20131028 intermine ag cati bbric
TRANSCRIPT

[email protected] - AG CATI-BBRIC - 20131028
Atelier InterMine
ABiMS / MIGALE / LIPMSemaine 35
Sebastien.Carrere, Ludovic.Legrand

[email protected] - AG CATI-BBRIC - 20131028
Contexte
Dans le cadre du WP7 du projet Investissement d’Avenir SUNRISE, la plateforme Bioinformatique du Laboratoire des Interactions Plantes-Microorganismes a en charge la mise à disposition d’outils pour la gestion de données massives et hétérogènes de tournesol.
En parallèle, l’infrastructure nationale EMBRC-France mène également une réflexion similaire dans le cadre du WP “E-infrastructure” qui a pour objectifs de développer un environnement intégré (données et outils) autour des modèles marins émergents (algues, bactéries, métazoaires…).
Enfin, à Jouy, Idex Institut de Modélisation des Systèmes Vivants, Saclay (IMSV) : intégration de données “omiques” de bacteries (plantes a terme)
C’est dans cette optique que nous avons identifié l’entrepôt de données Intermine (http://www.intermine.org) comme une solution potentielle.
Cet atelier nous permettrait :
- d’acquérir une culture commune dans le domaine de l’intégration de données
- de monter en compétence collectivement sur un outil s’affichant comme clef dans le domaine de l’intégration de données biologiques
- d’atteindre une masse critique afin de faire émerger une communauté d’utilisateurs et développeurs sur cet outil

[email protected] - AG CATI-BBRIC - 20131028
InterMine
● Data WareHouse :– entrepôt de données
– intégration de données hétérogènes
– orienté organismes modèles● FlyMine, YeastMine, RatMine

[email protected] - AG CATI-BBRIC - 20131028
Technologies
● git
● Java (javac, SDK, ant, tomcat)– construction du modèle
– chargement des données
– application Web
● Perl– Téléchargement de données (~ BioMAJ)
– Scripts de manipulation de fichiers XML
● PostgreSQL– customisé (boost des performances,beaucoup de données, nombreux accès)
– BioSEG : BioSEG● Procedures utilisant les structures d'index postGIS pour optimiser les recherches de type
region/overlap sur les sequences.
–

[email protected] - AG CATI-BBRIC - 20131028
Construire une mine en 4 étapes
● Création de la mine– création de l'arborescence du projet
– création deS bases de données
● Description du modèle de données– fichier project.xml
– description des sources et des relations
● Chargement des données● Déploiement de l'application web

