adaptation d'applications pervasives dans des...
TRANSCRIPT

N° d’ordre 07 ISAL 0058 Année 2007
Thèse
Adaptation d’applications pervasives dans des environnements multi-contextes
Présentée devant
L’institut national des sciences appliquées de Lyon
Pour obtenir
Le grade de docteur en informatique
École doctorale
École doctorale Informatique, Information et société
Spécialité
Informatique
Par
Tarak CHAARI
Soutenance prévue le 28/09/2007 devant la commission d’examen
Jury
Paul RUBEL Professeur (INSA de Lyon), Président du jury
Florence SÈDES Professeur (INP Toulouse), Rapporteur
Philippe ANIORTÉ Professeur (Université de Pau), Rapporteur
Augusto CELENTANO Professeur (Université de Venise), Examinateur
André FLORY Professeur (INSA de Lyon), Directeur de thèse
Frédérique LAFOREST Maître de conférences (INSA de Lyon), Co-directrice de thèse
Laboratoire d’Informatique en Image et Systèmes d’information (LIRIS)


Titre
Adaptation d’applications pervasives dans des environnements multi-contextes
Mot clés
Système d’information pervasifs, Sensibilité au contexte, Adaptation de services, Adaptation de contenu, Adaptation d’interfaces utilisateurs
Résumé
Les systèmes pervasifs ont pour objectif de rendre l’information disponible partout et à tout moment. Ces systèmes doivent pouvoir être utilisés dans différents contextes selon l’environnement de l’utilisateur, son profil et le terminal qu’il utilise. L’un des problèmes majeurs de ce type de systèmes concerne donc l’adaptation au contexte d’utilisation. Dans ce travail de thèse, nous proposons une stratégie complète, générique et évolutive d’adaptation d’applications au contexte d’utilisation sur trois volets: (i) les services offerts à l’utilisateur, (ii) les données renvoyées par ces services et (iii) leur présentation à l’utilisateur. L’adaptation des services consiste à intercepter les appels vers les services originaux de l’application et à modifier leur comportement à l’aide d’un ensemble d’opérateurs d’adaptation fonctionnelle. L’adaptation des données consiste à transformer ou à remplacer chaque objet multimédia renvoyé par les services de l’application qui n’est pas utilisable dans la situation contextuelle en question. L’adaptation de la présentation se base sur un processus de génération automatique du code de l’interface utilisateur qui garantit l’interaction avec les données et les services adaptées. La stratégie que nous avons élaborée atteint deux objectifs : (i) intégrer la sensibilité au contexte dans l’application de façon incrémentale et (ii) garantir l’adaptation à partir d’une description simple des services offerts à l’utilisateur. Nous avons mis en œuvre cette stratégie en développant une plateforme d’adaptation d’applications au contexte d’utilisation. Nous avons utilisé les technologies Java, OSGi et les services Web pour réaliser cette plateforme. Nous avons également validé nos modèles et notre approche d’adaptation sur une application médicale de suivi de patients dialysés à domicile.

Title
Adaptating pervasive applications in multi-contextual environments
Keywords
Pervasive information systems, Context-awareness, Service adaptation, Content adaptation, User interface adaptation
Summary
Pervasive systems aim to make information available anywhere and at anytime. These systems should be used in different contexts depending on the environment of the user, her/his profile and her/his device. Consequently, one of the main problems of this type of information systems is the adaptation to context. In this PHD thesis, we propose a complete, generic, and evolutionary strategy that guarantees the adaptation of applications to context on three facets: (i) the services offered to the user, (ii) the data returned by these services and (iii) their presentation to the user. Service adaptation consists of modules that intercept the application’s service calls and modifying their behaviour using a list of functional adaptation operators. Data adaptation consists in transforming or replacing the non-usable multimedia service outputs in the considered context situation. Presentation adaptation consists in automatically generating the complete code of the user interface that guarantees the interaction with the adapted data and services. Our adaptation strategy has achieved two goals: (i) integrate context incremental awareness in the application and (ii) guarantee the adaptation starting from a simple description of the services offered to the user. We have validated this strategy by developing a platform that guarantees the adaptation of applications to context. We have used Java, OSGi and Web service technologies to implement this platform. We have also successfully tested our adaptation approach on a home health care application of dialysed persons. In essence, we believe that this work is a step ahead towards building adaptive and evolutionary pervasive information systems.

SOMMAIRE
INTRODUCTION GENERALE ________________________________________ 15
I. Les systèmes d’information pervasifs ______________________________________ 17
II. La sensibilité au contexte dans les systemes d’information pervasifs _____________ 18
III. Problématique _________________________________________________________ 18
IV. Cas d’étude ____________________________________________________________ 19
V. Organisation du document _______________________________________________ 20
CHAPITRE I - ETAT DE L’ART : LES SYSTEMES SENSIBLES AU CONTEXTE _______ 23
I. Introduction ___________________________________________________________ 25
II. Notion de contexte ______________________________________________________ 25 1. Que disent les dictionnaires ? ___________________________________________________ 25 2. Contexte et informatique pervasive_______________________________________________ 26 3. Catégories de contexte ________________________________________________________ 27
III. Notion de sensibilité au contexte (Context-Awareness) ________________________ 29
IV. Architecture d’un système sensible au contexte ______________________________ 30 1. Couche de capture du contexte __________________________________________________ 31 2. Couche d’Interprétation et d’agrégation du contexte _________________________________ 33 3. Couche de stockage et historique du contexte_______________________________________ 33 4. Couche dissémination du contexte _______________________________________________ 36 5. Couche application ___________________________________________________________ 37
V. Principales plateformes existantes de sensibilité au contexte ___________________ 37 1. Context Toolkit ______________________________________________________________ 38 2. Context Broker Architecture (CoBrA) ____________________________________________ 39 3. Context Management Framework (CMF)__________________________________________ 42 4. Service oriented context-aware middleware (SOCAM) _______________________________ 43 5. Synthèse ___________________________________________________________________ 44
VI. Conclusion ____________________________________________________________ 46

CHAPITRE II – ETAT DE L’ART : LES TRAVAUX D’ADAPTATION EXISTANTS _____ 47
I. Introduction ___________________________________________________________ 49
II. Définition, utilité et caractérisation de l’adaptation ___________________________ 49 1. Définition __________________________________________________________________ 49 2. Utilité _____________________________________________________________________ 50 3. Caractérisation_______________________________________________________________ 50
III. L’adaptation dans les architectures à base de composants _____________________ 53 1. Concepts de la programmation à base de composants ________________________________ 53 2. Mécanismes d’adaptation existants_______________________________________________ 54 3. Techniques d'adaptation de composants ___________________________________________ 56 4. Quelques architectures existantes d’adaptation de composants _________________________ 58 5. Synthèse sur l'adaptation des architectures à base de composants _______________________ 61
IV. Adaptation de contenu multimédia ________________________________________ 61 1. Adaptation coté serveur________________________________________________________ 62 2. Adaptation coté client _________________________________________________________ 62 3. Adaptation intermédiaire_______________________________________________________ 62 4. Synthèse sur les approches d'adaptation de contenu __________________________________ 63
V. Adaptation des interfaces utilisateur _______________________________________ 64 1. Modélisation des interfaces utilisateurs____________________________________________ 64 2. Adaptation des interfaces homme-machine_________________________________________ 66 3. Synthèse sur l'existant dans l'adaptation de présentation_______________________________ 66
VI. Conclusion ____________________________________________________________ 67
CHAPITRE III - CONTRIBUTIONS : DEFINITIONS, OBJECTIFS ET ARCHITECTURE _ 69
I. Introduction ___________________________________________________________ 71
II. Notre vision du contexte _________________________________________________ 71 1. Définition du contexte_________________________________________________________ 71 2. Notion de situation contextuelle _________________________________________________ 73 3. Modélisation d’une situation contextuelle__________________________________________ 75
III. Modélisation fonctionnelle d’une application ________________________________ 78 1. Notion d’entité logicielle_______________________________________________________ 78 2. Notion de service_____________________________________________________________ 79 3. Notion de dépendance d’exécution de services______________________________________ 80 4. Notion de modèle fonctionnel ___________________________________________________ 81
IV. Objectifs de notre travail_________________________________________________ 85

V. SECAS : Plateforme pour l’adaptation d’applications à de nouveaux contextes
d’utilisation __________________________________________________________________ 87 1. Présentation de la plateforme SECAS_____________________________________________ 87 2. Couche de gestion du contexte __________________________________________________ 87 3. Couche d’adaptation __________________________________________________________ 89 4. Couche de déploiement d’applications ____________________________________________ 93
VI. Conclusion ____________________________________________________________ 94
CHAPITRE IV - CONTRIBUTIONS : STRATEGIE D’ADAPTATION AU CONTEXTE ___ 95
I. Présentation de notre stratégie d’adaptation ________________________________ 97
II. Adaptation fonctionnelle _________________________________________________ 98 1. Principe de l’adaptation fonctionnelle_____________________________________________ 98 2. Règles d’adaptation fonctionnelle________________________________________________ 99 3. Opérateurs d’adaptation fonctionnelle ___________________________________________ 101 4. Processus d’adaptation fonctionnelle dans SECAS__________________________________ 118 5. Synthèse sur l’adaptation fonctionnelle dans SECAS________________________________ 120
III. Adaptation de contenu__________________________________________________ 120 1. Principe de l’adaptation de contenu _____________________________________________ 120 2. Module d’adaptation de contenu ________________________________________________ 122 3. Planification de l’adaptation de contenu [Berhe05] _________________________________ 124 4. Synthèse sur l’adaptation de contenu dans SECAS__________________________________ 129
IV. Adaptation de présentation______________________________________________ 129 1. Principe de l’adaptation de présentation __________________________________________ 129 2. Modélisation d’une interface utilisateur dans SECAS _______________________________ 130 3. Processus de génération automatique d’interfaces adaptées ___________________________ 133 4. Synthèse sur l’adaptation de présentation dans SECAS ______________________________ 137
V. Conclusion ___________________________________________________________ 138
CHAPITRE V - CONTRIBUTIONS : IMPLANTATION ET UTILISATION DE NOTRE
PLATEFORME D’ADAPTATION _____________________________________________ 139
I. Introduction __________________________________________________________ 141
II. Conception de l’architecture SECAS______________________________________ 141 1. Modélisation fonctionnelle ____________________________________________________ 141 2. Modélisation dynamique______________________________________________________ 145 3. Modélisation statique ________________________________________________________ 149

4. Déploiement de la plateforme __________________________________________________ 156 5. Scénario générique d’utilisation de SECAS _______________________________________ 157
III. Développement de la plateforme SECAS___________________________________ 159 1. Implantation de la couche d’adaptation fonctionnelle________________________________ 159 2. Implantation de la couche d’adaptation de contenu _________________________________ 160 3. Implantation de la couche d’adaptation de présentation ______________________________ 161 4. Statistiques ________________________________________________________________ 161
IV. Utilisation de SECAS dans le projet SICOM _______________________________ 161 1. Déploiement de SICOM avec l’interface d’administration de SECAS___________________ 162 2. Adaptation de l’application « SICOM » __________________________________________ 163
V. Utilisation d’un nouveau modèle de contexte DANS SECAS __________________ 168
VI. Conclusion ___________________________________________________________ 170
CONCLUSIONS ET PERSPECTIVES _________________________________ 171
I. Bilan ________________________________________________________________ 173
II. Perspectives __________________________________________________________ 174
BIBLIOGRAPHIE __________________________________________________ 177
ANNEXES _________________________________________________________ 197

LISTE DES FIGURES Figure 1 - Architecture générale d'un système sensible au contexte__________________________________ 31 Figure 2 - Modélisation de la localisation de l'utilisateur en utilisant CC/PP__________________________ 34 Figure 3 - Exemple de représentation XML du contexte en utilisant l'ontologie CoOL ___________________ 35 Figure 4 - L'architecture du context Toolkit de Anind K. Dey ______________________________________ 38 Figure 5 - Architecture globale du système CoBrA ______________________________________________ 40 Figure 6 - Représentation OWL du contexte dans l'architecture CoBrA ______________________________ 41 Figure 7 - L'architecture générale du Context Management Framework (CMF) _______________________ 42 Figure 8 - L'architecture globale de la plateforme SOCAM________________________________________ 43 Figure 9 - Vue extérieur d'un composant logiciel________________________________________________ 53 Figure 10 – Architecture d’adaptation dans K-Component ________________________________________ 59 Figure 11 – Modèle de composants auto-adaptatifs de l’architecture ACEEL _________________________ 60 Figure 12 – Stratégie d’adaptation dans l’architecture SAFRAN ___________________________________ 61 Figure 13 - Représentation tridimensionnelle du contexte _________________________________________ 74 Figure 14 - Le modèle général du contexte_____________________________________________________ 76 Figure 15 - Exemple d’une situation contextuelle________________________________________________ 77 Figure 16 - Un exemple d'une entité logicielle _________________________________________________ 78 Figure 17 - Modélisation d'un service d'une entité logicielle _______________________________________ 79 Figure 18 – Dépendance en « et » entre services ________________________________________________ 80 Figure 19 – Dépendance en « ou » entre services _______________________________________________ 80 Figure 20 - Le modèle fonctionnel d'une application médicale _____________________________________ 82 Figure 21 - Diagramme de classes d'un modèle fonctionnel _______________________________________ 83 Figure 22 - Extrait de la représentation XML du modèle fonctionnel d’une application médicale __________ 84 Figure 23 - Modélisation d'un fournisseur de contexte____________________________________________ 88 Figure 24 - Modélisation d'un registre de contexte ______________________________________________ 88 Figure 25 - Modélisation d'un courtier de contexte ______________________________________________ 89 Figure 26 - Interaction entre l'interface de consommation du contexte et le broker _____________________ 90 Figure 27 – Architecture générale du module d'adaptation de services_______________________________ 91 Figure 28 – Architecture générale du module d'adaptation de données_______________________________ 91 Figure 29 - Architecture générale du module d'adaptation de présentation ___________________________ 92 Figure 30 - Orchestration du processus d'adaptation par le gestionnaire d'applications _________________ 92 Figure 31 - Architecture générale de SECAS ___________________________________________________ 93 Figure 32 - Principe général de l'adaptation dans SECAS_________________________________________ 97 Figure 33 - Exemple d'une règle d'adaptation __________________________________________________ 99 Figure 34 - Modélisation d'un opérateur d'adaptation fonctionnelle ________________________________ 102 Figure 35 - Entité d'adaptation d'un service initial f ____________________________________________ 103 Figure 36 - Exemple d’utilisation de l'opérateur de projection ____________________________________ 104 Figure 37 - Exemple d’utilisation de l’opérateur de sélection _____________________________________ 105 Figure 38 - Exemple d'utilisation de l'opérateur « produit » ______________________________________ 106

Figure 39 - Exemple d'utilisation de l'opérateur « union » _______________________________________ 107 Figure 40 - Exemple d’application de l’opérateur replaceService en mode simple _____________________ 110 Figure 41 - Résultat de l’application de l’opérateur replaceService en mode récursif __________________ 111 Figure 42 - Algorithme de l'opérateur de remplacement de services ________________________________ 112 Figure 43 - Algorithme de connexion en entrée d'un service isolé __________________________________ 113 Figure 44 - Algorithme de connexion en sortie d'un service isolé __________________________________ 113 Figure 45 - Résultat de l’application de l’opérateur InsertServiceAfter _____________________________ 114 Figure 46 - Algorithme de l'opérateur insertServiceAfter ________________________________________ 115 Figure 47 - Résultat de l'application de l'opérateur insertAlternativeService _________________________ 116 Figure 48 - Algorithme de l'opérateur insertServiceAfter ________________________________________ 117 Figure 49 - Algorithme de l'opérateur LockService _____________________________________________ 118 Figure 50 - Algorithme de l'opérateur UnlockService ___________________________________________ 118 Figure 51 - Algorithme de déploiement d’un modèle fonctionnel___________________________________ 119 Figure 52 - Algorithme d'application de règles d'adaptation ______________________________________ 119 Figure 53 - Algorithme général de la fonction de préparation de l'adaptation de contenu _______________ 123 Figure 54 - Algorithme général d'instanciation des adaptateurs de contenu __________________________ 124 Figure 55 - Algorithme général de calcul du plan d'adaptation de contenu___________________________ 124 Figure 56 - Structure générale de l'interface d'interaction avec un service ___________________________ 133 Figure 57 - Fonction de génération de l'interface d'interaction avec les services de l'application _________ 133 Figure 58 - Algorithme de la fonction de génération d'une fenêtre d'interaction avec un service __________ 134 Figure 59 - Algorithme de la fonction de génération de la vue d'une fenêtre__________________________ 134 Figure 60 - Algorithme de la fonction de génération du panneau d’entrée d’un service _________________ 135 Figure 61 - Algorithme de la fonction de génération du panneau de sortie d’un service_________________ 135 Figure 62 - Algorithme de la fonction de génération du modèle d'exécution d'un service ________________ 136 Figure 63 - Algorithmes des fonctions de navigation dans le modèle fonctionnel à partir d'un service f ____ 136 Figure 64 - Algorithme de la fonction de génération du modèle d'exécution d'un service ________________ 137 Figure 65 - Diagramme de cas d’utilisation : déploiement d’une application _________________________ 142 Figure 66 - Diagramme de cas d’utilisation : utilisation d’une application adaptée____________________ 143 Figure 67 - Diagramme de cas d’utilisation : gestion des comptes des utilisateurs de SECAS ____________ 143 Figure 68 - Diagramme de cas d’utilisation : gestion des modules de SECAS ________________________ 144 Figure 69 - Descripteur d'un paramètre d'adaptation de type "serviceOutput" ________________________ 144 Figure 70 - Descripteur de l’opérateur d'adaptation fonctionnelle "projection" ______________________ 144 Figure 71 - Diagramme d’état transition : gestionnaire de déploiement d’applications _________________ 145 Figure 72 - Diagramme d’activités du gestionnaire d’adaptation de services_________________________ 146 Figure 73 - Diagramme d’activités du gestionnaire d’adaptation de contenu _________________________ 147 Figure 74 - Diagramme d’activités de l’adaptateur de services____________________________________ 147 Figure 75 - Diagramme d’activités de l’adaptateur de contenu____________________________________ 148 Figure 76 - Diagramme d’activités du gestionnaire d’adaptation de présentation _____________________ 148 Figure 77 - Diagramme des paquetages de SECAS _____________________________________________ 149 Figure 78 - Diagramme de classes du paquetage "secas.application"_______________________________ 150

Figure 79 - Diagramme de classes du paquetage "secas.application.services" ________________________ 150 Figure 80 - Diagramme de classes du paquetage "secas.application.data"___________________________ 151 Figure 81 - Diagramme de classes du paquetage "secas.application.ui"_____________________________ 152 Figure 82 - Diagramme de classes du paquetage "secas.administration" ____________________________ 152 Figure 83 - Diagramme de classes du paquetage "util" __________________________________________ 153 Figure 84 - Diagramme de classes du paquetage "context" _______________________________________ 153 Figure 85 - Diagramme de classes du paquetage d’adaptation de services___________________________ 154 Figure 86 - Diagramme de classes du paquetage d’adaptation de contenu ___________________________ 155 Figure 87 - Diagramme de classes du paquetage d’adaptation de présentation _______________________ 156 Figure 88 - Diagramme de composants de SECAS______________________________________________ 157 Figure 89 - Diagramme de déploiement de SECAS _____________________________________________ 157 Figure 90 - Extrait de la description d’un service avant son adaptation _____________________________ 159 Figure 91. Extrait de la description d’un adaptateur de service ___________________________________ 159 Figure 92 - Interface d’administration de la plate-forme SECAS___________________________________ 163 Figure 93 - Visualisation d’un dossier de dialyse péritonéale sur un PC standard _____________________ 164 Figure 94 - Le modèle fonctionnel de l’application SICOM avant son adaptation avec SECAS ___________ 165 Figure 95 - Première règle d'adaptation de l'application SICOM __________________________________ 165 Figure 96 - Deuxième règle d'adaptation de l'application SICOM _________________________________ 166 Figure 97 - Troisième règle d'adaptation de l'application SICOM _________________________________ 166 Figure 98 - modèle fonctionnel adapté de l'application SICOM ___________________________________ 167 Figure 99 - Visualisation du même dossier médical que la figure 93 sur un terminal mobile _____________ 168 Figure 100 - Exemple de modélisation du contexte par une ontologie _______________________________ 169
LISTE DES TABLEAUX
Tableau 1 - Exemples de capteurs de contexte...................................................................................................... 32 Tableau 2 - Vue de synthèse des approches existantes de modélisation du contexte............................................ 36 Tableau 3 - Comparatif des quatres plateformes : Context Toolkit, CoBrA, CMF et SOCAM............................. 45 Tableau 4 – Exemples d’opérateurs d'adaptation inter-services ........................................................................ 109 Tableau 5 - Nombre de classes et de lignes de code dans le prototype SECAS .................................................. 161

DEDICACE
A la mémoire de mes deux grands-pères Mahmoud et Habib

REMERCIEMENTS
Je tiens à remercier, tout d’abord, mes directeurs de thèse, André FLORY et Frédérique
LAFOREST, pour leur encadrement ainsi que leur soutien tout au long de la thèse.
Je remercie tout particulièrement Mme Florence SÈDES et M. Philippe ANIORTÉ d’avoir
acceptés d’être rapporteurs de mon manuscrit. Je remercie également M. Paul RUBEL d’avoir
bien voulu présider le jury lors de ma soutenance de thèse ainsi que M. Augusto
CELENTANO d’avoir accepté d’être examinateur de ce travail.
Un grand merci à ma femme Kaouthar pour sa présence précieuse et pour ses
encouragements durant toutes les périodes et étapes de cette thèse. J’adresse aussi un merci
spécial à ma famille pour son soutien moral et à tous les collègues et amis qui m’ont aidé de
près ou de loin à finaliser mon travail de thèse.


L IIINNNTTTRRROOODDDUUUCCCTTTIIIOOONNN GGGEEENNNEEERRRAAALLEEE
“The most profound technologies are those that disappear. They weave themselves into the fabric of everyday life until they are
indistinguishable from it” (Mark Weiser)

Introduction générale
PLAN
I. LES SYSTEMES D’INFORMATION PERVASIFS _________________________________ 17
II. LA SENSIBILITE AU CONTEXTE DANS LES SYSTEMES D’INFORMATION PERVASIFS____ 18
III. PROBLEMATIQUE ______________________________________________________ 18
IV. CAS D’ETUDE__________________________________________________________ 19
V. ORGANISATION DU DOCUMENT ___________________________________________ 20
Tarak CHAARI - 16 - Thèse de doctorat

Introduction générale
I. LES SYSTEMES D’INFORMATION PERVASIFS
De nos jours, l’évolution technologique des systèmes embarqués et des moyens de
communication informatique a incité les développeurs à intégrer les terminaux mobiles dans
leurs applications, donnant ainsi naissance à de nouveaux systèmes d’information dits
pervasifs ou ubiquitaires [Birnbaum97]. Mark Weiser a introduit l’informatique pervasive en
décrivant l’ordinateur du 21ième siècle [Weiser95] comme un terminal intime ou compagnon
actif plus intelligent qu’un assistant de bureau comme les ordinateurs standard [Weiser99].
Les travaux de [Agoston00] ont repris les idées initiées par M. Weiser et ont donné la
définition des systèmes pervasifs, qui est maintenant la plus reconnue et répandue dans ce
nouveau domaine : « l’informatique pervasive rend l’information disponible partout et à tout
moment ».
A la différence des systèmes d’information classiques, ces nouvelles applications intègrent
des terminaux mobiles de différentes capacités matérielles et logicielles. Ainsi, avec ces
systèmes, le téléphone mobile ne sert plus uniquement à de simples communications vocales
ou textuelles. Les assistants personnels ne sont plus de simples gadgets de planning et
d’organisation. Les ordinateurs de poche ne sont plus isolés de l’Internet. Ces appareils
interagissent maintenant avec des services implantés sur des serveurs d’applications divers.
En conséquence, les administrateurs de parcs de machines veulent consulter l’état de leur parc
depuis leur domicile ou même en voyage avec leur téléphone mobile ; les enseignants veulent
consulter leur emploi de temps depuis leur téléphone; le directeur de l’entreprise veut accéder
aux différents tableaux de bord de son entreprise partout et même en déplacement;
l’infirmière veut consulter depuis son PDA le dossier d’un patient et les recommandations
prescrites par le médecin avant de se rendre à son domicile…
L’intégration des terminaux mobiles dans les nouveaux systèmes d’information n’est pas
une tâche aisée. En effet, les applications déjà développées n’ont pas été conçues pour être
utilisées sur des terminaux qui ont des performances très réduites par rapport à celles des PC
standards. La plupart d’entre eux ne dépassent pas 30 Mo de mémoire vive et morte réunies.
De plus, la bande passante de transmission est faible, ce qui rend les transferts de données
plus lents et plus coûteux. En outre, la taille de l’écran est considérablement réduite. Enfin, un
autre problème majeur est la diversité des API (Application Programming Interface) de
développement implantées sur ces terminaux.
Tarak CHAARI - 17 - Thèse de doctorat

Introduction générale
II. LA SENSIBILITE AU CONTEXTE DANS LES SYSTEMES
D’INFORMATION PERVASIFS
Dans les systèmes d’information pervasifs, on doit assurer une adaptation au type de
terminal et au type d’utilisateur connecté pour garantir une utilisation confortable des
applications dans ces nouveaux environnements. Dans la littérature, cette adaptation est aussi
appelée plasticité [Calvary02], elle définit le degré d’adaptation des applications à de
nouvelles situations et à de nouveaux besoins. Pour réaliser cette adaptation, beaucoup de
nouveaux paramètres entrent en jeu :
- paramètres réseau : dans les réseaux sans fil la bande passante est limitée, les connexions
sont intermittentes, la qualité de service n’est pas évaluée de la même façon…
- paramètres de l’utilisateur : l’utilisateur est devenu le point central de la conception des
systèmes d’information pervasifs. En effet, des contraintes d’utilisabilité et d’ergonomie se
présentent aux concepteurs de ce genre d’application. Ainsi, on doit prendre en considération
ses préférences, son emplacement géographique, son profil…
- paramètres du terminal : la diversité des terminaux mobiles influe sur la conception de
ces systèmes d’information. Le comportement de ces systèmes doit s’adapter aux capacités
matérielles et logicielles de ces appareils.
Tous ces paramètres forment des contextes d’utilisation différents [Shanon90]. Dans la
plupart des cas, ces paramètres n’ont pas été pris en compte lorsque l’application a été
développée. Ceci conduit généralement les informaticiens à reprendre leur cycle de vie dès
son début pour prendre en compte ces nouveaux paramètres.
La prise en compte du contexte d’utilisation dans les applications est un domaine de
recherche d’actualité connu sous le nom de « sensibilité au contexte » (ou context-awareness
en anglais) [Abowd99] : une application sensible au contexte doit percevoir la situation de
l’utilisateur dans son environnement et adapter par conséquent son comportement à la
situation en question.
III. PROBLEMATIQUE
Dey [Dey01a], l’un des premiers chercheurs dans le domaine de la sensibilité au contexte,
a spécifié trois étapes nécessaires pour qu’une application soit sensible au contexte. En
premier lieu, on doit capturer le contexte, et ce de manière transparente à l’utilisateur. Ensuite,
on doit effectuer une interprétation du contexte pour passer à une représentation de haut
niveau plus exploitable par l’application. Finalement, on doit fournir cette information
Tarak CHAARI - 18 - Thèse de doctorat

Introduction générale
interprétée à l’application. A l’image des travaux de Dey, la grande majorité des contributions
existantes dans le domaine de la sensibilité au contexte s’intéressent à comment capturer,
interpréter et apporter les informations contextuelles à l’application sans étudier comment
l’adapter à ces nouveaux contextes d’utilisation. De plus, les travaux existants se focalisent
sur la création incrémentale ou sur le prototypage d’applications sensibles au contexte en
incorporant le code d’adaptation dans le code métier de l’application. Ceci limite les capacités
à prendre en compte de nouveaux contextes qui n’auraient pas été prévus lors de son
développement. La majorité des solutions existantes proposent des approches ad hoc pour des
domaines spécifiques (surtout dans le domaine du tourisme). Pour que ces applications
puissent supporter d’autres environnements et besoins, les informaticiens se trouvent
généralement obligés de reprendre tout le cycle de vie de l’application afin de fournir une
nouvelle version qui supporte les nouveaux contextes d’utilisation.
Dans ce travail de thèse, nous nous intéressons à une stratégie complète et générique pour
garantir l’adaptation des applications existantes à différents contextes d’utilisation. Cette
adaptation se fait en aval du développement de ces applications, en leur ajoutant une
surcouche logicielle. Notre stratégie s’appuie sur trois volets d’adaptation : les services, les
données et l’interface utilisateur de ces applications. L’adaptation des services consiste à
modifier leurs comportements pour qu’ils soient compatibles avec le contexte d’utilisation de
l’application. L’adaptation des données se base sur un ensemble de transformations sur le
type, le format et les propriétés des données renvoyées par les services. Enfin, l’adaptation
des interfaces utilisateur consiste à générer automatiquement une interface homme-machine
fonctionnelle dans le contexte de son utilisation.
Dans ce mémoire nous présentons notre stratégie d’adaptation d’applications pervasives
dans une approche multi-contextes en se focalisant particulièrement sur l’adaptation
d’applications existantes à de nouveaux contextes d’utilisation. Notre approche reste aussi
valable et applicable pour la création incrémentale d’applications sensibles au contexte.
IV. CAS D’ETUDE
Pour mieux illustrer l’objectif de ce travail de thèse, nous utilisons tout le long de ce
mémoire, un exemple d’application, conçue et développée pour un PC standard, qui doit être
utilisée dans un environnement différent comme un PDA ou un téléphone mobile évolué
(Smartphone). Nous avons choisi cet exemple car il exprime un besoin d’actualité dans les
systèmes d’information pervasifs. Nous nous appuyons sur une application médicale qui
permet la consultation des dossiers de patients suivant un traitement de dialyse péritonéale
Tarak CHAARI - 19 - Thèse de doctorat

Introduction générale
(traitement pour les patients atteints d’insuffisance rénale). Cette application, développée dans
le cadre de l’hospitalisation de patients à domicile (HAD), offre un ensemble de services aux
professionnels de santé qui assurent la recherche et la visualisation des dossiers médicaux de
leurs patients. Les utilisateurs de cette application ont exprimé le besoin d’accéder à ces
mêmes services via des dispositifs mobiles comme les téléphones mobiles ou les PDA.
Nous constatons que dans la plupart des cas, il ne suffit pas seulement de développer une
autre version (ou un autre client) de ces applications pour les terminaux mobiles. En effet, les
résultats obtenus ne sont pas toujours satisfaisants puisque les services offerts par ces
systèmes d’information peuvent être incompatibles avec les capacités matérielles et logicielles
des terminaux mobiles. Dans notre exemple, il existe un service de recherche de dossiers
patients. Ce service peut renvoyer un grand nombre de lignes de la base de données médicale.
Ces données sont très volumineuses puisqu’elles peuvent contenir des images, des vidéos, des
rapports médicaux et des résultats d’analyse. Ce gros volume de données dépasse les
capacités matérielles du terminal utilisé (un téléphone mobile NOKIA 6230) et cause une
saturation mémoire au niveau de l’application cliente. Les développeurs se trouvent ainsi
obligés de recoder l’application allant jusqu’à ses services de base.
Cet exemple montre la nécessité et l’intérêt d’avoir des systèmes d’adaptation
automatiques (ou semi-automatiques) des applications existantes à de nouveaux contextes
d’utilisation. Ceci aide les développeurs à ne pas reprendre tout le cycle de développement
des applications et permet ainsi de gagner un temps considérable de conception et de
réalisation. Ces nouvelles situations ne se limitent pas au changement du type du terminal
mais à tout changement de l’environnement de l’utilisateur ou de l’application qui peut influer
sur son comportement en définissant de nouvelles vues sur ses données et ses services.
V. ORGANISATION DU DOCUMENT
Après cette introduction générale, ce mémoire de thèse comporte trois parties principales :
un état de l’art, les propositions de notre travail et l’implémentation de notre approche.
la partie état de l’art est composée de deux chapitres : « chapitre 1 : Les systèmes sensibles
au contexte » et « chapitre 2 : les travaux d’adaptation existants ». Le premier chapitre
présente le contexte scientifique de notre travail de thèse. Nous y détaillons la notion du
contexte, la notion de la sensibilité au contexte et quelques architectures. Le deuxième
chapitre est dédié aux différents travaux d’adaptation que nous avons considérés comme
intéressants pour l’adaptation au contexte. Ce chapitre fait un tour d’horizon sur les travaux
d’adaptation existants dans les architectures à base de composants, dans la gestion de contenu
Tarak CHAARI - 20 - Thèse de doctorat

Introduction générale
multimédia et dans le domaine de l’interaction-homme machine.
La deuxième partie, qui regroupe l'ensemble de nos contributions, comporte deux
chapitres : « chapitre 3 : définitions, modèles et architecture » et « chapitre 4 : stratégie
d’adaptation au contexte ». Le chapitre 3 présente les définitions, les modèles et l’architecture
que nous avons élaborés pour notre stratégie d’adaptation. Cette stratégie est présentée dans le
chapitre 4 où nous explicitons le principe de notre approche d’adaptation sur ses trois volets :
les services, les données et les interfaces utilisateur.
La troisième partie « chapitre 5 : implantation et utilisation de notre plateforme
d’adaptation » présente la conception et l’implémentation de notre architecture d’adaptation.
Nous y présentons aussi l’adaptation du cas d’étude présenté dans la section IV de cette
introduction générale.
Le document se termine par une conclusion générale qui présente une synthèse de nos
contributions ainsi que les perspectives que nous avons tracées pour la suite de ce travail.
Tarak CHAARI - 21 - Thèse de doctorat


CCCHHHAAAPPPIIITTTRRREEE III --- EEETTTAAATTT DDDEEE LLL’’’AAARRRTTT ::: LLLEEESSS SSSYYYSSSTTTEEEMMMEEESSS
SSSEEENNNSSSIIIBBBLLLEEESSS AAAUUU CCCOOONNNTTTEEEXXXTTTEEE
“Context is a poorly used source of information in our computing
environments” (Anind K. Dey)

