bases de données multimédia i - introduction · un système de gestion de base de données (dbms)...
TRANSCRIPT

Bases de données multimédiaI - Introduction
ENSIMAG
2009
Hervé Jégou & Matthijs Douze

Bases de données multimedia
Deux intervenants: ► Hervé Jégou, [email protected]► Matthijs Douze, [email protected]
12 x 1.5H = 18H de cours
Évaluation : examen écrit

Au programme
Introduction
Gestion des bases de données multimédia
Espaces de représentations
Mesures de similarité
Évaluation
Description globale
Description locale
Techniques d’indexation
Recherche dans des espaces de grande dimension
Indexation Vidéo
Catégorisation des images
Indexation Audio

Base de données
Une base de données est un ensemble structuré et organisé permettant le stockage de grandes quantités d'informations afin d'en faciliter l'exploitation (ajout, mise à jour, recherche de données).
Wikipedia

Multimédia
Qui utilise plusieurs moyens de diffusion
Qui concerne plusieurs média
Diffusé par plusieurs média
Adj: Qui utilise ou concerne plusieurs médias
Media: Tout support de diffusion de l’information constituant à la fois un moyen d’expression et un intermédiaire transmettant un message à l’attention d’un groupe

Multimédia
Le mot multimédia est apparu vers la fin des années 1980, lorsque les CD-ROM se sont développés. Il désignait alors les applications qui, grâce à la mémoire du CD et aux capacités de l'ordinateur, pouvaient générer, utiliser ou piloter différents médias simultanément […]
Aujourd'hui on utilise le mot multimédia pour désigner toute application utilisant ou servant à travailler sur au moins un média spécifique. […]
Par ailleurs, en recherche en informatique, on nomme multimédia l'étude des médias non textuels, principalement les images, les vidéo et les sons.
Note : Wikipedia est une encyclopédie libre. La qualité des informations présentes est généralement bonne, mais le contenu ne provient pas systématiquement d’expert et ne présente pas de garantie.
Wikipedia

Multimédia : définition de travail
Des contenus pouvant être de différents types, en particulier► Texte► Son► Image► Vidéos
Qui peuvent être combinés
Caractérisés par des besoins de stockage très importants
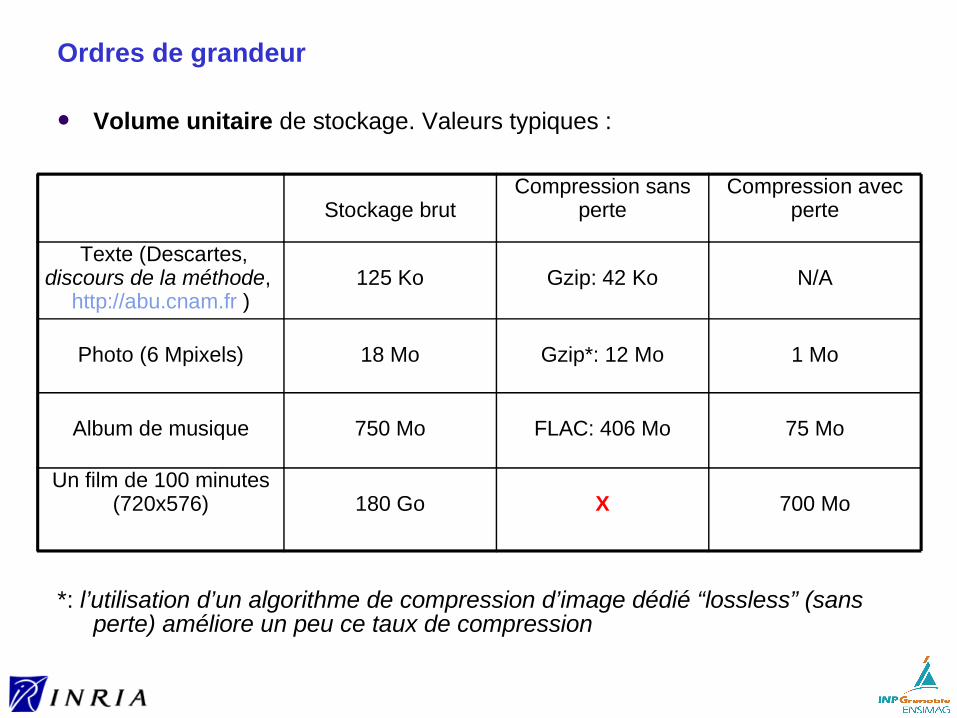
Ordres de grandeur
Volume unitaire de stockage. Valeurs typiques :
*: l’utilisation d’un algorithme de compression d’image dédié “lossless” (sans perte) améliore un peu ce taux de compression
Stockage brut Compression sans
perteCompression avec
perte
Texte (Descartes, discours de la méthode,
http://abu.cnam.fr )125 Ko Gzip: 42 Ko N/A
Photo (6 Mpixels) 18 Mo Gzip*: 12 Mo 1 Mo
Album de musique 750 Mo FLAC: 406 Mo 75 Mo
Un film de 100 minutes (720x576) 180 Go X 700 Mo

Ordres de grandeur
Nombre d’unités► Internet visible ≈ nécessite “seulement” 5-10 To de capacité de stockage
Août 2007: 61 milliards de recherches sur Internet recensées► Images : par exemple, Flickr, Web
→ ordre de grandeur: milliard à dizaine de milliards d’images► Films : http://www.imdb.org recense plus de 400 000 films► Croissance très importante, en raison de l’accumulation des contenus
numériques auto-produits par le grand public► http://www.flickr.com : “1578 images uploaded in the last minutes”
→ extrapolation : 2M d’images images par jour, 800M d’images par an► http://www.youtube.com : 100M de vidéos délivrées chaque jour
(hypothèse basse)► Images/vidéo spécifiques : photos satellites, vidéo-surveillance, etc

Chaîne du multimédia : besoins
Génération : outils de production et de création
Représentation : utilisation de formats de représentations différentes
Stockage
Transmission : problème de réseaux, architecture
Recherche d’information : recherche basée sur le contenu
Distribution : conception de serveur de streaming

Applications types
News/Films à la demande
Commerce electronique
Informations médicales
Systèmes d’informations géographiques
Architecture/Design
Protection du copyright
Géo-localisation
Enquêtes policières
Militaire
Expérimentations scientifiques
Enseignement
Archivage, gestion des bases de données de contenu (personnelles ou professionnelles)
Moteur de recherche (ex: Internet)
Applications industrielles
Dans les cours suivants :
focus sur la partie recherche et indexation dans de grandes bases d’images et de vidéos

Bases de données multimédiaII – Gestion des bases de données multimédia

Base de données multimédia
Multimedia Database (MMDB)
Initialement traitées comme des bases standards► Objets multimédia traités comme un seul item comme champs au sein
d’une base de données relationnelle (ex: Oracle, LOB –Large Object)► Recherche sur mots clés introduits manuellement dans le système par la
personne : nécessité d’un système d’annotation, par exemple Tag ID3 dans le MP3 Information Exif
► Utilisation des relations entre objets► Recherche sur les mots présents dans les pages Web
conjointement avec l’objet multimédiahttp://images.google.com http://www.exalead.fr/image

Base de données “standard”
Une base de données (DB) relationnelle est un ensemble de mise en relation.
Un système de gestion de base de données (DBMS) est un logiciel facilitant la création, la maintenance et la manipulation d’une base de données. Il garantit sécurité et intégrité de la base. ► Oracle, DB2, Sybase, PostgreSQL, Mysql
Système de base de données = la base + le système de gestion
Points clés :► Indépendance des données : données et logiciels de gestion séparés► Indépendant du mode de stockage ou de représentation de la base► Abstraction des données : représentation conceptuelle► Auto-suffisance de la base de données.
Pas de relation avec des données externes.

Relations entre données
Bases de données relationnelles :► définition d’ensembles et de relations entre ces ensembles► ensemble composés d’entités du même type caractérisé par des
champs de type simple (chaînes de caractères, de valeurs numériques, etc)
► relations entre objets bien définies (est en relation ou non)► utilisation d’un langage de requête par prédicat (en particulier SQL)
Succès important de ce type de système► répond à la plupart des besoins impliquant des données “simples”► accroît l’indépendance des données
Dans un contexte de données de type signal : nécessite la présence d’annotations (ou méta-données) et/ou d’outils d’analyse

Spécificités des bases de données multimédia (MMDB)
Ex de requête impossible avec un SGDB “classique”: ► récupérer tous les images “qui ressemblent” à une image requête
Grosky et Fotouhi (1) caractérisent le multimédia à partir du type d’activité impliquée dans la création des données
L’information portée par le multimédia est tout ce qui peut venir du monde réel, alors que l’information portée par une base de données classique ne peut être qu’une représentation symbolique de faits limités à l’univers de la base de données.
Le développeur d’une MMDB ne peut expliciter tous les aspects des données qui seront importants pour l’utilisateur► les informations ne peuvent se limiter à un ensemble de champs
prédéfinis► sauf pour certaines applications très spécifiques
[1]. W.I. Grosky, F. Fotouhi and Z. Ziang. Multimedia data Management. Using metadata to integrate and apply digital media, chapter Using metadata for the intelligent browsing of structured media objets, pages 123-148. In Sheth and Klas, 1998

Richesse des bases de données multimédia
Apprendre un concept (ici les couleurs) à partir “du monde réel” [2]→ c’est-à-dire Google ou tout autre base texte+images
Conclusion de l’article : utiliser Internet pour définir des couleurs de nouvelles images ⇒ meilleurs résultats que de demander à un groupe de personnes
[2]. J. Van-der-Weijer, C. Schmid and J. Verbeek, Learning Color Names from Real-world Images, CVPR 2007

MMDB avec contexte d’utilisation limité
Toutes les applications ne nécessitent pas de système de gestion sophistiqué→ en particulier celles qui correspondent à un besoin spécifique (type de requête unique ou limité)
Pour de telles applications spécifiques :► bases de données classiques
+ outils d’analyse adaptés à l’application
Exemple : base de données sur le remplissage des stades à partir d’images de retransmission

Objets actifs vs objets passifs
Bertino et al [4] distingue les objets multimédia en actifs et passifs
Objets actifs : participent au processus de recherche► Cette image contient-elle une voiture ?
⇒ utilisation de la représentation de l’image
Les objets passifs se contentent d’exister dans la base. Ils ne peuvent être retrouver qu’au moyen d’attributs (pas d’utilisation de l’objet pour la requête).
Remarque : En général, dans une DB: recherche associative (rechercher des propriétés/objets inconnus à partir d’attributs connus) = mode passif
Une MMDB contenant des objets passifs de satisfait pas les besoins des utilisateurs : besoin de recherche d’information sur le contenu des objets, non pas sur leurs attributs.
Recherche par attributs limitée à une recherche “exacte”. Recherche par le contenu implique recherche “approximative”
[3]. A. Hampapur and R. Jain. Multimedia data management. Using metadata to integrate and apply digital media, chaper Video data management systems: metadata and architecture, pages 245-286.,1998.

Contenu et meta-données
Les données “brutes” (fichier image, fichier son) provenant d’objets multimédia contiennent des informations sémantiques.
Grosky [4] distingue► La donnée brute (image, signal sonore)► Les méta-données décrivant le contenu
DEFINITION: le processus d’abstraction permet de décrire le contenu d’objets multimédia par des méta-données, soit manuellement, soit par des procédés (semi-)automatiques
Ces meta-données proviennent soit de propriétés de descripteurs des objets (couleur moyenne d’une image) ou d’annotations manuelles.
[4]. W.I. Grosky, F. Fotouhi and Z. Jiang. Multimedia data management. Using metadata to integrate and apply digital media, pages 123-149, 1998.

Annotations / Meta-données
Une annotation textuelle sera toujours trop restrictive, même si elle prend en compte à la fois des informations syntaxiques et symboliques.
Malgré cela, l’approche la plus utilisée reste l’annotation textuelle et manuelle
Avantage : recherche indépendante du type de media
Inconvénients► Le coût d’annotation manuel est très important► Différentes personnes utilisent un vocabulaire différent pour signifier la
même chose (ex: clair, lumineux). Connu sous le nom de “problème du vocabulaire”. L’utilisation d’un thésaurus ne règle pas tout.
► Différentes personnes peuvent décrire des aspects différents du média (polysémie du contenu), la même personne décrira différents aspects en fonction de la situation.
► Le non-verbal ne peut être exprimé sans ambiguité.

“Une carte n’est pas un territoire”
1. Une carte n'est pas le territoire. → les mots ne sont pas les choses qu'ils représentent.
2. Une carte ne couvre pas tout le territoire. → les mots ne peuvent pas couvrir tout ce qu'ils représentent.
3. Une carte est auto-réflexive. → dans le langage, nous pouvons parler à propos du langage.
Alfred Korzybski, Une carte n'est pas le territoire

Systèmes d’annotation : musique/image
Musique
1. pas de tag prévu dans le format originel CD2. Mais utilisation d’un identifiant unique par CD (CDID)► couplé avec un serveur qui associe des tags à chaque CDID
http://www.freedb.org → annotation par les utilisateurs finaux1. MP3 : utilisation de ID3
Images
1. annotation Exif, IPTC2. http://labelme.csail.mit.edu (MIT)
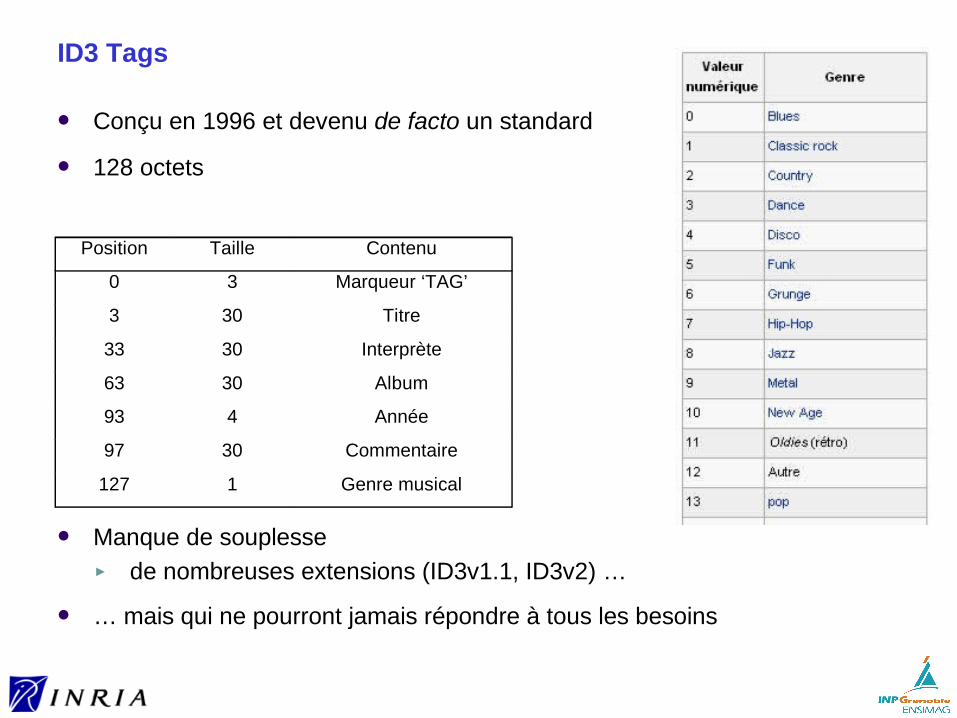
ID3 Tags
Conçu en 1996 et devenu de facto un standard
128 octets
Manque de souplesse ► de nombreuses extensions (ID3v1.1, ID3v2) …
… mais qui ne pourront jamais répondre à tous les besoins
Position Taille Contenu
0 3 Marqueur ‘TAG’
3 30 Titre
33 30 Interprète
63 30 Album
93 4 Année
97 30 Commentaire
127 1 Genre musical

Exchangeable image file format (Exif)
Spécification pour les formats d’images des appareils numériques► non géré par une organisation internationale, mais largement utilisé
Pour JPEG, TIFF, RIFF. Ne supporte pas JPEG2000, PNG ou GIF
Le format supporte► Date et heure, enregistrés par l’appareil► Les paramètres de l’appareil
Dépendent du modèle : inclus la marque et des informations diverses telles que le temps d’ouverture, l’orientation, la focale, l’ISO, etc.
► Une vignette de pré-visualisation► La description et les informations de copyright
Supporté par de nombreuses applications

Label Me
http://labelme.csail.mit.edu (MIT)

Recherche approximative/par similarité
L’idée clé dans la recherche de média est la recherche approximative
Utilise la notion de proximité, de similarité, de distance entre objets
Généralement, la requête est exprimée sous la forme d’un ou de plusieurs vecteurs dans un espace multi-dimensionnel. ► définition d’une distance (ou mesure de dissimilarité) sur cet espace► recherche des objets dont la distance est minimale
Les vecteurs d’attributs sont extraits de contenu de l’image
Recherche par le contenu (CBIR: content based information retrieval)
Possibilité d’utiliser un retour de pertinence

Retour de pertinence
Possibilité de mettre l’interaction au coeur du système► parmi les réponses, le système identifie ce qu’il trouve intéressant► puis affinage de la requête par l’utilisateur
Utilisateur
Liste triée
Retour depertinence
MMDB
ReprésentationDe la requête

Fonctionnalités d’un système de gestion de la MMDB
Ce qu’il doit (devrait) permettre► Les objets multimédia peuvent être actifs► Le processus de requête est interactif► Le processus de requête peut utiliser plusieurs modes de représentation
(ex: texte, puis image)
Il doit posséder deux modes► Gestion du contenu (ajout, modification des objets présents,
suppression)► Interrogation de la base
Il doit pouvoir combiner des informations provenant de différents modes de représentation, utiliser le retour de pertinence pour affiner la recherche
Nécessité d’une interface utilisateur permettant la manipulation des objets existants, la présentation de résultats, le retour de pertinence

Indexation
Structurer la base pour ne pas avoir à la parcourir entièrement à chaque recherche, comme dans un dictionnaire
Nécessite de décrire le contenu avec des index portant sur les médias
Difficulté : les médias en question sont représentés par des vecteurs de grande dimension
↓
The dimension curse
La malédiction de la dimension
Nous reviendrons largement sur cet aspect dans la suite de ce cours

Moteurs de recherche basés sur le contenu
http://images.google.com : non basé sur le contenu, utilisation de mots clés uniquement
Critère de similarité global► QBIC (Query By Image content) – IBM 93► Virage 93► Photobook – MIT’93
http://www.visualsearchlab.com : description par la couleur
http://bigimbaz.inrialpes.fr : recherche par description locale

Bases de données multimédiaIII – Mesures de comparaison et évaluation d’un système
de recherche d’information
ENSIMAG
2009
Hervé Jégou & Matthijs Douze

Mesures et évaluation : Plan
A) Distances et mesures de similarité
B) Mesures objectives, subjectives, psycho-visuelles
C) Évaluation d’un système de recherche d’information

Distances et mesures de similarité : objectif
Avoir un outil quantitatif pour répondre à la question
Est-ce que deux entités X et Y se ressemblent ?
Lorsqu’on désire comparer des entités, on cherche à obtenir un scalaire indiquant la proximité de ces entités
La mesure utilisée répond à un objectif particulier, soit final, soit intermédiaire, par exemple► comparer la qualité de reconstruction d’une image compressée avec
l’image originale (objectif final)► indiquer la similarité du contenu de deux images (objectif final)► comparer les formes contenues dans deux images (objectif
intermédiaire)

Distance
Une distance d sur un ensemble E est une application de E x E dans R+ vérifiant les axiomes suivants :► (P1) séparation: d(x,y) = 0 ⇔ x = y► (P2) symétrie : d(x,y) = d(y,x)► (P3) inégalité triangulaire: d(x,z) ≤ d(x,y) + d(y,z)

Distances usuelles sur Rn (rappels)
x = (x1,…,xi,…,xn) ∈ Rn
Distance Euclidienne (ou 2-distance)
Distance de Manhattan (ou 1-distance)
Plus généralement, distance de Minkowski (ou p-distance)
Cas particulier : ∞-distance

Distance de Mahalanobis
Observation : les différentes composantes d’un vecteur ne sont pas forcément homogènes, et peuvent être corrélées
Exemple : vecteur de description d’un objet roulant(nombres de roues, vitesse maximale en km/h, poids en kg, accélération)
Nécessité de pondérer les composantes
Matrice de covariance (apprise sur un jeu de données)
DEFINITION : la distance de Mahalanobis est la distance définie par
Si = Id, alors équivalente à la distance Euclidienne
Si diagonale, alors elle est équivalente à la distance Euclidienne normalisée

Distance de Hausdorff
Soit un espace métrique E munie d’une distance d
DEFINITION : Soit A ⊂ E. l’ensemble définie par
est appelé ε-voisinage de A
DEFINITION : la distance de Hausdorff dH entre deux parties A et B de E est définie comme
Cette mesure est utilisée comme une mesure de similarité entre formes (en considérant l’ensemble des recalages possibles).

Autres distances
Distance du 2 pour comparer deux distributions
Distances composées
d x , y = ∑i , x i≠0∨ y i≠0
xi− yi 2
xi yi

Quasi-distance
La notion de distance n’est pas toujours adaptée, car elle impose des axiomes très forts qui ne servent pas directement l’objectif recherché
Une quasi-distance q est une application qui vérifie les propriétés (P2) et (P3) et la propriété suivante► (P1’) q(x,x) = 0
Exemple : Soit E un ensemble d’images contenant un objet et C(X) la classe de ces objets (chat, voiture, …). L’application q: E2 → R+ telle que
q(x,y) = 0 si C(x)=C(y), c-a-d si x et y contiennent le même objetq(x,y) = 1 sinon
est une quasi-distance
Une quasi-distance peut être nulle entre des objets différents. Minimiser une quasi-distance permet de retrouver une propriété particulière d’un objet.

Mesure de similarité et dissimilarité
Plus général encore ?
→ mesure de dissimilarité ou de similarité
Une mesure de dissimilarité est une une application ExE→K, où K est un ensemble muni d’un ordre total
Même définition pour une mesure de similarité
Mesure de similarité et de dissimilarité diffèrent par le fait que ► grande valeur indique forte proximité pour la mesure de similarité► faible valeur indique forte proximité pour mesure de dissimilarité
Toute distance ou quasi-distance est une mesure de dissimilarité

Exemples (au tableau)
Le cosinus est une mesure de similarité ► pour des vecteurs normalisés, équivalent au produit scalaire► lien avec la distance Euclidienne
Divergence de Kullback-Leibler► loi entre distributions de probabilités► définition au tableau► non symétrique, pas forcément définie, axiome de séparation vérifié► interprétation en compression

Mesures objectives usuelles pour l’image
En compression image ou vidéo : MSE ou PSNR
MSE : Mean Square Error (Error quadratique moyenne)► le carré de la norme 2 entre les intensités de l’image► images de même taille► c’est une mesure de dissimilarité
SNR : Signal to Noise Ratio► mesure de similarité ► utilisée en traitement du signal
PSNR : Peak Signal to Noise► mesure la plus utilisée pour évaluer les algorithmes de compression► PSNR = 10 log10 (P2 / MSE)

Mesures et évaluation : Plan
A) Distances et mesures de similarité
B) Mesures objectives, subjectives, psycho-visuelles
C) Évaluation d’un système de recherche d’information

Mesures subjectives
Dans ce qui précédait : mesures objectives de comparaison
Pour beaucoup d’applications, le but est de maximiser l’espérance de la satisfaction de l’utilisateur.
→ seule une mesure subjective par l’utilisateur lui-même permettent d’optimiser pleinement ce critère
Exemple : comparaison d’images

Bruit Gaussien
①

Crop+mise à l’échelle
②
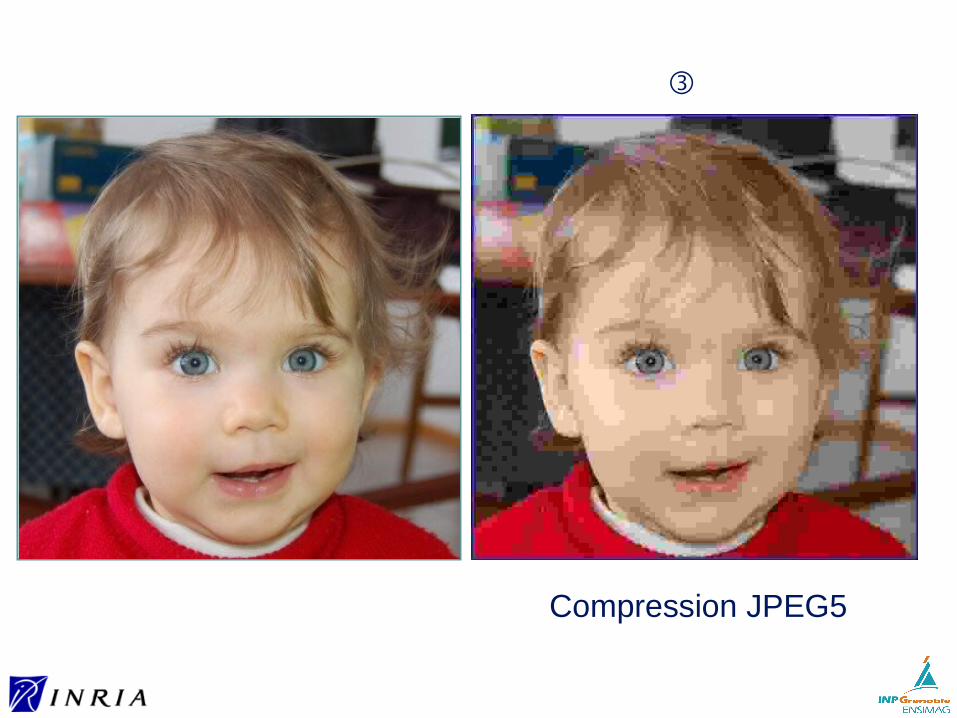
Compression JPEG5
③
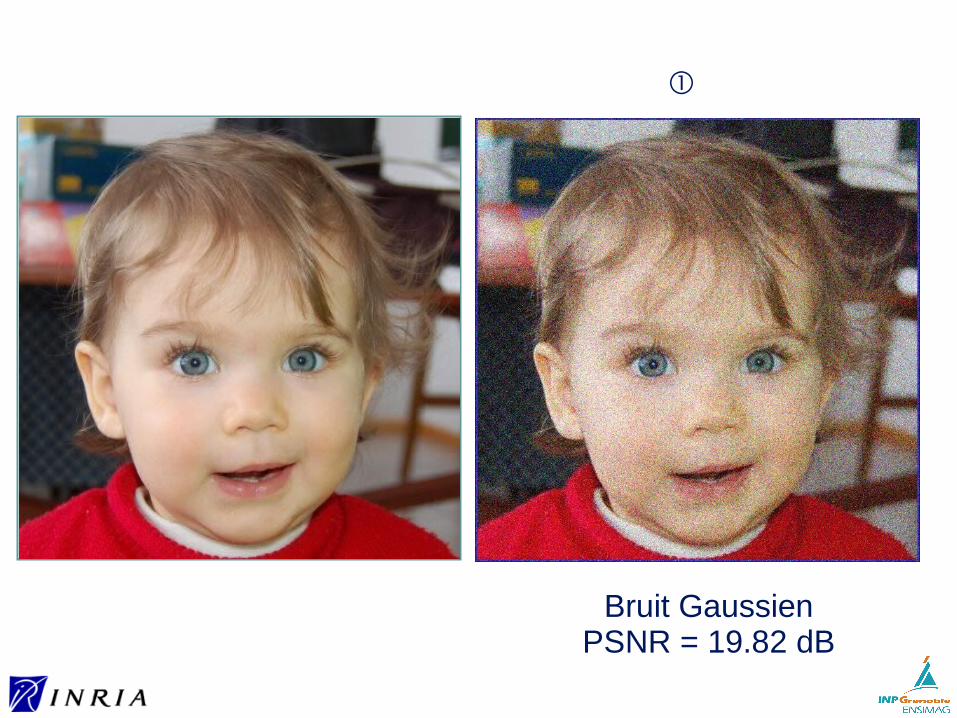
Bruit GaussienPSNR = 19.82 dB
①

