apache hadoop - pages.lip6.fr · apache hadoop : une plate-forme d'exécution de programmes...
TRANSCRIPT

Apache Hadoop : une plate-forme d'exécution deprogrammes Map-Reduce
Jonathan Lejeune
UPMC/LIP6-INRIA
CODEL � Master 2 SAR 2016/2017
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 1 / 51

Présentation
Qu'est ce que c'est ?
Une plate-forme open-source :
développée en Java par la fondation Apache
adaptée pour les données massives
stockage distribuétraitement via le modèle du Map-Reduce
Bref historique
2006 : création par Doug Cutting (version 0.1.0)
2008 : Yahoo utilise Hadoop pour l'indexage de page web
2009 : Yahoo ! tri 1 To en 62 sec avec Hadoop
�n 2013 : Hadoop 2
version stable actuelle : Hadoop 2.7
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 2 / 51

Utilisateurs d'Hadoop
Amazon (EMR? Elastic MapReduce )
Yahoo !
IBM : Blue Cloud
Joost (video distribution)
Last.fm (free internet radio)
New York Times
PowerSet (search engine natural laguage)
Veoh (online video distribution)
Plein d'autres sur http ://wiki.apache.org/hadoop/PoweredBy
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 3 / 51
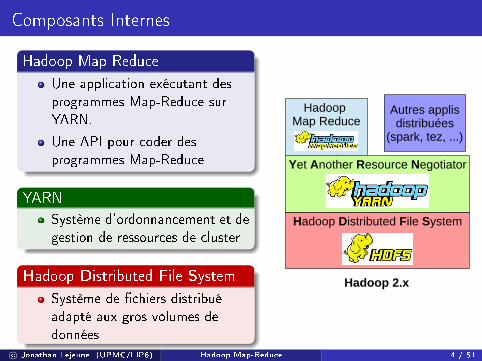
Composants Internes
Hadoop Map Reduce
Une application exécutant desprogrammes Map-Reduce surYARN.
Une API pour coder desprogrammes Map-Reduce
YARN
Système d'ordonnancement et degestion de ressources de cluster
Hadoop Distributed File System
Système de �chiers distribuéadapté aux gros volumes dedonnées
Hadoop Map Reduce
Hadoop Distributed File System
Hadoop 2.x
Yet Another Resource Negotiator
Autres applisdistribuées
(spark, tez, ...)
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 4 / 51
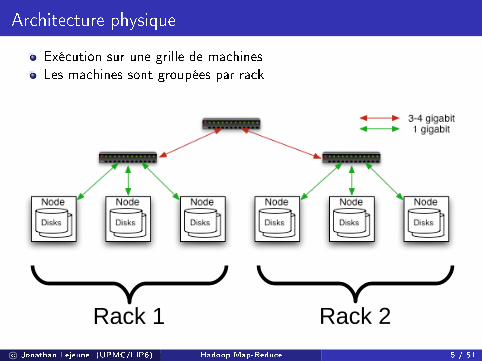
Architecture physique
Exécution sur une grille de machinesLes machines sont groupées par rack
Rack 1 Rack 2
généralement une architecture à 2 niveauxc© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 5 / 51

Hadoop Distributed File System
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 6 / 51

HDFS : Généralités
Objectif
Système de �chiers distribué, tolérant aux pannes et conçu pour
stocker des �chiers massifs (> To).
Caractéristiques
Les �chiers sont divisés en blocs de 128 Mo (valeur par défaut)⇒ adapté aux gros �chiers⇒ inadapté au multitude de petits �chiers
Mode 1 écriture/plusieurs lectures :
Lecture séquentielle⇒ on privilégie le débit à la latence⇒ la lecture d'une donnée implique une latence élevée
Écriture en mode append-only⇒ on ne peux pas modi�er les données existantes d'un �chier⇒ impossible d'avoir plusieurs écrivains, ou de modi�er un endroit
arbitraire du �chier
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 7 / 51
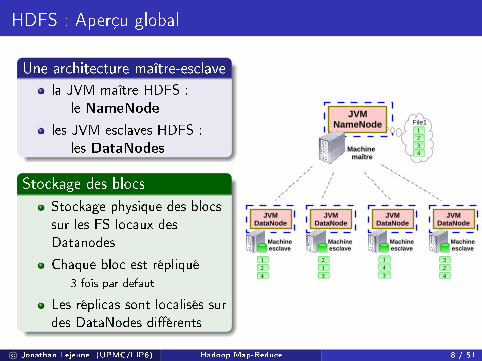
HDFS : Aperçu global
Une architecture maître-esclave
la JVM maître HDFS :le NameNode
les JVM esclaves HDFS :les DataNodes
Stockage des blocs
Stockage physique des blocssur les FS locaux desDatanodes
Chaque bloc est répliqué3 fois par defaut
Les réplicas sont localisés surdes DataNodes di�érents
124
213
143
324
JVMNameNode
1234
File1
Machine maître
JVMDataNode
Machineesclave
JVMDataNode
Machineesclave
JVMDataNode
Machineesclave
JVMDataNode
Machineesclave
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 8 / 51

