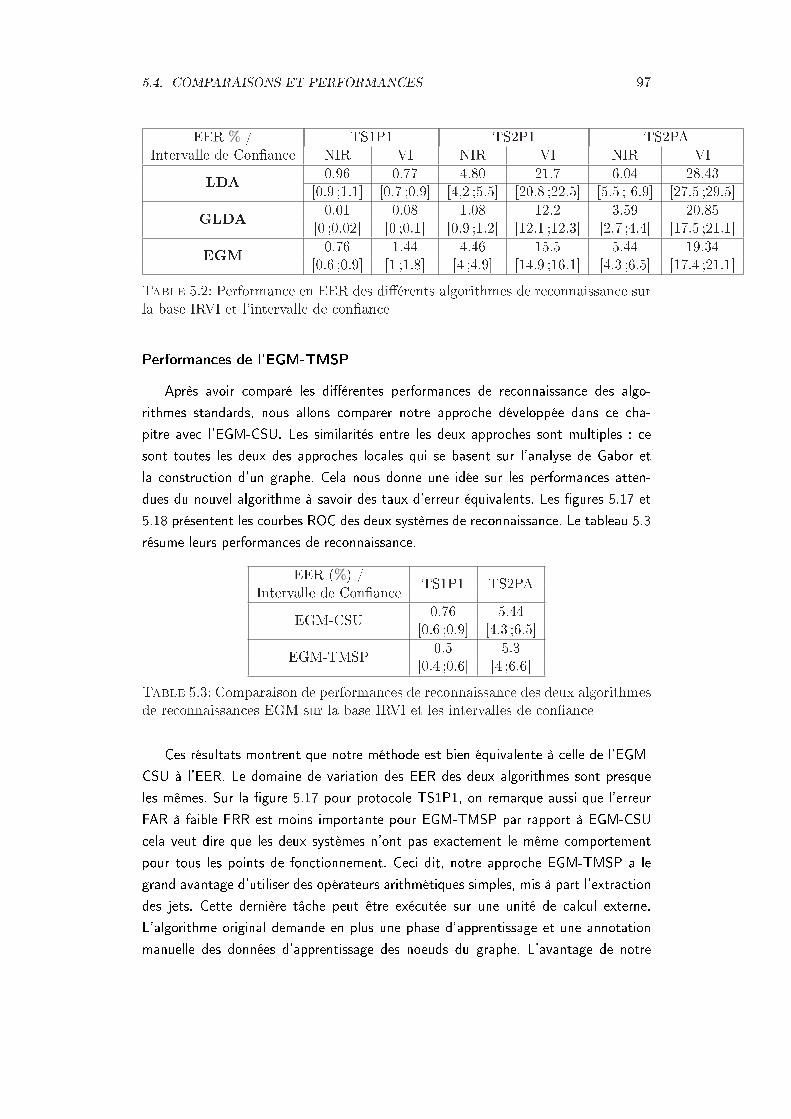
5.4. COMPARAISONS ET PERFORMANCES 97
EER % / TS1P1 TS2P1 TS2PAIntervalle de Conance NIR VI NIR VI NIR VI
LDA 0.96 0.77 4.80 21.7 6.04 28.43[0.9 ;1.1] [0.7 ;0.9] [4,2 ;5.5] [20.8 ;22.5] [5.5 ; 6.9] [27.5 ;29.5]
GLDA 0.01 0.08 1.08 12.2 3.59 20.85[0 ;0.02] [0 ;0.1] [0.9 ;1.2] [12.1 ;12.3] [2.7 ;4.4] [17.5 ;21.1]
EGM 0.76 1.44 4.46 15.5 5.44 19.34[0.6 ;0.9] [1 ;1.8] [4 ;4.9] [14.9 ;16.1] [4.3 ;6.5] [17.4 ;21.1]
Table 5.2: Performance en EER des diérents algorithmes de reconnaissance surla base IRVI et l'intervalle de conance
Performances de l'EGM-TMSP
Après avoir comparé les diérentes performances de reconnaissance des algo-rithmes standards, nous allons comparer notre approche développée dans ce cha-pitre avec l'EGM-CSU. Les similarités entre les deux approches sont multiples : cesont toutes les deux des approches locales qui se basent sur l'analyse de Gabor etla construction d'un graphe. Cela nous donne une idée sur les performances atten-dues du nouvel algorithme à savoir des taux d'erreur équivalents. Les gures 5.17 et5.18 présentent les courbes ROC des deux systèmes de reconnaissance. Le tableau 5.3résume leurs performances de reconnaissance.
EER (%) / TS1P1 TS2PAIntervalle de Conance
EGM-CSU 0.76 5.44[0.6 ;0.9] [4.3 ;6.5]
EGM-TMSP 0.5 5.3[0.4 ;0.6] [4 ;6.6]
Table 5.3: Comparaison de performances de reconnaissance des deux algorithmesde reconnaissances EGM sur la base IRVI et les intervalles de conance
Ces résultats montrent que notre méthode est bien équivalente à celle de l'EGM-CSU à l'EER. Le domaine de variation des EER des deux algorithmes sont presqueles mêmes. Sur la gure 5.17 pour protocole TS1P1, on remarque aussi que l'erreurFAR à faible FRR est moins importante pour EGM-TMSP par rapport à EGM-CSUcela veut dire que les deux systèmes n'ont pas exactement le même comportementpour tous les points de fonctionnement. Ceci dit, notre approche EGM-TMSP a legrand avantage d'utiliser des opérateurs arithmétiques simples, mis à part l'extractiondes jets. Cette dernière tâche peut être exécutée sur une unité de calcul externe.L'algorithme original demande en plus une phase d'apprentissage et une annotationmanuelle des données d'apprentissage des noeuds du graphe. L'avantage de notre

98 CHAPITRE 5. ALGORITHME DE RECONNAISSANCE DE VISAGE
approche est qu'elle demande moins de calculs car elle se base sur un échantillonnageadéquat de l'image de contour pour extraire un graphe robuste.
5.5 ConclusionOn a présenté dans ce chapitre l'approche locale la plus utilisée pour la recon-
naissance de visage : la comparaison élastique des graphes. Nous avons exploité cetteapproche ainsi que des approches globales (LDA,GLDA) pour montrer en premier lieula robustesse de notre méthode d'acquisition en proche infrarouge vis à vis des varia-tions de l'illumination. Pour cela, nous avons comparé les performances de ces diversalgorithmes en visible et en proche infrarouge sur divers protocoles. Dans tous les cas,on note une nette amélioration des performances en NIR par rapport au visible sur desprotocoles avec des images non contrôlées. Il faut noter que la petite taille de notrebase de donnée ne permet pas de comparer nement les algorithmes sur le protocolecontrôlé mono session TS1P1. Par contre, malgré cela, l'écart de performance entretous les algorithmes fonctionnant sur TS2PA entre VI et NIR est tellement importantque l'apport de l'acquisition en proche infrarouge en condition d'illumination variablene peut être mis en doute par la petite taille de la base.
Les approches de traitement local ont l'avantage de pouvoir être intégrées surSoC, cela nous a guidé pour développer une nouvelle approche locale adaptée auximages proche infrarouges acquises par ce capteur. La stabilité de l'image de contourspar rapport aux variations d'éclairage, est un point essentiel pour la bonne détectiondes points caractéristiques et cela nous a permis ensuite de construire un graphecorrespondant au visage. Notre méthode est proche de l'approche EGM-CSU et elleest équivalente en performance de reconnaissance. De plus elle possède l'avantageconsidérable d'être construite sur des opérateurs qui peuvent été intégrés sur SoC.L'association entre des opérateurs sur le capteur et sur le SoC réduirait le temps decalcul et l'utilisation de mémoire. Ces deux facteurs contribuent à la réduction dela consommation électrique qui est un avantage considérable dans un contexte demobilité. Nous estimons que ce nouvel algorithme pourra intégré par la suite.
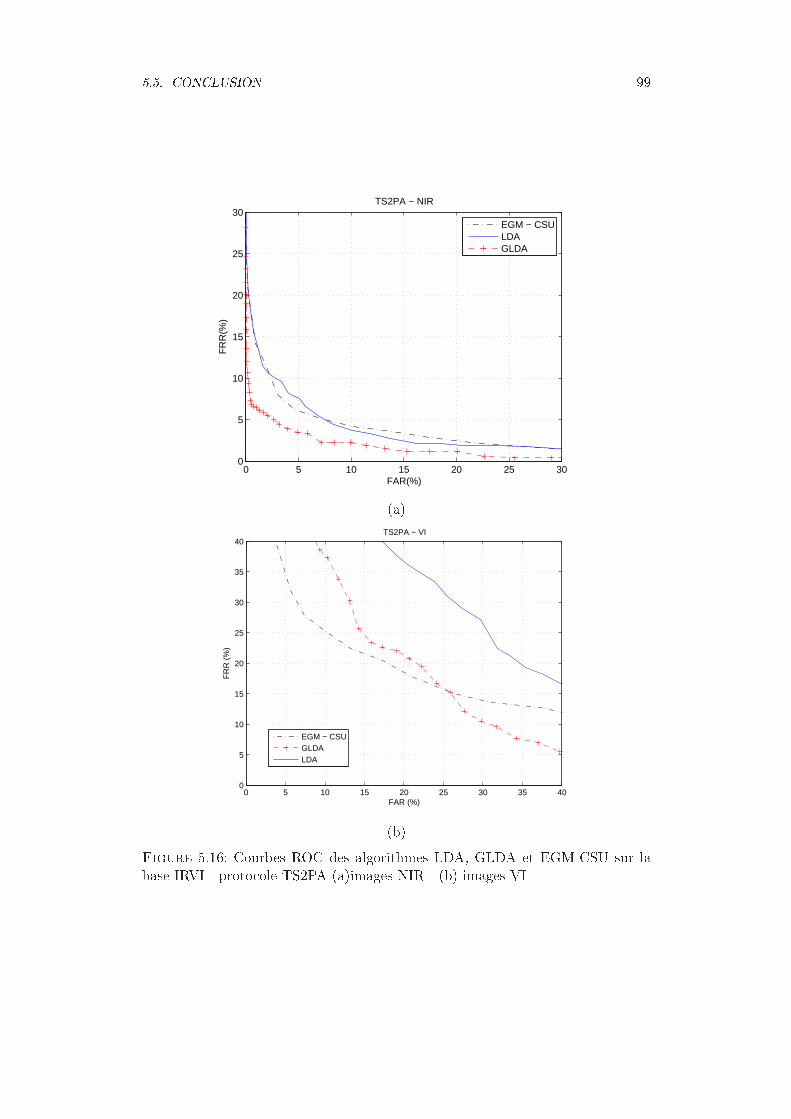
5.5. CONCLUSION 99
0 5 10 15 20 25 300
5
10
15
20
25
30
FAR(%)
FR
R(%
)
TS2PA − NIR
EGM − CSULDAGLDA
(a)
0 5 10 15 20 25 30 35 400
5
10
15
20
25
30
35
40
FAR (%)
FR
R (
%)
TS2PA − VI
EGM − CSUGLDALDA
(b)Figure 5.16: Courbes ROC des algorithmes LDA, GLDA et EGM-CSU sur labase IRVI - protocole TS2PA (a)images NIR - (b) images VI
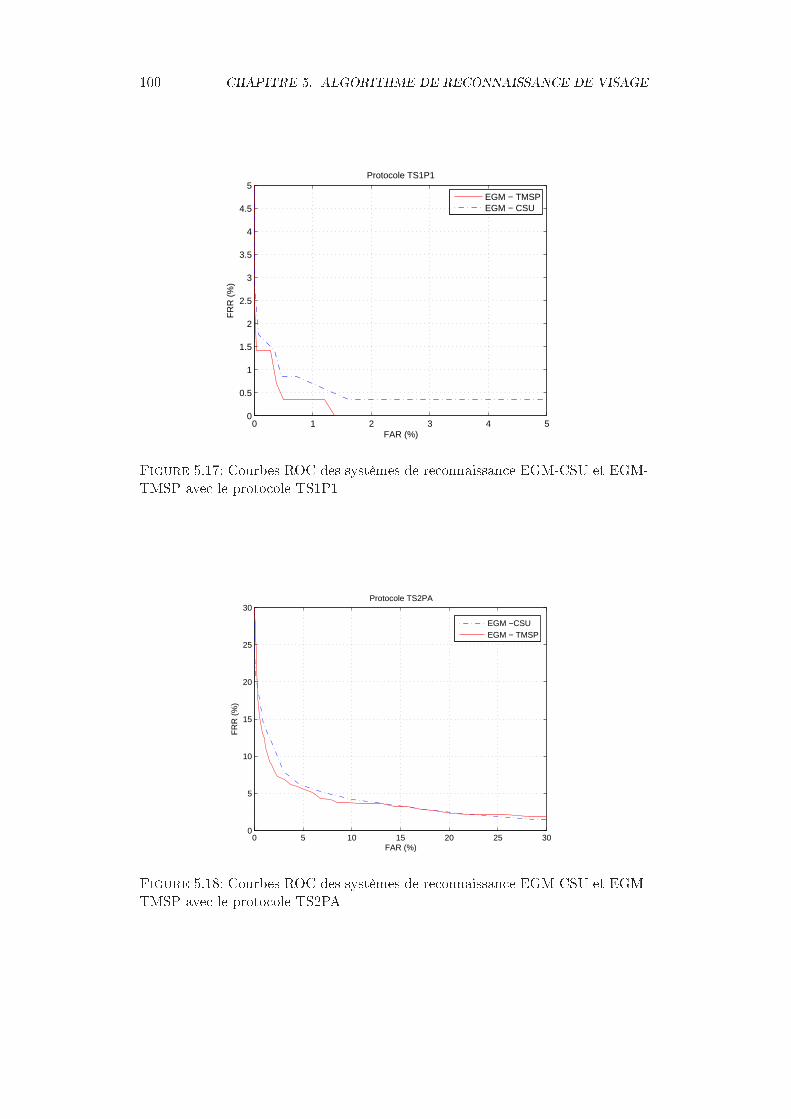
100 CHAPITRE 5. ALGORITHME DE RECONNAISSANCE DE VISAGE
0 1 2 3 4 50
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
FAR (%)
FR
R (
%)
Protocole TS1P1
EGM − TMSPEGM − CSU
Figure 5.17: Courbes ROC des systèmes de reconnaissance EGM-CSU et EGM-TMSP avec le protocole TS1P1
0 5 10 15 20 25 300
5
10
15
20
25
30
FAR (%)
FR
R (
%)
Protocole TS2PA
EGM −CSUEGM − TMSP
Figure 5.18: Courbes ROC des systèmes de reconnaissance EGM-CSU et EGM-TMSP avec le protocole TS2PA