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
TABLE DES MATIERES
I. INTRODUCTION ________________________________________________________ 25
II. NOTION DE CONTEXTE __________________________________________________ 25
1. Que disent les dictionnaires ? _____________________________________________ 25
2. Contexte et informatique pervasive ________________________________________ 26
3. Catégories de contexte ___________________________________________________ 27
III. NOTION DE SENSIBILITE AU CONTEXTE (CONTEXT-AWARENESS) ________________ 29
IV. ARCHITECTURE D’UN SYSTEME SENSIBLE AU CONTEXTE _______________________ 30
1. Couche de capture du contexte____________________________________________ 31
2. Couche d’Interprétation et d’agrégation du contexte _________________________ 33
3. Couche de stockage et historique du contexte ________________________________ 33
4. Couche dissémination du contexte _________________________________________ 36
5. Couche application______________________________________________________ 37
V. PRINCIPALES PLATEFORMES EXISTANTES DE SENSIBILITE AU CONTEXTE __________ 37
1. Context Toolkit_________________________________________________________ 38
2. Context Broker Architecture (CoBrA) _____________________________________ 39
3. Context Management Framework (CMF)___________________________________ 42
4. Service oriented context-aware middleware (SOCAM) ________________________ 43
5. Synthèse ______________________________________________________________ 44
VI. CONCLUSION__________________________________________________________ 46
Tarak CHAARI - 24 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
I. INTRODUCTION
Dans ce chapitre, nous nous intéressons aux travaux existants dans les systèmes sensibles
au contexte. Nous commençons par présenter les différentes définitions de la notion de
contexte et les principes de la sensibilité au contexte (ou context-awareness). Nous présentons
ensuite l'architecture générale d'un système sensible au contexte tirée d'une synthèse des
travaux existants. Dans le section V, nous analysons quelques plateformes existantes qui
aident au développement et au déploiement de ce genre de systèmes. Dans la conclusion de ce
chapitre, nous présentons l’importance de l’étape d’adaptation dans les applications sensibles
au contexte. Nos constatations tirés de la synthèse des travaux existants dans ce domaine
montrent que cette étape mérite plus d’intérêt et plus d’études.
II. NOTION DE CONTEXTE
1. Que disent les dictionnaires ?
Parmi les dictionnaires de référence nous citons les définitions suivantes de la notion de
contexte :
• Le Petit Robert : "ensemble des circonstances dans lesquelles s'insère un fait".
• L'encyclopédie Larousse : "ensemble des conditions naturelles, sociales, culturelles dans
lesquelles se situe un énoncé, un discours"; ou encore : "ensemble des circonstances dans
lesquelles se produit un événement, se situe une action".
• Hachette Multimédia : "ensemble des éléments qui entourent un fait et permettent de le
comprendre".
• Le Grand dictionnaire numérique en ligne [Granddictionnaire]: "Énoncé dans lequel
figure le terme étudié". Si l'on parle d'informatique, "Le contexte est un ensemble
d'informations concernant l'action du stylet, en rapport principalement avec sa localisation à
l'écran, qui permet au système d'exploitation de l'ordinateur à stylet de différencier les
commandes et l'entrée des données, et de fonctionner en conséquence."
Ces définitions partagent l'idée d'ensemble d'informations associé à quelque chose :
"ensemble […] qui entoure", "ensemble dans lequel se situe …". La nature du "quelque
chose" (fait, discours, événement, action, etc.), dépend précisément de l'utilité du contexte.
Cette utilité permet de "comprendre", de "fonctionner en conséquence", ou de donner un
"sens, [une] valeur…", ou de manière générique de "servir l'interprétation".
Nous abordons maintenant la notion de contexte dans le domaine de l'informatique
pervasive.
Tarak CHAARI - 25 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
2. Contexte et informatique pervasive
Dans le domaine de l'informatique pervasive ou ambiante, la notion de contexte prend
beaucoup d'ampleur et attire l'attention de plusieurs chercheurs. Schilit et Theimer
[Schilit94a] étaient les premiers à proposer une définition du contexte comme étant la
localisation de l'utilisateur, les identités et les états des personnes et objets qui l'entourent.
Dans une définition semblable, Brown, Bovey et Chen [Brown97] proposent : "le contexte est
l'identité de l'utilisateur, des personnes et objets qui l'entourent, sa localisation géographique,
son orientation, la saison, la température où il évolue...". Ryan, Pascoe, et Morse [Ryan98]
définissent le contexte en tant que la localisation, l'environnement, l'identité, et le temps de
l'utilisateur. Dey [Dey00] présente le contexte comme l'état émotionnel de l'utilisateur, son
centre d'attention, sa localisation, son orientation, la date et le temps où il évolue, les objets et
les gens qui existent dans son environnement. Il est difficile d'appliquer ces définitions dans
tous les cas. En effet, si on considère un nouveau type potentiel d'information de contexte, il
n'est pas évident de le classer en tant que contexte ou non.
Le contexte, selon Schilit, inclut la localisation et l'identité des personnes et des objets à
proximité ainsi que les modifications pouvant intervenir sur ces objets [Schilit94a],
[Schilit94b]. Étudier le contexte, c'est répondre aux questions "On est où? ", "Avec qui ?",
"Quelles sont les ressources qu'on utilise?"… Il définit donc le contexte comme les
changements de l'environnement physique, de l'utilisateur et des ressources de calcul. Brown
[Brown96] restreint le contexte aux éléments de l'environnement de l'utilisateur, puis il
introduit l'heure, la saison, la température, l'identité et la localisation de l'utilisateur
[Brown97].
Parallèlement aux travaux de Brown, des définitions émergent avec l'introduction explicite
du temps et la notion d'état. Ryan assimile le contexte à l'environnement, l'identité et la
localisation de l'utilisateur ainsi que le temps [Ryan97]. Ward voit le contexte comme les états
des environnements possibles de l'application [Ward97].
En 1998, Pascoe définit le contexte comme un sous-ensemble d'états physiques et
conceptuels ayant un intérêt pour une entité particulière [Pascoe98]. Nous relevons ici la
référence à la notion de pertinence. Puis Dey [Anind99] insiste sur cette notion de pertinence
de l'information en proposant une définition où il essaie de préciser la nature des entités
relatives au contexte :
Tarak CHAARI - 26 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
Le contexte couvre toutes les informations pouvant être utilisées pour
caractériser la situation d'une entité. Une entité est une personne, un lieu, ou
un objet qui peut être pertinent pour l'interaction entre l'utilisateur et
l'application, y compris l'utilisateur et l'application.
Cette définition encapsule toute les autres définitions précédentes puisqu'elle est d'ordre
très générique. Dey explique cette généricité du fait que les paramètres du contexte peuvent
être implicites ou explicites. En effet, les paramètres du contexte peuvent être fournis
directement par l'utilisateur ou par des capteurs situés dans l'environnement de l'utilisateur et
de l'application comme ils peuvent parvenir d'une interprétation plus ou moins complexe de
ces paramètres. Dey a veillé à ce que sa définition englobe toute donnée implicite ou explicite
qui peut être utile à l'application.
En 2001, Winograd [Winograd01] approuve la définition donnée par Dey et affirme qu'elle
couvre tous les travaux existants sur le contexte. Cependant, il considère que l'utilisation
d'expressions comme "toute information" et "caractériser une entité" reste d'ordre très général
et ne trace aucune limite à la notion de contexte (tout peut être contexte). Pour apporter plus
de précision par rapport à la définition de Dey, Winograd propose : le contexte est un
ensemble d'informations. Cet ensemble est structuré et partagé ; il évolue et sert
l'interprétation. Il détaille cette définition en disant : "La considération d'une information
comme contexte est due à la manière dont elle est utilisée et non à ses propriétés inhérentes".
Il appuie cette idée par l'exemple : "le voltage des lignes d'électricité fait partie du contexte si
le système en dépend; sinon, il ne peut être qu'un paramètre quelconque de l'environnement".
Nous considérons que cette définition de Winograd est plus utile pour l'exploitation du
contexte dans les applications. Nous avons repris les principes de cette définition et nous
avons apporté encore plus de précisions pour tracer des limites entre les données propres à
l'application et son contexte d'utilisation. Nous détaillons notre vision de la notion de contexte
dans le chapitre III.
3. Catégories de contexte
Etant donnée la diversité des informations composant le contexte, il est utile d'essayer de
les classer par catégorie pour faciliter leur utilisation. Dans cette section, nous présentons une
classification qui synthétise les informations contextuelles utilisées dans les solutions
existantes. Les entités principales concernées par la notion de contexte sont des lieux, des
personnes ou des objets. Les lieux sont des régions d'espaces géographiques comme des
Tarak CHAARI - 27 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
chambres, des bureaux, des bâtiments, des rues ou des zones bien définies. Les personnes
peuvent êtres des individus ou des groupes d'individus rassemblés ou répartis. Les objets
peuvent êtres des entités physiques, des composants logiciels ou des artefacts (applications,
fichiers, ressources…).
Nous classons les informations contextuelles utilisées dans la majorité des travaux
existants en quatre catégories principales : identité, localisation, état (ou activité) et temps.
L'identité se réfère à la capacité d'assigner un unique identifiant à une entité. Cet identifiant
doit être unique dans l'espace de nommage utilisé par les applications.
La localisation ne se limite pas à la position 2D des objets et des personnes. En effet, elle
peut concerner l'orientation, l'altitude et les relations spatiale entre les entités (comme les
relations de proximité, de co-existance et de contenance). Par exemple, le fait qu'un objet A
est orienté vers un objet B ou un autre objet C est une information qui peut être classé dans la
catégorie localisation. La localisation peut aussi référencer des lieux. Ces lieux peuvent être
identifiés par leurs emplacements géographiques absolus ou relatifs par rapport à des objets
de référence.
La catégorie état ou activité encapsule les caractéristiques intrinsèques des entités qui
interviennent dans le système. Par exemple, pour un lieu, l'état peut caractériser la
température ambiante, la quantité de lumière existante ou le niveau de bruit courant. Pour une
personne, l'état peut se référer à ses signes vitaux, sa fatigue ou son activité (par exemple, il
est en train de conduire, lire, marcher, courir…). Pour les composants logiciels, l'état est tout
attribut ou caractéristique qui peut être obtenue suite à une requête. Des exemples typiques de
ces caractéristiques sont le temps de réponse d'un service, son taux d'utilisation, son état
(disponible, activé, désactivé…).
Finalement, le temps peut aussi être une information contextuelle car il peut caractériser
une entité. Le temps permet aussi d'établir un historique de valeurs permettant d'enrichir le
contexte. En effet, l'enchaînement et l'ordonnancement d'actions ou d'évènements dans le
temps peuvent aussi être importants pour la décision prise par l'application.
Les données encapsulées par ces quatre catégories peuvent être interprétées ou corrélées
pour obtenir des informations contextuelles supplémentaires afin de garantir une évaluation
plus étendue d'une situation. Par exemple, en connaissant dans une salle, le nombre de
personnes, leurs positions relatives et la quantité de bruit, on peut déterminer s'ils sont en
conférence ou non.
Les différentes catégories que nous avons identifiées dans les travaux existants peuvent
être utilisées de différentes manières pour assurer la sensibilité au contexte dans une
Tarak CHAARI - 28 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
application. Nous détaillons dans le paragraphe suivant cette notion de "sensibilité de
contexte".
III. NOTION DE SENSIBILITE AU CONTEXTE (CONTEXT-
AWARENESS)
La notion de sensibilité au contexte concerne l'utilisation du contexte dans les applications.
Cette notion est une traduction de l'expression anglaise "context-awareness". Elle caractérise
la capacité d'un système à s'adapter aux changements du contexte. Selon Dey et Abowd, un
système est sensible au contexte s'il utilise le contexte pour fournir des informations et des
services pertinents pour l'utilisateur, où la pertinence dépend de la tâche demandée par
l'utilisateur [Dey00].
Cette définition d'un système sensible au contexte a été adoptée par tous les chercheurs
dans ce domaine. Elle a mis en évidence trois catégories de fonctions liées à la présentation
d'information, à l’exécution de services et au stockage d'informations selon le contexte.
La première catégorie, présentation d'information et services, se rapporte aux applications
qui présentent des informations du contexte. Ces applications peuvent proposer des choix
d'actions appropriées à l'utilisateur. Il y a plusieurs exemples de ce type de travaux dans la
littérature et dans quelques systèmes commercialisés. Par exemple, nous pouvons trouver des
applications pour montrer la localisation de l'utilisateur ou de son véhicule sur une carte. Elles
peuvent aussi proposer des icones (ou des alertes) des centres d'intérêts voisins de l'utilisateur
[Abowd97], [Bederson95], [Davies98], [Feiner97], [Fels98], [McCarthy99], [McCarthy00]).
Nous pouvons aussi citer les travaux de [Schilit94] qui présentent la liste des imprimantes
proches de l'utilisateur. Nous pouvons aussi trouver d'autres études sur la présentation
d'informations dans des systèmes ambiants [Heiner99], [Ishii97], [Mynatt98], [Weiser97]….
La deuxième catégorie, exécution automatique de services, décrit les applications qui
déclenchent une commande, ou reconfigurent le système à la place de l'utilisateur selon les
changements de contexte. Dans cette catégorie nous pouvons citer : le système Teleport qui
assure le transport automatique de profil utilisateur lorsqu'il passe d'une machine à une autre
[Bennett94], un système d'enregistrement automatique de son quand une réunion ou un
rassemblement non planifié se passe dans un certain lieu [Brotherton99], des téléphones
mobiles qui changent leurs comportement et leurs configurations (vibreur/sonnerie) selon
l'environnement de l'utilisateur [Harrison98], un système de sécurité portable qui détecte si
l'utilisateur est effrayé en utilisant des capteurs biométriques [Healey98], et des dispositifs qui
Tarak CHAARI - 29 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
fournissent des signaux de rappel quand les utilisateurs sont à un lieu précis ([Beigl00] et
[Marmasse00]).
Dans la troisième catégorie s’intéressant au stockage d'information selon le contexte, les
applications associent des données au contexte de leur utilisation. Par exemple, dans une
conférence, une application étiquette des notes prises par l'utilisateur avec le lieu et le temps
de l'observation [Pascoe98]. Dans des domaines similaires, Time-Machine Computing
[Rekimoto99] et Placeless Documents [Dourish00] sont deux systèmes qui attachent l'identité
des utilisateurs, leurs lieux et le temps de création et d'utilisation de ressources logicielles afin
de pouvoir les utiliser d'une façon plus facile et rapide ultérieurement. D'autres exemples plus
complexes dans cette catégorie sont des applications d'aide-mémoire telles que Forget-Me-
Not [Lamming94] et Rememberance Agent [Rhodes97].
Malgré tous ces travaux, le domaine de la sensibilité de contexte est loin d'être au point. En
effet, plusieurs éléments sont encore à approfondir et à étudier. Winograd a déjà énuméré trois
lacunes dans ce domaine : (i) la notion de contexte n'est pas encore bien définie; (ii) les
travaux existants manquent de modèles et de méthodes conceptuelles; (iii) il n'y a pas d'outils
disponibles pour le développement et l'hébergement d'applications sensibles au contexte.
Dans le paragraphe suivant, nous détaillons l'architecture générale et les fonctions qu'un
système doit accomplir pour qu'il puisse être sensible au contexte.
IV. ARCHITECTURE D’UN SYSTEME SENSIBLE AU CONTEXTE
La conception des applications sensibles au contexte soulève de nouveaux défis. En effet,
la manipulation du contexte est difficile pour différentes raisons : (1) les méthodes classiques
de développement des logiciels sont difficiles à appliquer sur les applications sensibles au
contexte; (2) les solutions proposées pour ce genre d'applications sont soit spécifiques à un
besoin précis soit elles manquent d'abstraction lors de leur conception (3) la capture du
contexte est souvent distribuée et mène à des conceptions complexes. Dey [Dey99] a été le
premier à proposer une séparation entre l'acquisition de contexte et son utilisation dans les
applications. Il s'appuie sur une étude de nouvelles méthodes de conception des systèmes
interactifs mobiles où la séparation entre l'application d'une part et le nouveau monde
d'interfaces, d'icones, de menus, de pointeurs et de moyens d'interaction sur les terminaux
mobiles d'autre part.
Dans les applications sensibles au contexte, on est confronté à des problèmes similaires à
ceux rencontrés lors du développement des systèmes interactifs mobiles. Pour cette raison,
Dey pense qu'il est utile de séparer la gestion du contexte de l'application, afin de pouvoir
Tarak CHAARI - 30 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
développer une plateforme générique de développement et déploiement d'applications
sensibles au contexte. La seule chose qui différencie, selon Dey, une application sensible au
contexte d'un système interactif mobile est que ce dernier manipule des données explicites qui
sont soit des variables internes de l'application soit des entrées explicites de l'utilisateur. Dey a
proposé une plateforme semblable aux systèmes interactifs tout en généralisant les types
d'entrées pour prendre en compte des données implicites déduites de l'environnement de
l'utilisateur (données du contexte). Inspiré par des concepts utilisés dans des outils
d'interaction, Dey a défini quelques abstractions [Dey99] qui aident à inférer une
interprétation de haut niveau du contexte, et qui supporte la séparation entre la gestion du
contexte et l'application. Cette idée a été reprise par la majorité des travaux actuels
[Matthias07] dans le domaine de la sensibilité au contexte, proposant ainsi des architectures à
plusieurs couches. Ces architectures diffèrent dans les fonctions, les noms et l'emplacement de
leurs couches. Cependant, nous remarquons que toutes ces propositions se basent sur cinq
couches principales : capture du contexte, interprétation/Agrégation du contexte,
stockage/historique du contexte, dissémination du contexte et application (figure 1). Dans les
paragraphes suivants, nous détaillons les fonctions de ces cinq couches et leurs différents
éléments.
Application
Stockage/Historique
Interprétation / Agrégation
Capture
Dissémination
Figure 1 - Architecture générale d'un système sensible au contexte
1. Couche de capture du contexte
La première couche d'une architecture sensible au contexte est composée d'une collection
de capteurs. Un capteur est une source matérielle ou logicielle qui peut générer une
information contextuelle. Nous distinguons trois types de capteurs : physiques, virtuels et
logiques [Indulska03].
1.1 CAPTEURS PHYSIQUES
Les capteurs physiques sont des dispositifs matériels qui sont capables de fournir des
Tarak CHAARI - 31 - Thèse de doctorat
Chapitre I – Etat de l’art : les systèmes sensibles au contexte
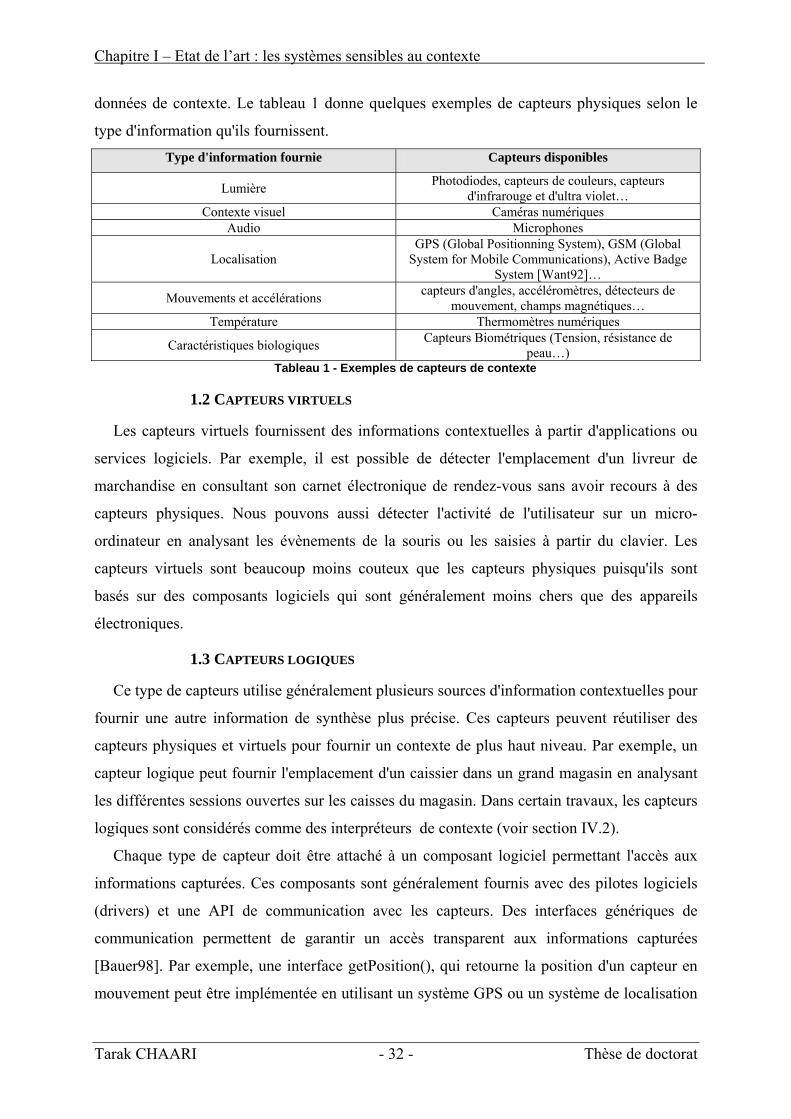
données de contexte. Le tableau 1 donne quelques exemples de capteurs physiques selon le
type d'information qu'ils fournissent. Type d'information fournie Capteurs disponibles
Lumière Photodiodes, capteurs de couleurs, capteurs d'infrarouge et d'ultra violet…
Contexte visuel Caméras numériques Audio Microphones
Localisation GPS (Global Positionning System), GSM (Global
System for Mobile Communications), Active Badge System [Want92]…
Mouvements et accélérations capteurs d'angles, accéléromètres, détecteurs de mouvement, champs magnétiques…
Température Thermomètres numériques
Caractéristiques biologiques Capteurs Biométriques (Tension, résistance de peau…)
Tableau 1 - Exemples de capteurs de contexte
1.2 CAPTEURS VIRTUELS
Les capteurs virtuels fournissent des informations contextuelles à partir d'applications ou
services logiciels. Par exemple, il est possible de détecter l'emplacement d'un livreur de
marchandise en consultant son carnet électronique de rendez-vous sans avoir recours à des
capteurs physiques. Nous pouvons aussi détecter l'activité de l'utilisateur sur un micro-
ordinateur en analysant les évènements de la souris ou les saisies à partir du clavier. Les
capteurs virtuels sont beaucoup moins couteux que les capteurs physiques puisqu'ils sont
basés sur des composants logiciels qui sont généralement moins chers que des appareils
électroniques.
1.3 CAPTEURS LOGIQUES
Ce type de capteurs utilise généralement plusieurs sources d'information contextuelles pour
fournir une autre information de synthèse plus précise. Ces capteurs peuvent réutiliser des
capteurs physiques et virtuels pour fournir un contexte de plus haut niveau. Par exemple, un
capteur logique peut fournir l'emplacement d'un caissier dans un grand magasin en analysant
les différentes sessions ouvertes sur les caisses du magasin. Dans certain travaux, les capteurs
logiques sont considérés comme des interpréteurs de contexte (voir section IV.2).
Chaque type de capteur doit être attaché à un composant logiciel permettant l'accès aux
informations capturées. Ces composants sont généralement fournis avec des pilotes logiciels
(drivers) et une API de communication avec les capteurs. Des interfaces génériques de
communication permettent de garantir un accès transparent aux informations capturées
[Bauer98]. Par exemple, une interface getPosition(), qui retourne la position d'un capteur en
mouvement peut être implémentée en utilisant un système GPS ou un système de localisation
Tarak CHAARI - 32 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
GSM.
2. Couche d’Interprétation et d’agrégation du contexte
Cette couche offre des moyens d'interprétation des données contextuelles fournies par les
capteurs du contexte. Elle sert à l'analyse et à la transformation des données brutes fournies
par la couche de capture du contexte dans d'autres formats de haut niveau qui sont plus faciles
à manipuler et à utiliser. En effet, les capteurs fournissent généralement des données
techniques qui ne sont pas appropriées pour une utilisation directe par l'application. Les
transformations effectuées sur les données brutes fournies par les capteurs peuvent être
réalisées par plusieurs opérations : extraction, quantification, raisonnement, agrégation... Par
exemple, les coordonnées GPS d'une personne peuvent être moins significatives qu'une
adresse physique sous forme de numéro de rue et de ville.
La complexité des interprétations de contexte peut varier d'une simple agrégation de
valeurs qui proviennent de plusieurs capteurs à des raisonnements ou analyses statistiques
complexes. Par exemple, la localisation de plusieurs personnes dans une seule salle peut
inférer le fait qu'ils sont en réunion. Dans ce cas, le niveau de bruit peut aussi être une
information importante pour savoir s'ils sont en réunion de travail ou de loisir.
Cette couche doit aussi assurer la résolution de conflits causés par l'utilisation de plusieurs
sources de contexte. En effet, ces sources peuvent donner des résultats contradictoires ou
peuvent aboutir à des situations imprécises. Cette couche doit donc avoir une certaine
intelligence d'interprétation pour résoudre ces conflits [Dey98], [Kiciman00].
3. Couche de stockage et historique du contexte
La troisième couche "stockage et historique du contexte" organise les données capturées et
interprétées et les stocke pour une utilisation ultérieure. Ce stockage peut être centralisé ou
distribué. La solution centralisée est l'option la plus répandue et la plus utilisée puisqu'elle
facilite la gestion des mises à jours et des variations des valeurs du contexte. La gestion
distribuée du contexte est beaucoup plus complexe puisqu'elle inflige des fonctions
additionnelles de découvertes de ressources et d'actualisation des valeurs du contexte. De
plus, cette gestion distribuée alourdit la tâche de l'application qui doit gérer la collecte des
différentes informations contextuelles d'une façon interne.
Pour stocker une information, nous avons besoin de définir un modèle pour la décrire.
Ainsi, un modèle de contexte est requis pour pouvoir l'utiliser dans l'application. Strang et
Linnhoff-Popien [Linnhoff04] ont résumé les approches de modélisation de contexte les plus
Tarak CHAARI - 33 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
intéressantes de la littérature. Ils ont proposé une classification des approches de modélisation
basée sur la structure de données utilisée pour la description et l'échange du contexte. Nous
présentons ces approches en trois catégories par degré de complexité de leur structure de
données : les modèles Attribut/Valeur, les modèles basés sur XML et les modèles basés sur
les ontologies.
3.1 MODELES ATTRIBUT-VALEUR
Plusieurs architectures présentent le contexte sous forme de paires (attribut, valeur).
L'attribut représente un nom d'une information contextuelle. La valeur représente la valeur
actuelle de cette information. Par exemple, (Name="context1", User="doctorEH102",
Localisation="Edouard Herriot Hospital", Time="Mon Jul 09 16:51:20 CEST 2007"). Le
contexte context1 est défini par "l’utilisateur x est localisé dans un emplacement y à un temps
t". Cette méthode présente l’avantage de la facilité d’implantation. En effet, la gestion du
contexte revient à parcourir la liste des contextes disponibles. Cependant, ce modèle manque
d’expression et de complétude. En effet, sa structure trop « plate » ne permet pas de définir
tous les aspects contextuels de l’application. Ce genre de modèle est aussi une source de
conflits. Par exemple, si nous définissons un nouveau contexte (Name="context2", User="x",
Localisation="z", Time="t") avec l’emplacement z est dans y (par exemple z="chambre 220"
et y="Hôpital Edouard Herriot"), on ne peut pas dire que context2 est un sous contexte de
context1 et que toutes les fonctionnalités offertes par l’application dans context1 doivent aussi
exister dans context2.
3.2 MODELES BASES SUR XML
Les modèles basés sur XML utilisent une structure de données hiérarchique. La profondeur
de cette structure dépend du contexte décrit. Les langages à base de profils sont largement
utilisés dans cette catégorie de modèles. Par exemple, nous pouvons citer le profil CC/PP
(Composite Capabilities / Preference Profile) [W3C04] et le profil UAProf (User Agent
Profile) [Wapforum].
La figure 2 montre un exemple CC/PP utilisé pour la modélisation de la localisation de
l’utilisateur [Indulska03] :
[LocationProfile [PhysicalLocation [Country, State, City, Suburb]] [LogicalLocation [IPAddress]] [GeodeticLocation [Longitude, Latitude, Altitude]] [Orientation [Heading, Pitch]] ]
Figure 2 - Modélisation de la localisation de l'utilisateur en utilisant CC/PP
Plusieurs autres exemples basés sur le langage XML avec un encodage RDF [Lassila99]
Tarak CHAARI - 34 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
peuvent être trouvés dans l'article [Linnhoff04].
3.3 MODELES BASES SUR LES ONTOLOGIES
Les ontologies représentent une autre solution pour modéliser le contexte [Chen03].
[Costa03] justifie l’utilisation des ontologies par trois arguments:
- Une ontologie permet de partager les connaissances dans un système distribué
- Une ontologie comprend des sémantiques déclaratives permettant d’élaborer des
raisonnements sur les informations contextuelles
- Avec une représentation explicite d’une ontologie commune, l’interopérabilité des
applications et des terminaux est assurée.
En utilisant les ontologies, le mapping utilisateur/services pertinents pour un contexte
donné (comme la localisation, activités…) est réalisé d’une manière (semi-)automatique. Le
filtrage automatique de messages selon les contextes est un exemple d’application
intéressante dans cette vision. CoOL [Strang03] est un exemple de langage de description de
contexte utilisant les ontologies. Il considère qu’une information du contexte a un certain
aspect (ou représentation) et représente une certaine entité. La figure 3 décrit la position
géographique (information du contexte) représentée par les coordonnées de Gauss-Krueger
(aspect ou représentation) relative à un téléphone mobile (entité).
<instance xmlns=http://demo.heywow.com/schema/cool xmlns:a=http://demo.heywow.com/schema/aspects xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <contextInformation> <entity system="urn:phonenumber">+49-179-1234567</entity> <characterizedBy> <aspect name="GaussKruegerCoordinate"> <observedState xsi:type="a:o2GaussKruegerType">367032533074</observedState> <units>10m</units> </aspect> <certaintyOfObserver>90</certaintyOfObserver> </characterizedBy> </contextInformation> </instance>
Figure 3 - Exemple de représentation XML du contexte en utilisant l'ontologie CoOL
3.4 SYNTHESE SUR LES MODELES DE CONTEXTE
Les trois approches de modélisation du contexte citées dans cette section présentent
chacune des avantages et des inconvénients. La première approche utilise un modèle très
simple à implémenter mais sa structure trop « plate » ne permet pas de définir tous les aspects
contextuels de l’application. Ce genre de modèles peut aussi être une source de conflits. La
Tarak CHAARI - 35 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
deuxième approche présente un modèle plus structuré et plus organisé. Il reste aussi facile à
implémenter mais n'atteint pas la richesse et le degré d'expressivité des ontologies. Cependant
la troisième approche basée sur les ontologies reste complexe à implanter dans des cas réels.
De notre point de vue, une ontologie est le résultat d'un consensus général. Le domaine de la
sensibilité au contexte est encore très effervescent où les points de vue divergent encore.
Ainsi, nous considérons que l'utilisation d'une ontologie pour modéliser le contexte est un
objectif très ambitieux dans l'état actuel du domaine de la sensibilité au contexte. Le tableau 2
présente une vue de synthèse sur les approches de modélisation du contexte en présentant
leurs avantages et leurs inconvénients sur trois critères : (1) le degré d'expression et la
richesse sémantique, (2) la facilité d'implantation technique et (3) la résistance du modèle aux
conflits.
Modèle\caractéristique degré d’expression et
richesse sémantique
Facilité
d’implantation Résistance aux conflits
Paires d’Attribut/valeur - + -
Extension de CC/PP + + -
Ontologies + - +
Tableau 2 - Vue de synthèse des approches existantes de modélisation du contexte
4. Couche dissémination du contexte
Cette couche assure la transmission des différentes informations contextuelles à
l'application. Ces informations sont distribuées sur différents lieux géographiques et
proviennent de plusieurs types de dispositifs, comme présenté dans le paragraphe 1 de cette
section. Ceci a poussé les chercheurs à dédier une couche à la transmission des données à
l'application. Cette couche assure une transparence totale de la communication avec
l'application. En conséquence, le développement de l'application devient plus simple. Sans
cette couche, on serait amené à développer des protocoles de communications avec les
différentes sources de contexte. La couche de dissémination du contexte offre des moyens de
communication standards pour notifier l'application des changements de contextes et leur
transmission à l'application. Plusieurs systèmes offrent des mécanismes de gestion
d'évènements qui se basent essentiellement sur les fonctions de gestion de requêtes directes ou
de notification [Bauer98]. L'application peut demander un accès direct à une information
contextuelle précise (pull) mais elle peut aussi s'abonner pour recevoir tous les changements
des valeurs de cette information (publish/subscribe). Ces deux fonctions principales assurent
un moyen de communication transparent et efficace pour la dissémination des valeurs de
contexte à l'application [Rodden98]. L'implantation de ces types de communication est
Tarak CHAARI - 36 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
nécessaire pour garantir la sensibilité au contexte dans une application.
5. Couche application
La couche application dans les systèmes sensibles au contexte existants [Chen03] est
représentée par l'application qui offre ses services aux différents clients concernés. Cette
couche est responsable de l'extraction des informations des différents sources de données
attachées à l'application. Elle doit aussi implémenter les réactions nécessaires aux
changements du contexte. Chaque application s'abonne à la couche de dissémination du
contexte pour accéder aux différentes informations contextuelles et être informée de leurs
changements. Une application peut accéder à ces informations de deux façons différentes :
synchrone et asynchrone. Dans le cas d'un accès synchrone, l'application demande à la couche
de dissémination de lui fournir une information contextuelle précise. Ceci est réalisé
généralement par des appels directs de fonctions au niveau de la couche dissémination. Dans
le cas de la communication asynchrone, l'application s'abonne à des évènements spécifiques
qui correspondent à des changements de valeurs de contexte. Dès qu'un événement est
déclenché, l'application est simplement notifiée ou bien l'un de ses services est directement
invoqué en utilisant des fonctions de callback implémentées dans la couche dissémination
(par exemple, la technique de callback dans CORBA [CORBA02]). Les architectures
existantes ne détaillent pas cette couche et insistent sur le fait que la réalisation de cette
couche dépend du domaine de l'application et que les services implémentés dépendent
fortement de la nature et du besoin des utilisateurs de l'application. Cependant, aucune des
architectures proposées ne présente une stratégie complète précisant comment l'application
peut s'adapter aux différentes variations du contexte. L'adaptation de l'application au contexte
capturé n'est pas une priorité dans ces études. Avant de présenter les travaux d’adaptation
existants dans d’autres domaines, nous présentons, dans la section V de ce chapitre, notre
étude des quatre architectures de référence dans le domaine de la sensibilité au contexte.
V. PRINCIPALES PLATEFORMES EXISTANTES DE SENSIBILITE AU
CONTEXTE
Dans cette section, nous présentons quatre implémentations de référence de plateformes
sensibles au contexte. Nous analysons les approches abordées par chaque plateforme pour
implémenter les couches principales d'un système sensible au contexte. Nous nous intéressons
spécifiquement aux plateformes suivantes:
- Context Toolkit [Dey01b] qui est un outil pour le développement et le déploiement
Tarak CHAARI - 37 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
d'applications sensibles au contexte.
- Context Broker Architecture CoBrA [Chen04] qui est une architecture pour le
développement d'applications sensibles au contexte dans des systèmes ambiants intelligents.
- Context Management Framework CMF [Korpipaa04] qui définit une API pour la gestion
du contexte
- Service Oriented Context-Aware Middleware SOCAM [Gu04] qui est une plateforme
d'aide à la création de services sensibles au contexte.
1. Context Toolkit
Application
Interpreter Interpreter
Server
Widget Widget
Sensor Sensor
Context Architecture
Figure 4 - L'architecture du context Toolkit de Anind K. Dey
Le context Toolkit offre une boite à outils et composants logiciels permettant le
développement et le déploiement d'applications sensibles au contexte. Le nom de cet outil,
Context-toolkit, vient de l’analogie avec les bibliothèques graphiques de widgets (composants
graphiques). Comme pour les « toolkits » graphiques qui offrent un modèle computationnel et
des widgets d’utilité publique (menu, formulaire, bouton), l’objectif du Context-Toolkit est
d’offrir un modèle d’exécution et des composants de base réutilisables pour les applications
sensibles au contexte.
Comme le montre la figure 4, le constituant de base de l’architecture est un «context
widget». Deux autres types de composants complètent l’architecture : les « interpréteurs » et
les « serveurs ».
− Un « context widget », ou widget de contexte, est un composant autonome qui encapsule
un capteur physique. Son rôle est de communiquer les informations perçues à un (ou
plusieurs) serveur(s) ou interpréteur(s) en fonction des données reçues par le capteur. Il a
aussi pour rôle de constituer un historique qui lui est propre. Ce stockage peut être désactivé
pour des fonctions qui n’en présentent pas l’intérêt.
Tarak CHAARI - 38 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
− Les interpréteurs ont pour objectif de donner une sémantique aux signaux qui leur sont
transmis par les « contexts widgets », et ceci au bon niveau de précision. Par exemple, un
interpréteur de localisation de personnes peut fournir comme informations :
o Personne A dans la salle 501.330
o Personne A dans le Bâtiment 501 de l’INSA de Lyon
o Personne A dans le Campus de La Doua
− Les serveurs ont pour objectif principal de collecter l’ensemble des signaux émis par les
autres composants et de faire le lien entre les applications et les « contexts-widgets ». Les
serveurs ont également la charge de synthétiser les informations contextuelles dans un niveau
d’abstraction supérieur. Cependant le mécanisme de synthèse n’est pas décrit et revient au
programmeur.
Dans le Context Toolkit nous retrouvons les différentes couches du modèle générique
présenté dans la figure 4 : Les context widgets permettent un accès simple au capteur (couche
capture de contexte). Les interpréteurs donnent un sens au contexte capturé (couche
interprétation du contexte), et les serveurs (couche stockage et historique de contexte et aussi
couche dissémination) font le lien entre les context widgets et les applications sensibles au
contexte. Cependant, les context widgets ne sont que de simples pilotes logiciels pour les
capteurs auxquels ils sont liés. Ils ne fournissent pas de sens aux informations qu’ils
transmettent et ont besoin pour cela des interpréteurs. Les serveurs, quant à eux, regroupent le
gros du travail. Ils doivent synthétiser de nouvelles informations avec celles que leur
fournissent les context widgets et faire le lien entre les applications et les context widgets.
2. Context Broker Architecture (CoBrA)
Context Broker Architecture (CoBrA) est une architecture orientée agents pour les
systèmes sensibles au contexte dans des environnements intelligents (par exemple, salles de
réunion intelligentes, maisons intelligentes, et véhicules intelligents). L'élément central de
cette architecture est un agent intelligent appelé le context broker (courtier de contexte) qui
maintient un modèle partagé de contexte pour une communauté d'agents, de services et de
capteurs. Le broker assure aussi la protection et la confidentialité des données échangées avec
les utilisateurs en se basant sur des politiques de sécurité définies par chaque utilisateur. Les
agents intelligents s'appuient sur des inférences basées sur des règles logiques pour la gestion
du contexte et son interprétation.
Tarak CHAARI - 39 - Thèse de doctorat
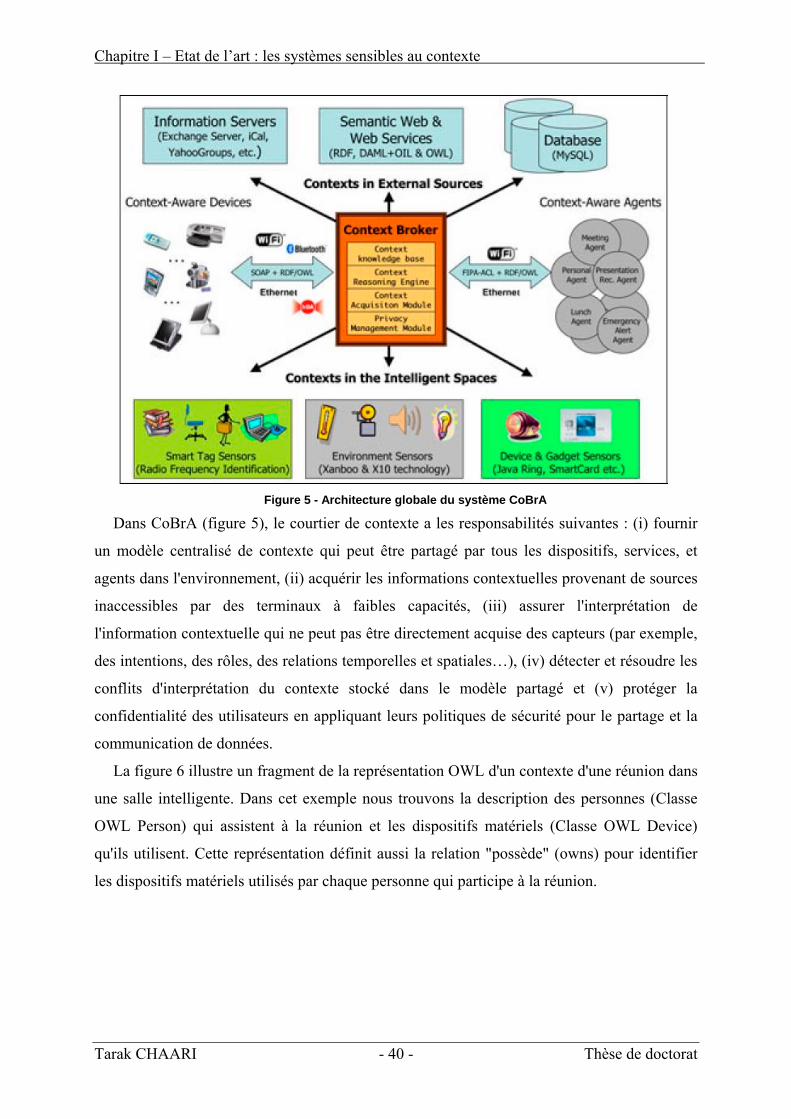
Chapitre I – Etat de l’art : les systèmes sensibles au contexte
Figure 5 - Architecture globale du système CoBrA
Dans CoBrA (figure 5), le courtier de contexte a les responsabilités suivantes : (i) fournir
un modèle centralisé de contexte qui peut être partagé par tous les dispositifs, services, et
agents dans l'environnement, (ii) acquérir les informations contextuelles provenant de sources
inaccessibles par des terminaux à faibles capacités, (iii) assurer l'interprétation de
l'information contextuelle qui ne peut pas être directement acquise des capteurs (par exemple,
des intentions, des rôles, des relations temporelles et spatiales…), (iv) détecter et résoudre les
conflits d'interprétation du contexte stocké dans le modèle partagé et (v) protéger la
confidentialité des utilisateurs en appliquant leurs politiques de sécurité pour le partage et la
communication de données.
La figure 6 illustre un fragment de la représentation OWL d'un contexte d'une réunion dans
une salle intelligente. Dans cet exemple nous trouvons la description des personnes (Classe
OWL Person) qui assistent à la réunion et les dispositifs matériels (Classe OWL Device)
qu'ils utilisent. Cette représentation définit aussi la relation "possède" (owns) pour identifier
les dispositifs matériels utilisés par chaque personne qui participe à la réunion.
Tarak CHAARI - 40 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
<rdf :RDF xmlns = " http://example.org/devices# " xmlns:exd = " http://example.org/devices# ” xmlns :owl = “ http://www.w3.org/2002/07/owl# " xmlns:rdfs = " http://www.w3.org/2000/01/rdf-schema# " xmlns:rdf = " http://www.w3.org/1999/02/22-rdf-syntax-ns# " xmlns:xsd = " http://www.w3.org/2001/XMLSchema# " > <owl :Ontology rdf :about = " http :example.org/devie" > <rdfs:comment>An ontology about people and devices</rdfs:comment> <rdfs:label>An Example Ontology</rdfs:label> </owl:Ontology> <owl:Class rdf:ID = "Person" /> < owl:Class rdf:ID = "Device" /> <owl:Class rdf:ID = "Cellphone" /> <rdfs:subClassOf rdf:resource = " #Device" /> </owl:Class> <owl:Class rdf:ID = "PDA" /> <rdfs:subClassOf rdf:resource = "#Device" /> </owl :Class> <owl:DatatypeProperty rdf:ID = "name" > <rdfs:domain = " http://www.w3.org/2002/07/owl#Things" /> </owl:DatatypeProperty> <owl:ObjectProperty rdf:ID = "ownedBy" > <rdfs:domain rdf:resource = "#Device" /> <rdfs:range rdf :ressource= "#Person / "> </owl:ObjectProperty > <owl:ObjectProperty rdf:ID = "owns"> <owl:inverseOf rdf:resource = "#ownedBy"/> </owl:ObjectProperty> <Person rdf:ID = "P1"> <name rdf:datatype = "&xsd;string">Harry Chen</name> <owns rdf:resource = "#D1" /> </Person> <Person rdf:ID = "P2"> <name rdf:datatype = "&xsd;string">Joe Smith</name> </Person> <Cellphone rdf:ID = "D1"> <name rdf:datatype = "xsd;string">Harry’s Blue Phone</name> </Cellphone> <PDA rdf:ID = "D2"> <name rdf:datatype = "&xsd;string">Blue Knight</name> <ownedBy rdf:resource = "P2"/> </PDA> <rdf:RDF>
Figure 6 - Représentation OWL du contexte dans l'architecture CoBrA
Tarak CHAARI - 41 - Thèse de doctorat
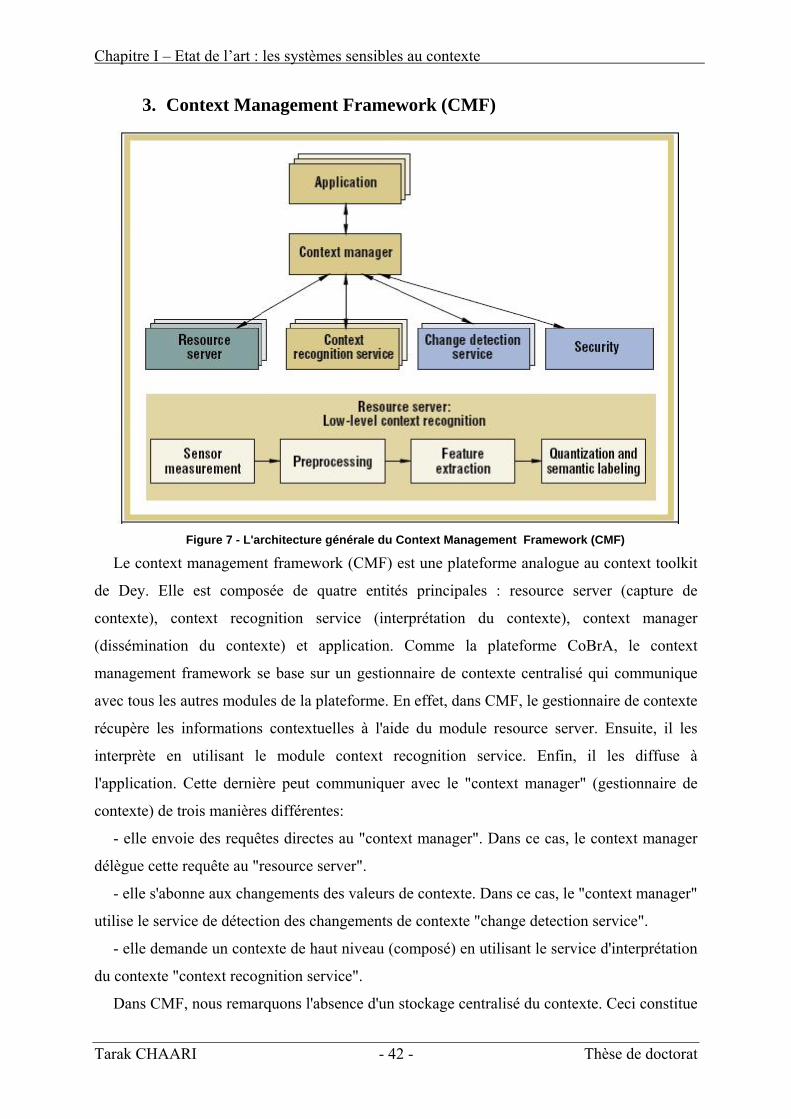
Chapitre I – Etat de l’art : les systèmes sensibles au contexte
3. Context Management Framework (CMF)
Figure 7 - L'architecture générale du Context Management Framework (CMF)
Le context management framework (CMF) est une plateforme analogue au context toolkit
de Dey. Elle est composée de quatre entités principales : resource server (capture de
contexte), context recognition service (interprétation du contexte), context manager
(dissémination du contexte) et application. Comme la plateforme CoBrA, le context
management framework se base sur un gestionnaire de contexte centralisé qui communique
avec tous les autres modules de la plateforme. En effet, dans CMF, le gestionnaire de contexte
récupère les informations contextuelles à l'aide du module resource server. Ensuite, il les
interprète en utilisant le module context recognition service. Enfin, il les diffuse à
l'application. Cette dernière peut communiquer avec le "context manager" (gestionnaire de
contexte) de trois manières différentes:
- elle envoie des requêtes directes au "context manager". Dans ce cas, le context manager
délègue cette requête au "resource server".
- elle s'abonne aux changements des valeurs de contexte. Dans ce cas, le "context manager"
utilise le service de détection des changements de contexte "change detection service".
- elle demande un contexte de haut niveau (composé) en utilisant le service d'interprétation
du contexte "context recognition service".
Dans CMF, nous remarquons l'absence d'un stockage centralisé du contexte. Ceci constitue
Tarak CHAARI - 42 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
une différence majeure par rapport aux autres plateformes présentées. Une autre
caractéristique intéressante de CMF, par rapport aux autres plateformes, consiste en
l'utilisation de la logique floue pour atteindre des informations contextuelles de haut niveau.
Les autres plateformes assument que le contexte (même de haut niveau) est bien spécifié et
représenté alors que CMF considère que l'obtention du contexte de haut niveau n’est ni simple
ni directe. Les auteurs de CMF proposent donc d'utiliser la logique floue pour obtenir des
informations de haut niveau et ainsi enrichir le contexte et la description de l'environnement
de l'utilisateur.
4. Service oriented context-aware middleware (SOCAM)
Figure 8 - L'architecture globale de la plateforme SOCAM
SOCAM est un projet qui vise à assurer le développement et le prototypage rapide de
services sensibles au contexte dans des environnements intelligents. Ce projet propose un
middleware distribué qui convertit les divers espaces physiques d'où le contexte est capturé en
un espace sémantique où le contexte peut être partagé et fourni à des services sensibles au
contexte. Ce middleware se base sur des ontologies pour modéliser le contexte. En première
étape, SOCAM utilise une première ontologie "pervasive" de haut niveau qui décrit les
Tarak CHAARI - 43 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
informations caractérisant l'environnement d'exécution de l'application d'une façon générale.
Ensuite, une ontologie spécifique au domaine de l'application doit être définie (par exemple
ontologie décrivant un utilisateur dans une maison intelligente). L'architecture de SOCAM,
présentée dans la figure 8, comprend les composants suivants (qui évoluent en tant que
services indépendants les uns des autres) :
- context providers (fournisseurs de contexte) : Ils capturent des informations contextuelles
utiles de sources hétérogènes de l'environnement de l'utilisateur et de l'application. Ensuite, ils
les convertissent en des représentations OWL pour que le contexte puisse être partagé et
réutilisé par d'autres composants de l'architecture.
- context interpreter (interprète de contexte) : Il fournit des services de raisonnement
logique sur les représentations OWL du contexte en appliquant des enchaînements de règles
d'interprétation. Il fournit aussi un service d'interrogation intelligent qui permet de résoudre
les conflits d'interprétation du contexte.
- context database (base de données de contexte) : Elle stocke les différents éléments de
l'ontologie "pervasive" décrivant l'environnement de l'application et les instances des
ontologies spécifiques au domaine de l'application décrivant l'environnement de l'utilisateur.
- context-aware services (services sensibles au contexte) : Ces services utilisent les
différentes informations stockées dans la base de données de contexte (context database) pour
modifier leur comportement selon le contexte courant.
- service-locating service (service de localisation de services) : ce service fournit un
mécanisme avec lequel des utilisateurs ou des applications peuvent localiser les fournisseurs
et les interpréteurs de contexte.
5. Synthèse
Le tableau 3 synthétise les aspects principaux de chaque architecture des plateformes
étudiées : Context Toolkit, CoBrA, CMF et SOCAM. Nous remarquons que ces plateformes
réutilisent d'une façon plus ou moins fidèle, le modèle général à base de cinq couches présenté
dans la figure 1.
Dans ces quatre plateformes, il y a un accord commun sur la séparation de l'acquisition du
contexte d'une part et de son utilisation d'autre part. En effet, il est très important d'encapsuler
les mécanismes d'acquisition du contexte dans des composants qui offrent une interface de
communication standard. Actuellement, il n'y a pas un modèle standard d'acquisition de
contexte à partir de plusieurs sources différentes. Chaque plateforme propose son propre
modèle d'acquisition et de collecte de contexte. SOCAM utilise l'approche la plus
Tarak CHAARI - 44 - Thèse de doctorat
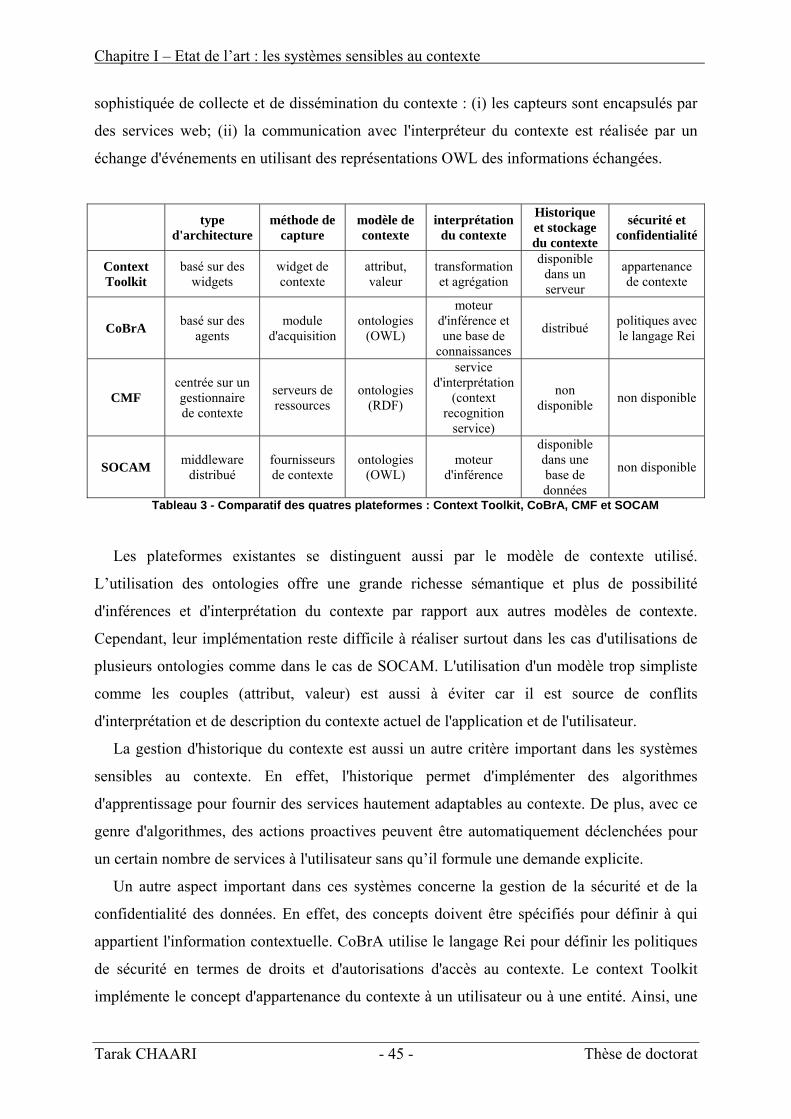
Chapitre I – Etat de l’art : les systèmes sensibles au contexte
sophistiquée de collecte et de dissémination du contexte : (i) les capteurs sont encapsulés par
des services web; (ii) la communication avec l'interpréteur du contexte est réalisée par un
échange d'événements en utilisant des représentations OWL des informations échangées.
type d'architecture
méthode de capture
modèle de contexte
interprétation du contexte
Historique et stockage du contexte
sécurité et confidentialité
Context Toolkit
basé sur des widgets
widget de contexte
attribut, valeur
transformation et agrégation
disponible dans un serveur
appartenance de contexte
CoBrA basé sur des agents
module d'acquisition
ontologies (OWL)
moteur d'inférence et une base de
connaissances
distribué politiques avec le langage Rei
CMF centrée sur un gestionnaire de contexte
serveurs de ressources
ontologies (RDF)
service d'interprétation
(context recognition
service)
non disponible non disponible
SOCAM middleware distribué
fournisseurs de contexte
ontologies (OWL)
moteur d'inférence
disponible dans une base de données
non disponible
Tableau 3 - Comparatif des quatres plateformes : Context Toolkit, CoBrA, CMF et SOCAM
Les plateformes existantes se distinguent aussi par le modèle de contexte utilisé.
L’utilisation des ontologies offre une grande richesse sémantique et plus de possibilité
d'inférences et d'interprétation du contexte par rapport aux autres modèles de contexte.
Cependant, leur implémentation reste difficile à réaliser surtout dans les cas d'utilisations de
plusieurs ontologies comme dans le cas de SOCAM. L'utilisation d'un modèle trop simpliste
comme les couples (attribut, valeur) est aussi à éviter car il est source de conflits
d'interprétation et de description du contexte actuel de l'application et de l'utilisateur.
La gestion d'historique du contexte est aussi un autre critère important dans les systèmes
sensibles au contexte. En effet, l'historique permet d'implémenter des algorithmes
d'apprentissage pour fournir des services hautement adaptables au contexte. De plus, avec ce
genre d'algorithmes, des actions proactives peuvent être automatiquement déclenchées pour
un certain nombre de services à l'utilisateur sans qu’il formule une demande explicite.
Un autre aspect important dans ces systèmes concerne la gestion de la sécurité et de la
confidentialité des données. En effet, des concepts doivent être spécifiés pour définir à qui
appartient l'information contextuelle. CoBrA utilise le langage Rei pour définir les politiques
de sécurité en termes de droits et d'autorisations d'accès au contexte. Le context Toolkit
implémente le concept d'appartenance du contexte à un utilisateur ou à une entité. Ainsi, une
Tarak CHAARI - 45 - Thèse de doctorat

Chapitre I – Etat de l’art : les systèmes sensibles au contexte
information contextuelle n'est accessible qu'à l'utilisateur ou l'entité auquel elle appartient.
VI. CONCLUSION
Malgré toutes ces propositions et tous ces critères évoqués par les travaux de recherche
dans le domaine de la sensibilité au contexte, les plateformes proposées restent à instancier
d'une manière ad hoc pour chaque application. Tous les travaux existants dans la conception
de plateformes de déploiement et de développement d'application sensibles au contexte se
basent sur le fait que la réaction de l'application par rapport aux changement du contexte
capturé doit être assuré d'une manière ad hoc et spécifique par l'application elle-même. Ces
travaux considèrent que les modifications du comportement de l'application restent une tâche
propre au développeur de l'application et qu'elles restent un paramètre à prendre en compte
lors de son développement. Une question se pose alors : que faire si l'application a été déjà
développée pour supporter un contexte particulier et si on veut l'adapter à de nouveaux
contextes d'utilisation?
Les solutions existantes dans le domaine de la sensibilité au contexte n'ont qu'une seule
réponse à cette question : reprendre tout le cycle de vie de l'application et redévelopper une
nouvelle version. Cette solution reste très lourde à effectuer. Elle nécessite un apprentissage
de la plateforme à utiliser pour pouvoir utiliser ses fonctions d'accès au contexte. La source de
ce problème est l'absence d'une étape importante. Cette étape doit décrire comment
l'application pourrait s'adapter aux changements du contexte. Pour répondre à ce besoin
important, négligé dans le domaine de la sensibilité au contexte, nous avons élaboré une étude
complète pour (i) identifier les moyens et les outils nécessaires avec lesquels nous pouvons
assurer cette adaptation; et (ii) définir une stratégie générique et complète qui utilise ces outils
pour réaliser et implémenter cette adaptation dans des cas concrets.
Avant d'entamer la présentation de notre proposition pour l'adaptation des applications au
contexte, nous présentons la notion d'adaptation et son utilisation dans d'autres domaines.
Tarak CHAARI - 46 - Thèse de doctorat

H CCCHHAAAPPPIIITTTRRREEE IIIIII ––– EEETTTAAATTT DDDEEE LLL’’’AAARRRTTT ::: LLLEEESSS TTTRRRAAAVVVAAAUUUXXX
DDD’’’AAADDDAAAPPPTTTAAATTTIIIOOONNN EEEXXXIIISSSTTTAAANNNTTSSS T
"L’intelligence dérive de l'adaptation du sujet à son milieu" (Jean Piaget)