Crop+mise à l’échellePSNR = 15.63 dB
②
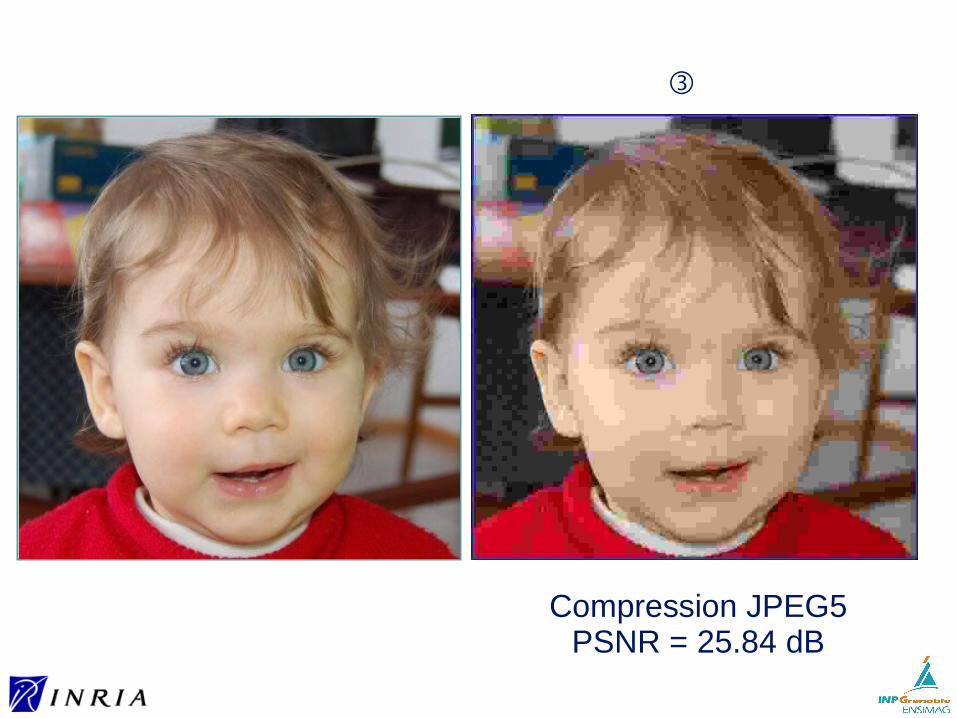
Compression JPEG5PSNR = 25.84 dB
③
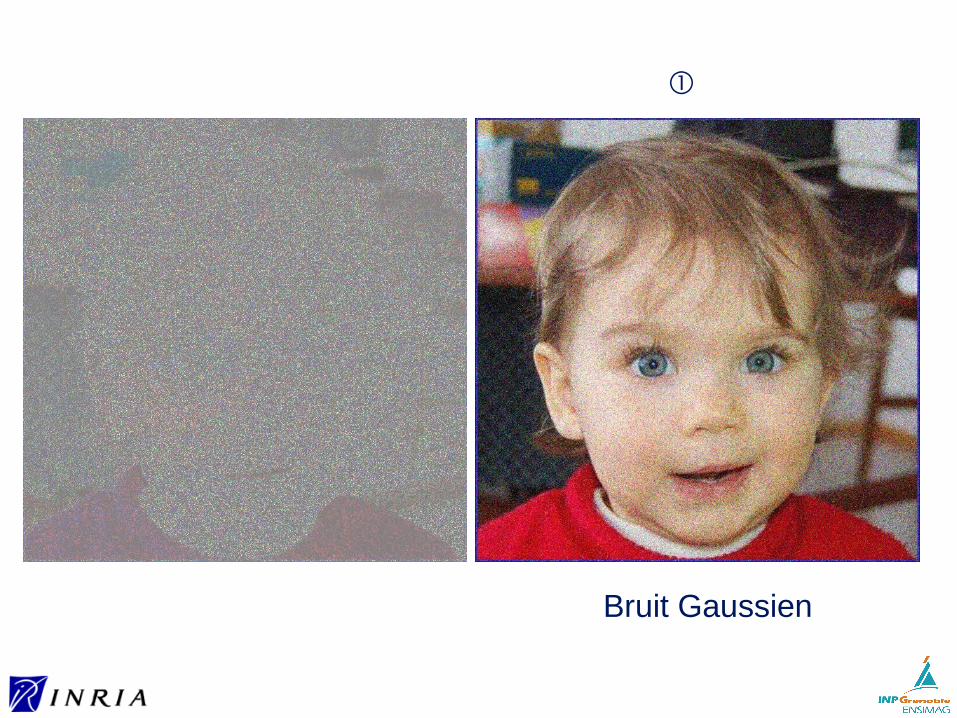
Bruit Gaussien
①

Crop+mise à l’échelle
②

Compression JPEG5
③
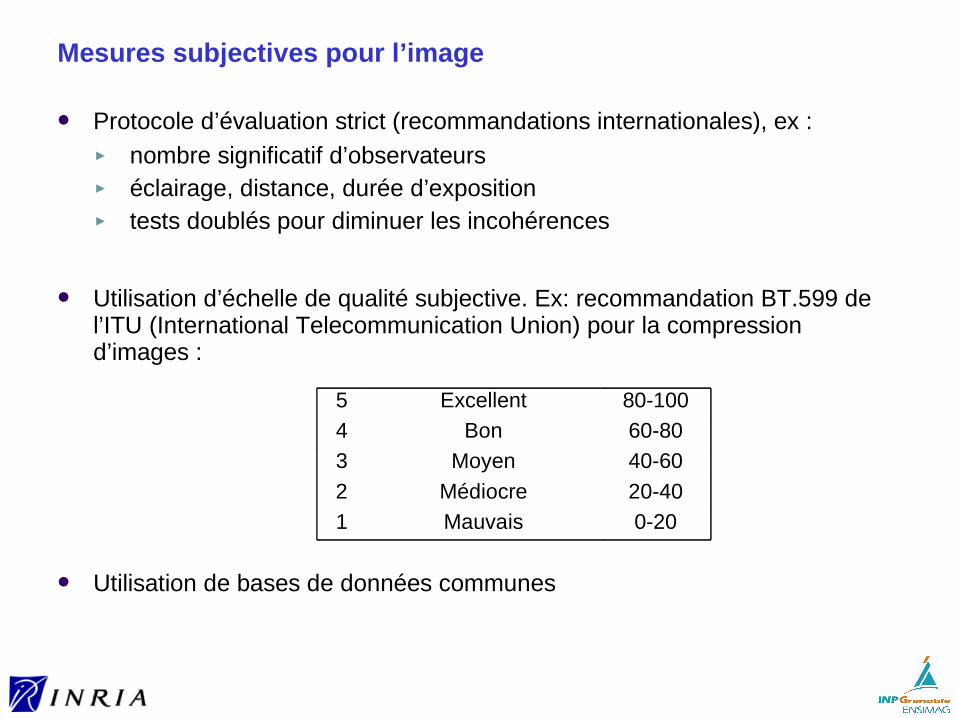
Mesures subjectives pour l’image
Protocole d’évaluation strict (recommandations internationales), ex :► nombre significatif d’observateurs► éclairage, distance, durée d’exposition► tests doublés pour diminuer les incohérences
Utilisation d’échelle de qualité subjective. Ex: recommandation BT.599 de l’ITU (International Telecommunication Union) pour la compression d’images :
Utilisation de bases de données communes
5 Excellent 80-100
4 Bon 60-80
3 Moyen 40-60
2 Médiocre 20-40
1 Mauvais 0-20

Mesures subjectives : difficultés
L’avis d’un utilisateur peut varié et n’instancie pas un ordre total
Deux utilisateurs distincts ne portent pas le même jugement
Les avis relatifs de qualité dépendent du type d’image
!!! Le coût !!!

Mesures objectives psycho-visuelles/acoustique/…
Idée : apprendre une mesure objective qui modélisera la mesure subjective► pour une tâche particulière► utilise la modélisation (difficile) du système de perception humain► en image : pas de consensus
Mesure objective
Mes
ure
subj
ectiv
e

Mesures et évaluation : Plan
A) Distances et mesures de similarité
B) Mesures objectives, subjectives, psycho-visuelles
C) Évaluation d’un système de recherche d’information

Pré-requis pour l’évaluation
Avoir à disposition ► un ensemble de test (base dans laquelle on recherche)► un ensemble de requêtes non incluses dans la base de test► une vérité terrain (ground truth) pour chaque couple (requête, élément
de la base) qui répond à la question : est-ce que l’élément de la base est pertinent pour la requête considérée ?
Remarques ► pour comparer deux méthodes, les mêmes ensembles de test et de
requêtes doivent être utilisés → bases de tests partagées par les chercheurs du domaine→ compétition avec introduction de nouvelles bases de test
► la taille de ces ensembles doit être suffisamment grande pour diminuer la variance de l’évaluation

Précision/rappel (début)
Soit E un ensemble d’objets (l’ensemble des textes, images, vidéos) muni d’une quasi-distance q telle que► x, y ∈ E, q(x,y) = 0 si y est pertinent pour x
q(x,y) = 1 sinon
Remarque: on suppose ici la symétrie de la relation q
Cette quasi-distance instancie la vérité terrain
Exemple : x et y sont 2 imagesq(x,y) = 0 si x et y se ressemblent, q(x,y) = 1 sinon
Soit un ensemble E’ ⊂ E, et x : x ∈ E et x ∉ E’► E’ : ensemble dans lequel on effectue la recherche► x : la requête

Précision/rappel (suite)
Le système de recherche est paramétré pour retourner plus ou moins de résultats► La quantité d’objets retournés varie entre 1 et #E’► plus on retourne de résultats, plus on a de chance de retourner toutes
les objets pertinents de la base► en général, moins on en retourne, plus le taux d’objets retournés et qui
sont pertinents est élevé
Ces deux notions sont couvertes par les mesures de précision et de rappel

Précision/rappel (suite)
Soit R l’ensemble des résultats retournés, de cardinal #R
Soit P l’ensemble des résultats pertinents dans E’ pour x, c-a-d
P = { y ∈ E’ / q(x,y) = 0 }
Soit A l’ensemble des résultats retournés et qui sont pertinentsA = { y ∈ R / q(x,y) = 0 }
DEFINITION : la précision = #A / #R est le taux d’éléments qui sont pertinents parmi ceux qui sont retournés par le système
DEFINITION : le rappel = #A / #P est le taux d’éléments qui sont pertinents qui sont retournés par le système
La performance du système peut être décrite par une courbe précision/rappel

Précision/rappel (suite et presque fin)
Remarques : ► P est indépendant de la requête. ► R varie en fonction de la paramétrisation (qui retourne + ou – de
résultats)
E’
R
PA
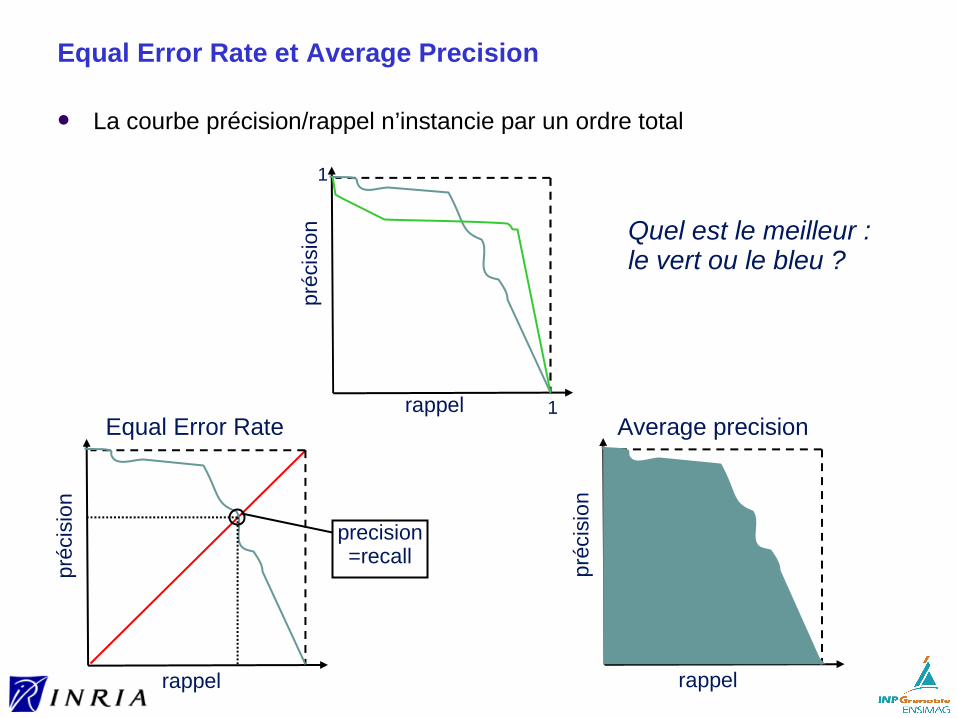
Equal Error Rate et Average Precision
La courbe précision/rappel n’instancie par un ordre total
rappel
préc
isio
n
rappel
préc
isio
n
Quel est le meilleur :le vert ou le bleu ?
rappel
préc
isio
n
1
1Equal Error Rate Average precision
precision=recall

Exercice : système de recherche d’objets
Pour la requête et les résultats triés suivants : tracer les courbes précision/rappel et ROC, calculer le rang normalisé moyen
1 2 3 4 5
6 7 8 9 10

ROC (Receiver operating characteristic)
Soit une vérité terrain q(.,.)
Réponse du système à une requête x► r(x,y)=0 si y est retourné (objet considéré pertinent), r(x,y)=1 sinon
REMARQUE : rappel = vp / (vp + fn)
DEFINITION : taux de faux positifs = fp / (fp + vn) = 1 - spécificité
Courbe ROC : rappel en fonction du taux de faux positifs
Vérité terrain
Sys
tèm
e
Pertinent (p) non pertinent (n)
Pertinent (p’)
Non pertinent (n’)
Vrai positif (vp)q(x,y)=0 r(x,y)=0
Faux négatif (fn)q(x,y)=0 r(x,y)=1
Faux positif (fp)q(x,y)=1 r(x,y)=0
Vrai négatif (vn)q(x,y)=1 r(x,y)=1

Area under Curve (AUC)
Mesure de performance calculée à partir de la courbe ROC
Exemple pour mesure la pertinence d’un test médical (voir http://gimm.unmc.edu/dxtests/roc3.html)
0.90-1.00 Excellent
0.80-0.90 Bon
0.80-0.70 Passable
0.60-0.70 Pauvre
0.50-0.60 Mauvais
Interprétation : l’AUC peut être interprétée comme la probabilité, quand on prend deux échantillons -un positif et un négatif-, que le système classe mieux le positif que le négatif

Et la pertinence ?
DEFINITION: la pertinence d’un système (pour une paramétrisation donnée) est le taux d’objets qui sont correctement jugées, c-a-d
pertinence = (vrais positifs + vrais négatifs) / taille de la base
En recherche d’information : mauvaise mesure de la qualité du système► en général, la plupart des objets ne sont pas pertinents► un système qui renverrait systématiquement “négatif” serait quasiment
imbattable
Intérêt d’avoir des courbes (precision/recall et ROC) pour l’évaluation► dépend de l’utilisation : certains utilisateurs cherchent la précision (ex:
requête sur Google), d’autres un grand rappel possible (recherche de contenu piraté)

Pour plus d’info
Introduction to Information Retrieval, C. D. Manning, P. Raghavan and H. Schütze, Cambridge University Press, 2008
Chapitre 8
http://www-csli.stanford.edu/~hinrich/information-retrieval-book.html

Mesures et protocole d’évaluation : conclusion
Mesure de (dis)-similarité nécessaire pour l’évaluation des proximités► utilisées dans les protocoles d’évaluation des étapes impliquées dans la
chaîne de représentation/indexation/recherche
Difficulté de trouver une bonne mesure► elle doit être adaptée à ce que l’on compare (ex: loi de probabilité)► elle doit répondre à l’objectif recherché
Il peut être dangereux de vouloir optimiser une mesure objective (exemple du PSNR) qui n’est pas directement liée au but recherché
Évaluation d’un système de recherche multimédia► méthodes identiques à celles utilisées en texte► utilisation de courbes plutôt que de scalaires (peuvent être interprétées
en fonction du besoin)► n’intègrent pas les mesures de similarités qui ont produit le rang!

Bases de données multimédiaIV – Espaces de représentations
ENSIMAG
2009
Hervé Jégou & Matthijs Douze

Espaces de représentation : Plan
Du monde réel à la description numérique
Représenter : pour quelle application ?
Difficultés
Indices visuels
Représentation globale vs représentation locale

Du monde réel à la représentation numérique
À notre échelle, les signaux que nous désirons acquérir sont continus
Leur représentation sur des supports numériques nécessite une opération de discrétisation necéssairement destructrice → par opposition aux supports analogiques
On distingue deux types d’opérations de discrétisation ► L’échantillonnage► La quantification

L’échantillonnage
C’est l’opération de discrétisation du support du signal► support temporel (son, vidéo, …)► support spatial (image, vidéo)► support 3D (scanner, …)
C’est l’opération qui consiste à choisir un support discret pour le signal
Il est généralement régulier, mais pas necéssairement
Voir exemple au tableau
Le niveau de discrétisation requis est fonction de la plage de fréquence que l’on veut pouvoir restituer → Théorème d’échantillonnage de Nyquist-Shannon: stipule que la fréquence d’échantillonnage doit être au moins 2* la fréquence maximale contenue dans le signal

Quantification (début)
C’est l’opération de discrétisation des amplitudes du signal
Exemple au tableau
Dans un sens plus général, la quantification peut être vectorielle
f: Rd → F, avec F={1,2,..k} ensemble fini d’entiers
La quantification définit un diagramme de Voronoï
DEFINITION : Un diagramme de Voronoï est une décomposition d’un espace métrique déterminée par les distances à un ensemble discret de points

Quantification (suite)
Quantification uniforme ► Calcul de l’erreur de reconstruction si le signal est uniforme► Impact de l’augmentation de la précision sur le rapport signal à bruit
au tableau
Autres quantifications usuelles (la plupart sont structurés)► Quantification uniforme► Quantification Lloyd-Max (non structuré)► Quantification par lattice (lattice hexagonale, lattice E8, lattice de Leech)► JPEG2000: quantification dead-zone ou codée en treillis (JPEG2000)
Pour plus d’infos, voir [5]
[5] R. M. Gray et D. L. Neuhoff, Quantization, IEEE Transactions on Information Theory, vol 44, pages 2325-2384, Oct. 1998
Quantification (fin)
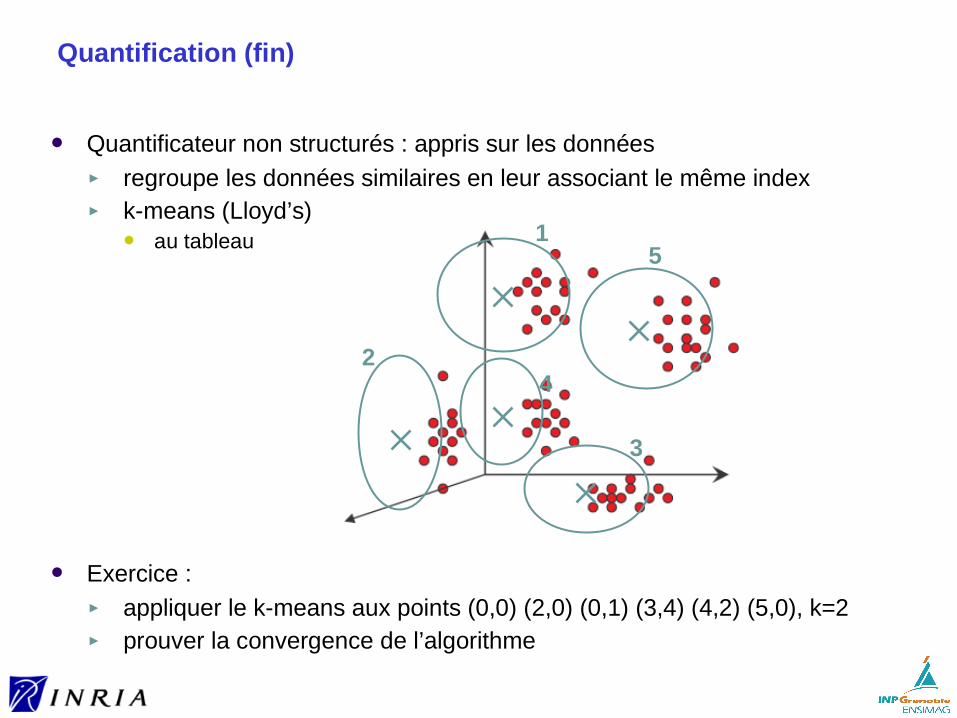
Quantificateur non structurés : appris sur les données► regroupe les données similaires en leur associant le même index► k-means (Lloyd’s)
au tableau
Exercice : ► appliquer le k-means aux points (0,0) (2,0) (0,1) (3,4) (4,2) (5,0), k=2► prouver la convergence de l’algorithme
15
4
3
2

Exemple de discrétisations de signaux
SON
Échantillonage : Régulier► 8 kHz pour une conversation téléphonique (fréquence de la voix < 4kHz)► 44.1 kHz (CD) ou 48 kHz (professionnel), parfois 96 kHz
Quantification :► 8 bits (premières cartes son, qualité pauvre)► 16 bits (CD), le bruit de quantification est d’environ 98 dB► 20 bits ⇒ bruit de quantification de 122 dB
IMAGE (couleur)
3 grilles de valeurs, 1 grille par composante de couleur
RGB : 8 bits de quantification pour chaque couleur
⇒ 24 bits par pixels (pixel=élément du support du signal)

La couleur
Espace de représentation RGB (Red, Green, Blue)► représentation additive des couleurs sur la base de la lumière émise► le plus souvent, chaque canal est représenté sur 8 bits
⇒ 16,7 millions de couleurs possibles
YUV (Y: luminosité, U et V: chrominance)► utilisé dans PAL
YCbCr, Y'CbCr ► Mise à l’échelle de YUV pour les signaux digitaux► utilisé dans JPEG, MPEG2► permet une quantification plus grossière des valeurs de chrominance
HSV (Hue, Saturation, Value) = HSB► Bonne représentation perceptuelle des couleurs, utilisé dans les logiciels
CMYK : Espace de couleur soustractive (application des encres)

Espaces de représentation : Plan
Du monde réel à la description numérique
Représenter : pour quelle application ?
Difficultés
Indices visuels
Représentation globale vs représentation locale
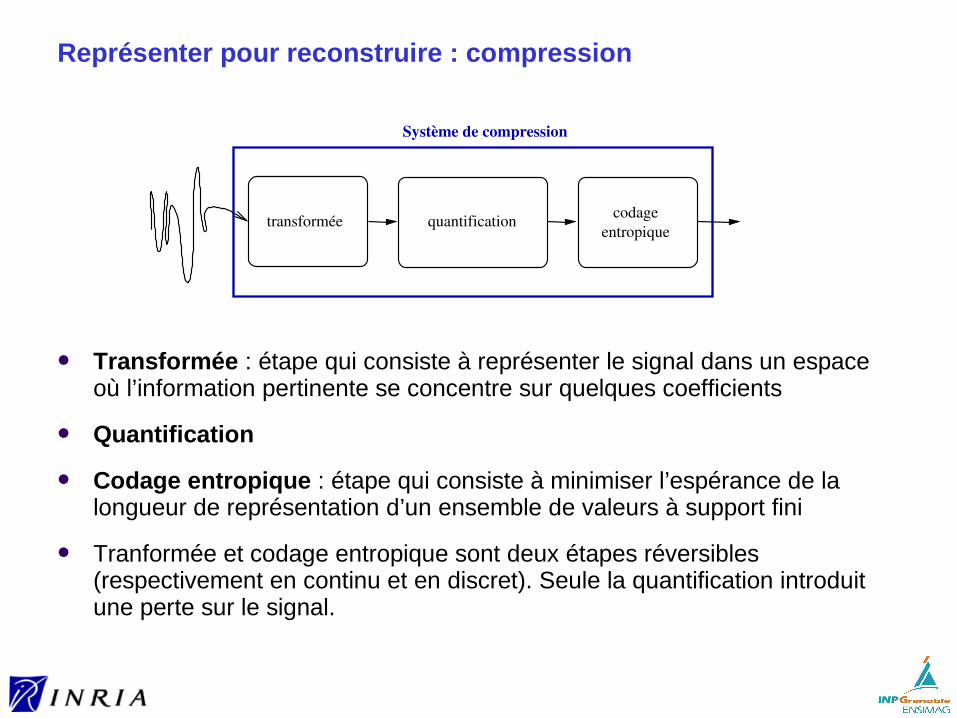
Représenter pour reconstruire : compression
Transformée : étape qui consiste à représenter le signal dans un espace où l’information pertinente se concentre sur quelques coefficients
Quantification
Codage entropique : étape qui consiste à minimiser l’espérance de la longueur de représentation d’un ensemble de valeurs à support fini
Tranformée et codage entropique sont deux étapes réversibles (respectivement en continu et en discret). Seule la quantification introduit une perte sur le signal.
codageentropique
transformée quantification
Système de compression

Représenter pour décrire
Application de recherche par le contenu► focus sur les images► description des images pour les retrouver par leur contenu
Problème très différent de celui de la compression► on ne cherche pas à reconstruire (la plupart des informations n’ont pas
d’utilité directe pour la recherche, alors qu’en reconstruction elles contribuent au confort visuel)
► on cherche à extraire ce qui sera pertinent pour l’application visée
Applications très variées

Recherche d’images similaires
?
image requête
base d’images

Recherche d’images ayant les mêmes propriétés
Exemple : couleur similaires
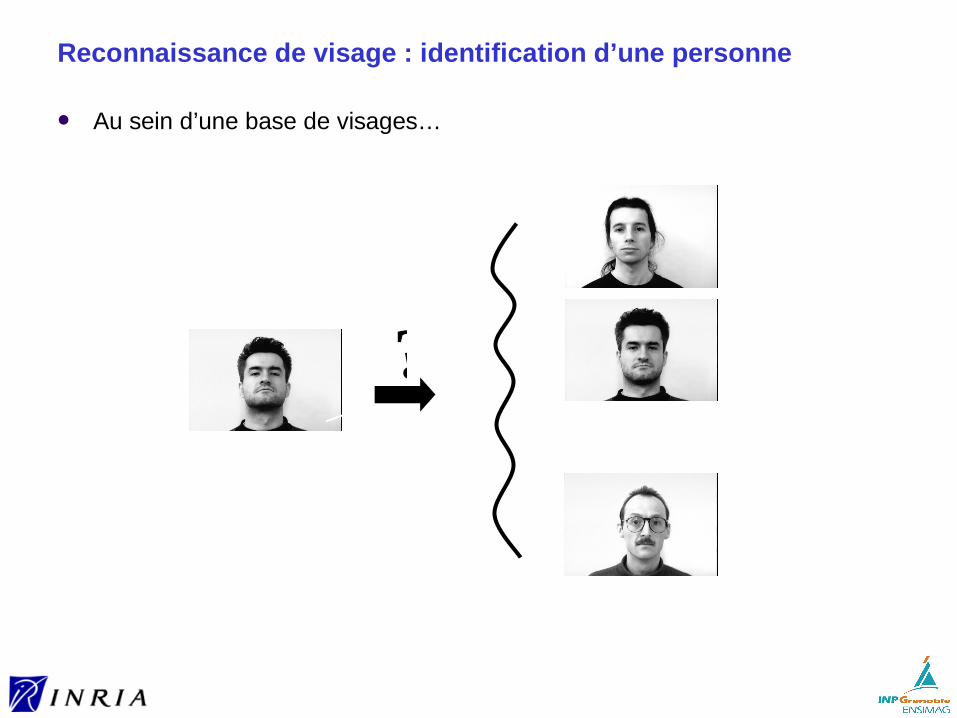
Reconnaissance de visage : identification d’une personne
Au sein d’une base de visages…
?