HDFS : le NameNode
Rôle du NameNode
Gère l'allocation, la distribution et la réplication des blocs
Interface du HDFS avec l'extérieur
Information et méta-données maintenues
liste des �chiers
liste des blocs pour chaque �chier et du DataNode hébergeur
liste des DataNodes pour chaque bloc
attributs des �chiers (ex : nom, date création, facteur de réplication)
Le nb de �chiers du HDFS est limité par la capacité mémoire du
NameNode
Journalisation des actions sur un support persistant
lectures, écritures, créations, suppressions
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 9 / 51

HDFS : le Datanode
Rôle du DataNode
Stocke des blocs de données dans le système de �chier local
Serveur de bloc de données et de méta-données pour le client HDFS
Maintient des méta-données sur les blocs possédés (ex : CRC)
Communication avec le NameNode
Heartbeat :
message-aller : capacité totale, espace utilisé/restantmessage-retour : des commandes
copie de blocs vers d'autres Datanodes
invalidation de blocs
...
Informe régulièrement le Namenode des blocs contenus localement
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 10 / 51
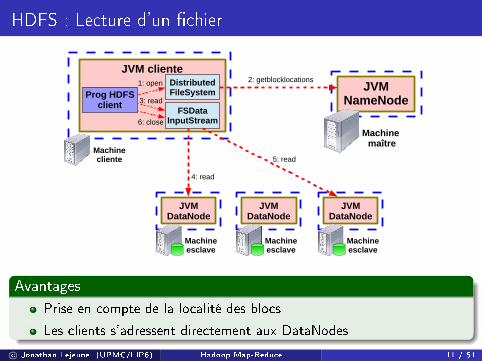
HDFS : Lecture d'un �chier
JVMNameNode
Machine maître
JVMDataNode
Machineesclave
JVMDataNode
Machineesclave
JVMDataNode
Machineesclave
JVM cliente
Machinecliente
DistributedFileSystem
FSDataInputStream
Prog HDFSclient
1: open 2: getblocklocations
3: read
4: read
6: close
5: read
Avantages
Prise en compte de la localité des blocs
Les clients s'adressent directement aux DataNodes
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 11 / 51
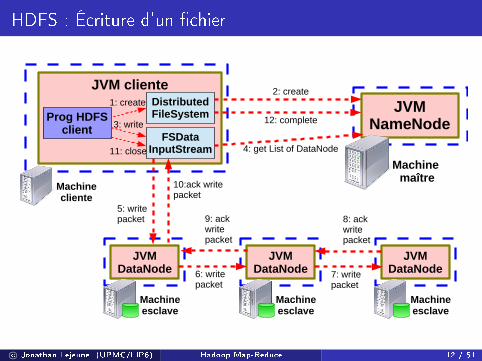
HDFS : Écriture d'un �chier
JVMNameNode
Machine maître
JVMDataNode
Machineesclave
JVMDataNode
Machineesclave
JVMDataNode
Machineesclave
JVM cliente
Machinecliente
DistributedFileSystem
FSDataInputStream
Prog HDFSclient
1: create2: create
3: write
5: write packet
11: close
12: complete
10:ack write packet
4: get List of DataNode
6: write packet
8: ack write packet
9: ack write packet
7: write packet
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 12 / 51

HDFS : stratégie de placement des blocs
Stratégie courante :
un réplica sur le rack local
un second réplica sur un autre rack
un troisième réplica sur un rack d'un autre datacenter
les réplicas supplémentaires sont placés de façon aléatoire
Le client lit le plus proche réplica
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 13 / 51
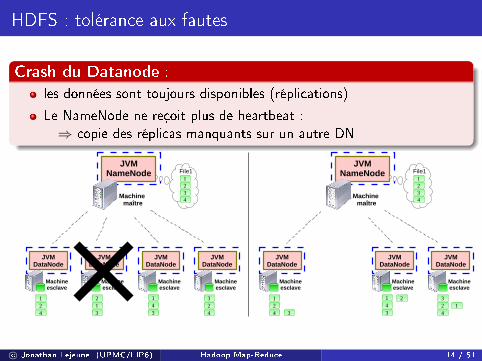
HDFS : tolérance aux fautes
Crash du Datanode :
les données sont toujours disponibles (réplications)
Le NameNode ne reçoit plus de heartbeat :⇒ copie des réplicas manquants sur un autre DN
124
213
143
324
JVMNameNode
1234
File1
Machine maître
JVMDataNode
Machineesclave
JVMDataNode
Machineesclave
JVMDataNode
Machineesclave
JVMDataNode
Machineesclave
124
21
3
143
324
JVMNameNode
1234
File1
Machine maître
JVMDataNode
Machineesclave
JVMDataNode
Machineesclave
JVMDataNode
Machineesclave
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 14 / 51