Chapitre II – Etat de l’art : les travaux d’adaptation existants
TABLE DES MATIERES
I. INTRODUCTION ________________________________________________________ 49
II. DEFINITION, UTILITE ET CARACTERISATION DE L’ADAPTATION _________________ 49
1. Définition _____________________________________________________________ 49
2. Utilité_________________________________________________________________ 50
3. Caractérisation_________________________________________________________ 50
III. L’ADAPTATION DANS LES ARCHITECTURES A BASE DE COMPOSANTS______________ 53
1. Concepts de la programmation à base de composants _________________________ 53
2. Mécanismes d’adaptation existants ________________________________________ 54
3. Techniques d'adaptation de composants ____________________________________ 56
4. Quelques architectures existantes d’adaptation de composants _________________ 58
5. Synthèse sur l'adaptation des architectures à base de composants_______________ 61
IV. ADAPTATION DE CONTENU MULTIMÉDIA____________________________________ 61
1. Adaptation coté serveur _________________________________________________ 62
2. Adaptation coté client ___________________________________________________ 62
3. Adaptation intermédiaire ________________________________________________ 62
4. Synthèse sur les approches d'adaptation de contenu __________________________ 63
V. ADAPTATION DES INTERFACES UTILISATEUR ________________________________ 64
1. Modélisation des interfaces utilisateurs _____________________________________ 64
2. Adaptation des interfaces homme-machine__________________________________ 66
3. Synthèse sur l'existant dans l'adaptation de présentation ______________________ 66
VI. CONCLUSION__________________________________________________________ 67
Tarak CHAARI - 48 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
I. INTRODUCTION
Les travaux existants dans le domaine de la sensibilité au contexte se sont focalisés sur
tous les aspects de capture, interprétation, modélisation, stockage et dissémination du
contexte. Cependant, il y a beaucoup moins de travaux qui s'intéressent à l'adaptation et
l'actualisation de l'application au contexte. Ce travail de thèse se focalise spécialement sur cet
aspect d'adaptation ou d'adaptabilité au contexte. Il constitue le dernier maillon de la chaîne
de sensibilité des applications au contexte. L'adaptation prend une dimension très importante
surtout dans le cas où on veut ajouter la sensibilité au contexte à des applications déjà
existantes qui ne sont pas adaptées aux nouveaux besoins dus au changement de leurs
environnements d'utilisation. Dans ce chapitre, nous présentons la notion d'adaptation. Nous
évoquerons aussi son utilité, ses objectifs et les domaines où elle est utilisée. La plus grande
partie de ce chapitre est dédiée aux travaux d'adaptation existants que l'ont peut classer en 3
catégories : l'adaptation des architectures à base de composants, l’adaptation des contenus
multimédia et l’adaptation de présentation. Enfin, nous synthétisons ces travaux et nous
présentons les objectifs de ce travail de thèse.
II. DEFINITION, UTILITE ET CARACTERISATION DE L’ADAPTATION
1. Définition
L'adaptation est, selon le grand dictionnaire [granddictionnaire], l'opération qui consiste à
apporter des modifications à un logiciel ou à un système informatique dans le but d'assurer ses
fonctions et, si possible, d'améliorer ses performances, dans un environnement d'utilisation"
[granddictionnaire].
Dans le domaine de la sensibilité au contexte, l'adaptation est étendue par la notion
d'adaptabilité qui caractérise un système qui est capable de changer son comportement lui-
même afin d'améliorer ses performances ou de continuer son exécution dans des
environnements différents. Dans [Layaïda99], on trouve la définition : « Par adaptabilité, on
entend les moyens automatiques ou semi-automatiques qui permettent aux contenus […]
d'être utilisables sur des terminaux ayant des caractéristiques et des ressources très variées. ».
Sur l’utilité de l’adaptation, M. Satyanarayanan a dit dans [Satyanarayanan01] «L’adaptation
est nécessaire quand il y a une disparité significative entre l’offre et la demande d’une
ressource».
Tarak CHAARI - 49 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
2. Utilité
Après avoir mis en œuvre une application, plusieurs raisons peuvent conduire à l’adapter.
Ces raisons peuvent être classées en quatre catégories [Ketfi02] :
2.1 ADAPTATION CORRECTIONNELLE
Dans certains cas, on remarque que l’application en cours de son exécution ne se comporte
pas correctement ou comme prévu. La solution est d’identifier le module de l’application qui
cause le problème et de le remplacer par une nouvelle version supposée correcte. Cette
nouvelle version fournit la même fonctionnalité que l’ancienne, elle se contente simplement
de corriger ses défauts. Dans ce travail de thèse, nous nous n’intéressons pas à ce type
d’adaptation. Par contre, on s’intéresse aux trois types qu’on va présenter - dans la suite de
cette section - par ordre de priorité de leur utilité pour l’adaptation au contexte.
2.2 ADAPTATION ADAPTATIVE
Même si l’application développée s’exécute correctement, parfois son environnement
d’exécution (comme le système d'exploitation), les composants matériels (ou d’autres
applications ou données dont elle dépend) changent. Dans ce cas, l’application est adaptée en
réponse aux changements affectant son environnement d’exécution.
2.3 ADAPTATION EVOLUTIVE
Au moment du développement de l’application, certaines fonctionnalités ne sont pas prises
en compte. Avec l’évolution des besoins de l’utilisateur, l’application doit être étendue avec
de nouvelles fonctionnalités. Cette extension peut être réalisée en ajoutant un ou plusieurs
modules pour assurer les nouvelles fonctionnalités ou même en modifiant les modules
existants pour étendre leurs fonctionnalités tout en gardant l’architecture de l’application.
2.4 ADAPTATION PERFECTIVE
L’objectif de ce type d’adaptation est d’améliorer les performances de l’application. A titre
d’exemple, on se rend compte que l’implémentation d’un module n’est pas optimisée. On
décide alors de remplacer l’implémentation du module en question. Un autre exemple peut
être un module qui reçoit beaucoup de requêtes et qui n’arrive pas à les satisfaire. Pour éviter
la dégradation des performances du système, on diminue la charge de ce module en installant
un autre module qui partage la charge avec le premier.
3. Caractérisation
Après avoir présenté les différentes raisons d'utilisation de l'adaptation dans une
Tarak CHAARI - 50 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
application, nous énumérons dans cette section les différentes classifications utilisées dans les
travaux existants d'adaptation. Cette classification élaborée par [Chassot06] dépend de la
manière d'application de l'adaptation : statique, dynamique, centralisée, distribuée,
comportementale ou architecturale.
3.1 STATIQUE VS DYNAMIQUE
L’adaptation statique ou manuelle consiste à préparer plusieurs versions de la même
ressource avant son exploitation. Cette ressource peut être un document, une image, une vidéo
ou même une application. La ressource est adaptée manuellement avant de pouvoir la
réutiliser dans son nouveau contexte. Cette technique a été adoptée pour plusieurs
développements au début de l’apparition des terminaux mobiles afin de pouvoir exploiter des
ressources initialement prévues pour des PC standards. Avec une adaptation statique, le
résultat est dédié au nouveau contexte d'utilisation de la ressource ce qui garantit la sûreté de
son exploitation. Elle présente aussi une solution simple et efficace car chaque fournisseur
s’occupe de l’adaptation de la ressource pour ses contextes. Cependant, elle présente
l’inconvénient de la difficulté d’évolution pour la prise en charge de nouveaux contextes
d'utilisation.
Contrairement à l’approche précédente, l’adaptation dynamique effectue les
transformations sur la ressource au cours de son utilisation. Un système d’adaptation
automatique intercepte les requêtes des utilisateurs et effectue à la volée des transformations
suivant les caractéristiques du contexte d'utilisation actuel. OPERA [Lemlouma01] et MUSA
[Menkhaus02] sont des applications où les données sont adaptées dynamiquement aux
caractéristiques du terminal utilisé. Elles présentent une adaptation des pages WEB pour
différents terminaux en agissant sur leur composition logique, spatiale, temporelle et
hypertextuelle. Avec une adaptation dynamique, on gagne un temps de développement
important puisque la ressource est transformée automatiquement à la demande de l’utilisateur.
Cependant, des problèmes d’adaptation peuvent surgir dans un nouveau contexte d'utilisation
inconnu, en fournissant un résultat d'adaptation qui n'est peut-être pas adéquat à ce contexte.
En outre, le temps d'attente nécessaire à l’adaptation de la ressource peut gêner l’utilisateur.
En effet, l'adaptation dynamique augmente automatiquement la latence de renvoi de
l'information demandée par l'utilisateur.
Malgré un grand intérêt pour l'adaptation dynamique, l'adaptation statique reste aussi un
moyen sûr et efficace pour assurer l'exploitation des ressources dans différents contextes
d'utilisation. Pour assurer une adaptation efficace et ouverte à plusieurs contextes, il est
Tarak CHAARI - 51 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
important, à notre point de vue, d'utiliser les deux approches de façon complémentaire.
3.2 VERTICALE VS HORIZONTALE
L'adaptation peut concerner une ressource locale à une machine ou distribuée sur plusieurs
machines (typiquement un protocole). Dans le cas où la ressource est distribuée, le processus
d'adaptation peut être centralisé ou réparti sur les différents pairs où les différentes parties de
la ressource ont été stockées. Si l'adaptation est centralisée alors elle est qualifiée de verticale,
sinon elle est horizontale. La solution centralisée est plus facile à implémenter et donne des
performances meilleures au niveau du temps d'accès à la ressource adaptée. Ceci limite
l'utilisation de la solution horizontale à des cas particuliers concernant les protocoles de
communication. [Bridges01] soulève les problèmes de synchronisation de l'adaptation
distribuée et propose un protocole dédié pour gérer cette synchronisation.
3.3 COMPORTEMENTALE VS ARCHITECTURALE
L’adaptation peut être qualifiée de comportementale (ou algorithmique) lorsqu'elle modifie
le comportement de la ressource sans affecter sa structure interne. Ceci facilite l'implantation
et l'exploitation de l'adaptation. En effet, puisque la structure est la même, la nouvelle
ressource reste directement exploitable comme la ressource d'origine. L'implantation est aussi
facilitée car cette adaptation n'effectue pas de changements profonds qui demanderaient une
ré-évaluation des modifications effectuées. Cependant, cette approche comportementale limite
le degré d'adaptation de la ressource. Elle est très utilisée pour l'adaptation de la couche
transport à la qualité de service comme dans [Akan04].
L'adaptation est architecturale lorsque la structure interne de la ressource peut être
modifiée en fonction des besoins applicatifs de l'utilisateur. Cette solution est intéressante car
elle offre un haut degré d'adaptabilité mais elle reste très difficile à implanter. Elle ne reste
possible que si on dispose d'une connaissance suffisante sur l'architecture de l'application et
ses différents composants. L'adaptation architecturale reste restreinte aux applications
orientées composant. Beaucoup de techniques d'adaptation intéressantes sont proposées pour
ce type d'applications. Nous dédions le paragraphe IV de ce chapitre à ces techniques. Les
paragraphes V et VI présentent les techniques existantes pour l’adaptation des données et des
interfaces utilisateur des applications.
Tarak CHAARI - 52 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
III. L’ADAPTATION DANS LES ARCHITECTURES A BASE DE
COMPOSANTS
Paradigme introduit dans les années 90, la programmation à base de composants
([Heineman01], [Szyperski02], [Riveill00]) a pour but d'améliorer la réutilisabilité, la sûreté
et la flexibilité des applications. Pour cela, elle se base sur les notions de « composant » et
« d'assemblage ». Elle propose de concevoir une application comme un assemblage de briques
logicielles préfabriquées. Grâce à la modularité de cette approche, un grand nombre de
travaux l'ont adoptée pour le développement d'applications adaptables. Dans cette section,
nous présentons les concepts de base de la programmation à base de composants et les
techniques existantes d’adaptation des architectures orientées composants.
1. Concepts de la programmation à base de composants
Un composant [Szyperski97] est une unité logicielle qui possède un état constitué par les
données qu'elle traite, une implantation qui est le code réalisant ce traitement et des interfaces
fournies et requises qui sont des ports d'entrée/sortie pour interagir avec le monde extérieur
(voir figure 9). Cette unité logicielle est liée à une infrastructure (conteneur) qui lui permet
d’échanger des messages avec des d’autres composants. Cet échange dépend d’un modèle
d’implantation de composants. Parmi les modèle les plus utilisés, nous citons les EJB
(Enterprise Java Beans) de Sun, le CCM (Corba Component Model) et Fractal du consortium
Object Web.
Figure 9 - Vue extérieur d'un composant logiciel
1.1 LE MODELE EJB
Les EJB [Roman02] sont des éléments clé de la plate-forme J2EE (Java 2 Enterprise
Édition). Ce sont des composants Java portables, réutilisables et déployables qui peuvent être
Tarak CHAARI - 53 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
assemblés pour créer des applications. Le cycle de vie d’un EJB est géré par un conteneur qui
fournit des services de gestion de l’utilisation de ses composants.
1.2 LE MODELE CCM
CCM [Raj99] est un modèle de composants indépendant de la plateforme et du langage de
programmation. Ce modèle propose une API générique pour définir l’interface du composant,
son comportement, son intégration dans une application et la manière dont il échange des
messages avec les autres composants. CCM est un modèle compatible avec les EJB.
1.3 LE MODELE FRACTAL
Fractal [Objectweb04] est un modèle de composants Java réflexif et générique qui supporte
la définition des composants et des liens entre leurs interfaces. Une application Fractal est vue
comme un assemblage de composants qui communiquent des envois de messages synchrones
entre leurs interfaces. Un composant Fractal est constitué d'un contrôleur par lequel passent
toutes les interactions avec les autres composants et d'un contenu qui peut être un objet simple
ou composé.
2. Mécanismes d’adaptation existants
Il existe plusieurs mécanismes qui permettent aux composants de réagir aux changements
de contexte. Sans être exhaustif, les mécanismes les plus connus sont : la réflexivité et
l'adaptation par contrat.
2.1 REFLEXIVITE
La réflexivité représente la capacité d’un composant à s’observer et à agir sur lui-même
durant son exécution [Cazzola99] [Maes87]. Un composant réflexif doit contenir deux
niveaux : un niveau de base et un niveau « méta ». Le niveau de base contient le code métier
qui traite le domaine d'application. Le niveau « méta » manipule la représentation abstraite de
système. Ces deux niveaux sont liés de façon causale, c'est-à-dire que tout changement dans
l'un d'eux se répercute sur l'autre. Les interactions entre les deux niveaux se font dans les deux
sens. Ainsi, on identifie deux aspects : l’introspection et l’intercession. L’introspection est la
capacité d’un système à observer et raisonner sur son propre état et l’intercession est la
capacité d’un programme à modifier son propre état d’exécution. Ainsi, la réflexivité permet
de modifier dynamiquement la structure et le comportement d'une application en réaction aux
changements de son environnement.
L'avantage majeur apporté par cette technique est la séparation entre le code métier des
applications et le code qui gère l'adaptation. Mais elle engendre un surcoût inévitable en
Tarak CHAARI - 54 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
temps d'exécution.
2.2 ADAPTATION PAR CONTRAT
Une politique (policy) définit généralement le comportement attendu des systèmes
distribués hétérogènes, des applications et des réseaux [Wies95]. La gestion d'un système
basée sur une politique (politique-based management) consiste à spécifier un ensemble de
règles qui sont appliquées dans des situations précises tout en assurant la cohérence et la
sécurité. Ces règles peuvent spécifier des actions correctives qui devraient être faites dans
certaines circonstances ou ajouter des contraintes aux états atteints par les composants du
système. Elles sont utilisées aussi pour donner une priorité à une tâche plus haute qu'une autre
ou pour définir des droits d'accès à un ensemble de ressources. La séparation entre la politique
et l'implémentation d'un système offre des avantages. Elle permet de changer dynamiquement
la stratégie de gestion du système en modifiant la politique. Ainsi, on modifie le
comportement d'un système sans changer son implémentation. Cette approche a été utilisée
dans différents domaines comme les bases de données actives et distribuées [Widom96]
[Baral96], les applications du Web sémantique [May05] ou les systèmes distribuées
[Sloman94].
Récemment, des systèmes d'adaptation (comme [Andrade03] et [Keeney03]) ont suivi la
même logique pour spécifier et appliquer une politique d’adaptation. Cette dernière est décrite
dans un fichier appelé « contrat d’adaptation » ou « fichier de règles d'adaptation ». Nous
présentons certains travaux qui illustrent ce principe dans le paragraphe 4 de cette section.
2.3 ADAPTATION PAR TISSAGE D’ASPECTS
Le paradigme de tissage d’aspects permet de développer des applications en séparant leur
code métier de leur code technique (non fonctionnel) [Kickzales97] [Pawlak01]. Cette
séparation permet de structurer l’application en modules indépendants :
• un noyau qui représente le cœur fonctionnel de l’application.
• les aspects qui correspondent à des propriétés non fonctionnelles d'usage général, qui
sont transversales à plusieurs composants du programme de base, telles que la
synchronisation, la tolérance aux fautes, l’équilibrage de charge ou la sécurité.
Les aspects sont écrits séparément dans des langages appropriés tel AspectJ [Kiczales01].
Ensuite, un compilateur appelé tisseur intègre (ou tisse) ces aspects avec le noyau de base
pour produire un seul composant exécutable. Pour utiliser ce mécanisme comme technique
d'adaptation, le procédé d’adaptation est considéré comme du code technique qui sera intégré
dans le code fonctionnel du composant. L’utilisation des aspects permet d’obtenir un code
Tarak CHAARI - 55 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
compréhensible et efficace. Le mécanisme de tissage d’aspects présente un moyen
d’adaptation intéressant puisque le tissage peut être fait dynamiquement en cours d'exécution.
2.4 SYNTHESE SUR LES MECANISMES D’ADAPTATION
Nous considérons que les mécanismes d’adaptation existants sont complémentaires. En
effet, lors de l’ajout d’un module d’adaptation à un système ou à un composant logiciel, il
devient naturellement réflexif puisqu’il doit percevoir les changements de son environnement
et adapter son comportement à ces changements. Nous considérons également que
l’adaptation par contrat est une approche intéressante et efficace pour réaliser la réflexivité au
sein d’un composant ou d’un système adaptatif. En effet, une politique d’adaptation est
nécessaire pour définir les règles selon lesquelles le système ou le composant va réagir pour
adapter son comportement aux changements du contexte de son utilisation. Le tissage
d’aspects peut aussi être considéré comme un mécanisme intéressant pour implémenter les
actions définies dans les contrats d’adaptation. En effet, les actions définies dans ces contrats
consistent généralement à l’exécution d’un code supplémentaire pour réaliser l’adaptation. En
conséquence, nous considérons que l’utilisation de différents mécanismes d’adaptation offre
plus de possibilités pour garantir une adaptation adéquate et complète dans un système
sensible au contexte. La section suivante « techniques d’adaptation de composants »
présentent les outils techniques qui permettent d’implémenter les différents mécanismes
d’adaptation abordés dans cette section.
3. Techniques d'adaptation de composants
Dans les travaux d'adaptation de composants comme ceux de [Aksit03] et [Ketfi02], nous
avons relevé quatre techniques principales utilisées pour modifier le comportement d'une
application : l'adaptation de l'architecture conceptuelle de l'application, l'adaptation de
l'implémentation des composants, l'adaptation de l'interface du composant et l'adaptation du
déploiement de l'application.
3.1 ADAPTER L’ARCHITECTURE CONCEPTUELLE DE L’APPLICATION
- Ajouter un nouveau composant. Cette adaptation implique l’adaptation des
interconnexions entre le nouveau composant et les composants existants. Ce type d’adaptation
peut être classé en deux catégories : instancier le nouveau composant à ajouter à partir d’un
type déjà chargé par l’application ou créer le nouveau composant à partir d’un nouveau type.
En général, quand un composant est ajouté à une application en cours d’exécution, il doit
prendre en compte l’état de l’application, il doit donc récupérer l’état à partir duquel il doit
Tarak CHAARI - 56 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
démarrer et se personnaliser en fonction de cet état.
- Supprimer un composant existant. Le composant supprimé ne doit pas bloquer
l’exécution des autres composants. Il doit aussi être dans un état stable avant d’être supprimé.
Par exemple, si un composant est en cours d’écriture de données dans un fichier, il ne doit par
être supprimé avant la terminaison de sa tâche. Un autre défi concerne les données et les
messages échangés entre le composant en question et les autres composants, ces données ou
messages ne doivent pas être perdus pour maintenir le bon fonctionnement de l'application.
- Modifier les interconnexions entre composants. Quand un nouveau composant est
ajouté, il doit être connecté aux composants existants. En général, pour connecter deux
composants, les types de leurs ports connectés doivent être compatibles. Dans une application
répartie, la connexion entre deux composants spécifie le type de communication entre eux et
dépend de leur localisation. En d’autres termes, la communication entre deux composants
dans le même espace d’exécution est différente de la communication entre deux composants
dans deux espaces d’exécution différents sur la même machine. Elle est également différente
de la communication entre deux composants s’exécutant sur deux machines différentes.
L’adaptation des interconnexions doit préserver les messages et les données en transit.
3.2 ADAPTER L’IMPLEMENTATION D’UN COMPOSANT
Cette adaptation consiste à remplacer un composant par un autre pour une raison
perfective, adaptative ou correctionnelle. Dans le premier cas, l’adaptation est motivée par des
raisons de performance. Par exemple, on décide de remplacer un composant de stockage
utilisant un vecteur par un autre composant utilisant une table de hachage. Autre exemple,
l'administrateur d’une application souhaite expérimenter plusieurs algorithmes implémentant
la même fonctionnalité; il doit pouvoir passer d’une implémentation à une autre sans arrêter
l’application. Du point de vue adaptatif, on peut donner l’exemple d’un utilisateur qui change
d’imprimante ou d’un autre dispositif, le pilote de ce dispositif doit changer. La vision
correctionnelle de l’adaptation consiste à modifier l’implémentation pour résoudre des bugs
ou des problèmes constatés dans l’implémentation courante.
3.3 ADAPTER LES INTERFACES D’UN COMPOSANT
Dans ce type d'adaptation, la liste des interfaces fournies par le composant est modifiée.
Ceci peut être réalisé en ajoutant/supprimant une interface à/de la liste des interfaces fournies
par le composant.
- Ajouter une interface : l’objectif est d’étendre les fonctionnalités du composant. Les
fonctionnalités exposées à travers les autres interfaces restent inchangées.
Tarak CHAARI - 57 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
- Supprimer une interface : Si les fonctions de l'interface en question ne seront pas
utilisées, il peut être utile de supprimer cette interface et par conséquent son implémentation
pour des raisons de performances.
3.4 ADAPTER L’ARCHITECTURE DE DEPLOIEMENT DE L’APPLICATION
Ceci correspond à la migration d’un composant d’un site vers un autre, par exemple pour la
répartition des charges. Ce type d’adaptation n’affecte pas la structure de l’application.
Cependant, la communication entre le composant déplacé et les autres composants doit être
adaptée selon la nouvelle localisation du composant. L’état interne du composant doit être
sauvegardé et réinjecté dans le composant déplacé. Les messages reçus et non encore traités
doivent être pris en compte.
4. Quelques architectures existantes d’adaptation de composants
Dans cette section, nous présentons trois architectures de référence d’adaptation
d’applications orientées composant : K-Component [Dowling01], ACEEL [Chefrour02] et
SAFRAN [David05]. Nous analysons les points forts et les points faibles des mécanismes
d’adaptation utilisés dans ces architectures.
4.1 K-COMPONENT
K-Component [Dowling01] est un modèle de composants pour construire des applications
adaptables au contexte. Il spécifie la reconfiguration dynamique comme la transformation
d'un méta-modèle d'architecture du système. Il utilise des contrats d'adaptation pour séparer le
code d'adaptation du code métier. L'architecture du logiciel est considérée comme un graphe
connexe et orienté où les sommets sont des interfaces, étiquetées avec les instances de
composant, et les arcs sont des connecteurs, étiquetés avec les propriétés de connecteur.
L'adaptation consiste à changer les implémentations des composants et les propriétés des
connecteurs pour étendre ou améliorer les services fournis. La logique de l’adaptation dans K-
components est spécifiée par des contrats qui décrivent le comportement adaptatif du logiciel
à l’aide du langage ACDL (Adaptation Contracts Declarative Language). L’adaptation se
produit en réponse à des événements adaptatifs envoyés par les composants de l’application.
Le gestionnaire d'adaptation interprète le fichier ACDL et reconfigure l'application si une
adaptation s’avère nécessaire. Le gestionnaire d'adaptation assure la configuration du graphe
de l’architecture et implémente les opérations et le protocole de la reconfiguration.
Tarak CHAARI - 58 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
Figure 10 – Architecture d’adaptation dans K-Component
Le K-Component fournit un modèle d'adaptation générique et dynamique applicable à
différents domaines. Le protocole de la reconfiguration assure la consistance et l'intégrité du
système modélisé par un graphe de composants. De plus, des contraintes existantes de K-
Component permettent d'assurer un niveau de sécurité satisfaisant. Par contre, K-Component
utilise pour la partie contrôle de l'adaptation un ensemble de règles spécifiques à chaque
composant pour décrire l'évolution d'un composant en fonction de l'évolution du contexte.
4.2 ACEEL
ACEEL [Chefrour02] est un modèle de composants auto-adaptatifs pour les
environnements mobiles. Il assure le changement dynamique de leurs comportements afin de
s'accommoder aux nouvelles conditions d'exécution. Le modèle se base sur un langage de
script pour décrire les règles d’adaptation dans le format ECA (when <event> if <condition>
do <action>). Il contient un mécanisme de détection et de notification des changements du
contexte. Une action d’adaptation consiste à commuter dynamiquement entre les différents
comportements du composant. Ainsi, une interface dispose de plusieurs implémentations
alternatives, chacune adaptée à un contexte d'exécution particulier. Selon le mécanisme de
réflexion, il existe deux niveaux séparés dans l'architecture d'ACEEL. Le niveau de base est
construit à l'aide du patron de conception stratégie. Le niveau méta contient une partie qui
prend en charge l'auto-adaptation du composant et un sous système de détection-notification
des changements de l'environnement.
Le framework ACEEL inclut aussi un protocole d'adaptation qui désactive le composant
avant de le reconfigurer, puis le réactive en garantissant qu'aucun message destiné au
composant n'a été perdu pendant sa reconfiguration.
Tarak CHAARI - 59 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
Figure 11 – Modèle de composants auto-adaptatifs de l’architecture ACEEL
L’impact d’adaptation dans cette approche est assez léger si on le compare avec celui de
K-Component. Par ailleurs, c'est un modèle orienté objet qui n’offre pas une séparation claire
des différentes fonctionnalités. De plus, pour assurer le protocole d'adaptation, ACEEL
impose des contraintes fortes sur les composants. Les comportements possibles de chaque
composant doivent être prévus à l’avance. Ceci garantit la cohérence architecturale mais
réduit l’ouverture et la dynamicité de l’adaptation.
4.3 SAFRAN
SAFRAN [David05] est un système pour le développement d'applications adaptatives basé
sur le modèle de composants Fractal. La dynamicité de configuration de ces composants et
leur réflexivité rendent ce modèle approprié pour la construction d’applications adaptables.
Les adaptations sont considérées comme des aspects qui sont tissés dynamiquement dans les
applications. Les politiques d'adaptation de SAFRAN sont structurées suivant un ensemble de
règles réactives de la forme ECA. Quand un événement survient, si la condition est
satisfaisante, une action sera exécutée. Toutes les actions de reconfigurations sont écrites dans
un langage dédié, nommé Fscript. Il permet de programmer les reconfigurations déclenchées
suite à la détection d'un événement. Un sous-système, nommé WildCAT, joue le rôle de
détection et de notification des événements qui déclenchent l’exécution de l’adaptation.
L’architecture de SAFRAN comprend un contrôleur Fractal, nommé AdaptationController.
Ce contrôleur implémente le tissage des politiques d'adaptation et rend ainsi les composants
adaptatifs. La figure 12 illustre le fonctionnement de ce contrôleur.
Tarak CHAARI - 60 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
Figure 12 – Stratégie d’adaptation dans l’architecture SAFRAN
L’avantage de cette architecture et son originalité résident dans l’utilisation de la notion
d’aspect qui sépare le code d’adaptation du code métier des composants. Cependant, les
instructions de tissage sont chargées par le système au démarrage et ne peuvent pas être
modifiées pendant l’exécution.
5. Synthèse sur l'adaptation des architectures à base de composants
Dans cette section, nous avons présentés les techniques utilisées pour adapter le
comportement fonctionnel des applications. Les seules solutions proposées dans ce domaine
concernent l'adaptation des architectures à base de composants qui restent spécifiques au
modèle de composants utilisé (EJB, CCM, .net…) ce qui limite leur utilité sur des
applications dont on ne connait pas leurs architectures exactes ou qui ne sont pas développées
à base de composants. Enfin, les possibilités d'adaptation existantes dans ce domaine se
limitent à des remplacements restreints de composants par d'autres ou de réassemblage de
composants prédéfinis.
IV. ADAPTATION DE CONTENU MULTIMEDIA
Depuis l'apparition des systèmes pervasifs, l'adaptation de contenu multimédia a fait l’objet
d’importantes recherches. Plusieurs techniques d'adaptation de données ont été proposées. Ces
techniques reposent sur la transformation textuelle [Nagao01], [Housel96], [Liljeberg95], le
transcodage d’image [Wee00], [Lee03], [Chandra99], [Smith98] ou le traitement vidéo et
audio [Libsie04], [Shanableh00], [Vetro02], [Bolot98].
Une des questions majeures en terme d’architecture pour le développement d’une
fonctionnalité d’adaptation de contenu est de savoir où se réalisent la prise de décision et les
opérations d’adaptation. Trois approches générales ont été proposées dans la littérature pour
la localisation de la fonctionnalité d’adaptation entre la source qui héberge le contenu et la
destination qui le demande : (i) coté serveur (qui héberge la source de données), (ii) coté
Tarak CHAARI - 61 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
client et (iii) au niveau d’un intermédiaire situés entre la source de données et le client.
1. Adaptation coté serveur
Dans la première approche, l’adaptation est opérée au niveau du serveur qui héberge la
ressource comme dans [Margaritidis01], [Mogul01], [Mohan99], [Bharghavan97] et
[Bolot98]. Le serveur se charge de découvrir les capacités du client et la bande passante
disponible et choisit la meilleure stratégie de transformation de contenu. Les solutions coté
serveur présentent quelques inconvénients. En effet, les transformations effectuées sur le
contenu demandé induisent une charge de calcul et une consommation de ressources
conséquentes sur le serveur. Cependant, cette approche reste très adaptée aux situations à
faible variabilité vu la simplicité de sa réalisation. Mais elle n'est pas fiable pour des cas où
les critères d'adaptation varient fréquemment.
2. Adaptation coté client
Dans la seconde approche, la fonctionnalité d’adaptation réside au niveau du destinataire
comme dans [Marriott02], [Lei01], [Björk99], [Yoshikawa97] et [Fisher97]. Les
transformations de contenu nécessaires sont effectuées par le terminal du client, prenant en
compte ses capacités matérielles qui sont ainsi directement accessibles. La source initialement
fournie demeure inchangée quel que soit le contexte de son utilisation. Le client, à la
réception du contenu, transforme celui-ci de manière à pouvoir le présenter ou l'exploiter.
L’adaptation coté client requiert des modifications minimales au niveau du récepteur et peut
être extrêmement efficace dans la personnalisation du contenu jusqu’à correspondre
exactement et efficacement aux capacités du récepteur. Cette approche est efficace lorsque les
caractéristiques de transmission sont moins critiques que les limites d’affichage du terminal
[Nandagopal99]. Toutefois, cette solution est mal adaptée aux situations où les propriétés de
transmission sont tout aussi importantes que celles de l’affichage. La complexité
habituellement élevée des mécanismes d'adaptation freine également l’adoption large de cette
approche [Perkis01]. En effet, le terminal du client est généralement très limité en capacités
de calcul et de stockage.
3. Adaptation intermédiaire
La troisième approche tente de constituer un compromis entre les deux solutions
précédentes : la fonctionnalité d’adaptation est placée sur un nœud intermédiaire
habituellement qualifié de proxy (proxy) ou passerelle (gateway). Des exemples de systèmes
à base de proxys se trouvent dans les références [Singh04], [Wee03], [Kim03], [Chandra99],
Tarak CHAARI - 62 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
[Fox98], [Angin98], [Bickmore97] et [Noble97]. Le proxy intercepte la réponse du serveur,
décide et effectue l’adaptation du contenu en fonction des préférences de l’utilisateur, des
capacités des terminaux et de l’état du réseau, puis envoie le contenu adapté au client.
L’adoption d’une solution à base de proxy présente plusieurs avantages. D’abord,
l’adaptation intermédiaire déplace la charge de calcul du serveur de contenu vers le proxy. En
second lieu, le proxy peut être positionné au point le plus critique du chemin de données. On
considère habituellement que la bande passante entre un proxy et un serveur est plus large que
celle qui est disponible entre un client et un proxy. Le placement du proxy dans un endroit
optimal entre le serveur de contenu et le client permet de disposer d’une vue globale sur les
ressources de l’environnement, telles que la latence du réseau, la bande passante, la taille du
contenu à transporter, les préférences de l’utilisateur, toute modification survenant dans le
temps, etc. En conséquence, la flexibilité du positionnement du mécanisme d’adaptation sur le
meilleur point de distribution de contenu constitue un avantage important en faveur de la
solution du proxy vis-à-vis des deux autres approches (coté client et coté serveur).
La solution basée sur un proxy présente aussi des inconvénients. En premier lieu, elle passe
difficilement à l’échelle à cause des coûts de calcul considérables induits par les opérations
d’adaptation [Lum02]. En second lieu, le fait de passer par un intermédiaire pour la
transmission d’un contenu soulève des problèmes de sécurité. Le tiers manipulant le proxy
doit être digne de confiance auprès du receveur et de la source. En l’absence d’un tiers de
confiance, l’approche "proxy" ne peut pas se charger d’adapter du contenu. De plus, le tiers
est susceptible de facturer son service et les ressources sollicitées pour la réalisation de
l’adaptation. De ce fait, des mécanismes de comptabilité devraient être intégrés à cette
solution afin de mesurer le coût global du processus d'adaptation. En troisième lieu, la liste
des mécanismes d’adaptation de contenu n’est pas exhaustive et pourrait s’enrichir dans un
futur proche ; l’intégration de ces nouveaux outils risque de ne pas être possible si le proxy
n’est pas extensible. Enfin, placer toutes les fonctionnalités d’adaptation au sein du proxy
requiert des unités de calcul puissantes et beaucoup de mémoire.
4. Synthèse sur les approches d'adaptation de contenu
En résumé, de nombreux efforts ont été menés pour développer différentes approches et
techniques d’adaptation de contenu. Des produits commerciaux (par exemple : IBM
Transcoding [IBM06], Web Clipping [Hillerson01], WebSphere [Rodriguez01], etc.) et des
prototypes issus de travaux de recherche (comme : TranSend [Fox98], Odyssey [Noble00],
Conductor [Yarvis01], Digestor [Bickmore97], etc.) ont été développés pour fournir des
Tarak CHAARI - 63 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
techniques d’adaptation de données multimédia dans des environnements hétérogènes. Ces
produits ont beaucoup contribué à l’élaboration de stratégies, d’architectures et de techniques
d’adaptation. Cependant aucune ne nous semble résoudre convenablement les problèmes
d’interopérabilité, d’extensibilité, de flexibilité et de passage à l’échelle qui sont des points
essentiels dans un environnement sensible au contexte. De plus, les systèmes existants sont
conçus pour des besoins spécifiques ; les types d’adaptation de contenu qui ont été abordés se
sont principalement focalisés sur la transformation d’images ou le transcodage vidéo, et ne
fournissent pas de solution générique d’adaptation.
V. ADAPTATION DES INTERFACES UTILISATEUR
L’adaptation des interfaces utilisateur au contexte consiste à produire des interfaces
d’interactions homme-machine qui peuvent être déployées et utilisées sur différent types de
terminaux et qui satisfassent les préférences de l’utilisateur. La plupart des travaux
d'adaptation des interfaces utilisateur s'appuient sur des modèles décrivant les différents
aspects de l’interaction entre l’homme et la machine. Dans la suite de cette section, nous
présentons les modèles principaux existants et nous illustrons leur utilisation dans le
processus d'adaptation.
1. Modélisation des interfaces utilisateurs
Des études approfondies ont été réalisées pour pouvoir modéliser les différents aspects des
interfaces homme – machine. Dans ces travaux, nous distinguons deux approches : cognitives
et d’ingénierie.
Les approches cognitives s’intéressent aux modes de communication entre l’homme et
l’interface graphique, traitant les problèmes d’ergonomie et des capacités intellectuelles et
physiques de l’utilisateur. Dans cette optique, des travaux essaient de définir des langages
d’expressions de tâches. Ces études sont centrées sur la définition et l’élaboration de trois
entités : BUT – ACTION – TACHE : on commence par définir les buts de l’utilisateur qui
décrit le rôle de l’interface graphique. Ensuite, on déduit les tâches associées. Enfin, on définit
l’action qui va déclencher l‘exécution de la tâche pour atteindre le but spécifié. Cette
approche touche aussi les domaines de l’extraction de connaissances et de la multimodalité
qui servent à détecter les gestes et les actes d’interaction de l'utilisateur avec l’interface du
système. Ces domaines se basent essentiellement sur la notion de modalité d’interaction. Le
terme modalité désigne le moyen physique ou logique permettant une communication entre
l’homme et la machine. Comme modalités physiques on peut citer la souris, le clavier, un
Tarak CHAARI - 64 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
capteur de gestes ou de voix… Une zone texte sur une interface graphique ou un logiciel de
reconnaissance vocale représentent des modalités logiques d’interaction. Ces modalités
peuvent aussi être classées suivant leur sens d’interaction : de l’utilisateur vers l’interface
(modalités d’entrées) ou de l’interface graphique vers l’utilisateur (modalités de sortie). Dans
cette approche, les modèles proposés décrivent les moyens d’interaction avec l’utilisateur. Les
modèles principaux sont : le modèle de tâches, le modèle de dialogue, et le modèle utilisateur.
Le modèle utilisateur décrit les caractéristiques cognitives et les préférences ergonomiques de
l’utilisateur. Le modèle de tâche décrit les actions que l’utilisateur peut effectuer sur le
système. Enfin, le modèle de dialogue décrit les moyens d’interaction de l’utilisateur avec le
système. Dans ce cadre, l’équipe de recherche IIHM [IIHM] présente de nouveaux outils
d’interaction comme la réalité et la virtualité augmentées [Dubois01] basées sur la gestualité.
Les approches d’ingénierie s’intéressent plus au développement des interfaces. Elles
proposent des outils de développement et de conception des interfaces homme – machines.
Ainsi, les chercheurs s’intéressent au passage d’une problématique de visualisation ou de
mise à jour de données à une solution concrète (le code de l’interface). Ce passage est
généralement basé sur des modèles techniques décrivant la structure et la composition logique
de l’interface d’une part et son interaction avec le système d’autre part. Ceci nécessite une
connaissance approfondie du système. C’est le rôle du modèle de domaine dans ces
approches. Il décrit tous les aspects fonctionnels du système (entités, relations,
collaboration…). Une formalisation de tous ces aspects est définie dans le langage UML
[Booch98]. Les autres modèles de ces approches d'ingénierie décrivent la structure logique de
l’interface, la disposition de ses composants et son interaction avec le système. Plusieurs
spécifications, modèles et langages de ce type ont été proposés. Voici une liste des modèles
les plus connus dans les approches d’ingénierie :
- UMLi [Pinheiro00] est une extension de UML permettant de décrire l’aspect interaction
d’une application. Basé sur le même concept (représentation graphique) de UML, UMLi
permet de spécifier les composants logiciels constituant l’interface graphique et leur
interaction avec le reste du système. Les diagrammes UMLi restent assez complexes et
fastidieux à construire pour aboutir à une description complète de l'interface utilisateur d'une
application.
- UIML [Abrams99], contrairement à UMLi, se base sur le langage de balisage XML. Ce
langage cherche à masquer la diversité des plateformes et des langages de développement. La
spécification de la présentation est dépendante de la plateforme cible. Si le développeur vise
une IHM pour WML et pour Java, il se doit de produire deux spécifications distinctes. L’une
Tarak CHAARI - 65 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
utilisera les balises WML, la seconde les classes awt/swing. AUIML [Merrick04] est une
amélioration de UIML. Il résout l’un des principaux problèmes de UIML puisque la
spécification est indépendante de la plate-forme cible.
- XIML [Puerta02], est un langage basé sur XML. Il présente l'avantage d'être totalement
indépendant des plateformes cibles en présentant un niveau d'abstraction très haut. Cependant,
l'instantiation de ce langage pour des plateformes concrètes reste très difficile et complexe à
réaliser.
2. Adaptation des interfaces homme-machine
A partir de ces modèles, une stratégie d’adaptation doit être définie pour assurer le bon
fonctionnement de l’interface utilisateur. Beaucoup de systèmes permettant l’adaptation des
interfaces hommes – machines aux préférences de l’utilisateur s'appuient sur l’un des modèles
cités dans le paragraphe précédent. Ces systèmes permettent d’obtenir le code source de ces
interfaces d’une façon automatique ou semi automatique. Les exemples les plus intéressants
sont : UIDE [Sukaviriya93], AME [Märtin96], JANUS [Balzert96], TRIDENT [Bodart95],
GENIUS [Janssen93], Mobi-D et MECANO [Puerta96]. Dans tous ces travaux d’adaptation,
nous distinguons deux techniques d’adaptation : par transformation et par génération.
L’adaptation par transformation consiste à partir d’une entrée assez proche du code qui doit
être généré. Cette solution a été adoptée par [Lemlouma02] pour assurer l’adaptation des
pages web aux terminaux cibles en partant d’un langage XML. Dans ce genre d’adaptation,
on utilise des feuilles de transformation comme XSLT [Clark99], basées sur des règles de
remplacement des informations du langage de départ pour obtenir le code d’arrivée.
L’adaptation par génération concerne surtout les interfaces graphiques programmées en
partant d’un langage de haut niveau, comme par exemple dans le système SEFAGI
[Chaari04]. LiquidUI [Hormonia06] est un autre produit permettant de générer des interfaces
graphiques à partir du langage UIML. Cependant, dans cette plateforme, le langage utilisé
n’est pas très loin du code généré. Ceci complique considérablement la description de
l'interface utilisateur voulue.
3. Synthèse sur l'existant dans l'adaptation de présentation
De nombreux travaux de recherche on été effectués sur l'adaptation de présentation surtout
pour les interfaces graphiques WEB basées sur un balisage. Cependant ces interfaces offrent
des moyens d'interaction limités et ne permettent pas d'accéder aux ressources des terminaux
utilisés pour détecter leurs propriétés. Sur le marché, nous trouvons aussi des produits
Tarak CHAARI - 66 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
commerciaux pour l'aide à la création des interfaces utilisateurs comme JBuilder [JBuilder06],
Eclipse [Eclipse06], Visual Studio [Johnson03] … Cependant, ces produits ne permettent pas
la génération complète du code et exigent un développement ad hoc pour chaque type de
terminaux. Ceci les rend peu utiles dans le domaine de la sensibilité au contexte où de
nombreux types d'interfaces utilisateurs nomades doivent être pris en compte. A l'image de
LiquidUI de Harmonia [Hormonia06], les approches existantes restent limitées à des
plateformes spécifiques et utilisent des langages de description très complexes pour pouvoir
générer le code complet de l'interface utilisateur nécessaire pour l'interaction avec les
différents services d'une application.
VI. CONCLUSION
Dans ce chapitre, nous avons fait un tour d’horizon des différents travaux d’adaptation
existants dans différents domaines. Ces contributions ont généralement concerné des besoins
spécifiques d’amélioration de la qualité de service en adaptant les informations envoyées d’un
serveur à un client aux différentes variations des propriétés de la transmission. D’autres
travaux d’adaptation ont concerné les architectures à base de composants. Ils proposent un
réassemblage de la structure globale de l’application en se basant sur un ensemble de
composants prédéfinis. Ces contributions présentent trois inconvénients majeurs : (i) la
majorité de ces travaux restent spécifique au modèle de composant choisi (EJB, CCM,
.NET…) ; (ii) les outils d’adaptation proposés se limitent à un remplacement d’un composant
ou un assemblage de composants prédéfinis et (iii) ces travaux ne prennent leur intérêt que
pour des applications en cours de développement et non pour des applications déjà
développées qu’on veut adapter à de nouveaux contextes d’utilisation.
De nouvelles contributions pour les systèmes d’information pervasifs sont aussi proposées
pour l’adaptation des documents WEB à plusieurs types de terminaux et aux préférences des
utilisateurs. Ces travaux ne sont pas suffisants pour adapter une application entière, déjà
développée, à de nouveaux contextes d’utilisation pour deux raisons principales : (i) ces
adaptations ne touchent pas les fonctions métier de l’application. En effet, les fonctions
offertes par l’application peuvent ne pas être adaptées à un nouveau contexte d’utilisation. Par
exemple, une fonction qui renvoie un gros volume de données (une requête sur une base de
données par exemple) ne peut pas être utilisée sur un terminal à faible capacité ; (ii) les
interfaces utilisateurs WEB sont très limitées par rapport aux interfaces programmées. Ces
dernières, contrairement à la solution WEB, autorisent l’accès aux ressources systèmes
(mémoire disponible, charge du processeur…) et fournissent des moyens d’interaction plus
Tarak CHAARI - 67 - Thèse de doctorat

Chapitre II – Etat de l’art : les travaux d’adaptation existants
évoluées à l’utilisateur (gestion évoluée des évènements d’interaction). Nous trouvons aussi
beaucoup de travaux intéressants sur l’adaptation des données multimédia échangées entre les
serveurs de contenus et les clients. Ces travaux sont spécifiques au domaine de l’extraction de
données multimédia (multimedia data retrieval). Cependant, ils présentent des techniques
intéressantes qui peuvent être reprises dans le domaine de la sensibilité au contexte afin
d’adapter les données échangées entre l’application et le client.
Dans ce travail de thèse, notre contribution consiste à proposer une architecture et une
stratégie d’adaptation d’applications à de nouveaux contextes d’utilisation en se basant sur les
objectifs suivants :
- Fournir une architecture générique et évolutive permettant l’adaptation des applications
à de nouveaux contextes d’utilisation.
- Fournir une stratégie d’adaptation globale (fonctionnalités, données et présentation)
d’une application à de nouveaux contextes d’utilisation.
- Garantir l’évolutivité des mécanismes d’adaptation disponibles que nous pouvons
appliquer à une application.
Tarak CHAARI - 68 - Thèse de doctorat

CCCHHHAAAPPPIIITTTRRREEE IIIIIIIII --- CCCOOONNNTTTRRRIIIBBBUUUTTTIIIOOONNNSSS ::: DDDEEEFFFIIINNNIIITTTIIIOOONNNSSS,,,
OOOBBBJJJEEECCCTTTIIIFFFSSS EEETTT AAARRRCCCHHHIIITTTEEECCCTTTUUURRREEE
“Context is an operational term: something is context because of the way it is used in interpretation, not due to its inherent
properties” (Terry Winograd)