Chapitre 6
Conclusion et perspectives
Dans cette thèse, nous avons utilisé et conçu plusieurs capteurs pour la suppressionde l'illumination ambiante. Vu l'importance de la qualité des images dans l'améliora-tion des performances de reconnaissance, nous avons conçu de nouveaux capteurs avecun soucis d'amélioration de la qualité d'images qui fournissent des images invariantespar rapport à l'éclairage. Nous avons utilisé pour ce fait l'illumination active avec deuxméthodes d'acquisition : la première avec un capteur CMOS diérentiel, la seconde,et qui présente notre apport personnel dans ce travail de thèse, une acquisition avecréduction du temps d'exposition et un ash synchrone à la période d'acquisition. Ceprocédé utilisé avec une caméra CCD permet d'avoir des images de bonne qualité enproche infrarouge et à moindre coût. Nous avons alors exploité la nature du capteurpour acquérir deux trames diérentes. Nous obtenons ainsi deux informations simul-tanées : la première issue de la lumière visible, la seconde de la lumière issue du ash.La présence de ces deux informations visible et proche infrarouge simultanément nouspermet d'évaluer l'apport de l'illumination active pour la suppression de la lumière am-biante par rapport au visible. Pour cela, nous avons mené une compagne d'acquisitionpour avoir une base de donnée de visage avec cette caméra (de 60 personnes).
Exploitant le bon niveau de contraste dans les images en proche infrarouge issuesdu capteur développé, nous avons conçu une nouvelle méthode de détection des pointscaractéristiques du visage. Nous avons extrait les contours du visage en utilisant unltre de même forme que le ltre DoG implémenté dans la littérature dans un imageur.L'image de contour comprend des éléments caractéristiques du visage à savoir, lesyeux, le nez et la bouche. Nous avons alors extrait 5 points particuliers de cetteimage et cela en n'utilisant uniquement des opérateurs qui ont été implémentés.Notre approche utilise uniquement une projection avec des traitements sur des petites
101

102 CHAPITRE 6. CONCLUSION ET PERSPECTIVES
zones de l'image pour limiter les ressources de calcul. Pour évaluer les performancesde notre approche, nous l'avons testée sur les bases de données de visage acquise enproche infrarouge à notre disposition. Nous avons obtenue de bonnes performancesde détection comparable à celles des méthodes présentes dans la littérature.
Une dernière contribution de ce travail de thèse concerne la mise au point une nou-velle approche de reconnaissance de visage. Cette approche locale se base sur l'imagede contour et elle s'inspire de l'algorithme de comparaison élastique des graphes. Nousavons exploité le fait que l'image de contour obtenue contient les points particuliersdu visage pour extraire des points de ce contour en utilisant une grille judicieusementplacée sur le visage. Elle est, en eet, placée selon les positions des yeux et de labouche et couvre ainsi tout le visage. La grille est utilisée comme un élément per-mettant d'échantillonner l'image et de construire l'ensemble des noeuds du graphe.Le voisinage des points extraits est analysé par un banc de ltres de Gabor. L'en-semble des points associés à l'analyse de Gabor constitue le graphe du visage. Nousavons adapté le calcul de comparaison des graphes classiques à notre méthode pourréduire le nombre de comparaisons entre les noeuds. Nous avons comparé les perfor-mances de notre méthode avec celles de l'algorithme original EGM-CSU, et trouvédes résultats équivalents en terme de EER. Ce résultat était assez prévisible vu lesressemblances entre les deux méthodes et l'utilisation du même outil d'analyse locale.Cependant, notre approche est mieux adaptée pour une implémentation future. Eneet, notre algorithme ne demande pas d'étape d'apprentissage pour déterminer laposition moyenne des points caractéristiques. Cette dernière technique est en eetaussi complexe que la comparaison de deux graphes.
Les perspectives de cette thèse sont en premier lieu la validation de notre algo-rithme de reconnaissance sur composants programmables. En eet, notre algorithmeest conçu pour une implémentation partagée entre le capteur et un composant pro-grammable. Outre l'acquisition diérentielle ou par réduction de temps de pose quisont les premières opérations eectuées dans l'imageur, nous estimons que les opé-rations de détection de contours et de projection peuvent être implémentées sur lecapteur. En eet, le ltrage DoG est un moyen pour extraire les contours. Ce ltrepeut être implémenté par un réseau RC ou un réseau capacitif tel décrit dans le2ème chapitre. Le deuxième opérande qui peut facilement être intégré dans le capteurest la fonction de projection qui n'est qu'une sommation sur une même ligne. Cetteopération si elle est eectuée numériquement demandera plusieurs cycles d'opérationd'addition, alors qu'en analogique, en exploitant la loi des noeuds, on arrive à fairela sommation instantanément avec des variables courant. Le traitement analogiquepeut ainsi nous faire gagner en temps de traitement et nous économise en ressourcede calcul ultérieurement.