Reconnaissance de visage : identification d’une personne
… ou à partir d’images ou de vidéos

Reconnaissance d’un lieu
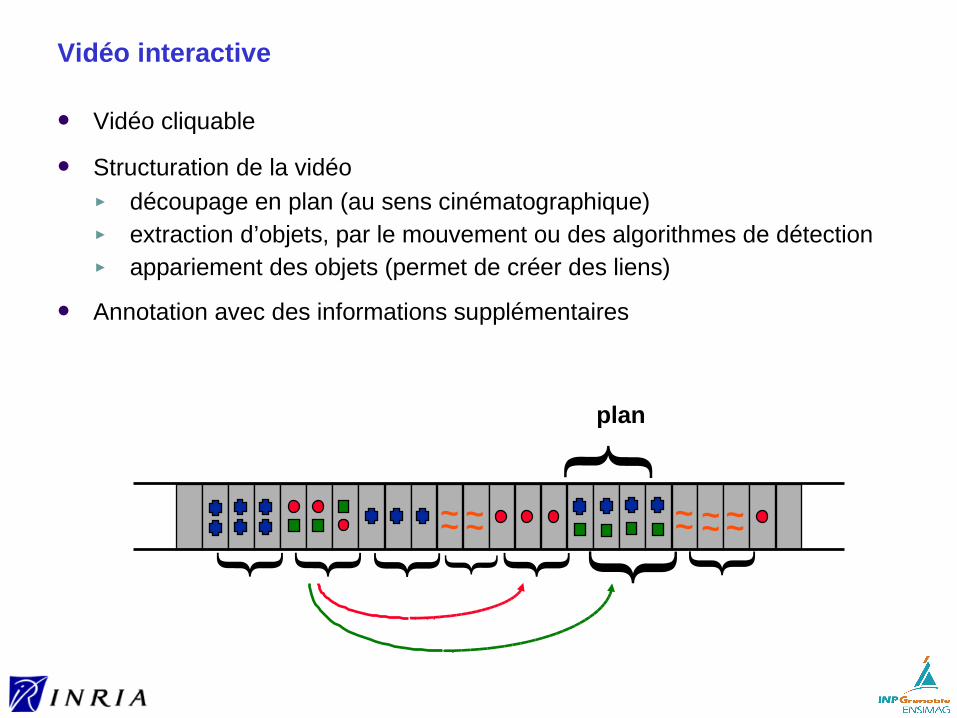
Vidéo interactive
Vidéo cliquable
Structuration de la vidéo► découpage en plan (au sens cinématographique)► extraction d’objets, par le mouvement ou des algorithmes de détection ► appariement des objets (permet de créer des liens)
Annotation avec des informations supplémentaires
plan
}}}}} } } }~~~~ ~~ ~~~~


Problèmes rencontrés
Pour l’image, par ordre de difficulté croissante
Contenu à reconnaître► une même image que l’image requête► une image contenant un objet donné► une instance d’une classe d’objet
Tâche à effectuer► reconnaissance (image similaire, l’image contient l’objet ou classe
d’objet)► détection (sous-partie de l’image similaire, bounding box de l’objet)► segmentation (détection des bords de l’objet)

Espaces de représentation : Plan
Du monde réel à la description numérique
Représenter : pour quelle application ?
Difficultés
Indices visuels
Représentation globale vs représentation locale

Premier aperçu : segmentation
Ce qu'on aimerait

Premier aperçu : segmentation
Ce qu'on a

Exemple du « Oxford Building Dataset »
Requêtes (objets)Exemples d’images à retourner
http://www.robots.ox.ac.uk/~vgg/data/oxbuildings/index.html

Difficultés
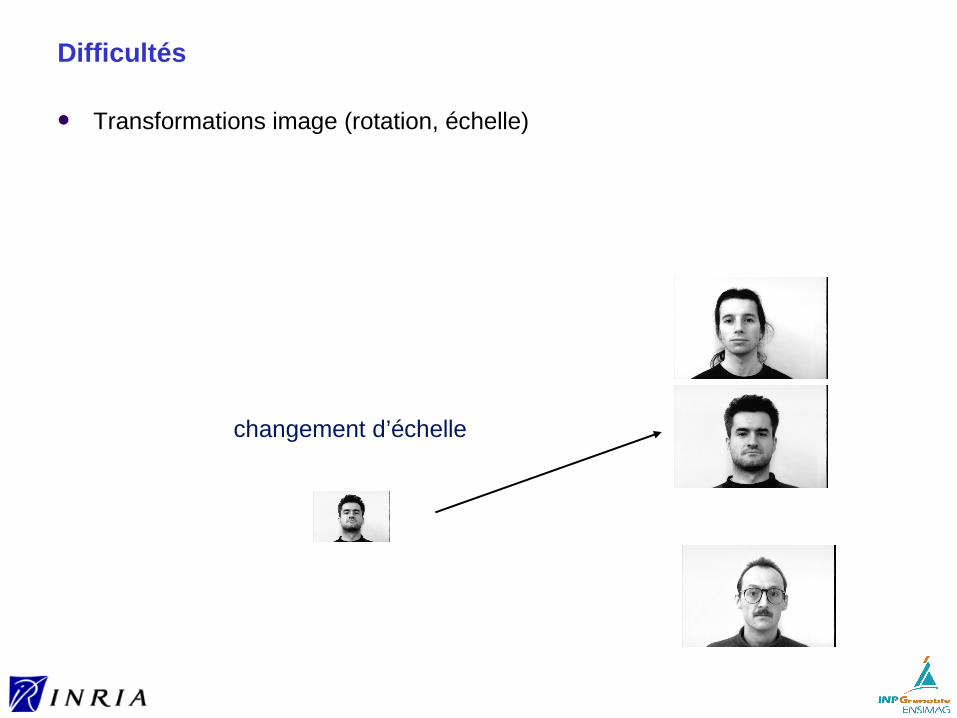
Transformations image (rotation, échelle)
rotation image
Difficultés
Transformations image (rotation, échelle)
changement d’échelle
Difficultés
Transformations image (rotation, échelle)
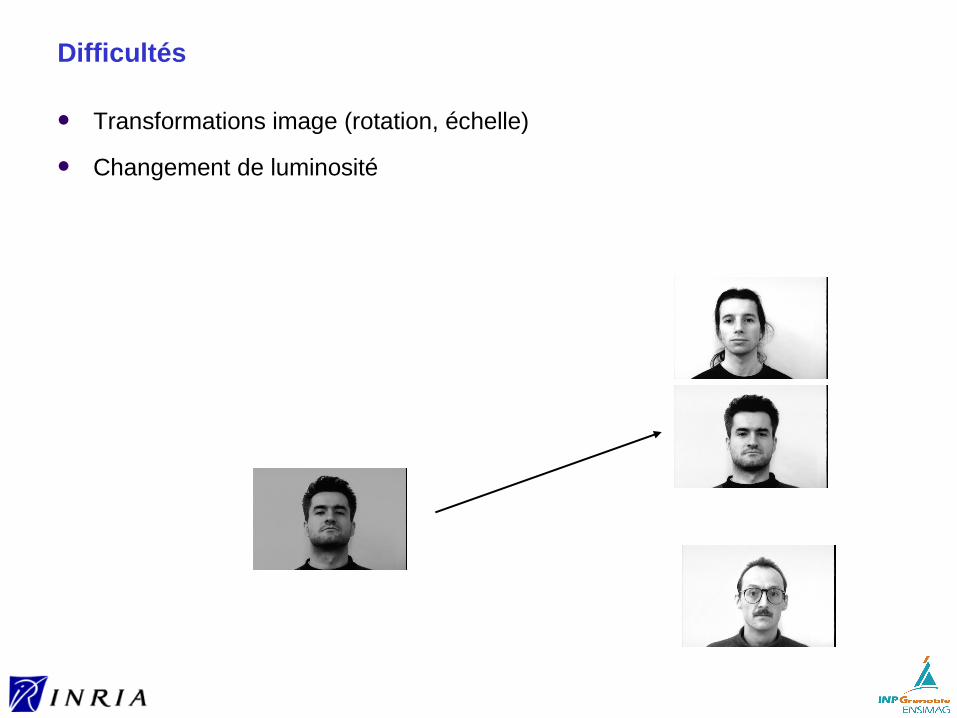
Changement de luminosité
Difficultés
Transformations image (rotation, échelle)
Changement de luminosité
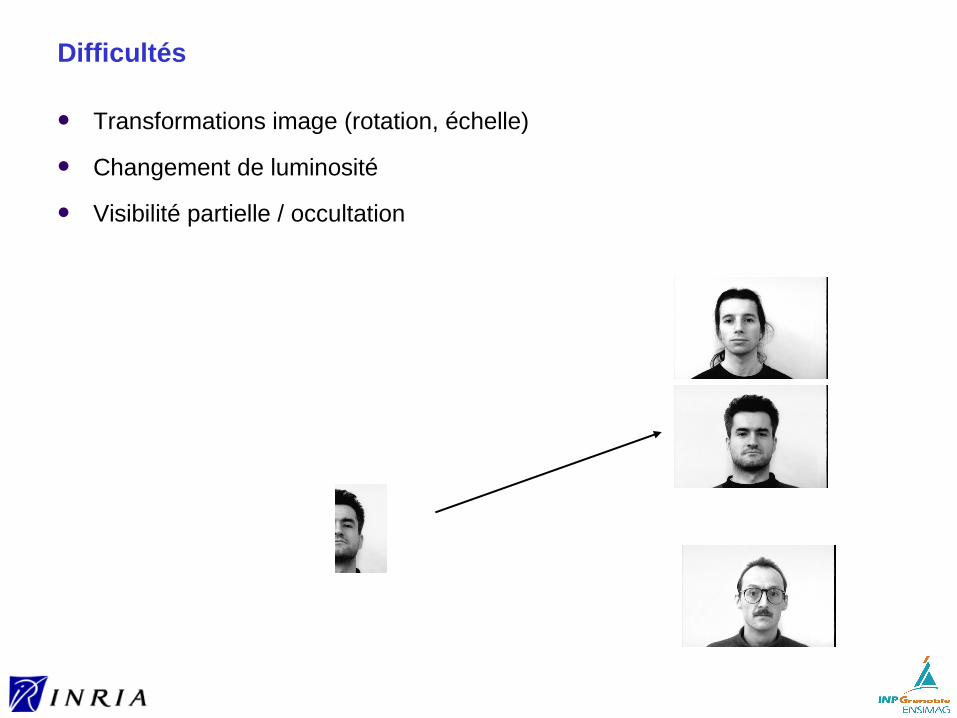
Visibilité partielle / occultation
Difficultés
Transformations image (rotation, échelle)
Changement de luminosité
Visibilité partielle / occultation
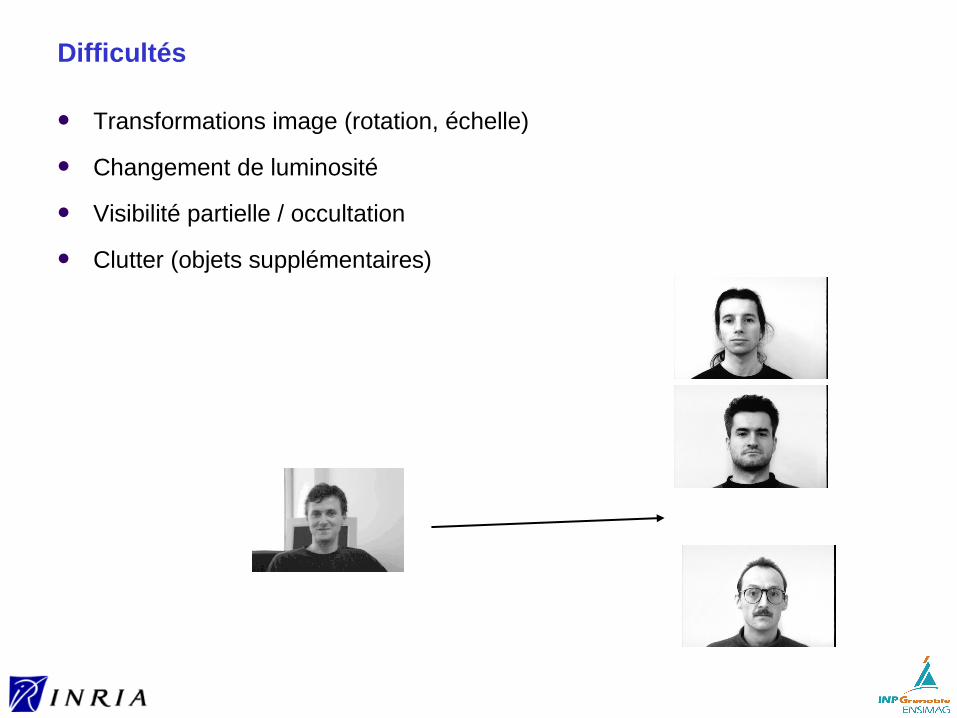
Clutter (objets supplémentaires)

Difficultés
Transformations image (rotation, échelle)
Changement de luminosité
Visibilité partielle / occultation
Clutter (objets supplémentaires)
Objets 3D

Difficultés
Transformations image (rotation, échelle)
Changement de luminosité
Visibilité partielle / occultation
Clutter (objets supplémentaires)
Objets 3D
Nombre important d’images dans la base
Nécessité d’apprendre les variations d’apparence → un modèle visuel

Espaces de représentation : Plan
Du monde réel à la description numérique
Représenter : pour quelle application ?
Difficultés
Indices visuels
Représentation globale vs représentation locale

Indices visuels
Ici, focus sur l’image, mais s’applique à la vidéo
Indice visuels : caractéristiques de l’image, au sens de notre perception d’humain, que l’on cherche à utiliser pour la tâche considérée
Principaux indices visuels► couleur► forme► texture► régions► mouvement (pour la vidéo)

Indice visuel : couleur (début)
Significatif pour la catégorisation (= trouver la classe d’objet) ou le tracking (suivre des objets)
Indice visuel ayant reçu beaucoup d’attention► de nombreux descripteurs (globaux ou locaux)
En indexation : utilisé depuis longtemps pour faire de la recherche d’image par similarité (description le plus souvent indépendante de la position et de l’orientation des objets dans l’image)
Robocup 2006...

Indice visuel : couleur (suite)
Problèmes► choix de la représentation de la couleur► distance entre couleurs► Invariance ?
Indice visuel insuffisant si utilisé seul, car peu discriminant : ► pomme rouge vs Ferrari
Remarque : une image en niveaux de gris ou même noir et blanc suffit à un humain pour effectuer la tâche demandée !
Plus tard dans ce cours : exemple de description (globale) utilisant la couleur

Indice visuel : couleur (fin)
http://labs.ideeinc.com/multicolour/
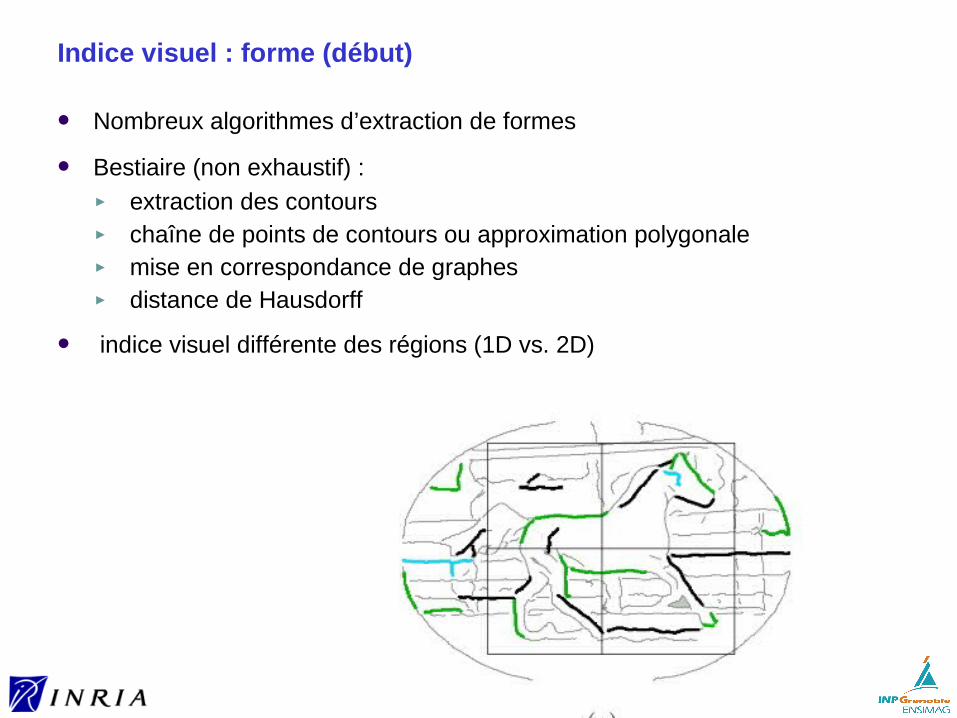
Indice visuel : forme (début)
Nombreux algorithmes d’extraction de formes
Bestiaire (non exhaustif) :► extraction des contours► chaîne de points de contours ou approximation polygonale► mise en correspondance de graphes► distance de Hausdorff
indice visuel différente des régions (1D vs. 2D)

Indice visuel : forme (fin)
Difficultés ► l’étape d’extraction des contours est souvent instable► séparer la forme du fond est difficile (problème de segmentation)
En général, ces algorithmes mènent à une description qui n’est pas invariante à des gros changement d’échelle, ni aux rotations (car invariance en rotation introduit alors forte perte de discriminance pour cet indice visuel)
V. Ferrari, L. Février, F. Jurie, C. Schmid, Groups of Adjacent Contour Segments for Object Detection, PAMI 2008

Indice visuel : texture
Variations répétitives de l’intensité
Elles résultent de propriétés physiques des surfaces 3D (herbe, nuages), ou de propriétés photométriques de surface (zèbre, tissu à fleurs)
De nombreuses parties des images/vidéos peuvent être caractérisées par des textures
L’humain reconnaît facilement les textures, mais difficile à définir (et donc représenter): transition micro/macro, textures irrégulières…
Deux types de méthodes► statistiques : distribution spatiales des intensités de l’image
→ co-occurrences, auto-corrélation► géométriques : segmentation de motifs qui se répètent

Régions texturées

Indice visuel : régions
Prend en compte la répartition spatiale de zones « homogènes »
+ attributs intrinsèques aux régions (taille, couleur, etc)
Relations spatiales entre ces régions (ciel en haut/mer en bas)
Sensible au bruit et aux occultations
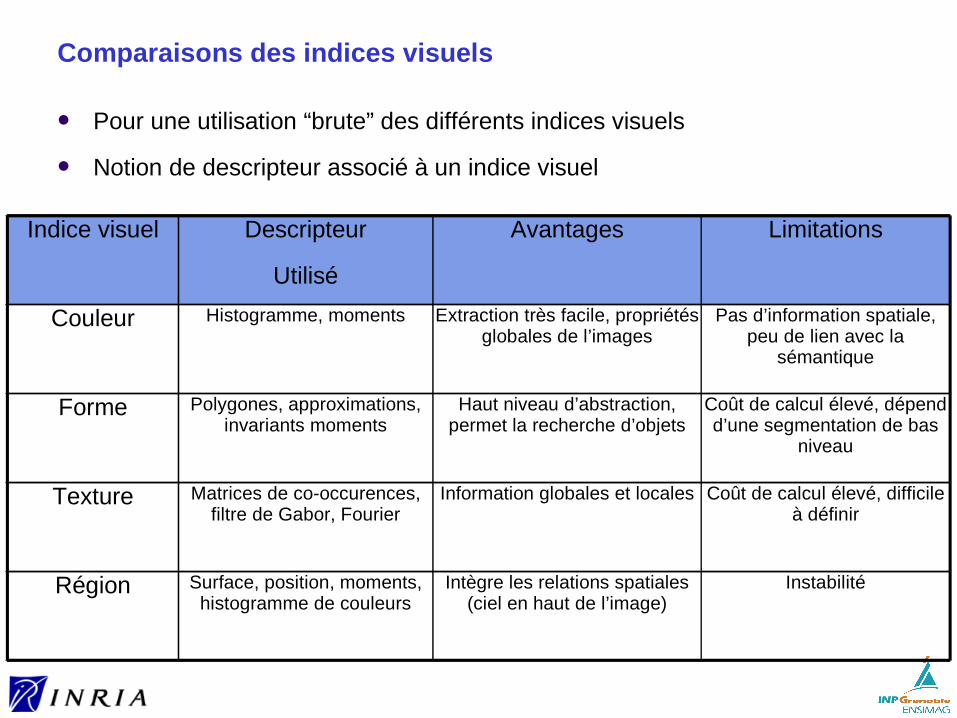
Comparaisons des indices visuels
Pour une utilisation “brute” des différents indices visuels
Notion de descripteur associé à un indice visuel
Indice visuel Descripteur
Utilisé
Avantages Limitations
Couleur Histogramme, moments Extraction très facile, propriétés globales de l’images
Pas d’information spatiale, peu de lien avec la
sémantique
Forme Polygones, approximations, invariants moments
Haut niveau d’abstraction, permet la recherche d’objets
Coût de calcul élevé, dépend d’une segmentation de bas
niveau
Texture Matrices de co-occurences, filtre de Gabor, Fourier
Information globales et locales Coût de calcul élevé, difficile à définir
Région Surface, position, moments, histogramme de couleurs
Intègre les relations spatiales (ciel en haut de l’image)
Instabilité

Espaces de représentation : Plan
Du monde réel à la description numérique
Représenter : pour quelle application ?
Difficultés
Indices visuels
Représentation globale vs représentation locale

Description globale
Une description globale est une représentation de l’image dans son ensemble, sous la forme d’un vecteur de taille fixe
Elle se contente le plus souvent d’exploiter un indice visuel unique
Caractéristiques► un type de vecteur de description par objet► mesure de (dis-)similarité définie sur l’espace de ces descripteurs

Exemple de description globale : histogramme de couleur
Swain, 1991
Chaque pixel est décrit par un vecteur de couleur► par exemple un vecteur RGB ∈ R3 , mais le plus souvent on utilise un
autre espace de couleur plus approprié
L’ensemble des vecteurs de couleurs forme une distribution► description de la distribution avec un histogramme► Nécessite discrétisation de l’espace + normalisation
Comparaison de deux histogrammes par une mesure de dissimilarité, par exemple la « distance » du Chi-2 ou earth mover's distance
d x , y = ∑i , x i≠0∨ y i≠0
xi− yi 2
xi yi
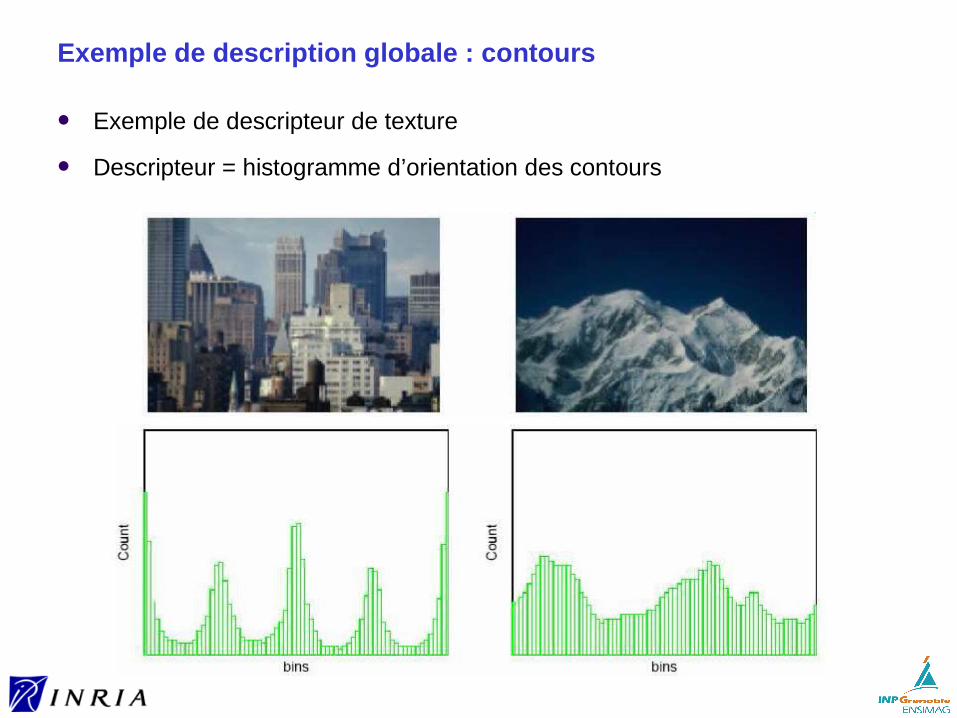
Exemple de description globale : contours
Exemple de descripteur de texture
Descripteur = histogramme d’orientation des contours

Description locale
Une description locale est une représentation de l’entité à décrire par un ensemble de descripteurs (vecteurs)► Vecteurs calculés localement pour différentes parties de l’entité
ex: plusieurs sous-parties d’une image► Ainsi, plusieurs descripteurs par entité► Mesure de similarité nécessite la mise en correspondance (appariement)
des descripteurs
Étude détaillée de ce type de description dans la suite de ce cours

Représentation globale ou locale ?
Avantages de la représention globale► certains invariances sont faciles à obtenir► extraction pour un coût de calcul plus faible► comparaison plus simple : comparaison des entités avec un vecteur
unique, donc pas d’appariemment► en description locale, chaque information individuelle n’est pas très
discriminante
Avantages de la répresentation locale► + de résistance à la plupart des transformations► Robuste: statistiques dépendantes de plusieurs descripteurs► description plus précise d’une image dans son ensemble (souvent la
description est aussi volumineuse que l’image d’origine)

Bases de données multimédiaV – Description locale des images
ENSIMAG
2009
Hervé Jégou & Matthijs Douze
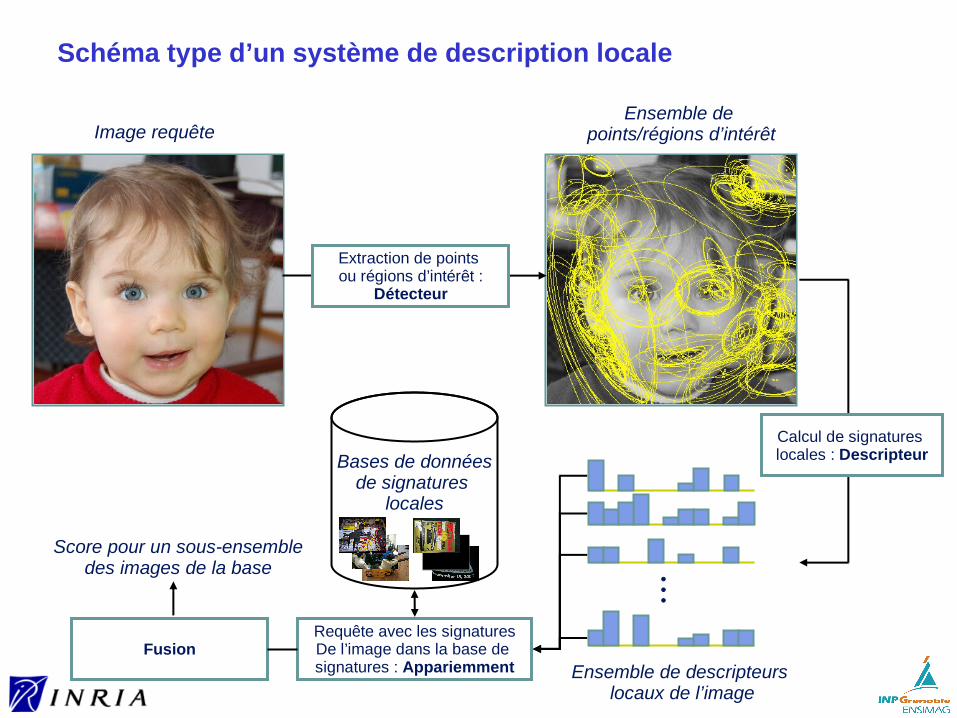
Schéma type d’un système de description locale
Extraction de points ou régions d’intérêt :
Détecteur
Ensemble de points/régions d’intérêtImage requête
Ensemble de descripteurs locaux de l’image
Calcul de signatures locales : DescripteurBases de données
de signatures locales
Requête avec les signaturesDe l’image dans la base de signatures : Appariemment
Fusion
Score pour un sous-ensembledes images de la base

Description locale : plan
Extraction de points/régions d’intérêt
Descripteurs locaux
Appariement de points

Extraction de régions d’intérêt : enjeux
Extraire des régions qui soient invariants à de nombreuses transformations
Transformations géométriques► translation
► rotation
► similitude (rotation + changement d’échelle isotrope)
► affine (en 3d, textures localement planaires)
Transformations photométriques► Changement d’intensité affine (I → a I + b)

Base d’évaluation des points/régions d’intérêt
Affine covariant region dataset : ► 8 ensembles de 6 images► transformation 2D fournie
(vérité terrain)
Bikes et Trees : flou
Graffiti et Wall : changement de point de vue
Bark et Boat : zoom + rotation
Leuven : changement de luminosité
UBC : compression JPEG

Principaux extracteurs de points/régions d’intérêt
Harris
Harris-Affine
Hessian-Affine
Edge-Based Region Detector (EBR)
Intensity Extrema-Based Regions Detector (IBR)
Maximally Stable Extremal Regions (MSER)
Salient Region Detector