Chapitre III – Contributions : Définitions, Objectifs et Architecture
TABLE DES MATIERES
I. INTRODUCTION ________________________________________________________ 71
II. NOTRE VISION DU CONTEXTE _____________________________________________ 71
1. Définition du contexte ___________________________________________________ 71
2. Notion de situation contextuelle ___________________________________________ 73
3. Modélisation d’une situation contextuelle ___________________________________ 75
III. MODELISATION FONCTIONNELLE D’UNE APPLICATION ________________________ 78
1. Notion d’entité logicielle _________________________________________________ 78
2. Notion de service _______________________________________________________ 79
3. Notion de dépendance d’exécution de services _______________________________ 80
4. Notion de modèle fonctionnel _____________________________________________ 81
IV. OBJECTIFS DE NOTRE TRAVAIL ___________________________________________ 85
V. SECAS : PLATEFORME POUR L’ADAPTATION D’APPLICATIONS A DE NOUVEAUX
CONTEXTES D’UTILISATION __________________________________________________ 87
1. Présentation de la plateforme SECAS ______________________________________ 87
2. Couche de gestion du contexte ____________________________________________ 87
3. Couche d’adaptation ____________________________________________________ 89
4. Couche de déploiement d’applications______________________________________ 93
VI. CONCLUSION__________________________________________________________ 94
Tarak CHAARI - 70 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
I. INTRODUCTION
Les applications client/serveur sont conçues et développées pour une utilisation dans un
environnement et dans des conditions spécifiques. En fonction de leur utilisation, de
nouveaux besoins apparaissent. Ces applications peuvent être intégrées dans de nouvelles
situations et de nouveaux environnements non prévus. Malgré les efforts fournis dans le
domaine du génie logiciel pour garantir l’évolutivité de ces applications, leur cycle de vie est
généralement totalement repris dès la phase d’analyse des besoins.
Dans ce chapitre, nous précisons ce que nous entendons par « contexte » et par
« adaptation ». Puis nous rappelons les objectifs de ce travail. Avant de conclure, nous
présentons notre architecture d’adaptation d’applications à de nouveaux contextes
d’utilisation. Nous avons nommée cette architecture SECAS pour « Simple Environment For
Context-Aware Systems ».
II. NOTRE VISION DU CONTEXTE
1. Définition du contexte
Dans le domaine de la sensibilité au contexte, les chercheurs n’ont pas encore abouti à une
définition de la notion de contexte d’utilisation qui soit à la fois générique et pragmatique. En
effet, les définitions proposées sont soit très abstraites soit très spécifiques à un domaine
particulier. Ces définitions variées rendent la formalisation du contexte difficile par manque
de précision ou par manque de généricité. La définition de Anind K. Dey [Dey01b]: “le
contexte couvre toutes les informations pouvant être utilisées pour caractériser la situation
d'une entité. Une entité est une personne, un lieu, ou un objet qui peut être pertinent pour
l'interaction entre l'utilisateur et l'application, y compris l'utilisateur et l'application“ est la
plus répandue et la plus acceptée par la majorité des chercheurs dans le domaine de la
sensibilité au contexte. Cependant, cette définition peut être une source de conflits parce
qu’elle ne précise pas de limite entre ce qui fait partie du contexte et ce qui n’en fait pas
partie.
Selon notre expérience dans le domaine, dans un souci d’évolutivité, les applications
doivent être conçues et même développées indépendamment du contexte. Le concepteur
d’une application peut identifier les données qui sont directement liées au domaine de
l’application d’une part et les autres informations caractérisant le contexte d’autre part. Les
paramètres du contexte peuvent être identifiés en aval de la conception de l’application. Ces
Tarak CHAARI - 71 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
considérations devraient permettre aussi de transformer une application existante (legacy) en
une application sensible au contexte sans toucher au code existant. Pour aboutir à ce but, la
limite entre le contexte et les données propres à l’application doit être clairement précisée.
Cette séparation n’est pas évidente et dépend généralement du domaine de l’application. Par
exemple, les coordonnées GPS de l’utilisateur constituent une donnée propre à l’application
dans une application de régulation de trafic routier alors qu’elle constitue un paramètre du
contexte dans une application de télémédecine. Ainsi, identifier les paramètres du contexte
n’est pas une tâche évidente. Nous avons élaboré une étude sur les caractéristiques des
paramètres du contexte afin de faciliter la tâche de leur identification lorsqu’on considère une
application donnée. Ces caractéristiques concernent principalement les sources qui produisent
ces paramètres d’une part et leur importance pour l’application et l’utilisateur d’une autre
part.
La première constatation que nous avons faite est que ces paramètres ne proviennent pas
d’un stockage permanent de l’application. En effet, les données stockées dans des sources du
domaine de l’application n’appartiennent pas à son environnement externe mais font partie de
ses constituants. A notre avis, l’utilisation du contexte est utile pour des raisons de
perfectionnement de l’application et ne constitue pas un élément primordial pour son
fonctionnement. Les paramètres du contexte ne sont pas fournis par des sources directement
liées au domaine de l’application. Le cas échéant, elles appartiennent au domaine de
l’application mais pas à son environnement externe.
La deuxième caractéristique, qui nous semble la plus importante, est que les paramètres du
contexte ne sont pas toujours significatifs pour l’utilisateur et doivent être gérés de façon
transparente. En effet, le contexte d’une application ne doit pas altérer ou changer
complètement les fonctionnalités attendues par l’utilisateur. Ce dernier peut intervenir et
participer à modifier certains paramètres du contexte (par exemple ses préférences) mais
d’une façon indépendante de l’utilisation de l’application.
Dans un cadre plus général, nous pouvons fournir une nouvelle définition du contexte :
Le contexte est l’ensemble des paramètres externes à l’application qui peuvent
influer sur son comportement en définissant de nouvelles vues sur ses données
et ses fonctionnalités. Ces paramètres peuvent être dynamiques et peuvent donc
changer durant l’utilisation de l’application.
Cette définition vient compléter les efforts de Winograd [Winograd01] qui a essayé
Tarak CHAARI - 72 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
d’apporter plus de précisions sur la définition de Dey en diminuant l’espace infini et illimité
tracé par Dey. Winograd insiste sur le fait que la considération d'une information comme
contexte est due à la manière dont elle est utilisée et non à ses propriétés inhérentes.
2. Notion de situation contextuelle
Une instance des paramètres d’un contexte donné caractérise une situation contextuelle.
Cette situation ne modifie pas l’information que l’utilisateur veut avoir de l’application à un
instant donné mais peut conduire à la traiter ou à la présenter différemment. Par exemple une
situation contextuelle peut être caractérisée par les paramètres suivants :
{utilisateur="médecin néphrologue", terminal="PDA", localisation="Domicile du patient
X"}. L’application doit être adaptée à cette situation selon le profil du médecin et son rôle
(avec ses droits d’accès, etc), selon la capacité du terminal utilisé (par exemple, en présentant
les données par petits blocs à la place de tables volumineuses) et selon la localisation
spécifique de l’utilisateur (par exemple, en retirant les interfaces indisponibles au domicile du
patient). Pour définir formellement une situation contextuelle, nous considérons un espace
multi-dimensionnel où chaque dimension représente une facette du contexte. Nous
définissions le contexte d’utilisation d’une application comme un vecteur à cinq dimensions :
Contexte = (terminal, communication, utilisateur, localisation, environnement)
- Terminal : Cette facette décrit toutes les caractéristiques matérielles et logicielles des
terminaux utilisés incluant par exemple la description de l’écran (taille, résolution,
nombre de couleurs), de sa mémoire (de stockage et volatile) et de l’API de
programmation disponible.
- Communication : Elle comprend les caractéristiques des réseaux utilisés comme leurs
bandes passantes, leurs connectivités et leurs qualités de services.
- Utilisateur : Cette facette décrit toutes les caractéristiques de l’utilisateur final de
l’application incluant ses capacités, ses préférences, son profil et ses droits d’accès.
- Localisation : Cette facette décrit l’emplacement logique et physique de l’utilisateur.
L’emplacement logique peut être une adresse IP alors que l’emplacement physique est
généralement l’adresse géographique de l’utilisateur (pièce, adresse postale).
- Environnement : Cette facette est complémentaire aux autres facettes du contexte.
Elle sert à enrichir le modèle de contexte par d’autres paramètres utiles selon le
domaine d’application. Par exemple, nous pouvons trouver dans cette facette la
température ambiante, l’activité ou l’état actuel de l’utilisateur (conduire une voiture,
dormir, occupé…)
Tarak CHAARI - 73 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
Les cinq facettes sont rarement utilisées en même temps pour une même application. La
figure 13 présente deux exemples de situations contextuelles C1 et C2 dans un espace
tridimensionnel {utilisateur, terminal, localisation}. C1 présente une situation contextuelle où
l'utilisateur est un médecin généraliste situé dans son bureau utilisant un PC standard et qui
modifie le traitement d'un patient. Dans le contexte C2, une infirmière consulte le même
dossier médical au domicile du patient en utilisant un PDA, pour appliquer la prescription du
médecin généraliste. Dans les deux contextes, les utilisateurs utilisent le même service «
prescription ». Cependant, l'application ne se comporte pas de la même manière car les deux
situations contextuelles sont différentes : le profil d'utilisateur (médecin et infirmière) affecte
les droits d'accès aux données ; le lieu (bureau et domicile du patient) modifie la liste des
services disponibles, puisque certains appareils médicaux ne sont pas présents au domicile du
patient ; la facette terminal modifie la forme de présentation des données et l'interaction de
l'utilisateur avec l'application. Par exemple, l’information est entièrement envoyée sur un PC
standard alors qu’elle doit être décomposée en plusieurs lots pour un terminal à faible
capacité.
Infirmier
C
P
Terminal
PDA
Téléphone
portable
Hospitalier C
Médecin généraliste CabineLocalisation
Extérieur
Utilisateur Figure 13 - Représentation tridimensionnelle du contexte
Chaque facette regroupe un ensemble de paramètres du contexte. A un instant donné, la
situation contextuelle est définie par les valeurs associées aux paramètres de contexte. La
modification d'une de ces valeurs correspond à une transition vers une autre situation
contextuelle. Cette transition peut modifier le comportement de l’application en définissant de
nouvelles vues sur ses données et ses fonctions.
Nous rappelons que la notion de situation contextuelle permet de décrire l’environnement
de l’application et de l’utilisateur à un instant donné. Nous avons défini cette notion afin (i) de
modéliser et de quantifier le contexte et (ii) d’y adapter le comportement de l’application.
Tarak CHAARI - 74 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
Nous détaillons la structure générale d’une situation contextuelle dans le paragraphe suivant.
3. Modélisation d’une situation contextuelle
Pour stocker les paramètres du contexte, nous utilisons une représentation XML basée sur
le modèle CSCP [Held02]. Nous avons utilisé la richesse et la généricité de ce modèle pour
définir un élément XML pour chaque facette du contexte (contextFacet). Par exemple, dans la
figure 15, la ligne 3 définit un élément qui représente la facette « terminal ».
Chaque facette regroupe un ensemble de paramètres de contexte (ContextParameter). Ces
paramètres peuvent appartenir à des structures hiérarchiques regroupées dans des catégories
(contextCategory). Par exemple, la ligne 5 de la figure 15, définit un paramètre « model »
représentant le modèle du terminal utilisé. Ce paramètre appartient à la facette « terminal ».
La ligne 11 de la même figure définit un paramètre « width » qui représente la largeur du
terminal utilisé. Ce paramètre appartient à la sous-catégorie « screenSize » (taille de l’écran)
qui est elle-même une sous catégorie de « hardwarePlatform » (plateforme matérielle) de la
facette « terminal ».
Chaque paramètre du contexte peut être statique s’il ne change pas durant une session
utilisateur ou dynamique si sa valeur peut varier dans une même session utilisateur. Nous
associons pour chaque paramètre, un attribut « mode » pour différencier les paramètres
dynamiques des paramètres statiques. Cette différenciation est très importante pour le
processus d’adaptation. En effet, l’application doit être informée immédiatement lors du
changement d’un paramètre dynamique alors que les paramètres statiques sont consultés en
cas de besoin. La ligne 8 de la figure 15 définit un exemple de paramètre statique qui
représente la mémoire vive totale du terminal. Le paramètre « availableMemory » de la ligne
9 du même listing présente un paramètre dynamique qui représente la mémoire virtuelle
disponible lors de l’utilisation de ce terminal. Contrairement à la mémoire totale du terminal,
la mémoire disponible varie selon l’utilisation du terminal.
Un paramètre de contexte requis dans une application peut être inutile dans d’autres
environnements. Ainsi, cette structure XML peut être étendue par des catégories et des
paramètres additionnels selon le domaine d'application. En particulier, la facette
« environnement » peut encapsuler toute information supplémentaire de contexte qui n'est pas
décrite dans les autres facettes de base.
La figure 14 présente la structure générale de notre modèle du contexte. Pour chaque
session utilisateur nous associons un profil « contextProfile » qui décrit les cinq facettes du
contexte. Chaque facette peut contenir des paramètres du contexte comme elle peut contenir
Tarak CHAARI - 75 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
des catégories « contextCategory » pour classer les paramètres. Chaque catégorie peut
contenir d’autres catégories.
1..n 0..n
1..n
nametype=static/dynamic
ContextSubCategoryname
ContextFacetfacetName
ContextProfileID
1..5
ContextParameter
Figure 14 - Le modèle général du contexte
La figure 15 donne l’exemple d’une situation contextuelle associée à une session
utilisateur. Ce dernier se connecte en utilisant un téléphone mobile de type NOKIA 6230 à
connectivité limité. La première facette du contexte « terminal » (ligne 3) décrit les
caractéristiques générales du terminal puis les formats de données qu’il accepte ainsi que
l’API disponible. La deuxième facette « network » (ligne 35) décrit la connectivité disponible
pour communiquer avec l’application. La troisième « userProfile » (ligne 41) donne les
caractéristiques générales de l’utilisateur et ses préférences. Enfin, la quatrième facette
« location » (ligne 56) présente les coordonnées logiques et physiques de la localisation de
l’utilisateur.
Tarak CHAARI - 76 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 6970
<?xml version="1.0" encoding="UTF-8"?> <contextProfile ID="U17T355008002783631"> <contextFacet name="terminal"> <contextParameter name="mode" mode="static">cldc</contextParameter> <contextParameter name="model" mode="static">NOKIA6230</contextParameter> <contextParameter name="serialNumber" mode="static">355008002783631</contextParameter> <contextCategory name="hardwarePlatform"> <contextParameter name="totalMemory" mode="static">6114</contextParameter> <contextParameter name="availableMemory" mode="dynamic">4322</contextParameter> <contextCategory name="screenSize"> <contextParameter name="width" mode="static">128</contextParameter> <contextParameter name="height" mode="static">128</contextParameter> </contextCategory> </contextCategory> <contextCategory name="softwarePlatform"> <contextCategory name="acceptedDataModes"> <contextParameter name="Images" mode="static">png, bmp</contextParameter> <contextParameter name="Text" mode="static">plain, String, html</contextParameter> <contextParameter name="Numeric" mode="static">int, short, long</contextParameter> <contextParameter name="Videos" mode="static">3gp</contextParameter> <contextParameter name="Applications" mode="static">vnd.nokia.ringing-tone </contextParameter> <contextParameter name="Audio" mode="static">wav, midi, mp3, 3gp</contextParameter> <contextParameter name="Other" mode="static">date</contextParameter> </contextCategory> <contextCategory name="api"> <contextParameter name="virtualMachine" mode="static">Monty 1.0 VM</contextParameter> <contextParameter name="userInterfaceLbrary" mode="static"> http://liris-7024/midpUILibrary.xml</contextParameter> <contextParameter name="serviceInvocationDescriptor" mode="static"> http://liris-7024/midpServiceInvocation.xml</contextParameter> </contextCategory> </contextCategory> </contextFacet> <contextFacet name="network"> <contextParameter name="connectionMode" mode="static">GPRS</contextParameter> <contextParameter name="bandWidth" mode="static">236.8</contextParameter> <contextParameter name="delay" mode="static">135</contextParameter> <contextParameter name="connectionState" mode="dynamic">connected</contextParameter> </contextFacet> <contextFacet name="userProfile"> <contextCategory name="basicInformation"> <contextParameter name="userID" mode="static">17</contextParameter> <contextParameter name="generalDomain" mode="static">medical</contextParameter> <contextParameter name="specificDomain" mode="static">nephrology</contextParameter> <contextParameter name="profession" mode="static">specialist</contextParameter> </contextCategory> <contextCategory name="preferences"> <contextParameter name="language" mode="dynamic">FR</contextParameter> <contextCategory name="display"> <contextParameter name="numericValues" mode="static">curves</contextParameter> <contextParameter name="images" mode="static">fullScreen</contextParameter> </contextCategory> </contextCategory> </contextFacet> <contextFacet name="location"> <contextCategory name="physical"> <contextParameter name="country" mode="dynamic">France</contextParameter> <contextParameter name="city" mode="dynamic">Villeurbanne</contextParameter> <contextParameter name="zipcode" mode="dynamic">69621</contextParameter> <contextParameter name="streetname" mode="dynamic">Jean Capelle</contextParameter> <contextParameter name="streetNumber" mode="dynamic">7</contextParameter> <contextParameter name="building" mode="dynamic">501</contextParameter> <contextParameter name="room" mode="dynamic">330</contextParameter> </contextCategory> <contextCategory name="logical"> <contextParameter name="IPAddress" mode=" dynamic ">134.214.107.20</contextParameter> </contextCategory> </contextFacet> </contextProfile>
Figure 15 - Exemple d’une situation contextuelle
Tarak CHAARI - 77 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
III. MODELISATION FONCTIONNELLE D’UNE APPLICATION
1. Notion d’entité logicielle
Pour garantir l’adaptation des applications aux différentes évolutions du contexte, nous
devons nous intéresser à deux aspects : quoi adapter ? Et comment réaliser cette adaptation ?
Dans le reste de ce chapitre, nous nous intéressons au quoi et nous détaillerons notre stratégie
d’adaptation (le comment) dans le chapitre suivant.
A un instant donné lors de l’utilisation d’une application, on échange des données avec
l’un de ses services à l’aide d’une interface utilisateur. En conséquence, nous définissons une
entité logicielle comme étant un triplet associant un service de l’application, une interface
utilisateur qui assure l’interaction avec ce service et les données échangées entre l’utilisateur
et le service. La figure 16 présente l’exemple concret d’une entité logicielle où l’utilisateur est
en train de visualiser des images radios fournies par un service d’images médicales. Le clic
sur l’URL d’une image entraîne son téléchargement à partir du service de gestion des images
médicales. Ce dernier prend en entrée l’URL d’une image et renvoie son contenu sous un
format binaire. L’image est affichée sur l’interface utilisateur.
Données
Entité logicielle
Service
Interface utilisateur
Service d’images médicales IMAGE
URL
Figure 16 - Un exemple d'une entité logicielle
L’élément principal d’une entité logicielle est son service puisque les données de l’entité
logicielle et son interface graphique dépendent fortement du service associé : ces données
constituent les entrées et les sorties du service. L’interface utilisateur d’une entité logicielle
est composée d’une interface d’entrée et d’une interface de sortie. L’interface d’entrée permet
de fournir les paramètres d’entrée du service et l’interface de sortie permet de transférer les
données de sortie du service à l’utilisateur.
Tarak CHAARI - 78 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
2. Notion de service
Nous définissons un service comme un processus applicatif autonome. Un service fournit
un ensemble de données de sorties suivant un ensemble de paramètres d’entrée. Un service f
qui prend en entrée un ensemble de paramètres INPUT=(x1,x2,…xm) et qui renvoie un
ensemble de valeurs OUTPUT=(c1, c2… cn) où INPUT et OUTPUT sont des vecteurs de
valeurs typées. Ainsi un service peut être modélisé par une fonction f :
)(INPUTfOUTPUT = où INPUT est le vecteur d’entrée du service f et OUTPUT est son
vecteur de sortie.
Chaque composant ci de OUTPUT est une classe qui a un nom et un type (ci.name et
ci.type). Le composant ci peut être récupéré à l’aide de l’opérateur [] sur le vecteur de sortie
(ci= OUTPUT[i]). Nous associons à chaque composant ci, un vecteur ri=(ria, rib…) où ria,
rib… sont les valeurs renvoyées par le service f et associées au composant de sortie ci. les
vecteurs ri peuvent être considérées comme des instances de ci. Cette définition générique
permet d’établir une structure d’échange commune entre les services ; ceci facilite la
composition et l’adaptation des services. La figure 17 illustre notre modélisation d’un service
d’une entité logicielle.
f INPUT=(x1,x2,…xm) OUPUT=(c1, c2… cn) ci
+ name
+ type
ri
+ value
*entrée
Service sortie
Paramètre de sortie Valeur de sortie
Figure 17 - Modélisation d'un service d'une entité logicielle
Contrairement à la majorité des travaux existants comme ceux de [Hamadi03], un service
comprend une seule opération qui est représentée par la fonction f selon notre approche. Les
autres travaux modélisent un service par un ensemble d’opérations qui échangent des
messages pour remplir une certaine tâche. L’échange de messages se fait à travers des états
représentés par un ensemble de propriétés (ou attributs en orienté objet). Nous remplaçons
cette notion d’état par la notion de dépendance d’exécution de services que nous présentons
dans le paragraphe suivant. Nous considérons que la connaissance de l’état d’un service est
restreinte à ses développeurs ou concepteurs. Cependant, notre but est de réaliser l’adaptation
de services dont on ne connait pas forcément la conception ou la réalisation. Par ailleurs, nous
considérons que ce choix reste compatible avec les modélisations existantes puisqu’un service
qui comprend plusieurs opérations peut être décomposé en un ensemble de services mono-
opération qui échangent des messages selon des dépendances d’exécution que nous
Tarak CHAARI - 79 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
modélisons dans le paragraphe suivant.
3. Notion de dépendance d’exécution de services
Les paramètres nécessaires à l’exécution d’un service f peuvent provenir de la sortie de
plusieurs services f1,f2…,fn. Nous disons dans ce cas que le service f dépend de f1, f2… et/ou fn.
Nous pouvons avoir des dépendances en « et » si f dépend de f1, f2… et fn. Nous pouvons aussi
avoir des dépendances en « ou » si f dépend de f1, f2… ou fn.
Nous utilisons la notation (f1∧f2∧…∧fn) f pour modéliser la dépendance « f dépend de f1,
f2… et fn ». Dans le cas présenté dans la figure 18, le service f ne peut pas être offert à
l’utilisateur avant l’exécution des services f1, f2… et fn.
f
… f1 f2 fn
Figure 18 – Dépendance en « et » entre services
Nous utilisons aussi la notation (f1∨f2∨…∨fn) f pour modéliser la dépendance « f dépend
de f1, f2… ou fn ». Dans ce cas, le service f ne peut être offert à l’utilisateur que si au moins
l’un des services f1, f2… ou fn a été déjà invoqué. Ce cas est valable quand les paramètres
nécessaires à l’exécution du service f peuvent parvenir de l’un des services f1, f2… fn. La
figure 19 illustre le cas de la dépendance en « ou ».
f
… fn f1 f2
Figure 19 – Dépendance en « ou » entre services
Nous utilisons cette modélisation pour décrire tous les services de l’application et leurs
dépendances, formant ainsi le modèle fonctionnel de l’application.
Tarak CHAARI - 80 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
4. Notion de modèle fonctionnel
Nous définissons le modèle fonctionnel d’une application par le réseau de pétri
non – autonome qui décrit tous les services d’une application et toutes les
dépendances d’exécution entre eux.
Les places dans un réseau de pétri représentent les descriptions des services de
l’application et les transitions détaillent les dépendances qui existent entre ces services. La
racine de ce réseau est le descripteur du service initial offert à l’utilisateur (par exemple, un
service d’authentification). Chaque transition est passée si l’exécution de tous ses services
d’entrée (en cas d’une dépendance en « et ») ou l’un de ses services d’entrée (en cas d’une
dépendance en « ou ») se passe sans erreur. Une condition générale supplémentaire qui
concerne des événements externes (comme par exemple, « le terminal supporte des images »)
peut aussi être définie pour chaque transition. Par défaut, cette condition prend la constante
booléenne « vraie ». Chaque transition est chronométrée ; elle possède un délai d’expiration
au bout duquel une erreur est générée et présentée à l’utilisateur pour éviter les blocages du
coté du client (time deadlocks). Les transitions peuvent générer des erreurs si les conditions
définies sur leurs paramètres de sortie ne sont pas satisfaites (Par exemple, « UserID is not
null »). Ainsi, le passage aux services suivants est bloqué.
A chaque moment de l’exécution de l’application, l’utilisateur peut revenir en arrière dans
le modèle fonctionnel par des transitions implicites qui sont déclenchées quand l’utilisateur
effectue une action explicite sur l’interface d’interaction avec l’application ou bien quand le
délai maximum d’une transition est dépassé.
Formellement, un modèle fonctionnel FM d’une application est un tuple FM=(f0, F, T) qui
satisfait les recommandations suivantes :
1. F est un ensemble fini de services f1, f2,…, fn
2. f0 est la racine du réseau de pétri. Il représente le service initial de l’application.
3. T est un ensemble fini de transitions t1, t2,…, tm
4. Chaque transition ti est un triplet (d, gc, A) où :
a) d est le délai maximum pour passer la transition
b) gc est la condition générale de la transition
c) A est un ensemble fini d’associations a1, a2, …, al entre les services.
d) ai est un ensemble fini de paires (inputExpression, destinationParameter) modélisant
une association entre deux services en liant un paramètre de sortie inputExpression d’un
Tarak CHAARI - 81 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
service à un paramètre d’entrée destinationParameter d’un autre service. La valeur de
inputExpression peut être une expression qui utilise un ensemble d’opérateurs standard
(comme l'addition de nombres, la concaténation de chaînes de caractères, l’évaluation
booléenne...) sur les paramètres de sortie des services sources. Chaque association ai
représente un lien de dépendance d’exécution entre un service source ai.sourceService et un
service destination ai.destinationService. Ainsi, l’exécution du service destination n’est
possible dans l’application qu’après avoir exécuté le service source de l’association.
La figure 20 donne le modèle fonctionnel d’une application médicale simple. Cette
application offre aux professionnels de santé un service d’authentification (Authentication),
un service qui permet de chercher un patient suivi par le professionnel de santé connecté
(PatientList) et des services de consultation des informations stockées dans le dossier médical
du patient sélectionné (Temperatures, RecordInfo, RecordImages).
Temperatures
Authentication
RecordInfo RecordImages
PatientList
UserID
PatientID PatientID PatientID
Figure 20 - Le modèle fonctionnel d'une application médicale
Nous avons utilisé le langage XML pour implémenter le modèle fonctionnel d’une
application. L’élément racine de cette structure XML est « application ». Chaque place est
représentée par un élément « place » identifié par un attribut « id » et caractérisé par l’url du
service correspondant. Chaque place est composée d’une méthode caractérisée par un
identifiant, une description éventuelle et un ensemble de paramètres d’entrée et de sortie.
Chaque transition est modélisée par un élément « transition ». Pour des raisons de cohérence
du modèle et de la représentation des dépendances entre les services, il est à noter qu’une
transition ne concerne qu’un et un seul service de sortie. Cependant, une transition peut être
liée à plusieurs services d’entrée. La figure 21 présente un diagramme de classes d’un modèle
fonctionnel et la figure 22 présente un extrait de la représentation XML du modèle
fonctionnel de la figure 20.
Tarak CHAARI - 82 - Thèse de doctorat
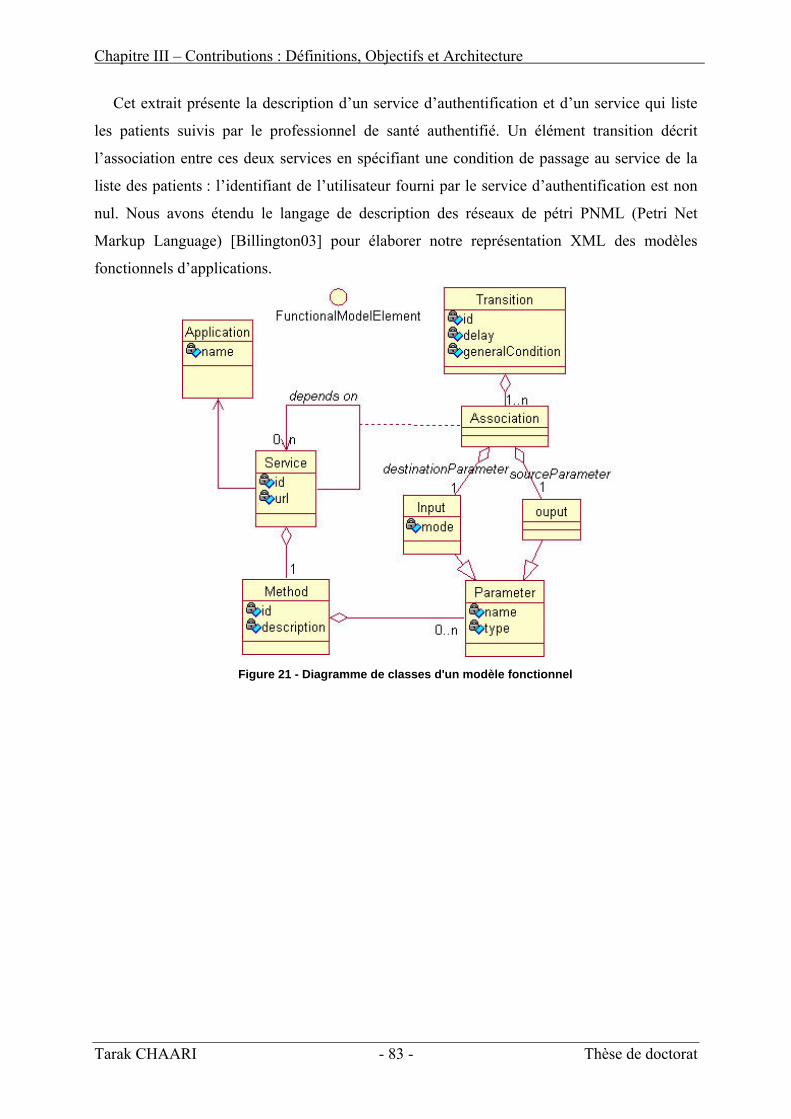
Chapitre III – Contributions : Définitions, Objectifs et Architecture
Cet extrait présente la description d’un service d’authentification et d’un service qui liste
les patients suivis par le professionnel de santé authentifié. Un élément transition décrit
l’association entre ces deux services en spécifiant une condition de passage au service de la
liste des patients : l’identifiant de l’utilisateur fourni par le service d’authentification est non
nul. Nous avons étendu le langage de description des réseaux de pétri PNML (Petri Net
Markup Language) [Billington03] pour élaborer notre représentation XML des modèles
fonctionnels d’applications.
Figure 21 - Diagramme de classes d'un modèle fonctionnel
Tarak CHAARI - 83 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
<?xml version="1.0" encoding="iso-8859-1"?> <application> <!-- A service is described by its service id, url and methods (with parameters) --> <service id="Authentication"> <url>http://secasserver.insa-lyon.fr/xmlrpc</url> <method id="sicom.identification"> <description>checks login and password of a Sicom user; returns userID and userName </description> <input name="sicom.login" type="secas:string"/> <input name="sicom.password" type="secas:string"/> <output name="sicom.userID" type="secas:int"/> <output name="sicom.userName" type="secas:string"/> </method> </service> <service id="PatientList"> <url>http://secasserver.insa-lyon.fr/xmlrpc</url> <method id="sicom.listePatient"> <description>returns the list of the dialyzed patients treated by the practionner identified by "sicom.userID"</description> <input name="sicom.userID" type="secas:int"/> <output name="sicom.recordID" type="secas:int"/> <output name="sicom.patientName" type="secas:string"/> <output name="sicom.patientBirthDate" type="secas:date"/> <output name="sicom.dialysisMode" type ="secas:string"/> <output name="sicom.dialysisType" type ="secas:string"/> <output name="sicom.recordCreationdate" type="secas:date"/> </method> </service> <!-- other services ... --> <!-- A transition specifies at least one association between a source service and a destination service. For each association
we list its source and destination parameters, and define a maximum delay in seconds for the execution of all the source services of all the associations of the transition. A transition can have a condition for every entry service. The
condition is represented by a logical expression on the output parameters of the entry service. --!> <transition id="t1" delay="100"> <generalCondition> <expression value=”always true”> </generalCondition> <association sourceService="Authentication" destinationService="Patientlist"> <sourceParameter methodID="sicom.identification" inputExpression="sicom.userID" condition=”sicom.userID is not null”/> <destinationParameter methodID="sicom.listePatient" parameterName="sicom.userID"/> </association> </transition> <!-- other transitions ...--> </application>
Figure 22 - Extrait de la représentation XML du modèle fonctionnel d’une application médicale
Tarak CHAARI - 84 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
IV. OBJECTIFS DE NOTRE TRAVAIL
Ce travail de thèse a pour objectif principal, la spécification et la réalisation d’une
plateforme d’adaptation automatique d’applications à de nouveaux contextes d’utilisation.
Nous définissons l’adaptation d’une application à une situation contextuelle
par les mécanismes et les transformations nécessaires pour modifier le
comportement de cette application afin qu’elle puisse être utilisée d’une façon
efficace et conviviale dans l’environnement décrit par la situation contextuelle.
Nous avons nommé notre plateforme d’adaptation « SECAS » (Simple Environment for
Context-Aware Systems). SECAS est composée de trois couches : une couche de gestion du
contexte, une couche d’adaptation et une couche d’intégration d’applications. La couche de
gestion du contexte assure la capture, l’interprétation et la dissémination du contexte à la
couche d’adaptation. La couche d’adaptation offre les fonctions et les outils nécessaires à
l’adaptation des applications à de nouveaux contextes d’utilisation. Enfin, la couche de
déploiement d’applications permet à SECAS d’intégrer de nouvelles applications pour les
adapter. Dans ce travail de thèse, nous nous focalisons sur la couche d’adaptation et plus
particulièrement sur les moyens et outils de génie logiciel nécessaires pour garantir
l’adaptation des applications à de nouveaux contextes d’utilisation. Cette adaptation doit être
effectuée sur les trois composantes de chaque entité logicielle de l’application : le service,
l’interface utilisateur et les données échangées entre l’interface et le service. Cet intérêt
particulier à la couche d’adaptation est dû principalement à l’absence d’une approche
complète d’adaptation dans les systèmes sensibles au contexte. En effet, plusieurs travaux
intéressants concernent la gestion du contexte au niveau de la capture, l’interprétation et la
dissémination du contexte alors que la question « comment adapter l’application au contexte ?
» reste sans réponse précise et complète.
Dans la suite de cette section, nous présentons les trois critères principaux que nous avons
fixés pour la réalisation de notre plateforme :
(1) Généricité
Plusieurs standards de communication et de développement pour des environnements fixes
et mobiles ont été testés et étudiés afin de choisir les meilleures technologies pour développer
notre plateforme. Nous avons fait ce choix pour que SECAS puisse être utilisée dans le
maximum d’environnements et sur le maximum de types d’applications. Nous considérons
Tarak CHAARI - 85 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
qu’une application existante est une boite noire composée d’un ensemble d’entités logicielles
identifiées par les services (qui représentent les fonctionnalités) offerts par l’application. Ceci
nous permet de supporter un plus grand nombre d’applications indépendamment de leur
conception et de leur développement. Notre modèle garantit aussi la généricité du processus
d’adaptation. En effet, le modèle abstrait d’entité logicielle est applicable à la majorité des
applications. En outre, toutes les transformations et modifications d’adaptation définies sur
une entité logicielle restent d’ordre générique et peuvent être appliquées indépendamment des
technologies de conception et de développement de l’application. Nous avons aussi choisi les
technologies les plus génériques et les plus répandues (comme JAVA et les services WEB)
pour développer notre plateforme. De plus, nous avons donné beaucoup d’importance à
l’interaction homme-machine pour que notre plateforme puisse être utilisée dans plusieurs
environnements cibles comme les PC standards, les téléphones mobiles ou les PC de poche.
(2) Evolutivité
Nous avons aussi accordé une grande importance à l’évolutivité de notre plateforme afin
de supporter le maximum de situations et le maximum d’adaptations possibles. De nouveaux
outils et moyens d’adaptation doivent être facilement intégrés dans SECAS. Une interface
d’administration et des fichiers de configuration doivent être fournis pour réaliser cette
adaptation sans toucher au code des applications et de la plateforme. De nouveaux
fournisseurs de contexte doivent être aussi facilement ajoutés à la plateforme sans arrêter le
fonctionnement de l’application. L’ajout de nouveaux services à une application existante est
aussi prévu afin d’enrichir des applications anciennes par de nouvelles fonctionnalités.
(3) Intégrité de l’information
Le processus d’adaptation que nous avons défini peut transformer ou modifier une donnée
afin de pouvoir l’exploiter dans un nouveau contexte. Certaines transformations sont avec
pertes comme elles peuvent aussi donner des résultats incompatibles avec le résultat
d’origine. Nous accordons une grande importance à la qualité de l’information produite par
les services de l’application. Tous les outils et les transformations d’adaptation ne doivent pas
biaiser l’intégrité sémantique de l’information transmise à l’utilisateur. Par exemple, il est
plus judicieux de remplacer une image médicale par le rapport textuel du médecin sur un
terminal mobile de capacités limitées que de réduire la taille de l’image et perdre sa valeur
sémantique.
Tarak CHAARI - 86 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
V. SECAS : PLATEFORME POUR L’ADAPTATION D’APPLICATIONS A
DE NOUVEAUX CONTEXTES D’UTILISATION
1. Présentation de la plateforme SECAS
Les architectures présentées dans les travaux existants pour assurer la sensibilité au
contexte (context-aware architectures) accordent une très grande importance à la gestion du
contexte sans présenter comment modifier le comportement de l’application pour qu’elle
s’adapte au contexte. Dans notre architecture, nous dédions une couche entière à l’adaptation
et nous détaillons les différents modules et outils qui permettent de garantir cette adaptation.
Nous avons aussi défini une couche de gestion du contexte afin de réaliser les étapes - que
nous considérons classiques pour notre travail - de capture, interprétation, stockage et
dissémination du contexte. Une dernière couche assure l’intégration de nouvelles applications
pour garantir leur adaptation. Nous avons choisi une architecture basée sur trois couches
indépendantes afin d’assurer une adaptation en aval du développement classique des services
de base de l’application. Ceci permet d’ajouter la sensibilité au contexte à des applications
non adaptées, où apparaissent de nouvelles situations contextuelles.
Dans cette section nous détaillons SECAS, notre plateforme d’adaptation avec ses trois
couches et leurs différents composants.
2. Couche de gestion du contexte
Pour pouvoir adapter une application au contexte, nous devons définir les moyens
nécessaires pour la capture, l’interprétation, le stockage et la dissémination du contexte. Nous
avons regroupé ces quatre fonctions dans la couche de gestion du contexte.
La fonction principale assurée par cette couche est la capture du contexte. Le contexte peut
parvenir de plusieurs sources comme les capteurs physiques, les capteurs logiques ou les
capteurs virtuels comme présenté dans l’état de l’art de ce mémoire (paragraphe IV.1 du
chapitre I). Puisque le contexte capturé peut ne pas être significatif à l'application dans son
format brut, un module d'interprétation du contexte traduit le contexte de bas niveau en une
représentation de niveau plus élevé. Par exemple, il transforme des coordonnées
géographiques en une adresse physique (Rue, ville et pays). Ensuite, les données
contextuelles interprétées sont stockées dans un registre contextuel (context repository) sous
le format XML présenté dans le paragraphe II.2 de ce chapitre. Enfin, un courtier (broker)
assure la communication entre la couche de gestion du contexte et la couche d’adaptation. Il
informe les différents modules d’adaptation des changements éventuels du contexte. Dans la
Tarak CHAARI - 87 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
suite de cette section, nous détaillons les différents composants de la couche de gestion du
contexte.
2.1 FOURNISSEUR DE CONTEXTE (CONTEXT PROVIDER)
Un fournisseur de contexte est un composant logiciel lié à un ou plusieurs dispositifs
matériels physiques ou virtuels qui assurent la capture du contexte de l’environnement de
l’utilisateur ou de l’application. Ce composant logiciel assure l’interprétation des données
capturées dans un format directement exploitable par la couche d’adaptation. Par exemple, un
capteur de température peut être associé à un module logiciel pour détecter le dépassement
d’un seuil fixé. La figure 23 présente la modélisation d’un fournisseur de contexte.
Figure 23 - Modélisation d'un fournisseur de contexte
2.2 REGISTRE DE CONTEXTE (CONTEXT REPOSITORY)
Le registre de contexte stocke les paramètres interprétés du contexte sous le format XML
défini dans le paragraphe II.2. Pour chaque session utilisateur, un profil de contexte est créé
comme présenté dans la figure 15. Dès la connexion d’un utilisateur, le dernier profil de
contexte associé à cet utilisateur est chargé. Ensuite, il est rafraîchi par les différents
fournisseurs de contexte au cours de l’utilisation de la plateforme. Le taux de rafraîchissement
dépend fortement du changement de contexte au niveau des fournisseurs. Par exemple, le type
du terminal utilisé est un élément statique dans une session utilisateur. Par contre, la
localisation de l’utilisateur peut varier rapidement dans une même session s’il est en
déplacement dans un véhicule.
Figure 24 - Modélisation d'un registre de contexte
La figure 24 illustre la modélisation d’un registre de contexte. Il fournit deux fonctions
principales : getContextParameter() et setContextParameter() pour accéder à (ou modifier) la
Tarak CHAARI - 88 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
valeur d’un paramètre de contexte dans son profil correspondant.
2.3 COURTIER DE CONTEXTE (CONTEXT BROKER)
Le courtier de contexte assure l’échange de données entre la couche d’adaptation et le
registre de contexte d’une part et entre les fournisseurs et le registre d’autre part. Les
différents composants de la couche d’adaptation doivent s’abonner au courtier pour pouvoir
accéder aux différents paramètres du contexte dans le registre. Le courtier offre deux modes
d’échange d’information : « Push » et « Pull ». Le mode « Push » permet d’informer la
couche d’adaptation à chaque changement d’un paramètre dynamique du contexte. Le mode
« Pull » est dédié aux paramètres statiques du contexte dont l’accès est conditionné par une
demande explicite de la couche d’adaptation. Les fournisseurs doivent aussi s’abonner au
courtier pour pouvoir stocker les paramètres de contexte capturés et interprétés dans le
registre du contexte. Le courtier transfère directement les paramètres contextuels dynamiques
à la couche d’adaptation avant leur stockage dans le registre contexte pour garantir une
adaptation rapide à des changements fréquents du contexte. La figure 25 présente la
modélisation d’un courtier de contexte avec les différentes entités qu’il utilise pour échanger
les paramètres du contexte avec le registre et le fournisseur du contexte d’une part et avec la
couche d’adaptation d’autre part.
Figure 25 - Modélisation d'un courtier de contexte
3. Couche d’adaptation
La couche d’adaptation permet la mise à jour et la réactualisation automatique des
applications existantes à de nouveaux contextes d’utilisation. Cette adaptation touche les trois
composantes de chaque entité logicielle de l’application : le service, l’interface utilisateur et
les données échangées entre l’utilisateur et le service. Nous dédions un module à l’adaptation
de chaque composante d’une entité logicielle. Ces trois modules effectuent des adaptations «
intra-entité logicielle » en modifiant le comportement de son service, en transformant les
données que le service échange avec l’utilisateur ou en générant automatiquement une
interface graphique adaptée au contexte d’utilisation de l’entité logicielle. Ces trois modules
sont orchestrés par un gestionnaire d’applications qui assure l’adaptation « inter-entités
Tarak CHAARI - 89 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
logicielles » en modifiant la structure globale du modèle fonctionnel. Nous détaillons dans les
paragraphes suivants les différents composants de la couche d’adaptation.
3.1 INTERFACE DE CONSOMMATION DE CONTEXTE
L’interface de consommation de contexte (context consumer) offre les différentes
fonctions nécessaires pour pouvoir échanger les paramètres du contexte entre la couche
d’adaptation et la couche de gestion de contexte. En effet, les trois modules d’adaptation de
services, de données et de présentation consomment du contexte et doivent être avertis des
changements des différents paramètres du contexte. Ces trois modules s’abonnent au
courtier (context broker) en indiquant les paramètres (context parameters) qui leur sont
pertinents et le mode (mode) d’échange de données avec la couche de gestion du contexte
(Push ou Pull). L’interface de consommation de contexte que nous avons conçue est
indépendante du modèle de contexte utilisé. Il suffit de préciser le nom du paramètre
éventuellement préfixé avec les informations nécessaires pour trouver ce paramètre dans le
modèle utilisé du contexte. Par exemple, pour le modèle que nous avons utilisé dans la figure
15, (context.terminal.screenSize.width) référence le paramètre (width) de la catégorie
(screenSize) de la facette (terminal) du contexte. La figure 26 illustre l’interaction possible
(opération d’abonnement subscribe) entre l’interface de consommation du contexte et le
courtier.
Figure 26 - Interaction entre l'interface de consommation du contexte et le broker
3.2 MODULE D’ADAPTATION DE SERVICES
Ce module applique les transformations nécessaires sur le modèle fonctionnel d’une
application pour modifier son comportement suivant une situation contextuelle donnée. Ce
module s’appuie sur un gestionnaire d’adaptation de services (service adaptation manager)
pour appliquer un ensemble de règles d’adaptation (adaptation rules) définies par le
concepteur de l’application à adapter. Ces règles configurent des entités d’adaptation, que
nous avons appelés adaptateurs (adapters), pour exécuter un ensemble d’actions d’adaptation
(adaptation actions) sur le modèle fonctionnel de l’application. Par exemple, ces actions
peuvent remplacer un service par un autre plus adéquat à la nouvelle situation ; elles peuvent
aussi éclater un service sur plusieurs services si le résultat est trop volumineux pour la
mémoire du terminal utilisé… Nous formalisons ces actions d’adaptation et nous détaillons
Tarak CHAARI - 90 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
notre stratégie d’adaptation de services dans la section II du chapitre suivant. La figure 27
présente les entités principales du module d’adaptation de services.
Figure 27 – Architecture générale du module d'adaptation de services
3.3 MODULE D’ADAPTATION DE DONNEES
Ce module assure l’adaptation des données multimédia renvoyées par les services vers
l’utilisateur. Il s’appuie sur un gestionnaire d’adaptation de contenu (content adaptation
manager) pour instancier un adaptateur de contenu (content adapter) pour chaque service de
l’application. Il identifie les données de sortie non adaptées à la situation contextuelle en
question. Les adaptateurs de contenu utilisent un mandataire d’adaptation de contenu (content
adaptation proxy) qui exécute un ensemble de services d’adaptation de contenu (content
adaptation services) afin d’effectuer les transformations nécessaires. Nous détaillons notre
stratégie d’adaptation de données dans la section III du chapitre suivant. La figure 28 présente
les entités principales du module d’adaptation de services.
Figure 28 – Architecture générale du module d'adaptation de données
3.4 MODULE D’ADAPTATION DE PRESENTATION
Ce module assure l’adaptation de la présentation des données échangées avec les différents
services de l’application. Il se base sur un gestionnaire d’adaptation de présentation
(presentation adaptation manager) pour générer une interface d’interaction avec chaque
service adapté de l’application. Le code de cette interface est produit par un générateur
d’interface utilisateur (user interface generator). Le processus de génération dépend
principalement du type des données échangées avec les services adaptés, de la facette
« terminal » du contexte et des préférences de l’utilisateur dans la facette «utilisateur ». Des
facilités de navigation entre les entités logicielles sont aussi générées pour que l’utilisateur
puisse interagir avec tous les services de l’application. Les interfaces générées sont enfin
déployées sur le terminal de l’utilisateur pour interagir avec l’application adaptée. Ces
interfaces sont mises en cache sur le serveur SECAS pour ne pas relancer tout le processus
d’adaptation de présentation chaque fois que le même utilisateur accède à une application
adaptée dans le même contexte. La figure 29 donne l’architecture générale du module
Tarak CHAARI - 91 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
d’adaptation de présentation. Nous détaillons cette architecture dans la section IV du chapitre
IV.
Figure 29 - Architecture générale du module d'adaptation de présentation
3.5 GESTIONNAIRE D’APPLICATIONS
Le gestionnaire d’applications de SECAS (SECAS application manager) orchestre les trois
modules d’adaptation : de services, de données et de présentation. Le gestionnaire
d’applications lance le processus d’adaptation de services en sollicitant le module
d’adaptation de services. Ce dernier notifie le gestionnaire d’applications lorsqu’il termine
l’adaptation de services. Le gestionnaire d’applications peut ainsi transmettre le modèle
fonctionnel adapté au module d’adaptation de contenu pour adapter les données d’entrée et de
sortie des services.
Figure 30 - Orchestration du processus d'adaptation par le gestionnaire d'applications
Enfin, le gestionnaire d’applications notifie le module d’adaptation de présentation pour
déclencher le processus de génération automatique d’interfaces utilisateur adaptées au
contexte en question. Le gestionnaire d’applications gère les différents modèles fonctionnels
adaptés pour chaque situation contextuelle. Il associe un modèle fonctionnel à chaque session
Tarak CHAARI - 92 - Thèse de doctorat
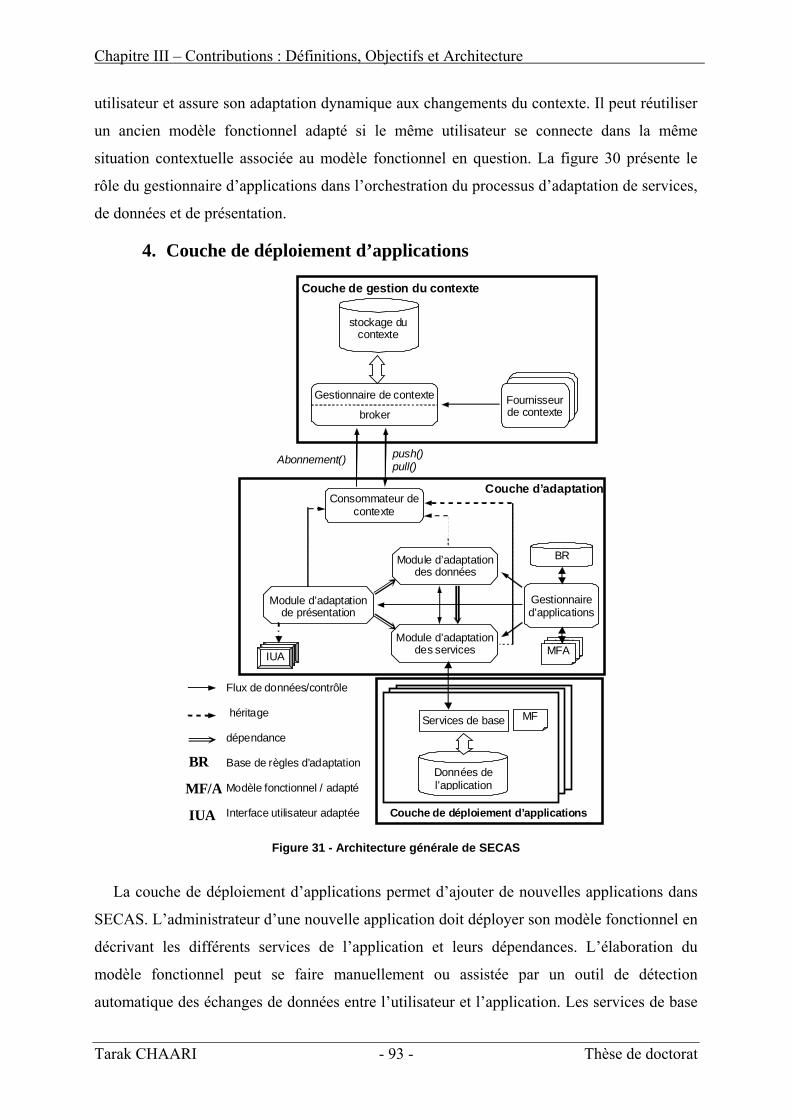
Chapitre III – Contributions : Définitions, Objectifs et Architecture
utilisateur et assure son adaptation dynamique aux changements du contexte. Il peut réutiliser
un ancien modèle fonctionnel adapté si le même utilisateur se connecte dans la même
situation contextuelle associée au modèle fonctionnel en question. La figure 30 présente le
rôle du gestionnaire d’applications dans l’orchestration du processus d’adaptation de services,
de données et de présentation.
4. Couche de déploiement d’applications
IUA IUA MFA MFA MFA
Interpréteur de contexte
Interpréteur de contexte
Couche d’adaptation Consommateur de
contexte
Module d’adaptation des services
Module d’adaptation de présentation
Abonnement() push() pull()
Couche de gestion du contexte
stockage du contexte
Fournisseur de contexte
Gestionnaire de contexte
broker
Gestionnaire d’applications
Module d’adaptation des données
Flux de données/contrôle héritage dépendance Base de règles d’adaptation Modèle fonctionnel / adapté Interface utilisateur adaptée
Données de l’application
Services de base
Couche de déploiement d’applications
MF
BR
IUA
BR
MF/A
IUA
Figure 31 - Architecture générale de SECAS
La couche de déploiement d’applications permet d’ajouter de nouvelles applications dans
SECAS. L’administrateur d’une nouvelle application doit déployer son modèle fonctionnel en
décrivant les différents services de l’application et leurs dépendances. L’élaboration du
modèle fonctionnel peut se faire manuellement ou assistée par un outil de détection
automatique des échanges de données entre l’utilisateur et l’application. Les services de base
Tarak CHAARI - 93 - Thèse de doctorat

Chapitre III – Contributions : Définitions, Objectifs et Architecture
de l’application peuvent renvoyer des données extraites d’une source de données. Le modèle
fonctionnel est la seule description nécessaire pour intégrer une application dans SECAS. La
figure 31 présente l’architecture générale de la plateforme SECAS avec ses trois couches : la
couche de gestion du contexte, la couche d’adaptation et la couche de déploiement
d’applications.
VI. CONCLUSION
Dans ce chapitre, nous avons défini les notions de contexte, d’adaptation et de modèle
fonctionnel, utiles pour élaborer notre approche d’adaptation des applications à de nouveaux
contextes d’utilisation. Puis, nous avons présenté notre objectif qui consiste à réaliser une
plateforme générique d’adaptation des applications au contexte d’utilisation. Avant Nous
avons enfin présenté l’architecture de notre plate-forme d’adaptation d’applications à de
nouveaux contextes d’utilisation, que nous avons nommée SECAS. Cette plate-forme est
basée sur trois couches. La première couche assure la gestion du contexte depuis sa capture,
son interprétation et sa dissémination à la couche d’adaptation. La deuxième couche assure
l’adaptation du comportement de l’application au contexte capturé. Cette adaptation est
assurée sur les trois composantes des entités logicielles de l’application : le service, l’interface
utilisateur et les données échangées avec le service. La troisième couche permet d’intégrer de
nouvelles applications à la plateforme en vue de leur adaptation. Dans ce travail de thèse,
nous n’irons pas loin dans la couche de gestion de contexte. Notre contribution principale se
situe dans la couche d’adaptation que nous détaillons dans le chapitre suivant.
Tarak CHAARI - 94 - Thèse de doctorat

I CCCHHHAAAPPPIIITTTRRREEE IIIVVV --- CCCOOONNNTTTRRRIIBBBUUUTTTIIIOOONNNSSS ::: SSSTTTRRRAAATTTEEEGGGIIIEEE
DDD’’’AAADDDAAAPPTTTAAATTTIIIOOONNN AAAUUU CCCOOONNNTTTEEEXXXTTTEEE P
“Sans innovation, la stratégie est inutile; sans stratégie,
l'innovation n'a pas de but“ (John KAO)