103
La sortie du capteur peut être l'image de contour avec la projection de celle-cisur l'axe horizontal. La sortie serait transmise à une unité de calcul qui peut êtresoit un FPGA, un DSP ou un ARM, tout dépend des performances que l'en veutatteindre. Cela nous permettra d'extraire les points caractéristiques du visage et ainsid'avoir les coordonnées des diérents points de la grille qui seront retenues. Si letemps de traitement est assez court nous pouvons acquérir une nouvelle image surlaquelle nous allons appliquer les ltres de Gabor autour des points ainsi trouvés. Eneet si le temps d'extraction de ces points est négligeable par rapport à un éventueldéplacement du client nous pouvons nous passer de l'enregistrement de l'image estainsi économiser en mémoire du système. Dans le cas où le temps d'extraction estassez grand, nous procédons à l'enregistrement d'une image en proche infrarouge.Cette image serait transmise directement vers l'unité de calcul pour la formationdes jets. Nous pouvons optimiser l'enregistrement de l'image en ne conservant quele voisinage des points caractéristiques qui forment le graphe. En eet, l'analyse deGabor est locale et ne s'applique que sur le voisinage des points extraits. Les ltresde Gabor peuvent être enregistrés sur des blocs mémoires présents à l'intérieur d'unFPGA ce qui peut réduire considérablement le temps d'accès mémoire ou dans unemémoire externe dans le cas d'une implémentation sur DSP ou ARM. La comparaisondes graphes peut s'eectuer ensuite sur l'unité de calcul après avoir lu et chargé legraphe référence. Cette architecture sommaire de notre approche est ainsi divisée entrele capteur qui eectue en plus de la capture diérentielle ou avec ash synchronisé,l'extraction de primitives et la projection. L'unité de calcul permet l'extraction despoints caractéristiques, l'analyse par les ltres de Gabor et la tâche de comparaisondes graphes.
Une autre perspective de ce travail concerne la fusion de données issues des 2types d'image soit au niveau des scores soit des caractéristiques extraites. En eet,grâce à la double capture en proche infrarouge et en visible, nous pouvons étudier avecplus de détails la complémentarité des deux images et la diérence de nature dans lescaractéristiques locales. Nous pouvons explorer une fusion des caractéristiques pouraméliorer les performances de reconnaissance et ainsi bénécier de l'apport de chaqueimage. La diérence de réectance de la peau dans les deux spectres peut donner uneréponse diérente aux ltres de Gabor.
Une fusion des scores de reconnaissances issues d'algorithmes avec diérents ap-proches globales et locales pourrait aussi permettre de proter des avantages dechaque méthode et ainsi améliorer les performances de reconnaissance.
Une autre perspective concerne le fait d'utiliser ce principe d'acquisition sur d'autresmodalités. L'acquisition de l'iris se fait aussi en proche infrarouge. Nous pouvons alorsexploiter cette caméra pour cette modalité, mais nous devons alors changer l'optique

104 CHAPITRE 6. CONCLUSION ET PERSPECTIVES
et la disposition des illuminateurs pour ne pas endommager l'oeil. Une autre modalitéqui commence à être exploitée dans les pays asiatiques est la reconnaissance par lesveines de la main. Cette modalité est bien acceptée car elle ne nécessite pas de contact,et est dicile à falsier Son acquisition se fait aussi dans le proche infrarouge. En ef-fet les ondes pénètrent l'épiderme et sont rééchis par les vaisseaux sanguins. Notreprocédé d'acquisition serait alors idéal pour capter les veines de la main. De mêmeque l'on peut étudier la complémentarité entre une image du visage dans les deuxspectres, on pourra dès lors étudier la complémentarité entre la paume de la main(empreinte palmaire) à travers l'image en visible et les veines de la main à traversl'image en proche infrarouge.

Bibliographie
[1] http ://www.oki.com/jp/FSC/ics/en/.
[2] http ://www.tsi.enst.fr/tsi/enseignement/ressources/mti/ellipses/Hough.html.
[3] Datasheet icx098bq. http ://www.sony.co.jp/ semi-con/english/img/sony01/a6809927.pdf.
[4] Yael Adini, Yael Moses, and Shimon Ullman. Face recognition : The problem of com-pensating for changes in illumination direction. IEEE Transactions on Pattern Analysisand Machine Intelligence, 19(7) :721732, 1997.
[5] O. Aubreton, B. Bellach, L. F. C. Voon, B. Lamalle, P. Gorria, and G. Cathébras. Retinafor pattern matching in standard 0.6-mu m complementary metal oxide semiconductortechnology. Journal of Electronic Imaging, 13(3) :559569, 2004.
[6] E. Bailly-Baillière, S. Bengio, F. Bimbot, M. Hamouz, J. Kittler, J. Mariéthoz, J. Matas,K. Messer, V. Popovici, F. Porée, B. Ruiz, and J.-P. Thiran. The banca database andevaluation protocol. In AVBPA, pages 625638, 2003.
[7] P.N. Belhumeur, J.P. Hespanha, and D.J. Kriegman. Eigenfaces vs. sherfaces : Recog-nition using class specic linear projection. In Proc. of the 4th European Conference onComputer Vision, ECCV'96, pages 4558, Cambridge, UK, April 1996.
[8] Thierry M. Bernard. Rétines articielles : Quelle intelligence au sein du pixel ? Calcula-teurs parallèles, 9(1) :77108, 1997.
[9] D.S. Bolme. Elastic bunch graph matching, 2003. Thesis for the Master of ScienceDegree ; Colorado State University.
[10] K.W. Bowyer, K.I. Chang, P.J. Flynn, and C. Xin. Face recognition using 2-d, 3-d, and infrared : Is multimodal better than multisample ? Proceedings of the IEEE,94(11) :20002012, 2006.
[11] W. S. Boyle and G.E. Smith. Charge-coupled semiconductor devices. Bell SystemsTechnical Journal, 49 :587593, 1970.
[12] R. Brunelli and T. Poggio. Face recognition : Features versus templates. IEEE Transac-tions on Pattern Analysis and Machine Intelligence, 15(10) :10421052, 1993.
105

106 BIBLIOGRAPHIE
[13] H.F. Chen, P.N. Belhumeur, and D.W. Jacobs. In search of illumination invariants.Computer Vision and Pattern Recognition, 2000. Proceedings. IEEE Conference on,1 :254261, 2000.
[14] Xin Chen, Patrick J. Flynn, and Kevin W. Bowyer. Ir and visible light face recognition.Computer Vision and Image Understanding, 99(3) :332358, 2005.
[15] I.J. Cox, J. Ghosn, and P.N. Yianilos. Feature-based face recognition using mixture-distance. Computer Vision and Pattern Recognition, 1996. Proceedings CVPR '96,1996 IEEE Computer Society Conference on, pages 209216, Jun 1996.
[16] J. Dowdall, I.T. Pavlidis, and G.N. Bebis. Face detection in the near-ir spectrum. IVC,21(7) :565578, July 2003.
[17] I.L. Dreden and K.V. Mardia. Statistical Shape Analysis. John Wiley, New York, 1998.
[18] B. Duc, S. Fischer, and J. Bigun. Face authentication with gabor information on defor-mable graphs. Image Processing, IEEE Transactions on, 8(4) :504516, Apr 1999.
[19] G. C. Feng and P. C. Yuen. Variance projection function and its application to eyedetection for human face recognition. Pattern Recogn. Lett., 19(9), 1998.
[20] S. Garcia-Salicetti, C. Beumier, G. Chollet, B. Dorizzi, J. Leroux les Jardins, J. Lunter,Y. Ni, and D. Petrovska-Delacrétaz. Biomet : A multimodal person authenticationdatabase including face, voice, ngerprint, hand and signature modalities. In AVBPA,pages 845853, 2003.
[21] J.M. Gilbert and W. Yang. A real-time face recognition system using custom vlsi hard-ware. Computer Architectures for Machine Perception, 1993. Proceedings, pages 5866,Dec 1993.
[22] A.J. Goldstein, L.D. Harmon, and A.B. Lesk. Identication of human faces. Proceedingsof the IEEE, 59(5) :748760, May 1971.
[23] D. Gonzalez-Jimenez and J.L. Alba-Castro. Shape-driven gabor jets for face descrip-tion and authentication. Information Forensics and Security, IEEE Transactions on,2(4) :769780, Dec. 2007.
[24] D.O. Gorodnichy. On importance of nose for face tracking. Automatic Face and GestureRecognition, 2002. Proceedings. Fifth IEEE International Conference on, pages 181186,May 2002.
[25] R. Gross and V. Brajovic. An image preprocessing algorithm for illumination invariantface recognition. In 4th International Conference on Audio- and Video-Based BiometricPerson Authentication (AVBPA). Springer, June 2003.
[26] T. Hamamoto and K. Aizawa. A computational image sensor with adaptive pixel-basedintegration time. Solid-State Circuits, IEEE Journal of, 36(4) :580585, Apr 2001.
[27] W. Hizem, Y. Ni, and B. Dorizzi. Near infrared sensing and associated landmark detec-tion for face recognition. Journal of Electronic Imaging, 17(1) :011005, 2008.

BIBLIOGRAPHIE 107
[28] Erik Hjelmåsa and Boon Kee Low. Face dectection : A survey. Computer Vision andImage Understanding, 83 :236274, September 2001.
[29] A. J. Howell and H. Buxton. Learning identity with radial basis function networks.Neurocomputing, 20 :1534, Aug 1998.
[30] D.P. Huttenlocher, G.A. Klanderman, and W.A. Rucklidge. Comparing images using thehausdor distance. IEEE Transactions on Pattern Analysis and Machine Intelligence,15(9) :850863, 1993.
[31] O. Jesorsky, K.J Kirchberg, and R.W Frisholz. Robust face detection using the hausdordistance. Int'l Conf. Audio- and video-Based Biometric Person Authentication, pages9095, 2001.
[32] Bernd Jähne. Practical Handbook on Image Processing for Scientic Applications. CRCPress, 1997.
[33] R. Kleihorst, H. Broers, A. Abbo, H. Ebrahimmalek, H. Fatemi, and H. Corporaal. Ansimdvliw smart camera architecture for real-time face recognition. In In Proceedings ofProRISC 2003, pages 17, 2003.
[34] C. Kotropoulos, A. Tefas, and I. Pitas. Morphological elastic graph matching appliedto frontal face authentication under optimal and real conditions. In ICMCS '99 : Pro-ceedings of the IEEE International Conference on Multimedia Computing and SystemsVolume II-Volume 2, pages 934938, 1999.
[35] B. Kröse and P. van der Smagt. An Introduction to neural network. The University ofAmsterdam, 1996.
[36] M. Kyomasu. A new mos imager using photodiode as current source. Solid-StateCircuits, IEEE Journal of, 26(8) :11161122, Aug 1991.
[37] M. Lades, J. C. Vorbruggen, J. Buhmann, J. Lange, C. von der Malsburg, R. P. Wurtz,and W. Konen. Distortion invariant object recognition in the dynamic link architecture.IEEE Trans. Comput., 42(3) :300311, 1993.
[38] Seong-Whan Lee, Sang-Woong Lee, and Ho-Choul Jung. Audio- and Video-Based Bio-metric Person Authentication, chapter Real-Time Implementation of Face RecognitionAlgorithms on DSP Chip, pages 294301. Springer, 2003.
[39] D. Y. Li and W.H. Liao. Facial feature detection in near-infrared images. In Proc. FifthInt'l Conf. Computer Vision, Pattern Recognition and Image Processing, pages 2630,Sept 2003.
[40] D.Y. Li and W.H. Liao. Facial feature detection in near-infrared images. In InternationalConference on computer vision , Pattern Recogntion and Image Processsing, pages 2630, 2003.
[41] Stan Z. Li, RuFeng Chu, ShengCai Liao, and Lun Zhang. Illumination invariant facerecognition using near-infrared images. IEEE Transactions on Pattern Analysis andMachine Intelligence, 29(4) :627639, 2007.