HDFS : tolérance aux fautes
Crash du NameNode :
Le service devient indisponible
Sauvegarde préventive des logs de transaction sur un support stable⇒ si redémarrage, chargement de la dernière image du HDFS et
application des logs de transaction
JVMNameNode
Machine maître
Logs
Journalisationdes modifdu HDFS
fsimage
JVMNameNode
Machine maître
Logs
fsimage
JVM NameNode(Recovery)
Machine maître
Logs
fsimage
2 :Recouvrementdes logs
nonpris encompte
1 : (re)démarage
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 15 / 51

HDFS : tolérance aux fautes
Problème !
Rares redémarrages du Namenode
⇒ énorme quantité de logs de transaction : stockage conséquent
⇒ Prise en compte de beaucoup de changements : redémarrages longs
Solution
Produire des images HDFS plus récentes :
utilisation d'un (ou plusieurs) processus distant(s) appeléSecondaryNameNode
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 16 / 51
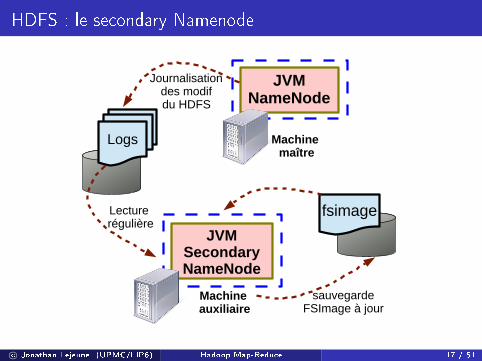
HDFS : le secondary Namenode
JVMNameNode
Machine maître
Logs
Journalisationdes modifdu HDFS
fsimage
JVMSecondaryNameNode
Machine auxiliaire
Lecture régulière
sauvegardeFSImage à jour
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 17 / 51

HDFS
Manipuler le HDFS
avec une API Java
avec un terminal grâce à la commande :
hdfs dfs <commande HDFS>
Exemple de commandes
Commandes HDFS similaires celles d'Unix en ajoutant un tiret devant :
hdfs dfs -ls <path>
hdfs dfs -mv <src> <dst>
hdfs dfs -cp <src> <dst>
hdfs dfs -cat <src>
hdfs dfs -put <localsrc> ... <dst>
hdfs dfs -get <src> <localdst>
hdfs dfs -mkdir <path>
RTFM pour les autres :).
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 18 / 51

HDFS : API Java
Obtenir une référence Java du HDFS
Le HDFS est représentée par un objet FileSystem :
final FileSystem fs = FileSystem.get(conf);
L'argument con�guration contient des properties JAVA indiquantl'URL du NameNode
Quelques méthodes
// cop i e d ' un f i c h i e r / d o s s i e r l o c a l c l i e n t v e r s l e HDFSf s . copyF romLoca lF i l e ( s r c , d s t ) ;// c op i e d ' un f i c h i e r / d o s s i e r HDFS v e r s l e f s l o c a l c l i e n tf s . c opyToLoca lF i l e ( s r , d s t ) ;// c r e a t i o n / ec rasement d ' un f i c h i e rFSDataOutputStream out = f s . c r e a t e ( f ) ;// t e s t d ' e x i s t e n c e d ' un f i c h i e rboolean b = f s . e x i s t s ( f ) ;// ou v e r t u r e en e c r i t u r e ( append on l y )FSDataOutputStream out = f s . append ( f ) ;// ou v e r t u r e en l e c t u r eFSDataInputStream i n = f s . open ( f ) ;
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 19 / 51

Yet Another Resource Negotiator
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 20 / 51

YARN : Généralités
Objectif
Service de gestion de ressources de calcul distribuées
Caractéristiques
Existe depuis la Hadoop 2
Une architecture maître-esclaves
Gestion d'applications distribuées :⇒ Allocation/placement de containers sur les n÷uds esclaves
Une container = une abstraction de ressources de calcul :⇒ couple <nb processeurs, quantité mémoire>
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 21 / 51