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
TABLE DES MATIERES
I. PRESENTATION DE NOTRE STRATEGIE D’ADAPTATION _________________________ 97
II. ADAPTATION FONCTIONNELLE ___________________________________________ 98
1. Principe de l’adaptation fonctionnelle ______________________________________ 98
2. Règles d’adaptation fonctionnelle__________________________________________ 99
3. Opérateurs d’adaptation fonctionnelle ____________________________________ 101
4. Processus d’adaptation fonctionnelle dans SECAS __________________________ 118
5. Synthèse sur l’adaptation fonctionnelle dans SECAS ________________________ 120
III. ADAPTATION DE CONTENU ______________________________________________ 120
1. Principe de l’adaptation de contenu_______________________________________ 120
2. Module d’adaptation de contenu _________________________________________ 122
3. Planification de l’adaptation de contenu [Berhe05] __________________________ 124
4. Synthèse sur l’adaptation de contenu dans SECAS __________________________ 129
IV. ADAPTATION DE PRÉSENTATION _________________________________________ 129
1. Principe de l’adaptation de présentation___________________________________ 129
2. Modélisation d’une interface utilisateur dans SECAS ________________________ 130
3. Processus de génération automatique d’interfaces adaptées ___________________ 133
4. Synthèse sur l’adaptation de présentation dans SECAS ______________________ 137
V. CONCLUSION_________________________________________________________ 138
Tarak CHAARI - 96 - Thèse de doctorat
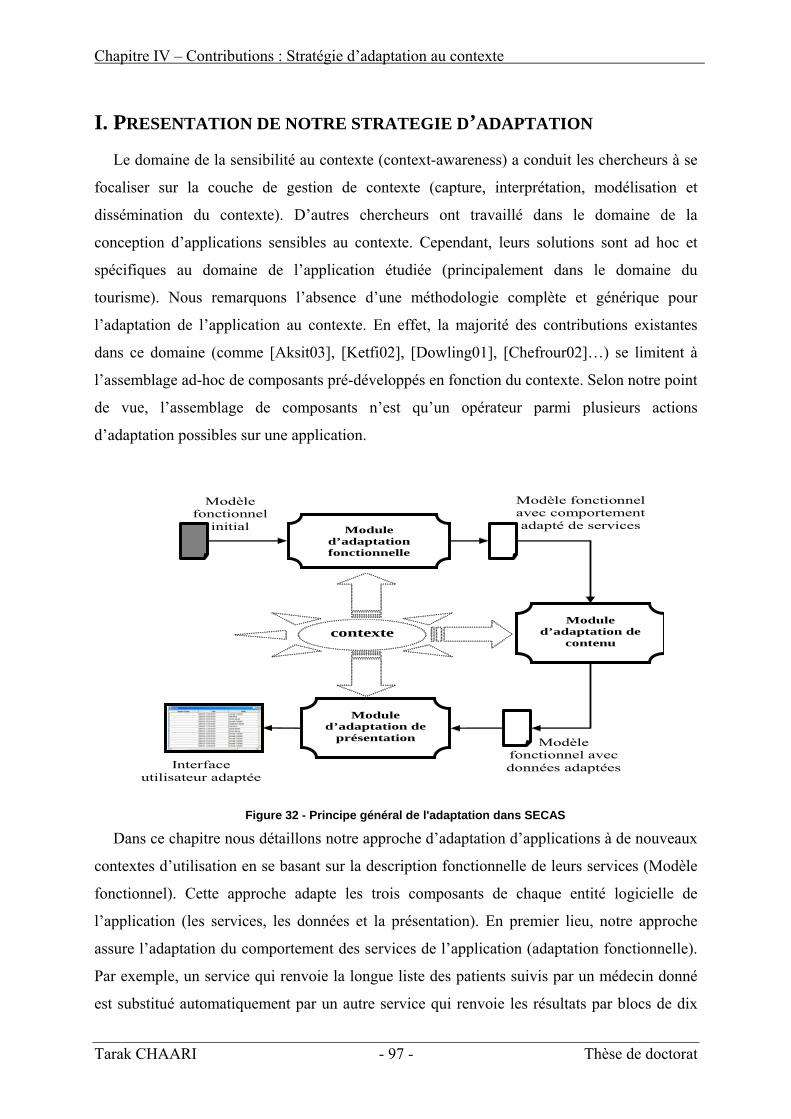
Chapitre IV – Contributions : Stratégie d’adaptation au contexte
I. PRESENTATION DE NOTRE STRATEGIE D’ADAPTATION
Le domaine de la sensibilité au contexte (context-awareness) a conduit les chercheurs à se
focaliser sur la couche de gestion de contexte (capture, interprétation, modélisation et
dissémination du contexte). D’autres chercheurs ont travaillé dans le domaine de la
conception d’applications sensibles au contexte. Cependant, leurs solutions sont ad hoc et
spécifiques au domaine de l’application étudiée (principalement dans le domaine du
tourisme). Nous remarquons l’absence d’une méthodologie complète et générique pour
l’adaptation de l’application au contexte. En effet, la majorité des contributions existantes
dans ce domaine (comme [Aksit03], [Ketfi02], [Dowling01], [Chefrour02]…) se limitent à
l’assemblage ad-hoc de composants pré-développés en fonction du contexte. Selon notre point
de vue, l’assemblage de composants n’est qu’un opérateur parmi plusieurs actions
d’adaptation possibles sur une application.
Module d’adaptation fonctionnelle
Module d’adaptation de
contenu contexte
Modèle fonctionnel avec comportement adapté de services
Module d’adaptation de
présentation Modèle fonctionnel avec données adaptées
Modèle fonctionnel
initial
Interface utilisateur adaptée
Figure 32 - Principe général de l'adaptation dans SECAS
Dans ce chapitre nous détaillons notre approche d’adaptation d’applications à de nouveaux
contextes d’utilisation en se basant sur la description fonctionnelle de leurs services (Modèle
fonctionnel). Cette approche adapte les trois composants de chaque entité logicielle de
l’application (les services, les données et la présentation). En premier lieu, notre approche
assure l’adaptation du comportement des services de l’application (adaptation fonctionnelle).
Par exemple, un service qui renvoie la longue liste des patients suivis par un médecin donné
est substitué automatiquement par un autre service qui renvoie les résultats par blocs de dix
Tarak CHAARI - 97 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
patients à la fois. Cette étape est suivie d’une adaptation des données échangées avec les
services adaptés (adaptation de contenu). Par exemple, le service précédent peut renvoyer les
photos d’identités des patients suivis par le médecin connecté. Le format des photos doit être
adapté aux types d’images supportées par le terminal utilisé. Enfin, une interface graphique
adaptée au contexte d’utilisation de l’application (environnement d’exécution de l’interface)
est générée automatiquement pour que l’utilisateur final de l’application puisse interagir avec
les services et les données adaptées (adaptation de présentation). La figure 32 présente le
principe général de notre approche d’adaptation.
Dans la suite de ce chapitre nous présentons les trois types d’adaptation que nous avons
élaborés durant ce travail de thèse.
II. ADAPTATION FONCTIONNELLE
1. Principe de l’adaptation fonctionnelle
Une application offre un ensemble de services à l’utilisateur. Certains services peuvent être
non exploitables lors du changement du contexte. Par exemple, un service qui retourne un
gros volume de données n’est plus utilisable sur un terminal de faible mémoire de traitement.
Le comportement de ce service doit être adapté aux limitations matérielles du dispositif de
l’utilisateur. Dans ce cas, nous décomposons les données renvoyées par le service en plusieurs
blocs, chacun étant directement exploitable par le terminal. Nous remplaçons le service
original par un autre service qui renvoie les données bloc par bloc.
Nous définissons l’adaptation fonctionnelle d’une application par le
changement du comportement de ses services pour qu’ils puissent être utilisés
d’une manière plus conviviale et plus correcte dans le contexte en question.
Dans SECAS, l’adaptation fonctionnelle consiste à transformer le réseau de pétri de
dépendances de services en un autre réseau de pétri de services adaptés. Cette transformation
porte sur les places du réseau de pétri (les services) et aussi sur ses arcs (dépendances entre les
services). Pour des raisons de simplification, nous utiliserons aussi le terme adaptation de
services dans quelques paragraphes de ce mémoire pour désigner la même notion d’adaptation
fonctionnelle.
Nous avons défini un ensemble d’opérateurs d’adaptation afin de réaliser les
transformations sur le modèle fonctionnel de l’application. Nous avons défini deux types
principaux d’opérateurs d’adaptation. Le premier type concerne les opérateurs inter-services
Tarak CHAARI - 98 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
qui sont gérés par le gestionnaire d’adaptation de services. Il spécifie les opérateurs qui
peuvent être appliqués sur le modèle fonctionnel d’une application. Le second concerne les
opérateurs intra-services qui sont gérés par des adaptateurs associés à chaque service. Ce
deuxième type d’opérateurs contient deux sous-types : les opérateurs de filtrage des
entrées/sortie des services et les opérateurs de gestion des versions des services. Ces
opérateurs sont utilisables dans des règles d’adaptation définies par l’administrateur de
l’application. Nous décrivons ces règles dans le paragraphe 3 et nous détaillons les différents
types d’opérateurs d’adaptation dans le paragraphe 4 de cette section.
2. Règles d’adaptation fonctionnelle
Une règle d’adaptation fonctionnelle définit les actions d’adaptation à effectuer sur le
modèle fonctionnel de l’application dans une situation contextuelle donnée. Nous modélisons
une règle par une paire (Expressions, Actions).
{(¬context.terminal.acceptedDataTypes.acceptImages) ∧ (∃ f∈F | ∃ i |f.OUTPUT[i].type=“image”)→ lockService(f) }
Figure 33 - Exemple d'une règle d'adaptation
La partie Expressions décrit une situation contextuelle de l’application. Elle est définie par
un ensemble d’expressions logiques basées sur des opérateurs logiques simples comme
« equal », « superior », « inferior », « exist »… Ces expressions concernent les valeurs des
paramètres du contexte et les propriétés de l’application.
Dans le cas où l’expression est une condition sur les paramètres du contexte, elle est
modélisée par le triplet (paramètre de contexte, opérateur logique, valeur). Par exemple le
triplet (context.terminal.softwarePlatform.acceptedDataTypes.acceptImages, equals, false)
décrit une situation où le terminal utilisé n’accepte pas les images. Pour simplifier l’écriture
de cette expression, nous utilisons la formule logique équivalente suivante :
(¬context.terminal.acceptedDataTypes.acceptImages)
Dans le cas où l’expression concerne des propriétés de l’application, nous utilisons des
expressions existentielles suivies de conditions sur les différents éléments du modèle
fonctionnel. Ces expressions doivent respecter la structure d’un modèle fonctionnel présentée
dans le paragraphe III.4 du chapitre 3 de ce mémoire). Les expressions existentielles peuvent
concerner l’ensemble F des services de l’application, l’ensemble T des transitions du modèle
fonctionnel, le vecteur d’entrée (et/ou de sortie) de chaque service f et/ou l’ensemble des
associations A de chaque transition ti. On modélise ces expressions existentielles par des
triplets : (entité élémentaire, opérateur existentiel, ensemble fini d’éléments). Par exemple,
Tarak CHAARI - 99 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
l’expression (f, belongsTo, F) ^ (i, belongsTo, [0..n])^(f.OUTPUT[i].type, equals,
secas:image), décrit l’existence d’un service f qui fournit un paramètre de sortie de type
image. Pour simplifier l’écriture de cette expression, nous utilisons la formule logique
équivalente suivante :
(∃ f∈F | ∃ i∈[0..n] | f.OUTPUT[i].type=“secas :image”)
La partie « Actions » décrit une liste d’actions à effectuer lorsque l’évaluation des
expressions est vraie. Chaque action correspond à un opérateur d’adaptation qui définit la
transformation à effectuer pour modifier le comportement de l’application ou d’un service
particulier. Nous reviendrons en détails sur ces opérateurs d’adaptation dans la section II.3.
La figure 33 donne un exemple simple de règle d’adaptation où la partie « expressions »
est composée de deux expressions logiques exprimant la situation contextuelle : « le terminal
ne supporte pas les images et il existe un service qui fournit un paramètre de sortie de type
image ». L’action associée à cette situation est « bloquer l’accès au service ».
Pour éviter les conflits d’exécution et d’interprétation des règles, l’administrateur de
chaque application doit spécifier une liste de règles d’adaptation avec un ordre de priorité afin
d’éviter les conflits d’exécution et d’interprétation. En effet, dans le cas général, l’exécution
des règles n’est pas commutative : l’application d’une règle A suivie d’une deuxième règle B
ne donne pas le même résultat d’adaptation que l’exécution de la règle B suivie de la règle A.
L’ordre de priorité d’exécution est représenté par une hiérarchie numérique. Par exemple, la
règle 1.2.3 est exécutée avant les règles de priorité 1.2.3.1, 1.2.3.1.1, 1.2.3.1.2…. Elle sera
aussi appliquée avant les règles de priorité 1.2.4, 1.2.5, 1.2.6…Cette numérotation permet
d’insérer facilement des règles avec un ordre de priorité intermédiaire entre deux règles déjà
définies. Il est à noter que lors de l’insertion d’une règle, tout le processus d’adaptation
fonctionnelle est réinitialisé pour garantir la cohérence du résultat d’adaptation. Ceci est dû à
la non commutativité de l’application des règles d’adaptation.
L’administrateur doit aussi spécifier le mode d’exécution de chaque règle. Nous avons
défini deux modes : le mode simple et le mode récursif. Avec le mode simple, la règle est
vérifiée une seule fois pour toutes les entités du modèle. Avec le mode récursif, la règle est ré-
évaluée plusieurs fois d’une façon récursive sur toutes les entités du modèle fonctionnel
jusqu’à ce que la partie expressions soit évaluée a false. Le mode récursif permet de réitérer
l’application de la règle d’adaptation et d’aboutir ainsi à un degré d’adaptabilité plus élevé.
Les règles d’adaptation fonctionnelle peuvent être génériques ou spécifiques. Les règles
génériques sont applicables sur plusieurs applications et sur plusieurs services (comme la
Tarak CHAARI - 100 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
règle de la figure 33). Les règles spécifiques concernent des services particuliers et permettent
de réaliser une adaptation personnalisée. Des règles spécifiques peuvent aussi être réalisées en
se basant sur d’autres règles génériques déjà enregistrées. Ceci peut être réalisé en ajoutant
des conditions sur le nom du service.
Dans les paragraphes suivants nous détaillons les types d’opérateurs d’adaptation que nous
avons définis et nous présentons le processus d’adaptation fonctionnelle d’une application à
de nouveaux contextes d’utilisation.
3. Opérateurs d’adaptation fonctionnelle
3.1 DEFINITION D’UN OPERATEUR D’ADAPTATION FONCTIONNELLE
Chaque action définie dans la partie « actions » des règles d’adaptation correspond à un
opérateur d’adaptation.
Un opérateur d’adaptation fonctionnelle effectue des transformations sur le
modèle fonctionnel de l’application en modifiant ses services ou ses transitions.
Nous modélisons un opérateur d’adaptation par une fonction operator qui prend en entrée
un ensemble « parameters » de paramètres typés et qui peut fournir un résultat res.
res = operator ( parameters)
Chaque paramètre (ainsi que le résultat de l’application de l’opérateur) représente une
instance d’un élément « FunctionalModelElement » du modèle fonctionnel de l’application.
Cet élément peut être un modèle fonctionnel, un service, un ensemble de paramètres
d’entrée/sortie, une transition... Par exemple, dans la figure 33, l’opérateur utilisé dans la
règle spécifiée est lockService. Il prend en entrée un service du modèle fonctionnel de
l’application et bloque l’accès à ce service ainsi qu’à tous les services qui en dépendent. Cet
opérateur fournit en sortie un nouveau modèle fonctionnel différent de l’initial. Nous
revenons à cet opérateur en détails dans la section 3.3.4 de cette partie. La figure 34 illustre le
diagramme de classes d’un opérateur d’adaptation fonctionnelle (Functional Adaptation
Operator). Il utilise un ensemble de paramètres d’adaptation (Adaptation Parameters) et
produit un résultat d’adaptation (Adaptation Result). Les paramètres et les résultats de ces
opérateurs sont des éléments du modèle fonctionnel (Functional Model Elements).
Tarak CHAARI - 101 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
Figure 34 - Modélisation d'un opérateur d'adaptation fonctionnelle
Dans le cas où l’opérateur effectue des modifications sur un service, nous le qualifions
d’opérateur intra-service. Dans le cas où l’opérateur effectue des transformations sur la
structure globale du modèle fonctionnel nous le qualifions d’opérateur inter-services. Nous
détaillons les opérateurs intra-service dans le paragraphe 3.2 et les opérateurs inter-services
dans la section 3.3.
3.2 OPERATEURS D’ADAPTATION INTRA-SERVICE
Un opérateur d’adaptation intra-service effectue des transformations locales sur un service
de l’application. Ce type d’opérateurs prend en entrée le service (f) à adapter et produit en
sortie un autre service adapté (res) selon la nature de l’opérateur et ses paramètres d’entrées
(parameters). L’exécution de ce type d’opérateur est assurée par une entité d’adaptation
associée à chaque service de l’application. Nous appelons cette entité « adaptateur ».
L’adaptateur constitue un intermédiaire entre l’utilisateur final de l’application et le service
original qui lui est associé par le gestionnaire d’adaptation de services. Les règles
d’adaptation configurent les adaptateurs pour qu’ils exécutent une liste d’opérateurs
d’adaptation intra-service suivant les règles d’adaptation fournies à la plateforme. Avant leur
configuration, les adaptateurs renvoient le résultat du service original associé. La figure 35
présente l’architecture globale d’un adaptateur. Ce dernier consomme une partie spécifique du
contexte c que nous notons Cad(c). Cette partie du contexte est définie par les règles
d’adaptation. En effet, dès qu’un service initial de l’application est concerné par une règle
d’adaptation, le gestionnaire d’adaptation de services abonne son adaptateur aux paramètres
contextuels mentionnés dans cette règle. L’adaptateur prend aussi en entrée, le vecteur
d’entrée INPUT du service d’origine. Il fournit une sortie adaptée OUTPUT’ qui dépend des
opérateurs d’adaptation qui lui ont été affectés par les règles d’adaptation et de la sortie
initiale OUTPUT.
Tarak CHAARI - 102 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
Adaptateur (ad)
Service initial (f)
Op1 Op2 … Opn Liste d’opérateurs
Paramètres d’entrée du
service initial (INPUT)
Vue du contexte cad(c)
Sortie adaptée (OUTPUT’)
Entrée (INPUT) Sortie initiale (OUTPUT)
Figure 35 - Entité d'adaptation d'un service initial f
L’adaptateur intercepte l’appel vers le service initial f et réalise la fonction d’adaptation
suivante :
ad(INPUT, cad(c))/{fa, fb...} = Op1 ° Op2 ° …°Opn( f)
où :
- ° est l’opérateur de composition de fonctions. Par exemple f’°f(x) = f’(f(x))
- ad est l’adaptateur au contexte
- {fa, fb…} est l’ensemble des versions disponibles du service initial f. Une version
particulière peut être activée selon le contexte.
- INPUT est le vecteur de paramètres d’entrée du service initial f.
- cad(c) est la vue du contexte c utile à l’adaptateur ad pour effectuer l’adaptation.
(Op1, Op2,…Opn) est la liste des opérateurs d’adaptation intra-services affectée à
l’adaptateur par les actions des règles d’adaptation.
L’adaptateur garantit l’exécution des actions d’adaptation intra-service (SActions : Service
adaptation Actions) indiquées dans les règles d’adaptation. Nous rappelons que chaque action
définie dans ces règles correspond à un opérateur d’adaptation fonctionnelle.
Nous distinguons deux types d’actions d’adaptation intra-service : filtrage des sorties de
services (OActions : Output adaptation Actions) et gestion des versions de services
(VActions : Version adaptation Actions) comme l’activation d’une version, ajout/suppression
d’une version…
3.2.1 Actions d’adaptation des sorties de services (OActions)
Les actions d’adaptation fonctionnelle des sorties de services (Output adaptation Actions)
correspondent à des opérateurs qui réalisent des transformations sur le vecteur de sortie
OUTPUT d’un service initial f. Ils fournissent un nouveau service res qui représente une
structure de sortie différente de celle du service initial f. Dans ce qui suit nous présentons
quelques exemples de ces opérateurs. Bien qu’ils soient inspirés d’opérateurs SQL, nous
Tarak CHAARI - 103 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
insistons sur le fait que nos opérateurs sont appliqués aux vecteurs de sortie résultant de
l’exécution de services et non à des tables soumises aux contraintes d’intégrité des bases de
données.
(1) Projection
Cet opérateur permet de choisir un sous-ensemble de paramètres de sortie d’un service afin
de sélectionner des paramètres précis de sa sortie. Il est appliqué sur un service f qui produit
un nouveau service f’ tel que :
f’ = projection(f, params)
où :
OUTPUT=f(INPUT) avec OUTPUT=(c1,..., cn)
params= (ci,..., ck) avec {ci,..., ck}∈OUTPUT et 0<i<= k<=n
f’(INPUT) = OUTPUT’ = (c1,..., ck)
Cet opérateur est utile pour sélectionner un sous-ensemble de paramètres de sortie d’un
service ou pour masquer des paramètres de sortie à l’utilisateur.
idClient nomClient Vecteur de sortie d’un service infosClients
idClient nomClient photoClientRésultat de l’application de la projection
projection(infoClients, (idClient, nomClient))
1 2
n
Nom 1 Nom 2
Nom n
1.jpg 2.jpg
n.jpg
Nom 1 Nom 2
Nom n
1.jpg 2.jpg
n.jpg
Figure 36 - Exemple d’utilisation de l'opérateur de projection
La figure 36 illustre un exemple où le paramètre de sortie photoClient d’un service
infosClients est masqué à l’utilisateur final de l’application avec l’opérateur de projection.
(2) Sélection
Cet opérateur permet d’enlever les instances qui ne sont pas pertinentes pour l’utilisateur
final de l’application dans une situation contextuelle donnée. La sélection est effectuée selon
un critère explicite exprimé selon une syntaxe analogue à l’opérateur SQL SELECT.
f’ = selection(f, params)
où :
Tarak CHAARI - 104 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
- f(INPUT)= OUTPUT = (c1,..., cn)
- params = ( param, (and/or, param)* )
- param = (ci, cmp, value) avec 0<=i<=n, cmp ∈ {=,>, <, <>, !=} et value est une
constante du même type que le paramètre ci.
idClient nomClient photoClient
Résultat de sortie d’un service infosClients
idClient nomClient photoClientRésultat de l’application de la selection
selection(infoClients, (idClient, =,3))
1 2 3 4
Nom 1 Nom 2 Nom 3 Nom 4
1.jpg 2.jpg 3.jpg 4.jpg
3
Nom 3
3.jpg
Figure 37 - Exemple d’utilisation de l’opérateur de sélection
La figure 37 illustre un exemple de sélection d’un client particulier parmi les clients
renvoyés par le service infosClients.
(3) Produit
Cet opérateur permet d’ajouter d’autres paramètres de sortie à un service en combinant sa
sortie sous forme de produit cartésien avec le résultat d’un autre service. Cet opérateur est
analogue au produit cartésien entre deux tables SQL. Il prend comme entrées le service
original f et le service qui va fournir les paramètres supplémentaires f’. Le résultat de
l’application de cet opérateur fournit un service res qui réalise le produit cartésien des deux
structures de sortie OUTPUT et OUTPUT’ des services f et f’ respectivement.
res = produit ( f, f’)
où :
- f(INPUT) = OUTPUT, est le service initial avec OUTPUT=(c1,..., cn) et INPUT=(x1,...,
xm)
- f’(INPUT’) = OUTPUT’ est le service qui va fournir les paramètres supplémentaires avec
OUTPUT’=(c’1,..., c’n’) et INPUT’=(x’1,..., x’m’)
- res(INPUTres)=OUTPUTres est le service qui prend en entrée le vecteur INPUTres=( x1,...,
xm, x’1,..., x’m’) et qui fourni en sortie le vecteur OUTPUTres=( c1,..., cn, c’1,..., c’n’)
Par exemple, considérons un service reservationHotel de réservation de chambres dans un
hôtel et un service reservationVol de réservation de vols. L’utilisateur final de l’application
Tarak CHAARI - 105 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
peut exprimer une préférence pour choisir le vol et la chambre qui lui conviennent dans une
seule action d’interaction. Le produit des résultats de ces deux services lui permet d’avoir
cette nouvelle fonctionnalité. La figure 38 présente un exemple de résultat fourni par
l’application de l’opérateur « produit » sur ces deux services.
numeroVol aller retour
TU750
Le 12/04/2007 de Tunis à 16h10. Arrivé à Lyon à
18h00
Résultat de sortie du service reservationVols
Résultat de sortie du service reservationHotel
Le 18/03/2007 de Lyon à 11h35.
Arrivé à Tunis à 13h25
313 411
NumeroChambre photoIntérieure
photoI313.jpgphotoI414.jpg
Résultat de sortie du service res = produit(reservationVol,reservationHotel) numeroVol aller retour NumeroChambre photoIntérieure
TU750
TU750
Le 18/03/2007 de Lyon à
11h35. Arrivé à Tunis à 13h25
Le 18/03/2007 de Lyon à
11h35. Arrivé à Tunis à 13h25
Le 12/04/2007 de Tunis à
16h10. Arrivé à Lyon à 18h00
Le 12/04/2007 de Tunis à
16h10. Arrivé à Lyon à 18h00
313
411
photoI313.jpg
photoI414.jpg
Figure 38 - Exemple d'utilisation de l'opérateur « produit »
(4) Union
Cet opérateur permet d’ajouter d’autres instances des paramètres de sortie d’un service f en
les intégrant à la fin des instances de sortie d’un autre service f’. Cet opérateur n’est
applicable que si les vecteurs de sorties OUTPUT et OUTPUT’ respectifs de f et de f’ ont le
même nombre de paramètres de sortie (OUTPUT.length = OUTPUT’.length). Cet opérateur
prend en entrée le service initial f, le service qui va fournir les instances supplémentaires f’ et
leurs vecteurs d’entrée respectifs INPUT et INPUT’. Le résultat de l’application de cet
opérateur fournit un service res qui a la même structure que le vecteur de sortie OUTPUT du
service initial f.
Tarak CHAARI - 106 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
res = union ( f, f’)
où :
- f(INPUT) = OUTPUT, est le service d’origine avec OUTPUT=(c1,..., cn) et ci = (ri1,
…,rik)
- f’(INPUT’) = OUTPUT’ est le service qui va fournir les instances supplémentaires avec
OUTPUT’=(c’1,..., c’n’) et ci = (r’i1, …,r’il)
- res(INPUT) = OUTPUT est le service résultant de l’union avec OUTPUT=(c1,..., cn) et
ci = (ri1, …,rik,r’i1, …,r’il)
Cet opérateur est généralement utile quand l’union est réalisée avec le même service pour
couvrir plus de cas possibles ou pour avoir des résultats plus pertinents. Par exemple,
supposons que l’utilisateur final de l’application veuille avoir la liste des restaurants proches
de lui. Le service disponible listeResto n’offre que la liste des restaurants par communes. Si
l’utilisateur se trouve sur les frontières de deux communes voisines, l’union des deux listes
des restaurants de chacune de ces communes présente un résultat plus pertinent à cet
utilisateur. La figure 39 présente un exemple de résultat fourni par l’application de l’opérateur
« union » de cette nouvelle situation contextuelle.
nomResto adresse
Barocco La Gargotte
Résultat de sortie du service listeResto(69001)
13 rue du Garet 15 rue Royale
Résultat de sortie du service res = union(listeResto(69001),listeResto(69002))
nomResto adresse
Barocco La Gargotte
Les belles saisons Benoît Restaurant
13 rue du Garet 5 rue Tupin
12 cours Verdun 15 rue Royale
nomResto adresse
Les belles saisons Benoît Restaurant
Résultat de sortie du service listeResto(69002)
12 cours Verdun 15 rue Royale
Figure 39 - Exemple d'utilisation de l'opérateur « union »
Tarak CHAARI - 107 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
3.2.2 Actions d’adaptation de gestion de versions de services
(VActions)
Les actions d’adaptation fonctionnelle de versions de services (Version adaptation Actions)
correspondent à des opérateurs qui gèrent un ensemble de versions affectées d’une façon
dynamique à chaque adaptateur. Ces actions assurent l’ajout, la suppression et l’activation
d’une version suivant le contexte d’utilisation. Voici une liste non exhaustive de ces
opérateurs :
(1) activateVersion
Cet opérateur permet de choisir une instance (ou version) d’un service. Il prend en
paramètre le service initial et l’identifiant de la version qui doit être activée. Il produit en
sortie un service res représenté par la nouvelle version sélectionnée.
res = activateVersion ( f, versionID)
où :
- f est le service initial
- versionID ∈{a,b,c…}
-res = fversionID est le service résultant de l’opérateur d’activation de la version versionID
Cet opérateur permet de modifier le comportement d’un service en activant une version
suivant le contexte d’utilisation.
(2) addVersion
Cet opérateur permet d’ajouter une version à l’adaptateur associé à un service donné. Il
prend en paramètre la description la nouvelle version à ajouter et la description du service
initial. Il produit en sortie un adaptateur ad qui peut activer ultérieurement la version ajoutée.
res = addVersion ( f, f’)
où :
- f est le service initial
- f’ est la description du service à ajouter
- res = ad(INPUT, cad(c))/{fa, fb..., f’} est le service résultant de l’ajout de la version f’ à
l’adaptateur ad(INPUT, cad(c))/{fa, fb...} de f.
Cet opérateur est utile pour l’ajout d’un nouveau comportement adapté à une nouvelle
situation contextuelle. Ceci permet aussi de réaliser une adaptation évolutive d’un service.
Tarak CHAARI - 108 - Thèse de doctorat
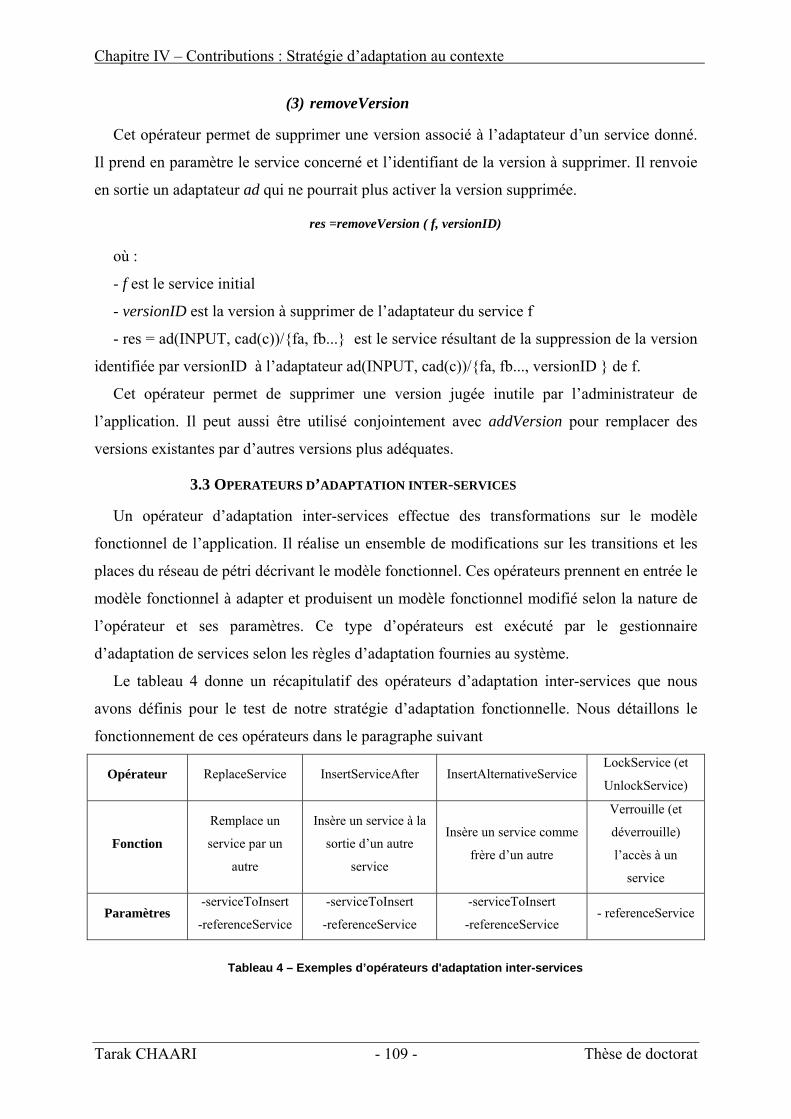
Chapitre IV – Contributions : Stratégie d’adaptation au contexte
(3) removeVersion
Cet opérateur permet de supprimer une version associé à l’adaptateur d’un service donné.
Il prend en paramètre le service concerné et l’identifiant de la version à supprimer. Il renvoie
en sortie un adaptateur ad qui ne pourrait plus activer la version supprimée.
res =removeVersion ( f, versionID)
où :
- f est le service initial
- versionID est la version à supprimer de l’adaptateur du service f
- res = ad(INPUT, cad(c))/{fa, fb...} est le service résultant de la suppression de la version
identifiée par versionID à l’adaptateur ad(INPUT, cad(c))/{fa, fb..., versionID } de f.
Cet opérateur permet de supprimer une version jugée inutile par l’administrateur de
l’application. Il peut aussi être utilisé conjointement avec addVersion pour remplacer des
versions existantes par d’autres versions plus adéquates.
3.3 OPERATEURS D’ADAPTATION INTER-SERVICES
Un opérateur d’adaptation inter-services effectue des transformations sur le modèle
fonctionnel de l’application. Il réalise un ensemble de modifications sur les transitions et les
places du réseau de pétri décrivant le modèle fonctionnel. Ces opérateurs prennent en entrée le
modèle fonctionnel à adapter et produisent un modèle fonctionnel modifié selon la nature de
l’opérateur et ses paramètres. Ce type d’opérateurs est exécuté par le gestionnaire
d’adaptation de services selon les règles d’adaptation fournies au système.
Le tableau 4 donne un récapitulatif des opérateurs d’adaptation inter-services que nous
avons définis pour le test de notre stratégie d’adaptation fonctionnelle. Nous détaillons le
fonctionnement de ces opérateurs dans le paragraphe suivant
Opérateur ReplaceService InsertServiceAfter InsertAlternativeService LockService (et
UnlockService)
Fonction
Remplace un
service par un
autre
Insère un service à la
sortie d’un autre
service
Insère un service comme
frère d’un autre
Verrouille (et
déverrouille)
l’accès à un
service
Paramètres -serviceToInsert
-referenceService
-serviceToInsert
-referenceService
-serviceToInsert
-referenceService - referenceService
Tableau 4 – Exemples d’opérateurs d'adaptation inter-services
Tarak CHAARI - 109 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
3.3.1 ReplaceService
Cet opérateur remplace un service “serviceToReplace" par un nouveau service
"newService". Il prend en entrée la description du service à remplacer “serviceToReplace", la
description du nouveau service "newService" et le mode de remplacement. Ce mode peut être
récursif ou simple. Dans le cas où le mode est récursif, une transition en boucle est ajoutée à
la sortie du nouveau service sur lui-même. Le mode récursif est utilisé pour renvoyer un
résultat sur plusieurs parties (opérateur de pagination). Après avoir vu la première page des
résultats du service, l’utilisateur final de l’application peut soit passer à la page suivante en
utilisant la nouvelle transition en boucle, soit passer au service suivant avec la transition
sortante d’origine (voir figure 40).
res = replaceService (serviceToReplace, newService, mode)
où :
- "serviceToReplace" est le service à remplacer
- "newService" est la description du nouveau service qui va remplacer "serviceToReplace"
- res = (f0, F, T) est le modèle fonctionnel modifié après le remplacement du service
"serviceToReplace".
replaceService (serviceToReplace, newService, simple)
serviceToReplace
f1
f2 f3
newService
f1
f2 f3
Figure 40 - Exemple d’application de l’opérateur replaceService en mode simple
L’opérateur de remplacement de service remplace le service "serviceToReplace" par le
service "newService" dans l’ensemble F des services du modèle fonctionnel. Cet opérateur
modifie aussi les transitions du modèle fonctionnel suivant les règles suivantes :
- Si les sorties du nouveau service "newService" correspondent aux entrées des services
sortants du service initial "serviceToReplace", toutes les transitions sortantes de
"serviceToReplace" sont mises à jour en modifiant leur source par "newService". Nous disons
dans ce cas, que le nouveau service "newService" remplace complètement l’ancien service
"serviceToReplace".
Tarak CHAARI - 110 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
- Si les entrées du nouveau service ne correspondent pas avec l’une des transitions
entrantes à l’ancien service "newService", le service newService est retiré de l’ensemble F des
services du modèle fonctionnel et l’ancien service "serviceToReplace" est remis dans cet
ensemble. Dans ce cas, nous disons que le nouveau service "newService" ne remplace pas
"serviceToReplace". Sinon, toutes les transitions entrantes de l’ancien service sont mises à
jour pour pointer vers le nouveau service "newService".
- Si les paramètres de sortie du nouveau service "newService" ne correspondent pas avec
l’une des entrées des services sortants de "serviceToReplace", la source des associations
correspondantes (entre l’ancien service et les services sortants en question), est modifiée à
"null". Le service associé devient ainsi temporairement inaccessible à partir du nouveau
service. Nous disons dans ce cas que le service remplace partiellement l’ancien service (cas de
la figure 40). Nous qualifions la transition modifiée de transition instable et le service qui en
dépend de service isolé.
newService
f1
f2 f3
replaceService (serviceToReplace, newService, recursive)
serviceToReplace
f1
f2 f3
Figure 41 - Résultat de l’application de l’opérateur replaceService en mode récursif
La figure 42 présente l’algorithme général de l’opérateur "replaceService" suivant les
règles ci-dessus.
Dans la figure 40, la source de la transition entre "serviceToReplace" et le service f2 est
modifiée vers "newService". Par contre, la source de la transition entre "serviceToReplace" et
le service f3 est modifiée à "null". Une application ultérieure d’un autre opérateur doit mettre
à jour cette valeur pour maintenir la cohérence du modèle fonctionnel. Nous avons préféré
cette solution à l’élimination de la transition instable et du service isolé pour laisser une
opportunité à son rattachement au réseau de pétri par d’autres opérateurs. Ceci nous permet de
ne pas perdre la fonctionnalité offerte par le service isolé.
Tarak CHAARI - 111 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
replaceService(serviceToReplace, newService, mode) { If (∃ ti= (d, gc, A) ∈T | ∃ ai= (sourceParameter, destinationParameter) ∈ A | ai.destinationService =
serviceToReplace && destinationParameter ∉ newService.INPUT) { // newService est incompatible avec serviceToReplace et ne peut pas le remplacer => quitter replaceService Break } For each (ti = (d,gc,A)∈T) { A’ := ∅ For each (ai= (sourceParameter,destinationParameter)∈A | ai.sourceService=serviceToReplace) { If (sourceParameter ∈ newService.OUTPUT) ai.sourceService :=newService else ai.sourceService :=null } If (mode=”recursive”) { a’:=(pageNumber, pageNumber) a’.sourceService :=newService a’.destinationService=newService T:=T ∪ {(defaultDelay, defaultGeneralCondition, { a’})} } } F=F \ {serviceToReplace} F=F {newService} ∪}
Figure 42 - Algorithme de l'opérateur de remplacement de services
Nous avons défini deux algorithmes qui permettent de vérifier s’il y a des transitions
instables connectables à un service isolé donné en entrée ou en sortie. La figure 43 donne
l’algorithme de connexion en entrée d’un service isolé et la figure 44 donne l’algorithme de
connexion en sortie.
Tarak CHAARI - 112 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
connectServiceInput (referenceService) { For each (ti = (d,gc,A)∈T) { transitionCompatibility := true if (∃ ai= (sourceParameter, destinationParameter) ∈ A | ai.destinationService = null && sourceParameter ∉
referenceService.INPUT) TransitionCompatibility := false if (transitionCompatibility) { For each (ai = (sourceParameter, destinationParameter) ∈ A | ai.destinationService = null &&
sourceParameter ∈ referenceService.INPUT) ai.destinationService :=referenceService } } }
Figure 43 - Algorithme de connexion en entrée d'un service isolé
connectServiceOutput (referenceService) { For each (ti = (d,gc,A)∈T) { transitionCompatibility := true if (∃ ai= (sourceParameter, destinationParameter) ∈ A | ai.sourceService = null && destinationParameter ∉
referenceService.OUTPUT) TransitionCompatibility := false if (transitionCompatibility) { For each (ai = (sourceParameter, destinationParameter) ∈ A | ai.sourceService = null &&
destinationParameter ∈ referenceService.OUTPUT) ai.sourceService=referenceService } } }
Figure 44 - Algorithme de connexion en sortie d'un service isolé
3.3.2 InsertServiceAfter
Cet opérateur d’adaptation insère un service “serviceToInsert" après un service de
référence "referenceService". Il ajoute le service “serviceToInsert" à l’ensemble F des
services du modèle fonctionnel.
res = insertServiceAfter(serviceToInsert, referenceService)
où :
- "serviceToInsert" est le service à insérer
Tarak CHAARI - 113 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
- "referenceService" est la description du service après lequel le nouveau service
"serviceToInsert" sera inséré
- res = (f0, F, T) est le modèle fonctionnel modifié après l’insertion du service
"serviceToInsert" à la sortie du service "referenceService"
referenceService
f1
f2 f3
referenceService
f1
f2
f3 serviceToInsert
Insert Service After
Figure 45 - Résultat de l’application de l’opérateur InsertServiceAfter
Cet opérateur effectue aussi des modifications sur les transitions sortantes de
"referenceService" suivant les règles suivantes :
- Si la sortie du service à insérer correspond à l’entrée des services sortants (f2, f3…) de
"referenceService", le nouveau service "serviceToInsert" est lié en sortie à tous ces services
(f2,f3…).
- Si la sortie du service à insérer ne correspond pas à l’entrée de l’un des services de sortie
du service de référence "referenceService", la liaison du service en question est gardée avec
"referenceService". Par exemple, dans la figure 45, la transition entre le service f3 et
"referenceService" est gardée car les sorties du nouveau service ne correspondent pas aux
entrées de f3.
- S’il existe une transition avec source à "null" et la sortie du service inséré correspond à
la destination de cette transition, la source de cette transition est mise à jour avec le nouveau
service (appel de la fonction "connectServiceOutput(serviceToInsert)").
La figure 46 présente l’algorithme correspondant à l’opérateur "insertServiceAfter" suivant
les règles citées ci-dessus.
Tarak CHAARI - 114 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
insertServiceAfter (serviceToInsert, referenceService) { F :=F∪ {serviceToInsert} For each (ti=(d,gc,A) ∈ T) { A’:=∅ For each (ai=(sourceParameter,destinationParameter) ∈ A | sourceParameter ∈ referenceService.OUTPUT) If (destinationParameter ∉serviceToInsert.OUTPUT) { A’:= ∅ Break } Else { a’:= (destinationParameter,destinationParameter) a’.sourceService :=serviceToInsert a’.destinationService := ai.destinationService A’:= A’ {a’} ∪ ai.destinationService :=serviceToInsert } If (A’ != ∅) { T :=T∪ {(d,gc, A’)) } } connectServiceOutput(serviceToInsert) }
Figure 46 - Algorithme de l'opérateur insertServiceAfter
3.3.3 InsertAlternativeService
Cet opérateur insère un service “serviceToInsert" comme une alternative au service
"referenceService" (c'est-à-dire dans les services immédiatement sortants du service qui
précède le service de référence "referenceService"). Par exemple, dans la figure 47, l’insertion
du service “serviceToInsert" avec cet opérateur, permet d’avoir deux alternatives après
l’exécution du service f1. En effet, l’utilisateur final de l’application peut désormais exécuter
l’ancien service "referenceService" ou le nouveau service inséré “serviceToInsert".
res = insertAlternativeService (serviceToInsert, referenceService)
où :
- "serviceToInsert" est le service à insérer
- "referenceService" est le service de référence
Tarak CHAARI - 115 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
- res = (f0, F, T) est le modèle fonctionnel modifié après l’insertion du service
"serviceToInsert" comme alternative au service "referenceService".
Cet opérateur ajoute le nouveau service "serviceToInsert" à l’ensemble F des services du
modèle fonctionnel et effectue des modifications sur les transitions du modèle fonctionnel
suivant les règles suivantes :
- Si la sortie du nouveau service correspond à l’entrée des services sortants du service de
référence "referenceService" (comme le service f2 dans la figure 45), une transition est créée
entre le nouveau service et ces services.
- S’il existe une transition avec source à "null" et la sortie du service inséré correspond à
la destination de cette transition, la source de cette transition est mise à jour avec le nouveau
service (appel de la fonction "connectServiceOutput(serviceToInsert)").
referenceService
f1
f2
referenceService
f1
f2
Insert Alternative (serviceToInsert, referenceService)
serviceToInsert
Figure 47 - Résultat de l'application de l'opérateur insertAlternativeService
La figure 48 donne l’algorithme correspondant à l’opérateur "insertAlternativeService".
Tarak CHAARI - 116 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
insertAlternativeService (ServiceToInsert, referenceService) { F :=F∪ {serviceToInsert} For each (ti=(d,gc,A) ∈ T) { A’:=∅ For each (ai= (sourceParameter,destinationParameter) ∈A | ai.destinationService=referenceService) If (destinationParameter ∉ ServiceToInsert.INPUT) { A’:=∅ Break } Else { a’:= (sourceParameter,destintionParameter) a’.sourceService := ai.sourceService a’.destinationService := serviceToInsert A’:= A’∪ { a’} } If (A’ != ∅) T :=T {(d, gc, A’)} ∪ } For each (ti= (d, gc, A) ∈T) { A’ := ∅ For each (ai= (sourceParameter,destinationParameter) ∈A | ai.sourceService = referenceService) If (sourceParameter ∉ serviceToInsert.OUTPUT) { A’:=∅ Break } Else { a’:=(sourceParameter,destinationParameter) a’.sourceService :=serviceToInsert a’.destinationService := ai.destinationService A’:= A’∪ { a’} } If (A’ != ∅) T:=T {(d, gc, A’)} ∪ } }
Figure 48 - Algorithme de l'opérateur insertServiceAfter
3.3.4 LockService & UnlockService
LockService et UnlockService permettent respectivement de verrouiller et de déverrouiller
Tarak CHAARI - 117 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
l’accès à un service dans le modèle fonctionnel. L’application de ces opérateurs sur un service
bloque (ou débloque) le passage des transitions entrantes au service concerné. Ils modifient la
condition générale des transitions entrantes à ce service.
res = lockService (referenceService) ou bien
res = UnlockService (referenceService)
où :
- "referenceService" est la description du service de référence
- res = (f0, F, T) est le modèle fonctionnel modifié après le verrouillage (ou le
déverrouillage) d’accès au service "referenceService".
La figure 49 et la figure 50 présentent respectivement les algorithmes des opérateurs
lockService et UnlockService.
lockService(referenceService) { For each (ti = (d,gc,A)∈T) { If (∃ ai= (sourceParameter, destinationParameter) ∈ A | ai.destinationService = referenceService) gc :=false } }
Figure 49 - Algorithme de l'opérateur LockService
unlockService(referenceService) { For each (ti = (d,gc,A)∈T) { If (∃ ai= (sourceParameter, destinationParameter) ∈ A | ai.destinationService = referenceService) gc :=true } }
Figure 50 - Algorithme de l'opérateur UnlockService
4. Processus d’adaptation fonctionnelle dans SECAS
Pour adapter une application à de nouveaux contextes d’utilisation, un administrateur
SECAS doit fournir le modèle fonctionnel de l’application et la liste des règles d’adaptation
qui utilisent les opérateurs définis dans les sections précédentes de ce chapitre. Dès le
déploiement du modèle fonctionnel, le gestionnaire d’adaptation de services commence par
instancier un adaptateur pour chaque service du modèle fonctionnel (figure 51).
Tarak CHAARI - 118 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
deployFunctionalModel(FM=(f0, F, T)) { adaptedFunctionalModel := clone(FM) For each (fi ∈F) { Adapter a := instanciateAdapter(fi) adaptedFunctionalModel := updateAdapter(adaptedFunctionalModel, fi, a) } return adaptedFunctionalModel }
Figure 51 - Algorithme de déploiement d’un modèle fonctionnel
Puis, dès que la liste des règles associée à ce modèle fonctionnel est déployée ou que le
contexte change (ou que la liste des règles est modifiée), le gestionnaire d’adaptation de
services applique les actions d’adaptation spécifiées dans ces règles. Chaque règle n’est
exécutée que si sa partie « expressions » est satisfaite (la fonction evaluateExpressions de la
figure 52 donne la valeur "true"). Pour chaque règle, l’application des actions d’adaptations
(la fonction applyActions de la figure 52) se fait sur deux étapes. En premier lieu, le
gestionnaire configure les adaptateurs par les opérateurs spécifiés dans les actions
d’adaptation intra-service. En second lieu, il applique les opérateurs correspondant aux
actions d’adaptation inter-services pour effectuer les modifications spécifiées sur la structure
du modèle fonctionnel.
Si le contexte change, toutes ces règles sont réévaluées pour adapter le comportement des
services à ce nouveau contexte. Ceci correspond à la ré-exécution de la fonction applyRules
de la figure 52. Cette fonction est aussi rappelée chaque fois que la liste des règles
d’adaptation est mise à jour ou modifiée.
applyRules(FunctionalModel FM=(f0, F, T), Rules R) { For each (ri = (expressions, actions)∈R) { if (ri .mode = “recursive”) while (∃fi∈F | evaluateExpressions(expressions, fi)=true ) FM := applyActions(FM, fi, actions) Else For each (fi∈F | evaluateExpressions(expressions, fi)=true ) FM := applyActions(FM, fi, actions) return FM }
Figure 52 - Algorithme d'application de règles d'adaptation
A la fin de l’application de ces règles, un modèle fonctionnel adapté est renvoyé au
gestionnaire d’application SECAS (sortie de la fonction applyRules de la figure 52). Ce
Tarak CHAARI - 119 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
modèle présente les services adaptés à la situation contextuelle courante. Dans ce modèle, les
références vers les services initiaux sont mises à jour pour pointer sur leurs adaptateurs.
5. Synthèse sur l’adaptation fonctionnelle dans SECAS
Dans le paragraphe II de ce chapitre, nous avons présenté notre stratégie d’adaptation
fonctionnelle d’une application au contexte. Cette stratégie est basée sur une liste de règles
d’adaptation qui associent une situation contextuelle à un ensemble d’actions d’adaptation de
services. La situation contextuelle est décrite par un ensemble de conditions logiques sur les
paramètres du contexte et les services de l’application. Les actions d’adaptation utilisent un
ensemble d’opérateurs intra et inter services. Les opérateurs inter-services effectuent des
transformations sur la structure du modèle fonctionnel. Ils sont exécutés par un gestionnaire
d’adaptation de services. Les opérateurs d’adaptation intra-services effectuent des
modifications sur les sorties des services et sur les versions associées aux services d’origine.
Ils sont gérés par des entités d’adaptation de services que nous avons appelé « adaptateurs ».
L’application des règles d’adaptation fonctionnelle produit un nouveau modèle fonctionnel
d’adaptateurs qui présentent un comportement fonctionnel adapté au contexte d’utilisation.
Dès que ce nouveau modèle est créé, le gestionnaire d’adaptation de services notifie le
gestionnaire d’applications de SECAS pour démarrer le processus d’adaptation de contenu.
III. ADAPTATION DE CONTENU
1. Principe de l’adaptation de contenu
Les services du modèle fonctionnel de l’application fournissent un ensemble de données
multimédia (images, vidéos, son, texte…). Ces données peuvent ne pas être exploitables dans
un contexte d’utilisation particulier. Par exemple, si le terminal de l’utilisateur final de
l’application ne supporte que des images de format PNG et que cet utilisateur invoque un
service qui fournit des images sous un autre format, un transcodage est nécessaire sur les
données. Le transcodage de format d’images n’est pas le seul opérateur d’adaptation requis.
En effet, plusieurs autres types d’adaptation peuvent être indispensables pour fournir des
données directement exploitables par le client.
Tarak CHAARI - 120 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
Nous définissons l’adaptation de contenu d’une application par l’ensemble des
opérations nécessaires pour garantir une exploitation directe et optimale des
données de l’application dans un contexte d’utilisation précis.
Le but de l’adaptation de données est de fournir la meilleure information possible à
l’utilisateur final de l’application dans un contexte donné. La réussite et l’efficacité de
l’adaptation de contenu dépendent fortement de la qualité et de la quantité de connaissances
recueillies sur : (i) le contexte d’utilisation de l’application, (ii) les outils d’adaptation de
données disponibles et (iii) le contenu.
Nous définissons les métadonnées de contenu comme étant l’ensemble des
propriétés décrivant les données échangées avec les services de l’application.
Les métadonnées de contenu sont utilisées pour décrire les caractéristiques du
contenu telles que le format, la taille, la dimension, etc.
Nous avons choisi le format de description MPEG-7 pour représenter ces métadonnées.
Notre choix repose sur le fait que MPEG-7 est indépendant du média. Ce format est
actuellement le standard qui fournit l’ensemble le plus riche et le plus souple de descriptions
de propriétés multimédia, il est considéré comme le standard le plus réputé et le plus
interopérable dans le milieu industriel. Les descripteurs de données MPEG-7 sont utilisés
dans le profil de contexte au niveau des formats de données acceptés par le terminal. Ils sont
aussi utilisés dans la description des paramètres d’entrée et de sortie des services au niveau du
modèle fonctionnel.
Les outils d’adaptation de données que nous avons utilisés sont des services Web qui
exécutent des opérateurs d’adaptations de contenu (comme la compression d’une image,
synthèse vocale, traduction de texte…). Ces services représentent des transformations dont
nous décrivons les entrées et les sorties. Chaque service d’adaptation de données prend en
entrée une donnée à adapter et sa description MPEG7 et fournit en sortie une donnée adaptée
et sa nouvelle description MPEG7.
Nous avons conçu et développé un module d’adaptation de contenu fondé sur le moteur
d’adaptation de données des travaux de [Berhe05]. Ce moteur assure la sélection et
l’orchestration d’un ensemble d’opérateurs d’adaptation de contenu afin de fournir des
données adaptées au contexte d’utilisation. Pour chaque service du modèle fonctionnel de
l’application, le module d’adaptation de contenu sélectionne les opérateurs d’adaptation de
données nécessaires pour adapter toutes ses sorties à leur contexte d’utilisation.
Tarak CHAARI - 121 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
Dans le paragraphe suivant, nous détaillons le fonctionnement et les composantes
principales du module d’adaptation de contenu.
2. Module d’adaptation de contenu
Le module d’adaptation de contenu réalise les transformations de données nécessaires afin
d’envoyer des données supportées par le terminal de l’utilisateur et conformes à ses
préférences et à son environnement. Il est basé sur quatre types de composants : l’annuaire de
services d’adaptation, les adaptateurs de contenu, le mandataire local d’adaptation et le
composant de planification d’adaptation de contenu.
2.1 ANNUAIRE DE SERVICES D’ADAPTATION DE CONTENU
L’annuaire de services d’adaptation ou ASR (Adaptation service registry) stocke des
références sur les différents opérateurs d’adaptations disponibles sous forme de services
WEB. L’ASR est similaire à un annuaire UDDI (Universal Description, Discovery and
Integration) [UDDI07] qui gère les descriptions fonctionnelles et non fonctionnelles des
services d’adaptation multimédia. L’ASR offre aussi des fonctions de recherche de services
d’adaptation. Les services sont décrits en suivant la représentation utilisée dans le modèle
fonctionnel (paragraphe IV.3 du chapitre 3). Une fonction qui calcule le coût de chaque
service d’adaptation de contenu est aussi référencée dans l’annuaire. Cette fonction mesure
des critères de qualité des services comme le temps d’exécution, la charge du service a le prix
de son utilisation si elle n’est pas gratuite.
2.2 ADAPTATEURS DE CONTENU
Un adaptateur de contenu est un service logiciel qui réalise les transformations nécessaires
pour adapter les données échangées entre un service du modèle fonctionnel et l’utilisateur.
Ces adaptateurs sont instanciés et déployés dynamiquement par le gestionnaire d’adaptation
de contenu pour chaque service de l’application. Pour chaque donnée qui n’est pas adaptée au
contexte d’utilisation, l’adaptateur délègue son adaptation à un mandataire (proxy) local
d’adaptation de contenu et récupère une URL sur la donnée adaptée.
2.3 MANDATAIRE D’ADAPTATION DE CONTENU
Le mandataire d’adaptation de contenu (Local adaptation proxies) assure, en premier lieu,
la récupération des paramètres du contexte. Ensuite, il décide du type et du nombre de
transformations de données nécessaires, découvre les services d’adaptation correspondants et
planifie leur exécution. L’élément fondamental de ce mandataire est le composant de
planification d’adaptation de contenu (Content Adaptation Planification Component). Ce
Tarak CHAARI - 122 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
dernier détermine un graphe des compositions possibles des différents services d’adaptation
de contenu qui réalisent l’adaptation du contenu et effectue le choix de la séquence optimale
dans ce graphe.
2.4 COMPOSANT DE PLANIFICATION D’ADAPTATION DE CONTENU
Ce composant détermine un plan d’exécution optimal pour le traitement adaptatif du média
associé. Après l’identification de ce plan, ce composant informe le mandataire local
d’adaptation de contenu pour mettre à jour le descripteur de l’adaptateur de contenu associé.
Le composant de planification d’adaptation de contenu que nous utilisons dans SECAS
s’appuie sur le générateur de graphes d’adaptation multimédia (Multimedia Adaptation Graph
Generator : MAGG) élaboré dans les travaux de [Berhe05] que nous détaillons dans le
paragraphe suivant. Le composant de planification d’adaptation de contenu utilise des critères
de qualité comme le coût du service et le temps d’exécution pour choisir les services
d’adaptation optimaux afin de réaliser les transformations nécessaires d’adaptation de chaque
paramètre de sortie des services de l’application. Ces critères de qualité sont extraits à partir
de l’annuaire des services d’adaptation de contenu.
Le plan d’adaptation calculé par ce composant n’est exécuté par le mandataire local que
lors de la première invocation du service. Après cette première invocation, la donnée adaptée
et son plan d’adaptation sont mis dans un cache local pour des invocations ultérieures du
même service dans le même contexte d’utilisation.
2.5 FONCTIONNEMENT DU MODULE D’ADAPTATION DE CONTENU
Dès que l’adaptation de services se termine, le gestionnaire d’application SECAS sollicite
le gestionnaire d’adaptation de données (Content Adaptation Manager) pour préparer le
processus d’adaptation de contenu (figure 53).
prepareContentAdaptation(FunctionalModel FM=(f0, F, T)) { For each (fi ∈F) { ContentAdapter ca := instanciateContentAdapter(fi) adaptedFunctionalModel := updateAdapter(adaptedFunctionalModel, fi, ca) } return adaptedFunctionalModel }
Figure 53 - Algorithme général de la fonction de préparation de l'adaptation de contenu
Le gestionnaire d’adaptation de contenu instancie un adaptateur de contenu (Content
Adapter) pour chaque service du modèle fonctionnel fourni au module d’adaptation de
Tarak CHAARI - 123 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
contenu (figure 54).
instanciateContentAdapter(ServiceDescription f) { ContentAdapter ca := new ContentAdapter(f) For each(cj ∈f) { adaptationPlan := LocalProxy.calculateAdaptation(cj) ca.updateDescription(adaptationPlan, cj) } return ca }
Figure 54 - Algorithme général d'instanciation des adaptateurs de contenu
L’adaptateur délègue le calcul de l’adaptation des données au mandataire d’adaptation de
contenu (figure 55). Ce dernier communique avec la couche de gestion de contexte de SECAS
à travers l’interface "ContextConsumer" afin de récupérer le profil de l’utilisateur et du
terminal dont il dispose et de vérifier si la donnée est adaptée à son contexte d’utilisation ou
non. Le mandataire utilise le composant de planification d’adaptation de contenu (Content
Adaptation Planification Component) pour chercher un plan d’adaptation (Adaptation Plan)
composé d’une séquence de services d’adaptation. Ces services sont identifiés dans l’annuaire
de services d’adaptation (Adaptation Service Registry). Nous détaillons la planification de
l’adaptation de contenu dans le paragraphe suivant.
calculateAdaptation(MediaObjectDescriptor c) { adaptationPlan :=ContentAdaptationPlanificationComponent.calculateAdaptation(c) intializeCache(adaptationPlan) return adaptationPlan }
Figure 55 - Algorithme général de calcul du plan d'adaptation de contenu
3. Planification de l’adaptation de contenu [Berhe05]
3.1 DEFINITIONS ET NOTATIONS UTILISEES DANS LA PLANIFICATION
3.1.1 Objet média
Un objet média est une donnée multimédia fournie par un service du modèle fonctionnel.
Cette donnée peut être un texte, une image, un son ou une vidéo représentée par :
M (m1, m2, …, mn)
où m1, m2, …, mn sont des propriétés du media comme le format, la taille, le nombre de
couleurs, la langue…
Tarak CHAARI - 124 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
3.1.2 État d’un objet média
L’état S d’un objet media M, noté S (M) est décrit par des valeurs des propriétés du média.
Par exemple : pour un objet image, l’état comporte les valeurs du format, de la couleur, de la
hauteur, de la largeur, etc. L’état S est une fonction qui renvoie les méta-données de M. Ces
méta-données servent à savoir si chaque donné est adaptée à son contexte d’utilisation.
Par exemple, S("identitePatient_91425378.bmp") = (bmp, 24 bits, 245 pixels, 300 pixels)
décrit une image en format bitmap dont chaque pixel est codé sur 24 bits et dont la taille est
de 245*300 pixels.
3.1.3 Tâche d’adaptation de contenu
Une tâche d’adaptation de contenu est une transformation t qui prend un vecteur de
paramètres d’entrées X = (x1, x2…xn) et qui renvoie un vecteur de paramètres de sortie
OUTPUT = (r1, r2…rm).
Par exemple, (imageOut) = ImageFormatConversion(imageIn, oldFormat, newFormat)
avec :
- imageIn : fichier-image en entrée,
- imageOut : fichier-image en sortie
- oldFormat : format d’entrée de l’image,
- newFormat : format de sortie de l’image.
Les tâches d’adaptation représentent une description abstraite des transformations qu’on
peut effectuer sur un objet média.
3.1.4 Opérateur d’adaptation de contenu
Un opérateur d’adaptation de contenu encapsule un service réalisant une tâche d’adaptation
et décrit les conditions nécessaires pour pouvoir exécuter le service correspondant. Nous
utilisons ces opérateurs pour réaliser l’adaptation d’un objet média à son contexte
d’utilisation.
L’opérateur d’adaptation de contenu est décrit par le service qu’il encapsule, ses entrées,
ses sorties, les pré-conditions nécessaires à son exécution et d’effets représentant l’état de
sortie du média adapté par cet opérateur. Nous décrivons aussi les attributs de qualités (coût,
temps, etc.) du service en termes de coût, temps de réponse, charge…
Nous dénotons un opérateur d’adaptation de contenu par o = (f, INPUT, OUTPUT, Pre,
Eff, Q)
avec :
Tarak CHAARI - 125 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
- f : un service de l’annuaire des services d’adaptation qui exécute une tâche d’adaptation t.
Une tâche d’adaptation peut être réalisée par plusieurs services.
- INPUT : les paramètres d’entrée du service,
- OUTPUT : les paramètres de sortie du service,
- Pre : les pré-conditions du service,
- Eff : les effets du service,
- Q = {q1, q2,…, qn}: représente les attributs de qualité (coût, temps, etc.) du service.
Pour l’exemple de la tâche d’adaptation d’images donnée dans le paragraphe III.3.1.3, nous
pouvons avoir l’instance de l’opérateur de planification suivant :
- Opérateur : ImageFormatConversionOperator
- Entrée : image1
- Sortie : image2
- Pré-condition : hasFormat (image1, jpeg)
- Effet : hasFormat (image2, bmp)
- Qualité : (cost=30 units, responseTime=97 ms)
3.1.5 Graphe d’adaptation de contenu
Un graphe d’adaptation de contenu est un graphe représentant toutes les séquences
possibles d’opérateurs d’adaptation de contenu permettant d’adapter un média M pour passer
d’un état non adapté SA à un état adapté SZ.
Un graphe d’adaptation de contenu G (V, E) est un graphe orienté acyclique (Directed
Acyclic Graph) dans lequel :
- V est l’ensemble des nœuds qui représentent les opérateurs d’adaptation ;
- E est l’ensemble des arcs qui représentent les connexions possibles entre les opérateurs
d’adaptation.
Le nœud initial A ∈ V est un opérateur avec effet (état initial) mais sans pré-condition. Le
nœud terminal Z ∈ V est un opérateur avec pré-condition (état final) mais sans effet.
Une liaison ou un arc orienté eij est associé entre un nœud source oi V et un noeud
destination o
∈
j ∈ V si la condition suivante est satisfaite oj.Pre o⊆ i.Eff où : oj.Pre dénote les
pré-conditions de oj et oi.Eff dénote les effets de oi. Ceci assure l’enchainement des opérateurs
d’adaptation de contenu pour réaliser une tâche d’adaptation. Par exemple, nous disposons de
deux opérateurs : le premier assure la traduction d’un texte français en anglais ; le deuxième
assure la synthèse vocale d’un texte anglais. Pour réaliser la synthèse vocale d’un texte fourni
en français, le graphe d’adaptation va enchainer successivement la traduction du texte
Tarak CHAARI - 126 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
d’origine et puis la synthèse vocale du texte traduit. Dans cet exemple, l’enchaînement est
possible puisque l’effet du premier service oi.Eff (langue du texte en anglais) est compatible
avec les préconditions du deuxième opérateur oj.Pre.
3.1.6 Problème de la planification de l’adaptation.
Un problème de planification d’adaptation est un 4-uplet (SA, SZ, T, D) où SA est l’état
initial de l’objet média, SZ est l’état final de l’objet média, T est une liste de tâches
d’adaptation et D est la liste des opérateurs d’adaptation. La résolution du problème de
planification d’adaptation produit un graphe d’adaptation de contenu G = (V, E).
3.2 ALGORITHME DE GENERATION DU GRAPHE D’ADAPTATION DE CONTENU
Pour construire le graphe d’adaptation, nous avons utilisé l’algorithme élaboré par
[Berhe05] (Multimedia Adaptation Graph Generator : MAGG). Cet algorithme cherche tous
les chemins possibles d’adaptation qui permettent d’aboutir à un résultat adapté au contexte
d’utilisation du média considéré. Le code de cet algorithme est détaillé dans l’annexe D de ce
mémoire. Le graphe produit par cet algorithme présente plusieurs chemins possibles pour
réaliser l’adaptation du média considéré. Nous utilisons le modèle de qualité de services
élaboré par Girma Berhe pour choisir le chemin optimal d’adaptation de contenu. Nous
détaillons ce modèle et son utilisation dans le paragraphe 3.3 de cette section.
3.3 RECHERCHE D’UN PLAN D’ADAPTATION OPTIMAL
3.3.1 Définition d’un plan d’adaptation
Un plan d’adaptation est un chemin dans le graphe d’adaptation G qui relie le nœud initial
au nœud terminal. Il est représenté par une liste de la forme p = (A o1 o2 … on Z) où :
A et Z sont le nœud initial et le nœud terminal du graphe d’adaptation G
oi est une instance d’opérateur d’adaptation.
Si p = (A o1 o2 … on Z) est un plan et que S est un état du média à adapter dans G, alors
S(p) est l’état de l’objet média produit après l’exécution de la suite ordonnée o1, o2, …, on sur
l’objet média en entrée. Q(p) est la valeur globale de qualité du chemin p calculée selon
l’équation (6).
3.3.2 Modèle de qualité de service (QoS)
Puisqu’un opérateur d’adaptation peut être réalisé par plusieurs services, le choix du
service optimal est important pour le résultat d’adaptation. Une fois le graphe d’adaptation
généré avec toutes les séquences d’adaptation possibles, le choix de la meilleure séquence est
Tarak CHAARI - 127 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
fait en se basant sur des critères de qualité de services extraits du contexte d’utilisation de
l’application. Le modèle de qualité de service utilisé dans les travaux de (Berhe & al) se base
sur deux caractéristiques : le temps de réponse du service et son coût (charge).
Soit p = (A s1 s2 … sN Z) un chemin dans le graphe d’adaptation où N est le nombre de
services. On définit la qualité de service du chemin, dénotée par Q(p), comme suit :
))(),(()( pQpQpQ TIMECOST= (1) où :
- : le coût total du chemin )( pQCOST
- : le temps total d’exécution du chemin. )( pQTIME
- est défini par (2) )( pQCOST )()(1
∑=
=N
iiCOSTCOST sQpQ
- ) représente le coût d’exécution du service d’adaptation et celui de la
transmission des données.
( iCOST sQ
- est défini par (3) )( pQTIME )()(1
∑=
=N
iiTIMETIME sQpQ
- ) : le temps d’exécution du service d’adaptation et le temps de transmission des
données.
( iTIME sQ
Pour agréger les valeurs qualitatives, on définit les qualités échelonnées et
comme suit :
)( iCOST sQs
)( iTIME sQs
00
1
)()( minmax
minmaxminmax
max
=−≠−
⎪⎩
⎪⎨⎧
−−
=COSTCOST
COSTCOSTCOSTCOST
iCOSTCOST
iCOST QQQQ
if
ifQQ
sQQsQs (4)
00
1
)()( minmax
minmaxminmax
max
=−≠−
⎪⎩
⎪⎨⎧
−−
=TIMETIME
TIMETIMETIMETIMe
iTIMeTIME
iTIME QQQQ
if
ifQQ
sQQsQs (5)
où , , et sont respectivement : le coût maximum, le coût minimum,
le temps d’exécution maximum et le temps d’exécution minimum des services disponibles.
maxCOSTQ min
COSTQ maxTIMEQ min
TIMEQ
Les utilisateurs peuvent indiquer leurs préférences sur la qualité de service en modifiant les
impacts des différents critères telle que le service le plus rapide ou le moins coûteux en
spécifiant des valeurs de pondération pour chaque critère. Le score d’un chemin avec des
valeurs pondérées est établi comme suit :
Tarak CHAARI - 128 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
( )∑=
∗+∗=N
iTIMEiTIMECOSTiCOST wsQswsQspScore
1)()()( (6)
où [0, 1] et COSTw ∈ TIMEw ∈ [0, 1] représentent les valeurs de poids affectées
respectivement au coût et au temps avec 1=+ TIMECOST ww (7)
Soit Pset = {p1, p2, …, pK} l’ensemble de tous les chemins possibles dans un graphe
d’adaptation. Le chemin optimal est le chemin dont la valeur du score est maximale, scoremax,
où scoremax est défini comme suit :
}{}{ )(max
,1max iKipScoreScore
ε= (8)
4. Synthèse sur l’adaptation de contenu dans SECAS
Dans cette section, nous avons présenté la stratégie d’adaptation de contenu que nous
avons élaborée pour SECAS. Cette stratégie garantit l’adaptation des données d’entrée et de
sortie des services résultant du module d’adaptation de services. Pour chaque donnée
échangée avec le client, si elle n’est pas adaptée à son contexte d’utilisation, le module
d’adaptation de contenu instancie un adaptateur de contenu qui s’occupe de l’adaptation de
cette donnée à la situation contextuelle en question. L’adaptateur utilise un algorithme élaboré
par [Berhe05] pour chercher et composer un ensemble de transformations possibles afin
d’adapter les données à leur contexte d’utilisation. Les adaptateurs exécutent le résultat de la
composition lors de la première invocation des services. Ensuite, ce résultat est mis en cache
local pour accélérer sa réutilisation dans la même situation contextuelle. Le processus
d’adaptation de contenu fournit ainsi un nouveau modèle fonctionnel avec des services
fournissant des données adaptées à leur contexte d’utilisation.
IV. ADAPTATION DE PRESENTATION
1. Principe de l’adaptation de présentation
Les interfaces d’interaction assurent les échanges de données entre l’utilisateur final de
l’application et les différents services de l’application. Ces interfaces doivent fonctionner
correctement dans leur contexte d’utilisation. La bonne exécution de ces interfaces est
conditionnée par leur capacité à s’adapter au terminal utilisé et aux préférences de
l’utilisateur.
Tarak CHAARI - 129 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
Nous définissons l’adaptation de présentation d’une application dans SECAS
par l’ensemble des opérations nécessaires pour créer automatiquement une
interface utilisateur fonctionnelle assurant l’interaction avec les services et les
données adaptées de l’application.
L’adaptation de présentation dépend principalement des caractéristiques du terminal utilisé
(facette terminal du contexte) et des préférences de l’utilisateur (facette utilisateur du
contexte). Elle dépend aussi de la description des données adaptées de l’application.
Dans SECAS, l’adaptation de présentation consiste à générer automatiquement le code
complet des interfaces graphiques qui permettent à l’utilisateur d’interagir avec les différents
services du modèle fonctionnel. Pour chaque service de l’application, le module d’adaptation
de présentation de SECAS génère l’interface graphique qui assure l’interaction entre
l’utilisateur et le service de l’application. Cette interface fournit des facilités de navigation
pour que l’utilisateur puisse interagir avec tous les services du modèle fonctionnel de
l’application. Le processus d’adaptation de présentation suit immédiatement le résultat de la
planification de l’adaptation de contenu afin de préparer l’interface homme-machine adéquate
qui va présenter les données adaptées à l’utilisateur.
Pour réaliser la génération de cette interface, nous avons réalisé une étude approfondie sur
les API d’interaction existantes dans le cadre du projet SEFAGI [Chaari04]. Dans cette étude,
nous avons remarqué que la difficulté de génération réside dans la diversité des machines
virtuelles implantées sur les différents terminaux mobiles du marché. Pour surmonter cette
difficulté, nous avons défini une API abstraite d’interaction qui doit être implémentée pour
chaque machine virtuelle cible. Cette API présente une modélisation orientée-objet des
différentes entités qui assurent l’interaction avec les services et les données adaptés de
l’application.
2. Modélisation d’une interface utilisateur dans SECAS
Pour pouvoir générer l’interface utilisateur qui assure l’interaction avec les services de
l’application et qui s’adapte à son contexte d’utilisation, nous avons élaboré un modèle
générique abstrait décrivant les différents éléments qui constituent l’interface. Ce modèle est
réifié dans le contexte d’utilisation de l’application afin de fournir le code nécessaire à
l’interaction avec ses différents services.
Pour chaque service du modèle fonctionnel de l’application, nous associons une fenêtre
graphique qui assure l’interaction avec ce service. Cette fenêtre est une entité qui regroupe
Tarak CHAARI - 130 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
deux panneaux graphiques : un panneau d’entrée et un panneau de sortie. Un panneau
regroupe un ensemble de composants d’interaction élémentaires qui encapsulent des
paramètres d’entrée ou de sortie du service. Un composant réalise l’affichage (ou la saisie)
d’une valeur correspondant à un paramètre de sortie (ou d’entrée) du service. Pour pouvoir
exécuter un service, nous avons défini des composants graphiques réactifs que nous avons
appelés commandes. Ces composants sont généralement des menus ou des boutons. La
figure 56 montre les éléments graphiques de l’interface d’interaction avec les services et
les données adaptés de l’application.
Ces éléments abstraits, que nous détaillons dans la suite de cette section, constituent un
environnement d’exécution abstrait (Abstract Interface Runtime Environment) de l’interface
d’interaction avec les services de l’application. L’implémentation de ces éléments est
nécessaire pour pouvoir générer le code concret de l’interface utilisateur de l’application.
2.1 COMPOSANT
Un composant (Component) représente le composant abstrait qui encapsule une donnée
d’entrée ou de sortie des services de SECAS. Pour chaque type de donnée dans les paramètres
d’entrée et de sortie des services, nous associons un composant graphique abstrait qui doit
être implémenté dans le langage de l’API d’interaction cible. Par exemple, nous avons le
composant ShortTextComponent pour les textes courts, BooleanComponent pour les valeurs
booléenne, ImageComponent pour les images, AudioComponent pour la lecture de son… Ces
composants sont implémentés et fournis par l’administrateur de SECAS. Nous nous basons
sur une table de correspondance des types de données définis dans les paramètres d’entrée et
de sortie des services et les composants abstraits qui permettent de les présenter ou de les
saisir. Cette table permet d’ajouter dans la plateforme de nouveaux types de données et leurs
composants d’interaction.
2.2 PANNEAU
Un panneau (Panel) représente le regroupement physique d’un ensemble de composants.
Dans SECAS, nous utilisons deux panneaux pour chaque service : un panneau d’entrée
(InputPanel) pour la saisie des valeurs d’entrée et un panneau de sortie (OutputPanel) pour
l’affichage des valeurs de sortie. Le panneau fournit également des moyens de sélection pour
que l’utilisateur puisse sélectionner une instance particulière des valeurs renvoyées par le
service. L’instance sélectionnée peut constituer une entrée d’un autre service du modèle
fonctionnel. Nous utilisons une structure d’échange (Exchange Structure) basée sur un
ensemble de paires (Paramètre, Valeur) afin de réaliser cet échange de données entre les
Tarak CHAARI - 131 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
services (cf section IV.2.6).
2.3 COMMANDE
Une commande (Command) est un composant graphique réactif qui permet de déclencher
un événement et d’exécuter le code qui lui est associé. Nous utilisons les commandes pour
exécuter un service, passer d’un service à un autre, revenir au panneau précédent… Chaque
Panneau contient deux commandes (Back et Next) pour naviguer entre les différents services
de l’application. Chacune de ces commandes est associée à un gestionnaire d’événements qui
assure l’exécution du code correspondant.
2.4 FENETRE
Une fenêtre (Window) est associée à chaque service de l’application. Elle offre toutes les
fonctions nécessaires pour la saisie des valeurs d’entrée du service, son invocation et
l’affichage des résultats renvoyées par ce service. Elle constitue un regroupement logique de
deux panneaux : un panneau d’entrée et un panneau de sortie. Le panneau d’entrée permet de
saisir les paramètres d’entrée du service et le panneau de sortie assure l’affichage des résultats
d’exécution du service. L’exécution du service est déclenchée lors de l’utilisation de la
commande Next du panneau d’entrée (InputPanel).
2.5 FENETRE DE NAVIGATION
La fenêtre de navigation (NavigationWindow) est une fenêtre (window) particulière qui
interagit avec un service particulier (getAvailableServices) du module d’adaptation de
présentation. Ce service renvoie la liste des services disponibles que l’utilisateur pourrait
exécuter à un instant donné de l’exécution de l’application. La fenêtre de navigation n’est
composée que d’un seul panneau (OutputPanel) qui affiche les résultats d’exécution du
service getAvailableServices.
2.6 FENETRE PRINCIPALE
La fenêtre principale (MainWindow) est un élément graphique qui assure le lancement de
l’interface d’interaction avec l’application. Elle permet de lancer (ou de quitter)
l’application et de naviguer entre les fenêtres d’exécution des services et la fenêtre de
navigation. Cette fenêtre principale maintient une structure de données qui assure l’échange
de paramètres entre les services de l’application. Chaque valeur renvoyée par un service et
sélectionnée par l’utilisateur est enregistrée dans cette structure d’échange. Cette structure est
une table de hachage qui stocke la valeur actuelle de chaque paramètre.
Tarak CHAARI - 132 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
MainWindow
Window
InputPanel
Component
Command
OutputPanel
Figure 56 - Structure générale de l'interface d'interaction avec un service
3. Processus de génération automatique d’interfaces adaptées
Le processus de génération automatique d’interfaces adaptées consiste à générer une
interface qui assure l’interaction avec les différents services de l’application pour chaque
plateforme cible. La génération du code de cette interface se base sur (i) l’implémentation de
l’environnement abstrait d’exécution de l’interface (Abstract Interface Runtime Environment)
et (ii) le modèle fonctionnel de l’application. En effet, pour chaque service du modèle
fonctionnel, le module d’adaptation de présentation génère une fenêtre concrète qui assure
l’interaction avec ce service (algorithme présenté dans la figure 57). Nous utilisons la notation
L pour la librairie des éléments qui implémentent l’environnement abstrait d’exécution de
l’interface.
generateUI(FunctionalModel FM=(f0, F, T), RunTimeEnvironmentLibrary L) { For each (fi ∈ F) { W :=generateWindow(fi, L) storeInCache(W) ; } }
Figure 57 - Fonction de génération de l'interface d'interaction avec les services de l'application
Pour organiser le code des fenêtres générées, nous avons utilisé le modèle MVC
[Krasner88]. Ce modèle nous facilite la génération du code en séparant l’affichage, les
données et les traitements. Ainsi, suivant ce modèle MVC, le code d’une fenêtre (Window) W
est composé d’une vue V (présentation graphique), un modèle M (traitements et stockage de
données) et un contrôleur C (gestionnaire d’évènements).
W = {M, V, C}
Le contrôleur réalise la liaison entre le modèle et la vue lors du déclenchement d’un
évènement suite à une action de l’utilisateur final de l’application sur l’interface.
Tarak CHAARI - 133 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
generateWindow(ServiceDescription f, RunTimeEnvironmentLibrary L) { M:= generateModel(f, L) V:= generateVue(f, L) C := generateController(f, L) W:= {M, V, C} return W }
Figure 58 - Algorithme de la fonction de génération d'une fenêtre d'interaction avec un service
La vue d’une fenêtre est composée de deux panneaux : un panneau d’entrée Pi (Input
Panel) et un panneau de sortie Po (Output Panel).
V= (Pi, Po)
generateVue(ServiceDescription f, RunTimeEnvironmentLibrary L) { Pi:= generateInputPanel(f.INPUT, L) Po:= generateOutputPanel(f.OUTPUT, L) V:= {Pi, Po} return V }
Figure 59 - Algorithme de la fonction de génération de la vue d'une fenêtre
Le panneau d’entrée Pi est composé d’un affichage Ai et de deux commandes d’interaction
InputBack et InputNext. L’affichage Ai est un vecteur de composants associés chacun à un
paramètre d’entrée du service actuel.
Pi = {Ai, InputBack, InputNext} avec
- Ai = (c1, c2…cn) où n est le nombre de paramètres d’entrée du service associé
- InputBack est la commande qui permet de revenir à la fenêtre de navigation qui affiche la
liste des services disponibles de l’application.
- InputNext est la commande qui permet d’exécuter le service avec les valeurs d’entrée
saisies dans les composants (c1, c2…cn) du panneau. Cette commande instancie ensuite le
panneau de sortie Po pour afficher le résultat d’exécution du service.
La figure 60 présente l’algorithme de la fonction de génération du panneau d’entrée d’un
service.
Tarak CHAARI - 134 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
generateInputPanel(Parameters Params=(x1,x2…xn), RunTimeEnvironmentLibrary L) { A := ∅ For each (xi∈ Params) { c := generateComponent(xi, L) // instancie un composant c de la librairie L à partir du type du paramètre xi A :=A ∪ { c } } Pi:={A, L.InputBack, L.OutputBack} return Pi }
Figure 60 - Algorithme de la fonction de génération du panneau d’entrée d’un service
Le panneau de sortie Po est composé d’un affichage Ao et de deux commandes
d’interaction OutputBack et OutputNext. L’affichage Ao est un vecteur de composants
associés chacun à un paramètre de sortie du service actuel.
Po = {Ao, OutputBack, OutputNext} avec
- Ao = (c1, c2…cm) où m est le nombre de paramètres de sortie du service associé
- OutputBack est la commande qui permet de revenir au panneau d’entrée de la fenêtre
pour pouvoir fournir de nouvelles valeurs d’entrée afin de ré-exécuter le service.
- OutputNext est la commande qui permet de valider la sélection de l’utilisateur dans les
valeurs de sortie affichées sur le panneau. Cette commande instancie ensuite la fenêtre de
navigation qui présente la liste des services disponibles suite à l’exécution du service actuel.
La figure 61 présente l’algorithme de la fonction de génération du panneau de sortie d’un
service.
generateOutputPanel(Parameters Params=(x1,x2…xn), RunTimeEnvironmentLibrary L) { A := ∅ For each (xi∈ Params) { c := generateComponent(xi, L) // instancie un composant c de la librairie L à partir du type du paramètre xi A :=A ∪ { c } } Po:={A, L.OutputBack, L.OutputNext} return Po }
Figure 61 - Algorithme de la fonction de génération du panneau de sortie d’un service
Le modèle M de chaque fenêtre assure l’exécution du service qui lui est associé. Nous
utilisons la même entité ServiceInvoker pour exécuter tous les services du modèle fonctionnel.
Tarak CHAARI - 135 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
Cette entité prend en entrée la description du service et ses paramètres d’entrée, elle invoque
le service et renvoie ses valeurs de sortie. Pour chaque plateforme cible la librairie L contient
l’implémentation de ServiceInvoker. La figure 62 donne l’algorithme de la fonction de
génération du modèle de la fenêtre d’interaction avec un service f.
M = {ServiceInvoker}
generateModel(ServiceDescriptor f, RunTimeEnvironmentLibrary L) { M:=generateServiceInvocation(f, L.ServiceInvoker) /* la fonction generateServiceInvocation génère le code nécessaire à l’invocation du service f en utilisant l’invocateur de
services de la plateforme cible L */ Return M }
Figure 62 - Algorithme de la fonction de génération du modèle d'exécution d'un service
Afin d’assurer la navigation entre les différents services de l’application, le module
d’adaptation de présentation offre deux services getPreviousServices et getNextServices qui
renvoient respectivement la liste des services immédiatement entrants au service actuel et la
liste des services immédiatement sortants du service actuel dans le modèle fonctionnel. La
figure 63 donne l’algorithme de ces fonctions.
getPreviousServices(FunctionalModel FM=(f0, F, T), ServiceDescriptor f) { S:= ∅ For each (fi ∈F) if (∃(ti = (d,gc,A)∈T) | ∃ ai= (sourceParameter, destinationParameter) ∈ A && ai.destinationService = f &&
ai.sourceService=fi) S:=S { fi} ∪ return S } getNextServices(FunctionalModel FM=(f0, F, T), ServiceDescriptor f) { S:= ∅ For each (fi ∈F) // chercher un service fi condidat pour être un service disponible après l’exécution de f if (∃(ti = (d,gc,A)∈T) | ∃ ai= (sourceParameter, destinationParameter) ∈ A && ai.sourceService = f &&
ai.destinationService=fi) // Si tous les services à la transition ti sont déjà exécutés par l’utilisateur if (For all (ai= (sourceParameter, destinationParameter) ∈ A ), executed(ai.sourceService) ) S:=S { fi} ∪ return S }
Figure 63 - Algorithmes des fonctions de navigation dans le modèle fonctionnel à partir d'un service f
Le contrôleur C de la fenêtre contient toutes les actions nécessaires qui doivent être
Tarak CHAARI - 136 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
exécutée lorsqu’une commande est utilisée dans la vue de l’interface. Ainsi, le contrôleur
regroupe les gestionnaires d’événements des quatre commandes définies dans la description
abstraite de l’interface d’interaction avec l’application (InputBack, InputNext, OutputBack et
OutputNext). La figure 64 illustre l’algorithme de la fonction de génération du contrôleur.
C= {InputBackAction, InputNextAction, OutputBackAction, OutputNextAction}
generateController(ServiceDescriptor f, RunTimeEnvironmentLibrary L) { InputBackAction:= generateInputBackAction(f, L) /* le lancement de la commande InputBack instancie une fenêtre de navigation qui affiche la liste des services précédents de
f en appelant le service de navigation getPreviousServices(f) */ InputNextAction:= generateInputNextAction(f, L) /* le lancement de la commande InputNext entraîne l’exécution du service f et l’instanciation du panneau de sortie Po avec
les valeurs de sortie de f */ OutputBackAction:= generateOutputBackAction(f, L) /* le lancement de la commande OutputBack entraîne l’instanciation du panneau d’entrer Pi pour réexécuter le service
service f */ OutputNextAction:= generateOutputNextAction(f, L) /* le lancement de la commande OutputNext instancie une fenêtre de navigation qui affiche la liste des services sortants de f
en appelant le service de navigation getNextServices(f) */ C= {InputBackAction, InputNextAction, OutputBackAction, OutputNextAction} return C }
Figure 64 - Algorithme de la fonction de génération du modèle d'exécution d'un service
Ainsi tout le code de l’interface d’interaction avec les services de l’application est généré
et mis en cache puis renvoyé à l’utilisateur. A chaque changement du contexte qui induit des
modifications sur l’interface, l’utilisateur est averti pour mettre à jour son code sur son
terminal.
4. Synthèse sur l’adaptation de présentation dans SECAS
Dans le paragraphe III de ce chapitre, nous avons présenté le module d’adaptation de
présentation de SECAS. Ce module garantit la génération automatique et complète
d’interfaces utilisateur adaptées au contexte d’utilisation des applications. Ce module s’appuie
sur le modèle fonctionnel des applications pour générer le code de l’interface utilisateur
permettant d’interagir avec les services de ces applications. Les interfaces générées
fournissent des facilités de navigation pour pouvoir parcourir les services décrits dans le
modèle fonctionnel de l’application. Nous avons élaboré un environnement d’exécution
abstrait qui décrit les composants d’interaction nécessaires pour réaliser ces interfaces. Le
générateur d’interfaces utilise une librairie qui implémente ces composants dans le contexte
Tarak CHAARI - 137 - Thèse de doctorat