108 BIBLIOGRAPHIE
[42] S.Z. LI and A.K. Jain. Handbook of Face Recognition. Springer, 2005.
[43] Y. Li and H. Kobatake. Extraction of facial sketch image based on morphologicalprocessing. icip, 3 :316, 1997.
[44] D. Lowe. Distinctive image features from scaleinvariant key-points. International Journalfor Compute rVision, 2 :91110, 2004.
[45] D. Marr. Vision : A Computational Investigation into the Human Representation andProcessing of Visual Information. W. H. Freeman and Co., 1982.
[46] K. Matou and Y. Ni. Precise fpn compensation circuit for cmos aps [imager]. ElectronicsLetters, 38(19) :10781079, Sep 2002.
[47] H. Miura, H. Ishiwata, Y. Lida, Y. Matunaga, S. Numazaki, A. Morisita, N. Umeki,and M. Doi. A 100 frame/s cmos active pixel sensor for 3d-gesture recognition system.Solid-State Circuits Conference, 1999. Digest of Technical Papers. ISSCC. 1999 IEEEInternational, pages 142143, 1999.
[48] Jean-Luc Nagel. Algorithms and VLSI Architectures for Low-Power Mobile Face Veri-cation. PhD thesis, Institut de Microtechnique - Université de Neuchâtel, juin 2005.
[49] Jean-Luc Nagel, Patrick Stadelmann, Michael Ansorge, and Fausto Pellandini. A low-power vlsi architecture for face verication using elastic graph matching. In EuropeanSignal Processing Conference, volume 3, pages 577580, 2004.
[50] T. Nakano and T. Morie. A digital lsi architecture of elastic graph matching andits fpga implementation. Neural Networks, 2005. IJCNN '05. Proceedings. 2005 IEEEInternational Joint Conference on, 2 :689694, July-4 Aug. 2005.
[51] I. Ng, T. Tan, and J. Kittler. On local linear transform and gabor lter representationof texture. Pattern Recognition, 1992. Vol.III. Conference C : Image, Speech and SignalAnalysis, Proceedings., 11th IAPR International Conference on, pages 627631, Aug-3Sep 1992.
[52] Y. Ni. Smart image sensing in cmos technology. Circuits, Devices and Systems, IEEProceedings, 152(5) :547555, Oct. 2005.
[53] Y. Ni and K. Matou. A cmos log image sensor with on-chip fpn compensation. Solid-State Circuits Conference, 2001. ESSCIRC 2001. Proceedings of the 27th European,pages 101104, Sept. 2001.
[54] Y. Ni, Yi min Zhu, B. Arion, and F. Devos. Yet another analog 2d gaussian convolver.Circuits and Systems, 1993., ISCAS '93, 1993 IEEE International Symposium on, pages192195, May 1993.
[55] Y. Ni and Xie-Long Yan. Cmos active dierential imaging device with single in-pixelanalog memory. Proceeding of ISSCC02, pages 359362, 2002.
[56] Yang Ni, F. Devos, M. Boujrad, and Jian Hong Guan. Histogram-equalization-basedadaptive image sensor for real-time vision. Solid-State Circuits, IEEE Journal of,32(7) :10271036, Jul 1997.

BIBLIOGRAPHIE 109
[57] T. Ozaki, H. Kinugasa, and T. Nishida. A low-noise line-amplied mos imaging devices.Electron Devices, IEEE Transactions on, 38(5) :969975, May 1991.
[58] Vivek E. P and N. Sudha. Robust hausdor distance measure for face recognition.Pattern Recogn., 40(2) :431442, 2007.
[59] F. Paillet, D. Mercier, T.M. Bernard, and E. Senn. Low power issues in a digital pro-grammable articial retina. Low-Power Design, 1999. Proceedings. IEEE AlessandroVolta Memorial Workshop on, pages 153161, Mar 1999.
[60] E. Painkras and C. Charoensak. A vlsi architecture for gabor ltering in face processingapplications. Intelligent Signal Processing and Communication Systems, 2005. ISPACS2005. Proceedings of 2005 International Symposium on, pages 437440, Dec 2005.
[61] D. Petrovska-Delacrètaz, G. Chollet, and B. Dorizzi. Guide to Biometric ReferenceSystems and Performance Evaluation. Springer, 2009.
[62] L. Pierrefeu, J. Jay, and C. Barat. Auto-adjustable method for gaussian width op-timization on rbf neural network. application to face authentication on a mono-chipsystem. IEEE Industrial Electronics, IECON 2006 - 32nd Annual Conference on, pages34813485, Nov. 2006.
[63] A. Pérez-Uribe and E. Sanchez. Fpga implementation of an adaptable-size neural net-work. In ICANN 96 : Proceedings of the 1996 International Conference on ArticialNeural Networks, pages 383388, London, UK, 1996. Springer-Verlag.
[64] Behzad Razavi. Design of Analog CMOS Integrated Circuits. McGRAW-HILL, 2001.
[65] P.-F. Ruedi, P. Heim, F. Kaess, E. Grenet, F. Heitger, P.-Y. Burgi, S. Gyger, and P. Nuss-baum. A 128x128 pixel 120-db dynamic-range vision-sensor chip for image contrast andorientation extraction. Solid-State Circuits, IEEE Journal of, 38(12) :23252333, Dec.2003.
[66] M. Sadeghi, J. Kittler, A. Kostin, and K. Messer. A comparative study of automaticface verication algorithms on the banca database. In AVBPA, pages 3543, 2003.
[67] F. Wanlass Fairchild Semiconductor. Low stand-by power complementary eld eectcircuitry. U.S. Patent 3,356,858, 1963.
[68] N. Shams, I. Hosseini, M.S. Sadri, and E. Azarnasab. Low cost fpga-based highlyaccurate face recognition system using combined wavelets with subspace methods. InICIP06, pages 20772080, 2006.
[69] J. Shi, A. Samal, and D. Marx. How eective are landmarks and their geometry for facerecognition ? Comput. Vis. Image Underst., 102(2) :117133, 2006.
[70] Terence Sim, Simon Baker, and Maan Bsat. The cmu pose, illumination, and expressiondatabase. IEEE Transactions on Pattern Analysis and Machine Intelligence, 25(12) :1615 1618, December 2003.
[71] Saad A. Sirohey and Azriel Rosenfeld. Eye detection in a face image using linear andnonlinear lters. Pattern Recognition, 34 :13671391, 2001.

110 BIBLIOGRAPHIE
[72] D.A. Socolinsky and A. Selinger. Thermal face recognition in an operational scenario.Computer Vision and Pattern Recognition, 2004. CVPR 2004. Proceedings of the 2004IEEE Computer Society Conference on, 2 :II1012II1019, June-2 July 2004.
[73] Pierre Soille. Morphological Image Analysis, Principles and Applications. Springer-Verlag, 1999.
[74] M. Tabet and R. Hornsey. Cmos image sensor camera with focal plane edge detection.Electrical and Computer Engineering, 2001. Canadian Conference on, 2 :11291133,2001.
[75] M.A. Turk and A.P. Pentland. Face recognition using eigenfaces. Computer Vision andPattern Recognition, 1991. Proceedings CVPR '91., IEEE Computer Society Conferenceon, pages 586591, Jun 1991.
[76] Paul A. Viola and Michael J. Jones. Robust real-time face detection. InternationalJournal of Computer Vision, 57(2) :137154, 2004.
[77] L. F. C. L. Voon, G. Cathebras, B. Lamalle, P. Gorria, B.Bellach, and O.Aubreton. 100-x 100-pixel cmos retina for real-time binary pattern matching. Optical Engineering,41 :924925, may 2002.
[78] G.P. Weckler. Operation of p-n junction photodetectors in a photon ux integratingmode. Solid-State Circuits, IEEE Journal of, 2(3) :6573, Sep 1967.
[79] J. Wilder, P.J. Phillips, Cunhong Jiang, and S. Wiener. Comparison of visible andinfra-red imagery for face recognition. Automatic Face and Gesture Recognition, 1996.,Proceedings of the Second International Conference on, pages 182187, Oct 1996.
[80] L. Wiskott, N. Kruger J.-M. Fellous, and C. von der Malsburg. Face recognition byelastic bunch graph matching. Tech. Report 96-08, Ruhr-Universitat Bochum, April1996.
[81] Laurenz Wiskott, Jean-Marc Fellous, Norbert Krüger, and Christopher von der Malsburg.Face recognition by elastic bunch graph matching. IEEE Trans. Pattern Anal. Mach.Intell., 19(7) :775779, 1997.
[82] Fan Yang and M. Paindavoine. Implementation of an rbf neural network on embed-ded systems : real-time face tracking and identity verication. Neural Networks, IEEETransactions on, 14(5) :11621175, Sept. 2003.
[83] Alan L. Yuille, Peter W. Hallinan, and David S. Cohen. Feature extraction from facesusing deformable templates. Int. J. Comput. Vision, 8(2) :99111, 1992.
[84] Z. Zhu and Q. Ji. Robust real-time eye detection and tracking under variable lightingconditions and various face orientations. Comput. Vis. Image Underst., 98(1) :124154,2005.
[85] X. Zou, J. Kittler, and K. Messer. Illumination invariant face recognition : A survey. Bio-metrics : Theory, Applications, and Systems, 2007. BTAS 2007. First IEEE InternationalConference on, pages 18, Sept. 2007.