[email protected] - AG CATI-BBRIC - 20131028
Création de la mineCréation de l'arborescence et des fichiers par défaut.
make_minemymine| data| dbmodel| default.intermine.integrate.properties| default.intermine.webapp.properties| download_logs| integrate| postprocess| project.xml` webapp
createdbcreateuser E W interminecreatedb O intermine T template1 myminecreatedb O intermine T template1 itemsmyminecreatedb O intermine T template1 userprofilemymine
3 bases de données sont crées pour une mine:base de données correspondant au modèle de données et aux sources de la minebase items correspondant à une sorte de cache lors de la constructionbase users gérant les profils utilisateurs (sauvegarde de leur requêtes, templates, listes de gènes, etc...)
Création des bases de données
[email protected] - AG CATI-BBRIC - 20131028
Description du modèle de données
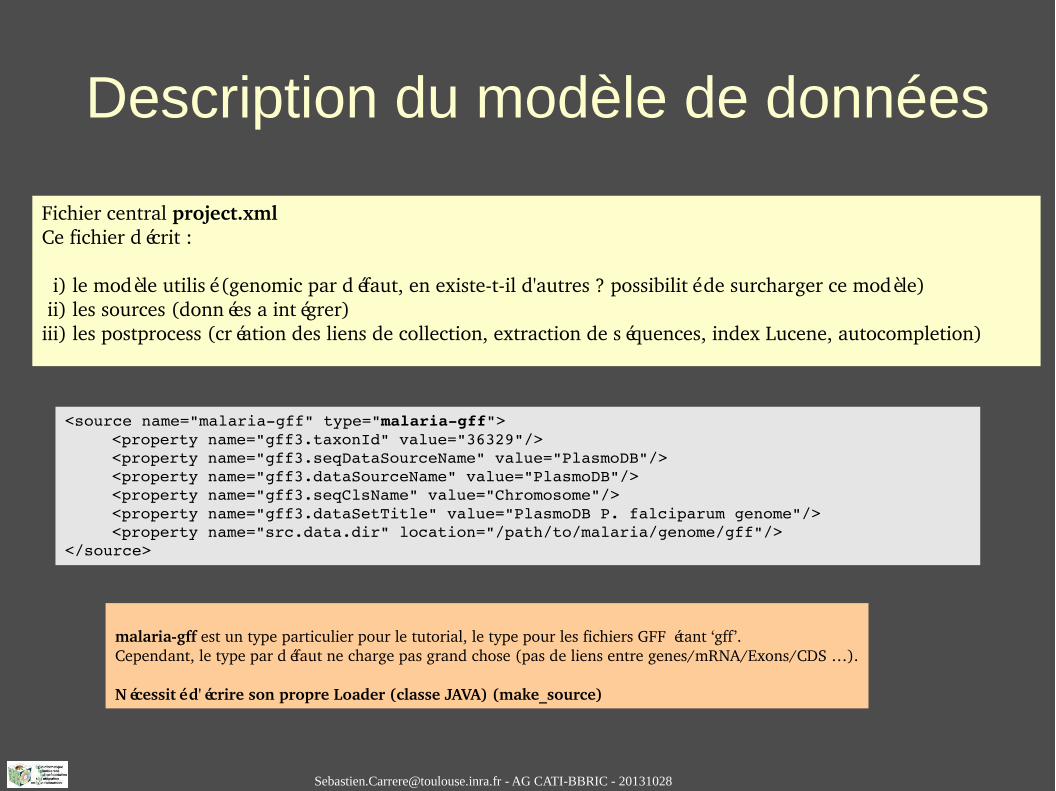
Fichier central project.xmlCe fichier décrit :
i) le modèle utilisé (genomic par défaut, en existetil d'autres ? possibilité de surcharger ce modèle) ii) les sources (données a intégrer)iii) les postprocess (création des liens de collection, extraction de séquences, index Lucene, autocompletion)
<source name="malariagff" type="malariagff"><property name="gff3.taxonId" value="36329"/><property name="gff3.seqDataSourceName" value="PlasmoDB"/><property name="gff3.dataSourceName" value="PlasmoDB"/><property name="gff3.seqClsName" value="Chromosome"/><property name="gff3.dataSetTitle" value="PlasmoDB P. falciparum genome"/><property name="src.data.dir" location="/path/to/malaria/genome/gff"/>
</source>
malariagff est un type particulier pour le tutorial, le type pour les fichiers GFF étant ‘gff’.Cependant, le type par défaut ne charge pas grand chose (pas de liens entre genes/mRNA/Exons/CDS …).
Nécessité d'écrire son propre Loader (classe JAVA) (make_source)

[email protected] - AG CATI-BBRIC - 20131028
Chargement des données // Deploiement de l'application web
● Si tout le reste a été réglé, il n' y a pas grand chose à faire (3 commandes ant)– insertion dans la base de données temporaire
– vérification des contraintes d’intégrité
– bascule dans la base de production
– génération des liens, extraction des séquences, construction d'index Lucene
– déploiement web (tomcat)