YARN : les démons maîtres-esclaves
ResourceManager (RM)
JVM s'exécutant sur le n÷udmaître
contrôle toutes les ressourcesdu cluster
ordonnance les requêtes clientes
NodeManager (NM)
une JVM par machine esclave
gère les ressources du n÷ud
lance les container et lesmonitore
Machine maître
JVMResourceManager
JVMNameNode
Machine esclave
JVMDataNode
JVMNodeManager
Machine esclave
JVMDataNode
JVMNodeManager
Machine esclave
JVMDataNode
JVMNodeManager
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 22 / 51
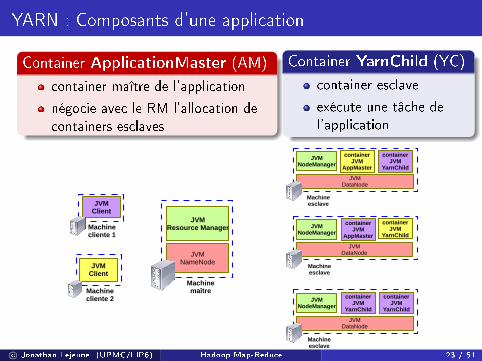
YARN : Composants d'une application
Container ApplicationMaster (AM)
container maître de l'application
négocie avec le RM l'allocation decontainers esclaves
Container YarnChild (YC)
container esclave
exécute une tâche del'application
Machine maître
JVMResource Manager
JVMNameNode
Machine cliente 2
JVMClient
Machine cliente 1
JVMClient
Machine esclave
JVMDataNode
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
Machine esclave
JVMDataNode
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
Machine esclave
JVMDataNode
JVMNodeManager
containerJVM
YarnChild
containerJVM
YarnChild
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 23 / 51
YARN : ResourceManager
Machine maître
JVMResource Manager
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
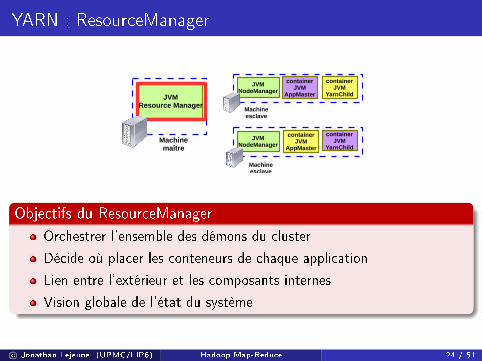
Objectifs du ResourceManager
Orchestrer l'ensemble des démons du cluster
Décide où placer les conteneurs de chaque application
Lien entre l'extérieur et les composants internes
Vision globale de l'état du système
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 24 / 51
YARN : ResourceManager
Machine maître
JVMResource Manager
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
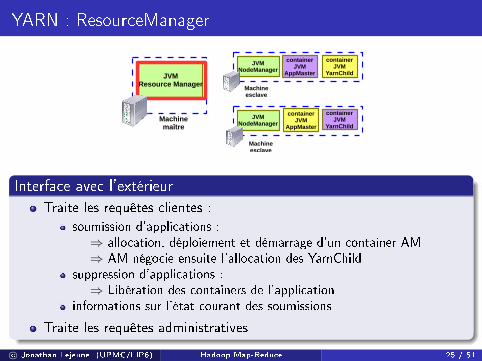
Interface avec l'extérieur
Traite les requêtes clientes :
soumission d'applications :⇒ allocation, déploiement et démarrage d'un container AM⇒ AM négocie ensuite l'allocation des YarnChild
suppression d'applications :⇒ Libération des containers de l'application
informations sur l'état courant des soumissions
Traite les requêtes administratives
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 25 / 51
YARN : ResourceManager
Machine maître
JVMResource Manager
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
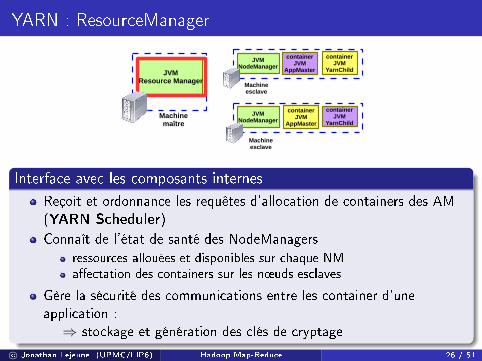
Interface avec les composants internes
Reçoit et ordonnance les requêtes d'allocation de containers des AM(YARN Scheduler)
Connaît de l'état de santé des NodeManagers
ressources allouées et disponibles sur chaque NMa�ectation des containers sur les n÷uds esclaves
Gère la sécurité des communications entre les container d'uneapplication :⇒ stockage et génération des clés de cryptage
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 26 / 51
YARN : NodeManager
Machine maître
JVMResource Manager
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
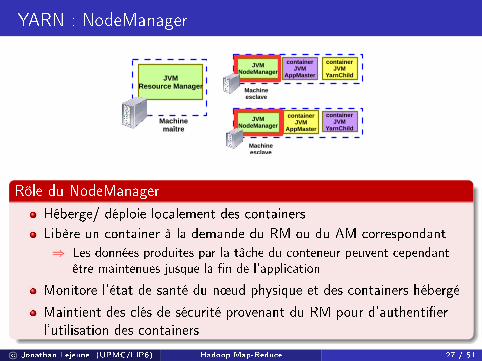
Rôle du NodeManager
Héberge/ déploie localement des containers
Libère un container à la demande du RM ou du AM correspondant