BIBLIOGRAPHIE 111
[86] Xin Zou. Illumination Invariant Face Recognition Based in Active Near-Infrared Die-rential Imaging. PhD thesis, University of surrey, march 2007.
[87] F. Zuo and P. H. N. de With. Facial feature extraction by a cascade of model-basedalgorithms. Image Commun., 23(3) :194211, 2008.


Appendices
113


Annexe A
Liste des Publications
Articles de Journaux : Yang Ni, E. Krichen, W. Hizem, S. Garcia-Salicetti and B. Dorizzi, "Active dif-
ferential CMOS imaging device for human face recognition", Signal ProcessingLetters, IEEE , vol.13, no.4, pp. 220-223, April 2006.
Walid Hizem, Yang Ni and Bernadette Dorizzi, "Near infrared sensing and asso-ciated landmark detection for face recognition", J. Electron. Imaging 17, 011005(2008).
Conférences Internationale : Walid Hizem, Emine Krichen, Yang Ni, Bernadette Dorizzi and Sonia Garcia-
Salicetti, "Specic Sensors for Face Recognition". International Conference onBiometrics ICB 2006. p 47-54.
Colloques Nationaux : Walid Hizem, Yang Ni, Emine Krichen, "Ambient Light Suppression Camera for
Human Face Recogntion", Colloque Read05 Rétines électroniques, Asic-FPGAet DSP pour la vision et le traitement d'images en temps réel. p 21-23, Juin2005.
B. Dorizzi, S. Garcia-Salicetti, W. Hizem, L. Allano et Y. Ni, "Capture infra-rouge et fusion multimodale de scores dans le projet VINSI : Vérication d'Iden-tité Numérique Sécurisée Itinérante", Workshop Interdisciplinaire sur la sécuritéglobale, Janvier 2008.
115


Annexe B
"Active dierential CMOSimaging device for human facerecognition"
[1] Yang Ni, E. Krichen, W. Hizem, S. Garcia-Salicetti and B. Dorizzi, Activedierential CMOS imaging device for human face recognition", Signal Proces-sing Letters, IEEE , vol.13, no.4, pp. 220-223, April 2006.
117

220 IEEE SIGNAL PROCESSING LETTERS, VOL. 13, NO. 4, APRIL 2006
Active Differential CMOS Imaging Devicefor Human Face Recognition
Yang Ni, Emine Krichen, Walid Hizem, Sonia Garcia-Salicetti, and Bernadette Dorizzi
Abstract—This letter describes an original CMOS imagingsystem dedicated to human face recognition. The main interestof this work is to provide ambient light invariant images andfacilitate segmentation of the face from the background. Thissystem has been implemented in a specially designed CMOS smartimage sensor with only one analog memory per pixel. This simplepixel design gives the possibility to incorporate this functionalityinto classic low-cost CMOS image sensors. One of its possible ap-plications is face recognition, since the human face appearance isdramatically dependent on illumination conditions. A first indoorexperience with different illumination conditions shows that asimple correlation-based verification algorithm on face images of25 people of the INT database gives promising results.
Index Terms—CMOS sensor, correlation, differential imaging,face recognition.
I. INTRODUCTION
HUMAN face recognition is a complex computer visionproblem. In the visible/near-infrared spectrum, an image
is formed by the reflection of ambient light sources. This re-flected image formation makes the visual aspects of a humanface dramatically dependent on lighting conditions. Indeed, thesame human face can have very different visual aspects underdifferent illumination source configurations, which makes faceverification very difficult. However, research on face recogni-tion offers numerous possible solutions. First, geometric fea-ture-based methods [1], [2] are insensitive to a certain extentto variations in illumination since they are based on measuresbetween facial features (e.g., eyes, nose, mouth); the problemwith these methods is the precision of the detection of such fea-tures, which is far from being straightforward, particularly inbad illumination conditions. Also, statistical methods like prin-cipal component analysis [3], Fisherfaces [4], and independentcomponent analysis [5] emerged as an alternative to a certainvariability of facial appearance. Such methods, despite successin certain conditions, have the drawback of being reliable onlywhen the face references used by the system and the face testimages present similar illumination conditions; for this reason,some studies have proposed to model illumination effects [6].
Manuscript received May 3, 2005; revised October 19, 2005. This work wassupported by the GET (Groupe des Ecoles de Télécommunications) and theFrench government under the Bio_MUL project. The associate editor coordi-nating the review of this manuscript and approving it for publication was Dr.Mauro Barni.
The authors are with the Institut National des Télécommunication, 91160Evry, France (e-mail: [email protected]; [email protected];[email protected]; [email protected]; [email protected]).
Digital Object Identifier 10.1109/LSP.2005.863661
To cope with this problem, another approach relies in thecombination of a specific sensor with a dedicated algorithm.Such a sensor can remove or considerably reduce the image de-pendency on ambient illumination, leading to a more reliablerecognition system.
This consideration is the main motivation of this work. Wepresent here a complete face verification system with a smartCMOS imaging device combined with a computationally lightcorrelation-based algorithm. This system has been tested on adatabase of 25 individuals, acquired with this imaging deviceand a normal CCD camera.
II. SMART CMOS IMAGE SENSOR
Our proposal is based on an active differential imaging prin-ciple. Indeed, in the presence of ambient light, one of the solu-tions is to use an artificial light source attached to the imagingsystem, of greater intensity than the ambient light to diminishthe effect of the latter (using a synchronized flash bulb is oneexample). This solution is the simplest one, but the associatedpower consumption is a big issue because in an outdoor con-figuration, the ambient light level can be very high. Another al-ternative is to use a differential imaging method. In this case,two images are captured: one image with the artificial light onand the other one with the artificial light off. The output imageis obtained from the difference between these two images. Thisway, all the stationary objects illuminated by the light sourceswill be removed. This solution is very interesting because theambient light suppression is based only on the spatiotemporalstationarity of the light. In order to verify this condition, the dif-ferential process needs to be much faster than the possible spa-tiotemporal change during the double-image shooting. There-fore, a specially designed sensor that can give the differentiatedimages directly is highly preferable. Besides, we think that thisspecial image sensor should be compatible with the usual phys-ical constraints, such as optic size and power consumption im-posed on a classic image sensor.
The first smart sensor with this purpose has been designed byToshiba [8]; it has the advantage of optimizing the time intervalbetween the images ON and OFF (the differentiation is doneduring the readout phase by a differential amplifier) but resultsin a large pixel pitch (50 um) that gives not only low spatialresolution (64 64 pixels) but also an optical size problem.
We propose a very simple active differential image sensing,carried out totally on-chip, without any other component. Thebasic idea is the following. In the first phase, we capture the“ON” image by setting the pixel array in parallel mode (allpixels take the image at the same time), and the captured imageis stored in the analog memory. Then, in the second phase, we
1070-9908/$20.00 © 2006 IEEE