[email protected] - AG CATI-BBRIC - 20131028
Création du modèle
Chargement des données cd mymine/integrateant Dsource=all
cd mymine/posprocessant Post-process
cd mymine/dbmodel/buildant clean builddb
cd mymine/webappant builddbuserprofile ant default removewebapp releasewebappDéploiement web
[email protected] - AG CATI-BBRIC - 20131028
Charger un GFF3
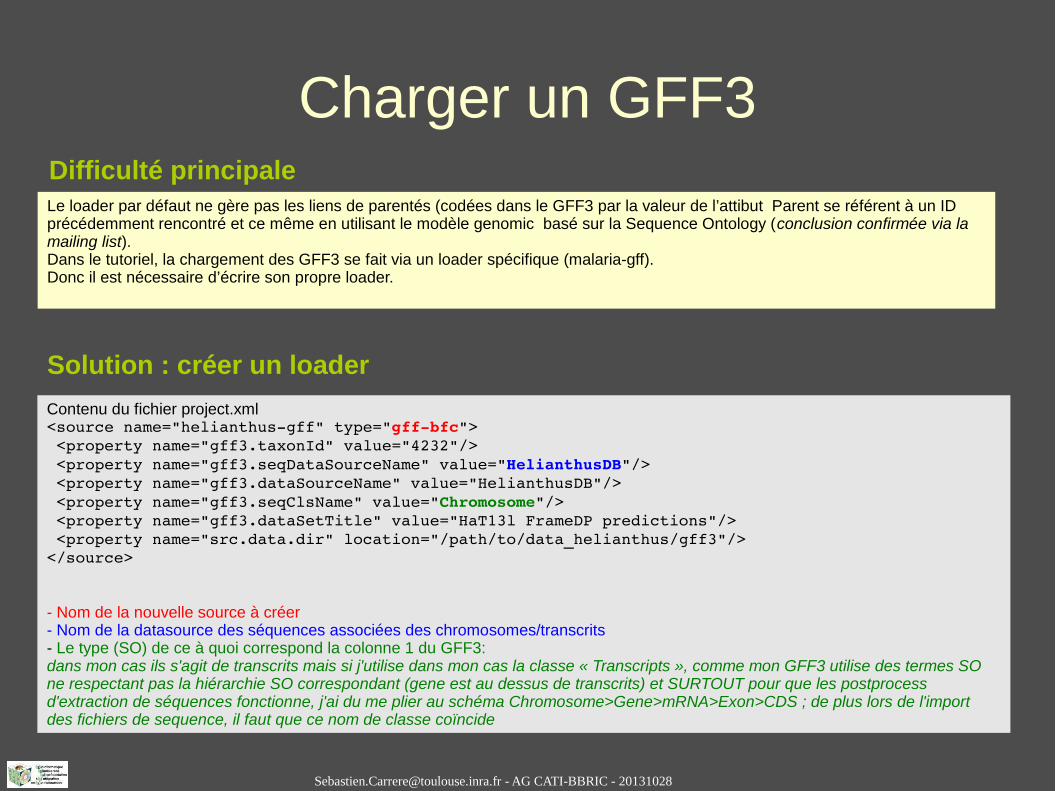
Le loader par défaut ne gère pas les liens de parentés (codées dans le GFF3 par la valeur de l’attibut Parent se référent à un ID précédemment rencontré et ce même en utilisant le modèle genomic basé sur la Sequence Ontology (conclusion confirmée via la mailing list).Dans le tutoriel, la chargement des GFF3 se fait via un loader spécifique (malaria-gff).Donc il est nécessaire d’écrire son propre loader.
Difficulté principale
Contenu du fichier project.xml<source name="helianthusgff" type="gffbfc"> <property name="gff3.taxonId" value="4232"/> <property name="gff3.seqDataSourceName" value="HelianthusDB"/> <property name="gff3.dataSourceName" value="HelianthusDB"/> <property name="gff3.seqClsName" value="Chromosome"/> <property name="gff3.dataSetTitle" value="HaT13l FrameDP predictions"/> <property name="src.data.dir" location="/path/to/data_helianthus/gff3"/></source>