Chapitre IV – Contributions : Stratégie d’adaptation au contexte
actuel d’utilisation de l’application. Cette librairie est référencée dans la description du
contexte.
V. CONCLUSION
Dans ce chapitre, nous avons présenté notre stratégie d’adaptation d’applications à de
nouveaux contextes d’utilisation. Notre plateforme SECAS prend en entrée le modèle
fonctionnel de l’application. Ce modèle contient la description de tous les services de
l’application ainsi que leurs dépendances d’exécution. Une fois ce modèle déployé, le module
d’adaptation de comportement de services de SECAS applique une liste de règles
d’adaptation fonctionnelle. Elles sont stockées dans une base de règles d’adaptation qui peut
être enrichie par l’administrateur de la plateforme. Le module d’adaptation de comportement
génère un modèle fonctionnel avec un comportement adapté au contexte d’utilisation. Ce
modèle est repris par le module d’adaptation de contenu pour assurer l’adaptation de toutes
les entrées et les sorties des services du modèle fonctionnel. Ce dernier est mis à jour avec les
formats et les types de données adaptés ; ensuite il est passé au module d’adaptation de
présentation. Ce dernier génère des interfaces utilisateurs adaptées à l’environnement de leur
utilisation.
Lorsque le contexte d’utilisation change, les règles du module d’adaptation fonctionnelle
sont réévaluées. S’il y a des modifications sur le modèle fonctionnel de l’application, tous les
processus d’adaptation fonctionnelle, de contenu et de présentation sont réinitialisés.
Afin de valider notre approche d’adaptation, nous avons développé un prototype de la
couche d’adaptation et de la couche de déploiement d’applications de SECAS. Nous
présentons la conception et l’utilisation de ce prototype dans le chapitre suivant.
Tarak CHAARI - 138 - Thèse de doctorat

R CCCHHHAAAPPPIIITTTRREEE VVV --- CCCOOONNNTTTRRRIIIBBBUUUTTTIIIOOONNNSSS ::: IIIMMMPPPLLLAAANNNTTTAAATTTIIIOOONNN EEETTT
UUUTTTIIILLLIISSSAAATTTIIIOOONNN DDDEEE NNNOOOTTTRRREEE PPPLLLAAATTTEEEFFFOOORRRMMMEEE DDD’’’AAADDDAAAPPPTTAAATTTIIIOOONNN I T
" L'espoir n'est pas une formule mais une pratique" (Nicole Notat)