⇒ Les données produites par la tâche du conteneur peuvent cependantêtre maintenues jusque la �n de l'application
Monitore l'état de santé du n÷ud physique et des containers hébergé
Maintient des clés de sécurité provenant du RM pour d'authenti�erl'utilisation des containers
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 27 / 51
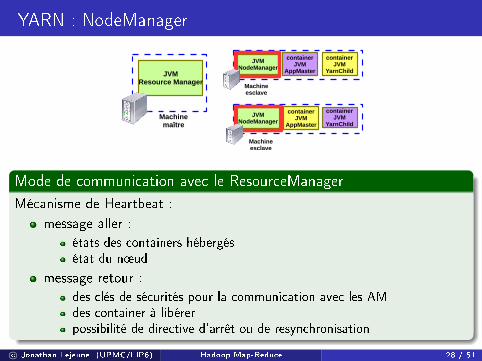
YARN : NodeManager
Machine maître
JVMResource Manager
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
Mode de communication avec le ResourceManager
Mécanisme de Heartbeat :
message aller :
états des containers hébergésétat du n÷ud
message retour :
des clés de sécurités pour la communication avec les AMdes container à libérerpossibilité de directive d'arrêt ou de resynchronisation
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 28 / 51
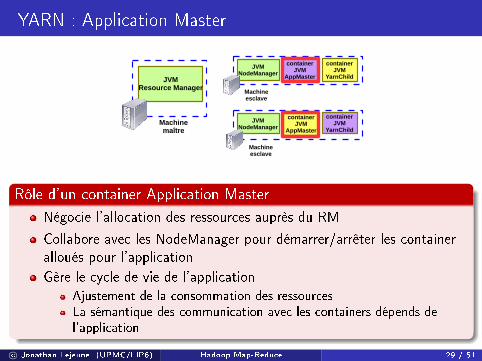
YARN : Application Master
Machine maître
JVMResource Manager
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
Rôle d'un container Application Master
Négocie l'allocation des ressources auprès du RM
Collabore avec les NodeManager pour démarrer/arrêter les containeralloués pour l'application
Gère le cycle de vie de l'application
Ajustement de la consommation des ressourcesLa sémantique des communication avec les containers dépends del'application
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 29 / 51
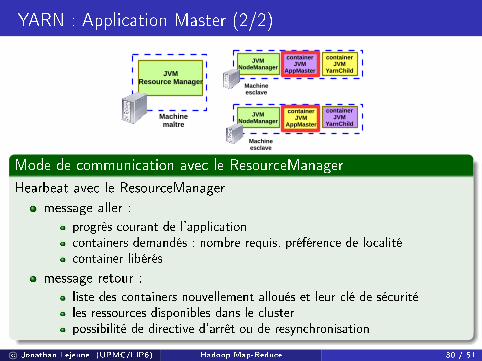
YARN : Application Master (2/2)
Machine maître
JVMResource Manager
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
Mode de communication avec le ResourceManager
Hearbeat avec le ResourceManager
message aller :
progrès courant de l'applicationcontainers demandés : nombre requis, préférence de localitécontainer libérés
message retour :
liste des containers nouvellement alloués et leur clé de sécuritéles ressources disponibles dans le clusterpossibilité de directive d'arrêt ou de resynchronisation
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 30 / 51
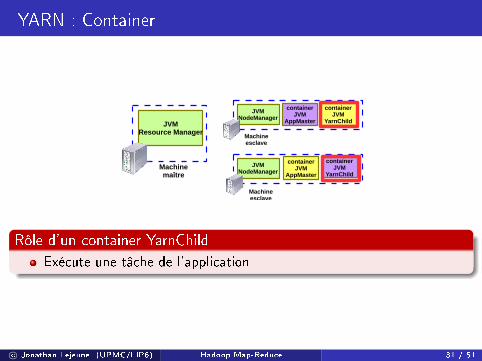
YARN : Container
Machine maître
JVMResource Manager
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
Machine esclave
JVMNodeManager
containerJVM
YarnChild
containerJVM
AppMaster
Rôle d'un container YarnChild
Exécute une tâche de l'application
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 31 / 51
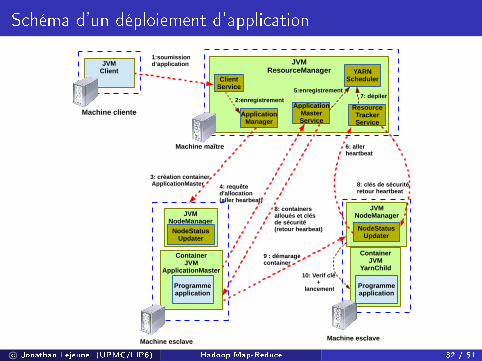
Schéma d'un déploiement d'application
JVMResourceManager
Machine maître
ClientService
Machine cliente
JVMClient
1:soumissiond’application
4: requête d'allocation(aller hearbeat)
9 : démaragecontainer
ContainerJVM
YarnChild
ApplicationManager
2:enregistrement
Machine esclave
JVMNodeManager
3: création container ApplicationMaster
ContainerJVM
ApplicationMaster
ApplicationMasterService
YARNScheduler
5:enregistrement
6: aller heartbeat
7: dépiler
8: containers alloués et clés de sécurité(retour hearbeat)
8: clés de sécuritéretour heartbeat
JVMNodeManager
NodeStatusUpdater
Programmeapplication
NodeStatusUpdater
Programmeapplication
ResourceTrackerService
Machine esclave
10: Verif clé +
lancement
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 32 / 51