Détecteur de Harris : Introduction
Détecter les « coins » = des structures ► répétables de l’image► et localisent des endroits très discriminatifs d’une image
Harris► analyse locale► lorsqu’on est sur un « coin », un déplacement dans n’importe quelle
direction produit un fort changement des niveaux de gris« A Combined Corner and Edge Detector », C. Harris et M. Stephens, 1988
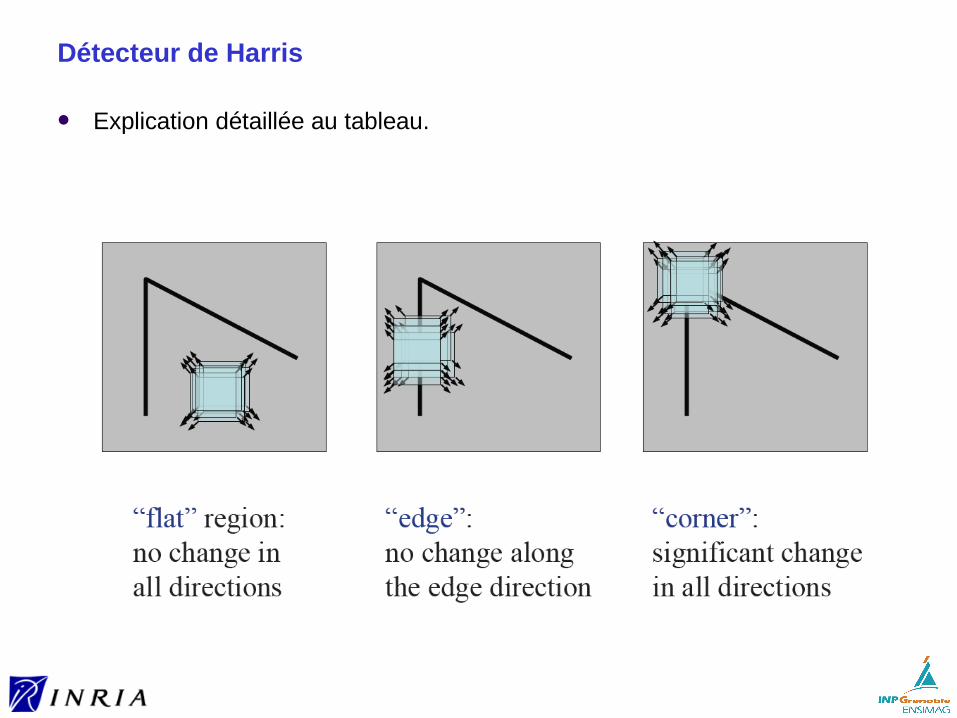
Détecteur de Harris
Explication détaillée au tableau.
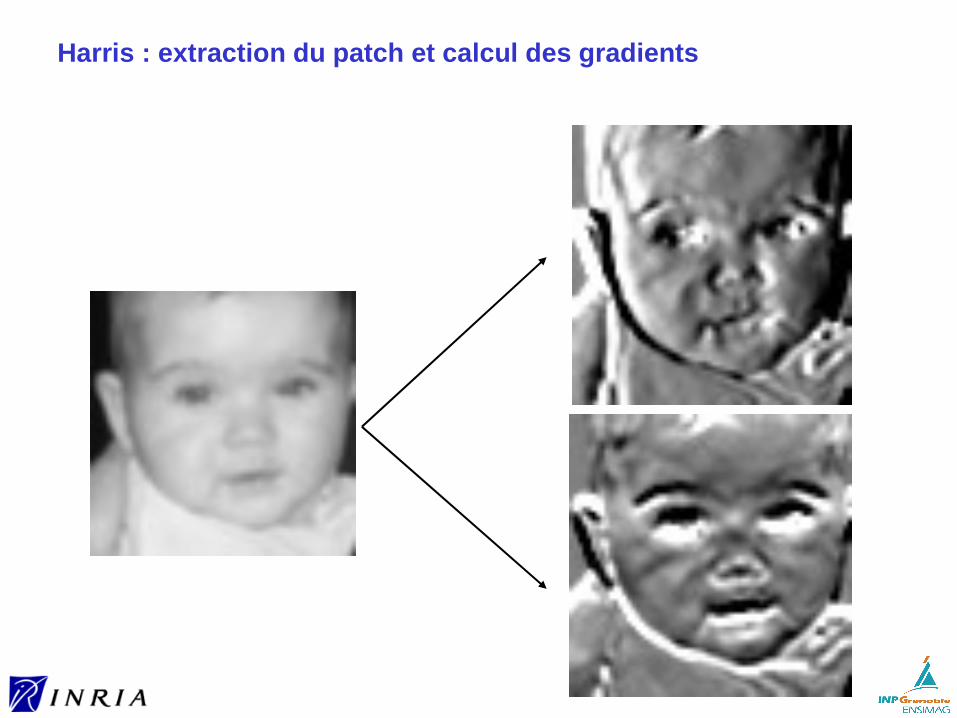
Harris : extraction du patch et calcul des gradients
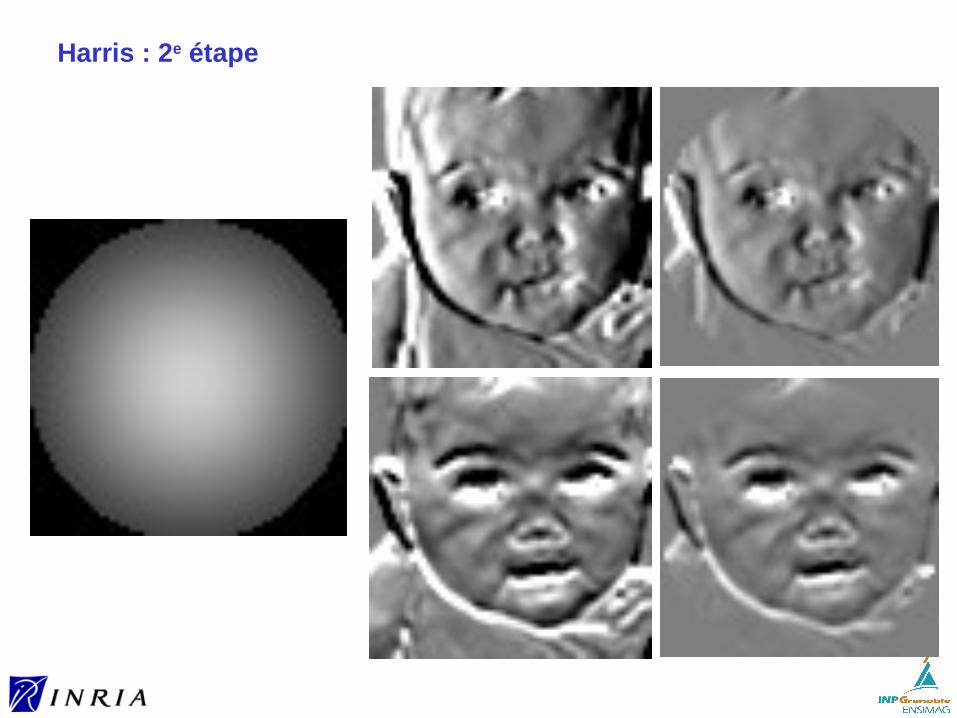
Harris : 2e étape

Harris : classification des types de régions
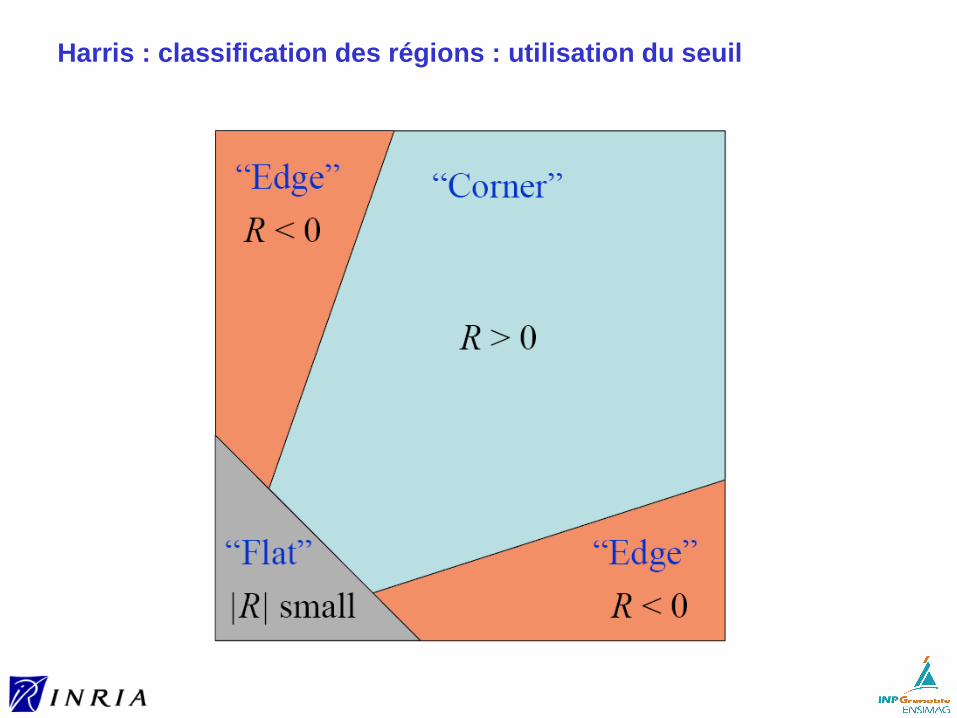
Harris : classification des régions : utilisation du seuil

Harris : exemple

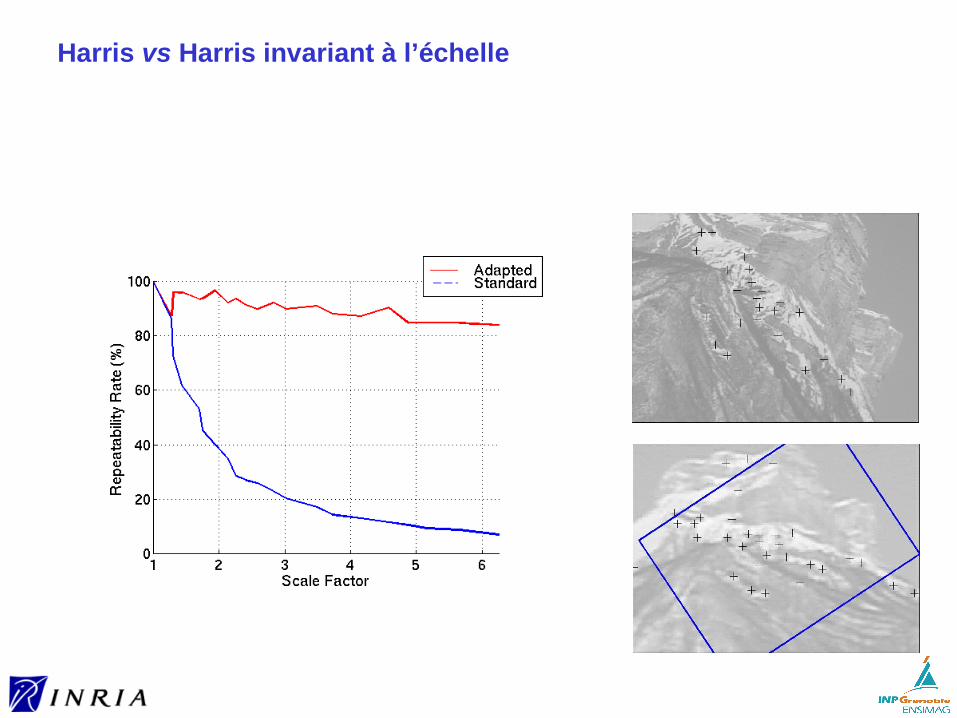
Harris : Invariance
Invariance à la translation et aux changements affines d’intensité : inhérente à la sélection des maxima locaux
Invariance à la rotation► l’ellipse tourne► mais la forme reste identique► les valeurs propres restent identiques
Mais pas d’invariance à des changements d’échelle ► exemple simple au tableau
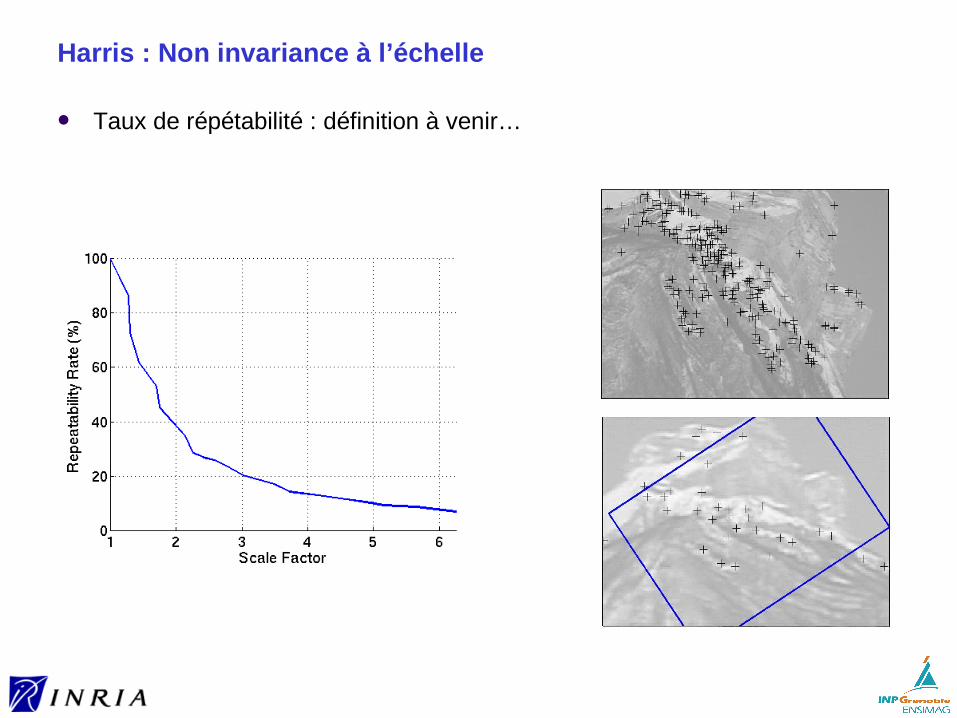
Harris : Non invariance à l’échelle
Taux de répétabilité : définition à venir…

Détecteurs hessien & laplacien
Analogue au détecteur de Harris
Les valeurs propres de la matrice des dérivées secondes (hessienne) caractérisent la forme locale du voisinage d’un point.
Max sur le déterminant
Forte réponse sur les « blobs » et les crêtes
Différence détecteur de coins/blobs► Blob classique : DoG
H=[ I xx I xy
I xy I xx]

Invariance à l’échelle (début)
Étape suivante pour obtenir un extracteur invariant aux transformations affines► avec l’invariance à l’échelle, Harris devient invariant à une similitude
Echelle de calcul de Harris/hessien/laplacien/DoG► Déterminée par la taille des filtres de dérivation : σ des filtres gaussiens► Réagit à une certaine taille de détails / une certaine plage de fréquences
spatiales
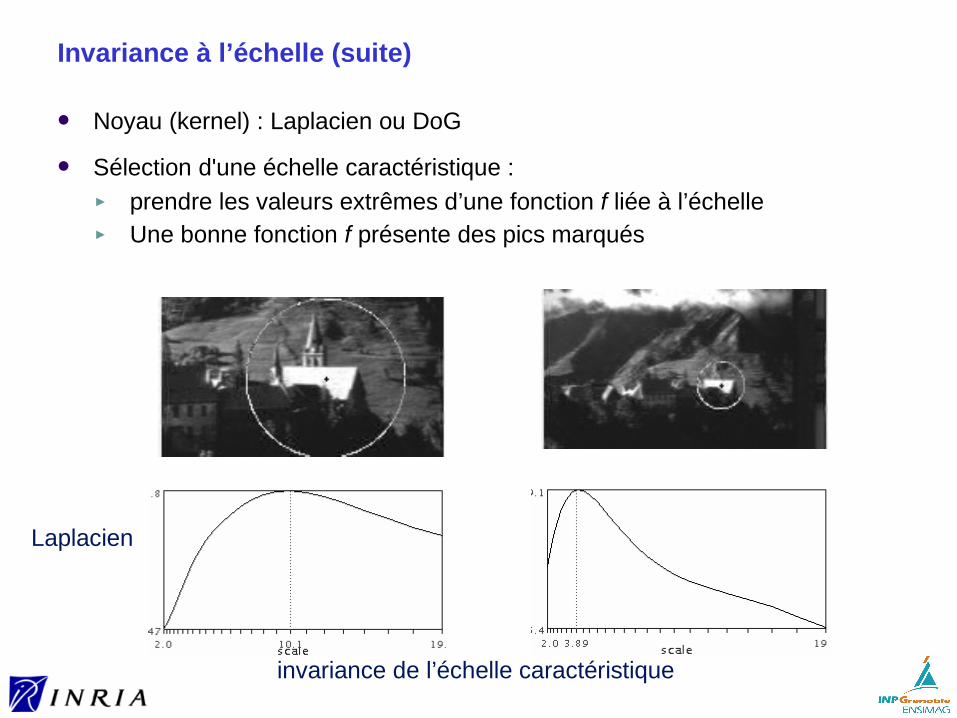
Invariance à l’échelle (suite)
Noyau (kernel) : Laplacien ou DoG
Sélection d'une échelle caractéristique : ► prendre les valeurs extrêmes d’une fonction f liée à l’échelle► Une bonne fonction f présente des pics marqués
Laplacien
invariance de l’échelle caractéristique

Invariance à l’échelle (suite)
Détecteur de Harris-Laplace► Sélectionner le maximum de Harris en espace pour plusieurs échelles
► sélection des points à leur échelle caractéristiques avec le Laplacien
Dans SIFT: recherche des maxima de DoG et position et en échelle

Invariance à l’échelle (fin)
Implémentation d'un filtre gaussien► Valeurs coupées à w proportionnel à σ, séparable► Complexité en O(w2)
Multi-échelle en pratique: ► pyramide d'images► Gaussiennes de taille constante

Invariance affine (début)
Transformations affines► Approximation locale d'homographie► Sauf discontinuité
Pour obtenir l’invariance affine sur un détecteur de blobs (EBR)► partir d’un maximum local en espace et en échelle► exploration radiale dans toutes les directions► calcul des valeurs extrêmes de la fonction d’échelle sur chaque direction
On obtient l’échelle approximative sur chaque axe
L’ensemble de ces échelles radiales induit une forme

Invariance affine (suite)
Approximation des régions par des ellipses► calcul des moments géométriques centrés► l’ellipse a les mêmes moments d’ordre 2 que la région
La matrice de covariance de la région définit l’ellipse et permet de calculer la transformée affine vers une région normalisée (voir au tableau)
Il faut y ajouter une sélection en orientation► en effet, une transformation ellipse → cercle est définie à une rotation
près
► méthode : sélection de la direction principale du gradient
?

Harris-Affine et Hessian Affine (début)
Détecteur de région de l’état de l’art
K. Mikolajczyk, C. Schmid An affine invariant interest point detector, ECCV 2002
Algorithme : estimation itérative des paramètres► localisation : Harris► échelle : sélection automatique avec le Laplacien► voisinage affine : normalisation avec la matrice des second moments
→ jusqu’à convergence
Initialisation à partir de points d’intérêts multi-échelle
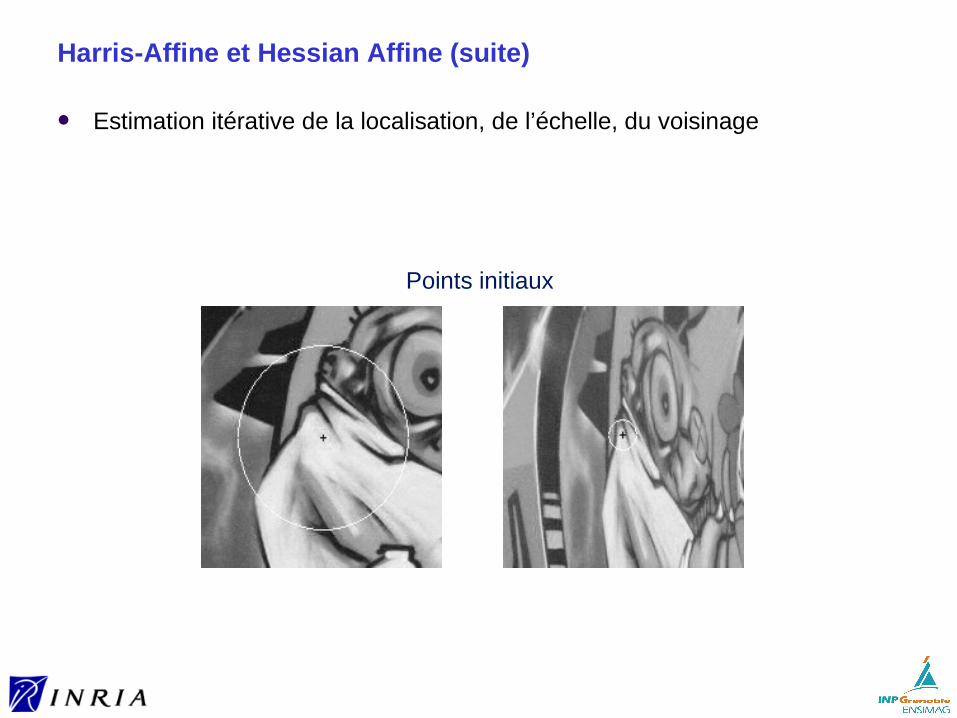
Harris-Affine et Hessian Affine (suite)
Estimation itérative de la localisation, de l’échelle, du voisinage
Points initiaux
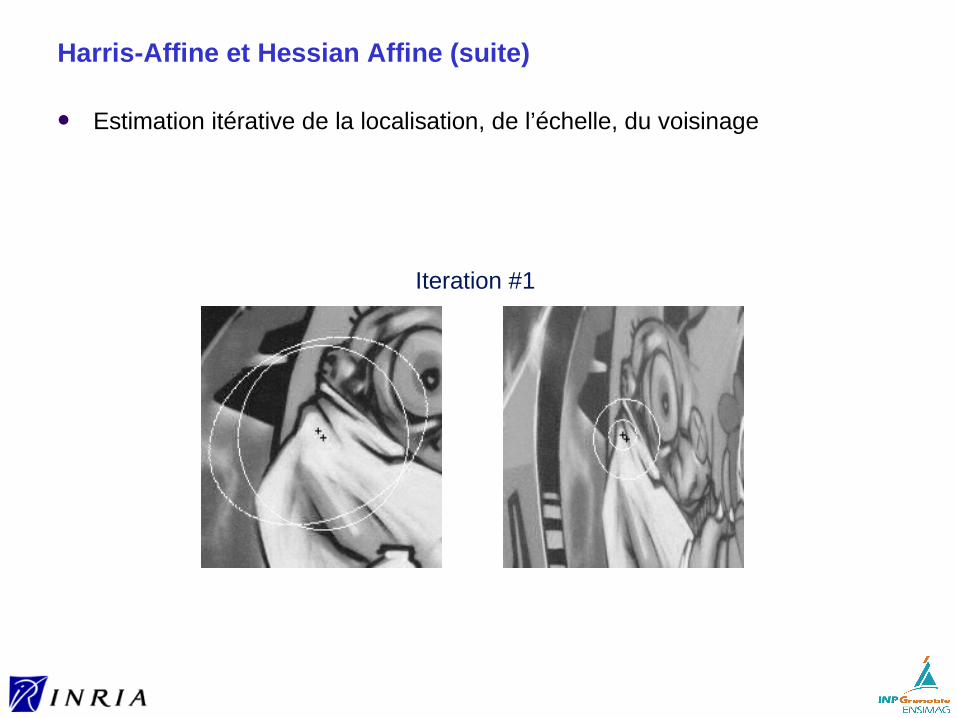
Harris-Affine et Hessian Affine (suite)
Estimation itérative de la localisation, de l’échelle, du voisinage
Iteration #1

Harris-Affine et Hessian Affine (suite)
Estimation itérative de la localisation, de l’échelle, du voisinage
Iteration #2

Harris-Affine et Hessian Affine (suite)
Estimation itérative de la localisation, de l’échelle, du voisinage
Iteration #3, #4, ...

Harris-Affine et Hessian Affine : pour résumer
Initialisation avec des points d’intérêt multi-échelle
Estimation itérative de la localisation, de l’échelle, du voisinage

MSER
Principe (voir séquence de seuils)► trier les pixels par intensité ► tous les seuils d’intensité possibles sont testés► localisation des régions qui sont stables par changement du seuil
Pourquoi ça marche (bien)► la binarisation locale est stable sur une large plage de seuils
Robust wide-baseline stereo from maximally stable extremal regions, J. Matas,, O. Chum, M. Urbana and T. Pajdlaa, Image and Vision Computing 22(10), 2004

Comment évaluer un extracteur ?
Évaluation quantitative des détecteurs de régions d’intérêt► les points / regions doivent être à la même position relative
Mesure de performance : le taux de répétabilité► taux de régions qui se correspondent (vérité terrain 2D)
Deux points se correspondent si ► l’erreur de localisation est inférieure à 1.5 pixel► l’erreur d’intersection est inférieure à 20%
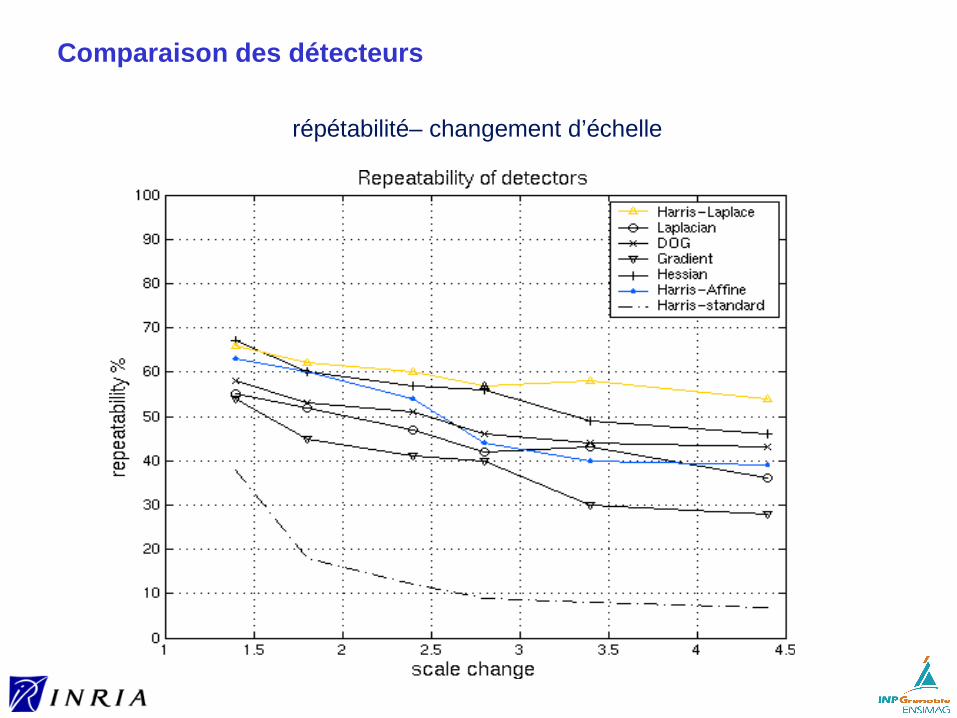
A Comparison of Affine Region Detectors, Mikolajczyk et al., IJCV 2005
homographie
Harris vs Harris invariant à l’échelle
Comparaison des détecteurs
répétabilité– changement d’échelle

Comparaison des détecteurs
0
40
60
70
repétabilité – transformation perspective

Description locale : plan
Extraction de points/régions d’intérêt
Descripteurs locaux
Appariement de points