Chapitre V – Contributions : Implantation et utilisation de SECAS
TABLE DES MATIERES
I. INTRODUCTION _______________________________________________________ 141
II. CONCEPTION DE L’ARCHITECTURE SECAS ________________________________ 141
1. Modélisation fonctionnelle ______________________________________________ 141
2. Modélisation dynamique ________________________________________________ 145
3. Modélisation statique___________________________________________________ 149
4. Déploiement de la plateforme ____________________________________________ 156
5. Scénario générique d’utilisation de SECAS ________________________________ 157
III. DEVELOPPEMENT DE LA PLATEFORME SECAS _____________________________ 159
1. Implantation de la couche d’adaptation fonctionnelle ________________________ 159
2. Implantation de la couche d’adaptation de contenu__________________________ 160
3. Implantation de la couche d’adaptation de présentation ______________________ 161
4. Statistiques ___________________________________________________________ 161
IV. UTILISATION DE SECAS DANS LE PROJET SICOM __________________________ 161
1. Déploiement de SICOM avec l’interface d’administration de SECAS___________ 162
2. Adaptation de l’application « SICOM » ___________________________________ 163
V. UTILISATION D’UN NOUVEAU MODELE DE CONTEXTE DANS SECAS ____________ 168
VI. CONCLUSION_________________________________________________________ 170
Tarak CHAARI - 140 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
I. INTRODUCTION
Pour valider notre approche d’adaptation, nous avons développé un prototype de la
plateforme SECAS. Nous nous sommes spécialement intéressés à la couche de déploiement
d’applications et à la couche d’adaptation de l’architecture de SECAS. Nous avons intégré
une application médicale dans notre plateforme pour l’adapter à de nouveaux contextes
d’utilisation. Cette intégration nous a permis de valider notre architecture et notre approche
d’adaptation. Dans ce chapitre, nous présentons la conception et la réalisation de notre
prototype et nous montrons comment nous l’avons utilisé pour adapter l’application médicale
à de nouveaux contextes d’utilisation. Avant de conclure nous validons l’objectif de la
généricité de notre approche d’adaptation en intégrant un nouveau modèle de contexte dans
notre plateforme.
II. CONCEPTION DE L’ARCHITECTURE SECAS
1. Modélisation fonctionnelle
Dans cette section, nous identifions les acteurs qui interagissent avec SECAS et nous
spécifions ses cas d'utilisation.
1.1 IDENTIFICATION DES ACTEURS DU SYSTEME
Nous avons identifié 3 acteurs principaux qui peuvent intervenir dans SECAS.
Administrateur SECAS (SECAS Administrator): il gère les comptes utilisateurs et les
modules de SECAS
Concepteur d’applications (Designer): il déploie des applications dans SECAS pour les
adapter à de nouveaux contextes d’utilisation
Utilisateur (User): il utilise une application adaptée
1.2 IDENTIFICATION DES CAS D’UTILISATION DU SYSTEME
1.2.1 Déployer une application dans SECAS
Le déploiement d’une application dans SECAS permet au concepteur (designer)
d’applications d’ajouter des nouvelles applications afin de les adapter à de nouveaux
contextes d’utilisation. À travers l’interface graphique de SECAS (Figure 92), le concepteur
lance le processus d'ajout d'une nouvelle application en déployant son modèle fonctionnel
(deployFunctionalModel) et en fournissant la liste des règles d’adaptation fonctionnelle qui
vont être appliquée à cette application (deployRules).
Tarak CHAARI - 141 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
Le concepteur d’applications peut modifier la liste des règles d’adaptation des applications
qu’il a déployées (upadteRules). Il peut aussi mettre à jour ses applications
(updateApplication) en leur ajoutant ou supprimant des services ou en fournissant directement
un nouveau modèle fonctionnel (updateFunctionalModel). La figure 65 présente les cas
d’utilisation du concepteur d’applications SECAS.
Figure 65 - Diagramme de cas d’utilisation : déploiement d’une application
1.2.2 Utiliser une application adaptée
Après avoir passé la phase d’authentification dans notre plateforme, l’utilisateur peut
obtenir la liste des applications qui lui sont accessibles (cas d’utilisation listApplications). Il
peut aussi sélectionner une application (selectAplication) parmi cette liste. L’utilisateur peut
ensuite invoquer les services (invokeServices) de cette application en respectant leurs
dépendances d’exécution dans le modèle fonctionnel. La figure 66 illustre le diagramme
UML du cas d’utilisation des applications déployées dans notre plateforme.
Tarak CHAARI - 142 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
Figure 66 - Diagramme de cas d’utilisation : utilisation d’une application adaptée
1.2.3 Gérer les comptes des utilisateurs
Après la phase d’authentification (cas d’utilisation connect), l’administrateur de la
plateforme SECAS peut ajouter ou supprimer des utilisateurs. Il peut aussi modifier les droits
d’accès des utilisateurs aux applications déployées ou à un ensemble de ses services (cas
d’utilisation UserManagement). La
figure 67 présente le diagramme des cas d’utilisation de la gestion des comptes des
utilisateurs de SECAS.
SecasApplicationManager
addUserremoveUser
modifyUser
authenticationconnect
UserManagementAdministrator
<<include>>
Figure 67 - Diagramme de cas d’utilisation : gestion des comptes des utilisateurs de SECAS
1.2.4 Gérer les modules de SECAS
Pour assurer l’évolutivité de notre plate-forme, l’administrateur peut ajouter de nouveaux
opérateurs d’adaptation (cas d’utilisation addAdaptOperator dans la figure 68). Ceci peut
nécessiter l’ajout de nouveaux paramètres nécessaires pour ces opérateurs
(addAdaptParameter dans la figure 68). Il peut aussi enrichir les expressions logiques
utilisées pour l’élaboration des règles d’adaptation en ajoutant de nouveaux opérateurs
Tarak CHAARI - 143 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
logiques sur les paramètres des services (addBooleanOperator dans la figure 68).
Figure 68 - Diagramme de cas d’utilisation : gestion des modules de SECAS
L’ajout d’un nouvel opérateur ou d’un paramètre d’adaptation nécessite le déploiement
d’un descripteur XML pour identifier la classe qui implémente l’élément ajouté et l’ensemble
de ses propriétés. La figure 69 présente le descripteur d’un paramètre d’adaptation modélisant
un paramètre de sortie d’un service. La figure 70 détaille le descripteur de l’opérateur
d’adaptation projection qui utilise le paramètre serviceOutput de la figure 69.
<parameter name="serviceOutput"> <description>An output parameter of a service</description> <class>secas.application.service.Parameter</class> </parameter>
Figure 69 - Descripteur d'un paramètre d'adaptation de type "serviceOutput"
<AdaptationOperator name="projection"> <description>This operator is applied to service output vector to project the result on a subset of its
components</description> <class>secas.adaptation.services.sactions.ProjectOutput</class> <parameters> <parameter occurrence=”many” name="outputParameter" type="serviceOutput"/> </parameters> </AdaptationOperaor>
Figure 70 - Descripteur de l’opérateur d'adaptation fonctionnelle "projection"
Dans la suite de cette section, nous nous intéressons essentiellement aux deux cas
d’utilisation correspondant au déploiement des applications dans SECAS et à leur adaptation.
Nous présentons le fonctionnement dynamique des entités principales de ces deux couches
dans le paragraphe 2 et nous détaillons leur conception statique dans le paragraphe 3.
Tarak CHAARI - 144 - Thèse de doctorat
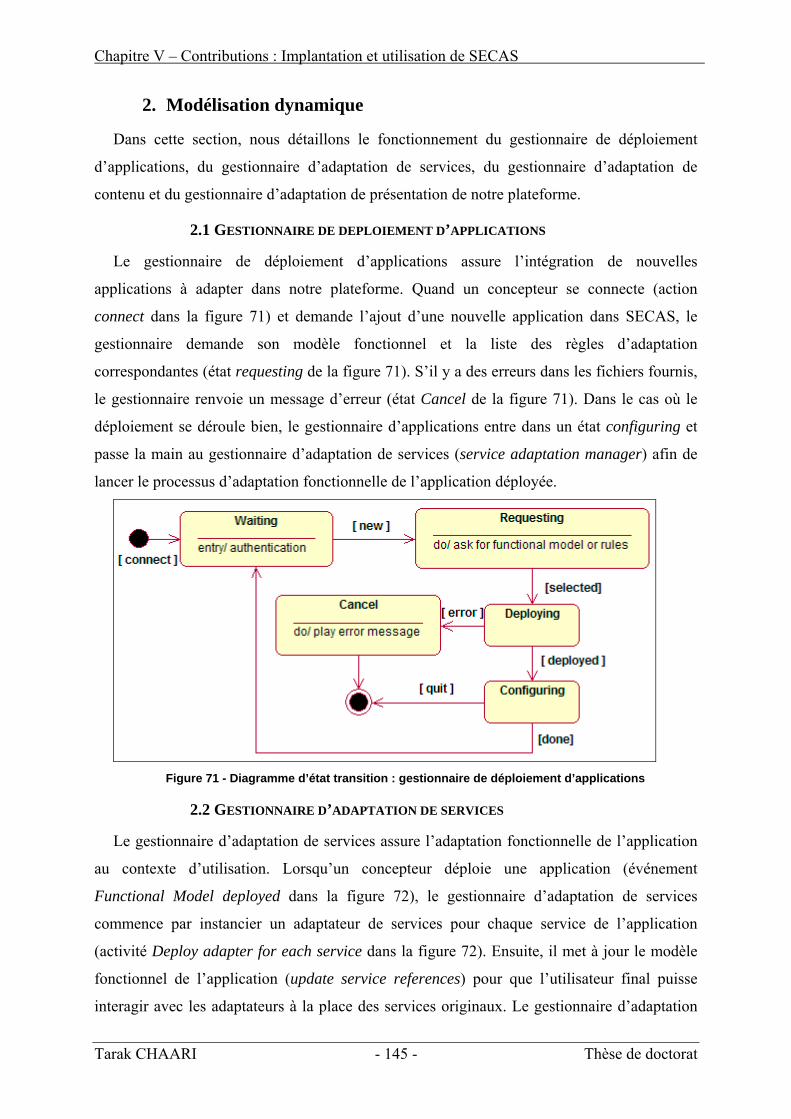
Chapitre V – Contributions : Implantation et utilisation de SECAS
2. Modélisation dynamique
Dans cette section, nous détaillons le fonctionnement du gestionnaire de déploiement
d’applications, du gestionnaire d’adaptation de services, du gestionnaire d’adaptation de
contenu et du gestionnaire d’adaptation de présentation de notre plateforme.
2.1 GESTIONNAIRE DE DEPLOIEMENT D’APPLICATIONS
Le gestionnaire de déploiement d’applications assure l’intégration de nouvelles
applications à adapter dans notre plateforme. Quand un concepteur se connecte (action
connect dans la figure 71) et demande l’ajout d’une nouvelle application dans SECAS, le
gestionnaire demande son modèle fonctionnel et la liste des règles d’adaptation
correspondantes (état requesting de la figure 71). S’il y a des erreurs dans les fichiers fournis,
le gestionnaire renvoie un message d’erreur (état Cancel de la figure 71). Dans le cas où le
déploiement se déroule bien, le gestionnaire d’applications entre dans un état configuring et
passe la main au gestionnaire d’adaptation de services (service adaptation manager) afin de
lancer le processus d’adaptation fonctionnelle de l’application déployée.
Figure 71 - Diagramme d’état transition : gestionnaire de déploiement d’applications
2.2 GESTIONNAIRE D’ADAPTATION DE SERVICES
Le gestionnaire d’adaptation de services assure l’adaptation fonctionnelle de l’application
au contexte d’utilisation. Lorsqu’un concepteur déploie une application (événement
Functional Model deployed dans la figure 72), le gestionnaire d’adaptation de services
commence par instancier un adaptateur de services pour chaque service de l’application
(activité Deploy adapter for each service dans la figure 72). Ensuite, il met à jour le modèle
fonctionnel de l’application (update service references) pour que l’utilisateur final puisse
interagir avec les adaptateurs à la place des services originaux. Le gestionnaire d’adaptation
Tarak CHAARI - 145 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
de services évalue les règles d’adaptation (evaluate rules) et affecte à chaque adaptateur une
liste d’actions d’adaptation selon les règles fournies lors du déploiement de l’application
(configure adapters). Ces actions modifient la structure du modèle fonctionnel de
l’application (Update Functional Model). Après cette modification, le gestionnaire
d’adaptation de services notifie le gestionnaire d’adaptation de contenu (Notify Service
Adaptation End). Enfin, ce gestionnaire entre dans un état (waiting for context change) pour
attendre les éventuels changements de contexte et réévaluer les règles d’adaptation.
Figure 72 - Diagramme d’activités du gestionnaire d’adaptation de services
2.3 GESTIONNAIRE D’ADAPTATION DE CONTENU
Le gestionnaire d’adaptation de contenu assure l’adaptation des données renvoyées par les
services de l’application. Dès que le module d’adaptation de services envoie une notification
signalant la fin du processus de préparation de l’adaptation fonctionnelle (évènement service
adaptation end dans la figure 73), le gestionnaire d’adaptation de contenu instancie et déploie
un adaptateur de contenu pour chaque service de l’application (activité deploy content adapter
for each service dans la figure 73). Le modèle fonctionnel est ainsi mis à jour pour que
l’utilisateur puisse interagir avec les adaptateurs de contenu à la place des adaptateurs de
services (update service references). Ensuite, ce gestionnaire calcule le plan d’adaptation de
contenu (calculate adaptation plan) et met à jour les descripteurs des entrées et des sorties des
services du modèle fonctionnel (update service parameters). Les adaptateurs de contenu
s’appuient sur les adaptateurs de services afin de récupérer les données à adapter. Enfin, le
gestionnaire d’adaptation de contenu envoie une notification de fin de préparation de
l’adaptation de contenu et revient en attente d’autres notifications du gestionnaire
d’adaptation de services (état waiting for service adaptation manager notification).
Tarak CHAARI - 146 - Thèse de doctorat
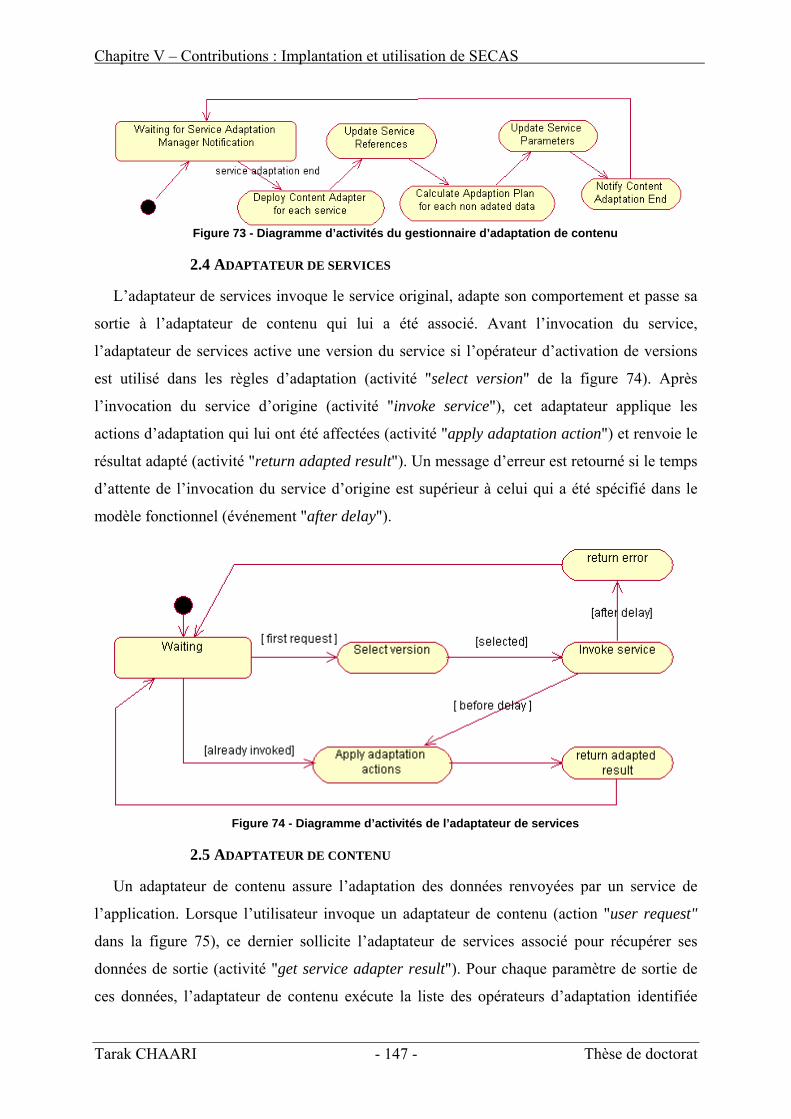
Chapitre V – Contributions : Implantation et utilisation de SECAS
Figure 73 - Diagramme d’activités du gestionnaire d’adaptation de contenu
2.4 ADAPTATEUR DE SERVICES
L’adaptateur de services invoque le service original, adapte son comportement et passe sa
sortie à l’adaptateur de contenu qui lui a été associé. Avant l’invocation du service,
l’adaptateur de services active une version du service si l’opérateur d’activation de versions
est utilisé dans les règles d’adaptation (activité "select version" de la figure 74). Après
l’invocation du service d’origine (activité "invoke service"), cet adaptateur applique les
actions d’adaptation qui lui ont été affectées (activité "apply adaptation action") et renvoie le
résultat adapté (activité "return adapted result"). Un message d’erreur est retourné si le temps
d’attente de l’invocation du service d’origine est supérieur à celui qui a été spécifié dans le
modèle fonctionnel (événement "after delay").
Figure 74 - Diagramme d’activités de l’adaptateur de services
2.5 ADAPTATEUR DE CONTENU
Un adaptateur de contenu assure l’adaptation des données renvoyées par un service de
l’application. Lorsque l’utilisateur invoque un adaptateur de contenu (action "user request"
dans la figure 75), ce dernier sollicite l’adaptateur de services associé pour récupérer ses
données de sortie (activité "get service adapter result"). Pour chaque paramètre de sortie de
ces données, l’adaptateur de contenu exécute la liste des opérateurs d’adaptation identifiée
Tarak CHAARI - 147 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
dans la phase de calcul du plan d’adaptation (activité "run adaptation plan"). Enfin cet
adaptateur renvoie les données adaptées. Dans le cas où il y a un problème d’exécution du
plan d’adaptation (événement "content adaptation error"), l’adaptateur de contenu renvoie les
données originales obtenues après l’invocation de l’adaptateur de services. Par exemple, ce
cas peut avoir lieu quand l’un des services du plan d’adaptation ne répond pas à cause d’un
problème de connexion.
Figure 75 - Diagramme d’activités de l’adaptateur de contenu
2.6 GESTIONNAIRE D’ADAPTATION DE PRESENTATION
Le gestionnaire d’adaptation de présentation assure la génération automatique d’interfaces
homme - machine adaptées à leur contexte d’utilisation. Dès que le module d’adaptation de
contenu envoie une notification signalant la fin du processus de préparation de l’adaptation de
contenu, le gestionnaire d’adaptation de présentation génère une fenêtre graphique pour
chaque service du modèle fonctionnel adapté (generate window for each service dans la
figure 76). Cette fenêtre assure la saisie des valeurs d’entrée du service, son invocation, et
l’affichage du résultat de son exécution. Ensuite, le gestionnaire d’adaptation de présentation
ajoute des facilités de navigation pour les fenêtres générées afin de garantir l’utilisation
correcte des différents services de l’application adaptée (generate navigation facilities dans la
figure 76). Le code généré est mis en cache pour une réutilisation ultérieure de l’application
dans le même contexte. Enfin, le gestionnaire d’application de SECAS est notifié de la fin du
processus de génération de l’interface utilisateur adaptée (notify presentation adaptation end
dans la figure 76).
Figure 76 - Diagramme d’activités du gestionnaire d’adaptation de présentation
Tarak CHAARI - 148 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
3. Modélisation statique
Dans cette partie, nous divisons notre plateforme SECAS en paquetages et nous détaillons
les diagrammes de classes des paquetages principaux. La figure 77 présente le diagramme des
paquetages principaux de SECAS. Notre prototype comprend cinq paquetages principaux :
secas.adaptation, secas.application, secas.context, secas.util et secas.administration. Nous
détaillons le rôle et le contenu de ces paquetages dans la suite de cette section.
adaptation
presentation content
services
context
application
administrationutil
secas
services
ui
data
Figure 77 - Diagramme des paquetages de SECAS
3.1 PAQUETAGE «SECAS.APPLICATION »
Ce paquetage modélise une application et gére son intégration dans la plateforme SECAS.
Nous retrouvons dans ce paquetage le gestionnaire d’applications de SECAS
(SecasApplicationManager) qui permet de déployer des applications (SecasApplication) à
l’aide d’une classe ApplicationDeployer. Nous associons une session (UserSession) dès la
connexion d’un utilisateur à une application adaptée (représentée par une instance de
SecasApplication). Ce paquetage comprend aussi une structure d’échange
(exchangeStructure) qui garantit le passage de paramètres entre les services de l’application.
Tarak CHAARI - 149 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
Figure 78 - Diagramme de classes du paquetage "secas.application"
3.2 PAQUETAGE «SECAS.APPLICATION.SERVICES »
Le paquetage « secas.application.services » décrit l’aspect fonctionnel d’une application.
On trouve dans ce paquetage la classe FunctionalModel qui représente le modèle fonctionnel
d’une application, composé d’un ensemble de services décrits par un descripteur de service
(ServiceDescriptor). Nous avons aussi dédié une classe Parameter à la description des
paramètres d’entrée et de sortie de chaque service. Nous associons une instance du modèle
fonctionnel à chaque session utilisateur dès qu’il se connecte à une application déployée dans
SECAS.
Figure 79 - Diagramme de classes du paquetage "secas.application.services"
3.3 PAQUETAGE «SECAS.APPLICATION.DATA »
Le paquetage « secas.application.data » décrit les données renvoyées par les services de
l’application. On retrouve dans ce paquetage, la classe MediaObjectDescriptor qui décrit la
donnée encapsulée par un paramètre de sortie ou d’entrée d’un service. Cette classe maintient
Tarak CHAARI - 150 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
les différentes propriétés des données comme la taille, le format, le type, le nombre de
couleurs, la description MPEG7...
Figure 80 - Diagramme de classes du paquetage "secas.application.data"
3.4 PAQUETAGE «SECAS.APPLICATION.UI »
Le paquetage « secas.application.ui » concerne l’interface utilisateur des applications
déployées dans SECAS. Nous avons défini l’ensemble des entités graphiques nécessaires pour
assurer l’interaction avec les services et les données adaptés de l’application. Ces entités sont
définies d’une façon abstraite indépendante du contexte d’utilisation de l’application. Elles
constituent l’environnement d’exécution abstrait de l’interface utilisateur de l’application
(Abstract Interface Runtime Environment). Notons que le concepteur de l’application doit
fournir une implémentation de ces entités pour chaque plateforme cible (API graphique
disponible sur le terminal utilisé).
Nous retrouvons dans ce paquetage : (i) la classe MainWindow qui représente l’écran
principal de l’application, (ii) la classe Window qui représente une fenêtre graphique associée
à un service de l’application, (iii) la classe Panel qui représente le panneau d’entrée ou de
sortie d’un service, (vi) la classe Component qui représente les composants d’interaction qui
encapsulent les paramètres d’entrée et de sortie des services et (v) la classe Command qui
encapsule les actions qu’un utilisateur peut effectuer sur l’interface d’interaction avec
l’application. Chaque commande doit être associée à un gestionnaire d’évènement
EventManager qui exécute le code nécessaire pour réagir aux actions de l’utilisateur.
Tarak CHAARI - 151 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
Figure 81 - Diagramme de classes du paquetage "secas.application.ui"
3.5 PAQUETAGE « SECAS.ADMINISTRATION»
Figure 82 - Diagramme de classes du paquetage "secas.administration"
Le paquetage « secas.administration » offre à l’administrateur et aux concepteurs les
interfaces graphiques qui permettent le déploiement des applications et l’administration des
modules de la plate-forme SECAS. Nous avons dédié une classe à chaque cas d’utilisation
pour l’administration de la plateforme. Par exemple, UsersManageInternalFrame pour la
gestion des utilisateurs, ApplicationsInternalFrame pour lister les applications déployées dans
la plateforme et ConfigurationInternalFrame pour la configuration et la gestion de ces
applications. Une fenêtre principale MainWindow, assure l’accès à ces classes.
Tarak CHAARI - 152 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
3.6 PAQUETAGE «SECAS.UTIL »
Ce paquetage offre un ensemble d'outils utilisés par les classes des autres paquetages. Ces
outils offrent des fonctions génériques comme l’accès aux fichiers XML, l’évaluation des
expressions logiques et le chargement des fichiers de configuration de la plateforme.
Figure 83 - Diagramme de classes du paquetage "util"
3.7 PAQUETAGE « SECAS.CONTEXT»
Le paquetage context assure la communication de la couche d’adaptation avec la couche de
gestion de contexte. Il s’appuie sur une classe principale contextConsumer qui offre les
fonctions nécessaires pour récupérer les valeurs des paramètres du contexte. Dans notre
prototype nous avons simulé cette communication par des accès à un fichier XML local
contenant un profil de contexte (LocalContextConsumer). Nous avons simulé le changement
des valeurs de contexte par des modifications directes sur des paramètres de contexte dans ce
fichier.
ContextConsumerconection : Connectionproducer : MessageProducersession : Session
getContextValues() : HashtablegetContext()getContextValue()
LocalContextConsumerroot : ElementcontextHasChanged : boolean
getContext() : voidgetContextValues() : HashtablegetContextValue() : String
dependsOn
context
Figure 84 - Diagramme de classes du paquetage "context"
3.8 PAQUETAGE « SECAS.ADAPTATION.SERVICES »
Ce paquetage contient les classes qui réalisent l’adaptation fonctionnelle des applications
déployées. Nous y retrouvons le gestionnaire d’adaptation de services
(ServiceAdaptationManager) qui permet de lancer le processus d’adaptation fonctionnelle. Ce
Tarak CHAARI - 153 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
gestionnaire utilise la classe (Rule) pour appliquer les règles d’adaptation spécifiées pour
l’application. Cette classe permet d’évaluer les conditions des règles et d’appliquer leurs
actions d’adaptation. Cette classe n’applique que les actions inter-services (Faction) et
délègue les actions intra-services (VAction et SAction) à l’adaptateur (adapter). Dans ce
paquetage, nous avons défini aussi la classe ParameterHolder qui représente les paramètres
des actions d’adaptation. Nous nous basons sur un fichier de configuration écrit en XML qui
détaille le nom de classe de chaque action d’adaptation et ses différents paramètres (voir
figure 69 et figure 70). Ceci garantit l’évolutivité de notre stratégie d’adaptation en
l’enrichissant avec de nouvelles actions d’adaptation sans modifier le code de la plateforme.
La figure 85 illustre le diagramme de classes du paquetage d’adaptation de services.
Figure 85 - Diagramme de classes du paquetage d’adaptation de services
3.9 PAQUETAGE « SECAS.ADAPTATION.CONTENT »
Ce paquetage contient les classes nécessaires pour réaliser l’adaptation des données
renvoyées par les services de l’application. Nous y retrouvons le gestionnaire d’adaptation de
contenu (ContentAdaptationManager) qui permet de lancer le processus d’adaptation des
données renvoyées par les adaptateurs de services. Ce gestionnaire utilise le proxy local
d’adaptation de contenu (LocalAdaptationProxy) pour déterminer les plans d’adaptation
(AdaptationPlan) optimaux de chaque paramètre de sortie des différents services de
l’application. Le proxy s’appuie sur le composant de planification de l’adaptation de contenu
(AdaptationPlanificationComponent) pour calculer ces plans d’adaptation. Ce composant
utilise l’annuaire des services d’adaptations de contenu (AdaptationServiceRegistry) pour
Tarak CHAARI - 154 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
construire les différentes séquences possibles de services qui peuvent fournir un résultat
adapté au contexte d’utilisation. La figure 86 illustre le diagramme de classes du paquetage
d’adaptation de contenu.
Figure 86 - Diagramme de classes du paquetage d’adaptation de contenu
3.10 PAQUETAGE « SECAS.ADAPTATION.PRESENTATION »
Ce paquetage contient les classes nécessaires pour réaliser la génération automatique du
code des interfaces utilisateur qui garantissent l’interaction avec les services et les données
adaptées grâce aux deux paquetages précédents. Nous y retrouvons le gestionnaire
d’adaptation de présentation (PresentationAdaptationManager) qui permet de lancer le
processus de génération des interfaces utilisateur. Pour chaque service du modèle fonctionnel,
le générateur d’interfaces utilisateur (UserInterfaceGenerator) construit une fenêtre adaptée à
son contexte d’utilisation en se basant sur la librairie des composants graphiques disponibles
dans la plateforme cible (currentTargetPlatform). Cette fenêtre assure l’interaction avec le
service en question. Nous avons utilisé le modèle MVC [Krasner88] pour organiser le code
des fenêtres générées. Ainsi, le générateur utilise les classes VueGenerator, ModelGenerator
et ControllerGenerator pour produire respectivement la vue, le modèle et le contrôleur de
chaque fenêtre. La figure 87 illustre le diagramme de classes du paquetage d’adaptation de
présentation.
Tarak CHAARI - 155 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
Figure 87 - Diagramme de classes du paquetage d’adaptation de présentation
4. Déploiement de la plateforme
Dans cette section, nous illustrons l’organisation du code de la plateforme SECAS en
présentant un diagramme de composants et un diagramme de déploiement UML.
4.1 DIAGRAMME DE COMPOSANTS
La figure 88 présente un diagramme de composants de notre plateforme. Elle illustre
l’organisation logique du prototype que nous avons développé. Le code de ce prototype est
essentiellement archivé dans un fichier (SECAS.jar). Cette application offre deux
fonctionnalités principales à l’utilisateur final : lister les applications disponibles (IListApps)
et invoquer leurs services adaptés (IAdapt). Elle offre aussi une interface d’administration
(IConfiguration) aux concepteurs afin de pouvoir déployer et gérer des applications à adapter
(ApplicationToAdapt). Le prototype que nous avons développé utilise principalement quatre
ressources XML : "configuration.xml" pour décrire les différents opérateurs d’adaptation
fonctionnelle que SECAS utilise, "context.xml" pour décrire des contextes d’utilisation,
"FunctionalModel.xml" pour décrire les modèles fonctionnels des applications et "rules.xml"
pour décrire les règles d’adaptation fonctionnelle.
Tarak CHAARI - 156 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
Figure 88 - Diagramme de composants de SECAS
4.2 DIAGRAMME DE DEPLOIEMENT
Pour déployer notre plateforme, nous avons utilisé le conteneur OSGI oscar [OSGi03]. Ce
conteneur offre un développement modulaire et dynamique d’applications. En effet, OSGI
garantit l’ajout de nouveaux modules et de nouvelles fonctionnalités à une application sans la
redémarrer ou la recompiler. OSGI nous a été très utile surtout pour le déploiement
dynamique des adaptateurs de services et des adaptateurs de contenu sous formes de services
XML-RPC [UserLand99]. Les tests que nous avons réalisés ont montré que ce protocole est
beaucoup plus léger et plus efficace que le protocole SOAP [Scribner00] surtout pour les
terminaux mobiles à faible capacité. La figure 89 présente le diagramme de déploiement de la
plateforme SECAS. Ce diagramme illustre la distribution des différents modules de SECAS
sur la configuration matérielle de notre prototype.
Figure 89 - Diagramme de déploiement de SECAS
5. Scénario générique d’utilisation de SECAS
Pour rappeler notre stratégie d’adaptation, nous décrivons dans cette section, le scénario
générique d’adaptation d’une application à de nouveaux contextes d’utilisation grâce à notre
plateforme SECAS. Ce scénario est basé sur onze étapes principales :
Tarak CHAARI - 157 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
1- Un concepteur utilise le gestionnaire d’applications pour déployer le modèle
fonctionnel de l’application.
2- SECAS prépare la couche d’adaptation en instanciant et déployant un adaptateur pour
chaque service de l’application. Le modèle fonctionnel est ainsi mis à jour pour utiliser les
adaptateurs à la place des services d’origine.
3- Le concepteur fournit le descripteur des règles d’adaptation fonctionnelle nécessaires
pour réaliser l’adaptation de services.
4- Le gestionnaire d’adaptation de services instancie ces règles et les abonne aux
paramètres du contexte qui les concernent auprès du courtier de contexte.
5- Le gestionnaire d’adaptation de services configure les adaptateurs selon les règles
d’adaptation fournies et selon le contexte d’utilisation de l’application.
6- Ce même gestionnaire notifie le gestionnaire d’applications de SECAS pour lancer le
processus de préparation de l’adaptation de contenu.
7- Le gestionnaire d’adaptation de contenu instancie un adaptateur de contenu pour
chaque service du modèle fonctionnel et calcule les transformations nécessaires pour
adapter les données renvoyées par les services de l’application.
8- Le gestionnaire d’adaptation de contenu met à jour le modèle fonctionnel de
l’application pour utiliser les adaptateurs de contenu à la place des adaptateurs de services.
Les types de données renvoyées sont aussi modifiés selon les transformations calculées
dans l’étape précédente.
9- Le gestionnaire d’adaptation de contenu envoie une notification de fin de préparation
de l’adaptation des données renvoyées par les services de l’application.
10- Le gestionnaire d’adaptation de présentation (PresentationAdaptationManager)
capture cette notification et lance le processus de génération de l’interface utilisateur
nécessaire pour l’interaction avec les services et les données adaptées de l’application.
Cette interface est mise en cache pour qu’elle puisse être utilisée dans le contexte actuel de
l’application.
11- Dès que le contexte d’utilisation de l’application change, le scénario d’adaptation est
repris à partir de l’étape 5.
L’adaptation effective des services et des données de l’application est réalisée lorsque
l’utilisateur final se connecte à la plateforme et interagit avec l’application adaptée en
invoquant ses services à travers l’interface graphique générée. Nous utilisons ce scénario dans
un cas concret pour l’adaptation d’une application médicale dans la section IV de ce chapitre.
Tarak CHAARI - 158 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
III. DEVELOPPEMENT DE LA PLATEFORME SECAS
Dans cette section nous détaillons quelques considérations techniques qui concernent le
développement de la plateforme SECAS.
1. Implantation de la couche d’adaptation fonctionnelle
1.1 REGLES D'ADAPTATION
Le gestionnaire d'adaptation de services utilise un ensemble de règles d'adaptation pour
effectuer le processus d'adaptation du modèle fonctionnel de l'application. Il gère aussi une
base de règles génériques que la plateforme doit appliquer pour garantir l'adaptation de
services. Les règles sont organisées par ordre de priorité pour définir un plan d'adaptation
fonctionnel pour l'application. La définition de ces règles est réalisée par le concepteur. Ce
dernier peut se contenter de choisir une liste de règles prédéfinies dans la base des règles
génériques de la plateforme afin de les attacher à l’application qu’il veut adapter. Il peut
ensuite raffiner et personnaliser le processus d’adaptation de services en ajoutant des règles
spécifiques à son application. Ces règles modifient le modèle fonctionnel de l’application
selon les mécanismes que nous présentons dans le paragraphe suivant.
1.2 ADAPTATION DU MODELE FONCTIONNEL
L'adaptation du modèle fonctionnel se base sur un ensemble de mécanismes que nous
détaillons dans les sous-sections suivantes:
1.2.1 Redirection des appels de services
L'appel d’un service est redirigé vers l'adaptateur qui est un intermédiaire entre l'utilisateur
et le service d’origine de l’application. Pour réaliser cette redirection, nous adaptons l'url et le
nom de la méthode de chaque service. La figure 90 présente un extrait de la description d’un
service avant son adaptation. La figure 91 représente la description de l’adaptateur attaché à
ce service.
<url>http://sicomserver.insa-lyon.fr/xmlrpc</url> <method id="sicom.listeAlerte">
Figure 90 - Extrait de la description d’un service avant son adaptation
<url>http://secasserver.insa-lyon.fr/xmlrpc</url> <method id="sicom_listeAlertesAdapter.adapt">
Figure 91. Extrait de la description d’un adaptateur de service
Tarak CHAARI - 159 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
1.2.2 Ajout de données de contrôle
Nous ajoutons un paramètre de sortie « rang » à chaque service initial de l’application. Ce
paramètre est nécessaire pour assurer l’unicité des valeurs renvoyées par les services. Par
exemple, nous pouvons décomposer un service qui retourne un tableau contenant les
températures d’un patient en deux services : Le premier affiche les dates de mesures de
température et le deuxième retourne la valeur de la température correspondante à la date
sélectionnée par l'utilisateur. Comme plusieurs mesures peuvent être prises le même jour,
l'ajout d'un « rang » pour chaque ligne assurera la distinction entre les différentes valeurs
sélectionnées.
1.3 IMPLEMENTATION DES ADAPTATEURS
Nous avons choisi la technologie des services web pour implémenter les adaptateurs de
services et les adaptateurs de contenu. Cette technologie offre des moyens d’intégration
faciles pour le développement distribué [Austin02]. Grâce à leur auto-description
fonctionnelle par le langage WSDL, les services Web ont constitué une implémentation
adéquate de la formalisation que nous avons élaborée (i) des services applicatifs, (ii) des
adaptateurs de services et (iii) des adaptateurs de contenu.
1.4 CONFIGURATION DES ADAPTATEURS DE SERVICES
L'exécution des règles d’adaptation fonctionnelle permet de configurer les adaptateurs de
services. Suite à l'application d'une règle, un service S initial peut être décomposé en un
ensemble de services adaptés {S1, S2, ..., Sk}. Ces services peuvent être eux aussi adaptés en
appliquant les règles qui suivent. Ainsi, l'adaptateur gère une pile qui stocke la liste des
opérateurs d'adaptation qui doivent être appliqués sur le service initial lors de son invocation.
2. Implantation de la couche d’adaptation de contenu
La couche d’adaptation de contenu assure l’adaptation des données renvoyées par les
services au contexte de l’utilisation de l’application. Le gestionnaire d’adaptation de contenu
« ContentAdaptationManager » vérifie si les services résultant de l’adaptation fonctionnelle
fournissent des données adaptées au contexte. Pour chaque service, ce gestionnaire instancie
un adaptateur de contenu qui assure leur adaptation. L’adaptateur délègue cette tâche au
mandataire local d’adaptation de contenu que nous avons importé du prototype de thèse de G.
Berhe [Berhe05].
Tarak CHAARI - 160 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
3. Implantation de la couche d’adaptation de présentation
La couche d’adaptation de présentation assure la génération automatique d’interfaces
utilisateur adaptées permettant d’interagir avec les différents services et données de
l’application. Le gestionnaire d’adaptation de présentation (Presentation Adaptation Manager)
récupère le modèle fonctionnel adapté sollicité par l’utilisateur. Pour chaque service de ce
modèle, le gestionnaire génère une fenêtre graphique qui permet de communiquer avec ce
service. Le processus de génération se base sur les types de données renvoyées par le service
et sur la librairie des composants d’interaction disponibles sur le terminal de l’utilisateur. Le
générateur prend aussi en compte les préférences de présentation spécifiée par l’utilisateur
dans son profil de contexte. Le prototype que nous avons mis en œuvre permet de générer
pour une même application, une interface d’interaction JAVA pour des PC standard
(compatible avec J2SE [Sun07a]), des PC de poche (compatibles avec le profil
CDC/PERSONNEL JAVA [Sun00]) et des téléphones mobiles (compatible avec le profil
CLDC/MIDP [Sun07b]).
4. Statistiques
Le prototype que nous avons développé comporte environ 80 classes et 14500 lignes de
code Java. Le tableau 5 donne la répartition des ces classes dans les différents paquetages de
SECAS.
Paquetage Classes Lignes
adaptation.services 20 4000
adaptation.content 13 2200
adaptation.presentation 9 2300
Application 16 2900
Util 6 2000
Context 2 150
Administration 13 1000
Total 79 14450 Tableau 5 - Nombre de classes et de lignes de code dans le prototype SECAS
IV. UTILISATION DE SECAS DANS LE PROJET SICOM
Le projet régional Systèmes d’Information COMmunicants pour la Santé (SICOM) a été
financé par la Région Rhône-Alpes dans le cadre des thématiques prioritaires de septembre
2000 à septembre 2003 [Flory04]. L’objectif de ce projet était de définir une architecture
Tarak CHAARI - 161 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
générique de système de suivi de patients à distance (prise en charge à domicile). Dans le
cadre de ce projet, notre collaboration avec le service de néphrologie de l’hôpital Edouard
Herriot, l’association de suivi de patients à domicile AURAL, la société Baxter France qui a
fourni des dialyseurs, et avec France Telecoms R&D (dont la plate-forme de visioconférence
permet de relier l’association de suivi et le patient) a permis de définir les besoins d’un suivi
de qualité des patients dialysés à domicile atteints d’une insuffisance rénale.
Un dossier de dialyse péritonéale comporte la description du traitement prescrit, la
description de chaque acte de dialyse effectué, une liste d’images qui permet de voir
l’évolution du cathéter au besoin, des mesures médicales disponibles (températures, poids,
volumes de filtration…). Le médecin de l’association de suivi accède à des services
supplémentaires, tels une liste d’alarmes reçues au sujet de l’ensemble des patients suivis
(données anormales détectées par le système, demandes de patients…). Les services utiles à
l’infirmière de l’association de suivi concernent la gestion des prescriptions et des fournitures,
les prises de rendez-vous avec les acteurs devant se rendre au domicile… D’autres services
ont été définis pour les assistantes sociales, les infirmières en charge du traitement du patient,
les médecins de ville, les pharmaciens… L’application développée dans le cadre du projet
SICOM ne permet que l’utilisation de ses services sur un PC standard. Les professionnels de
santé nous ont exprimé le besoin d’accéder à ces mêmes services en utilisant des PDA et des
téléphones mobiles. Nous avons validé l’approche d’adaptation que nous avons définie dans
SECAS sur cette application. Nous avons vérifié le bon fonctionnement des différents
modules de SECAS par les tests suivants :
- Test de déploiement de SICOM.
- Test de l’adaptation du comportement global (services, données et présentation) de
l’application SICOM.
- Test de la connexion/déconnexion d’un utilisateur.
- Test de l’utilisation des services adaptés.
Nous avons utilisé un micro-ordinateur Pentium 4, 2.4 GHz avec une mémoire de 512 Mo
pour déployer la plateforme SECAS et un téléphone mobile de type Nokia 6230 pour le test
de l’application adaptée du coté de l’utilisateur final.
1. Déploiement de SICOM avec l’interface d’administration de
SECAS
L’interface présentée sur la figure 92 assure le déploiement et la mise à jour de nouvelles
applications. La fenêtre « Configuration » permet de déployer ou de mettre à jour une
Tarak CHAARI - 162 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
application à adapter. Pour déployer une nouvelle application comme SICOM, le concepteur
déploie le modèle fonctionnel dans la zone « Functional Model » et les règles d’adaptation
dans la zone « Rules » de cette interface d’administration. Le modèle fonctionnel de
l’application et ses règles d’adaptation sont fournies sous la forme de fichiers XML. Les
annexes A et B de ce mémoire illustrent le contenu de ces deux fichiers pour l’application
SICOM. Une fois déployée, l’application apparait dans la fenêtre « Applications ».
Figure 92 - Interface d’administration de la plate-forme SECAS
2. Adaptation de l’application « SICOM »
Le premier contexte d’utilisation que nous avons considéré illustre un médecin qui
interagit avec les différents services de SICOM sur un PC standard. Le deuxième contexte
concerne l’utilisation de la même application par le même médecin avec un téléphone mobile.
Pour pouvoir utiliser cette application sur ce genre de terminaux à faibles capacité de calcul et
de stockage, nous l’avons intégré dans notre plateforme pour l’adapter. Le contexte décrivant
l’utilisation de cette application sur un téléphone mobile est listé en annexe C de ce mémoire.
Cet exemple nous a permis de valider notre architecture et notre stratégie d’adaptation.
Tarak CHAARI - 163 - Thèse de doctorat
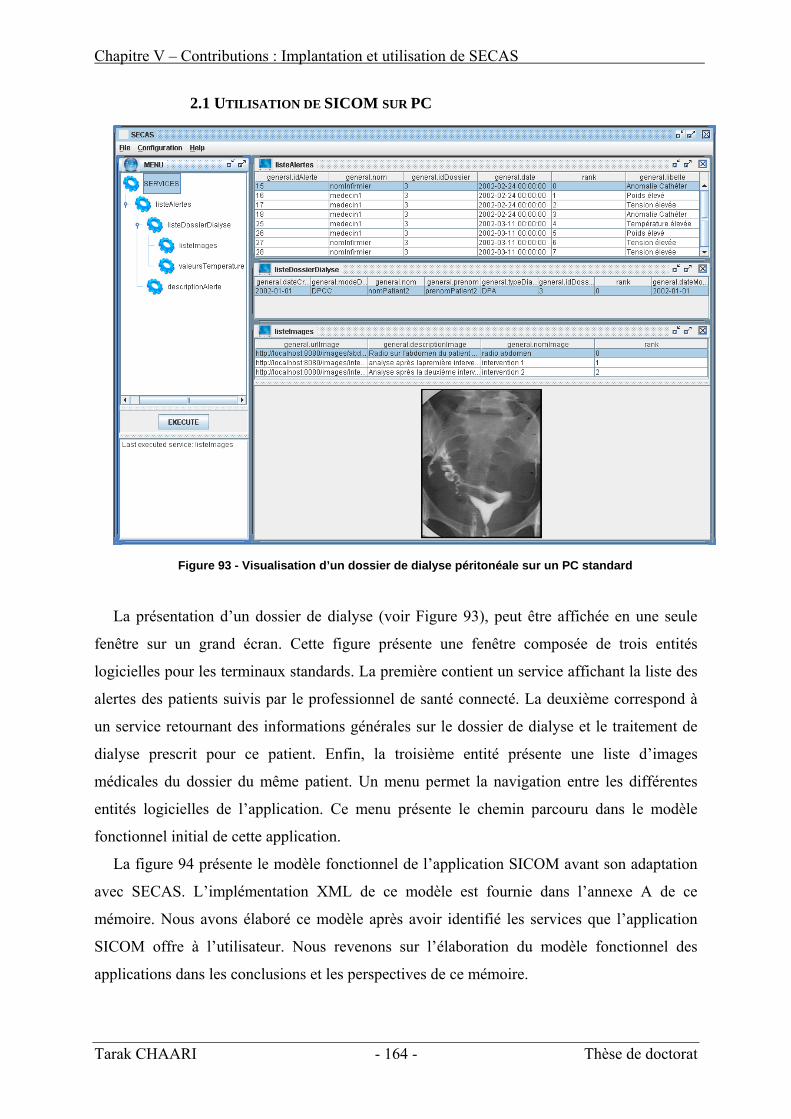
Chapitre V – Contributions : Implantation et utilisation de SECAS
2.1 UTILISATION DE SICOM SUR PC
Figure 93 - Visualisation d’un dossier de dialyse péritonéale sur un PC standard
La présentation d’un dossier de dialyse (voir Figure 93), peut être affichée en une seule
fenêtre sur un grand écran. Cette figure présente une fenêtre composée de trois entités
logicielles pour les terminaux standards. La première contient un service affichant la liste des
alertes des patients suivis par le professionnel de santé connecté. La deuxième correspond à
un service retournant des informations générales sur le dossier de dialyse et le traitement de
dialyse prescrit pour ce patient. Enfin, la troisième entité présente une liste d’images
médicales du dossier du même patient. Un menu permet la navigation entre les différentes
entités logicielles de l’application. Ce menu présente le chemin parcouru dans le modèle
fonctionnel initial de cette application.
La figure 94 présente le modèle fonctionnel de l’application SICOM avant son adaptation
avec SECAS. L’implémentation XML de ce modèle est fournie dans l’annexe A de ce
mémoire. Nous avons élaboré ce modèle après avoir identifié les services que l’application
SICOM offre à l’utilisateur. Nous revenons sur l’élaboration du modèle fonctionnel des
applications dans les conclusions et les perspectives de ce mémoire.
Tarak CHAARI - 164 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
Temperatures
Authentification
DossierDialyse listeImages
ListeAlerte
UserID
PatientID PatientID PatientID
Figure 94 - Le modèle fonctionnel de l’application SICOM avant son adaptation avec SECAS
2.2 UTILISATION DE SICOM SUR TELEPHONE MOBILE
La figure 99 donne l’équivalent de l’application de la
figure 93 pour les téléphones mobiles après son adaptation avec la plateforme SECAS. Le
menu de navigation entre les services est remplacé par des écrans (E1), (E4), (E6) et (E7)
fournissant la liste des services accessibles dans l’application grâce à la fonction
getAvailableServices() du module d’adaptation de présentation. Le premier service de cette
application (affichage des alertes) est éclaté en deux services en utilisant la règle de la figure
95. Le premier service listeAlertes(idAlerte) récupère la liste des identifiants des alertes qui
ont été déclenchées (écran E2). Le deuxième service récupère la valeur correspondant à
l’identifiant sélectionné par l’utilisateur (écran E3). La représentation XML de cette règle est
donnée dans l’annexe B de ce mémoire (rule 1).
{(context.terminal.hardwarePlatform.memory < 10240) ∧ (∃ f∈F | f.OUTPUT.length > 1) → firstValues=projection(f, f.OUTPUT[1]) ∧ replaceService(f, firstValues) ∧ selectedInstance=selection(f, f.OUTPUT[1] = selected(firstValues))
∧ insertServiceAfter(firstValues.selectedInstance)} Figure 95 - Première règle d'adaptation de l'application SICOM
Le deuxième service de l’application initiale (affichage des données générales sur le
traitement de dialyse) correspond à l’écran E5. Les données sont affichées verticalement ;
alors que sur les terminaux standards elles sont présentées horizontalement (adaptation de
présentation). Le même service initial est utilisé dans le nouveau contexte (pas d’adaptation
Tarak CHAARI - 165 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
fonctionnelle).
{(context.terminal.softwarePlatform.acceptedDataTypes.acceptImages) ∧ (context.terminal.type=“cldc”) ∧ (∃ f∈F | f.OUTPUT.length > 1) ∧ (∃ i∈[0, f.OUTPUT.length] |
f.OUTPUT[i].type=“secas:binaryImage”) → (displayNonImage = projection( f, ¬(f.OUTPUT[i]) )
∧ (displayImage = projection( f, f.OUTPUT[i]) ) ∧ replaceService(f,displayNonImage) ∧ insertAlternativeService(displayNonImage, displayImage) }
Figure 96 - Deuxième règle d'adaptation de l'application SICOM
Le troisième service affichant les images médicales est éclaté sur trois services après
l’application de la règle de la figure 95 suivie de la règle de la figure 96. En effet, la première
règle éclate le service listeImages() en deux services : le premier listeImages(nomImage)
affiche la liste des images renvoyées par le service d’origine et le second renvoie les autres
informations (urlImage, descriptionImage et binaireImage) correspondant à l’image
sélectionnée dans le premier. Ensuite, l’application de la deuxième règle divise ce deuxième
service en deux autres services : le premier renvoie les paramètres dont le type n’est pas une
image listeImages(urlImage :descriptionImage) et le deuxième renvoie l’image binaire
listeImages(binaireImage). Ainsi nous obtenons les trois services : listeImages(urlImage)
(écran E8), listeImages(urlImage :descriptionImage) (écran E9) et listeImages(binaireImage)
(écran E10). L’image présentée par ce dernier service est reformatée et redimensionnée à la
taille de l’écran (adaptation de contenu). La représentation XML de la règle de la figure 96 est
donnée dans l’annexe B de ce mémoire (rule 2).
{ (¬context.terminal.acceptedDataTypes.acceptImages) ∧ (∃ i∈[0, f.OUTPUT.length] | f.OUTPUT[i].type=“secas:binaryImage”) → lockService(f) }
Figure 97 - Troisième règle d'adaptation de l'application SICOM
Dans le cas où le terminal utilisé ne supporte pas l’affichage d’images, le service
listeImages(binaireImage) est verrouillé en utilisant la règle de la figure 97. La représentation
XML de cette règle est donnée dans l’annexe B de ce mémoire (rule 3).
Le modèle fonctionnel résultant de l’application des trois règles que nous venons de
présenter est illustré sur la figure 98. La plateforme SECAS utilise ce modèle fonctionnel
pour adapter les données renvoyées par les services définis dans ce modèle. Ainsi, SECAS
fournit un nouveau modèle fonctionnel où chaque service renvoie des données directement
exploitable sur le terminal de d’utilisateur. Enfin, ce nouveau modèle fonctionnel est utilisé
Tarak CHAARI - 166 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
pour générer automatiquement l’interface utilisateur qui garantit l’interaction avec les services
et les données adaptés de l’application SICOM. Cette interface est présentée dans la figure 99.
Authentification
traitement listeImages(nom)
ListeAlertes(id)
UserID is not null
listeImages(binaire) listeImages (description,url)
Context:terminal:software:acceptimages
Temperatures (dates)
Temperatures (value)
Selected(ListeAlertes)
idAlerte
idDossier idDossier idDossier
idMesure idImage
idImage
Figure 98 - modèle fonctionnel adapté de l'application SICOM
Pour l’adaptation de l’application SICOM à des environnements mobiles, nous avons
utilisé des règles d’ordre générique (celles de la figure 95, de la figure 96 et de la figure 97).
Elles peuvent être utilisées pour d’autres applications afin de les adapter pour des téléphones
mobiles du même type. La base de règles d’une application peut être enrichie par des règles
spécifiques en ajoutant une clause logique qui référence un élément spécifique du modèle
fonctionnel. Par exemple, nous pouvons ajouter la clause f.name=“listeAlertes” dans la partie
expressions d’une règle pour qu’elle ne soit appliquée qu’au service particulier listeAlertes. Il
faut également vérifier la consistance des règles d’adaptation d’une application en détectant
les conflits ou les erreurs d’écriture de ces règles et en proposant des solutions pour les
résoudre. Ce travail a été effectué durant un master de recherche dans notre équipe
[Zouari07].
Tarak CHAARI - 167 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
E0
E1 E2 E3
E4 E5
E7 E8 E9 E10
E6
Figure 99 - Visualisation du même dossier médical que la
figure 93 sur un terminal mobile
V. UTILISATION D’UN NOUVEAU MODELE DE CONTEXTE DANS
SECAS
Afin de valider les objectifs de généricité et de réutilisation, nous avons intégré un nouveau
modèle de contexte dans SECAS. Nous avons substitué notre modèle de contexte par celui de
Tarak CHAARI - 168 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
Dejene Ejigu [Chaari07] sans modifier notre approche d’adaptation. Ce modèle est basé sur
une représentation du contexte sous la forme d’une ontologie à deux niveaux : un niveau de
base et un niveau spécifique au domaine de l’application. Le niveau de base contient les
concepts qui définissent les concepts généraux du contexte (utilisateur, terminal,
localisation…). Ce niveau de base correspond aux cinq facettes du contexte définies dans
notre modèle (section II du chapitre III). Le niveau spécifique contient des sous-classes des
concepts définis dans le niveau de base (par exemple : médecin comme sous classe de
utilisateur, PDA comme sous classe de terminal, hôpital comme sous classe de
localisation…). Les concepts de cette ontologie à deux niveaux peuvent être liés par des
relations représentées par des prédicats comme utilise(Utilisateur, Terminal) pour désigner le
terminal utilisé par un utilisateur donné. La figure 100 donne un exemple d’une partie de
l’ontologie modélisant le contexte. Le niveau de base de cette ontologie comporte deux
concepts User et Terminal. Le niveau spécifique comprend Specialist, practitioner, nurse et
patient comme spécialisations de User. Il contient aussi les concepts SmartPhone, PDA et PC
spécialisant le concept de base Terminal.
Figure 100 - Exemple de modélisation du contexte par une ontologie
Nous avons intégré ce nouveau modèle de contexte sans changer notre approche
d’adaptation. En effet, nous avons seulement modifié la partie expressions des règles
d’adaptation afin de référencer les nouveaux éléments (concepts et relations) définis dans
l’ontologie du contexte. Ensuite, nous avons réutilisé les mêmes opérateurs pour l’adaptation
de l’application SICOM à des environnements mobiles.
Enfin, l’intégration du modèle de contexte de Dejene Ejigu dans notre plateforme nous a
permis de valider la généricité de notre approche d’adaptation d’une part et d’atteindre un
Tarak CHAARI - 169 - Thèse de doctorat

Chapitre V – Contributions : Implantation et utilisation de SECAS
degré d’expressivité sémantique plus élevé au niveau de la description du contexte d’autre
part.
VI. CONCLUSION
Dans ce chapitre, nous avons présenté le prototype réalisé pour valider notre approche
d’adaptation. Nous avons détaillé la conception et la réalisation technique de ce prototype.
Nous avons testé notre approche d’adaptation en déployant une application médicale
(SICOM) et en l’adaptant à de nouveaux contextes d’utilisation. Cette application a été
conçue et réalisée pour des professionnels de santé dans le domaine de la néphrologie dans le
but de leur permettre d’accéder aux dossiers médicaux de leurs patients. Dans leur première
version, les services de cette application ne peuvent être exploités qu’à travers des PC de
bureau ou des PC portables. Après son intégration dans SECAS, l’application est désormais
accessible avec des terminaux mobiles qui ont des capacités matérielles et logicielles
totalement différentes des PC standards. Pour l’intégration de cette application, nous avons
fourni son modèle fonctionnel, un fichier de règles d’adaptation fonctionnelle et un fichier
décrivant le nouveau contexte d’utilisation de l’application. Ces fichiers sont donnés
respectivement dans les annexes A, B et C de ce mémoire. Pour réaliser l’adaptation de
présentation de cette application nous avons aussi fourni l’implémentation de notre API
graphique abstraite (Abstract Interface Runtime Environment) pour les types de terminaux
utilisés (PCs standards, PCs de poche et téléphones mobiles).
Tarak CHAARI - 170 - Thèse de doctorat

P CCCOOONNNCCCLLLUUUSSSIIIOOONNNSSS EEETTT PPPEEERRRSSSPPEEECCCTTTIIIVVVEEESSS
“Imagination is more important than knowledge” (Albert Einstein)

Conclusions et perspectives
PLAN
I. BILAN ______________________________________________________________ 173
II. PERSPECTIVES _______________________________________________________ 174
Tarak CHAARI - 172 - Thèse de doctorat

Conclusions et perspectives
I. BILAN
Lors de notre étude des travaux existants dans le domaine de la sensibilité au contexte,
nous avons remarqué un grand intérêt aux étapes de capture, d’interprétation, de modélisation
et de dissémination du contexte. Par contre, nous avons constaté l’absence d’une approche
générique et complète pour adapter les applications au contexte. La majorité des contributions
existantes pour combler ce manque présentent des approches d’adaptation ad hoc spécifiques
à un domaine particulier (comme la sensibilité à la localisation de l’utilisateur). Dans ce
travail de thèse, nous avons conçu et développé une plateforme d’adaptation d’applications à
de multiples contextes d’utilisation. Cette plateforme nous a permis de réaliser les
contributions suivantes :
- Conception d’une architecture générique qui offre les moyens et les outils
nécessaires pour réaliser l’adaptation d’applications à de nouveaux contextes
d’utilisation. Cette architecture est basée sur trois couches principales : (i) une couche
de déploiement d’applications pour intégrer de nouvelles applications en vue de leur
adaptation, (ii) une couche d’adaptation instanciée dynamiquement au dessus des
applications déployées et (iii) une couche de gestion de contexte qui permet de
capturer et de disséminer le contexte vers la couche d’adaptation.
- Définition d’une stratégie d’adaptation globale au contexte sur trois volets : le
comportement fonctionnel des services que l’application offre à l’utilisateur, les
données renvoyées par ses services et l’interface utilisateur qui assure l’interaction
avec ses services.
- Facilité de l’intégration et de l’adaptation puisque notre approche d’adaptation se
base essentiellement sur une description fonctionnelle simple des services que
l’application d’origine offre à l’utilisateur. Ainsi, nous gagnons le temps considérable
de développement d’autres versions qui auraient été nécessaires sans SECAS pour
supporter les nouveaux contextes d’utilisation.
- Evolutivité de notre stratégie d’adaptation puisqu’elle permet d’ajouter facilement
de nouveaux outils et de nouvelles actions d’adaptations à l’architecture sans devoir
recompiler notre moteur d’adaptation.
- Implémentation de notre architecture en développant un prototype qui nous a permi
de tester et de valider notre approche d’adaptation.
Afin de vérifier l’évolutivité et l’ouverture de notre approche d’adaptation à d’autres
contributions dans le domaine de la sensibilité au contexte, nous avons testé et validé notre
Tarak CHAARI - 173 - Thèse de doctorat

Conclusions et perspectives
plateforme avec le modèle de contexte élaboré par Dejene Ejigu [Chaari07]. Ce modèle se
base sur une ontologie pour la description du contexte d’utilisation de l’application. Nous
pensons également que notre plateforme d’adaptation n’est pas restreinte au domaine de
l’informatique pervasive. En effet, son utilisation peut être généralisée pour garantir
l’évolution de tout type de système d’information en fournissant la description de ses services
et les opérateurs nécessaires pour réaliser son adaptation ou son extension.
II. PERSPECTIVES
Ce travail de thèse nous a permis de tracer plusieurs perspectives de recherche :
- Pour pouvoir adapter des applications avec notre plateforme, le concepteur doit
donner une description XML des services (comme l’exemple en annexe A) qu’elles
offrent à l’utilisateur. Il serait intéressant de proposer un outil qui permet d’aider à la
création de cette description avec des techniques de reverse – engineering et/ou avec
un monitoring des appels distants dans les applications client-serveur. Ceci permet de
générer d’une façon automatique, ou semi-automatique, la description des services
offerts par ces applications.
- Le modèle que nous avons établi pour décrire le noyau fonctionnel des applications
est assez générique pour qu’il puisse être utilisé pour la majorité des applications
actuelles. Ce modèle constitue le minimum d’informations qu’on doit savoir sur
l’application pour qu’elle puisse être adaptée avec notre approche. Il nous a permis de
réaliser une stratégie d’adaptation complète sur les services, les données et les
interfaces utilisateur de ces applications. Cependant, le résultat de l’adaptation et son
impact sur le code interne de l’application peut être raffiné et approfondi si nous
disposons de plus de connaissances sur son noyau fonctionnel (architectures de
l’application, l’ensemble des classes qui la constituent, l’ensemble des services
internes de l’application…). Nous pensons à élaborer un modèle générique à
granularité variable qui permettrait d’incorporer ces connaissances supplémentaires et
ainsi d’approfondir l’impact de l’adaptation sur l’application.
- Pour pouvoir générer les interfaces utilisateur, notre plateforme utilise une
bibliothèque de composants graphiques correspondant aux types de données
renvoyées par les services de l’application. Ces composants doivent être fournis pour
chaque API implantée sur les terminaux utilisés. Notre plateforme supporte
maintenant trois API JAVA : J2SE pour les pc standards, CDC Hotspot pour les PDA
et J2ME Midp pour les téléphones mobiles. Pour intégrer d’autres machines virtuelles,
Tarak CHAARI - 174 - Thèse de doctorat

Conclusions et perspectives
nous pensons à enrichir notre plateforme avec un générateur de composants
graphiques en se basant sur la description de l’API disponible sur le terminal.
- Enfin, nous envisageons d’intégrer l’utilisateur final dans le processus d’adaptation
pour qu’il puisse modifier des décisions actuellement prises d’une façon automatique
par notre plateforme. Ceci nous permettrait d’avoir un retour d’expérience sous la
forme d’une évaluation empirique du résultat produit par notre plateforme d’une part
et de raffiner notre processus d’adaptation d’autre part. Dans cette perspective, nous
proposons d’utiliser le paradigme de programmation par aspects afin de fournir des
points d’intervention de l’utilisateur dans le processus d’adaptation. Par ailleurs, nous
pensons que l’utilisation d’un mécanisme d’apprentissage pour mémoriser les
décisions prise par l’utilisateur peut être une solution intéressante pour améliorer les
résultats d’adaptation.
Tarak CHAARI - 175 - Thèse de doctorat


BBBIIIBBBLLLIIIOOOGGGRRRAAAPPPHHHIIIEEE

Bibliographie
[Abowd97] Abowd G. D., Atkeson, C. G., Hong et al.. Cyberguide : A mobile context-
aware tour guide. ACM Wireless Networks, 1997, Vol. 5, N°3, pp. 421-433
[Abowd99] Abowd, G. D., Dey, A. K., Brown, P. J., Davies, N., Smith, M., and
Steggles, P. 1999. Towards a Better Understanding of Context and Context-
Awareness. In Proceedings of the 1st international Symposium on Handheld
and Ubiquitous Computing, September 27 - 29, 1999 Karlsruhe, Germany.
H. Gellersen, Ed. (Lecture Notes In Computer Science, Vol. 1707, pp. 304-
307)
[Abrams99] M. Abrams, C. Phanouriou. UIML: an XML language for building device
independent user interfaces. XML99, December 1999, Philadelphia.
[Agoston00] Thomas Agoston, Tatsuro Ueda, and Yukari Nisimura, Pervasive computing
in a networked world, In Proc. of INET 2000, 18-21 july 2000, Japan,.
[Akan04] Ö B Akan and I F Akyildiz, ATL. An adaptive transport layer suite for next-
generation wireless internet. IEEE Journal on Selected Areas in
Communications, June 2004, Vol. 22, N° 5, pp. 802-817
[Aksit03] Aksit M., Choukair Z. Dynamic Adaptive and Reconfigurable Systems. In
Overview and Prospective Vision. Actes des ICDCS Workshops 03,
Providence, 2003, Rhode Island, USA, p. 84-92
[Andrade03] L-F.Andrade, J-Luiz.Fiadeiro. Architecture Based Evolution of Software
Systems. In the Third International School on Formal Methods for the design
of Computer,communication and Software Systems: Software Architectures,
SFM 2003, Italy, 2003
[Angin98] O. Angin, AT. Campbell, ME. Kounavis et al. The mobiware Toolkit:
Programmable Support for Adaptive Mobile Networking. IEEE Personal
Communication, 1998, Vol.5, No.4, pp. 32-43
[Austin02] D. Austin, A. Barbir, C. Ferris, S. Garg. Web Services Architecture
Requirements. 19 August 2002. W3C Working Draft,
http://www.w3.org/TR/2002/WD-wsa-regs20020819 (consulté le
02.07.2007)
Tarak CHAARI - 178 - Thèse de doctorat

Bibliographie
[Balzert96] H. Balzert, F. Hofmann, V. Kruschinski, C. Niemann. The Janus Application
Development Environment Generating More than the User Interface. In J.
Vanderdonckt (ed.): Computer-Aided Design of User Interfaces. Namur:
Namur University Press, 1996, pp. 183-205
[Baral96] C. Baral, J. Lobo. Formal characterization of active databases. In
Proceedings of the international Workshop on Logic in Databases (July 01 -
02, 1996). D. Pedreschi and C. Zaniolo, Eds. Lecture Notes In Computer
Science, vol. 1154. Springer-Verlag, London, 175-195, 1996
[Bauer98] Bauer M., Heiber, T., Kortuem, G. & Segall, Z. A collaborative wearable
system with remote sensing. Proceedings of the 2nd International
Symposium on Wearable Computers (ISWC98), CA : IEEE, 1998, Los
Alamitos, pp. 10-17
[Bederson95] Bederson, B. B. Audio Augmented Reality: A Prototype Automated Tour
Guide. In Proceedings of Human Factors in Computing Systems (CHI 95)
New York : ACM Press, 1995, pp. 210-211
[Beigl00] Beigl M. MemoClip: A location based remembrance appliance. Personal
Technologies, 2000, Vol. 4, N°4, pp. 230-233.
[Bennett94] F. Bennett, T. Richardson and A. Harter. Teleporting - Making Applications
Mobile. Proc. In IEEE Workshop on Mobile Computing Systems and
Applications, December 1994, Santa Cruz, California, pp. 82-84
[Berhe05] Girma Berhe, Lionel Brunie, Jean-Marc Pierson. Distributed Content
Adaptation for Pervasive Systems. ITCC, 2005, Vol. 2, pp. 234-241
[Bharghavan97] V. Bharghavan, V. Gupta. A Framework for Application Adaptation in
Mobile Computing Environments. In Proceedings of the IEEE Compsoc97,
Aug 1997, Washington, D.C., USA, pp. 11-15
[Bickmore97] T. Bickmore and B. Schilit. Digestor. Device-independent Access to the
World Wide Web. In Proceedings of the 6th World Wide Web Conference
(WWW6), April 7-11, 1997, Santa Clara, California USA, pp. 655–663
[Bickmore97] T. Bickmore and B. Schilit. Digestor. Device-independent Access to the
World Wide Web. In Proceedings of the 6th World Wide Web Conference
(WWW6), April 7-11, 1997, Santa Clara, California USA, pp. 655–663
Tarak CHAARI - 179 - Thèse de doctorat

Bibliographie
[Billington03] Billington J., Christensen S., Van Hee K. et al.. The Petri Net Markup
Language : Concepts, Technology, and Tools. In W. van der Aalst and E.
Best, editors, Application and Theory of Petri Nets 2003, 24th International
Conference, Springer .(LNCS, Vol. 2679, June 2003, pp. 483–505)
[Birnbaum97] Birnbaum, J. 1997. Pervasive information systems. Commun. ACM 40, 2
(Feb. 1997), 40-41. DOI= http://doi.acm.org/10.1145/253671.253695
(consulté le 02.07.2007)
[Björk99] S. Björk, L.E. Holmquist, J. Redström et al. WEST: a Web browser for small
terminals. In Proceedings of the 12th annual ACM symposium on User
interface software and technology, Asheville, 07-10 November 1999, North
Carolina, USA, pp.187-196
[Bodart95] F. Bodart, A.-M. Hennebert, J.-M. Leheureux et al.. Towards a Systematic
Building of Software Architectures: the TRIDENT Methodological Guide. In
P. Palanque, R. Bastide (eds.): Design, Specification and Verification of
Interactive Systems. Wien : Springer, 1995, pp. 262-278
[Bolot98] J.C. Bolot, T. Turletti. Experience with rate control mechanisms for packet
video in the Internet. Computer Communication Review, ACM, January
1998, Vol. 28, N° 1, pp.4-15
[Bolot98] J.C. Bolot, T. Turletti. Experience with rate control mechanisms for packet
video in the Internet. Computer Communication Review, ACM, January
1998, Vol. 28, N° 1; pp.4-15
[Booch98] Grady Booch, James Rumbaugh, and Ivar Jacobson. Unified Modeling
Language User Guide. Reading (Mass.) : Adison Wesley, 1998, 482 p.
(Addison Wesley Object Technology Series)
[Bridges01] P G Bridges, W K Chen, M A Hiltunen and al.. Supporting coordinated
adaptation in networked systems. 8th Workshop on Hot Topics in Operating
Systems (HotOS-VIII), May 2001, Elmau, Germany, pp. 162-168
[Brotherton99] Brotherton J., Abowd, G. D. & Truong, K. Supporting capture and access
interfaces for informal and opportunistic meetings. In Atlanta, GA : Georgia
Institute of Technology, GVU Center, (GIT-GVU-99-06), January 1999.
Tarak CHAARI - 180 - Thèse de doctorat

Bibliographie
[Brown96] P.J. Brown. The Stick-e Document: a framework for creating Context aware
applications. In Electronic Publishing 96, (1996), Document Manipulation
and Typography, 24-26 September 1996, Pala-Alto, California, USA, pp.
259-272
[Brown97] P.J. Brown, J.D. Bovey, X. Chen. Context-Aware applications : From the
Laboratory to the Marketplace. IEEE Personal Communications, 1997, Vol.
4, N°5, pp. 58-64
[Calvary02] G. Calvary et J. Coutaz “Plasticité des interfaces : une nécessité !”,
information-interaction-intelligence, Actes des deuxièmes Assises nationales
du GDR I3, Nancy, décembre 2002. Toulouse : Cépaduès Editions, pp 247-
261
[Cazzola99] W. Cazzola, A. Sosio, A. Savigni et al. Architectural Reflection: Concepts,
Design, and Evaluation. Technical Report RI-DSI 234-99. DSI. 1999,
University degli Studi di Milano
[Chaari04] T. Chaari, F. Laforest Génération. Adaptation automatiques des interfaces
utilisateurs pour des environnements multi-terminaux Le projet SEFAGI :
Simple Environment For Adaptable Graphical Interfaces. Revue Ingénierie
des systèmes d’Information, n° spécial systèmes d’information pervasifs,
2004, Vol. 9, N°2/2004: pp. 11-38
[Chaari07] T. Chaari, D. Ejigu, F. Laforest and V.-M. Scuturici. A Comprehensive
Approach to Model and Use Context for Adapting Applications in Pervasive
Environments. Int. Journal of Systems and software, 2007, 26 p. (à paraître).
[Chandra99] S. Chandra and C.S. Ellis. JPEG Compression Metric as a Quality Aware
Image Transcoding. In 2nd Usenix Symposium on Internet Technologies
and Systems (USITS 99), Oct. 1999, Berkeley, CA, USA, pp.81-92
[Chandra99] S. Chandra and C.S. Ellis. JPEG Compression Metric as a Quality Aware
Image Transcoding. In 2nd Usenix Symposium on Internet Technologies
and Systems (USITS 99), Oct. 1999, Berkeley, CA, USA, pp.81-92
[Chassot06] C. Chassot, K. Drira, K. Guennoun et al.. Towards autonomous management
of QoS through model-driven adaptability in communication-centric
systems. International Transactions on Systems Science and Applications,
2006, Vol. 2, N° 3, pp. 255-264
Tarak CHAARI - 181 - Thèse de doctorat

Bibliographie
[Chefrour02] Djalel Chefrour and Françoise André. ACEEL : modèle de composants auto-
adaptatifs. Application aux environnements mobiles. In Actes du colloque
Systèmes à composants adaptables et extensibles, October 2002, Grenoble,
France.
[Chen03] Chen, H., et al.. An Ontology for Context-Aware Pervasive Computing
Environments. In Workshop on Ontologies and Distributed Systems (IJCAI
2003), August 2003, Mexico.
[Chen04] Chen, H. An Intelligent Broker Architecture for Pervasive Context-Aware
Systems. PhD thesis. Baltimore County : Department of CSEE, University of
Maryland, 2004.
[Clark99] Clark, J. (ed.): XSL Transformations (XSLT) Version 1.0. World Wide Web
Consortium. Boston 1999. Disponible sur : <http://www.w3.org/TR/xslt>
(consulté le 01.06.2007)
[CORBA02] CORBA overview, Object Management Group. Disponible sur
:<http://www.omg.org/corba/> (consulté le 14.03.2002)
[Costa03] Patricia Dockhorn Costa. Towards a services platform for context – aware
applications. Master thesis. Enschede, The Netherlands : University of
Twente, august 2003.
[David05] Pierre-Charles David and Thomas Ledoux. Une approche par aspects pour
le développement de composants Fractal adaptatifs. In 2ème Journée
Francophone sur le Développement de Logiciels Par Aspects (JFDLPA05),
September 2005, Lille, France (L'objet, Vol. 12, N°-23)
[Davies98] Davies N., Mitchell, K., Cheverst et al. . Developing a context-sensitive tour
guide. In Proceedings of the 1st Workshop on Human Computer Interaction
for Mobile Devices, 1998, Glasgow, Scotland.
[Dey00] A. K. Dey and G. D. Abowd. Towards a Better Understanding of Context
and Context Awareness. In Proceedings of the Workshop on the What, Who,
Where, When and How of Context-Awareness, affiliated with the CHI 2000
Conference on Human Factors in Computer Systems, The Hague,
Netherlands. New York, NY : ACM Press, 2000.
Tarak CHAARI - 182 - Thèse de doctorat