YARN : les di�érentes politiques du YARN Scheduler
FIFO scheduler
Les requêtes sont traités dans l'ordre de leur arrivée
Très simple
Partage du cluster peu e�cace
Capacity scheduler
Plusieurs �les d'attentes hiérarchiques avec une capacité max prédé�nie
Les petites requêtes ne sont pas pénalisés
Toutes les ressources ne sont pas utilisées
Fair scheduler
La capacité allouée à chaque client est la même :
Allocation dynamique, pas d'attente
La capacité allouée à un job diminue avec la charge
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 33 / 51

YARN : tolérance aux panne du ResourceManager
Actions préventives
Sauvegardes régulières de l'état du RM sur support stable (ex : HDFS) :
liste de toutes les applications soumises et de leur méta-données
liste des états des n÷uds esclaves du cluster
Au redémarrage du Resource Manager
1ère phase : restauration de sa connaissance des applicationssoumises et de l'état des n÷uds depuis le support stable
2ème phase : restauration de sa vision du contexte d'exécution detoute les applications et de leurs conteneurs :
depuis les méta-données sauvegardéespuis progressivement via les heartbeats (statut des conteneur) des NMet des AM (requêtes de conteneur) :
Permet de reconstruire l'ordonnanceur du RM sans
redémarrer depuis le début l'ensemble des applications
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 34 / 51

YARN : tolérance aux crashs d'un n÷ud esclave
Pour le NodeManager
Le NodeManager n'émet plus de heartbeat au RM
−→ Le RM supprime le n÷ud de ses esclaves opérationnels tant qu'il n'apas redémarré
Pour les ApplicationMaster
Les containers AppMaster n'émettent plus de heartbeat au RM
−→ redémarrage d'une nouvelle instance de l'application en créant unnouvel AppMaster l'application
Pour les YarnChild
Les containers YarnChild ne peuvent plus communiquer avec leur AM
−→ Le traitement à faire dépend de l'application
Mécanisme de recovery au redémarrage du NodeManager
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 35 / 51

Les applications YARN
Exemples d'applications pouvant s'exécuter sur YARN
Hadoop MapReduce : traitement de jobs MapReduce
Spark : traitement/analyse de large volume de données
Giraph : calcul de graphe
Hbase : Base de données NoSQL utilisant le HDFS
Tez : Exécution de work�ow complexes
Toutes ces applications peuvent s'exécuter sur le même cluster
Hadoop
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 36 / 51

Coder une application YARN
From Scratch
Pas de couche logicielle intermédiaire entre l'appli et Yarn
Assez complexe et fastidieux à programmer
Adapté si l'application à des exigences complexes d'ordonnancement
Apache Slider
Couche logicielle permettant d'exécuter et de déployer des plate-formesdistribuées existantes.
Apache Twill
Programmation simpli�ée : dé�nition des tâches via des Java Runnable
Des outils intégrés : Logging temps-réel, messages de commande (duclient vers les Runnables), recouvrement d'état, ....
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 37 / 51

Hadoop Map Reduce
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 38 / 51

Hadoop MapReduce : Assignation des tâches Map et Reduce
Objectif
Appli Yarn pour l'exécution et le déploiement de programmes Map-Reduce
Responsabilité des containers YarnChild
exécutent une instance de tâche de map ou de reduce
fournissent leur état d'avancement à l'AM correspondant
Responsabilité du container AM
Coordination du Job Map-Reduce :
Dé�nit à sa création le nombre de containers à demander au RM
Les requêtes de container prennent en compte la localité des donnéesd'entrée du job
Déploie les tâches dans les containers alloués par le RM :
les maps : le plus proche possible de leur split respectifles reduces : à partir d'une certaine proportion de maps terminés
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 39 / 51
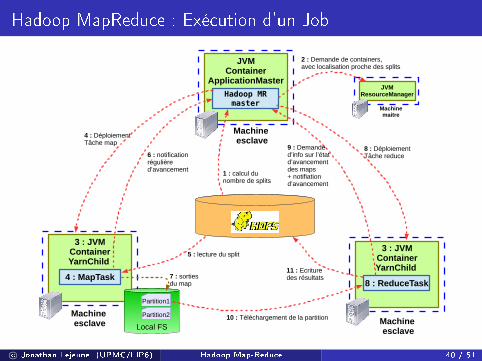
Hadoop MapReduce : Exécution d'un Job
3 : JVMContainerYarnChild
8 : ReduceTask
Machine esclave
3 : JVMContainerYarnChild
4 : MapTask
Local FS
Machine esclave
JVMContainer
ApplicationMaster
Hadoop MRmaster
JVMResourceManager
Machine esclave
1 : calcul du nombre de splits
Machine maitre
2 : Demande de containers, avec localisation proche des splits
4 : DéploiementTâche map
8 : DéploiementTâche reduce
5 : lecture du split
6 : notification régulièred’avancement
7 : sortiesdu map
Partition1
Partition2
9 : Demanded’info sur l’état d’avancementdes maps + notifiation d’avancement
10 : Téléchargement de la partition
11 : Ecriture des résultats
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 40 / 51