Et une fois qu’on a défini l’ellipse ?
Synthèse du patch (imagette)► On calcule un patch de taille donnée
► Problème d’aliasing (apparition de haute fréquence) : application d’un filtrage (filtrage convolutif, par exemple gaussien)
► En pratique: sur la pyramide d'images
Tailles typiques de patch : 32x32, 64x64
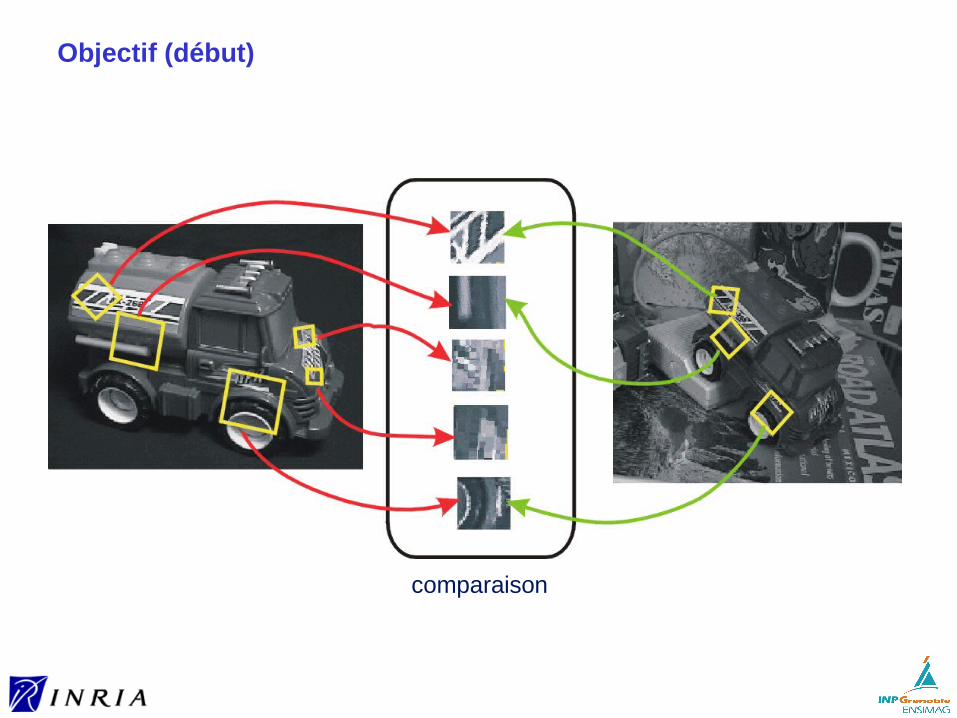
Objectif (début)
comparaison

Objectif (fin)
En utilisant un détecteur, on est capable de détecter des zones robustes (et informatives) de l’image
Mais à ce stade, ces zones ne peuvent pas être comparées entre elles
Qu’est qu’un descripteur ?► une représentation de la zone d’intérêt ► sous la forme d’un vecteur► qui appartient à un espace muni d’une distance
Qu’est qu’un bon descripteur ? ► invariant► discriminant► compact
Remarque : ces objectifs sont contradictoires
invariance
compacité
capacité dediscrimination

Descripteurs
Descripteurs basiques
Descripteurs invariants à la luminosité/rotation : invariants différentiels
Descripteurs à base de moments couleurs affine-invariants
État de l’art : le descripteur SIFT
Descripteur CS-LBP
Descripteurs de régions texturées
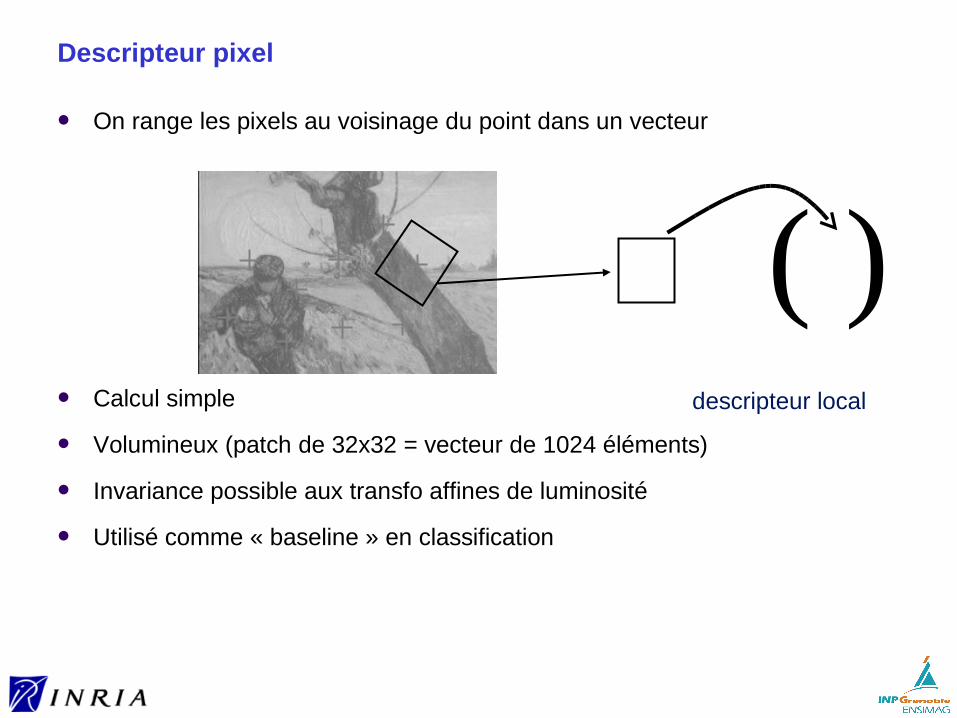
Descripteur pixel
On range les pixels au voisinage du point dans un vecteur
Calcul simple
Volumineux (patch de 32x32 = vecteur de 1024 éléments)
Invariance possible aux transfo affines de luminosité
Utilisé comme « baseline » en classification
( )descripteur local

Invariants différentiels (début)
Descripteurs de points (on ne part pas d’un patch)
Basés sur des dérivées calculées en un point (x,y). Idée :
Normalisation pour être invariant aux changements affines de luminosité
v x , y=[I x , y I x x , yI y x , yI xx x , y I xy x , y I yy x , y
]

Invariants différentiels : interprétation
Approximation locale d’une fonction par la série de Taylor
→ lien avec le détecteur Hessien
Le descripteur : les coefficients de cette série tronquée décrivent le voisinage d’un point
( )descripteur local

Invariants différentiels (suite)
Calcul stable des dérivées par convolution avec dérivées gaussiennes
où σ correspond à un choix d’échelle ► σ fixé si normalisation en échelle effectué avant, (invariants différentiels
développés plus tôt que la normalisation en échelle)
En pratique: pyramide d’images (convolution en O(σ2))
v x , y =[I x , y ∗G I x , y ∗G x
I x , y ∗G y
I x , y ∗G xx
I x , y ∗G xy
I x , y ∗G yy
]
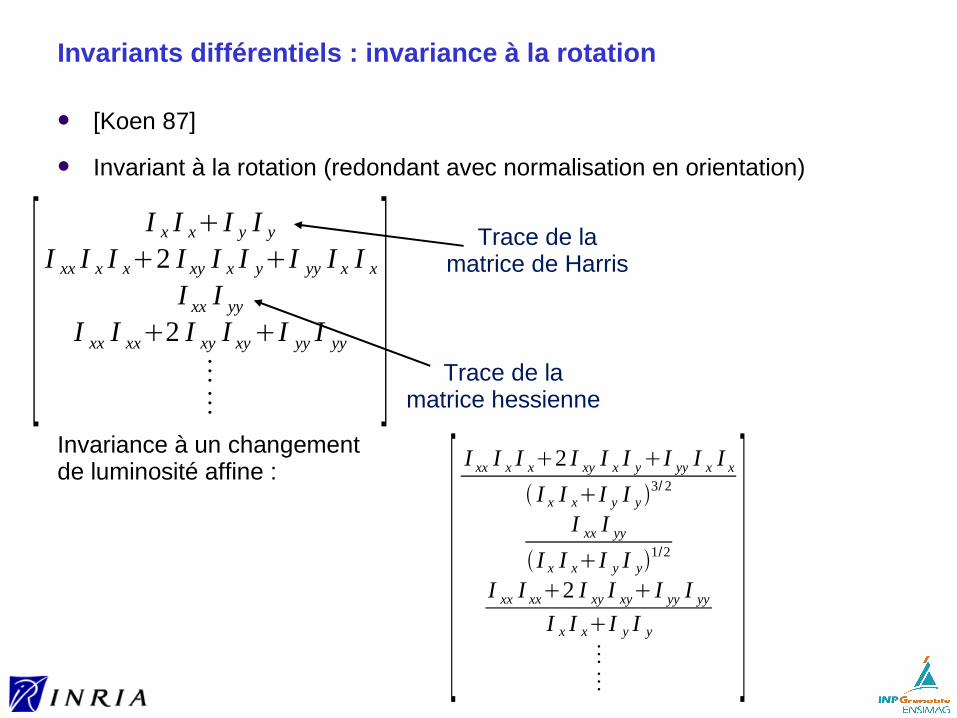
Invariants différentiels : invariance à la rotation
[Koen 87]
Invariant à la rotation (redondant avec normalisation en orientation)
Invariance à un changementde luminosité affine :
Trace de la matrice de Harris
Trace de la matrice hessienne
[I x I x I y I y
I xx I x I x2 I xy I x I yI yy I x I x
I xx I yy
I xx I xx2 I xy I xyI yy I yy
][I xx I x I x2 I xy I x I yI yy I x I x
I x I xI y I y 3/ 2
I xx I yy
I x I xI y I y1/2
I xx I xx2 I xy I xy I yy I yy
I x I xI y I y
]

Invariants différentiels (fin)
Remarque: changement d’échelle I2(x)= I1(s x) → dérivées liées par
Aujourd’hui, ces descripteurs sont encore utilisés (mais donnent en général de moins bons résultats que SIFT)
Taille typique du descripteur : 24
I 1x∗Gi1⋯in =sn I 2 s x ∗G i1⋯in
s

20 40 60 80 100 120 140 160
20
40
60
80
100
120
140
160
Autres descripteurs invariants à la rotation
Calcul des moments en coordonnées polaires (0<k<1, l entier)
Une rotation α correspond à une transformation
Cette transformation influence la phase des mk,l, pas sur leur amplitude
Choix naturel pour la description invariante à la rotation : les modules | mk,l |
La mise en correspondance des descripteurs s’effectue en comparant ces vecteurs de description
Remarque : approche a priori redondante avec la normalisation en orientation (mais celle-ci peut être imparfaite…)
[Ref] J. Matas et al. “Rotational Invariants for Wide-baseline Stereo”. Research report of CMP, 2003
20 40 60 80 100 120 140 160
20
40
60
80
100
120
140
160
mkl=∬ rk e−i l I r ,dr d
mklmkl ei l

Descripteurs moments couleurs invariants affines
Moments couleurs affine-invariants
Différentes combinaisons de ces moments sont invariantes à des transformations affines
Egalement invariantes à des transformées photométriques I → a I + b
[Ref] F.Mindru et.al. “Recognizing Color Patterns Irrespective of Viewpoint and Illumination”. CVPR99
m pqabc=∫region
x p y qRa x , y Gbx , y Bc x , y dx dy

SIFT (Scale invariant feature transform) [Lowe 04]
► Calculé sur un patch déjà normalisé : échelle (ou affine) + en orientation► description détaillée au tableau► Cas particulier de Histogram of Oriented Gradients (HOG)

CS-LBP (Center-symmetric local binary pattern)
Description au tableau

Comparaison de descripteurs
On se donne des paires d’images pour lesquelles on connaît les points qui doivent être appariés► Ex: base de Krystian Mikolajczyk
On fixe une distance et un seuil μ pour lequel on considère que deux descripteurs p (dans I1) et q (dans I2) matchent :
dist (p,q) < μ
En faisant varier le seuil μ, on obtient une courbe precision/rappel qui caractérise la qualité du descripteur

Résultats de comparaison
A performance evaluation of local descriptors Krystian Mikolajczyk, Cordelia Schmid, PAMI, Volume 27, Number 10 - 2005

Descripteurs : conclusion
Invariances : force des méthodes génériques► normalisation affine de la région vers un patch de taille constante en
utilisant un detecteur affine invariant► normalisation affine en luminosité avant le calcul du descripteur pour
garantir l’invariance affine
Utilisation d’un descripteur de relativement grande dimension (128 pour SIFT) pour obtenir une bonne capacité de discrimination

Description locale : plan
Extraction de points/régions d’intérêt
Descripteurs locaux
Appariement de points

Appariemment de points
Problème : étant donné des points ou régions d’intérêt et les descripteurs associés, comment apparier de manière robuste les points de deux images ?
Dans ce sous-chapitre : sélection des meilleurs couples de points

Comparer directement deux régions normalisées
À partir des détecteurs uniquement : plusieurs distances► SSD (sum of square differences)► NSSD (normalized SSD)► ZNCC (zero-normalized cross-correlation)
Rôle concurrent avec les descripteurs, pour lesquels la mesure de proximité entre régions donne une ressemblance entre celles-ci. On conserve le couple si cette mesure de dissimilarité est inférieure à un seuil μ :
d(p1i,p2j) < μ, avec p1i dans I1 et p2j dans I2
μ est fixé à partir de la courbe précision/rappel du descripteur
Comparaison entre descripteurs est + rapide (vecteur plus court)

Sélection des meilleurs couples
Hypothèse : pour tout couple de points (p1i, p2j), (p1i dans I1 et p2j dans I2), on a une mesure de similarité sij entre régions
Remarque: ambiguité
Différentes stratégies:► Winner-takes-all (symétrique ou à sens unique)► Filtrage ultérieur par géométrie
0.9
0.8
0.7

Vérification géométrique par mise en correspondance d’images
Contraintes de voisinages
RANSAC
LO-RANSAC
Transformée de Hough

Problème : appariemments entre deux images

Vérification des contraintes de voisinage
À ce stade, on n’a pas utilisé d’information géométrique→ seules les informations sur le point ont été utilisées
Vérification des contraintes de voisinages
Motivation : ► il y a beaucoup d’appariemments dans un voisinage► Si les appariements du voisinage se trouvent à la même position
relative, il est probable que l’appariemment considéré soit correct
Idée► utilisation d’un voisinage circulaire► calcul d’un score entre voisinages (fonction des affinités sij entre les
points des voisinages de p1i et p2j),
s ' p1i , p2j=sij ∑n1k∈N p1i
maxn2l∈N p 2j
skl ddist n1k− p1i , n2l− p2j

Contraintes géométriques : un peu plus loin
Pour cela : estimation robuste de la géométrie épipolaire → prise en compte des contraintes géométriques de 2 prises de vue
Rappel : coordonnées homogènes► P=(x,y,z,w)► (x,y,z,w) et (x’,y’,z’,w’) représentent le même point
ssi il existe λ tel que x’=λx, y’=λy, z’=λz et w’=λw⇒ la correspondance point ↔ coordonnées n’est pas bijective
► Intérêt : écriture uniforme des transformations affines et de projection
Dans le cas de 2D, on se contente de P=(x,y,w)

Rappel : exploitation de la géométrie épipolaire
Hypothèse : I1 et I2 sont deux projections de la même scène 3D
Deux points P1 et P2 des images I1 et I2, sont en coordonnées homogènes
Schéma au tableau
DEFINITION : épipoles
DEFINITION : droites épipolaires
DEFINITION : matrice fondamentale
Dans le cas de scènes planaires, on simplifie le problème► Mise en correspondance directe par homographie
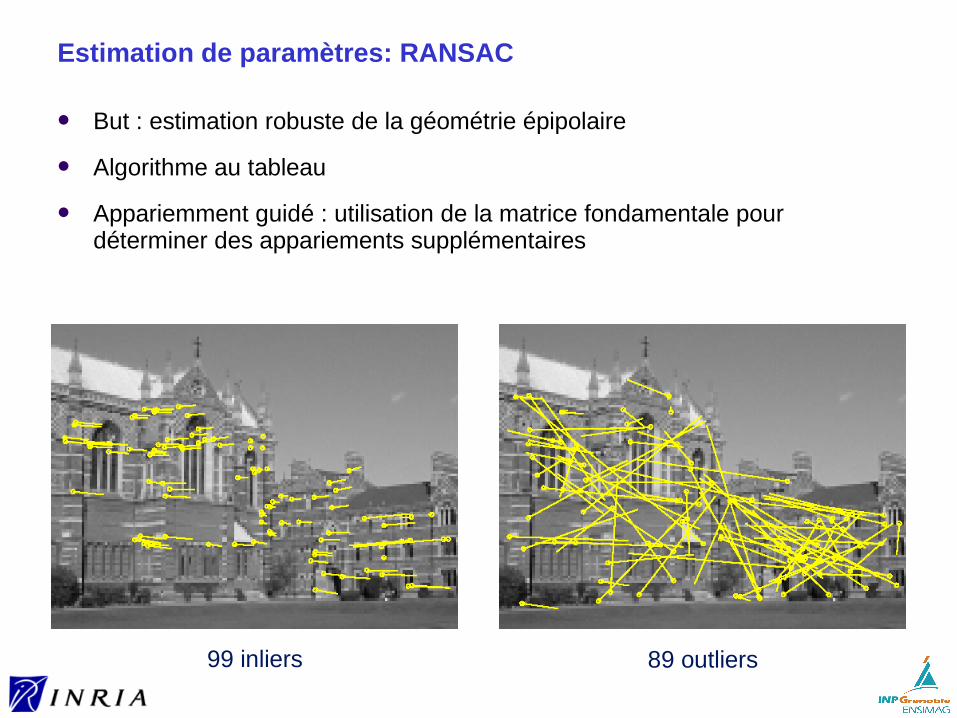
Estimation de paramètres: RANSAC
But : estimation robuste de la géométrie épipolaire
Algorithme au tableau
Appariemment guidé : utilisation de la matrice fondamentale pour déterminer des appariements supplémentaires
99 inliers 89 outliers

Estimation de paramètres : LMS
LMS (Least Median of squares)► similaire à RANSAC
Algorithme : répéter N fois► choix aléatoire de 8 points concordant dans les deux images► calcul de la transformation► calcul de la médiane des distances entre points observés et calculés
On retient alors F avec la plus petite médiane
Avantage : pas besoin d’un seuil (contrairement à RANSAC)
Désavantage : ne marche pas avec plus de 50% d’outliers (pourquoi ?)

Sous-classes de transformations
Pour diminuer l’incertitude et/ou en en fonction du problème, on réduit le nombre de degré de libertés des transformations possibles► Ex: copyright
Le plus souvent, on se contente de transformées planaires
Exemple d’utilisation dans un système de recherche de scènes :
[6] Philbin, J. , Chum, O. , Isard, M. , Sivic, J. and Zisserman, A.Object retrieval with large vocabularies and fast spatial matching http://www.robots.ox.ac.uk/~vgg/publications/papers/philbin07.pdf
→ différentes classes de transformations, suppression de l’invariance à la rotation

Hiérarchie des transformations planaires (2D ↔ 2D)
nombre de degré de liberté
invariants forme
translation 2 tout, sauf les positions absolues
transformée
rigide
3 longueur, angle, surface, courbure
similitude 4 angle, rapport de longueur
transformation
affine
6 parallélisme, rapport de surface, rapport de
longueur sur une droite, coordonnées
barycentriques
Homographie 8 Birapport
[ X 'Y ' ]=[a b
c d ] [ XY ][ t XtY ]
[ X 'Y ' ]=s [ cos sin
−sin cos ][ XY ][ t XtY ][ X 'Y ' ]=[ cos sin
−sin cos ] [ XY ][ t XtY ][ X 'Y ' ]=[XY ][ t XtY ]
[ X 'Y ' ]=
1h31 Xh32Yh33 [h11 h12
h21 h22] [ XY ][h13
h23]

LO-RANSAC
≠ RANSAC (comme son nom ne l’indique pas)
Idée: utiliser tous les couples de point qui matchent► estimation de la transformation à partir des caractéristiques des régions
autour du point (position, orientation, forme de la région)► calculer le nombre de points qui satisfont cette transformation
Avantages► tous les appariemments possibles sont testés (+ grande robustesse)► efficace
Inconvénient► le nombre de degrés de liberté possible pour la transformée est limité
par le nombre de paramètres fournis pour le point
O.Chum, J. Matas, S. Obdrzalek, Enhancing Ransac by generalized model optimization, ACCV 2004

Transformée de Hough
Utilisé initialement pour détecter des segments/droites à partir de points dans les images► Chercher les droites possibles dans un espace de paramètre, (espace
de Hough)
Principe : ► discrétiser l’espace de paramètres en “bins”► Pour chaque observation, incrémenter le(s) bin(s) consistants avec
l’observation► Résultat = le bin de le plus peuplé ► affinage possible avec Mean-shift
Difficulté: dépendance à la paramétrisation et la quantification
Dans le cas de la vérification géométrique, le nombre de degré de liberté possibles doit être petit (Pourquoi?)
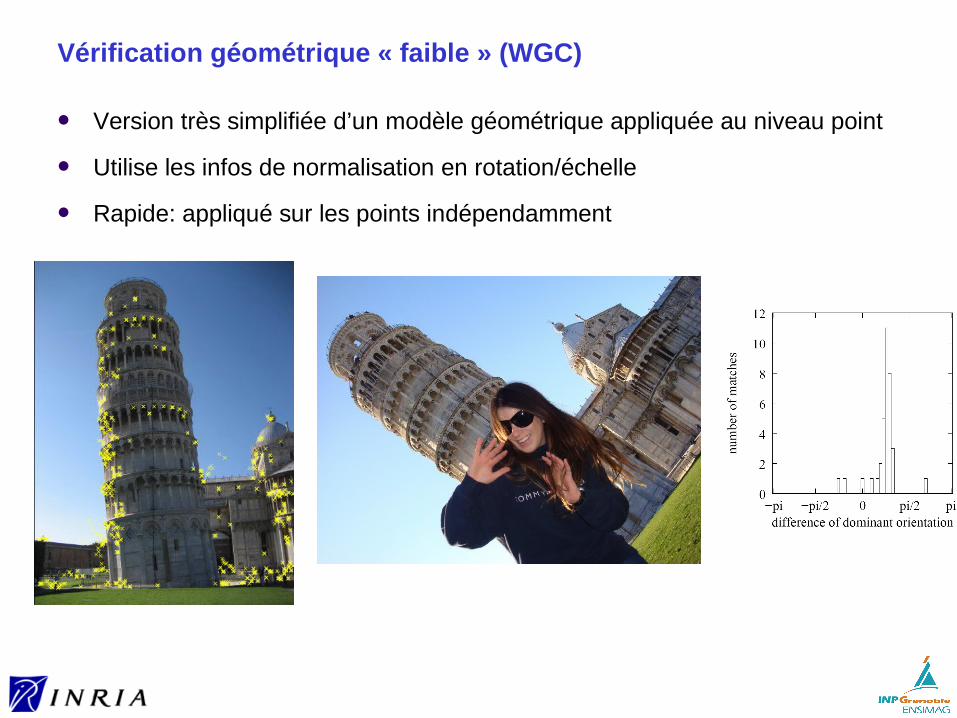
Vérification géométrique « faible » (WGC)
Version très simplifiée d’un modèle géométrique appliquée au niveau point
Utilise les infos de normalisation en rotation/échelle
Rapide: appliqué sur les points indépendamment

WGC: en échelle
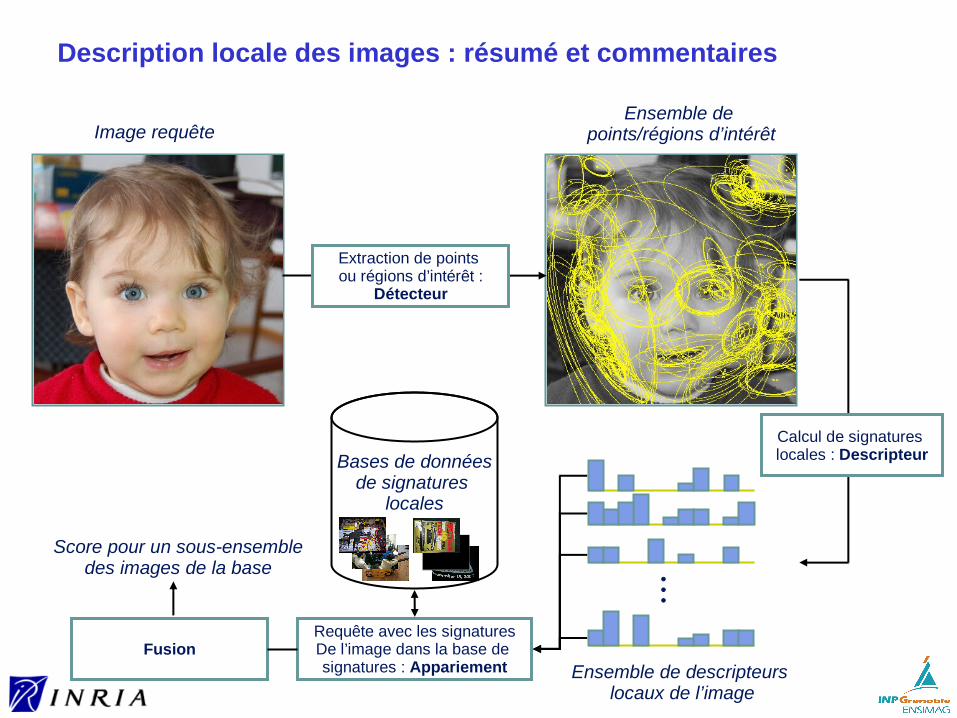
Description locale des images : résumé et commentaires
Extraction de points ou régions d’intérêt :
Détecteur
Ensemble de points/régions d’intérêtImage requête
Ensemble de descripteurs locaux de l’image
Calcul de signatures locales : DescripteurBases de données
de signatures locales
Requête avec les signaturesDe l’image dans la base de signatures : Appariement
Fusion
Score pour un sous-ensembledes images de la base

Description locale des images : résumé et commentaires
Étapes► recherche de points/régions d’intérêt► calcul des descripteurs pour chacune de ces régions
► vérification de la cohérence géométrique► algorithme de vote
Commentaires:► problème en suspens : il faut apparier les descripteurs d’une image avec
tous les descripteurs d’une base d’image → c’est très lent !
► la vérification de la cohérence géométrique est relativement lente→ on ne peut l’utiliser que pour un sous-ensemble d’images a priori plus
pertinentes

Bases de données multimédiaVI – Indexation rapide
ENSIMAG
2009
Hervé Jégou & Matthijs Douze

Indexation
Problème : rechercher efficacement des vecteurs de caractéristique (=descripteurs) proches au sein d’une base de descripteurs→ on voudrait éviter de faire une comparaison exhaustive
Opérations supportées : recherche (critique), ajout/suppression (+ ou – critique) selon l’application
Deux types de recherche► Recherche à ε► Recherche des k plus proches voisins
objets complexes
vecteurs de caractéristiquesde haute dimension
extraction dedescripteurs
ajout ourequête
structured’indexation

Plan
Préliminaires
Indexation mono-dimensionnelle
Indexation multi-dimensionnelle
Perspectives

Notations
base de n vecteurs : Y= { yi ∈ ℝd }i=1..n
vecteur requête : q in ℝd
on note N(q) ⊂ Y les voisins de q → les vecteurs “similaires”
Le voisinage est relatif à une distance (ou une similarité/dissimilarité)
→ on se concentre sur la distance Euclidienne
d(x,y) = ||x-y||2

Qu’est ce qu’un “voisin” ?
un vecteur qui répond à une propriété de proximité absolue ou relative
recherche à ε recherche des k plus proches voisins
Nε(q) = { yi ∈ Y : d(yi,q) < ε } Nk(q) = k-arg-mini d(yi,q)
k=2
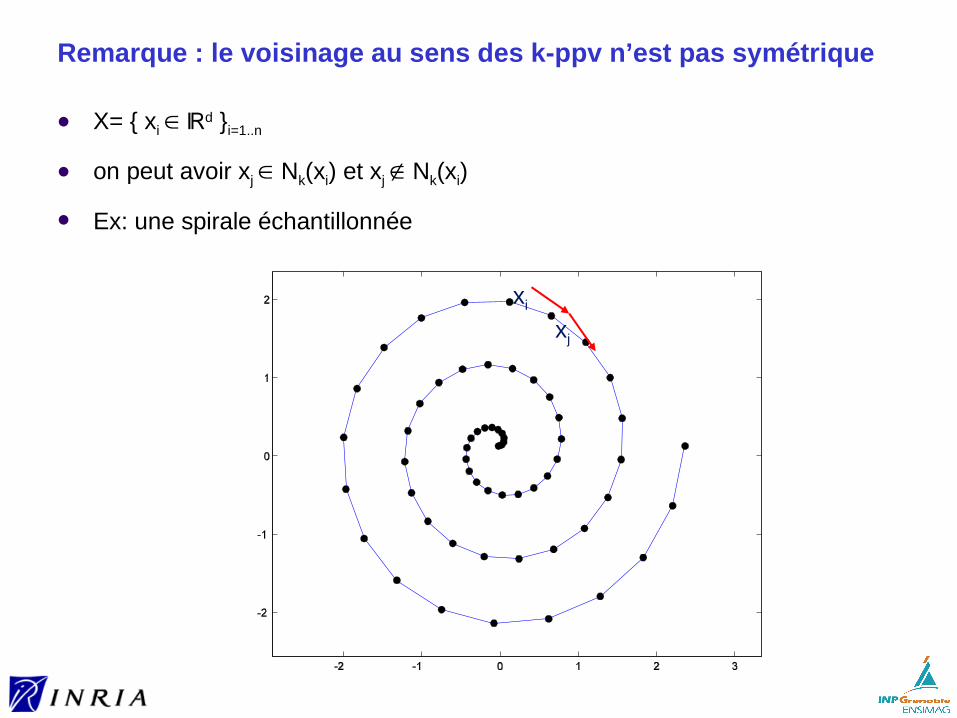
Remarque : le voisinage au sens des k-ppv n’est pas symétrique
X= { xi ∈ ℝd }i=1..n
on peut avoir xj ∈ Nk(xi) et xj ∉ Nk(xi)
Ex: une spirale échantillonnée
xi
xj

Algorithme naif : complexité
Si la base Y n’est pas organisée (=indexée), calculer Nk ou Nε nécessite le calcul de l’ensemble des distances d(q,yi)
► O(n×d)
Pour Nk(q), il faut de plus trouver effectuer l’opération k-arg-mini d(q,yi)
Exemple: on veut 3-argmin {1,3,9,4,6,2,10,5}► Méthode naïve 1: trier ces distances → O(n log n)► Méthode naïve 2: maintenir un tableau des k-plus petits éléments, mis à
jour pour chaque nouvelle distance considérée → O(n k)
Intuitivement, on peut faire mieux…

Max-heap
Binary max heap► structure d’arbre binaire équilibré► dernier niveau rempli de gauche à droite► à chaque noeud n on associe une valeur v(n)► propriété : si ni est un noeud fils de nj, alors v(ni) < v(nj)
Remarque : il admet une représentation linéaire simple: ni a pour père ni/2
10
9 5
6 2 3 1
4
n1
10
n2
9
n3
5
n4
6
n5
2
n6
3
n7
1
n8
4

Max-heap : opérations élémentaires
heap_push: ajout inconditionnel d’un élément dans le heap ► ajouter le noeud k+1, et y placer le nouvel élément► mise à jour (pour garder les propriétés d’ordre) :
l’élément inséré remonte : inversion avec son parent s’il est plus grand jusqu’à vérification de la relation d’ordre complexité en O(log k) au pire, mais O(1) en pratique
heap_pop: suppression inconditionnelle de la plus grande valeur► on supprime le noeud racine et on le remplace par l’élément du noeud k► mise à jour :
on descend l’élément : inversion avec le fils le plus grand jusqu’à ce que la relation d’ordre soit vérifiée
10
9 7
6 2 3 5
4
10
9 5→7
6 2 3 7→5
1
2 3
4
9
6 5
4 2 3 1
1
2

Algorithme: Max-heap pour chercher les k plus petites valeurs
Pb: on cherche k-argmini {a1,…ai,…an}
Initialisation du heap à l’arbre vide
Pour i=1..n, ► si l’arbre n’est pas encore de taille k → heap_push► si l’arbre est déjà de taille k, on compare ai à v(n1)
si ai ≥ v(n1) → on passe à l’élement suivant sinon
heap_pop heap_push
Exemple: 3-argmin {1,3,9,4,6,2,10,5}

Algorithme: Max-heap pour chercher les k plus petites valeurs
Complexité : O(n log k) au pire, bien meilleure en moyenne► un nouveau nième élement doit être plus grand que le noeud racine► probabilité de k/i de faire effectivement un push
→ décroit rapidement
Peut être utilisé pour trier (algorithme heapsort).