- Nom de la nouvelle source à créer- Nom de la datasource des séquences associées des chromosomes/transcrits- Le type (SO) de ce à quoi correspond la colonne 1 du GFF3: dans mon cas ils s'agit de transcrits mais si j'utilise dans mon cas la classe « Transcripts », comme mon GFF3 utilise des termes SO ne respectant pas la hiérarchie SO correspondant (gene est au dessus de transcrits) et SURTOUT pour que les postprocess d'extraction de séquences fonctionne, j'ai du me plier au schéma Chromosome>Gene>mRNA>Exon>CDS ; de plus lors de l'import des fichiers de sequence, il faut que ce nom de classe coïncide
Solution : créer un loader
[email protected] - AG CATI-BBRIC - 20131028
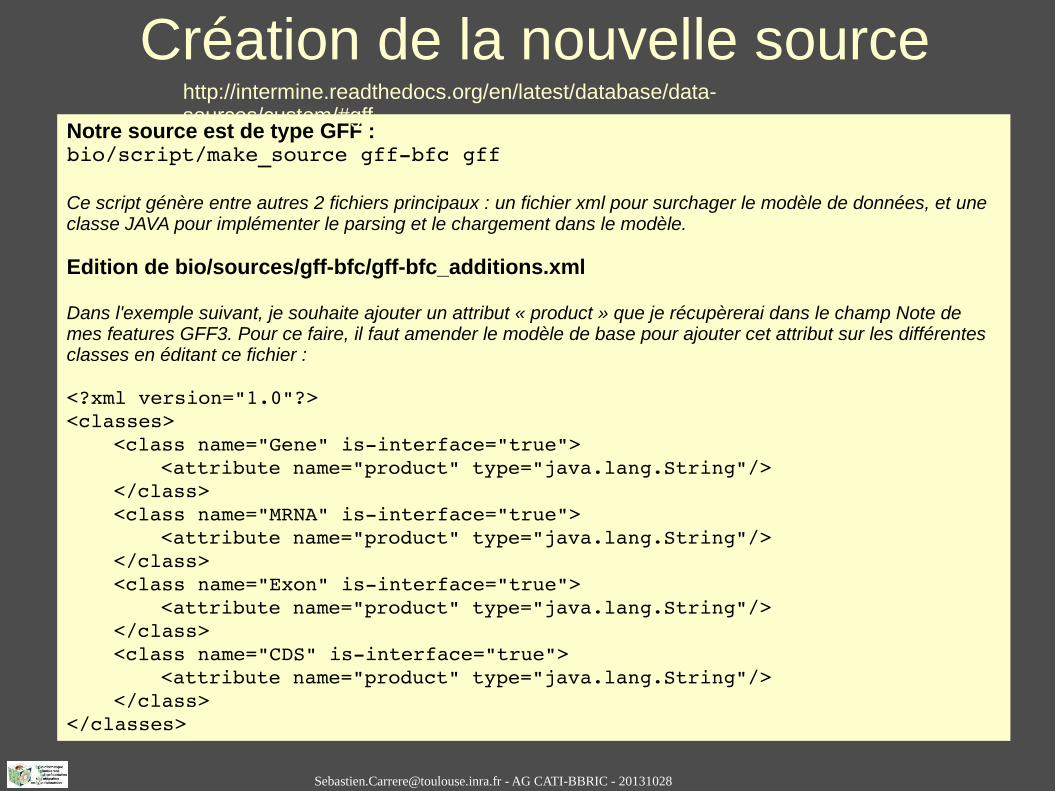
Création de la nouvelle sourceNotre source est de type GFF :bio/script/make_source gffbfc gff
Ce script génère entre autres 2 fichiers principaux : un fichier xml pour surchager le modèle de données, et une classe JAVA pour implémenter le parsing et le chargement dans le modèle.
Edition de bio/sources/gff-bfc/gff-bfc_additions.xml
Dans l'exemple suivant, je souhaite ajouter un attribut « product » que je récupèrerai dans le champ Note de mes features GFF3. Pour ce faire, il faut amender le modèle de base pour ajouter cet attribut sur les différentes classes en éditant ce fichier :
<?xml version="1.0"?><classes>
<class name="Gene" isinterface="true"><attribute name="product" type="java.lang.String"/>
</class><class name="MRNA" isinterface="true">
<attribute name="product" type="java.lang.String"/></class><class name="Exon" isinterface="true">