Hadoop MapReduce : Spéculation
Principe
Possibilité de démarrer de nouvelles instances de tâche en cours
d'exécution
Mécanismes
la décision d'un lancement d'une spéculation est faite par l'AppMaster
si la spéculation est jugée nécessaire, a�ectation d'une nouvelleinstance de tâche dans un container.
Intérêt
Permettre d'anticiper les tâches jugées trop lentes et donc potentiellementdéfaillante
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 41 / 51

Hadoop MapReduce : Écriture des données �nales
Principe
Chaque reduce écrit ses résultats dans son �chier HDFS
Problème
Plusieurs instances d'une même tâche peuvent s'exécuter. Commentassurer la cohérence sur le �chier HDFS ?
Solution
1) chaque instance écrit dans un �chier temporaire
2) L'appMaster désigne l'instance qui peut copier dé�nitivement sesdonnées sur le HDFS (en général la première qui se termine)
3) Les autres instances ainsi que leur données sont détruites une fois quela copie s'est terminée
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 42 / 51

API JAVA Hadoop MapReduce : Typage des clé/valeur
Dé�nir ses types de clé/valeur
les valeurs doivent implémenter l'interface Writable de l'API Hadoop
les clés doivent implémenter l'interface WritableComparable<T> ( = unextends de Writable et Comparable<T> de Java)
Writable contient deux méthodes :
void write(DataOutput out) : sérialisationvoid readFields(DataInput in) : dé-sérialisation
Quelques Writables prédé�nis dans l'APIBooleanWritable, DoubleWritable, FloatWritable, IntWritable, LongWritable,Text, NullWritable
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 43 / 51

API JAVA Hadoop MapReduce : format d'entrée et de sortie
Dé�nir le format des données d'entrée
Toute classe héritant de InputFormat<K,V>.
Classe fournies par l'API Hadoop :TextInputFormat (format par défaut)
clé : LongWritable, o�set du premier caractère de la ligne
valeur : Text, contenu de la ligne
SequenceFileInputFormat<K,V> : format binaireKeyValueTextInputFormat : <Text,Text> avec séparateur
Dé�nir le format des données de sortie
Toute classe héritant de OuputFormat<K,V>.
Classe fournies par l'API Hadoop :TextOutputFormat (format par défaut)
clé : Text, première partie de la ligne + un séparateur
valeur : Text, deuxième partie de la ligne
SequenceFileOutputFormat<K,V>
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 44 / 51
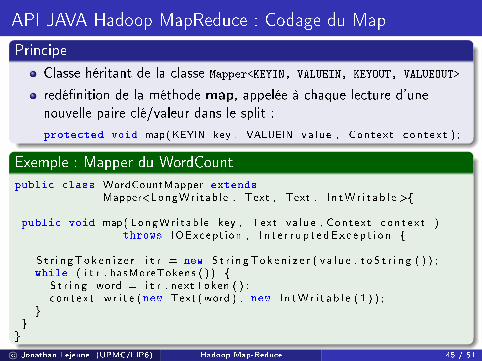
API JAVA Hadoop MapReduce : Codage du Map
Principe
Classe héritant de la classe Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
redé�nition de la méthode map, appelée à chaque lecture d'unenouvelle paire clé/valeur dans le split :
protected void map(KEYIN key , VALUEIN va lue , Context c on t e x t ) ;
Exemple : Mapper du WordCount
public class WordCountMapper extendsMapper<LongWri tab le , Text , Text , I n tWr i t a b l e >{
public void map( LongWr i tab l e key , Text va lue , Context c on t e x t )throws IOExcept ion , I n t e r r u p t e dE x c e p t i o n {
S t r i n gTok e n i z e r i t r = new S t r i n gTok e n i z e r ( v a l u e . t o S t r i n g ( ) ) ;while ( i t r . hasMoreTokens ( ) ) {
S t r i n g word = i t r . nextToken ( ) ;c on t e x t . w r i t e (new Text ( word ) , new I n tW r i t a b l e ( 1 ) ) ;
}}
}
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 45 / 51

API JAVA Hadoop MapReduce : Codage du Reduce
Principe
Classe héritant de la classe Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
redé�nition de la méthode reduce, appelée à chaque lecture d'unenouvelle paire clé/list(valeur) :
protected void r educe (KEYIN key , I t e r a b l e <VALUEIN> va lu e s ,Context con t e x t )
Exemple : Reducer du WordCountpublic class WordCountReducer
extends Reducer<Text , I n tWr i t a b l e , Text , I n tWr i t a b l e > {public void r educe ( Text key , I t e r a b l e <I n tWr i t a b l e > va l u e s ,
Context con t e x t )throws IOExcept ion , I n t e r r u p t e dE x c e p t i o n {
int sum = 0 ;for ( I n tW r i t a b l e v a l : v a l u e s )
sum += va l . ge t ( ) ;r e s u l t . s e t ( sum ) ;c on t e x t . w r i t e ( key , new I n tW r i t a b l e ( sum ) ) ;
}}
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 46 / 51