Plan
Préliminaires
Indexation mono-dimensionnelle
Indexation multi-dimensionnelle
Perspectives

Indexation mono-dimensionnelle
Application phare : les bases de données (au sens classique du terme)
Différents types d’opérations de recherche► recherche d’un point/vecteur : PAM (point access method)► recherche de structures spatiales plus complexes : SAM (spatial access
method) Ex: recherche d’une valeur dans un intervalle, ou du plus proche voisin d’une valeur
Les structures de références :► Hashing► B+ tree► Fichier inversé

Estimation de la performance
Les données sont supposées stockées sur des disques(souvent pas le cas pour les algorithmes en vision…)
Unité minimum pouvant être transférée : ► une page = b bytes,► qui correspond à B enregistrements de données.► N enregistrements accédés O(⌈N/B⌉) pages à accéder
La complexité, en base de données, est donnée en nombre de pages
Éléments non pris en compte► Impact du cache► Proximité des données sur le disque (temps du fseek)
CPU mémoire
disque
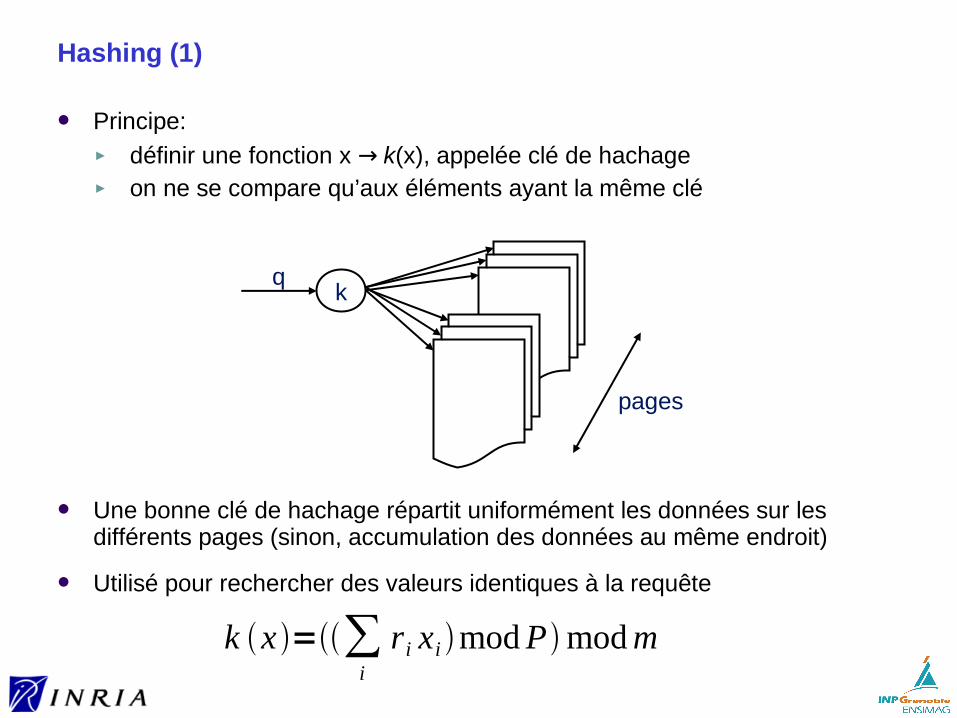
Hashing (1)
Principe:► définir une fonction x → k(x), appelée clé de hachage► on ne se compare qu’aux éléments ayant la même clé
Une bonne clé de hachage répartit uniformément les données sur les différents pages (sinon, accumulation des données au même endroit)
Utilisé pour rechercher des valeurs identiques à la requête
qk
pages
k x =∑i
ri xi modPmodm

Hashing (2)
Excellent pour un accès de type point (PAM)
SELECT name FROM PERSON WHERE name = ‘herve’
Peu adapté aux requêtes comparatives (type intervalle, donc SAM) du type
SELECT taille FROM PERSON WHERE taille > 1.70 and taille < 1.90
→ dans ce cas, complexité en O(n)
Typiquement, 1-2 I/O par requête pour les requêtes PAM

B+ tree (début)
Dérivé du B-tree (différence soulignée plus tard)
Utilisation d’un ordre sur les éléments
Pour requêtes exactes ou requête sur des plages
Permet d’optimiser les requêtes du type
SELECT taille FROM PERSON WHERE taille > 1.70 and taille < 1.90
Mais permet également un accès direct
SELECT name FROM PERSON WHERE name = ‘herve’
Dans ce cas, plus lent que le hashing

B+ tree : structure
Structure arborescente avec deux types de noeuds
Noeuds index (noeuds internes à l’arbre)► contiennent des pointeurs vers d’autres noeuds ou des feuilles ► ces noeuds ordonnent les sous-noeuds par des valeurs de séparation
Les entrées (valeurs de séparation) ne sont pas nécessairement remplies
Paramètres : ► B : maximum d’entrées dans un noeud► Bm : minimum
Usuellement B = 2 Bm
115153
175
yi<115 115<yi<153 153<yi<175 yi>175
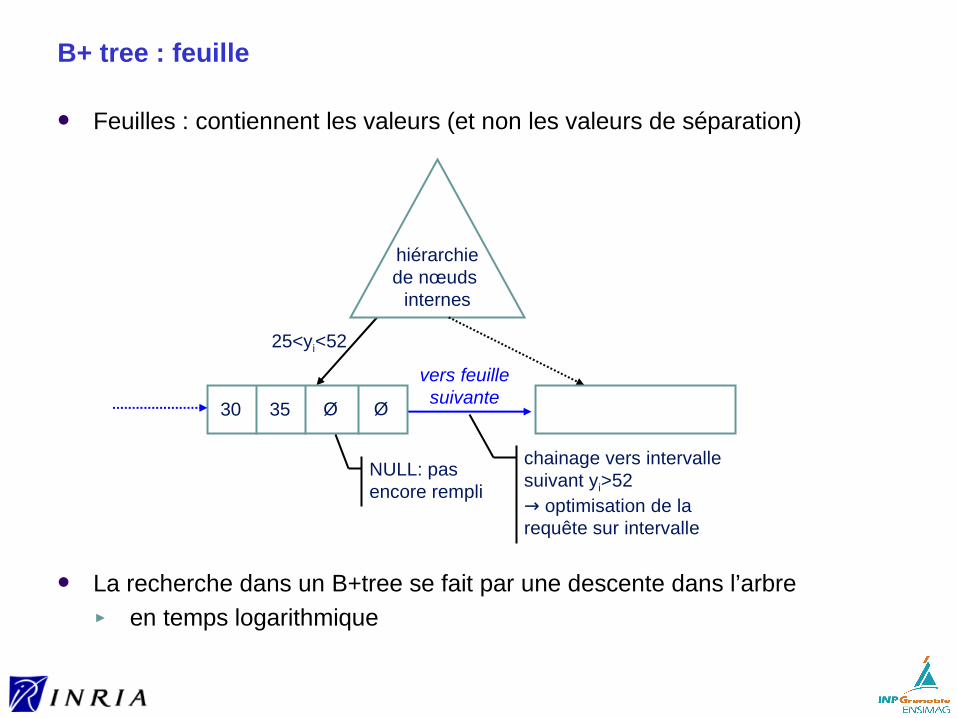
B+ tree : feuille
Feuilles : contiennent les valeurs (et non les valeurs de séparation)
La recherche dans un B+tree se fait par une descente dans l’arbre► en temps logarithmique
vers feuillesuivante
30 35 Ø
NULL: pas encore rempli
hiérarchiede nœuds
internes
chainage vers intervalle suivant yi>52→ optimisation de la requête sur intervalle
25<yi<52
Ø

B+ tree : insertion
Trouver la feuille L → descente dans l’arbre
Introduire la donnée dans L► si L possède suffisamment de place, insertion► sinon, diviser L (en L et un nouveau noeud L2)
redistribuer les entrées insérer un index sur L2 dans le noeud parent P de L→ si il y a la place, stop
Sinon, la division doit être faite récursivement sur les noeuds parents► les divisions de noeuds interne (sauf le noeud racine) élargissent l’arbre► la division du noeud racine accroît sa hauteur
Remarque:► les feuilles sont toujours à hauteur constante

B+ tree : exemple d’insertion
Insertion de 30► on cherche la feuille► on insère 30 (il y a de la place)
Insertion de 120► on cherche la feuille► elle est pleine → création d’une nouvelle feuille► redistribution► ajout de 120 dans le nouveau L► on lie L2 à son parent→ il y a de la place, arrêt
99 Ø Ø
28 50 Ø Ø 115 153 175 200
23
30
28 30 50 Ø 115 120 175 200
1
153
99 Ø153
Ø Ø Ø

B+ tree : suppression (par souci d’exhaustivité)
Recherche de la feuille concernée
Suppression de l’entrée► si L demeure avec au moins d entrée, aucune ré-équilibrage► sinon, si L contient B
m-1 entrées, tentative de redistribution en prenant
des entrées sur les noeuds adjacents. ► en cas d’échec (pas assez d’entrée sur les noeuds adjacents), fusion.► si fusion, destruction de l’entrée du noeud dans le parent de L► si nécessaire, propagation jusqu’à la racine → avec éventuellement réduction de la hauteur de l’arbre

B+ tree : propriétés
Recherche d’une valeur donnée, {yi in Y : yi = a}
► on cherche la feuille contenant la valeur► on se compare aux éléments
Recherche sur intervalle [a,b] ► recherche de L correspondant à a► utilisation du chaînage horizontal pour récupérer toutes les entrées
jusqu’à b
Complexité► insertion/suppression/recherche en temps logarithmique (amorti)► effectuer une recherche à ε est en O (log + |Nε(q)|)
Utilisation de l’espace paginé : ► 50% au moins pour B=2Bm
► 67% pour des nombres aléatoires (uniformes)

B-tree
Le B-tree original est presque identique► mais les noeuds internes sont aussi utilisés pour stocker des
enregistrements► pas de chaînage horizontal
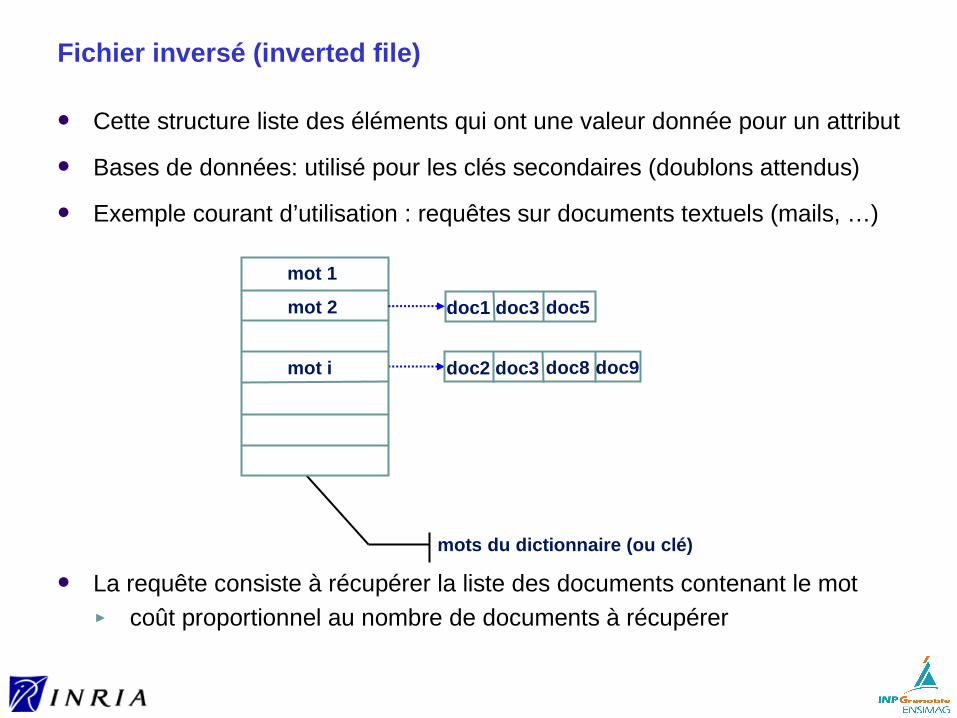
Fichier inversé (inverted file)
Cette structure liste des éléments qui ont une valeur donnée pour un attribut
Bases de données: utilisé pour les clés secondaires (doublons attendus)
Exemple courant d’utilisation : requêtes sur documents textuels (mails, …)
La requête consiste à récupérer la liste des documents contenant le mot► coût proportionnel au nombre de documents à récupérer
mot 1
mots du dictionnaire (ou clé)
mot 2
mot i doc2 doc3 doc8 doc9
doc1 doc3 doc5

Parenthèse : recherche de documents textuels (1)
Modèle vectoriel► on définit un dictionnaire de mots de taille d► un document texte est représenté par un vecteur f=(f1,…,fi,…fd) ∈ ℝd
► chaque dimension i correspond à un mot du dictionnaire► fi = fréquence du mot dans le document
en pratique, on ne garde que les mots discriminants dans le dictionnaire “le”, “la”, “est”, “a”, etc, sont supprimés, car peu discriminants
Ces vecteurs sont creux► dictionnaire grand par rapport au nombre de mots utilisés

Parenthèse : recherche de documents textuels (2)
Exemple► dictionnaire = {“vélo”, “voiture”, “déplace”, “travail”, “école”, “Rennes”} ► espace de représentation: ℝ6
► “Rennes est une belle ville. Je me déplace à vélo dans Rennes”→ f=(1/4,0,1/4,0,0,1/2)t
Recherche de document = trouver les vecteurs les plus proches► au sens d’une mesure de (dis-)similarité, en particulier le produit scalaire

1 0 0 0 5 0 0 0
0 0 1 0 0 0 2 0
0 0 0 0 0 0 1 1
y1
y2
y3
2
3
y2 1
y1 1
y2 5
y1 2
y3 1
y3 1
0 2 0 0 3 0 0 0q
Retour sur notre fichier inversé : distances entre vecteurs creux
requête q et base Y: vecteurs creux
Fichier inversé: calcul efficace du produit scalaire (en fait, toute distance Lp)
Exemple pour le produit scalaire
Complexité : O(n×C), ► C : espérance du nombre de positions non nulles en commun, très petit
(=d s2 si uniforme et indépendant)
y1 y2 y3
+15
15 00

Optimisation de requête
Lors de la création d’une table pour un SGDB (e.g., Oracle), ► Un index doit être créé pour tous les champs qui peuvent apparaître
dans les clauses WHERE► le type de structure d’index utilisé peut (doit!) être choisi en fonction du
type de requête effectué
Ce n’est pas forcément possible dans tous les SGDB► MySQL ne supporte que les B-tree (Question : pourquoi ce choix ?)
http://dev.mysql.com/doc/refman/5.0/fr/mysql-indexes.html

Plan
Préliminaires
Indexation mono-dimensionnelle
Indexation multi-dimensionnelle ► préliminaires► R-tree► KD-tree► la malédiction de la dimension► LSH (Locality-Sensitive Hashing)
Perspectives

Préliminaires
Pour d ≥ 2, on perd l’ordre total► compromet la recherche en temps logarithmique
Nécessité d’organiser l’espace pour éviter de se comparer à tout les vecteurs
Deux approches pour l’organisation des données► à partir des données
(comme pour le B-tree)
► pré-définicomme pour le hachage)
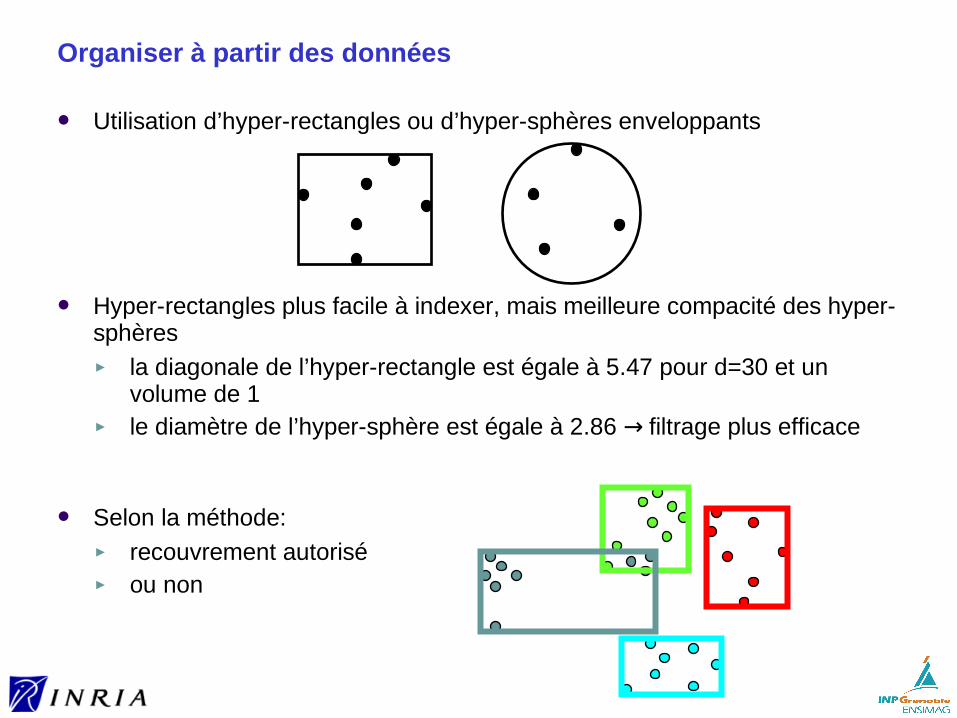
Organiser à partir des données
Utilisation d’hyper-rectangles ou d’hyper-sphères enveloppants
Hyper-rectangles plus facile à indexer, mais meilleure compacité des hyper-sphères ► la diagonale de l’hyper-rectangle est égale à 5.47 pour d=30 et un
volume de 1► le diamètre de l’hyper-sphère est égale à 2.86 → filtrage plus efficace
Selon la méthode:► recouvrement autorisé ► ou non

Sur l’utilisation de cellules
Bien moins de cellules que de descripteurs► trouver les cellules non vides les plus proches d’un descripteur requête
est relativement efficace► donc ce pré-filtrage de la plus grande partie des données apporte a
priori un gros gain de performance
Peu de paramètres à associer à chaque cellule► hyper-rectangle englobant : deux points► sphère : centre et rayon
Qu’est-ce que l’on exploite ?► l’inégalité triangulaire
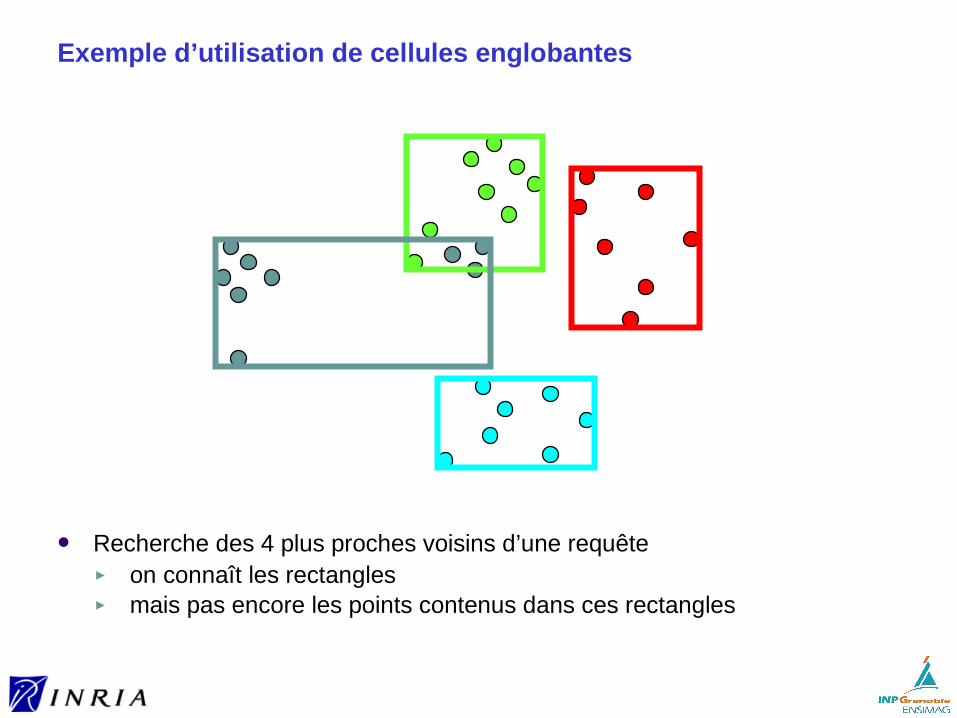
Exemple d’utilisation de cellules englobantes
Recherche des 4 plus proches voisins d’une requête► on connaît les rectangles► mais pas encore les points contenus dans ces rectangles

Exemple d’utilisation de cellules englobantes
q
Dmin(q,C1)
Dmax(q,C2)
• On peut rejeter C1 sans analyser son contenu
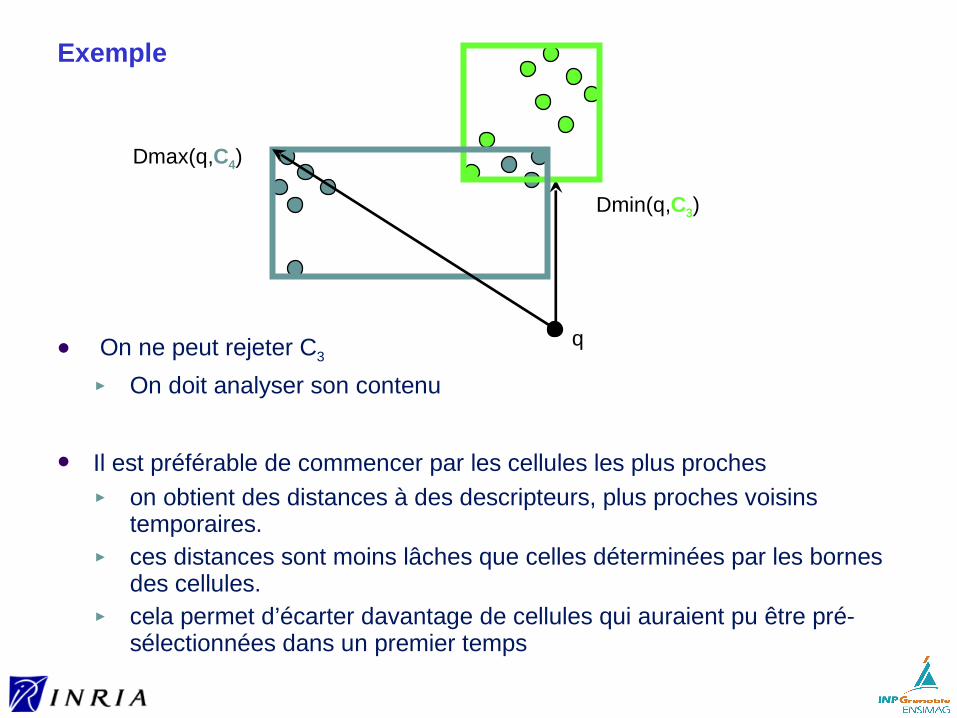
Exemple
q
Dmin(q,C3)
Dmax(q,C4)
On ne peut rejeter C3
► On doit analyser son contenu
Il est préférable de commencer par les cellules les plus proches► on obtient des distances à des descripteurs, plus proches voisins
temporaires. ► ces distances sont moins lâches que celles déterminées par les bornes
des cellules. ► cela permet d’écarter davantage de cellules qui auraient pu être pré-
sélectionnées dans un premier temps

Première structure de référence: R-Tree Guttman, 1984, ACM SIGMOD
“Extension” des B/B+-Tree aux espaces multi-dimensionnels► arbre équilibré► chaque noeud représente un rectangle englobant les rectangles des fils→ hiérarchie de rectangle
Notation : REM = rectangle englobant minimum(MBR=minimum bounding rectangle)
Arbre équilibré, rectangles englobant minima, hiérarchie de rectangles► noeud interne : (rectangle englobant, ptr_child_node)*► feuille : (vector)*
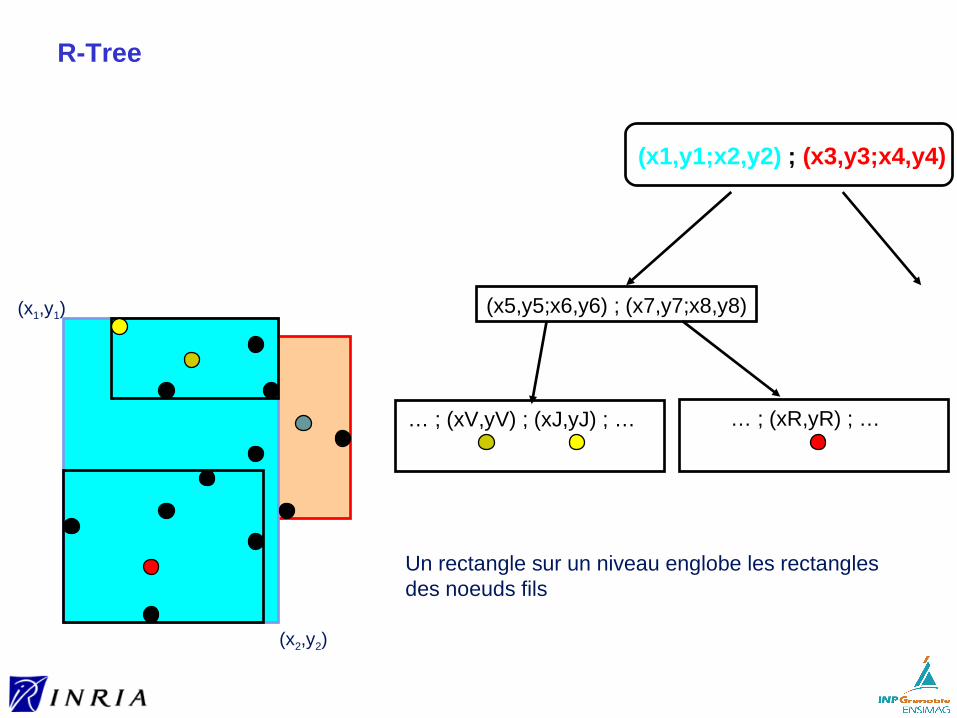
R-Tree
(x1,y1;x2,y2) ; (x3,y3;x4,y4)
(x5,y5;x6,y6) ; (x7,y7;x8,y8)
… ; (xV,yV) ; (xJ,yJ) ; … … ; (xR,yR) ; …
Un rectangle sur un niveau englobe les rectangles des noeuds fils
(x1,y1)
(x2,y2)