NI et al.: ACTIVE DIFFERENTIAL CMOS IMAGING DEVICE FOR HUMAN FACE RECOGNITION 221
Fig. 1. Structure of the pixel.
Fig. 2. Active differential imaging system.
capture the “OFF” image, during the differential image readoutphase. The sensor has a special pixel design (see Fig. 1). Eachpixel has a photodiode and an analog memory cell. Image cap-ture begins with a photodetector’s reset (Prec) and terminateswith a charge transfer (Samp) into the analog memory (MA inFig. 1). During the first phase (“ON” image capture), we exposethe whole matrix of pixels to ambient light with an infrared flash.In the second phase (OFF image capture), in order to have thedifferential operation at the same time as the read-out phase, weexpose, only to ambient light, the matrix line by line. Right afterthe first phase, we load the line to be exposed in a line buffer(LB1). Then, we expose this line of pixels (phase 2), and weload it in a second buffer (LB2). Finally, we calculate the differ-ence of the two lines.
The designed prototype sensor chip has a resolution limitedto 160 120 pixels. A flash ADC with 8-bit resolution has beenincorporated on the same chip that gives a readout speed greaterthan 10 MHz [9]. A prototype camera system has been realizedwith an interface to PC for image capturing and storing (seeFig. 2).
III. ASSOCIATED FACE VERIFICATION ALGORITHM
A. Face Segmentation and Verification
The first step is to extract the face from the original image.Our approach consists of taking advantage of the fact that thebackground is much darker than the area of the face. Segmenta-tion of the face is carried out through a binarization process thatinvolves the use of
1) adaptive threshold;2) object labeling following the hierarchical connected com-
ponents method;3) simple face test;
Fig. 3. Samples of normalized faces.
Fig. 4. Segmentation and preprocessing (size normalization, grey-levelnormalization, smoothing).
4) face extraction step.Our face test (step 3) is based on the size of each object de-
tected. We consider each connex component; if its size is in therange of an acceptable face size, the object is labeled as a face;otherwise, we may make a closing to concatenate the object,considered as small, to other small neighboring objects (to con-catenate the object, considered as small, to other small neigh-boring objects) if the object size is less than a minimum associ-ated threshold. This is the case in particular when the face is seg-mented in two parts due to the presence of a beard or of a differ-ently colored headband on the upper face. We can also performopening (to separate the object, considered as large, from otherlarge neighboring objects) when the object size is greater thana maximum associated threshold. The segmentation process isshown in Fig. 4.
Before performing recognition, we must normalize the im-ages; this step is very important independently of the algorithminvolved later [7]. In general, normalization relies on eyes’ lo-calization, but this may not be feasible in our case because ofpeople wearing glasses. For this reason, the only possible nor-malization is on face size. We chose the 100 70 pixels normal-ized format and applied a histogram equalization to a normal-ized image, to perform grey-level normalization. We also ap-plied Gaussian smoothing to the face image as a preprocessingbefore performing correlation-based algorithms. Fig. 3 showsexamples of resulting normalized and preprocessed face images.
B. Recognition Process and Results
The verification process is done by computing the Euclidiandistance between a reference image template (template) and atest image. As the grey-level corresponding to the backgroundis known, during distance computation, pixels from the back-ground are not taken into account. The resulting Euclidean dis-tance between a reference image and a test image is comparedto a decision threshold. If the distance is lower than a threshold,the claimed identity is accepted; if not, it is rejected.
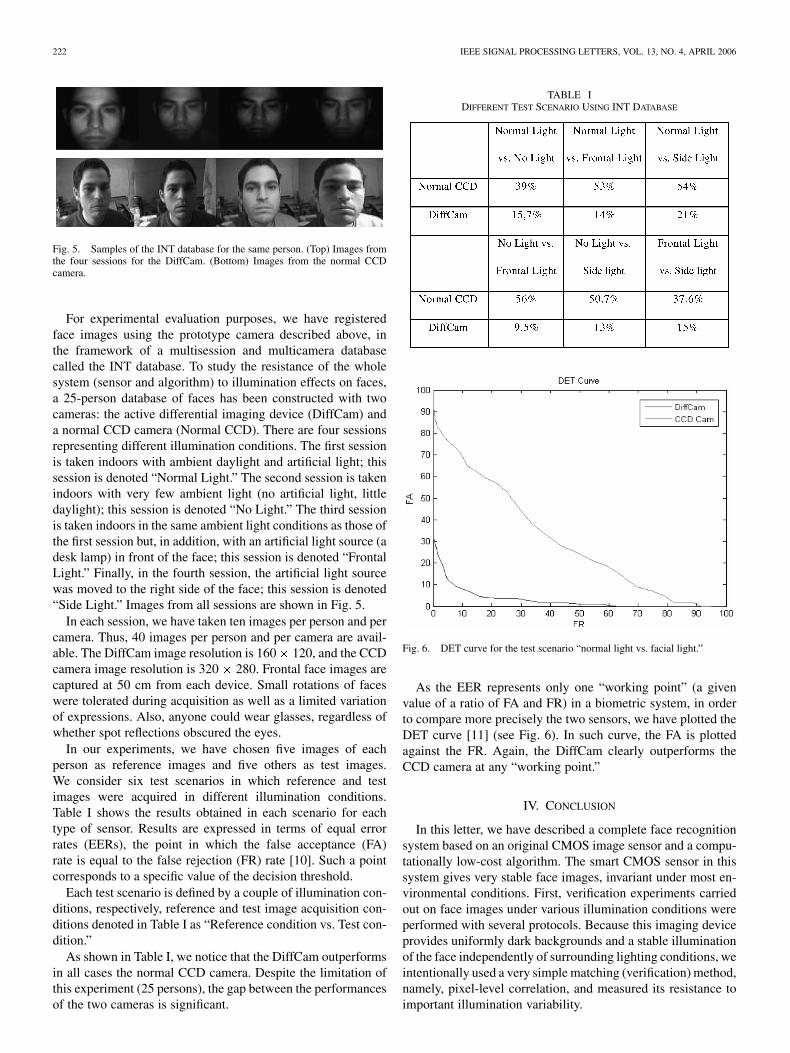
222 IEEE SIGNAL PROCESSING LETTERS, VOL. 13, NO. 4, APRIL 2006
Fig. 5. Samples of the INT database for the same person. (Top) Images fromthe four sessions for the DiffCam. (Bottom) Images from the normal CCDcamera.
For experimental evaluation purposes, we have registeredface images using the prototype camera described above, inthe framework of a multisession and multicamera databasecalled the INT database. To study the resistance of the wholesystem (sensor and algorithm) to illumination effects on faces,a 25-person database of faces has been constructed with twocameras: the active differential imaging device (DiffCam) anda normal CCD camera (Normal CCD). There are four sessionsrepresenting different illumination conditions. The first sessionis taken indoors with ambient daylight and artificial light; thissession is denoted “Normal Light.” The second session is takenindoors with very few ambient light (no artificial light, littledaylight); this session is denoted “No Light.” The third sessionis taken indoors in the same ambient light conditions as those ofthe first session but, in addition, with an artificial light source (adesk lamp) in front of the face; this session is denoted “FrontalLight.” Finally, in the fourth session, the artificial light sourcewas moved to the right side of the face; this session is denoted“Side Light.” Images from all sessions are shown in Fig. 5.
In each session, we have taken ten images per person and percamera. Thus, 40 images per person and per camera are avail-able. The DiffCam image resolution is 160 120, and the CCDcamera image resolution is 320 280. Frontal face images arecaptured at 50 cm from each device. Small rotations of faceswere tolerated during acquisition as well as a limited variationof expressions. Also, anyone could wear glasses, regardless ofwhether spot reflections obscured the eyes.
In our experiments, we have chosen five images of eachperson as reference images and five others as test images.We consider six test scenarios in which reference and testimages were acquired in different illumination conditions.Table I shows the results obtained in each scenario for eachtype of sensor. Results are expressed in terms of equal errorrates (EERs), the point in which the false acceptance (FA)rate is equal to the false rejection (FR) rate [10]. Such a pointcorresponds to a specific value of the decision threshold.
Each test scenario is defined by a couple of illumination con-ditions, respectively, reference and test image acquisition con-ditions denoted in Table I as “Reference condition vs. Test con-dition.”
As shown in Table I, we notice that the DiffCam outperformsin all cases the normal CCD camera. Despite the limitation ofthis experiment (25 persons), the gap between the performancesof the two cameras is significant.
TABLE IDIFFERENT TEST SCENARIO USING INT DATABASE
Fig. 6. DET curve for the test scenario “normal light vs. facial light.”
As the EER represents only one “working point” (a givenvalue of a ratio of FA and FR) in a biometric system, in orderto compare more precisely the two sensors, we have plotted theDET curve [11] (see Fig. 6). In such curve, the FA is plottedagainst the FR. Again, the DiffCam clearly outperforms theCCD camera at any “working point.”
IV. CONCLUSION
In this letter, we have described a complete face recognitionsystem based on an original CMOS image sensor and a compu-tationally low-cost algorithm. The smart CMOS sensor in thissystem gives very stable face images, invariant under most en-vironmental conditions. First, verification experiments carriedout on face images under various illumination conditions wereperformed with several protocols. Because this imaging deviceprovides uniformly dark backgrounds and a stable illuminationof the face independently of surrounding lighting conditions, weintentionally used a very simple matching (verification) method,namely, pixel-level correlation, and measured its resistance toimportant illumination variability.

NI et al.: ACTIVE DIFFERENTIAL CMOS IMAGING DEVICE FOR HUMAN FACE RECOGNITION 223
Our experiments show that the DiffCam coupled with thepixel-level correlation algorithm has a good performance, evenin the presence of strong illumination variability, and outper-forms clearly the normal CCD camera coupled with the samerecognition algorithm. Such a system is particularly suited forface verification on mobile platforms like smart phones, sincethe mobility context involves a great variability of lighting con-ditions and complex backgrounds and also a strong hardwareperformance limitation. Our intimate conviction is that this pro-totype system has great room for improvement, especially byincreasing sensor resolution and frame rate.
REFERENCES
[1] R. Brunelli and T. Poggio, “Face recognition: Features vs. templates,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 15, no. 10, pp. 1042–1053,Oct. 1993.
[2] S. Li and J. Lu, “Face recognition using nearest feature line,” IEEETrans. Neural Netw., vol. 10, no. 2, pp. 439–443, Mar. 1999.
[3] M. A. Turk and A. P. Pentland, “Face recognition using eigenfaces,” inProc. IEEE Conf. Computer Vision Pattern Recognition, Jun. 1991, pp.586–591.
[4] J. Li, S. Zhou, and C. Shekhar, “A comparison of subspace analysis forface recognition,” in Proc. IEEE Int. Conf. Acoustics, Speech, SignalProcessing, vol. 3, Apr. 2003, pp. 121–124.
[5] M. S. Bartlett, J. R. Movellan, and T. J. Sejnowski, “Face recognition byindependent component analysis,” IEEE Trans. Neural Netw., vol. 13,no. 6, pp. 1450–1464, Nov. 2002.
[6] A. Georghiades, P. N. Belhumeur, and D. J. Kriegman, “From few tomany: Illumination cone models for face recognition under variablelighting and pose,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 23, no.6, pp. 643–660, Jun. 2001.
[7] Colorado State University. Evaluation of Face Recognition Algorithms.[Online]http://www.cs.colostate.edu/evalfacerec/.
[8] H. Miura, H. Ishiwata, Y. Lida, Y. Matunaga, S. Numazaki, A. Morista,N. Umeki, and M. Doi, “A 100 frame/s CMOS active pixel sensor for3D-gesture recognition system,” in IEEE Int. Solid-State Circuits Conf.,1999, pp. 142–143.
[9] Y. Ni and X. L. Yan, “CMOS active differential imaging device withsingle in-pixel analog memory,” in Proc. IEEE Eur. Solid-State CircuitsConf., Sep. 2002, pp. 359–362.
[10] S. J. Raudys and A. K. Jain, “Small sample size effects in statisticalpattern recognition: Recommendations for practitioners,” IEEE Trans.Pattern Anal. Mach. Intell., vol. 13, no. 3, pp. 252–264, Mar. 1991.
[11] A. Martin, G. Doddington, T. Kamm, M. Ordowski, and M. Przybocki.The DET Curve in Assessment of Detection Task Performance. [On-line]http://www.nist.gov/speech/publications/papersrc/det.doc.