<attribute name="product" type="java.lang.String"/></class><class name="CDS" isinterface="true">
<attribute name="product" type="java.lang.String"/></class>
</classes>
http://intermine.readthedocs.org/en/latest/database/data-sources/custom/#gff
[email protected] - AG CATI-BBRIC - 20131028
Création de la nouvelle source
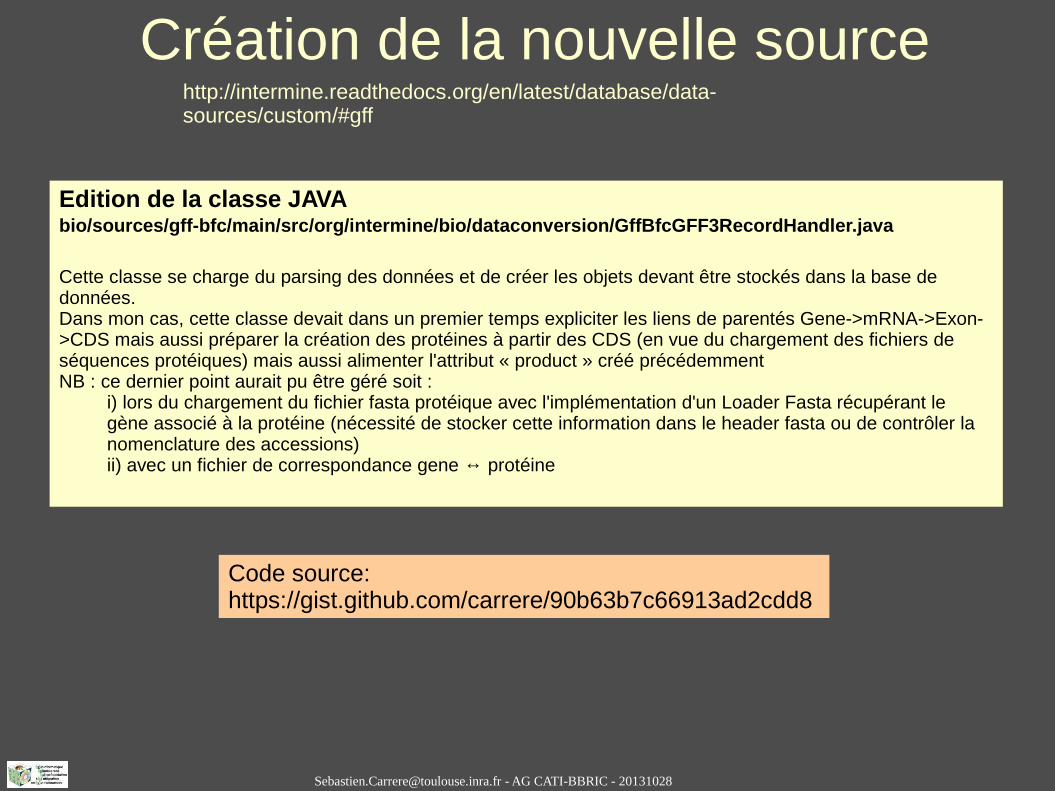
Edition de la classe JAVAbio/sources/gff-bfc/main/src/org/intermine/bio/dataconversion/GffBfcGFF3RecordHandler.java
Cette classe se charge du parsing des données et de créer les objets devant être stockés dans la base de données.Dans mon cas, cette classe devait dans un premier temps expliciter les liens de parentés Gene->mRNA->Exon->CDS mais aussi préparer la création des protéines à partir des CDS (en vue du chargement des fichiers de séquences protéiques) mais aussi alimenter l'attribut « product » créé précédemmentNB : ce dernier point aurait pu être géré soit :
i) lors du chargement du fichier fasta protéique avec l'implémentation d'un Loader Fasta récupérant le gène associé à la protéine (nécessité de stocker cette information dans le header fasta ou de contrôler la nomenclature des accessions)ii) avec un fichier de correspondance gene ↔ protéine
http://intermine.readthedocs.org/en/latest/database/data-sources/custom/#gff
Code source: https://gist.github.com/carrere/90b63b7c66913ad2cdd8