R-Tree (suite)
(x1,y1;x2,y2) ; (x3,y3;x4,y4)
(x5,y5;x6,y6) ; (x7,y7;x8,y8)
… ; (xV,yV) ; (xJ,yJ) ; …
La recherche procède en descendant l’arbre en utilisant les coordonnées des rectangles
Mais la requête peut tomber dans plusieurs régions à la fois (≠B+tree)
… ; (xR,yR) ; …
(xq, yq)
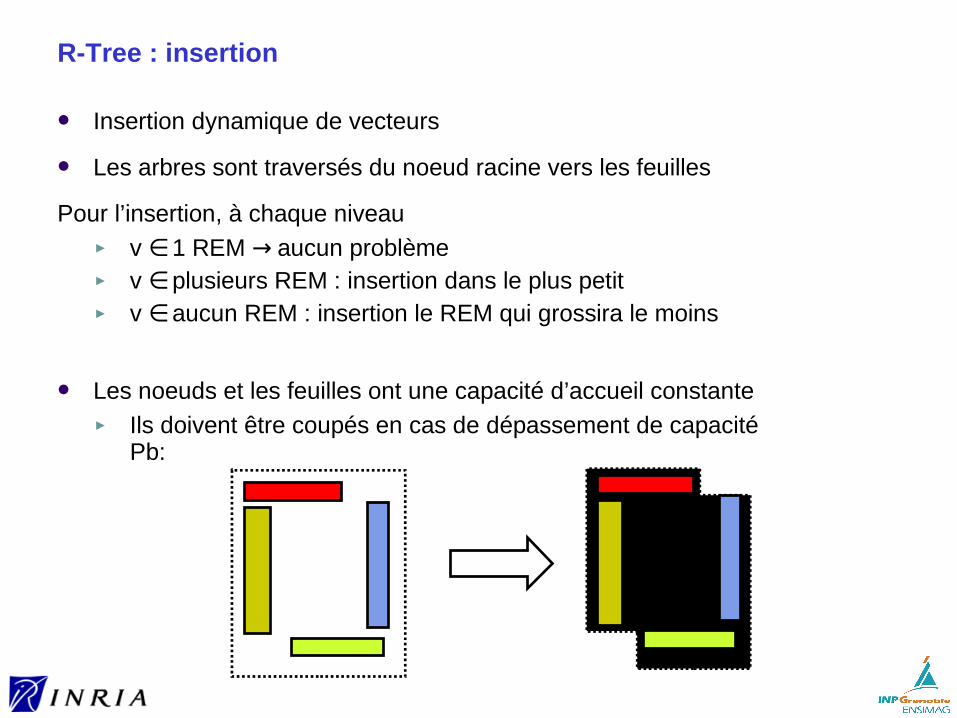
R-Tree : insertion
Insertion dynamique de vecteurs
Les arbres sont traversés du noeud racine vers les feuilles
Pour l’insertion, à chaque niveau► v ∈ 1 REM → aucun problème► v ∈ plusieurs REM : insertion dans le plus petit► v ∈ aucun REM : insertion le REM qui grossira le moins
Les noeuds et les feuilles ont une capacité d’accueil constante► Ils doivent être coupés en cas de dépassement de capacité
Pb:
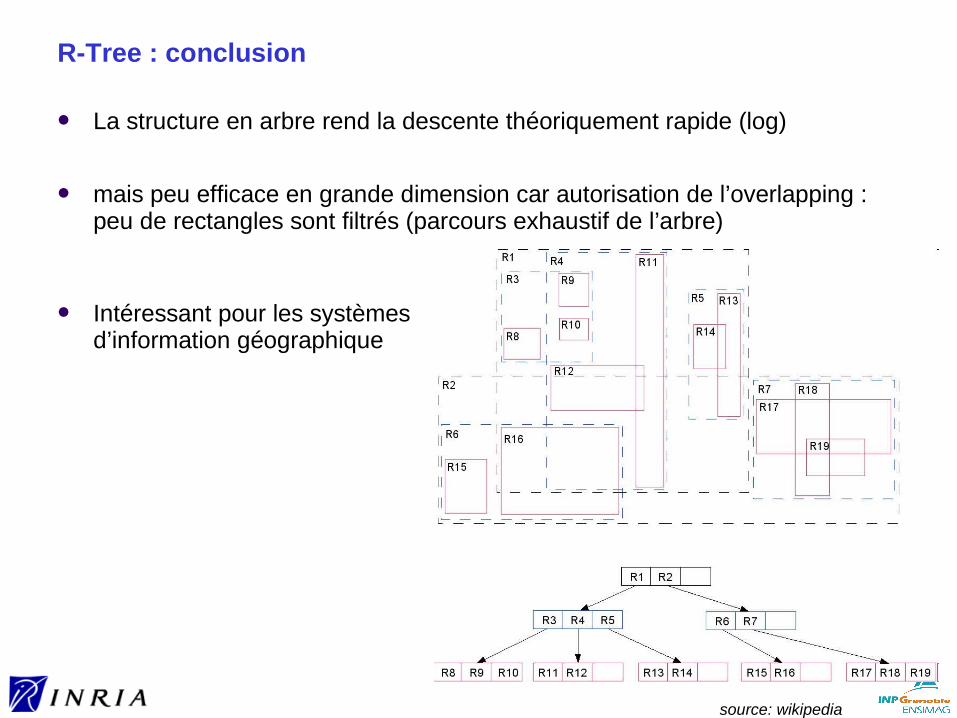
R-Tree : conclusion
La structure en arbre rend la descente théoriquement rapide (log)
mais peu efficace en grande dimension car autorisation de l’overlapping : peu de rectangles sont filtrés (parcours exhaustif de l’arbre)
Intéressant pour les systèmesd’information géographique
source: wikipedia

Kd-Tree
Technique (populaire) de partitionnement de l’espace des vecteurs
Espace découpé récursivement en utilisant des hyperplans ► parallèles aux axes (base de représentation initiale du vecteur)► point de découpage = valeur médiane sur l’axe considéré► choix du prochain axe : plus grande variance résiduelle
mais plusieurs variantes

Kd-Tree : construction
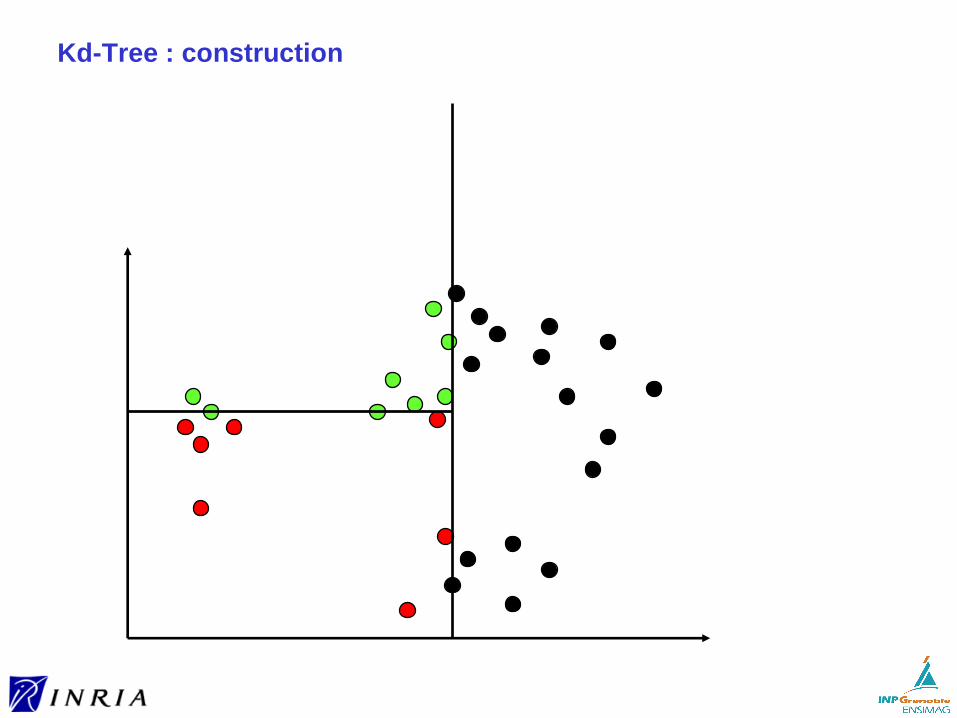
Kd-Tree : construction
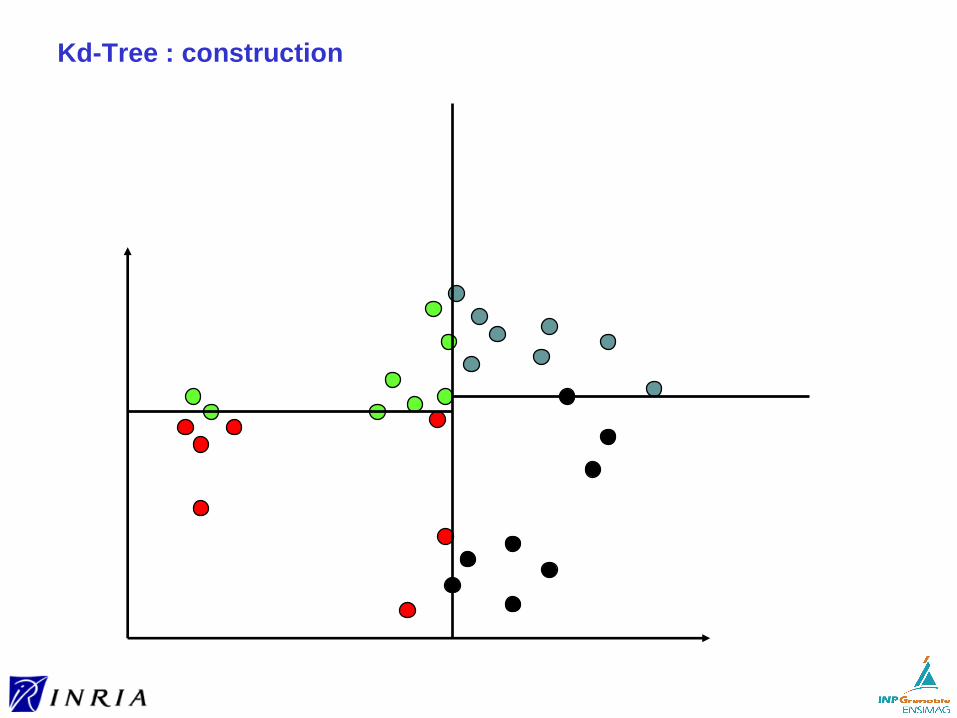
Kd-Tree : construction
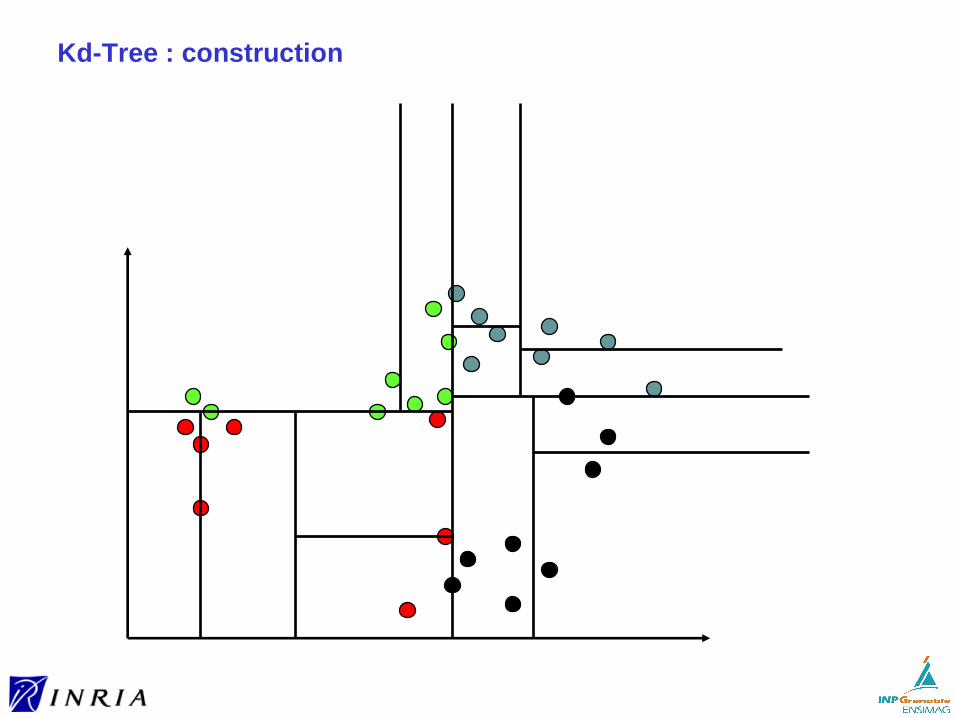
Kd-Tree : construction

Kd-Tree
C’est une partition de l’espace► toutes les cellules sont disjointes (pas de recouvrement)► cellules de tailles initialement équilibrées (par construction)► mais se déséquilibrent si insertion de vecteurs additionnels
peu efficace en grande dimension (ne filtre que peu de cellules)

Kd-Tree : recherche du ppv
arbre de recherche ► descente dans l’arbre (log) pour trouver la cellule ou tombe le point
on cherche le ppv dans la cellule → donne la meilleure distance r
recherche de l’intersection entre l’hypersphère de rayon r et l’hyperplan séparant la cellule► si non vide, analyse de l’autre côté de l’hyperplan► si un point plus proche est trouvé, on met à jour r
on analyse toutes les cellules de l’arbre qu’on l’on ne peut filtrer► dans le pire des cas, parcours total de l’arbre

Kd-tree : variantes
Elles sont nombreuses…
BSP Tree (Binary Space Partitioning)► la subdivision n’est pas parallèle au système de coordonnées
Variations► où on coupe une dimension donnée► quelle dimension est coupée► arbre équilibré ou non…

Malédiction de la dimension!
ou « fléau de la dimension » (The dimension curse)
Quelques propriétés surprenantes► vanishing variance► phénomène de l’espace vide► proximité des frontières

Vanishing variance
La distance entre paires de points tend à être identique quand d augmente► le plus proche voisin et le point le plus éloigné sont à des distances qui
sont presque identiques
Conséquence► le plus proche voisin devient très instable► inégalité triangulaire peu efficace pour filtrer
Les jeux de données uniformes ne peuvent pas être indexés efficacement► c’est moins vrai pour des données naturelles (ouf !)
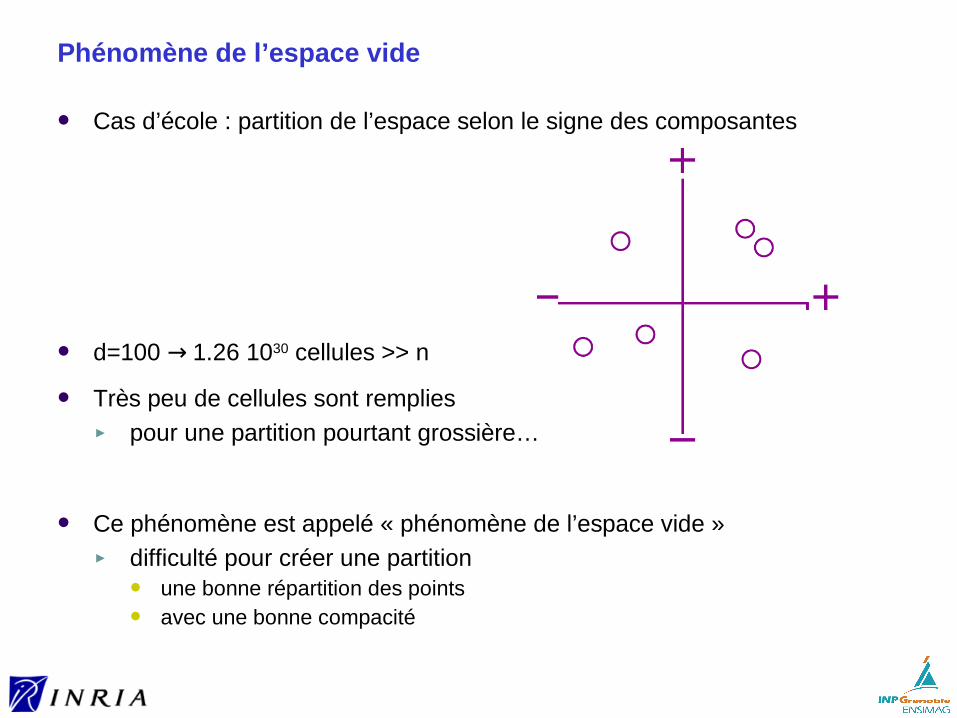
Phénomène de l’espace vide
Cas d’école : partition de l’espace selon le signe des composantes
d=100 → 1.26 1030 cellules >> n
Très peu de cellules sont remplies► pour une partition pourtant grossière…
Ce phénomène est appelé « phénomène de l’espace vide »► difficulté pour créer une partition
une bonne répartition des points avec une bonne compacité

Tout les vecteurs sont près des frontières
Pour un partitionnement de l’espace► les vecteurs sont très proches des surfaces de séparation avec une très
grande probabilité→ le plus proche voisin d’un point appartient à une cellule différente avec
une grande probabilité
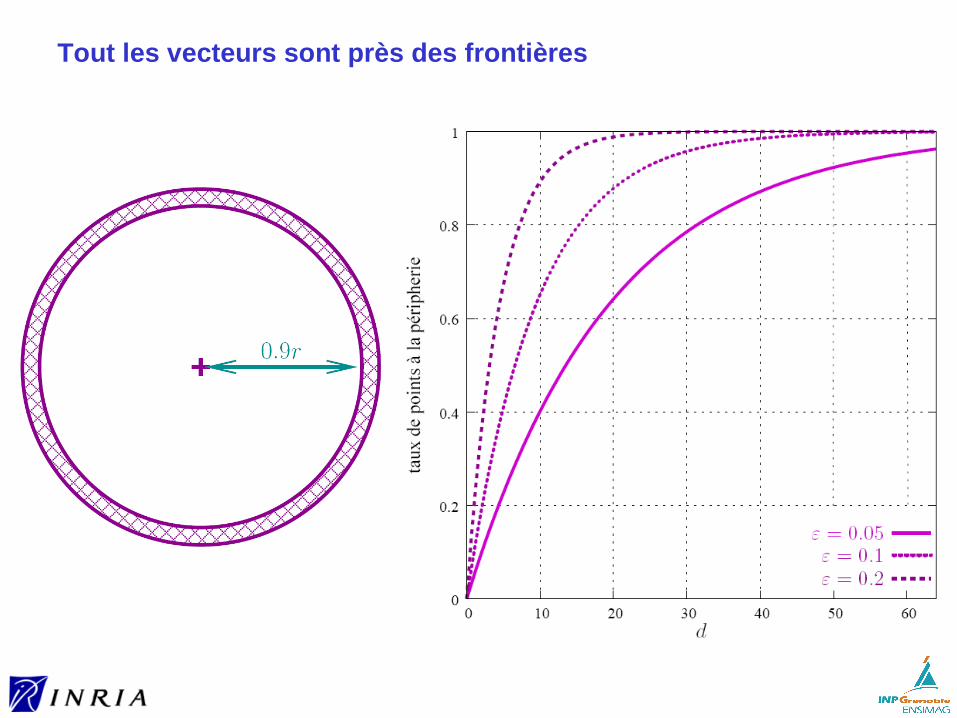
Tout les vecteurs sont près des frontières

LSH (1999)
Constat d’échec: pas d’algorithme de recherche de ppv efficace en grande dimension► pour d>15, il vaut mieux faire une recherche exhaustive !
Nouvel objectif : trouver nos voisins en probabilité ► que l’on peut faire varier en fonction du compromis pertinence/coût
recherché► c’est la recherche approximative de plus proches voisins
Cas d’échec (attendu)► lorsque le plus proche voisin n’est pas significativement plus proche
→ pas forcément grave en pratique
Explication au tableau

Euclidean Locality Sensitive Hashing (E2LSH)
1) Projection sur m directions aléatoires
2) Construction de fonctions de hashage: concatenation de k index hi par fonction de hash
3) Pour chaque gj, calcul de deux valeurs de hash
- fonctions de hash universelles: u1(.), u2(.)
- stockage de l’identifiant id du vecteur dans une table de hashage(1,0) (2,0) (3,0)
(0,0)
(3,1)(2,1)(1,1)(0,1)
(0,-1) (1,-1) (2,-1)
bi
0
1
1
1
1
22
2
w
O
a1
hi x=⌊x.ai−bi
w⌋
g j x =h j1 , ... , h jk

LSH marche correctement, mais pas à très grande échelle► nécessite beaucoup de hachages distincts de l’espace→ coût mémoire prohibitif en grande dimension→ temps de recherche linéaire avec le nombre de hachage
Utilisable jusqu’à (disons), 100x106 descripteurs (100000 images)
Le domaine de la recherche approximative est très actif ► outil de base dans de nombreux domaines/applications
Et la recherche d’images?

Réduction de la dimensionnalité
“La dimension gagne toujours” (Bill Triggs)
Réduisons la!
Approche la plus courante : analyse en composantes principales (ACP)► PCA en anglais : Principal Component Analysis
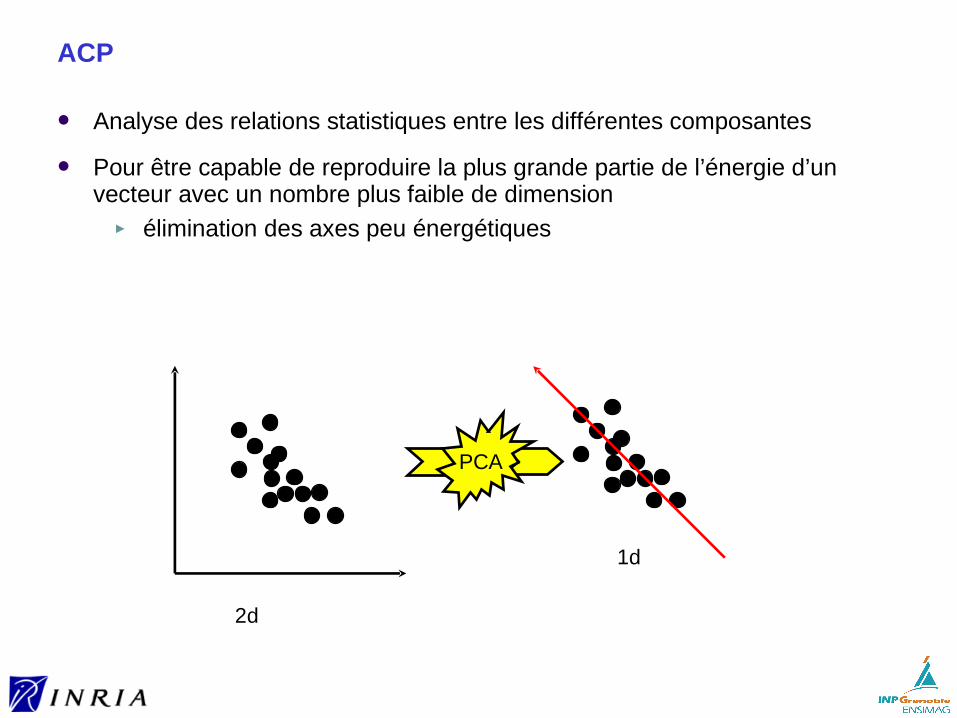
ACP
Analyse des relations statistiques entre les différentes composantes
Pour être capable de reproduire la plus grande partie de l’énergie d’un vecteur avec un nombre plus faible de dimension
► élimination des axes peu énergétiques
2d
1d
PCA

ACP
Il s’agit d’un changement de base► translation (centrage des données) + rotation
4 étapes (off-line)► centrage des vecteurs► calcul de la matrice de covariance► calcul des valeurs propres et vecteurs ► choix des d’ composantes les plus énergétiques (+ grandes valeurs
propres)
Pour un vecteur, les nouvelles coordonnées sont obtenues par centrage et multiplication du vecteur par la matrice d’ x d des vecteurs propres conservés

ACP
Moins de dimensions, donc meilleur comportement des algorithmes de recherche
Si la réduction préserve la plupart de l’énergie► les distances sont préservées► donc le + proche voisin dans l’espace transformé est aussi le plus
proche voisin dans l’espace initial
Limitations► utile seulement si la réduction est suffisamment réduite► lourdeur de mise à jour de la base (choix fixe des vecteurs propres
préférable)► peu adapté à certains types de variétés

Plan
Indexation mono-dimensionnelle
La malédiction de la dimension
Indexation multi-dimensionnelle
Perspectives

Bases de données multimédiaVII – “Video-Google”
ENSIMAG
2009
Hervé Jégou & Matthijs Douze

Video-Google
LA référence : Josef Sivic and Andrew Zisserman« Video Google: A Text Retrieval Approach to Object Matching in Videos »International Conference on Computer Vision, 2003 (ICCV’2003)
Idée : calquer le fonctionnement d’un moteur de recherche d’images sur celui d’un moteur de recherche de texte/page web
La plupart des systèmes de recherche d’images/de vidéos de l’état de l’art capable d’indexer de très gros volumes de données sont dérivés de cette approche► D. Nister and H. Stewenius : CVPR’2006► H. Jegou, M. Douze and C. Schmid : ECCV’2008

Étapes
Description locale : détecteurs + descripteurs
Filtrage spatial et temporel
Bag-of-words
Fichier inversé pour la requête
Re-ranking après vérification de la cohérence spatiale
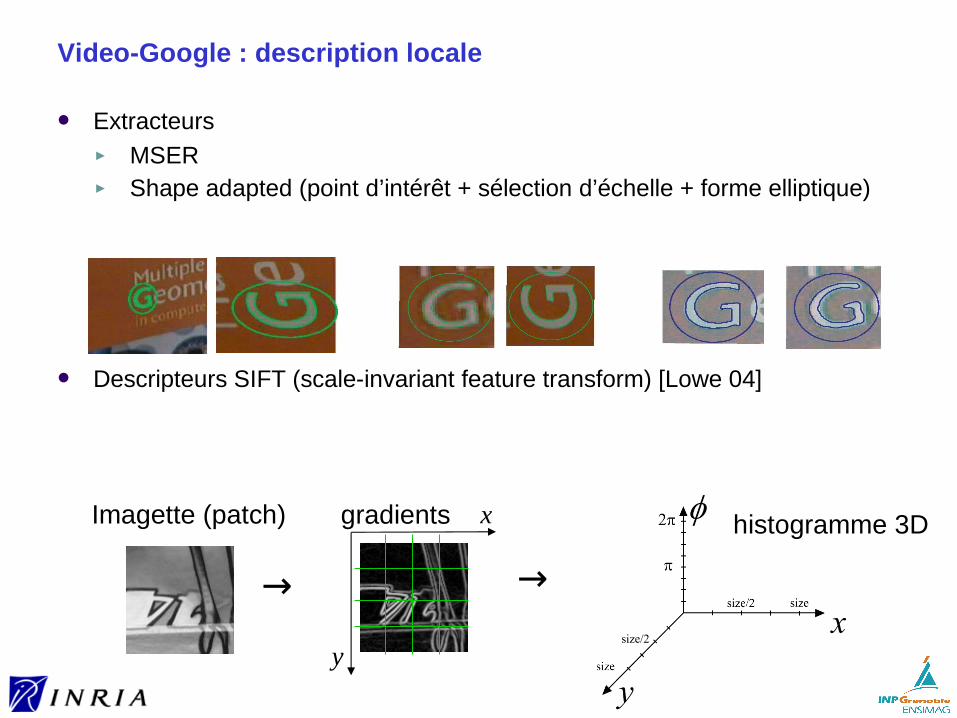
Video-Google : description locale
Extracteurs► MSER► Shape adapted (point d’intérêt + sélection d’échelle + forme elliptique)
Descripteurs SIFT (scale-invariant feature transform) [Lowe 04]
gradients histogramme 3D
→ →
Imagette (patch)
y
x

Video-Google : filtrage spatial et temporel
Idée : obtenue par analogie avec Google► Google améliore le score des pages pour lesquelles les mots-clés se
retrouvent à des positions proches dans le texte
Filtrage spatial► on ne garde un match que si ses voisins géométriques matchent aussi► variante : vérification géométrique plus forte (voir chapitre IV)
→ calcul de la transformée affine
Filtrage temporel (pour les vidéos uniquement)► utilisation d’un modèle dynamique simple d’une frame à l’autre► on ne garde une région de description que si elle est suffisamment
stable d’une frame sur l’autre

Video-Google : bag-of-words (début)
L’objectif est d’obtenir l’équivalent des “mots” en requête textuelle
Pour cela, quantification vectorielle des descripteurs via un k-means
Algorithme du k-means au tableau
Exercice : montrer que cet algorithme minimise l’erreur quadratique moyenne des vecteurs d'apprentissage à leur centroide

Video-Google : bag-of-words (suite)
Exercice : où sont- MSER- Harris

Video-Google : bag-of-words (fin)
Une fois le clustering défini (une fois pour toutes), un document est représenté par un histogramme de ses mots visuels
Application d’une pondération “TFIDF” aux composantes de cet histogramme► objectif : donner plus d’importance aux mots visuels rares qu’à ceux qui
sont fréquents► même pondération que celle utilisée en indexation de documents
textuels
ti=nid
nd
log Nni
Nb d'occurrences de idans doc d
Nb de mots dans doc d
Nb de documentsdans la base
Nb d'occurrences dei dans toute la base

Video-Google : fichier inversé
Voir le cours sur cette structure d’indexation
Utilisé pour comparer les vecteurs de fréquence
Mesure de similarité usuellement utilisée : produit scalaire
Analogie avec le texte► description d’un document► pondération des mots► utilisation de stoplists

Stoplists
On supprime 5% en haut, 10% en bas

Avec vocabulaire mieux équilibré
Obtenu avec plus de données d'apprentissage pour k-means
Stoplist moins utile
Cas idéal : répartition uniforme. ► complexité de la recherche en
fichier inversé en O(d s2)

Variante 1 : méthode hiérarchique de Nister et Stewénius
Motivation : réduire le coût d’assignement des “visual words”
Comment : utilisation d’un vocabulaire visuel hiérarchique
Voir au tableau
Autre éléments de la chaîne modifiés :► modification de la métrique de comparaison des mots visuels (L1)
Scalable Recognition with a Vocabulary Tree David Nistér and Henrik Stewénius, CVPR 06

Variante 2 : Jégou, Douze et Schmid
Principales idées : ► interpréter le système de sac-de-mots comme un système de recherche
approximative de plus proche voisins► Augmenter la sélectivité de celui-ci en rafinant la description du
descripteur► Utilisation de la “Weak geometry consistency” pour intégrer de
l’information spatiale
Méthode état de l’art en indexation image et vidéo► utilisée dans la compétition de copyright vidéo Trecvid► voir exposé séparé dans le chapitre suivant sur l’indexation vidéo

Bases de données multimédiaVIII – indexation vidéo
ENSIMAG
2009
Hervé Jégou & Matthijs Douze

Plan
Spécificité du problème
Filtrage temporel
Détecteur spatio-temporels
Aggrégation temporelle
Zoom sur deux méthodes d’indexation vidéo
MPEG7
Quelques perspectives

Spécificité du problème (début)
Vidéo = suite d’images
L’axe temporel t est singulier► processus physique différent des axes x et y : mouvement de la caméra
et des objets qui la composent► la nature des attaques est différente sur cet axe
Segmentation temporel en “plans” (au sens cinématographique)► c’est un problème en soi → assez bien maîtrisé aujourd’hui► indexation au niveau des plans plutôt que des images composant la
vidéo► Avantage?