Annexe C
Near infrared sensing andassociated landmark detectionfor face recognition
[2] Walid Hizem, Yang Ni and Bernadette Dorizzi, "Near infrared sensingand associated landmark detection for face recognition", J. Electron. Imaging17, 011005 (2008).
119

Near Infrared Sensing and Associated Landmark Detection
for Face Recognition
Walid Hizem, Yang Ni and Bernadette Dorizzi
INT\GET, 9 Rue Charles Fourier, Evry, France;
Walid.Hizem, Yang.Ni, [email protected]
ABSTRACT
We present, in this work, a new system of Near-Infrared capture that aims to eliminate ambient light effects. We
designed this sensor to be integrated into the mobile platform VINSI. One of the originalities of this sensor is
that we can acquire two images at the same time: one in infrared and the other in visible light. We developed a
novel method for landmark detection of sufficiently low complexity so that it can be implemented on our mobile
platform. We tested this method on three different near-infrared face databases, and we observed stability in
the precision of localization over these databases associated to performance comparable to the state of the art.
Keywords: Near-Infrared sensing, Landmark Detection, illumination suppression
1. INTRODUCTION
The illumination problem is one of the limitations in face recognition, especially in an outdoor environment.
In (1), the influence of the illumination - in the uncontrolled session in FRGC (Face Recognition Grand Challenge)
- on the performance of the algorithms can be easily observed as the performance decreases by a factor of 1.6
between the controlled and uncontrolled cases. There are two solutions to tackle this problem. The first and most
commonly used one is to eliminate analytically the illumination effect (2)(3)(4). However, the performance of
these algorithms depends on the quality of the original image and the conditions of illumination. The analytical
approach has also the disadvantage of being complex and time consuming. These algorithms are therefore not
suitable for mobile devices where the processing capacities and memory are limited. The other direction (active
approach) is to design active imaging techniques to obtain face images captured under consistent illumination
conditions. The VINSI (Verification d’Identite Numerique Securise Itinerante) project aims at designing and
implementing a mobile device for biometric identity verification through face and fingerprints. This device could
be used to verify the identity of travellers carrying a biometric visa or passport. In this context of mobility and
high illumination variations, active approaches are recommended. We therefore designed a new sensor capable
of acquiring simultaneously a normal-light image and an image in near infrared, thus allowing us to suppress the

influence of the ambient light. The accurate finding of landmark position (like position of the eyes, the nose,
the mouth) is an important process for image normalization (scale, pose and face expressions), and it is an a
priori treatment before any face verification procedure. Landmarks can be well detected on Near InfraRed (NIR)
images while their determination is more difficult in saturated normal lightened images because some part of
the face could be undetectable. By acquiring both images at the same time, we can detect the facial landmarks
in the NIR image and subsequently position them on the normal light image. We propose in this paper a new
scheme for accurate landmark detection on NIR images which we validate on several different databases acquired
in our laboratory. One of the characteristics of thes scheme is its ability to be integrated in the sensor itself.
Our paper is divided into four sections. After a brief recall of the state of the art in Near Infrared sensing,
we describe in more details the architecture and design of our VINSI sensor. A description of our landmark
detection method, suitable for mobile devices, is presented in the third section. Finally, we validate our approach
on different near-infrared face databases at our disposal.
2. NEAR INFRARED SENSORS
Active sensing consists of eliminating ambient light during the acquisition of the image. In this process, the
acquired image depends on an additional and controlled light and therefore requires a dedicated sensor. In this
paper we will focus on infrared sensors for ambient lighting suppression. These sensors use the near infrared
lighting to illuminate the scene instead of the ambient light. Much recent research (5)(6) has been done on this
type of image, but using different sensor architectures. The most robust architecture relies on the differential
acquisition. It is assumed that the ambient light is a DC component, so it can be suppressed by using a differential
process. Two images are then acquired; one with ambient light and the second one with a near infrared light (7)
and then a subtraction is performed between the two images. The resulting image is in near infrared. The
disadvantage of this method is that the subtraction is done outside the sensor, which slows the acquisition flow
and in consequence a motion problem can appear. In (8) we have shown that the differential operation can be
done in the sensor. The idea is to do the subtraction analogically in the sensor. With this procedure we have
improved the ambient light suppression resulting in a faster sensor than the method subtracting the two images
outside the sensor. Another method uses a visible cut filter in the front of the camera (9)(10) and adds a near
infrared illumination. This solution is optimized for indoor acquisitions or dark environmental conditions but
not in situations where ambient light contains too much Near Infrared (sunlight) in which the long acquisition
time does not allow any attenuation of ambient light.
In our laboratory, we developed another ambient light suppression sensor based on a CCD sensor with a
pulsed flash (11) as a preliminary step forwards the actual VINSI sensor presented in 3. In this approach, we

have shortened the acquisition time and we have used a synchronized flash. This sensor is based on a modified
Logitech QuickCam Pro 4000 webcam equipped with a CCD sensor and the exposure time was controlled by
the software of the webcam. The resolution of this camera is 640× 480. This solution presents the advantage of
being built on a standard sensor similar to the differential sensor, but the acquisition time is set by software and
then can’t be set freely. We developed then a new sensor (VINSI infrared sensor) that can achieve an acquisition
in infrared with programmable acquisition time and in ambient light with a small delay time (20ms).
3. VINSI INFRARED SENSOR
This new sensor can therefore acquire successively images in ambient and in infrared light. The acquisition is
nearly simultaneous: indeed the delay time is only 20ms. We combined the video acquisition protocol and the
FlashCam principle to perform the dual acquisition. The output of our sensor is an image composed of two
frames, the odd one being the visible image and the even one, the near infrared image. During the acquisition of
the visible image, the Timing and synchro generator component fix the acquisition time. The integration time
of the CCD sensor is set by the lapse of time between the last reset signal of the substrate (Vxsub) and the
transfert signal (Vxsg). During the odd frame, we use the same principle as in the FlashCam. We modify the
reset signal Vxsub by adding extra ones before the charge transfer from the CCD matrix to the charge lecture
circuit (Vxsg). By this way, we are reducing the exposure time of the pixels (fig.1). During this time, we activate
the flash through the Vled signal. We settled the exposure time in the odd frame to 50µs. This exposure time
is short enough to suppress the ambient light and long enough to have a good image quality in the near infrared
spectrum.
Figure 1. Acquisition Principle
The VINSI infrared sensor is a Black and White CCD of 500× 582 (TV resolution) pixels. The architecture

of the module is shown in figure. 2. The module is composed of the CCD, a Samsung component, controlled
via the vertical CCD driver with a Timing and synchro generator. We use the outputs of this component to
control the acquisition mode and timing. We add to the CCD module a Video Sync Separator LM1881 and
an ATMEGA32 microcontroller. To have a good image quality in infrared, we designed a flash composed of 40
LEDS surrounding the lens of the camera (2). We choose a powerful LEDS that can be pulsed and can emit an
infrared light of 880nm. In order to get optimized images, the subject must stand at 50cm from the camera.
Figure 2. Architecture of the VINSI Module
This distance depends on the radiant intensity and on the optic used in the prototype. After the acquisition
phase, we extract the frames from the video and separate the odd and even lines from each frame. A linear
interpolation allows the production of 2 images: one in near infrared and a second in visible light. We see in
figure.3 that the ambient light has no effect on the near infrared image. The suppression of the ambient light is
therefore very efficient.
Figure 3. Image subsampling from the VINSI sensor

4. LANDMARKS DETECTION
During the development of the sensor described above, we noticed the remarkable image stability across illumi-
nation variation. We therefore know that the landmark detection performed on these images will be of equal
quality, independently of the illumination conditions, contrary to what occurs in the case of normal light images.
Moreover, we developed a landmark detection algorithm suitable for this type of images with the constraint of
an easy integration on the chip. This does not allow us the use of statistical models, neither of high complexity
methods. Taking into account that the characteristics of the near infrared images is their high contrast which
facilitates the edge detection, we first apply a height-direction edge filter (figure 4). The resulting image accen-
Figure 4. Edge detection in Infrared images
tuates the edges of the face and the landmarks (namely eyes, nose, mouth). We have noticed that a horizontal
projection allows us to detect the ordinate of the landmarks (5)(10). The maxima of the projection coincide with
the eyes, the nose, the mouth, the chin and the nostrils. Therefore, we are going to analyze the area of those
maxima to find out the position of the landmarks at interest (namely the eyes, the nose and the mouth which
are the most stable and common landmarks. The same processing has been done on the visible images. Due to
Figure 5. Samples of acquired images and corresponding edge detection
the sensitivity of the edges to the illumination, the edge image doesn’t contain enough information to be treated
as the infrared image. Indeed, we can see in figure 6 that due to the illumination problem, we can’t get the right
part of the face in the edge image.

Figure 6. visible and infrared edge image
Detection of the mouth: The analysis of the three bottom pre-selected areas (by the horizontal projection)
will lead us to the ordinate of the mouth. The mouth is present in the area where we can find the longest
horizontal line. We apply an opening operation in the pre-selected region with a line structuring element to
highlight the line elements. The longest line is selected by a horizontal projection. After that we calculate the
barycentre of that line to fix the centre of the mouth.
Detection of the nose: The nose is selected from the zones which were pre-selected during the horizontal
projection. The nose is indeed located just above the mouth. So, we analyze the upper areas of the mouth where
we can find the model of the nose (presented in figure 7). Using a vertical projection, we will find two important
gradients relative to the nose vertical borders.
Figure 7. Model of the nose
Detection of the eyes: The eyes are selected from the upper pre-selected zones, just above the nose. Erosion
with a round structuring element in those areas will allow to select the two bigger area. Depending on their size
we will know whether the zone contains or not the eyes. The centre of each eye is obtained by calculating the
barycentre of the two main objects in that zone.
5. EXPERIMENTATIONS
In order to validate and test our method and the robustness of the VINSI sensor, we have acquired two databases
called IV2 and INT-VINSI. We also tested our algorithm on images acquired with other infrared sensors in order
to study its stability relative to the different NIR datasets. In this context, we have tested our method on the
Differential sensor (DiffCam(8)) using the BIOMET infrared database (12) .

5.1 Databases Description :
Infrared IV2 face database: We took advantage of a recent acquisition campaign in our institute to acquire this
infrared face database using a first version of our sensor. This sensor was equipped with a wide angle lens (fisheye
lens), and that led to hemispherical images. The acquisition took place in an indoor environment. We built
a booth with a system designed to control the illumination composed of four halogen lamps: two behind the
subject, one at his right and the last one at his left. There are 50 people in this database. For each person, we
have at our disposal a video of 40 seconds. The resolution of those videos is 640x480. Every ten seconds we
change the illumination conditions: all the four lamps are on, all the four lamps are off, left illumination and
right illumination. We have extracted 10 images from videos from which we separate the odd and even frames
in order to get the infrared image and the visible one. Some samples of this data base are shown in figure. 8.
Note that none of the subjects wear glasses.
Figure 8. Samples of the visible light images in the IV2 database
INT-VINSI face database: This database contains a set of 25 persons acquired in two sessions over several
weeks. Each session contains three videos of ten seconds recorded using the VINSI infrared sensor. Three different
illumination conditions are considered for each video. The difference with the previous database lies in the lens
used in the sensor (6mm); we also modified the flash to a more powerful one. The first session corresponds to
an ambient office lighting. In the second session we illuminate the face with a light source directed to the left.
The last one is taken near an open window. The face is illuminated laterally from the right. The intensity of
the illumination depends on the daytime and on the weather. Some samples of this database are illustrated in
figure 9.
BIOMET: This NIR face database was acquired during the BIOMET acquisition campaign (12) with the
differential sensor(8). The resolution of the images is 160x120 i.e: lower than in the two previous databases. We
have excluded from our tests people who wear glasses, in order to avoid the problem of reflection.