API JAVA Hadoop MapReduce : partitionneur
Principe
dé�ni la politique de répartition des sorties de map
classe héritant de la classe abstraite Partitioner<KEY, VALUE>
implémentation de la méthode abstraite getPartition, appelée par lecontext.write() du map :
public abstract int getPartition(KEY key , VALUE value ,
int numPartitions );
Partitionneur par défaut
Hachage de la clé (HashPartitioner) :
public class HashPa r t i t i o n e r <K, V> extends Pa r t i t i o n e r <K, V>{public int g e t P a r t i t i o n (K key , V va lue ,
int numReduceTasks ) {return ( key . hashCode ( ) & I n t e g e r .MAX_VALUE) % numReduceTasks ;
}}
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 47 / 51

API JAVA Hadoop MapReduce : squelette client
public class MyProgram {public static void main ( S t r i n g [ ] a r g s ){
Con f i g u r a t i o n con f = new Con f i g u r a t i o n ( ) ;Job job = Job . g e t I n s t a n c e ( conf , "Mon Job" ) ;j ob . s e t J a rByC l a s s (MyProgram . class ) ; // j a r du programmejob . s e tMappe rC la s s ( . . . ) ; // c l a s s e Mapperj ob . s e tR edu c e rC l a s s ( . . . ) ; // c l a s s e Reducerj ob . setMapOutputKeyClass ( . . . ) ; // c l a s s e c l é s o r t i e mapjob . setMapOutputVa lueClass ( . . . ) ; // c l a s s e v a l e u r s o r t i e mapjob . s e tOutputKeyC la s s ( . . . ) ; // c l a s s e c l é s o r t i e j objob . s e tOu tpu tVa l u eC l a s s ( . . . ) ; // c l a s s e v a l e u r s o r t i e j objob . s e t I n pu tFo rma tC l a s s ( . . . ) ; // c l a s s e InputFormatj ob . s e tOutputFormatC la s s ( . . . ) ; // c l a s s e OutputFormatj ob . s e t P a r t i t i o n e r C l a s s ( Ha s hPa r t i t i o n e r . class ) ; // p a r t i t i o n e rj ob . setNumReduceTasks ( . . . ) ; // nombre de reduceF i l e I n pu tFo rma t . add InputPath ( job , . . . ) ; // chemins e n t r é eF i l eOutputFormat . setOutputPath ( job , . . . ) ; // chemin s o r t i ej ob . wa i tFo rComp le t i on (true ) ; // lancement du job
}}
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 48 / 51
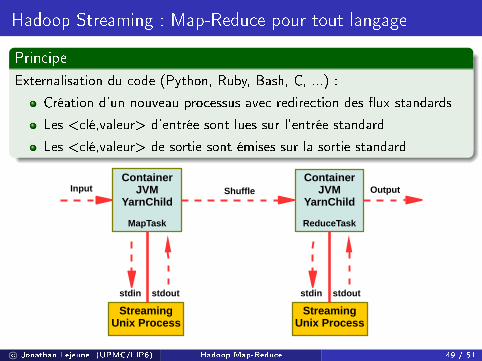
Hadoop Streaming : Map-Reduce pour tout langage
Principe
Externalisation du code (Python, Ruby, Bash, C, ...) :
Création d'un nouveau processus avec redirection des �ux standards
Les <clé,valeur> d'entrée sont lues sur l'entrée standard
Les <clé,valeur> de sortie sont émises sur la sortie standard
ContainerJVM
YarnChild
MapTask
StreamingUnix Process
ContainerJVM
YarnChild
ReduceTask
StreamingUnix Process
ShuffleInput Output
stdin stdout stdin stdout
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 49 / 51

Vers une version 3
Version Alpha disponible depuis le 3 sept 2016.
Principales évolutions
Java 8 ou supérieur
Erasure Coding⇒ Réduit le coût de la réplication de blocs de 200% à 50%
Amélioration du Shell
Optimisation des I/O⇒ Performance Shu�e augmenté de 30%
Plusieurs NameNode possible
une meilleure gestion des ports d'écoute
Compatibilité avec le système de �chier de Microsoft Azure
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 50 / 51

Références
[1] Je�rey Dean and Sanjay Ghemawat, MapReduce : Simpli�ed Data Processingon Large Clusters, OSDI'04 : Sixth Symposium on Operating System Design andImplementation, San Francisco, CA, December, 2004.
[2] Hadoop : the de�nitive guide 4th edition, White Tom, O'Reilly, 2015, ISBN :978-1-491-90163-2
[3] Hadoop web site : http ://hadoop.apache.org/
[4] http ://hortonworks.com/hadoop/yarn/
c© Jonathan Lejeune (UPMC/LIP6) Hadoop Map-Reduce 51 / 51