Bibliographie
[Dey01a] Dey, A.. Understanding and Using Context. Personal Ubiquitous Comput,
Jan. 2001, Vol. 5, N°1, p. 4-7. DOI=
http://dx.doi.org/10.1007/s007790170019 (consulté le 02.07.2007)
[Dey01b] Anind K. Dey, Daniel Salber and Gregory D. Abowd, A Conceptual
Framework and a Toolkit for Supporting the Rapid Prototyping of Context-
Aware Applications. special issue on context-aware computing in the
Human-Computer Interaction (HCI), 2001, Vol. 16, N° 2-4, pp. 97-166
[Dey98] Dey A. K., Abowd, G. D. & Wood, A. CyberDesk : A framework for
providing self– integrating context–aware services. Knowledge Based
Systems, 1998, Vol.11, N°1, pp. 3-13
[Dey99] K. Dey, Daniel Salber, Masayasu Futakawa and Gregory D.Abowd. An
Architecture To Support Context-Aware Applications. GVU Technical
Report GIT-GVU-99-23. Submitted to the 12th Annual ACM Symposium
on User Interface Software and Technology (UIST 99), June 1999
[Dourish00] Dourish P., Edwards, W. K., LaMarca et al.. Extending document
management systems with active properties. ACM Transactions on
Information Systems, 2000, Vol.18, N°2, p. 140-170.
[Dowling01] Jim Dowling and Vinny Cahill. The K-Component Architecture Meta-Model
for Self-Adaptive Software. In The Third International Conference on
Metalevel Architectures and Separation of Crosscutting Concerns,
September, Reflection 2001, Kyoto, Japan, p. 81-88
[Dubois01] Dubois, E., Nigay, L., Troccaz, J. Consistency in Augmented Reality
Systems. Proceedings of EHCI01, IFIP WG2.7 (13.2) Conference, May
2001, Toronto. (LNCS, 2001, Vol.2254, pp.111-122)
[Eclipse06] Eclipse IDE, Disponible sur : < http://www.eclipse.org/> (consulté le
26.12.2006)
[Feiner97] Feiner S., MacIntyre, B., Hollerer, et al.. A Touring Machine : Prototyping
3D mobile augmented reality systems for exploring the urban environment.
Personal Technologies, 1997, Vol. 1, N°4, pp. 208-217
Tarak CHAARI - 183 - Thèse de doctorat

Bibliographie
[Fels98] Fels S., Sumi, Y., Etani et al.. Progress of C-MAP: A context-aware mobile
assistant. (1998). In Proceedings of the AAAI 1998 Spring Symposium on
Intelligent Environments. Menlo Park, CA : AAAI Press, pp. 60-67
[Fisher97] B. Fisher, G. Agelidis, J. Dill et al. CZWeb : Fish-Eye Views for Visualizing
the World-Wide Web. In Proc. of the 7th Int. Conf. on Human-Computer
Interaction (HCI International 97). Amsterdam : Elsevier, 1997, pp. 719-722
[Flory04] Flory et al, Projet SICOM : Rapport de fin de contrat, "thématiques
prioritaires". Région Rhône-Alpes, 2004
[Fox98] A. Fox, I. Goldberg, S. Gribble et al. Experience with TopGun Wingman: A
Proxy-Based Web Browser for the 3Com PalmPilot. In Proceedings of the
IFIP International Conference on Distributed Systems Platforms and Open
Distributed Processing (Middleware 98), Sept. 1998, Lake District, England,
pp.407-426
[Fox98] A. Fox, I. Goldberg, S. Gribble et al. Experience with TopGun Wingman: A
Proxy-Based Web Browser for the 3Com PalmPilot. In Proceedings of the
IFIP International Conference on Distributed Systems Platforms and Open
Distributed Processing (Middleware 98), 1998, Lake District, England,
pp.407-426
[Granddictionnaire] Office québécois de la langue française. Le grand dictionnaire
terminologique [en ligne]. Disponible sur :
<http://www.granddictionnaire.com/> (consulté le 01.06.2007)
[Gu04] Gu T., Pung H. K., and Zhang D. Q. A middleware for building context-
aware mobile services. In Proceedings of IEEE Vehicular Technology
Conference (VTC), 2004, Milan, Italy
[Hamadi03] Hamadi, R. and Benatallah, B. 2003. A Petri net-based model for web
service composition. In Proceedings of the 14th Australasian Database
Conference - Volume 17 (Adelaide, Australia). K. Schewe and X. Zhou, Eds.
ACM International Conference Proceeding Series, vol. 143. Australian
Computer Society, Darlinghurst, Australia, 191-200
[Harrison98] Harrison, B. L., Fishkin, K. P., Gujar et al.. Squeeze me, hold me, tilt me! An
exploration of manipulative user interfaces. In Proc. CHI 98, April 18-23,
Los Angeles. New York, NY, USA : ACM, 1998, pp.17-24
Tarak CHAARI - 184 - Thèse de doctorat

Bibliographie
[Healey98] Healey J. & Picard, R. W. StartleCam: A cybernetic wearable camera. In
Proceedings of the 2nd International Symposium on Wearable Computers
(ISWC98), Pittsburgh, Pennsylvania, 19-20 October 1998. Los Alamitos CA
: IEEE ,1998, p. 42-49
[Heineman01] Heineman G. T.& Council W. T.. Component-Based Software Engineering,
Putting the Pieces Together. Amsterdam : Addison Weysley, 2001.
[Heiner99] Heiner J. M., Hudson, S. E. & Tanaka, K. The Information Percolator:
Ambient information display in a decorative object. In Proceedings of the
12th Annual ACM Symposium on User Interface Software and Technology
(UIST96). New York, NY: ACM Press, 1999.
[Held02] A. Held. Modeling of Context Information for Pervasive Computing
Applications. In Proc. 6th World Multiconference on Systemics, Cybernetics
and Informatics (SCI2002), 2002, Orlando, FL.
[Hillerson 01] Gary Hillerson. Web Clipping Developer's Guide. Santa Clara, Calif. : Palm
Inc., May 2001.
[Hormonia06] Hormonia, Disponible sur :
<http://www.harmonia.com/products/index.php>, (consulté le 26.12.2006)
[Horrocks04] I. Horrocks, P. F. Patel-Schneider, H. Boley, S. Tabet, B. Grosof, and M.
Dean. SWRL: A semantic web rule language combining OWL and RuleML.
W3C Member Submission, 21 May 2004. [en ligne]
http://www.w3.org/Submission/2004/SUBM-SWRL-20040521/
[Housel96] B. C. Housel and D. B. Lindquist. WebExpress: A System for Optimizing
Web Browsing in a Wireless Environment. In Proceedings of ACM/IEEE of
the Second Annual International Conference on Mobile Computing and
Networking (MobiCom 96) November 1996, Rye, New York, pp. 108-116
[IBM06] Inc. Internet Transcoding for Universall Access [ en ligne ], September
2000.
http://www.research.ibm.com/networked_data_systems/transcoding/index.ht
ml, (consulté le 01.06.2007)
[IIHM] Équipe Ingénierie de l'Interaction Homme-Machine [en ligne]. Disponible
sur : <http://iihm.imag.fr> (consulté le 02.07.2007)
Tarak CHAARI - 185 - Thèse de doctorat

Bibliographie
[Indulska03] Indulska, J. and Sutton, P. Location management in pervasive systems. In
CRPITS 03: Proceedings of the Australasian Information Security
Workshop, 2003, Adelaide, Australia, p. 143–151
[Indulska03] Indulska, J., Robinson, R., Rakotonirainy, A., and Henricksen, K. 2003.
Experiences in Using CC/PP in Context-Aware Systems. In Proceedings of
the 4th international Conference on Mobile Data Management, January 21 -
24, 2003, Melbourne, Australia. (Lecture Notes In Computer Science, 2003,
Vol. 2574, pp.247-261)
[Ishii97] Ishii H. & Ullmer, B. Tangible Bits: Towards seamless interfaces between
people, bits and atoms. In Proceedings of the CHI 97 Conference on Human
Factors in Computing Systems. New York, NY: ACM Press, 1997, pp. 234-
241
[Janssen93] C. Janssen, A. Weisbecker, J. Ziegler. Generating User Interfaces from Data
Models and Dialogue Net Specifications. In Proceedings InterCHI93,
Amsterdam, April 1993. New York : ACM Press, 1993, pp. 418-423
[JBuilder06] Borland JBuilder. Disponible sur :
<http://www.borland.com/fr/products/jbuilder> (consulté le 26.12.2006)
[Johnson03] Johnson, B., Skibo, C., Young, M., Inside Microsoft Visual Studio .NET.
Washington : Microsoft Press, 2003.
[Keeney03] J.Keeney, V.Cahill. Chisel: A Policy-Driven, Context-Aware, Dynamic
Adaptation Framework. Proceedings of the Fourth IEEE International
Workshop on Policies for Distributed Systems and Networks ‘POLICY
2003’, Italy, 2003
[Ketfi02] Ketfi, A. and Belkhatir, N. and Cunin, P. Y.. Adaptation Dynamique,
concepts et expérimentations. In Proceedings of the 15th International
Conference on Software & Systems Engineering and their Applications
ICSSEA02, December 2002, Paris, France, 8 p.
[Kiciman00] Kiciman E. & Fox, A. Using dynamic mediation to integrate COTS entities
in a ubiquitous computing environment. In Proceedings of the 2nd
International Symposium on Handheld and Ubiquitious Computing
(HUC2K). Heidelberg, Germany : Springer Verlag, 2000.
Tarak CHAARI - 186 - Thèse de doctorat

Bibliographie
[Kiczales01] G. Kiczales, E. Hilsdale, J. Hugunin et al. Getting started with ASPECTJ.
Communications of the ACM, vol. 44, no. 10, pages 59-65, 2001
[Kickzales97] G. Kickzales, J. Lamping, A. Mendhekar et al. Aspect-Oriented
Programming. Proceedings of the ECOOP'97 Conference, LNCS 1241,
Finland, 220-242, 1997
[Kim03] J.-G. Kim, Y. Wang, and S.-F. Chang. Content-adaptive utility-based video
adaptation. In Proc. of IEEE Int'l Conference on Multimedia & Expo, July
2003, pp. 281-284
[Korpipaa04] Korpipaa, P., Mantyjarvi, J., Kela, J. et al.. Managing context information in
mobile devices. IEEE Pervasive Computing, November/December 2004,
Vol. 19, N°6, pp. 21-29
[Krasner88] G. Krasner and S. Pope, A cookbook for using the model-view controller
user interface paradigm in Smalltalk-80, Journal of Object-Oriented
Programming, August /September 19881, Vol. 3, pp.26-49.
[Lamming94] Lamming M. & Flynn, M. Forget-me-not: Intimate computing in support of
human memory. Proceedings of the FRIEND 21: International Symposium
on Next Generation Human Interfaces, 1994, Tokyo, pp.125-128
[Lassila99] O. Lassila and R. R. Swick. Resource description framework (rdf) model and
syntax specification. W3C Recommendation 22, February 1999.
[Layaïda99] N. Layaïda, Adaptabilité. Pistes d'étude pour la définition d'une
infrastructure d'accès au contenu multimédia pour des machines hétérogènes.
Rapport Technique. Grenoble : INRIA Rhône-Alpes, octobre 1999
[Lee03] D. G. Lee, D. Panigrahi, and S. Dey. Network-Aware Image Data Shaping
for Low-Latency and Energy-Efficient Data Services over the Palm Wireless
Network. In Proc. of World Wireless Congress (3G Wireless Conference),
May 2003, San Francisco.
[Lei01] Z. Lei and N.D. Georganas. Context-based Media Adaptation in Pervasive
Computing. In Proc. of Canadian Conference on Electrical and Computer
Engineering (CCECE), May 2001, Toronto
Tarak CHAARI - 187 - Thèse de doctorat

Bibliographie
[Lemlouma01] T. Lemlouma, N. Layaïda. A Framework for Media Resource Manipulation
in an Adaptation and Negotiation Architecture. OPERA project. Grenoble :
INRIA Rhône-Alpes, august 2001.
[Lemlouma02] T. Lemlouma, N. Layaďda. Content Adaptation and Generation Principles
for Heterogeneous Clients. In W3C Workshop on Device Independent
Authoring Techniques, September 2002, St. Leon-Rot, Germany
[Libsie04] M. Libsie. Metadata Supported Content Adaptation in Distributed
Multimedia Systems. PhD thesis. Austria : University Klagenfurt, defended
on June 2004
[Liljeberg95] M. Liljeberg, T. Alanko, M. Kojo et al. Optimizing World-Wide Web for
Weakly Connected Mobile Workstations: An Indirect Approach. In Proc. 2nd
International Workshop on Services in Distributed and Networked
Environments (SDNE95), June 5th - 6th, 1995, Whistler, Canada.
[Linnhoff 04] Strang and Claudia Linnhoff-Popien: A context modeling survey. In
UbiComp 1st International Workshop on Advanced Context Modelling,
Reasoning and Management, 2004, Nottingham, pp. 34-41
[Maes87] P. Maes. Concepts and experiments in computational reflection. In
Conference Proceedings on Object-Oriented Programming Systems,
Languages and Applications (Orlando, Florida, United States, October 04 -
08, 1987). N. Meyrowitz, Ed. OOPSLA '87. ACM Press, New York, NY,
147-155, 1987
[Margaritidis01] M. Margaritidis and G.C. Polyzos. Adaptation Techniques for Ubiquitous
Internet Multimedia. Wireless Communications and Mobile Computing,
2001, Vol. 1, N°2, pp. 141-164
[Marmasse00] Marmasse N. & Schmandt, C. Location aware information delivery with
comMotion. In Proceedings of the 2nd International Symposium on
Handheld and Ubiquitous Computing (HUC2K). Heidelberg, Germany :
Springer Verlag, 2000.
[Marriott02] K. Marriott, B. Meyer, and L. Tardif. Fast and Efficient client-Side
Adaptivity for SVG. In Proc. of WWW 2002Honolulu, Hawaii, USA, May
2002. New York : ACM Press, 2002, pp. 496–507
Tarak CHAARI - 188 - Thèse de doctorat

Bibliographie
[Märtin96] C. Märtin. Software Life Cycle Automation for Interactive Applications: The
AME Design Environment. In J. Vanderdonckt (ed.): Computer-Aided
Design of User Interfaces. Namur: Namur University Press, 1996, pp. 57-74
[Matthias07] Matthias Baldauf and Schahram Dustdar. A survey on context-aware
systems. International Journal of Ad Hoc and Ubiquitous Computing,
forthcoming, 2007, Vol.2, N°4, pp. 263-277.
[May05] W. May, J. Alferes, R. Amador. Active rules in the SemanticWeb: Dealing
with language heterogeneity. In Proceedings of International Conference on
Rules and Rule Markup Languages for the Semantic Web (RuleML-2005),
Galway, Ireland (10th - 12th November 2005), LNCS 3791, 30-44, 2005
[McCarthy00] McCarthy J. F. & Anagost, T. D. EventManager: Support for the peripheral
awareness of events. In Proceedings of the 2nd International Symposium on
Handheld and Ubiquitious Computing (HUC2K). Heidelberg, Germany:
Springer Verlag, 2000.
[McCarthy99] McCarthy J. F. & Meidel, E. S. ActiveMap: A visualization tool for location
awareness to support informal interactions. In Proceedings of the 1st
International Symposium on Handheld and Ubiquitous Computing (HUC
99). Heidelberg, Germany: Springer Verlag, 1999.
[Menkhaus02] G. Menkhaus. Adaptive User Interface Generation in a Mobile Computing
Environment. PhD Thesis. Austria : Salzburg University, 2002.
[Merrick2004] Roland Merrick, Brian Wood, William Krebs, ABSTRACT USER INTERFACE
MARKUP LANGUAGE, In Kris Luyten, Marc Abrams, Jean Vanderdonckt,
Quentin Limbourg (ED.), Proceedings of the Workshop on Developing User
Interfaces with XML: Advances on User Interface Description Languages,
May 2004, Gallipoli, Italy.
[Mogul01] J.C. Mogul. Server-Directed Transcoding. Computer Communications, Feb.
2001, Vol. 24, N°2, p. 155-162
[Mohan99] R. Mohan, J.R. Smith and C.S. Li. Adapting Multimedia Internet Content for
Universal Access. IEEE Trans. on Multimedia, 1999, Vol. 1, N°1, p. 104-
114
Tarak CHAARI - 189 - Thèse de doctorat

Bibliographie
[Mynatt98] Mynatt E. D., Back, M., Want, R., et al. Designing Audio Aura. In
Proceedings of the CHI 98 Conference on Human Factors in Computing
Systems.New York, NY: ACM Press, 1998, pp. 566-573
[Nagao01] K. Nagao, Y. Shirai, and K. Squire. Semantic annotation and transcoding :
Making web content more accessible. IEEE Multimedia, April-June 2001,
pp. 69-81
[Noble00] B. Noble. System Support for Mobile, Adaptive Applications. IEEE Personal
Communications, February 2000, Vol. 7, N°1, pp. 44-49
[Noble97] B.D. Noble, M. Satyanarayanan, D. Narayanana et al. Agile application
aware adaptation for mobility. In Proceedings of the 16th ACM Symposium
on Operating Systems Principles, December 1997, Vol.31, N°5, pp. 276-287
[Objectweb04] ObjectWeb. (2004, Octobre) Objectweb ambition and scope,
http://consortium.objectweb.org/ (consulté le 02.07.2007)
[OSGi03] OSGi Alliance, OSGi Service Platform, Release 3. Amsterdam : IOS Press,
Inc., 2003.
[Pascoe98] J. Pascoe. Adding generic contextual capabilities to wearable computers. In
Proceedings of 2 nd International Symposium on Wearable Computers,
October 1998, pp. 92-99
[Pascoe98] Pascoe J. Adding generic contextual capabilities to wearable computers. In
Proceedings of the 2nd International Symposium on Wearable Computers
(ISWC98). Los Alamitos CA : IEEE, 1998, 92-99
[Pawlak01] R. Pawlak, L. Seinturier, L. Duchien et al. JAC: A Flexible Solution for
Aspect-Oriented Programming in Java. Proceedings of Reflection'01,
volume 2192 de Lecture Notes in Computer Science, pages 1-24. Springer,
2001
[Pinheiro00] P. Pinheiro da Silva and N. W. Paton. UMLi: The Unied Modeling Language
for Interactive Applications. In Proceedings of UML2000, York, UK,
October 2000. (LNCS, 2000, Vol. 1939, pp. 117-132)
Tarak CHAARI - 190 - Thèse de doctorat

Bibliographie
[Puerta02] Puerta, A. and Eisenstein, J. 2002. XIML: a common representation for
interaction data. In Proceedings of the 7th international Conference on
intelligent User interfaces (San Francisco, California, USA, January 13 - 16,
2002). IUI 02. New York, NY : ACM Press, pp. 214-215.
[Puerta96] A. Puerta. Issues in Automatic Generation of User Interfaces in Model-
Based Systems. 1996. In J. Vanderdonckt (ed.): Computer-Aided Design of
User Interfaces. Namur: Namur University Press, p. 323-325
[Raj99] G. S. Raj. (1999, Octobre) The CORBA Component Model (CCM),
http://my.execpc.com/ gopalan/corba/ccm.html (consulté le 02.07.2007)
[Rekimoto99] Rekimoto J. Time-Machine Computing : A time-centric approach for the
information environment. In Proceedings of the 12th Annual ACM
Symposium on User Interface Software and Technology (UIST99),
Asheville, USA. New York : ACM Press, 1999, p .45 - 54
[Rhodes97] Rhodes B. J. The wearable remembrance agent. Los Alamitos. In
Proceedings of the 1st International Symposium on Wearable Computers
(ISWC97), October 13-14, 1997, Cambridge, Massachusetts. Los Alamitos,
Calif. : IEEE Press, 1997, 123-128
[Riveill00] Riveill M.et Merle P. Programmation par composants. Rapport Technique
numéro H 2 759, Techniques de l'ingénieur, traité Informatique, novembre
2000.
[Rodden98] Rodden T., Cheverst, K., Davies, K. & Dix, A. Exploiting context in HCI
design for mobile systems. In Proceedings of the Workshop on Human
Computer Interaction with Mobile Devices, 1998, Glasgow, Scotland
[Rodriguez01] J. Rodriguez, B. Dakar, F. L. Marras, et al. Transcoding in WebSphere
Everyplace Suite. Chapter 11. In: New Capabilities in IBM WebSphere
Transcoding Publisher Version 3.5 Extending Web Applications to the
Pervasive World. New York : IBM Redbooks, 30 May 2001, 446 p. ISBN
0738421545
[Roman02] E. Roman, S. Ambler, and T. Jewell. Mastering Enterprise JavaBeans. 2nd
ed. New York : John Wiley and Sons, Inc, 2002, 639 p.
Tarak CHAARI - 191 - Thèse de doctorat

Bibliographie
[Ryan98] N. S. Ryan, J. Pascoe,and D.R. Morse. Enhanced reality fieldwork : the
context-aware archaeological assistant. In V.Gaffney, M. van Leusen, and
S. Exxon, editors, Computer Applications in Archaeology 1997. Oxford :
Tempus Reparatum, , Oct. 1998. (British Archaeological Reports)
[Satyanarayanan01] M. Satyanarayanan. Pervasive Computing : Vision and challenge. IEEE
Personnal Communications, August 2001, Vol.8, N°4, pp. 10 -17
[Schilit94] Schilit B., Adams, N. & Want, R. Context-aware computing applications. In
Proceedings of the 1st International Workshop on Mobile Computing
Systems and Applications. Los Alamitos, CA : IEEE. 1994, pp. 85-90
[Schilit94a] B.N. Schilit, M. Theimer. Disseminating Active Map Information to Mobile
Hosts. Network, IEEE , September/October 1994, Vol.8, N°5, pp. 22-32.
[Schilit94b] B.N. Schilit, N.I. Adams and R. Want. Context-Aware Computing
Applications. In Proceedings of the IEEE Workshop on Mobile Computing
Systems and Applications (WMCSA94), Santa Cruz CA, December 1994.
Los Alamitos, CA : IEEE computer society press, 1995, pp 85-90
[Scribner00] Scribner, K., Scribner, K., and Stiver, M. C. Understanding Soap: Simple
Object Access Protocol. Indianapolis, Ind. : Sams, 2000, 514 p.
[Shanableh00] T. Shanableh and M. Ghanbari. Heterogeneous video transcoding to lower
spatio-temporal resolutions and different encoding formats. IEEE Trans.
Multimedia, June 2000, Vol.2, pp. 101-110
[Shanon90] Shanon, B. “What is Context?”, Journal for the Theory of Social Behavior
1990, Vol.20, pp. 157–166
[Singh04] A. Singh, A. Trivedi, K. Ramamritham, and P. Shenoy. PTC : Proxies that
Transcode and Cache in Heterogeneous Web Client Environments. World
Wide Web Journal, 2004, Vol.7, N°1, pp. 7-28.
[Smith98] J.R Smith, R.Mohan, C.S. Li. Transcoding Internet Content for
Heterogenouse Client Devices. Proceeedings IEEE International Symposium
on Circuits and Systems (ISCAS), Special session on Next Generation
Internet, June 1998, Monteret, California
Tarak CHAARI - 192 - Thèse de doctorat

Bibliographie
[Sloman94] M. Sloman. Policy driven management for distributed systems. Journal of
Network and Systems Management, 2:333–360, 1994
[Strang03] Strang, T., et al.. Service Interoperability on Context Level in Ubiquitous
Computing Environments. International Conference on Advances in
Infrastructure for Electronic Business, Education, Science, Medicine, and
Mobile Technologies on the Internet (SSGRR2003w), January 2003,
L'Aquila/Italy
[Sukaviriya93] P. Sukaviriya, J. Foley, T. Griffith. A Second Generation User Interface
Design Environment. In S. Ashlund, et.al. (eds.): Bridges between Worlds.
Proceedings InterCHI93, 1993, Amsterdam. New York : ACM Press, April
1993, p. 375-382
[Sun00] Sun Microsystems, Inc., Personal Java Application Environment
Specification, Version 1.2a (Final), November 2000.
[Sun07a] Sun Developer Network (SDN) [en ligne]. Java 2 Platform, Standard Edition
(J2SE). Inc. http: //java.sun.com/j2se (consulté le 01.06.2007)
[Sun07b] Mobile Information Device Profile (JSR 37) [en ligne], Java Community
Process, Java 2 Platform Micro Edition, Sun Microsystems. Disponible sur
le <http://java.sun.com/products/midp/> (consulté le 01.06.2007)
[Szyperski02] Szyperski C. Component Software Beyond Object-Oriented Programming.
Second Edition. London : Addison-Wesley / ACM Press, 2002, 589 p.
[Szyperski97] Clements Szyperski. Component Software. New York : ACM Press, 1997,
411 p
[UDDI07] UDDI, Advancing Web Services Discovery Standard. Disponible sur :
<http://www.uddi.org/> (consulté le 01.06.2007)
[UserLand99] UserLand Software. XML-RPC Specification, 1999.
http://www.xmlrpc.com/spec (consulté le 02.07.2007)
[Vetro02] A. Vetro, Y. Wang, and H. Sun. Rate-distortion optimized video coding
considering frameskip. In Proc. IEEE Int'l Conference on Image Processing
(ICIP2001), vol.3, Oct. 2001, Thessaloniki, Greece, pp.534 -537
Tarak CHAARI - 193 - Thèse de doctorat

Bibliographie
[W3C04] W3C Recommandation. Composite Capability/Preference Profiles (CC/PP):
Structure and Vocabularies 1.0, Janvier 2004 [en ligne]. Disponible sur :
<http://www.w3.org/TR/2004/REC-CCPP-struct-vocab-20040115>
(consulté le 01.06.2007)
[Want92] Want, R., Hopper, A., Falc˜ao, V., et al. The Active Badge Location System.
ACM Transactions on Information Systems, 1992, Vol.10, N°1, pp. 91-102
[Wapforum] Open Mobile Alliance [en ligne]. Disponible sur :
<http://www.wapforum.org> (consulté le 01.06.2007)
[Ward97] Ward, A. Jones, A. Hopper. A New Location Technique for the Active Office.
IEEE personnal Communications, 1997, Vol. 4, N°5, pp. 42-47
[Wee 03] S. Wee and J. Apostolopoulos. Secure scalable streaming and secure
transcoding with JPEG-2000. IEEE International Conference on Image
Processing, September 2003, Barcelona, Spain.
[Weiser95] Weiser, M. 1995. The computer for the 21st century. In Human-Computer
interaction: Toward the Year 2000, R. M. Baecker, J. Grudin, W. A. Buxton,
and S. Greenberg, Eds. San Francisco, CA : Morgan Kaufmann Publishers,
pp. 933-940
[Weiser97] Weiser M. & Brown, J. S. The coming age of calm technology. In Denning,
P. J. & Metcalfe, R. M. (Eds.) Beyond Calculation: The Next Fifty Years of
Computing. New York : Springer Verlag, 1997.
[Weiser99] Weiser, M. 1999. Some computer science issues in ubiquitous computing. In
Mobility: Processes, Computers, and Agents. New York, NY : ACM
Press/Addison-Wesley Publishing Co., pp. 420-430
[Widom96] J. Widom, S. Ceri, editors. Active Database Systems – Triggers and Rules
For Advanced Database Processing. Morgan Kaufmann Publishers, 1996,
332p
[Wies95] R. Wies, Using a Classification of Management Policies for Policy
Specification and Policy Transformation. In Proceedings of the Fourth
international Symposium on integrated Network Management IV A. S.
Sethi, Y. Raynaud, and F. Faure-Vincent, Eds. Chapman & Hall Ltd.,
London, UK, 44-56, 1995
Tarak CHAARI - 194 - Thèse de doctorat

Bibliographie
[Winograd01] Winograd, Terry. Architectures for Context. Human-Computer Interaction
Journal, 2001, Vol. 6, N°2-3, pp. 401-419.
[Yarvis01] M. Yarvis. Conductor: Distributed Adaptation for Heterogeneous Networks.
Ph.D. Dissertation. Los Angeles , CA : UCLA Department of Computer
Science, November 2001.
[Yoshikawa97] C. Yoshikawa, B. Chun, P. Eastham et al. Using smart clients to build
scalable services. Proc. Winter 1997 USENIX Technical Conf, January 6-
10, 1997, Anaheim, California, USA.
[Zouari07] M. Zouari, Politique d’adaptation d’applications dans les systèmes pervasifs
: rapport de master de recherche. Lyon : INSA de Lyon, 2007, 30 p.
Tarak CHAARI - 195 - Thèse de doctorat


AAANNNNNNEEEXXXEEESSS

Annexes
ANNEXE A
MODELE FONCTIONNEL DE L’APPLICATION SICOM
<?xml version="1.0" encoding="iso-8859-1"?> <application name="sicom"> <!-- Last modified : 2007/05/19 11:20 --> <!-- A place (representing a service) is described by its service id, url and method. For every method, we specify its input and output parameters --> <place id="Authentication"> <url>http://127.0.0.1/xmlrpc</url> <method id="sicom.identification"> <description>This method verifies the login and the password of a sicom user and returns its userID and userName
in the sicom database</description> <input name="sicom.login" type="secas:string" mode="user"/> <input name="sicom.password" type="secas:string" mode="user"/> <output name="sicom.userId" type="secas:int"/> <output name="sicom.userName" type="secas:string"/> <output name="sicom.userFirstName" type="secas:string"/> </method> </place> <place id="listeAlertes"> <url>http://127.0.0.1/xmlrpc</url> <method id="sicom.listeAlertes"> <description>This method returns the list of alerts identified by "sicom.userID"</description> <input name="sicom.userId" type="secas:int" mode="application"/> <output name="sicom.general.idAlerte" type="secas:int"/> <output name="sicom.general.idDossier" type="secas:int"/> <output name="sicom.general.date" type="secas:date"/> <output name="sicom.general.libelle" type ="secas:string"/> <output name="sicom.general.nom" type ="secas:string"/> </method> </place> <place id="descriptionAlerte"> <url>http://127.0.0.1/xmlrpc</url> <method id="sicom.descriptionAlerte"> <description>This method returns the list of the dialyzed patients treated by the practionner identified by
"sicom.userID"</description> <input name="sicom.general.idAlerte" type="secas:int" mode="application"/> <output name="sicom.general.descriptionAlerte" type="secas:string"/>
Tarak CHAARI - 198 - Thèse de doctorat

Annexes
</method> </place> <place id="listeDossierDialyse"> <url>http://127.0.0.1/xmlrpc</url> <method id="sicom.listeDossierDialyse"> <description>This method returns the list of the dialyzed patients treated by the practionner identified by
"sicom.userID"</description> <input name="sicom.general.idDossier" type="secas:int" mode="application"/> <output name="sicom.general.idDossier" type="secas:int"/> <output name="sicom.general.typeDialyse" type="secas:string"/> <output name="sicom.general.modeDialyse" type="secas:string"/> <output name="sicom.general.dateCreation" type="secas:date"/> <output name="sicom.general.dateModification" type="secas:date"/> <output name="sicom.general.nom" type ="secas:string"/> <output name="sicom.general.prenom" type ="secas:string"/> </method> </place> <place id="valeursTemperature"> <url>http://127.0.0.1/xmlrpc</url> <method id="sicom.valeursTemperature"> <description>This method returns the list of the dialyzed patients treated by the practionner identified by
"sicom.userID"</description> <input name="sicom.general.idDossier" type="secas:int" mode="application"/> <output name="sicom.general.abscisses" type="secas:date"/> <output name="sicom.general.ordonnées" type="secas:int"/> </method> </place> <place id="listeImages"> <url>http://127.0.0.1/xmlrpc</url> <method id="sicom.listeImages"> <description>This method returns the list of the dialyzed patients treated by the practionner identified by
"sicom.userID"</description> <input name="sicom.general.idDossier" type="secas:int" mode="application"/> <output name="sicom.general.nomImage" type ="secas:string"/> <output name="sicom.general.urlImage" type ="secas:image"/> <output name="sicom.general.descriptionImage" type ="secas:string"/> <output name="sicom.general.binaireImage" type ="secas:dicom"/> </method> </place> <!-- A transition specifies at least one association between a source service and a destination service. If a service depends on n services there will be n associations in the transition. For each association we indicate its source Parameters (parameters that we gather from a source service) and its destination parameters (parameters that will be some entries for the destination service). We specify a maximum delay in seconds to the execution of all the source services of all the associations of the transition. A transition can have a condition for every entry service. The condition is represented by a logical expression involving the output parameters of the concerned entry service. --> <transition delay="100">
Tarak CHAARI - 199 - Thèse de doctorat

Annexes
<generalCondition> <expression value="true"/> </generalCondition> <association sourceService="Authentication" destinationService="listeAlertes"> <sourceParameter methodID="sicom.identification" inputExpression="sicom.userId" condition="sicom.userID is not null"/> <destinationParameter methodID="sicom.listeAlertes" parameterName="sicom.userId"/> </association> </transition> <transition delay="100"> <generalCondition> <expression value="true"/> </generalCondition> <association sourceService="listeAlertes" destinationService="listeDossierDialyse"> <sourceParameter methodID="sicom.identification" inputExpression="sicom.general.idDossier" condition="sicom.general.idDossier is not null"/> <destinationParameter methodID="sicom.listeDossierDialyse" parameterName="sicom.general.idDossier"/> </association> </transition> <transition delay="100"> <generalCondition> <expression value="true"/> </generalCondition> <association sourceService="listeAlertes" destinationService="descriptionAlerte"> <sourceParameter methodID="sicom.listeAlertes" inputExpression="sicom.general.idAlerte" condition="sicom.general.idAlerte is not null"/> <destinationParameter methodID="sicom.descriptionAlerte" parameterName="sicom.general.idAlerte"/> </association> </transition> <transition delay="100"> <generalCondition> <expression value="true"/> </generalCondition> <association sourceService="listeDossierDialyse" destinationService="listeImages"> <sourceParameter methodID="sicom.listeDossierDialyse" inputExpression="sicom.general.idDossier" condition="sicom.general.idDossier is not null"/> <destinationParameter methodID="sicom.listeImages" parameterName="sicom.general.idDossier"/> </association> </transition> <transition delay="100"> <generalCondition> <expression value="true"/> </generalCondition>
Tarak CHAARI - 200 - Thèse de doctorat

Annexes
<association sourceService="listeDossierDialyse" destinationService="valeursTemperature"> <sourceParameter methodID="sicom.listeDossierDialyse" inputExpression="sicom.general.idDossier" condition="sicom.general.idDossier is not null"/> <destinationParameter methodID="sicom.valeursTemperature" parameterName="sicom.general.idDossier"/> </association> </transition> </application>
Tarak CHAARI - 201 - Thèse de doctorat

Annexes
ANNEXE B
REGLES D’ADAPTATION UTILISEES POUR L’APPLICATION SICOM
<?xml version="1.0" encoding="UTF-8"?> <!-- Last modified : 2007/05/19 17:30 --> <rules> <rule ID="1" mode="simple"> <expressions> <expression operator="inferior"> <parameter type="context" name="context.terminal.hardwarePlatform.totalMemory" value="10240"/> </expression> <expression operator="exist"> <parameter type="secas:serviceDescriptor" alias="S"> <expression operator="superior"> <parameter type="int" name="S.OUTPUT.length" value="1"/> </expression> </parameter> </expression> </expressions> <actions> <action type="SAaction" output="firstValues"> <operator name="projection"> <parameter name="service" type="secas:serviceDescriptor">S</parameter> <parameter name="outputParameter" type="secas:serviceOutput">S.OUTPUT[0]</parameter> </operator> </action> <action type="SAaction" output="selectedInstance"> <operator name="selection"> <parameter name="service" type="secas:serviceDescriptor">S</parameter> <parameter name="criteria" type="secas:booleanExpression"> <expression operator="equal"> <parameter type="secas:serviceOutput" name="S.OUTPUT[0]" value="selected(firstValues.OUTPUT[0])"/> </expression> </parameter> </operator> </action> <action type="FAaction"> <operator name="replaceService"> <parameter name="referenceService" type="secas:serviceDescriptor">S</parameter> <parameter name="serviceToReplace" type="secas:serviceDescriptor">firstValues</parameter> <parameter name="mode" type="string">simple</parameter> </operator> </action>
Tarak CHAARI - 202 - Thèse de doctorat

Annexes
<action type="FAaction"> <operator name="insertServiceAfter"> <parameter name="referenceService" type="secas:serviceDescriptor">firstValues</parameter> <parameter name="serviceToInsert" type="secas:serviceDescriptor">selectedInstance</parameter> </operator> </action> </actions> </rule> <rule ID="2" mode="recursive"> <expressions> <expression operator="equal"> <parameter type="context" name="context.terminal.softwarePlatform.acceptedDataTypes.acceptImages"
value="true"/> </expression> <expression operator="equal"> <parameter type="context" name="context.terminal.type" value="cldc"/> </expression> <expression operator="exist"> <parameter type="secas:serviceDescriptor" alias="S"> <expression operator="superior"> <parameter type="int" name="S.OUTPUT.length" value="1"/> </expression> <expression operator="exist"> <parameter type="int" alias="i"> <expression operator="exist"> <parameter type="string" name="S.OUTPUT[i].type" value="secas:binaryImage"/> </expression> </parameter> </expression> </parameter> </expression> </expressions> <actions> <action type="SAaction" output="displayNonImage"> <operator name="projection"> <parameter name="service" type="secas:serviceDescriptor">S</parameter> <parameter name="outputParameter" type="secas:serviceOutput">not(S.OUTPUT[i])</parameter> </operator> </action> <action type="SAaction" output="displayImage"> <operator name="projection"> <parameter name="service" type="secas:serviceDescriptor">S</parameter> <parameter name="outputParameter" type="secas:serviceOutput">S.OUTPUT[i]</parameter> </operator> </action> <action type="FAaction">
Tarak CHAARI - 203 - Thèse de doctorat

Annexes
<operator name="replaceService"> <parameter name="referenceService" type="secas:serviceDescriptor">S</parameter> <parameter name="serviceToInsert" type="secas:serviceDescriptor">displayNonImage</parameter> <parameter name="mode" type="secas:string">simple</parameter> </operator> </action> <action type="FAaction"> <operator name="insertAlternativeService"> <parameter name="referenceService" type="secas:serviceDescriptor">displayNonImage</parameter> <parameter name="serviceToInsert" type="secas:serviceDescriptor">displayImage</parameter> </operator> </action> </actions> </rule> </rules>
Tarak CHAARI - 204 - Thèse de doctorat

Annexes
ANNEXE C
DESCRIPTION D’UN CONTEXTE D’UTILISATION DE L’APPLICATION
SICOM AVEC UN TELEPHONE MOBILE DE TYPE NOKIA 6230
<?xml version="1.0" encoding="UTF-8"?> <contextProfile ID="U17T355008002783631"> <contextFacet name="terminal"> <contextParameter name="type" type="static">cldc</contextParameter> <contextParameter name="model" type="static">NOKIA6230</contextParameter> <contextParameter name="serialNumber" type="static">355008002783631</contextParameter> <contextCategory name="hardwarePlatform"> <contextParameter name="totalMemory" type="static">6114</contextParameter> <contextParameter name="availableMemory" type="dynamic">4322</contextParameter> <contextCategory name="screenSize"> <contextParameter name="width" type="static">128</contextParameter> <contextParameter name="height" type="static">128</contextParameter> </contextCategory> </contextCategory> <contextCategory name="softwarePlatform"> <contextCategory name="acceptedDataTypes"> <contextParameter name="acceptImages" type="static">true</contextParameter> <contextParameter name="Images" type="static">png, bmp</contextParameter> <contextParameter name="Text" type="static">plain, String, html</contextParameter> <contextParameter name="Nuemric" type="static">int, short, long</contextParameter> <contextParameter name="Videos" type="static">3gp</contextParameter> <contextParameter name="Applications" type="static">vnd.nokia.ringing-tone</contextParameter> <contextParameter name="Audio" type="static">wav, midi, mp3, 3gp</contextParameter> <contextParameter name="Other" type="static">date</contextParameter> </contextCategory> <contextCategory name="api"> <contextParameter name="virtualMachine" type="static">Monty 1.0 VM</contextParameter> <contextParameter name="userInterfaceVocabulary" type="static"> http://liris-7024.insa-lyon.fr/midpUILibrary.xml</contextParameter> <contextParameter name="serviceInvocationDescriptor" type="static"> http://liris-7024.insa-lyon.fr/midpServiceInvocation.xml</contextParameter> </contextCategory> </contextCategory> </contextFacet> <contextFacet name="network"> <contextParameter name="connectionType" typse="static">GPRS</contextParameter> <contextParameter name="bandWidth" type="static">236.8</contextParameter>
Tarak CHAARI - 205 - Thèse de doctorat

Annexes
<contextParameter name="delay" type="static">135</contextParameter> <contextParameter name="connectionState" type="dynamic">connected</contextParameter> </contextFacet> <contextFacet name="userProfile"> <contextCategory name="basicInformation"> <contextParameter name="userID" type="static">17</contextParameter> <contextParameter name="generalDomain" type="static">medical</contextParameter> <contextParameter name="specificDomain" type="static">nephrology</contextParameter> <contextParameter name="profession" type="static">specialist</contextParameter> </contextCategory> <contextCategory name="preferences"> <contextParameter name="language" type="dynamic">FR</contextParameter> <contextCategory name="display"> <contextParameter name="numericValues" type="static">curves</contextParameter> <contextParameter name="images" type="static">fullScreen</contextParameter> </contextCategory> </contextCategory> </contextFacet> <contextFacet name="location"> <contextCategory name="pysical"> <contextParameter name="country" type="dynamic">France</contextParameter> <contextParameter name="city" type="dynamic">Villeurbanne</contextParameter> <contextParameter name="zipcode" type="dynamic">69100</contextParameter> <contextParameter name="streetname" type="dynamic">Jean Capelle</contextParameter> <contextParameter name="streetNumber" type="dynamic">7</contextParameter> <contextParameter name="building" type="dynamic">501</contextParameter> <contextParameter name="room" type="dynamic">330</contextParameter> </contextCategory> <contextCategory name="logical"> <contextParameter name="IPAdress" type="static">134.214.107.20</contextParameter> </contextCategory> </contextFacet> </contextProfile>
Tarak CHAARI - 206 - Thèse de doctorat

Annexes
ANNEXE D
ALGORITHME DE GENERATION DU GRAPHE D’ADAPTATION DE
CONTENU MULTIMEDIA DE GIRMA BERHE [BERHE05]
Algorithm: graph (SA, SZ, T, D) Input: Initial state SA, final state SZ, adaptation task list T and adaptation operators D Output: an adaptation graph G (V, E) // Global constant // Limit maximum number of neutral operators allowed in a connection // Global variables // V a set of nodes in a graph // E a set of edges in a graph // ao start node // zo end node // NO a set of neutral operators available in the system // Local variables // T a set of adaptation tasks // t an adaptation task element of T // O a set of nodes for adaptation operators realizing an adaptation task // PO a set of parent nodes // Pz a set containing the end node var V, E, T, t, O, PO, ao, zo, Pz, NO begin ao= ConstructStartNode(SA) // constructs the start node from the initial state zo= ConstructEndNode(SZ) // constructs the end node from the goal state NO= ConstructNeutralOperators( ) // returns the list of the neutral operators available in //the system V= {ao} //initialization E= Ø //initialization PO= {ao} //initialization for each t ∈ T begin Construct nodes O from D with operators realizing t //several operators can realize a task Connect(O, PO) //after the process PO holds the value of O end //T is processed Pz={zo} Connect(Pz, PO) // connects the end node return G (V, E) end // graph
Tarak CHAARI - 207 - Thèse de doctorat

Annexes
----------------------------------------------------------------------------------------------------------------- // procedure Connect: connects child nodes (O) with parent nodes (PO) // O a set of nodes-input variable // PO a set of nodes-input and output variable ----------------------------------------------------------------------------------------------------------------- procedure Connect(in O, inout PO) //Local variables // CO a set of nodes-temporal variable used to store child nodes (O) // TPO a set of nodes-temporal variable used to store parent nodes (PO) // CPO a set of nodes-temporal variable used to store connected parent nodes // po a node in PO // o a node in O // UNO a set of operators-variable to store already used neutral operators // Link a Boolean variable to check if a node has a connection // Connected a Boolean variable, true if a node is connected by neutral operator // LimitC an integer- number of neutral operators in a connection //Notations // po.Pre preconditions of node po // po.Eff effects of node po // o.Pre preconditions of node o // o.Eff effects of node o var CO, TPO, CPO, UNO, o, po, LimitC, Link, Connected begin CO= Ø //initialization CPO= Ø //initialization Link = false // connect each o ∈ O with each node of the parent nodes PO for each o ∈ O begin for each po ∈ PO begin if (o.Pre po. Eff) then // direct connection of node o with node po ⊆begin if(o∉V) then begin V= V ∪ {o} end E= E ∪ {(po, o)} Link = true // o is connected in the graph end else // for indirect connection of node o with po using neutral operators begin
Tarak CHAARI - 208 - Thèse de doctorat

Annexes
LimitC=0 UNO= Ø Connected=ConnectWithNeutralOperators (o, po, LimitC, UNO) Link=Link or Connected // Link is true if o has at least one connection // if po is connected add it to the connected parent nodes list if (Connected) then CPO=CPO {po} ∪end end // PO is processed if (not Link) then // checks if o has at least one direct or indirect connection begin if(o=zo) then // it is the end node so the graph construction fails begin V= Ø E= Ø return end else O=O-{o}// o can not be connected so remove it end end // O is processed // remove parent nodes which have no connection for each po ∈ PO begin if (po ∉CPO ) then begin V=V-{po} for each (x, po) ∈ E begin E=E-{(x, po)} Remove(x) // removes x with its ancestors end end end PO= O //child nodes become parent nodes for the next process end // end connect procedure ----------------------------------------------------------------------------------------------------------------- // function ConnectWithNeutralOperators it connects o and op using neutral operators //recursively // o a node- input variable // op a node- input variable //LimitC an integer- input variable // UNO a set of nodes- input and output variable ----------------------------------------------------------------------------------------------------------------- function Boolean ConnectWithNeutralOperators (in o, in op, in LimitC, inout UNO)
Tarak CHAARI - 209 - Thèse de doctorat

Annexes
//Local variables // TNO a set of operators-a temporal variable for neutral operators // TE a set of edges-a temporal variable to store connectable edges // TV a set of nodes-a temporal variable to store connectable nodes // no a node var TNO, TE, TV, no begin TNO=NeutralOperators(o, UNO)// it returns neutral operators connectable with o for each no ∈ TNO begin if (no.Pre op.Eff) then ⊆begin TE= TE ∪ {(op, no)} TE= TE ∪ {(no, o)} TV= TV ∪ {no} TV= TV ∪ {o} E= E ∪ TE V= V ∪ TV return true end else begin TE= TE ∪ {(no, o)} TV= TV ∪ {no} TV= TV ∪ {o} if (LimitC+ 1=Limit) or (UNO {no}=NO) then //terminating condition ∪return false else return ConnectWithNeutralOperators(no, op, LimitC+1, UNO {no}) ∪end end // TNO is processed end // ConnectWithNeutralOperators ----------------------------------------------------------------------------------------------------------------- // function NeutralOperators returns the set of neutral operators satisfying the preconditions //of o // o a node-input variable // UNO a set of nodes- input variable ----------------------------------------------------------------------------------------------------------------- function Operators NeutralOperators(in o,in UNO) //Local variables // TNO a set of operators-temporal variable for neutral operators // no a node //Notations // o.Pre preconditions of node o // no.Eff effects of node no var
Tarak CHAARI - 210 - Thèse de doctorat

Annexes
TNO, no begin TNO= Ø for each no ∈ NO begin if (o.Pre no.Eff) then ⊆if (no ∉UNO) then TNO=TNO {no} ∪end return TNO end // NeutralOperators ----------------------------------------------------------------------------------------------------------------- // procedure Remove it removes the node x recursively until it finds a node with a branch //connection or it reaches the start
node // x a node- input variable ----------------------------------------------------------------------------------------------------------------- procedure Remove(in x) //Local variables // z a node for which (z, x) is an edge in E // y a node for which (x, y) is an edge in E var z, y begin if (x=ao) then // it is the start node make V empty and return begin V= Ø return end else if ((y ∈ V) and ((x, y) ∈ E)) then // x has a branch connection begin return end else begin for each (z, x) ∈ E begin E=E-(z, x) Remove(z) end V=V-{x} end // each (z, x) is processed end //Remove
Tarak CHAARI - 211 - Thèse de doctorat

FOLIO ADMINISTRATIF
THESE SOUTENUE DEVANT L'INSTITUT NATIONAL DES SCIENCES APPLIQUEES DE LYON
NOM : CHAARI DATE DE SOUTENANCE : 28/09/2007
Prénoms : Tarak
TITRE : Adaptation d’applications pervasives dans des environnements multi-contextes
NATURE : Doctorat Numéro d'ordre : 07 ISAL
Ecole doctorale : Ecole Doctorale Informatique, Information et société
Spécialité : Informatique
Cote B.I.U. - Lyon : T 50/210/19 / et bis CLASSE :
RESUME :
Les systèmes pervasifs ont pour objectif de rendre l’information disponible partout et à tout moment. Ces systèmes doivent pouvoir être
utilisés dans différents contextes selon l’environnement de l’utilisateur, son profil et le terminal qu’il utilise. L’un des problèmes majeurs de
ce type de systèmes concerne donc l’adaptation au contexte d’utilisation. Dans ce travail de thèse, nous proposons une stratégie complète,
générique et évolutive d’adaptation d’applications au contexte d’utilisation sur trois volets: (i) les services offerts à l’utilisateur, (ii) les
données renvoyées par ces services et (iii) leur présentation à l’utilisateur. L’adaptation des services consiste à intercepter les appels vers
les services originaux de l’application et à modifier leur comportement à l’aide d’un ensemble d’opérateurs d’adaptation fonctionnelle.
L’adaptation des données consiste à transformer ou à remplacer chaque objet multimédia renvoyé par les services de l’application qui
n’est pas utilisable dans la situation contextuelle en question. L’adaptation de la présentation se base sur un processus de génération
automatique du code de l’interface utilisateur qui garantit l’interaction avec les données et les services adaptées. La stratégie que nous
avons élaborée atteint deux objectifs : (i) intégrer la sensibilité au contexte dans l’application de façon incrémentale et (ii) garantir
l’adaptation à partir d’une description simple des services offerts à l’utilisateur. Nous avons mis en œuvre cette stratégie en développant
une plateforme d’adaptation d’applications au contexte d’utilisation. Nous avons utilisé les technologies Java, OSGi et les services Web
pour réaliser cette plateforme. Nous avons également validé nos modèles et notre approche d’adaptation sur une application médicale de
suivi de patients dialysés à domicile.
MOTS-CLES :
Système d’information pervasifs, Sensibilité au contexte, Adaptation de services, Adaptation de contenu, Adaptation
d’interfaces utilisateurs
LABORATOIRE (S) DE RECHERCHE :
Laboratoire d'InfoRmatique en Images et Systèmes d'information (LIRIS), UMR 5205, INSA de Lyon
20, avenue Albert Einstein, 69621 Villeurbanne CEDEX
DIRECTEURS DE THESE:
André FLORY, Professeur à l’INSA de Lyon
Frédérique LAFOREST, Maître de conférences à l’INSA de Lyon
COMPOSITION DU JURY :
Paul RUBEL, Professeur à l’INSA de Lyon (Président du jury)
Philippe ANIORTE, Professeur à l’université de Pau (Rapporteur)
Florence SEDES, Professeur à l’INP de toulouse (Rapporteur)
Augusto CELENTANO, Professeur à l’université de Venise (Examinateur)