Figure 9. Sample of the INT-VINSI database
5.2 Performance:
The criteria that we use for landmark detection evaluation is the one originally proposed by Jesorsky and al.(13).
This criterion is based on the intraocular distance as follows:
deye =max(dl, dr)
‖ Cl − Cr ‖
Where Cl, Cr are the real centre of the left(respectively right eye) and dl, dr are the distances between the
detected eye left (respectively right) centre and the real left (respectively right) eye coordinate. Note that the
real centre positions are detected manually and can be subject to some error.
To measure the performance of the nose and mouth detection, we used the same principle as for deye:
dnose = dn
‖Cl−Cr‖, where dn is the distance between the detected position of the nose and the one manually
determined.
dmouth = dm
‖Cl−Cr‖, where dm is the distance between the detected position of the mouth and the one manually
determined.
In (14), it was established experimentally that in order to perform a good verification, the deye localization
precision has to be lower than 0.05. In other work(13), it is shown that for an eye localization accuracy of 0.25,
the centre of the eye can still be detected inside the eye region. The results of the tests on the IV2 database are
shown in figure 10.
Our method has a ratio of 75% of good eye localization at factor of 0.05 on the IV2 database. The performance
of our method on the INT-VINSI database is shown in figure 11.
On this database the precision of the eye localization is better than on the IV2 database. Indeed, even if
we use the same capture method, images in INT-VINSI are of better quality (no hemispherical distortion and
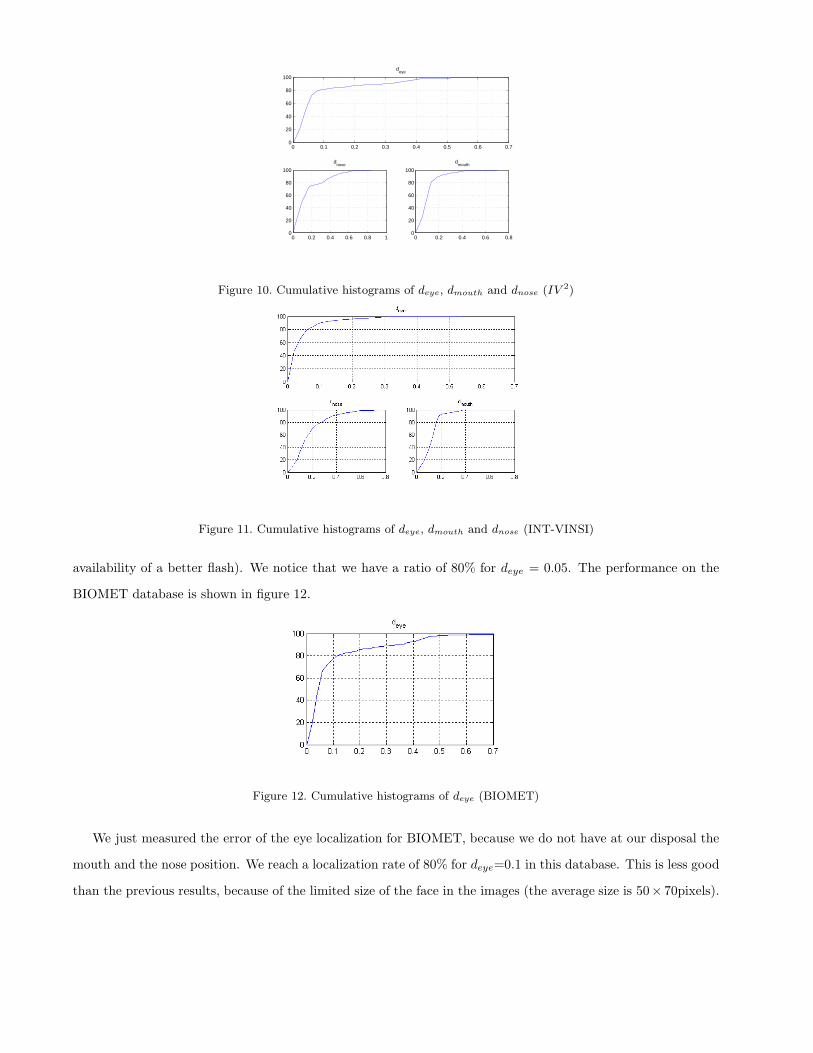
0 0.1 0.2 0.3 0.4 0.5 0.6 0.70
20
40
60
80
100
deye
0 0.2 0.4 0.6 0.8 10
20
40
60
80
100
dnose
0 0.2 0.4 0.6 0.80
20
40
60
80
100
dmouth
Figure 10. Cumulative histograms of deye, dmouth and dnose (IV2)
Figure 11. Cumulative histograms of deye, dmouth and dnose (INT-VINSI)
availability of a better flash). We notice that we have a ratio of 80% for deye = 0.05. The performance on the
BIOMET database is shown in figure 12.
Figure 12. Cumulative histograms of deye (BIOMET)
We just measured the error of the eye localization for BIOMET, because we do not have at our disposal the
mouth and the nose position. We reach a localization rate of 80% for deye=0.1 in this database. This is less good
than the previous results, because of the limited size of the face in the images (the average size is 50× 70pixels).

6. CONCLUSION
In this work we presented a new sensor for ambient light suppression. This sensor is to be imbedded in the VINSI
mobile platform to control the identity of citizens who hold biometric passports. This new sensor is capable of
acquiring two images at the same time: the first one is taken in visible light; the second in near-infrared. We
also developed a method of landmark detection which we tested on near infrared images acquired with different
types of sensors. The best result, in terms of precision of the localization, was found on the images acquired with
our new VINSI sensor, which was to be expected because they have the best quality. However, our experiments
show that this method can be used on different types of infra-red images and with sufficiently good results.
Better performance could eventually be obtained with learning-based methods (such SVM in(15)), but these
methods can not be simply implemented on a mobile device having limited resources; for these reasons we did
not considered them.
Our future works will aim to use these NIR landmarks to provide eye localization on the associated visible
image for further processing. Another direction concerns the realization of a verification algorithm for NIR
images suitable for analogical architecture.
ACKNOWLEDGMENTS
This work has been founded by the French project VINSI (Verification d’identite Numerique Securise Itinerante)
REFERENCES
1. P. Phillips and Al., “Overview of the face recognition grand challenge,” Conference on Computer Vision
and Pattern Recognition 1, pp. 947 – 954, 2005.
2. S. Shan and Al., “Illumination normalization for robust face recognition against varying lighting conditions,”
IEEE International Workshop on Analysis and Modeling of Faces and Gestures , pp. 157–164, 2003.
3. D. Jobson, Z. Rahman, and G. Woodell, “A multiscale retinex for bridging the gap between color images
and the human observation of scenes,” IEEE Transactions on Image Processing 6, pp. 965–976, 1997.
4. X. Xie and K. Lam, “An efficient illumination normalization method for face recognition,” Pattern Recog-
nition Letters 27, 2005.
5. J. Dowdall, I. Pavlidis, and G. Bebis, “Face detection in the near-ir spectrum,” Image and Vision Comput-
ing 21, pp. 565–579, 2003.
6. D. Li and W. Liao, “Facial feature detection in near infrared images,” Proc. Fifth Int’l Conf. Cumputer
vision Pattern Recognition and Image Processing , pp. 26–30, 2003.

7. X. Zou, J. Kittler, and K. Messer, “Ambient illumination variation removal by active near-ir imaging,”
Proceedings of IAPR International Conference on Biometric , pp. 19–25, 2006.
8. Y. NI and X.-L. YAN, “Cmos active differential imaging device with single in-pixel analog memory,” Pro-
ceeding of ISSCC02 , pp. 359–362, 2002.
9. S. Z. Li and Al., “Illumination invariant face recognition using near-infrared images,” IEEE Transactions
on Pattern Analysis and Machine Intelligence 29(4), pp. 627–639, 2007.
10. W.-H. Liao and D.-Y. Li, “Homomorphic processing techniques for near-infrared images,” Proceedings of
Acoustics, Speech, and Signal Processing. (ICASSP ’03) 3, pp. III– 461–4, 2003.
11. W. Hizem and Al., “Specific sensors for face recognition,” Int’l Conf. Audio- and video-Based Biometric
Person Authentication , pp. 47–54, 2006.
12. S. Garcia-Salicetti and Al., “Biomet : A multimodal person authentication database including face, voice,
fingerprint, hand and signature modalities,” AVBPA Proceedings 2688, p. 1056, 2003.
13. O. Jesorsky, K. Kirchberg, and R. Frisholz, “Robust face detection using the hausdorff distance,” Int’l Conf.
Audio- and video-Based Biometric Person Authentication , pp. 90–95, 2001.
14. M. Sadeghi, J. Kittler, A. Kostin, and K. Messer, “A comparative study of automatic face verification
algorithms on the banca database,” Proc. Fourth Int’l Conf. Audio- and Video-Based Biometric Person
Authentication , pp. 35–43, 2003.
15. X. Zou, J. Kittler, and K. Messer, “Accurate face localisation for faces under active near-ir illumination,”
Proceedings of the 7th Int’l Conference on Automatic Face and Gesture Recognition (FGR’06) , pp. 369–374,
2006.
List of Figures
1 Acquisition Principle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Architecture of the VINSI Module . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
3 Image subsampling from the VINSI sensor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
4 Edge detection in Infrared images . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
5 Samples of acquired images and corresponding edge detection . . . . . . . . . . . . . . . . . . . . 5
6 visible and infrared edge image . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
7 Model of the nose . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
8 Samples of the visible light images in the IV 2 database . . . . . . . . . . . . . . . . . . . . . . . 7

9 Sample of the INT-VINSI database . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
10 Cumulative histograms of deye, dmouth and dnose (IV 2) . . . . . . . . . . . . . . . . . . . . . . . 9
11 Cumulative histograms of deye, dmouth and dnose (INT-VINSI) . . . . . . . . . . . . . . . . . . . 9
12 Cumulative histograms of deye (BIOMET) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9