Spécificité du problème (fin)
Indexation de vidéos = plusieurs problèmes distincts
1) Requête vidéo (souvent un plan)► problème qui est le plus souvent considéré
2) Requête image► asymétrie de la requête ► plus difficile (car moins d’information dans la requête, et pas de
description spatio-temporelle possible)► toutes les techniques ne s’appliquent pas
Dans l’état de l’art, deux classes d’approches► indexation des images composant la vidéo + intégration cohérence
temporelle► indexation spatio-temporelle (pas utilisable avec une requête image)

Plan
Spécificité du problème
Filtrage temporel
Détecteur spatio-temporels
Aggrégation temporelle
Zoom sur deux méthodes d’indexation vidéo
MPEG7
Quelques perspectives

Filtrage temporel
Idée [Sivic et Zisserman 2003]► indexation 2D « usuelle »► utilisation de la cohérence temporelle pour supprimer les descripteurs
non stables
Méthode► optionnellement, sous-échantillonnage (régulier ou par sélection
d’images clés) pour réduire le nombre d’images► génération de descripteurs pour chacune des images► appariemment des descripteurs de l’image t avec ceux des frames
voisines► calcul d’un modèle dynamique simple (non détaillé, plusieurs variantes
possibles) sur la position des descripteurs► suppression des descripteurs qui ne se reproduisent sur un voisinage
temporel suffisant ou d’une manière non cohérente avec le modèle

Détecteur spatio-temporel
Détecteur spatio-temporel [Laptev et Lindeberg 2003] : “Space-time Interest Points”
Extension de Harris à (x,y,t)
1) calcul de la matrice M d’auto-corrélation 3x3 : utilisation des dérivées gaussiennes avec une variance distincte pour l’axe temporel
2) modification du critère de Harris :
Ce critère permet de détecter les points qui présentent de fortes variations de luminosité en x, y et t (voir vidéo)
Comme pour les images, une sélection automatique d’échelle est possible via une selection des maxima de l’opérateur de Laplace (étendu à 3 dimensions)
Cette méthode donne le même status à l’axe temporel et aux axes spatiaux (sauf σ de dérivation)
H=det M−k trace3 M= 1 2 3−k 1 2 33

Aggrégation temporelle (1)
La première étape consiste usuellement à considérer que la base de vidéos est une base d’images (= ensemble des frames extraites)
Chaque frame de la requête est soumise à une base de frames qui représentent l’ensemble des vidéos à indexer
→ produit un ensemble de couple de frames et le score associé (tq, b, tb , s)
tq position temporelle dans la vidéo requête
b numéro de vidéo dans la basetb position temporelle dans la vidéo de la base
s score obtenu par l’algorithme d’appariemment d’image
• Dans ce qui suit : méthode utilisée lors de la compétition Trecvid

Aggrégation temporelle (2)
Problème : estimer une fonction entre tq et tb
Modèles possibles : ► simple (décalage temporel uniquement): tq = tb + t
► incluant des variations globale de vitesse (slow-motion): tq =a* tb + t
► complexe avec une table de décalage: tq = tb + shift [tq]
Méthodes d’estimation possibles► RANSAC► transformée de Hough► Dynamic Time Wrapping (DTW)
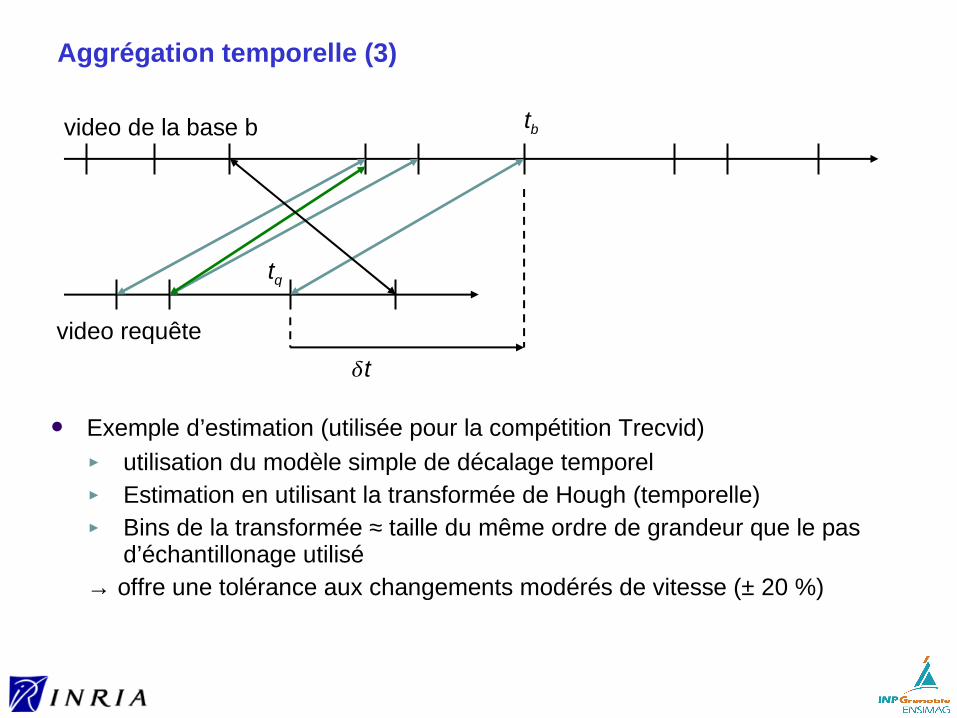
Aggrégation temporelle (3)
Exemple d’estimation (utilisée pour la compétition Trecvid)► utilisation du modèle simple de décalage temporel► Estimation en utilisant la transformée de Hough (temporelle)► Bins de la transformée ≈ taille du même ordre de grandeur que le pas
d’échantillonage utilisé→ offre une tolérance aux changements modérés de vitesse (± 20 %)
video requête
video de la base b
t
tq
tb
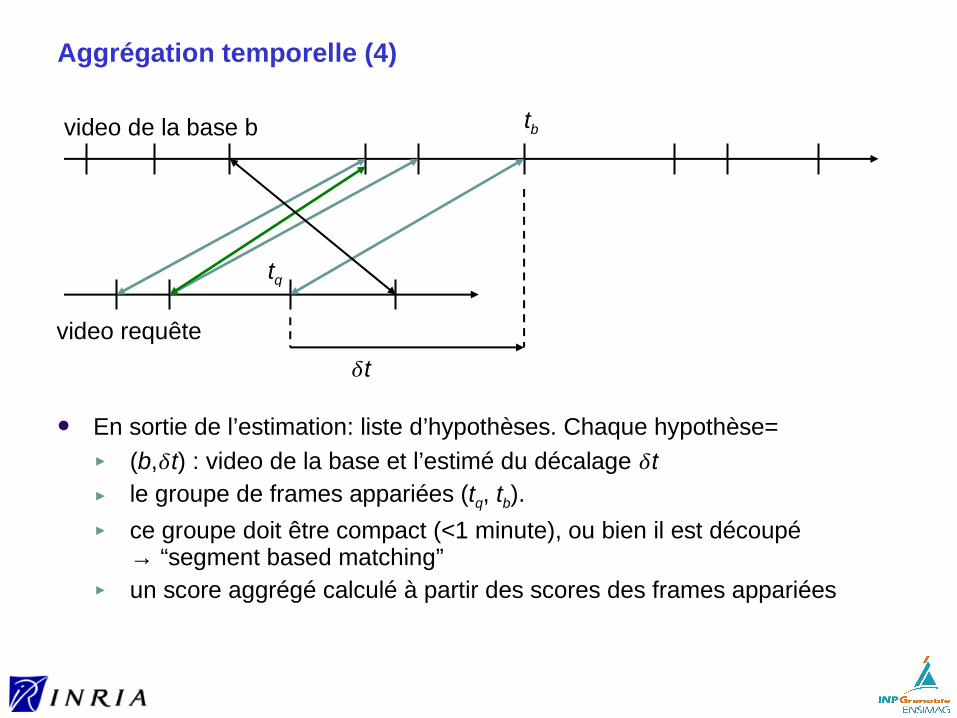
Aggrégation temporelle (4)
En sortie de l’estimation: liste d’hypothèses. Chaque hypothèse=► (b,t) : video de la base et l’estimé du décalage t ► le groupe de frames appariées (tq, tb). ► ce groupe doit être compact (<1 minute), ou bien il est découpé
→ “segment based matching”► un score aggrégé calculé à partir des scores des frames appariées
video requête
video de la base b
t
tq
tb

Vérification spatio-temporelle (1)
Objectif : estimation d’une transformée 2D entre la vidéo requête et la vidéo de la base de données
→ extension des techniques utilisées en image
Modèles possibles :► Pour des caméras différentes: géométrie épipolaire► Pour le camcording : modèle homographique► Modèle affine 2D (affine complet, similitude, translation, etc)
Problèmes► modèles peuvent changer dans le temps (d’une frame à l’autre)→ Question : pourquoi ?► échantillonnage différent côté base et requête (voir exemple au Tableau)

Vérification spatio-temporelle (2)
“Bon” choix: modèle affine 2D complet, avec paramètres fixés
Le modèle est estimé sur un groupe de frames appariées
→ c’est-à-dire, prend en entrée une hypothèse générée en sortie de l’aggrégation
Avantage d’un modèle de paramètres supposé fixe► tous points de tous les couples d’images appariées sont utilisés
→ beaucoup plus de points pour l’estimation que dans le cas image
• Modèle imparfait, mais pour lequel on peut obtenir une bonne estimation
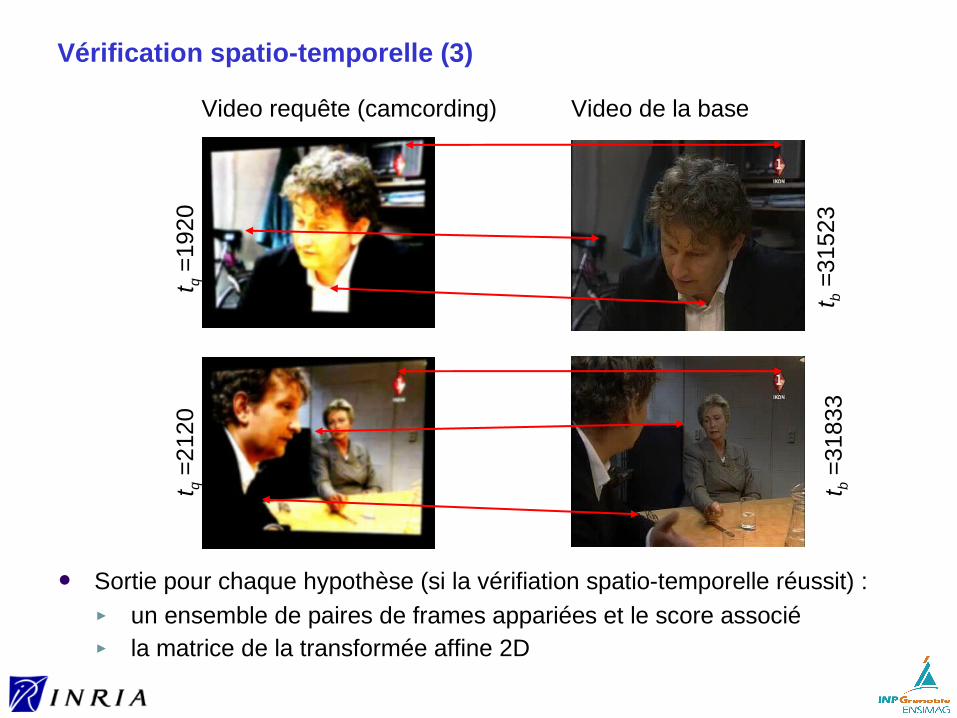
Vérification spatio-temporelle (3)
Sortie pour chaque hypothèse (si la vérifiation spatio-temporelle réussit) : ► un ensemble de paires de frames appariées et le score associé► la matrice de la transformée affine 2D
Video requête (camcording) Video de la base
t q =
192
0t q
=2
120
t b =
3152
3t b
=31
833

Dynamic Time Wrapping (DTW)
Algorithme de calcul de distance entre deux séquences► similaire à la distance d’édition► utilisée pour comparer les séquences sonores
Algorithme au tableau
Nécessité de normaliser les scores (typiquement, par la longueur de la séquence)
Question : quelle est la complexité de cet algorithme ?
Optimisation : techniques de “pruning”

Méthode utilisée pour la compétition Trecvid : vision d’ensemble

Exemple de requêtes

Exemples de requêtes

Indexation de gros volumes
Hypothèses : ► attaques faibles (pas/peu de déformation géométrique)► volume élevé (1000s d’heures)
Méthode► sélection d’images clés► calcul d’une signature binaire de petite taille (DCT, 64 bits)► utilisation d’une structure de hachage pour la requête : accès en O(1)
Xavier Naturel, Patrick Gros. A Fast Shot Matching Strategy for detecting duplicate sequences in a television stream. CVDB'05.

Plan
Spécificité du problème
Filtrage temporel
Détecteur spatio-temporels
Aggrégation temporelle
Zoom sur deux méthodes d’indexation vidéo
MPEG7
Quelques perspectives

MPEG7
Standard pour la description du contenu multimédia, en XML► cadre de description des données audio-visuelles► ensemble de méthodes pour les différentes phases de la description des
documents multimédias► définit des descripteurs pour les différents indices visuels présents dans
une vidéo
Norme : assurer l’interopérabilité des systèmes de génération, gestion, distribution des descriptions des contenus audio-visuels
Éléments d’intérêt pour l’indexation par le contenu :► descripteurs d’image globaux (couleur, texture, forme) + fonctions de
comparaison associées► une mesure de pertinence (average normalized modified retrieved rank)
d’une recherche

Plan
Spécificité du problème
Filtrage temporel
Détecteur spatio-temporels
Aggrégation temporelle
Zoom sur une méthode d’indexation ultra-rapide
MPEG7
Quelques perspectives

Problèmes d’intérêt et perspectives
Descripteurs spatio-temporels : en émergence► dérivés des invariants différentiels (Joly et al.)► Harris 3D (Laptev et al.)► en compression : mouvement = 30% du train binaire
→ info sous-utilisée en indexation
En conclusion► domaine de recherche très actif car récent
→ les capacités de calcul des ordinateurs permettent depuis très peu de temps de traiter des grands volumes de données
► Compétitions pour comparer les méthodes : Trecvid, VideOlympics

Bases de données multimédiaIX – compléments de cours
ENSIMAG
2009
Hervé Jégou & Matthijs Douze

Plan
Expansion de requêtes
Classification
Retour de pertinence
Data-Mining and Latent Semantic Indexing

Principe
Utile pour une requête populaire ► c-a-d, beaucoup d’occurrences de la scène dans la base d’images► permet de renvoyer toute les occurrences (augmentation du rappel)
Exemple:► trouver tous les points de vue
12 résultats 41 résultats 44 résultats

Algorithmes: expansion transitive (TCE)
queue = [requête]
résultats = vide
tant que queue non vide
requête2 = queue.pop()
résultats2 = recherche(requête2)
pour image dans résultats2
ajouter image à résultats
si image très fiable, queue.push(image)
retourner résultats
Total Recall: Automatic Query Expansion with a Generative Feature Model for Object RetrievalO. Chum, J. Philbin, J. Sivic, M. Isard, A. Zisserman, ICCV 07

Algorithmes: expansion moyenne (AQE)
descripteurs = descripteurs_points_intérêt(requête)
résultats = vide
tant que descripteurs non stable
résultats2 = recherche(descripteurs)
pour image dans résultats2
ajouter image à résultats
si image très fiable
dtran = transfo(descripteurs_points_intérêt(image))
ajouter dtran à descripteurs
retourner résultats

Plan
Expansion de requêtes
Classification
Retour de pertinence
Data-Mining and Latent Semantic Indexing

Classification: objectif
On veut reconnaître► une classe d’objets (visages, piétons, montagnes, voiture, etc)► un objet (en tenant compte de ses différents aspects) : visages ??

Classification: objectif
est plus dur que rechercher des images de contenu similaire à une image requête
il requiert des informations sémantiques
moins ambitieux en volume de données et invariance…

Classification : modèle visuel
Modèle visuel = description d’image + algorithme d’apprentissage
Construction d’un modèle visuel : approche générique► à partir d’un ensemble d’images annotées
positif/négatif labels
► description des images descripteurs locaux/globaux, invariants aux transformations images descripteurs discriminants pour les classes considérées ou génériques (SIFT)
► variations d’apparence : déterminer une fonction discriminante Support Vector Machines (SVM) réseaux neuronaux

Classification: descripteurs
Principe : plus de données c’est mieux
Détecteurs :► points d’intérêt : souvent trop peu de points, invariance inutile► dense : sliding window, multi-échelle► aléatoires : paramétrage facile du nombre de fenêtres
Descripteurs :► SIFT ou généralisation (HOG)► couleurs ► souvent une combinaison
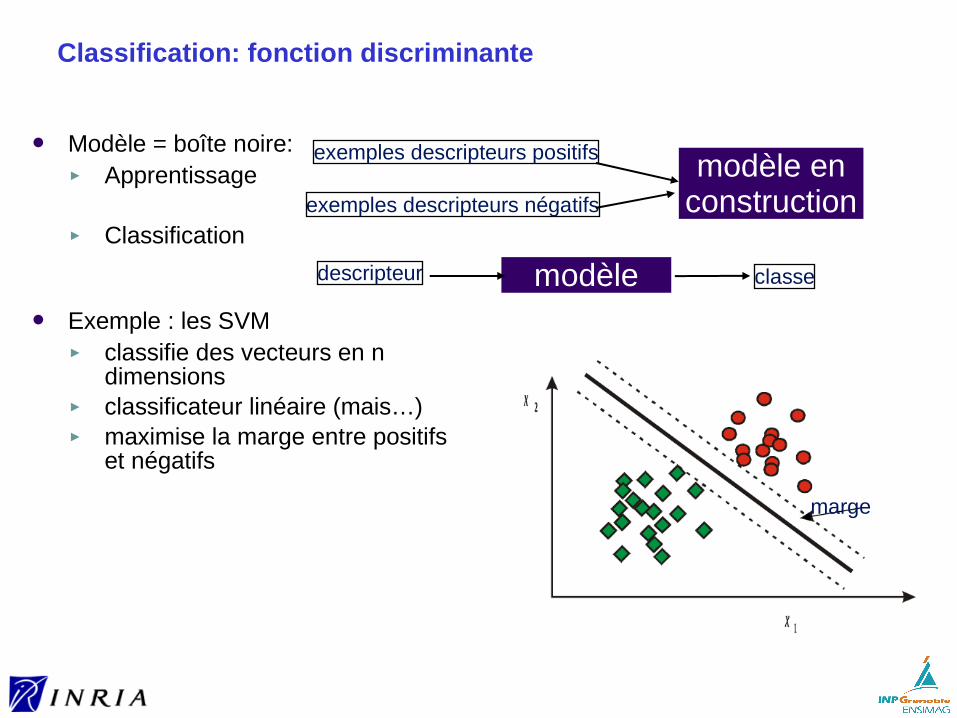
Classification: fonction discriminante
Modèle = boîte noire:► Apprentissage
► Classification
Exemple : les SVM► classifie des vecteurs en n
dimensions► classificateur linéaire (mais…)► maximise la marge entre positifs
et négatifs
exemples descripteurs positifs
exemples descripteurs négatifs
modèle en construction
descripteur modèle classe
marge

Classification: conclusion
Domaine en développement► exemple: détection de visages ok, reconnaissance, hum► nécessite puissance de calcul► peu d’invariance► classificateurs spécialisés (lettres, visages,…)
Généralisation à la vidéo (cf. clip)

Plan
Expansion de requêtes
Classification
Retour de pertinence
Data-Mining and Latent Semantic Indexing

Retour de pertinence
Motivation : la recherche d’information multimédia par le contenu donne souvent des résultats décevants
Plusieurs raisons à cela► un document multimédia est très riche► les primitives sont extraites à partir d’informations brutes► deux utilisateurs n’attendent pas la même chose d’une même requête :
quels indices visuels exploiter ?

Retour de pertinence (suite)
Hiérarchie de représentations, avec poids► O: objet (poids U)► P: primitive (poids V)► R: représentations (poids w)
Questions : Comment fixer les poids? Qu’est-ce qu’une bonne représentation?
Premiers travaux : choix des poids à la main par le développeur. L’utilisateur pouvait ensuite jouer sur les poids → interaction et résultats peu satisfaisants
SOLUTION : utiliser l’interaction avec l’utilisateur► apprentissage des distances par ajustement des poids► l’utilisateur indique de manière interactive les résultats pertinents► méthodes IA, bayésienne, de type « recherche d’information »

Interface pour le retour de pertinence
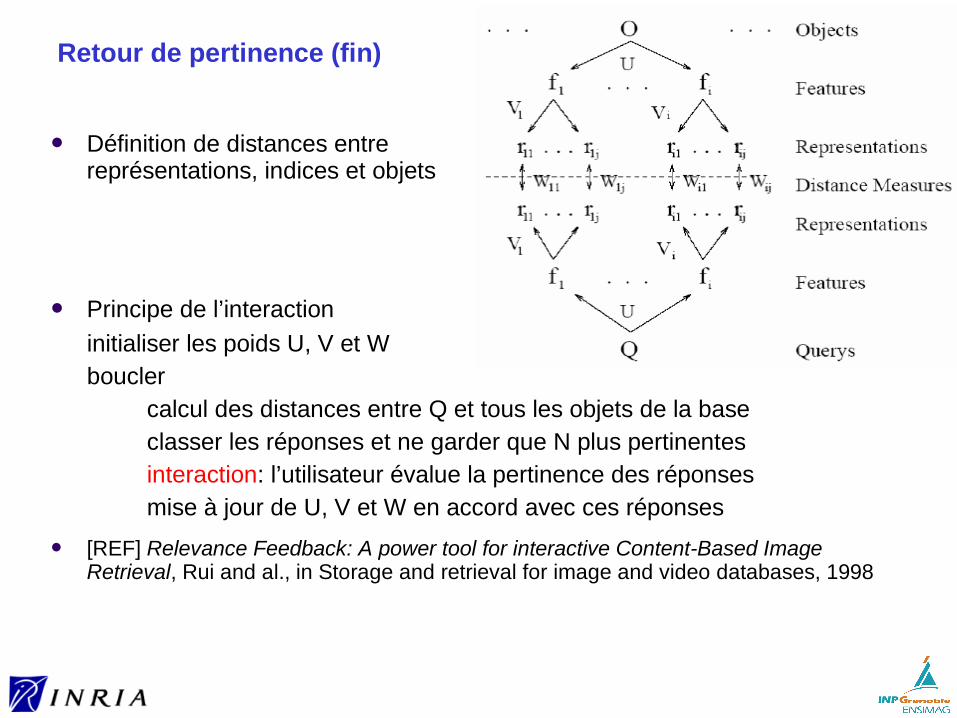
Retour de pertinence (fin)
Définition de distances entrereprésentations, indices et objets
Principe de l’interaction
initialiser les poids U, V et Wboucler
calcul des distances entre Q et tous les objets de la baseclasser les réponses et ne garder que N plus pertinentesinteraction: l’utilisateur évalue la pertinence des réponsesmise à jour de U, V et W en accord avec ces réponses
[REF] Relevance Feedback: A power tool for interactive Content-Based Image Retrieval, Rui and al., in Storage and retrieval for image and video databases, 1998

Plan
Expansion de requêtes
Classification
Retour de pertinence
Data-Mining and Latent Semantic Indexing

Latent Semantic Indexing (début)
C’est une technique de « data-mining », c-a-d d’inférence automatique d’information à partir de gros volumes de données
Latent Semantic Indexing (LSI)► très efficace pour la recherche de documents « textes », mais aussi
performante pour l’analyse d’image construit de manière statistique les relations entre mots et documents permet de découvrir « les expressions clefs » d’un document
Traditionnellement, recherche des mots-clés de la requête dans les documents
Mais : polysémie, synonymie
Avec LSI, la notion de « mot » est remplacée par celle de « concept »

Latent Semantic Indexing (suite)
Hypothèse : il existe une relation entre mots et documents qui est gouvernée par un paramètre caché : le sens
LSI► construction de la matrice mots/documents► calcul d’une décomposition SVD de la matrice termes/documents A={ai,j}
ai,j est la fréquence du mot i dans le document j (le + souvent pondérée)
► l’espace des sens sera l’espace réduit des k premiers vecteurs propres→ espace vectoriel sémantique
► documents et mots deviennent des points de cet espace
Une requête peut être vue comme un pseudo-document et projetée dans cet espace → recherche des voisins dans cet espace
Dans un contexte d’image, LSI s’applique en utilisant des mots visuels

FIN
Bonne chance pour la suite