[email protected] - AG CATI-BBRIC - 20131028
Autres tests d'import de données
● Import de fichiers Fasta – quelques zones d'ombres
● Import de résultats InterProScan– développement d'un Loader
● Connexion Chado – Par défaut seules les données de types Chromosome, Gene, CDS et Exons
sont exportées → développement

[email protected] - AG CATI-BBRIC - 20131028
Evaluation de la webApp
● évaluation rapide...● … mais semble facilement customisable● intérêt des widgets disponibles (expression, cytoscape, jbrowse)● pas très orienté séquence (pas de recherche par blast par
exemple) → plus orienté fouille (QueryBuilder)● interopérabilité (API, connexion Galaxy, xref, exports standards)● restriction d'accès non gérée (multiplication des mines)

[email protected] - AG CATI-BBRIC - 20131028
Bilan semaine
● Assez complexe a prendre en main– de nombreux fichiers de conf avec des ordres de priorité pas toujours
clairs
– la doc est assez mal structurée
● Difficile d'intégrer des données maison (même si les formats sont standards)
● Coût de developpement nécessaire vs. le coût de mettre en place une telle solution
● Interface Web claire et assez simplement customisable● Des bases de référence en support● Pas d'alternative ? SRS / EnsEMBL / BioMART
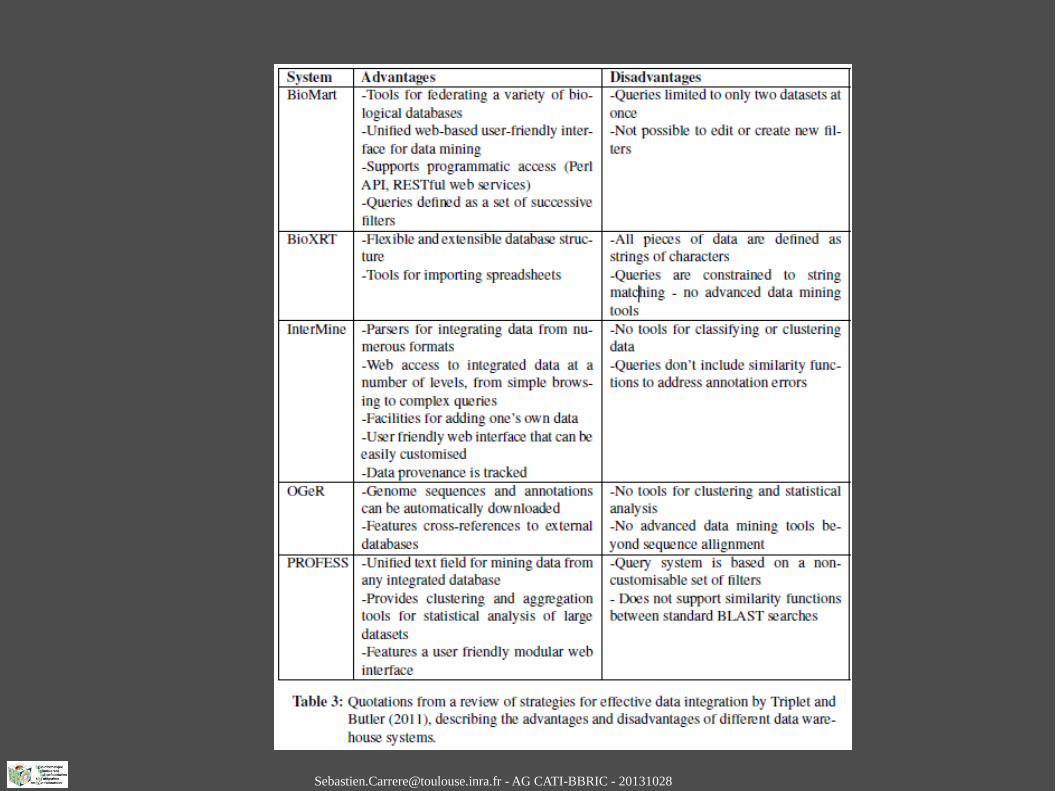

[email protected] - AG CATI-BBRIC - 20131028
Sources
● http://www.intermine.org
● Rapport LIPM/Abims/Migale
● Bioinformatics. 2012InterMine: a flexible data warehouse system for the integration and analysis of heterogeneous biological data.Smith RN, Aleksic J, Butano D, Carr A, Contrino S, Hu F, Lyne M, Lyne R, Kalderimis A, Rutherford K, Stepan R, Sullivan J, Wakeling M, Watkins X, Micklem G.
● Brief Bioinform. 2013 May 14.A review of genomic data warehousing systems.Triplet T, Butler G.